
Abstract
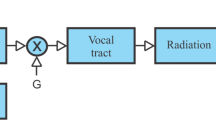
The transmission protocol of voiced speech is hypothesized to be based on a funda mental drive process, which synchronizes the vocal tract excitation on the trans mitter side and evokes the pitch perception on the receiver side. A band limited fundamental drive is extrac ted from a voice specific subband decom position of the speech signal. When the near periodic drive is used as fun damental drive of a two-level drive-response model, a more or less aperiodic voiced excitation can be recon struc ted as a more or less aperiodic trajectory on a low dimensional continuous syn chro nization manifold (surface) described by speaker and phoneme specific coupling functions. In the case of vowels and nasals the excitation can be described by a univariate coupling function, which depends on the momentary phase of the funda mental drive. In the case of other voiced consonants the coupling function may as well depend on a delayed funda mental phase with a phoneme speci fic time delay. The delay may exceed the length of the analysis window. The resulting long range correlation cannot be analysed or synthesized by models assuming stationary excitation.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Fant, G.: Acoustic theory of speech production. Mouton, S-Gravenhage (1960)
Vary, P., Heute, U., Hess, W.: Digitale Sprachsignalverarbeitung. B.G. Teubner Verlag, Stuttgart (1998)
Schroeder, M.R.: Computer Speech. Springer, Heidelberg (1999)
Titze, I.R.: Acta Acustica, vol. 90, pp. 641–648 (2004)
Kantz, H., Schreiber, T.: Nonlinear time series analysis. Cambridge Univ. Press, Cambridge (1997)
Kocarev, L., Parlitz, U.: Phys. Rev. Lett. 76, 1816 (1996)
Schoentgen, J.: Stochastic models of jitter. J. Acoust. Soc. Am. 109(4), 1631–1650 (2001)
Herzel, H., Berry, D., Titze, I.R., Steinecke, I.: Nonlinear dynamics of the voice: Signal analysis and biomechanical modeling. Chaos 5, 30–34 (1995)
Seebeck, A.: Über die Sirene., Annalen der Physik, LX, 449 ff, ibid. LXIII, 353 ff and 368 ff (1843)
Moore, B.C.J.: An introduction to the psychology of hearing. Academic Press, London (1989)
De Cheveigné, A., Kawahara, H.: Comparative evaluation of F0 estimation algorithms. In: Eurospeech 2001, Alborg (2001)
Winholtz, W.S., Ramig, L.O.: Vocal tremor analysis with the vocal demodulator. J.Speech Hear. Res. 35, 562–573 (1992)
Hanquinet, J., Grenez, F., Schoentgen, J.: Synthesis of disordered voices. In: Faundez-Zanuy, M., Janer, L., Esposito, A., Satue-Villar, A., Roure, J., Espinosa-Duro, V. (eds.) NOLISP 2005. LNCS (LNAI), vol. 3817, pp. 231–241. Springer, Heidelberg (2006)
Kubin, G.: Nonlinear processing of speech. In: Kleijn, W.B., Paliwal, K.K. (eds.) Speech Coding and Synthesis, pp. 557–610. Elsevier, Amsterdam (1995)
Moakes, P.A., Beet, S.W.: Analysis of non-linear speech generating dynamics. In: ICSLP 1994, Yokohama, pp. 1039–1042 (1994)
Drepper, F.R., Manfredi, C. (eds.): MAVEBA 2003. Firenze University Press (2004)
Drepper, F.R.: Selfconsistent time scale separation of instationary speech signals. In: Fortschritte der Akustik-DAGA 2005 (2005)
Teager, H.M., Teager, S.M.: Evidence for nonlinear sound production mechanisms in the vocal tract. In: Proc NATO ASI on Speech Production and Speech Modelling, pp. 241–261 (1990)
Jackson, P.J.B., Shadle, C.H.: Pitch scaled estimation of simultaneous voiced and turbulence-noise components in speech. IEEE trans. speech audio process 9, 713–726 (2001)
Maragos, P., Kaiser, J.F., Quatieri, T.F.: Energy separation in signal modulations with application to speech analysis. IEEE Trans. Signal Processing 41, 3024–3051 (1993)
Zhao, W., Zhang, C., Frankel, S.H., Mongeau, L.: Computational Aeroacoustics of Phonation, Part I. J. Acoust. Soc. Am. 112(5), 2134–2154 (2002)
Hohmann, V.: Acta Acustica 10, 433–442 (2002)
Zwicker, E., Feldtkeller, R.: Das Ohr als Nachrichtenempfänger. Hirzel Verlag (1967)
Sottek, R.: Modelle zur Signalverarbeitung im menschlichen Gehör. Verlag M. Wehle, Witterschlick/Bonn (1993)
Drepper, F.R.: Rekonstruktion stationärer Mannigfaltigkeiten der Teilbanddynamik instationärer Sprachsignale. Fortschritte der Akustik-DAGA 2003 (2003)
Drepper, F.R.: Voiced excitation as entrained primary response of a reconstructed glottal master oscillator. In: Fortschritte der Akustik-DAG 2005 (2005)
Afraimovich, V.S., Verichev, N.N., Rabinovich, M.I.: Radiophys. Quantum Electron 29, 795 (1986)
Rulkov, N.F., Sushchik, M.M., Tsimring, L.S., Abarbanel, H.D.I.: Phys. Rev. E 51, 980–994 (1995)
Rulkov, N.F., Afraimovich, V.S., Lewis, C.T., Chazottes, J.R., Cordonet, A.: Phys. Rev. E. 64, 016217 (2001)
Schoentgen, J.: Shaping function models of the phonatory excitation signal. J. Acoust. Soc. Am. 114(5), 2906–2912 (2003)
Kawahara, H., Zolfaghari, P.: Systematic F0 glitches around nasal-vowel transitions. In: Eurospeech 2001 (2001)
Graf, J.T., Hubing, N.: Dynamic time warping comb filter for the enhancement of speech degraded by white Gaussian noise. In: Proc. ICASSP, vol. 2, pp. 339–342 (1993)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2006 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Drepper, F.R. (2006). A Two-Level Drive – Response Model of Non-stationary Speech Signals. In: Faundez-Zanuy, M., Janer, L., Esposito, A., Satue-Villar, A., Roure, J., Espinosa-Duro, V. (eds) Nonlinear Analyses and Algorithms for Speech Processing. NOLISP 2005. Lecture Notes in Computer Science(), vol 3817. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11613107_11
Download citation
DOI: https://doi.org/10.1007/11613107_11
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-31257-4
Online ISBN: 978-3-540-32586-4
eBook Packages: Computer ScienceComputer Science (R0)