
Abstract
In covering location models, one seeks the location of facilities optimizing the weight of individuals covered, i.e., those at the distance from the facilities below a threshold value. Attractive facilities are wished to be close to the individuals, and thus the covering is to be maximized, while for repulsive facilities the covering is to be minimized. On top of such individual-facility interactions, facility-facility interactions are relevant, since they may repel each other. This chapter is focused on models for locating facilities using covering criteria, taking into account that facilities are repulsive from each other. Contrary to the usual approach, in which individuals are assumed to be concentrated at a finite set of points, we assume the individuals to be continuously distributed in a planar region. The problem is formulated as a global optimization problem, and a branch and bound algorithm is proposed.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

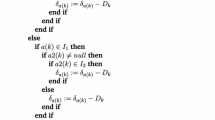
Keywords
1 Introduction
Locational Analysis addresses decision problems involving the location of facilities which interact with a set of individuals, and, eventually interact among them. For attractive facilities, such as schools, libraries, emergency services or supermarkets, individuals wish the facilities to be as close as possible to them. Such pull models (facilities are pulled towards demand) do not properly model repulsive facility location problems (Alonso et al. 1998; Carrizosa and Plastria 1998; Erkut and Neuman 1989; Fliege 2001; Plastria and Carrizosa 1999), like, for instance, the location of a polluting plant, wished to be as far as possible from the individuals. For such undesirable facilities, a push model, pushing facilities away from the sites affected by facilities nearness, is more suitable: the location for the facilities is then sought maximizing a certain non-increasing function of the distances from the individuals to the facilities. For both desirable and undesirable facilities, interactions may be measured as a function of the individual-facility distance (or time), or, as studied here, via coverage; see e.g. Kolen and Tamir (1990), Li et al. (2011), Murray et al. (2009), Schilling and Barkhi (1993) for extensive reviews on covering models and solution approaches. It is important to stress here that, independently of the nature of the facility, either attractive or repulsive, the very same models for covering function apply (Farhan and Murray 2006), the difference being algorithmic: such covering is to be maximized for desirable facilities and minimized for undesirable facilities.
On top of individual-facility interactions, facility-facility interactions are also likely to be relevant. Such interactions may be critical when facilities are obnoxious, and risk or damage to population scales nonlinearly (e.g., with hazadarous materials deposits or dangerous plants which may suffer chain reactions) and thus negative impacts are to be dispersed. Facility-facility interactions are also important in models for locating facilities which, although they are perceived as attractive by the users, they are perceived as repelling by other facilities competing for the very same market. In these models, locating the facilities far away from each other avoids cannibalization and optimizes competitive market advantage (Christaller 1966; Curtin and Church 2006; Lei and Church 2013).
Although the models described are general, the algorithmic approach presented here is restricted to the planar case (Drezner and Wesolowsky 1994; Plastria 2002; Plastria and Carrizosa 1999): facilities are identified with points in the plane, and interact with the remaining facilities and with individuals, also identified with points in the plane. Interactions are measured via distances in the plane. See Plastria (1992) for an excellent review of planar distances and planar location models. For covering models for which interactions are not measured via planar distances, but network distances instead (typically shortest-path distances) the works (Berman et al. 1996; Berman and Huang 2008; Berman and Wang 2011; Colebrook and Sicilia 2013) give a good overview.
Contrary to most papers in the literature, affected individuals are not assumed here to be concentrated at a finite number of points, and, instead, an arbitrary distribution (in particular, a continuous distribution) on their location is given. This way we can directly address models in which affected individuals are densely spread on a region, but we also address models in which uncertainties exist about the exact location of the individuals, due to their mobility (Carrizosa et al. 1998b).
Regional models are not so common in the location literature, since, even when individuals are assumed to be continuously distributed, a discretization process is usually done, and such continuous distribution is replaced by a discrete one, by e.g. replacing all points in each district by its centroid, or other central point, see e.g. Francis and Lowe (2011), Francis et al. (2000, 2002, 2008), Murray and O’Kelly (2002), Plastria (2001), Tong and Church (2012). Nevertheless, discretization is well known not to perform well in applications, this issue being especially relevant in covering models, since significant discrepancies may exist between what is modeled as covered and what is actually covered, see e.g. Current and Schilling (1990), Daskin et al. (1989), Kim and Murray (2008), Murray (2005), Murray and Wei (2013), Tong (2012), Tong and Murray (2009). For this reason, some papers are found in which the regional aspect is directly handled. See for instance (Blanquero and Carrizosa 2013; Carrizosa et al. 1995, 1998c; Fekete et al. 2005; Yao and Murray 2014) for single-facility Weber problems with regional demand (Murat et al. 2010) for a heuristic method for the extension to p facilities, and Tong (2012), Tong and Murray (2009) for discrete covering problems, in which the individuals are identified with objects (polygons) in the plane, which can be considered as fully or partially covered.
The remainder of the chapter is structured as follows. In Sect. 6.2, a rather general p-facility covering model for continuously distributed demand is described; how to address the optimization problem is presented in Sect. 6.3, and illustrated in Sect. 6.4. Conclusions and future lines of research are outlined in Sect. 6.5.
2 Regional Covering Model
Location models are specific in the way the interactions are modeled. Two types of interactions take place, namely, individual-facility interactions and facility-facility interactions. Depending on the specific problem, just one or the two types of interactions may be relevant; see e.g. Erkut and Neuman (1989).
Since these two types of interactions have different nature, they are discussed separately in what follows.
2.1 Individual-Facility Interactions
For a given individual location a and any facility location x, let c(a, x) ∈ [0, 1] denote how much a is covered (affected) by the facility at x. In its general form, c(⋅, ⋅) may be any function \(\varphi : \,{\mathbb R}^+ \longrightarrow [0,1],\) which is non-increasing in the (Euclidean) distance ∥x − a∥ separating a and x,
so that, the lower the distance, the higher the coverage. This assumption, yet sensible, may not be sound for specific problems of locating undesirable facilities; for instance (Karkazis and Papadimitriou 1992) addresses the problem of locating a polluting plant whose pollutant is discharged by means of high stacks, and thus maximal interaction (damage) takes place at a non-negligible distance of the facility.
We remark that we are using the Euclidean distance, but this is not the only choice of distance function ∥⋅∥ found in the literature in covering models: see e.g. Fernández et al. (2000) for a proposal of (weighted) ℓp norms and Plastria (2002) for a thorough discussion on planar distances.
The basic form of φ is an all-or-nothing function, already suggested in Church and ReVelle (1974), see also e.g. Drezner and Wesolowsky (1994),
where the threshold value R is called the range (Christaller 1966) or coverage standard. For an attractive facility, R represents the highest distance a user is willing to overcome to utilize a facility, whereas for undesirable facilities, R represents the distance of the boundary of the zone within which the facility would have a negative impact (Farhan and Murray 2006). Extensions of (6.2) abound in the literature, leading to so-called gradual covering models (Berman et al. 2009c, 2003; Drezner et al. 2004). For instance the all-or-nothing function above is replaced by a piecewise constant function modeling different levels of coverage in Berman and Krass (2002), by a piecewise linear function in Berman et al. (2003), Berman and Wang (2011), Drezner et al. (2004), or by more general nonlinear functions, such as the logistic model
in Fernández et al. (2000), see also Berman et al. (2003, 2010), Karasakal and Karasakal (2004), Brimberg et al. (2015). Observe that in some of the papers cited above the coverage functions c are introduced for attractive facilities, and thus maximization, instead of minimization, is pursued. However, the models for c are the very same.
Expressions above for c, as (6.2), are adequate just for the single-facility case. When several facilities are to be located, the covering model (6.1) can be extended in several ways, by first defining, for each facility i = 1, 2, …, p, the function φi converting distances into coverage. In the simplest and most popular model in the literature, for a p-tuple of facility locations x = (x1, …, xp), covering c of an individual location a by x is given by
In the particular form of individual covering ci given by (6.2) using φi instead of φ and Ri instead of R, one considers the individual location a to be covered by the p-tuple of facility locations x = (x1, …, xp) if it is covered by at least one of the p facilities, i.e., if at least one facility i is at a distance smaller than its threshold value Ri.
Multifacility covering functions other than (6.4) can be found in the literature, see Berman et al. (2010) for an updated review. One may consider fuzzy operators to aggregate the covering functions ci, yielding, for example, the proposal of Hwang et al. (2004),
which, if each ci has the form (6.2) is identical to (6.4). Alternatively, realizing that the \(\max \) operator used in (6.4) is nothing but taking one of the ordered values of ci(a, xi), further extensions are natural:
for a given Λ. Taking as Λ the set
one recovers (6.4); taking
for some integer r ∈{1, 2, …, p}, one obtains as coverage the weighted sum of the r highest covers. These covering models belong to the class of so-called ordered covering models (Berman et al. 2009c), in which a weighted sum of the ordered values of the covers are considered.
Another class of models is given by the so-called cooperative cover model, discussed in Berman et al. (2009a):
for some positive fixed scalars λi and threshold value τ. Assuming that each facility covering function ci follows the all-or-nothing model (6.2), model (6.7) means that we may consider an individual to be covered if the weighted sum of 1-facility covers yields a value above a threshold limit τ.
Summing up, the different proposals in the literature can be considered as particular cases of a general model of the form
where Ψ should take values in [0, 1] and should be componentwise non-decreasing, so that the higher each individual-facility cover, the higher the cover of individual location a by the p facilities.
So far we have modeled the interaction between an affected individual at a and the facilities at x = (x1, …, xp). Now we address the problem of defining a global individuals-facilities covering measure C(x).
If the main concern is how much the highest coverage is, a worst-case performance measure is suitable:
Under (6.9) as criterion, searching locations x for the facilities such that C(x) ≤ α means that no individual at all suffers a coverage of more than α.
The (safe) worst-case approach (6.9) may be unfeasible for densely populated regions, and, instead of searching locations not affecting individuals, the average coverage may be a suitable choice. Formally, assume that affected individuals are distributed along the plane, following a distribution given by a probability measure μ on a set \(A \subset {\mathbb R}^2,\) and the individuals-facilities coverages are aggregated into one single measure, namely, the expected coverage, given by
Assuming, as in (6.10), an arbitrary probability measure μ for the distribution of affected individual locations gives us full freedom to accommodate different important models. Obviously, for a finite set A of affected individual locations, A = {a1, …, an}, denoting μa = μ({a}), we recover the basic covering model,
in which the covering is given by the weighted sum of the covers of the different points a. However, we can consider absolutely continuous distributions, in which μ has associated a probability density function f in the plane, and now (6.10) becomes
Several types of density functions f are worthy to be considered. One can take, for instance, f as the uniform density on a region \(A \subset {\mathbb R}^2\) (a polygon, a disc), and thus f is given as
where ar(A) denotes the area of the region A; assuming a uniform density of individuals along the full region A under study seems to be rather unrealistic; instead, one may better split the region A into smaller and more homogeneous subregions Aj (e.g. polygons), give a weight ωj to each Aj, and assume a uniform distribution fj for each Aj :
where each fj is uniform on Aj, and thus its expression is given in (6.13).
Let us particularize (6.14) for the all-or-nothing case in which the covering function is given by (6.4), and each ci is given by (6.2), i.e., c(a, x) takes the value 1 if at least one facility i is at a distance from a below the threshold Ri, and takes the value 0 otherwise. Then, for any x, C(x) takes the form
where, for each i = 1, …, p, Bi(xi) gives the set of points covered by facility i, i.e., the disc centered at xi and radius Ri. Hence, the problem is reduced to calculating areas of intersections of discs Bi(xi) with the subregions Aj. Such calculation, although cumbersome in general, are supported in GIS, see Kim and Murray (2008), Murray et al. (2009), Tong and Murray (2009).
Needless to say, the density f does not need to be piecewise constant, and one can take, for instance, a mixture of bivariate gaussians, \(f(a) = \sum _{j=1}^r \omega _j f_j(a), \) where each fj is a bivariate gaussian density centered at some uj and with covariance matrix Sj,
or, more generally, a radial basis function (RBF) density,
for some decreasing function gj, so that the density is the highest at some knot point uj and decreasing in all directions.
A model like (6.16), or in general (6.17), may be rather promising when the only information provided for the region is just a set u1, …, ur of points, aggregating the actual coordinates of affected individuals around, and then a kernel density estimation process (Bowman and Foster 1993; Wand and Jones 1993, 1995) is done. For instance, Fig. 6.1 represents the probability density function (pdf) of the form (6.16) with 50 knots.

Pdf of a mixture of 50 bivariate gaussians
2.2 Facility-Facility Interactions
The facility-facility interactions may be defined similarly. As in (6.1), the effect caused by facility at xi on facility at xj is measured by the scalar \(c_{ij}^F(x_i,x_j),\)
for some non-increasing function \(\varphi _{ij}^F.\) All pairwise facility-facility effects are aggregated into one single facility-facility interactions measure CF(x), which, similarly to (6.8), is assumed to take the form
for some componentwise non-decreasing ΨF. The simplest case is given by
and thus CF(x) is calculated as the highest facility-facility interaction, i.e., the one of the closest pairs of facilities. Hence, under (6.19),
Assuming all \(c_{ij}^F\) in (6.18) are modeled by means of the same \(\varphi _{ij}^F\) function, \(\varphi _{ij}^F=\varphi ^F\), we have
with \(\gamma =\left ( \varphi ^F\right )^{-1}(\delta )\). See Lei and Church (2013) for a discussion and extension of (6.19) to so-called partial-sum criteria.
2.3 The Anti-covering Model
Depending on the specific problem under consideration, either one or the two covering criteria C, CF are to be optimized. Pure repulsion among facilities naturally leads to a dispersion criterion (Erkut and Neuman 1991; Kuby 1987; Lei and Church 2013; Saboonchi et al. 2014; Sayyady and Fathi 2016), that has been combined with the p-center, p-median and Max-Sum diversity objectives into a bi-objective problem in Tutunchi and Fathi (2019), Sayyady et al. (2015), Colmenar et al. (2018), respectively. By (6.20), minimizing CF amounts to maximizing the minimal distance among facilities. This criterion alone yields a simple geometrical interpretation: a set of p non-overlapping circles (the location of the facilities) is sought so that their (common) radius is maximized (Mladenović et al. 2005).
When both C and CF are relevant, one naturally faces a biobjective optimization problem in which both C and CF are to be minimized,
where \(\mathscr S \subset ({\mathbb R}^2)^p\) is the feasible region, which is assumed to be a compact subset, and thus embedded in a box. Sensible examples for \(\mathscr {S}\) may be \(\mathscr {S} = S^p,\) where S is a polygon in the plane, or \(\mathscr {S} = \{\xi _1\}\times \{\xi _2\}\times \ldots \times \{\xi _k\}\times S^{p-k} ,\) where S is a polygon in the plane, and ξ1, …, ξk are fixed points in the plane, corresponding to facilities already located.
One can address the problem of finding (an approximation to) the set of Pareto-optimal solutions to (6.21), as done for other problems in Blanquero and Carrizosa (2002), Romero-Morales et al. (1997). Alternatively, one can consider one of the criteria as constraint, and address instead the problem of minimizing the covering C(x) keeping the facility-facility cover CF(x) below a threshold limit δ:
Assuming for CF the model given by (6.18), problem (6.22) amounts to finding p points x1, …, xp so that they are at a distance at least \(\left (\varphi ^F\right )^{-1}(\delta )\) from each other and the covering C is minimized. This is the approach proposed e.g. in Berman and Huang (2008), in which undesirable facilities are located (on a network) so as no facilities are allowed to be closer than a pre-specified distance. In Drezner et al. (2019) the same problem on the plane was solved by a Voronoi based heuristic.
3 Computational Approach
While nowadays computational tools allow one to address discrete p-facility problems with a very large p, e.g. Avella and Boccia (2007), Avella et al. (2006), nonconvex continuous location problems, as those addressed here, can only be solved exactly for a very small number of facilities to be located. The most popular and most effective technique is a geometric branch and bound, which can already be found under the name of Big Square Small Square (BSSS) (Hansen et al. 1985), and later modified by a number of authors (Blanquero and Carrizosa 2008; Drezner and Suzuki 2004; Plastria 1992; Schöbel and Scholz 2010), coining names such as BTST (Big Triangle Small Triangle) or Big Cube Small Cube. See Drezner (2012) for a recent review of such variants. In our case the search space is the set of p rectangles for the p facilities, that gives a multi-dimensional interval, also called a box. The main steps of the branch and bound are as usual: a list of boxes is handled, each box being associated with a subproblem, namely, the covering location problem in which facilities are to be located within such box; at each step one box is selected from the list and divided into smaller boxes. Bounds on the optimum over the subboxes are calculated, so that boxes which are found not to contain the global optimum are removed, while the rest is saved for further processing. The branching and bounding rules are iterated until the gap between the underestimation and underestimation of the optimal value is smaller than the prescribed accuracy.
In our implementation, selection of the next box is done by the smallest lower bound, and the division rule is defined by halving both sides of the largest rectangle into four equal sized rectangles. An upper bound on the minimum is calculated evaluating the objective function at the midpoint of the selected box. In what follows, a bounding procedure, valid for arbitrary probability density functions (pdf), is discussed.
A branch and bound can only be used as soon as increasingly tight bounds are built for C(x) on a box X = (X1, …, Xp). Each Xi is a rectangle Xi = ([ai, bi], [ci, di]) where the i-th facility is allowed to be located. One has then on a given box X
For the general function c(a, x) = Ψ(c1(a, x1), c2(a, x2), …, cp(a, xp)), as in (6.8), with Ψ non-decreasing function of ci(a, xi) ∀i, it can be derived further to
where, as in (6.1), ci(a, xi) = φi(∥a − xi∥) for a non-increasing function φi of the distance for all i. This leads to
where \( \mathop {\mathrm {ext}}(X_i)\) denotes the set of vertices of the box Xi. For the particular case of an all-or-nothing covering function as given in (6.2), the above integral simplifies to
where the set \(I({\mathbf {X}})=\bigcup _{i=1}^p I_i(X_i)\) with \(I_i(X_i)=\{a\in A | c_i(a,x_i)=1 \, \forall x_i \in \mathop {\mathrm {ext}}(X_i) \}\), i.e. Ii(Xi) is the set of points a such that, for facility i, all points in Xi cover a (the gray region in Fig. 6.2). For an easier description of the set Ii(Xi) one can consider its inscribed circle, \(I_i^*(X_i)\) as shown in Fig. 6.2.

Intersection of covered areas from \( \mathop {\mathrm {ext}}(X_i)\) giving the region which is covered by all points in the box. The integral is computed over the inscribed circle of this region, \(I_i^*(X_i)\)
This leads to
In what follows, the so obtained lower bound will be denoted by LB(X),
Notice, that the integral could be computed directly as ∫Af(a)minx ∈X c(a, x)da, but that is not practical for the all-or-nothing covering function. Numerical integrators take many sample points around discontinuities, that are introduced with c(a, x), therefore taking a very long time for a single integration.
4 Numerical Examples
The branch and bound method outlined above was implemented in Fortran 90 (IntelⒸFortran Compiler XE 12.0), using the integration tools of the IMSL Fortran Numerical Library. Executions were carried out on an Intel Core i7 computer with 8.00 Gb of RAM memory at 2.8 GHz, running Windows 7.
Two types of experiments were performed. First, a series of problems with randomly generated demand functions were solved for p = 1 and p = 2. The demand function was generated as a mixture of r bivariate gaussian distribution functions (6.16) with centers and weights uniformly generated in [0, 10]2 and [0.1, 0.1 + 1∕(10r)], respectively. We set the covariance matrix to wiE, that is the identity matrix scaled by the knot weight. The location of the facilities were sought in the square [2, 8]2. Three parameters were considered, leading to different problems: the radius R, the minimal distance γ in (6.20), and the number of knots r. As stopping criterion, the algorithm, stopped when the gap was smaller than 10−2.
In order to reduce the random variability of the results, for each choice of radius R, minimal distance γ and number of knots r, three independent instances were generated and solved. The results presented in the tables correspond to the median out of the three values obtained.
In Table 6.1 running times in seconds are shown for the problem of locating one facility with a smaller and a larger radius (R = 1.8 and R = 2.4). It is not surprising that the computational time grows with the number of knots, as for all knots we need to do at least one integration.
Running times in seconds are reported in Table 6.2 for the problem of locating two facilities. Again, the values presented are the median value of the three runs performed. When at least two out of the three instances could not reach the desired accuracy in 8 h, the message “>8 h” is reported. The results clearly show that, the higher the number of knots or the radius, the higher the running times. The connection between the elapsed time and the minimal distance is not so evident. One can find cases where either smaller or higher minimal distance can be solved faster, so it looks rather problem dependent.
A second experiment was done in order to analyze the impact of the radius, displaying the Pareto frontier if one maximizes the radius and minimizes the coverage. In Fig. 6.3 the Pareto front is displayed for a problem with a mixture of 50 bivariate gaussian distributions setting minimal distance γ = R, and radii R = 0.45, 0.6, …, 1.65, 1.8. The pdf of such mixture of gaussians was shown in Fig. 6.1, while the solutions for the different radii are drawn in Fig. 6.4. In the latter, the demand function contours as well as the knots (with small crosses) are shown. On the left, we focus on the optimal solution of the two extreme radii (R = 0.45 and R = 1.8). The optimal covered regions, i.e., the disc centered at the optimal facilities and radius R, are plotted. On the right, the optimal covered regions for all radii addressed are given.

Pareto frontier of the problem of maximizing the radius and minimizing covering

Optimal covering for extreme radii (left) and all radii (right)
5 Conclusions
While we have focused on purely repulsive facilities, the approach described here can be used to address location problems of semi-desirable facilities (Carrizosa and Plastria 1999; Blanquero and Carrizosa 2002; Romero-Morales et al. 1997; Plastria et al. 2013), in which, instead of having a set A of affected individuals, all negatively affected and wishing to have the facilities as far as possible, one has two separated sets, A+ and A−, identifying respectively the individuals feeling the facilities attractive, and thus want them as close as possible, and those feeling the facilities repulsive, and thus want them as far as possible. This would imply replacing the expected coverage function (6.10) by
where c+ and c− are the covering models respectively for positively and negatively affected individuals. For finite probability measures μ+ and μ−, this model corresponds to minimizing a weighted sum of the points covered, where now the points in A+ have a negative weight, already studied in Berman et al. (2009b) in a discrete setting. The planar version, including the regional case, remains unexplored. It calls for deriving new bounds for the branch and bound; but, as done here in the repulsive case, on can construct bounds after obtaining bounds for the covering functions c(a, x). Whilst for c− the key is that c− is nonincreasing, monotonicity (in this case, decreasingness) can be used to bound − c+. This approach is not new, since it already dates back to the seminal branch and bound BSSS (Hansen et al. 1985), but it deserves being tested.
The basic all-or-nothing cover function c in (6.2) is built assuming R fixed, and given R, the cover C is minimized. A dual problem consists of maximizing R so that the cover C remains below a threshold value. This so-called maxquantile problem (Plastria and Carrizosa 1999), would be solved by doing a binary search in the space of the values R, and solving, for each R, one problem as those solved in this chapter.
While affected individuals have been assumed to be (continuously) distributed in a planar region, facilities are considered here to have negligible size, so they are properly modeled as points. Adapting the branch and bound (in particular, the design of bounds) for the case of extensive facilities, e.g. Carrizosa et al. (1998a), deserves further study.
We have considered from the beginning the number of facilities p to be fixed. A related, somehow dual, problem is the problem of locating as many facilities as possible so that the coverage function C (or CF, or both) remain(s) within a given interval. Such is the case of the so-called anticovering location problem, e.g. Chaudhry (2006), Moon and Chaudhry (1984), Murray and Church (1997), which, in its simplest version, seeks the highest number p∗ of facilities such that no two are at a distance smaller than a threshold value R. To mention a few extensions (Wei and Murray 2014, 2017), include spatial uncertainty minimization (Niblett and Church 2015), introduce the disruptive anti-covering location problem.
Aggregation of the individual-facility cover functions c(a, x) to C(x) by any of the procedures described in Sect. 6.2 is easily shown to be monotonic in the number p of facilities. The same holds for the aggregation of the facility-facility cover \(c_{jk}^F(x_j,x_k)\) to CF(x). Hence, in order to find the highest p∗ for which such covers remain within a given interval, one only needs to solve sequentially the problem for different values of p. The design of more direct and efficient procedures is definitely a promising research line.
References
Alonso I, Carrizosa E, Conde E (1998) Maximin location: discretization not always works. Top 6:313–319
Avella P, Boccia M (2007) A cutting plane algorithm for the capacitated facility location problem. Comput Optim Appl 43:39–65
Avella P, Sassano A, Vasil’ev I (2006) Computational study of large-scale p-median problems. Math Program 109:89–114
Berman O, Huang R (2008) The minimum weighted covering location problem with distance constraints. Comput Oper Res 35:356–372
Berman O, Krass D (2002) The generalized maximal covering location problem. Comput Oper Res 29:563–581
Berman O, Wang J (2011) The minmax regret gradual covering location problem on a network with incomplete information of demand weights. Eur J Oper Res 208:233–238
Berman O, Drezner Z, Wesolowsky GO (1996) Minimum covering criterion for obnoxious facility location on a network. Networks 28:1–5
Berman O, Krass D, Drezner Z (2003) The gradual covering decay location problem on a network. Eur J Oper Res 151:474–480
Berman O, Drezner Z, Krass D (2009a) Cooperative cover location problems: the planar case. IIE Trans 42:232–246
Berman O, Drezner Z, Wesolowsky GO (2009b) The maximal covering problem with some negative weights. Geogr Anal 41:30–42
Berman O, Kalcsics J, Krass D, Nickel S (2009c) The ordered gradual covering location problem on a network. Discret Appl Math 157:3689–3707
Berman O, Drezner Z, Krass D (2010) Generalized coverage: new developments in covering location models. Comput Oper Res 37:1675–1687
Blanquero R, Carrizosa E (2002) A DC biobjective location model. J Glob Optim 23:139–154
Blanquero R, Carrizosa E (2008) Continuous location problems and big triangle small triangle: constructing better bounds. J Glob Optim 45:389–402
Blanquero R, Carrizosa E (2013) Solving the median problem with continuous demand on a network. Comput Optim Appl 56:723–734
Bowman A, Foster P (1993) Density based exploration of bivariate data. Stat Comput 3:171–177
Brimberg J, Juel H, Körner MC, Shöbel A (2015) On models for continuous facility location with partial coverage. J Oper Res Soc 66:33–43
Carrizosa E, Plastria F (1998) Locating an undesirable facility by generalized cutting planes. Math Oper Res 23:680–694
Carrizosa E, Plastria F (1999) Location of semi-obnoxious facilities. Stud Locat Anal 12:1–27
Carrizosa E, Conde E, Muñoz-Márquez M, Puerto J (1995) The generalized Weber problem with expected distances. RAIRO- Oper Res 29:35–57
Carrizosa E, Muñoz-Márquez M, Puerto J (1998a) Location and shape of a rectangular facility in \(\Re ^n\). Convexity properties. Math Program 83:277–290
Carrizosa E, Muñoz-Márquez M, Puerto J (1998b) A note on the optimal positioning of service units. Oper Res 46:155–156
Carrizosa E, Muñoz-Márquez M, Puerto J (1998c) The Weber problem with regional demand. Eur J Oper Res 104:358–365
Chaudhry SS (2006) A genetic algorithm approach to solving the anti-covering location problem. Expert Syst 23:251–257
Christaller W (1966) Central places in Southern Germany. Prentice-Hall, London
Church R, ReVelle C (1974) The maximal covering location problem. Pap Reg Sci 32:101–118
Colebrook M, Sicilia J (2013) Hazardous facility location models on networks. In: Batta R, Kwon C (eds) Handbook of OR/MS models in Hazardous materials transportation. Springer, New York, pp 155–186
Colmenar JM, Martí R, Duarte A (2018) Heuristics for the bi-objective diversity problem. Expert Sys Appl 108:193–205
Current JR, Schilling DA (1990) Analysis of errors due to demand data aggregation in the set covering and maximal covering location problems. Geogr Anal 22:116–126
Curtin KM, Church RL (2006) A family of location models for multiple-type discrete dispersion. Geogr Anal 38:248–270
Daskin MS, Haghani AE, Khanal M, Malandraki C (1989) Aggregation effects in maximum covering models. Ann Oper Res 18:113–139
Drezner Z (2012) Solving planar location problems by global optimization. Logist Res 6:17–23
Drezner Z, Suzuki A (2004) The big triangle small triangle method for the solution of nonconvex facility location problems. Oper Res 52:128–135
Drezner Z, Wesolowsky G (1994) Finding the circle or rectangle containing the minimum weight of points. Locat Sci 2:83–90
Drezner Z, Wesolowsky GO, Drezner T (2004) The gradual covering problem. Nav Res Logist 51:841–855
Drezner Z, Kalczynski P, Salhi S (2019) The planar multiple obnoxious facilities location problem: a Voronoi based heuristic. Omega 87:105–116. https://doi.org/10.1016/j.omega.2018.08.013
Erkut E, Neuman S (1989) Analytical models for locating undesirable facilities. Eur J Oper Res 40:275–291
Erkut E, Neuman S (1991) Comparison of four models for dispersing facilities. Inf Syst Oper Res 29:68–86
Farhan B, Murray AT (2006) Distance decay and coverage in facility location planning. Ann Reg Sci 40:279–295
Fekete SP, Mitchell JSB, Beurer K (2005) On the continuous Fermat-Weber problem. Oper Res 53:61–76
Fernández J, Fernández P, Pelegrín B (2000) A continuous location model for siting a non-noxious undesirable facility within a geographical region. Eur J Oper Res 121:259–274
Fliege J (2001) OLAF—a general modeling system to evaluate and optimize the location of an air polluting facility. OR Spectr 23:117–136
Francis RL, Lowe TJ (2011) Comparative error bound theory for three location models: continuous demand versus discrete demand. Top 22:144–169
Francis RL, Lowe TJ, Tamir A (2000) Aggregation error bounds for a class of location models. Oper Res 48:294–307
Francis RL, Lowe TJ, Tamir A (2002) Demand point aggregation for location models. In: Drezner Z, Hamacher HW (eds) Facility location. Springer, Berlin, pp 207–232
Francis RL, Lowe TJ, Rayco MB, Tamir A (2008) Aggregation error for location models: survey and analysis. Ann Oper Res 167:171–208
Hansen P, Peeters D, Richard D, Thisse JF (1985) The minisum and minimax location problems revisited. Oper Res 33:1251–1265
Hwang M, Chiang C, Liu Y (2004) Solving a fuzzy set-covering problem. Math Comput Model 40:861–865
Karasakal O, Karasakal EK (2004) A maximal covering location model in the presence of partial coverage. Comput Oper Res 31:1515–1526
Karkazis J, Papadimitriou C (1992) A branch-and-bound algorithm for the location of facilities causing atmospheric pollution. Eur J Oper Res 58:363–373
Kim K, Murray AT (2008) Enhancing spatial representation in primary and secondary coverage location modeling. J Reg Sci 48:745–768
Kolen A, Tamir A (1990) Covering problems. In: Mirchandani P, Francis R (eds) Discrete location theory. Wiley, New York
Kuby MJ (1987) Programming models for facility dispersion: the p-dispersion and maxisum dispersion problems. Geogr Anal 19:315–329
Lei TL, Church RL (2013) A unified model for dispersing facilities. Geogr Anal 45:401–418
Li X, Zhao Z, Zhu X, Wyatt T (2011) Covering models and optimization techniques for emergency response facility location and planning: a review. Math Meth Oper Res 74:281–310
Mladenović N, Plastria F, Urošević (2005) Reformulation descent applied to circle packing problems. Comput Oper Res 32:2419–2434
Moon ID, Chaudhry SS (1984) An analysis of network location problems with distance constraints. Manag Sci 30:290–307
Murat A, Verter V, Laporte G (2010) A continuous analysis framework for the solution of location—allocation problems with dense demand. Comput Oper Res 37:123–136
Murray AT (2005) Geography in coverage modeling: exploiting spatial structure to address complementary partial service of areas. Ann Assoc Am Geogr 95:761–772
Murray AT, Church RL (1997) Solving the anti-covering location problem using Lagrangian relaxation. Comput Oper Res 24:127–140
Murray AT, O’Kelly ME (2002) Assessing representation error in point-based coverage modeling. J Geogr Syst 4:171–191
Murray AT, Wei R (2013) A computational approach for eliminating error in the solution of the location set covering problem. Eur J Oper Res 224:52–64
Murray AT, Tong D, Kim K (2009) Enhancing classic coverage location models. Int Reg Sci Rev 33:115–133
Niblett MR, Church RL (2015) The disruptive anti-covering location problem. Eur J Oper Res 247:764–773
Plastria F (1992) Gbsss: the generalized big square small square method for planar single-facility location. Eur J Oper Res 62:163–174
Plastria F (2001) On the choice of aggregation points for continuous p-median problems: a case for the gravity centre. Top 9:217–242
Plastria F (2002) Continuous covering location problems. In: Drezner Z, Hamacher HW (eds) Facility location. Springer, Berlin, pp 39–83
Plastria F, Carrizosa E (1999) Undesirable facility location with minimal covering objectives. Eur J Oper Res 119:158–180
Plastria F, Gordillo J, Carrizosa E (2013) Locating a semi-obnoxious covering facility with repelling polygonal regions. Discret Appl Math 161:2604–2623
Romero-Morales D, Carrizosa E, Conde E (1997) Semi-obnoxious location models: a global optimization approach. Eur J Oper Res 102:295–301
Saboonchi B, Hansen P, Perron S (2014) MaxMinMin p-dispersion problem: a variable neighborhood search approach. Comput Oper Res 52:251–259
Sayyady F, Fathi Y (2016) An integer programming approach for solving the p-dispersion problem. Eur J Oper Res 253:216–225
Sayyady F, Tutunchi GK, Fathi Y (2015) p-Median and p-dispersion problems: a bi-criteria analysis. Comput Oper Res 61:46–55
Schilling VJ DA, Barkhi R (1993) A review of covering problems in facility location. Locat Sci 1:25–55
Schöbel A, Scholz D (2010) The big cube small cube solution method for multidimensional facility location problems. Comput Oper Res 37:115–122
Tong D (2012) Regional coverage maximization: a new model to account implicitly for complementary coverage. Geogr Anal 44:1–14
Tong D, Church RL (2012) Aggregation in continuous space coverage modeling. Int J Geogr Inf Sci 26:795–816
Tong D, Murray AT (2009) Maximising coverage of spatial demand for service. Pap Reg Sci 88:85–97
Tutunchi GK, Fathi Y (2019) Effective methods for solving the Bi-criteria p-Center and p-Dispersion problem. Comput Oper Res 101:43–54
Wand MP, Jones MC (1993) Comparison of smoothing parameterizations in bivariate kernel density estimation. J Am Stat Assoc 88:520–528
Wand MP, Jones MC (1995) Kernel smoothing. Springer, Berlin
Wei, R, Murray, AT (2014) A multi-objective evolutionary algorithm for facility dispersion under conditions of spatial uncertainty. J Oper Res Soc 65:1133–1142
Wei, R, Murray, AT (2017). Spatial uncertainty challenges in location modeling with dispersion requirements. In: Thill JC (ed) Spatial analysis and location modeling in Urban and regional systems. Springer, Berlin, pp 283–300
Yao J, Murray AT (2014) Serving regional demand in facility location. Pap Reg Sci 93:643–662
Acknowledgements
Research partially supported by research grants and projects ICT COST Action TD1207 (EU), the Hungarian National Research, Development and Innovation Office—NKFIH (OTKA grant PD115554), MTM2012-36163 (Ministerio de Ciencia e Innovación, Spain), P11-FQM-7603, FQM329 (Junta de Andalucía, Spain), all with EU ERDF funds.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Carrizosa, E., G.-Tóth, B. (2019). Anti-covering Problems. In: Laporte, G., Nickel, S., Saldanha da Gama, F. (eds) Location Science. Springer, Cham. https://doi.org/10.1007/978-3-030-32177-2_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-32177-2_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-32176-5
Online ISBN: 978-3-030-32177-2
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)