
Abstract
Functional, structural and operational testing are three broad categories of software testing methods driven by the product functionalities, the way it is implemented, and the way it is expected to be used, respectively. A large body of the software testing literature is devoted to evaluate and compare test techniques in these categories. Although it appears reasonable to devise hybrid methods to merge their different strengths - because different techniques may complement each other by targeting different types of faults and/or using different artifacts - we still miss clear guidelines on how to best combine them.
We discuss differences and limitations of two popular testing approaches, namely coverage-driven and operational-profile testing, belonging to structural and operational testing, respectively. We show why and how test coverage and operational profile can cross-fertilize each other, improving the effectiveness of structural testing or, conversely, the product reliability achievable by operational testing.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Testing is an essential part of the software development and maintenance processes. It consists of the dynamic assessment of software behavior on a finite sample of executions. To make testing systematic and to measure progress while tests are executed, some strategy is necessary. It will help testers to keep costs within reasonable bounds and to identify those test cases deemed the most effective.

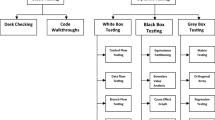
Test strategies and their potential relations.
Broadly speaking, systematic testing strategies are driven by three major aspects of the software under test (SUT): (i) what it is expected to do, (ii) how it is implemented, and (iii) how it will be used. Such three aspects correspond to three major categories of software testing techniques, namely functional, structural and operational testing (Fig. 1).
Each category relies on different assumptions and artifacts, and a broad variety of techniques and tools for each one has been proposed.
Since the early years of software testing discipline, researchers have conducted analytical and empirical studies to evaluate and compare the effectiveness of the different test techniques, in search for the most cost-effective approach.
From such studies we have learned that testing techniques may suffer from saturation effects and from various other limitations, and that there exist no one technique which best suits all circumstances. Different test techniques target different types of faults and thus may complement each other. For this reason, it is reasonable to invest resources by properly combining different techniques, rather than employing all the testing budget in only one selected strategy.
However, there are not many proposals for hybrid techniques merging the respective strengths of functional, structural and operational testing (examples are [7, 8, 10]), and no widely accepted guidelines on how different methods could be combined into one effective strategy are available. Further research is needed to understand how such strategies could be combined, depending on the testing purpose and the available artifacts.
As a step forward in this direction, we discuss the differences and respective limitations of two popular testing approaches: techniques driven by code coverage information, and techniques driven by the operational profile. Traditionally these two test approaches are adopted to address different purposes: coverage-driven testing aims at finding as many faults as possible, whereas operational-profile driven testing aims at improving software reliability. So, apparently, they seem to belong to two worlds apart, and in fact there is little overlap between research progresses. However, we have found that on the one side coverage criteria can be made more effective if not all entities are considered equal, but software usage in operation is referred to assign them different weights. On the other side, software reliability testing can be made more effective as well if coverage information is considered alongside the operational profile in selecting the test cases.
Our reported results provide only an incomplete vision of several other potential “hybridizations”. For instance, we have not considered yet the usage of functional strategies where software specifications or models are available. In presenting how coverage criteria and reliability improvement can benefit each other our contribution is one step towards unleashing the potential of many more useful combination of techniques.
The chapter is structured as follows. Section 2 describes the main concepts of test coverage and related measures in debug testing. Section 3 presents the rationale behind software reliability testing techniques. Section 4 discusses the relationship between coverage and reliability, and how these can benefit each other. Section 5 describes related work on combining white-box and operational testing. Section 6 concludes the chapter.
2 On Test Coverage Measures
Software testing can pursue different goals. Along the development process, testing may aim at detecting as many faults as possible so that these can be removed before the software goes in production. For this reason, this type of testing is referred to in the literature as debug testing [15].
Measures of effectiveness of debug testing techniques are related with its faults finding capability. For example, a test technique would be evaluated more effective than another if it detects the first fault by executing a lower number of test cases, or otherwise if by executing an equal number of test cases the former finds a higher number of faults than the latter.
Along such line of reasoning, measuring the coverage of which and how many program elements are exercised during test execution is seen by many as an appealing proxy for assessing fault finding effectiveness. The intuition is that if a fault resides in a part of code that is never tested, such fault would never be activated and hence would survive testing, probably remaining undetected until the final user will eventually trigger it. In his seminal and highly-referenced book on “Software Testing Techniques” [3], Beizer defined leaving parts of code untested as “stupid, shortsighted and irresponsible”.
Depending on which elements of code are targeted, in the years a broad variety of test coverage criteria have been proposed [16, 47]. All of them basically share the following scheme: an element of the program source code is identified as the type of entity to be covered. This element can be as basic as every statement or every branch of the program control flow, or become more sophisticated, such as for example every association between the definition of a variable and all its potential usages, for every variable in the program (all definition-use associations [16]). Then the source code of the SUT is parsed and instrumented, so that the coverage of the targeted elements can be monitored during testing. While test proceeds, a quantitative assessment of the thoroughness of testing is provided by the ratio between the number of entities that have been already covered and the cardinality of the whole set of entities, expressed by the percentage:
The underlying idea of coverage criteria is that until there remain entities that have not been exercised, the testing cannot be deemed complete, and more test cases have to be executed that can increase the above ratio. Therefore, coverage measures provide both a practical stopping rule (when a satisfying coverage is achieved), and a guide for the selection of additional test cases (i.e., those covering yet uncovered entities).
There exist no proven direct relation, for any of the existing criteria, that when complete test coverage is achieved, then the SUT can be guaranteed to be defect-free. Since testing is essentially a sampling from a practically infinite set of executions [4], it is obvious to everyone that no finite test campaign can ensure correctness. Indeed, the most famous quotation about software testing is probably Dijkstra’s aphorism that software testing can only show the presence of bugs, but never their absence [13]. In search for more effective testing strategies, the realistic goal is not to remove all faults, but rather to maximize the likelihood of revealing potential failures.
Coverage criteria can be considered as belonging to partition testing strategies that divide the input domain into equivalence classes (even though they generally create overlapping subdomains and not true partitions), and ensure to pick representative test cases (at least one) from each class. Theoretical analyses of partition testing strategies [44] have early shown that their effectiveness depends on how and where the failure-causing inputs are located, which is of course beyond testers’ control and knowledge. The root of the problem is what Roper called the “missing link”: we still cannot (will we ever be able to?) establish a logical or practical “link between the adequacy criteria and attributes of the program under test such as its reliability or number of faults” [37]. Thus, the only way to establish whether a relation exists between coverage of some entity type and fault finding effectiveness is through empirical studies, and in fact a series of such studies has been and continues to be undertaken by several researchers, e.g., [23, 43], but no definitive answers are available yet.
More properly, we must understand that what coverage measures provide us is an assessment of a test suite thoroughness. At the same time, some researchers have raised concerns against misusing coverage as the main goal of testing [18, 27]. In such light, additional test cases that do not contribute to increase coverage would be considered “redundant” and not useful, however such test cases could indeed be able to catch still undetected faults. We should also never forget the cost in terms of time consumed in monitoring coverage, which makes white-box testing impractical on large scales [21].
In conclusion, coverage criteria provide a very useful and practical means towards systematic thorough testing. However, “100% coverage should always be the result of good testing but it makes few sense as a goal in itself”[36].
3 On Software Reliability
Testing to find as many faults as possible may seem a good strategy. However, in real-world production we have to face stringent time and budget constraints, which make Herzig note that “There’s never enough time to do all the testing you want” [20]. Henceforth, this strategy could not be the best choice.
The point is that debug testing targets all faults indiscriminately, without considering the important difference between a fault (the cause) and a failure (its manifestation), nor the likelihood and potential impacts of the failure originating from a given fault. Indeed, not all faults are created equal. An early seminal study by Adams [1] showed, for example, that the 30% of the faults found in the systems he studied (at the time in IBM production) would each show itself less then once every 5,000 years of operational use. Clearly any testing effort spent to find these “tiny” faults would not be well employed.
This brings us to the fundamental concept of software reliability, which is “the probability of failure-free operation for a specified period of time in a specified environment” [24]. When the SUT is not safety-critical, testing to improve software reliability may be a more convenient aim than debug testing: in other words, we acknowledge that we would never be able to find all faults, and aim at focusing our efforts towards those ones whose removal mostly contributes to increase reliability.
Pioneered in the 70’s by Musa [30], software reliability testing is based on the notion of the operational profile [31, 40], which provides a quantitative characterization of how a system will be used in the field. In operational profile-based testing (OP testing in the following), the SUT is thus tested by trying to reproduce how its final users will exercise it, so that the failures are detected with the same likelihood they would be experimented by those users in operation.
The operational profile is normally built by associating the points in the input domain D with values representing the probability to be invoked in operation. Making such association is a difficult task; the best case is when historical data are available, otherwise this can be done by domain experts. Usually, D is divided into M subdomains \(D_1, \dots , D_m\), so that the inputs within a partition are estimated as having the same probability of occurrence in operation. The operational profile is then defined by a probability distribution over the partitions \(D_i\): a value \(p_i\) denotes the probability that in operation an input is selected from \(D_i \), with \(\sum _{i=1}^{M} p_i = 1\). The software reliability, R, can then be defined [15] as:
where F is the (unknown) set of failure-causing inputs and \(p_t\) is the expected probability of occurrence in operation of input t.
OP testing has been shown to be an effective strategy, both in theory [15] and in practice, e.g., [14, 42]. With this strategy, when the test is stopped (for instance because of imperative schedule constraints) and the software released, testers are ensured that the most-frequently invoked operations have received the greatest attention, so that the delivered reliability is at the maximum level achievable under the given test resources [26].
However, OP testing faces difficult challenges that may hinder its broad take-up: first, an operational profile may not be readily available and its derivation can be costly and complex [22]; second, as more frequent failures are detected and removed, the application of OP testing may progressively lose efficacy.
The latter problem is known as the saturation effect [22]. Actually, it is not a prerogative of OP testing, but could affect any test technique. To counteract saturation, research has shown that it is convenient to always consider a combination of different testing strategies, which target different types of faults and can together achieve higher effectiveness than the individual application of the most effective technique [25]. Considering specifically reliability improvement, the authors of [11] suggest that the combination of techniques should aim at exposing failures with high occurrence probability, but also as many failure regions as possible.Footnote 1
4 How Are Coverage and Reliability Related?
4.1 Ways of Combining Coverage Measures and Operational Profile
In the previous sections we have overviewed two widely used testing strategies, which employ different techniques and pursue different goals. Indeed, coverage testing and OP testing have formed two separate threads of the software testing literature, with little overlaps (see Sect. 5).
In recent work, we have addressed the question whether and how coverage and OP testing techniques could mutually benefit each other towards the goal of increasing software testing effectiveness for reliability improvement. Indeed, we have achieved encouraging results in either directions.
On the one hand, we have found that coverage testing can be made more cost-effective if not all entities are indiscriminately targeted, but a subset of entities is selected based on their relevance for the final user. In other terms, we have somehow embedded a notion of operational profile within the definition of coverage measures. This research has been presented in [29], and is summarized in Sect. 4.2.
On the other hand, we have found that using coverage information can help prevent the saturation effect of OP testing and achieve higher effectiveness in reliability improvement. In other terms, to further improve reliability beyond a certain point, within a selected input subdomain the testing should target those entities that are the most rarely covered. This research has been presented in [5], and is summarized in Sect. 4.3.
4.2 Mimicking Operational Profile by Means of Coverage Count Spectrum
The leading idea of OP testing is exercising the SUT in similar way to how their final users would do. OP testing is inherently a black-box technique, since it disregards the SUT internal structure. Conversely, in coverage testing, a tester tries to exercise the SUT thoroughly without leaving parts untested, no matter of whether and how final users will exercise them. One attractive feature of coverage testing is the availability of a simple and intuitive stopping rule, which is provided, as said, by the coverage measure. On its side, OP testing lacks such a straightforward adequacy criterion.
In traditional coverage testing, while testing proceeds each entity is marked as covered or not covered, i.e., from monitoring code coverage testers derive the so-called hit spectrum. In general, a program spectrum [19] characterizes a program’s behavior by recording the set of entities that are exercised as it executes. The hit spectrum, in particular, records if an entity is covered (“hit”) or not. When used in operation, the different program entities will be covered with different frequencies. Some entities will never be exercised, others will be accessed only few times, and others will be covered very frequently. The hit spectrum does not give any information about this varied usage of program entities, beyond revealing that some entities have never been exercised and hence are probably “out-of-scope”. Conversely, the count spectrum records how many times an entity is exercised: by referring during coverage testing to the count spectrum rather than to the normally used hit spectrum, we keep track of the frequency with which each entity is covered.
As an example, Table 1 displays the branch-hit and branch-count spectra of two test cases \(TC_1\) and \(TC_2\) exercised during a test campaign. Both \(TC_1\) and \(TC_2\) cover the same set of branches, thus their hit spectra are identical. If we look at their count spectra, we can notice that \(TC_1\) and \(TC_2\) exercise the SUT quite differently.
Hence, the count spectrum could be used to obtain an approximate representation of how the final users behaviour impacts on the SUT code. Such intuition inspired us the idea of “operational coverage”: using the count spectrum, it measures code coverage taking into account whether and how the entities are relevant with respect to a user’s operational profile.
In principle, the notion can be applied to any existing coverage criterion. In previous work [28, 29], we studied operational coverage for three types of entities, namely statements, branches and functions.
To measure operational coverage, we developed the following method. First, program entities are classified into different importance groups based on the count spectrum. Consider, for instance, three importance groups, denominated high, medium, and low. To cluster entities into these three groups, the list of entities is ordered according to their usage frequency; the first 1/3 entities are assigned to the high frequency group; the second 1/3 entities to the medium frequency group; and the last 1/3 entities to the low frequency group. Of course, different grouping schemes could be adopted.
Then, different weights are assigned to the importance groups to reflect the operational profile. We gave the highest weight to entities in the high group, and the lowest weight to the low group. Entities that are never covered are assign a zero weight (they are out-of-scope).
Finally, the operational coverage is computed as the weighted arithmetic mean of the rate of covered entities according to the Equation:
where: \(x_{i}\) is the rate of covered entities from group i; \(w_{i}\) is the weight assigned to group i. Note that reducing the above formula to only one group we re-obtain the formula of traditional coverage as per Eq. 1.
Operational coverage can be used both as an adequacy criterion and as a selection criterion. In the former case, we use operational coverage for deciding when to stop testing: intuitively, the coverage measure that we achieve during testing gives a weighted estimation of how many of the entities that are more relevant for the final users have been covered. The weights allow testers to take into account if the not yet covered entities may have a large impact on the delivered reliability. For the same reason, using operational coverage in test selection provides a criterion to prioritize the next test cases to be executed.
In [29], we performed some empirical studies to assess operational coverage and the results confirmed the above intuition. Precisely, operational coverage is better correlated than traditional coverage with the probability that the next test case will not fail while performing OP testing. Regarding test case selection, operational coverage on average outperforms traditional coverage in terms of test suite size and fault detection capability.
4.3 Boosting Reliability Improvement by Targeting the Lowest Covered Entities
As described in Sect. 3, in OP testing the test cases are selected from the operational profile, aiming at finding the failure-causing inputs that have the highest likelihood of being invoked in operation. However, as we already observed, due to the saturation effect [22], after some testing campaign in which the most frequent faults have been revealed and removed, continuing to perform OP testing will progressively lose its efficacy.
Saturation is a well-known problem, and advanced approaches have been proposed to counteract it. For example, Cotroneo and coauthors [11] have recently developed the RELAI technique that uses an adaptive scheme for redefining the operational profile, dynamically learning from the test outcomes. Indeed, to continue improving reliability, at a certain point it becomes necessary to find a proper strategy to move farther from the most frequently exercised operations and start “digging” in less frequent zones of the input domain.
In line with [25] that suggests to combine different testing approaches, we explored whether considering code coverage as an additional information to the operational profile helps achieving higher reliability. The intuition is that coverage-driven selection can point to parts of the program that have not been exercised by the operational profile driven test cases and that may contain faults. However, even so, we would like to take into account the user’s profile, because the aim remains to improve reliability.
Along such line of reasoning, we have recently developed a hybrid approach that relies on both operational profile and coverage information, the latter specifically considering the above introduced count spectrum [5]. The approach, called covrel, works in iterations: each iteration dynamically uses the test outcomes from previous iteration to re-arrange the operational profile. This adaptation is based on an inference method called Importance Sampling (IS) method [6], which was previously used in the already cited work [11].
Each iteration consists of two steps. First, a partition of the input domain into subdomains \(D_i\) is dynamically redefined. In line with traditional OP testing (see Sect. 3), this step allows to assign probability values to inputs. More precisely, at each iteration the output of the first step is the number of test cases to execute from within each partition (for more details we refer the reader to [5]). In the second step, among all the inputs within a partition (i.e., having a same occurrence probability), covrel selects those that exercise the least covered entities according to the count spectrum. This is the novel aspect of covrel, in comparison with the more usual approach of selecting such test cases in random way. Of course, to do so covrel assumes that the SUT is instrumented and test traces are tracked, as in any white-box testing strategy.
Note that similarly to operational coverage (Sect. 4.2), the covrel strategy derives the count spectrum and classifies the entities into three different importance groups: high, medium, and low. However, differently from operational coverage, in covrel we are interested in covering the most “hidden” entities. Therefore, we assign the weights for the importance groups prioritizing the low group. Then, for each partition, we select the test cases with the highest ranks. The two steps are repeated until the available budget of test cases exhausts.
In [5] we have evaluated covrel against traditional OP testing with controlled experiments. The results showed that covrel can outperform OP testing and achieve faster a given reliability value. The performance of covrel is better considering high values of reliability, confirming the intuition that the extra costs it requires for coverage measurement do pay when a high value of reliability is required.
5 Related Work
While a huge literature exists about the topics of coverage testing and OP testing considered individually, here we are concerned with the interplay between the two worlds. As anticipated in Sect. 4.1, there have been only few overlaps between the two research communities. These overlaps have interested mostly the investigation of the effectiveness of coverage testing in terms of reliability improvement instead of fault finding, as, e.g., in [12, 17] and the usage of coverage information for refining software reliability growth models, as surveyed in [2].
Related approaches of interest are those exploring some direct or indirect knowledge derived from the program code (i.e., white-box information) or from the development process in order to either improve or assess reliability.
Smidts et al. consider operational testing as a means to corroborate (rather than to assess) an already assessed reliability, by complementing evidences gained in previous phases of the development process (e.g., by white-box testing) [39]. This is a problem particularly felt in ultra-reliable systems, where no failures are observed during testing, making operational testing not able, by itself, to give confidence about reliability.
Neil et al. propose to use Bayesian networks (BN) as a means to combine evidences: in their example, many pieces of information coming from development-time activities, including code coverage and operational profile, are used together with test results as evidence to assess reliability [32]. A Bayesian approach is also proposed by Singh et al., who use reliability prediction obtained from UML models as the prior belief for reliability assessment in system operational testing [38].
In a PhD proposal by Omri [33], white-box information is used in combination with the operational profile, again with the aim of estimating reliability; the author applies symbolic execution combined with stratified sampling to derive the most favorable partitions for minimizing the variance of the estimate. We too have conjectured the usage of white-box information such as coverage as a means to modify the belief about the partitions’ failure proneness, with the aim of driving the profile-based test generation process [34, 35].
All these approaches try to augment the profile-based testing with other pieces of information so as to expose more reliability-impacting failing inputs. None, however, directly embeds code coverage information into the test selection or generation process like covrel [5].
Our operational coverage and covrel approaches rely on the coverage count spectrum. The idea of using program spectra to help software validation tasks is not new: program spectra have been used, among others, for fault localization [45] and regression testing [46]. To the best of our knowledge, however, we are the first to compute coverage measures based on program count spectra, for the purpose of reflecting the importance of program entities.
One more feature of our approaches is adaptivity. Many authors have exploited adaptivity for improving testing. A noticeable example is the well-known family of Adaptive Random Testing (ART) techniques by Chen et al. [8], in which the intuition is to improve random testing by using test results online in order to evenly distribute test cases across the input domain. ART is aimed at debug testing; as such, it does not explicitly target reliability improvement and/or assessment like OP testing. Adaptive testing, proposed by Cai et al., uses the operational profile for reliability assessment and foresees adaptation (via controlled Markov chains) in the assignment of test cases to partitions [7]. Both these approaches use neither coverage nor any other development-time information to boost reliability.
To implement adaptivity, we used Importance Sampling, a statistical sampling method to approximate the true distribution of a variable of interest [6]. We used it to approximate the unknown distribution of the number of test cases for each partition to maximize delivered reliability. While Importance Sampling is successfully used in many fields, its usage for testing is limited to few papers: Sridharan and Namin used it to prioritize mutation operators in mutation testing [41]; we ourselves used it for test techniques selection [9].
6 Conclusions
A large part of software testing literature evaluates the effectiveness of testing techniques based on the faults found, irrespectively of the potential likelihood and impact of such faults. In this way, among several test techniques the one that finds the highest number of faults would be considered the most effective, but this might not correspond to reality. If the faults found are never experienced in practice, the test technique would not be very effective.
In this work, considering that test effectiveness should be evaluated based on the delivered reliability [15], we have discussed some results from combining two usually separated test strategies: white-box coverage criteria and black-box operational testing. The former exploits knowledge of program internals, the latter of program usage.
We have overviewed two approaches that mix the two strategies following two different intuitions. In operational coverage, we have augmented coverage testing criteria with a notion of user’s relevance. The intuition is that if an entity is rarely or never used in operation, coverage of this entity should contribute to coverage measure with lower weight. On the contrary, entities that, based on operational profile, are frequently covered, should be given higher weights. In covrel, we have augmented OP testing with coverage information, targetting the selection of test cases within a domain partition towards those entities that remain hidden, i.e. yielding a lower coverage count. The intuition here is that monitoring coverage along OP testing may help increasing faster the reliability.
The approaches we have developed are just a first attempt to implement what seems a very attractive perspective: by combining information from coverage and operational profile we can achieve a stronger testing technique that yields both a practical stopping rule and mitigates the inherent saturation problem.
Having opened a novel research thread, we are also aware that a myriad of other potential techniques could be devised, only limited by creativity. For example, we have considered coverage of only three more common entities, statement, branch and function. Other entities could have been considered. Moreover, as we hinted in the introduction, we could consider a model of software behaviour and different combinations also involving functional testing strategies.
Notes
- 1.
A failure region is the set of failure points eliminated by a program change [15].
References
Adams, E.N.: Optimizing preventive service of software products. IBM J. Res. Dev. 28(1), 2–14 (1984)
Alrmuny, D.: A comparative study of test coverage-based software reliability growth models. In: Proceedings of the 11th International Conference on Information Technology: New Generations, pp. 255–259. ITNG, IEEE (2014)
Beizer, B.: Software Testing Techniques, 2nd edn. Van Nostrand Reinhold Co., New York (1990)
Bertolino, A.: Software testing. In: Bourque, P., Dupuis, R. (eds.) Software Engineering Body of Knowledge (SWEBOK), Chap. 5. IEEE Computer Society (2001)
Bertolino, A., Miranda, B., Pietrantuono, R., Russo, S.: Adaptive coverage and operational profile-based testing for reliability improvement. In: Proceedings of the 39th International Conference on Software Engineering, pp. 541–551. ICSE, IEEE (2017)
Bishop, C.: Pattern Recognition and Machine Learning. Information Science and Statistics. Springer-Verlag, New York (2006)
Cai, K.Y., Li, Y.C., Liu, K.: Optimal and adaptive testing for software reliability assessment. Inf. Softw. Technol. 46(15), 989–1000 (2004)
Chen, T.Y., Leung, H., Mak, I.K.: Adaptive random testing. In: Maher, M.J. (ed.) ASIAN 2004. LNCS, vol. 3321, pp. 320–329. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-30502-6_23
Cotroneo, D., Pietrantuono, R., Russo, S.: A learning-based method for combining testing techniques. In: Proceedings of the 35th International Conference on Software Engineering (ICSE), pp. 142–151. IEEE (2013)
Cotroneo, D., Pietrantuono, R., Russo, S.: Combining operational and debug testing for improving reliability. IEEE Trans. Reliab. 62(2), 408–423 (2013)
Cotroneo, D., Pietrantuono, R., Russo, S.: RELAI testing: a technique to assess and improve software reliability. IEEE Trans. Software Eng. 42(5), 452–475 (2016)
Del Frate, F., Garg, P., Mathur, A., Pasquini, A.: On the correlation between code coverage and software reliability. In: Proceedings of the 6th International Symposium on Software Reliability Engineering, pp. 124–132. ISSRE, IEEE, October 1995
Dijkstra, E.W.: Structured programming. In: N.Buxton, J., Randell, B. (eds.) Software Engineering Techniques. NATO Science Committee (1970)
Donnelly, M., Everett, B., Musa, J., Wilson, G., Nikora, A.: Best current practice of SRE. In: Handbook of software Reliability Engineering, Chap. 6, pp. 219–254. IEEE Computer Society Press and McGraw-Hill (1996)
Frankl, P.G., Hamlet, R.G., Littlewood, B., Strigini, L.: Evaluating testing methods by delivered reliability. IEEE Trans. Software Eng. 24(8), 586–601 (1998)
Frankl, P.G., Weyuker, E.J.: An applicable family of data flow testing criteria. IEEE Trans. Software Eng. 14(10), 1483–1498 (1988)
Frankl, P.G., Deng, Y.: Comparison of delivered reliability of branch, data flow and operational testing: a case study. ACM SIGSOFT Software Eng. Notes 25(5), 124–134 (2000)
Gay, G., Staats, M., Whalen, M., Heimdahl, M.P.: The risks of coverage-directed test case generation. IEEE Trans. Software Eng. 41(8), 803–819 (2015)
Harrold, M.J., Rothermel, G., Wu, R., Yi, L.: An Empirical Investigation of Program Spectra. In: Proceedings of the 1998 ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering, pp. 83–90. PASTE, ACM (1998)
Herzig, K.: There’s never enough time to do all the testing you want. In: Perspectives on Data Science for Software Engineering, pp. 91–95. Elsevier (2016)
Herzig, K.: Let’s assume we had to pay for testing. In: Keynote at the 11th IEEE/ACM International Workshop on Automation of Software Test (2016). https://www.kim-herzig.de/2016/06/28/keynote-ast-2016/
Horgan, J., Mathur, A.: Software testing and reliability. The Handbook of Software Reliability Engineering, pp. 531–565 (1996)
Inozemtseva, L., Holmes, R.: Coverage is not strongly correlated with test suite effectiveness. In: Proceedings of the 36th International Conference on Software Engineering, pp. 435–445. ICSE, ACM (2014)
Institute of Electrical and Electronic Engineers: IEEE standard glossary of software engineering terminology. IEEE Standard 610 12, 09 1990
Littlewood, B., Popov, P., Strigini, L., Shryane, N.: Modelling the effects of combining diverse software fault detection techniques. In: Hierons, R.M., Bowen, J.P., Harman, M. (eds.) Formal Methods and Testing. LNCS, vol. 4949, pp. 345–366. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-78917-8_12
Lyu, M.R.: Software reliability engineering: a roadmap. In: Future of Software Engineering, pp. 153–170. FOSE, IEEE (2007)
Marick, B.: How to misuse code coverage. In: Proceedings of the 16th International Conference on Testing Computer Software, pp. 16–18 (1999)
Miranda, B., Bertolino, A.: Does code coverage provide a good stopping rule for operational profile based testing? In: Proceedings of the 11th International Workshop on Automation of Software Test, pp. 22–28. AST, ACM (2016)
Miranda, B., Bertolino, A.: An assessment of operational coverage as both an adequacy and a selection criterion for operational profile based testing. Software Qual. J. 26(4), 1571–1594 (2018)
Musa, J.D.: A theory of software reliability and its application. IEEE Trans. Software Eng. SE–1(3), 312–327 (1975)
Musa, J.D.: Operational profiles in software-reliability engineering. IEEE Softw. 10(2), 14–32 (1993)
Neil, M., Fenton, N., Nielson, L.: Building large-scale Bayesian networks. Knowl. Eng. Rev. 15(3), 257–284 (2000)
Omri, F.: Weighted statistical white-box testing with proportional-optimal stratification. In: WCOP 2014 Proceedings of the 19th International Doctoral Symposium on Components and Architecture, pp. 19–24. ACM (2014)
Pietrantuono, R., Russo, S.: On adaptive sampling-based testing for software reliability assessment. In: Proceedings of the 27th International Symposium on Software Reliability Engineering, pp. 1–11. ISSRE, IEEE, October 2016
Pietrantuono, R., Russo, S.: Probabilistic sampling-based testing for accelerated reliability assessment. In: Proceedings of the IEEE 18th International Conference on Software Quality, Reliability and Security (QRS), pp. 35–46. IEEE, July 2018
Prause, C.R., Werner, J., Hornig, K., Bosecker, S., Kuhrmann, M.: Is 100% test coverage a reasonable requirement? Lessons learned from a space software project. In: Felderer, M., Méndez Fernández, D., Turhan, B., Kalinowski, M., Sarro, F., Winkler, D. (eds.) PROFES 2017. LNCS, vol. 10611, pp. 351–367. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-69926-4_25
Roper, M.: Software testing–searching for the missing link. Inf. Softw. Technol. 41(14), 991–994 (1999)
Singh, H., Cortellessa, V., Cukic, B., Gunel, E., Bharadwaj, V.: A Bayesian approach to reliability prediction and assessment of component based systems. In: Proceedings of the 12th International Symposium on Software Reliability Engineering, pp. 12–21. ISSRE, November 2001
Smidts, C., Cukic, B., Gunel, E., Li, M., Singh, H.: Software reliability corroboration. In: Proceedings of the 27th Annual NASA Goddard/IEEE Software Engineering Workshop, pp. 82–87. IEEE, December 2002
Smidts, C., Mutha, C., Rodríguez, M., Gerber, M.J.: Software testing with an operational profile: OP definition. ACM Comput. Surv. 46(3), 39:1–39:39 (2014)
Sridharan, M., Namin, A.: Prioritizing mutation operators based on importance sampling. In: 21st International Symposium on Software Reliability Engineering, pp. 378–387. ISSRE, IEEE, November 2010
Tian, J., Lu, P., Palma, J.: Test-execution-based reliability measurement and modeling for large commercial software. IEEE Trans. Software Eng. 21(5), 405–414 (1995)
Wei, Y., Meyer, B., Oriol, M.: Is branch coverage a good measure of testing effectiveness? In: Meyer, B., Nordio, M. (eds.) LASER 2008-2010. LNCS, vol. 7007, pp. 194–212. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-25231-0_5
Weyuker, E.J., Jeng, B.: Analyzing partition testing strategies. IEEE Trans. Software Eng. 17(7), 703–711 (1991)
Wong, W., Gao, R., Li, Y., Abreu, R., Wotawa, F.: A survey on software fault localization. IEEE Trans. Software Eng. 42(8), 707–740 (2016)
Xie, T., Notkin, D.: Checking inside the black box: regression testing by comparing value spectra. IEEE Trans. Software Eng. 31(10), 869–883 (2005)
Zhu, H., Hall, P.A.V., May, J.H.R.: Software unit test coverage and adequacy. ACM Comput. Surv. 29(4), 366–427 (1997)
Acknowledgements
This work has been partially supported by the PRIN 2015 project “GAUSS” funded by MIUR. B. Miranda wishes to thank the postdoctoral fellowship jointly sponsored by CAPES and FACEPE (APQ-0826-1.03/16; BCT-0204-1.03/17).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Bertolino, A., Miranda, B., Pietrantuono, R., Russo, S. (2019). Hybrid Is Better: Why and How Test Coverage and Software Reliability Can Benefit Each Other. In: Escalona, M., Domínguez Mayo, F., Majchrzak, T., Monfort, V. (eds) Web Information Systems and Technologies. WEBIST 2018. Lecture Notes in Business Information Processing, vol 372. Springer, Cham. https://doi.org/10.1007/978-3-030-35330-8_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-35330-8_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-35329-2
Online ISBN: 978-3-030-35330-8
eBook Packages: Computer ScienceComputer Science (R0)