
Abstract
Progressive censoring has received great attention in the last decades especially in life testing and reliability. This review highlights fundamental applications, related models, and probabilistic and inferential results for progressively censored data. Based on the fundamental models of progressive type I and type II censoring, we present related models like adaptive and hybrid censoring as well as, e.g., stress-strength and competing risk models for progressively censored data. Focusing on exponentially and Weibull distributed lifetimes, an extensive bibliography emphasizing recent developments is provided.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
- Censoring models
- Ordered data
- Hybrid censoring
- Exponential distribution
- Weibull distribution
- Exact statistical inference
- Lifetime analysis
- Reliability
- Step-stress testing
- Competing risks
- Experimental design
- Ageing notions
1 Introduction and Fundamental Models
Monograph-length accounts on progressive censoring methodology have been provided by Balakrishnan and Cramer [1] and Balakrishnan and Aggarwala [2], while detailed reviews are due to [3] and [4]. In particular, [1] provides an up-to-date account to progressive censoring including many references and detailed explanations. Therefore, we provide essentially the basic models and results in the following, accompanied by recent developments and references which are not covered in the mentioned monograph.
1.1 Basic Ideas of Progressive Censoring
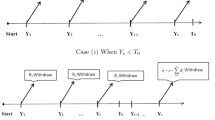
According to [5], a progressively censored life testing experiment is conducted as follows. n items are put simultaneously on a test. At times τ1 < ⋯ < τm, some items are randomly chosen among the surviving ones and removed from the experiment (see Fig. 9.1). In particular, at time τj, Rj items are withdrawn from the experiment. Originally, [5] had introduced two versions of progressive censoring, called type I and type II progressive censoring. In progressive type I censoring, the censoring times τ1 < ⋯ < τm are assumed to be fixed in advance (e.g., as prefixed inspection or maintenance times). For a better distinction, fixed censoring times are subsequently denoted by T1 < ⋯ < Tm. Moreover, the censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\) is prespecified at the start of the life test. But, as failures occur randomly, it may happen that at some censoring time Tj, less than Rj items have survived. In that case, all the remaining items are withdrawn, and the life test is terminated at Tj. Notice that, due to this construction, observations beyond the largest censoring time Tm are possible. At this point, it is worth mentioning that the understanding of progressive type I censoring has changed over time. As has been noted in [6], the understanding of the term progressive type I censoring has been used differently after the publication of monograph [2] [see also 7]. Since then, right censoring has been considered as a feature of progressive type I censoring, that is, Tm is considered as a termination time of the experiment (see Fig. 9.2). Therefore, in progressive type I censoring, we distinguish the initially planned censoring plan \(\mathscr {R}^0=(R^0_1,\dots , R^0_{m-1})\) from the effectively applied one denoted by \(\mathscr {R}=(R_1,\dots , R_{m-1})\). Notice that we drop the mth censoring number Rm in the plan since it is always random due to the right censoring. In order to distinguish these scenarios, [6] called the original scenario Cohen’s progressive censoring scheme with fixed censoring times.

Progressive censoring scheme with censoring times τ1 < ⋯ < τm and censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\)

Progressive type I censoring with censoring times T1 < ⋯ < Tm−1, time censoring at Tm, and initial censoring plan \(\mathscr {R}^0=(R^0_1,\dots , R^0_{m-1})\)
Notation | Explanation |
|---|---|
cdf | Cumulative distribution function |
(Probability) density function | |
iid | Independent and identically distributed |
BLUE | Best linear unbiased estimator |
MLE | Maximum likelihood estimator |
UMVUE | Uniformly minimum variance unbiased estimator |
PHR model | Proportional hazard rates model |
\(\mathbb {R}\) | Set of real numbers |
\(\mathbb {N}, \mathbb {N}_0\) | Set of positive and nonnegative integers, respectively |
F ← | Quantile function of a cdf F |
\(\mathbb {I}_{A}(t)\) | Indicator function for a set A; \(\mathbb {I}_{A}(t)=1\) for t ∈ A, \(\mathbb {I}_{A}(t)=0\), otherwise |
\( \overset {d}=\) | Identical in distribution |
x m | xm = (x1, …, xm) |
xn ∧yn | \(\boldsymbol {x}_n \wedge \boldsymbol {y}_n= (\min (x_1, y_1),\dots , \min (x_n, y_n))\) |
xn ∨yn | \(\boldsymbol {x}_n \vee \boldsymbol {y}_n= (\max (x_1, y_1),\dots , \max (x_n, y_n))\) |
[x]+ | \(\max (x, 0)\) |
d •m | \(d_{\bullet m}=\sum _{i=1}^{m} d_i\) for \(d_1,\dots , d_m\in \mathbb {R}\) |
\(\mathscr {R}\) | Censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\) with censoring numbers R1, …, Rm |
\(\mathscr {C}^m_{m,n}\) | Set of admissible (progressive type II) censoring plans defined in (9.1) |
(γ1, …, γm) | \(\gamma _i=\sum _{j=i}^{m}(R_j+1)\), 1 ≤ i ≤ m, for a censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\) |
X1:m:n, …, Xm:m:n, \(X_{1:m:n}^{\mathscr {R}},\dots , X_{m:m:n}^{\mathscr {R}}\) | Progressively type II censored order statistics based on a sample X1, …, Xn and censoring plan \(\mathscr {R}\) |
\(\boldsymbol {X}^{\mathscr {R}}\) | \(\boldsymbol {X}^{\mathscr {R}}=(X_{1:m:n}^{\mathscr {R}},\dots , X_{m:m:n}^{\mathscr {R}})\) |
U1:m:n, …, Um:m:n | Uniform progressively type II censored order statistics |
\(X_{1:K:n}^{I}, \ldots , X_{K:K:n}^{I}\) | Progressively type I censored order statistics or progressively censored order statistics with fixed censoring times based on a sample X1, …, Xn |
\(\boldsymbol {X}^{I,\mathscr {R}}\) | \(\boldsymbol {X}^{I,\mathscr {R}}=(X_{1:K:n}^{I}, \ldots , X_{K:K:n}^{I})\) |
X1:n, …, Xn:n | Order statistics based on a sample X1, …, Xn |
Exp(μ, 𝜗) | Two-parameter exponential distribution with pdf \(f(t)=\frac {1}{\vartheta } \mbox{\textsf {e}}^{-(t-\mu )/\vartheta }\), t > μ |
Exp(𝜗) = Exp(0, 𝜗) | Exponential distribution with mean 𝜗 and pdf \(f(t)=\frac {1}{\vartheta } \mbox{\textsf {e}}^{-t/\vartheta }\), t > 0 |
\(F_{\exp }\) | cdf of standard exponential distribution Exp(1); \(F_{\exp }(t)=1- \mbox{\textsf {e}}^{-t}\), t ≥ 0 |
Wei(𝜗, β) | Weibull distribution with parameters 𝜗, β > 0 and pdf \(f(t)=\frac {\beta }{\vartheta }t^{\beta -1} \mbox{\textsf {e}}^{-t^\beta /\vartheta }\), t > 0 |
U(0, 1) | Uniform distribution on the interval (0, 1) |
χ2(r) | χ2-distribution with r degrees of freedom |
X ∼ F | X is distributed according to a cdf F |
\(X_1,\dots , X_n\overset {\text{iid}}\sim F\) | X1, …, Xn are independent and identically distributed according to a cdf F |
The second version of progressive censoring proposed by Cohen [5] is called progressive type II censoring which may be considered as the most popular version of progressive censoring. Here, the censoring times are induced by the lifetimes of the surviving units in the sense that the next withdrawal is carried out the first failure after the removal of items. Suppose the items are numbered by 1, …, n with lifetimes X1, …Xn and denote by the set \(\mathcal {R}_j\) the numbers of the items available before the jth removal. Then, the next removal time is defined by \(X_{j:m:n} = \min _{i\in \mathcal {R}_j} X_i\) (see Fig. 9.3), j = 1, …, m. Clearly, \(\mathcal {R}_1=\{1,\dots , n\}\) and X1:m:n = X1:n is given by the minimum of the lifetimes. Furthermore, \(|\mathcal {R}_j|=n-j+1 -\sum _{i=1}^{j-1}R_i=\gamma _j\), j = 1, …, m. The censoring times are iteratively constructed and random so that they are not known in advance (in contrast to the type I censoring scheme). However, the censoring plan and the sample size are fixed here. In fact, given n and m, the set of admissible progressive type II censoring plans is given by

Progressive type II censoring with censoring times X1:m:n < ⋯ < Xm:m:n and censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\)
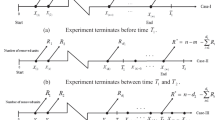
Based on the above fundamental models, further versions of progressive censoring have been proposed. Progressive type I interval censoring uses only partial information from a progressively type I censored life test. In particular, it is assumed that only the number Dj of items failing in an interval (Tj−1, Tj] is known (see Fig. 9.4 for Cohen’s progressive censoring with fixed censoring times). The corresponding situation under type I right censoring is depicted in Fig. 9.5.

Progressive interval censoring with censoring times T1 < ⋯ < Tm, initial censoring plan \(\mathscr {R}^0=(R_1^0,\dots , R_m^0)\), and random counters D1, …, Dm+1

Progressive type I interval censoring with censoring times T1 < ⋯ < Tm−1, time censoring at Tm, initial censoring plan \(\mathscr {R}^0=(R^0_1,\dots , R^0_{m-1})\), and random counters D1, …, Dm
The above censoring schemes have been extended in various directions. For instance, a wide class of models called progressive hybrid censoring has been generated by combining type I and type II censoring procedures. In type I progressive hybrid censoring, a type I censoring mechanism has been applied to progressively type II censored data X1:m:n, …, Xm:m:n by Childs et al. [8] [see also 9, 10], extending a model of [11] by introducing a threshold T. The resulting time censored data \( X^{h,I}_{j:m:n}=\min \{X_{j:m:n}, T\}\), j = 1, …, m, will be discussed further in Sect. 9.4.2. Considering the so-called extended progressively type II censored sample by dropping the right censoring (see (9.15)), that is, \(X_{1:m+R_m:n},\dots , X_{m+R_m:m+R_m:n}\), a type II progressively hybrid censored sample can be defined by the condition \(X_{K:m+R_m:n}\le T< X_{K+1:m+R_m:n}\), m ≤ K ≤ m + Rm. Further versions have been summarized in [12]. An extensive survey on (progressive) hybrid censoring schemes is provided in the recent monograph by [380].
Motivated by the Ng-Kundu-Chan modelintroduced in [13], adaptive progressive censoring schemes have been proposed by Cramer and Iliopoulos [14] and Cramer and Iliopoulos [15]. In these models, censoring plans and censoring times may be chosen adaptively according to the observed data. Such models are presented briefly in Sect. 9.4.3.
In most cases, progressive censoring is studied under the assumption that the underlying lifetimes X1, …, Xn are independent and identically distributed (iid) random variables. If not noted explicitly, all results presented in the following are based on this assumption. However, relaxations of this assumption have been made. For instance, [16] discussed the case of heterogeneous distributions, that is, Xi ∼ Fi, 1 ≤ i ≤ n, are independent random variables but may have a different cumulative distribution function (see also [17, 18]). Rezapour et al. [19, 20] assumed dependent underlying lifetimes. For a review, we refer to [1, Chapter 10].
1.2 Notation
Throughout, we use the following notation and abbreviations.
1.3 Organization of the Paper
In the following sections, we discuss the most popular versions of progressive censoring in detail, that is, progressive type II censoring (Sect. 9.2) and progressive type I censoring (Sect. 9.3). Further, progressive censoring with fixed censoring times is also addressed in Sect. 9.3. In Sect. 9.4, related data like progressive interval censoring, progressive hybrid censoring, and adaptive progressive censoring as well as applications in reliability and lifetime analysis are discussed. Due to their importance, we focus on exponentially and Weibull distributed lifetimes. Except when otherwise stated, the underlying lifetimes X1, …, Xn are supposed to be independent and identically distributed according to a cdf F, that is, \(X_1,\dots , X_n\overset {\text{iid}}\sim F\).
2 Progressive Type II Censoring
2.1 Probabilistic Results
Fundamental tools in studying properties of progressively type II censored order statistics are the joint pdf of X1:m:n, …, Xm:m:n and the quantile representation. The joint pdf of progressively type II censored order statistics X1:m:n, …, Xm:m:n based on an (absolutely continuous) cdf F with pdf f is given by
where \(\gamma _j=\sum _{i=j}^{m}(R_i+1)\) denotes the number of items remaining in the experiment before the jth failure, 1 ≤ j ≤ m. Notice that n = γ1 > ⋯ > γm ≥ 1. It is immediate from (9.2) that progressively type II censored order statistics are connected to the distributional model of generalized order statistics (see [21,22,23]) which covers progressively type II censored order statistics as a particular case (for details, see [1], Section 2.2).
2.1.1 Exponential Distributions
From (9.2), the pdf for an exponential population Exp(μ, 𝜗) can be directly obtained, that is, the pdf of exponential progressively type II censored order statistics \(\boldsymbol {X}^{\mathscr {R}} =(X_{1:m:n},\dots , X_{m:m:n})\) is given by
This expression is important in deriving, e.g., properties of exponential progressively type II censored order statistics as well as in developing statistical inference. As pointed out by Thomas and Wilson [24] (see also [25]), the normalized spacings \(S_j^{\mathscr {R}} =\gamma _j (X_{j:m:n}-X_{j-1:m:n})\), 1 ≤ j ≤ m, with X0:m:n = μ defined as left endpoint of support are iid random variables, that is (see [1], Theorem 2.3.2),
On the other hand, exponential progressively type II censored order statistics can be written in terms of their spacings yielding the identity
where X0:m:n = μ. This representation allows us to derive many properties of exponential progressively type II censored order statistics. For instance, using (9.3) and (9.4), the one-dimensional marginal pdfs and cdfs are given by (see also [26])
where \(a_{j,r} = \prod ^r_{\substack {i=1\\ i\neq j}} \frac {1}{\gamma _i-\gamma _j}\), 1 ≤ j ≤ r ≤ n. Representations of bivariate and arbitrary marginals can be found in [1, Section 2.4], (see also [27, 28]). Moreover, it follows from (9.4) that X1:m:n, …, Xm:m:n form a Markov chain, that is, for 2 ≤ r ≤ m,
Furthermore, \(X_{1:m:n} \overset {d}= \mbox{\textsf {Exp}}(\mu , \vartheta /\gamma _1)\). These representations allow direct calculation of moments. For instance, one gets
Further results on moments, e.g., higher order moments, existence of moments, bounds, and recurrence relations, can be found in [1] and the references cited therein.
2.1.2 Other Distributions
Probabilistic results for other distributions can be obtained from the pdf in (9.2) or, alternatively, from the results obtained for the exponential distribution and the following result due to [29, 30] (for a proof, see [1]). It shows that most of the distributional results can be obtained for a uniform distribution and then transformed to an arbitrary cdf F.
Theorem 9.2.1
Suppose X1:m:n, …, Xm:m:n and U1:m:n, …, Um:m:n are progressively type II censored order statistics based on a cdf F and a uniform distribution, respectively. Then,
Theorem 9.2.1, together with the representation of the joint pdf for uniform distributions, yields an expression for progressively type II censored order statistics based on an arbitrary cdf F, that is,
If F is absolutely continuous with pdf f, then the pdf is given by
Similar representations can be obtained for multiple progressively type II censored samples (see [1], p.41, [28, 31]). Log-concavity and unimodality properties of the distributions are studied in [32,33,34,35,36].
From (9.4), it follows that \(F_{\exp }(X_{r:m:n}) = 1-\prod _{j=1}^r \left (\mbox{\textsf {e}}^{-S_j^{\mathscr {R}}/\vartheta }\right )^{1/\gamma _j}\) with \(S_1^{\mathscr {R}},\dots , S_m^{\mathscr {R}}\) as in (9.3). Thus, \(U_j= \mbox{\textsf {e}}^{-S_j^{\mathscr {R}}/\vartheta }\), 1 ≤ j ≤ m, are independent uniformly distributed random variables. This yields the identity
of Ur:m:n as a product of independent random variables. Combining this expression with the quantile representation from Theorem 9.2.1, we arrive at the following representation [see also 37].
Theorem 9.2.2
Let X1:m:n, …, Xm:m:n be progressively type II censored order statistics from an arbitrary cdf F and \(U_1,\dots U_m \overset {\mathit{\text{iid}}}\sim \mathit{\mbox{\textsf {U}}}(0, 1)\). Then,
As has been noticed in [38], this representation provides an alternative method to simulate progressively type II censored order statistics from a cdf F (for a survey on simulation methods, see [1, Chapter 8]). Alternatively, one can also write
with \(Z_1,\dots , Z_m \overset {\text{iid}}\sim \mbox{\textsf {Exp}}(1)\). This result illustrates that X1:m:n, …, Xm:m:n form a Markov chain with transition probabilities
Further results on the dependence structure of progressively type II censored order statistics are available. For instance, [28] has shown that progressively type II censored order statistics exhibit the MTP2-property which implies that progressively type II censored order statistics are always positively correlated. The block independence property has been established by Iliopoulos and Balakrishnan [39]. In order to formulate the result, we introduce the number of progressively type II censored order statistics that do not exceed a threshold T, i.e., \(D=\sum _{j=1}^m \mathbb {I}_{(-\infty , T]}(X_{j:m:n})\). Then, the probability mass functionof D is given by the probabilities
Given d ∈{1, …, m − 1}, a cdf F, and a censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\), the block independence property is as follows: Conditionally on D = d, the random vectors (X1:m:n, …, Xd:m:n) and (Xd+1:m:n, …, Xm:m:n) are independent with
where Kd = (K1, …, Kd) is a random censoring plan on the Cartesian product  with probability mass function
with probability mass function
\(\kappa _d=\sum _{j=1}^d (1+K_j)\), and \(\eta _i(d)=\sum _{j=i}^d(k_j+1)\), 1 ≤ i ≤ d. Further:
-
1.
V1, …, Vn are iid random variables with right truncated cdf FT given by \(F_T(t)= \frac {F(t)}{F(T)}\), t ≤ T.
-
2.
\(W_1,\dots , W_{\gamma _d}\) are iid random variables with left truncated cdf GT given by \(G_T(t)=1-\frac {1-F(t)}{1-F(T)}\), t ≥ T.
The sample size κd of the progressively type II censored order statistics \(V_{1:d:\kappa _d}^{{\mathbf {K}}_{d}},\dots \), \(V_{d:d:\kappa _d}^{{\mathbf {K}}_{d}}\) is a random variable. The above representation means that the distribution of (X1:m:n, …, Xd:m:n), given D = d, is a mixture of distributions of progressively type II censored order statistics with mixing distribution \(p^{{\mathbf {K}}_{d}}\). It is well known that right truncation of progressively type II censored order statistics does not result in progressively type II censored order statistics from the corresponding right truncated distribution [see, e.g., 2]. This is due to the fact that those observations (progressively) censored before T could have values larger than T.
2.1.3 Connection to Order Statistics and Other Models of Ordered Data
Order statistics [see, e.g., 40, 41] can be interpreted as special progressively type II censored order statistics by choosing the censoring plan \(\mathscr {O}=(0,\dots , 0)\). Then, we have m = n and \(X_{j:n:n}^{\mathscr {O}}=X_{j:n}\), 1 ≤ j ≤ n. Furthermore, the censoring plan \(\mathscr {O}^*=(0,\dots , 0,R_m)\) with n = m + Rm yields \(X_{j:m:n}^{\mathscr {O}}=X_{j:m+R_m}\), 1 ≤ j ≤ m, leading to a type II right censored sample. Thus, all the results developed for progressively type II censored order statistics can be specialized to order statistics. Detailed accounts to order statistics are provided by Arnold et al. [40] and David and Nagaraja [41].
As mentioned above, progressively type II censored order statistics can be seen as particular generalized order statistics and sequential order statistics, respectively (see [21, 23, 37]). In this regard, results obtained in these models hold also for progressively type II censored order statistics by specifying model parameters and distributions suitably. For pertinent details, we refer to the references given above.
2.1.4 Moments
Many results on moments have been obtained for progressively type II censored order statistics (see, e.g., [1], Chapter 7). This discussion includes explicit results for selected distributions, e.g., exponential distributions (see (9.5)), Weibull, Pareto, Lomax, reflected power, and extreme value distributions. Further topics are existence of moments (see [42, 43]), bounds (see, e.g., [32, 44, 45]), recurrence relations (see, e.g., [27, 46]), and approximations (see, e.g., [47]). Furthermore, the accurate computation of moments has been discussed in [48] (see also [49]). It should be noted that an enormous number of papers have discussed moments as well as related recurrence relations for particular distributions.
2.1.5 Stochastic Orders and Stochastic Comparisons
Results on various stochastic orders of progressively type II censored order statistics have been mostly established in terms of generalized and sequential order statistics (see [1], Section 3.2). Therefore, the results can be applied to progressively type II censored order statistics by choosing particular parameter values. For information, we present definitions of the most important stochastic orders discussed for progressively type II censored order statistics. For a general discussion, we refer to [50, 51], and [52]. A review of results on multivariate stochastic orderings for generalized order statistics is provided in [53] (see also [1]).
Let X ∼ F, Y ∼ G be random variables and let f and g denote the respective pdfs. For simplicity, it is assumed that the supports are subsets of the set of positive values. In the following, we present some selected results on stochastic orderings under progressive type II censoring and provide references for further reading.
Stochastic Order/Multivariate Stochastic Order
-
(i)
X is said to be stochastically smaller than Y , that is, X ≤stY or F ≤stG, iff \(\overline {F}(x) \le \overline {G}(x)\) for all x ≥ 0.
-
(ii)
Let X = (X1, …, Xn)′, Y = (Y1, …, Yn)′ be random vectors. Then, X is said to be stochastically smaller than Y , that is, X ≤stY or FX ≤stFY, iff Eϕ(X) ≤ Eϕ(Y ) for all nondecreasing functions \(\phi :\mathbb {R}^n\longrightarrow \mathbb {R}\) provided the expectations exist.
Notice that, for n = 1, the definition of the multivariate stochastic order is equivalent to the (common) definition in the univariate case.
Belzunce et al. [54] has established the preservation of the stochastic order when the baseline distributions are stochastically ordered.
Theorem 9.2.3
Let \(\boldsymbol {X}^{\mathscr {R}}\) and \(\boldsymbol {Y}^{\mathscr {R}}\) be vectors of progressively type II censored order statistics from continuous cdfs F and G with censoring plan \(\mathscr {R}\), respectively. Then, for F ≤stG, \(\boldsymbol {X}^{\mathscr {R}} \le _{\textsf {st}} \boldsymbol {Y}^{\mathscr {R}}\).
A comparison in terms of the univariate stochastic order has been established by Khaledi [55] using the following partial ordering of γ-vectors (see [56, 57]). Let \(\mathscr {R}\) and \(\mathscr {S}\) be censoring plans with corresponding γ-values \(\gamma _i(\mathscr {R})=\sum _{k=i}^{m_1} (R_k+1)\) and \(\gamma _i(\mathscr {S})=\sum _{k=i}^{m_2} (S_k+1)\). For 1 ≤ j ≤ i,
iff
Theorem 9.2.4
Let F, G be continuous cdfs with F ≤stG and X ∼ F, Y ∼ G. Moreover, let \(\mathscr {R}\in \mathscr {C}_{m_1,n_1}^{m_1}, \mathscr {S}\in \mathscr {C}_{m_2,n_2}^{m_2}\) with \(m_1, m_2\in \mathbb {N}\) be censoring plans. Then:
-
(i)
\(X_{i:m_1:m_1}^{\mathscr {R}}\le _{\textsf {st}} Y_{i:m_1:m_1}^{\mathscr {R}}\), 1 ≤ i ≤ m1.
-
(ii)
If 1 ≤ j ≤ i and condition (9.7) holds, then \(X_{j:m_2:m_2}^{\mathscr {S}} \le _{\textsf {st}} Y_{i:m_1:m_1}^{\mathscr {R}}\).
Applications to stochastic ordering of spacings of progressively type II censored order statistics can be found in [58].
Failure Rate/Hazard Rate Order, Reversed Hazard Rate Order
-
(i)
X is said to be smaller than Y in the hazard rate order, that is, X ≤hrY or F ≤hrG, iff \(\overline {F}(x)\overline {G}(y) \le \overline {F}(y)\overline {G}(x) \) for all 0 ≤ y ≤ x.
-
(ii)
X is said to be smaller than Y in the reversed hazard rate order, that is, X ≤rhY or F ≤rhG, iff F(x)G(y) ≤ F(y)G(x) for all 0 ≤ y ≤ x.
For the hazard rate order, the ratio \(\frac {\overline {F}(x)}{\overline {G}(x)}\) is nonincreasing in x ≥ 0 where \(\frac {a}{0}\) is defined to be ∞. If F and G are absolutely continuous cdfs with pdfs f and g, respectively, then hazard rate ordering is equivalent to increasing hazard rates, that is,
For the reversed hazard rate order, the ratio \(\frac {F(x)}{G(x)}\) is nonincreasing in x ≥ 0, where \(\frac {a}{0}\) is defined to be ∞.
Results for (multivariate) hazard rate orders of progressively type II censored order statistics have been obtained by Belzunce et al. [54], Khaledi [55], and Hu and Zhuang [59]. For instance, replacing the stochastic order by the hazard rate order in Theorem 9.2.4, an analogous result is true (see [1, Theorem 3.2.3]).
Likelihood Ratio Order/Multivariate Likelihood Ratio Order
-
(i)
X is said to be smaller than Y in the likelihood ratio order, that is, X ≤lrY or F ≤lrG, iff f(x)g(y) ≤ f(y)g(x) for all 0 ≤ y ≤ x.
-
(ii)
Let X = (X1, …, Xn)′, Y = (Y1, …, Yn)′ be random vectors with pdfs fX and fY. Then, X is said to be smaller than Y in the multivariate likelihood ratio order, that is, X ≤lrY or FX ≤lrFY, iff
$$\displaystyle \begin{aligned} f^{\boldsymbol{X}}(\boldsymbol{x}_n) f^{\boldsymbol{Y}}( \boldsymbol{y}_n) \le f^{\boldsymbol{X}}(\boldsymbol{x}_n \wedge \boldsymbol{y}_n) f^{\boldsymbol{Y}}(\boldsymbol{x}_n \vee \boldsymbol{y}_n) \end{aligned}$$for all \(\boldsymbol {x}=(x_1,\dots , x_n)', \boldsymbol {y}=(y_1,\dots , y_n)'\in \mathbb {R}^n\).
The (multivariate) likelihood ratio order has been discussed, e.g., by Korwar [60], Hu and Zhuang [59], Cramer et al. [61], Belzunce et al. [54], Zhuang and Hu [62], Balakrishnan et al. [63], Sharafi et al. [64], and Arriaza et al. [65]. The following result is due to [60] (see [59] for generalized order statistics).
Theorem 9.2.5
Let \(\mathscr {R}\in \mathscr {C}_{m_1,n_1}^{m_1}, \mathscr {S}\in \mathscr {C}_{m_2,n_2}^{m_2}\) with \(m_1, m_2\in \mathbb {N}\) be censoring plans and \(X_{j:m_2:m_2}^{\mathscr {S}} , X_{i:m_1:m_1}^{\mathscr {R}}\) be progressively type II censored order statistics from the same absolutely continuous cdf F. If 1 ≤ j ≤ i and \(\gamma _k(\mathscr {R})\le \gamma _k(\mathscr {S})\), k = 1, …, j, then \(X_{j:m_2:m_2}^{\mathscr {S}} \le _{\textsf {lr}} X_{i:m_1:m_1}^{\mathscr {R}}\).
Comparisons of vectors of progressively type II censored order statistics (generalized order statistics) with different cdfs and different censoring plans have been considered in [54]. In particular, they found the following property.
Theorem 9.2.6
Let \(X_{i:m:n}^{\mathscr {R}}, Y_{i:m:n}^{\mathscr {R}}\), 1 ≤ i ≤ m ≤ n, be progressively type II censored order statistics from absolutely continuous cdfs F and G, respectively, with F ≤lrG and censoring plan \(\mathscr {R}\). Then, \(X_{i:m:n}^{\mathscr {R}}\le _{\textsf {lr}} Y_{i:m:n}^{\mathscr {R}}\), 1 ≤ i ≤ m.
Ordering of p-spacings is discussed in [54, 66,67,68].
Dispersive Order
X is said to be smaller than Y in the dispersive order, i.e., X ≤dispY or F ≤dispG, iff F←(x) − F←(y) ≤ G←(x) − G←(y) for all 0 < y < x < 1.
Results for the (multivariate) dispersive order are established in [55, 69,70,71]. For instance, [55] has shown a result as in Theorem 9.2.4 for the dispersive order provided that the cdf F has the DFR-property. Belzunce et al. [54] have shown that \(\boldsymbol {X}^{\mathscr {R}} \le _{\textsf {disp}} \boldsymbol {Y}^{\mathscr {R}}\) and that \(X_{i:m:n}^{\mathscr {R}}\le _{\textsf {disp}} Y_{i:m:n}^{\mathscr {R}}\), 1 ≤ i ≤ m, when F ≤dispG.
Further orderings like mean residual life, total time on test, and excess wealth orders have also been discussed (see [72,73,74,75]). Results for the increasing convex order of generalized order statistics have been established in [76]. Orderings of residual life are discussed in [77, 78]. Stochastic orderings of INID progressively type II censored order statistics have been studied in [79].
2.1.6 Ageing Notions
Ageing properties have also been studied for progressively type II censored order statistics. For general references on ageing notions and their properties, we refer to, e.g., [80,81,82]. Results have been obtained for various ageing notions, e.g., increasing/decreasing failure rate (IFR/DFR), increasing/ decreasing failure rate on average (IFRA/DFRA), and new better/worse than used (NBU/NWU). Fundamental results on progressively type II censored order statistics for the most common ageing notions are mentioned subsequently.
IFR/DFR
A cdf F is said to be IFR (DFR) iff the ratio \(\frac {F(t+x)-F(t)}{1-F(t)}\) is increasing (decreasing) in x ≥ 0 for all t with F(t) < 1.
If F exhibits a pdf then the IFR-/DFR-property means that the hazard rate function λF = f∕(1 − F) is increasing (decreasing).
IFRA/DFRA
A cdf F is said to be IFRA (DFRA) iff, for the hazard function \(R=-\log \overline {F}\), the ratio R(x)∕x is increasing (decreasing) in x > 0.
NBU/NWU
A cdf F is said to be NBU (NWU) iff \(\overline {F}(t+x)\le (\ge ) \overline {F}(t)\overline {F}(x)\) for all x, t ≥ 0.
The IFR- and IFRA-property of progressively type II censored order statistics have been investigated in [33]. It has been shown that all progressively type II censored order statistics are IFR/IFRA provided that the baseline cdf F is IFR/IFRA. The respective result for the NBU-property as well as further results can be found in [83] in terms of sequential order statistics (see also [84]). Preservation properties are presented in [23], e.g., it has been proved that the DFR-property is preserved by spacings (see also [21]). The reversed hazard rate has been studied in [85]. Belzunce et al. [86] considered multivariate ageing properties in terms of nonhomogeneous birth processes and applied their results to generalized order statistics. A restriction to progressive censoring shows that progressively type II censored order statistics \(\boldsymbol {X}^{\mathscr {R}}\) are M-IFR if F is an IFR-cdf. Moreover, \(\boldsymbol {X}^{\mathscr {R}}\) is multivariate Polya frequency of order 2 (MPF2) if the pdf of F is log-concave. Further notions of multivariate IFR/DFR and its applications to generalized order statistics have been discussed in [87]. The connection of ageing properties and residual life has been considered in [88] in terms of generalized order statistics.
2.1.7 Further Topics
The following probabilistic topics have also been discussed in progressive type II censoring, but, for brevity, we only mention them here briefly. Many publications deal with various kinds of characterizations of probability distributions [see, e.g., 1, Chapter 3.1]. Limit theorems have also been established imposing different assumptions on the censoring plans and distributions. For instance, [89] considered normal approximations using an approach inspired by Hoadley [90]. Cramer [91] discussed extreme value analysis which includes extreme, central, and intermediate progressively type II censored order statistics [see also 92, 93]. Counting process approaches in combination with limiting distributions have been extensively discussed in [94] [see also 95, 96]. Hofmann et al. [97] has discussed a block censoring approach.
Information measures have also found some interest [see, e.g., 1, Chapter 9]. Results on the Fisher information have been established in, e.g., [98,99,100,101,102]. A detailed approach in terms of the more general model of generalized order statistics is discussed in [103, 104]. Asymptotic results are provided in [105]. Entropy-type measures are investigated in [106,107,108,109,110]. Kullback-Leibler-related measures are addressed in [106, 107, 111,112,113,114,115]. Pitman closeness for progressively type II censored data has been considered in, e.g., [116,117,118,119].
Concomitants for progressively type II censored order statistics have been addressed [120,121,122] (see also [1]).
As already mentioned above, progressive type II censoring has also been discussed under nonstandard conditions. Specifically, the underlying random variables X1, …, Xn are supposed to be distributed according to some (multivariate) distribution function \(F^{X_1,\dots , X_n}\). A general mixture representation of the distribution in terms of distributions of order statistics has been established by Fischer et al. [17]. Assuming independence but possibly different marginals, [16] found representations of the joint density functions. Inference in such a model has been discussed in [123]. Given a copula of the lifetimes X1, …, Xn, [19, 20] addressed dependent random variables. Progressive censoring of random vectors has been discussed in [124] [see also 125, 126].
2.2 Inference
Inference for progressively type II censored data has been widely discussed in the literature. Most of the material is devoted to parametric inference. In the following, we present a selection of results for exponential and Weibull distribution. In addition, references to other distributions are provided. A standard reference for all these results is [1]. If nothing else is mentioned, we discuss inference on a single progressively type II censored sample X1:m:n, …, Xm:m:n.
2.2.1 Point Estimation
The most popular parametric estimation concepts applied to progressively type II censored data are linear, likelihood, and Bayesian estimation. Assuming a location-scale family of distributions
with a known cdf F, a progressively type II censored sample \(\boldsymbol {X}^{\mathscr {R}}\) from Fμ,𝜗 can be written as a linear model:
where \(E\boldsymbol {W}^{\mathscr {R}}=0\), \( \operatorname {\mathrm {\text{Cov}}}(\boldsymbol {W}^{\mathscr {R}})= \vartheta ^2\Sigma \) denotes the variance-covariance matrix of \(\boldsymbol {W}^{\mathscr {R}}\), \(\Sigma = \operatorname {\mathrm {\text{Cov}}}(\boldsymbol {Y}^{\mathscr {R}})\), B = [1, b] is the known design matrix, and θ = (μ, 𝜗)′ is the (unknown) parameter vector. Notice that the distribution of \(\boldsymbol {Y}^{\mathscr {R}}\) is parameter free, and it depends only on the standard member F.
Thus, as pointed out in [1, Chapter 11], least squares estimation can be applied in order to obtain the best linear unbiased estimator (BLUE) of θ (see, e.g., [127]) as
Obviously, the estimator can be applied when the first and second moments of \(\boldsymbol {X}^{\mathscr {R}}\) can be computed (at least numerically). This has been done for many distributions. For instance, given exponential distributions, explicit expressions result since the respective moments have a closed form expression (see, e.g., [128,129,130]). For m ≥ 2, the BLUEs \(\widehat \mu _{\textsf {LU}}\) and \(\widehat \vartheta _{\textsf {LU}}\) are given by
Further results for particular distributions are summarized in [1, Chapter 11]. In case of Weibull distributions, the model can be transformed to a linear model from extreme value distributions by a log-transformation of the data. Thus, estimators of the Weibull parameters can be obtained by using the BLUEs of the transformed parameters when the data results from an extreme value distribution. Results in this direction can be found in [24, 131, 132]. The mixture representation in terms of order statistics can also be utilized to compute the moments (see [17, 133, 134]).
Similar to least squares estimation, one can consider the best linear equivariant estimators (BLEEs). This problem has been discussed, e.g., by Balakrishnan et al. [135], Burkschat [136] (see also [137] for the best linear (risk) invariant estimators).
The most popular approach to the estimation problem is likelihood inference since the joint pdf given in (9.2) leads to tractable expressions in many situations (see [1, Chapter 12]). For generalized Pareto distributions, explicit expressions result. For exponentially distributed lifetimes with mean 𝜗, the MLE is given by
which is also the BLUE in this model. The representation in terms of the spacings \(S_1^{\mathscr {R}},\dots , S_m^{\mathscr {R}}\) is important in the analysis of the MLE since it enables easy derivation of the exact distribution of the MLE. For two-parameter exponential distribution, explicit expressions for the MLEs are also available. For Weibull distribution Wei(𝜗, β), the MLE \((\widehat \vartheta ,\widehat \beta )\) of (𝜗, β) uniquely exists (see [138]). They are given by \(\widehat \vartheta =\frac {1}{m}\sum _{j=1}^m(R_j+1)X_{j:m:n}^{\widehat \beta }\) where, for the observed data Xj:m:n = xj, 1 ≤ j ≤ m, the estimate \(\widehat \beta \) is the unique solution of the equation:
The above equation has to be solved numerically, e.g., by the Newton-Raphson procedure. Ng et al. [98] proposed an EM-algorithm approach to compute the MLE (see also [139]) which, suitably adapted, has successfully been applied for other distributions, too. Results on likelihood inference for other distributions can be found in [1, Chapter 12]. Recent references for other distributions are, e.g., [140] (Rayleigh), [141] (modified Weibull), [142, 143] (Lindley), and [144] (Gompertz).
For some distributions, related concepts like modified and approximate maximum likelihood estimation have been discussed. The latter concept due to [145] has been successfully applied in many cases, e.g., for extreme value distribution [146] and Weibull distributions [147] (see also [1, Chapter 12.9.2]).
Bayesian inference has also been discussed considerably for progressively type II censored data under various loss functions (see [1, Chapter 15]). Under squared error loss function, the Bayes estimate of the scale parameter α = 1∕𝜗 of an exponential lifetime is given by the posterior mean
given a gamma prior
with hyperparameters a, b > 0. Using a similar inverse gamma prior, [148] obtained the corresponding Bayes estimator of 𝜗 as
where X0:m:n = 0. Two-parameter Weibull distribution with appropriate priors has been discussed in [149] and [150]. For further results, we refer to [1, Chapter 15].
Using a counting process approach, [94] and [151] have addressed nonparametric inference with progressively type II censored lifetime data for the population cdf F and the survival function. For instance, they presented a Nelson-Aalen-type estimator and a smoothed hazard rate estimator as well as asymptotic results for these estimators. A survey is provided in [1, Chapter 20].
2.2.2 Statistical Intervals
Various kinds of statistical intervals have been discussed for progressively type II censored data. In particular, confidence intervals have been studied under different assumptions. In some situations, exact confidence intervals with level 1 − α can be constructed using properties of the estimators. For exponential distribution, it follows from the independence of the spacings (9.3) that the distribution of the MLE \(\widehat \vartheta _{\textsf {MLE}}\) in (9.8) can be obtained as \(2m\widehat \vartheta _{\textsf {MLE}}/\vartheta \sim \chi ^2 (2m)\). Hence, \(\left [\frac {2m\widehat {\vartheta }_{\textsf {MLE}}}{\chi ^2_{1-\alpha /2}(2m)}, \frac {2m\widehat {\vartheta }_{\textsf {MLE}}}{\chi ^2_{\alpha /2}(2m)}\right ]\) is a two-sided (1 − α)-confidence interval for 𝜗. Similarly, one may obtain confidence intervals and confidence regions for the two-parameter exponential distribution (see [1, Chapter 17], [152]). For Wei(𝜗, β)-distribution, [153] has obtained confidence intervals for the scale and shape parameters of a Wei(𝜗, β)-distribution using a transformation to exponential data and the independence of the spacings. An exact (1 − α)-confidence interval for β is given by
where \( \psi ^*(\boldsymbol {X}^{\mathscr {R}}, \omega )\) is the unique solution for β of the equation
Wang et al. [154] established a confidence interval for β using the pivotal quantity
They showed that an exact (1 − α)-confidence interval for β is given by

where \(\tau ^{-1}(\boldsymbol {X}^{\mathscr {R}}, \omega )\) is the unique solution for β of the equation \( \tau (\boldsymbol {X}^{\mathscr {R}}, \beta )=\omega \) with ω > 0. A simultaneous confidence region has been obtained by Wu [153]. The same ideas may be applied to Pareto distributions (see [155,156,157,158]). In [158, 159], and [160], optimal confidence regions are discussed (for a location-scale family, see [161]). Nonparametric confidence intervals for quantiles have been discussed in [133] (for multiple samples, see [162, 163]). Exact confidence intervals based on conditional inference have been proposed for progressively type II censored data by Viveros and Balakrishnan [25] (see also [2, Chapter 9]). In particular, exponential, extreme value, log-gamma distributions, Pareto, and Laplace have been discussed. Asymptotic confidence intervals have been applied in various situations by assuming asymptotic normality of some pivotal quantities. The asymptotic variance is estimated by the observed likelihood. Generalized confidence intervals for distribution parameters using Weerahandi’s approach (see [164]) can be found in [154].
Furthermore, prediction intervals and tolerance intervals have been discussed. References for the latter concept are [134, 162, 165, 166]. The highest posterior density credible intervals have been established in [148, 149], and [167].
2.2.3 Prediction
Prediction problems have been discussed for both point and interval prediction, respectively (see [1, Chapter 16 & 17.4]). In particular, they have been considered for:
-
(I)
Progressively censored failure times at censoring steps 1, …, m; in particular, the progressively censored ordered failure times \(W_{j,1:R_j},\dots , W_{j,R_j:R_j}\), 1 ≤ j ≤ m, are predicted.
-
(II)
For future observations in the same sample (this is a particular case of (I) in the sense that the lifetimes of the items removed in the final progressive censoring step are predicted).
-
(III)
Observations of an independent future sample from the same population.
Problem (I) has been considered by Basak et al. [168] (the special case \(W_{m,1:R_m},\dots , W_{m,R_m:R_m}\) is addressed by Balakrishnan and Rao [169]). Given exponential lifetimes with unknown mean 𝜗, they found that the best unbiased predictor of the rth ordered progressively censored lifetime \(W_{j,r:R_j}\) in step j is given by
where \(\widehat \vartheta _{\textsf {MLE}}\) is the MLE of 𝜗. Further results have been obtained for extreme value distribution [168], normal distribution [170], and Pareto distribution [171]. Prediction intervals based on various prediction concepts (e.g., best linear unbiased prediction, maximum likelihood prediction, and median unbiased prediction) have been obtained for exponential and extreme value distributions in [168]. Normal and Pareto distributions are considered in [170] and [171], respectively. Generalized exponential and Rayleigh distributions are discussed in [172] and [173], respectively.
The best linear unbiased/equivariant prediction of future observations Xr+1:m:n, …, Xm:m:n, based on the first r progressively type II censored order statistics X1:m:n, …, Xr:m:n, has been discussed in [136]. The same problem has been investigated in a Bayesian framework, too, and the corresponding results can be found in [148] and [152]. Prediction intervals for a general class of distributions, including exponential, Weibull, and Pareto distributions, can be seen in [174]. Results for Weibull distribution have also been presented in [175].
Problem (III) has mainly been discussed in a Bayesian framework. Relevant references are [141, 143, 175,176,177,178,179,180,181,182,183]. Results on nonparametric prediction of future observations can be found in [134, 162, 184].
2.2.4 Testing
Statistical tests under progressive censoring have mainly been discussed in the context of precedence-type testing, homogeneity, and goodness-of-fit tests. A good source for precedence-type tests is [185] (see also [1, Chapter 21]). Particular results can be found in [186] and [187]. Homogeneity tests based on several progressively type II censored samples have been addressed in [188]. For related results in terms of sequential order statistics, we refer to [23]. A review on goodness-of-fit-tests for exponential distributions, including a power study, has recently been presented in [114] (see also [1, Chapter 19]). Goodness-of-fit tests for location-scale families are discussed in, e.g., [189]. Tests have been constructed by means of spacings and deviations from the uniform distribution as well as from the empirical distribution function (e.g., Kolmogorov-Smirnov-type statistics; see [190, 191]). Furthermore, information measures like (cumulative) Kullback-Leibler information and entropy have been used (see [106, 111, 113]).
2.3 Experimental Design
Initiated by Balakrishnan and Aggarwala [2, Chapter 10], problems of experimental design have been discussed extensively for progressively type II censored lifetime experiments. A review on various results and optimality criteria has been provided by Balakrishnan and Cramer [1, Chapter 26]. Assuming that progressive type II censoring is carried out by design, the experimenter has to choose an appropriate censoring plan prior to the start of the experiment. Thus, assuming the sample size n and the number m of observed items as fixed, the censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\) has to be chosen in an optimal way. Burkschat [58] has formulated the problem as a mathematical optimization problem in a very general way (see also [192, 193]), that is, given a criterion \(\psi : \mathscr {C}^m_{m,n}\longrightarrow \mathbb {R}\), a censoring plan \(\mathscr {S}\) is said to be ψ-optimal if
where \(\mathscr {C}^m_{m,n}\) is given in (9.1). Various optimality criteria have been used, e.g., probabilistic criteria [58], variance criteria [2, 139, 192,193,194], information measures like Fisher information [100, 104, 105, 139] and entropy [107, 195, 196], optimal estimation of quantiles [139, 149, 197, 198], Pitman closeness [117], and optimal block censoring [97]. A detailed review is provided in [1, Chapter 26].
It turns out that the optimal designs depend heavily on both the optimality criterion to be used and the distributional assumption made. Due to the large number of admissible censoring plans, i.e., \(\binom {n-1}{m-1}\) (see [1, p. 531]), [199] proposed a variable neighborhood search algorithm to identify optimal plans in a reasonable time. It should be mentioned that the so-called one-step censoring plans turn out to be optimal in many cases. This means that progressive censoring is carried out only at one failure time, whereas at the other failure times no censoring occurs. Such plans are discussed in [100, 102], and [200]. Recently, restrictions on censoring plans have been addressed in [49].
2.4 Connection of Progressive Type II Censoring to Coherent Systems
Cramer and Navarro [201] established a connection of failure data from coherent systems to progressively type II censored order statistics. They showed that the joint distribution of the component failures (Y(1), …, Y(m)) (given the number M = m of component failures leading to the system failure) in a coherent system can be seen as a mixture of progressively type II censored order statistics:
where \(\mathcal {S}_m\) denotes the set of all admissible censoring plans r = (r1, …, rm) of length m. The probabilities \(P(\mathscr {R}=\boldsymbol {r}|M=m)\) depend only on the structure of the coherent system and therefore can be calculated directly [see also 202]. Utilizing this connection, inference for coherent system data can be carried out using inferential methods for progressively type II censored data. For exponentially distributed lifetimes as well as PHR models, we refer to [201], while Weibull distribution is discussed in [203].
Cramer and Navarro [202] applied this connection to define a progressive censoring signature (PC-signature)which can be used to compare the lifetimes of different coherent systems with respect to stochastic orderings.
2.5 Connection of Progressive Type II Censoring to Ordered Pooled Samples
In (9.9), a mixture of some random variables in terms of progressively type II censored order statistics has been established. A similar mixture representation has been found in the context of pooling two independent type II censored samples. Let X1:n, …, Xr:n and Y1:m, …, Ys:m be independent right censored samples from a uniform distribution with sample sizes n and m, respectively. Without loss of any generality, let r ≥ s and denote the ordered pooled sample by W(1) ≤⋯ ≤ W(r+s). Then, [162] showed that the joint distribution of the ordered pooled sample W(1), …, W(r+s) is a mixture of uniform progressively type II censored order statistics, that is,
with appropriately chosen discrete probability distributions π0, …, πr−1 and \(\pi _0^*,\dots , \pi _{s-1}^*\) and two-step censoring plans \(\mathscr {R}_j\), 0 ≤ j ≤ r − 1 and \(\mathscr {R}_j^*\), 0 ≤ j ≤ s − 1, respectively [162], [1, Section 17.1.6]. An extension to multiple pooled samples is presented in [204].
3 Progressive Type I Censoring
As mentioned in Sect. 9.1, progressive type I censoring as introduced in [5] does not have a prefixed termination time, that is, the last censoring time Tm (see Fig. 9.1) has not been considered as termination time. As pointed out in [6], inference for this model has been considered up to the early 1990s (see, e.g., [5, 205,206,207,208,209], and the monographs by Nelson [210] and Cohen and Whitten [211]). In the following, we call this censoring scheme Cohen’s progressive censoring with fixed censoring times. The understanding of Tm as a time censoring point seems to have changed after the publication of the monograph [2] [see also 7]. Since then, almost all publications dealing with progressive type I censoring interpret Tm as the termination time of the experiment.
3.1 Distributional Results for Cohen’s Progressive Censoring with Fixed Censoring Times
We start with a short review of progressive censoring with fixed censoring times as presented in [6]. In principle, the procedure is quite similar to progressive type II censoring, but the censoring times are fixed in advance. Due to this property, we have to distinguish the initially planned censoring plan \(\mathscr {R}^0 = (R_1^0, \ldots , R_{m}^0)\) and the effectively applied censoring plan \(\mathscr {R} = (R_1, \ldots , R_{m})\) (see [1, 2]) where
with \(m, n\in \mathbb {N}\) and \(0\le R_j\le R_j^0\), 1 ≤ j ≤ m, and \(\mathscr {C}^{m}_{l,n}\) denotes the set of admissible censoring plans. As mentioned in the introduction, the censoring times of a progressively type I censored life test are prefixed, and the number of observations is random. Thus, we get a sample \(X_{1:K:n}^{I} \leq \cdots \leq X_{K:K:n}^{I}\) with random censoring plan \(\mathscr {R}\) and random sample size K. Notice that the important difference between progressive censoring with fixed censoring times and progressive type I censoring is the fact that we can ensure a minimum number of observations, that is, \(K\ge n - R_{\bullet m}^0 \geq n - (n - l) = l\). Moreover, it is possible to observe values exceeding the threshold Tm. Progressive type I censoring can be interpreted as a type I hybrid version of progressive censoring with fixed censoring times (see Sect. 9.4.2). Denoting the number of observations in the intervals
by the random variables D1, D2, …, Dm, Dm+1 and by d1, …, dm+1 their realizations, the effectively applied censoring numbers are given by
where n − d•i − R•i−1 equals the number of units still remaining in the experiment before the ith withdrawal at time Ti. Notice that Dm+1 is a (deterministic) function of D1, …, Dm, i.e., Dm+1 = n − D•m − R•m. Then, the set
denotes the support of (D1, …, Dm+1) for a progressively censored life test with fixed censoring times.
Similarly to Theorem 9.2.1, we get the following quantile representation.
Theorem 9.3.1
Suppose \(X_{1:K:n}^{I} \leq \cdots \leq X_{K:K:n}^{I}\) and \(U_{1:K:n}^{I} \leq \cdots \leq U_{K:K:n}^{I}\) are progressively censored order statistics with fixed censoring times based on a continuous cdf F and a standard uniform distribution, respectively. The censoring times are given by T1, …, Tm and F(T1), …, F(Tm), respectively. Then,
Assuming \(X_1, \ldots , X_n \overset {\text{iid}}\sim F\) with an absolutely continuous cdf F and a pdf f, Tm+1 = ∞, and Rm+1 = 0, the joint pdf \(f^{\boldsymbol {X}^{I},\boldsymbol {D}_{m+1}}\) of \(\boldsymbol {X}^{I,\mathscr {R}}=(X_{1:K:n}^{I}, \ldots , X_{K:K:n}^{I})\) and Dm+1 = (D1, …, Dm+1) is given by
for \(\boldsymbol {d}_{m+1} \in \mathfrak {D}_{(m+1)}\) with k = d•m+1 and x1 ≤⋯ ≤ xk. Clearly, (9.10) can be rewritten as
which illustrates the structural similarities to the pdf under progressive type II censoring given in (9.2). Notice that the value of D(m+1) is defined uniquely by \(\boldsymbol {X}^{I,\mathscr {R}}=(X_{1:K:n}^{I}, \ldots , X_{K:K:n}^{I})\).
The joint probability mass function \(p^{\boldsymbol {D}_{m+1}}\) of Dm+1 is given by
Further, the conditional density function of \(\boldsymbol {X}^{I,\mathscr {R}}\), given Dm+1, is given by
for \(\boldsymbol {d}_{m+1} \in \mathfrak {D}_{(m+1)}\) with m = d•m+1 and x1 ≤⋯ ≤ xk. \(f^{(j)}_{1 \ldots d_j:d_j}\) denotes the density function of order statistics \(X^{(j)}_{1:d_j}, \ldots , X^{(j)}_{d_j:d_j}\) from the (doubly) truncated cdf F in the interval (Tj−1, Tj].
As for progressive type II censoring, the conditional block independence of progressively censored order statistics with fixed censoring times holds which for progressive type I censoring and progressive type II censoring has first been established by Iliopoulos and Balakrishnan [39]. It follows directly from the joint pdf. Conditionally on (D1, …, Dm+1) = (d1, …, dm+1), the progressively censored order statistics with fixed censoring times are block independent, that is, the random vectors
are independent with
where \(X^{(j)}_{1:d_j}, \ldots , X^{(j)}_{d_j:d_j}\) are order statistics from the (doubly) truncated cdf F in the interval (Tj−1, Tj], j ∈{1 ≤ i ≤ k∣di > 0}.
3.2 Distributional Results for ProgressiveType I Censoring
Since progressive type I censoring results from Cohen’s progressive censoring model with fixed censoring times by interpreting the final censoring time Tm as a threshold or termination point, the respective sample results from \(X_{1:K:n}^{I} \leq \cdots \leq X_{K:K:n}^{I}\) is given by \(\boldsymbol {X}^{I,\mathscr {R},T_m}=(X_{1:K:n}^{I} ,\dots , X_{D_{\bullet m}:K:n}^{I})\). Notice that this sample may result in an empty sample when all items are either progressively censored at T1, …, Tm−1 or right censored at Tm. Thus, no failures have been observed due to the time censoring at Tm. As a consequence, inferential results are often obtained and discussed subject to the assumption that at least one failure has been observed, that is, D•m ≥ 1 which happens with probability
Then, the distributional results presented before can be applied to progressive type I censoring. For instance, the quantile representation in Theorem 9.3.1 holds, too. The pdf of \(\boldsymbol {X}^{I,\mathscr {R},T_m}\) and Dm can be seen as a marginal pdf of (9.10) with an appropriate restriction on the domain. This leads to the pdf
for \(\boldsymbol {d}_m\in \mathfrak {D}_{(m)}\) with k = d•m ≥ 1 and x1 ≤⋯ ≤ xk ≤ Tm (see [1, p. 121]). Notice that Rm is defined differently in comparison with (9.10).
Apart from the above presented results, almost no probabilistic results seem to be available for (Cohen’s) progressively type I censored order statistics. Obviously, this is caused by the problems due to the random sample size K and the random censoring plan \(\mathscr {R}\). Nevertheless, numerous inferential results have been obtained.
3.3 Inference
Most of the results established in progressive type I censoring are connected to likelihood inference. Since the likelihood functions are given by the joint pdfs (9.10) and (9.12), respectively, the MLEs can be obtained by direct optimization. In the following, we present only the progressive type I censoring model (with time censoring). Similar results can be obtained for Cohen’s progressive censoring with fixed censoring times model (see, e.g., [6]). A summary with more details is provided in [1, Chapter 12]. Notice that, due to the similarity of the likelihood function to the progressive type II censoring case, the computation of MLEs proceeds quite similarly to this case. In particular, explicit expressions result in the same cases, and the likelihood equations are similar (replace the censoring time Ti in progressive type I censoring by the observed failure time Xi:m:n in progressive type II censoring; cf. (9.8) and (9.13)). For exponentially distributed lifetimes with mean 𝜗, one gets the MLE as
Although the structure is similar to the MLE under progressive type II censoring, the distribution of the estimator is quite complicated. Using a moment generating function approach, [212] established the conditional pdf of \(\widehat \vartheta ^{I}_{\textsf {MLE}}\), given D•m ≥ 1, as a generalized mixture of (shifted) gamma distributions (for a direct approach under progressive censoring with fixed censoring times, see [6]). Establishing the stochastic monotonicity of the (conditional) survival function by the three monotonicity lemmas (see also [212,213,214]), constructed exact (conditional) confidence intervals for 𝜗 using the method of pivoting the cdf (see [215,216,217]). A multi-sample model has been studied in [218] who presented an alternate representation of the pdf in terms of B-spline functions. Two-parameter exponential distribution Exp(μ, 𝜗) has been considered, e.g., in [211, 219], and [220]. Cohen [219] proposed also modified MLEs. Weibull distribution has been discussed in [205, 219, 221, 222], and [2]. Explicit expressions for the MLEs are not available, and the estimates have to be computed by numerical procedures. Balakrishnan and Kateri [138] have established the existence and uniqueness of the MLEs. Three-parameter Weibull distributions are considered in [206, 208], and [223]. Further distributions considered are, e.g., extreme value distribution [219], normal distribution [5], Burr-XII distribution [209], and logistic distribution [224].
4 Sampling Models Based on Progressively Censored Data
Progressively type I and type II censored data have been considered as a basis for inferential purposes in various models. In the following, we sketch some of these applications and provide some recent references.
4.1 Progressive (Type I) Interval Censoring
In progressive type I censoring, the number of observations observed between censoring times is random. It is assumed that only these numbers are observed (see Fig. 9.5), whereas the exact values of the failure times are not observed. This kind of data has been introduced in [7] (see also [1, Chapter 12]) assuming an absolutely continuous cdf Fθ. This yields the likelihood function (cf. (9.11))
where \(\boldsymbol {\theta }=(\theta _1,\dots , \theta _p)'\in \Theta \subseteq \mathbb {R}^p\) denotes the parameter vector and d1, …, dm are realizations of the number of observed failures D1, …, Dm. T0 = −∞ < T1 < ⋯ < Tm are the censoring times, and \(\mathscr {R}=(R_1,\dots , R_m)\) is the effectively applied censoring plan.
Inferential results have been established for various distributions. Asymptotic results for MLEs with general distribution have been established in [225]. Exponential distribution has been discussed in [7] and [226]. For (inverse) Weibull distribution, we refer to [226, 227], and [228]. Further distributions considered are generalized exponential distributions [228,229,230], generalized Rayleigh distribution [231], gamma distribution [232], and Burr-XII [233]. Further examples are given in [1, Chapter 18].
Under progressive type I censoring, the optimal choice of both inspection times and censoring proportions has been addressed by many authors [1, Chapter 18.2 & 18.3]. Other relevant references in this direction are [225, 233,234,235,236,237,238,239,240,241].
4.2 Progressive Hybrid Censoring
In progressive hybrid censoring, progressive type II censored data is subject to, e.g., additional time censoring at some threshold T. There are many variations available in the literature so far. For reviews, see [242], [1, Chapter 5 & 14], [12, 243, 244] and the recent monograph [380]. For illustration, we sketch the idea of the two basic hybrid censoring models under progressive censoring. Let \(D= \sum _{i=1}^m \mathbb {I}_{(-\infty , T]}(X_{i:m:n})\) denote the total number of observed failures. As in [10], we perceive the data with possibly less than m observed failure times as a sample of size m by adding the censoring time in the required number. For a progressively type II censored sample X1:m:n, …, Xm:m:n with censoring plan \(\mathscr {R}\), type I progressively hybrid censored order statistics \(X^{h,I}_{1:m:n},\dots , X^{h,I}_{m:m:n}\) are defined via
Notice that the names type I/type II progressive hybrid censoring are differently used in the literature which may result in some confusion. From (9.14), it is evident that the sample may include both observed failure times and censoring times. Conditionally on D = d, d ∈{0, …, m}, we have

For d = 0, the experiment has been terminated before observing the first failure, and, thus, the sample is given by the constant data \((T,\dots , T)\in \mathbb {R}^m\). Some probabilistic results have been obtained (see [1, Chapter 5], [10]). For instance, as under progressive type II censoring, a quantile representation similar to that given in Theorem 9.2.1 holds. The (conditional) joint pdf is given by Childs et al. [see also 8, 9]:
where \(f_{1,\dots , d:d:n-\gamma _{d+1}}^{\mathscr {R}_d}\) denotes the pdf of the progressively type II censored sample with a censoring plan \(\mathscr {R}_d\). In case of the exponential distribution, [10] established the (conditional) joint density function of the spacings \(W^{h,I}_{j:m:n}= \gamma _j (X^{h,I}_{j:m:n}-X^{h,I}_{j-1:m:n})\), 1 ≤ j ≤ d, as
with support
As a difference to the case of progressive type II censoring, the spacings are no longer independent although the pdf exhibits a product structure. These results can be utilized to obtain the exact distribution of the MLE for exponential lifetimes. A moment generating function approach is advocated in, e.g., [8]. The MLE of 𝜗 exists provided D > 0 and is given by
Its distribution can be written in terms of B-spline functions (see [10]) or in terms of shifted gamma functions (see [8]). The connection of the particular representations has been studied in [243]. The result can be applied to construct exact (conditional) confidence intervals by pivoting the cdf since the corresponding survival function is stochastically monotone (see [213, 214, 245]). For the multi-sample case, we refer to [246]. Results for two-parameter exponential distribution are given in [10] and [247]. Inference for Weibull distribution has been discussed in [248]. Results for other distributions can be found in, e.g., [249,250,251,252,253,254,255]. Optimal censoring plans are discussed in [256, 257].
Childs et al. [8] and Kundu and Joarder [9] proposed an alternative hybrid censoring procedure called type II progressive hybrid censoring. Given a (fixed) threshold time T, the life test terminates at \(T_2^*=\max \{X_{m:m:n},T\}\). This approach guarantees that the life test yields at least the observation of m failure times. Given the progressively type II censored sample X1:m:n, …, Xm:m:n with an initially planned censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\), the right censoring at time Xm:m:n is not carried out. The monitoring of the failure times after Xm:m:n is continued until time T is reached or the maximum in the extended progressively type II censored sample
is observed. Notice that this sample can be viewed as progressively type II censored data with extended censoring plan \(\mathscr {R}^*=(R_1,\dots , R_{m-1}, 0,\dots , 0)\) of length m + Rm. Furthermore, \(\gamma _j=\sum _{i=j}^m(R_i+1)\), j = 1, …, m − 1, γj = m + Rm − j + 1, j = m, …, m + Rm. As in the case of type I progressive hybrid censoring, the random counter \( D= \sum _{i=1}^{m+R_m} \mathbb {I}_{(-\infty , T]}(X_{i:m+R_m:n})\) represents the sample size having support {0, …, m + Rm}. Again, the exact distribution of the MLE given by
can be obtained. Furthermore, exact confidence intervals can be established (see [8, 258]) since the cdf is stochastically monotone (see [214]). For the multi-sample case, we refer to [259]. Inferential results for this kind of data have been obtained in, e.g., [8, 9, 258, 260]. Mokhtari et al. [261], Alma and Arabi Belaghi [262], and Noori Asl et al. [263].
There are many extensions on this basic progressive hybrid censoring. Generalized progressive hybrid censoring is discussed in, e.g., [243, 264,265,266,267,268,269,270]. Further extensions can be found in [12] and [271]. The Fisher information in hybrid censoring schemesis discussed in [272] and [273]. Furthermore, interval censored data have been studied in [274].
4.3 Adaptive Progressive Censoring
A common feature of the abovementioned progressive censoring schemes is that the design of the experiment (i.e., initially planned censoring plan, censoring times) is prefixed, that is, these quantities are known in advance. Since such a design may not be possible or be useful in practical situations, [13] came up with the idea that the censoring plan may be adapted during the experiment. Given some prefixed censoring plan \(\mathscr {S}=(S_1,\ldots , S_m)\) and a threshold T, the plan is adapted after step \(j^*=\max \{j:X_{j:m:n}<T\}\) such that no further censoring is carried out until the mth failure time has been observed. Hence, the censoring plan is changed at the progressive censoring step j∗ + 1, i.e., at the first observed failure time exceeding the threshold T. The effectively applied censoring plan in the Ng-Kundu-Chan model is given by \(\mathscr {S}^*=(S_1,\ldots , S_{j^*},0,\dots , 0,n-m-\sum _{i=1}^{j^*} S_i)\). This model has been extensively investigated, and many results have been obtained (see [248, 260, 275, 276]).
A general approach to adaptive progressive censoring has been proposed by Cramer and Iliopoulos [15] allowing for a flexible choice of the censoring plan and the censoring times. This approach covers both adaptive progressive type I and adaptive progressive type II censoring. Adaptive progressive type II censoring has been discussed in detail in [14] who particularly showed that the model covers the Ng-Kundu-Chan model as well as the model of progressive type II censoring with random removals (see also [1, Chapter 6]). The latter model has been proposed by Yuen and Tse [277] assuming that the censoring numbers are chosen according to some probability distribution on the set of possible censoring numbers. Further references discussing this model are, e.g., [278,279,280]. For interval censored data, we refer to [281] and [282]. Flexible progressive censoring introduced in [283] can also be seen as a special adaptive progressive censoring model (see also [284, 285]).
4.4 Reliability and Stress-Strength Reliability
Applications in reliability based on progressively type II censored data have been addressed by many authors. The analysis is mostly based on a single progressively type II censored sample X1:m:n, …, Xm:m:n, but the situation of multiple samples has also been taken into account. In the following, we summarize some scenarios where this kind of data has been considered.
Given a lifetime X with cdf F, the reliability function \(R=\overline {F}=1-F\) can be estimated parametrically and nonparametrically. Nonparametric estimators under progressive censoring are mentioned in Sect. 9.2.2. Parametric estimators of Rθ can be constructed as plug-in estimators by replacing θ by an appropriate estimator \(\widehat {\theta }\), e.g., the MLE (see, e.g., [142, 286,287,288,289,290,291]). Furthermore, Bayesian approaches have also been extensively discussed. However, for exponential distributions and \(t\in \mathbb {R}\), the UMVUE of R𝜗(t) = P𝜗(X > t) is given by (see (9.8))
(see [292]). The result can be slightly extended to an exponential family with cdf F𝜗 defined by \(F_\vartheta (t) =1-\exp (-g(t)/\vartheta )\) and a suitable function g (see, e.g., [23, 293]).
Inference for the stress-strength reliability R = P(X < Y ) has also been addressed under progressive censoring for various distributions (for a general account, see [294]). For exponential distribution, the problem has been considered in terms of Weinman exponential distributions in [295] and [296]. For two independent progressively type II censored samples \(X_{1:m:n}^{\mathscr {R}},\dots , X_{m:m:n}^{\mathscr {R}}\) and \(Y_{1:r:s}^{\mathscr {S}},\dots , Y_{r:r:s}^{\mathscr {S}}\), based on exponential distributions Exp(𝜗1) and Exp(𝜗2), the MLEs of the parameters are given by \(\widehat \vartheta _{j,\textsf {MLE}}\), j = 1, 2, as in (9.8). Then, the MLE of \(R=\frac {\vartheta _2}{\vartheta _1+\vartheta _2}\) is given by \(R_{\textsf {MLE}}=\frac {\widehat \vartheta _2}{\widehat \vartheta _1+\widehat \vartheta _2}\). Furthermore, the UMVUE is given by
Saraçoğlu et al. [see also 297, who addressed Bayesian inference, too]. Confidence intervals are discussed in [295, 296], and [297]. Two-parameter exponential distributions with common location parameter are investigated in [295, 296] [see also 1, Chapter 24]. Other distributions considered in the literature are generalized (inverted) exponential distribution [289, 298], Weibull distribution [299, 300], generalized Pareto distributions [301], the PHR model [302, 303], Birnbaum-Saunders distribution [304], generalized logistic distribution [305], and finite mixtures [306].
Stress-strength models under joint progressive censoring have been considered in [307]. Progressively type I interval censored data has been discussed by Bai et al. [306].
4.5 Competing Risks
In competing risk modeling, it is assumed that a unit may fail due to several causes of failure. For two competing risks, the lifetime of the ith unit is given by
where Xji denotes the latent failure time of the ith unit under the jth cause of failure, j = 1, 2. In most models considering competing risks under a progressive censoring scheme, the latent failure times are assumed to be independent with Xji ∼ Fj, j = 1, 2, i = 1, …, m. Additionally, the sample X1, …, Xn is progressively type II censored, and it is assumed that the cause of each failure is known. Therefore, the available data are given by
where Ci = 1 if the ith failure is due to first cause and Ci = 2 otherwise. The observed data is denoted by (x1, c1), (x2, c2), …, (xm, cm). Further, we define the indicators
Thus, the random variables \(m_1 = \sum _{i=1}^m \mathbb {I}_{\{1\}}(C_i)\) and \(m_2 = \sum _{i=1}^m \mathbb {I}_{\{2\}}(C_i)\) describe the number of failures due to the first and the second cause of failure, respectively. Given the assumptions, m1 and m2 are binomials with sample size m and probability of success R = P(X11 ≤ X21) and 1 − R, respectively. For a given censoring plan \(\mathscr {R}=(R_1,\ldots , R_m)\), the joint pdf is given by Kundu et al. [see 308]
[308] discussed competing risks for Exp(𝜗j)-distributions, j = 1, 2, under progressive type II censoring. The MLEs of the parameters are given by
provided that mj > 0. In this framework, inferential topics like point and interval estimation as well as prediction problems have been discussed. To keep things short, we provide references for further reading. Competing risks under progressive type II censoring have been considered for, e.g., Weibull distribution [309,310,311], Lomax distribution [312], half-logistic distribution [313], and Kumaraswamy distribution [314].
Progressive type I interval censoring in the presence of competing risks has been investigated by Wu et al. [234], Azizi et al. [315], and Ahmadi et al. [316]. Competing risks under hybrid censoring are investigated in, e.g., [317,318,319,320,321,322,323,324,325].
4.6 Applications to System Data
In the standard models of progressive censoring, it is assumed that the underlying random variables are iid random variables distributed according to a cdf F. Progressive censoring has also been studied in terms of iid system data \(Y,\dots , Y_n\overset {\text{iid}}\sim G\), where G = h ∘ F with some known function h and a cdf F. F is supposed to model the component lifetime, whereas h describes the technical structure of the system. In a series system with s components, we have G = Fs with h(t) = ts. For a parallel system with s components, the function h is given by h(t) = 1 − (1 − t)s.
As pointed out in [1, Chapter 25], the case of progressively type II censored series system data is included in the standard model by adapting the censoring plan appropriately. Given a censoring plan \(\mathscr {R}=(R_1,\dots , R_m)\) and series systems with s components, the corresponding progressively type II censored system data can be interpreted as standard progressively type II censored data with censoring plan
This kind of data has also been entitled first-failure censored data (see, e.g., [326, 327]), and many results have been published for this model. However, as mentioned before, the respective results are covered in the standard model by adapting the censoring plan.
The situation is more involved for parallel or, more general, for coherent systems. Parallel systems are studied in [166, 328, 329], and [330]. k out-of-n system data is addressed in [331], and coherent systems are addressed in [332].
4.7 Applications in Quality Control
Applications of progressively censored data in quality control have been discussed in terms of reliability sampling plans (acceptance sampling plans) and the lifetime performance index, respectively.
Reliability sampling plans based on progressively type II censored exponential lifetimes have been considered by Balasooriya and Saw [333], Balakrishnan and Aggarwala [2], and [334] [see also 1, Chapter 22]. For a progressively censored sample \(\boldsymbol {X}^{\mathscr {R}}\) from an Exp(μ, 𝜗)-distribution, the MLEs of the parameters are used to estimate the parameters and, thus, to construct the decision rule. Since the distributions of the MLEs do not depend on the censoring plan \(\mathscr {R}\), the resulting sampling plans coincide with those for type II right censoring. Pérez-González and Fernández [335] established approximate acceptance sampling plans in the two-parameter exponential case. Balasooriya et al. [147] addressed reliability sampling plans for a Weibull distribution employing the Lieberman-Resnikoff procedure for a lower limit using the approximate MLEs of the parameters. Ng et al. [139] tackled the same problem using the MLEs. Fernández et al. [336] considered progressively censored group sampling plans for Weibull distributions. For a log-normal distribution, [337] applied the Lieberman-Resnikoff approach using approximate BLUEs for the location and scale parameters. Further reference in this direction is [338].
Inference for the lifetime performance index (or capability index) has been discussed for various distributions in [339] including exponential and gamma distributions (see also [340,341,342,343]). Weibull distribution has been considered in [344, 345], and Rayleigh distribution in [341]. Lomax and Pareto distributions are discussed by Mahmoud et al. [346] and Ahmadi and Doostparast [347], respectively. Progressively type I interval censored data has been considered in [348,349,350].
4.8 Accelerated Life Testing
In accelerated life testing, progressive censoring has been mostly discussed in terms of step-stress testing. Recent reviews on the topic are provided by Kundu and Ganguly [351] and Balakrishnan and Cramer [1, Chapter 23] (see also [352]). Assuming a cumulative exposure model for the lifetime distribution, the basic model in simple step-stress model with a single stress change point is applied to progressively type II censored data, that is, at a prefixed time τ, the stress level is to be increased to a level s1 > s0 (see Fig. 9.6). Then, the data
results where D denotes the number of failures observed before τ. Obviously, the sample X1:r:n, …, XD:r:n is a type I progressive hybrid censored sample so that the inferential results can be taken from this area. Assuming exponential lifetimes with means 𝜗1 and 𝜗2 (before and after τ) as well as a cumulative exposure model, the MLEs of the parameters are given by
provided that 1 ≤ D ≤ r − 1. As mentioned above, distributional results for \(\widehat \vartheta _1\) are directly obtained from type I progressive hybrid censoring leading to, e.g., exact (conditional) confidence intervals (see [353, 354]). Using the result in (9.6), we get \(2(r-D)\widehat \vartheta _2/\vartheta _2|D=d \sim \chi ^2(2r-2d)\), d < r. In particular, \(E(\widehat \vartheta _2|D=d) =\vartheta _2\) and \( \operatorname {\mathrm {\text{Var}}}(\widehat \vartheta _2|D=d)=\vartheta ^2_2/(r-d)\). Weibull lifetimes are investigated in [355]. Extensions to multiple stress changing times are discussed in [356, 357]. The model has also been discussed for progressive type I interval censored data (see [358,359,360]).

Step-stress testing with single stress change time τ
Wang and Yu [361] discussed a simple step-stress model where the stress changing time τ is replaced by a failure time \(X_{r_1:r:n}\). It is shown in [1, p. 492] that this model is connected to sequential order statistics which can be utilized to establish easily properties of the resulting MLEs. Following the ideas of [362], a multiple step-stress model with additional progressive censoring has been proposed in [1, p. 503]. The resulting model corresponds to that proposed in [361] and is further discussed in [363].
Another kind of accelerated life testing model in the presence of progressive censoring, called progressive stress model, has been proposed by Abdel-Hamid and AL-Hussaini [364].
4.9 Stage Life Testing
A common argument used to justify progressive censoring is that the intentionally removed objects are utilized for other tests (cf., e.g., [2, p. 3], [365, p. 336]). In order to include such an information in the statistical analysis, [366] connected the notion of progressive censoring with ideas from accelerated life testing and proposed a stage life testing model with a single stage change time. In fact, they adapted the idea of step-stress testing and assumed that the removed objects are tested on a different level, whereas the remaining items are still tested under standard conditions. The basic situation with a single censoring time τ and two stages s0, s1 is depicted in Fig. 9.7.

Stage life testing with single stage change time τ
Inspired by simple step-stress testing (see Fig. 9.6), the stage life testing model is introduced as follows. Assume that n identical objects are placed on a life test. The initial conditions are called stage s0. At the prefixed stage-change time τ, \(0\le R_1^\star \le n\) of the surviving items are randomly withdrawn (if possible) and further tested on stage s1. Notice that this may be regarded as a different life test with used components. The testing of the remaining items is continued on stage s0. The life test terminates when all n objects have failed.
Let D1 and D2 denote the random number of failures occurring on stage s0 before and after τ1, respectively. Furthermore, M = D1 + D2 and
-
\(\boldsymbol {Y}_{1,D_1} = \big (Y_{1:M:n}, \ldots , Y_{D_1:M:n}\big )\) denote the (ordered) observations on stage s0 before τ.
-
\(\boldsymbol {Y}_{2,D_2} = \big (Y_{D_1+1:M:n}, \ldots , Y_{D_1+D_2:M:n}\big )\) denote the (ordered) observations on stage s0 after τ.
-
\(\boldsymbol {Z}_{R^{\star }_1} = \big (Z_{1:R^{\star }_1}, \ldots , Z_{R^{\star }_1:R^{\star }_1}\big )\) denote the (ordered) observations on stage s1 after τ with \(Y_{D_1:M:n} \leq \tau < Z_{1:R^{\star }_1}\).
The order statistics on stage s0 and the order statistics on stage s1 are represented by the random vectors \(\boldsymbol {Y} = \big (\boldsymbol {Y}_{1,D_1} , \boldsymbol {Y}_{2,D_2}\big )\) and Z, respectively. Figure 9.7 illustrates this representation of the stage life testing order statistics.
Assuming a cumulative exposure model with cdfs F0 and F1 and utilizing progressive censoring with fixed censoring times (see [6]), inferential results have been obtained for exponential, Weibull, and other lifetime distributions. The results are based on the joint pdf \(f^{\boldsymbol {Y},\boldsymbol {Z},D_1}_{1 \ldots n}\) of (Y , Z) and D1 given by
for \(\boldsymbol {y}_{1,d_1} {=} (y_{1:m:n}, \ldots , y_{d_1:m:n})\), \(\boldsymbol {y}_{2,d_2} {=} (y_{d_1+1:m:n}, \ldots , y_{d_1+d_2:m:n})\), and \(\boldsymbol {z} = (z_{1:r^{\star }_1}, \ldots , z_{r^{\star }_1:r^{\star }_1})\), where \(d_2 = n - d_1 -r^{\star }_1\), and \(r^{\star }_1 = \varrho (d_1)\) denotes the number of objects selected for testing on stage s1. fi denotes the pdf of Fi, i ∈{0, 1}.
In fact, the function ϱ may be chosen according to the needs of the experimenter. Inspired by procedures to generate the censoring number in progressive censoring (see [7]), [366] proposed two options to define \(R^{\star }_1\), that is,
where the proportion π1 ∈ [0, 1] and the number \(R^0_1 \in \mathbb {N}\) are prespecified, respectively. Under the type P scheme, at τ, a (fixed) proportion π1 of the surviving objects is selected for testing on stage s1. In case of the type M scheme, given a prefixed number \(R_1^0\), it is intended to select at τ as many items as possible (at most \(R_1^0\)) for testing on stage s1.
Assuming exponential lifetimes with means 𝜗0 and 𝜗1, the corresponding MLEs are obtained as
As for other progressive censoring models, exact inferential results, e.g., exact confidence intervals, can be established. An extension to multiple stage change times τ1 < ⋯ < τm has been introduced in [367]. Stage changes at failure times are discussed in [368]. For a survey on these models as well as more details, we refer to [369].
4.10 Joint Progressive Censoring Schemes
In joint progressive type II censoring, the sample is based on two baseline samples \(X_1,\dots , X_{n_1}\overset {\text{iid}}\sim F_1\) (product/type A) and \(Y_1,\dots , Y_{n_2}\overset {\text{iid}}\sim F_2\) (product/type B) of independent random variables. The progressive censoring is applied to the pooled sample \(X_1,\dots , X_{n_1}, Y_1,\dots , Y_{n_2}\) given a prefixed censoring \(\mathscr {R}\in \mathscr {C}^m_{m,n_1+n_2}\). Moreover, it is assumed that the type of the failed unit as well as the types of withdrawn units are known. Therefore, the sample is given by \((\boldsymbol {C}, \boldsymbol {W}^{\mathscr {R}}, \mathscr {S})\), where
The indicators Cj have the value 1 if the failed unit is of type A, and otherwise Cj = 0. Wj:m:n denotes the jth failure time in the progressively censored experiment. Finally, \(\mathscr {S}\) denotes a random censoring plan. Sj is the number of removed units of type A in the jth withdrawal. Thus, Rj − Sj denotes the numbers of withdrawn units of type B at the jth censoring step. This model has been discussed in [370,371,372,373,374,375,376]. Joint progressive type I censoring has been proposed in [377]. A hybrid version is discussed in [378]. Another version of joint progressive censoring leading to more tractable results has been investigated in [376] and [379].
References
Balakrishnan, N., Cramer, E.: The Art of Progressive Censoring. Applications to Reliability and Quality. Birkhäuser, New York (2014)
Balakrishnan, N., Aggarwala, R.: Progressive Censoring: Theory, Methods, and Applications. Birkhäuser, Boston (2000)
Balakrishnan, N.: Progressive censoring methodology: an appraisal (with Discussions). TEST 16, 211–296 (2007)
Cramer, E.: Progressive Censoring Schemes. In: Wiley StatsRef: Statistics Reference Online. Wiley, New York (2017)
Cohen, A.C.: Progressively censored samples in life testing. Technometrics 5, 327–329 (1963)
Laumen, B., Cramer, E.: Progressive censoring with fixed censoring times. Statistics 53, 569–600 (2019)
Aggarwala, R.: Progressive interval censoring: some mathematical results with applications to inference. Commun. Statist. Theory Methods 30(8-9), 1921–1935 (2001)
Childs, A., Chandrasekar, B., Balakrishnan, N.: Exact likelihood inference for an exponential parameter under progressive hybrid censoring schemes. In: Vonta, F., Nikulin, M., Limnios, N., Huber-Carol, C. (eds.) Statistical Models and Methods for Biomedical and Technical Systems, pp. 323–334. Birkhäuser, Boston (2008)
Kundu, D., Joarder, A.: Analysis of Type-II progressively hybrid censored data. Comput. Statist. Data Anal. 50(10), 2509–2528 (2006)
Cramer, E., Balakrishnan, N.: On some exact distributional results based on Type-I progressively hybrid censored data from exponential distributions. Statist. Methodol. 10, 128–150 (2013)
Epstein, B.: Truncated life tests in the exponential case. Ann. Math. Stat. 25, 555–564 (1954)
Górny, J., Cramer, E.: Modularization of hybrid censoring schemes and its application to unified progressive hybrid censoring. Metrika 81, 173–210 (2018)
Ng, H.K.T., Kundu, D., Chan, P.S.: Statistical analysis of exponential lifetimes under an adaptive Type-II progressive censoring scheme. Naval Res. Logist. 56, 687–698 (2009)
Cramer, E., Iliopoulos, G.: Adaptive progressive Type-II censoring. TEST 19, 342–358 (2010)
Cramer, E., Iliopoulos, G.: Adaptive Progressive Censoring. In: Choudhary, P.K., Nagaraja, C.H., Ng, H.K.T. (eds.) Ordered Data Analysis, Modeling and Health Research Methods—In Honor of H.N. Nagaraja’s 60th Birthday, pp. 73–86. Springer, New York (2015)
Balakrishnan, N., Cramer, E.: Progressive censoring from heterogeneous distributions with applications to robustness. Ann. Inst. Statist. Math. 60, 151–171 (2008)
Fischer, T., Balakrishnan, N., Cramer, E.: Mixture representation for order statistics from INID progressive censoring and its applications. J. Multivariate Anal. 99, 1999–2015 (2008)
Cramer, E., Lenz, U.: Association of progressively Type-II censored order statistics. J. Statist. Plann. Inference 140(2), 576–583 (2010)
Rezapour, M., Alamatsaz, M.H., Balakrishnan, N., Cramer, E.: On properties of progressively Type-II censored order statistics arising from dependent and non-identical random variables. Statist. Methodol. 10(1), 58–71 (2013)
Rezapour, M., Alamatsaz, M.H., Balakrishnan, N.: On properties of dependent progressively Type-II censored order statistics. Metrika 76, 909–917 (2013)
Kamps, U.: A Concept of Generalized Order Statistics. Teubner, Stuttgart (1995)
Kamps, U.: A concept of generalized order statistics. J. Statist. Plann. Inference 48, 1–23 (1995)
Cramer, E., Kamps, U.: Sequential k-out-of-n systems. In: Balakrishnan, N., Rao, C.R. (eds.) Handbook of Statistics: Advances in Reliability, vol. 20, pp. 301–372. Elsevier, Amsterdam (2001). Chap. 12
Thomas, D.R., Wilson, W.M.: Linear order statistic estimation for the two-parameter Weibull and extreme value distributions from Type-II progressively censored samples. Technometrics 14, 679–691 (1972)
Viveros, R., Balakrishnan, N.: Interval estimation of parameters of life from progressively censored data. Technometrics 36, 84–91 (1994)
Kamps, U., Cramer, E.: On distributions of generalized order statistics. Statistics 35, 269–280 (2001)
Balakrishnan, N., Cramer, E., Kamps, U.: Relation for joint densities of progressively censored order statistics. Statistics 39(6), 529–536 (2005)
Cramer, E.: Dependence structure of generalized order statistics. Statistics 40, 409–413 (2006)
Balakrishnan, N., Dembińska, A.: Progressively Type-II right censored order statistics from discrete distributions. J. Statist. Plann. Inference 138, 845–856 (2008)
Balakrishnan, N., Dembińska, A.: Erratum to ’Progressively Type-II right censored order statistics from discrete distributions’ [J. Statist. Plann. Inference 138 (2008) 845–856]. J. Statist. Plann. Inference 139, 1572–1574 (2009)
Schenk, N.: Point Estimation with Sequential Order Statistics from Exponential Distributions Ph.D. Thesis. University of Oldenburg, Oldenburg (2001)
Cramer, E., Kamps, U., Rychlik, T.: Unimodality of uniform generalized order statistics, with applications to mean bounds. Ann. Inst. Statist. Math. 56, 183–192 (2004)
Cramer, E.: Logconcavity and unimodality of progressively censored order statistics. Statist. Probab. Letters 68, 83–90 (2004)
Chen, H., Xie, H., Hu, T.: Log-concavity of generalized order statistics. Statist. Probab. Letters 79, 396–399 (2009)
Alimohammadi, M., Alamatsaz, M.H.: Some new results on unimodality of generalized order statistics and their spacings. Statist. Probab. Lett. 81(11), 1677–1682 (2011)
Alimohammadi, M., Alamatsaz, M.H., Cramer, E.: Convolutions and generalization of logconcavity: Implications and applications. Nav. Res. Logist. (NRL) 63(2), 109–123 (2016)
Cramer, E., Kamps, U.: Marginal distributions of sequential and generalized order statistics. Metrika 58, 293–310 (2003)
Balakrishnan, N., Sandhu, R.A.: A simple simulational algorithm for generating progressive Type-II censored samples. Am. Statist. 49, 229–230 (1995)
Iliopoulos, G., Balakrishnan, N.: Conditional independence of blocked ordered data. Statist. Probab. Letters 79, 1008–1015 (2009)
Arnold, B.C., Balakrishnan, N., Nagaraja, H.N.: A First Course in Order Statistics. Society for Industrial and Applied Mathematics (SIAM), Philadelphia (2008)
David, H.A., Nagaraja, H.N.: Order Statistics, 3rd edn. Wiley, Hoboken (2003)
Cramer, E., Kamps, U., Rychlik, T.: On the existence of moments of generalized order statistics. Statist. Probab. Letters 59, 397–404 (2002)
Cramer, E.: A note on moments of progressively Type II censored order statistics. Commun. Statist. Theory Methods 31, 1301–1307 (2002)
Balakrishnan, N., Cramer, E., Kamps, U.: Bounds for means and variances of progressive type II censored order statistics. Statist. Probab. Letters 54, 301–315 (2001)
Raqab, M.Z.: P-norm bounds for moments of progressive type II censored order statistics. Statist. Probab. Letters 64(4), 393–402 (2003)
Aggarwala, R., Balakrishnan, N.: Recurrence relations for single and product moments of progressive type-II right censored order statistics from exponential and truncated exponential distributions. Ann. Inst. Statist. Math. 48, 757–771 (1996)
Balasooriya, U., Saw, S.L.C.: A note on approximate moments of progressively censored order statistics. Metron 57(1-2), 117–130 (1999)
Pérez-González, C.J., Fernández, A.J.: Accurate computation of single and product moments of order statistics under progressive censoring. J. Stat. Comput. Simul. 89(13), 2489–2504 (2019)
Cramer, E., Davies, K.: Restricted optimal progressive censoring. Commun. Stat. Simul. Comput. 47, 1216–1239 (2018)
Shaked, M., Shanthikumar, J.G.: Stochastic Orders. Springer, Berlin (2007)
Müller, A., Stoyan, D.: Comparison Methods for Stochastic Models and Risks. Wiley, Chichester (2002)
Belzunce, F., Riquelme, C., Mulero, J.: An Introduction to Stochastic Orders. Academic Press, London (2015)
Belzunce, F.: Multivariate comparisons of ordered data. In: Stochastic Orders in Reliability and Risk: In: Li, H., Li, X. (eds.) Honor of Professor Moshe Shaked, pp. 83–102. Springer, New York (2013)
Belzunce, F., Mercader, J.-A., Ruiz, J.-M.: Stochastic comparisons of generalized order statistics. Probab. Engrg. Inform. Sci. 19, 99–120 (2005)
Khaledi, B.-E.: Some new results on stochastic orderings between generalized order statistics. J. Iran. Stat. Soc. (JIRSS) 4, 35–49 (2005)
Bon, J.-L., Păltănea, E.: Ordering properties of convolutions of exponential random variables. Lifetime Data Anal. 5(2), 185–192 (1999)
Khaledi, B.-E., Kochar, S.C.: Stochastic ordering among order statistics and sample spacings. In: Misra, J.C. (ed.) Uncertainty and Optimality—Probability, Statistics and Operations Research, pp. 167–203. World Scientific Publications, Singapore (2002)
Burkschat, M.: On optimality of extremal schemes in progressive Type-II censoring. J. Statist. Plann. Inference 138, 1647–1659 (2008)
Hu, T., Zhuang, W.: A note on stochastic comparisons of generalized order statistics. Statist. Probab. Letters 72(2), 163–170 (2005)
Korwar, R.: On the likelihood ratio order for progressive type II censored order statistics. Sankhyā A 65, 793–798 (2003)
Cramer, E., Kamps, U., Raqab, M.Z.: Characterizations of exponential distributions by spacings of generalized order statistics. Appl. Math. 30, 257–265 (2003)
Zhuang, W., Hu, T.: Multivariate dispersive ordering of spacings of generalized order statistics. Appl. Math. Letters 22(6), 968–974 (2009)
Balakrishnan, N., Belzunce, F., Hami, N., Khaledi, B.-E.: Univariate and multivariate likelihood ratio ordering of generalized order statistics and associated conditional variables. Probab. Eng. Inform. Sci. 24, 441–455 (2010)
Sharafi, M., Khaledi, B.-E., Hami, N.: On multivariate likelihood ratio ordering among generalized order statistics and their spacings. J. Iranian Stat. Soc. 13, 1–29 (2014)
Arriaza, A., Belzunce, F., Mulero, J., Suárez-Llorens, A.: On a new multivariate IFR ageing notion based on the standard construction. Appl. Stoch. Model. Bus. Ind. 32(2), 292–306 (2016)
Belzunce, F., Lillo, R.E., Ruiz, J.-M., Shaked, M.: Stochastic comparisons of nonhomogeneous processes. Probab. Eng. Inform. Sci. 15(2), 199–224 (2001)
Xie, H., Hu, T.: Conditional ordering of generalized order statistics revisited. Probab. Eng. Inform. Sci. 22, 333–346 (2008)
Xie, H., Hu, T.: Ordering p-spacings of generalized order statistics revisited. Probab. Eng. Inform. Sci. 23, 1–16 (2009)
Belzunce, F., Ruiz, J.M., Suárez-Llorens, A.: On multivariate dispersion orderings based on the standard construction. Statist. Probab. Letters 78(3), 271–281 (2008)
Chen, J., Hu, T.: Multivariate dispersive ordering of generalized order statistics. J. Iran. Stat. Soc. (JIRSS) 6, 61–75 (2007)
Xie, H., Hu, T.: Some new results on multivariate dispersive ordering of generalized order statistics. J. Multivariate Anal. 101(4), 964–970 (2010)
Hashemi, M., Tavangar, M., Asadi, M.: Some properties of the residual lifetime of progressively Type-II right censored order statistics. Statist. Probab. Letters 80(9–10), 848–859 (2010)
Xie, H., Zhuang, W.: Some new results on ordering of simple spacings of generalized order statistics. Probab. Eng. Inform. Sci. 25(01), 71–81 (2011)
Belzunce, F., Martínez-Riquelme, C.: Some results for the comparison of generalized order statistics in the total time on test and excess wealth orders. Stat. Pap. 56(4), 1175–1190 (2015)
Belzunce, F., Martínez-Riquelme, C., Ruiz, J.M., Sordo, M.A.: On sufficient conditions for the comparison in the excess wealth order and spacings. J. Appl. Probab. 53(1), 33–46 (2016)
Balakrishnan, N., Belzunce, F., Sordo, M.A., Suárez-Llorens, A.: Increasing directionally convex orderings of random vectors having the same copula, and their use in comparing ordered data. J. Multivariate Anal. 105(1), 45–54 (2012)
Zhao, P., Balakrishnan, N.: Stochastic comparisons and properties of conditional generalized order statistics. J. Statist. Plann. Inference 139(9), 2920–2932 (2009)
Tavangar, M., Bairamov, I.: A note on the residual lifetimes in a life-test under progressive type-II right censoring scheme. Appl. Comput. Math. 11, 368–377 (2012)
Mao, T., Hu, T.: Stochastic properties of INID progressive Type-II censored order statistics. J. Multivariate Anal. 101(6), 1493–1500 (2010)
Barlow, R.E., Proschan, F.: Mathematical Theory of Reliability. Wiley, New York (1965)
Lai, C.-D., Xie, M.: Stochastic Ageing and Dependence for Reliability. Springer, New York (2006)
Marshall, A.W., Olkin, I.: Life Distributions. Structure of Nonparametric, Semiparametric, and Parametric Families. Springer, New York (2007)
Burkschat, M., Navarro, J.: Aging properties of sequential order statistics. Probab. Eng. Inform. Sci. 25(04), 449–467 (2011)
Torrado, N., Lillo, R., Wiper, M.: Sequential order statistics: ageing and stochastic orderings. Method. Comput. Appl. Probab. 14, 579–596 (2012)
Burkschat, M., Torrado, N.: On the reversed hazard rate of sequential order statistics. Statist. Probab. Lett. 85, 106–113 (2014)
Belzunce, F., Mercader, J.A., Ruiz, J.M.: Multivariate aging properties of epoch times of nonhomogeneous processes. J. Multivariate Anal. 84(2), 335–350 (2003)
Arias-Nicolás, J.P., Belzunce, F., Núñez Barrera, O., Suárez-Llorens, A.: A multivariate IFR notion based on the multivariate dispersive ordering. Appl. Stoch. Models Bus. Ind. 25(3), 339–358 (2009)
Tavangar, M., Asadi, M.: On stochastic and aging properties of generalized order statistics. Probab. Eng. Inform. Sci. 25(02), 187–204 (2011)
Lin, C.-T., Balakrishnan, N.: Asymptotic properties of maximum likelihood estimators based on progressive Type-II censoring. Metrika 74, 349–360 (2011)
Hoadley, B.: Asymptotic properties of maximum likelihood estimators for the independent not identically distributed case. Ann. Math. Stat. 42(6), 1977–1991 (1971)
Cramer, E.: Extreme value analysis for progressively Type-II censored order statistics. Commun. Statist. Theory Methods 43, 2135–2155 (2014)
Cramer, E.: Contributions to Generalized Order Statistics. Habilitationsschrift. University of Oldenburg, Oldenburg (2003)
Schmiedt, A.B.: Domains of attraction of asymptotic distributions of extreme generalized order statistics. Commun. Stat. Theory and Methods 45(7), 2089–2104 (2016)
Bordes, L.: Non-parametric estimation under progressive censoring. J. Statist. Plann. Inference 119(1), 171–189 (2004)
Alvarez-Andrade, S., Bordes, L.: Empirical quantile process under type-II progressive censoring. Statist. Probab. Letters 68(1), 111–123 (2004)
Alvarez-Andrade, S., Bordes, L.: Type-II progressive censoring and related processes. Rev. Roumaine Math. Pures Appl. 63, 267–276 (2008)
Hofmann, G., Cramer, E., Balakrishnan, N., Kunert, G.: An asymptotic approach to progressive censoring. J. Statist. Plann. Inference 130(1-2), 207–227 (2005)
Ng, H.K.T., Chan, P.S., Balakrishnan, N.: Estimation of parameters from progressively censored data using EM algorithm. Comput. Statist. Data Anal. 39(4), 371–386 (2002)
Zheng, G., Park, S.: On the Fisher information in multiply censored and progressively censored data. Commun. Statist. Theory Methods 33(8), 1821–1835 (2004)
Balakrishnan, N., Burkschat, M., Cramer, E., Hofmann, G.: Fisher information based progressive censoring plans. Comput. Statist. Data Anal. 53, 366–380 (2008)
Abo-Eleneen, Z.A.: Fisher information in type II progressive censored samples. Commun. Statist. Theory Methods 37, 682–691 (2008)
Park, S., Ng, H.K.T.: Missing information and an optimal one-step plan in a Type II progressive censoring scheme. Statist. Probab. Letters 82(2), 396–402 (2012)
Burkschat, M., Cramer, E.: Fisher information in generalized order statistics. Statistics 46, 719–743 (2012)
Dahmen, K., Burkschat, M., Cramer, E.: A- and D-optimal progressive Type-II censoring designs based on Fisher information. J. Stat. Comput. Simul. 82, 879–905 (2012)
Cramer, E., Ensenbach, M.: Asymptotically optimal progressive censoring plans based on Fisher information. J. Statist. Plann. Inference 141, 1968–1980 (2011)
Balakrishnan, N., Habibi Rad, A., Arghami, N.R.: Testing exponentiality based on Kullback-Leibler information with progressively Type-II censored data. IEEE Trans. Reliab. 56, 301–307 (2007)
Cramer, E., Bagh, C.: Minimum and maximum information censoring plans in progressive censoring. Commun. Statist. Theory Methods 40, 2511–2527 (2011)
Ahmadi, J.: Some results based on entropy properties of progressive Type-II censored data. J. Statist. Res. Iran 4, 191–202 (2007)
Abo-Eleneen, Z.A.: The entropy of progressively censored samples. Entropy 13(2), 437–449 (2011)
Abo-Eleneen, Z., Almohaimeed, B., Ng, H.K.T.: On cumulative residual entropy of progressively censored order statistics. Statist. Probab. Lett. 139, 47–52 (2018)
Habibi Rad, A., Yousefzadeh, F., Balakrishnan, N.: Goodness-of-fit test based on Kullback-Leibler Information for progressively Type-II censored data. IEEE Trans. Reliab. 60, 570–579 (2011)
Baratpour, S., Habibi Rad, A.: Exponentiality test based on the progressive type II censoring via cumulative entropy. Commun. Stat. Simul. Comput. 45(7), 2625–2637 (2016)
Park, S., Pakyari, R.: Cumulative residual Kullback-Leibler information with the progressively Type-II censored data. Statist. Probab. Lett. 106, 287–294 (2015)
Döring, M., Cramer, E.: On the power of goodness-of-fit tests for the exponential distribution under progressive Type-II censoring. J. Stat. Comput. Simul. 89, 2997–3034 (2019)
Zhang, Y., Gui, W.: A goodness of fit test for the Pareto distribution with progressively Type II censored data based on the cumulative hazard function. J. Comput. Appl. Math. 368, 112557 (2020)
Volterman, W., Davies, K.F., Balakrishnan, N.: Simultaneous Pitman closeness of progressively Type-II right-censored order statistics to population quantiles. Statistics 47, 439–452 (2013)
Volterman, W., Davies, K.F., Balakrishnan, N.: Pitman closeness as a criterion for the determination of the optimal progressive censoring scheme. Statist. Methodol. 9(6), 563–572 (2012)
Volterman, W., Davies, K.F., Balakrishnan, N.: Two-sample Pitman closeness comparison under progressive Type-II censoring. Statistics 47, 1305–1320 (2013)
Raqab, M.Z., Alkhalfan, L.A., Balakrishnan, N.: Pitman comparisons of predictors of censored observations from progressively censored samples for exponential distribution. J. Stat. Comput. Simul. 86(8), 1539–1558 (2016)
Bairamov, I., Eryılmaz, S.: Spacings, exceedances and concomitants in progressive Type II censoring scheme. J. Statist. Plann. Inference 136(3), 527–536 (2006)
Izadi, M., Khaledi, B.-E.: Progressive Type II censored order statistics and their concomitants: some stochastic comparisons results. J. Iran. Stat. Soc. (JIRSS) 6, 111–124 (2007)
Berred, A., Stepanov, A.: Asymptotic properties of the number of near minimum-concomitant observations in the case of progressive type-II censoring. Metrika 78(3), 283–294 (2015)
Razmkhah, M., Simriz, S.: Statistical inferences based on INID progressively type II censored order statistics. Ann. Inst. Stat. Math. 70, 583–604 (2018)
Bairamov, I.: Progressive type II censored order statistics for multivariate observations. J. Multivariate Anal. 97(4), 797–809 (2006)
Amirzadeh, V., Rezapour, M.: On properties of progressively Type-II censored conditionally N-ordered statistics arising from a non-identical and dependent random vector. J. Stat. Comput. Simul. 86, 1818–1828 (2016)
Rezapour, M.: Progressively Type-II censored conditionally N-ordered statistics from a unified elliptically contoured copula. Commun. Stat. Theory Methods 46(11), 5595–5611 (2017)
Christensen, R.: Plane Answers to Complex Questions: The Theory of Linear Models, 4th edn. Springer, New York (2011)
Balakrishnan, N., Sandhu, R.A.: Linear estimation under censoring and inference. In: Balakrishnan, N., Basu, A.P. (eds.) The Exponential Distribution, pp. 53–72. Gordon and Breach, Amsterdam (1995)
Cramer, E., Kamps, U.: Estimation with sequential order statistics from exponential distributions. Ann. Inst. Statist. Math. 53, 307–324 (2001)
Balakrishnan, N., Cramer, E., Kamps, U., Schenk, N.: Progressive type II censored order statistics from exponential distributions. Statistics 35, 537–556 (2001)
Mann, N.R.: Best linear invariant estimation for Weibull parameters under progressive censoring. Technometrics 13, 521–533 (1971)
Cramer, E., Kamps, U.: Sequential k-out-of-n systems with Weibull components. Econom. Quality Control 13, 227–239 (1998)
Guilbaud, O.: Exact non-parametric confidence intervals for quantiles with progressive Type-II censoring. Scand. J. Stat. 28, 699–713 (2001)
Guilbaud, O.: Exact non-parametric confidence, prediction and tolerance intervals with progressive type-II censoring. Scand. J. Stat. 31(2), 265–281 (2004)
Balakrishnan, N., Burkschat, M., Cramer, E.: Best linear equivariant estimation and prediction in location-scale families. Sankhyā B 70, 229–247 (2008)
Burkschat, M.: Linear estimators and predictors based on generalized order statistics from generalized Pareto distributions. Commun. Statist. Theory Methods 39(2), 311–326 (2010)
Mann, N.R.: Optimum estimators for linear functions of location and scale parameters. Ann. Math. Stat. 40, 2149–2155 (1969)
Balakrishnan, N., Kateri, M.: On the maximum likelihood estimation of parameters of Weibull distribution based on complete and censored data. Statist. Probab. Letters 78, 2971–2975 (2008)
Ng, H.K.T., Chan, P.S., Balakrishnan, N.: Optimal progressive censoring plans for the Weibull distribution. Technometrics 46(4), 470–481 (2004)
Dey, T., Dey, S., Kundu, D.: On progressively type-II censored two-parameter Rayleigh distribution. Commun. Stat. Simul. Comput. 45(2), 438–455 (2016)
Kotb, M., Raqab, M.: Statistical inference for modified Weibull distribution based on progressively Type-II censored data. Math. Comput. Simul. 162, 233–248 (2019)
Krishna, H., Kumar, K.: Reliability estimation in Lindley distribution with progressively Type II right censored sample. Math. Comput. Simulation 82(2), 281–294 (2011)
Valiollahi, R., Raqab, M.Z., Asgharzadeh, A., Alqallaf, F.A.: Estimation and prediction for power Lindley distribution under progressively Type II right censored samples. Math. Comput. Simul. 149, 32–47 (2018)
Ahmed, E.A.: Estimation of some lifetime parameters of generalized Gompertz distribution under progressively type-II censored data. Appl. Math. Model. 39(18), 5567–5578 (2015)
Balakrishnan, N., Varadan, J.: Approximate MLEs for the location and scale parameters of the extreme value distribution with censoring. IEEE Trans. Reliab. 40(2), 146–151 (1991)
Balakrishnan, N., Kannan, N., Lin, C.T., Wu, S.J.S.: Inference for the extreme value distribution under progressive Type-II censoring. J. Stat. Comput. Simul. 74(1), 25–45 (2004)
Balasooriya, U., Saw, S.L.C., Gadag, V.: Progressively censored reliability sampling plans for the Weibull distribution. Technometrics 42, 160–167 (2000)
Schenk, N., Burkschat, M., Cramer, E., Kamps, U.: Bayesian estimation and prediction with multiply Type-II censored samples of sequential order statistics from one- and two-parameter exponential distributions. J. Statist. Plann. Inference 141, 1575–1587 (2011)
Kundu, D.: Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring. Technometrics 50(2), 144–154 (2008)
Li, F., Shi, Y., Tian, Y.: Bayesian estimation of a Weibull model based on progressively censored data. Chinese J. Engrg. Math. 25(4), 641–650 (2008)
Balakrishnan, N., Bordes, L.: Non-parametric hazard rate estimation under progressive Type-II censoring. In: Balakrishnan, N., Rao, C.R. (eds.) Advances in Survival Analysis. Handbook of Statistics, vol. 23, pp. 227–249. Elsevier, Amsterdam (2004)
Wu, S.-F.: Interval estimation for the two-parameter exponential distribution under progressive censoring. Qual. Quant. 44, 181–189 (2010)
Wu, S.-J.: Estimations of the parameters of the Weibull distribution with progressively censored data. J. Jap. Stat. Soc. 32(2), 155–163 (2002)
Wang, B.X., Yu, K., Jones, M.: Inference under progressively Type II right censored sampling for certain lifetime distributions. Technometrics 52, 453–460 (2010)
Kuş, C., Kaya, M.F.: Estimation for the parameters of the Pareto distribution under progressive censoring. Commun. Statist. Theory Methods 36(5–8), 1359–1365 (2007)
Parsi, S., Ganjali, M., Farsipour, N.S.: Simultaneous confidence intervals for the parameters of Pareto distribution under progressive censoring. Commun. Statist. Theory Methods 39, 94–106 (2009)
Wu, S.-F.: Interval estimation for the Pareto distribution based on the progressive Type II censored sample. J. Stat. Comput. Simul. 80(4), 463–474 (2010)
Fernández, A.J.: Computing optimal confidence sets for Pareto models under progressive censoring. J. Comput. Appl. Math. 258, 168–180 (2014)
Asgharzadeh, A., Fernández, A.J., Abdi, M.: Confidence sets for the two-parameter Rayleigh distribution under progressive censoring. Appl. Math. Model. 47, 656–667 (2017)
Wang, L.: Optimal interval estimation for a family of lower truncated distribution under progressive censoring. J. Comput. Appl. Math. 287, 67–77 (2015)
Bedbur, S., Kamps, U., Lennartz, J.: On a smallest confidence region for a location–scale parameter in progressively type-II censored lifetime experiments. Statist. Probab. Lett. 154, 108545 (2019)
Balakrishnan, N., Beutner, E., Cramer, E.: Exact two-sample non-parametric confidence, prediction, and tolerance intervals based on ordinary and progressively Type-II right censored data. TEST 19, 68–91 (2010)
Volterman, W., Balakrishnan, N., Cramer, E.: Exact meta-analysis of several independent progressively Type-II censored data. Appl. Math. Model. 38, 949–960 (2014)
Weerahandi, S.: Generalized Inference in Repeated Measures. Exact Methods in MANOVA and Mixed Models. Wiley, Hoboken (2004)
Aggarwala, R., Childs, A.: Conditional inference for the parameters of Pareto distributions when observed samples are progressively censored. In: Balakrishnan, N., Melas, V.B., Ermakov, S. (eds.) Advances in Stochastic Simulation Methods, pp. 293–302. Birkhäuser, Boston (2000). Chap. 17
Pradhan, B.: Point and interval estimation for the lifetime distribution of a k-unit parallel system based on progressively Type-II censored data. Econom. Quality Control 22, 175–186 (2007)
Sultan, K.S., Alsadat, N.H., Kundu, D.: Bayesian and maximum likelihood estimations of the inverse Weibull parameters under progressive type-II censoring. J. Stat. Comput. Simul. 84, 2248–2265 (2014)
Basak, I., Basak, P., Balakrishnan, N.: On some predictors of times to failure of censored items in progressively censored samples. Comput. Statist. Data Anal. 50(5), 1313–1337 (2006)
Balakrishnan, N., Rao, C.R.: Large-sample approximations to the best linear unbiased estimation and best linear unbiased prediction based on progressively censored samples and some applications. In: Panchapakesan, S., Balakrishnan, N. (eds.) Advances in Statistical Decision Theory and Applications, pp. 431–444. Birkhäuser, Boston (1997)
Basak, I., Balakrishnan, N.: Predictors of failure times of censored units in progressively censored samples from normal distribution. Sankhyā 71-B, 222–247 (2009)
Raqab, M.Z., Asgharzadeh, A., Valiollahi, R.: Prediction for Pareto distribution based on progressively Type-II censored samples. Comput. Stat. Data Anal. 54(7), 1732–1743 (2010)
Madi, M.T., Raqab, M.Z.: Bayesian inference for the generalized exponential distribution based on progressively censored data. Commun. Statist. Theory Methods 38(12), 2016–2029 (2009)
Raqab, M.Z., Madi, M.T.: Inference for the generalized Rayleigh distribution based on progressively censored data. J. Statist. Plann. Inference 141(10), 3313–3322 (2011)
Abdel-Aty, Y., Franz, J., Mahmoud, M.A.W.: Bayesian prediction based on generalized order statistics using multiply Type-II censoring. Statistics 41(6), 495–504 (2007)
Huang, S.-R., Wu, S.-J.: Bayesian estimation and prediction for Weibull model with progressive censoring. J. Stat. Comput. Simul. 82(11), 1607–1620 (2012)
Ghafoori, S., Habibi Rad, A., Doostparast, M.: Bayesian two-sample prediction with progressively Type-II censored data for some lifetime models. J. Iran. Stat. Soc. (JIRSS) 10, 63–86 (2011)
Wu, S.-J., Chen, D.-H., Chen, S.-T.: Bayesian inference for Rayleigh distribution under progressive censored sample. Appl. Stoch. Models Bus. Ind. 22(3), 269–279 (2006)
Soliman, A.A., Al-Hossain, A.Y., Al-Harbi, M.M.: Predicting observables from Weibull model based on general progressive censored data with asymmetric loss. Statist. Methodol. 8(5), 451–461 (2011)
Ali Mousa, M.A.M., Jaheen, Z.F.: Bayesian prediction for progressively censored data from the Burr model. Statist. Papers 43(4), 587–593 (2002)
Jaheen, Z.F.: Prediction of progressive censored data from the Gompertz model. Commun. Statist. Simulation Comput. 32(3), 663–676 (2003)
Klakattawi, H.S., Baharith, L.A., AL-Dayian, G.R.: Bayesian predictions of progressive censored data from the exponentiated modified Weibull distribution. Canad. J. Comput. Math. Natur. Sci. Eng. Med. 3, 247–255 (2012)
Mohie El-Din, M.M., Shafay, A.R.: One- and two-sample Bayesian prediction intervals based on progressively Type-II censored data. Statist. Papers 54, 287–307 (2013)
Ali Mousa, M.A.M., Al-Sagheer, S.: Bayesian prediction for progressively Type-II censored data from the Rayleigh model. Commun. Statist. Theory Methods 34(12), 2353–2361 (2005)
Beutner, E., Cramer, E.: Using linear interpolation to reduce the order of the coverage error of nonparametric prediction intervals based on right-censored data. J. Multivariate Anal. 129, 95–109 (2014)
Balakrishnan, N., Ng, H.K.T.: Precedence-Type Tests and Applications. Wiley, Hoboken (2006)
Ng, H.K.T., Balakrishnan, N.: Weighted precedence and maximal precedence tests and an extension to progressive censoring. J. Statist. Plann. Inference 135(1), 197–221 (2005)
Balakrishnan, N., Tripathi, R.C., Kannan, N., Ng, H.K.T.: Some nonparametric precedence-type tests based on progressively censored samples and evaluation of power. J. Statist. Plann. Inference 140(2), 559 – 573 (2010)
Alvarez-Andrade, S., Balakrishnan, N., Bordes, L.: Homogeneity tests based on several progressively Type-II censored samples. J. Multivariate Anal. 98, 1195–1213 (2007)
Balakrishnan, N., Ng, H.K.T., Kannan, N.: A test of exponentiality based on spacings for progressively type-II censored data. In: Huber-Carol, C., Balakrishnan, N., Nikulin, M., Mesbah, M. (eds.) Goodness-of-Fit Tests and Model Validity, pp. 89–111. Birkhäuser, Boston (2002)
Marohn, F.: A characterization of generalized Pareto distributions by progressive censoring schemes and goodness-of-fit tests. Commun. Statist. Theory Methods 31(7), 1055–1065 (2002)
Pakyari, R., Balakrishnan, N.: A general purpose approximate goodness-of-fit test for progressively Type-II censored data. IEEE Trans. Reliab. 61, 238–244 (2012)
Burkschat, M., Cramer, E., Kamps, U.: On optimal schemes in progressive censoring. Statist. Probab. Letters 76(10), 1032–1036 (2006)
Burkschat, M., Cramer, E., Kamps, U.: Optimality criteria and optimal schemes in progressive censoring. Commun. Statist. Theory Methods 36, 1419–1431 (2007)
Salemi, U.H., Rezaei, S., Si, Y., Nadarajah, S.: On optimal progressive censoring schemes for normal distribution. Annals of Data Science 5(4), 637–658 (2018)
Abo-Eleneen, Z.A.: A novel approach for optimal schemes in progressive censoring plans. J. Commun. Comput. 9, 426–433 (2012)
Mishra, N.: Optimal one-step censoring schemes under entropy criterion. Commun. Stat.- Simul. Comput. 49(8), 2068–2081 (2018)
Pradhan, B., Kundu, D.: On progressively censored generalized exponential distribution. TEST 18, 497–515 (2009)
Pradhan, B., Kundu, D.: Inference and optimal censoring schemes for progressively censored Birnbaum-Saunders distribution. J. Statist. Plann. Inference 143(0), 1098–1108 (2013)
Bhattacharya, R., Pradhan, B., Dewanji, A.: On optimum life-testing plans under Type-II progressive censoring scheme using variable neighborhood search algorithm. TEST 25(2), 309–330 (2016)
Salemi, U.H., Rezaei, S., Nadarajah, S.: A-optimal and D-optimal censoring plans in progressively Type-II right censored order statistics. Stat. Pap. 60(4), 1349–1367 (2017)
Cramer, E., Navarro, J.: Progressive Type-II censoring and coherent systems. Nav. Res. Logist. 62, 512–530 (2015)
Cramer, E., Navarro, J.: The progressive censoring signature of coherent systems. Appl. Stoch. Model. Bus. Ind. 32(5), 697–710 (2016)
Jablonka, A., Cramer, E., Hermanns, M.: Statistical inference for coherent systems with Weibull distributed component lifetimes under complete and incomplete information. Appl. Stoch. Model. Bus. Ind. 35(4), 1011–1027 (2019)
Volterman, W., Balakrishnan, N.: Exact nonparametric confidence, prediction and tolerance intervals based on multi-sample Type-II right censored data. J. Statist. Plann. Inference 140(11), 3306–3316 (2010)
Cohen, A.C.: Maximum likelihood estimation in the Weibull distribution based on complete and on censored samples. Technometrics 7, 579–588 (1965)
Cohen, A.C.: Multi-censored sampling in the three parameter Weibull distribution. Technometrics 17, 347–351 (1975)
Cohen, A.C.: Progressively censored sampling in the three parameter log-normal distribution. Technometrics 18, 99–103 (1976)
Wingo, D.R.: Solution of the three-parameter Weibull equations by constrained modified quasilinearization (progressively censored samples). IEEE Trans. Reliab. R-22, 96–102 (1973)
Wingo, D.R.: Maximum likelihood methods for fitting the Burr type XII distribution to multiply (progressively) censored life test data. Metrika 40, 203–210 (1993)
Nelson, W.: Applied Life Data Analysis. Wiley, New York (1982)
Cohen, A.C., Whitten, B.J.: Parameter Estimation in Reliability and Life Span Models. Marcel Dekker, New York (1988)
Balakrishnan, N., Han, D., Iliopoulos, G.: Exact inference for progressively Type-I censored exponential failure data. Metrika 73, 335–358 (2011)
Balakrishnan, N., Iliopoulos, G.: Stochastic monotonicity of the MLE of exponential mean under different censoring schemes. Ann. Inst. Statist. Math. 61, 753–772 (2009)
van Bentum, T., Cramer, E.: Stochastic monotonicity of MLEs of the mean for exponentially distributed lifetimes under sequential hybrid censoring. Statist. Probab. Lett. 148, 1–8 (2019)
Casella, G., Berger, R.L.: Statistical Inference, 2 edn. Duxbury Press, Boston (2002)
Hahn, G.J., Meeker, W.Q., Escobar, L.A.: Statistical Intervals: A Guide for Practitioners. Wiley, New York (2017)
Balakrishnan, N., Cramer, E., Iliopoulos, G.: On the method of pivoting the CDF for exact confidence intervals with illustration for exponential mean under life-test with time constraints. Statist. Probab. Lett. 89, 124–130 (2014)
Cramer, E., Górny, J., Laumen, B.: Multi-sample progressive Type-I censoring of exponentially distributed lifetimes. Commun. Statist. Theory Methods 50(22), 5285–5313 (2020)
Cohen, A.C.: Truncated and Censored Samples. Theory and Applications. Marcel Dekker, New York (1991)
Cramer, E., Tamm, M.: On a correction of the scale MLE for a two-parameter exponential distribution under progressive Type-I censoring. Commun. Statist. Theory Methods 43, 4401–4414 (2014)
Cohen, A.C.: Life testing and early failure. Technometrics 17, 347–351 (1966)
Gibbons, D.I., Vance, L.C.: Estimators for the 2-parameter Weibull distribution with progressively censored samples. IEEE Trans. Reliab. 32, 95–99 (1983)
Lemon, G.H.: Maximum likelihood estimation for the three parameter Weibull distribution based on censored samples. Technometrics 17, 247–254 (1975)
Gajjar, A., Khatri, C.: Progressively censored samples from log-normal and logistic distributions. Technometrics 11, 793–803 (1969)
Budhiraja, S., Pradhan, B., Sengupta, D.: Maximum likelihood estimators under progressive Type-I interval censoring. Statist. Probab. Lett. 123, 202–209 (2017)
Cheng, C., Chen, J., Li, Z.: A new algorithm for maximum likelihood estimation with progressive Type-I interval censored data. Commun. Statist. Simulation Comput. 39(4), 750–766 (2010)
Ng, H.K.T., Wang, Z.: Statistical estimation for the parameters of Weibull distribution based on progressively type-I interval censored sample. J. Statist. Comp. Simul. 79(2), 145–159 (2009)
Lin, Y.-J., Lio, Y.L.: Bayesian inference under progressive type-I interval censoring. J. Appl. Stat. 39(8), 1811–1824 (2012)
Chen, D.G., Lio, Y.L.: Parameter estimations for generalized exponential distribution under progressive Type-I interval censoring. Comput. Statist. Data Anal. 54(6), 1581–1591 (2010)
Peng, X.-Y., Yan, Z.-Z.: Bayesian estimation for generalized exponential distribution based on progressive type-I interval censoring. Acta Math. Appl. Sin. Engl. Ser. 29(2), 391–402 (2013)
Lio, Y.L., Chen, D.-G., Tsai, T.-R.: Parameter estimations for generalized Rayleigh distribution under progressively Type-I interval censored data. Open J. Statist. 1(2), 46–57 (2011)
Xiuyun, P., Zaizai, Y.: Parameter estimations with gamma distribution based on progressive Type-I interval censoring. In: IEEE International Conference on Computer Science and Automation Engineering (CSAE), 2011, pp. 449–453. IEEE, New York (2011)
Arabi Belaghi, R., Noori Asl, M., Singh, S.: On estimating the parameters of the Burr XII model under progressive Type-I interval censoring. J. Stat. Comput. Simul. 87(16), 3132–3151 (2017)
Wu, S.-J., Chang, C.-T., Liao, K.-J., Huang, S.-R.: Planning of progressive group-censoring life tests with cost considerations. J. Appl. Stat. 35(11), 1293–1304 (2008)
Lin, C.-T., Wu, S.J.S., Balakrishnan, N.: Planning life tests with progressively Type-I interval censored data from the lognormal distribution. J. Statist. Plann. Inference 139(1), 54–61 (2009)
Lin, C.-T., Balakrishnan, N., Wu, S.J.S.: Planning life tests based on progressively Type-I grouped censored data from the Weibull distribution. Commun. Statist. Simulation Comput. 40(4), 574–595 (2011)
Kuş, C., Akdoğan, Y., Wu, S.-J.: Optimal progressive group censoring scheme under cost considerations for pareto distribution. J. Appl. Stat. 40(11), 2437–2450 (2013)
Singh, S., Tripathi, Y.M.: Estimating the parameters of an inverse Weibull distribution under progressive Type-I interval censoring. Stat. Pap. 59, 21–56 (2018)
Roy, S., Pradhan, B.: Bayesian optimum life testing plans under progressive Type-I interval censoring scheme. Qual. Reliab. Eng. Int. 33(8), 2727–2737 (2017)
Roy, S., Pradhan, B.: Bayesian C-optimal life testing plans under progressive type-I interval censoring scheme. Appl. Math. Model. 70, 299–314 (2019)
Kaushik, A.: A progressive interval type-I censored life test plan for Rayleigh distribution. Austrian Journal of Statistics 48(3), 76–86 (2019)
Balakrishnan, N., Kundu, D.: Hybrid censoring: Models, inferential results and applications (with discussions). Comput. Statist. Data Anal. 57, 166–209 (2013)
Górny, J., Cramer, E.: From B-spline representations to gamma representations in hybrid censoring. Stat. Pap. 60, 1119–1135 (2019)
Górny, J., Cramer, E.: A volume based approach to establish B-spline based expressions for density functions and its application to progressive hybrid censoring. J. Korean Stat. Soc. 38, 340–355 (2019)
Burkschat, M., Cramer, E., Górny, J.: Type-I censored sequential k-out-of-n systems. Appl. Math. Model. 40(19–20), 8156–8174 (2016)
Górny, J., Cramer, E.: Type-I hybrid censoring of multiple samples. J. Comp. Appl. Math. 366, 112404 (2020)
Chan, P.S., Ng, H.K.T., Su, F.: Exact likelihood inference for the two-parameter exponential distribution under Type-II progressively hybrid censoring. Metrika 78(6), 1–24 (2015)
Lin, C.-T., Chou, C.-C., Huang, Y.-L.: Inference for the Weibull distribution with progressive hybrid censoring. Comp. Statist. Data Anal. 56(3), 451–467 (2012)
Golparvar, L., Parsian, A.: Inference on proportional hazard rate model parameter under Type-I progressively hybrid censoring scheme. Commun. Stat.- Theory Methods 45(24), 7258–7274 (2016)
Hemmati, F., Khorram, E.: Statistical analysis of the log-normal distribution under Type-II progressive hybrid censoring schemes. Commun. Statist. Simulation Comput. 42(1), 52–75 (2013)
Tomer, S.K., Panwar, M.S.: Estimation procedures for Maxwell distribution under type-I progressive hybrid censoring scheme. J. Statist. Comp. Simul. 85, 339–356 (2014)
Kayal, T., Tripathi, Y.M., Rastogi, M.K., Asgharzadeh, A.: Inference for Burr XII distribution under Type I progressive hybrid censoring. Commun. Stat.- Simul. Comput. 46(9), 7447–7465 (2017)
Sen, T., Singh, S., Tripathi, Y.M.: Statistical Inference for Lognormal Distribution with Type-I Progressive Hybrid Censored Data. Am. J. Math. Manag. Sci. 38(1), 70–95 (2019)
Arabi Belaghi, R., Noori Asl, M.: Estimation based on progressively type-I hybrid censored data from the Burr XII distribution. Stat. Pap. 60, 411–453 (2019)
Górny, J., Cramer, E.: Type-I hybrid censoring of uniformly distributed lifetimes. Commun. Stat.- Theory Methods 48, 412–433 (2019)
Bhattacharya, R., Pradhan, B.: Computation of optimum Type-II progressively hybrid censoring schemes using variable neighborhood search algorithm. TEST 26(4), 802–821 (2017)
Bhattacharya, R., Saha, B.N., Farías, G.G., Balakrishnan, N.: Multi-criteria-based optimal life-testing plans under hybrid censoring scheme. TEST 29(2), 430–453 (2020)
Cramer, E., Burkschat, M., Górny, J.: On the exact distribution of the MLEs based on Type-II progressively hybrid censored data from exponential distributions. J. Stat. Comp. Simul. 86, 2036–2052 (2016)
Jansen, M., Górny, J., Cramer, E.: Exact likelihood inference for an exponential parameter under a multi-sample Type-II progressive hybrid censoring model. submitted for publication. Am. J. Math. Manag. Sci. 41, 101–127 (2022)
Lin, C.-T., Ng, H.K.T., Chan, P.S.: Statistical inference of Type-II progressively hybrid censored data with Weibull lifetimes. Commun. Statist. Theory Methods 38(10), 1710–1729 (2009)
Mokhtari, E.B., Rad, A.H., Yousefzadeh, F.: Inference for Weibull distribution based on progressively Type-II hybrid censored data. J. Statist. Plann. Inference 141(8), 2824–2838 (2011)
Alma, O.G., Arabi Belaghi, R.: On the estimation of the extreme value and normal distribution parameters based on progressive type-II hybrid-censored data. J. Stat. Comput. Simul. 86(3), 569–596 (2016)
Noori Asl, M., Arabi Belaghi, R., Bevrani, H.: On Burr XII distribution analysis under progressive type-II hybrid censored data. Methodol. Comput. Appl. Probab. 19(2), 665–683 (2017)
Cho, Y., Sun, H., Lee, K.: Exact likelihood inference for an exponential parameter under generalized progressive hybrid censoring scheme. Statist. Methodol. 23, 18–34 (2015)
Cho, Y., Sun, H., Lee, K.: Estimating the entropy of a Weibull distribution under generalized progressive hybrid censoring. Entropy 17, 102–122 (2015)
Górny, J., Cramer, E.: Exact likelihood inference for exponential distributions under generalized progressive hybrid censoring schemes. Stat. Methodol. 29, 70–94 (2016)
Lee, K., Sun, H., Cho, Y.: Exact likelihood inference of the exponential parameter under generalized Type II progressive hybrid censoring. J. Korean Stat. Soc. 45(1), 123–136 (2016)
Seo, J.I., Kim, Y.: Robust Bayesian estimation of a two-parameter exponential distribution under generalized Type-I progressive hybrid censoring. Commun. Stat. Simul. Comput. 46(7), 5795–5807 (2017)
Seo, J.I., Kim, Y.: Robust Bayesian analysis for exponential parameters under generalized Type-II progressive hybrid censoring. Commun. Stat.- Theory Methods 47(9), 2259–2277 (2018)
Mohie El-Din, M.M., Nagy, M., Abu-Moussa, M.H.: Estimation and prediction for Gompertz distribution under the generalized progressive hybrid censored data. Annals of Data Science 6, 673–705 (2019)
Górny, J. Cramer, E.: Exact inference for a new flexible hybrid censoring scheme. Journal of the Indian Society for Probability and Statistics 19(1), 169–199 (2018)
Park, S., Balakrishnan, N., Kim, S.W.: Fisher information in progressive hybrid censoring schemes. Statistics 45, 623–631 (2011)
Sen, T., Pradhan, B., Tripathi, Y.M., Bhattacharya, R.: Fisher information in generalized progressive hybrid-censored data. Statistics 52(5), 1025–1039 (2018)
Kohansal, A., Nadarajah, S.: Stress–strength parameter estimation based on type-II hybrid progressive censored samples for a Kumaraswamy distribution. IEEE Trans. Reliab. 68, 1296–1310 (2019)
Lin, C.-T., Huang, Y.-L.: On progressive hybrid censored exponential distribution. J. Stat. Comput. Simul. 82, 689–709 (2012)
Sobhi, M.M.A., Soliman, A.A.: Estimation for the exponentiated Weibull model with adaptive Type-II progressive censored schemes. Appl. Math. Model. 40(2), 1180–1192 (2016)
Yuen, H.-K., Tse, S.-K.: Parameters estimation for Weibull distributed lifetimes under progressive censoring with random removals. J. Stat. Comput. Simul. 55(1-2), 57–71 (1996)
Tse, S.-K., Yang, C., Yuen, H.-K.: Statistical analysis of Weibull distributed lifetime data under Type II progressive censoring with binomial removals. J. Appl. Stat. 27(8), 1033–1043 (2000)
Tse, S.-K., Xiang, L.: Interval estimation for Weibull-distributed life data under Type II progressive censoring with random removals. J. Biopharm. Stat. 13, 1–16 (2003)
Xiang, L., Tse, S.K.: Maximum likelihood estimation in survival studies under progressive interval censoring with random removals. J. Biopharm. Stat. 15(6), 981–991 (2005)
Kaushik, A., Singh, U., Singh, S.K.: Bayesian inference for the parameters of Weibull distribution under progressive Type-I interval censored data with beta-binomial removals. Commun. Stat. Simul. Comput. 46(4), 3140–3158 (2017)
Budhiraja, S., Pradhan, B.: Point and interval estimation under progressive type-I interval censoring with random removal. Statistical papers 61(1), 445–477 (2020)
Bairamov, I., Parsi, S.: On flexible progressive censoring. J. Comput. Appl. Math 235(16), 4537–4544 (2011)
Kinaci, I.: A generalization of flexible progressive censoring. Pakistan J. Stat. 29, 377–387 (2013)
Park, S., Ng, H.K.T., Chan, P.S.: On the Fisher information and design of a flexible progressive censored experiment. Statist. Probab. Lett. 97, 142–149 (2015)
Li, F.: Reliability analysis for the Pareto model based on the progressive type II censored sample. In: Jin, D., Lin, S. (eds.) Advances in Computer Science, Intelligent System and Environment, pp. 467–472. Springer, Berlin (2011)
Krishna, H., Kumar, K.: Reliability estimation in generalized inverted exponential distribution with progressively type II censored sample. J. Stat. Comput. Simul. 83, 1007–1019 (2013)
Rastogi, M.K., Tripathi, Y.M.: Parameter and reliability estimation for an exponentiated half-logistic distribution under progressive type II censoring. J. Stat. Comput. Simul. 84, 1711–1727 (2014)
Guo, L., Gui, W.: Statistical inference of the reliability for generalized exponential distribution under progressive Type-II censoring schemes. IEEE Trans. Reliab. 67(2), 470–480 (2018)
Maiti, K., Kayal, S.: Estimation of parameters and reliability characteristics for a generalized Rayleigh distribution under progressive type-II censored sample. Commun. Stat. Simul. Comput. 50(11), 3669–3698 (2021)
Zhang, Z., Gui, W.: Statistical inference of reliability of Generalized Rayleigh distribution under progressively type-II censoring. J. Comput. Appl. Math. 361, 295–312 (2019)
Asgharzadeh, A., Valiollahi, R.: Inference for the proportional hazards family under progressive Type-II censoring. J. Iran. Stat. Soc. (JIRSS) 8, 35–53 (2009)
Chaturvedi, A., Kumar, N., Kumar, K.: Statistical inference for the reliability functions of a family of lifetime distributions based on progressive type II right censoring. Statistica 78(1), 81–101 (2018)
Kotz, S., Lumelskii, Y., Pensky, M.: The Stress-Strength Model and Its Generalizations—Theory and Applications. World Scientific Publications, Singapore (2003)
Cramer, E., Kamps, U.: The UMVUE of P(X < Y ) based on Type-II censored samples from Weinman multivariate exponential distributions. Metrika 46, 93–121 (1997)
Cramer, E.: Inference for stress-strength systems based on Weinman multivariate exponential samples. Commun. Statist. Theory Methods 30, 331–346 (2001)
Saraçoğlu, B., Kinaci, I., Kundu, D.: On estimation of R = P(Y < X) for exponential distribution under progressive type-II censoring. J. Stat. Comput. Simul. 82, 729–744 (2012)
Krishna, H., Dube, M., Garg, R.: Estimation of P(Y < X) for progressively first-failure-censored generalized inverted exponential distribution. J. Stat. Comput. Simul. 87(11), 2274–2289 (2017)
Asgharzadeh, A., Valiollahi, R., Raqab, M.Z.: Stress-strength reliability of Weibull distribution based on progressively censored samples. Statist. Oper. Res. Trans. 35, 103–124 (2011)
Valiollahi, R., Asgharzadeh, A., Raqab, M.Z.: Estimation of P(Y < X) for Weibull distribution under progressive Type-II censoring. Commun. Statist. Theory Methods 42(24), 4476–4498 (2013)
Rezaei, S., Noughabi, R.A., Nadarajah, S.: Estimation of stress-strength reliability for the generalized Pareto distribution based on progressively censored samples. Annals of Data Science 2(1), 83–101 (2015)
Basirat, M., Baratpour, S., Ahmadi, J.: Statistical inferences for stress-strength in the proportional hazard models based on progressive Type-II censored samples. J. Stat. Comput. Simul. 85, 431–449 (2014)
Bai, X., Shi, Y., Liu, Y., Liu, B.: Reliability inference of stress–strength model for the truncated proportional hazard rate distribution under progressively Type-II censored samples. Appl. Math. Model. 65, 377–389 (2019)
Xiuyun, P., Yan, X., Zaizai, Y.: Reliability analysis of Birnbaum–Saunders model based on progressive Type-II censoring. J. Stat. Comput. Simul. 89(3), 461–477 (2019)
Babayi, S., Khorram, E.: Inference of stress-strength for the Type-II generalized logistic distribution under progressively Type-II censored samples. Commun. Stat. Simul. Comput. 47(7), 1975–1995 (2018)
Bai, X., Shi, Y., Liu, Y., Liu, B.: Reliability estimation of stress–strength model using finite mixture distributions under progressively interval censoring. J. Comput. Appl. Math. 348, 509–524 (2019)
Lin, C.-T., Ke, S.-J.: Estimation of P(Y < X) for location-scale distributions under joint progressively type-II right censoring. Quality Technology & Quantitative Management 10(3), 339–352 (2013)
Kundu, D., Kannan, N., Balakrishnan, N.: Analysis of progressively censored competing risks data. In: Balakrishnan, N., Rao, C.R. (eds.) Advances in Survival Analysis. Handbook of Statistics, vol. 23, pp. 331–348. Elsevier, Amsterdam (2004)
Pareek, B., Kundu, D., Kumar, S.: On progressively censored competing risks data for Weibull distributions. Comput. Statist. Data Anal. 53, 4083–4094 (2009)
Kundu, D., Pradhan, B.: Bayesian analysis of progressively censored competing risks data. Sankhyā B 73(2), 276–296 (2011)
Chacko, M., Mohan, R.: Bayesian analysis of Weibull distribution based on progressive Type-II censored competing risks data with binomial removals. Comput. Stat. 34(1), 233–252 (2019)
Cramer, E., Schmiedt, A.B.: Progressively Type-II censored competing risks data from Lomax distributions. Comp. Statist. Data Anal. 55, 1285–1303 (2011)
AL-Hussaini, E.K., Abdel-Hamid, A.H., Hashem, A.F.: Bayesian prediction intervals of order statistics based on progressively Type-II censored competing risks data from the half-logistic distribution. J. Egypt. Math. Soc. 23(1), 190–196 (2015)
Wang, L.: Inference of progressively censored competing risks data from Kumaraswamy distributions. J. Comput. Appl. Math. 343, 719–736 (2018)
Azizi, F., Haghighi, F., Gilani, N.T.: Statistical inference for competing risks model under progressive interval censored Weibull data. Commun. Stat. Simul. Comput. 49(7), 1–14 (2018)
Ahmadi, K., Yousefzadeh, F., Rezaei, M.: Analysis of progressively type-I interval censored competing risks data for a class of an exponential distribution. J. Stat. Comput. Simul. 86(18), 3629–3652 (2016)
Kundu, D., Gupta, R.D.: Analysis of hybrid life-tests in presence of competing risks. Metrika 65(2), 159–170 (2006)
Kundu, D., Joarder, A.: Analysis of Type-II progressively hybrid censored competing risks data. J. Mod. Appl. Statist. Methods 5(1), 152–170 (2006)
Mao, S., Shi, Y.-M., Sun, Y.-D.: Exact inference for competing risks model with generalized Type-I hybrid censored exponential data. J. Stat. Comp. Simul. 84(11), 2506–2521 (2014)
Bhattacharya, S., Pradhan, B., Kundu, D.: Analysis of hybrid censored competing risks data. Statistics 48(5), 1138–1154 (2014)
Feizjavadian, S., Hashemi, R.: Analysis of dependent competing risks in the presence of progressive hybrid censoring using Marshall–Olkin bivariate Weibull distribution. Comput. Stat. Data Anal. 82, 19–34 (2015)
Iliopoulos, G.: On exact confidence intervals in a competing risks model with generalized hybrid type-I censored exponential data. J. Stat. Comp. Simul. 85, 2953–2961 (2015)
Koley, A., Kundu, D.: On generalized progressive hybrid censoring in presence of competing risks. Metrika 80, 401–426 (2017)
Koley, A., Kundu, D., Ganguly, A.: Analysis of Type-II hybrid censored competing risks data. Statistics 51(6), 1304–1325 (2017)
Wang, L.: Inference for Weibull competing risks data under generalized progressive hybrid censoring. IEEE Trans. Reliab. 67(3), 998–1007 (2018)
Wu, S.-J., Kuş, C.: On estimation based on progressive first-failure-censored sampling. Comp. Statist. Data Anal. 53(10), 3659–3670 (2009)
Soliman, A.A., Abd-Ellah, A.H., Abou-Elheggag, N.A., Abd-Elmougod, G.A.: Estimation of the parameters of life for Gompertz distribution using progressive first-failure censored data. Comp. Statist. Data Anal. 56(8), 2471–2485 (2012)
Potdar, K.G., Shirke, D.T.: Inference for the scale parameter of lifetime distribution of k-unit parallel system based on progressively censored data. J. Stat. Comput. Simul. 84, 171–185 (2013)
Hermanns, M., Cramer, E.: Likelihood inference for the component lifetime distribution based on progressively censored parallel systems data. J. Stat. Comput. Simul. 87, 607–630 (2017)
Amiri, L., Ganjali, M., Hashemi, R., Khazaei, M.: The competing risks analysis for parallel and series systems using Type-II progressive censoring. Commun. Stat.- Theory Methods 49(22) (2019)
Hermanns, M., Cramer, E.: Inference with progressively censored k-out-of-n system lifetime data. TEST 27, 787–810 (2018)
Hermanns, M., Cramer, E., Ng, H.K.T.: EM algorithms for ordered and censored system lifetime data under a proportional hazard rate model. J. Stat. Comput. Simul. 90(18), 3301–3337 (2020)
Balasooriya, U., Saw, S.L.C.: Reliability sampling plans for the two-parameter exponential distribution under progressive censoring. J. Appl. Stat. 25, 707–714 (1998)
Fernández, A.J.: Progressively censored variables sampling plans for two-parameter exponential distributions. J. Appl. Stat. 32(8), 823–829 (2005)
Pérez-González, C., Fernández, A.J.: Accuracy of approximate progressively censored reliability sampling plans for exponential models. Statist. Papers 50, 161–170 (2009)
Fernández, A.J., Pérez-González, C.J., Aslam, M., Jun, C.-H.: Design of progressively censored group sampling plans for Weibull distributions: An optimization problem. Eur. J. Oper. Res. 211(3), 525–532 (2011)
Balasooriya, U., Balakrishnan, N.: Reliability sampling plans for the lognormal distribution, based on progressively censored samples. IEEE Trans. Reliab. 49, 199–203 (2000)
Wu, S.-J., Huang, S.-R.: Progressively first-failure censored reliability sampling plans with cost constraint. Comp. Statist. Data Anal. 56(6), 2018–2030 (2012)
Laumen, B., Cramer, E.: Inference for the lifetime performance index with progressively Type-II censored samples from gamma distributions. Econom. Quality Control 30, 59–73 (2015)
Lee, W.-C., Wu, J.-W., Hong, C.-W.: Assessing the lifetime performance index of products with the exponential distribution under progressively type II right censored samples. J. Comput. Appl. Math. 231(2), 648–656 (2009)
Lee, W.-C., Wu, J.-W., Hong, M.-L., Lin, L.-S., Chan, R.-L.: Assessing the lifetime performance index of Rayleigh products based on the Bayesian estimation under progressive Type II right censored samples. J. Comput. Appl. Math. 235(6), 1676–1688 (2011)
Lee, W.-C., Wu, J.-W., Hong, C.-W.: Assessing the lifetime performance index of products from progressively Type II right censored data using Burr XII model. Math. Comput. Simulation 79(7), 2167–2179 (2009)
Ahmadi, M.V., Doostparast, M., Ahmadi, J.: Statistical inference for the lifetime performance index based on generalised order statistics from exponential distribution. Int. J. System Sci. 46, 1094–1107 (2014)
Ahmadi, M.V., Doostparast, M., Ahmadi, J.: Estimating the lifetime performance index with Weibull distribution based on progressive first-failure censoring scheme. J. Comput. Appl. Math. 239, 93–102 (2013)
Hong, C.W., Lee, W.C., Wu, J.W.: Computational procedure of performance assessment of lifetime index of products for the Weibull distribution with the progressive first-failure-censored sampling plan. J. Appl. Math. 2012(Article ID 717184), 13 pages (2012)
Mahmoud, M.A.W., El-Sagheer, R.M., Soliman, A.A.-E., Ellah, A.H.A.: Inferences of the lifetime performance index with Lomax distribution based on progressive type-II censored data. Econom. Quality Control 29, 39–51 (2014)
Ahmadi, M.V., Doostparast, M.: Pareto analysis for the lifetime performance index of products on the basis of progressively first-failure-censored batches under balanced symmetric and asymmetric loss functions. J. Appl. Stat. 46(7), 1196–1227 (2019)
Wu, S.-F., Hsieh, Y.-T.: The assessment on the lifetime performance index of products with Gompertz distribution based on the progressive type I interval censored sample. J. Comput. Appl. Math. 351, 66–76 (2019)
Wu, S.-F., Lin, Y.-P.: Computational testing algorithmic procedure of assessment for lifetime performance index of products with one-parameter exponential distribution under progressive type I interval censoring. Math. Comput. Simul. 120, 79–90 (2016)
Wu, S.-F., Lin, M.-J.: Computational testing algorithmic procedure of assessment for lifetime performance index of products with Weibull distribution under progressive type I interval censoring. J. Comput. Appl. Math. 311, 364–374 (2017)
Kundu, D., Ganguly, A.: Analysis of Step-Stress Models. Academic Press Inc., London (2017)
Balakrishnan, N.: A synthesis of exact inferential results for exponential step-stress models and associated optimal accelerated life-tests. Metrika 69, 351–396 (2009)
Xie, Q., Balakrishnan, N., Han, D.: Exact inference and optimal censoring scheme for a simple step-stress model under progressive Type-II censoring. In: Balakrishnan, N. (ed.) Advances in Mathematical and Statistical Modeling, pp. 107–137. Birkhäuser, Boston (2008)
Balakrishnan, N., Xie, Q., Kundu, D.: Exact inference for a simple step-stress model from the exponential distribution under time constraint. Ann. Inst. Statist. Math. 61(1), 251–274 (2009)
Liu, F., Shi, Y.: Inference for a simple step-stress model with progressively censored competing risks data from Weibull distribution. Commun. Stat.- Theory Methods 46(14), 7238–7255 (2017)
Gouno, E., Sen, A., Balakrishnan, N.: Optimal step-stress test under progressive Type-I censoring. IEEE Trans. Reliab. 53, 388–393 (2004)
Han, D., Balakrishnan, N., Sen, A., Gouno, E.: Corrections on ’Optimal step-stress test under progressive Type-I censoring’. IEEE Trans. Reliab. 55, 613–614 (2006)
Wu, S.-J., Lin, Y.-P., Chen, Y.-J.: Planning step-stress life test with progressively type I group-censored exponential data. Stat. Neerl. 60(1), 46–56 (2006)
Wu, S.-J., Lin, Y.-P. Chen, S.-T.: Optimal step-stress test under type I progressive group-censoring with random removals. J. Statist. Plann. Inference 138(4), 817–826 (2008)
Yue, H.-B., Shi, Y.-M.: Optimal sample size allocation for multi-level stress testing under progressive hybrid interval censoring. Appl. Mech. Materials 423–426, 2423–2426 (2013)
Wang, B.X., Yu, K.: Optimum plan for step-stress model with progressive Type-II censoring. TEST 18, 115–135 (2009)
Balakrishnan, N., Kamps, U., Kateri, M.: A sequential order statistics approach to step-stress testing. Ann. Inst. Statist. Math. 64, 303–318 (2012)
Wang, B.X.: Interval estimation for exponential progressive Type-II censored step-stress accelerated life-testing. J. Statist. Plann. Inference 140(9), 2706–2718 (2010)
Abdel-Hamid, A.H., AL-Hussaini, E.K.: Inference for a progressive stress model from Weibull distribution under progressive type-II censoring. J. Comput. Appl. Math. 235(17), 5259–5271 (2011)
Balakrishnan, N., Cramer, E., Dembińska, A.: Characterizations of geometric distribution through progressively Type-II right censored order statistics. Statistics 59, 559–573 (2011)
Laumen, B., Cramer, E.: Stage life testing. Nav. Res. Logistics 53, 632–647 (2019)
Laumen, B., Cramer, E.: k-step stage life testing. Stat. Neerlandica 75, 203–223 (2021)
Laumen, B., Cramer, E.: Stage life testing with random stage changing times. Commun. Stat.- Theory Methods 51, 3934–3959 (2022)
Laumen, B.: Progressive Censoring and Stage Life Testing Ph.D. Thesis. RWTH Aachen University, Aachen (2017)
Rasouli, A., Balakrishnan, N.: Exact likelihood inference for two exponential populations under joint progressive Type-II censoring. Commun. Statist. Theory Methods 39(12), 2172–2191 (2010)
Parsi, S., Bairamov, I.: Expected values of the number of failures for two populations under joint Type-II progressive censoring. Comp. Statist. Data Anal. 53(10), 3560–3570 (2009)
Parsi, S., Ganjali, M., Farsipour, N.S.: Conditional maximum likelihood and interval estimation for two Weibull populations under joint Type-II progressive censoring. Commun. Statist. Theory Methods 40(12), 2117–2135 (2011)
Doostparast, M., Ahmadi, M.V., Ahmadi, J.: Bayes estimation based on joint progressive type II censored data under LINEX loss function. Commun. Stat. Simul. Comput. 42(8), 1865–1886 (2013)
Balakrishnan, N., Su, F., Liu, K.-Y.: Exact likelihood inference for k exponential populations under joint progressive type-II censoring. Commun. Stat. Simul. Comput. 44(4), 902–923 (2015)
Mondal, S., Kundu, D.: Point and interval estimation of Weibull parameters based on joint progressively censored data. Sankhya B 81, 1–25 (2019)
Mondal, S., Kundu, D.: On the joint Type-II progressive censoring scheme. Commun. Stat.- Theory Methods 49, 958–976 (2020)
Ashour, S.K., Abo-Kasem, O.E.: Statistical inference for two exponential populations under joint progressive Type-I censored scheme. Commun. Stat.- Theory Methods 46(7), 3479–3488 (2017)
Abo-Kasem, O.E. Nassar, M., Dey, S., Rasouli, A.: Classical and Bayesian estimation for two exponential populations based on joint type-I progressive hybrid censoring scheme. Am. J. Math. Manag. Sci. 38, 373–385 (2019)
Mondal, S., Kundu, D.: Bayesian inference for Weibull distribution under the balanced joint Type-II progressive censoring scheme. Am. J. Math. Manag. Sci. 39(1), 56–74 (2019)
Balakrishnan, N., Cramer, E., Kundu, D.: Hybrid censoring know-how. In: Designs and Implementations. Academic Press (2023)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Section Editor information
Rights and permissions
Copyright information
© 2023 Springer-Verlag London Ltd., part of Springer Nature
About this chapter
Cite this chapter
Balakrishnan, N., Cramer, E. (2023). Progressive Censoring Methodology. In: Pham, H. (eds) Springer Handbook of Engineering Statistics. Springer Handbooks. Springer, London. https://doi.org/10.1007/978-1-4471-7503-2_9
Download citation
DOI: https://doi.org/10.1007/978-1-4471-7503-2_9
Published:
Publisher Name: Springer, London
Print ISBN: 978-1-4471-7502-5
Online ISBN: 978-1-4471-7503-2
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)