
Abstract
In medical problems both the information and the reasoning used by clinicians for drawing conclusions about patients’ health are inherently uncertain and vague. Fuzzy logic is a powerful tool for representing and handling this uncertainty, leading to fuzzy systems that can support decisions in medical diagnosis. In this work we propose a fuzzy rule-based system to support the expert in decision making for cardiovascular diseases that are of particular interest due to their obvious medical diagnostic importance. Preliminary experimental results on both healthy and ill people show the effectiveness of the fuzzy system in simulating the decision of the expert.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Medical Informatics is a recent multidisciplinary field dealing with the use of the information technology for the healthcare industry.
The amount of patient health data is increasing exponentially. The volume of healthcare data in 2013 has been estimated at 153 Exabytes and it will reach 2314 Exabytes by 2020Footnote 1. Traditional manual data analysis techniques have became unsuitable to extract useful information from this big amount of data, thus automatic mechanisms are necessary [1, 2]. However, expert knowledge cannot be completely replaced by machines. Intelligent data analysis (IDA) aims at combining human expertise and computational models for advanced data analysis [3,4,5], in order to narrow the gap between data gathering and their comprehension [6]. In the medical field, more than in others, this interaction is mandatory: on the one hand the experts need automatic tools to transform raw and complex data into easily interpretable information, on the other hand algorithm outputs alone are not sufficient for medical diagnosis, since expert knowledge is needed to understand them. Several IDA methods have been applied for supporting decision making in medicine [6,7,8,9].
The representation of medical knowledge and the decision making in the presence of uncertainty and imprecision are of fundamental importance to derive a suitable model for medical decision making. Indeed, in medical problems, both patient information and the reasoning used by clinicians for drawing conclusions about patients’ health, are inherently uncertain and vague [10]. Among the different IDA methods, fuzzy logic is the most suitable mean for representing and handling this uncertainty. In particular, fuzzy logic proved to be a powerful tool for decision support systems (DSSs), such as medical rule-based systems [11]. Several medical Decision Support Systems (DSSs) have been developed using fuzzy rule-based systems [10,11,12,13,14,15,16,17,18,19,20]. These fuzzy systems use linguistic terms to represent the patients’ symptoms, and a fuzzy inference mechanism to derive a suggestion. The domain knowledge is embedded into the knowledge base in form of fuzzy rules.
In this paper we propose a fuzzy rule-based system to support the medical expert in decision making for cardiovascular risk assessment. Starting from the patients’ vital signs such as heart rate (HR), breath rate (BR), peripheral oxygen saturation (SpO2) and lips color, we designed a fuzzy rule-based system that can suggest a level of cardiovascular risk. The fuzzy rules are defined according to the expert knowledge with the help of the FISDeT tool [21].
The rest of the paper is organized as follows. In Sect. 2 the vital signs related to cardiovascular diseases are introduced. The fuzzy rule-based decision support system is described in Sect. 3. Section 4 reports preliminary results of experiments aimed to prove the accuracy of the fuzzy system in simulating the expert reasoning. In Sect. 5 we draw conclusions and outline future works.
2 Vital Signs of Cardiovascular Disease
Heart rate (HR), breath rate (BR), and peripheral oxygen saturation (SpO2) are parameters typically considered by physicians to formulate a diagnosis of cardiovascular disease. All of them are descriptive enough of the human health condition providing also the additional benefit of being easily detectable.
HR is defined as the speed of the heartbeat, i.e., the number of heart contractions per minute (BPM). Such a value is varying according to a number of conditions affecting the human organism, ranging from the physical exercise to the stress, the illness, and the drug consumption. Even age, sex, and physical fitness provoke change in the HR values. However, the average HR of a resting male adult falls in the range of 60 to 90 BPM.
BR is defined as the speed of the breath sequence, i.e., the number of breaths occurring per minute. The common factors influencing the BR evaluation are age and physical exercise. However, the average BR of a resting male adult falls in the range of 12 to 18 breaths per minute. A modified value of BR (which can be a reduced rate, bradypnea, or an augmented rate, tachypnea) is commonly associated to various illness conditions.
SpO2 is evaluated as the percentage of oxygen-saturated hemoglobin with respect to the total hemoglobin (unsaturated and saturated) present in the blood. SpO2 values are considered normal when falling in the range of 95 to 100%. Values below 90% indicate pathological conditions (hypoxemia), inducing organ impairment when falling below 80%.
Different methods can be adopted to measure the vital signs previously described. Among them, photoplethysmography (PPG) is commonly employed in several medical settings and is implemented in simple devices that are commercially available at the present days. By means of photoplethysmograph techniques it is possible to perform optical measurements to detect volumetric change of organs and to assess skin perfusion [22]. PPG is easy to use, noninvasive and is founded on the idea that plethysmoograph signals, acquired through the enlightenment of the skin, provide information concerning changes in blood flow, thus contributing to design a picture of the cardiovascular state [23]. Some PPG systems are applied directly on specific anatomical parts (which can be fingers, forearms, etc.). Some other systems are contactless, thus constituting a kind of remote-PPG (rPGG) systems which typically rely on facial examination. The simple employment of computer webcams proved to be effective in detecting the vital signs of interest for subsequent analysis [24,25,26,27,28].
The human face provides also several clues about the health condition. Some kinds of pathologies can be identified through the analysis of some face features. In particular, a specific element useful to assess human wellness is the color of lips. Normal people show a pinkish nuance in their lips, while altered states or illness may provoke a modification of this color. Pale lips are a symptom of different problems, ranging from vitamin deficiency to anemia. Lips appearing purplish or bluish can refer to cardiovascular or respiratory disorders which may require a punctual medical consulting. Automatic analysis of the lips color can be suitably performed by means of image processing techniques applied to a specific ROI (region of interest) extracted from the image of the patient’s face.
In the following section we discuss how the described vital signs have been involved in the design of a fuzzy inference system capable to provide a risk level of cardiovascular disease.
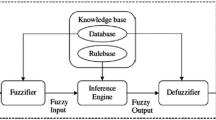
3 The Fuzzy Rule-Based Decision Support System
The aim of this work is to set up a fuzzy rule-based system which can support the diagnosis of cardiovascular diseases by assessing a risk level for each patient according to her measured vital signs.
To design the rule base of the fuzzy inference system (FIS) we exploited FISDeT (Fuzzy Inference System Development Tool) [21], a software conceived to facilitate the creation and the management of fuzzy rule-based systems. Key-points of FISDeT are the adoption of the FCL standard for the description of a FIS, the freely availability through the open-source development methodology, and a general-purpose approach which allows both the creation of a knowledge base and the inference of results from the analysis of input data. Developed in Python, FISDeT is endowed with a GUI supporting the user through all the steps required to define a FIS. FISDeT has been successfully applied to create FIS for classification problems [29].
The input-output configuration we considered to design the FIS draws a relationship between the four vital signs (HR, BR, SpO2, lips color) and a risk level referred to cardiovascular diseases. The parameters involved in the FIS design have been investigated with the support coming from a physician. Specifically, the fuzzy variables and their fuzzy sets have been arranged as follows.

Fuzzy sets partitioning the domain of the linguistic variables related to the vital signs.
- HR :
-
This parameter is associated with the linguistic input variable Heart_rate, whose domain is the numerical range [10–180]. Such a linguistic variable may assume the values corresponding to three linguistic terms: Bradycardia, Normal, and Tachycardia. Triangular fuzzy sets are associated to the linguistic terms, partitioning the domain of the Heart_rate variable as follows (triangle vertices are reported in parenthesis as coordinates):
–Bradycardia: (30, 0) (35, 1) (52, 0);
–Normal: (48, 0) (75, 1) (100, 0);
–Tachycardia: (95, 0) (110, 1) (180, 0).
Figure 1(a) shows the FISDeT GUI illustrating the fuzzy sets involved in the definition of the Heart_rate variable.
- BR :
-
This parameter is associated to the linguistic input variable Respiration_rate, whose domain is the numerical range [0–80]. Such a linguistic variable may assume the values corresponding to three linguistic terms: Bradypnea, Normal, and Tachypnea. Triangular fuzzy sets are associated to the linguistic terms, partitioning the domain of the Respiration_rate variable as follows:
–Bradypnea: (0, 0) (6, 1) (8, 0);
–Normal: (7, 0) (15, 1) (23, 0);
–Tachypnea: (20, 0) (35, 1) (80, 0).
Figure 1(b) shows the FISDeT GUI illustrating the fuzzy sets involved in the definition of the Respiration_rate variable.
- SpO2 :
-
This parameter is associated to the linguistic input variable Blood_oxygen, whose domain is the numerical range [75–100]. Such a linguistic variable may assume the values corresponding to three linguistic terms: Critical, Low, and Normal. Triangular fuzzy sets are associated to the linguistic terms, partitioning the domain of the Blood_oxygen variable as follows:
–Critical: (75, 0) (83, 1) (90, 0);
–Low: (87, 0) (93, 1) (95, 0);
–Normal: (94, 0) (97, 1) (100, 0).
Figure 1(c) shows the FISDeT GUI illustrating the fuzzy sets involved in the definition of the Blood_oxygen variable.
- Lips color :
-
This parameter is associated to the linguistic input variable Color_lips, whose domain is identified in the numerical range [0–14]. Such a domain derives from the identification of 15 hues in the color scale which can be properly labeled through linguistic expressions. They are altogether reported in Fig. 2, where the hues are grouped into three reference categories, corresponding to the linguistic terms related to the Color_lips variable. Triangular fuzzy sets are associated with the linguistic terms, partitioning the domain of the Color_lips variable as follows:
–Regular: (0, 0) (3, 1) (6, 0);
–Altered: (5, 0) (7.5, 1) (10, 0);
–Purplish: (8, 0) (12, 1) (16, 0).
Figure 1(d) shows the FISDeT GUI illustrating the fuzzy sets involved in the definition of the Color_lips variable.
- Risk level :
-
This parameter is associated to a linguistic output variable named Risk_level that assumes the values of four linguistic terms to be intended as class labels: Risk_low, Risk_medium, Risk_high, and Risk_very_high.
As concerning the structural organization of the FIS designed by FISDeT, we adopted the common choices regarding the t-norm and the t-conorm operators. The inference of the fuzzy system is carried on through the employment of the \(\text {min}\) and the \(\text {max}\) functions, determining the rule activation strength and the aggregation of rules respectively.
Once the input-output configuration has been properly set up, we defined the knowledge base to be embedded in the FIS. We considered all the possible combinations of input values, so that a number of 81 rules has been compiled. The rules have been crafted following some general guidelines collected during an interview with the physician. Such guidelines can be sketched as follows:
-
when all the vital signs exhibit standard values, the risk level is low;
-
when one vital sign exhibits a nonstandard value, the risk is medium;
-
when two vital signs exhibit some nonstandard values, the risk is high;
-
when three vital signs exhibit some nonstandard values, the risk is very high.

The set of 15 hues describing the domain of the Color_lips variable. They are grouped into three categories: Regular, Altered, and Purplish.
Following such guidelines, we compiled the fuzzy rule base of the decision-support FIS. The derived fuzzy rules embed the expert knowledge in a very interpretable linguistic form. This can be appreciated by the illustrative excerpt shown in Table 1.
4 Experimental Results
To test the effectiveness of the fuzzy inference system, we performed an evaluation based on real data coming from the examination of 116 persons. The vital signs related to the HR, BR, and SpO2 parameters have been obtained through the collection of PPG signals. To acquire the information concerning the lips color, we processed the face image of each person so as to identify the ROI related to the lips. Subsequently the ROI was processed to derive the dominant color information. To do this, the K-means clustering algorithm was applied to perform a quantization of the color into \(K=3\) levels (see Fig. 3). Finally, the K colors were averaged to derive a unique dominant color.

Example of lips color quantization using K-means.
Once collected the data related to vital signs, we asked the physician to associate a risk level to each sample. Table 2 reports an illustrative excerpt from the dataset. Then, we applied the FIS to each sample in order to compare the inferred result with the human decision. In practice, we intended the physician’s hints as the actual classes to be considered against the risk levels provided by the fuzzy system. The results of comparison were examined at different levels.
As a first note, we observe that the overall value of classification accuracy is \(68.97\%\). However, accuracy alone may be a misleading index, especially when it is considered during the analysis of unbalanced datasets (which is the case at hand, since the individuals who underwent the screening were mostly healthy persons). Therefore, we performed a further analysis evaluating the accuracy related to each of the four output classes, together with additional measures that are commonly considered in classification tasks. In particular, while analyzing a single class c, we consider true positive (tp), true negative (tn), false positive (fp), and false negative (fn) classification results, and we take into account the following measures:
-
Accuracy: ratio of correct discriminations w.r.t. class c
$$\textsc {acc}=\frac{\textsc {tp}+\textsc {tn}}{\textsc {tp}+\textsc {fp}+\textsc {fn}+\textsc {tn}}$$ -
Positive Predictive Value: ratio of correctly classified samples w.r.t. those identified as pertaining to class c
$$\textsc {ppv}=\frac{\textsc {tp}}{\textsc {tp}+\textsc {fp}}$$ -
Negative Predictive Value: ratio of correctly classified samples w.r.t. those identified as not pertaining to class c
$$\textsc {npv}=\frac{\textsc {tn}}{\textsc {tn}+\textsc {fn}}$$ -
True Positive Rate: ratio of samples correctly classified as belonging to class c w.r.t. those actually belonging to class c
$$\textsc {tpr}=\frac{\textsc {tp}}{\textsc {tp}+\textsc {fn}}$$ -
True Negative Rate: ratio of samples correctly classified as not belonging to class c w.r.t. those actually not belonging to class c
$$\textsc {tnr}=\frac{\textsc {tn}}{\textsc {fp}+\textsc {tn}}$$
Table 3 reports the values of these measures evaluated for each class. It can be observed how the tnr and npv values are generally greater than those of tpr and ppv. This means that the knowledge embedded into the FIS is more effective in determining the non-membership to each class than the sensitivity to each specific risk level. This could be related to the fact that an unbalanced dataset is tackled by a set of rules crafted while keeping in mind a more general setting.
The obtained results can be further analyzed by considering the information conveyed by the overall confusion matrix depicted in Table 4. Such an overview allows to better focus a specific feature of the classification problem at hand: the involved classes are ranked in a range going from a low to a very high risk level. In this sense, a misclassification involving classes that are distant in this rank is more troublesome than others involving one class next to another. From the analysis of Table 4 we can argue that only 66 out of 86 low risk samples have been correctly identified. However, almost every misclassified low risk sample has been associated with the most similar class (Risk_medium). The same argument goes with the misclassification of medium risk samples (only one case has been shifted toward a very high risk) and high risk samples (misclassified samples are related to adjacent classes). On the other hand, management of the Risk_very_high class is somewhat troublesome since 7 out of 15 cases have been incorrectly related to a medium risk level.
As a conclusive remark, we point out that the misclassifications produced by the fuzzy system in most cases represent an overestimation of the risk level. In medical contexts this can be read as a problem with reduced harm, the opposite occurrence being regarded as the cause of much more serious consequences.
5 Conclusions
In this work we have presented a fuzzy rule-based system for decision support in the medical realm of cardiovascular diseases. Preliminary experimental results on both healthy and ill people show the effectiveness of the fuzzy system in simulating the decision of the expert. The fuzzy rules developed so far rely only on four main vital signs of a person, namely heart rate, breath rate, blood oxygen saturation and lips color. The choice of these parameters lies in the simplicity of their measurement together with the reliability of their associated information. For these reasons they represent the ideal parameters to be involved in a wearable device or in a domotic system endowed with the inferring capabilities provided by our fuzzy system. As a further improvement, we intend to enrich the knowledge base of the fuzzy decision support system by including other information about the patient, such as demographic features (age and sex) and information coming from the patient’s history and the family history.
References
Casalino, G., Castiello, C., Del Buono, N., Mencar, C.: Intelligent Twitter data analysis based on nonnegative matrix factorizations. In: Gervasi, O., et al. (eds.) Computational Science and Its Applications – ICCSA 2017. LNCS, vol. 10404, pp. 188–202. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-62392-4_14
Del Buono, N., Mencar, C., Casalino, G., Castiello, C.: A framework for intelligent Twitter data analysis with non-negative matrix factorization. Int. J. Web Inf. Syst. 14(3), 334–356 (2018)
Berthold, M., Hand, D.J. (eds.): Intelligent Data Analysis: An Introduction, 1st edn. Springer, New York (1999). https://doi.org/10.1007/978-3-662-03969-4
Berthold, M.R., Borgelt, C., Höppner, F., Klawonn, F.: Guide to Intelligent Data Analysis: How to Intelligently Make Sense of Real Data. TCS, 1st edn. Springer, London (2010). https://doi.org/10.1007/978-1-84882-260-3
Casalino, G., Del Buono, N., Mencar, C.: Nonnegative matrix factorizations for intelligent data analysis. In: Naik, G.R. (ed.) Non-negative Matrix Factorization Techniques. SCT, pp. 49–74. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-48331-2_2
Bellazzi, R., Zupan, B.: Intelligent data analysis in medicine and pharmacology: a position statement. In: IDAMAP Workshop Notes at the 13th European Conference on Artificial Intelligence, ECAI, vol. 98 (1998)
Lavrač, N., Kononenko, I., Keravnou, E., Kukar, M., Zupan, B.: Intelligent data analysis for medical diagnosis: using machine learning and temporal abstraction. AI Commun. 11(3,4), 191–218 (1998)
Lavrač, N., Keravnou-Papailiou, E., Zupan, B.: Intelligent Data Analysis in Medicine and Pharmacology, vol. 414. Springer, New York (2012). https://doi.org/10.1007/978-1-4615-6059-3
Magdalena-Benedito, R.: Medical Applications of Intelligent Data Analysis: Research Advancements: Research Advancements. IGI Global, Hershey (2012)
Adlassnig, K.P.: Fuzzy set theory in medical diagnosis. IEEE Trans. Syst. Man Cybern. 16(2), 260–265 (1986)
Phuong, N.H., Kreinovich, V.: Fuzzy logic and its applications in medicine. Int. J. Med. Inform. 62(2–3), 165–173 (2001)
Begum, S.A., Devi, O.M.: Fuzzy algorithms for pattern recognition in medical diagnosis. Assam Univ. J. Sci. Technol. 7(2), 1–12 (2011)
Sanz, J.A., Galar, M., Jurio, A., Brugos, A., Pagola, M., Bustince, H.: Medical diagnosis of cardiovascular diseases using an interval-valued fuzzy rule-based classification system. Appl. Soft Comput. 20, 103–111 (2014)
Tsipouras, M.G., et al.: Automated diagnosis of coronary artery disease based on data mining and fuzzy modeling. IEEE Trans. Inf. Technol. Biomed. 12(4), 447–458 (2008)
Dagar, P., Jatain, A., Gaur, D.: Medical diagnosis system using fuzzy logic toolbox. In: 2015 International Conference on Computing, Communication & Automation (ICCCA), pp. 193–197. IEEE (2015)
Rana, M., Sedamkar, R.R.: Design of expert system for medical diagnosis using fuzzy logic. Int. J. Sci. Eng. Res. 4(6), 2914–2921 (2013)
Awotunde, J.B., Matiluko, O.E., Fatai, O.W.: Medical diagnosis system using fuzzy logic. Afr. J. Comput. ICT 7(2), 99–106 (2014)
Gorgulu, O., Akilli, A.: Use of fuzzy logic based decision support systems in medicine. Stud. Ethno-Med. 10(4), 393–403 (2016)
Alonso, J.M., Castiello, C., Lucarelli, M., Mencar, C.: Modeling interpretable fuzzy rule-based classifiers for medical decision support. In: Medical Applications of Intelligent Data Analysis: Research Advancements, pp. 255–272. IGI Global (2012)
Cannone, R., Castiello, C., Fanelli, A.M., Mencar, C.: Assessment of semantic cointension of fuzzy rule-based classifiers in a medical context. In: 2011 11th International Conference on Intelligent Systems Design and Applications, pp. 1353–1358, November 2011
Castellano, G., Castiello, C., Pasquadibisceglie, V., Zaza, G.: FISDeT: Fuzzy inference system development tool. Int. J. Comput. Intell. Syst. 10(1), 13–22 (2017). https://doi.org/10.2991/ijcis.2017.10.1.2
Challoner, A.V.J.: Photoelectric plethysmography for estimating cutaneous blood flow. Non-invasive Physiol. Meas. 1, 125–151 (1979)
Kamal, A.-A.M., Gomaa, A., El Kafif, M., Hammad, A.S.: Plasma lipid peroxides among workers exposed to silica or asbestos dusts. Environ. Res. 49(2), 173–180 (1989)
Hu, S., Peris, V.A., Echiadis, A., Zheng, J., Shi, P.: Development of effective photoplethysmographic measurement techniques: from contact to non-contact and from point to imaging. In: 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBC 2009, pp. 6550–6553. IEEE (2009)
Wieringa, F.P., Mastik, F., van der Steen, A.F.W.: Contactless multiple wavelength photoplethysmographic imaging: a first step toward “SpO2 camera” technology. Ann. Biomed. Eng. 33(8), 1034–1041 (2005)
Rouast, P.V., Adam, M.T.P., Chiong, R., Cornforth, D., Lux, E.: Remote heart rate measurement using low-cost RGB face video: a technical literature review. Front. Comput. Sci. 12(5), 858–872 (2018). https://doi.org/10.1007/s11704-016-6243-6
Hassan, M.A., et al.: Heart rate estimation using facial video: a review. Biomed. Signal Process. Control 38, 346–360 (2017)
Poh, M.-Z., McDuff, D.J., Picard, R.W.: Non-contact, automated cardiac pulse measurements using video imaging and blind source separation. Opt. Express 18(10), 10762–10774 (2010)
Castellano, G., Castiello, C., Fanelli, A.M.: The FISDeT software: application to beer style classification. In: Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE 2017), Naples, Italy, 9–12 July 2017. https://doi.org/10.1109/FUZZ-IEEE.2017.8015503
Acknowledgement
The authors are thankful to Dr. Ilaria Engaddi from “Istituti Milanesi Martinitt e Stelline e Pio Albergo Trivulzio” (Milan, Italy) for providing her knowledge and expertise useful to define the fuzzy rule base.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Casalino, G., Castellano, G., Castiello, C., Pasquadibisceglie, V., Zaza, G. (2019). A Fuzzy Rule-Based Decision Support System for Cardiovascular Risk Assessment. In: Fullér, R., Giove, S., Masulli, F. (eds) Fuzzy Logic and Applications. WILF 2018. Lecture Notes in Computer Science(), vol 11291. Springer, Cham. https://doi.org/10.1007/978-3-030-12544-8_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-12544-8_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-12543-1
Online ISBN: 978-3-030-12544-8
eBook Packages: Computer ScienceComputer Science (R0)