
Abstract
Previous studies have shown that information entropy and its variants are useful at reducing data dimensionality. Yet, most existing approaches based on entropy exploit the correlations between features and labels, lacking of taking into account the relevance between features. In this paper, we propose a new index for feature selection, named fuzzy conditional distinction degree (FDD), based on fuzzy similarity relation by combining feature correlations with the relationship between features and labels. Different from existing approaches based on entropy, FDD considers the cardinality of the relation matrix instead of the similarity classes. Meanwhile, we encode the feature correlations into distance to measure the relevance of any two features. Some useful properties are discussed. Based on the FDD, a greedy forward algorithm for feature selection is presented. Experimental results on benchmark data sets denote the feasibility and effectiveness of the proposed approach.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In machine learning, data often contain redundant features, which can lead to heavy storage burden and high time-consuming [11]. The enormous pointless features may bring about performance degradation of the learning algorithms. To mitigate this problem, feature selection has become a necessity.
During the past few years, mutual information based approaches have been widely used in feature selection [1, 10]. These methods employ a greedy scheme to select representative features one by one. It’s noticeable that these approaches are prone to obtain suboptimal feature subset due to the computational complexity.
Generally, conditional entropy and its variants are extensively used for feature selection. Some kinds of conditional entropies do not have monotonicity. Thus, they are not reasonable to be used as indices for evaluating the distinguishment ability of feature subset [2, 4]. Compared with Yager’s entropy [17] and its varieties [7, 8], the computational complexity of using the cardinality of relations is smaller. Such as the neighborhood discrimination index proposed by Wang [13], which considers the cardinality of relations between the selected features and labels. However, it lacks of exploring the relevance between features.
Encoding the influence of feature correlations and guaranteeing the monotonic of the proposed index are the main motivations of this paper. Hence, we propose a fuzzy conditional distinction degree (FDD) based on fuzzy rough set [12, 15] by computing the cardinality of relationship instead of the class, which measures the distinguishment ability of a feature subset. Based on FDD, a greedy scheme is employed to get the final feature subset. In particular, the advantages of FDD are summarized as follows:
-
From the viewpoint of the cardinality of relation, we propose a new index for feature selection. The monotonicity has been proved theoretically and experimentally in this paper. Hence, the proposed FDD is reasonable and effective to be used as indexes for mutual information based approaches.
-
We encode the influence of feature correlations into distance to quantify the relevance of any two features. This is a considerable difference from neighborhood discrimination index [13].
2 Preliminaries
In the following, a data set is called as a decision table, denoted as \(T = \left\langle {U,A,V,f} \right\rangle \), where \(U=\left\{ u_{1},u_{2},\cdots u_{n} \right\} \) is a nonempty finite set of objects; \(A=C\cup D\), where \(C=\left\{ a_{1},a_{2},\cdots a_{m} \right\} \) is feature set and \(D=\left\{ d \right\} \) is the set of labels. V is the union of feature domains, \(V=\bigcup _{a \in A}V_{a}\), where \(V_{a}\) is the value set of feature a, called the domain of a; \(f:U\times A\rightarrow V\) is an information function which assigns particular values from domains of feature to objects such as \(\forall a\in A,x\in U,f\left( a,x \right) \in V_{a}\), where \(f\left( a,x \right) \) denotes the values of feature a for object x. An equivalence relation (also called as indiscernibility relation) is defined as:
where \(x,y \in U\) and \(B \subseteq C\). According to the equivalence relation, the equivalence class of Ind(B) containing x can be denoted as \({\left[ x \right] _B}\):
The family of all equivalence classes forms a partition, denoted as \(U/D = \left\{ {{P_1},{P_2}, \cdots {P_r}} \right\} \). Meanwhile, \(P = \left( {{p_{ij}}} \right) \in {R^{n \times n}}\) is an equivalence matrix induced by U / D, where \({p_{ij}} = 1\) if instances i and j satisfy \(i,j \in {P_k},\exists k \in \left\{ {1,2, \cdots ,r} \right\} \), otherwise \({p_{ij}} = 0\). In what follows, \(\left| \cdot \right| \) represents the cardinality of a set or matrix. In this paper, we use fuzzy similarity relation [9] to capture the correlations.
For a given decision table \(T = \left\langle {U,A,V,f} \right\rangle \), where \(U=\left\{ u_{1},u_{2},\cdots u_{n} \right\} \), and \(B \subseteq C\), \({\tilde{R}_B}\) is a fuzzy similarity relation induced by B defined on U if \({\tilde{R}_B}\) satisfies
-
Reflectivity: \({\tilde{R}_B}\left( {x,x} \right) = 1\), for \(\forall x \in U\).
-
Symmetry: \({\tilde{R}_B}\left( {x,y} \right) = {\tilde{R}_B}\left( {y,x} \right) \), for \(\forall x,y \in U\).
-
T-transitivity: \({\tilde{R}_B}\left( {x,x} \right) \ge \left( {{{\tilde{R}}_B}\left( {x,y} \right) \wedge {{\tilde{R}}_B}\left( {y,x} \right) } \right) \).
Induced by \({\tilde{R}_B}\), an instance similarity matrix \({M_B}\) is denoted as:
where \({m_{ij}} = \mathop \cap \limits _{\forall a \in B} {\tilde{R}_a}\left( {i,j} \right) \)
\({\tilde{R}_a}\left( {i,j} \right) \) is the degree to which instances i and j are similar for feature a. Usually, there are many operators can be used to construct the similarity, for example
where \(a \in C\) and \({\sigma _a}\) is standard deviation of feature a.
We expect to encode the feature correlations into distance to measure the relevance of any two features to improve the performance of learning algorithms. Based on this motivation, a new index, called fuzzy conditional distinction degree is introduced to compute the distinguishing ability of subset features.
3 Fuzzy Conditional Distinction Degree
In this section, fuzzy conditional distinction degree is proposed to identify salient features and some properties are discussed.
Given a decision table \(T = \left\langle {U,A,V,f} \right\rangle \), and \(B \subseteq C\), \({\tilde{R}_B}\) is a fuzzy similarity relation induced by B defined on U. Then, an instance similarity matrix on the universe can be denoted as \({M_B}\). \({M_B}\) represents the minimum similarity between samples on the feature set B. In order to measure the relevance of any two features, we encode the feature correlations into distance by using a crisp similarity relation. A crisp similarity relation \({R_B}\) on feature set B with respect to U can be represented as:
where \(\left| C \right| = m\). For arbitrary features i and j, the value of \({s_{ij}}\) is calculated as follows:
and \(\theta \left( {i,j} \right) = \sqrt{\sum \limits _{k = 1}^n {{{\left( {{x_{ki}} - {x_{kj}}} \right) }^2}} }\) where \({x_{ki}}\) represents the value of sample \(x_k\) at feature i and \(\left| U \right| = n\). One thing to emphasize is that we define \({s_{ii}}=1\) to avoid the situation that the cardinality of \(S_B\) is 0. That is to say, if \(B = \emptyset \), the feature relevance matrix \(S_{B}=I\) and I is the identity matrix. In addition, we only pay attention to the selected feature set B not all feature set C. It’s obvious that \(S_B\) represents the strength of the relevance between features. \(S_B\) is a symmetric matrix with diagonal equal to 1. Especially, if only one feature a is selected, then the feature relevance matrix \(S_B\) is the identity matrix \(I \in {R^{m \times m}}\), too.
According to the definitions of \(M_B\) and \(S_B\), it’s easy to get the following properties.
Theorem 1
Let \(T = \left\langle {U,A,V,f} \right\rangle \) be a decision table, \(A = C \cup D\), \(B_1\), \(B_2\) are subsets of C, and \(B_1 \subseteq B_2\), then
This theorem shows that the instance similarity matrix \(M_B\) is monotonically decreasing with increasing the number of features. But in contrast with \(M_B\), the feature relevance matrix \(S_B\) is monotonically increasing.
Theorem 2
Let \(T = \left\langle {U,A,V,f} \right\rangle \) be a decision table. \(B_1\) and \(B_2\) are two subset features. \(S_B\) is feature relevance matrix on feature set B with respect to U. Then
Obviously, the feature relevance matrix satisfies the law of combination. Especially, when \({B_1} \subseteq {B_2}\), we have
It means that the discriminative power of core features is invariable as increasing feature sets. Meanwhile, expanding feature sets can increase the diversity of features.
Theorem 3
Given a decision table T, \(M_{B_1}\) and \(M_{B_2}\) are fuzzy similarity matrices induced by \(B_1\) and \(B_2\), respectively. If \({B_1} \subseteq {B_2}\), then
From the definition of \(M_{B}\) and \(S_{B}\), it’s obvious that they are based on pairwise relations between features, not addressing the joint contribution of three or more features. It’s the prior assumption of independent between features and instances in the proposed method.
Now, we introduce a new index, named fuzzy conditional distinction degree, to capture the intrinsic structure of feature subset by considering feature relevance and sample similarity.
Definition 1
Let \(T = \left\langle {U,A,V,f} \right\rangle \) be a decision table, \(A = C \cup D\). For any subset \(B \subseteq C\), \({M_B}\) and \(S_B\) are instance similarity matrix and feature relevance matrix induced by B, respectively. P is an equivalence matrix induced by U / D. The fuzzy conditional distinction degree (FDD) is defined as:
The fuzzy conditional distinction degree measures the discriminative power of feature subsets relative to all features. It indicates that FDD(D|B) reveals the discriminative capability of B. In addition, let
where F(B) represents the rate of feature relevance degree of B on C and \(I\left( {D|B} \right) \) is the difference degree of B on C. We have \(F\left( B \right) \ge 1\) and \(I\left( {D|B} \right) \ge 0\). According to the Theorem 1, \(F\left( B \right) \) and \(I\left( {D|B} \right) \) are monotonically decreasing. In particular, \(F\left( B \right) =1\), \(I\left( {D|B} \right) =0\), and \(FDD\left( {D|B} \right) =0\) if \(B=C\).
Theorem 4
If \({B_1} \subseteq {B_2}\), then
Proof
If \({B_1} \subseteq {B_2}\), due to Theorem 1 we have
According to the definitions of \(I\left( {D|B} \right) \) and \(F\left( B \right) \), the fuzzy conditional distinction degree can be rewritten as: \(FDD\left( {D|B} \right) = F\left( B \right) I\left( {D|B} \right) \). From the perspective of function, by deriving the above formula, obviously
What’s more, \(F{\left( B \right) ^\prime } \le 0\) and \(I{\left( {D|B} \right) ^\prime } \le 0\) are apparent due to the monotonicity of \(F\left( B \right) \) and \(I\left( {D|B} \right) \). Meanwhile, \(I\left( {D|B} \right) \ge 0\) and \(F\left( B \right) \ge 1\) are established. Hence, \({\left( {FDD\left( {D|B} \right) } \right) ^\prime } \le 0\) is satisfied. The fuzzy conditional distinction degree FDD(D|B) is decreasing with increasing the number of features. Therefore, we can get \(FDD\left( {D|{B_2}} \right) \le FDD\left( {D|{B_1}} \right) \). \(\square \)
This theorem reveals the difference of data distribution under feature sets B and C. As increasing the number of features, the difference becomes smaller. In machine learning, finding a feature subset, which is relevant to the learning task, is a commonly used method. Supposed that \(FDD\left( {D|{C}} \right) \) represents the structure information of the original data and \(FDD\left( {D|{R}} \right) \) represents the structure information obtained by using the feature subset R, the goal of objective function is to find a subset feature R:
Because of the monotonicity of fuzzy conditional distinction degree, \(DD\left( {D|C} \right) =0\), it’s easy to find that \({R^*}\) is called a reduct of C relative to decision D:
That is to say, if a subset of features denoted as \({R^*}\) is a reduct of C relative to decision D, then it satisfies such properties in theory:
-
\(FDD\left( {D|{R^*}} \right) = FDD\left( {D|C} \right) \)
-
\(\forall a \in {R^*} \Rightarrow FDD\left( {D|{R^*} - \left\{ a \right\} } \right) > FDD\left( {D|{R^*}} \right) \)
Hence, the less a decision attribute D has fuzzy conditional distinction degree with respect to a feature subset, the more important the feature subset is. Adding a new feature into the selected feature set, the fuzzy conditional distinction degree will decrease. The decrement of fuzzy conditional distinction degree reveals the increment of distinction ability produced by a new feature subset. In this case, the significance of a feature can be defined as follows.
Definition 2
Supposed a decision table \(T = \left\langle {U,A,V,f} \right\rangle \), \(A = C \cup D\), \(B \subseteq C\) and \(a \in C - B\), the significance degree of feature a with respect to B and D is defined as:
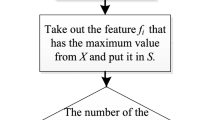
Especially, we define \(SIG\left( {a,B,D} \right) = DD\left( {D|a} \right) \) if \(B = \emptyset \). Before we describe the algorithm, it’s worth to well-considered the details of SIG, which represents the maximum step length of descent. Considering the convergence speed, we use the gradient \(\nabla \) as the termination condition instead of SIG.
According to the above definition, the algorithm is described as:

The parameter \(\delta \) is a threshold to stop the loop when the change is small in each iteration. As described above, the DDFS algorithm terminates when the gradient \(\nabla \left( {a,B} \right) \) of FDD(D|B) is less than \(\delta \), which means that the addition of any remaining features does not obviously decrease the FDD(D|B). If there are n samples and m features, the time complexity for computing the fuzzy similarity relations is \(\mathrm{O}\left( {m{n^2}} \right) \). By greedy scheme, the worst search time for a reduct is \({{m^2}} \). Hence, the overall time complexity of DDFS is \(\mathrm{O}\left( {m{n^2} + {m^2}} \right) \).
4 Experiments
In this section, we conduct experiments to verify the effectiveness of the proposed DDFS method on several data sets. Meanwhile, we compare DDFS with other representative feature selection methods.
4.1 Datasets and Experimental Setup
Datasets: All datasets are available at the UCIFootnote 1 repository and KeukemiaaFootnote 2. The number of features in all datasets varies from 15 to 11225. The characteristics of datasets are described in Table 1. The meaning of abbreviations is as follows.
NI: the number of instance; NF: the number of features; NC: the number of labels.
Comparison: We compare DDFS with five representative feature selection methods: CFS [6], FCBF [18], FRS [3], HANDI [13] and NFRS [14]. In addition to feature selection algorithms, we also select two different learning algorithms: KNN and C4.5 [16], to evaluate the accuracy of selected features. Each data set are divided into train and test data. After selecting the most representative features and training the learning algorithms on train data, we further use KNN and C4.5 to evaluate the performance on test data. Since the KNN algorithm is susceptible to initialization results, we performed a random initialization and repeat 20 times. The average results are recorded. In addition, we also use 10-fold cross-validation to ensure the accuracy of experimental results. During the result recording, we record the mean of all the algorithms under the evaluation criteria. To verify the effectiveness, a widely used evaluation metrics, classification accuracy, is employed to assess the performance. The larger metrics is, the better performance is.
Parameter setting: There are two parameters in HANDI [13] algorithm, \(\varepsilon \) and \(\delta \). The parameter \(\delta \) is set as 0.001 for low dimensional data and 0.01 for high dimensional data. The parameter \(\varepsilon \) varies from 0 to 1 with a step of 0.05 to select an optimal feature subset for each data set. For the algorithm NFRS [14], we set \(\varepsilon \) to a value between 0.1 and 0.5 in steps of 0.05 and \(\lambda \) to a value between 0.1 and 0.6 in steps of 0.1. As for \(\delta \) in FCBF [18], the value of \(\delta \) is same as that in HANDI.

The monotonicity of F(B), I(B) and \(FDD\left( {D|B} \right) \) on different data sets.
4.2 Monotonicity Experiment
Figure 1 shows the results of the monotonicity, where x axis represents the number of features and y axis denotes the corresponding values of D(D|B), I(D|B) and F(B), respectively. From Fig. 1, it’s noticeable that the values of FDD(D|B), I(D|B) and F(B) are decreasing gradually with increasing the number of features. Meanwhile, it’s obvious that FDD(D|B) is equal to zero when all attributes are selected. In other words, all samples are distinguishable in this case. With only partial features selected, the value of FDD(D|B) is almost equal to zero on some data sets. It is noticeable that with increasing the number of features, the uncertainty is reduced leading to the decrementing of fuzzy conditional distinction degree. This property guarantees the validity and feasibility of the FDD(D|B) in feature selection.
4.3 Redundancy Experiment
As mentioned above, the FDD(D|B) takes into account the correlations between features and the similarity between instances and labels. Taking wdbc data set as an example. Let \(T = \left\langle {U,A,V,f} \right\rangle \) represent wdbc and \(A = C \cup D\), where U represents the samples and C is the feature set of wdbc. It has 30 features and two classes. Then, a copy of C is generated, named \(C'\). Finally, we get a new data set \(T{}' = \left\langle {U,A{}',V,f} \right\rangle \) and \(A{}'=\left( C\cup C{}' \right) \cup D\), where it satisfies \(a \in C\), \(a' \in C'\). In order to show the ability of FDD(D|B) to distinguish redundant features, we present the distributions of the data in two-dimension feature space with the top two selected features by different algorithms in Fig. 2.

The data distribution on wdbc data set by using the selected top two features of different algorithms. The red points and blue points represent the two classes in wdbc.
From Fig. 2, it’s easily observed that the features chosen by the proposed FDD(D|B) have best discernibility than its competitors. Meanwhile, the selected top two features of FCBF and NFRS are same in T and \(T'\). It’s due to the fact that the two algorithms only consider the discriminative power of features, ignoring the relevance between features. That is to say, in a redundant dataset, if one feature a has better discernibility, these two algorithms will add feature a into the selected feature set, even though a copy of this feature already exists in the selected feature set. The proposed DDFS involves the relevance of features and the correlation between features and labels to circumvent duplicate attributes.
4.4 Classification Experiment
Average accuracy(acc) and standard deviation(std) are calculated to represent the performance of classification by KNN and C45. The results are shown in Tables 2 and 3 in the form of acc±std(rank value), where the bold symbols highlight the highest classification accuracies among the selected features and the rank value represents the merits of learning performance. The smaller rank value is, the better performance is.
Tables 2 and 3 give the classification performance of HANDI, FCBF, FRS, NFRS, CFS, and DDFS. Considering classification accuracy, we can conclude that DDFS is better than other algorithms with respect to the KNN classifier and C45 classifier except for colon and hepat. The slight differences between these two data sets may be due to the unbalanced of features and samples. Compared with HANDI algorithm, the classification performance is similar may due to the same motivation by considering the cardinality of a relation rather than similarity classes.
In addition, we perform Friedman test and the Bonferroni-Dunn test to show the statistical significance of the result [5]. The Friedman test is defined as:
where k is the number of algorithms, N is the number of data sets, and \({r_i}\) is the mean value of algorithms i among all data sets. Then, by using the value of \({F_F} = \frac{{\left( {N - 1} \right) {\tau _F}}}{{N\left( {k + 1} \right) - \tau _F^2}}\), we can determine whether the performance of these algorithms are same. If the assumption that “all algorithms have the same performance” is rejected, the performance of the algorithms are significantly different, and post-hoc test is needed to further differentiate the algorithms. If the distance of the average ranks exceeds the critical distance: \(C{D_\alpha } = {q_\alpha }\sqrt{\frac{{k\left( {k + 1} \right) }}{{6N}}}\), where \({q_\alpha }\) is the critical tabulated value for post-hoc test [5]. Tables 2 and 3 demonstrate the ranking values of different algorithms under different classifiers. It’s obvious that the average ranking value is different. That is to say, these algorithms are different. According to the [5], the critical value of F for \(\alpha =0.05\) is 2.4495. and \({q_{0.05} }=2.850\). Friedman test shows that at the 0.05 significance level, the average accuracies of DDFS is best among all algorithms. For both of KNN and C4.5, the Bonferroni-Dunn tests reveal that DDFS is statistically better than its competitors.
5 Conclusion
In this work, we introduce a new index to measure the discriminative power of feature subsets. Under the proposed index, a greedy scheme algorithm is proposed for feature selection. Compared with the classic entropy approaches, the proposed fuzzy conditional distinction degree is defined on the cardinality of the relation matrix. In addition, it associates the relevance between feature space and the similarity of samples. Extensive experiments demonstrate that DDFS is more efficient than some popular existing algorithms in classification.
Future work should include the study of reducing the computational complexity of greedy scheme due to the high time-consuming.
References
Battiti, R.: Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 5(4), 537–550 (1994)
Dai, J., Wang, W., Xu, Q.: An uncertainty measure for incomplete decision tables and its applications. IEEE Trans. Cybern. 43(4), 1277–1289 (2013)
Dai, J., Xu, Q.: Attribute selection based on information gain ratio in fuzzy rough set theory with application to tumor classification. Appl. Soft Comput. J. 13(1), 211–221 (2013)
Dai, J., Xu, Q., Wang, W., Tian, H.: Conditional entropy for incomplete decision systems and its application in data mining. Int. J. Gen. Syst. 41(7), 713–728 (2012)
Demsar, J.: Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 7, 1–30 (2006)
Hall, M.A.: Correlation-based feature selection for discrete and numeric class machine learning. In: Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), pp. 359–366 (2000)
Hu, Q., Yu, D., Xie, Z., Liu, J.: Fuzzy probabilistic approximation spaces and their information measures. IEEE Trans. Fuzzy Syst. 14(2), 191–201 (2006)
Hu, Q., Zhang, L., Zhang, D., Pan, W., An, S., Pedrycz, W.: Measuring relevance between discrete and continuous features based on neighborhood mutual information. Expert Syst. Appl. 38(9), 10737–10750 (2011)
Jensen, R., Shen, Q.: New approaches to fuzzy-rough feature selection. IEEE Trans. Fuzzy Syst. 17(4), 824–838 (2009)
Tallón-Ballesteros, A.J., Riquelme, J.C.: Tackling ant colony optimization meta-heuristic as search method in feature subset selection based on correlation or consistency measures. In: Corchado, E., Lozano, J.A., Quintián, H., Yin, H. (eds.) IDEAL 2014. LNCS, vol. 8669, pp. 386–393. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10840-7_47
Tang, J., Liu, H.: Unsupervised feature selection for linked social media data. In: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 904–912 (2012)
Tiwari, A.K., Shreevastava, S., Som, T., Shukla, K.K.: Tolerance-based intuitionistic fuzzy-rough set approach for attribute reduction. Expert Syst. Appl. 101, 205–212 (2018)
Wang, C., Hu, Q., Wang, X., Chen, D., Qian, Y., Dong, Z.: Feature selection based on neighborhood discrimination index. IEEE Trans. Neural Netw. Learn. Syst. 29(7), 2986–2999 (2017)
Wang, C., Qi, Y., Shao, M., Hu, Q., Chen, D., Qian, Y., Lin, Y.: A fitting model for feature selection with fuzzy rough sets. IEEE Trans. Fuzzy Syst. 25(4), 741–753 (2017)
Wang, C., Shao, M., He, Q., Qian, Y., Qi, Y.: Feature subset selection based on fuzzy neighborhood rough sets. Knowl.-Based Syst. 111, 173–179 (2016)
Witten, I.H., Eibe, F., Hall, M.A.: Data Mining: Practical Machine Learning Tools and Techniques, 3rd edn. Morgan Kaufmann, Elsevier, Burlington (2011)
Yager, R.R.: Entropy measures under similarity relations. Int. J. Gen. Syst. 20(4), 341–358 (1992)
Yu, L., Liu, H.: Feature selection for high-dimensional data: A fast correlation-based filter solution. In: Machine Learning, Proceedings of the Twentieth International Conference (ICML 2003), August 21–24, 2003, Washington, DC, pp. 856–863 (2003)
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (Nos. 61473259, 61502335, 61070074, 60703038) and the Hunan Provincial Science and Technology Project Foundation (2018TP1018, 2018RS3065).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, Q., Dai, J. (2018). Feature Selection Based on Fuzzy Conditional Distinction Degree. In: Cheng, L., Leung, A., Ozawa, S. (eds) Neural Information Processing. ICONIP 2018. Lecture Notes in Computer Science(), vol 11304. Springer, Cham. https://doi.org/10.1007/978-3-030-04212-7_7
Download citation
DOI: https://doi.org/10.1007/978-3-030-04212-7_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-04211-0
Online ISBN: 978-3-030-04212-7
eBook Packages: Computer ScienceComputer Science (R0)