
Abstract
The objective of the content-based image retrieval (CBIR) system is to retrieve the visually identical images from the database efficiently and effectively. It is a broad research realm with the availability of numerous applications. Performance dependence of CBIR focuses on the extraction, reduction, and selection of the features along with the practice of classification technique. In this work, we have proposed the hybrid approach of two different feature descriptors: global color histogram and multi-scale local binary pattern (MS-LBP); furthermore, the use of PCA for dimension reduction and LDA for the selection of features. The proposed method is evaluated concerning various benchmark datasets, viz., Corel-1k, Corel-5k, Corel-10k, and Ghim-10k together with result comparison based on the precision and recall values at different thresholds. The classification purposes are satisfied with Euclidean and City Block distance. The performance study of the proposed work displays it as outperformer than the identified state-of-the-art literature.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Content-based image retrieval (CBIR) is a solution to the image retrieval problem using the contents of the images. Image retrieval is defined as the retrieval of semantically relevant images from a database of images. The requirement of retrieving similar images from a large database is the need of the hour; to surpass this hiccup, there should be some explanation and quick fix. Images can be retrieved based on the metadata or content of the query image. Assigning naming in traditional image retrieval systems is a clumsy task. As time goes, retrieving, processing, searching, browsing, and managing of images became hard. To solve the image retrieval problem, images are retrieved based on high-level or low-level features or sometimes a combination of both. Retrieving the images based on a query from the large database is not an easy task when you are adopting a traditional approach like text-based image retrieval (TBIR) where the search is based on automatic or manual annotation of images. The TBIR retrieves the images from the database based on the metadata of the query image. Therefore, the problem of annotation of the images and laboring cost arises. The most known problems with the TBIR are annotation of the images, human perception, and deeper needs of the queries for searching images [1]. To overcome the above disadvantages in TBIR, content-based approach was introduced in the early 1980s. CBIR is the use of computer vision to the image retrieval difficulty that is the crisis of searching for digital images in huge databases. In CBIR, images are indexed by their visual content, such as color, texture, shapes, and spatial information. Though many sophisticated algorithms have been designed to describe color, shape, and texture features, these algorithms cannot adequately model image semantics and have many limitations when dealing with broad content image databases [2]. Netra, QBIC, SIMPLIcity, MetaSEEK, VisualSeek, Blobworld, PicHunter, Google Image Search, Camfind, Pixolution, and DRAWSEARCH are some well-known CBIR systems. Jet.com—an elastic search-based E-Commerce, PictPicks (Google’s material design interface), and Veracity (reverse image search on iOS) are also some other innovative examples. The semantic gap and intention gap are issues in current CBIR systems. A difficulty that a user suffers to precisely express the expected visual content by a query at hand is called the intention gap. Another is the semantic gap originates from the difficulty in describing a high-level semantic concept with low-level visual features [2,3,4]. The image retrieval problem is alive because of not the availability of satisfactory retrieval results. As we know, challenges are boon to discovery in the era of science, engineering, and computing. Let us discuss some of the open challenges in CBIR. First, no single feature extraction technique can provide all the robust features. A deciding set of feature extraction techniques for CBIR is a vital task. Second is selecting the low number of handy features from the extracted ones. Different dimensionality reduction techniques like principal component analysis (PCA) [5], non-negative matrix factorization (NMF) [6], and independent component analysis (ICA) [7] can be used for reducing the size of the feature. Then, robust features can be selected using linear discriminant analysis (LDA) [8], Genetic Algorithm, and/or other feature selection techniques. Feature selection strategies can be taken from evolutionary computing (EC), Swarm Optimization (SO), and artificial intelligence (AI). The third point which can be discussed is matching similarity in between images. It can be done using template matcher or machine learning classifiers. In the last, we must focus on the ranking of the images, because after all, the user is only interested in the range of visually similar images. Furthermore, achieving high precision and recall for large datasets is also a challenging task. CBIR applications: art collections [9, 10], crime prevention [11,12,13], geographical information and remote sensing systems [14, 15], intellectual property [16,17,18,19], medical imaging [20,21,22,23,24,25], military and defence [26], photograph archives and retail catalogs [27,28,29], nudity-detection filters [30,31,32], and face finding systems [33,34,35].
We have focused on the issue of low retrieval rates of CBIR when working with benchmark datasets, viz., Corel-1k, Corel-5k, Corel-10k, and Ghim-10k. The use of MS-LBP at \(7\times 7\) scale for texture representation instead of the simple LBP operator to compute large-scale dominant texture details. We have suggested a modified version of MS-LBP (at \(7\times 7\) scale) to encounter more texture than the existing MS-LBP. Only texture detail will not improve retrieval rates, so color features combined with it. However, both types of descriptors have high dimensionality. Therefore, to decrease the spatial dimensions with less impact on performance, the proposal of PCA for eliminating redundant features and LDA for optimal selection from the reduced set of features is suggested. The results and discussion section demonstrates the impactful performance of the proposed work.
In this section, we have covered the prerequisite knowledge of the topic with the scope, challenges, and usability of the CBIR system. Furthermore, we have also discussed our contribution to the existing work. The next section provides the literature study done with the traditional and deep learning-based practices. Later on, the methodological overview demonstrated to grasp the useful details of the proposed hybrid technique. The upcoming fourth section of the document covers the proposed system. The second last section describes the experimental analysis of the proposed work over four distinct benchmark datasets. The discussion about the conclusion of the proposed work can be seen clearly in the last section.
Related Work
A feature or a piece of visual information is extracted from image contents to distinguish two images from one another. Feature extraction converts the input images into a set of feature values or feature vectors [1]. Mainly, there are four types of visual information: (1) color, (2) texture, (3) shape, and (4) spatial information. Those features that can be extracted automatically from the image without any spatial information are known as low-level features. Color, texture, and shape descriptors are low-level features of the image. Feature extraction methods broadly fall into two categories, viz., global methods and local methods. In the global methods, the feature extraction process considers complete image, whereas, in local methods, some portion of the image is taken into account for extracting features. This section covers the studied literature of the field.
Traditional Retrieval Practices
Boparai et al. [36] used HSV color histogram and color moments as color descriptors in their hybrid approach by blending it with wavelet transform and Zernike Moment. Kundu et al. [37] presented the relevance feedback-based approach with multi-scale geometric analysis (MGA) of non-subsampled contourlet transform (NSCT) for CBIR. Dubey et al. [38] suggested the quantization of RGB colorspace to a single channel for retrieving color and texture details and introduced fused features named as a scale-invariant hybrid image descriptor (RSHD). Soni et al. [39] proposed a method combining color histogram and color correlogram in their paper to enhance performance. In that article, they compared the results with color histogram, and the proposed approach works fine with the Wang dataset. Mary et al. [40] used color moments as a color descriptor in their paper and combined it with gray-level co-occurrence matrices (GLCM) and Fourier descriptor. Effat et al. [41] used color moments and blended it with other texture and shape descriptors, but the focus was mainly on machine learning techniques like K-means clustering, and neural network along with genetic algorithm. Ansari et al. [42] propounded HSV color histogram using quantization-based color features and texture contents with DWT and edge histogram (from V channel of HSV image) to form descriptor. Formally, The GLCM was proposed by Haralick [43] which is one of the methods for representing the texture features of images. Spatial patterns like LBP [44], LDP [45], LTP [46], and LTrP [47] are still famous in the area of CBIR. Some of the spatial patterns are multi-scale local binary Patterns (MS-LBP) [48, 49], local smoothness patterns (LSP) [50], local curve patterns (LCP) [51], color directional local quinary patterns (CDLQP) [52], and so many more. The main reason that these approaches became popular and successful is their easiness of feature extraction stage and supremacy on the feature classification performance. Jabid et al. [45] proposed local directional patterns for texture description to overcome the issue of LBP [44] of not considering directions for feature extraction. Rao et al. [53] proposed a new texture feature descriptor local mesh quantized extrema patterns (LMQEP) for CBIR and they combined it with RGB color Histogram for enhancing performance and experimented on MIT VisTex and Corel-1k databases. Lu et al. [54] proposed an improved LBP descriptor for texture description. The proposed ILBP is based on pattern uniformity measure and the number of ones in the LBP codes. ILBP is invariant in terms of monotonic gray-scale change, histogram equalization operation, and rotation transformation. A major advantage of ILBP over traditional LBP is that it detects a large group of local primitives from non-uniform patterns. They used Outex and RotInv_16_10 datasets for the experiment. Subashkumar et al. [50] proposed local smoothness pattern (LSP) in their work. The idea of LSP is to follow the smooth regions, so that the smoothness over the curves can be captured. It was tested on Brodatz datasets. It performs better than LBP [44] as per the results of the paper shows. Later on, they also introduced the local curve pattern (LCP) in their further work of texture description in another literature [51]. LCP technique uses image line/curve characteristics to derive the local patterns. Implementation was done on Corel 1K, Corel 10K, and Brodatz. The results of the paper show that it outshines when compared with the other patterns like LTrp [47], BOF-LBP (LBP with Bag-of-Filters), and DBWP (Directional Binary Wavelet Patterns).
Prashant and Ashish [49] proposed a CBIR technique utilizing multi-scale local binary patterns (MS-LBP) and GLCM, in which consecutive neighborhood pixels are considered and LBP of different combinations of eight neighborhood pixels is computed at multiple scales. As shown by authors, it outshines the simple LBP operator because of using \(5\times 5\) and \(7 \times 7\) patch sizes of the image. After calculating MS-LBP, the authors applied GLCM to achieve a feature vector. The advantage of the proposed MS-LBP scheme is that it overcomes the limitations of single-scale LBP and acted as the more robust feature descriptor. It efficiently captures large-scale dominant features of some textures which single-scale LBP fails to do and also overcomes some of the limitations of other MS-LBP techniques. They only calculated texture features so by adding missed color features, we can enhance the performance. So far, much amount of work has been done on LBP because of its computational simplicity. LBP operator does not consider directions for achieving the intensity value of center pixel, it only considers the magnitude of the neighborhood pixel intensities. So that, it is the main issue related to the LBP operator which led us to other spatial patterns like LDP [45], LTP [46], LTrp [47], MS-LBP [48, 49], LSP [50], LMQEP [53], LCP [51], etc.
Deep Learning-Based Retrieval Practices
Apart from these traditional practices, some of the deep feature-based praxes have outstanding retrieval performance in this new era of deep learning. Thus, we will see here discussion over some of the useful works in this image retrieval domain utilizing deep learning. Convolutional neural network (CNN) is the most promising deep neural network when considering the image applications. Gordo et al. [55] proposed the use of a three-stream siamese network with triplet loss for image retrieval that computes the global representation of each image (using the regional maximum activations of convolutions known as R-MAC descriptor) to serve the rate of similarity. They used VGGNet-16 and ResNet-101 as backbone CNN architecture. The authors have given a cleaning method for noisy large-scale landmarks dataset. The experimentation purposes fulfilled with Oxford-5k, Paris-6k, INRIA Holidays, and UKB datasets. Tzelepi and Tefas [56] came up with the idea of retraining the eight-layer CaffeNet model for retrieval motives. The authors evaluated results on the Paris-6k, UKB, and UKB-2 datasets. Revaud et al. [57] propounded the use of listwise loss instead of triplet loss to optimize the average precision. The authors used previously pre-trained ResNet-101 architecture (on the ImageNet dataset) and appended the generalized mean pooling layer. In this introduced approach, the authors suggested the batch size of 4096 and utilized P40 GPU for training the model. They exerted the PyTorch library for implementation. The performance measured over three datasets, viz., Landmarks dataset (cleaned version consisting of 42,410 images and 586 landmarks) and revisited versions of Paris and Oxford datasets. Radenovic et al. [58] proposed the finetuning of the CNN with the Generalized Mean (GeM) Pooling layer. One more prime focus of the work was to learn whitening descriptors with the use of whitening transform instead of PCA whitening. The authors used AlexNet, VGGNet, and ResNet architectures for finetuning. The Paris-6k, Oxford-5k, and Holidays datasets satisfy evaluation goals. Sezavar et al. [59] mentioned the application of sparse representation with a pre-trained AlexNet model. The test case performance discussed with Corel, ALOI, and MPEG7 datasets. Saritha et al. [60] presented the use of unsupervised deep belief Network (DBN) and parametric relu activations for image retrieval.
Methodology Overview
Color Histogram
A color histogram is a commonly used and more famous feature in image retrieval. It is very popular, because color histograms are computationally trivial to compute. Small changes in the camera viewpoints do not affect the color histogram. It provides the feature vector by counting the number of occurrences of each color in an image.
Mathematically, it can be defined as:
where \(\theta =\) pixels in I and \(H_{c_i}(I)=\Vert I_{c_i}\Vert =\) numbers of pixels which color is \(c_i\), \(i= {1,2,\ldots ,L}\)
Color histogram is rotation, translation, and scale-invariant feature descriptor which does not take account the space information concerning the color [61]. the color histogram can be applied locally or globally to the image. The histogram provides a large vector size of the features which may lead to more amount of time processing if dimensions of the feature vectors are not reduced.
Local Binary Patterns
Local binary patterns (LBP) were proposed by Timo Ojala, Matti Pietikhenl, and David Harwood for texture classification, but were first introduced by Wang and He [62]. It is a two-level version of the method of Wang and He. The LBP is a gray-scale invariant texture measure that labels the pixels of an image by thresholding the \(3 \times 3\) neighborhood of each pixel with the value of the central pixel and concatenating the results binomially to form a number [45, 62]. LBP operator is easy to implement texture descriptors because of its simplicity. It is successful in many image processing applications such as identification of faces, content-based image retrieval, object recognition, etc.
Mathematically, it can be represented as:
where \(I(n_c)=\) intensity value of center pixel and \(I(n_p)=\) gray level of its surrounding elements:
where X is the no. of neighbors and Y is the length of the neighborhood.
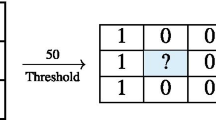
A \(3 \times 3\) patches are selected from the image and thresholded based on the center pixel value of the patch. Then, some binary pattern is applied which is further converted into decimal values, as shown in Fig. 1. This process is followed for the whole image and the LBPcode of the image is generated. The histogram features of these LBPcode are calculated to form the feature vector.

Basic LBP operator
Proposed System
Pre-Processing
We have resized the images of the dataset to \(100\times 100\). The reasons behind resizing are: (1) to take care of varying sized images of the dataset, (2) to reduce the computation complexity and retrieval time, and (3) to put in the same algorithm to all of the datasets.
Proposed Method Explanation
We have discussed well the \(3 \times 3\) blocks of the LBP. Let us aim for the larger block portion. If we consider the \(5 \times 5\) blocks of the image for feature generation, it covers more texture detail. Any single \(5 \times 5\) patch of an image contains 25 pixels consisting of 24 neighborhood pixels and one center pixel. Now, take eight different pixels each time from \(5 \times 5\) blocks to form three LBP operators. Then, a histogram of each can be calculated to form a concatenated feature vector. Same as \(5 \times 5\) blocks, it may also possible to take a \(7 \times 7\) block of the image to get more patterns along with more texture details. In the case of \(7 \times 7\) blocks of MS-LBP, 49 pixels can be used to form six \(3 \times 3\) LBP blocks. These patterns are used to calculate the histogram features. Six pattern formation from the \(7 \times 7\) block is as shown in Fig. 2. Here, different neighborhoods are assigned to form different patterns and the same center pixel is used to calculate LBP operator. It can also be possible to use mean or mid of pixels instead of the center pixel value. We have proposed a modified version of \(7 \times 7\) block LBP for CBIR, as shown in Fig. 2. Color is one of the remarkable characteristics of the image for the CBIR system. Color histogram is the most widely used color descriptor because of its capability of capturing the most dominant colors of the image. The histogram provides a better color description as compared to the color moments. However, it has a problem related to the high dimensionality of the feature vector. This is the main problem with the color histogram, whereas the dimensionality of the feature vector is very less in the case of color moments and it also provides a considerable amount of result. In this work, we are using color moments along with color histograms as color features. The first four moments mean, standard deviation, skewness, and kurtosis are used for constructing Moments and used along with 256 bins of color histogram for each color channel. Color image contains \(2^{24}\) colors in an image which results in 64 million colors. That much of the number of details are not required for discrimination, because the small number of colors is sufficient for comparison. In our work, we are proposing PCA to achieve reduced features because of feature complexity. To improve the performance of the CBIR system, color descriptors should be used with other descriptors like the texture or shape for better discriminability of features. So here, idea is to fuse the two different color descriptors, color histogram and color moments along with another texture descriptor, MS-LBP (as we calculated above with \(7 \times 7\) scales). The proposed combination can have larger sized feature vector which must be reduced for efficiency purposes and computation ease. The achieved features are reduced using PCA, and then concatenated to achieve a combined feature vector for selecting features. In the later part, we have selected features with LDA. Images are ranked based on the similarity. Two types of distance measures are used in our work, one is Euclidean and another is city block distance. The images are ranked based on the threshold values to achieve relevant images. After generating the features from both MS-LBP and color histogram, PCA is applied to decrease the complexity of the feature vector. Reduced features can be selected by changing the number of eigenvalues. The number of calculated texture features is 1536 (256-bin histogram features of 6 LBPcode) and color features are 780 (768 from RGB color histogram + 12 from color moments). In the proposed work, 131 eigenvectors are selected for MS-LBP and 90 for color histogram + color moments to produce the proposed feature vector. Features are selected using LDA from the set of total concatenated features.

\(7 \times 7\) block with six different LBP

Proposed system diagram
Proposed Algorithm
-
1.
Load template features
\(\Rightarrow\) Load previously computed MS-LBP and Color Histogram features.
-
2.
Process features
-
(a)
Reduction with PCA Reduce MS-LBP features to 131 (Fv1) and Color Histogram to 90 (Fv2).
-
(b)
Concatenation Forming a single feature vector from Fv1 and Fv2.
-
(c)
Optimal selection with LDA If there are C classes in the dataset then, LDA will give us \(C-1\) features for discrimination.
-
(a)
-
3.
Generate random queries
\(\Rightarrow\) Produce random query image indices for each class of the dataset. The number of queries will be equal to the number of categories in the dataset.
-
4.
Template matching
\(\Rightarrow\) Match similarity in between queries and dataset features with Euclidean or city block distance.
-
5.
Ranking
\(\Rightarrow\) Rank the images based on the similarity index and sorted distances.
-
6.
Compute performance measures
\(\Rightarrow\) Compute the precision and recall based on relevant and irrelevant indices. Furthermore, compute the total processing time (using tic-toc in MATLAB).
Repeat the above algorithm ten times to compute the averaged values of precision and recall for ten times run. Furthermore, the retrieval time of the algorithm will be the ratio of total processing time and 10. The diagram of the proposed work is shown in Fig. 3 for ease of understanding.
Similarity Measures
We have used two template matcher classifier for our work. One is Euclidean distance and another one is city block distance. Performance of the classifier depends upon the type of the features retrieved. Initially, we have checked the performance of the proposed method with other similarity measures too. However, these two are most convincing to our features.
Euclidean: A straight-line distance between two corresponding elements of a feature vector. It is a bin-by-bin distance, also known as Pythagoras distance. Each pixel in converted image has a value corresponding to the distance to the nearest pixel in image:
City block: Apart from Euclidean distance, another popular distance metric of \(L_P\) family is Manhattan distance, also known as taxi-cab distance or city block distance. It is basically the sum of absolute differences of corresponding elements of two feature vectors:
Performance Measures
The performance of the CBIR can be measured using precision and recall based on the relevancy of the retrieved results:
where \(R_{ID}\) stands for relevant images, \(N_{ID}\) stands for irrelevant images, and \(C_{ID}\) stands for relevant images from database. The total number of retrieved images \((R_{ID}+N_{ID})\) can be set to the different threshold constants ranging from 10 to number of images in the class. We have taken five different constant thresholds 10, 20, 30, 40, and 50 in our result analysis. We have used average retrieval precision (ARP) and average retrieval recall (ARR) for performance analysis which are nothing but, the average values of precision and recall, respectively.
Results and Discussion
Experimental Setup
This subsection covers a small review of the dataset. We have focused on four different datasets, namely, Corel-1k [63, 64], Corel-5k [65], Corel-10k [65], and Ghim-10k [65], to carry out the proposed work. The images in the Corel-1k database have been classified into ten categories, namely, Africans, beaches, buildings, buses, dinosaurs, elephants, flowers, horses, mountains, and food. Each image has a size of either \(256 \times 384\) or \(384 \times 256\). Each category of the image consists of 100 images. All images are in JPEG format. The Corel-5k dataset contains the first 5000 images from the Corel-10k dataset. The first 50 object categories are taken the original Corel-10k dataset. The Corel-10k dataset contains 100 categories, and there are 10,000 images from diverse contents such as sunset, beach, flower, building, car, horses, mountains, fish, food, door, etc. Each category contains 100 images of size \(192 \times 128\) or \(128 \times 192\) in the JPEG format. The Corel-10k dataset consists of the 10,000 images. The Ghim-10k dataset has 20 categories. There are 10000 images from diverse contents such as sunset, ship, flower, building, car, mountains, insect, etc. Each category involves 500 images of size \(400 \times 300\) or \(300 \times 400\) in JPEG format. Samples from these datasets are shown in Table 1. In that table, C: Number of Classes, SPC: Samples Per Class, and SOI: Size of Images. The results are obtained using MATLAB 2018a with the help of a laptop containing an i7-3612QM processor and 10GB RAM with integrated graphics.
Performance on Corel-1k
Figs. 4 and 5 show the graph of ARP and ARR over Corel-1k dataset. We can see from the figures that the performance of the system has not much degradation as varying thresholds.

Average retrieval precision on Corel-1k

Average retrieval rate on Corel-1k
The result demonstration on Corel-1k is given in Tables 2 and 3 at different thresholds (10 and 20) with the different state-of-the-art methods. The state-of-the-art comparison shows the supremacy of the proposed work in the terms of retrieval rates. We can recognize the bold texted ARPs of the proposed method in Tables 2 and 3 at ease.
The proposed method outshines distinct identified literature, viz., CH + DWT + EDH [66] by 17.55%, LCP [51] by 17.15%, DCD + Wavelet + curvelet [67] by 14.55%, CCV + LBP [68] by 14.45%, CH + LDP [69] by 12.74%, SGLCM + 2D-CS Model [70] by 10.95%, CH + LDP + SIFTBOF [71] by 5.95%, and adaptive tetrolet transform + joint histogram + correlation histogram [72] by 3.55% at the threshold value of 20. When threshold value is 10, the proposed technique beats color moments [73] by 56.96%, Gabor histogram [74] by 51.6%, Image-based HOG-LBP [75] by 46.9%, LF-SIFT histogram [74] by 44.7%, and RICE Algorithm selection model [76] by 43.18% marginally.
Furthermore, it also outshines color histogram [74] by 42.4%, moments of LTP [77] by 39.2%, LCP [51] by 14.6%, CCV + LBP [68] by 10.38%, DWT + SURF + GLCM [78] by 7.93%, low-level featues + relevance feedback [79] by 7.31%, and MS-LBP \((7\times 7)\) + GLCM by 7.18%, respectively, at threshold 10.
Performance on Corel-5k
The performance achieved by proposed method on this dataset is demonstrated in Figs. 6 and 7 based on the ARP and ARR values. The maximum achieved ARP is 70.92 with city block distance at threshold 10. The state-of-the-art comparison with different identified methods lies in Table 4 and the ARP of the proposed method is demonstrated with bold text for eye-catching. It can be seen that the proposed work performs better than the identified existing approaches. The ARP of the proposed system has more stability when used with Euclidean distance rather than city block as threshold increases on Corel-5k dataset. The proposed method beats existing work, namely, MS-LBP [48] by 55.47%, color moments [73] by 53.81%, moments of wavelet transform [80] by 38.97%, Moments of LTP [77] by 38.74%, CDLQP [52] by 16.52%, MS-LBP (\(7\times 7\)) + GLCM by 11.42%, CH + LDP [69] by 10.52%, LECoP [81] by 7.92%, CH + LDP + SIFTBOF [71] by 5.02%, and CCV + LBP [68] by 3.79%, respectively, at threshold 10.

Average retrieval precision on Corel-5k

Average retrieval rate on Corel-5k
Thus, the proposed technique surpasses over the literature of Xia et al. [48], Srivastava et al. [73, 77, 80], Vipparthi and Nagar [52], Srivastava and Khare [49], Zhou et al. [69], Verma et al. [81], Zhou et al. [71], and Mohiuddin et al. [68], as shown in Table 4.
Performance on Corel-10k
The performance evaluation of the proposed approach with respect to both classifiers can be identified by looking at Figs. 8 and 9. The state-of-the-art comparison is given in Table 5 with observed values of the ARP at threshold 10. The bold texted highlighted value of ARP of the proposed technique be seen in Table too. The retrieval outcomes by the proposed work outperform the existing identified results.

Average retrieval precision on Corel-10k

Average retrieval rate on Corel-10k
The ARP performance story over Corel-10k dataset can be summarized as follow: it overshadows color moments [73] by 41.34%, moments of wavelet transform [80] by 32.11%, moments of LTP [77] by 29.54%, CSLBP + LNDP [82] by 18.25%, LTrP [47] by 18.16%, low-level features + relevance feedback [79] by 17.3%, BOF of LBP [83] by 15.26%, DLEP + LNDP [82] by 13.97%, LTrP + LNDP [82] by 13.35%, LBP + LNDP [82] by 11.65%, LCP [51] by 11.36%, CDH [84] by 9.22%, MS-LBP (\(7\times 7\)) + GLCM [49] by 5.77%, CH + LDP [69] by 2.55%, and multi-trend structure descriptor [85] by 2.51% on an individual basis.
Performance on Ghim-10k
The implementation outcomes of the proposed system on Ghim-10k dataset are shown in Figs. 10 and 11. The comparative test results with recognized techniques are given in Table 6. The proposed algorithm provides better result than all of the identified state-of-the-art methods given by Xia et al. [48], Srivastava et al. [73, 77], Pardede et al. [79], Zhou et al. [69], Liu and Yang [84], and Srivastava and Khare [78] except MS-LBP \((7\times 7)\) + GLCM [49]. The ARP of the proposed method and MS-LBP (7×7) + GLCM [49] demonstrated with bold text as shown in Table 6. The MS-LBP (7×7) + GLCM [49] have better ARP of 76.99 than the proposed method. The number shows less effectiveness of the proposed method compared to that particular method. However, do not forget that the number of features selected by the proposed algorithm is only 19 for this dataset whereas, MS-LBP (7×7) + GLCM [49] have high dimensionality. Therefore, we can deduce that the proposed method is a lot more robust and effective than that particular method.

Average retrieval precision on Ghim-10k

Average retrieval rate on Ghim-10k
Retrieval Time Analysis and Proposed Method Complexity
The complexity of the algorithm depends on the retrieval time. Table 7 gives an overview of the total processing time and retrieval time of the proposed technique. The retrieval time is varied in nature as each dataset contains a variable number of images. The Corel-10k and Ghim-10k datasets have the same number of images still retrieval rate over the Corel-10k dataset is maximum. The reason behind this is the complexity of the Corel-10k dataset (more classes than Ghim-10k).
\(\Rightarrow\) TT: Total processing time of the algorithm (including ten times looping).
\(\Rightarrow\) RT: It is the retrieval time of the proposed algorithm.
\(\Rightarrow\) RT per class query: We have passed random query images from each category of the dataset simultaneously. The number of passed queries from the dataset at a time is equivalent to the number of classes in the given dataset. As an example, a hundred query images from the Corel-10k dataset at a time. Therefore, RT per class query is nothing but the ratio of RT and C.
Most researchers do not give as much merit to retrieval time as it deserves. Table 8 demonstrates a comparison of the state-of-the-art methods with proposed work on the Corel-1k benchmark dataset concerning ARP and RT. As we can see from Table 8, it outperforms Kundu et al. [37], ElAlami [86], Fadaei et al. [67], and Dubey et al. [38, 83] concerning RT and ARP. The lower value of RT and higher ARP shows the superiority of the proposed work. Thus, we can say that the proposed algorithm is more efficient and effective than its counterpart.
Comparison on Various Benchmark Datasets
The comparative performance of the proposed method is demonstrated in Figs. 12 and 13 based on ARP and ARR. The highest achieved ARR is 45.18 at threshold 50 for the Corel-1k dataset, whereas the lowest one is 1.36 for the Ghim dataset. The maximal value for ARP by the proposed method is on Corel-1k at threshold 10 and a minimal one at threshold 50 on the Corel-10k dataset.

Average retrieval precision on various datasets
The analysis of the ARP and ARR values shows that the proposed method utilizes well-execution on the Corel-1k dataset. The performance story of the Corel-5k is also quite good. The implementation of the proposed method on Corel-10k and Ghim-10k provides a different tale. The proposed method executes a bit lower on the complex dataset, namely Corel-10k than all of the other datasets in terms of ARP. The ARR values of the Ghim-10k are relatively flattered as a large number of images in each category of the dataset. The hike in the threshold leads to the additional gain in ARR values, but ARP gradually decreases with the threshold hike.

Average retrieval rate on various datasets
Conclusions
The dimension complexity of the proposed algorithm is very low because of a feature selection strategy, LDA. The PCA and LDA help to produce better features from the given dataset. The outcome of the proposed work has better ARP than all of the collected literature on Corel-1k, Corel-5k, and Corel-10k benchmark datasets. The noticeable thing is on the Ghim-10k dataset as the method has low ARP than MS-LBP (\(7\times 7\)) + GLCM, but we should also consider the complexity of the feature vector. The small variation in the retrieval rates is an obvious thing when working with a lesser number of features. Overall, the proposed work provides a pleasant outcome by dominating over all of its counterparts. The result clearly states that getting higher ARP and ARR with Corel-10k and Ghim-10k is still hard. The proposed work can be made even better by using machine learning classifiers. Furthermore, the exert of deep leaning can give much better outcomes, but it is still challenging to fine-tune or train a model for image retrieval.
Availability of Data and Material
The authors declare that datasets supporting the findings of this study are available at http://www.ci.gxnu.edu.cn/cbir/Dataset.aspx.
References
Rui Y, Huang TS, Chang SF. Image retrieval: current techniques, promising directions, and open issues. J Vis Commun Image Represent. 1999;10:39–62. https://doi.org/10.1006/jvci.1999.0413.
Liu Y, Zhang D, Lu G, Ma WY. A survey of content-based image retrieval with high-level semantics. Pattern Recogn. 2007;40:262–82. https://doi.org/10.1016/j.patcog.2006.04.045.
Zhou W, Li H, Tian Q. Recent advance in content-based image retrieval: a literature survey. 2017. arXiv:1706.06064.
Tyagi V. Content-based image retrieval: Ideas, Influences, and Current Trends. Springer Nature, Singapore Pte Ltd; 2017. https://www.springer.com/gp/book/9789811067587.
Jolliffe I. Principal component analysis. In: International Encyclopedia of Statistical Science. Berlin, Heidelberg: Springer; 2011. pp. 1094–96. https://doi.org/10.1007/978-3-642-04898-2_455.
Lee Daniel D, Sebastian SH. Learning the parts of objects by non-negative matrix factorization. Nat Sci J. 1999;401:788–91. https://doi.org/10.1038/44565.
Pierre C. Independent component analysis, a new concept? Sig Process. 1994;36(3):287–314. https://doi.org/10.1016/0165-1684(94)90029-9.
Dong X, Shuicheng Y, Dacheng T, Stephen L, Hong-Jiang Z. Marginal fisher analysis and its variants for human gait recognition and content-based image retrieval. IEEE Trans Image Process. 2007;16(11):2811–21. https://doi.org/10.1109/TIP.2007.906769.
Bonnie H, Laura H. Retrieving art images by image content: the UC Davis QBIC project. Aslib Proc. 1994;46(10):243–8. https://doi.org/10.1108/eb051371.
Ivanova K, Stanchev P. Color harmonies and contrasts search in art image collections. In: Advances in Multimedia. Colmar, France: IEEE; 2009. pp. 180–87. https://doi.org/10.1109/MMEDIA.2009.41.
Ying L, Yuan H, Ziming G. Feature extraction and similarity measure for crime scene investigation image retrieval. J Xian Univ Posts Telecommun. 2014;19:11–6.
Shriram KV, Priyadarsini PLK, Baskar A. An intelligent system of content-based image retrieval for crime investigation. Int J Adv Intell Paradig. 2015;7(3–4):264–79. https://doi.org/10.1504/IJAIP.2015.073707.
Liu Y, Huang Y, Zhang S, Zhang D, Ling N. Integrating object ontology and region semantic template for crime scene investigation image retrieval. In: Industrial electronics and applications. Siem Reap, Cambodia: IEEE; 2017. pp. 149–53. https://doi.org/10.1109/ICIEA.2017.8282831.
Adel H, Subhasis C, Guna S, Bertrand Z. Region-based CBIR in GIS with local space filling curves to spatial representation. Pattern Recogn Lett. 2006;27(4):259–67. https://doi.org/10.1016/j.patrec.2005.08.007.
Joshi C, Purohit GN, Mukherjee S. Impact of CBIR journey in satellite imaging. Gurgaon: CRC Press; 2017. p. 341–5.
Tiwari A, Bansal VP. PATSEEK: Content-based image retrieval system for patent database. In: International Conference on Electronic Business. Beijing, China: Tsinghua University; 2004. pp. 1167–71. https://aisel.aisnet.org/iceb2004/199.
Jane L. How drawings could enhance retrieval in mechanical and device patent searching. World Patent Inf. 2007;29(3):210–8. https://doi.org/10.1016/j.wpi.2007.01.001.
Stefanos V, Symeon P, Anastasia M, Panagiotis S, Emanuelle P, Ioannis K. Towards content-based patent image retrieval: a framework perspective. World Patent Inf. 2010;32(2):94–106. https://doi.org/10.1016/j.wpi.2009.05.010.
Zhu L, Jin H, Zheng R, Zhang Q, Xie X, Guo M. Content-based design patent image retrieval using structured features and multiple feature fusion. In: 6th International Conference on Image and Graphics. Hefei, Anhui, China: IEEE; 2011. pp. 969–74. https://doi.org/10.1109/ICIG.2011.121.
Shyu CR, Kak A, Brodley CE, Broderick LS. Testing for human perceptual categories in a physician-in-the-loop CBIR system for medical imagery. In: Workshop on content-based access of image and video libraries. Fort Collins, USA: IEEE; 1999. pp. 102–8. https://doi.org/10.1109/IVL.1999.781132.
Jones BF, Schaefer G, Zhu SY. Content-based image retrieval for medical infrared images. In: 26th International Conference on Engineering in Medicine and Biology Society. San Francisco, CA: IEEE; 2004. pp. 1186–7. https://doi.org/10.1109/IEMBS.2004.1403379.
Ruiz ME. Combining image features, case descriptions and UMLS concepts to improve retrieval of medical images. In: American Medical Informatics Association Annual Symposium. Chicago, US: AMIA; 2006. pp. 674-78.
Antani S, Long LR, Thoma GR. Bridging the gap: enabling CBIR in medical applications. In: International Symposium on Computer-Based Medical Systems. University of Jyvaskyla, Finland: IEEE; 2008. pp. 4–6. https://doi.org/10.1109/CBMS.2008.133.
Chuctaya H, Portugal C, Beltran C, Gutierrez J, Lopez C, Tupac Y. M-CBIR: a medical content-based image retrieval system using metric data-structures. In: 30th International Conference of the Chilean Computer Science Society. Curico, Chile: IEEE; 2011. pp. 135–41. https://doi.org/10.1109/SCCC.2011.18.
Zhou XS, Zillner S, Moeller M, Sintek M, Zhan Y, Krishnan A, Gupta A. Semantics and CBIR: a medical imaging perspective. In: The International Conference on Content-based Image and Video Retrieval. Niagara Falls Canada: ACM; 2008. pp. 571–80. https://doi.org/10.1145/1386352.1386436.
Van Der Merwe JS, Ferreira HC, Clarke WA. Towards detecting man-made objects in natural environments for a man-made object mpeg-7 CBIR descriptor-sandf application. In: Annual Symposium of the Pattern Recognition Association of South Africa, Langebaan, South Africa: University of Cape Town; 2005. pp. 19–24.
Graham ME. The cataloguing and indexing of images: time for a new paradigm? Art Libr J. 2001;26(1):22–7. https://doi.org/10.1017/S0307472200012001.
Colombo C, Del Bimbo A. Visible image retrieval. Image Databases Search Retr Digital Imagery. 2002;2:11–33. https://doi.org/10.1002/0471224634.ch2.
Enser PGB, Sandom CJ, Lewis PH. Surveying the reality of semantic image retrieval. In: International conference on advances in visual information systems. Berlin, Heidelberg: Springer; 2005. pp. 177–88. https://doi.org/10.1007/11590064_16.
Lopes APB, de Avila Sandra EF, Peixoto ANA, Oliveira RS, Araujo ADA. A bag-of-features approach based on hue-sift descriptor for nude detection. In: 17th European Conference on Signal Processing. Glasgow, Scotland: IEEE; 2009a. pp. 1552–6.
Lopes APB, de Avila SEF, Peixoto ANA, Oliveira RS, Araujo ADA, Coelho MDM. Nude detection in video using bag-of-visual-features. In: 22nd Brazilian Symposium on computer graphics and image processing. Rio de Janiero, Brazil: IEEE; 2009b. pp. 224–31. https://doi.org/10.1109/SIBGRAPI.2009.32.
Choras RS. Cbir system for detecting and blocking adult images. In: the 9th international conference on Signal processing. Stevens Point, Wisconsin, US: WSEAS; 2010. pp. 52–7. https://doi.org/10.5555/1844625.1844636.
Abate AF, Nappi M, Ricciardi S, Tortora G. Faces: 3D facial reconstruction from ancient skulls using content based image retrieval. J Visual Lang Comput. 2004;15(5):373–89. https://doi.org/10.1016/j.jvlc.2003.11.004.
Zhang L, Hu Y, Li M, Ma W, Zhang H. Efficient propagation for face annotation in family albums. In: The 12th Annual International Conference on Multimedia. New York, US: ACM; 2004. pp. 716–23. https://doi.org/10.1145/1027527.1027689.
Kumar N, Berg A, Belhumeur PN, Nayar S. Describable visual attributes for face verification and image search. IEEE Trans Pattern Anal Mach Intell. 2011;33(10):1962–77. https://doi.org/10.1109/TPAMI.2011.48.
Boparai NK, Chhabra A. A hybrid approach for improving content based image retrieval systems. In: 1st International Conference on next generation computing technologies. Dehradun, India: IEEE; 2015. pp. 944–9. https://doi.org/10.1109/NGCT.2015.7375260.
Kundu MK, Chowdhury M, Bulo SR. A graph-based relevance feedback mechanism in content-based image retrieval. Knowl Based Syst. 2015;73:254–64. https://doi.org/10.1016/j.knosys.2014.10.009.
Dubey SR, Singh SK, Singh RK. Rotation and scale invariant hybrid image descriptor and retrieval. Comput Electr Eng. 2015a;46:288–302. https://doi.org/10.1016/j.compeleceng.2015.04.011.
Soni D, Mathai KJ. An efficient content based image retrieval system based on color space approach using color histogram and color correlogram. In: 5th International Conference on communication systems and network technologies. Gwalior, India: IEEE; 2015. pp. 488–92. https://doi.org/10.1109/CSNT.2015.80.
Mary ITB, Vasuki A, Manimekalai MAP. An optimized feature selection CBIR technique using ANN. In: International conference on electrical, electronics, communication computer technologies and optimization techniques. Mysuru, India: IEEE; 2017. pp. 470–7. https://doi.org/10.1109/ICEECCOT.2017.8284550.
Naaz E, Kumar AT. Enhanced content based image retrieval using machine learning techniques. In: Innovations in information, embedded and communication systems, international conference on. Coimbatore, India: IEEE; 2017. pp. 1–12. https://doi.org/10.1109/ICIIECS.2017.8275994.
Ansari MA, Dixit M. An enhanced CBIR using HSV quantization, discrete wavelet transform and edge histogram descriptor. In: International Conference on computing, communication and automation. Greater Noida, India: IEEE; 2017. pp. 1136–41. https://doi.org/10.1109/CCAA.2017.8229967.
Haralick R, Shanmugam K. Textural features for image classification. IEEE Trans Syst Man Cybern. 1973;SMC–3:610–21. https://doi.org/10.1109/TSMC.1973.4309314.
Timo O, Matti P, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans Pattern Anal Mach Intell. 2002;24:971–87. https://doi.org/10.1109/TPAMI.2002.1017623.
Jabid T, Kabir MH, Chae O. Local directional pattern (ldp)-a robust image descriptor for object recognition. In: The 7th International Conference on advanced video and signal based surveillance. Boston, MA, USA: IEEE; 2010. pp. 482–87. https://doi.org/10.1109/AVSS.2010.17.
Tan X, Triggs B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. In: International workshop on analysis and modeling of faces and gestures. Berlin, Heidelberg: Springer; 2007. pp. 168–82. https://doi.org/10.1007/978-3-540-75690-3_13.
Murala S, Maheshwari RP, Balasubramanian R. Local tetra patterns: a new feature descriptor for content-based image retrieval. IEEE Trans Image Process. 2012;21:2874–86. https://doi.org/10.1109/TIP.2012.2188809.
Xia Y, Wan S, Jin P, Yue L. Multi-scale local spatial binary patterns for content-based image retrieval. In: International Conference on Active Media Technology. Cham, Switzerland: Springer; 2013. pp. 423–32. https://doi.org/10.1007/978-3-319-02750-0_45.
Prashant S, Ashish K. Utilizing multiscale local binary pattern for content-based image retrieval. Multimedia Tools Appl. 2018a;77:12377–403. https://doi.org/10.1007/s11042-017-4894-4.
Kumar TGS, Nagarajan V. Local smoothness pattern for content based image retrieval. In: Communications and signal processing. Melmaruvathur, India: IEEE; 2015. pp. 1190–3. https://doi.org/10.1109/ICCSP.2015.7322694.
Kumar TGS, Nagarajan V. Local curve pattern for content-based image retrieval. Pattern Anal Appl. 2019;22:1233–42. https://doi.org/10.1007/s10044-018-0724-1.
Vipparthi SK, Nagar SK. Color directional local quinary patterns for content based indexing and retrieval. Human-Centric Comput Inf Sci. 2014;4(1):1–13. https://doi.org/10.1186/s13673-014-0006-x.
Rao KL, Rao V, Reddy LP. Local mesh quantized extrema patterns for image retrieval. SpringerPlus. https://doi.org/10.1186/s40064-016-2664-9.
Lu F, Jun H. An improved local binary pattern operator for texture classification. In: International conference on acoustics, speech and signal processing. Shanghai, China: IEEE; 2016. https://doi.org/10.1109/ICASSP.2016.7471888.
Albert G, Jon A, Jerome R, Diane L. End-to-end learning of deep visual representations for image retrieval. Int J Comput Vision. 2017;124:237–54. https://doi.org/10.1007/s11263-017-1016-8.
Maria T, Anastasios T. Deep convolutional learning for content based image retrieval. Neurocomputing. 2018;275:2467–78. https://doi.org/10.1016/j.neucom.2017.11.022.
Revaud J, Almazan J, Rezende R, Souza CD. Learning with average precision: training image retrieval with a listwise loss. In: International Conference on Computer Vision. Seoul, Korea (South): IEEE; 2019. pp. 5106–15. https://doi.org/10.1109/ICCV.2019.00521.
Radenovic F, Tolias G, Chum O. Fine-tuning CNN image retrieval with no human annotation. IEEE Trans Pattern Anal Mach Intell. 2019;41(7):1655–68. https://doi.org/10.1109/TPAMI.2018.2846566.
Amir S, Hassan F, Sajad M. Content-based image retrieval by combining convolutional neural networks and sparse representation. Multimedia Tools Appl. 2019;78:20895–912. https://doi.org/10.1007/s11042-019-7321-1.
Saritha RR, Paul V, Kumar PG. Content based image retrieval using deep learning process. Cluster Comput. 2019;22:4187–200. https://doi.org/10.1007/s10586-018-1731-0.
Shao H, Wu Y, Cui W, Zhang J. Image retrieval based on mpeg-7 dominant color descriptor. In: The 9th International Conference for Young Computer Scientists. Hunan, China: IEEE; 2008. pp. 753–7. https://doi.org/10.1109/ICYCS.2008.89.
Ojala T, Pietikainen M, Harwood D. Performance evaluation of texture measures with classification based on kullback discrimination of distributions. In: The 12th International Conference on Pattern Recognition. Jerusalem, Israel: IEEE; 1994. pp. 582–5. https://doi.org/10.1109/ICPR.1994.576366.
James W, Jia L, Gio W. Simplicity: semantics-sensitive integrated matching for picture libraries. IEEE Trans Pattern Anal Mach Intell. 2001;23(9):947–63. https://doi.org/10.1109/34.955109.
James W, Jia L. Automatic linguistic indexing of pictures by a statistical modeling approach. IEEE Trans Pattern Anal Mach Intell. 2003;25(9):1075–88. https://doi.org/10.1109/TPAMI.2003.1227984.
Guang-Hai L, Jing-Yu Y. Content-based image retrieval using computational visual attention model. Pattern Recogn. 2015;48:2554–66. https://doi.org/10.1016/j.patcog.2015.02.005.
Nazir A, Ashraf R, Hamdani T, Ali N. Content based image retrieval system by using HSV color histogram, discrete wavelet transform and edge histogram descriptor. In: International Conference on Computing, Mathematics and Engineering Technologies. Sukkur, Pakistan: IEEE; 2018. pp. 1–6. https://doi.org/10.1109/ICOMET.2018.8346343.
Fadaei S, Amirfattahi R, Ahmadzadeh MR. New content-based image retrieval system based on optimised integration of dcd, wavelet and curvelet features. IET Image Proc. 2017;11:89–98. https://doi.org/10.1049/iet-ipr.2016.0542.
Mohiuddin F, Hossain I, Kabir MWU. A noble color-texture hybrid method for content-based image retrieval. In: The 20th International Conference of computer and information technology. Dhaka, Bangladesh: IEEE; 2017. pp. 1–6. https://doi.org/10.1109/ICCITECHN.2017.8281841.
Zhou J-X, Liu X, Tian-Wei X, Gan J, Liu W. A new fusion approach for content based image retrieval with color histogram and local directional pattern. Int J Mach Learn Cybern. 2018;9(4):677–89. https://doi.org/10.1007/s13042-016-0597-9.
Zhou Y, Zeng FZ, Zhao HM, Murray P, Ren J. Hierarchical visual perception and two dimensional compressive sensing for effective content-based color image retrieval. Cogn Comput. 2016;8(5):877–89. https://doi.org/10.1007/s12559-016-9424-6.
Zhou J-X, Liu X, Liu W, Gan J. Image retrieval based on effective feature extraction and diffusion process. Multimedia Tools Appl. 2019;78:6163–90. https://doi.org/10.1007/s11042-018-6192-1.
Pradhan J, Kumar S, Pal AK, Banka H. A hierarchical CBIR framework using adaptive tetrolet transform and novel histograms from color and shape features. Digit Signal Proc. 2018;82:258–81. https://doi.org/10.1016/j.dsp.2018.07.016.
Srivastava P, Binh NT, Khare A. Content-based image retrieval using moments. In: International Conference on context-aware systems and applications. Cham: Springer; 2014a. pp. 228–37. https://doi.org/10.1007/978-3-319-05939-6_23.
Thomas D, Daniel K, Hermann N. Features for image retrieval: an experimental comparison. Inf Retr. 2008;11(2):77–107. https://doi.org/10.1007/s10791-007-9039-3.
Jing Yu, Zengchang Q, Tao W, Xi Z. Feature integration analysis of bag-of-features model for image retrieval. Neurocomputing. 2013;120:355–64. https://doi.org/10.1016/j.neucom.2012.08.061.
Hamreras S, Boucheham B. Adaptive content based image retrieval based on rice algorithm selection model. In: International Symposium on Programming and Systems. Algiers, Algeria: IEEE; 2018. pp. 1–6. https://doi.org/10.1109/ISPS.2018.8379022.
Srivastava P, Binh NT, Khare A. Content-based image retrieval using moments of local ternary pattern. Mobile Netw Appl. 2014b;19(5):618–25. https://doi.org/10.1007/s11036-014-0526-7.
Srivastava P, Khare A. Content-based image retrieval using multiresolution speeded-up robust feature. Int J Comput Vision Robot. 2018b;8(4):375–87. https://doi.org/10.1504/IJCVR.2018.093967.
Pardede J, Sitohang B, Akbar S, Khodra ML. Re-weighting relevance feedback in HSV quantization for CBIR. In: 19th International Conference on software engineering, artificial intelligence, networking and parallel/distributed computing. Busan, South Korea: IEEE/ACIS; 2018. pp. 58–63. https://doi.org/10.1109/SNPD.2018.8441075.
Srivastava P, Binh NT, Khare A. Content-based image retrieval using moments of wavelet transform. In: The International Conference on control, automation and information sciences. Gwangju, South Korea: IEEE; 2014c. pp. 159–164.
Manisha V, Balasubramanian R, Subrahmanyam M. Local extrema co-occurrence pattern for color and texture image retrieval. Neurocomputing. 2015;165:255–69. https://doi.org/10.1016/j.neucom.2015.03.015.
Manisha V, Balasubramanian R. Local neighborhood difference pattern: A new feature descriptor for natural and texture image retrieval. Multimedia Tools Appl. 2018;77(10):11843–66. https://doi.org/10.1007/s11042-017-4834-3.
Dubey SR, Singh SK, Singh RK. Boosting local binary pattern with bag-of-filters for content based image retrieval. In: UP Section Conference on electrical computer and electronics. Allahabad, India: IEEE; 2015. pp. 1–6. https://doi.org/10.1109/UPCON.2015.7456703.
Guang-Hai L, Jing-Yu Y. Content-based image retrieval using color difference histogram. Pattern Recogn. 2013;46(1):188–98. https://doi.org/10.1016/j.patcog.2012.06.001.
Meng Z, Huaxiang Z, Jiande S. A novel image retrieval method based on multi-trend structure descriptor. J Vis Commun Image Represent. 2016;38:73–81. https://doi.org/10.1016/j.jvcir.2016.02.016.
ElAlami ME. A novel image retrieval model based on the most relevant features. Knowl Based Syst. 2011;24(1):23–32. https://doi.org/10.1016/j.knosys.2010.06.001.
Funding
There are no financial conflicts of interest to disclose.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chavda, S., Goyani, M. Hybrid Approach to Content-Based Image Retrieval Using Modified Multi-Scale LBP and Color Features. SN COMPUT. SCI. 1, 305 (2020). https://doi.org/10.1007/s42979-020-00321-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-020-00321-w