
Abstract
In clinical trials it is common that the treatment has different effects on different subjects. This motivates the precision medicine, the goal is to identify the treatment favorable or unfavorable subgroups, if they exist, and classify the subjects into one of the subgroups based on their covariate values. In practice, some covariate(s) is known to affect the response non-linearly, in this case the existing linear model is not adequate. To address this issue, we use a partial linear model, in which the effect of some specific covariates is a non-linear monotone function, along with a linear part for the rest of the covariates. This approach not only makes the model more flexible than the parametric linear model, and more interpretable and efficient than the full nonparametric model. The Wald statistics is used to test the existence of subgroups, and the Neyman-Pearson rule is used to classify the subjects. Simulation studies are conducted to evaluate the performance of the method, and then the method is used to analyze a real clinical trial data.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

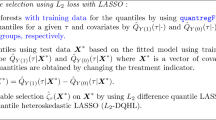

1 Introduction
In clinical studies, often treatment effect is not uniform over all the patients, some subgroup of patients may benefit significantly from the treatment and others may not so. Thus one of goals of precision medicine is to find out if such subgroups exist or not, and if existence is justified, identify the subgroups of patients according to their covariate values. For example, in IBCSG (2002), patients with ER-negative tumors were likely to benefit from chemotherapy, while those with ER-positive tumors did not.
Subgroup analysis is recently a very active research area see, e.g., Sabine (2005), Song and Chi (2007), Ruberg et al. (2010), Foster et al. (2011), Lipkovich et al. (2011), Friede et al. (2012), Shen and He (2015), Fan et al. (2017), and Ma and Huang (2017). Rothmann et al. (2012) discussed issues for subgroups testing and analysis. Fokkema (2018) used generalized linear mixed-effect model tree (GLMM tree) algorithm detecting treatment-subgroup interactions in clustered datasets. Yuan et al. (2018, 2020) proposed semiparametric methods for this problem.
Existing methods for this problem often use linear model. In practice, sometimes it is known that some covariate has non-linear effect on the response, incorporating such information can improve the quality of the analysis. Here we consider such case and apply a more featured partial linear model to identify the existence of subgroups and to classify the subjects into different subgroups if the existence of subgroup is confirmed. This model assumes a monotone non-linear effect of some covariate, and linear effects from the rest covariates. First, a partial model with individual subgroup membership as latent variable and with a covariate whose effect are known as non-linear are formulated and the model regression parameters is estimated with expectation-maximization algorithm (E-M algorithm), and isotonic regression method is used for the maximum likelihood of the nonparametric non-linear part. Then null hypothesis of non-existence of subgroups are tested with Wald Statistics. If the existence of subgroup is confirmed, we use the Neyman-Pearson rule to classify each subject so that the misclassification error for the treatment favored group is under control while the misclassification error for the other subgroup is minimized.
The rest of the chapter is organized as follows. In Sect. 11.2 we describe the model and parameter estimation, Sect. 11.3 elaborates the testing and classification method, and Sect. 11.4 illustrates the simulation study and real data analysis.
2 The Method
The observed data is denoted as D n = {(y i, x i, z i), i = 1, …, n}, where y i ∈ R is the response variable of i-th subject, x i = (x i1, …, x id)′∈ R d and z i is another covariate, which is known to have a non-linear monotone effect on the response. Each subject i receives the same treatment, and we assume that bigger value of the response corresponds to better treatment effects. We want to test if there are treatment favorable and non-favorable subgroups in the patients. If subgroup does exist, we need to classify each subject into corresponding subgroup based on his/her covariate profile. In this paper, we assume that there are only two potential subgroups: treatment-favorable and treatment-nonfavorable subgroups. We need first to specify the model, estimate the model parameters, and then perform the hypothesis test and classification of subjects.
2.1 The Semiparametric Model Specification
We specify the semiparametric partial linear model as
where δ i is a latent indicator for whether subject i belongs to the treatment favorable subgroup (δ i = 1) or not (δ i = 0). β is a d-vector of unknown parameters, η is the effect of treatment favorable subgroup, and the constraint η ≥ 0 is used for the identifiability with the intercept vector term in β. It is assumed that the covariate z i has a non-linear effect g(⋅) to the response y i, we only know that \(g(\cdot )\in \mathcal {G}\), the collection of all monotone increasing functions on R.
Denote the i.i.d. copy of the (y i, x i, z i, δ i, ε i)’s as (y, x, z, δ, ε). Let λ = P(δ = 1) and θ = (β′, η, λ)′ be the vector of all the Euclidean parameters. Conditioning on (x, z), the density of y is the mixture
where ϕ(⋅) is the density function of the standard normal distribution. The log-likelihood of the observed data is
Direct computation of the maximum likelihood estimate (MLE) from a mixture model (11.1) is not convenient, especially in the presence of the nonparametric component g(⋅), and it is known that E-M algorithm (Dempster et al. 1977) is typically easy to use. For this, we treat the latent variable δ i’s as missing data, with δ i = 1 if the i-th subject belongs to the treatment-favorable subgroup, otherwise δ i = 0. The likelihood based on the ‘complete data’ \(D^c_n=\{(y_i,\boldsymbol {x}_i,z_i,\delta _i): i=1,\ldots ,n)\}\) is
the corresponding log-likelihood is
The semiparametric MLE \((\hat {\boldsymbol {\theta }}_n,\hat {f}_n)\) of the true parameter (θ 0, f 0) is given by
2.2 Estimation of Model Parameters
As the δ i’s are missing, \((\hat {\boldsymbol {\theta }}_n,\hat {g}_n)\) in (11.3) cannot be computed directly, the EM algorithm is used instead. For this a starting value θ (0) of θ is needed, then find \(g^{(1)}(\cdot ) \in \mathcal {G}\) as the maxima of \(\ell (\boldsymbol {\theta }^{(0)},g|D^c_n)\), then fix g (1), find θ (1) ∈ Θ as the maxima of ℓ n(θ, g (1)), and so on…. until convergence of the sequence {(θ (r), g (r))}, which is increasing the likelihood at each iteration, and will converge to at least some local maxima of ℓ n(θ, g). In fact, the increasing likelihood property is obvious, as for all integer r,
A formal justification of the convergence of the above iterative algorithm is a case of the block coordinate descent methods in Bertsekas (2016).
Our algorithm is a semiparametric version of EM algorithm, see also Tan et al. (2009, chap. 2) for bio-medical applications of this algorithm. The semiparametric and nonparametric EM algorithm was used in a large number of literatures, such as in Mun̂oz (1980), Campbell (1981), Hanley and Parnes (1983), Groeneboom and Wellner (1992, Section 3.1), and see the argument there for the convergence of such algorithm (p. 67–68). Chen et al. (2002) applied the EM algorithm to a semiparametric random effects model, Bordes et al. (2007) applied the EM algorithm to a semiparametric mixture model, using simulation studies to justify the convergence of the algorithm. Balan and Putter (2019) developed an R-package of EM algorithm for semiparametric shared frailty models.
Now we give the detail of the algorithm. At each iteration r, do the following:
-
Step 0. For fixed (g (0), θ (0)), compute \(\{\delta _i^{(0)}\}\) with E-step of E-M algorithm.
-
Step 1. For fixed (g (r), θ (r)), compute
$$\displaystyle \begin{aligned}H_n(\boldsymbol{\theta},g|\boldsymbol{\theta}^{(r)}, g^{(r)}) &= E_{\boldsymbol{\delta}}[\ell(\boldsymbol{\theta},g|D^c_n)|D_n,\boldsymbol{\theta}^{(r)}, g^{(r)}] \\ &= \sum_{i=1}^n\Big(\delta^{(r)}_i \log \phi(y_i-\boldsymbol{\beta}'\boldsymbol{x}_i-g(z_i)-\eta)\\&\quad +\delta^{(r)}_i\log\lambda) + (1-\delta^{(r)}_i)\log \phi(y_i-\boldsymbol{\beta}'\boldsymbol{x}_i-g(z_i)) \\&\quad +(1-\delta^{(r)}_i)\log(1-\lambda))\Big),\raisetag{12pt}\end{aligned} $$(11.4)where the expectation is taken with respect to the missing δ, and as if the true data is generated from parameters (θ (r), g (r)). In particular, the r-th step estimates of the δ i’s (for i = 1, …., n;r = 0, 1, 2,…), are
$$\begin{aligned} \delta_i^{(r)} &=E(\delta_i|y_i,x_i,z_i,g^{(r)},\boldsymbol{\theta}^{(r)})=P(\delta_i=1|y_i,x_i,z_i,g^{(r)},\boldsymbol{\theta}^{(r)})\\ &=\frac{P(y_i|\delta_i=1,x_i,z_i,g^{(r)},\boldsymbol{\theta}^{(r)})P(\delta_i=1|x_i,z_i,g^{(r)},\boldsymbol{\theta}^{(r)})}{P(y_i|x_i,z_i,g^{(r)},\boldsymbol{\theta}^{(r)})}\\ &=\frac{\lambda^{(r)}\phi\Big(\boldsymbol{y}_i{-}\boldsymbol{\beta}^{'(r)}\boldsymbol{x}_i{-}g^{(r)}(z_i){-}\eta^{(r)}\Big)}{\lambda^{(r)}\phi\Big(\boldsymbol{y}_i{-}\boldsymbol{\beta}^{'(r)}\boldsymbol{x}_i{-}g^{(r)}(z_i){-}\eta^{(r)}\Big)+(1{-}\lambda^{(r)})\phi\Big(\boldsymbol{y}_i{-}\boldsymbol{\beta}^{'(r)}\boldsymbol{x}_i{-}g^{(r)}(z_i)\Big)}. \end{aligned} $$ -
Step 2. In the M-step for θ, compute
$$\displaystyle \begin{aligned}\boldsymbol{\theta}^{(r+1)} = \arg\sup_{\theta\in\Theta} H_n(\boldsymbol{\theta}, g^{(r)}|\boldsymbol{\theta}^{(r)}, g^{(r)}) .\end{aligned}$$This step can be computed by standard optimization packages. Especially,
$$\displaystyle \begin{aligned}\lambda^{(r+1)} = \frac{1}{n}\sum_{i=1}^n\delta_i^{(r)}.\end{aligned} $$ -
Step 3. For fixed \((\boldsymbol {\theta }^{(r+1)},\delta _i^{(r+1)})\) compute
$$\displaystyle \begin{aligned}g^{(r+1)}(\cdot)= \arg\max_{g\in \mathcal{G}} H_n(\boldsymbol{\theta}^{(r+1)}, g|\boldsymbol{\theta}^{(r)}, g^{(r)}).\end{aligned} $$This step computes the nonparametric maximum likelihood estimate of \(\hat {g}\) under shape restriction, which is non-trivial, we describe it below.
2.2.1 Computation of g (r+1)
The pool adjacent violators algorithm (PAVA, see for example, Best and Chakravarti (1990)) is a convenient computational tool to perform such order restricted maximization or minimization, and is available in R. Patrick et al. (2009) gives a review of the algorithm history and computational aspects. In particular, the computation of \(\hat {g}(z_i)=\hat {g}_i\) is as follows.
Generally, let v i = y i −β′x i − δ iη, w i = 1, then
The above is the standard form of isotonic regression procedure, and \(\hat {g}\) can be computed using the R-function isoreg(⋅).
2.3 Asymptotic Results of the Estimates
Zhou et al. (2019) derived asymptotic results for \(\hat {\boldsymbol {\theta }}\) and \(\hat {g}(\cdot )\), as presented below. Detailed regularity conditions and proofs can be found there.
Theorem 11.1
Under regularity conditions, as n →∞
Denote \(\stackrel {D}{\to }\) for convergence in distribution.
Theorem 11.2
Under regularity conditions, as n →∞,
where I ∗(θ 0|g 0) = E[ℓ ∗(X, Z|θ 0, g 0)ℓ ∗‘(X, Z|θ 0, g 0)] is the efficient Fisher information matrix of θ for fixed g 0, and ℓ ∗(X, Z|θ 0, g 0) is the efficient score for θ.
Let \(\mathbb {B}(\cdot )\) be the two-sided Brownian motion originating from zero: a mean zero Gaussian process on R with \(\mathbb {B}(0)=0\), and \(E\big (\mathbb {B}(s)-\mathbb {B}(h)\big )^2=|s-h|\) for all s, h ∈ R.
Theorem 11.3
Denote \({\dot g}_0(z)=d g_0(z)/dz\) and density of z as q(z). Assume q(z) > 0. Under regularity conditions, as n →∞,
3 Testing the Null Hypothesis and the Classification Rules
3.1 Test the Null Hypothesis
After the model parameters are estimated, we need to test the existence of subgroups, which is formulated as testing the null hypothesis H 0 : η = 0 vs the alternative H 1 : η ≠ 0. For parametric model, commonly used test statistic including the likelihood ratio statistic, score statistic and the Wald statistic, and the three statistics are asymptotically chi-squared distributed and equivalent. However, in our case when η = 0, λ is non-identifiable in the model, although the other parameters are still identifiable and estimable. In this case, the likelihood ratio statistic cannot be applied. So we use the Wald statistic.
Denote θ = (θ 1, θ 2) with dim(θ) = d and dim(θ 1) = d 1, and \(\hat {\boldsymbol {\theta }}=(\hat {\boldsymbol {\theta }}_1,\hat {\boldsymbol {\theta }}_2)\) is the MLE of θ under the full model. Consider the null hypothesis H 0 : θ 1 = θ 1,0. The Wald test statistic is
If \(Cov(\hat {\boldsymbol {\theta }}_1)\) is known, then asymptotically \(W_n \sim \chi ^2_{d_1}\). If \(Cov(\hat {\boldsymbol {\theta }}_1)\) is estimated, asymptotically \(W_n/d_1 \sim F_{d_1,n-d}\). For our problem, θ 1 = η, θ 1,0 = 0, we treat \(Cov(\hat {\eta })\) to be known, so \(W_n=\hat {\eta }_nVar^{-1}(\hat {\eta }_n)\hat {\eta }_n \sim \chi ^2_1\) asymptotically, and if \(W_n > \chi ^2_1(1-\alpha )\), which is the upper (1 − α)-th quantile of the \(\chi ^2_1\) distribution, then H 0 is rejected.
3.2 The Classification Rule
After the existence of subgroup is justified, or the null hypothesis above is rejected, we need to classify the subjects. There are different classification rules. In subgroup analysis, the correct classification of the treatment favorable subgroup is of significant clinical meaning, so we use the Neyman-Pearson rule in Yuan et al. (2018, 2020) as it can control the miss-classification error for the treatment favorable subgroup.
To be specific, for each subject i, denote the i-th likelihood ratio
Parallel to the NP uniformly most powerful test procedure for testing the simple hypothesis H 0 : η = 0 vs. H 1 : η ≠ 0. For given significance level α, the optimal classification rule is: classify the i-th subject to subgroup S 1 if
or, with \(\epsilon = y-\hat {\boldsymbol {\beta }}'\boldsymbol {x}-\hat {g}(z_i)\) generated under H 0,
We can find approximate solution for K(α). For simulated data, let {LR j : j = 1, …, n 0} be the LR j’s of patients from the treatment unfavorable subgroup (for simulated data, the subgroup memberships are known), then set K(α) is estimated by the (1 − α)-th upper quantile of \(LR_1,\ldots ,LR_{n_0}\), it is the cut-off beyond which patients will be classified to the treatment favorable subgroup, even though they are from the treatment unfavorable subgroup.
However, for real data {(y i, x i, z i) : i = 1, …, n}, the subgroup memberships are unknown, we cannot use the above method to decide K(α), instead we obtain it by the following way. Set \(LR_i = \phi (\epsilon _i-\hat {\eta })/\phi (\epsilon _i)\), let
be a weighted empirical distribution of the LR i’s under the null hypothesis. Note that \(1-\hat {\delta }_i\) is the estimated membership of subject i belonging to group 0, corresponding to the null hypothesis, and \(1-\hat {\delta }_i\) scaled by \(\sum _{j=1}^n(1-\hat {\delta }_j)\) makes the w ni’s a set of actual weights. So intuitively, Q n(⋅) is a reasonable estimate of the distribution of the LR i’s under the null hypothesis. We set \(K(\alpha )=Q_n^{-1}(1-\alpha )\) to be the (1 − α)-th upper quantile of Q n.
For coming patient with covariate x but without response y, we define
where y i (i = 1, …, n 0) are the responses of the subjects already in the trail, and being classified to group 0, and classify this patient to group 1 if LR(x, z) > K(α), with K(α) given above.
4 Simulation Study and Application
4.1 Simulation Study
We simulate four examples with non-linear effect of z i to y i. We simulate n = 1000 i.i.d. data with 1-dimensional response y i’s and with covariates x i = (x i1, x i2, x i3). We first generate the covariates, sample the x i’s from the 3-dimensional normal distribution with mean vector μ = (3.1, 1.8, −0.5)′ and a given covariance matrix Γ. sample the z i’s from the normal distribution with mean μ = 0 and σ 2 = 1. The ε i are also sampled from normal distribution with mean μ = 0 and σ 2 = 1.We will display estimation results with four different choices of θ 0 = (β 0, η 0, λ 0) and four choices of g 0(⋅) below. What is more, we fixed a point (0, 0) for the non-linear effect.
Example 1
g 0(z) = 6 × Exponential(z + 2) − 6 × Expnential(0 + 2);
Example 2
g 0(z) = 5 × Beta((z + 2)∕4, 5, 1) − 5 × Beta((0 + 2)∕4, 5, 1);
Example 3
g 0(z) = 6×I(z < 0)×((N(z, 0, 0.5))−N(0, 0, 0.5))+6×I(z ≥ 0)×(N (z, 0, 0.2)−N(0, 0, 0.2)));
Example 4
g 0(z) = 3×I(z < 0)×(Beta((z+2)∕4, 0.2, 0.2)−Beta((0+2)∕4, 0.2, 0.2))+7×I(z ≥ 0)×(Beta((z+2)∕4, 0.7, 0.7)−Beta((0+2)∕4, 0.7, 0.7)).
The estimated \(\hat {g}\) and g 0 are shown in Fig. 11.1.

Solid line: true g 0(⋅); Step line: estimate \(\hat {g}(\cdot )\)
The parameter estimates from the proposed model are displayed in Tables 11.1, 11.2, 11.3 and 11.4, along with the estimates from commonly used linear model as comparison. The estimated standard errors are displayed as [se].
The hypothesis testing results from both partial linear and linear model are given in Table 11.5, and the classification results using the partial linear model are in Table 11.6.
From Table 11.5 we see that the partial linear model gives reasonable estimates, while the estimates from the linear model is not reasonable, may due to the fact that it seriously over-estimate the effect η for small value of it.
From Table 11.6, it is seen that the mis-classification error for the treatment favorable subgroup is well controlled around the specified level α = 0.05, and the overall classification error depends on the effect size η. It is small when η is large and vice versa. Note that for η = 0.95 and 1.70, the N-P error is larger than 0.05 this is because the estimate of η is not that accurate when the true value of η is small.
Interpretation of the Results
From Tables 11.1, 11.2, 11.3 and 11.4, we see that when the effect η of treatment favorable subgroup is tiny, the biases of the estimates from the linear model are much larger than those with the proposed partial linear model. That also can be used to explain the results of hypothesis testing with linear model. When the effect of treatment favorable subgroup is small, linear model tend to give an estimate with positive bias. So, type I error here is large and type II error is small. If the effect of treatment favorable subgroup is large, partial linear model and linear model tend to give similiar estimates of parameters.
4.2 Application to Real Data Problem
Now we analyze the real data ACTG175 with the proposed method. The trial was conducted by the AIDS Clinical Trials Group (ACTG), which was supported by the National Institute of Allergy and Infectious Diseases (NIAID). Participants were enrolled into the study between December 1991 and October 1992, and received treatment through December 1994. Follow-up and final evaluations of participants took place between December 1994 and February 1995.
The purpose of this data was to investigate whether treatment of HIV infection with one drug (monotherapy) was the same, better than, or worse than treatment with two drugs (combination therapy) in patients under some conditions.Three different drugs were used to conduct this study: (1) zidovudine (AZT), (2) didanosine (ddI), and (3) zalcitabine (ddC). The three drugs are nucleotide analogues that act as reverse transcriptase inhibitors (RT-inhibitors). The original study noted no clear differences between the ddI and AZT + ddI treatments—both appeared to be approximately equal effective in preventing HIV progressing. Treatment with AZT + ddC provided no additional benefit to continued treatment with AZT. However, the results of ACTG 175 together with the results from earlier studies demonstrate that antiretroviral therapy is beneficial to HIV-infected people who have less than 500 CD4+ T cells/mm3. This study also shows, for the first time, that an improvement in survival can be achieved in a sub-population.
We analyze this data using the proposed method on the combined therapy (ZDV+ddI). The number of patients is 522. The response variable is the CD4 counts after 20 weeks of the corresponding treatment, and the covariates are age, baseline CD4 counts, karnofsky score and number of days of previously received antiretroviral therapy. We assume the effect of baseline CD4 counts on the response variable is non-linear.
The analysis results are presented in Tables 11.7 and 11.8. We see that the null hypothesis of no subgroup is rejected, and there is a treatment favorable subgroup which is about 5% of the total patients. This is consistent with the result in Yuan et al. (2020). This case is of particular interest for hypothesis generating for developmental therapeutics. We can examine the small group of patients who are not benefiting from the treatment and identify underlying reasons and study them.
5 Conclusion
A partial linear model is proposed for the analysis of subgroups in clinical trial, for the case one of the covariate has monotone non-linear effect on the response. The non-linear part is modeled by a monotone function along with the linear part of other covariates. The semiparametric maximum likelihood is used to estimate model parameters. Simulation study is conducted to evaluate the performance of the proposed method, and results show that the proposed model perform much better than linear models especially when treatment effect is relatively small. Then the model is applied to analyze a real data.
References
Balan TA, Putter H (2019) frailtyEM: an R package for estimating Semipaarametric shared frailty models. J Stat Softw 90(7)
Bertsekas DP (2016) Nonlinear programming, 3rd edn. Athena Scientific, Nashua
Best MJ, Chakravarti N (1990) Active set algorithms for isotonic regression; a unifying framework. Math Program 47:425–439
Bordes L, Chauveau D, Vandekerknove P (2007) A stochastic EM algorithm for a semiparametric mixture model. Comput Stat Data Anal 51:5429–5443
Campbell G (1981) Nonparametric bivariate estimation with ranodmly censored data. Biometrica 68:417–422
Chen J, Zhang D, Davidian M (2002) A Monte Carlo EM algorithm for generalized linear mixed models with ïňĆexible random effects distribution. Biometrics 3(3):347–360
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the EM algorithm, J R Stat Soc Ser B 39:1–38
Fan A, Song R, Lu W (2017) Change-plane analysis for subgroup detection and sample size calculation. J Am Stat Assoc 112:769–778
Fokkema M, Smits N, Zeileis A et al (2018) Detecting treatment-subgroup interactions in clustered data with generalized linear mixed- effects model trees. Behav Res Methods 50:2016–2034
Foster JC, Taylor JMC, Ruberg SJ (2011) Subgroup identification from randomized clinical trial data. Stat Med 30:2867–2880
Friede T, Parsons N, Stallard N (2012) A conditional error function approach for subgroup selection in adaptive clinical trials. Stat Med 31:4309–4320
Groeneboom P, Wellner J (1992) Information bounds and nonparametric maximum likelihood estimation. Birkh\(\acute {a}\)user Verlag, Basel
Hanley JA, Parnes MN (1983) Nonparametric estimation of a multivariate distribution in the presence of censoring. Biometrics 39:129–139
International Breast Cancer Study Group (IBCSG) (2002) Endocrine responsiveness and tailoring adjuvant therapy for postmenopausal lymph node-negative breast cancer: a randomized trial. J Natl Cancer Inst 94:1054–1065
Lipkovich I, Dmitrienko A, Denne J, Enas G (2011) Subgroup identification based on differential effect search (SIDES)—A recursive partitioning method for establishing response to treatment in patient sub-populations. Stat Med 30:2601–2621
Ma S, Huang J (2017) A concave pairwise fusion approach to subgroup analysis. J Am Stat Assoc 112:410–423
Mun̂oz A (1980) Nonparametric estimation from censored bivariate observations. Technical Report, Department of Statistics, Stanford University
Patrick M, Kurt H, Jan DL (2009) Isotonic optimization in R: pool-adjacent-violators algorithm (PAVA) and active set methods. J Stat Softw 32(5):1–24
Rothmann MD, Zhang J, Lu L, Fleming TR (2012) Testing in a pre-specified subgroup and the intent-to-treat population. Drug Inf J 46(2):175–179
Ruberg SJ, Chen L, Wang Y (2010) The mean doesn’t mean as much any more: finding sub-groups for tailored therapeutics. Clin Trials 7:574–583
Sabine C (2005) AIDS events among individuals initiating HAART: do some patients experience a greater benefit from HAART than others? AIDS 19:1995–2000
Shen J, He X (2015) Inference for subgroup analysis with a structured logistic-normal mixture model. J Am Stat Assoc 110:303–312
Song Y, Chi GY (2007) A method for testing a pre-specified subgroup in clinical trials. Stat Med 26:3535–3549
Tan M, Tian G-L, Ng KW (2009) Bayesian missing data problems: EM, data augmentation and non-iterative computation. Chapman and Hall/CRC, London/Boca Raton
Yuan A, Chen X, Zhou Y, Tan MT (2018) Subgroup analysis with semiparametric models toward precision medicine. Stat Med 37(2):1830–1845
Yuan A, Zhou Y, Tan MT (2020) Subgroup analysis with a nonparametric unimodal symmetric error distribution. Comm Statist Theory Methods. Published online
Zhou Y, Yuan A, Tan MT (2019) Subgroup analysis with semiparametric partial linear regression model. Submitted to Statistical Methods in Medical Research
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Zhou, Y., Yuan, A., Tan, M.T. (2020). Subgroup Analysis with Partial Linear Regression Model. In: Ting, N., Cappelleri, J., Ho, S., Chen, (G. (eds) Design and Analysis of Subgroups with Biopharmaceutical Applications. Emerging Topics in Statistics and Biostatistics . Springer, Cham. https://doi.org/10.1007/978-3-030-40105-4_11
Download citation
DOI: https://doi.org/10.1007/978-3-030-40105-4_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-40104-7
Online ISBN: 978-3-030-40105-4
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)