
Abstract
There has been growing interest in recent years in the use of homogeneously reprocessed ground-based GNSS, VLBI, and DORIS measurements for climate applications. Existing datasets are reviewed and the sensitivity of tropospheric estimates to the processing details is discussed. The uncertainty in the derived IWV estimates and linear trends is around 1 kg m−2 RMS and ± 0.3 kg m−2 per decade, respectively. Standardized methods for ZTD outlier detection and IWV conversion are proposed. The homogeneity of final time series is limited however by changes in the stations equipment and environment. Various homogenization algorithms have been evaluated based on a synthetic benchmark dataset. The uncertainty of trends estimated from the homogenized times series is estimated to ±0.5 kg m−2 per decade. Reprocessed GNSS IWV data are analysed along with satellites data, reanalyses and global and regional climate model simulations. A selection of global and regional reprocessed GNSS datasets and ERA-interim reanalysis are made available through the GOP-TropDB tropospheric database and online service. A new tropo SINEX format, providing new features and simplifications, was developed and it is going to be adopted by all the IAG services.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

5.1 Introduction
In the following sections material is republished with kind permission: Sects. 5.3.2, 5.3.3, 5.3.4, 5.3.5 and 5.3.6, 5.3.9, 5.3.10 and 5.3.11, 5.4.3, 5.7.1, 5.7.3, 5.7.5 and 5.7.6.
5.1.1 Motivation
Water vapour plays a key role in the climate system as it is the dominant greenhouse gas and a strong feedback variable (temperature changes are enhanced typically by a factor of 2–3 by the atmospheric water vapour content). Global warming and hydrological cycle are tightly linked, with a global scaling ratio of 5–7% of IWV per 1 K. Water vapour is also the main resource for precipitation as about 70% results from moisture convergence and a crucial ingredient of moist processes which are responsible for severe weather events such as heavy precipitation and flooding.
Our knowledge of the global water vapour distribution and its long term evolution is limited due to sparsity and inhomogeneity of the global observing system. As a consequence, both global and regional reanalyses suffer from observation system limitations and model uncertainties. Model uncertainties, especially regarding the water cycle, are also limiting the quality climate model simulations.
Strong interest grew in recent years to assess the benefit of ground-based GNSS measurements for climate research, both as a basic observable of the water cycle, e.g. to evaluate IWV trends and variability, and as a validation data for atmospheric models. Indeed, IWV was recognized as an essential climate variable by GCOS, and global GNSS measurements cover now about 20 years (e.g., IGS and EPN networks include hundreds of stations) which make them an interesting independent observational dataset for climate model validation. Moreover, several global and regional homogeneously reprocessed GNSS datasets were produced in recent years which were not analysed in this respect so far.
5.1.1.1 Context
At the beginning of this COST Action, few studies had investigated the requirements and the potential of ground-based GNSS measurements for climate research.
Accuracy requirements for water vapour profiles in the troposphere for climate monitoring were specified in GCOS-112 (2007) as: precision = 2%, accuracy = 2%, stability = 1% or 0.3% per decade. They were complemented in GCOS-171 (2013) more specifically for satellite IWV measurements as: random error = 5% and systematic error = 3%, but not for stability. If one applies these recommendations for GNSS, the acceptable limits for IWV expressed in kg/m2 for a 5% systematic error, a 3% random error, and a 0.3% per decade error are: 0.15 kg/m2, 0.25 kg/m2, 0.015 kg/m2per decade for a dry atmosphere of 5 kg/m2 (polar regions and high mountain sites) and 1.5 kg/m2, 2.5 kg/m2, and 0.15 kg/m2 per decade in a wet atmosphere of 50 kg/m2 (tropics or temperate climate summer extremal values).
Accuracy and stability, and good spatial and temporal homogeneity and coverage are key features required for a climate data record. GNSS measurements satisfy some these characteristics. Especially, high accuracy and good temporal coverage was demonstrated in many past studies comparing GNSS IWV data to other techniques (especially radiosondes and microwave radiometers) and the all-weather capability is a unique characteristic of GNSS water vapour measurements. Good spatial coverage is achieved thanks to the dense and well documented permanent global and regional networks. Temporal coverage is reasonably well achieved back to the early 1990s, but it is recognized that early measurements (before 1995) are much noisier and more difficult to process because the quality of the equipment was lower. The quality of the IGS satellite products (orbits, clocks, EOPs) is of highest quality after 2000. Inhomogeneities in GNSS ZTD time series are related to processing changes (updates of the reference frame and applied models, implementation of different mapping functions, use of different elevation cut-off angles and any other updates in the processing strategies) and instrumental changes. To reduce processing-related inconsistencies, a homogenous reprocessing of the whole GNSS data set is mandatory and, for doing it properly, well-documented, long-term metadata set is required.
Changes in equipment and subsequent changes in the measurement characteristics are beneficial to most applications as they go along with quality improvement, but they generate a distinct issue for climate monitoring. Indeed, equipment changes are known to introduce small breaks in the observed time series which may mix up with the underlying climate trends and variability. The homogeneity issue is one of the major unsolved topics of GNSS data analysis for climate research. Activity on this topic was initiated during the course of the Action and is foreseen to continue well after. Improvement of processing and post-processing techniques aiming at retrieving better homogenised GNSS IWV times series will be a central concern of methodological research for the upcoming years.
5.1.1.2 Objectives and Organisation of Activities
The general objectives of WG3 were the following:
-
Review and evaluate existing reprocessed long-term GNSS datasets, processing and post-processing methods.
-
Establish standards and recommendations for processing and post-processing of GNSS measurements consistent with climate research requirements.
-
Establish a database of qualified GNSS IWV data for climate research.
-
Cooperate with climate community on the exploitation of GNSS IWV data.
Figure 5.1 illustrates the flow of GNSS data from observation to climate application. The various steps the data typically undergo are identified, with indication of the main options (methods, settings, and necessary auxiliary data and metadata).

Logical Scheme of GNSS Data Processing from the collection of GNSS data, metadata and products to the validation of the GNSS-estimated ZTD and GNSS-derived IVW
Questions regarding observations (data, metadata, and products), data processing (which software, processing options and products) and dissemination of results (sinex topo format) implied tight cooperation with the geodetic community and WG1. Post-processing (screening, IWV conversion, and homogenization) as well as validation (IWV intercomparisons between GNSS and other techniques) was more at the heart of the activities of WG3 participants and stimulated cooperation with the remote sensing community (e.g. GRUAN, NDACC). Finally, thematic studies on IWV trends and variability with GNSS data and climate models were conducted as well by participants and stimulated collaborations with WG2 and the climate community.
Five work packages were defined at the beginning of the Action to organise more efficiently the activity in the different fields.
-
WP3.1 Processing: aimed at making an inventory of available reprocessed GNSS datasets, which included DORIS and VLBI as well. Sensitivity studies, tests and evaluations were also conducted on processing options and products.
-
WP3.2 Post-processing: aimed at developing ZTD screening methods, standardize the ZTD to IWV conversion procedure, and assess the homogeneity of existing GNSS datasets and existing homogenisation methods.
-
WP3.3 IWV intercomparisons: aimed at making a literature review from previous multitechnique campaigns and stimulate new intercomparison with well qualified IWV data (from GNSS and other techniques).
-
WP3.4 GNSS and climate research: aimed at conducting studies of IWV trends and variability using GNSS data as well as other observations, reanalyses and climate model simulations.
-
WP3.5 Database, formats, and dissemination: aimed at providing support to other WPs, develop a GNSS/climate database and update SINEX tropo format in cooperation with IAG, IGS, and EUREF.
It is worth noting that cooperation was established with experts from GRUAN, GEWEX, WMO, ECMWF, previous COST Action HOME, and results were communicated in climate meetings from EGU, AGU, EMS, GEWEX, IAMAS, among others.
At the end of the Action, both a global reference GNSS IWV dataset (1995–2010) and a European reference ZTD dataset (1996–2014) were established.
5.2 Available Reprocessed ZTD and IWV Datasets
5.2.1 Inventory of Available Reprocessed ZTD Datasets
At the beginning of the COST action, with updates in the course of the action, an inventory of available GNSS, VLBI and DORIS reprocessed ZTD and IWV datasets was carried out. For each dataset in the inventory the following information is reported:
-
Network coverage (global, Europe, other regions, national, campaigns) and number of stations,
-
Availability of RINEX data,
-
Availability of ZTD, horizontal gradients and IWV estimates,
-
Data file format,
-
Archive address (url, ftp) & type of access,
-
GNSS data processing software,
-
Processing Mode (double differences, precise point positioning) and options (GNSS Product used…), elevation cut-off angle, handling of site coordinate, mapping function…).
Information was collected for about 24 GNSS datasets as well as global DORIS and VLBI reprocessed datasets. The global GNSS datasets included IGS repro1 (PPP solution) produced by JPL, IGS repro2 solutions from various Analysis Centres, and TIGA solutions from various ACs. The European GNSS datasets included EPN repro1 (a combined solution) and EPN repro2 from various Analysis Centres. Several regional and national reprocessed datasets are also described (e.g. for Scandinavia, West Africa…).
Some of the datasets have been uploaded to the GOP tropo database (ref. Sect. 5.1).
At the beginning of the Cost Action, several GNSS reprocessed solutions were available. Since a majority of groups had already been using IGS repro1, and this dataset is a global, fully reprocessed dataset, it was adopted by the WG3 participants as a first reference dataset for community activities throughout the course of the Action. This dataset is further described in the next subsection. Other GNSS, VLBI, and DORIS datasets produced and/or used during the course of the Action are described in subsequent subsections, including forthcoming datasets that may be of interest for future studies.
Several long-term (20+ years) reprocessed tropospheric solutions currently exist and are available for climate studies. These time series have been produced using various software and various strategies, and include GNSS stations belonging to various network scale: global (IGS troposphere Repro 1 and TIGA), regional (EPN troposphere Repro 2) and local.
International Reprocessing Activities:
-
EUREF Tropospheric 2nd Reprocessing Campaign http://www.epncb.oma.be/_productsservices/troposphere/
-
TIGA Reprocessing Campaign http://adsc.gfz-potsdam.de/tiga/index_TIGA.html
-
GRUAN Reprocessing Campaign http://www.gfz-potsdam.de/en/section/space-geodetic-techniques/projects/gruan/
-
IGS 2nd reprocessing campaign (http://acc.igs.org/reprocess2.html)
More details about some of the reprocessed datasets can be found in the Chap. 3.
5.2.2 IGS Repro1 as First Reference GNSS IWV Dataset
5.2.2.1 Objectives
The motivations for using a common ZTD and/or IWV dataset are the following:
-
Avoid extra uncertainty due to the use of different datasets when the results from a large community are to be intercompared (e.g. compare results from various post-processing methods: screening, ZTD to IWV conversion, homogenisation, trend estimation…),
-
Provide a well-documented and validated IWV dataset to the climate community for model verification.
5.2.2.2 Description of the ZTD Dataset
The tropospheric parameters (ZTD and gradients) were produced by JPL as coordinator of the IGS tropo working group in 2010. The dataset actually used here and referred to as repro1 is composed of two streams:
-
IGS repro1 (1995/01-2007/12): produced by JPL in May 2010,
-
IGS trop_new (2008/01-2010/12): consistently reprocessed by JPL after May 2010.
The reason why two batches are available is that the official IGS repro1 campaign (which aim was to reprocess satellite orbits and clocks mainly) covered the period from 1995/01 to 2007/12 only. However, JPL extended the length of the reprocessed tropospheric solution beyond that period using consistent operationally produced satellite orbits and clocks (combined final IGS products). Unfortunately, we noticed that in the 2008 and 2009 archive, a few days of the trop_new dataset were not reprocessed for a number of stations. The impact of this mix of old and new tropospheric estimates is small at most sites except in Antarctica which exhibit small ZTD biases (<5 mm) due to the use of different mapping functions (NMF in the old solution, GMF in the new).
The main processing options used to produce the IGS repro1 dataset are summarised below:
-
Software: GIPSY-OASIS II in PPP mode,
-
Fixed orbits and clocks: IGS Final Re-Analysed Combined (1995–2007), and IGS Final Combined 2008–2011,
-
Earth orientation: IGS Final Re-Analysed Combined (1995–2007), and IGS Final Combined (2008–2011),
-
Transmit/Receiver antenna phase centre map: IGS Standards (APCO/APCV),
-
Elevation angle cutoff: 7 degrees,
-
Mapping function (hydrostatic and wet): GMF,
-
A priori delay (m): hyd = 1.013*2.27*exp(−0.116*ht) wet = 0.1,
-
Data arc: 24 hours = > increased errors at 00:00 UTC,
-
Data rate: 5 min,
-
Temporal resolution of tropospheric estimates: 5 min,
-
Estimated parameters: station position (daily), station clock (white noise), wet zenith delay (3 mm/h1/2 random walk), delay gradients (0.3 mm/h1/2 random walk), phase biases (white noise) = > smooth tropo solution.
More information and validation results are available in (Byun and Bar-Sever 2009) and in [IGSMAIL-6298].
The dataset includes tropospheric products for 460 stations over the full period. However, not all stations have been operating since 1995. Figure 5.2 shows the sites with more than 10 and 15 years of observations. For climate related studies (e.g. analysis of trends) a subset of 120 stations with more than 15 years of data can be selected (Bock 2016a).

Map of GPS stations from the IGS network for which reprocessed ZTD data are available in the IGS repro1 dataset over the period from January 1995 to December 2010
The selected ZTD dataset was screened for outliers and converted to IWV using the following procedures. The screening included a range check and an outlier check for ZTD estimates and their formal errors (σZTD) at the highest temporal resolution (5 min sampling):
-
range check: ZTD ϵ [1 m, 3 m] and σZTD ϵ [0, 6 mm],
-
outlier check: ZTD ϵ median (ZTD) ± 0.5 m and formal error for σZTD < 2.5 * median (σZTD).
It rejected about 0.08% of all ZTD estimates.
The conversion of ZTD to IWV was done using surface pressure at the GPS sites interpolated from ERA-Interim reanalysis, pressure level data (geopotential), and weighted mean temperature (Tm) also computed from ERA-Interim reanalysis, pressure level data. The reanalysis data were bi-linearly interpolated in the horizontal plane from the 4 grid points surrounding each GPS site. Refractivity constants from Thayer 1974, were used here. More information on the post-processing methods is given in Bock 2016b, c, d, and in Sect. 5.4 of this report.
Temporal averaging was applied to the ZTD data to reduce them from 5 min interval to 1-hourly, with at least 4 values in each 1-h bin. The conversion from ZTD to IWV was performed on the 1-hourly ZTD data at the 6-hour time interval of the reanalysis. The resulting 6-hourly GPS IWV data were further averaged to daily and monthly values. Weighted daily means were computed from the corresponding t = 00:00, 06:00, 12:00, 18:00 and 24:00 UTC estimates with half weights at the edges. The daily values were aggregated to monthly means when at least 15 days were available in a given month.
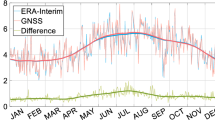
Validation of the resulting GPS IWV data was done by comparison with ERA-Interim. In order to minimize representativeness differences, the ERA-Interim IWV data were recomputed from the pressure level data at the 4 grid points surrounding each GPS site and then bi-linearly interpolated in the horizontal plane (Bock and Parracho 2019). The vertical integration of specific humidity was performed from the height (altitude) of the GPS station to the top of the atmosphere. Thanks to these precautions, good agreement was found between GPS and ERA-Interim at most sites. Figure 5.3 shows the overall mean difference and standard deviation of difference (in % of IWV) for the daily data. Ten stations are identified in this figure for which the difference is quite large. The number grows up to 14 when absolute differences are analysed. A careful analysis of the time series and comparison with independent DORIS data, helped to understand or hypothesize the origin of the differences. In most cases, representativeness differences are suspected (Bock and Parracho 2019). Indeed, the GPS IWV is representative of a local IWV content while the ERA-Interim values is computed from 4 grid points on a 0.75° × 0.75° mesh. Representativeness differences occur in regions of steep orography and in coastal regions. Absolute differences are magnified in regions and periods of high IWV contents (e.g. in the tropics or in summer), but relative difference can also be large in regions of low differences (e.g. CFAG, SANT, AREQ in the Andes mountains, MCM4, SYOG, MAW1, in Antarctica). Few sites could be detected with evidence of problems in the GPS observations or in the ZTD estimates (e.g. MCM4 in Antarctica) as days with problematic observations they would typically be rejected during the data processing and ZTD outliers by the screening procedure.

comparison of IGS repro1 GPS IWV data and ERA-Interim reanalysis at 120 global sites: standard deviation of difference as a function of mean difference (both in % of IWV) for the daily data
Homogeneity issues in the GPS series due to equipment changes do not show up in this figure as they are usually quite small, but they impact more strongly ZTD and IWV trend estimates, as gaps in the time series do. These issues are discussed in Sect. 5.5. Trend estimates are thus a useful diagnostic for the detection of inhomogeneities in the time series and have been used extensively by the community. The final IWV dataset is publicly available at: ftp://ftp.climserv.ipsl.polytechnique.fr/GPS_IWV_VEGA/cost/
Citable with DOI: 10.14768/06337394-73a9-407c-9997-0e380dac5590
5.2.3 EPN Repro2 GNSS Reprocessing Campaign
In Europe, in the framework of the EPN-Repro2, the second reprocessing campaign of the EPN, five Analysis Centres homogenously reprocessed the EPN network for the period 1996–2014. Both individual and combined tropospheric products (Pacione et al. 2011) along with reference coordinates and other metadata, are stored in SINEX TRO format, Gendt (1997), and are available to the users at the EPN Regional Data Centres (RDC), located at BKG (Federal Agency for Cartography and Geodesy, Germany, https://igs.bkg.bund.de/root_ftp/EPNrepro2/products/).
For each EPN station, plots on ZTD time series, ZTD monthly mean, comparison versus radiosonde data (if collocated), are publicly available at the EPN Central Bureau (Royal Observatory of Belgium, Brussels, Belgium, http://www.epncb.oma.be/_productsservices/analysiscentres/repro2.php).
The evaluation with respect to other sources or products, such as radiosonde data from the E-GVAP and numerical weather reanalysis from the European Centre for Medium-Range Weather Forecasts, ECMWF (ERA-Interim), provides a measure of the accuracy of the EPN-Repro2 ZTD combined products.
The assessment of the EPN Repro1 (Voelksen 2011) and Repro2 with respect to the radiosonde data has an improvement of approximately 3–4% in the overall standard deviation. The assessment of the EPN Repro1 and Repro2 with respect to the ERA-Interim re-analysis showed the 8–9% improvement of the latter over the former in both overall standard deviation and systematic error, which was obvious for the majority of the stations.
The EPN-Repro2 data record can be used as a reference for a variety of scientific applications and has a high potential for monitoring trend and variability in atmospheric water vapour, improving the knowledge of climatic trends of atmospheric water vapour and being useful for regional Numerical Weather Prediction (NWP) reanalyses as well as climate model simulations.
For five EPN stations, among those with the longest time span, GOPE (Ondrejov, Czech Republic, integrated in the EPN since 31-12-1995), METS (Kirkkonummi, Finland, integrated in the EPN since 31-12-1995), ONSA (Onsala, Sweden, integrated in the EPN since 31-12-1995), PENC (Penc, Hungary, integrated in the EPN since 03-03-2096) and WTZR (Bad Koetzting, Germany, integrated in the EPN since 31-12-1995), we have computed ZTD trends using EPN Repro2, EPN Repro1 completed with the EUREF operational products, radiosonde and ERA-Interim data. All of them are also in the IGS Network, for which IGS Repro1 completed with the IGS operational products are available and extracted from the GOP-TropDB. We have screened all data sets (classical 3 sigma). Then for all GPS ZTD data sets we have estimated and removed shifts related to the antenna replacement. No homogenization has been done for radiosonde data since radiosonde metadata are not available. A LSE method is applied to estimate trends and seasonal component. ZTD trends for all three GPS ZTD data sets are consistent, as soon as the same homogenisation procedure is applied. Then overall RMS is 0.02 mm/year. Among all five ZTD sourced, we find the best agreement for ONSA (RMS = 0.04 mm/year) and WTZR (RMS = 0.02 mm/year). For PENC we have good agreement with respect to ERA-Interim (0.05 mm/year), but a large discrepancy versus radiosonde (−0.31 mm/year). This large discrepancy is probably due to the distance to the radiosonde launch site (40.7 km, radiosonde code 12843) and to the lack of the homogenisation stage. For the five considered stations, the agreement with respect to ERA-Interim (RMS = 0.11 mm/year) is better than that with respect to radiosonde (RMS = 0.16 mm/year) even though the EPN Repro2 does not change significantly the detection of ZTD trends, it has a better agreement with respect to radiosonde and ERA-Interim data than EPN Repro1. It has also the best spatial resolution compared to IGS Repro1 and radiosonde data, which are used today for long-term analysis over Europe. Taking into account the good consistency among trends, EPN Repro2 can be used for trend detection in areas where other data are not available (Fig. 5.4).

ZTD trend comparisons at five EPN stations. The error bars are the formal error of the trend values
The reprocessing activity of the five EPN ACs is a very large effort generating homogeneous products not only for station coordinates and velocities, but also for tropospheric products. The knowledge gained will certainly help for future reprocessing activities which will most likely include Galileo and BeiDou and therefore will be started some years from now after having successfully integrated these new data into the current operational near real-time and daily EUREF products. The consistent use of identical models in various software packages is another challenge for the future to be able to improve the consistency of the combined solution. Prior to any next reprocessing, it was agreed in EUREF to focus on cleaning and documenting data in the EPN historical archive, as it should highly facilitate any future work. For this purpose, all existing information needs to be collected from all the levels of data processing, combination and evaluation which includes initial GNSS data quality checking, generation of individual daily solutions, combination of individual coordinates and ZTDs, long-term combination for velocity estimates and assessments of ZTDs and gradients with independent data sources. A detailed description of the EPN-Repro2 campaign is reported in Pacione et al. (2017).
5.2.4 VLBI Reprocessing Campaign
For the sake of comparison and validation of long-term GNSS atmospheric parameters within the EU COST Action GNSS4SWEC zenith total and wet delays (ZTD, ZWD) and gradients (NS, EW) were provided from a GFZ VLBI solution employing VieVS@GFZ software (Nilsson et al. 2015) with high temporal resolution: 10 min for the zenith delays and 1 hour for gradients.
Since all VLBI stations run under IVS (International VLBI Service for Geodesy and Astrometry) are co-located with GNSS, the solution includes all VLBI stations in the common GNSS-VLBI time span: 1995.0–2013.0. Currently the Analysis Centres (AC) of the IVS apply different analysis strategies e.g., mapping functions and meteorological data sets for the analysis of atmospheric parameters what hinders the determination of a homogeneous long-term combined solution.
For the climate applications foreseen in WG3 of this COST action, it is of specific importance to apply consistent models and in particular long-term homogenized meteorological data. Thus, analytical models of this solution largely adhere to IERS Conventions (Petit and Luzum 2010). In principle a long-term homogenized data set of in-situ observed meteorological variables, atmospheric pressure and temperature, would be the best input for climate studies. For the sake of comparison with GNSS, however, we used GPT2 model values instead because this model is available for GNSS solutions as well.
The data set was uploaded to the Pecný Observatory’s ftp server.
5.2.5 DORIS Reprocessing Campaign
A high quality, consistent, global, long-term dataset of ZTD and IWV estimates was produced from Doppler Orbitography Radiopositioning Integrated by Satellite (DORIS) measurements at 81 sites (Bock et al. 2014). The DORIS Doppler observations were processed using GIPSY-OASIS II software package (Zumberge et al. 1997) with the same strategy as the one used by Bock et al. [2010] but over a longer period of time (January 1993 to August 2008). Compared to previous releases, this strategy (referred to as ignwd08 (Willis et al. 2012) uses an improved method for mitigating errors in solar radiation pressure models (Gobinddass et al. 2009) and atmospheric drag corrections (Gobinddass et al. 2010) (Fig. 5.5).

Map showing the locations of DORIS sites with more than 10 years (42 sites) and with more than 15 years (21 sites) over the period from January 1993 to August 2008 used in Bock et al. 2014. The historical DORIS data cover the period from 1990 to present, for which 27 sites have more than 20 years of data
The ZTD dataset was screened using range checks and outlier checks were applied to ZTD and formal error estimates (see Sects. 5.2.2 and 5.4.1). Further quality check and validation was done by comparing DORIS ZTD with ECMWF reanalysis (ERA-Interim) data. The outlier checks rejected 3% of the data, while the ERA-Interim comparison further rejected 1% of data based on a normality test. A linear drift was evidenced in the screened DORIS ZTD data compared to ERA-Interim and to the IGS repro1 GPS ZTD data (Sect. 5.2.2), which was associated to the progressive replacement of Alcatel antennas with Starec antennas at the DORIS sites. The DORIS IWV data was homogenized by applying a bias correction computed from comparison with ERA-Interim data, each time station equipment was changed (mostly for antenna replacement). The homogenized DORIS data showed excellent agreement with the GPS data (correlation coefficient of 0.98 and standard deviation of differences of 1.5 kg/m2). Comparison with ERA-Interim and satellite IWV data was also quite good (correlation coefficient > 0.95 and standard deviation of differences <2.7 kg/m2). The agreement with radiosonde data was less good, however. Preliminary results of IWV trends and variability at 31 sites with more than 10 years of data showed good consistency between DORIS, ERA-Interim, and GPS. This study demonstrated the high potential of the DORIS IWV data for climate applications. This DORIS IWV dataset is public available at: http://onlinelibrary.wiley.com/doi/10.1002/2013JD021124/
Later improvements in the DORIS processing procedure are related to zenith tropospheric gradients estimation strategies, for example when estimating such parameters on an hourly basis, instead of once a day as before (Willis et al. 2014; Heinkelmann et al. 2016), to the use of more recent DORIS satellites, such as Jason2 (Willis et al. 2016a), and trying to cope with the effect on the on-board oscillator when passing over the South Atlantic Anomaly region (SAA) around South America, and to the realization of an updated version of the DORIS terrestrial reference frame, known as DPOD2008 (Willis et al. 2016b), and to its newest version (DPOD2014), aligned on the ITRF2014 (Altamimi et al. 2016).
Following the availability from CNES of antenna correction models (corrections in azimuth and elevation) derived from anechoic chamber measurements for the Starec antennas (newer type), we reprocessed the DORIS data, showing a better consistency in ZTD between Starec and Alcatel antennas results. The bias observed in the first results (Bock et al. 2010) was decreased, thanks to this new type of corrections, frequently used for GNSS receivers. For Alcatel antennas (the older ones), as no anechoic measurements could be performed by then, we used phase centre correction models provided by the manufacturers.
Finally, the use of the new DORIS/RINEX format, providing DORIS phase and pseudorange instead of previously destructive integrated Doppler data, for the most recent satellites was investigated using the current JPL software (GIPSY/OASIS II) used for all the above results. New developments are currently on-going to incorporate the DORIS data processing capability to the most recent JPL software package (GipsyX), in addition to the current GNSS data (GPS, GLONASS, Galileo and BeiDou), to the Satellite laser ranging (SLR) data and, in the future to the VLBI data as well as other type of data.
5.3 Sensitivity Studies on GNSS Processing Options
5.3.1 An Overview of the GNSS Data Processing Strategies
Ground-based GNSS data can be processed according to the standard technique of network adjustment or in Precise Point Positioning mode (Zumberge et al. 1997). Advantages and disadvantages of both processing techniques are reported in Guerova et al. (2016) and in the next subsection.
In this subsection we describe how GNSS data are processed in the framework of the EUREF (http://www.euref.eu/) Permanent Network (EPN, http://www.epncb.oma.be) (Bruyninx et al. 2012), being the reference for best practices in Europe concerning data management and data processing.
The EPN is a science-driven network of continuously operating GNSS reference stations, covering the European continent, and with precisely known coordinates. All contributions to the EPN are voluntary, with more than 100 European agencies/universities involved and the reliability of the network is based on redundancy. Since 1996, GNSS data collected at approximately 300 operating stations of EPN have been routinely analysed by 16 EPN Analysis Centres (ACs). The strategy to analyse EPN observations is in accordance with the so-called distributed processing approach. Each EPN AC processes the observations of a dedicated sub-network of EPN stations and, in order to guarantee the redundancy of the estimates, the same station is processed by at least 3 ACs. Each AC estimates daily and weekly station coordinates and station zenith tropospheric path delays for its own EPN sub-network that are later combined by the EPN Analysis Centre Coordinator and by the EPN Tropospheric Coordinator in order to deliver the EPN official product. Processing strategies used by all ACs are followed consistent with the general EUREF recommendations included in “Guidelines for the EPN Analysis Centres” prepared by the EPN Coordination Group and the EPN Central Bureau, (http://www.epncb.oma.be/_documentation/guidelines/guidelines_analysis_centres.pdf). The EPN ACs rely on a network approach and 15 over 16 processes data with Bernese GNSS Software v.5.2 (Dach et al. 2015) while only one AC uses GIPSY-OASIS II Software (Webb and Zumberge 1997). All systematic errors are modelled according to IERS Conventions 2010 (Petit and Luzum 2010). For the final solution, in order to obtain the highest precision and accuracy, the IGS final precise satellite orbits, clocks, and earth rotation parameters are applied. Also, azimuth/elevation-dependent phase centre variations and offsets from IGS, including individual phase centre corrections, are used for ground and satellite antennas. It is also mandatory to include second order of ionospheric corrections and ionospheric ray bending corrections to minimize the impact of ionospheric delays on station estimates. For tropospheric modelling, half of the ACs apply Global Mapping Function (GMF; Boehm et al. 2006a) and the remaining Vienna Mapping Function (VMF1; Boehm et al. 2006b) along with Chen-Herring gradient model (Chen and Herring 1997) for the Bernese solution while in GIPSY-OASIS, gradients are modelled according to Bar-Sever et al. (1998). These mapping functions go along with specific a priori zenith hydrostatic and wet delay models: GPT (an empirical model based on ERA-40 reanalysis, Boehm et al. 2007) is recommended with GMF whereas gridded a priori delay models computed from ECMWF operational analysis are recommended with VMF1 (Boehm et al. 2006b). More recently, the group from the Technical University of Vienna released two updates of the GPT empirical model: GPT2 (Lagler et al. 2013) and GPT2w (Böhm et al. 2015).
At the last EPN Analysis Centres (AC) Workshop held in Brussels in October 2017, it was agreed that all EPN must use the Vienna Mapping Function. In the Bernese software, the ZTD parameters are modelled as piecewise linear functions of time and usually estimated at 1-hourly intervals and the tropospheric gradients are estimated every 24 hours, with absolute and relative constraints of 5 m. In GIPSY-OASIS II software wet zenith delay is modelled with a sampling rate of 5 min as random walk with unconstrained a priori and a random walk sigma. In processing strategies of some ACs, ambiguity resolution is performed by using the quasi-ionosphere-free (QIF) strategy in conjunction with regional TEC information. However, most of ACs follow the recommended procedure with Bernese software which applies several methods depending on the length of baselines. Ambiguities are resolved in a baseline-by-baseline mode, fixed to integer values and introduced in the final network solution. In most of ACs in the network processing, independent baselines are defined by the criterion of maximum common observations. More details can be found at: http://www.epncb.oma.be/_productsservices/analysiscentres/LAC.php.
5.3.2 Software Agreement
The agreement among different GNSS SW package has been investigated in the framework of the second EPN Reprocessing Campaign where the three main GNSS software packages, Bernese (Dach et al. 2015), GAMIT (King et al. 2010) and GIPSY-OASIS II (Webb and Zumberge 1997), have been used to reprocess the whole EPN network.
The agreement in terms of the standard deviation with respect to the combination (see Figure below) is below 3 mm before GPS week 1055 (26 March 2000) and 2 mm thereafter. This is related to the worse quality of data and products during the first years of the EPN/IGS activities (Fig. 5.6).

Weekly mean ZTD biases (a) and standard deviations (b) of each contributing solution with respect to the final EPN-Repro2 combination
All the details about the combination procedure are reported in Pacione et al. (2011) and Pacione et al. (2017).
5.3.3 PPP vs. DD Processing Modes
Two approaches of GNSS data processing can be used to estimate ZTD: relative and precise point positioning (PPP). Relative processing mode uses double-difference observations from a network of stations, while PPP uses zero-difference observations from a single station. Relative processing is usually considered as being more precise, but not necessarily more accurate and more stable. Indeed, the network configuration (extent and geometry of the baselines) can have a significant impact on estimated parameters in double-difference processing. PPP is an absolute technique since there is no propagation of errors between stations. However, the accuracy of data processing in PPP mode depends strongly on the quality of external products: satellite orbits and clocks. It should be noted that currently very accurate products are not available in real time (e.g. for now-casting weather applications). This is one of reasons why most of E-GVAP analysis centres use double-difference processing where the dependency on the clock products is much smaller. Data processing in PPP mode is a faster method than the DD solution, because only the observations for the stations of interest are processed while in relative processing additional stations are required to form long baselines and reduce the correlation between tropospheric parameters.
Many researches have used tropospheric delay estimates from DD and PPP strategies in the context of weather and climate studies. Ahmed et al. (2014) observed that for globally distributed stations the RMS of the difference between the ZTD estimates from PPP and DD solutions has a latitude dependence and is largest at the equator and smaller in high latitudes (Fig. 5.7a). A latitude dependence of the bias between the PPP and DD ZTD estimates is shown in Fig. 5.7. It is commonly observed that discrepancies are larger at the equator, where the higher concentration of atmospheric water vapour occurs, than in mid-to-high latitudes.

(top) Station-wise RMS of the difference between the ZTD from PPP and DD solutions; (bottom) Distribution of the RMS difference (Gaussian fit in red) with respect to latitude
Stępniak et al. (2016) discussed the impact of network design strategy on the quality and homogeneity of relative (double difference) strategy and comparison to absolute PPP solutions. In order to compare PPP and DD solutions, the ZTD estimates were computed using both processing techniques and the same processing options were set. Figure 5.8 shows long time series of ZTD estimates and formal error of ZTD for DD and PPP strategies and a zoom on a period when ZTD outliers can be observed in DD solution. These outliers are due to very few observations in common with other stations in baseline and are not seen in PPP ZTD time series. It can be assumed that PPP might be an interesting alternative to prevent outliers arising from defects in the baseline geometry in a double-difference processing.

Comparison of ZTD estimates and formal error for the DD and PPP solutions; (top) all year 2014 (bottom) Zoom on a period (end of January 2014) when the DD solution has outliers due the geometry of the network
5.3.4 Baseline Strategy in DD Processing
The baseline design strategy in a double-difference network processing has a strong impact on the quality and continuity of ZTD time series. Stępniak et al. (2017) show that ZTD outliers are most of the time caused by sub-daily data gaps at reference stations which provoke disconnections of clusters of stations from the reference network and common–mode biases due to the strong correlation between stations in short baselines. Outliers can reach a few centimetres and more in ZTD and coincide usually with a jump in formal errors. The magnitude and sign of these biases are impossible to predict, because they depend on different errors in the observations and on the geometry of the baselines. Therefore, an alternative baseline strategy for GNSS data from moderate-size network (e.g. national scale) was developed that ensures that all the stations remain connected to the main reference network (Stępniak et al. 2017). The main ingredients of this strategy are: apply a selection of the reference stations based on results from an initial processing, connect the other stations only to stations of the reference network and not between them, and introduce redundancy in the baselines. As an example, the results of this new processing strategy are compared to the standard one and to obs-max in Table 5.1. In the standard solution, a pre-defined network is composed of a skeleton of reference stations to which secondary stations are connected in a star-like structure; in the second variant the same network was processed using Bernese obs-max strategy; and the third variant is the alternative/new baseline strategy. Columns 3 and 4 in Table 5.1 report the numbers of stations for which the standard deviation of ZTD and formal error are the largest among all: the new solution has the largest ZTD variations at only 7 sites, whereas obs-max has the largest number at 43 sites and the pre-defined solution at 54 sites. The number of rejected ZTDs (and thus the number of used ZTDs) are very similar between the new and obs-max strategies (columns 5 and 6), and the mean standard deviations of ZTD and formal errors (columns 7 and 8) are slightly smaller for the new/alternative solution, i.e. this solution is more stable and more accurate. The only spikes remaining in the ZTD series in the new solution are due to small number of observations or short gaps at sub-regional stations. Therefore, it is still necessary to apply a post-processing screening procedure to provide a clean ZTD dataset.
This study shows that many outliers can be avoided using the new baseline strategy. The strategy is well adapted to post-processing when the network can be optimized by successive processing tests, e.g. to get the most stable time series (what is important for climate applications), but also for NRT applications when e.g. national networks are processed in DD – then adopting the star design would help avoiding the disconnections and large outliers.
5.3.5 Mapping Functions
5.3.5.1 Tests with DD and PPP Processing of GNSS Data
Mapping function plays a key role in GNSS observations processing. It delivers a priori ZTD value, which is often identified as a ZHD value. This results from the fact that the hydrostatic part of the atmosphere is subject to relatively minor changes in time and therefore is easy to model. Consequently, in GNSS processing, next to the humidity delay, also correction to this value is estimated. Therefore, no matter what kind of mapping function would be applied, the final ZTD value should be the same for all solutions, through proper estimation of these corrections. Nowadays, the most common used mapping functions are GMF (Global Mapping Function) (Boehm et al. 2006a) and VMF1 (Vienna Mapping Function1) (Boehm et al. 2006b). For some time, also an extension of NMF (Niell Mapping Function) (Niell 1996), IMF (Isobaric mapping Function) (Niell 2000), was used. As it was mentioned, theoretically all functions should return the same ZTD value, which practically does not happen in reality. Vey et al. (2006) has verified this by comparing results from NMF and IMF. On the basis of one year of data, the mean ZTD difference between these two functions was at the level of 5 mm. Steingerberger et al. (2009) have analysed GMF and VMF1. They focused mostly on coordinates, however they found out that an improper estimation of a priori ZHD value translates also into discrepancies in coordinate solutions. Bałdysz et al. (2016) have shown that they are also differences in long-term changes between consecutive reprocessings of EPN, which inter alia may result from using various mapping functions. To verify the possible impact of mapping functions on short and long time changes of ZTD parameter, an additional reprocessing of EPN was conducted.
Firstly, in Bernese 5.2 software we reprocessed 18 years of data both in DD and PPP mode. Each of these approaches was conducted two times, with applying only one change in the processing scheme: the mapping function. In the first one GMF was used, whereas in the second one VMF1 was used. In term of short-time changes like annual and semi-annual amplitudes, only negligible changes occurred between the compared solutions, as it can be seen on the Fig. 5.9 (annual amplitudes) and Table 5.2.

Comparison of annual amplitude between GMF and VMF1 for double difference (top) and precise point positioning (bottom) modes
From the point of view of climate monitoring the most important parameters are the long–time changes, which will be described here by a linear trend. Therefore, for our 18-years time span of data, we also calculated the linear trend values. Similar to the annual amplitude, the trend differences between the solutions obtained from these two mapping functions were very small. This was true both for DD and PPP approaches. We can therefore state that in case of Bernese software, using GMF or VMF1 both in DD and PPP mode does not introduce large differences in the obtained results. This is despite the fact that there are differences between these both approaches, as it can be found on Fig. 5.10.

Linear trend values from 18-years ZTD time series and four analysed strategies, obtained in Bernese software
In Table 5.2 there is a statistical summary of differences in seasonal components between DD and PPP solutions, as well as differences in linear trend values. As can be noted, discrepancies in annual and semi-annual amplitudes were less than 0.5 mm. In case of the PPP approach, standard deviations of both these components was only slightly higher than in DD solutions, but at the same time, its absolute mean values were smaller. Differences in linear trends were negligible, as both the mean value of differences and its standard deviations were the same in DD and PPP approach.
5.3.5.2 Tests for EPN Repro2 at GOP
Douša et al. (2017a, b) compared two solutions with different mapping functions for 172 stations in Europe: GO0 (legacy repro1 using GMF, 3°) and GO1 (repro2 using VMF, 3°). GO1 improves slightly the coordinate repeatability. The change in mean ZTD is about −0.36 mm (GO1 ZTD estimates are slightly lower) and the standard deviation of differences is about 2.0 mm. In terms of ZTD trends, the mean difference is about 0.36 mm/decade, with extreme values of −1.18 mm/decade and 0.45 mm/decade.
5.3.5.3 Tests with VLBI Data
We tested the impact of mapping functions and a priori zenith delay data on VLBI-derived baseline length, tropospheric parameters and derived products (e.g. IWV trends) using the Potsdam Mapping Factor (PMF) concept (Zus et al. 2014) and a new a priori zenith delay empirical model called GFZ-PT (Balidakis et al. 2018). The PMF coefficients have been estimated based on 6-hourly 0.5° ERA Interim reanalysis fields. In contrast to VMF1 where only the “a” coefficients are calculated epoch-wise, PMF provides “b” and “c” coefficients in addition, thus improving the elevation-dependent fit. The change in height estimates between the VMF1 and PMF is in the range − 2 to +2 mm, globally.
GFZ-PT is an empirical model for pressure, temperature, relative humidity, zenith delays, mapping function coefficients (a, b, c), gradient components of first and second order, and water vapour-weighted mean temperature. In essence, it is a fit at annual, semi-annual, inter-annual, diurnal, semi-diurnal, and inter-diurnal frequencies – linear trend included – to ray-tracing products as well as other parameters. The seasonal signals and trend stem from ERA Interim, and the high-frequency signals are estimated from hourly ERA5.
Owing to its more rigorous parametrization, PMF is slightly more accurate than VMF1, in terms of the assembled slant delays. Despite the fact that changing the mapping function affects the scale of the geodetic networks from the different VLBI analysis set-ups (mm level), no significant relative errors appear in the estimated IWV rates. Therefore, PMF, GFZ-PT or VMF1 may be used interchangeably in this regard (Fig. 5.11).

IWV rates from the VLBI solutions where the mapping functions were alternated. NI stands for numerical integration, which was used to obtain the water vapour-weighted mean temperature. Shown are the stations with long observation record and statistically significant trends
The ZHD is mainly a function of pressure and as such is prone to inhomogeneities in the related observations. We have addressed the impact of using several different pressure and ZHD datasets on the VLBI results: raw in-situ meteorological observations recorded at VLBI stations, the same observations but homogenized, ERA Interim reanalysis, and GFZ-PT. The raw in-situ meteorological observations have been homogenized employing the penalized maximal t-test and series from the model levels of ERA Interim reanalysis (ERAinML) as a reference (Balidakis et al. 2018) (Fig. 5.12).

IWV rates from the VLBI solutions where the meteorological data were alternated. NI stands for numerical integration, which was used to obtain the water vapour-weighted mean temperature. Shown are the stations with long observation record and statistically significant trends
Using meteorological data homogenized in such a manner for VLBI analysis improves the baseline length repeatability due to improved a priori zenith delays (mainly) and thermal deformation (secondary). However, more appropriate ZHD applied a-posteriori, compensate for most cases.
5.3.6 Trends in the IWV Estimated from Ground-Based GPS Data: Sensitivity to the Elevation Cutoff Angle
The observations acquired from the ground-based GNSS stations may contain the inconsistencies due to effects of signal multipath, which are highly elevation dependent. The multipath effects are worse for observations at low elevation angles. Therefore, the selection of the elevation cutoff angle used in the GNSS data processing can have a significant impact on the resulting trend in the atmospheric integrated water vapour content (IWV). Using 14 years of data from 12 GPS sites in Sweden and Finland, Ning and Elgered (2012) found that a higher elevation cutoff angle (25°) gives the best agreement between the GPS-derived IWV trends and the ones obtained from profiles measured by radiosondes at nearby launching sites.
In a more recent study (Ning et al. 2017) the problem was readdressed by using 20 years of GPS data from 13 sites in Sweden and Finland, and applying two different elevation cutoff angles, 10° and 25°, to estimate the atmospheric IWV. The estimated linear trends in the IWV were compared to the corresponding trends from radiosonde data at 7 nearby (< 120 km) sites and the trends given by the European Centre for Medium-Range Weather Forecasts (ECMWF) reanalysis data (ERA-Interim).
The results show that due to the larger formal errors of the individual IWV estimates a larger standard deviation is seen in the IWV difference between the GPS elevation 25° solution and the other two techniques. However, such larger formal error is not the limiting factor for the uncertainty of the estimated IWV trend. Figure 5.13 shows similar correlation coefficients of 0.74 and 0.71 when comparing the trends obtained from the GPS elevation cutoff angle 25° and 10° solutions with the ones obtained from the radiosonde data. A significantly higher correlation is seen for the GPS 25° solution compared to the 10° solution when the two are compared to the IWV trends given by the ERA-Interim data. The study indicates that using different elevation cutoff angles is a valuable diagnostic tool that can be used for the validation purpose and detection of possible multipath impacts. When using GPS data to monitor the long-term change of the IWV, e.g. as linear trends, it is recommended to apply at least two significantly different elevation cutoff angles in the data processing. Ideally the IWV trends obtained from the two solutions should be the same if there is no significant multipath, or any other elevation dependent phenomena in addition to the atmosphere, that affects the observations.

Correlations between the IWV trends from the GPS and the radiosonde data (a), and the ERA-Interim data (b) for 10° and 25° elevation cutoff angles, from Ning et al. (2017)
5.3.7 Improving Stochastic Tropospheric Model for Better Estimates During Extreme Weather Events
Developing and evaluating advanced tropospheric products for monitoring severe weather events and climate was one of the main objectives of the ESSEM COST Action ES1206. Zenithal Wet Delays (ZWD) are estimated during GNSS data processing and used to retrieve Integrated Water Vapour (IWV) with a usual precision around 1–2 kg/m2. During the GNSS data processing, the temporal evolution of ZWD is generally modelled as a random walk (ZWD(t + dt) = ZWD(t) + ε(t)), where the variance of ε(t) equals qrw 2.dt with dt the sampling rate and qrw the parameter of the random walk. Depending on the software, qrw is fixed to 3 mm.h-1/2 with uniform weighting (with σ = 10 mm) in GIPSY-OASIS (Bar-Sever et al. 1998) or 20 mm.h-1/2 with elevation-dependent weighting in GAMIT (King and Bock 2005). As for the temporal evolution model of tropospheric gradients, it is common to use a random walk whose parameter qtgrd is ten times smaller than that of ZWD in GIPSY-OASIS (Bar-Sever et al. 1998). More recently, Selle and Desai (2016) reassessed the parameterization of the random walk and the weighting function in GIPSY-OASIS using water vapour radiometer measurements as a reference. They confirmed the [3, 0.3] mm.h-1/2 random walk parameters when using a uniform weighting (UNIF) of the observations, and suggested [8.4, 0.84] mm.h-1/2 as random walk parameters if σ = a/sin(elev.) (SINE) is used as a weighting function for the observations. Fixing these random walk parameters regardless of the location of the station and of local weather conditions is one limitation for the accuracy of GNSS-derived IWV, especially during extreme weather events.
Nahmani and Bock (2014) demonstrated the sensitivity of GPS tropospheric estimates during mesoscale convective system (MCS) events in West Africa to the random walk parameters used to constrain the temporal evolution of ZWD and tropospheric gradients. As an example, Fig. 5.14 shows tropospheric estimates obtained with different random walk parameters and weighting functions of the GPS observations during the MCS over Niamey (Niger) on August 11, 2006.
-
An unsuitable parameterization of the random walk and the weighting function leads to an underestimation of ZWD and tropospheric gradients during severe weather events (dotted green curves). This is the case for the model using [3, 0.3] mm.h-1/2 with SINE weighting included in Fig. 5.14 only to illustrate the unrealistic results provided by an inaccurate parameterization.
-
Both standard GIPSY-OASIS parameterizations proposed by Selle and Desai (2016) allow observing the sudden increase of ZWD induced by the passage of the MCS (red and cyan curves), even if the shapes of both curves are not exactly the same. The estimated tropospheric gradients, however, are clearly different: The East/West displacement of the MCS is clearly reflected in the East component of the tropospheric gradient estimated using the [3, 0.3] mm.h-1/2 parameters with UNIF weighting, which is not the case with the [8.4, 0.84] mm.h-1/2 parameters with SINE weighting. The random walk parameter for tropospheric gradients fixed at 0.84 mm.h-1/2 is not suitable for this case study.

Tropospheric estimates from GISPY-OASIS during the mesoscale convective system of August 11th, 2016 at Niamey (Niger): Zenithal Wet Delay [mm] (a), North (b) and East (c) components of tropospheric gradients (TGRD) [mm] retrieved using different random walk parameters [qzwd, qtgrd] to constrain their temporal evolution. Rainfall data are retrieved from ARM Mobile Facility (Miller and Slingo 2007)
Selle and Desai (2016) advise increasing the random walk parameters in order to track high variability events, but without specifying which values to use. In the rare cases where a radiometer or LIDAR is collocated with the GPS station, the measurements obtained are of poor quality during an intense meteorological event, which makes it impossible to have an external evaluation of the stochastic parameters to be used.
Nahmani and Bock (2014) carried out some tests to set the random walk parameters to be used in the Niamey MCS case study (Fig. 5.14) by increasing them to [10, 1] mm.h-1/2 and [20, 2] mm.h-1/2 with UNIF weighting, and to [20, 2] mm.h-1/2 and [40, 4] mm.h-1/2 with SINE weighting. These different parameterizations lead to different conclusions about the studied MCS:
-
The time series of ZWD (Fig. 5.14) can have one or two local maxima interspersed with a more or less emphasized local minimum. The ZWD differences at these extrema can reach 35 mm, corresponding to IWV differences of around 5 kg/m2.
-
The North component of the tropospheric gradient consistently shows a peak between 5:00 and 6:00 am, which is, however, more or less emphasized depending on the parameterization used. Other features appear for certain parameterizations only, like the sharp peaks between 2:15 and 3:00 am of the curves from [10, 1] mm.h-1/2 and [20, 2] mm.h-1/2 with UNIF weighting.
-
The East component of the tropospheric gradient globally reflects the East/West displacement of the MCS when the stochastic constraints are not too tight (i.e. except the curves from [3, 0.3] mm.h-1/2 and [8.4, 0.84] mm.h-1/2 with SINE weighting). The increase from 1:30 am on corresponds to the approach of the MCS near the station. However, the local maximum has more or less stressed amplitude, between 1.5 mm ([3, 0.3] mm.h-1/2 – UNIF) and almost 7 mm ([10, 1] mm.h-1/2 – UNIF) and is more or less delayed, between 2:30 and 3:15 am. It is followed by a steep fall to a local minimum around −2 to −3 mm between 4:00 and 5:00 am with a zero crossing indicating the presence of the MCS above the GPS station.
Thus, an empirical approach to set the parameters of the random walks to be used during extreme weather events is not appropriate: the tropospheric estimates indeed differ significantly depending on the stochastic constraints and the weighting of the GPS observations used.
Using simulated data, Nahmani et al. (2017) showed the potential interest of using a Bayesian approach to overcome this problem. For a given dataset, the evidence (probability of a model given the observations) can be computed for different models and used to select the most appropriate modelling. One can thus decide whether ZWD should rather be modelled as a random walk or as a step or piecewise linear function. One can also discriminate between different weighting functions of the GPS observations. Using the Bayesian Variance Component Estimation (VCE) technique, it is also possible to determine optimal random walk parameters for the ZWD and tropospheric gradients, as well as the optimal variance of GPS observations. To apply this approach to real GPS data, it is mandatory to get observation equations from GPS data processing software, which is not possible with the standard version of GIPSY-OASIS software. Nahmani et al. (2017) extracted observation equations from ESA NAPEOS software for the case study of the MCS over Niamey (Niger) on August 11, 2006. They first demonstrated that it is preferable to choose an elevation-dependant weighting function as σ = a/sin(elev.) rather than a uniform weighting of the GPS observations. Then, applying the Bayesian VCE, they estimated a standard deviation of a = 3.9 mm for zenith GPS observations, and the random walk parameters [qzwd = 10.5, qtgrd = 1.3] mm.h-1/2. Those parameters were finally used to process the GPS data again with the GIPSY-OASIS software. The final estimates of ZWD and tropospheric gradients are shown in Fig. 5.14 as the solid black curves. It can be concluded that:
-
The two peaks on ZWD are confirmed.
-
The North component of the gradient is mostly weak, except between 5:00 and 6:00 am indicating the passage of a small cell in the North of the station.
-
The East component of the gradient shows a strong and clear signal: the increase starts at 1:30 am to reach a maximum around 4 mm at 3:18 am. It then drops quickly, crossing zero at 3:48 am, and reaches a minimum around −2.7 mm at 4:36 am.
The Bayesian VCE approach is relevant to validate the stochastic parameterization of GPS data processing and better estimate tropospheric parameters during severe weather events. It opens the way to an adaptive processing of GPS data according to the location of the station and the local weather conditions. One could even consider using a time-varying stochastic parameterization. In the case of the Niamey MCS, at least three sets of stochastic parameters would indeed be required to take into account the physics of the phenomenon: one set before, one during and one after the passage of the MCS. Nahmani et al. (2016) indeed demonstrated that this specific modelling has higher evidence than when using a single stochastic parameterization. The Bayesian approach is thus particularly promising, but it remains to be assessed more thoroughly before a software implementation for operational use can be considered.
5.3.8 Multi-GNSS Data Processing
GLONASS observations have been available since 2003 but only from 2008 onwards, the amount of GLONASS data is significant. In the framework of the second EPN Reprocessing Campaign (Pacione et al. 2017), the impact of GLONASS observations has been evaluated in terms of raw differences between ZTD estimates as well as on the estimated linear trend derived from the ZTD time series. Two solutions were prepared and compared, using the same software and the same processing characteristics, but different observation data: one with GPS and GLONASS, and one with GPS data only. The difference in ZTD trends between a GPS-only and a GPS + GLONASS solution shows no significant rates for more than 100 stations (rates usually derived from more than 100 000 ZTD differences). This indicates that the inclusion of additional GLONASS observations in the GNSS processing has a neutral impact on the ZTD trend analysis. Satellite constellations are continuously changing over time due to satellites being replaced and newly added for all systems. For instance, in the near future the inclusion of additional Galileo and BeiDou data will become operational in the GNSS data processing. These data will certainly improve the quality of the tropospheric products and this study points out that the ZTD trends might be determined independently of the satellite systems used in the processing, and therefore multi-GNSS data processing might not introduce systematic changes in terms of ZTD trends.
5.3.9 Impact of IGS Type Mean and EPN Individual Antenna Calibration Models
According to the processing options listed in the EPN guidelines for the Analysis Centre (http://www.epncb.oma.be/_documentation/guidelines/guidelines_analysis_centres.pdf), EPN individual antenna calibration models have to be used instead of IGS type mean calibration models, when available. Currently, individual antenna calibration models are available at about 70 EPN stations. However, in the second EPN Reprocessing campaign, there are individual solutions carried out with IGS type mean antenna calibration models only (Schmid et al. 2016) while others use IGS type mean plus EPN individual antenna calibration models. Therefore, for the same station, there are contributing solutions obtained by applying different antenna models. To evaluate the impact of using these different antenna calibration models on the ZTD, two solutions were prepared and compared using the same software and the same processing, but different antenna calibration models. The first solution used the IGS type mean models only, and the second one used the individual calibrations whenever it was possible and the IGS type mean for the rest of the antennas.
An example of the time series of the ZTD differences obtained by applying individual and type mean antenna calibration models for the EPN station KLOP (Kloppenheim, Frankfurt, Germany) is shown in Fig. 5.15.

EPN station KLOP (Kloppenheim, Frankfurt, Germany) ZTD differences time series between solutions processed with individual and type mean antenna calibration models. Two instrumentation changes occurred at the station (marked by vertical dashed red lines): the first in 27 June 2007, when the previous antenna was replaced with a TRM55971.00 and a TZGD radome, and the second in 28 June 2013 with the installation of a TRM57971.00 and a TZGD radome
Switching between phase centre corrections from type mean to individual (or vice versa) causes a disagreement in the estimated up component of the stations, as was mentioned by Araszkiewicz and Voelksen (2017), and therefore in their ZTD time series. Depending on the antenna model, the offset at station KLOP in the up component (vertical displacement) is −5.2 ± 0.5, 8.7 ± 0.6 and 5.6 ± 0.8 mm with a corresponding offset in the ZTD of 0.2 ± 0.5, −1.5 ± 0.5, −1.4 ± 0.8 mm, respectively. Similar values were obtained between solutions calculated for all stations/antennas for which individual calibration models are available. The corresponding offset in the ZTD has the opposite sign for the antennas with an offset in the up component larger than 5 mm (16 antennas) and, generally, does not exceed 2 mm. Such inconsistencies in the ZTD time series are not large enough to be captured during the combination process upon which the official EPN product is based, where a 10 mm threshold in the ZTD bias (about 1.5 kg/m2 IWV) is set in order to flag problematic ACs or stations. The detailed analysis is reported in Pacione et al. (2017).
5.3.10 Impact of Non-Tidal Atmospheric Loading Models
Non-tidal atmospheric loading models are not yet considered as Class 1 models by the IERS (Petit and Luzum 2010), indicating that there are currently no standard recommendations for data reduction. To evaluate their impact, two solutions, one with and one without a non-tidal atmospheric loading model, have been compared for the year 2013. In the solution with the model, the National Centres for Environmental Prediction (NCEP) model is used at the observation level during data reduction (Tregoning and Watson 2009). Dach et al. (2010) have already found that the repeatability of the station coordinates improves by 20% when applying the non-tidal atmospheric loading correction directly on the data analysis and by 10% when applying a post processing correction to the resulting weekly coordinates. However, the effect on the ZTDs seems to be negligible. Generally, it causes a difference below 0.5 mm with a standard deviation not larger than 0.3 mm. The detailed analysis is reported in Pacione et al. (2017).
5.3.11 Using Estimated Horizontal Gradients as a Tool for Assessment of GNSS Data Quality
5.3.11.1 Background
It is a common view that because the basic observable in GNSS is the time of arrival the system is well suited for climate monitoring of the atmospheric water vapour content. This is obtained via the estimates of the total equivalent zenith delay and the delay due to water vapour. It is also common practice to estimate two-dimensional horizontal linear gradients for each site in the GNSS data processing because it improves the reproducibility of estimated geodetic parameters, see e.g. Bar-Sever et al. (1998). We have addressed the question if also these estimated gradients are useful in climate research, i.e. if they can detect any long term systematic changes. While doing so it became clear that first of all estimating horizontal linear gradients is a tool to assess the quality of the observations of the GNSS signals. It was also early recognised, using GPS data from Sweden, that no significant long-term trends were detected for the horizontal gradients.
In this subsection, we first give a short background on the cause of horizontal gradients in the atmosphere, then we show a comparison between gradients estimated using data from two collocated GNSS stations and one microwave radiometer. Thereafter we study if the GNSS gradients contain any information about the atmosphere by comparing them to gradients estimated from the ERA-Interim analyses from the ECMWF. Finally, we give some conclusions related to the present and future use of linear horizontal gradients.
5.3.11.2 Cause of Horizontal Gradients
The refractivity in the atmosphere is determined mainly by the total pressure, the temperature and the partial pressure of water vapour. Pressure gradients exist mainly over global scales and regional scales (e.g. mesoscale weather systems). Temperature and especially water vapour exists also over local scales. The large local gradients over a GNSS site have spatial scales ranging from hundreds of metres to a few kilometres. For example, during the passage of a weather front the gradients can be significant, especially for distinct cold fronts. Other specific weather phenomena that can cause horizontal variability are sea breeze (Munn 1966), cloud rolls (Brown 1970) and convection processes in general. We note that none of the known processes is expected to be strictly linear, but the strength in the geometry and the data quality do not provide the option to determine additional atmospheric parameters.
5.3.11.3 Gradients from Two Collocated GNSS Sites
Two GNSS sites have been operating continuously at the Onsala Space Observatory, on the west coast of Sweden for many years. The primary site, ONSA, was established already in the late 1980s and the other site, ONS1, was taken into operation in 2011. The two sites are shown in Fig. 5.16. The antennas of these two sites are located within 100 m from each other and should observe similar gradients.

The two GNSS stations ONSA (left) and ONS1 (right) at the Onsala Space Observatory
We have used 4 years of GPS data (2013–2016) from these two sites and estimated the horizontal gradients in the east and the north directions every 5 min. The analysis follows the same lines as described by Ning et al. (2013). We have also included a comparison with the microwave radiometer Konrad that has been observing the sky continuously, in a sky mapping mode, during most of the time during these 4 years. Correlation plots are shown in Fig. 5.17 and show a much higher correlation between the gradients from the two GNSS sites compared to when the GNSS gradients are correlated with the gradients from the microwave radiometer. This is expected because GNSS is estimating the gradients in the total refractivity whereas the radiometer is only sensitive to gradients in the water vapour. Also, the directions of the observations are towards the same satellites using GNSS but the radiometers observation are evenly spread of the sky. More details on this study have been given by Forkman et al. (2017).

Comparisons of the total east and north gradients estimated from the ONSA and ONS1 stations with a temporal resolution of 5 min (top). Below is a corresponding comparison between the gradients from the microwave radiometer Konrad (wet gradients only) and ONS1 (total gradients), here using a temporal resolution of 15 min, from Forkman et al. (2017)
5.3.11.4 Comparison Between Gradients from GNSS Data and the ERA Interim Analyses
We have searched for any systematic changes in the horizontal gradients using 17 years (1997–2013) of estimated gradients from GPS data for 21 sites in Sweden. The temporal resolution of the originally estimated gradients was 5 min. Based on these data we formed average values of 1 hour, 1 day, and 1 month. The ECMWF data (see e.g. Boehm and Schuh 2007) that were available while doing this study were from the mid of 2005, resulting in a subset of almost 9 years of data.
The results, in terms of correlation coefficients, are shown in Table 5.3. The correlations seen in all cases confirm that an atmospheric signal in terms of gradients is detected by the GPS observations. We note that the correlation coefficients increase for longer averaging time periods. Our interpretation for that is that we compare a larger fraction of the gradient that is caused by large scale temperature and pressure gradients, which is better modelled by the ERA Interim analysis. Another result worth noting is that the two sites with the highest correlation coefficients for the monthly averages are ONSA and SPT0. These two sites are the only ones that are equipped with ECCOSORB® material below the antenna. This could reduce the impact from unwanted multipath effects. The phenomenon calls for further studies.
In the future, we also plan to subtract the hydrostatic gradients calculated using the ECMWF data in order to study the estimated wet gradients from GPS only. Unfortunately, the temporal resolution of the ECMWF data is not sufficiently high to resolve many of the short lived small-scale gradients. In order to carry out comparisons we are therefore turning to microwave radiometer data.
5.3.11.5 On Estimating Trends Based on Estimated Horizontal Gradients from VLBI Data
Given that horizontal gradients in general are small and that the larger values typically occur for a short time we expect that any long-term trends would be very small and therefore also difficult to detect. An estimated gradient has a direction and from a time series we estimate trends for the east and the north gradients. Combining these two trends will give a change in the average gradient at the site. There is also a second possibility and that is to estimate a trend in a time series with absolute values of the gradients. Such a positive trend will occur if there is an increase in the variability at the site, which can happen even if there are no trends in the east and north gradients.
We have estimated trends for the two VLBI sites Wettzell and Onsala for the time period 1997–2014. The resulting 17 years long time series is then the base for estimating linear trends. To be sensitive to the short-term variability we used gradients with a temporal resolution of 1 h. The results are shown in Table 5.4. We note that there are no indications of change in the absolute values at any of the two sites. There are small trends detected in the east and north gradients. Preliminary results using ECMWF data from the period 2005–2014 suggest that these trends may be caused by systematic changes in the hydrostatic and the wet horizontal gradients. Such changes will occur randomly over time periods of a few years due to the motion of mesoscale weather systems and is already well known from existing meteorological observation networks. We conclude that no trends related to small scale variability in the water vapour has been detected. Because no trends are seen in the absolute value of the gradients we have at the same time an indication that the two sites had a stable electromagnetic environment during the studied time period.
5.3.11.6 GNSS Tropospheric Gradients and Problems with Low-Elevation Data Quality
When developing a new interactive web interface over tropospheric parameter comparisons within the GOP-TropDB (Győri and Douša 2016), we could easily observe large systematic behaviour in GNSS-derived tropospheric gradients from the GOP European second reprocessing (Douša et al. 2017a, b) during specific years at several stations of the EUREF Permanent network (EPN). We can estimate only total tropospheric horizontal gradients from GNSS data, i.e. without being able to distinguish between dry and wet contributions. The former is mostly due to horizontal asymmetry in atmospheric pressure, and the latter is due to asymmetry in the water vapour content being more variable in time and space than the former (Li et al. 2015). However, mean wet gradients should be close to zero, whereas dry gradients may tend to point slightly to the equator, corresponding to latitudinal changes in atmosphere thickness (Meindl et al. 2004). Similarly, orography-triggered horizontal gradients can appear due to the presence of high mountain ranges in the vicinity of the station (Morel et al. 2015). Such systematic effects can reach the maximum sub-millimetre level, while a higher long-term gradient (i.e. that above 1 mm), is likely more indicative of issues with site instrumentation, the environment, or modelling effects.
Therefore, in order to clearly identify these systematic effects, we compared GOP gradients with those calculated from the ERA Interim data during period 1996–2014. During the study, we could observe a strong impact in the most extreme case identified at the MALL station (Mallorca, Spain). The monthly differences in gradients steadily increased from 0 mm up to −4 mm and 2 mm for the east and north gradients, respectively, within the period of June 2003–October 2008, Fig. 5.16. Such large differences were not realistic and were attributed to data processing because long-term increasing biases dropped down to zero on November 1, 2008, immediately after the antenna and receiver were changed at the station. During the same period, also yearly mean ZTD differences to ERA-Interim steadily changed from about 3 mm to about −12 mm and immediately dropping down to −2 mm in 2008 after the antenna change, see Fig. 5.18.

MALL station – monthly mean differences in GNSS tropospheric horizontal gradients vs ERA Interim data
The EPN Central Bureau (http://epncb.oma.be), operating at the Royal Observatory of Belgium (ROB), provides a web service for monitoring GNSS data quality and includes monthly snapshots of the tracking characteristics of all stations. The sequence of plots displayed in Fig. 5.19, representing the interval of interest (2002, 2004, 2006 and 2008), reveals a slow but systematic and horizontally asymmetric degradation of the capability of the antenna to track low-elevation observations at the station. Therefore, we analysed days of the year (DoY) 302 and 306 (corresponding to October 28 and November 1, 2008) with the in-house G-Nut/Anubis software (Václavovic and Douša 2016) and observed differences in the sky plots of these 2 days. The left-hand plot in Fig. 5.20 depicts the severe loss of dual-frequency observations up to a 25° elevation cut-off angle in the South-East direction (with an azimuth of 90°–180°), which cause the tropospheric linear gradient of approximately 5 mm to point in the opposite direction. The figure also demonstrates that an increasing loss of second frequency observations appears to occur in the East (represented as black dots). The right-hand plot in this figure demonstrates that both of these effects fully disappeared after the antenna was replaced on October 30, 2008 (DoY 304), resulting in the appearance of normal sky plot characteristics and a GLONASS constellation with one satellite providing only single frequency observations (represented as black lines).

Low-elevation tracking problems at the MALL station during the period of 2003–2008. From left-top to right-bottom: January 2002, 2004, 2006 and 2008 (courtesy of the EPN Central Bureau, ROB)

Sky plots before (top) and after (bottom) replacing the malfunctioning antenna at the MALL site (Oct. 30, 2008). Black dots indicate single-frequency observations available only
This situation demonstrates the high sensitivity of the estimated gradients on data asymmetry, particularly at low-elevation angles. The systematic behaviour of these monthly mean gradients, their variations from independent data and a profound progress over time, seem to be useful indicators of instrumentation-related issues at permanent GNSS stations. It has to be noted that the strategy of elevation-dependent weighting plays a significant role here, as the main impact is due to an asymmetry and poor quality of low-elevation observations. It is also considered that gradient parameters can be valuable method as a part of ZTD data screening procedure (Bock 2016b).
Although the station MALL represented an extreme case, biases at other stations were observed too, e.g. GOPE (1996–2002), TRAB (1999–2008), CREU (2000–2002), HERS (1999–2001), GAIA (2008–2014) and others. Site-specific, spatially or temporally correlated biases suggest different possible reasons such as site-instrumentation effects including the tracking quality and phase centre variation models, site-environment effects including multipath and seasonal variation (e.g. winter snow/ice coverage), edge-network effects when processing double-difference observations, spatially correlated effects in reference frame realization and possibly others.
5.3.11.7 Conclusions
The gradients estimated from GPS data are clearly reflecting the atmospheric conditions since there is a significant correlation with ERA-Interim results. However, the very small-scale water vapour variability seems, as expected, not to be captured by the ERA-Interim model. We also noted that long-term trends in estimated gradients from GPS data are insignificant given the uncertainties involved. Statistics of gradient time series can be a valuable tool to search for problems in the GPS data, such as sudden changes in the electromagnetic environment of the GNSS antenna and this calls for further more detailed case studies.
5.3.12 Conclusions and Recommendations on Processing Options
While standards for GNSS processing for positioning devted to geodetic and geodynamic applications (e.g. Reference frame realization, tectonics, GIA monitoring…) are well established, nothing similar is available for long ZTD/IWV time series devoted to climate applications (e.g. monitoring seasonal to decadal trends and variability). The results reported in this subsection are a quite comprehensive overview of the sensitivity of ZTD time series to the most important processing options from which we can draw some first conclusions.
In general, the main scientific GNSS software packages used by the geodetic community for data processing agree at 5–6 mm ZTD level (~1 kg/m2 IWV) for instantaneous estimates, or about ~ 2 mm ZTD (0.3 kg/m2 IWV) for weekly estimates, and about 0.15–0.30 kg/m2 per decade for IWV trends.
Both widely used processing modes based either on double-difference (DD) combination of observations or using undifferenced observations in a PPP processing are consistent at the level of ~1 kg/m2 IWV and 0.30 kg/m2 per decade for IWV trends. For the retrieval of long time series, the quality of satellite orbits and clock corrections are of prime importance and may be a significant source of uncertainty in PPP for the early GPS period (before 2001). Processing in a double-difference mode is much less impacted by the uncertainty in the external products but suffers from network effects, e.g. changes in the baseline design over time might induce spurious trends and gaps in data have been shown to be a major source of outliers in the ZTD time series.
The details of the tropospheric delay modelling (mapping functions and a priori zenith delay corrections, deterministic vs. stochastic model for ZTD parameters) in the GNSS processing software has a direct impact on the properties of the derived ZTD parameters, e.g. unconstrained ZTD parameters are prone to become outliers in case of gaps or errors in the observations (at the station or at nearby stations in case of DD processing). Similarly, over-constrained ZTD parameters may hide the true ZTD variability in case of strong short-lived events (e.g. convective systems passing over the station). Optimal approaches for better constraining the tropospheric models are foreseen as an active area of investigation in the near future.
For tropospheric modelling mapping functions play a key role. Nowadays two mapping functions are mainly used: GMF and VMF1. Althought it is recommended to use VMF1, from the point of view of climate monitoring (that is in terms of linear trends) the differences between these two mapping functions are very small.
The selection of the elevation cut-off angle used in the GNSS data processing can have a significant impact on the resulting IWV biases and trends. This result is explained by the well known sensivitiy of GNSS ZTD estimates to elevation dependent errors (e.g. due to signal multipath, tropospheric model, antenna model, etc.). For linear trend estimation, it is recommended to apply a cutoff test using at least two different elevation cut-off angles in the data processing and compare the results. In case the difference in ZTD trends obtained from the two solutions is above the acceptable level (ca 0.5 mm/decade), the underlying elevation-dependent error source should be tracked and reduced.
As the GNSS satellite constellations are growing, the impact of using observations from different systems in the recent years compared to GPS-only in the older ones was questionable for trend monitoring. Tests conducted in the framework of the second EPN Reprocessing campaign helped to investigate this question. It was shown that the impact of GLONASS observations on linear ZTD trends wes not significant.
To improve the site coordinates repeatability, it is a common practice to estimate two-dimensional horizontal linear gradients for each site in the GNSS data processing and the estimated gradients are clearly reflecting the asymmetry in the atmospheric refractivity. The question whereas the gradient parameters contain some interesting signature for climate research has been investigated. However, so far, analysis of long time series of gradient parameters did reveal any significant signal (e.g. trends in gradients are insignificant given the uncertainties involved). However, gradient parameters have been shown toresponds strongly to the presence of problems in the GNSS data (e.g. degradation of antenna pattern).
The sensitivity studies on GNSS data modelling and processing settings devoted to climate applications that were initiated during the COST Action have pointed to the most important areas of uncertainty that shall be futher investigated in the future.
5.4 Standardisation of ZTD Screening and IWV Conversion
5.4.1 ZTD Screening
Screening is the process of inspecting data for errors and correcting them prior to doing data analysisFootnote 1 (Bock 2016b). In GNSS data processing software, outliers in phase and code observations are typically rejected based on both a priori and a posteriori statistical tests (e.g. Sect. 5.2 “Pre-processing on the RINEX Level” and Section 5.6 “Screening of Post–Fit Residuals” in Dach et al. 2015). In NWP assimilation systems, as well, observations have to pass several quality checks and statistical tests to be actually used (Järvinen and Undén 1997). One of the main reasons for the necessity of screening is that most processing algorithms rely on the assumption that input data have well behaved statistical properties. This is obviously not the case for most observational data, which can include outliers (gross errors) due to equipment malfunctioning or mishandling, or simply due to a human operator’s typing errors.
Despite the precautions taken with the use of efficient screening algorithms at the observation level, it is often observed that processing results contain discontinuities and outliers. This is the case for GNSS coordinate time series (Klos et al. 2015) and ZTD time series (Stepniak et al. 2017). Figure 5.21 below shows a typical example of ZTD time series and their corresponding formal errors produced with Bernese software in double-difference mode. Outliers in the original ZTD estimates can be clearly detected visually. Stepniak et al. 2017, identified several causes for ZTD outliers in a double-difference mode processing: (1) deficiencies in the baseline strategy that lead to temporary disconnections of a station from the main network due to observation gaps in connecting baseline, (2) short observation gaps at the station that lead to poorly determined ZTD estimates, (3) other causes (e.g. incorrect ambiguity fixing, increased measurement noise, etc.). The latter two impact also PPP. All three causes lead usually also to an increase in formal error as can be seen in the lower plot of Fig. 5.21.

Time series of ZTD estimates (upper) and corresponding formal errors (lower) for GNSS station WLAD (Poland) over year 2014 as resulting from a regular post-processing procedure with Bernese GNSS software (Stepniak et al. 2017)
According to Fig. 5.21, one has the impression that spikes in formal error are much more frequent than spikes in ZTD estimates. This is due to the fact that ZTD natural fluctuations due to changing weather conditions are quite large and not easy to distinguish from small outliers and erroneous fluctuations due to measurement noise.
5.4.1.1 Screening Based on GNSS Results Only
If we want to detect erroneous ZTD values based on a simple range-check (comparison with fixed upper and lower limits for all stations), we need to use an interval large enough to accommodate for extremal natural variations encountered at all stations of interest. This interval can be determined from the physical basis of natural ZHD and ZWD variations due to variations in surface pressure and IWV. Monthly data from ERA-Interim reanalysis yield ZHD variations in the range [1.20, 2.41] m and ZWD in the range [0.00, 0.54] m, globally. A reasonable range check interval for ZTD would thus be [1.00, 3.00] m. If a regional network is considered, this interval can be further reduced.
The range-check on ZTD values alone is not sufficient. It can be complemented with an outlier check (comparison with station-dependent upper and lower limits). The choice of interval limits is not trivial because ZTD values don’t follow a known empirical probability distribution function (PDF). Nevertheless, it is common to use an interval such as the mean ± 3, 4, or 5 standard deviations (Kouba 2003; Wang et al. 2007a, b, c). In the case of a normal PDF, these limits correspond to a fraction between 0.0027 and 5.7·10−7 of the data. In the case of real data, the fraction of rejected data is much higher because of several reasons: the PDF of ZTD data is not normal, the mean and standard deviation estimates are not robust (i.e. they are biased when outliers are included), outliers in the data yield larger deviations from the mean than expected for a normal PDF (this is what we want to detect). As an example, the ZTD data from the IGS repro1 solution (Sect. 5.2.2) for year 1996 give a fraction of rejected data between 0.0065 (mean ± 3σ) and 1.6 10−5 (mean ± 5σ) over all available stations. Inspection of results station by station reveals that only a small number of stations contain a significant number of outliers. For these stations, a rejection rate of 0.01 (i.e. 1%) is achieved when the limits are taken at the mean ± 3.5σ. We thus recommend to use the latter interval.
Because formal errors are very sensitive to changes in the quality of ZTD estimates, we can improve the screening procedure by applying a range check and an outlier check on the formal errors. Inspection of empirical PDFs and percentiles of the formal errors from various reprocessed ZTD datasets showed that the PDFs of stations with no or only few outliers resemble a Chi distribution and that the 95, 98, and 99% percentiles can be used to detect stations with large numbers of outliers (Bosser and Bock 2016). However, the results are highly dependent on the processing options, especially the constraints on the temporal evolution of the estimated ZTDs (see Sect. 5.3). Hence, the 95% percentile for a global dataset such as the IGS repro1 solution produced with GIPSY OASIS II (one ZTD parameter estimated every 5 min with a random walk model constraint of 3 mm h-1/2) ranges between 2.0 mm (good stations) and 4.0 mm (bad stations), while for a EPN repro2 solution with Bernese software (one ZTD parameter estimated every 2 h and no constraints) the range is extended to between 1.2 mm (good stations) and 9.0 mm (bad stations).
We thus recommend to use range check limits matched to the data processing options. An upper limit for the formal error of 10 or 15 mm is adequate to unconstrained tropospheric models (e.g. Bernese EPN repro2), while a limit of 5 to 6 mm seems more reasonable in case of a constrained model (e.g. IGS repro1).
The range check on formal errors should be station-specific (thus implicitly processing specific). We tested two estimators for the upper limit: median + k × σ and p × median. The former yields good results with k = 3 or k = 3.5, but σ is not a robust scale estimator. The latter yields good results with p = 2 or p = 2.5 and is more robust to outliers because it does not use the standard deviation. A trial and error approach is suggested here to examine the results from different parametrizations.
Note that for the tests of both ZTD and formal errors, it is important to apply both the range check and the outlier check. Even if the range check might appear unnecessary because it is more permissive than the outlier check, its role is mainly to eliminate the largest outliers before data-dependent limits are computed for the range checks.
When the screening is applied to long (multi-annual) time series, the limits for outlier checks should account for the variation in observation and processing quality over time. We suggest to update the limits yearly.
5.4.1.2 Screening Based on Comparison with Reference ZTD Data
Because the ZTD data can have large temporal variability, it is necessary to set the limits for the range check and outlier check quite far apart. It is hence impossible to distinguish between small outliers and large natural variations based on the ZTD values alone. Only the comparison to a predicted ZTD value, or first guess, used as reference can help reducing the detection interval. This procedure is commonly used in data assimilation systems for the screening of observations (Järvinen and Undén 1997). Short-range forecast from the NWP model are used as a reference to compute background departures (observation minus background). In this procedure, the square of the normalized background departure is considered suspect when it exceeds its expected variance more than a predefined multiple.
Such a procedure can be applied offline to GNSS ZTD data using e.g. a NWP model such as ERA-Interim reanalysis. We will refer to it as a model departure quality control (MDQC). The reference ZTD values can be computed from the model IWV and ZHD/pressure data by following the reverse procedure as used for the conversion of GNSS ZTD into IWV (see next subsection). The ZTD differences (GNSS minus model) are expected to follow a normal PDF. A normality test can thus be applied to detect the anomalous values (outliers). Various tests have shown that it is most efficient to check the data station-wise in yearly batches using as limits the median ± 3σ. According to the normal PDF, the fraction of values outside of this range should be smaller than 0.0027. Because σ is sensitive to outliers we suggest to use a robust scale estimator such as σ* = (84th – 16th percentile)/2. In addition, if we don’t want to be too strict we can allow a higher fraction than the theoretical one, e.g. 2 × 0.0027, and apply the test iteratively. In brief, the recommended procedure is the following:
-
Form ZTD differences: GNSS – model (e.g. Reanalysis),
-
Do the normality test: if the number of values outside the interval median ± 3 σ > 2 × 0.0027 then reject all these values; a robust estimate for σ is σ* = (84th – 16th percentile)/2,
-
Do up to 10 iterations (usually 2 or 3 are enough).
The performance of the MDQC depends on the spatial and temporal resolution of the model at hand. Using e.g. ERA-Interim with 0.75° x 0.75° horizontal resolution might be problematic for stations in mountainous regions because of representativeness differences (Bock and Parracho 2019). Most model archives have also limited temporal resolution, e.g. from 6-hourly data it will be difficult to compute accurate departures for 5-min resolution GNSS ZTD data.
Other reference datasets or approaches might be interesting to screen GNSS ZTD data, e.g. comparison ZTD data from collocated GNSS, DORIS or VLBI stations can be realized at a number of sites.
5.4.1.3 Conclusions
Screening the ZTD data is a mandatory step before they can be further used for a scientific purpose.
Two approaches have been described in this subsection: (1) a method based on GNSS results only, composed of range checks (with fixed limits) and outlier checks (with station and time-dependent limits) applied to ZTD and formal errors; (2) a method based on comparison with reference ZTD data (e.g. NWP model or reanalysis) inspired from the background departure quality control using in data assimilation systems. Both approaches can be used independently and yield consistent results (Bock 2015; Stepniak et al. 2015). Higher efficiency is however gained when both methods are applied sequentially.
Reduction of outlier in the GNSS ZTD data would also be achieved by a more careful screening at observation level and improved processing options (e.g. optimized baseline design and constraints on ZTD parameters, Stepniak et al. 2017).
5.4.2 ZTD to IWV Conversion
At the beginning of the COST Action, a survey on the conversion methods used by the community was organized with the WG3 participants (Pacione et al. 2014b; Bock and Pacione 2014). Thirteen contributions were received which revealed that there was no established methodology. Debate at the Munich workshop confirmed that there was no clear consensus and it was decided to review the state of the art methods, try to highlight their limits and uncertainties, and come up with recommendations, distinguishing between real-time (now-casting) and offline applications (climate monitoring).
The specification of the conversion method recovers three different aspects: the conversion formulas, the constants, and the auxiliary data (Bock 2016c).
5.4.2.1 Conversion Formulas
The most commonly admitted formulas are presented below:
Definition | Application to GPS ZTD conversion | ||
ZTD = ZHD + ZWD | 5.1a | ZTD GPS = ZHD ap + ZWD estim | 5.1b |
\( ZTD={10}^{-6}{k}_1{R}_d\frac{P_s}{g_m} \) | 5.2a | ZHD GPS computed from Equation 5.2a with pressure at GPS stations P s | |
\( ZWD={10}^{-9}{R}_v\underset{0}{\overset{\infty }{\int }}{\rho}_v(z)\left[{k}_2^{\prime }+\frac{k_3}{T(z)}\right] dz \) | 5.3a | ZWD GPS = (ZTD GPS − ZHD GPS) | 5.3b |
\( IWV=\underset{0}{\overset{\infty }{\int }}{\rho}_v(z) dz \) | 5.4a | IWV GPS = κ(T m) × ZWD GPS | 5.4b |
\( k\left({T}_m\right)=\frac{1}{10^{-6}{R}_v\left[{k}_2^{\prime }+\frac{k_3}{T{}_m}\right]} \) | 5.5a | κ(T m) computed from T m | |
\( {T}_m=\frac{\underset{0}{\overset{\infty }{\int }}{\rho}_v(z) dz}{\underset{0}{\overset{\infty }{\int }}\frac{\rho_v(z)}{T(z)} dz} \) | 5.6a | T m computer from… | |
\( {g}_m=\frac{\underset{0}{\overset{\infty }{\int }}\rho (z)g(z) dz}{\underset{0}{\overset{\infty }{\int }}{\rho}_v(z) dz} \) | 5.7a | gm=9.784 [1−0.00266cos (2λ) − (2.8·10-7) × H] | 5.7b |
The definitions of ZTD, ZHD, ZWD, and gm as in Eqs. 5.1a, 5.2a, 5.3a, 5.7a and 5.7b follow the formalism from Saastamoinen (1972) and Davis et al. (1985).
It is important to note that the GPS ZWD quantity that should be used in Eq. 5.4b is the one defined by Eq. 5.3b and not the estimated ZWD which may be biased if the a priori ZHD used in the processing is biased (e.g. when an empirical a priori delay model such as GPT is used). Indeed, the estimated ZWD would compensate for an a priori ZHD bias. However, the total delay ZTD obtained from the sum of a priori ZHD and the estimated ZWD (see Eq. 5.1b) is correct. For the computation of ZWD, a better ZHD estimate must be used such as computed from Eq. 5.2a.
Note also that ZHD is sometimes computed as an integral of the total density of the air (see the definition in Davis et al. 1985). We do not recommend this approach as it is likely to introduce numerical errors depending on the limited vertical resolution and extent of the air density profile. Under hydrostatic equilibrium, the integral expressed as in Eq. 5.1a can be computed with much higher accuracy from the surface pressure Ps either from observations or a Numerical Weather Prediction model.
The definition of κ(Tm) and Tm in Eqs. 5.5a and 6.6a are from Askne and Nordius (1987) and Bevis et al. (1992). These authors proposed empirical formulas for Tm depending on the surface temperature, Ts, only (Bevis et al. 1994), and on additional scaling parameters (Askne and Nordius 1987). The most commonly used formulation is Tm = 70.2 + 0.72Ts, from Bevis et al. (1994), where the coefficients were derived from a linear regression of radiosonde data over the USA. Other linear formulations have been proposed for different regions of the globe but all empirical formulations have limited accuracy in representing the spatial and temporal variations of Tm (Wang et al. 2005). NWP models offer an interesting alternative for the computation of Tm by numerical integration of Eq. 5.6a as they are available at any place globally and any time with high temporal resolution (e.g. 6-hourly) in almost real-time.
5.4.2.2 Constants
The calculation of ZHD and κ(Tm) involve specific gas constants for dry air Rd. = 287.04 ± 0.02 J K−1 kg−1 (ICAO 1993) and water vapour Rv = 461.522 ± 0.008 J K−1 kg−1 (Kestin et al. 1984), and refractivity coefficients k1, k2 and k3 with k’2 = k2−k1 × (Rd/Rv).
Many authors published coefficient values from experimental work performed from the 1950s to the 1970s. Smith and Weintraub (1953) compiled and averaged the early measurements, and Hasegawa and Stokesberry (1975) compiled and characterized a significantly larger number of experimental results. Thayer (1974) developed an alternative and hybrid approach which includes measurements extrapolated from optical frequencies. Bevis et al. (1994) revisited the data used by Hasegawa and Stokesberry (1975) and determined a new set of average values and associated uncertainties. Finally, Rueger (2002) proposed a new set of ‘best average’ coefficients after reassessing the dataset used by Bevis et al. (1994). While there has been a broad consensus on the value of k1 from previous authors, Rueger’s new k1 coefficient is 0.115% larger than the standard value. The impact on ZHD computed from Eq. 5.2a is an increase of about 2.6 mm at mean sea level (i.e. a bias of IWV =0.4 kg/m2). The impact is also significant on the determination of bending angles from GNSS radio-occultation measurements (Healy 2011). Healy (2011) examined the reasons of increase in Rueger’s k1 estimate and identified two obvious reasons: a numerical inconsistency in the value of 0° = 273 K instead of 273.15 K and the inclusion or not of CO2 in the gas mixture composing the dry air by the previous authors. Rueger’s estimate of k1 includes 0.0375% of CO2, while the values reported by Hasegawa and Stokesberry (1975) and Bevis et al. (1994) are for dry CO2 free air. Healy (2011) highlights that though Rueger’s estimate of k1 appears to be more robust and defendable than the standard value, it does not account for non-ideal gas effects. This point requires further discussion and clarification because it is unclear in some of the older literature how and when non-ideal gas effects were included. Finally, this study reinforces the need for new measurements of refractivity constants taking all these aspects into account.
Note that in Eq. 5.2a, it is the product of Rd. k1 that appears. Hence the Rd. value used should be consistent in CO2 concentration with k1. The value Rd = 287.04 J K−1 kg−1 from ICAO (1993) assumes a 0.0314% of CO2.
As for the other coefficients, the values for k2 from Bevis et al. (1994) and Rueger (2002) are fairly consistent. The values for k3 differ by −0.01563 105 K2 hPa−1 leading to a small fractional change in IWV of −0.42% (or 0.21 kg/m2 in a high humidity content of IWV = 50 kg/m2).
According to the significant work done by Rueger (2002) in re-assessing past measurements and re-evaluating the refractivity coefficients we recommend to use his results after correction for the non-ideal gas effects, as suggested by Healy (2011). Using the compressibility factors given by Owens (1967), i.e. 1/Zd = 1.000588 for dry air at 273.15 K and 1013.25 hPa, and 1/Zw = 1.000698 for water vapour at 293.15 K and a partial pressure of 13.33 hPa (the conditions of measurements of refractivity use by Rueger, 2002), Rueger’s ‘best average’ coefficients become:
Which should be used with an updated value of the specific gas constant for dry air including 0.0375% of CO2, Rd = 287.027 J K−1 kg−1.
Note that the uncertainties of the refractivity coefficients indicated in Eq. 5.8 are those given by Rueger (2002).
5.4.2.3 Auxiliary Data
The computation of ZHD from Eq. 5.2a requires surface pressure at the GPS station. However, surface pressure is not often observed at GPS stations. Only a small number of IGS stations are equipped with pressure sensors and Wang et al. (2007a, b, c) and Heise et al. (2009) have pointed out inaccuracies in these data. On the other hand, surface pressure observations are available from the World Meteorological Organization (WMO) surface synoptic network (SYNOP) at about 8500 sites globally, with mostly 1- to 6-hourly reports. The main issues that arise with these data are related to sensor calibration, which has not been performed in a consistent manner across all stations over time, and height correction when reduced to mean sea level pressure (Ingleby 1995). Parracho (2017) compared ERA-Interim and SYNOP data over Europe and observed that altitude changes larger than 10 m are not uncommon in this dataset and that the update of station altitudes in the WMO and national weather services can be delayed by several months, hence introducing spurious biases and breaks in the observed pressure data. Recalibration of sensors, relocations of stations, equipment changes and changes in data processing, produce inhomogeneity in the times series which are detrimental to the analysis of climate trends. NWP model outputs, such as operational analysis/forecasts or reanalysis, offer again an interesting alternative to sparse and inhomogeneous observational data.
Keeping in mind that an error of 1 hPa in Ps leads to an error of 2.3 mm in ZHD and an error of 0.35 kg/m2 in IWV, it is important to choose the most accurate pressure data available (e.g. with an error < 1 hPa) compliant with the specific space and time scales of the application.
Whatever pressure data is used, a vertical adjustment is usually required to correct for the height difference between the barometer or the model topography and the location of the GPS antenna. A modified version from the Berg (1948) formula is commonly used to relate pressure between the two heights z1 and z2: P2 = P1(1–0.0000226(z2−z1))5.225. Unfortunately, this formula assumes a standard temperature profile with T0 = 288 K at mean sea level and a lapse rate of – 6.5 K km−1 (Parracho 2017). A primary limitation of this formulation is with the constant mean sea level temperature which can induce a large bias when used globally (note that the lapse rate effect is only of second order). Instead, we recommend to use the ICAO (1993) formula:
where α is the temperature lapse rate (in K km−1), and P 1 and T 1 are the pressure and temperature at the initial height z 1, R d=287.04 J K−1 kg−1 and g 0=9.80665 m s−2. This formulation assumes the temperature varies linearly within the layer. With no other indication of the lapse rate, one can use α= − 6.5 K km−1.
Pressure data in NWP models are usually available at the model surface (orography), at model levels (usually from a few meters above the surface up to a constant pressure level in the stratosphere, e.g. 0.01 hPa or 80 km for the current ECMWF operational model), or at a predetermined number of standard pressure levels (e.g. 37 pressure levels going from 1000 to 1 hPa with ERA-Interim). Extrapolation from the nearest model level can be done using Eq. 5.9a + 5.9b in the case when only data on the surface are available or when the final height is below the lowest model level. When the final height is between two model levels or pressure levels then it might be interesting to interpolate the temperature and pressure data from the two adjacent levels rather than doing a pure extrapolation based on a single level. Linear interpolation can be used with temperature and the logarithm of pressure.
When 3D gridded model data are available, it can be interesting to interpolate also data in horizontal dimension from the nearest grid points if the horizontal resolution is not too coarse. However, in regions of complex topography (mountains) or with transition from land to sea, horizontal interpolation is questionable as the adjacent grid points may have significant representativeness (Bock and Parracho 2019).
Wang et al. (2017) compared ERA-Interim pressure level data on a 0.75° by 0.75° grid, GPT2w (an empirical model derived from ERA-Interim on a 1° by 1° grid with annual and semi-annual oscillations, Böhm et al. 2015), and pressure measurements at 99 GPS stations, globally. They showed that the 6-hourly pressure data from ERA-Interim have a RMSE compared to observations <2 hPa (to a few exceptions), with no clear benefit from horizontal interpolation using 4 grid points versus nearest grid point. The empirical model is shown to be unable to represent properly the temporal variations at short time scales (6-hourly and even monthly) with the required accuracy and furthermore does not include trends in surface pressure. If pressure trends in ERA-Interim and in reanalyses in general are correct merits further discussion.
The sensitivity of IWV errors to errors in Tm is about 0.069 kg/m2 per K (Parracho 2017). The spatial and temporal variation of Tm, evaluated from the Earth surface to the top of the atmosphere, is in the range 220–300 K, globally. Hence, to guarantee an accuracy at the 0.2 kg/m2 (resp. 1%) level, Tm should be determined with an error < 3 K (resp. < 1% or 2.2 K).
Estimates of Tm can be computed from Eq. 5.6a when vertical profiles of temperature and specific humidity are available. Radiosonde data are sometimes used to derive local or regional empirical models for that purpose but may not be adequate for applications requiring high accuracy (at 1–2 K level) and high temporal resolution (e.g. resolving the diurnal cycle and/or seasonal variations). Empirical Tm models derived from NWP data (e.g. GPT2w) have similar limitations. When high spatial and temporal resolutions are required, e.g. for climate applications, numerical integration of NWP model data is the best option (Wang et al. 2005, 2016b).
When Tm values are provided on a reference height, a vertical adjustment is required which can be computed from the following formula:
where αm is the lapse rate for Tm, and Tm0 is the reference Tm value valid at height and z0, and zs is the final height. If no other information is available, a standard value αm = −5.4 K km−1 can be used (Parracho 2017).
Ready to use gridded data for ZHD and Tm are provided for example by the Technical University of Vienna (TUV). The data can be accessed from:
http://ggosatm.hg.tuwien.ac.at/DELAY/GRID/STD/ for ZHD,
http://ggosatm.hg.tuwien.ac.at/DELAY/ETC/TMEAN/ for weighted mean temperature,
http://ggosatm.hg.tuwien.ac.at/DELAY/GRID/ orography for the model orography.
The data are distributed on global grid with a horizontal resolution of 2° latitude and 2.5° longitude, and 6-hourly temporal resolution, and are valid on the model orography. A vertical correction using Eq. 5.9a, 5.9b + 5.2a and 5.10 is usually required to extrapolate them to the altitude of the GNSS antenna.
The TUV data are computed from the ERA-40 reanalysis until 2002 and ECMWF operational analysis afterwards. While their use is fine for short term studies, their use for trend analysis is questionable, however, since the switch from ERA-40 to operational data and subsequent changes in the operational model may induce small inhomogeneities. In order to minimize such discontinuities, the conversion data should be better computed from a reanalysis (e.g. ERA-Interim). Though the homogeneity of current reanalyses is not guaranteed either (Thorne and Vose 2010), they nevertheless are the best and most stable representation of the atmospheric state.
5.4.2.4 Recommendations
As of the end of this COST Action, the recommended methodology and datasets for the conversion of GNSS ZTD data to IWV are the following:
-
Use set of conversion equations presented in this subsection: Eq. 5.1a to 5.7b
-
Use the set of ‘best average’ refractivity constants published by Rueger (2002) adjusted for non-ideal gas and updated for a CO2 concentration of 0.0375%: Eq. 5.8
-
Use NWP model data for the calculation of surface pressure and Tm at the station, e.g. provided by TUV or, better, recomputed from ERA-Interim pressure-level data
-
Apply a vertical adjustment for Ps (or ZHD) and Tm if these data are not valid at the altitude of the GNSS station: Eqs. 5.9a, 5.9b and 5.10
5.4.3 The Uncertainty of the Atmospheric Integrated Water Vapour Estimated from GNSS Observations
All GNSS measurements are subject to error sources that influence the uncertainty of the estimated IWV. Those errors can be random or systematic, or more commonly a mixture of both, depending on the timescale studied. Since the expected (mean) value of random errors is zero, the impact of such errors is reduced as the number of measurements increases. Systematic errors cannot be averaged out as the time series becomes longer. They can however change at a specific time epoch. For example, a change of the GNSS antenna or its environment may introduce such an offset.
In order to obtain the total uncertainty, all relevant error sources in GNSS-derived IWV are essential to be investigated. This work was initially motivated by GCOS (Global Climate Observing System) Reference Upper-Air Network (GRUAN) (Bodeker et al. 2016) and was at the same time highly relevant for the COST action. The results were reported by Ning et al. (2016a, b) and are summarised here.
A theoretical analysis was carried out where the uncertainties associated with the input variables in the estimations of the IWV were combined in order to obtain the total uncertainty of the IWV. We calculated the IWV uncertainties for several sites, used by the GRUAN, with different weather conditions. Table 5.5 below is taken from Ning et al. (2016a, b) which summarises the calculated total IWV uncertainties for three GRUAN sites: LDBO, LDRZ, and NYA2. For each site, the GPS data acquired from the year 2014 were processed using a Precise Point Positioning (PPP) strategy to obtain ZTD time series. The corresponding total ZTD uncertainties were then determined after taking both random and systematic errors into account. The estimated ZTD was converted to the IWV using the measured ground pressure and the mean temperature obtained from the ECMWF reanalysis data, ERA-Interim. In Table 5.5, the corresponding absolute values for IWV, ZTD, ground pressure, and mean temperature are given using the mean values of the year 2014 for each site. The table shows a similar relative importance of all uncertainty contributions where the uncertainties in ZTD dominate the error budget of the IWV, contributing over 75% of the total IWV uncertainty. The impact of the uncertainty associated with the conversion factor between the IWV and the ZWD is proportional to the IWV and increases slightly for moist weather conditions.
5.5 ZTD/IWV Homogenisation
This section is partly a summary of “Van Malderen R., Pottiaux E., Klos A., Bock O., Bogusz J., Chimani B., Elias M., Gruszczynska M., Guijarro J., Zengin Kazancı S. and Ning T.,” “Homogenizing GPS integrated water vapour time series: methodology and benchmarking the algorithms on synthetic datasets” in Proceedings of the Ninth Seminar for Homogenization and Quality Control in Climatological Databases and Fourth Conference on Spatial Interpolation Techniques in Climatology and Meteorology, Budapest, Hungary, 2017, WMO, WCDMP-No. 845, edited by T. Szentimrey, M. Lakatos, L. Hoffmann, pp. 102–114 (http://www.wmo.int/pages/prog/wcp/wcdmp/wcdmp_series/WCDMP_85.pdf)”.
5.5.1 Introduction
As water vapour is an important greenhouse gas and is responsible for the strongest positive feedback effect, estimating the long-term trends in water vapour is important for climate monitoring. However, the potential temporal shifts in the IWV time series obtained from GNSS can change the resulting trends significantly. In order to obtain realistic and reliable climate signals a homogenization of the IWV time series is necessary. In earlier work (Vey et al. 2009, Ning et al. 2016a, b) the time series of the differences between the GPS-derived IWV and the one obtained from the ERA-Interim model (Dee et al. 2011) are used for the data homogenization. Ning et al. (2016a, b) used a statistical test, the penalized maximal t test modified to account for first-order autoregressive noise in time series (PMTred, see Sect. 5.5.5), to identify the possible mean shifts (change points) in the difference time series. This approach allows for identification of the change points not only in the GPS IWV time series but also in ERA-Interim. After the correction of the mean shifts for the GPS data, an improved consistency in the IWV trends is evident between nearby sites, while a better agreement is seen between the trends from the GPS and ERA-Interim data on a global scale. In addition, the IWV trends estimated for 47 GPS sites were compared to the corresponding IWV trends obtained from nearby homogenized radiosonde data. The correlation coefficient of the trends increases significantly by 38% after using the homogenized GPS data.
Within the COST action, a homogenization activity was also set up, targeting the following objectives: (i) select one or two long-term reference datasets, (ii) apply different homogenization algorithms on these reference datasets, and build up a list of commonly identified inhomogeneities based on statistical detection and metadata information, and (iii) come up with an homogenized version of the reference dataset that can be re-used to study climate trends and time variability by the entire community.
As a first reference dataset, we decided to focus on the existing first tropospheric product given by the data reprocessing of the International GNSS Service (IGS) network, named hereafter IGS repro 1. This homogeneous reprocessing (one single strategy) of the data results from a set of 120 GPS stations distributed worldwide providing continuous observations from 1995 until the end of 2010, see Fig. 5.22. The retrieved ZTDs estimated from the GNSS receiver observations at the stations have been screened, and the outliers have been removed as described in Bock (2015) and in Sect. 5.4.1. To convert those ZTD measurements in IWV, the surface pressure at the station location and a weighted mean temperature are needed, which are taken or calculated from ERA-interim (or ERAI), see Bock (2016a, b, c, d) and Sect. 5.4.2.

Distribution of the 120 IGS repro 1 stations with data available from 1995 until the end of 2010
5.5.2 Methodology
As in the previously mentioned studies (Vey et al. 2009; Ning et al. 2016a, b), for a particular GNSS station, we chose to use the ERA-interim IWV time series at this GNSS site location as the reference series for the candidate IGS repro 1 IWV time series. As can be seen in Fig. 5.23, for the large majority of the sites, the IGS repro 1 and ERA-interim IWV time series are highly correlated; the lower correlations are ascribed to a bad spatial representation by the model at those sites (e.g. large differences in orography in adjacent pixels). It should however be mentioned that the IGS repro 1 and ERA-interim IWV time series are not completely independent from each other: ERA-interim is used in the ZTD screening process and, as has been noted already above, the surface pressure and weighted mean temperature values, needed for the IGS repro 1 ZTD to IWV conversion, are taken from ERA-interim as well.

Histograms of the relative biases (a), relative standard deviations (b), correlation coefficients (c), and linear correlation slope coefficients (d) between the IGS repro 1 and ERA-interim IWV time series for our sample of 120 GNSS stations
Most of the inhomogeneities in the GNSS-derived IWV time series due to antenna or radome changes and changes in the observation statistics (= events) are characterized by jumps in the IWV time series (Vey et al. 2009). Therefore, for each site, we calculate differences time series between the IGS repro 1 and ERA-interim IWV datasets, and we will look for the epochs of those events causing offsets in the difference time series.
5.5.3 Assessment of the Homogeneity of ERA-Interim
Although ERA-interim is used as reference dataset in our activity, ERA-interim might have inhomogeneities of its own, e.g. when new satellite datasets are introduced in the data assimilation system (see e.g. Ning et al. 2016a, b; Schröder et al. 2016). ERA-interim is also used for the development of tropospheric blind models which includes the temporal modelling of the model parameters. Therefore, Eliaš et al. (2019) tried to detect potential change-points that may occur in the ERA-Interim ZHD and ZWD time series.
They applied a statistical method that is based on the maximum value of two-sample t-statistics. More than 64.000 original time series for both products are then analysed, whereas the time span of the series included the years 1990–2015 with a time resolution of 6 h.
The epochs and the offsets of the detected change points for the ERA-interim ZWD time series are presented in Fig. 5.24. The regions in which change points are detected are mostly located near the equator, such as in the Pacific, but also in the Amazonia region, in Africa, and in Indonesia. Another interesting area is in the North Pacific. The average offset values are approximately around 20 mm. Those ERA-interim ZWD time series strongly depend on satellite humidity observations in areas such as oceans and deserts, which might introduce inhomogeneities due to changes in satellite missions and their calibrations. Overall a change point was identified in more than 12% of the total amount of the node profiles. Eliaš et al. (2019) did not detect change points for the ZHD series from the ERA-Interim reanalysis. This can be explained by the fact that the ZHD is related strongly with the atmospheric pressure, a rather smooth variable, which is easily observed and modelled.

The epochs in MJD (a) and offsets in mm (b) of the detected change points in the ERA-interim ZWD time series
5.5.4 Synthetic Gataset Generation
We tested different homogenization algorithms on the ERAI-IGS repro 1 differences, and compared their lists of identified epochs of offsets with a list of manually detected breakpoints from the metadata information. At some sites, breakpoints were detected in the metadata and by visual inspection, but not by any of the algorithms. In other cases, breakpoints were detected by a number of (or all) statistical tools, but no metadata information was available for the considered epoch. Therefore, we decided to first generate synthetic time series, with known inserted offsets, on which the different homogenization tools could be blindly applied and assessed. Additionally, we undertook a sensitivity analysis of the performance of the homogenization algorithms on varying characteristics of the synthetic time series.
It should be noted here that we generated synthetic time series of IWV differences directly, based on the characteristics of the real IGS repro 1 and ERA-interim IWV differences. By considering the differences, seasonal variability will be removed and the complexity of the noise will be reduced, making the generation of synthetic time series an easier task. First, we characterized the properties of the offsets (typical number per site and amplitudes) in the real IWV differences, based on the manual detection of 1029 events of instrumental changes, reported in the metadata files of the stations. Of those 1029 events, about 164 epochs were confirmed by visual inspection, and 57 new epochs were added. We derived the amplitudes of the offsets arising at those epochs and these are used for a first-order correction of the real IWV differences at those 221 identified epochs. Subsequently, we analysed the significant frequencies, the noise model, the presence of a linear trend and gaps in those corrected IWV differences with a Maximum Likelihood Estimation (MLE) in the Hector Software (Bos et al. 2013). As it is illustrated for the KOSG station in Fig. 5.25, we found that the most adapted noise model is given by the combination of white noise (WN) plus autoregressive noise of the first order (AR (1)), characterised by the amplitudes of white noise (with median value 0.35 mm) and autoregressive noise (median value 0.81 mm), the fraction and coefficient of AR (1), with respective median values 0.71 and 0.50. Another important finding is the presence of trends (of the order of ±0.05 kg/m2/year) in the IWV differences series.

Power spectrum of the IGS repro 1 and ERA-interim IWV residual differences at the site KOSG (Kootwijk, the Netherlands, 52.18°N, 5.81°E). The colour lines denote different noise models that we tested to decide on the noise model and that best characterize the IWV residuals
So, based on the characteristics of the IWV differences series at each site separately, we generated for every site a synthetic time series of daily values that includes a number of offsets in the mean. As a matter of fact, to test the sensitivity of the performance of the homogenization tools on the complexity of the time series, 3 datasets of 120 synthetic daily IWV differences time series have been created, with increasing complexity:
-
“easy” dataset: includes seasonal signals (annual, semi-annual, inter- and quarter-annual, if present for a particular station) + offsets + white noise (WN)
-
“less-complicated” dataset: same as “easy” + autoregressive process of the first order (noise model = AR (1) + WN)
-
“fully-complicated” dataset: same as “less-complicated” + trend + gaps (up to 20% of missing data). This dataset is closest to the real IWV differences.
These sets of synthetic time series were made available to the community for a blind testing of homogenization algorithms in use. The inserted offsets of the easy dataset are available to be revealed, if asked for by a participant, for fine-tuning of the algorithm on the use of IWV differences.
5.5.5 Involved Homogenization Algorithms
In this subsection, we give a small summary of the homogenization algorithms that participated so far in the blind homogenization of at least one of the variants of the synthetic time series. Those homogenization tools have been applied on daily and/or monthly values of the synthetic datasets.
5.5.5.1 Two-Sample t Test (Operator: M. Elias)
The procedure applied for the purpose of breakpoint detection is based on hypothesis testing. In this study we used a test statistic that is of so-called “maximum type” (see Jaruskova 1997). Within the field of mathematical statistics, the problem can be solved by testing the null hypothesis that claims that there is no change in the distribution of the series, against the alternative hypothesis that claims that the distribution of the series changed at the time k. The null hypothesis is then rejected if at least one of the estimated statistics is larger than the corresponding critical value. Approximate critical values are obtained by the asymptotic distribution (see Yao and Davis 1986). Two ways of time series proceedings and method application were discussed; (i) the proposed method was applied to the uncorrected original series of IGS repro 1 and ERA-interim IWV differences and (ii) the method was applied to corrected difference series when the seasonality was removed and also the gaps were filled in the series before the breakpoint detection, for instance. The method of breakpoint detection is applicable on both monthly and daily time series. A confidence interval for the detected breakpoint is also possible to estimate.
5.5.5.2 PMTred (operator: T. Ning)
The rationale of this adapted t test is based on Wang et al. (2007a, b, c), which describes this penalized maximal t test (PMT) to empirically construct a penalty function that evens out the U-shaped false-alarm distribution over the relative position in the time series. Another modification, named the PMTred test, accounts for the first-order autoregressive noise and it was this test that was used for the homogenization. The critical values (CVs) of the PMTred test were obtained by Monte Carlo simulations running for 1,000,000 times as a function of the sample length N (monthly data, might have to be redone for daily data). In addition, the CVs were calculated for the lag-1 autocorrelation from 0 to 0.95 with an interval of 0.05 and for the confidence levels of 90%, 95%, 99%, and 99.9% (see Ning et al. 2016a, b). This test runs on monthly and daily values, but the critical values are calculated based on monthly data. The detection of multiple breakpoints is achieved by applying the test to the remaining segments.
5.5.5.3 HOMOP (Operator: B. Chimani)
The homogenization code HOMOP is a combination of PRODIGE (for detection, Caussinus and Mestre 2004), SPLIDHOM (adjustment, Mestre et al. 2011), an adapted interpolation (Vincent et al. 2002), and improved by some additional plots for facilitating the decision of the homogenisation and extended with some uncertainty information by using different reference stations as well as bootstrapping methods (HOMOP, Gruber et al. 2009). The approach is neighbour-based, and in the particular case of our synthetic datasets, a lower limit of 0.6 for the correlation coefficients was imposed for selecting potential reference stations. Break detection is done at annual or seasonal base.
5.5.5.4 CLIMATOL (Operator: J. Guijarro)
Another neighbour-based homogenization algorithm is CLIMATOL, which performs a form of orthogonal regression known as Reduced Major Axis (RMA, Leduc 1987) between the standardized anomalies (x-μx)/σx and (y- μy)/σy of the two distributions. Orthogonal regression is adjusted by minimizing the perpendicular distance of the scatter points to the regression line, instead of minimizing the vertical distance to that line as in Ordinary Least Squares regression (OLS). In the case of our synthetic datasets, it was imposed that the only reference time series at the site is the ERA-interim time series. The Standard Normal Homogeneity Test (SNHT, Alexandersson 1986) is applied to find shifts in the mean of the anomaly series in two stages. The code incorporates a filling in of missing data and outlier removal. The adjustment of the identified offsets can be done with a varying amplitude: by including e.g. σx in the standardization, you might include seasonality in the amplitudes. As in the other algorithms described so far, the detection of multiple breakpoints is done by applying the test to the remaining segments. CLIMATOL can be applied to any time scale data, but it is advised to detect the breakpoints at the monthly scale, and then use the break dates to adjust the daily series. This algorithm does not provide the amplitudes of breaks, as they are time varying. We might obtain the amplitudes by differencing the non-homogenized series with the homogeneous series.
5.5.5.5 Non-parametric Tests (Operator: R. Van Malderen)
In this case, the used statistical tests are non-parametric distributional tests that utilize the ranks of the time series to find breakpoints (or more general to test the equality of the medians of two distributions). Because such tests are based on ranks, there are not adversely affected by outliers and can be used when the time series has gaps. On the other hand, the significance of the test statistic cannot be evaluated confidently within 10 points of the ends of the time series and those tests show an increased sensitivity to breakpoints in the middle of the time series, when a clear trend is present (Lanzante 1996). We used two of such non-parametric tests: The Mann-Whitney (-Wilcoxon) test and the Pettitt (−Mann-Whitney) test, nicely described in Lanzante (1996). As an additional reference, the CUSUM test, based on the sum of the deviations from the mean, is also used. We developed an iterative procedure to detect multiple breakpoints: if 2 out of those 3 tests identify a statistical significant breakpoint, the time series is corrected (by adjustment of the oldest segment with the detected amplitude of the offset) and the 3 tests are applied again on the complete corrected time series. These tests have been applied on both the monthly and daily values.
5.5.5.6 Pettitt Test (Operator: S. Zengin Kazancı)
The Pettitt test (Petitt 1979) has been applied by another operator on the ranks of the daily values, together with the von Neumann ratio (von Neumann 1941) to determine if there is a breakpoint in the time series. If the series is homogeneous, the von Neumann ratio is equal to 2, for lower values of this ratio the series has a breakpoint (Wijngaard et al. 2003). The Pettitt test statistic is related to the Mann-Whitney statistic (see above).
5.5.6 Assessment of the Performance of the Tools on the Synthetic Datasets
In this subsection, we will assess the performance of the different homogenization tools on the synthetic datasets on two different aspects: (i) the identification of the epochs of the inserted breakpoints (+ sensitivity analysis) in the synthetic datasets, and (ii) the estimation of the trends that were or were not imposed to the 3 sets of synthetic IWV differences.
5.5.6.1 Identification of the Breakpoints
To assess whether or not the breakpoint given by a statistical detection tool coincides with the inserted, known, epoch of the break depends on the choice of the time window. Some homogenization algorithms give a confidence interval for the detected breakpoints, but other tools do not. To treat those different methods in a consistent manner, a proper, fixed time window for successful detection has to be set. A sensitivity study revealed that an adopted time window of 2 months is a good compromise.
Then we calculate for every breakpoint detection tool the statistical scores: the true positives (TP, “hits”), true negatives (TN: no breaks inserted, no break found), false positives (FP, “false alarms”), and false negatives (FN, “misses”). More details on how to calculate these scores can be found in e.g. Venema et al. (2012). To visualize the performance of the different tools in terms of those different statistical scores, we adapted the ternary graph representation from Gazeaux et al. (2013), shown in Fig. 5.26, for the fully complicated dataset. It depicts the ratios of the statistical detection scores (TP + TN, FP, and FN) by their position in an equilateral triangle, highlighting the trade-off between those. A perfect solution would appear on the bottom right corner of the triangle (see blue lines in the figure). From a glance on this figure, it can be directly noted that the involved homogenization tools do not perform very well for the fully complicated dataset: especially the number of false positives are too high. Fortunately, the probabilities of true detection are also high. Some methods nearly detect all the inserted breakpoints, but at the cost of a high number of false alarms, while other methods are more conservative in detecting breakpoints, resulting in low scores for both true detection and false alarms.

Ternary graph representing the ratio between three performance measures of the breakpoint detection solutions (TP + TN, FP, and FN). The performance increases with decreasing numbers of false positives and false negatives and increasing numbers of true positives and negatives, so that a perfect solution is located in the lower right corner, marked by the blue area. The different solutions are marked with the symbols and colours outlined in the legend and in the table
So far, we only discussed the results on the breakpoint detection on the fully complicated dataset. It should however be noted that a good performance of the tools is achieved for the majority of the participating methods on the easy and less complicated datasets, especially due to a lower amount of false positives. So, we can conclude that the performance decreases for almost all the tools when adding gaps and a trend in the benchmark time series; adding autoregressive noise of the first order has less impact.
Some of the homogenization algorithms also provided the (constant) amplitudes of the detected offsets. These were compared with the amplitudes of the offsets that were put in the synthetic time series. The result, again for the fully complicated dataset, is shown in Fig. 5.27. From this figure, it could be seen that some methods tend to underestimate the number of offsets with small amplitudes relatively (e.g. ME1 and ME2), while other methods on the contrary overestimate the amount of those offsets (e.g. RVM 2of3 D), but on the other hand underestimate the number of offsets with large amplitudes. Clearly, the different methods have a different sensitivity to the amplitudes of the offsets, and some fine-tuning on the statistical thresholds might be advised for some methods. For the other variants of the synthetic datasets, the amplitude distribution of the detected offsets more closely follows the amplitude distribution of the true inserted offsets.

The histograms of the amplitudes of the detected offsets by the different methods (in red in all figures), compared to the amplitude distribution of the inserted offsets in the fully complicated synthetic dataset of IWV differences (in blue)
5.5.6.2 Trend Estimation for the Homogenized Datasets
Only in the fully complicated dataset, a trend was inserted in the IWV differences series, and the homogenized time series by the different time series should hence reveal the same trend. However, for some stations, trends as large as 0.1 kg/m2 (or mm) per year arise after correcting for the detected offset by some methods. Overall, for the fully complicated synthetic datasets, most trends differ within ±0.05 kg/m2 per year. As one of the main goals of our homogenization activity is the provision of a homogenized dataset of GNSS IWV time series for use in trend analysis, special care should be taken not to introduce spurious trends in the time series after correction. In this sense, the impact of homogenization on the estimated trend uncertainties should also be further elaborated.
5.5.7 Conclusions and Outlook
In this contribution, we described the current activity in homogenizing a world-wide dataset of IWV measurements retrieved from observations made at ground-based GNSS stations. As the distances between those 120 stations are large and correlations are generally low (lower than 0.6 for distances larger than 1°), we used the ERA-interim reanalysis IWV fields at those station locations as the reference time series for relative statistical homogenization. Based on the characteristics of the IWV differences series between the GNSS dataset and ERA-interim and the properties of manually checked instrumental change events reported in the metadata of the GNSS sites, we generated three variants of 120 synthetic IWV difference time series with increasing complexity: we first added autoregressive noise of the first order and subsequently trends and gaps. Those synthetic time series enable us to test the performances of six participating breakpoint detection algorithms and their sensitivity to this increasing dataset complexity.
We found that the performances of those algorithms in identifying the epochs of the inserted offsets especially decreases when adding trends and gaps to the synthetic datasets, due to a larger number of false alarms. On the other hand, the hit rates of most tools are rather good, even when applied on daily values instead of on monthly values. Different tools show a different sensitivity for detecting different ranges of amplitudes of offsets, especially for the most complex (fully complicated) synthetic time series: some tools overestimate (underestimate) the number of small-amplitude (large-amplitude) offsets, while the opposite is true for other breakpoint detection algorithms. After eliminating differences due to different calculation methodologies, we found trend differences mostly within ±0.05 kg/m2 per year between the inserted trends and trends calculated from the different homogenization solutions.
Owing to the fact that metadata on instrumental changes are available for the GNSS stations, we primarily focused on the identification of the epochs of offsets until now. At the end, we would like to combine the outcome of statistical breakpoint detection with these metadata. However, we will also assess the performances of the different tools by comparing the final solutions for the time series given by different tools with the original time series (e.g. calculating Centred Root Mean Square errors as in Venema et al. (2012), calculating trends directly from the final solutions, etc.).
Of course, we highly welcome contributions from other groups running homogenization tools, and in the future, our benchmark will already be extended with few more contributions. After providing solutions for the synthetic time series, the participants will get the opportunity to fine-tune their methods on the specifications of the datasets with the help of the knowledge of the true inserted offsets and their amplitudes. Thereafter, a second round of blind homogenization on a newly generated synthetic dataset of IWV values (probably with simulated metadata information) will be held. Based on the performance of the statistical homogenization tools on these synthetic datasets, we will develop a methodology for combining the results of good performing homogenization tools with metadata information. This methodology and those tools will then be applied on the IGS repro 1 dataset of retrieved GPS IWV time series, resulting in a homogenized dataset, which will be validated by other sources of IWV time series and finally made available to the community for assessing the time variability of IWV and for validation of climate model IWV outputs.
5.6 IWV Intercomparisons
5.6.1 A Literature Overview
5.6.1.1 Introduction
Already in 1992 demonstrated Bevis et al. the potential of GNSS ground-based receivers for measuring the IWV amount in the zenithal column of the atmosphere (Bevis et al. 1992). Summing up the uncertainties of the individual contributions (the uncertainties of the ZTD estimations, the ZHD modelling, and the conversion from ZWD to IWV) to the GNSS IWV retrieval, the estimated total uncertainty is generally less than 2 mm (e.g. Wang et al. 2007a, b, c; Van Malderen et al. 2014). Ning et al. (2016a, b) calculated, from a theoretical point of view, the total IWV uncertainty from the individual uncertainties of each of the input variables, according to the rule of uncertainty propagation for uncorrelated errors (see also Sect. 5.4.3. The results show a similar relative importance of all uncertainty contributions where the uncertainties in the ZTD dominate the error budget of the IWV, contributing over 75% of the total IWV uncertainty. Alternatively, in the same paper, a statistical analysis is proposed to evaluate the uncertainty of the GNSS-derived IWV if independent estimates are available from at least three co-located techniques, measuring the same true variability of the IWV.
Clearly, one of the aims of IWV intercomparison studies is to assess the quality, consistency, accuracy, and stability of different techniques measuring IWV, with respect to each other or a chosen reference. This can be on a local, regional, or global scale, and considering only a short time period or on a decadal time scale, when the usability of the different techniques for long-term climate research is investigated. Examples of intercomparison analyses focusing on one of those different aspects can be found in the inventory of past studies in the literature, which has been built up in the course of the COST action (http://www.meteo.be/IWVintercomp). Whereas in the beginning of the GNSS (GPS) era, the accuracy of GNSS retrieved IWV was evaluated through comparison studies with radiosonde (RS) and microwave radiometer (MWR) IWV measurements, the focus of recent IWV intercomparison studies involving GNSS is the validation of the satellite IWV retrievals and (climate) model IWV output with GNSS as reference.
Recent reports or papers overviewing IWV inter-technique comparisons hang up a rather pessimistic view of the consistency of the results between those different studies, or to cite Buehler et al. (2012): “A literature survey reveals that reported systematic differences between different techniques are study-dependent and show no overall consistent pattern.” Also Guerova et al. (2016) conclude that “it is, however, not possible to draw final conclusions regarding the absolute accuracies of the instruments and techniques. All techniques suffer from systematic errors at different timescales meaning that case studies using specific sensors, at specific locations, at different times, will give different comparison results, often presented as biases and root mean square (RMS) differences. For example, an error appearing as a bias in a 2-week long comparison may present itself as a random error over a period of many years.” Additionally, the Global Energy and Water Cycle Experiment Data and Assessments Panel (GDAP) has found that assessment activities should not be viewed as static but rather as dynamic activities that need to be repeated every 5–10 years. In this contribution, we will nevertheless try to distillate some general findings from the inventory of the IWV intercomparison studies, but, of course, taking into account that those studies cover different instruments, sites, periods, methodologies, etc.
5.6.1.2 Datasets and Methods in Past IWV Intercomparisons
We compiled an online inventory of past IWV intercomparisons involving GNSS: http://www.meteo.be/IWVintercomp, which will be regularly updated. As can be seen from this inventory, the GNSS IWV retrievals have been compared with a wide range of other techniques. Each instrument has its own specific sensing properties, which have to be taken into account when giving an overview of different inter-technique analyses.
5.6.1.3 Differences in Instruments
There are numerous techniques measuring IWV, from ground-based devices, in-situ (radiosondes) and from space on board satellites. Remote sensing techniques can be divided into 3 categories: (1) differential time of arrival measurements, like GNSS, Very Long Baseline Interferometry (VLBI) and Doppler Orbitography Radio Positioning Integrated by Satellite (DORIS), (2) active techniques like LIght Detection And Ranging (LIDAR) and RAdio Detection And Ranging (RADAR) (3) passive techniques based on emission/absorption measurements (Guerova et al. 2016). Among ground-based emission/absorption measurements there are microwave radiometers, photometers (with the sun, the moon or a star as light source), and Fourier-Transform Infrared Spectroscopy (FTIR). Also space measurements of IWV make advantage of different parts of the electromagnetic spectrum of the Earth’s atmosphere: microwave (AMSU-B, AMSR-E, SSM/I, SSMIS, HSB, etc.), visible (OMI, GOME, GOME-2, SCIAMACHY, etc.), near-infrared (MODIS) and thermal infrared (MODIS, AIRS, SEVIRI, IASI, ISCCP (TOVS), etc.).
Those different techniques have some specific constraints on the capability of measuring the IWV: the opacity of clouds makes the measurements in the visible or (near) infrared spectral range unreliable under cloudy sky conditions. When data in the visible or near infrared range are analysed, measurements are also restricted to daytime, which is the case for e.g. GOME, SCIAMACHY, GOME-2 and of course for a ground-based sun photometer. For passive microwave nadir sensors (like SSM/I, AMSU-A), the large variability of the surface emissivity over land and sea ice makes the retrievals generally more difficult than over the ocean where the emissivity is well known. The operational products retrieved from those sensors provide therefore only data over the oceans (Urban 2013). Microwave radiometers from the ground cannot observe during rain or snow. The GNSS technique, on the other hand, can be used under all weather conditions and therefore has no weather bias as some of the other techniques. This weather bias, and in particular the presence of clouds, might have an impact on the comparison of the IWV measurements between two instruments. For instance, the IWV linear regressions at Brussels between (i) a sun photometer and GNSS and (ii) satellite retrievals and GNSS have different properties when comparing clear sky and partly cloudy scenes (see Figs. 6 and 9 respectively in Van Malderen et al. 2014).
Furthermore, the instruments have a different horizontal representativeness of the IWV field they measure. The satellite devices use mostly nadir techniques for the IWV measurements, but depending on their orbits, the horizontal resolution vary between 1 × 1 km (MODIS) to 40 × 320 km (GOME). On the other hand, ground-based techniques like MWR and Lidar measure in the zenith, while a sun photometer traces the water vapour amount in the solar slant. The GNSS IWV is retrieved in a cone, representative for about 100 km2, and the radiosonde is drifted away from the launch site during its ascent. The disadvantage of ground-based techniques with respect of satellite retrievals is that the coverage of stations is quite often not sufficient to represent the high spatial variability of water vapour. Satellite observations can cover the whole planet in 1–2 days.
Water vapour has also a high temporal variability, and instruments on board of low Earth orbiting satellites, cannot adequately sample e.g. the diurnal cycle of IWV, as at most one or two measurements a day are available at a given location. Sun photometers have a temporal resolution of about 15 min, but of course can only measure during daytime and at clear skies in the direction of the sun. Microwave radiometers and GNSS measure continuously and hence are the devices with the highest temporal resolutions. In practice, GNSS IWV retrievals are available at time scales of 5 min to 1 hour, depending on the processing options but also on the time resolution of the auxiliary meteorological variables required to convert ZTD into IWV.
So, due to the different characteristics of the different techniques, the agreement between IWV retrievals by different techniques will not be perfect. Moreover, Buehler et al. (2012) also showed that systematic differences between subsets of the same technique (e.g. FTIRa/FTIRb) at one site may exceed differences between different techniques (as demonstrated by their Figure 9) at this site.
5.6.1.4 Differences in Methodology
Given the high spatial and temporal variability of the integrated water vapour and because the different instruments have a different horizontal representativeness and different spatial and temporal samplings, co-location and coincidence criteria have to be chosen in IWV inter-technique analyses. Starting with the temporal separation, past studies have used only concurrent time stamped data, others have interpolated data to the time of other measurements, and others have used the temporally nearest data point within a certain time limit, ranging from less than 10 min to less than 2 hours, depending on the temporal resolutions of the compared techniques. Spatial co-location is achieved by imposing an upper limit for the distance between two sites (ranging from on site to more than 150 km, e.g. Torres et al. 2010) or between the site and the satellite ground pixel centre or by demanding that the site lies in the satellite ground pixel. Of course, due to the large differences in horizontal resolutions between the satellite samplings, those site-satellite co-location criteria will impact the IWV agreement to a large extent, even when comparing with satellite instruments that make use of the same wavelength range for the IWV retrieval (e.g. GOME and SCIAMACHY).
To prevent the presence of a systematic bias between two datasets of IWV measurements, the vertical separation between sites should be taken into account and corrected for. This can be most easily done when vertical profile measurements of temperature and humidity are present (by radiosonde measurements), e.g. Buehler et al. (2012) found for the Arctic station Esrange a relative bias ΔIWV/IWV of −3.5% per 100 m altitude difference. However, the actual scaling factors seem to depend on location, as Bock et al. (2007) found a value of −4.0% per 100 m for Africa, and might therefore not generally applicable. Other possible corrections rely on the assumption of a constant temperature lapse rate, a constant dew point depression with height (Deblonde et al. 2005) or a constant relative humidity with height (Hagemann et al. 2003). In this context, it should also be noted that a vertical correction is also required for the surface temperature and pressure measurements needed to convert ZTD into IWV, if an altitude difference exists between the GNSS station and the co-located meteorological station or reanalysis grid pixels that provide the surface measurements.
Finally, past studies also use different statistical parameters to describe the agreement between two (or more) IWV datasets. The most commonly used variables are the (absolute and relative) bias and the standard deviation, but also the median of the differences, the mean bias error, RMS, RMSE, the linear regression slope and the linear regression offset are widely used. Vaquero-Martinez et al. (2017a) calculated the pseudo median and the interquartile range of the relative differences as estimators for the accuracy and the precision respectively of their satellite data with respect to ground-based GNSS data.
-
Discussion of “Common” Results from Past Intercomparison Studies
5.6.1.5 General Overview
The range of values reported for the most common statistical parameters, with the GNSS IWV retrievals as reference, are summarized in Table 5.6 for the IWV intercomparison studies present in the inventory http://www.meteo.be/IWVintercomp. A first thing to note is the very wide range of biases (GNSS – instrument), even within one technique, except for the MWR and FTIR. But only 3 different studies compared GNSS and FTIR IWV retrievals. The highest variability in the statistical parameters is obtained in the GNSS-model and GNSS-satellite comparisons. In those cases, the possible large differences in spatial representativeness of the IWV field between the GNSS station and the grid pixel(s) surrounding this station might cause large disagreements, especially in stations located in regions with large topographical variability (e.g. coastal stations, mountain areas, etc.). But several other factors are likely to affect the observed biases (see Buehler et al. 2012): for the radiosonde, important factors are the sensor type (see e.g. Fig 6. in Wang et al. 2007a, b, c), launching procedures and the local time, as some sensors suffer from a radiation dry bias. For the GNSS, the exact antenna characteristics play a role, including the characteristics of a radome covering the antenna, and the presence or absence of microwave absorber material around the antenna. Ning et al. (2011) reported that the addition of absorber material decreased the GNSS IWV bias by 1.3 kg/m2, and the addition of a radome made a difference of 0.4 kg/m2. How strongly these hardware differences actually affect the IWV data also depends on the data analysis, particularly how slant wet delays are mapped to the zenith and what satellite elevation angle cut-offs are applied (Ning et al. 2011).
The ranges shown in Table 5.6 are of course study-dependent and also vary from region to region. We however note that the ranges become narrower when applying a uniform methodology for different sites and different instruments. We also believe that the range of the slopes reflects the presence of a weather bias in the instruments: the all-weather devices like RS and MWR have higher minimal regression slope coefficients with respect to GNSS, and the low upper limit of the regression slope coefficients for SPM and FTIR is believed to be caused by the weather observation bias of these instruments. We will come back to this point later.
5.6.1.6 IWV Dependence of the Differences
Despite the differences between the techniques and the different applied methodologies, some general properties could be observed in the past studies. It turns out that the IWV bias and standard deviation of the differences between GNSS and other instruments both show a dependency on the IWV value measured (see e.g. the plots in Vaquero-Martínez et al. (2017a, b, c) for GNSS-satellite, and in Campanelli et al. (2017) for GNSS-SPM). Because the IWV values are higher in summer than in winter, past studies have mentioned the same dependency indirectly by pointing to a seasonal behaviour of the GNSS-RS IWV bias (Ohtani and Naito 2000; Basili et al. 2001; Deblonde et al. 2005; Kwon et al. 2007; Van Malderen et al. 2014), the GNSS IWV MWR bias (Sohn et al. 2012), the GNSS-SPM IWV bias (Nyeki et al. 2005; Morland et al. 2006; Prasad and Singh 2009; Van Malderen et al. 2014, Pérez-Ramírez et al. 2014), the GNSS-model IWV bias (NCEPNCAR reanalysis: Prasad and Singh 2009; Vey et al. 2010; AMPS: Vázquez and Grejner-Brzezinska 2013), the GNSS-satellite IWV bias (AIRS: Prasad and Singh 2009; Van Malderen et al. 2014; MODIS: Prasad and Singh 2009; Bennouna et al. 2013; Joshi et al. 2013; GOMESCIA: Van Malderen et al. 2014, GOME-2: Román et al. 2015, OMI: Wang et al. 2016a, b), the GNSS-MWR IWV standard deviation (Basili et al. 2001; Sohn et al. 2012), and the GNSS-satellite standard deviation (MODIS: Joshi et al. 2013; Ningombam et al. 2016; OMI: Wang et al. 2016a, b). Also, Ning et al. (2012) noted a seasonal behaviour in the GNSS–RS/ECMWF/MWR standard deviations of the ZWD. Additionally, because the IWV is higher for lower latitudes, global IWV inter-technique analyses observed a latitudinal dependency of the GNSS-NCEP IWV biases (Vey et al. 2010), the GNSS-GOME-2 IWV biases (Kalakoski et al. 2016), the GNSS-HIRLAM ZTD biases (Haase et al. 2003), the GNSS- RS/SPM/AIRS/GOMESCIA IWV standard deviations (Van Malderen et al. 2014), and the GNSS-DORIS ZTD standard deviations (Bock et al. 2010).
In the literature, several causes have been addressed for this IWV dependency of the differences (bias and SD) of several techniques with GNSS. Let us first concentrate on the IWV dependency of the biases with GNSS. This seems related to the fact that the different techniques and GNSS have different sensitivities: under dry conditions, the GNSS data are known to be less precise (Wang et al. 2007a, b, c) and therefore underestimates the IWV values (Schneider et al. 2010) or satellite retrievals tend to overestimate the low IWV values (Bennouna et al. 2013; Van Malderen et al. 2014; Kalakoski et al. 2016; Vaquero-Martínez et al. 2017c), whereas at large IWV values, a weather observation bias (clear sky) or sampling bias (Bennouna et al. 2013) might lead to an IWV underestimation by other techniques (Prasad and Singh 2009; Van Malderen et al. 2014). In particular, several studies comparing IWV satellite retrievals with ground-based measurements noted an underestimation of satellite (large) IWV values (AIRS, GOME, MODIS, GOMESCIA, see e.g. Van Malderen et al. 2014 Román et al. 2015, and Vaquero-Martínez et al. 2017c) with increasing cloud fraction. This can be due to the so called shielding effect (Román et al. 2015): clouds can hide the water vapour under them. In this context, we also mention that several studies found a solar zenith angle (SZA) dependency of the GNSS-satellite IWV differences (and of the GNSS-MWR IWV difference, see Pérez-Ramírez et al. 2014), which is also linked with the seasonal variation of the IWV differences: small SZA exclusively arise in summer, large SZA exclusively in winter. For GOME-2, Antón et al. (2015) suggested that the SZA dependency (increasing biases with increasing SZA) could be related to inaccuracies in the geometrical correction factor applied in the GOME-2 retrieval algorithm to determine the air mass factor (AMF) of the water vapour. The SZA dependency of the GOME-2/GNSS differences may be also affected by other factors like cloudiness and albedo conditions (Román et al. 2015). But a SZA dependency of the GNSS-satellite biases is also present for other satellites (OMI, MODIS-Aqua, SEVIRI-daytime show the same dependency as GOME-2, see Vaquero-Martínez et al. 2017c). Another reason for the different sensitivities of satellites and GNSS to different IWV regions is given by those same authors (and phrased as “all satellites tend to homogenize water vapour: low IWV tends to be overestimated, while high IWV tends to be underestimated”): the spatial resolution of satellites is much lower than GNSS ground-based stations, and thus the IWV measurement is somehow averaged over the whole pixel. Other explanations for the IWV dependency of biases are uncertainties in the spectroscopic data base used for the MODIS retrieval, so that large differences with large amount of water vapour are caused by uncertainties in the calculation of the atmospheric transmittance for water vapour (Joshi et al. 2013), the RS day-night humidity bias, which scales with humidity (Haase et al. 2003; Kwon et al. 2007), deficiencies in the water vapour modelling due to e.g. assimilation of dry biased radiosondes (Vey et al. 2010) or insufficient model resolution or physics parameterization (Haase et al. 2003), uncertainties in the RS measurements, which are used as reference data for the MWR IWV estimation algorithm or from influences of protecting film of the scanning mirror (Sohn et al. 2012), the variation of the GNSS station position caused by ocean tidal loading (Ohtani and Naito 2000) and the seasonal change of the mapping function, which varies as the height scale of the atmosphere changes (Ohtani and Naito 2000; Nyeki et al. 2005), and a GNSS antenna phase centre mis-calibration or the lack of proper calibration parameters (Vázquez and Grejner-Brzezinska 2013).
The tendency for the GNSS–RS SD to increase with IWV was attributed (Ohtani and Naito 2000; Basili et al. 2001; Haase et al. 2003; Deblonde et al. 2005) in part to stronger humidity gradients that can exist between dry and moist air when moister air is involved. In the presence of strong gradients, the location and sampling differences between GNSS and RS can be more significant than for lower IWV conditions. In addition, Ohtani and Naito (2000) claimed that the presence of strong horizontal gradients in atmospheric properties can have a negative impact on the ZTD accuracy due to a breakdown of the azimuthal symmetry assumption. Other authors point to the fact that uncertainties of some techniques are dependent on the absolute measured value (e.g. RS accuracy of 4%, Ning et al. 2012), on the number of measurements and the number of satellites simultaneously in view (e.g. for DORIS, Bock et al. 2010). The standard deviations between GNSS and MODIS IWV retrievals during summer and autumn (monsoon) seasons in India are due to large variation of the daily PWV data at the site. Such large variation in values may be attributed to larger uncertainties associated in the MODIS retrieval algorithm particularly during monsoon season (Prasad and Singh 2009; Joshi et al. 2013; Ningombam et al. 2016).
5.6.1.7 Conclusions
Due to its high accuracy and precision, growing coverage, long-term stability and all weather observing capability, the GNSS technique for IWV retrieval is recently been used more frequently as reference device for e.g. the validation of IWV satellite retrievals. Also the validation of the IWV time series from climate models is an emerging field. Assessing the long-term stability and homogeneity of GNSS IWV datasets is therefore of great importance. However, past IWV inter-technique studies including GNSS (http://www.meteo.be/IWVintercomp) concluded that the results of those studies are hard to intercompare, because study and time dependent to a large extent.
Here, we summarized some of the most important characteristics of the different instruments and we described major differences between the past studies. Because IWV is highly variable in space and time, we also want to highlight the need for spatial co-location and temporal coincidence criteria that reflect the horizontal representativeness of the different instruments. Additionally, when comparing ground-based devices, a correction for the vertical separation between sites is indispensable. The ranges of IWV biases and standard deviations and linear regression coefficients of one technique with respect to GNSS, extracted from the inventory of IWV intercomparison studies (http://www.meteo.be/IWVintercomp), are very broad, but we believe that, when applying a uniform methodology for different sites, those could be narrowed down.
A general property that has been observed by many past studies is the IWV dependence of the IWV differences with GNSS (both the bias and the standard deviation). Apart from some specific deficiencies in the IWV retrieval methodology, the fact that GNSS is an all-weather technique and other techniques clearly show an observation bias (partially clear sky or low cloud cover), with a clear dependence on the cloud cover, will certainly be a role in this feature. Also the SZA dependence of some techniques is clearly linked. Of course, sampling issues between satellite retrieved IWV and GNSS might, at least for some sites, be partly responsible. This IWV dependence of the IWV differences with GNSS is mimicked by a seasonal or latitudinal variation of the IWV differences.
5.6.2 A Comparison of Precipitable Water Vapour Products Over the Iberian Peninsula
5.6.2.1 Abstract
This work compares GNSS PWV estimates over Iberia with independent sources of the parameter such as the clear-sky TPW estimate based on SEVIRI observations provided by the NWC-SAF, ECMWF forecasts and local radiosondes. A general quality assessment of the products is performed and the biases between datasets are discussed.
5.6.2.2 Introduction
A team from the Instituto Português do Mar e da Atmosfera (IPMA) and the Space & Earth Geodetic Analysis Laboratory (SEGAL) – who already demonstrated the usefulness of GNSS PWV retrievals for weather and climate purposes (Adams et al. 2011), developed an operational scheme to produce these estimates for the Iberian Peninsula. The main objective of this work is to validate GNSS PWV by comparison with other standard datasets for this region, which are used routinely at IPMA for nowcasting of extreme precipitation events.
5.6.2.3 Data and Methods
The GNSS PWV is estimated operationally for a set of receivers located over Portugal and Spain using the GIPSY software, maintained by NASA JPL, every 5 min with a 2 h delay (Bevis et al. 1992, 1994; Calori et al. 2016; Duan et al. 1996). The inputs used in this method include: 1) the raw GNSS observations from 146 GNSS receivers located over Central and Western Iberia, collected every hour, from the Portuguese networks SERVIR and ReNEP (59 stations) and the Spanish networks ANDALUCIA, CASTILLA, EXTREMADURA and IGN (88 stations); 2) surface pressure and temperature, provided in advance by IPMA, from the hourly ECMWF forecasts initialized at least 12 h before a given measurement to avoid the model spin-up and so that the operational GNSS-PWV scheme is not limited by the timeliness of these data. A height correction is performed, assuming hydrostatic equilibrium for pressure and a dry lapse rate for temperature; 3) GNSS satellite orbits, provided by the NASA Jet Propulsion Laboratory (JPL).
An independent estimate of PWV is provided by the Spinning Enhanced Visible and Infrared Imager (SEVIRI) instrument on-board the Meteosat Second Generation (MSG), for clear sky pixels only. For the retrieval of the data, the iSHAi software (Martínez and Calbet 2016) is used, developed by the European Organisation for the Exploitation of Meteorological Satellites (EUMETSAT) Satellite Application Facility on support to Nowcasting and Very Short-Range Forecasting (SAF-NWC). The algorithm is based on an optimal estimation approach, and uses the SEVIRI brightness temperatures (BTs) of the channels 6.2 μm, 7.3 μm, 8.7 μm, 10.8 μm, 12.0 μm, and 13.4 μm, with ECMWF forecast profiles of temperature and specific humidity for the first guess of the iterative algorithm. The used radiative transfer model is RTTOV (Radiative Transfer for TOVS – https://nwpsaf.eu/site/software/rttov/).
A third PWV estimate is given by the operational ECMWF hourly forecast (9 km resolution). In this work, the ECMWF PWV time series is extracted from the forecasts using time steps 12 to 23 from the forecasts initialized at 0:00 UTC and 12:00 UTC, so that hourly values may be used.
Finally, radiosondes launched daily (mostly around 12:00 UTC but there are a few that were launched at 00:00, 06:00 and 18:00 UTC) at the Lisboa – Gago Coutinho station were used to calculate the PWV. This station uses RS292-SGP Vaisala radiosondes.
5.6.2.4 Results
In Fig. 5.28, all the different estimates of PWV are compared for the Lisboa – Gago Coutinho station from December 2016 to March 2017. There is a good overall agreement between the 4 analysed datasets, but the GNSS estimates being wetter than the other techniques for most of the observing period. Part of the mismatch between estimates is likely attributable to errors in colocation.

Time series of the PWV for Lisboa – Gago Coutinho, using GNSS (blue), the SAF-NWC (orange), the ECMWF (green) and the radiosondes (red dots)
The scatter plots between GNSS and the other data sets are shown in Fig. 5.29. A Hampel filter was used for outlier removal (Liu et al. 2004). The comparison with the SAF-NWC shows the lowest RMSE, of about 1.3 mm, and lowest bias (SAF-NWC-GNSS) of about −0.7 mm. However, this is also the comparison with the lowest correlation coefficient (R2 = 0.918). Note that this comparison only reflects clear sky conditions, as the SAF-NWC product is not produced over cloudy pixels. A major source of uncertainty of this clear sky product is introduced by the possibility of a cloud not being detected by the cloud mask algorithm. In this case the brightness temperatures measured by SEVIRI correspond to energy emitted mainly by the cloud top and not by the surface, as is assumed by the iSHAi algorithm. In such cases a negative bias will arise.

Comparison of GNSS estimates to the remaining data sets (SAF-NWC on the right, ECMWF in the centre and radiosondes in the right)
When compared to the ECMWF PWV, the GNSS shows a bias of +1.8 mm and a RMSE of 2.3 mm. The correlation coefficient is similar to the previous comparison (R2 = 0.926). This overall slightly worse comparison could be due to the inclusion of cloudy pixels and also the forecast errors in the model. The comparison to radiosondes is the one showing the highest correlation coefficient (R2 = 0.968) but also a significant bias of −2.4 mm, which may be indicating that some systematic error (the known daytime radiation dry bias in the RS92 radiosondes) is affecting the comparison (currently under investigation). The RMSE is therefore quite high (around 2.6 mm).
The error statistics (bias, RMSE, R2, number of observations) for each GNSS receiver are illustrated in Fig. 5.30 (SAFNWC-GNSS on top and ECMWF-GNSS in the bottom). The positive bias of GNSS versus ECMWF and SAFNWC (negative values in the leftmost panels) is confirmed for the bulk of the stations, which should be investigated in closer detail. The RMSEs are generally below 2 mm for most of the stations, with some exceptions that include the Lisboa – Gago Coutinho. The correlation coefficients are generally substantially above 0.90, especially vs ECMWF, except for a few stations that need further attention. Also shown is the number of data points used for each statistic. Major limitations are the 1 h time sample of ECMWF, the number of cloud masked cases of SAF-NWC (which has a time sampling of 15 min), and the failure of the GNSS networks to deliver their estimates on time.

Error statistics for all the GNSS locations with valid measurements
5.6.2.5 Conclusions
A GNSS-based operational Precipitable Water Vapour product was developed for nowcasting support by the SEGAL/IPMA team. The product is available every 5 min with a 2 h delay for 146 stations from 6 GNSS receiver networks over Portugal and Spain. The estimates of ZTD are computed using the GIPSY software and then converted into PWV estimates using surface temperature and temperature data from ECMWF forecasts.
The GNSS PWV product was compared to other high-availability products such as SAF-NWC (clear-sky), ECMWF hourly forecast, and the Lisboa – Gago Coutinho radiosondes. Although slightly biased positively against other products, the GNSS shows good performance and allows a comprehensive spatial and temporal coverage, all-weather observations (in contrast with the SAF-NWC product, for example) and high frequency variability sampling. Despite the systematic biases that were identified, the correlation with the other high frequency datasets is encouraging and suggests that simple corrections could be applied in order to make the products more comparable, e.g. the orographic correction proposed by Bock et al. (2007).
There is still room for fine-tuning of the product, namely through proper identification of outliers, development of a quality flag for the retrievals, reducing timeliness and increasing station availability. Given the high annual variability of the PWV over Iberia, using a more extended period, as well as comparison to more data sources could also provide a more complete validation – this is ongoing work. A measure of the product uncertainty is also key and it is envisaged to the near future so that the product usage can be expanded for applications such as data assimilation by limited area numerical weather forecast models.
5.6.3 Comparing Precipitable Water from Remote Sensing and Space Geodetic Techniques with Numerical Weather Models
Space geodetic applications such as GNSS and VLBI open new possibilities in obtaining tropospheric water vapour. GNSS has proven to be ideally suited for deriving meteorological parameters such as PW and is currently further gaining in importance. Less well known is the ability to determine water vapour through observations of radio waves from quasars billions of light years away using the space geodetic technique VLBI. The presence of water vapour and water particles in the troposphere decelerates these signals similarly to those from GNSS satellites, which enables accurate estimations of their amount. Some VLBI stations make observations for almost 40 years now, yielding fairly long time series of water vapour. Another dataset stems from microwave radiometry by remote sensing satellites as, e.g., combined and provided by the GlobVapour product by the European Space Agency (ESA). In GlobVapour, data of several Earth observation missions (MERIS, GOME, SSM,) was combined with the aim of providing global and consistent time series of IWV, which, in simplified terms, can be equated with PW.
In this study, we analyse the correlation between all these datasets and compare them with NWM data from the European Centre for Medium-Range Weather Forecasts (ECWMF). Eventually we draw conclusions about possible synergies and the dataset’s ability and performance in describing the amount and variation of water vapour in the troposphere.
As to derive more information from the datasets, all observations are plugged into a least squares fitting for Eq. 5.11 below, the so-called seasonal fit. This outputs information about seasonal variations as well as long-term changes in the data.
In Eq. 5.11, b(mjd) denotes the respective output quantity dependent on the modified Julian date mjd, A 0 the mean value, A 1 and B 1 the annual terms, A 2 and B 2 the semi-annual terms, and k the linear trend. Figure 5.31 shows an example of how the fitting affects the data.

IWV from VLBI at station WETTZELL in southern Germany. Top: the observed IWV. Bottom: the IWV resulting from application of the seasonal fit
The seasonal fits are determined for the whole data at all 18 globally distributed VLBI/GNSS stations which are considered in this study. The temporal resolution of the datasets is slightly different:
-
NWM: 1995–2016 (6-hourly)
-
VLBI: 1995–2014 (6-hourly)
-
GNSS: 1995–2007 (6-hourly)
-
GlobVapour: 1996–2008 (weekly)
In Fig. 5.32, the comparison of IWV from all four datasets is shown for station MATERA in Italy.

IWV from all four techniques at station MATERA in Italy. Top: the observed IWV. Bottom: the IWV resulting from application of the seasonal fit
Figure 5.32 proves that the datasets in general fit quite well to each other. Averaging the IWV from all 18 considered stations yields the main results of this study (Table 5.7).
Highest correlation is reached between IWVs from VLBI and GNSS, with the NWM data yielding very high correlation coefficients with VLBI and GNSS as well. The GlobVapour data, on the other hand, does not correlate that well with the other datasets, although a correlation coefficient between 0.6 and 0.7 is not bad either. A comparison between GlobVapour and VLBI is not possible, as they have too few identical epochs. The biases of the dataset pairs are generally very small, which means that none of the datasets is systematically higher or lower than the others. The standard deviation is inversely proportional to the correlation coefficient; a high correlation coefficient is therefore accompanied by a low standard deviation, and vice versa. Furthermore, we also took a look at the linear trends k, that is, the long-term changes of the respective IWVs (Fig. 5.33).

The IWV linear trends k of all four datasets, as resulting from the seasonal fit
Unfortunately, no clear systematics can be derived whether the IWV increases or decreases at the considered stations, as all datasets provide contradicting results. Only at one single station, SESHAN25 in China, the datasets agree about the algebraic sign of the gradient. As a result, no safe statements can be made about long-term changes of IWV from this study. The reason is most likely that the considered time spans are too short.
In summary we can conclude that the considered datasets agree very well with each other. VLBI turns out to be a very appropriate technique for deriving long time series of IWV as well. The GlobVapour data is highly beneficial, in particular because it is available globally and not bound to terrestrial stations such as GNSS and VLBI, however its performance suffers from the fairly low temporal resolution compared to the other techniques. In further research we will consider longer time spans, more sample stations and more remote sensing products, as to derive even more meaningful results.
5.6.4 Inter-Comparison Analysis of Tropospheric Parameters Derived from GPS and RAOB Data Observed in Sodankylä, Finland
This study compares tropospheric parameters derived from GPS and radiosondes (RAOB) data at Sodankylä (GRUAN and EPN site, at the Arctic Research Centre of the Finnish Meteorological Institute, 67°37’N, 26°65′E) These entire databases were processed to estimate ZTD, ZWD, and IWV. Using the Sodankylä RAOB database collected from 1999 to 2013, synthetic climatic and radiometric parameters were calculated by applying the microwave radiative transfer equation (RTE) together with a cloud model. This allowed the generation of simulated long-term ZTD, ZWD and IWV. The radiosonde station is located near the EPN GPS permanent station. From that GPS ground-receiver homogeneously reprocessed ZTD time series (1999–2013) (Pacione et al. 2014a), carried out in the framework of the EPN Repro2 campaign (hereafter AS0), and combined ZTD Near-Real time time-series (2008-present) (Pacione et al. 2011) derived in the E-GVAP framework (hereafter ASIC), were utilized in the present analysis. To derive ZTD from GPS the AS0 solution characterized by a 5-min sampling was applied and GPS data were averaged over 15 min. A scatter plot of GPS and RAOB-derived ZTD for the entire dataset is shown in Fig. 5.34.

Scatterplot of ZTD computed at Sodankylä (1999–2013) from GPS versus RAOB. The solid line represents the linear correlation
A relatively small bias and standard deviation (SD) of −0.092 cm and 0.575 cm respectively, with a correlation coefficient of 0.993 were found. The bias value highlights a slight underestimation of GPS-derived ZTD. However, the scatter plot in Fig. 5.34 shows a good agreement between GPS and RAOB over a large ZTD range covering a long-term observation period in the Arctic climatic region. Figure 5.35 shows the yearly trends of bias and SD from 1999 to 2013. The bias on the right hand side displays three anomalous values in 2001, 2005 and 2011. The 2005 anomaly could be correlated with the use of the RS80-15 L radiosonde, however the anomalous values in 2001 and 2011 are so far unexplained. Interestingly, Fig. 5.35 (left) shows that until 2004, when RS90 radiosondes were in use, the GPS-derived ZTD is less than the RAOB-derived ZTD. After 2004 when the radiosondes were changed to RS92 the GPS-derived ZTD is generally higher than the RAOB-derived. Except for the year 2005 (when the RS80-15 L radiosonde were used) the SD values shown on the right hand panel of Fig. 5.35 display a pronounced and constant decreasing trend probably due to the improvement of the RS92 radiosonde data quality. From 1999 to 2013, the SD decreases from 0.671 to 0.435 cm with an average value of 0.575 cm. The bias has a long-term average value of −0.092 cm.

(Left): Yearly ZTD Bias (GPS – RAOB) and (Right) error standard deviation (SD) at Sodankylä from 1999 to 2013
Using the same database, yearly bias and SD between GPS and ZTD RAOB were computed for all corresponding values at 00:00 UTC and 12:00 UTC and are shown in Fig. 5.36. The results are consistent with those shown in Fig. 5.35, although the magnitudes of the day-time (red points) and night-time (blue points) biases appear to be different.

Same as Fig. 5.35 but at 00:00 and 12:00 UTC time using 30-min averaged data
As part of the analysis the GPS data collected at Sodankylä from 2008 to 2013 were processed using the ASIC and ASO solutions. The ZTD GPS values from the ASIC solution have a sampling time of 15 min, while the corresponding values referred to the AS0 solution have a sampling time of 5 min. Fig. 5.37 shows the bias and SD of the ZTD obtained with the two methodologies with respect to the RAOB. The GPS ASIC solution produces a considerably higher positive bias than the AS0 solution. On the contrary, the AS0 solution lead to smaller bias values that however show a slight seasonal dependence: slightly negative in summer and almost zero during colder months. The monthly SDs associated with the two GPS solutions have a similar seasonal behaviour, but with slight better performance of the AS0 solution. The overall better performance of AS0 solution w.r.t. ASIC is expected. As AS0 is a homogeneously reprocessed ZTD solution, not affected by inconsistencies due to updates of reference frame or applied models, it might be suitable for long-term analysis, while ASIC is mainly devoted to NWP data assimilation and quality control of the contribution solution.

(Left): Monthly ZTD bias and standard deviation (SD) (right) for the ASIC (blue) and AS0 (red) GPS solutions with respect to the corresponding RAOB. Data are 30-min averages from Sodankylä (period 2008–2013)
We can conclude that ZTD inter-comparison performed on 14 years (1999–2013) of concurrent GPS and RAOB values collected at Sodankylä showed a small bias, that was radiosonde-dependent and decreasing trend of standard deviations. Considering all the data, the bias and SD assumed values of −0.092 cm and 0.575 cm respectively. Results also showed that the GPS ASO solution performs better that than the ASIC solution.
5.7 IWV Trends & Variability from GNSS Data and Atmospheric Models
Parts from this section were previously published in Parracho et al. (2018).
5.7.1 Analysis of IWV Trends and Variability from GNSS and Re-Analyses
Water vapour plays a key role in the climate system. However, its short residence time in the atmosphere and its high variability in space and time make it challenging when it comes to study trends and variability. In this work, IWV estimated from GPS ZTD observations reprocessed by JPL (repro1) at 104 stations of the IGS network (see Sect. 5.2.2) was intercompared with data from two atmospheric reanalyses: ECMWF’s ERA-Interim (Dee et al. 2011) and NASA’s MERRA-2 (Gelaro et al. 2017). Monthly and seasonal (December–January-February and June–July-August) means, inter-annual variability, and linear trends were analysed and compared for the 1995–2010 period (period with GPS data).
5.7.1.1 Means and Variability
Figure 5.38a, b show the mean ERA-Interim fields superposed with the GPS mean values (as points) corrected to the ERA-Interim model height. Globally, the mean IWV is strongest in the tropics where strong evaporation occurs from the warm oceans and land surface and where trade winds transport moisture to the Intertropical Convergence Zone (ITCZ). Lower IWV is observed at mid to high latitudes, where lower evaporation occurs due to the cooler oceans and land surface, and over arid regions (e.g. Sahara, Arabic peninsula, south-eastern Africa, Australia), where lack of water limits evaporation. IWV is also lower at higher altitudes (e.g. the Himalayas and the Andes cordillera) due to the rapid decrease of water vapour saturation pressure with altitude as predicted by Clausius–Clapeyron equation. Figure 5.38a, b also show a strong seasonal variation is driven by the movement of the incoming solar radiation from one hemisphere to the other and back along the course of the year, resulting in a global swinging of the trade winds and ITCZ across the Equator.

(a) Mean value of IWV from ERA-Interim between 1995 and 2010 for JJA. Filled circles correspond to IWV retrieved by GPS. (b) same as a) for DJF. (c) relative variability (standard deviation of the IWV series divided by its mean) for JJA, between 1995 and 2010. (d) Same as c) for DJF
In general, there is good agreement between ERA-Interim and GPS, with ERA-Interim reproducing the spatial variability well, including the sharper gradients in IWV (e.g. northern and southern flanks of the ITCZ in both seasons, and in the regions of steep orography). ERA-Interim is slightly moister on average than GPS. The median bias is 0.51 kg/m2 (6.2%) in DJF and 0.52 kg/m2 (2.7%) in JJA, and the standard deviation of the bias across the network amounts to 0.83 kg/m2 (6.9%) in DJF and 0.95 kg/m2 (7.8%) in JJA. There is some spatial variation in the mean difference, namely a negative mean difference in the tropics (ERA-Interim < GPS) which is compensated in the global median by the larger number of stations in the extra-tropics which have a positive difference (ERA-Interim > GPS). A paired two-sample t-test detected 20 stations with significant differences in the mean IWV values at 0.01 confidence level in DJF and 17 in JJA. These sites are located in coastal regions and/or regions with complex topography, and representativeness errors are suspected to be the cause of these biases (Bock and Parracho 2019).
The inter-annual variability was computed as the relative standard deviation of the seasonal IWV time series (i.e. standard deviation of seasonal time series divided by its mean value), and is presented for ERA-Interim (fields) and GPS sites (points), for DJF and JJA, in Fig. 5.38c, d. In DJF (Fig. 5.38c), strong inter-annual variability (> 15%) is found for northern high-latitude regions (north-eastern Canada and eastern Greenland, polar Artic area, and a large part of Russia and north-eastern Asia) and for the tropical arid regions (Sahara, Arabic peninsula, central Australia). Some correlation was found between the seasonal IWV anomalies and the North Atlantic Oscillation (NAO) index (Barnston and Livezey 1987) over Siberia (r = 0.5) and Greenland (r = −0.5) (not shown). Noticeable variability is also seen in the central tropical Pacific in DJF but this is due to the extremely large variability in absolute IWV contents (up to 6 kg/m2) associated with the El Niño Southern Oscillation (ENSO). Linear correlation coefficients between the seasonal IWV anomalies and the Multivariate ENSO Index (MEI; Wolter and Timlin 1993, 1998) in this region reach r = 0.80 (not shown). In JJA, large inter-annual variability is observed mainly over Antarctica and Australia (Figure 1d). Locally enhanced variability is also seen over the Andes cordillera, but this is mainly due to the very low IWV values at high altitudes.
Most of the marked regional features of inter-annual variability are also confirmed by GPS observations (Fig. 5.38c, d), with a median difference between ERA-Interim and GPS close to zero for both DJF and JJA with a standard deviation across the stations of 1.7% in DJF and 4.1% in JJA. One can especially notice the good representation of the relative variability over Australia or South America, both in DJF and JJA, and in the northern high latitudes, where the gradients are strong and well captured. However, a few stations show different values compared to the ERA-Interim background. These are located in Antarctica and Hawaii, where representativeness errors are again expected, due to the large variability in the IWV values of the surrounding grid points connected with large variations in the altitudes (> 500 m). In the case of Hawaii, the error is due to the limited imprint of Mauna Kea Island on the 0.75° resolution grid of ERA-Interim. In the case of MCM4 and SYOG (in Antarctica), the time series of monthly mean IWV and IWV differences reveal variations in the means which coincide with GPS equipment changes and processing changes and unexplained variations in the amplitude of the seasonal cycle resulting in a marked oscillation in the monthly mean differences (ERAI – GPS). Variations in the means introduce a spurious component of variability in the GPS IWV series.
Finally, in addition to representativeness differences and errors in the GPS data, errors in the reanalysis data (expected in data-sparse regions and regions where the performance of model physics and dynamics are poor) can also be responsible for differences in the IWV means and variability. These can be diagnosed by comparing several reanalyses based on different models and different observational data or hypothesized by eliminating the other causes.
5.7.1.2 Linear Trends
The linear trends were computed using the Theil-Sen method (Theil 1950; Sen 1968) applied to the anomalies obtained by removing the monthly climatology from the monthly data. The statistical significance of the monthly and seasonal trends was assessed using a modified Mann-Kendall trend test (Hamed and Rao 1998), which is suitable for auto-correlated data, at a 10% significance level.
Results from ERA-Interim based on the full monthly time series (Fig. 5.39a) showed generally significant positive trends over the ocean (over most of the tropical oceans and over the Arctic). Significant negative trends were observed in south-tropical eastern Pacific region, west of the United States and generally south of 60°S. The dipole structure in the south-eastern tropical Pacific area is consistent with the findings of Mieruch et al. (2014) and is due to the different ENSO phases for this time period, as reported by Trenberth et al. (2005). Over land, significant positive trends were observed in the equatorial region along the ITCZ, especially in northern South America, Central Africa, and Indonesia, and in the northern hemisphere, especially over northern North America, Greenland, most of Europe and Siberia. Significant negative trends over land are observed over North Africa, Australia, Antarctica, central Asia, south of South America, and most of the USA. In general, there is continuity between oceanic and continental trends (e.g. North and South America, Central Africa), suggesting a trend in air mass advections. However, the magnitudes of the larger trends (e.g. −3.5 kg/m2 per decade or −17% per decade over northern Africa) are questionable. Comparison to GPS observations, when they are available, helps to address this question.

Relative trends in IWV in ERA-Interim (left) and MERRA-2 (right) reanalysis for 1995–2010
In general, the monthly trends computed at the GPS stations are in good agreement with ERA-Interim even in areas of marked gradients (e.g. between western Canada and the USA, or from central to Western Europe). However, there are a number of GPS stations where the trend estimates are large and of opposite sign compared to ERA-Interim. For some of these stations, the discrepancy is due to gaps and/or inhomogeneities (due to equipment changes) in the GPS time series which corrupt the trend estimates (e.g. CCJM station, south of the Japanese home islands). Representativeness differences are also suspected at mountainous and coastal sites. Finally, some sites also show more gradual drifts in the times series which do not seem connected with known GPS equipment changes (e.g. MAW1, in Antarctica). At such sites, drifts in the reanalysis, due to changes in the data assimilated by the reanalysis over time, are plausible.
Therefore, a second reanalysis, MERRA-2, was used to complement ERA-Interim and GPS, namely in regions of high uncertainty in these datasets (e.g. Antarctica) or in regions where few or no GPS data are available (e.g. Africa, Asia, the global oceans). The monthly IWV trends computed for MERRA-2 (Fig. 5.38b) are in good agreement with ERA-Interim for most regions. They describe consistent global moistening/drying dipoles along the inter-tropical Pacific Ocean, across Australia, South America and between eastern and western USA, and general moistening over the Arctic and Europe. However, there appears to be also significant differences over several parts of the globe, in particular over Indonesia and the Indian Ocean, central Africa, western (coastal) and northern Africa, Central Asia and Antarctica.
To better understand the trends, we separated them by seasons (DJF or JJA), which are presented for ERA-Interim in Figure 3a and b. The seasonal trends have a larger magnitude than the monthly trends, which emphasizes the role of atmospheric circulation (which is largely changing between seasons) on IWV trends. On the other hand, trends of opposite signs between winter and summer can be observed in western Antarctica, central South America, South Africa, Eastern Europe, and off the West coast of the USA. A strong drying occurs over Antarctica in JJA and over central Asia during JJA and DJF (though not exactly at the same location). Western Europe shows a drying in winter (DJF) and a moistening in summer, leading to weak trend when considering the full time series. Over Australia, according to ERA-Interim, the drying is stronger in DJF, i.e. when associated with a decrease of the intensity of the moist flow during the monsoon period. Another area likely sensitive to the intensity of the monsoon flow is northern Africa, where the drying is occurring in JJA over eastern Sahel, in a band covering Chad, Sudan and Eritrea. Overall, the seasonal trends estimated from the GPS data are in good agreement with ERA-Interim. The sites with largest differences in the seasonal estimates include: KIRU in Sweden, COCO in the Indian Ocean, IRKT in Russia, and ANKR in Turkey. However, trend estimates at some of these sites might be inaccurate due to the enhanced impact of time gaps for the short seasonal time series (based on 16 years at best).
The seasonal trends computed from MERRA-2 (Figs. 5.40c, d) show quite good agreement with ERA-Interim and GPS in DJF (e.g. dipole in the trends over Antarctica, strong drying trend over Siberia, the Arabic peninsula, western Australia, western Europe, and most of the USA; and the strong moistening over the Arctic). In JJA, there are considerable differences between the reanalyses, with opposite trends seen in Indonesia and in most of southern Asia, north and central Africa, Antarctica, and in the eastern Arctic region. These differences emphasize the uncertainty of reanalyses in data sparse regions.

Relative trends in IWV in ERA-Interim (top) and MERRA-2 (bottom) reanalysis for the 1995–2010 period for DJF (a, c) and JJA (b, d). The statistically significant trends are highlighted by stippling
5.7.1.3 Conclusions
GPS data proves to be useful in the study of IWV trends and variability. In spite of some differences at handful of stations, there is a general good agreement between GPS and ERA-Interim IWV means, variability and trends. The main drawback of GPS is the lack of long term data in certain regions where ERA-Interim shows intense IWV trends. To curb this issue in regions lacking in GPS data or regions of disagreement, MERRA-2 reanalysis was used. The IWV means, variability, and trends in both reanalyses agree well in most regions. However, the comparison of seasonal trends in both reanalyses also highlighted areas where the reanalyses disagree. These differences emphasized the uncertainty of reanalyses in data sparse regions, and the uncertainty of trend estimation for such a limited time period. A more detailed analysis over two of these regions, Western Australia and North Africa, as well as an extension of the trend analysis to a longer period (1980–2016) is presented in Parracho et al. (2018).
5.7.2 Analysis of IWV Trends and Variability from GNSS and Satellite Data
The IGS repro 1 dataset and ERA-Interim have been compared to satellite IWV data. In this analysis, a long (1995–2014), homogenized, global dataset of monthly mean IWV data was retrieved from three VIS measuring satellite instruments: GOME, SCIAMACHY, and GOME-2 (Beirle et al. 2018), hereafter named GOMESCIA.
5.7.2.1 Frequency Distributions
We first looked at the histograms of all available IWV data for both IGS repro 1 and ERA-interim (with time resolution of 6 h, which for IGS repro 1 depends additionally on the ZTD availability). We found that almost all stations of our sample follow a lognormal distribution for their IWV field, in consistency with Foster et al. (2006). The traditional lognormal distribution is found for every station at the Australian continent, and is commonly found in Scandinavia and USA (except at the entire west coast). A reversed lognormal form is found for some tropical island or coastal sites. Other tropical sites are characterized by distinct bimodal lognormal distributions, which might be explained by the impact of the monsoon. The remaining stations or regions (in particular the USA west coast and Europe) have mainly a standard lognormal distribution, but with a clear, secondary lognormal distribution which is responsible for an additional peak (or “shoulder”) in the histogram, at the higher IWV range. The frequency distribution is hence composed by a winter and summer IWV distribution. Apart from some site to site exceptions, this geographical distribution is similar for both IGS repro 1 and ERA-interim.
5.7.2.2 Seasonal Variability
Now we study how the seasonal cycle is represented (geographically) by the different IWV datasets. We therefore plot harmonic functions through the IWV time series and compare the amplitudes and phases of those functions, see Fig. 5.41. Overall, we found that the seasonal cycle and its geographical variability are similarly depicted by all datasets. GOMESCIA underestimates the number of sites with small amplitudes of the seasonal cycle (< 4 mm), especially with respect to ERA-interim, and the phase of the maximum in the seasonal cycle also peaks one month later in the Northern Hemisphere in the GOMESCIA dataset. Additionally, the GOMESCIA time series also more often contain higher order periodic signals (e.g. 6 months) than the IGS Repro 1 and ERA-interim datasets.

Phase and amplitude of the seasonal cycle of the IWV time series of the different datasets (coloured) at the locations of the IGS Repro 1 sites. The direction of the arrow denotes the month of the maximum IWV value (1 h = Jan, 2 h = Feb, etc.); the arrow length gives an idea of the amplitude of the seasonal cycle
5.7.2.3 Linear Trends
From the IWV monthly anomalies, we calculated linear trends for the different datasets. These are shown in Fig. 5.42 for IGS Repro 1 and GOMESCIA. Overall, we found that IGS Repro 1 has the highest number of sites with (statistically significant) positive trends in IWV: about two third of the sites have positive trends. GOMESCIA on the other hand, has the highest number of sites with negative trends in IWV. The sign of the trend is hence dependent on the dataset used, and only above Europe (moistening) and West Australia (drying) a consistent geographical pattern is achieved among the three considered datasets here (ERA-interim not shown). We also want to note that the ERA-interim IWV trends can, at least from a qualitative point of view, nicely be explained by the ERA-interim surface temperature trends.

IWV linear trends [%/decade] calculated for the period 1996–2010 for IGS Repro 1 (top) and GOMESCIA (bottom)
5.7.2.4 Stepwise Multiple Linear Regression
To gain insight in the processes responsible for the IWV time variability present in the 3 datasets, we tried to fit the monthly mean time series with a linear regression that uses explanatory variables as the surface temperature, surface pressure, tropopause pressure, but also teleconnection patterns like ENSO, NAO, etc. The approach is stepwise: first, we include all the explanatory variables in the linear regression and rank them according to the explained variability; then we include the explanatory variables one by one, according to this ranking, and only the explanatory variables that explain a statistically significant part of the variability are retained in the regression. An example of a fit is given in Fig. 5.43.

Linear regression fit (in red) for the IGS Repro-1 time series of the site ALGO (Canada). The explanatory variables used are the long-term means, the surface temperature, the tropopause pressure, the EP flux, the Tropical/Northern Hemisphere pattern, East Atlantic/West Russia pattern (4 months leading), Polar/Eurasia pattern, and the Pacific Transition pattern. About 97.9% of the variability is explained by the fit and the correlation coefficient equals 0.989
One important outcome of the analysis is that a large fraction of the variability, and for the majority of the sites, can be explained by the surface temperature, of course after accounting for the seasonal cycle by the use of long term means or harmonic functions. Given the already mentioned qualitative agreement between the ERA-interim trends in IWV and surface temperature, this is not very surprising and this might be explained by the link between the time variability of both parameters through the Claussius-Clapeyron equation. Another explanation might be that the surface temperature accounts for some remaining seasonality in the IWV time series, even after accounting for it by using the long term means or harmonics. Another important explanatory variable is the surface pressure, so that it should not be a surprise that the IWV time series of ERA-interim can be best fitted by the linear regression (the surface pressure and temperature time series are calculated from ERA-interim). The GOMESCIA IWV time series are fitted worst by the linear regression. The highest explained variabilities are achieved for European and USA sites (except at the southern part of the west coast), but this might be due to the large number of NH teleconnection patterns that were included in the regression. There is certainly some regional consistency in the use of explanatory variables (ENSO in Australia, NAO in USA/Canada, East Atlantic in Europe), but not always (e.g. Arctic Oscillation in Antarctica, Pacific/North America pattern in Australia), so some more work is needed to guide the selection process of the explanatory variables.
Only for a few sites, a linear trend was retained as explanatory variable. Furthermore, the residuals between the IWV time series and the linear regression fit only show for a very limited number of sites a significant trend. The stepwise multiple linear regression fits are hence able to capture the (overall positive) trend in IWV.
5.7.2.5 Conclusions
We examined three completely different IWV datasets (GNSS, ERA-interim and GOMESCIA satellite retrievals) to study the IWV variability of a set of 120 global IGS Repro 1 sites. Although every used dataset might have its own remaining issues like homogeneity, spatial representativeness, etc.), we can conclude that combining the analysis results of the three of them, has the potential to characterize and understand the IWV time variability from a geographical consistent point of view.
5.7.3 Evaluation of IWV Diurnal Variation in Regional Climate Models using GPS
Given the ability of operating under all weather conditions and the long-term stability, the GPS technique has a superiority to measure long time series of the IWV with a temporal resolution as high as several minutes. Therefore, the GPS data are valuable to study the diurnal cycle of atmospheric IWV. In addition, in difference to the radiosonde data, the ground-based GPS data have not yet been assimilated into the climate reanalysis products, meaning that they offer an independent data set suitable for the evaluation of climate models.
GPS measurements acquired at 99 European sites were processed to estimate the atmospheric IWV time series for a period of 14 years (January 1997 to December 2010). The GPS-derived IWV were used to evaluate the simulations obtained from the regional Rossby Centre Atmospheric climate model (RCA) driven at the boundaries by ECMWF reanalysis data (ERA-Interim). The comparison was first made using the monthly mean values. Averaged over the domain and the 14 years covered by the GPS data, IWV differences of 0.47 kg/m2 and 0.39 kg/m2 are obtained for RCA–GPS and ECMWF–GPS, respectively. The RCA–GPS standard deviation is 0.98 kg/m2 whereas it is 0.35 kg/m2 for the ECMWF–GPS comparison.
Figure 5.44 depicts the diurnal cycles of IWV for the summer months, June, July, and August, as a function of the local solar time (LST) averaged for all sites using data from GPS, RCA, and ECMWF. The RCA captures the diurnal cycle reasonably well but with a slightly later phase, especially for the minimum, and a smaller amplitude. The mean peak time is at 18 LST compared to the mean peak time of the GPS at 17 LST. The amplitude and phase differences may partly be explained by the fact that the model value is an average over 50 × 50 km and a time step of 30 min whereas the GPS data represent one point with a time step of 5 min. The differences in amplitude and phase may, however, also be due to errors in the convective and surface parameterizations, as found by Jeong et al. (2011) investigating the RCA diurnal cycle of precipitation. For ECMWF, we only have values every 6 h, but as for RCA, the IWV amplitude is smaller and the mean value is higher both for the night and the day compared to the GPS data. The variation of the peak time of the diurnal cycle for each site for the summer months is shown in Fig. 5.45 where a clear positive correlation is seen between GPS and RCA. The peak varies from 16 to 19 LST for the GPS data while there is a dominant peak at 18 LST for the RCA data. The RCA captures the geographical variations from west to east, with later peaks in the afternoon further east, and the late night and early morning peaks along the east coast of Sweden. These coastal IWV outliers may be related to the observed and modelled peaks in precipitation in early morning at 4–7 LST, found by Jeong et al. (2011), which they suggested could be linked to deep convection development over the Baltic Sea. Future studies using a model with a higher horizontal resolution of 2–3 km will enable a study of these local effects and also help to investigate the differences in the GPS and modelled IWV.

Diurnal cycles of IWV as a function of local solar time for the summer months (JJA) obtained from the data for all sites and all years, from Ning et al. (2013)

The peak time of the diurnal cycle of the IWV, for the summer months (JJA), obtained from the GPS data and the RCA simulation for each GPS site (upper panels) and histograms of the peak time (lower panels). The hour is in local solar time (LST), from Ning et al. (2013)
5.7.3.1 Some More Recent Results by Ning et al.
We have analysed 17 years (from January 1997 to December 2013) of the GPS data from 123 sites in Europe and obtained time series of IWV in the atmosphere. We selected in total 69 sites for which we have data from a period longer than 10 years. Again, we calculated diurnal cycles of IWV for the summer months, June, July, and August.
We investigated the diurnal signal by calculating the mean IWV for each hour (local solar time). The result shows that it is reasonable to model the variation in the diurnal signal using a sine function, although significant deviations are seen for some sites. Thereafter we studied the stability of the diurnal signal over the years where we calculated the amplitude and the phase averaged over periods of 1, 3, and 5 years. The result is shown for four example sites in Figure 3. It is clear that both the amplitude and the phase averaged over only 1 year are highly variable and, as can be expected, the results are more stable for longer averaging time periods (Fig. 5.46).

The amplitude and the phase of the diurnal cycle estimated for the summer months (JJA) and averaged over 1, 3, and 5 years for four example sites
Figure 5.47 summarises the results of the amplitude of the diurnal signal for all 69 sites with data covering at least 10 years. The estimated amplitude varies from 0.16 kg/m2 to 1.46 kg/m2. In general, an increase of the amplitude is seen when the latitude decreases. Fig. 5.48 depicts the peak time of the hourly IWV mean. Similar to the results shown in Ning et al. (2013) the peak time of the hourly IWV mean is varying from 16 to 20 local solar time for most of the sites. In addition, it shows a systematic variation from west to east over the Scandinavian peninsula.

Estimated amplitudes of the diurnal cycle in the IWV at the 69 sites with more than 10 years of data, the unit of the colour bar is kg/m2

The peak of the hourly mean of the IWV in local solar time (same sites and time periods as in Fig. 4)
5.7.4 Validation of the Regional Climate Model ALARO-SURFEX by EPN Repro2
The use of ground-based observations is suitable for the assessment of atmospheric water vapour in climate models. We used IWV observations at 100 European sites to evaluate the regional climate model ALARO coupled to the land surface model SURFEX (Berckmans et al. 2017), driven by the European Centre for Medium-Range Weather Forecasts (ECMWF) Interim Re-Analysis (ERA-Interim) data. The selected stations provide data for a minimum of 10 years, resulting from the second reprocessing campaign of EPN (EPN Repro2, Pacione et al. 2017).
The yearly cycle of the IWV for the 19-year period from 1996 to 2014 reveals that the model simulates well the seasonal variation. The intra-annual variability is higher than the inter-annual variability. Although the model overestimates IWV during winter and spring, it is consistent with the driving field of ERA-Interim. However, the results for summer demonstrate an underestimation of the modelled IWV and a larger standard deviation, which is not present in ERA-Interim (Fig. 5.49). The dry bias in summer can be explained by fewer evaporation by the model, hence an underestimation of the IWV.

Monthly averaged Integrated Water Vapour (IWV, kg/m2) values averaged over the 19-year period of 1996–2014 and all stations from EPN-Repro2 in a Western European domain and corresponding grid points modelled by ERA-Interim and ALARO-SURFEX. The vertical bars represent the standard deviations
The spatial variability among the sites is high and varies between −1.4 kg/m2 and + 4.6 kg/m2 in winter and between −2.0 kg/m2 and 4.9 kg/m2 in summer. The standard deviation shows a latitudinal dependence with increasing values towards the south of the domain. Overall, these findings are in agreement with the distribution of the cold and wet bias by the model in winter, and the cold and mixed dry and wet bias in summer.
In summary, the model ALARO-SURFEX performed better for the simulation of water vapour in autumn and winter than for spring and summer. The underestimation of the IWV in summer by the model could be related to an underestimation of the evaporation. This mechanism was most pronounced in summer as land-atmosphere feedbacks are strongest in summer. The spatial distribution demonstrated a high variability of the IWV. We recommend to investigate the relations between stations with similar characteristics.
5.7.5 Evaluation of IWV Trends and Variability in a Global Climate Model
Water vapour is responsible for the most important positive feedback in climate change. Globally, as temperatures increase, evaporation and the water-holding ability of the atmosphere also increase, leading to an increase in atmospheric water vapour. Because water vapour is a powerful greenhouse gas, its increase leads to a further rise in temperature, creating a vicious cycle. Although the water vapour feedback is a robust feature across all climate models (Soden et al. 2005), simulated water vapour variabilities have been found to differ from observations (Pierce et al. 2006). Uncertainties in convective and turbulent parameterizations, cloud microphysics, land surface/atmosphere interactions in climate models lead to uncertainties in the accuracy of simulated water vapour and, ultimately, to uncertainties in climate predictions. An effort has been made to improve model representation of clouds and water vapour, guided by different types of observation (e.g. Jiang et al. 2012).
In this subsection, the trends and variability in IWV in the IPSL-LMDZ model (at a 1.9° × 3.75° resolution, for the 1995–2009 period) were compared with those obtained from GPS observations and ERA-Interim. Two versions of model were used: LMDZ5A (Hourdin et al. (2013a)), used within the Coupled Model Intercomparison Project 5 (CMIP5) under the name IPSL-CM5A and LMDZ5B (Hourdin et al. (2013b)), used within CMIP5 as IPSL-CM5B model. LMDZ5A uses similar physical parametrizations to LMDZ4, a previous version of the model used in the CMIP3, described in Hourdin et al. (2006), while LMDZ5B uses different parameterizations of turbulence, convection and clouds. In addition, for each physics, two runs were performed: a free run and a run that is nudged towards ERA-Interim wind fields every 6 hours, so that the large-scale dynamics is very close to that of ERA-Interim. In the following, the four simulation runs will be referred to as CM5A (LMDZ5A free run), CM5An (LMDZ5A nudged), CM5B (LMDZ5B free run), and CM5Bn (LMDZ5B nudged).
GPS data from 104 globally-distributed stations with over 15 years of data was used. In order to solve the problem of breaks in the GPS data, the time series were homogenized using ERA-Interim as a reference. In this case, the GPS IWV means were bias corrected to be consistent with ERAI means for each and every segment of time delimited by equipment or processing changes (in the rare case when no change occurred, the overall bias was simply corrected). Although the means of the corrected GPS data and the ERA-Interim data were strictly equal, the variability and trends could still differ slightly.
The ERA-Interim data used was filtered and interpolated to the model grid. As in Sect. 5.7.1, the analysis was done in terms of mean IWV, inter-annual variability, and linear trends, and divided into two seasons: December–January-February (DJF) and June–July-August (JJA).
5.7.5.1 Means and Variability
In terms of the mean IWV, both the free and nudged simulations show a consistent global pattern with the one seen previously for ERA-Interim (presented in Sect. 5.7.1). However, there are differences in the magnitude of mean IWV and the free runs of the model have difficulty in representing regional features such as the monsoon flows over West Africa and India in JJA (Fig. 5.50a). This is improved in the nudged simulations (Fig. 5.50b), as the nudging improves the water advection in both regions and allows the monsoon to penetrate further north. This is observed in the dipole structure over both regions in the difference fields between nudged and free simulations (Fig. 5.50c). For the mean IWV, nudging and difference in physics (Fig. 5.50d) have an impact of the same order of magnitude, with differences between models of up to around 6 kg/m2. From Fig. 5.50d it is also noticeable that the new physics is moister in general over the tropics. Comparison between the model and ERA-Interim (not shown) also highlighted a moist bias in the new physics (both free and nudged) for the tropical oceans in both seasons, which is also seen in the comparison between the model and the GPS stations in the region.

Mean IWV for JJA, for CM5B and CM5B nudged (a, b). Difference in mean IWV between nudged and free run of the new physics (c). Difference in mean IWV between physics (both nudged) (d)
The free runs of the model have difficulty in reproducing the inter-annual variability in IWV, especially in the winter hemisphere. For DJF (Fig. 5.51) the inter-annual variability of IWV is noticeably different in the free and nudged simulations. The nudged simulations have well-defined regions of higher variability over the Arctic and Siberia, West Africa, India, Australia and the tropical Pacific Ocean around the Equator, whereas the free configurations have maximum values over Canada and Alaska. In comparison with GPS, it is clear that the nudged simulations are better at representing the IWV inter-annual variability for DJF. Although there are no GPS stations over the Arctic and Siberia, the stations over Canada and Alaska have lower variability than the free simulations (around 10%, as opposed to over 20% in CM5A and CM5B). They are in better agreement with nudged simulations, but some stations still indicate an overestimation of inter-annual variability in CM5An and CM5Bn (e.g. Alaska, Greenland).

Variability in IWV fields in model with GPS variability as points for DJF
On the other hand, over Australia, GPS station ALIC presents higher variability, which is once again better captured by the nudged simulations than by the free ones. This can be observed in more detail in the time-series at the ALIC station for CM5A and CM5An (in Fig. 5.52). From the time series for CM5A it is observed that higher (lower) IWV events for DJF in 2000 (2005) are not well captured by the model. The nudged simulations are also in better agreement with ERA-Interim (not shown), with differences of between −5% and 5%, in contrast with differences of up to 15% in the free simulations.

Time series of GPS IWV at the ALIC (Alice Springs in Australia) site and IWV for CM5A and CM5An at the GPS site
For JJA (Fig. 5.53), the inter-annual variability in IWV shows more similar patterns across the four models. There is a maximum of variability over Antarctica, which appears to be overestimated in the model in comparison with GPS, especially for CM5A and with the exception of the easternmost station. There is also strong variability over Australia, which is slightly underestimated in all models, in comparison with the GPS station ALIC (in the centre of Australia). For the nudged simulations, the differences in variability with ERA-Interim (not shown) are relatively small (mostly within 2%) and similar between the two physics, which highlights the importance of the large-scale dynamics in the IWV inter-annual variability. Over the variability, the difference in model physics has a smaller impact than the nudging (about one half of the magnitude).

Variability in IWV fields in model with GPS variability as points for JJA
5.7.5.2 Linear Trends
The monthly trends are shown for the four configurations of the model in Fig. 5.54. Although there are differences in the computed trends, especially when it comes to the free and nudged simulations, there are trend structures that are consistent in all four configurations. These include a moistening over Northern Europe and Siberia, western coast of North America, the Western Pacific, and over part of the Indian Ocean; and a drying over the Western United States and off the coast into the Pacific. On the other hand, the drying over Western Australia and the moistening over southern Africa are observed for CM5An, CM5B and CM5Bn (but not CM5A) and are consistent with the trends computed at the GPS stations over these regions. Furthermore, CM5B is also able to reproduce the dipole structure in IWV trends in the tropical Pacific, which had been observed for ERA-Interim (Sect. 5.7.1), and which is a result of the strong 1997/98 El Niño event. This structure is not as significant in CM5A. On the other hand, there are significant trends which are only present in the nudged simulations, such as the moistening over Eastern Antarctica, which is in agreement in sign with the GPS stations, and most of South America; and the drying in Eastern Sahel, which is more significant in CM5Bn.

Trends in IWV fields in model with GPS trends as points
For the seasonal trends in both seasons, there is poorer agreement between the trend patterns observed for the free and nudged simulations, although the nudged simulations show similar trend patterns. For DJF in particular (Fig. 5.55), the nudged simulations show strong moistening over the Arctic and Northern Europe, Antarctica, China and South America; and strong drying over the West and East coasts of North America, the Arabian Peninsula, and Eastern Siberia. Some of these strong trends are confirmed by the GPS observations (e.g. some stations over Antarctica, and North America), but there are notable exceptions, such as the two stations over China and the station over Sweden, which register a drying (instead of moistening). However, overall, the trends observed at the GPS sites are in better agreement with the nudged simulations.

Trends in IWV fields in model with GPS trends as points for DJF
This confirms the importance of dynamics over the trends in IWV. The impact of the difference in physical parametrizations is much lighter. While the impact of nudging is in the 20% range, the impact of the physics is in the 5% range.
Most of the conclusions found for DJF are also seen for the JJA season, although for this season, there are trend structures that are observed in all four simulations. In Fig. 5.56, a few same sign significant trends are observed for Australia (drying), Western Europe (moistening), and the Indian Ocean (mostly positive, but partly negative in the eastern part, which is confirmed by the two GPS stations in the area. More results can be found in Parracho (2017).

Trends in IWV fields in model with GPS trends as points for JJA
5.7.5.3 Conclusions
The four configurations of the model are able to represent the global mean IWV patterns seen in ERA-Interim and at the majority of GPS stations, although some regional features such as the monsoon flows are only well represented when the model is nudged with wind fields. In addition to the important impact of the nudging over the means, the differences between physics are of the same order of magnitude, and denote a moist bias for the new physics over the tropical oceans.
The free runs have difficulty in representing the trends and variability in IWV. For the variability, the impact of nudging outweighs the impact of the difference in physics. In fact, when the simulations are nudged, the variability follows that observed for ERA-Interim more closely, and the agreement with GPS is improved. The same is observed for the IWV trends to some extent, although some regions still show relatively high differences between the model and GPS and ERA-Interim, even when the model is nudged (e.g. North Africa, Australia and Antarctica).
Finally, the fact that nudging significantly improves the results, demonstrates that dynamics (moisture transport) controls IWV variability and trends at both global and regional scales.
5.7.6 Anomalies of Hydrological Cycle Components During the 2007 Heat Wave in Bulgaria
5.7.6.1 Motivation
Heat waves have large adverse social, economic and environmental effects including increased mortality, transport restrictions and a decreased agricultural production. The estimated economic losses of the 2007 heat wave in South-east Europe exceed 2 billion EUR with 19,000 hospitalisations in Romania only. Understanding the changes of the hydrological cycle components is essential for early forecasting of heat wave occurrence. Valuable insight of two components of the hydrological cycle, namely IWV and Terrestrial Water Storage Anomaly (TWSA), is now possible using observations from GNSS and Gravity Recovery And Climate Experiment (GRACE) mission. In this work the IWV is derived from the GNSS station in Sofia (SOFI), which is processed within the first reprocessing campaign of the International GNSS Service.
5.7.6.2 Main Results
In 2007, positive temperature anomalies are observed in January (5 °C), February (3.4 °C) and July (2.1 °C). There is a negative IWV and precipitation anomalies in July 2007 (−2.7, −56 mm) that coincide with the heat wave in Bulgaria. TWSAs in 2007 are negative in January, May and from July to October being largest in August. Long-term trends of 1) temperatures have a local maximum in March 2007, 2) TWSA local minimum in May 2007, 3) IWV has a local minimum in September 2007, and 4) precipitation has a local maximum in July 2007. In Fig. 5.57 are shown the long-term time series of temperature (red line), precipitation (blue line), IWV (green line) and TWSA (black line) for the 2003–2010 period. There is an increase visible in the values of the four parameters for the studied period. Clearly is seen that there is a local maximum for the temperature early in 2007. Values of TWSA start from −94 mm in July 2003 and rise to 121 mm in December 2010. However, the trend is nonlinear and there is a local minimum of −30 mm in the summer of 2007. In the first months of 2007 downward trends of precipitation, IWV and TWSA are observed. The combination of above average temperatures and negative anomalies of IWV, precipitation and TWSA characterize the extreme hot weather situation in Bulgaria during the 2007 summer (Mircheva et al. 2017). To analyse the differences between the observed SYNOP, GNSS and GRACE anomalies are compared with ALADIN-Climate model simulations for period 2003–2008 and particularly for 2007. In Fig. 5.58 are shown anomaly differences (model minus observed) of monthly pairs of 1) temperature (top left), 2) IWV (top right), 3) precipitation (bottom left) and 4) TWSA (bottom right). Plotted are anomaly differences for each month of the years from 2003 to 2008. The heat wave year (2007) is plotted with a solid red line with dots. Positive and negative values correspond respectively with overestimation and underestimation of the computed RCM monthly anomalies against observations. The following features stand out for the distribution of monthly temperature anomaly differences (Fig. 5.58 top left): (1) mean monthly distribution range is generally in the interval ± 2 ° C and (2) there are two positive outliers in 2007 (May and June) and one in 2003 (February), indicating model overestimation with more than 2 °C. One negative outline in 2007 (January) shows underestimation of about 2 °C. The monthly IWV anomaly differences (figure 2 top right) are: 1) generally in the range ± 2, 2) negative in August 2003 and July 2006 and 3) positive in March 2003, August 2004, October 2005 and July 2007. The precipitation anomaly difference (bottom left panel of figure 12) is generally in the range ± 50 mm. There are large model underestimations in May and October 2003, August 2005 and May 2007. The model strongly overestimates the precipitation in October 2007 (112 mm) and April 2006 (88 mm). The TWSA differences are also generally in the range ± 50 mm with good agreement between the model and GRACE data sets from March to August (Fig. 5.58 bottom right). In winter months of 2007 TWSA observations and model data differ strongly. The largest positive anomaly differences are observed in November (103 mm) and December (62 mm) while the negative anomaly differences are in January (111 mm) and February (82 mm). It is noteworthy that TWSA anomalies for winter months of 2007 are modelled less well than every other time period. The computed cross-correlation coefficients of 2007 anomalies between observations and the ALADIN-Climate model indicates: 1) high correlation for temperature and IWV data pairs (over 0.7) and 2) no correlation for precipitation anomalies and TWSA data pairs (0.3).

Long-term time series of monthly temperature (red line), precipitation (blue line), IWV (green line) and TWSA (black line) for the 2003–2010 period

Monthly anomaly (ALADIN-Climate minus observed) of: (a) temperature, (b) IWV, (c) precipitation and (d) TWSA
5.7.6.3 Future Work
In the near future the remotely sensed data sets like GRACE and GNSS observations are likely to have large impact in regions like Bulgaria where in situ data are sparse. Future work will include comparison of the studied observation with long term climate data. Also the results will be used to analyse the changes of the hydrological cycle components and its relation with the heat wave and flood occurrence in Bulgaria.
5.8 Database, Formats and Dissemination
5.8.1 GOP-TropDB – Comparison Tropospheric Database
The system for a long-term evaluation of the tropospheric parameters estimated as a product of space geodetic data analyses (GNSS, VLBI, DORIS), numerical weather model (NWM) analyses or in situ observations (radiometers, radio sounding) has been implemented within the frame of IGS Troposphere Working Group (TWG). The initial goal aimed at improving the accuracy and usability of GNSS-based tropospheric parameters through the inter-comparison to the independent observation techniques. For this purpose, GOP developed a Postgres database system GOP-TropDB (Douša and Győri 2013; Győri and Douša 2016) which was completed with a web graphic user interface for interactive view of the inter-comparison results. GOP also performed comparison of tropospheric parameters from a variety of IGS and EUREF solutions and implemented service for online user calculation of tropospheric, meteorological and other auxiliary parameters from a NWM re-analysis. USNO coordinated the effort within the TWG and developed new portal linking all these services together. The GOP-TropDB can also serve for the assessment of NWM or climate models. Finally, the development of inter-technique troposphere comparison services, the provision of the NWM-based online tropospheric service and recent study on optimal modelling of tropospheric ties contributed to the IAG Joint Working Group ‘Tropospheric ties’ (Douša et al. 2017a, b). The service is available at the http://twg.igs.org.
5.8.1.1 Comparisons of Tropospheric Parameters
The GOP-TropDB was extensively used for evaluating results of the 2nd EUREF reprocessing including solutions provided by individual ACs (Pacione et al. 2017), variants of troposphere modelling performed at GOP (Douša et al. 2017a, b, subsection 3.5.2) and results of the 1st/2nd IGS reprocessing (Douša et al. 2014, 2016). Differences between various GNSS solutions as well as NWM and radiosondes products were calculated for both ZTDs and tropospheric gradients (when available). The time series of differences were analysed by performing monthly, yearly and total statistics which have been provided for each station or as a mean over all stations. Figure 5.59 shows an example of the visualization of ZTD statistics for the EUREF 2nd reprocessing vs. ERA-Interim reanalysis.

Summary statistics for ZTD from EUREF second reprocessing and ERA-Interim reanalysis (1996–2014)
Assessment of the global IGS tropospheric products with respect to the ERA-Interim (Dee et al. 2011) has been performed for the IGS 1st reprocessing and the 2nd reprocessing from CODE and GFZ analysis centres. Table 5.8 shows summary statistics for all stations and the differences of ZTD and tropospheric gradients (GRD) between GNSS product and ERA-Interim reanalysis over the period 1996–2014.
Figure 5.60 shows comparisons of two CODE reprocessing solutions, namely 3-day (CO2) and 1-day (CF2), indicating the impact of combining tropospheric parameters at the daily boundaries on ZTD parameters. The mean standard deviation of ZTD differences is 0.8 mm over a day, but almost 1.8 mm at the day boundaries and about 2–3 larger dispersion characterized by 1-sigma over all stations. Actual differences in ZTD could even be larger, because of necessary approximations used to compute statistics from low-resolution product when close to the day boundaries.

Mean bias and standard deviation between two CODE reprocessing solutions (all stations over year 2013)
5.8.1.2 GOP TropDB Visualization Tools
In order to facilitate browsing and interpreting huge statistical data sets from the GOP-TropDB, a new interactive web-based visualization tool was developed too. It is configurable for plotting data in spatial and temporal scopes for user selection of parameters, stations, products etc. Optionally, spatio-temporal statistics can be viewed using the animation of a single selected parameter. With adaptable value ranges, users can plot parameters of site metadata, statistical values and original data; the last one for a limited period only.
Figure 5.61 shows an example of metadata viewing page with selecting different data sources (or source groups), filtering data by station name or through a user spatial domain. Similarly, Fig. 5.62 shows the statistical results on a geographical map. Wheather a single station or a group of stations, an individual solution or a group of products, the time series can be plotted in the optional bottom panel when selecting a particular parameter. The time series can be zoomed in and the graph can be switched for plotting individual values or average (+dispersion) over all the values.

Web interactive visualization of station metadata with various tropospheric products

Web interactive visualization of statistics from troposphere parameter comparisons
5.8.1.3 GOP TropDB Online Service
The online service makes it possible for a user to calculate tropospheric, meteorological or other interesting parameters (e.g. mean temperature and its lapse rate, scale heights, vertical reduction rates) on request using 3D data from a historical NWM archive, currently the ERA-Interim reanalysis, but in the future possibly others too. The service can be used for calculating: (1) ZTD, ZWD and ZHD values at different positions (not limited to Earth’s surface), (2) mean temperature for converting ZWD to IWV, (3) tropospheric ties for space-geodetic inter-technique comparisons/combinations, or for other purposes.
Figure 5.63 shows the web form where a user may request up to 100 locations for which parameters are calculated with requested sampling. Although the ERA-Interim reanalysis contains data at 00, 06, 12 and 18 hours, any higher time resolution is supported by using spline interpolations. Currently, requests are ordered in a processing queue, and results files, each of which limited to 1 year in length are provided in TRO_SINEX v2.0 (Pacione and Douša 2017) or in a plain-text column format. The user can download the results from a temporary storage location after being informed by e-mail about the completed job.

Web service for user-specific calculation of tropospheric, meteorological and other parameters
5.8.2 Tropo SINEX Format
The effort to standardize the exchange format for tropospheric products has started in early 1997 by a number of IGS participants (Gendt 1997). In November 2010 [IGSMAIL-6298] SINEX_TRO format was slightly expanded to accommodate the addition of gradients. This expanded format has never been officially accepted and adopted. Due to the lack of the standardization, different software packages and organizations have started to use different field names referring to the same variables ad-hoc supporting optional and mandatory metadata, output files with different naming conventions and overall data contents. As a result, the format cannot be handled with a unique decoder.
According to further developments, new demands arose on the format for exchanging tropospheric parameters, in particular supporting:
-
(a)
Parameters from different sources than space geodetic techniques such as numerical weather prediction models and re-analyses, radiosondes and water vapour radiometers,
-
(b)
Long station names (9 characters) in concordance with RINEX 3 data format,
-
(c)
Products including slant tropospheric delays,
-
(d)
Parameters corresponding to long-term time series of individual stations.
This was the driver to develop a unique format to be adopted within all the IAG services and by all the techniques dealing with tropospheric parameters. However, because of difficulties in supporting all legacy and new features, it was decided to revise the format without keeping a full compatibility with any previous SINEX_TRO unofficial version. In this way new features, such as long station names or time series data support, could be introduced much easier while simplifying the format definition and usage.
The SINEX-TRO v2.00 format description is reported in Appendix D.
The SINEX-TRO v2.00 format has been officially presented at the IGS Workshop (July 3–7, 2017, 2017), at the Unified Analysis Workshop (July 10–12, 2017, Paris), at the EPN Analysis Centre Workshop (October, 25–26, 2017 Brussels).
Tropospheric zenith total delay and precipitable water vapour delivered in the framework of the NASA SESES– MEaSUREs project are in SINEX-TRO v2.00 format, (https://cddis.nasa.gov/Data_and_Derived_Products/GNSS/SESES_time_series_products.html).
Notes
- 1.
Parts from this section were previously published in Pacione et al. (2017).
- 2.
Parts from this section were previously published in Ahmed et al. (2014).
- 3.
Parts from this section were previously published in Stepnaik et al. (2017).
- 4.
Parts from this section were previously published in Bałdysz et al. (2016).
- 5.
- 6.
- 7.
Parts from this section were previously published in Pacione et al. (2017).
- 8.
Parts from this section were previously published in Forkman et al. (2017).
- 9.
- 10.
- 11.
Parts from this section were previously published in Ning et al. (2013).
- 12.
Parts from this section were previously published in Parracho (2017).
- 13.
Parts from this section were previously published in Mircheva et al. (2017).
References
Adams, D. K., Fernandes, R. M. S., & Maia, J. M. F. (2011). GNSS precipitable water vapour from an Amazonian rain forest flux tower. Journal of Atmospheric and Oceanic Technology, 28(10), 1192–1198. https://doi.org/10.1175/JTECH-D-11-00082.1.
Ahmed F., Teferle N., Bingley R., & Hunegnaw A. (2014). A comparative analysis of tropospheric delay estimates from network and precise point positioning processing strategies. Presented at IGS Workshop 2014, 23–27.06.2014, Pasadena, California, USA.
Alexandersson, H. (1986). A homogeneity test applied to precipitation data. Journal of Climatology, 6, 661–675.
Altamimi, Z., Rebisching, P., Metivier, L., & Collilieux, X. (2016). ITRF2014: A new release of the International Terrestrial Reference Frame modelling nonlinear station motions. Journal of Geophysical Research – Solid Earth, 121(8), 6109–6131. https://doi.org/10.1002/2016JB013098.
Antón, M., Loyola, D., Román, R., & Vömel, H. (2015). Validation of GOME-2/MetOp-A total water vapour column using reference radiosonde data from the GRUAN network. Atmospheric Measurement Techniques, 8, 1135–1145. https://doi.org/10.5194/amt-8-1135-2015
Araszkiewicz, A., & Voelksen, C. (2017). The impact of the antenna phase centre models on the coordinates in the EUREF Permanent Network. GPS Solutions, 21, 747–757. https://doi.org/10.1007/s10291-016-0564-7.
Askne, J., & Nordius, H. (1987). Estimation of tropospheric delay for microwaves from surface weather data. Radio Science, 22(3), 379–386. https://doi.org/10.1029/RS022i003p00379.
Bałdysz Z, Nykiel G, Araszkiewicz A, Figurski M, Szafranek K (2016) Comparison of GPS tropospheric delays derived from two consecutive EPN reprocessing campaigns from the point of view of climate monitoring. Atmospheric Measurement Techniques, 9(9), 4861–4877. https://doi.org/https://doi.org/10.5194/amt-9-4861-2016 (licensed under CC BY 3.0, https://creativecommons.org/licenses/by/3.0/).
Balidakis, K., Nilsson, T., Zus, F., Glaser, S., Heinkelmann, R., Deng, Z., & Schuh, H. (2018). Estimating integrated water vapour trends from VLBI, GPS and numerical weather models: sensitivity to tropospheric parameterization. Journal of Geophysical Research: Atmospheres, 123, 6356–6372. https://doi.org/10.1029/2017JD028049.
Barnston, A. G., & Livezey, R. E. (1987). Classification, seasonality and persistence of low-frequency atmospheric circulation patterns. Monthly Weather Review, 115(6), 1083–1126. https://doi.org/https://doi.org/10.1175/1520-0493(1987)115<1083:CSAPOL>2.0.CO;2
Bar-Sever, Y. E., Kroger, P. M., & Borjesson, J.A. (1998). Estimating Horizontal Gradients of Tropospheric Path Delay with a Single GPS Receiver. Journal of Geophysical Research, 103, 5019–5035.
Basili, P., Bonafoni, S., Ferrara, R., Ciotti, P., Fionda, E., & Arnbrosini, R. (2001). Atmospheric water vapour retrieval by means of both a GPS network and a microwave radiometer during an experimental campaign in Cagliari, Italy. In 1999, Geoscience and Remote Sensing, IEEE Transactions on, Vol. 39, No.11, pp. 2436–2443. https://doi.org/10.1109/36.964980
Beirle, S., Lampel, J., Wang, Y., Mies, K., Dörner, S., Grossi, M., Loyola, D., Dehn, A., Danielczok, A., Schröder, M., & Wagner, T. (2018). The ESA GOME-Evolution “Climate” water vapor product: a homogenized time series of H2O columns from GOME, SCIAMACHY, and GOME-2. Earth System Science Data, 10, 449–468. https://doi.org/10.5194/essd-10-449-2018.
Bennouna, Y. S., Torres, B., Cachorro, V. E., Ortiz de Galisteo, J. P., & Toledano, C. (2013). The evaluation of the integrated water vapour annual cycle over the Iberian Peninsula from EOS-MODIS against different ground-based techniques. Quarterly Journal of the Royal Meteorological Society, 139, 1935–1956. https://doi.org/10.1002/qj.2080.
Berckmans, J., Giot, O., De Troch, R., Hamdi, R., Ceulemans, R., & Termonia, P. (2017). Reinitialised versus continuous regional climate simulations using ALARO-0 coupled to the land surface model SURFEXv5. Geoscientific Model Development, 10, 223–238.
Berg, H. (1948). Allgemeine meteorologie. Bonn: Dümmler’s Verlag.
Bevis, M., Businger, S., Herring, T. A., Rocken, C., Anthes, R. A., & Ware, R. H. (1992). GPS meteorology: remote sensing of atmospheric water vapour using the global positioning system. Journal of Geophysical Research, 97(D14), 15787–15801.
Bevis, M., Businger, S., Chiswell, S., Herring, T. A., Anthes, R. A., Rocken, C., & Ware, R. H.(1994). GPS meteorology: Mapping Zenith wet delays onto precipitable water. Journal of Applied Meterology, 33(3), 379–386. https://doi.org/https://doi.org/10.1175/1520−0450(1994)033<0379:GMMZWD>2.0.CO;2
Bock, O. (2015, May) ZTD assessment and screening. COST ES1206 GNSS4SWEC Workshop, Thessaloniki, Greece, 11–13 May 2015.
Bock, O. (2016a). A reference IWV dataset combining IGS repro1 and ERA-Interim reanalysis for the assessment of homogenization algorithms. 3rd COST ES1206 Workshop, 8–11 March 2016, Reykjavik, Island.
Bock, O. (2016b). Post-processing of GNSS ZTD, COST ES1206 GNSS4SWEC Summer School, 29–31 August 2016, GFZ, Potsdam, Germany. Available at: ftp://ftp.gfz-potsdam.de/pub/GNSS/workshops/gnss4swec/Summer_School/D2/3_Bock_PostProc.pdf
Bock, O. (2016c). Conversion of GNSS ZTD to IWV, COST ES1206 GNSS4SWEC Summer School, 29–31 August 2016, GFZ, Potsdam, Germany. Available at: ftp.gfz-potsdam.de/pub/GNSS/workshops/gnss4swec/Summer_School/D3/2_Bock_Homogenization.pdf
Bock, O. (2016d). Screening and validation of new reprocessed GNSS IWV data in Arctic region, COST ES1206 GNSS4SWEC Workshop, Potsdam, Germany, 31 August–2 September 2016.
Bock O., & Pacione, R. (2014). ZTD to IWV conversion, COST action ES1206 – GNSS4SWEC. 2nd WG meeting, Varna, Bulgaria, 11–12 September, 2014.
Bock, O., Bouin, M.-N., Walpersdorf, A., Lafore, J. P., Janicot, S., Guichard, F., & Agusti-Panareda, A. (2007). Comparison of ground-based GPS precipitable water vapour to independent observations and NWP model reanalyses over Africa. Quarterly Journal of the Royal Meteorological Society, 133, 2011–2027. https://doi.org/10.1002/qj.185.
Bock, O., P. Willis, M. Lacarra, & P. Bosser (2010) An inter-comparison of zenith tropospheric delays derived from DORIS and GPS data, Advances in Space Research, 46(12), 1648–1660. https://doi.org/10.1016/j.asr.2010.05.018
Bock, O., Willis, P., Wang, J., & Mears, C. (2014). A high-quality, homogenized, global, long-term (1993-2008) DORIS precipitable water dataset for climate monitoring and model verification. Journal of Gephysics Research Atmosphere, 119(12), 7209–7230. https://doi.org/10.1002/2013JD021124.
Bock O., & Parracho, A. C. (2019) Consistency and representativeness of integrated water vapour from ground-based GPS observations and ERA-Interim reanalysis, Atmos. Chem. Phys. Discuss., https://doi.org/10.5194/acp-2019-28
Bodeker, G. E., Bojinski, S., Cimini, D., Dirksen, R. J., Haeffelin, M., Hannigan, J. W., Hurst, D. F., Leblanc, T., Madonna, F., Maturilli, M., Mikalsen, A. C., Philipona, R., Reale, T., Seidel, D. J., Tan, D. G. H., Thorne, P. W., Vömel, H., and Wang, J. (2016) Reference upper-air observations for climate: From concept to reality, Amer Meteorological Society, 123–135. https://doi.org/10.1175/BAMSD-14-00072.1
Boehm, J., & Schuh, H. (2007). Troposphere gradients from the ECMWF in VLBI analysis. Journal of Geodesy, 81, 403–408. https://doi.org/10.1007/s00190-0144-2.
Boehm, J., Niell, A., Tregoning, P., & Schuh, H. (2006a). Global Mapping Function (GMF): A new empirical mapping function based on numerical weather model data. Geophysical Research Letters, 33, L07304. https://doi.org/10.1029/2005GL025546.
Boehm, J., Werl, B., & Schuh, H. (2006b). Troposphere mapping functions for GPS and very long baseline interferometry from European Centre for Medium-Range Weather Forecasts operational analysis data. Journal of Geophysical Research, 111, B02406. https://doi.org/10.1029/2005JB003629.
Boehm, J., Heinkelmann, R., & Schuh, H. (2007). Short Note: A global model of pressure and temperature for geodetic applications. Journal of Geodesy, 81(10), 679–683. https://doi.org/10.1007/s00190-007-0135-3.
Böhm, J., Möller, G., Schindelegger, M., Pain, G., & Weber, R. (2015). Development of an improved empirical model for slant delays in the troposphere (GPT2w). GPS Solutions, 3, 433–441.
Bos, M. S., Fernandes, R. M. S., Williams, S. D. P., & Bastos, L. (2013). Fast Error Analysis of Continuous GNSS Observations with Missing Data. Journal of Geodesy, 87(4), 351–360. https://doi.org/10.1007/s00190-012-0605-0.
Bosser, P., & Bock, O. (2016). Screening of GPS ZTD estimates. 3rd COST ES1206 Workshop, 8–11.03.2016, Reykjavik, Island.
Brown, R. A. (1970). A secondary flow model for the planetary boundary layer. Journal of the Atmospheric Sciences, 27, 742–757.
Bruyninx, C. H., Habrich, W., Söhne, A., Kenyeres, G., & Stangl, V. C. (2012). Enhancement of the EUREF Permanent Network Services and Products. Geodesy for Planet Earth, IAG Symposia Series, Vol. 136, pp. 27–35. https://doi.org/10.1007/978-3-642-20338-1_4.
Buehler, S. A., Östman, S., Melsheimer, C., Holl, G., Eliasson, S., John, V. O., Blumenstock, T., Hase, F., Elgered, G., Raffalski, U., Nasuno, T., Satoh, M., Milz, M., & Mendrok, J. (2012). A multi-instrument comparison of integrated water vapour measurements at a high latitude site. Atmospheric Chemistry and Physics, 12, 10925–10943. https://doi.org/10.5194/acp-12-10925-2012.
Byram S., Hackman C., & Tracey J. (2011). Computation of a high-precision GPS-based troposphere product by the USNO. In Proceedings of ION GNSS.
Byun, S. H., & Bar-Sever, Y. E. (2009). A new type of troposphere zenith path delay product of the International GNSS Service. Journal of Geodesy, 83(3–4), 1–7.
Calori, A., Santos, J. R., Blanco, M., Pessano, H., Llamedo, P., Alexander, P., & de la Torre, A. (2016). Ground-based GNSS network and integrated water vapour mapping during the development of severe storms at the Cuyo region (Argentina). Atmospheric Research, 176–177, 267–275. https://doi.org/10.1016/j.atmosres.2016.03.002.
Campanelli, M., Mascitelli, A., Sanò, P., Diémoz, H., Estellés, V., Federico, S., Iannarelli, A. M., Fratarcangeli, F., Mazzoni, A., Realini, E., Crespi, M., Bock, O., Martìnez-Lozano, J. A., & Dietrich, S. (2017). Precipitable water vapour content from ESR/SKYNET Sun-sky radiometers: Validation against GNSS/GPS and AERONET over three different sites in Europe. Atmospheric Measurement Techniques Discussions, 1–27. https://doi.org/10.5194/amt-2017-221,. in review.
Caussinus, H., & Mestre, O. (2004). Detection and correction of artificial shifts in climate series. Journal of the Royal Statistical Society, Series C, 53, 405–425.
Chen, G., & Herring, T. A. (1997). Effects of atmospheric azimuthal asymmetry on the analysis of space geodetic data. Journal of Geophysical Research, 102, 20489–20502. https://doi.org/10.1029/97JB01739.
Dach, R., Böhm, J., Lutz, S., Steigenberger, P., & Beutler, G. (2010). Evaluation of the impact of atmospheric pressure loading modelling on GNSS data analysis. Journal of Geodesy, 85, 75–91. https://doi.org/10.1007/s00190-010-0417-z.
Dach, R., Lutz, S., Walser, P., & Fridez, P. (2015). User manual of the Bernese GNSS Software, Version 5.2. University of Bern, Bern Open Publishing. https://doi.org/10.7892/boris.72297.
Davis, J. L., Herring, T. A., Shapiro, I. I., Rogers, A. E., & Elgered, G. (1985). Geodesy by radio interferometry: Effects of atmospheric modelling errors on estimates of baseline length. Radio Science, 20, 1593–1607.
Deblonde, G., Macpherson, S., Mireault, Y., & Heroux, P. (2005). Evaluation of GPS precipitable water over Canada and the IGS network. Journal of Applied Meteorology, 44, 153–166. https://doi.org/10.1175/JAM-2201.1
Dee, D. P., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, P., & Bechtold, P. (2011). The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Quarterly Journal of the Royal Meteorological Society, 137(656), 553–597. https://doi.org/10.1002/qj.828.
Douša, J., & Győri, G. (2013). Database for tropospheric product evaluations – implementation aspects. Geoinformatics, 10, 39–52.
Douša, J., Byram, S., Győri, G., Böhm, O., Hackman, C., & Zus, F.. (2014). Development towards inter-technique troposphere parameter comparisons and their exploitation. 2014 IGS Workshop, Pasadena, CA.
Douša, J., Böhm, O., Byram, S., Hackman, C., Deng, Z., Zus, F., Dach, R., & Steigenberger, P. (2016). Evaluation of GNSS reprocessing tropospheric products using GOP-TropDB. Presentation at IGS Workshop 2016, Sydney, March 8–10.
Douša, J., Heikelmann, R., & Balidakis, K. (2017a). Tropospheric ties for inter-technique comparisons and combinations, Presentation at IAG – IASPE, July 30 – August 4, 2017. Japan: Kobe.
Douša, J., Václavovic, P., & Elias, M. (2017b). Tropospheric products of the second GOP European GNSS reprocessing (1996–2014). Atmospheric Measurement Techniques, 10, 3589–3607. https://doi.org/10.5194/amt-10-3589-2017 (licensed under CC BY 3.0, https://creativecommons.org/licenses/by/3.0/).
Duan, J., Bevis, M., Fang, P., Bock, Y., Chiswell, S., Businger, S., Rocken, C., Solheim, F., van Hove, T., Ware, R., McClusky, S., Herring, T. A., & King, R. W. (1996). GPS meteorology: Direct estimation of the absolute value of precipitable water. Journal of Applied Meteorology, 35(6), 830–838. https://doi.org/https://doi.org/10.1175/1520-0450(1996)035<0830:GMDEOT>2.0.CO;2.
Eliaš, M., Douša, J., & Jarušková, D. (2019). An assessment of method for change-point detection applied in tropospheric parameter time series given from numerical weather model (submitted to Acta Geodyn Geomater).
Forkman, P., Elgered, G., & Ning, T. (2017). Accuracy assessment of the two WVRs, Astrid and Konrad, at the Onsala Space Observatory. In Proceedings of the 23rd European VLBI Group for Geodesy and Astrometry Working Meeting, Chalmers University of Technology, Gothenburg, Sweden (pp. 65–69).
Foster, J., Bevis, M., & Raymond, W. (2006). Precipitable water and the lognormal distribution. Journal of Geophysical Research, 111, D15102. https://doi.org/10.1029/2005JD006731.
Gazeaux, J., et al. (2013). Detecting offsets in GPS time series: First results from the detection of offsets in GPS experiment. Journal of Geophysical Research – Solid Earth, 118, 2397–2407. https://doi.org/10.1002/jgrb.50152.
GCOS-112. (2007, April). GCOS Reference Upper-Air Network (GRUAN): Justification, requirements, siting and instrumentation options. April 2007. WMO Tech. Doc. No. 1379, WMO.
GCOS-171. (2013, March). The GCOS Reference Upper-Air Network (GRUAN) GUIDE. GCOS-171, Version 1.1.0.3, March 2013, WIGOS Technical Report No. 2013–03.
Gelaro, R., McCarty, W., Suárez, M. J., Todling, R., Molod, A., Takacs, L., Randles, C. A., Darmenov, A., Bosilovich, M. G., Reichle, R., & Wargan, K. (2017). The modern-era retrospective analysis for research and applications, version 2 (MERRA-2). Journal of Climate, 30(14), 5419–5454. https://doi.org/10.1175/JCLI-D-16-0758.1.
Gendt, G. (1997). SINEX TRO – solution (Software/technique) independent exchange format for combination of TROpospheric estimates Version 0.01, 1 March 1997. Available at: https://igscb.jpl.nasa.gov/igscb/data/format/sinex_tropo.txt. (Last access 29 April 2017).
Gobinddass, M. L., Willis, P., Sibthorpe, A., Zelensky, N. P., Lemoine, F. G., Ries, J. C., Ferland, R., Bar-Sever, Y. E., de Viron, O., & Diament, M. (2009). Improving DORIS geocenter time series using an empirical rescaling of solar radiation pressure models. Advances in Space Research, 44(11), 1279–1287. https://doi.org/10.1016/j.asr.2009.08.004.
Gobinddass, M. L., Willis, P., Menvielle, M., & Diament, M. (2010). Refining DORIS atmospheric drag estimation in preparation of ITRF2008. Advances in Space Research, 46(12), 1566–1577. https://doi.org/10.1016/j.asr.2010.04.004.
Gruber C., Auer I., & Böhm R. (2009). Endberichte HOM-OP Austria Aufbau und Installierung eines Tools zur operationellen Homogenisierung von Klimadaten mit 3 Annexen.
Guerova, G., Jones, J., Douša, J., Dick, G., de Haan, S., Pottiaux, E., Bock, O., Pacione, R., Elgered, G., Vedel, H., & Bender, M. (2016). Review of the state of the art and future prospects of the ground-based GNSS meteorology in Europe. Atmospheric Measurement Techniques, 9, 5385–5406. https://doi.org/10.5194/amt-9-5385-2016.
Győri, G., & Douša, J. (2016). GOP-TropDB developments for tropospheric product evaluation and monitoring – Design, functionality and initial results. IAG Symposia Series, Springer, 143, 595–602.
Haase, J., Ge, M., Vedel, H., & Calais, E. (2003). Accuracy and variability of GPS tropospheric delay measurements of water vapour in the Western Mediterranean. Journal of Applied Meteorology, 42(11), 1547–1568.
Hagemann, S., Bengtsson, L., & Gendt, G. (2003). On the determination of atmospheric water vapour from GPS measurements. Journal of Geophysical Research, 108(D21), 4678. https://doi.org/10.1029/2002JD003235.
Hamed, K. H., & Rao, A. R. (1998). A modified Mann-Kendall trend test for autocorrelated data. Journal of Hydrology, 204(1–4), 182–196. https://doi.org/10.1016/S0022-1694(97)00125-X.
Hasegawa, S., & Stokesberry, D. (1975). Automatic digital microwave hygrometer. The Review of Scientific Instruments, 46, 867–873. https://doi.org/10.1063/1.1134331.
Healy, S. B. (2011). Refractivity coefficients used in the assimilation of GPS radio occultation measurements. Journal of Geophysical Research, 116, D01106. https://doi.org/10.1029/2010JD014013.
Heinkelmann, R., Willis, P., Deng, Z., Dick, G., Nilsson, T., Soja, B., Zus, F., Wickert, J., & Schuh, H. (2016). The effect of the temporal resolution of atmospheric gradients on atmospheric parameters. Advances in Space Research, 58(12), 2758–2773. https://doi.org/10.1016/j.asr.2016.09.023.
Heise, S., Bender, M., Beyerle, G., Dick, G., Gendt, G., Schmidt, T., & Wickert, J. (2009). Integrated water vapor from IGS ground-based GPS observations: Initial results from a global 5-minute data set. (Geophysical Research Abstracts, Vol. 11, EGU2009-5330), General Assembly European Geosciences Union (Vienna, Austria 2009).
Hourdin, F., Musat, I., Bony, S., Braconnot, P., Codron, F., Dufresne, J. L., et al. (2006). The LMDZ4 general circulation model: Climate performance and sensitivity to parametrized physics with emphasis on tropical convection. Climate Dynamics, 27(7–8), 787–813.
Hourdin, F., Foujols, M. A., Codron, F., Guemas, V., Dufresne, J. L., Bony, S., et al. (2013a). Impact of the LMDZ atmospheric grid configuration on the climate and sensitivity of the IPSL-CM5A coupled model. Climate Dynamics, 40(9–10), 2167–2192.
Hourdin, F., Grandpeix, J. Y., Rio, C., Bony, S., Jam, A., Cheruy, F., et al. (2013b). LMDZ5B: The atmospheric component of the IPSL climate model with revisited parameterizations for clouds and convection. Climate Dynamics, 40(9–10), 2193–2222.
ICAO. (1993). Manual of the ICAO standard atmosphere, Doc 7488/3 (3rd ed.). International Civil Aviation Organisation, Montreal.
IGSMAIL-6298, Reprocessed IGS Trop Product now available with Gradients. (2012, November 11). http://igscb.jpl.nasa.gov/pipermail/igsmail/2010/007488.html
Ingleby, N. B. (1995). Assimilation of station level pressure and errors in station height. Weather and Forecasting 10: 172-182.
Jaruskova, D. (1997). Some problems with application of change-point detection methods to environmental data. Environmetrics, 8(5), 469–483.
Järvinen, J. and Undén, P. (1997) Observation screening and background quality control in the ECMWF 3D Var data assimilation system. Technical memorandum of the European Centre for Medium-Range Weather Forecasts, 1997, Vol. 236.
Jeong, J.-H., Walther, A., Nikulin, G., Chen, D., & Jones, C. (2011). Diurnal cycle of precipitation amount and frequency in Sweden: Observation versus model simulation. Tellus A, 63, 664–674. https://doi.org/10.1111/j.1600-0870.2011.00517.x.
Jiang, J. H., Su, H., Zhai, C., Perun, V. S., Del Genio, A., Nazarenko, L. S., et al. (2012). Evaluation of cloud and water vapour simulations in CMIP5 climate models using NASA “A-Train” satellite observations. Journal of Geophysical Research: Atmospheres, 117(D14).
Joshi, S., Kumar, K., Pande, B., & Pant, M. C. (2013). GPS-derived precipitable water vapour and its comparison with MODIS data for Almora, Central Himalaya, India. Meteorology and Atmospheric Physics, 120, 177–187. https://doi.org/10.1007/s00703-013-0242-z.
Kalakoski, N., Kujanpää, J., Sofieva, V., Tamminen, J., Grossi, M., & Valks, P. (2016). Validation of GOME-2/Metop total column water vapour with ground-based and in situ measurements. Atmospheric Measurement Techniques, 9, 1533–1544. https://doi.org/10.5194/amt-9-1533-2016.
Kestin, J., Sengers, J. V., Kamgar-Parsi, B., & Sengers, J. L. (1984). Thermophysical properties of fluid H2O. Journal of Physical and Chemical Reference Data, 13(1), 175–183.
King, R. W., & Bock, Y. (2005). Documentation for the GAMIT GPS processing software release 10.2. Massachusetts Institute of Technology, Cambridge.
King, R., Herring, T., & Mccluscy, S. (2010). Documentation for the GAMIT GPS analysis software 10.4. Technical Report. Massachusetts Institute of Technology, Cambridge, MA, USA.
Klos, A., Bogusz, J., Figurski, M., & Kosek, W.. (2015) On the handling of outliers in the GNSS time series by means of the noise and probability analysis. In C. Rizos, & P. Willis (Eds.), IAG 150 Years. International Association of Geodesy Symposia (Vol. 143). Cham: Springer.
Kouba J (2003) A guide to using International GPS Service (IGS) products. Pasadena: IGS Central Bureau (available at http://igscb.jpl.nasa.gov/igscb/resource/pubs/GuidetoUsingIGSProducts.pdf)
Kwon, H-. T., Iwabuchi, T., & Lim, G. –H. (2007). Comparison of precipitable water derived from ground-based GPS measurements with radiosonde observations over the Korean Peninsula. Journal of the Meteorological Society of Japan Series II, 85(6), 733–746.
Lagler, K., Schindelegger, M., Böhm, J., Krásná, H., & Nilsson, T. (2013). GPT2: Empirical slant delay model for radio space geodetic techniques. Geophysical Research Letters, 40, 1069–1073. https://doi.org/10.1002/grl.50288.
Lanzante, J. (1996). Resistant, robust and non-parametric techniques for the analysis of climate data: Theory and examples, including applications to historical radiosonde station data. International Journal of Climatology, 16, 1197–1226.
Leduc, D. J. (1987). A comparative analysis of the reduced major axis technique of fitting lines to bivariate data. Canadian Journal of Forest Research, 17, 654–659.
Li, X., Zus, F., Lu, C., Ning, T., Dick, G., Ge, M., Wickert, J., & Schuh, H. (2015). Retrieving high-resolution tropospheric gradients from multiconstellation GNSS observations. Geophysical Research Letters, 42(10), 4173–4181.
Liu, H., Shah, S., & Jiang, W. (2004). On-line outlier detection and data cleaning. Computers and Chemical Engineering, 28(9), 1635–1647. https://doi.org/10.1016/j.compchemeng.2004.01.009.
Martínez, M. A., & Calbet, X. (2016). Algorithm theoretical basis document for the clear air products processor of the NWC/GEO. [online] Available from: http://www.nwcsaf.org/AemetWebContents/ScientificDocumentation/Documentation/GEO/v2016/NWC-CDOP2-GEO-AEMET-SCI-ATBD-ClearAir_v1.1.pdf
Meindl, M., Schaer, S., Hugentobler, U., & Beutler, G. (2004). Tropospheric gradient estimation at CODE: Results from global solutions. Journal of the Meteorological Society of Japan, 82, 331–338.
Mestre, O., Gruber, C., Prieur, C., Caussinus, H., & Jourdain, S. (2011). SPLIDHOM: A method for homogenization of daily temperature observations. Journal of Applied Meteorology and Climatology, 50, 2343–2358.
Mieruch, S., Schröder, M., Noël, S., & Schulz, J. (2014). Comparison of decadal global water vapour changes derived from independent satellite time series. Journal of Geophysical Research – Atmospheres, 119(22), 12489–12499. https://doi.org/10.1002/2014JD021588.
Miller, M. A., & Slingo, A. (2007). The arm mobile facility and its first international deployment: Measuring radiative flux divergence in West Africa. Bulletin of the American Meteorological Society, 88, 1229–1244. https://doi.org/10.1175/BAMS-88-8-1229.
Mircheva, B., Tsekov, M., Meyer, U., & Guerova, G. (2017). Anomalies of hydrological cycle components during the 2007 heat wave in Bulgaria. Journal of Atmospheric and Solar-Terrestrial Physics, 165-166, 1–9. https://doi.org/10.1016/j.jastp.2017.10.005.
Morel, L., Pottiaux, E., Durand, F., Fund, F., Follin, J. M., Durand, S., Bonifac, K., Oliveira, P. S., van Baelen, J., Montibert, C., Cavallo, T., Escaffit, R., & Fragnol, L. (2015). Global validity and behaviour of tropospheric gradients estimated by GPS. Presentation at the 2nd GNSS4SWEC Workshop held in Thessaloniki, Greece, May 11–14.
Morland, J., Liniger, M. A., Kunz, H., Balin, I., Nyeki, S., Mätzler, C., & Kämpfer, N. (2006). Comparison of GPS and ERA40 IWV in the Alpine region, including correction of GPS observations at Jungfraujoch (3584 m). Journal of Geophysical Research, 111, D04102. https://doi.org/10.1029/2005JD006043.
Munn, R. E. (1966). Descriptive micrometeorology. New York: Academic Press.
Nahmani, S., & Bock, O. (2014). Sensitivity of GPS measurements and estimates during extreme meteorological events: The issue of stochastic constraints used for ZWD estimation in West Africa. Joint ES1206 MC and MC meeting, Golden Sands Resort, 11/09/2014 to 12/09/2014, Varna, Bulgaria.
Nahmani, S., Rebischung, P., & Bock, O. (2016). Statistical modelling of ZWD in GNSS processing. 3rd ES1206 Workshop, Rugbrauðsgerdin, 08-03-2016 to 10-03-2016, Reykjavik, Iceland.
Nahmani, S., Rebischung, P., & Bock, O. (2017). Bayesian approach to apply optimal constraints on tropospheric parameters in GNSS data processing: Implications for meteorology. ES1206 Final Workshop, ESTEC, 2017-02-21 to 2017-02-23. Noordwijk, Netherlands.
Niell, A. E. (1996) Global mapping functions for the atmospheric delay at radio wavelengths, Journal of Geophysical Research, 101(B2), doi: https://doi.org/10.1029/95JB03048, 1996, pp 3227–3246.
Niell, A. E. (2000). Improved atmospheric mapping functions for VLBI and GPS. Earth Planet Sp, 52, 699–702. https://doi.org/10.1186/BF03352267.
Nilsson, T., Soja, B., Karbon, M., Heinkelmann, R., & Schuh, H. (2015). Application of Kalman filtering in VLBI data analysis. Earth, Planets and Space, 67(136), 1–9. https://doi.org/10.1186/s40623-015-0307-y.
Ning, T., & Elgered, G. (2012). Trends in the atmospheric water vapour content from ground-based GPS: the impact of the elevation cutoff angle. IEEE J-STARS, 5(3), 744–751. https://doi.org/10.1109/JSTARS.2012.2191392.
Ning, T., Elgered, G., & Johansson, J. (2011). The impact of microwave absorber and radome geometries on GNSS measurements of station coordinates and atmospheric water vapour. Advances in Space Research, 47, 186–196.
Ning, T., Haas, R., Elgered, G., & Willén, U. (2012). Multi-technique comparisons of 10 years of wet delay estimates on the west coast of Sweden. Journal of Geodesy, 86, 565–575. https://doi.org/10.1007/s00190-011-0527-2.
Ning, T., Elgered, G., Willén, U., & Johansson, J. M. (2013). Evaluation of the atmospheric water vapour content in a regional climate model using ground-based GPS measurements. Journal of Geophysical Research, 118, 1–11. https://doi.org/10.1029/2012JD018053.
Ning, T., Wang, J., Elgered, G., Dick, G., Wickert, J., Bradke, M., Sommer, M., Querel, R., and Smale, D. (2016a) The uncertainty of the atmospheric integrated water vapour estimated from GNSS observations, Atmospheric Measurement Techniques, 9, 79–92, doi:https://doi.org/10.5194/amt-9-79-2016 (licensed under CC BY 3.0, https://creativecommons.org/licenses/by/3.0/).
Ning, T., Wickert, J., Deng, Z., Heise, S., Dick, G., Vey, S., & Schöne, T. (2016b). Homogenized Time Series of the Atmospheric Water Vapour Content Obtained from the GNSS Reprocessed Data. Journal of Climate, 29, 2443–2456. https://doi.org/10.1175/JCLI-D-15-0158.1.
Ning, T., Elgered, G., & Heise, S. (2017). Trends in the atmospheric water vapour estimated from two decades of ground-based GPS data: Sensitivity to the elevation cutoff angle. In Proceedings of 6th international colloquium scientific and fundamental aspects of the Galileo programme, Valencia, Spain, 25–27 October 2017.
Ningombam, S. S., Jade, S., Shrungeshwara, T. S., & Song, H.-J. (2016). Validation of water vapour retrieval from Moderate Resolution Imaging Spectro-radiometer (MODIS) in near infrared channels using GPS data over IAO-Hanle, in the trans-Himalayan region. Journal of Atmospheric and Solar-Terrestrial Physics, 137, 76–85,. ISSN 1364-6826. https://doi.org/10.1016/j.jastp.2015.11.019.
Nyeki, S., Vuilleumier, L., Morland, J., Bokoye, A., Viatte, P., Mätzler, C., & Kämpfer, N. (2005). A 10-year integrated atmospheric water vapour record using precision filter radiometers at two high-alpine sites. Geophysical Research Letters, 32, L23803. https://doi.org/10.1029/2005GL024079.
Ohtani, R., & Naito, I. (2000). Comparisons of GPS-derived precipitable water vapors with radiosonde observations in Japan. Journal of Geophysical Research, 105(D22), 26917–26929. https://doi.org/10.1029/2000JD900362.
Owens, J. C. (1967). Optical Refractive Index of Air: Dependence on Pressure, Temperature and Composition. Applied Optics, 6(1), 51–59.
Pacione R., & Douša J. (2017). SINEX-TRO V2.00 format description, COST Action 1206 Final Report, J. Jones et al eds.
Pacione, R., Pace, B., de Haan, S., Vedel, H., Lanotte, R., & Vespe, F. (2011). Combination methods of tropospheric time series. Advances in Space Research, 47, 323–335. https://doi.org/10.1016/j.asr.2010.07.021.
Pacione, R., Pace, B., & Bianco, G.. (2014a). Homogeneously reprocessed ZTD long-term time series over Europe, EGU GA 2014. http://meetingorganizer.copernicus.org/EGU2014/EGU2014-2945.pdf
Pacione, R., O. Bock, & Douša, J. (2014b). GNSS atmospheric water vapor retrieval methods. COST Action ES1206 – GNSS4SWEC, 1st Workshop, Munich, 26–28 February 2014.
Pacione, R., Araszkiewicz, A., Brockmann E., & Douša J. (2017). EPN-Repro2: a reference tropospheric data set over Europe, Atmospheric Measurement Techniques, 10, 1689–1705, https://doi.org/10.5194/amt-10-1689-2017 (licensed under CC BY 3.0, https://creativecommons.org/licenses/by/3.0/)..
Parracho, A. (2017). Study of trends and variability of atmospheric integrated water vapour with climate models and observations from global GNSS network. PhD report from Université Pierre et Marie Curie, Paris, France.
Parracho, A. C., Bock, O., & Bastin, S. (2018). Global IWV trends and variability in atmospheric reanalyses and GPS observations, Atmospheric Chemistry and Physics Discussions. https://doi.org/10.5194/acp-2018-137, in review (licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/).
Pérez-Ramírez, D., Whiteman, D. N., Smirnov, A., Lyamani, H., Holben, B. N., Pinker, R., Andrade, M., & Alados-Arboledas, L. (2014). Evaluation of AERONET precipitable water vapour versus microwave radiometry, GPS, and radiosondes at ARM sites. Journal of Geophysical Research – Atmospheres, 119, 9596–9613. https://doi.org/10.1002/2014JD021730.
Petit, G., & Luzum, B. (2010). IERS Conventions, 2010. IERS Technical Note No. 36. Frankfurt am Main: Verlag des Bundesamts für Kartographie und Geodäsie, ISBN 3-89888-989-6.
Pettitt, A. N. (1979). A nonparametric approach to the change-point problem. Applied Statistics, 28, 126–135. https://doi.org/10.2307/2346729.
Pierce, D. W., Barnett, T. P., AchutaRao, K. M., Gleckler, P. J., Gregory, J. M., & Washington, W. M. (2006). Anthropogenic warming of the oceans: Observations and model results. Journal of Climate, 19(10), 1873–1900.
Prasad, A. K., & Singh, R. P. (2009). Validation of MODIS Terra, AIRS, NCEP/DOE AMIP-II Reanalysis-2, and AERONET Sun photometer derived integrated precipitable water vapour using ground-based GPS receivers over India. Journal of Geophysical Research, 114, D05107. https://doi.org/10.1029/2008JD011230.
Román, R., Antón, M., Cachorro, V. E., Loyola, D., Ortiz de Galisteo, J. P., de Frutos, A., & Romero-Campos, P. M. (2015). Comparison of total water vapour column from GOME-2 on MetOp-A against ground-based GPS measurements at the Iberian Peninsula. Science of the Total Environment, 533, 317–328,. ISSN 0048-9697. https://doi.org/10.1016/j.scitotenv.2015.06.124.
Rüeger, J. (2002) Refractive index formulae for electronic distance measurements with radio and millimetre waves. Unisurv Rep. 109, pp. 758–766, Univerity of New South Wales, Sydney, Australia.
Saastamoinen, J. (1972). Atmospheric correction for the troposphere and stratosphere in radio ranging of satellites. The use of artificial satellites for geodesy, American Geophysics Union. Geophysics Monograph Series, 15, 274–251.
Schmid, R., Dach, R., Collilieux, X., Jäggi, A., Schmitz, M., & Dilssner, F. (2016). Absolute IGS antenna phase center model igs08.atx: status and potential improvements. Journal of Geodesy, 90, 343–364. https://doi.org/10.1007/s00190-015-0876-3.
Schneider, M., Romero, P. M., Hase, F., Blumenstock, T., Cuevas, E., & Ramos, R. (2010). Continuous quality assessment of atmospheric water vapour measurement techniques: FTIR, Cimel, MFRSR, GPS, and Vaisala RS92. Atmospheric Measurement Techniques, 3, 323–338. https://doi.org/10.5194/amt-3-323-2010.
Schröder, M., Lockhoff, M., Forsythe, J. M., Cronk, H. Q., Vonder Haar, T. H., & Bennartz, R. (2016). The GEWEX water vapour assessment: Results from intercomparison, trend, and homogeneity analysis of total column water vapour. Journal of Applied Meteorology and Climatology, 55, 1633–1649. https://doi.org/10.1175/JAMC-D-15-0304.1.
Selle, C. & Desai, S. (2016). Optimization of tropospheric delay estimation parameters by comparison of GPS-based precipitable water vapour estimates with microwave radiometer measurements. IGS Workshop 2016, 8–12 February 2016, Sydney, NSW, Australia.
Sen, P. K. (1968). Estimates of the regression coefficient based on Kendall’s tau. Journal of the American Statistical Association, 63(324), 1379–1389,. JSTOR 2285891, MR 0258201. https://doi.org/10.2307/2285891.
Smith, E., & Weintraub, S. (1953). The constants in the equation for atmospheric refractive index at radio frequencies. Proceedings of the IRE, 41, 1035–1037.
Soden, B. J., Jackson, D. L., Ramaswamy, V., Schwarzkopf, M. D., & Huang, X. (2005). The radiative signature of upper tropospheric moistening. Science, 310(5749), 841–844.
Sohn, D.-H., Park, K.-D., Won, J., Cho, J., & Roh, K.-M. (2012). Comparison of the characteristics of precipitable water vapour measured by Global Positioning System and microwave radiometer. Journal of Astronomy Space Science, 29, 1–10. https://doi.org/10.5140/JASS.2012.29.1.001.
Steigenberger, P., Boehm, J., & Tesmer, V. (2009). Comparison of GMF/GPT with VMF1/ECMWF and Implications for Atmospheric Loading. Journal of Geodesy, 83, 943–951. https://doi.org/10.1007/s00190-009-0311-8.
Steigenberger, P., Lutz, S., Dach, R., Schaer, S., & Jäggi, A. (2014). CODE repro2 product series for the IGS. Published by Astronomical Institute, University of Bern. URL: http://www.aiub.unibe.ch/download/REPRO_2013; https://doi.org/10.7892/boris.75680.
Stepniak, K., Bock, O., & Wielgosz, P. (2015). Assessment of ZTD screening methods and analysis of water vapour variability over Poland. 2nd COST GNSS4SWEC Workshop, Thessaloniki, Greece, 11–14 May 2015.
Stepniak, K., Bock, O., & Wielgosz, P. (2016). Improved methods for reprocessing of GNSS data for climate monitoring over Poland. Presented at 3rd ES1206 Workshop, 8–11.03.2016, Reykjavik, Iceland.
Stepniak, K., Bock, O., & Wielgosz, P. (2017). Reduction of ZTD outliers through improved GNSS data processing and screening strategies. Atmospheric Measurement Techniques Discussions. https://doi.org/10.5194/amt-2017-371, 2017 (licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/).
Thayer, G. (1974). An improved equation for the refractive index of air. Radio Science, 9(10), 803–807. https://doi.org/10.1029/RS009i010p00803.
Theil, H. (1950). A rank-invariant method of linear and polynomial regression analysis, I, II, III, Nederl. Akad Wetensch Proceedings, 53, 386–392, 521–525, 1397–1412, MR 0036489. https://doi.org/10.1007/978-94-011-2546-8_20.
Thorne, P. W., & Vose, R. S. (2010). Reanalyses suitable for characterizing long-term trends: Are they really achievable? Bulletin of the American Meteorological Society, 91(3), 353–361.
Torres, B., Cachorro, V. E., Toledano, C., Ortiz de Galisteo, J. P., Berjón, A., de Frutos, A. M., Bennouna, Y., & Laulainen, N. (2010). Precipitable water vapour characterization in the Gulf of Cadiz region (southwestern Spain) based on Sun photometer, GPS, and radiosonde data. Journal of Geophysical Research, 115, D18103. https://doi.org/10.1029/2009JD012724.
Tregoning, P., & Watson, C. (2009). Atmospheric effects and spurius signals in GPS analyses. Journal of Geophysical Research, 114. https://doi.org/10.1029/2009JB006344.
Trenberth, K. E., Fasullo, J., & Smith, L. (2005). Trends and variability in column-integrated atmospheric water vapour. Climate Dynamics, 24(7–8), 741–758. https://doi.org/10.1007/s00382-005-0017-4.
Urban, J. (2013). Satellite sensors measuring atmospheric water vapour. In Monitoring Atmospheric Water Vapour, ISSI Scientific Report Series, 10, Kämpfer, N. https://doi.org/10.1007/978-1-4614-3909-7_9.
Václavovic, P., & Douša, J. (2016) G-Nut/Anubis – Open-source tool for multi-GNSS data monitoring. In Ch. Rizos, & P. Willis (Eds.), IAG 150 Years. IAG Symposia Series (Vol. 143, pp. 775–782). Springer.
Van Malderen, R., Brenot, H., Pottiaux, E., Beirle, S., Hermans, C., De Mazière, M., Wagner, T., De Backer, H., & Bruyninx, C. (2014). A multi-site intercomparison of integrated water vapour observations for climate change analysis. Atmospheric Measurement Techniques, 7, 2487–2512. https://doi.org/10.5194/amt-7-2487-2014.
Vaquero-Martínez, J., Antón, M., Pablo Ortiz de Galisteo, J., Cachorro, V. E., Costa, M. J., Román, R., & Bennouna, Y. S. (2017a). Validation of MODIS integrated water vapour product against reference GPS data at the Iberian Peninsula. International Journal of Applied Earth Observation and Geoinformation, 63, 214–221,. ISSN 0303-2434. https://doi.org/10.1016/j.jag.2017.07.008.
Vaquero-Martínez, J., Antón, M., Pablo Ortiz de Galisteo, J., Cachorro, V. E., Wang, H., Abad, G. G., Román, R., & Costa, M. J. (2017b). Validation of integrated water vapour from OMI satellite instrument against reference GPS data at the Iberian Peninsula. Science of the Total Environment, 580, 857–864,. ISSN 0048-9697. https://doi.org/10.1016/j.scitotenv.2016.12.032.
Vaquero-Martínez, J., Antón, M., de Galisteo, J. P. O., Victoria E. Cachorro, Álvarez-Zapatero, P., Román, R., Loyola, D., Costa, M. J., Wang, H., Abad, G. G., & Noël, S. (2017c) Inter-comparison of integrated water vapour from satellite instruments using reference GPS data at the Iberian Peninsula. In Remote Sensing of Environment. ISSN 0034-4257. https://doi.org/10.1016/j.rse.2017.09.028
Vázquez B, G. E., & Grejner-Brzezinska, D. A. (2013). GPS-PWV estimation and validation with radiosonde data and numerical weather prediction model in Antarctica. GPS Solutions, 17, 29–39. https://doi.org/10.1007/s10291-012-0258-8.
Venema, V. K. C., Mestre, O., Aguilar, E., Auer, I., Guijarro, J. A., Domonkos, P., Vertacnik, G., Szentimrey, T., Stepanek, P., Zahradnicek, P., Viarre, J., Müller-Westermeier, G., Lakatos, M., Williams, C. N., Menne, M. J., Lindau, R., Rasol, D., Rustemeier, E., Kolokythas, K., Marinova, T., Andresen, L., Acquaotta, F., Fratianni, S., Cheval, S., Klancar, M., Brunetti, M., Gruber, C., Prohom Duran, M., Likso, T., Esteban, P., & Brandsma, T. (2012). Benchmarking homogenization algorithms for monthly data. Climate of the Past, 8, 89–115. https://doi.org/10.5194/cp-8-89-2012.
Vey, S., Dietrich, R., Fritsche, M., Rülke, A., Rothacher, M., & Steigenberger, P. (2006). Influence of mapping functions parameters on global GPS network analyses: Comparison between NMF and IMF. Geophysical Research Letters, 33, L01814. https://doi.org/10.1029/2005GL024361.
Vey, S., Dietrich, R., Fritsche, M., Rülke, A., Steigenberger, P., & Rothacher, M. (2009). On the homogeneity and interpretation of precipitable water time series derived from global GPS observations. Journal of Geophysical Research, 114, D10101. https://doi.org/10.1029/2008JD010415.
Vey, S., Dietrich, R., Rülke, A., Fritsche, M., Steigenberger, P., & Rothacher, M. (2010). Validation of precipitable water vapour within the NCEP/DOE reanalysis using global GPS observations from one decade. Journal of Climate, 23, 1675–1695. https://doi.org/10.1175/2009JCLI2787.1.
Vincent, L. A., Zhang, X., Bonsal, B. R., & Hogg, W. D. (2002). Homogenization of daily temperatures over Canada. Journal of Climate, 15, 1322–1334. https://doi.org/10.1175/1520-0442(2002)015<1322:HODTOC>2.0.CO;2.
Voelksen, C. (2011). An update on the EPN reprocessing project: Current achievements and status. Presented at EUREF 2011 symposium, 25–28 May 2011, Chisinau, Republic of Moldova. Available at: http://www.epncb.oma.be/_documentation/papers/eurefsymposium2011/an_update_on_epn_reprocessing_project_current_
Von Neumann, J. (1941). Distribution of the ratio of the mean square successive difference to the variance. Annals of Mathematical Statistics, 13, 367–395.
Wang, J., Zhang, L., & Dai, A. (2005). Global estimates of water-vapour-weighted mean temperature of the atmosphere for GPS applications. Journal of Geophysical Research: Atmosphers, 110(D21).
Wang, J., Zhang, L., Dai, A., Van Hove, T., & Van Baelen, J. (2007a). A near-global, 2-hourly data set of atmospheric precipitable water from ground-based GPS measurements. Journal of Geophysical Research, 112, D11107. https://doi.org/10.1029/2006JD007529.
Wang, X. L., Wen, Q. H., & Wu, Y. (2007b). Penalized maximal t test for detecting undocumented mean change in climate data series. Journal of Applied Meteorology and Climatology, 46, 916–931. https://doi.org/10.1175/JAM2504.1.
Wang, J., Zhang, L., Dai, A., Van Hove, T., & Van Baelen, J. (2007c). A near-global, 2-hourly data set of atmospheric precipitable water from ground-based GPS measurements. Journal of Geophysical Research, 112, D11107. https://doi.org/10.1029/2006JD007529.
Wang, H., Gonzalez Abad, G., Liu, X., & Chance, K. (2016a). Validation and update of OMI total column water vapour product. Atmospheric Chemistry and Physics, 16, 11379–11393. https://doi.org/10.5194/acp-16-11379-2016.
Wang, X., Zhang, K., Wu, S., Fan, S., & Cheng, Y. (2016b). Water vapour-weighted mean temperature and its impact on the determination of precipitable water vapour and its linear trend. Journal of Geophysical Research – Atmospheres, 121, 833–852. https://doi.org/10.1002/2015JD024181.
Wang, X., Zhang, K., Wu, S., He, C., Cheng, Y., & Li, X. (2017). Determination of zenith hydrostatic delay and its impact on GNSS-derived integrated water vapour. Atmospheric Measurement Techniques, 10, 2807–2820. https://doi.org/10.5194/amt-10-2807-2017.
Webb, F. H. and Zumberge, J. F. (1997) An introduction to GIPSY/OASIS II, Jet Propulsion Laboratory Document JPL D-11088. California Institute of Technology.
Wijngaard, J. B., Klein Tank, A. M. G., & Können, G. P. (2003). Homogeneity of 20th century European daily temperature and precipitation series. International Journal of Climatology, 23, 679–692. https://doi.org/10.1002/joc.906.
Willis, P., Gobinddass, M.-L., Garayt, B., & Fagard, H. (2012). Recent improvements in DORIS data processing in view of ITRF2008, the ignwd08 solution. IAG Symposium, 136, 43–49. https://doi.org/10.1007/978-3-642-20338-1_6.
Willis, P., Bock, O., & Bar-Sever, Y. E. (2014). DORIS tropospheric estimation at IGN: current strategies, GPS intercomparisons and perspectives. IAG Symposium, 139, 11–18. https://doi.org/10.1007/978-3-642-37222-3_2.
Willis, P., Heflin, M. B., Haines, B. J., Bar-Sever, Y. E., Bertiger, W. B., & Mandea, M. (2016a). Is the Jason2 DORIS oscillator still affected by the South Atlantic Anomaly? Advances in Space Research, 58(12), 2617–2627. https://doi.org/10.1016/j.asr.2016.09.015.
Willis, P., Zelensky, N. P., Ries, J. C., Soudarin, L., Cerri, L., Moreaux, G., Lemoine, F. G., Otten, M., Argus, D. F., & Heflin, M. B. (2016b). DPOD2008, A DORIS-oriented terrestrial reference frame for precise orbit determination. IAG Symposium, 143, 175–181. https://doi.org/10.1007/1345_2015_125.
Wolter, K., & Timlin, M. S. (1993) Monitoring ENSO in COADS with a seasonally adjusted principal component index. In Proceedings of the 17th climate diagnostics workshop (Vol. 5257).
Wolter, K., & Timlin, M. S. (1998). Measuring the strength of ENSO events: How does 1997/98 rank? Weather, 53(9), 315–324. https://doi.org/10.1002/j.1477-8696.1998.tb06408.x.
Yao, Y.-C., & Davis, R. A. (1986). The asymptotic behaviour of the likelihood ratio statistic for testing a shift in mean in a sequence of independent normal variates. Sankhya, 48, 339–353.
Zumberge, J. F., Heflin, M. B., Jefferson, D. C., & Watkins, M. M. (1997). Precise point positioning for the efficient and robust analysis of GPS data from large networks. Journal of Geophysical Research – Solid Earth, 102, 5005–5017.
Zus, F., Dick, G., Douša, J., Heise, S., & Wickert, J. (2014). The rapid and precise computation of GPS slant total delays and mapping factors utilizing a numerical weather model. Radio Science, 49, 207–216. https://doi.org/10.1002/2013RS005280.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Bock, O. et al. (2020). Use of GNSS Tropospheric Products for Climate Monitoring (Working Group 3). In: Jones, J., et al. Advanced GNSS Tropospheric Products for Monitoring Severe Weather Events and Climate. Springer, Cham. https://doi.org/10.1007/978-3-030-13901-8_5
Download citation
DOI: https://doi.org/10.1007/978-3-030-13901-8_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-13900-1
Online ISBN: 978-3-030-13901-8
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)