
Abstract
The way a scientific field applies theories shapes its intellectual structure and determines its development and survival as a discipline. Information Systems (IS) with its multidimensional nature and innovatory essence has a different contingence with its original theories, which are basically rooted in a diverse spectrum of fields. This research is designed to investigate which theories have been deployed in different IS research streams in the last decade, and by analyzing the perceived gap, how it might be changed in the future. To this aim, a data-driven method for analyzing the published papers’ cited references in the top two IS journals is designed and implemented. This study is directed based on the co-citation network analysis, text analysis, and investigation of the highly cited references in MISQ and ISR from 2009 to 2018. The analysis of the top-cited references co-citation network revealed six distinct clusters representing the research areas in our field including IS Value, IS Research, E-commerce, IS in Organization, Social Network Analysis, and IS Usage. Further, text analysis and interpretations disclosed the main and the dominant theoretical foundation in each cluster and their linkages. By examining the relationships between the clusters and their theories, the eminent theoretical gap in E-commerce cluster is distinguished. Subsequently, some fact-based hypotheses about what would be changed in this cluster in the future are represented. Considering a wider timespan, including data from basket of 8 journals and deeply analyzing all clusters, this study could be continued.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others
Keywords
1 Introduction
Information Systems (IS) field of research has been the subject to identity crisis during the time [1,2,3]. The multidisciplinary nature of this field raises lots of debates about the main origin, focus, and scientific contribution of IS and how it could survive and grow as a discipline [4]. Although the importance of IS in value creation and how it affects business success and competitiveness are proven [5, 6], the way its intellectual structure founded and its scientific originality are continuously controversial. Based on its nature, IS field of research is rooted in different basic fields such as psychology, sociology, system science, management, economics, and strategy and these fields have contributed toward IS emergence and growth [7]. As a very rapidly changing knowledge domain, scientific focus in this field has been shifted from time to time and the researchers’ concentration changed frequently [8]. IS research also covers wide range of topics including IS usage/adoption, IS design and development, e-commerce/e-business, IS research, knowledge management, IS evaluation, software and programming languages, IS functional applications, telecommunication and networking, and internal/external environment of IT [8], which are diverse and different in concept and impact. The diverse nature of IS and how its semantic structure is shaped from one side, and the emerging concepts and technologies on the other side make this field both complicated to comprehend and essential to be examined.
The multidimensional essence of IS besides the variant typology for discussing the nature of theory in this field [9] cause the increasing level of ambiguity in the discourse of IS theory. Although some debates about the role and the importance of theory in IS are stated [10], there is no doubt that theoretical foundation of each scientific discipline is very crucial for shaping the semantic structure of discipline, for moving further than the patterns and simply for explanation, and prediction of the associated phenomena [11]. Additionally, IS scholars’ ability to understand and contribute to theory is considered an essential qualification in research practice [11]. Generally, it is perceived that the theory foundation in any scientific field is the main platform for the growth and the survival of the discipline; and IS field is not an exemption. A theory is mainly perceived as a systematic explanatory scheme for describing the patterns and regularities in a discipline [12].
There are several of grounds for believing that examining the theories used in IS research is both essential and timely. Firstly, IS, as an ever-changing field of research, periodically needs to take the stock and represent how the core theoretical ideas are developing. It seems that the previous theories becoming out of date or ill-suited mainly due to major and radical change in type of data [13]. Secondly, calls continue for “next-generation information systems theories” principally based on the fundamental change in the core phenomenon, which is becoming increasingly intelligent, interconnected, and infused through all the contexts [14]. Finally, looking at the previous trends might help in depicting a better picture of what would happen in the future in a research discipline [15]. Therefore, investigation of theories applied in the IS field, understanding their connections and the foundational gaps make essential contributions in clarification of IS context and its backbone, hence are important for the scholars.
1.1 Literature Review and Related Works
The theoretical foundation of IS has been an issue in the field occasionally [16,17,18,19,20]. Researchers followed different approaches to study cornerstone theories in IS research ranging from pure quantitative technical methods including n-gram analysis [19], complex network analysis [17], statistical methods [18], to mixed approaches [16], and even absolutely subjective and judgmental investigation [20]. Soper, Turel and Geri [19] reported on the list of IS field’s most commonly used theories, their co-occurrence and their priority in the top three IS journals from 1990 through 2011. They applied the measurement model considering the “relative frequency” of a theory in the literature, which might be biased in reflecting the real importance and effect of a theory. Similarly, Lim, Saldanha, Malladi and Melville [17] tried to investigate the type of theories are borrowed in IS by analyzing the published papers during 1998–2006 in MISQ and ISR and their analysis is limited to the top five theories in each IS stream. Moody, Iacob, Amrit and Müller [18] conducted comparable analysis using the reference lists of all papers published in the five leading IS journals over 5 years (2003–2007) and they revealed the top 10 influential sources including six important theories and four significant research method sources. Although, de Vaujany, Lesca, Fomin and Loebbecke [16] used a different approach by concentrating on the General Editorials Statements (GES) of the top 30 IS journals for the years 1997 and 2007. They reported on the words with similar repetition and related concepts in these two different time horizons and their study showed that not the expectations by journals from researchers have changed and nor the lexical diversity increased over time. Considering the limitation of GES in representing IS foundations, the ultimate change during the time could not be discovered by their study. Weber [20] was seeking to propose a framework with which evaluation of the quality of an existing theory could be facilitated. The result of this qualitative research does not assist in choosing the focal phenomena and the ways these phenomena might be conceived.
Considering the recent major evolution in our field due to the massive technological enhancement during the last decade, and regarding the intrinsic limitation of the previous studies, this research is designed to investigate the highlighted theoretical base of the recent IS studies and to indicate what might be changed in the future.
1.2 Motivations and Contributions
This study is defined to represent the recent and probable future status of the IS theoretical background deploying a systematic and data-driven approach in analyzing the highly cited references in the two top IS journals in the last ten years. Considering the contribution of clarifying the theoretical context of any discipline in defining its boundaries and recalling the more interconnected economy and society and the recent data revolution, we are motivated to define this research to answer the following major questions:
-
1.
Which prominent theories formulate the intellectual core of the IS research streams in the last decade?
-
2.
What would be the probable future contribution of distinctive theories in the different IS research areas?
These important issues not only contribute massively toward our discipline intellectual structure definition, also are the basic concern of scholars in IS, which necessitate this study focusing on the recent publications and applying innovative mixed method.
2 Research Method
This research is conducted in five steps shown in Fig. 1. In the first step, the bibliographic data of scholarly articles published in MIS Quarterly (MISQ) and Information Systems Research (ISR) journals during the last decade (from 2009 to 2018) are retrieved through the Web of Science database. Since the selected journals are two pioneering research journals in IS discipline [9], the analyses are anchored on data extracted from these journals’ publications. The chosen timespan implies that the research questions needed pretty recent scientific evidence to be addressed. Concerning the research aim, from all the bibliographic attributes in the result dataset, we used the cited references attribute, which represents the references cited in the articles published in the mentioned journals and timespan (target articles).

An overview on the research design
In the second and the third steps, the references cited together are analyzed applying co-citation analysis, and the hidden clusters based on the co-citation relationships are revealed. To this end, 154 cited references with the highest number of citations in the target articles are selected and their co-citation network is prepared. The appropriate number of the nodes is determined based on the software’s default suggestion alongside the authors’ judgment about other numbers. In the co-citation network, each node represents a cited reference that its size is defined based on the number of reference’s citations, and the edges between references indicate their co-citations. Since the visualization of the network is distance-based, the more proximity of references cues to their more co-citations and consequently, their more content relatedness. Therefore, it is expected that a group of adjacent nodes forms a cluster of related cited references. The cluster analysis determines these groups and differentiates them with different colors. The apt number of clusters is defined based on the interpretability of different networks with varying numbers of clusters. These two steps are performed using VOSviewer software [21].
It is worth to mention the VOSviewer unified approach based on the compendious discussion provided by Van Eck and Waltman [22]. VOSviewer accomplishes three major tasks, including normalization, mapping, and clustering to generate any variant of clustered bibliometric network, such as a clustered co-citation network. Firstly, VOSviewer takes the association strength normalization, which is extensively explained by Van Eck and Waltman [23], to normalize the high variances between nodes in the number of links they have. Secondly, it maps the normalized network based on a distance-based approach in a two-dimensional space. For this aim, VOSviewer employs the VOS mapping technique discussed by Van Eck, Waltman, Dekker and van den Berg [24] in detail. This technique tries to solve a minimizing problem using a kind of Scaling by MAjorizing a COmplicated Function (SMACOF) algorithm similar to Borg and Groenen [25]. The problem is to minimize a sum of the squared Euclidean distances between all pairs of nodes, in which the squared distance between a pair of nodes is weighted by the similarity between them, subject to the constraint that the average distance between two nodes must be equal to one. Finally, VOSviewer clusters the nodes in the mapped network in such a way that a cluster comprises a group of closely related nodes without any overlap with any other cluster. The VOS clustering technique is completely described by Waltman, Van Eck and Noyons [26]. In this technique, VOSviewer solves a maximizing problem using the Smart Local Moving (SLM) algorithm introduced by Waltman and Van Eck [27]. The problem is to maximize a weighted and parameterized type of the modularity function introduced by Newman and Girvan [28]. In other words, the VOS clustering is a kind of modularity-based clustering. Therefore, VOSviewer solves an optimization problem in both mapping and clustering tasks. There is a notable mathematical relationship between the problems, which is the basis of a unified approach used by VOSviewer to map and cluster the nodes in a bibliometric network.
In the fourth step, the abstracts of cited references appeared in the network are collected. For references without an abstract, the titles have been substituted. Then, the authors attempted to process resulting corpus using text-processing techniques to analyze the references’ content. To this aim, firstly, pre-processing tasks have been conducted by python coding to cleanse the corpus. These tasks include conversion of upper cases to lower cases, removing punctuations and digits, stripping from double-spaces, elimination of stopwords, and stemming. Then, WordItOutFootnote 1, which is an online application for a word-cloud generation, is used to produce clusters’ word-cloud of the clean corpus. Each word-cloud depicts about 100 words with the highest number of frequencies in the corresponding text, in which the size and color of words are defined based on their repetition. RapidMiner software is utilized to analyze words’ occurrences in the clusters’ clean corpus. Thus, the top 20 meaningful words with the highest number of occurrences in the corresponding text for each cluster are detected.
In the last step, the results are evaluated and interpreted. To increase the validity of the results, the authors conducted this step separately and then, they crosschecked the findings and discussed to reach consensus. The dominant research subjects in IS discipline are identified using the text analysis results and scrutinizing the titles and the abstracts of the references appeared in the network. It is expected that combining both quantitative and qualitative findings bring forward some senses which neither of the two methods can achieve solely [29]. Hence, applying both quantitative text-mining techniques and authors’ qualitative judgments in this research led to improved findings. Furthermore, the originating or seminal articles of well-known theories used in the IS research are identified by thorough analyzing the network’s references. In this case, the pertinent literature in IS theories are considered for the inquiry [17, 30,31,32]. By doing so, at the end of this step, in addition to the dominant research subjects, prominent theories applied in IS studies are identified for each cluster to address the research questions.
3 Analysis and Results
Overall, the 929 retrieved articles analyzed contain 41916 bibliographical cited references. This represents an approximate average of 45 references per work. Concerning the numbers, it is impossible to conduct a co-citation analysis of the whole cited references. McCain [33] suggested that a cut-off point could be established to select the most influential studies. Therefore, the current study selected 154 references, which had been cited at least 20 times by the target articles. This threshold is considered based on the software’s default suggestion. The 154 most cited references by MISQ and ISR during the last decade are analyzed in this study.
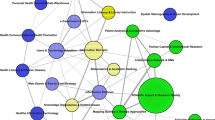
The co-citation network of the highly cited references identifies and illustrates an overall view of the recent IS discipline structure and knowledge groups containing both dominant research subjects and prominent cited theories (see Fig. 2). The size of bubbles represents the normalized number of citations received by the target articles and the thickness of links shows the strength of co-citation ties. The color of a bubble indicates the cluster with which the bubble’s reference is associated. Each bubble is labeled by the author(s) and the publication year of the respective document. As shown in Fig. 2, the co-citation network formed six clusters and analysis of the clusters discloses the groups of references with similarities.

Top cited references co-citation network with clusters
In Table 1 the word clouds show specific common terms that are frequently mentioned in the abstracts (or titles) of the clustered cited references. Each word cloud comprises around 100 items with the highest number of repetitions, in which the color and size of each word is based on its frequency. Additionally, Table 1 includes the top 20 terms as dominant concepts stemmed from the abstracts (or titles) of the cited references and sorted by their occurrences. In other words, the word clouds were generated based on frequencies, but the top 20 terms were identified based on occurrences, each of which has own meaning and provide specific contribution.
3.1 Perceived Recent Intellectual Structure of IS
By meticulous investigation of co-cited pairs identified by VOSviewer, considering the word clouds and the top 20 terms in each cluster, and also by reading the titles and the abstracts of the documents, the dominant research subjects in IS discipline were revealed. Additionally, reflecting the majority of references and carefully reading the whole content of the top 5 cited references in each cluster, we labeled the six clusters shown in Table 2, ranked based on the number of documents they contain and the total number of citations. The first two clusters are the most prominent, jointly representing 42.7% of the documents in the co-citation network and obtaining 44.8% of the citations. Meanwhile, the distribution of documents and citations are almost uniform in other clusters.
The visualization of the density view based on the items proximity analysis carried out by VOSviewer provides a new view of the influential references in IS studies. This particular view allows us to acquire an overview of the general structure of a map and identify specific items, which are at the center of very dense co-citation networks. According to Van Eck and Waltman [21], the density of a point in a map depends on the number of its neighbors and also on the weights of these neighbors. The larger the number of the neighbors and the smaller the distances between them, the more the point density. Point densities are then translated into colors, red corresponds with the highest density and blue relates with the lowest one. The colors indicate the amount of attention researchers pay to the items located in the various areas of the map. In this sense, Fig. 3 shows that there are strong relations between clusters 1 (IS Value), 2 (IS Research), 4 (IS in Organization), and 6 (IS Usage) implying that studies in these clusters use common theories and share a set of cited references heavily. Alongside there are some bridges between clusters 1, 4, and cluster 5 (Social Network Analysis). It represents that these clusters are interrelated and the researchers reciprocally use theories from each other. By contrast, cluster 3 (E-commerce) appears more disconnected from clusters 1 and 4 and it just has some fragile neighborhood and weak links with clusters 2, 5, and 6, which indicates fragmented use of theories in the cluster. The next section will focus on this gap and deeply investigate the relationship between studies in this cluster with theories in other clusters to see if any perceived theoretical gaps could be found.

Top cited references co-citation network with density-based visualization
3.2 Theoretical Foundation of IS Research
Cluster 1 brings up many interesting insights on the underlying strategic dimensions related to the IS practices, such as the contribution of IS in achieving competitive advantages and the IS value in organizations. Studies in this cluster have been mainly built on strategic effects and values theories. Dynamic capabilities [34,35,36], resource-based view [34], theory of competitive strategy [37], theory of administrative behavior [38], absorptive capacity theory [39], and diffusion of innovations theory [40] are the most important theories which have been applied in the cluster 1 studies.
Cluster 2 is named IS research which focused more on the major research issues, methods, and techniques in IS. With the proliferation of Structural Equation Modeling (SEM) methods [41], many IS scholars deployed them as the key multivariate analysis methods to conduct their studies. Therefore, in the second cluster, studies largely cited to the publications about SEM methodologies, issues, or errors. Since some studies in this cluster used psychological metrics, methods, or measurements, theories that were exploited by IS researchers for this purpose are psychometric theory [42, 43] and general deterrence theory [44].
During the last two decades, research about e-commerce aligned with its dramatic growth has been significantly increased. In the target articles, it is perceived that researchers mainly studied e-commerce adoption covering online trust and e-marketing issues including the impact of e-WoM and recommender systems in online customer purchase decisions. Most influential references in the field of e-commerce have been enlisted in cluster 3, and the theory of industrial organization [45] and prospect theory [46] are the two most important theories cited by the target articles.
The main subject of cluster 4 is IS in organization. The research theme of this cluster is primarily about implementing IS in organizations and its effects on organizational performance, structure, business processes, and employees. Design theory [47] and adaptive structuration theory [48] were extensively utilized and also many scholars applied grounded theory [49] to conduct their studies.
According to the popularity of social media as an important part of the people’s daily life, academics, and practitioners increasingly observe social networks, and it becomes the focus of attention in recent studies. Cluster 5 represents a number of studies directed to investigate the relationships, interactions, knowledge sharing, and social structures in different virtual platforms. Social network theories [50,51,52,53,54], organizational ambidexterity [55], and diffusion of innovations theory [56] are the influential theories in this cluster.
Due to the huge amount of investment in IS, identifying influential factors on IS usage and technology acceptance across different settings have been an important and focal interest in IS scholarship (cluster 6). With these purpose, IS academics mainly refer to Unified Theory of Acceptance and Use of Technology (UTAUT) [57], Technology Acceptance Model (TAM) [58, 59], DeLone and McLean IS success model [60, 61], theory of planned behavior [62], task-technology fit [63], and computer self-efficacy [64].
In summary, Fig. 4 shows the mind-map of dominant IS research subjects and prominent theories have been exploited in these areas, which is produced using MindMupFootnote 2 software.

Mind-map of dominant IS research subjects with respective prominent theories
3.3 The Eminent Theoretical Gap and the Future Direction
Meticulously consideration of the publications in each cluster reveals that studies in cluster 3, e-commerce, used fewer theories and it seems that a strong theoretical base has not yet evolved in this cluster. Therefore, a theoretical gap could be perceived in applying the fundamental related theories by the research in this cluster. To objectively examine this cluster in-depth, we built a table to check the strength of the co-citation links by mapping cited references in cluster 3 with the extracted theories in the other clusters (Table 3)Footnote 3. Accordingly, the codes are assigned to the cited references in cluster 3 and the applied theories in other clusters (Appendix 1).
In accordance with the density view (Fig. 3), which mentioned before, the results of Table 3 show that e-commerce studies are almost disintegrated from theories in clusters 1 and 4. However, dynamic capabilities (18 points) and design research (14 points) have been used in some e-commerce studies. For the other clusters, it is noticeable that social network theories (66 points) have been used comparatively more in e-commerce research. Acceptance models such as UTAUT (53 points), TAM (48 points), and IS success models (40 points) are the other highlighted theories that were applied in this field. Also, some e-commerce studies were found in examining trust, which especially exploited psychological metrics (37 points) for measuring knowledge, abilities, attitudes, and personality traits.
Generally, our analysis divulged that besides social network theories, there are some links between cluster 3 studies and theories in cluster 6. On the other side, it can be seen that the applications of cluster 1 and 4 theories are thin, and the e-commerce research is less related to those two clusters. Furthermore, it seems that SEM methods have been used much less in e-commerce research in comparison to the other IS studies.
4 Conclusion
In this research, we tried to shed light on the IS theoretical foundation in the last decade, especially with respect to how different groups of studies interrelate with one another in the context of the theory exploitation. One of the innovations of this research is applying a mixed method, which provides us an objective tool besides qualitative interpretation to identify the main research streams and the potential new directions within the field under investigation. Six different clusters in the co-citation network were identified as the pillars of the semantic structure shaping the IS discipline: IS Value (Cluster 1, in red), IS Research (Cluster 2, in green), E-commerce (Cluster 3, in blue), IS in Organization (Cluster 4, in yellow), Social Network Analysis (Cluster 5, in purple), and IS Usage (Cluster 6, in cyan). Among these groups, cluster 1 and cluster 2 have the most citations and documents. It shows strategic theories such as dynamic capabilities and theory of competitive advantage and IS research methods and theories are prominent cited theories in the recently published articles in MISQ and ISR. Investigating theories used in each cluster shows that some of the IS research streams have stronger theoretical foundations than the others. Alternatively, studies in these weaker clusters might be getting published in other journals. By analyzing inter-cluster linkages, the other contribution of this research is clearly emerging the fact that some clusters have more theoretical relations with each other. It means that studies in these clusters have extensively applied theoretical foundations of each other. In contrast, few relations of cluster 3 (E-commerce) with other clusters were discovered that demonstrates interrelated theoretical gap in this type of studies. Examining the relationships of cited references of e-commerce studies with explored theories in the other clusters let us suppose that future research in this area could mainly focus on theoretical foundations which were used less in the recent years. So as the final contribution, we propose some hypotheses about the application of the prominent theories related to clusters 1, 2, and 4 in e-commerce future studies. Firstly, the relationships between e-commerce and strategic values and competitive advantages (cluster 1) could be better analyzed by future studies through focusing on aspects that are either internal or external to the firms. Also, using of SEM methods or other IS research methods (cluster 2) in this group of studies might be more considered. Finally, capturing complexity of e-commerce in organizations and societies (cluster 4) is another probable research theme that could be followed.
4.1 Limitations and Future Research
This study only set out the starting point for further analyses that aim at a better understanding of the current IS theoretical foundation and its future destiny. Therefore, some limitations in the current study have to be mentioned. The source data in the last decade from MISQ and ISR does not consist of all the research articles in our discipline. Future research could include the AIS ‘‘basket of eight” IS journalsFootnote 4 and expand the timespan to 20 years. We tried to minimize subjectivity by adopting a consistent procedure but a little bit of human opinion and interpretations were needed to make the results meaningful. In future research, other complementary quantitative methods along the co-citation networks could be exploited to assess intra- and inter-cluster analysis.
Notes
- 1.
- 2.
- 3.
In the case of co-citation links between cited references, the strength of a link indicates the number of publications in which two references are cited together.
- 4.
http://aisnet.org/?SeniorScholarBasket, accessed 26-04-2019.
References
Agarwal, R., Lucas Jr., H.C.: The information systems identity crisis: focusing on high-visibility and high-impact research. MIS Q. 29, 381–398 (2005)
Benbasat, I., Zmud, R.W.: The identity crisis within the IS discipline: defining and communicating the discipline’s core properties. MIS Q. 27, 183–194 (2003)
Galliers, R.D.: Change as crisis or growth? Toward a trans-disciplinary view of information systems as a field of study: a response to Benbasat and Zmud’s Call for returning to the IT artifact. J. Assoc. Inf. Syst. 4, 337–351 (2003)
Teo, T.S., Srivastava, S.C.: Information systems (IS) discipline identity: a review and framework. Commun. Assoc. Inf. Syst. 20, 518–544 (2007)
Kohli, R., Grover, V.: Business value of IT: an essay on expanding research directions to keep up with the times. J. Assoc. Inf. Syst. 9, 23–39 (2008)
Melville, N., Kraemer, K., Gurbaxani, V.: Information technology and organizational performance: an integrative model of IT business value. MIS Q. 28, 283–322 (2004)
Raghupathi, V., Weiser Friedman, L.: A framework for information systems metaresearch: the quest for identity. Commun. Assoc. Inf. Syst. 24, 333–350 (2009)
Palvia, P., Kakhki, M.D., Ghoshal, T., Uppala, V., Wang, W.: Methodological and topic trends in information systems research: a meta-analysis of IS journals. Commun. Assoc. Inf. Syst. 37, 630–650 (2015)
Gregor, S.: The nature of theory in information systems. MIS Q. 30, 611–642 (2006)
Avison, D., Malaurent, J.: Is theory king?: questioning the theory fetish in information systems. J. Inf. Technol. 29, 1–10 (2014)
Mueller, B., Urbach, N.: Understanding the why, what, and how of theories in IS research. Commun. Assoc. Inf. Syst. 41, 349–388 (2017)
Beller, S., Bender, A.: Theory, the final frontier? A corpus-based analysis of the role of theory in psychological articles. Front. Psychol. 8, 1–16 (2017)
Rai, A.: Editor’s comments: beyond outdated labels: the blending of IS research traditions. MIS Q. 42, 3–6 (2018)
Burton-Jones, A., Butler, B., Scott, S., Xu, S.X.: Next-generation information systems theories. MIS Quarterly Call for Papers (2018). http://www.misq.org/skin/frontend/default/misq/pdf/CurrentCalls/NextGenerationIS_Full.pdf
Asatani, K., Mori, J., Ochi, M., Sakata, I.: Detecting trends in academic research from a citation network using network representation learning. PLoS ONE 13, 1–13 (2018)
de Vaujany, F.X., Lesca, N., Fomin, V.V., Loebbecke, C.: The espoused theories of IS: a study of general editorial statements. In: Proceedings of the 29th International Conference on Information Systems, pp. 1–18. AIS, Paris (2008)
Lim, S., Saldanha, T.J., Malladi, S., Melville, N.: Theories used in information systems research: insights from complex network analysis. JITTA J. Inf. Technol. Theory Appl. 14, 5–44 (2013)
Moody, D.L., Iacob, M.E., Amrit, C., Müller, R.: In search of paradigms: identifying the theoretical foundations of the is field. In: Alexander, P.M., Turpin, M., van Deventer, J.P. (eds.) Proceedings of the 18th European Conference on Information Systems, pp. 1–13. AIS, Pretoria (2010)
Soper, D.S., Turel, O., Geri, N.: The intellectual core of the IS field: a systematic exploration of theories in our top journals. In: Sprague Jr, R.H. (ed.) Proceedings of the 47th Hawaii International Conference on System Sciences, pp. 4629–4638. IEEE, Waikoloa (2014)
Weber, R.: Evaluating and developing theories in the information systems discipline. J. Assoc. Inf. Syst. 13, 1–30 (2012)
Van Eck, N.J., Waltman, L.: Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 84, 523–538 (2010)
Van Eck, N.J., Waltman, L.: Visualizing bibliometric networks. In: Ding, Y., Rousseau, R., Wolfram, D. (eds.) Measuring Scholarly Impact: Methods and Practice, pp. 285–320. Springer, New York (2014). https://doi.org/10.1007/978-3-319-10377-8_13
Van Eck, N.J., Waltman, L.: How to normalize cooccurrence data? An analysis of some well-known similarity measures. J. Am. Soc. Inf. Sci. Technol. 60, 1635–1651 (2009)
Van Eck, N.J., Waltman, L., Dekker, R., van den Berg, J.: A comparison of two techniques for bibliometric mapping: multidimensional scaling and VOS. J. Am. Soc. Inf. Sci. Technol. 61, 2405–2416 (2010)
Borg, I., Groenen, P.: Modern Multidimensional Scaling. Springer, New York (2005). https://doi.org/10.1007/0-387-28981-X
Waltman, L., Van Eck, N.J., Noyons, E.C.: A unified approach to mapping and clustering of bibliometric networks. J. Informetr. 4, 629–635 (2010)
Waltman, L., Van Eck, N.J.: A smart local moving algorithm for large-scale modularity-based community detection. Eur. Phys. J. B 86, 1–33 (2013)
Newman, M.E., Girvan, M.: Finding and evaluating community structure in networks. Phys. Rev. E 69, 1–16 (2004)
Ivankova, N.V., Creswell, J.W.: Mixed methods. In: Heigham, J., Croker, R.A. (eds.) Qualitative Research in Applied Linguistics: A Practical Introduction, pp. 135–161. Palgrave Macmillan, New York (2009)
Dwivedi, Y.K., Wade, M.R., Schneberger, S.L.: Information Systems Theory: Explaining and Predicting Our Digital Society. Springer, Dordrecht (2011). https://doi.org/10.1007/978-1-4419-6108-2
Larsen, K.R., Eargle, D.: Theories Used in IS Research Wiki (2015). http://IS.TheorizeIt.org
Lim, S., Saldanha, T.J., Malladi, S., Melville, N.: Theories used in information systems research: identifying theory networks in leading IS journals. In: Nunamaker Jr, J.F., Currie, W.L. (eds.) Proceedings of the 30th International Conference on Information Systems, pp. 1–10. AIS, Phoenix (2009)
McCain, K.W.: Mapping authors in intellectual space: a technical overview. J. Am. Soc. Inf. Sci. 41, 433–443 (1990)
Barney, J.: Firm resources and sustained competitive advantage. J. Manag. 17, 99–120 (1991)
Eisenhardt, K.M., Martin, J.A.: Dynamic capabilities: what are they? Strateg. Manag. J. 21, 1105–1121 (2000)
Teece, D.J., Pisano, G., Shuen, A.: Dynamic capabilities and strategic management. Strateg. Manag. J. 18, 509–533 (1997)
Porter, M.E.: Competitive Strategy. Free Press, New York (1980)
March, J.G., Simon, H.A.: Organizations. Wiley, New York (1958)
Cohen, W.M., Levinthal, D.A.: Absorptive capacity: a new perspective on learning and innovation. Adm. Sci. Q. 35, 128–152 (1990)
Rogers, E.M.: Diffusion of Innovations. Free Press, New York (1995)
Gefen, D., Rigdon, E.E., Straub, D.W.: Editor’s comments: an update and extension to SEM guidelines for administrative and social science research. MIS Q. 35, 3–14 (2011)
Nunnally, J.C.: Psychometric Theory. McGraw-Hill, New York (1978)
Nunnally, J.C., Bernstein, I.H.: Psychometric Theory. McGraw-Hill, New York (1994)
Straub, D.W., Welke, R.J.: Coping with systems risk: security planning models for management decision making. MIS Q. 22, 441–469 (1998)
Tirole, J.: The Theory of Industrial Organisation. MIT Press, Cambridge (1988)
Kahneman, D., Tversky, A.: Prospect theory: an analysis of decision under risk. Econometrica 47, 262–291 (1979)
Hevner, A.R., March, S.T., Park, J., Ram, S.: Design science in information systems research. MIS Q. 28, 75–105 (2004)
DeSanctis, G., Poole, M.S.: Capturing the complexity in advanced technology use: adaptive structuration theory. Organ. Sci. 5, 121–147 (1994)
Glaser, B.G., Strauss, A.L.: The Discovery of Grounded Theory: Strategies for Qualitative Research. Aldine, Chicago (1967)
Burt, R.S.: Structural holes: the social structure of competition. Harvard University Press, Cambridge (1992)
Constant, D., Sproull, L., Kiesler, S.: The kindness of strangers: the usefulness of electronic weak ties for technical advice. Organ. Sci. 7, 119–135 (1996)
Freeman, L.C.: Centrality in social networks conceptual clarification. Soc. Netw. 1, 215–239 (1979)
Granovetter, M.S.: The strength of weak ties. Soc. Netw. 78, 1360–1380 (1973)
Wasserman, S., Faust, K.: Social Network Analysis: Methods and Applications. Cambridge University Press, New York (1994)
March, J.G.: Exploration and exploitation in organizational learning. Organ. Sci. 2, 71–87 (1991)
Rogers, E.M.: Diffusion of Innovations. Free Press, New York (2003)
Venkatesh, V., Morris, M.G., Davis, G.B., Davis, F.D.: User acceptance of information technology: toward a unified view. MIS Q. 27, 425–478 (2003)
Davis, F.D.: Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 13, 319–340 (1989)
Davis, F.D., Bagozzi, R.P., Warshaw, P.R.: User acceptance of computer technology: a comparison of two theoretical models. Manag. Sci. 35, 982–1003 (1989)
DeLone, W.H., McLean, E.R.: Information systems success: the quest for the dependent variable. Inf. Syst. Res. 3, 60–95 (1992)
Delone, W.H., McLean, E.R.: The DeLone and McLean model of information systems success: a ten-year update. J. Manag. Inf. Syst. 19, 9–30 (2003)
Ajzen, I.: The theory of planned behavior. Organ. Behav. Hum. Decis. Process. 50, 179–211 (1991)
Goodhue, D.L., Thompson, R.L.: Task-technology fit and individual performance. MIS Q. 19, 213–236 (1995)
Compeau, D.R., Higgins, C.A.: Computer self-efficacy: development of a measure and initial test. MIS Q. 19, 189–211 (1995)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix 1. Cited Theories in Clusters 1, 2, 4, 5, and 6
Appendix 1. Cited Theories in Clusters 1, 2, 4, 5, and 6
Theory | ID | Theory | ID |
|---|---|---|---|
Dynamic capabilities | T1 | Grounded theory | T11 |
Resource-based view of the firm | T2 | Social network theories | T12 |
Competitive strategy | T3 | Organizational ambidexterity | T13 |
Theory of administrative behaviour | T4 | Unified theory of acceptance and use of technology | T14 |
Absorptive capacity theory | T5 | Technology acceptance model | T15 |
Diffusion of innovations theory | T6 | DeLone and McLean IS success model | T16 |
Psychometric theory | T7 | Theory of planned behaviour | T17 |
General deterrence theory | T8 | Task-technology fit | T18 |
Design theory | T9 | Computer self-efficacy | T19 |
Adaptive structuration theory | T10 | ||
Rights and permissions
Copyright information
© 2019 IFIP International Federation for Information Processing
About this paper

Cite this paper
Hajiheydari, N., Delgosha, M.S., Talafidaryani, M. (2019). IS Research Theoretical Foundation: Theories Used and the Future Path. In: Doucek, P., Basl, J., Tjoa, A., Raffai, M., Pavlicek, A., Detter, K. (eds) Research and Practical Issues of Enterprise Information Systems. CONFENIS 2019. Lecture Notes in Business Information Processing, vol 375. Springer, Cham. https://doi.org/10.1007/978-3-030-37632-1_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-37632-1_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-37631-4
Online ISBN: 978-3-030-37632-1
eBook Packages: Computer ScienceComputer Science (R0)