
Abstract
In this chapter, two aspects of database systems, namely database management and data mining, for the smart grid are covered. The uses of database management and data mining for the electrical power grid comprising of the interrelated subsystems of power generation, transmission, distribution, and utilization are discussed.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
7.1 Introduction
Since the smart grid rely on modern information and communication technology (ICT) infrastructure, database systems, which are one of the vital components of ICT, are indispensable in the smart grid. Database systems allow the data in the smart grid to be stored in a systematic manner and enable them to be retrieved, processed, and analyzed either immediately (i.e., online data processing/analysis) or later (i.e., historical data processing/analysis).
Because of the involvement in database systems, the smart grid is no longer a business dominated by utility companies and electricity hardware companies alone. Several big software companies in data-centric business such as Teradata [1], Oracle [2], SAS [3], SAP [4], IBM [5], Microsoft [6], and Google [7] are active players in the smart grid arena now.
There are two main aspects of a database system, namely database management (data storage, transaction processing, and querying) and data mining (analysis of data to gain certain knowledge or facilitate certain decision making). These two aspects are naturally interrelated and are like the two sides of a coin. Both are essential for the business process of the smart grid’s operations.
In this chapter, we will cover the applications of database management and data mining in the smart grid for power generation, transmission, distribution, and utilization (consumption). Again, these four application areas are interrelated and somewhat overlapping, especially because of the interconnected nature of the smart grid.
The development of smart grid is an evolutionary process. During the smart grid’s introduction phase, the two generations of technologies will coexist [8]. For ICT components (both software and hardware), a majority of legacy systems are first to be integrated into the smart grid and later phased out and replaced by the newer technologies. However, for power system components, the introduction of smart gird will not even drastically change the basic mechanisms of the power system’s mechanical and electrical equipment (except that they will now be more intelligent and responsive because of incorporation of ICT). For example, a gas turbine will still operate just in the same way to convert natural gas into electrical power as it did in the old non-smart grid — albeit it may now use less amount of gas because of a more intelligent control system. So, a database recording the operations of such a gas turbine will be more or less the same in both the traditional grid and the smart grid.
For the aforementioned reasons, we believe that both the earlier systems for systematic power grid data management/data mining even before the word smart grid was coined and the newer systems which were explicitly proposed for the smart grid are worth covering. As such, in this chapter, we will include the literature on power grid database systems both before and after the concept of the smart grid was conceived.
In the following two sections, database management and data mining for power grids will be, respectively, covered.
7.2 Power Grid Database Management
In this section, we will cover the database management technologies in general and then the applications of database management for a power grid in its four subsystems: generation, transmission, distribution, and utilization.
7.2.1 Database Management Technologies
In modern days, management of data in an ICT system is centered around a proper database management system (DBMS) or sometimes simply a file system (FS). In both cases, the basic operations of data management are as follows:
-
Schema creation: defining format of data and relationships among data.
-
Data insertion: populating the database/files with data.
-
Data maintenance: updating or deleting existing data.
-
Querying and reporting: retrieval of stored data as per users’ business requirements.
-
Performance optimization: making the retrieval process faster by using indexes, etc.
-
User account management: defining which user has a right to do which operations on which data.
-
Backup and recovery: preventing accidental loss of data.
For DBMS, relational database (composing of tables which are mathematically termed “relations”) is the most common standard. Some commonly used relational DBMSs are Oracle (proprietary), Microsoft SQL Server (proprietary), IBM DB2 and Informix (proprietary), SAP Sybase (proprietary), MySQL (open source), and PostgreSQL (open source). Structured query language (SQL) is a common interface to retrieve data from relational DBMS.
Recently, post-relational database systems called NoSQL (Not only SQL) [9] become more and more common. NoSQL database systems include document-oriented databases (e.g., MongoDB), XML databases (e.g., BaseX), graph databases (e.g., InfiniteGraph), key-value stores (e.g., Apache Cassandra), multi-value databases (e.g., OpenQM), object-oriented databases (e.g., db4o), RDF (resource description framework) databases (e.g., Meronymy SPARQL), tabular databases (e.g., BigTable), tuple databases (e.g., Jini), and column-oriented databases (e.g., c-store). NoSQL database systems use conventional programming languages like C++, C#, Java, and Erlang, or XQuery in the case of XML databases in order to interface and retrieve data from the databases.
In addition to NoSQL databases, parallel and distributed file systems such as Apache Hadoop [10] and Google MapReduce [11] become increasingly popular. Since the smart grid by its own nature is distributed and the resources (like smart meters, meter data concentrators, substation transformers) in it are geographically scattered, distributed file systems can potentially be very useful for the smart grid.
Generally, databases are stored on centralized or distributed magmatic hard disk drives. However, new paradigms of databases stored on main memory (such as voltDB) and solid-state drives (such as [12]) are emerging because of the increased availability of high-capacity main memory and solid-state equipment at low costs.
Another increasing popular approach nowadays is to store databases in the cloud. Cloud computing and cloud database [13] are also the emerging trends that are much relevant to the smart grid. A cloud database can be in the form of either a virtual machine instance which can be purchased for a limited time or a database as a service in which the service provider installs and maintains the database, and application owners pay according to their usage. Amazon’s DynamoDB and SimpleDB are examples of database as a service.
“Big data” (meaning several tera- to petabytes of data) is one of the current hot topics. Big data is a crucial issue for the smart grid since an enormous volume of data is expected to be generated from its large number of connected devices and sensors at every short time interval. IBM Netezza is one of the examples of DBMS that can handle big data. The parallel/distributed data management techniques of Hadoop and MapReduce are also highly relevant to deal with big data because usually the big data is not centralized but distributed among several computing resources.
Finally, data integration is an important issue for complex systems with multiple components like the smart grid. Data from different sources, probably by different vendors, having different formats and semantics are to be systematically integrated to form a single uniform data source, which can be either virtual or physical. Such an integrated data source can facilitate an integrated information system that streamlines various business processes in a utility company. Most common data integration techniques are data warehousing, XML, and ontology-based techniques.

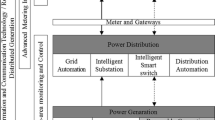
Modern database management technologies and their applications in power grid database management
A high-level diagram illustrating the interrelationships among the various modern database management technologies and their applications in the different areas of power grid data management is shown in Fig. 7.1.
7.2.2 Generation Data Management
Power plants generate electrical power from traditional sources such as natural gas, petroleum, coal, nuclear or hydropower as well as modern renewable sources such as wind or solar power. Database systems for power plants have different structures and contents depending on the type of the energy source.
Li et al. [14] describe a database system for a coal-based power plant which records and processes the data specific to coal-operated stream turbines (such as main steam pressure, feed water temperature, reheater spray, flue gas temperature, excess air coefficient, and condenser vacuum).
Huang et al. [15] discuss data management systems for a hydropower plant, particularly the automatic generator tripping and load shedding system installed at the Churchill Falls hydropower plant in Labrador, Canada by Hydro-Quebec.
Swartz et al. [16] propose a wireless sensor network-based data collection and management system for wind farms to provide information about the dynamic behavior of the wind turbines and their response to loading.
7.2.3 Transmission and Distribution Data Management
After the power has been generated, it is transformed into high-voltage electricity using step-up transformers and is transmitted along the transmission lines to multiple substations. At a substation, the electricity’s voltage is transformed again to a level suitable for consumption by using a step-down transformer. Then, the electricity is distributed to the consumers for utilization.
Early examples of database systems for power transmission/distribution systems in the literature are [17] and [18].
Generally, distributed control system (DCS) and supervisory control and data acquisition (SCADA) are employed to operate various equipment used in power transmission and distribution. DCS and SCADA are usually proprietary systems from big industrial players in the power industry such as GE [19] and Siemens [20]. Being proprietary systems, they are closed and sometimes can be legacy systems. In some cases, the data format they provide can be non-standard (especially for old legacy systems). Thus, acquiring data from all these systems to build a common database system can be sometimes difficult. In the worst cases, manual data entry can be required [21].
It is not uncommon to have systems from multiple vendors in a single power facility. In order to provide a standardized interface and allow easy exchange of data among different prices of software by different vendors, common information model (CIM) [22],[23], generic substation events [24], and substation configuration language (SCL) [25] have been proposed.
Depending on the nature of application, the data generated by various pieces of power system equipment have to be stored in different formats [26]. They are as follows:
-
Raw waveforms (voltage and currents) sampled at relatively high sampling frequencies.
-
Pre-processed waveforms (e.g., RMS) typically sampled at low sampling frequencies.
-
Status variables (e.g., if a relay is opened or closed) typically sampled at low sampling frequencies.
A number of white papers and research articles on the database systems for power transmission/distribution systems exist in the literature. Some examples, which are by no means complete, are as follows.
Simpson [21] describes a power system database recording transformer nameplate data, single line diagrams, measured data, protective device coordination, harmonic analysis, transistent calculation, load flow calculation, and short-circuit calculation. Martinez et al. [27] give detailed descriptions about comprehensive archiving and management of power system data for real-time performance monitoring using CERTS (Consortium for Electric Reliability Technology Solutions) architecture. Qiu et al. [28] propose a system of real-time and historical (archived) databases to allow operations, controls, and analysis of power transmission and distribution. An example of a practical database schema to be used for in transmission utility enterprise-wide framework using ArcGIS, ArcSDE, Microsoft SQL Server, and .NET is given in [29]. In [30] and [31], the issues of data integration in power systems are discussed. In [32], Zheng et al. propose a cloud computing and cloud database framework for substations of the smart gird. Rusitschka et al. [33] discuss the use of cloud data management for outage management [34] and virtual power plant [35].
A comprehensive list of monitoring subsystems whose measurement data are to be collected and stored in the database for a modern power transmission/distribution system of the smart grid is provided by Kaplan et al. [36]. These collected data allow advanced tools to analyze system conditions, perform real-time contingency analysis, and initiate a necessary course of action as needed. These monitoring subsystems as described in [36] are
-
Wide-area monitoring system: GPS (global positioning system)-based phasor monitoring unit (PMU) that measures the instantaneous magnitude of voltage or current at a selected grid location. This provides a global and dynamic view of the power system.
-
Dynamic line rating technology: it measures the ampacity of a line in real time.
-
Conductor/ compression connector sensor: it measures conductor temperature to allow accurate dynamic rating of overhead lines and line sag, thus determining line rating.
-
Insulation confirmation leakage sensor: it continuously monitors leakage current and extracts key parameters. This is critical to determining when an insulator flashover is imminent due to contamination.
-
Backscatter radio: it provides improved data and warning of transmission and distribution component failure.
-
Electronic instrument transformer: it replaces precise electromagnetic devices (such as current transformers and potential transformers) that convert high voltages and currents to manageable, measurable levels.
-
Other monitoring systems:
-
Fiber-optic, temperature monitoring system.
-
Circuit breaker real-time monitoring system.
-
Cable monitor.
-
Battery monitor.
-
Sophisticated monitoring tool which combines several different temperature and current measurements.
-
7.2.4 Utilization Data Management
The distributed electricity is utilized (consumed) at the consumers’ end. Consumers may be of several types: residential (e.g., individual houses and apartment buildings), commercial (e.g., banks), industrial (e.g., factories), transportation (e.g., subways), emergency services (e.g., hospitals), and governmental services (e.g., police), etc. Obviously, power utilization is most visible aspect of a power grid for the public.
In the old traditional grid, a traditional meter on customer’s premises is read by a meter reading staff at a regular interval (e.g., once a month), and the meter readings (utilization data) are manually entered into the database system in the utility company. These utilization data are quite passive and are mainly used for the purpose of billing. It has no or little use in real-time monitoring and control of the power system in operation because of a very long time lag (e.g., up to one month) between actual power utilization and data gathering.
However, in the era of the smart grid, smart meters are installed in consumers’ premises. Among its many functionalities, the main function of a smart meter is to record and transmit the utilization data to the utility company at relatively short time intervals (e.g., every 5, 10, or 15 minutes). The utilization data can be either fine-grained (separate data for individual appliances or groups of appliances in the same electrical circuits) or coarse-grained (aggregated data for the whole premises). A smart meter may be equipped with a small local storage (e.g., SD card) to store some intermediate utilization data.
The data collection is hierarchical in nature. The power utilization data from a number of smart meters are first transmitted to a data concentrator, and a number of data concentrators relay the data to the central server at the utility company where the data are stored in the utilization database covering a large number of consumers.
The above process of data collection is called automatic meter reading (AMR) [37]. It is a one-way communication process in which the data are transmitted from the smart meter end to the server end through the data concentrator. Later, AMR is improved into a more sophisticated system named advanced metering infrastructure (AMI) [38],[39]. AMI allows two-way communication between the smart meter and the server end. The server can send messages regarding real-time pricing, control commands to switch on/off certain appliances, etc. to the smart meter.
In a smart home environment, where modern technologies such as smart appliances, intelligent heating, ventilation, air conditioning (HVAC), rooftop solar generation, and electric/hybrid vehicles coexist, a smart meter alone will not be able to handle all the data regarding the operations and interactions among those equipment. In addition to the smart meter, there requires a local PC/server to host an integrated information management platform. Its purpose is to store, process, and manage the data from all those smart installations and to communicate with the utility to exchange the relevant information regarding them. Lui et al. [40] describe in detail such a platform namely Whirlpool integrated services environment (WISE), which is a proprietary system.
Since every customer connected to the smart grid is expected to generate a large volume of data from his/her smart meter as well as from the other multiple smart equipments, there is a pressing need for the smart grid to handle the big data (as also discussed above in Section 7.2.1). In [41], the application of IBM’s big data technologies for smart meters is discussed.
Kaplan et al. [36] provide the following detailed list of customer-focused applications (for each of which the relevant utilization data are needed to be recorded and processed).
-
Consumer gateway:
-
Bidirectional communications between service organizations and equipment on customer premises.
-
Advanced meter reading.
-
Time-of-use and real-time pricing (RTP).
-
Load control.
-
Metering information and energy analysis via website.
-
Outage detection and notification.
-
Metering aggregation for multiple sites and facilities.
-
Integration of customer-owned generation.
-
Remote power quality monitoring and services.
-
Remote equipment performance diagnosis.
-
Theft control.
-
Building energy management systems.
-
Automatic load controls integrated with RTP.
-
Monitoring of electrical consumption of total load and, in some cases, various load components.
-
Functions embodied in meters, cable modems, set-top boxes, thermostats, etc.
-
-
Residential consumer network: subset of consumer gateway concept.
-
Reads the meter, connects controllable loads, and communicates with service providers.
-
End users and suppliers monitor and control the use and cost of various resources (e.g., electricity, gas, water, temperature, air quality, secure access, and remote diagnostics).
-
Consumers monitor energy use and determine control strategies in response to price signals.
-
-
Advanced meter:
-
Employs digital technology to measure and record electrical parameters (e.g., watts, volts, and kilowatt hours).
-
Communication ports link to central control and distributed loads.
-
Provides consumption data to both consumer and supplier.
-
Switches loads on and off in some cases.
-
At the utility side, billing is the most important application for the utilization data. Arenas-Martinez et al. [42] developed a smart grid simulation platform to study the pros and cons of different database architectures for massive customer billing. These architectures are single relational database, distributed relational database, key-value distributed database storage, and hybrid storage (DBMS and FS).
Another utility-side application relying on the utilization data is real-time pricing to facilitate demand response by having the consumers reduce their demand at critical times or in response to market prices [43].
7.3 Power Grid Data Mining
In this section, we will cover the data mining technologies in general and then applications of data mining for a power grid in its four subsystems: generation, transmission, distribution, and utilization.
7.3.1 Data Mining Technologies
The purpose of data mining is to uncover the knowledge or interesting patterns of data that lie within a large database and use them for decision support at various levels (strategic, tactical, or operational). Data mining is also known by other names such as data analytics, knowledge discovery, and statistical data analysis. Data mining is closely related to database management, machine learning, artificial intelligence, and statistics.
The most common data mining tasks are
-
Frequent pattern mining: to discover some subpatterns or motifs that occur frequently in a dataset. (Note: a dataset means a collection of data organized in rows and columns. It can be a table in relational DBMS or just a comma-separated values (CSV) file in FS. A row represents an instance, and a column represents an attribute.) Some well-known frequent pattern mining algorithms include a priori, FP-tree, and Eclat.
-
Association rule mining: to uncover which causes usually lead to which effects in a dataset. The association rules can generally be derived from the frequent patterns described above.
-
Classification: to classify instances in a dataset into pre-defined groups (called class labels). Classification is a supervised learning process in which we first have to train the classifier with instances whose class labels are known. Then, we use this training classifier to predict the class labels of the new instances whose labels are not known yet. Some popular classification algorithms are decision tree, naive Bayes, artificial neural networks, hidden Markov model, support vector machine, and k-nearest neighbors.
-
Clustering: to organize similar instances in a dataset into groups which are not pre-defined. Clustering is an unsupervised learning process in which we do not know the class labels of all the instances in the dataset in advance. The number of groups (clusters) may or may not be pre-defined, depending on the clustering algorithm. Some widely used clustering algorithms are k-means, fuzzy c-means, expectation maximization, DBSCAN, BIRCH, and hierarchical clustering.
-
Regression: to predict the value of the target attribute (called dependent variable) of an instance based on the values of other attributes (independent variables). Regression is also a type of supervised learning which works in the similar way as classification. Their main difference is that while the outputs of classification are class labels (discrete values), those of regression are real numbers (continuous values). Some common regression algorithms are Gauss–Newton algorithm, logistic regression, neural network regression, support vector regression, and autoregressive integrated moving average (ARIMA).
-
Outlier detection: to identify anomalous instances, which might be interesting, or indicate errors that require further investigation. It can be supervised, unsupervised, or semi-supervised learning. Some popular methods are local outlier factor, single-class support vector machine, replicator neural networks, and cluster analysis.
Data can rarely be mined in their raw forms as originally stored in the DBMS or FS. We usually need to perform one or more of the following data processing tasks [44] before performing a data mining task.
-
Data cleaning: to fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies.
-
Data integration: to integrate multiple databases, data cubes, or files.
-
Data reduction: to obtain reduced representation in volume but produces the same or similar analytical results. It may be in the form of dimensionality reduction, numerosity reduction, or data compression. Data reduction is usually done for the sake of efficiency and/or better generalization.
-
Data transformation and discretization: to normalize data, aggregate data, and generate concept hierarchy.
After the data mining task has been performed, the result can be optionally presented in a visual format in order to better facilitate decision making by the user.
Some popular data mining software are SAS Enterprise Miner (proprietary), IBM SPSS Modeler (proprietary), Oracle Data Mining (proprietary), Microsoft Analysis Services (proprietary), Weka (open source), RapidMiner (open source), and ELKI (open source).
In addition to the traditional data mining paradigm on static and centralized data, the new paradigms of distributed data mining [45], data stream mining [46], and time series data mining [47] are much relevant to the smart grid because of its very nature of distributiveness and having to deal with numerous data streams and time series data from various data sources: smart meters, sensors, and power system machinery.
Privacy is one of the top concerns in the smart grid’s deployment, especially from consumer’s perspective [48]. Thus, privacy-preserving data mining techniques [49] are much relevant for mining the data in the smart grid. An example of a proposed framework for privacy-preserving data integration and subsequent analysis for the smart grid is [50].

Data mining technologies and their applications in power grids
A high-level diagram depicting the interrelationships among the various data mining technologies and their applications in the different subsystems of power grids is shown in Fig. 7.2.
7.3.2 Data Mining for Generation
In a similar manner as discussed above in Section 7.2.2, the data mining applications for power generation can be quite diverse because of the different natures of power sources. Li et al. [14] propose a fault diagnosis system for a coal-based power plant using association rule mining. In [51], the operational performance and the efficiency characteristics for photovoltaic power generation are analyzed against various environmental conditions using statistical analysis.
For fossil fuel-based power plants where the amount of power produced can be fully controlled, the amount of generation (supply) is much dependent on the amount of electricity load (demand). So, forecasting the future load enables them to plan for the required fuel accordingly, and consequently, accurate forecasting can save utility companies millions of dollars a year [52]. Also, for renewable energy generations, load forecasting can help the utilities to plan ahead to shave the peak load by means of demand response mechanisms [43] so that the demand will not exceed the available power output from the renewable source.
Load forecasting can be for very-short term (24 hours ahead of the present time), short term (\(\sim \)2 weeks), medium term (\(\sim \)3 years), and long term (\(\sim \)30 years) [54]. Some examples of load forecasting methods in the literature are Deng and Jirutitijaroen [53] using the time series models of multiplicative decomposition and seasonal ARIMA, Hong [54] using multiple linear regression, Zhang et al. [55] using artificial neural network, and Aung et al. [56] using least square support vector regression. Taylor [57] provides a good survey and evaluation of several existing load forecasting methods.
7.3.3 Data Mining for Transmission and Distribution
The prospects and challenges of data mining for the smart grid, particularly in the areas of transmission, distribution, and utilization, are highlighted in [58]. Similarly, Ramchurn et al. [59] discuss the uses of artificial intelligence and data mining solutions to provide “smartness” to the smart grid.
There exists a number of papers in the literature regarding the application of data mining for power transmission and distribution systems. Some examples, which are by no means exhaustive, are as follows.
Dissolved gas analysis (DGA) [60] is the study of dissolved gases in transformer oil (insulating oil which is stable at high temperatures and possesses excellent electrical insulating properties). The information about the gases being generated by a particular transformer unit can be very useful in fault detection and maintenance. Sharma et al. [61] provide a survey on artificial intelligence and data mining techniques for DGA.
Power system state estimation provides an estimate for all metered and unmetered quantities throughout the whole power system. It is useful in ensuring the stability of the grid and preventing blackouts. Chen et al. [62] describe computation of power system state estimation using weighted least square method on a high-performance computing platform. Zhong et al. [63] try to solve a more specific problem of state assessment for transformer equipment using association rule mining and fuzzy logic.
Islanding detection is also important for the stability of a grid in which multiple small distributed renewable energy generation sources are integrated into the main grid. Islanding occurs when part of the network becomes disconnected from the grid and is powered by one or more distributed generations only. Such an event can potentially lead to problems in the grid. Samantaray et al. [64] proposed an islanding detection system using a rule-based approach that employs fuzzy membership functions. In [65], naive Bayes classifier is used to solve the problem of islanding detection.
Again, fault identification and fault cause identification are obviously important problems for power systems. Calderaro et al. [66] uses Petri Nets to solve the fault identification problem. Xu et al. [67] try to identify fault causes in a power distribution system using a fuzzy classification algorithm.
Contingency analytics is to understand the impact of potential component failures and assess the power system’s capability to tolerate them. Adolf et al. [68] develop a filtering technique based on multi-criteria optimization to address it.
Power quality is another important issue in the power system, especially in the smart grid era. Common problems that can disturb the quality of power are sags (undervoltages), harmonics, spikes, and imbalances [36]. He et al. [69] propose a self-organizing learning array system for power quality classification based on wavelet transform. Hongke and Linhai [70] describe a practical data analysis platform for power quality using Microsoft SQL Server and OLAP (online analytical processing).
The reliability of the power distribution network is an important issue, especially for the old networks that were first setup nearly a century ago. Gross et al. [71] develop a support vector machine–based model to rate the feeder lines in New York City for their reliability and identify the ones that need maintenance or replacement.
Morais et al. [26] present a good survey of 13 research articles on data mining for power systems for various purposes such as fault classification and location, detection and diagnosis of transient faults, power quality detection for power system disturbances. Similarly, Mori [72] provides a list of 42 research papers on various applications of data mining for power systems.
Apart from the physical power system, the logical energy market draws much attention recently, especially after its deregulation. Price forecasting is an indispensable tool for both the energy wholesaler and the retailer in such a market. Arenas-Martinez et al. [73] present a price forecasting model using local sequence patterns, while Neupane et al. [74] tackle price forecasting by means of artificial neural networks.
7.3.4 Data Mining for Utilization
At the power utilization (demand) side, load forecasting for large commercial and residential buildings plays a crucial role. Building load forecasting is an integral part of a building management system. It enables the building operator to plan ahead, shave loads if required, and carry out fault identification and diagnosis in the building’s electrical system if necessary. Fernandez et al. [75] present a study on building load forecasting using autoregressive model, polynomial model, neural network, and support vector machine. Edwards et al. [76] compare the performance of seven machine learning/data mining methods for load forecasting in buildings.
Customer profiling is also related to the demand-side load forecasting task mentioned above. It is useful both for customer behavior prediction for appliance scheduling automation and for dynamic pricing of electricity to suit individual customers’ usage patterns. Proposed research works for customer profiling using data mining techniques include [77, 78], and [79].
Finally, security is one of the major concerns for the smart grid’s deployment at the customer side [80]. To partially address this problem, Faisal et al. [81] present an intrusion detection system for advance metering infrastructure (AMI) using data stream mining methods. Fatemieh et al. [82] apply classification techniques to improve the attack resilience of TV spectrum data fusion for AMI communications.
7.4 Conclusion
Database systems are one of the keystones of the ICT infrastructure that provides smartness to the smart gird. In this chapter, we have discussed both the conventional and the state-of-the-art database system technologies regarding database management and data mining and their applications to the smart grid. We hope our chapter to be useful as a reference material for both the researchers and the practitioners of the smart grid.
References
Teradata Corporation. http://www.teradata.com
Oracle Corporation. http://www.oracle.com
SAS Institute, Inc. http://www.sas.com
SAP AG http://www.sap.com
IBM corporation. http://www.ibm.com
Microsoft Corporation. http://www.microsoft.com
Google Inc. http://www.google.com
Farhangi H (2010) The path of the smart grid. IEEE Power Energy Mag 8:18–28
Wikipedia: NoSQL (2013). http://en.wikipedia.org/wiki/NoSQL
Apache Hadoop. http://hadoop.apache.org
Wikipedia: MapReduce (2013). http://en.wikipedia.org/wiki/MapReduce
Rizvi SS, Chung TS (2010) Flash memory SSD based DBMS for high performance computing embedded and multimedia systems. In: Proceedings of the 2010 international conference on computer engineering and systems (ICCES), pp 183–188
Wikipedia: Cloud database (2013). http://en.wikipedia.org/wiki/Cloud_database
Li Jq, Wang Sl, Niu Cl, Liu Jz (2008) Research and application of data mining technique in power plant. In: Proceedings of the 2008 international symposium on computational intelligence and design (ISCID), vol 2, pp 250–253
Huang, JA, Vanier G, Valette A, Harrison S, Wehenkel L (2003) Application of data mining techniques for automat settings in emergency control at Hydro-Quebec. In: Proceedings of the 2003 IEEE power engineering society general meeting, vol 4, pp 2037–2044
Swartz RA, Lynch JP, Zerbst S, Sweetman B, Rolfes R (2010) Structural monitoring of wind turbines using wireless sensor networks. Smart Struct Syst 6:1–14
Ben-Yaacov GZ (1979) Interactive computation and data management for power system studies. Comput J 22:76–79
Papadakis M, Hatzjargyriou N, Gazidellis D (1989) Interactive data management system for power system planning studies. IEEE Trans Power Syst 4:329–335
GE Power Controls. http://www.gepowercontrols.com
Siemens Energy. http://www.energy.siemens.com
Simpson, RH (2000) Power system database management. In: Conference record of 2000 annual pulp and paper industry technical conference (PPIC), pp 79–83
Wikipedia: Common information model (electricity) (2013) http://en.wikipedia.org/wiki/Common_Information_Model_(electricity)
Simmins JJ (2011) The impact of PAP 8 on the Common Information Model (CIM). In: Proceedings of the 2011 IEEE/PES power systems conference and exposition (PSCE), pp 1–2
Wikipedia: Generic substation events (2013) http://en.wikipedia.org/wiki/Generic_Substation_Events
Wikipedia: Substation configuration language (2013) http://en.wikipedia.org/wiki/Substation_Configuration_Language
Morais J, Pires Y, Cardoso C, Klautau A (2009) An overview of data mining techniques applied to power systems. In: Ponce J, Karahoca A (eds) Data mining and knowledge discovery in real life applications. I-Tech education and publishing
Martinez C, Huang H, Guttromson R (2005) Archiving and management of power systems data for real-time performance monitoring platform. Tech. rep, Consortium of electric reliability technology solutions
Qiu J, Liu J, Hou Y, Zhang J (2011) Use of real-time/historical database in smart grid. In: Proceedings of the 2011 international conference on electric information and control engineering (ICEICE), pp 1883–1886
Owoola MA (2004) A generic spatial database schema for a typical electric transmission utility. In: Proceedings of the geospatial information and technology association’s 27th Annual Conference (GITA), pp. 1–12
Lu B, Song W (2010) Research on heterogeneous data integration for smart grid. In: Proceedings of the 2010 3rd IEEE international conference on computer science and information technology (ICCSIT), vol 3, pp. 52–56
SISCO Inc: Integration of substation data. http://cimug.ucaiug.org/KB/Knowledge Base/Integration of Substation Data ver 06.pdf
Zheng L, Chen S, Hu Y, He J (2011) Applications of cloud computing in the smart grid. In: Proceedings of the 2nd international conference on artificial intelligence, management science and electronic commerce (AIMSEC), pp 203–206
Rusitschka S, Eger K, Gerdes C (2010) Smart grid data cloud: a model for utilizing cloud computing in the smart grid domain. In: Proceedings of the 1st IEEE international conference on smart grid communications (SmartGridComm), pp 483–488
Wikipedia: Outage management system (2013) http://en.wikipedia.org/wiki/Outage_management_system
Awerbuch S, Preston AM (1997) The virtual utility: accounting technology and competitive aspects of the emerging industry. Kluwer Academic Publisher
Kaplan SM, Sissine F, Abel A, Wellinghoff J, Kelly SG, Hoecker JJ (2009) Smart grid: modernizing electric power transmission and distribution; energy independence, storage and security; energy independence and security Act of 2007 (EISA); Improving electrical grid efficiency, communication, reliability, and resiliency; integrating new and renewable energy sources. TheCapitol.Net, Inc.
Wikipedia: Automatic meter reading (2013) http://en.wikipedia.org/wiki/Automatic_meter_reading
Wikipedia: Advanced metering infrastructure (2013) http://en.wikipedia.org/wiki/Advanced_Metering_Infrastructure
Hart DG (2008) Using AMI to realize the smart grid. In: Proceedings of the conference on power and energy society general meeting - conversion and delivery of electrical energy in the 21st Century, pp 20–24
Lui TJ, Stirling W, Marcy HO (2010) Get smart: using demand response with appliances to cut peak energy use, drive energy conservation, enable renewable energy sources and reduce greenhouse-gas emissions. IEEE Power Energy Mag 8:66–78
IBM Software Group (2012) Managing big data for smart grids and smart meters. IBM Corporation, Tech. rep
Arenas-Martinez M, Herrero-Lopez S, Sanchez A, Williams JR, Roth P, Hofmann P, Zeier A (2010) A comparative study of data storage and processing architectures for the smart grid. In: Proceedings of the 1st IEEE international conference on smart grid communications (SmartGridComm), pp 285–290
Fan Z (2011) Distributed demand response and user adaptation in smart grids. In: Proceedings of the 2011 IFIP/IEEE international symposium on integrated network management (IM), pp 726–729
Han J, Kamber M, Pei J (2011) Data mining: concepts and techniques. Morgan Kaufmann Publishers
Talia D, Trunfio P (2010) How distributed data mining tasks can thrive as knowledge services? Commun ACM 53:132–137
Gama J (2010) Knowledge discovery from data streams. Chapman and Hall/CRC
Last M, Kandel A, Bunke H (2004) Data mining in time series databases. Word Scientific Press
Li D, Aung Z, Williams J, Sanchez A (2012) P3: privacy preservation protocol for appliance control application. In: Proceedings of the 3rd IEEE international conference on smart grid communications (SmartGridComm), pp 294–299
Lindell Y, Pinkas B (2000) Privacy preserving data mining. In: Proceedings of the 20th annual international cryptology conference on advances in cryptology (CRYPTO), pp 36–54
Kursawe K, Danezis G, Kohlweiss M (2011) Privacy-friendly aggregation for the smart-grid. In: Proceedings of the 11th international symposium on privacy enhancing technologies (PETS), pp 175–191
Li DHW, Cheung GHW, Lam JC (2005) Analysis of the operational performance and efficiency characteristic for photovoltaic system in Hong Kong. Energy Convers Manag 46:1107–1118
Fan S, Chen L, Lee W (2008) Short-term load forecasting using comprehensive combination based on multi-meteorological information. In: Proceedings of the 2008 IEEE/IAS industrial and commercial power systems technical conference (ICPS), pp 1–7 19
Deng J, Jirutitijaroen P (2010) Short-term load forecasting using time series analysis: a case study for Singapore. In: Proceedings of the 2010 IEEE conference on cybernetics and intelligent systems (CIS), pp 231–236
Hong T (2010) Short term electric load forecasting. Ph.D. thesis, North Carolina State University, USA
Zhang HT, Xu FY, Zhou L (2010) Artificial neural network for load forecasting in smart grid. In: Proceedings of the 2010 international conference on machine learning and cybernetics (ICMLC), vol 6, pp 3200–3205
Aung Z, Toukhy M, Williams J, Sanchez A, Herrero S (2012) Towards accurate electricity load forecasting in smart grids. In: Proceedings of the 4th international conference on advances in databases, knowledge, and data applications (DBKDA), pp 51–57
Taylor JW (2008) An evaluation of methods for very short term electricity demand forecasting using minute-by-minute British data. Int J Forecast 24:645–658
Krishnaswamy S (2012) Energy analytics: when data mining meets the smart grid. http://smartgrid.i2r.a-star.edu.sg/2012/slides/i2r.pdf
Ramchurn SD, Vytelingum P, Rogers A, Jennings NR (2012) Putting the “smarts” into the smart grid: a grand challenge for artificial intelligence. Commun ACM 55:86–97
Wikipedia: Dissolved gas analysis (2013) http://en.wikipedia.org/wiki/Dissolved_gas_analysis
Sharma NK, Tiwari PK, Sood YR (2011) Review of artificial intelligence techniques application to dissolved gas analysis on power transformer. Int J Comput Electr Eng 3:577–582
Chen Y, Huang Z, Liu Y, Rice MJ, Jin S (2012) Computational challenges for power system operation. In: Proceedings of the 2012 Hawaii international conference on system sciences (HICSS) pp 2141–2150
Zhong W, Sun Y, Xu M, Liu J (2010) State assessment system of power transformer equipments based on data mining and fuzzy theory. In: Proceedings of the 2010 international conference on intelligent computation technology and automation (ICICTA), vol 3, pp 372–375
Samantaray SR, El-Arroudi K, Joós G, Kamwa I (2010) A fuzzy rule-based approach for islanding detection in distributed generation. IEEE Trans Power Delivery 25:1427–1433
Najy W, Zeineldin H, Alaboudy AK, Woon WL (2011) A Bayesian passive islanding detection method for inverter-based distributed generation using ESPRIT. IEEE Trans Power Delivery 26:2687–2696
Calderaro V, Hadjicostis C, Piccolo A, Siano P (2011) Failure identification in smart grids based on Petri Net modeling. IEEE Trans Ind Electron 58:4613–4623
Xu L, Chow MY, Taylor LS (2007) Power distribution fault cause identification with imbalanced data using the data mining-based fuzzy classification E-algorithm. IEEE Trans Power Syst 22:164–171
Adolf R, Haglin D, Halappanavar M, Chen Y, Huang Z (2011) Techniques for improving filters in power grid contingency analysis. In: Proceedings of the 7th international conference on machine learning and data mining in pattern recognition (MLDM), pp 599–611
He H, Starzyk J (2006) A self-organizing learning array system for power quality classification based on wavelet transform. IEEE Trans Power Delivery 21:286–295
Hongke H, Linhai Q (2010) Application and research of multidimensional data analysis in power quality. In: Proceedings of the 2010 international conference on computer design and applications (ICCDA), vol 1, pp 390–393
Gross P, Boulanger A, Arias M, Waltz D, Long PM, Lawson C, Anderson R, Koenig M, Mastrocinque M, Fairechio W, Johnson JA, Lee S, Doherty F, Kressner A (2006) Predicting electricity distribution feeder failures using machine learning susceptibility analysis. In: Proceedings of the 18th conference on innovative applications of artificial intelligence (IAAI), vol 2, pp 1705–1711
Mori H (2006) State-of-the-art overview on data mining in power systems. In: Proceedings of the 2006 IEEE PES power systems conference and exposition (PSCE), pp 33–34
Martínez-Álvarez F, Troncoso A, Riquelme JC, Aguilar-Ruiz JS (2011) Energy time series forecasting based on pattern sequence similarity. IEEE Trans Knowl Data Eng 23:1230–1243
Neupane B, Perera KS, Aung Z, Woon WL (2012) Artificial neural network-based electricity price forecasting for smart grid deployment. In: Proceedings of the 2012 IEEE international conference on computer systems and industrial informatics (ICCSII), pp 1–6
Fernandez I, Borges CE, Penya YK (2011) Efficient building load forecasting. In: Proceedings of the 16th IEEE conference on emerging technologies and factory automation (ETFA), pp. 1–8
Edwards RE, New J, Parker LE (2012) Predicting future hourly residential electrical consumption: a machine learning case study. Energy Buildings 49:591–603
Chicco G, Napoli R, Postolache P, Scutariu M, Toader C (2003) Customer characterization options for improving the tariff offer. IEEE Trans Power Syst 18:381–387
Fernandes RAS, Silva IN, Oleskovicz M (2010) Identification of residential load profile in the Smart Grid context. In: Proceedings of the 2010 IEEE power and energy society general meeting, pp 1–6
Figueiredo V, Rodrigues F, Vale Z, Gouveia JB (2005) An electric energy consumer characterization framework based on data mining techniques. IEEE Trans Power Syst 20:596–602
Li D, Aung Z, Williams J, Sanchez A (2012) Efficient authentication scheme for data aggregation in smart grid with fault tolerance and fault diagnosis. In: Proceedings of the 2012 IEEE PES conference on innovative smart grid technologies (ISGT), pp 1–8
Faisal MA, Aung Z, Williams JR, Sanchez A (2012) Securing advanced metering infrastructure using intrusion detection system with data stream mining. In: Proceedings of the 2012 Pacific Asia workshop on intelligence and security informatics (PAISI), pp 96–111
Fatemieh O, Chandra R, Gunter CA (2010) Low cost and secure smart meter communications using the TV white spaces. In: Proceedings of the 2010 IEEE international symposium on resilient control systems (ISRCS), pp 1–6
Acknowledgments
The author thank the Government and Abu Dhabi, United Arab Emirates, for sponsoring this research through its funding of Masdar Institute–Massachusetts Institute of Technology (MIT) collaborative research project titled “Data Mining for Smart Grids”.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag London
About this chapter
Cite this chapter
Aung, Z. (2013). Database Systems for the Smart Grid. In: Ali, A. (eds) Smart Grids. Green Energy and Technology. Springer, London. https://doi.org/10.1007/978-1-4471-5210-1_7
Download citation
DOI: https://doi.org/10.1007/978-1-4471-5210-1_7
Published:
Publisher Name: Springer, London
Print ISBN: 978-1-4471-5209-5
Online ISBN: 978-1-4471-5210-1
eBook Packages: EnergyEnergy (R0)