
Abstract
The segmentation of images with intensity inhomogeneity is always a challenging problem. For the segmentation of these kinds of images, traditional active contour models tend to reduce or correct the intensity inhomogeneity. In this chapter, we present a framework to make use of the intensity inhomogeneity in images to help to improve the segmentation performance. We use self-similarity measure to quantify the degree of the intensity inhomogeneity in images and incorporate it into a variational level set framework. The total energy functional of the proposed algorithm consists of three terms: a local region fitting term, an intensity inhomogeneity energy term, and a regularization term. The proposed model treats the intensity inhomogeneity in images as useful information rather than alleviates the effect of it. The proposed method is applied to segment various intensity inhomogeneous images with promising segmentation results. Comparison results also prove that the proposed method outperforms four state-of-the-art methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image segmentation is a fundamental task in many image processing and computer vision applications. However, due to the presence of noise, complex background, low contrast, and intensity inhomogeneity, image segmentation is still a challenging problem. In the past decades, a variety of algorithms for image segmentation have been introduced. Among them, active contour models have attracted considerable interest. The basic idea of the active contour models is to evolve the initial contour towards the object boundaries by minimizing a given energy functional. Although the energy functionals of the active contour models are diverse, they can be divided into two kinds: edge-based methods and region-based methods. Edge-based methods [1,2,3,4] guide a given contour to the object boundaries based on image gradients. The geodesic active contour model [5] is one of the most commonly used models. It utilizes the gradient information to construct an edge stopping function to stop the evolving contours on the object boundaries. Generally, edge-based approaches can provide stable segmentation results when segmenting images with strong object boundaries. However, these models suffer from the leakage problem when segmenting objects with weak boundaries. Moreover, the performance is dependent on the presence of noise as well as the position of initial contours. To overcome these problems, region-based active models have been widely studied. They use intensities or statistics like mean and standard deviation in the energy minimization frameworks. Thus, they are less sensitive to noise and initializations and perform better than edge-based active contour models for the segmentation of images with noise, intensity inhomogeneities, weak and missing boundaries. Specifically, Chan and Vese [6] simplified the Mumford–Shah [7] energy functional by using the variational level set [8] formulation and apply it to image segmentation. Suppose I : Ω → R is the input image, C is a closed contour which can be represented by the level set function ϕ(x), x ∈ Ω . The region inside/outside the contour C can be represented as Ω in = {x ∈ Ω|ϕ(x)〉0} and Ω out = {x ∈ Ω| ϕ(x) < 0}, respectively. Then the energy functional of the C-V model becomes:
where μ, λ 1, λ 2 are positive constants. u 1 and u 2 are two constants that represent the average intensities inside and outside the contour. H ε(ϕ(x)) is the regularized approximation of the Heaviside function defined in [8]:
The derivative of H ε(ϕ(x)) is:
The C-V model assumes that the image intensity is homogeneous. However, when the image intensity is inhomogeneous, the C-V model fails to produce acceptablesegmentation results. To solve the problem of segmenting intensity inhomogeneous images, a popular way is to treat the image information in local region. Li et al. proposed the active contour models: the region-scalable fitting (RSF) [9] model and the local binary fitting (LBF) [10] model which utilize the local intensity information instead of global average intensities inside and outside the contour. The energy functional of the RSF model is defined as:
where μ, λ 1, λ 2 are weights of each term, u 1(x), u 2(x) are smooth functions to approximate the local image intensities inside and outside the contour C. K σ(y − x) is the Gaussian kernel function with variance σ 2 defined as:
K σ has the localization property that it decreases and approaches 0 as |y − x| increases. Due to the usage of local image information, these models can achieve better segmentation results than the C-V model when segmenting images with inhomogeneous intensities. Various kinds of operators that utilize local image information have been proposed to correct or reduce the effect of inhomogeneity. Zhang et al. [11] introduced a local image fitting (LIF) energy and incorporated it into the variational level set framework for the segmentation of images with intensity inhomogeneity. Wang et al. [12] proposed a local Chan–Vese model that utilizes the Gaussian convolution of the original image to describe the local image statistics. Lankton et al. [13] proposed a localized region-based active contour model, which can extract the local image information in a narrow band region. Zhang et al. [14] proposed a level set method for the segmentation of images with intensity inhomogeneity. The inhomogeneous objects are modeled as Gaussian distribution with different means and variances. Wang et al. [15] proposed an improved region-based active contour model which is based on the combination of both global and local image information (LGIF). A hybrid energy functional is defined based on a local intensity fitting term used in the RSF model and a global intensity fitting term in the C-V model. In most of the methods that can deal with intensity inhomogeneous images, the original image is modeled as a multiplicative of the bias or shading which accounts for the intensity inhomogeneity and a true image. These methods seem to produce promising segmentation results when the intensity inhomogeneity varies smoothly [16,17,18,19,20,21,22,23]. However, when the intensity inhomogeneity varies sharply (e.g., the image of a cheetah), they still cannot yield correct segmentation results. Recently, more algorithms are proposed to solve this by employing more features. Qi et al. [24] proposed an anisotropic data fitting term based on local intensity information along the evolving contours to differentiate the sub-regions. A structured gradient vector flow is incorporated into the regularization term to penalize the length of the active contour. Kim et al. [25] proposed a hybrid active contour model which incorporates the salient edge energy defined by higher order statistics on the diffusion space. Zhi et al. [26] proposed a level set based method which utilizes both saliency information and color intensity as region external energy. These models were reported effective for the segmentation of image with intensity inhomogeneity. But these kinds of features seem not powerful enough to handle images with significantly inhomogeneous intensities. More related works can be found in [27,28,29,30,31,32].
In this chapter, we propose a level set framework which can make use of the intensity inhomogeneity in images to accomplish the segmentation. Self-similarity [33] is firstly used to measure and quantify the degree of the intensity inhomogeneity in images. Then a region intensity inhomogeneity energy term is constructed based on the quantified inhomogeneity and incorporated into a variational level set framework. The total energy functional of the proposed algorithm consists of three terms: a local region fitting term, an intensity inhomogeneity energy term, and a regularization term. By integrating these three terms, the intensity inhomogeneity is converted into useful information to improve the segmentation accuracy. The proposed method has been tested on various images and the experimental results show that the proposed model effectively drives the contours to the object boundary compared to the state-of-the-art methods.
2 Model and Algorithm
Image intensity inhomogeneity exists in both medical images and natural images. Intensity inhomogeneity occurs when the intensity between adjacent pixels is different. It is observed that the pattern of intensity inhomogeneity in the same object may be similar. In other words, the intensity difference may have some continuity or consistency in the same object. That is, the quantification of intensity inhomogeneity in the same object may be homogeneous to some extent. Inspired by this, we use the self-similarity to quantify it and then incorporate it into the level set framework. In this way, the intensity inhomogeneity which is often treated as a negative effect is converted to positive effect that can help accomplish the segmentation. Figure 1 shows the flowchart of the proposed algorithm.

The flowchart of the proposed model
Firstly, we give the definition of self-similarity. For a given M × M window W centered at x in an input image I, W can be divided into N nonoverlap small n × n patches. We denote the set of features (e.g., image intensity) in the ith small patch as \( {F}_n^i,\kern0.5em i=1,\dots, N \), then the difference between each small patch inside the window W can be defined as:
Here the \( \mathrm{Diff}\left({F}_n^i,{F}_n^j\right) \) can be calculated as follows:
Here \( {f}_n^i \) is the image intensity value in the ith patch. \( {D}_{W_x} \) evaluates the structure similarity inside W. It is a symmetric positive semi-definite matrix with zero-valued diagonal. If one patch is similar with the other patches inside W, then its corresponding element in \( {D}_{W_x} \) will be small; on the other hand, if one patch is dissimilar with the other patches, then its corresponding element in \( {D}_{W_x} \) will be large. Figure 2 shows the details of computing \( {D}_{W_x} \). After getting the difference inside W, we can define the self-similarity measure. For a given pixel p, t p is a template window region centered at p. The self-similarity measure (SSM) can be obtained by comparing the similarity of the \( {D}_{t_p} \) to \( {D}_{W_x} \) which is the difference of M × M window centered at x in the image. The sum of the squares differences is used to measure the similarity.

The details of the computation of \( {D}_{W_x} \). The \( {D}_{W_x} \) is a symmetric positive semi-definite matrix with zero-valued diagonal
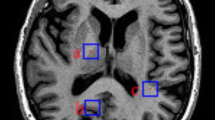
In Fig. 3, we show an example of computing the self-similarity measure. A template region on the object is first selected. From Fig. 3, we can see that, for the region with similar intensity structure with the template region, the SSM of this region is approximately 0, and for the region with the intensity structure significantly different from the template region, the SSM of this region is bigger than 0.

One example of the SSM. Yellow point is the center of the template. Blue point and red point are two center points of the 9 × 9 region selected from object and background, respectively (The center pixels are marked as the same color in the original image). We also show the D w inside each region and the SSM value around the center points, respectively
In Fig. 4, more images and their corresponding SSMs are shown. We found that one can use the SSM to define a new image that describes the inhomogeneity of the original image. In this chapter, we call this image intensity inhomogeneity image. Locations with small SSM values are regarded as the same texture as the template. After we get the intensity inhomogeneity image, we can define the intensity inhomogeneity energy under the framework of C-V model:
where IIH denotes the intensity inhomogeneity image. Ω 1 and Ω 2 denote the regions inside and outside the contour, respectively. and Ih 2 are the average intensities of the IIH image inside and outside the contour.

The intensity inhomogeneity images (SSM) and the original images. W is a 9 × 9 region and it is divided into 9 nonoverlapping 3 × 3 small patches
Due to the complexity of natural images, the intensity inhomogeneity image is not powerful enough to yield an accurate result. It is necessary to also consider the intensity information of the original images. In this chapter, we use the region-scalable fitting energy in [8] to utilize the information of the original images:
I is the original image. u 1(x), u 2(x) are smooth functions to approximate the local image intensities inside and outside the contour C. K σ(y − x) is the Gaussian kernel function with variation σ 2:
By combining these energies together, we can get the following energy functional:
Here λ 1, λ 2 and λ 3 are positive constants to balance each energy term. R is the level set regularization term defined as:
Then the total energy functional becomes:
Here Ih 1, Ih 2, u 1, u 2 have the following form:
By taking the irst variation of the energy functional with respect to ϕ, we can get the following updating equation of ϕ:
Different SSMs may be obtained by choosing different template regions. For example, in Fig. 5, we show different SSMs computed by using different templates. Comparing the SSMs of (b) and (c), we can see that the SSMs of (c) are more suitable to assist the segmentation. In other words, an appropriate template is very important for segmentation. In order to automatically choose the optimal position of the template, we use the following strategy: L pixels are randomly selected in the whole image and L templates can be obtained. Then we can get L SSMs by using these templates. The optimal position of the template can be selected by:
where \( \mathrm{mean}\left(\mathrm{SSM}\left({T}_i,L\right)\right)=\frac{1}{L}\sum \limits_{j=1}^L\mathrm{SSM}\left({T}_i,{T}_j\right) \). This means that the template region is selected on the pixel whose standard deviation of SSM is the minimum.

(a) The original image. (b, c) The SSM computed by using different template. The red dots are the center points of the template region
3 Experimental Results
In this section, we evaluate and compare the proposed model with the C-V model [5], the RSF [9] model, the LGIF model [15], and the LSM model [14]. In these comparisons, for the C-V model, λ 1 = λ 2 = 1, Δt = 0.1, μ which is the weight of the regularization term is set to 6500. For the RSF model, λ 1 = λ 2 = 1, Δt = 0.1, σ = 3, μ is set to 5400. The LGIF model, λ 1 = 0.5, λ 2 = 0.95, they are the weights of the C-V data force and the RSF data force. Δt = 0.1, σ = 3, and the weight for the regularization term is set as μ = 6500. For the LSM model, σ = 3, , the weight for the regularization term is set to 0.2. For the proposed algorithm, N = 9, W = 9, n = 3, σ = 3, λ 1 = 4, λ 2 = 0.1, λ 3 = 5. All the experiments are implemented with Matlab R2017b on a PC of CPU 2.8 GHz, RAM 16G.
We test the segmentation performance of the proposed model on 40 natural images with extremely inhomogeneous intensities which are collected from MSRA dataset [34] and the ECSSD dataset [35]. For quantitative analysis, we compute the F 1-measure given as:
Here \( \mathrm{Precision}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}},\mathrm{Recall}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}\ } \). TP is the number of true positive pixels, FP is the number of false positive pixels, and the FN is the number of false negative pixels. In Fig. 6, we show the comparison results. Results of the quantitative evaluation of these methods are shown in Table 1. In Fig. 6, the original images are shown in the first column, and the ground truths are shown in the second column. The segmentation results of the C-V, RSF, LGIF, LSM, and the proposed algorithm are shown in the other columns, respectively. In the first three images, the extremely inhomogeneous intensities are mainly in the objects and in the last three images, the backgrounds are extreme intensity inhomogeneity. It is shown that the LGIF model and the LSM model perform better than the C-V and the RSF models. In the LGIF model, the author proposed a hybrid model that combines the advantages of both global information (C-V data force) and the local intensity information (RSF data force). For the proposed algorithm, the global information is replaced by the region intensity inhomogeneity term. From the segmentation results, we can see that the proposed algorithm has the overall best performance, which further illustrates that the intensity inhomogeneity in the images can be useful information to assist the segmentation.

Segmentation performance of each algorithm
4 Conclusion
In this chapter, a novel active contour model is proposed for the segmentation of images with intensity inhomogeneity. We use self-similarity to quantify the intensity inhomogeneity in the images. Based on the quantified inhomogeneity, we design a region intensity inhomogeneity energy term and then incorporate it into the level set framework. The proposed model can get promising segmentation results on images with extreme intensity inhomogeneity. The experimental results show that, compared with traditional methods, the proposed segmentation model is more effective.
References
Kass, M., Witkin, A., & Terzopoulos, D. (1988). Snake: Active contour models. International Journal of Computer Vision, 1(4), 321–331.
Kichenassamy, S., Kumar, A., Olver, P., et al. (1995). Gradient flows and geometric active contour models., In Proceedings of International Conference on Computer Vision (pp. 810–815).
Xu, C., & Prince, J. L. (1998). Snakes, shapes, and gradient vector flow. IEEE Transactions on Image Processing, 7(3), 359–369.
Gelas, A., Bernard, O., Friboulet, D., & Prost, R. (2007). Compactly supported radial basis functions based collocation method for level-set evolution in image segmentation. IEEE Transactions on Image Processing, 16(7), 1873–1887.
Caselles, V., Kimmel, R., & Sapiro, G. (1997). Geodesic active contours. International Journal of Computer Vision, 22(1), 61–79.
Chan, T., & Vese, L. (2001). Active contours without edges. IEEE Transactions on Image Processing, 10(22), 266–277.
Mumford, D., & Shah, J. (1989). Optimal approximations of piecewise smooth functions and associated variational problems. Communications on Pure and Applied Mathematics, 42(5), 577–685.
Osher, S., & Sethian, J. A. (1998). Fronts propagating with curvature-dependent speed: algorithms based on Hamilton-Jacobi formulations. Journal of Computational Physics, 79(1), 12–49.
Li, C., Kao, C., Gore, J., & Ding, Z. (2008). Minimization of region-scalable fitting energy for image segmentation. IEEE Transactions on Image Processing, 17(10), 1940–1949.
Li, C., Kao, C., Gore, J., & Ding, Z. (2007). Implicite active contours driven by local binary fitting energy. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, Washington, DC, USA (pp. 1–7).
Zhang, K., Song, H., & Zhang, L. (2010). Active contours driven by local image fitting energy. Pattern Recognition, 43(4), 1199–1206.
Wang, X., et al. (2010). An efficient local Chan-Vese model for image segmentation. Pattern Recognition, 43(3), 603–618.
Lankton, S., & Tannenbaum, A. (2008). Localizing region based active contours. IEEE Transactions on Image Processing, 17(11), 2029–2039.
Zhang, K., Zhang, L., Lam, K. M., & Zhang, D. (2016). A level set approach to image segmentation with intensity inhomogeneity. IEEE Transactions on Cybernetics, 46(2), 546–557.
Wang, L., Li, C., Sun, Q., Xia, D., & Kao, C. (2009). Active contours driven by local and global intensity fitting energy with application to brain MR image segmentation. Computerized Medical Imaging and Graphics, 33(7), 520–531.
Jiang, X., Wang, Q., He, B., et al. (2016). Robust level set image segmentation algorithm using local correntropy-based fuzzy c-means clustering with spatial constraints. Neurocomputing, S0925231216302351.
Wang, X., Min, H., Zou, L., & Zhang, Y. G. (2015). A novel level set method for image segmentation by incorporating local statistical analysis and global similarity measurement. Pattern Recognition, 48(1), 189–204.
Zhou, Y., Shi, W. R., Chen, W., Chen, Y. L., Li, Y., Tan, L. W., et al. (2015). Active contours driven by localizing region and edge-based intensity fitting energy with application to segmentation of the left ventricle in cardiac CT images. Neurocomputing, 156, 199–210.
He, C., Wang, Y., & Chen, Q. (2012). Active contours driven by weighted region-scalable fitting energy based on local entropy. Signal Processing, 92, 587–600.
Niu, S., Chen, Q., Sisternes, L., Ji, Z., Zhou, Z., & Rubin, D. (2017). Robust noise region-based active contour model via local similarity factor for image segmentation. Pattern Recognition, 61, 104–119.
Zhang, K., Zhang, L., Song, H., & Zhou, W. (2010). Active contours with selective local or global segmentation: A new formulation and level set method. Image and Vision Computing, 28, 668–676.
Li, C., Xu, C., Gui, C., & Fox, M. (2010). Distance regularized level set evolution and its application to image segmentation. IEEE Transactions on Image Processing, 19(12).
Wang, L., Chen, G., Shi, D., et al. (2018). Active contours driven by edge entropy fitting energy for image segmentation. Signal Processing, 149, 27–35.
Ge, Q., Li, C., Shao, W., et al. (2015). A hybrid active contour model with structured feature for image segmentation. Signal Processing, 108, 147–158.
Kim, W., & Kim, C. (2013). Active contours driven by the salient edge energy model. IEEE Transactions on Image Processing, 22, 1667–1673.
Zhi, X. H., & Shen, H. B. (2018). Saliency driven region-edge-based top down level set evolution reveals the asynchronous focus in image segmentation. Pattern Recognition, 80, 241–255.
Chung, G., & Vese, L. A. (2009). Image segmentation using a multilayer level-set approach. Computing and Visualization in Science, 12, 267–285.
Liu, B., Cheng, H. D., Huang, J., Tian, J., Tang, X., & Liu, J. (2010). Probability density difference-based active contour for ultrasound image segmentation. Pattern Recognition, 43, 2028–2042.
Liu, S., & Peng, Y. (2012). A local region-based Chan–Vese model for image segmentation. Pattern Recognition, 45(7), 2769–2779.
Dong, F., Chen, Z., & Wang, J. (2013). A new level set method for inhomogeneous image segmentation. Image and Vision Computing, 31(10), 809–822.
Wang, L., & Pan, C. (2014). Robust level set image segmentation via a local correntropy-based K-means clustering. Pattern Recognition, 47, 1917–1925.
Xie, X., Wang, C., Zhang, A., & Meng, X. (2014). A robust level set method based on local statistical information for noisy image segmentation. Optik, 125(9), 2199–2204.
Foote, J.T., & Cooper, M. L. (2003). Media segmentation using self-similarity decomposition. In SPIE Proceedings, Storage and Retrieval for Media Databases (Vol. 5021, pp. 167–175).
Achanta, R., Hemami, S., Estrada, F., & Susstrunk, S. (2009). Frequency-tuned saliency region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1597–1604).
Shi, J., Yang, Q., Li, X., et al. (2016). Hierarchical image saliency detection on extended CSSD. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(4), 717–729.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Li, X., Liu, H., Yang, X. (2019). Intensity Inhomogeneity Image Segmentation Based on Active Contours Driven by Self-Similarity. In: Quinto, E., Ida, N., Jiang, M., Louis, A. (eds) The Proceedings of the International Conference on Sensing and Imaging, 2018. ICSI 2018. Lecture Notes in Electrical Engineering, vol 606. Springer, Cham. https://doi.org/10.1007/978-3-030-30825-4_16
Download citation
DOI: https://doi.org/10.1007/978-3-030-30825-4_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-30824-7
Online ISBN: 978-3-030-30825-4
eBook Packages: Physics and AstronomyPhysics and Astronomy (R0)