
Abstract
The progress of geospatial technique can help to minimise the losses as it emerges as a powerful technique for mapping landslide hazard zonation. Different researchers use different methods for landslide hazard assessment. But, there is not a single method which has been universally accepted for effective assessment of landslide hazard. In Indian subcontinent, 12.6% of land area is susceptible to landslide hazard and the estimated total economic damage due to landslide hazard is 4,500,000US$. This review article represents the temporal development of different methodologies towards landslide hazard zonation up to a recent year and their advantages and disadvantages. The review indicates that mostly three methods i.e., knowledge driven, data driven and physical based method are followed among which, knowledge driven and bivariate analysis are mostly used during last decade but from the twenty-first century onwards multivariate statistical modelling is mostly popularised as it gives the most accurate result of landslide hazard zonation in comparison to other methods. Geospatial modelling of landslide susceptibility is useful for monitoring, mapping and formulating proper management plans that will be helpful for future landslide mitigation measures.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Landslides are natural occurring events but may change into the hazard and cause loss of lives and damage to man-made and natural structures. The definition of landslide hazard is expressed by many authors in different ways but, among them definition stated by Burton et al. [1], Varnes and IAEG [2], and Abella [3] etc. are worthy to mention and among these definition proposed by Varnes and IAEG [2] is adopted and modified by most of the researchers. Landslides are the most vulnerable geological hazard in the Himalayan region, Western Ghats and Nilgiri range of India (Fig. 1). These cause injuries and damages to the property as well as infrastructure and affect a large number of resources and may even cause the loss of lives when they occur in a catastrophic way. Compared to the Himalayas, the Nilgiris (Tamil Nadu, Karnataka, Kerala and western Ghats along the West coast) are relatively tectonically stable and are mostly made up of hard rocks but still debris avalanches and landslides occur, though not as frequently as landslides in the Himalayan regions. In June 2013, a multi-day cloudburst in and around the Uttarakhand caused devastating floods and landslides, which caused more than 5700 casualties. Recently occurred Malin landslides (2014) are also caused by heavy rainfall in the northern Western Ghats. According to EM-DAT database, the total loss of lives and economic damages were in the tune of 2185 and 4,500,000US$ (1980–2014) respectively in India (Fig. 2).

Map showing landslide hazard zones in India (Source Geological Survey of India)

Number of landslide occurrence and total death caused due to landslide in India during 1980–2014 (Source EMDAT)
In 1990, also known as ‘International Decade for Natural Disaster Reduction’ (IDNDR) as declared by the UN General Assembly, the Indian government had entered into the field of disaster management with a permanent and institutionalised setup of a disaster management cell under the Ministry of Agriculture. The management cell was formed for drawing up a systematic, comprehensive and holistic approach towards disasters. After 1998 Malpa tragedy in India, which killed 380 villagers and 200 Hindu pilgrims on their way to Mansarovar lake, Tibet, widespread awareness of the problem was created and disaster management policy was changed from the steps of relief through assistance to a holistic one. Consequently, the disaster management division was moved under the Ministry of Home Affairs in 2002 vide Cabinet Secretariat’s Notification No. DOC.CD-108/2002 dated 27/02/2002 and a hierarchical structure for disaster management was formulated. Among the government’s nodal agencies, National Disaster Management Authority (NDMA), Geological Survey of India (GSI) and National Remote Sensing Centre (NRSC) have involved in studies related to landslide hazard assessment and vulnerability throughout India. Department of science and technology (DST) of India has prepared the landslide hazard zonation Atlas in 2011 and Bureau of Indian Standards (BIS) has standardised and formulated guidelines for landslide susceptibility zonation on a medium scale (1:50,000), on the basis of expert-based indirect weighting approach [4]. National Landslide Risk Mitigation Project (NLRMP) approved by the Planning Commission of India is an ongoing project on landslide under NDMA. There are several undergoing projects like landslide site assessment project for Sports Complex of Aizawl town under Mizoram state, where database on landslide is being generated using GIS and nodal agencies are routinely assess the site-specific projects, the latest one being Vaishno Devi landslide project and another one Amarnath Yatra. In 2001, NRSC [5] has completed landslide hazard zonation mapping for the Uttaranchal and Himachal Pradesh state with the approach of high-resolution satellite data and aerial photographs. After June 2013 Kedarnath tragedy, NRSC has programmed its satellites to acquire data over the affected area for Uttarakhand disaster and initial results were uploaded in the NRSC web portal (www.bhuvan.nrsc.gov.in). Research work on landslide has gained attention to many research scientists of India in recent years [6, 7] and hence increasing the research publication on landslides. Figure 3 shows the number of publication on landslide hazard in the International journal from 2000 to 2015 in India.

Number of publication on landslide hazard in India published in International Journals from 2000 to 2015
Over the past few years, there have been significant developments of GIS for spatial data analysis. For the last 20 years, remote sensing and GIS has been widely used in the field of landslide susceptibility mapping [8] including hazard and indices of risk assessment [9, 10].
This article contributes to the comparative evaluation of different approaches for landslide susceptibility and hazard zonation that are in vogue around the India.
2 Methods
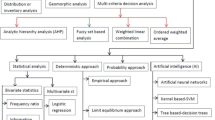
In recent years, a wide variety of environments and diverse approaches can be used for the assessment of landslide susceptibility in the form of hazard zonation. Landslide susceptibility zonation (LSZ) depends on the triggering factors, complex knowledge of slope movements, amount and quality of available data, working scale, and the selection of the appropriate methodology of analysis and modelling. There are two processes of creating these maps i.e., qualitative (landslide inventory analysis, and knowledge driven methods) and quantitative (data driven and physically-based models) processes. The different methods adopted for landslide initiation susceptibility assessment are shown in the Fig. 4.

Methods for landslide initiation susceptibility assessment divide methodology in two phases qualitative and quantitative instead of validation (Source ITC/CNRS)
2.1 Qualitative methods
In general qualitative approaches are entirely based on the expert knowledge and experiences of the persons carrying out the susceptibility or hazard assessment. Marrapu and Jakka [11] said that Qualitative models are the simplest method for LHZ; geologist or geomorphologists used this technique directly in the field. This method was mostly used during 1970–1980 [12] and can be widely classified into two types: field geomorphological analysis and use of the combination or overlaying index maps or parameter maps with or without weights.
2.1.1 Knowledge-driven methods (direct method)
Expert opinion plays a decisive role in Knowledge-driven/heuristic methods. It is a direct method as the expert predicts the susceptibility of the terrain directly in the field, the geomorphological/geological setting and based on the observed phenomena. Several techniques such as Boolean overlay, analytic hierarchy process (AHP) multiclass overlay and spatial—criteria evaluation are developed for qualitative methods where qualitative map combination has become widely used in slope instability zonation. The drawback of this approach is that the exact weighting of the various parameter maps is difficult. There are some research works on qualitative approaches include analytic hierarchy process [13], predictive modelling [14], spatial multi-criteria analysis [15], and weighted linear combination [16]. According to expert views, the most common type of qualitative model is applying landslide inventories to derive sites of similar geomorphological and geological features susceptible to failure. The limitation of these methods is their subjectivity associated with empirical ranking. van Westen [17] said that heuristic method is not necessarily bad when it is based on an expert opinion.
2.1.2 Field study based on geomorphological analysis
Geomorphological mapping of landslide hazard zonation in the field is also known as one of the direct methods that are dependent on the efficiency of the investigator to estimate the actual and potential failure of slope based on his/her earlier experience. As this analysis is hampered by different ways like investigators are unable to differentiate the various parts of landslide viz., scarp, deposit and toe portion, old landslides are covered or partially covered with dense vegetation or the landslide portion may be dismantled by physical weathering or anthropogenic activity. In the field, it is difficult to identify the extent boundary of landslide especially in the case of large landslide where the topography is hummock. There is a misconception that mapping landslide in the field is more accurate than with geospatial data. Geological Survey of India (GSI) is the leading geo-exploration agencies, has been carrying out the nationwide geological mapping of the landslide. Most of the solely geotechnical work has been completed within 2010 for landslide assessment and nowadays GSI is compiling the geotechnical work with landslide hazard zonation.
2.2 Quantitative methodologies (data driven methods)
The quantified methodology has been proposed to improve the output of landslide zonation which is earlier based expert knowledge. The statistical approach reduces the subjectivity in allotting weights to the predictors that are responsible for a landslide. This type of analyses can be either bivariate or multivariate.
2.2.1 Bivariate statistical analysis
In bivariate analysis, each geo-factor maps (geology, geomorphology, slope, land use etc.) are compared with landslide inventory map and thereby weighted each factor and factor class are assessed on the basis of landslide frequencies. There are various important models like weighted overlay method, the weight of evidence model, informative value approach, frequency ratio model and Bureau of Indian Standard (BIS) which are used in the bivariate analysis.
2.2.1.1 Weighted overlay method (WOM)
It is the fast and simplest technique to integrate binary thematic layers wherein weights are allotted on the basis of the relationship of triggering factors with landslide density. In some past and recent research work carried out by Indian scientist WOM with statistical approach has been proven as beneficiary techniques for geospatial modelling of landslide zonation by Indian scientist [13].
2.2.1.2 Weight of evidence model (WofE)
The weight of evidence model is the quantitative statistical model i.e. a Bayesian approach which can assess the relationship of the dependent variable to independent predictive variable. It is represented by linear logarithm division of events (%) and non-events (%) to estimate the relative importance of evidence through statistical means. The WofE method represents the spatial association between evidential themes and known landslide area, where each evidential theme are assigned with weights in terms of correlation with landslide occurrence. This is combined with the probability of occurrence of the landslide to find out the posterior probability of occurrences. According to Bonham-Carter et al. [18], WofE is calculated as:
where P is the probability; A and \({\bar{\text{A}}}\) is the presence and absence of landslide responsible factors; B and \({\bar{\text{B}}}\) is presence and absence of landslide in the area. WofE offers the flexible way of testing the importance of input evidential themes for landslide mapping. WofE gives effective result when it is integrated with other statistical techniques and is most effective when there are a few relevant geo-environmental variables and inventory of landslide occurrence and cause exists. In regards to landslide occurrence, all the variables must be conditionally independent to assess the variables separately of one another for WofE analysis.
2.2.1.3 Informative value approach (IVM)
Yin and Yan [19] proposed the Informative value method and later modified by van Westen [20]. IVM of landslide hazard zonation is an indirect bivariate statistical method based on the relationship between landslides related variables and occurrence of a landslide for spatial prediction. This model allows crossing of each landslide conditioning factors with landslide distribution and weight of predictors (Wi) can be done through ratioing the density of landslide occurrences in each class to the total area of landslide density occurrence (Eqs. 3, 4).
2.2.1.4 Frequency ratio method (FR)/probabilistic likelihood model
FR method is a simplest probabilistic bivariate statistical method. The accuracy of the model is acceptable and it is used to subtract the thematic layers [21]. The spatial association between landslide and conditioning factors can be calculated by applying the probabilistic likelihood model, computes the ratio of the pixel number of the area where the landslide occurred to a number of pixels for given conditioning factor class that is responsible for a landslide. It is conspicuous that susceptibility of the factor class is high where the FR ratio is higher.
2.2.1.5 Bureau of Indian Standard (BIS)
In 1998 India developed standards for macro scale zonation of landslide i.e. popularly known as Bureau of Indian Standard (BIS) [22]. It is the simplest, cost effective and subjective method for mapping at 1:25,000 and 1:50,000 scale. In several regions of India, many scientists applied this method for landslide hazard assessment/zonation and developed the effectiveness of BIS on medium scale mapping [8]. The main limitation of this bivariate statistical method is the independence between different explanatory maps with respect to the probability of landslide occurrence, due to the hypothesis of conditional independence. This hypothesis is generally invalid. The problem can be solved by developing the joined dependent maps from the data and then preparing a new parameter map [23].
2.2.2 Multivariate statistical analysis
The multivariate statistical analysis includes several methods like Conditional analysis, Logistic regression model, multiple regression models, Discriminant analysis and Artificial Neural Networks (ANN) etc. These methods calculate the landslide area for each pixel in percentage form and thereafter landslide presence–absence data layer is produced.
2.2.2.1 Discriminant analysis method
Fisher [24] introduced a Discriminant analysis (DA) method to classify samples into alternative groups on the basis of a set of measurements. According to Lee et al. [25], DA allows us to determine the maximum difference for each independent variable (e.g. landslide causative factor) between landslide group and non-landslide group and to determine weights for these factors. DA normally required the data which is derived from a frequently violated, normally distributed population. Significant amount of research works has carried out by DA for landslide susceptibility zonation [26]. DA is used to identify the best discrimination between presence and absence landslide area. The analytical result is represented in terms of a combination of the weighted variable as (Eq. 5):
where D is the Discriminant function, A is the coefficient estimated in such a way that variability is maximum between the landslide and non-landslide group and minimum within each group and X is the factors responsible for a landslide. One of the limitations of DA is the capability to analyse only the continuous data.
2.2.2.2 Logistic regression method (LR)
LR is used to describe the relationship of several independent factors to dichotomous dependent factors related to a landslide Kleinbaum and Klein [27]. LR can be of two types-one is binary (when the dependent variable is dichotomous and independent variable is of any type) and another one is multinomial (dependent variable with more than two classes) LR [28]. LR is calculated in terms of logistic function which is stated as follow (Eq. 6):
To obtain the logistic model from a logistic function, z is linear constant (Eq. 7). Where z ranges from −∞ to +∞.
In Eq. 7. α is the constant βi and Xi are the corresponding coefficient and independent variable respectively.
Many landslide susceptibility research works reported from Garhwal Himalaya and Garhwal lesser Himalaya [29, 30] are done by means of LR and binary logistic regression model.
LR analysed data at any scale (categorical, continuous, or their combination) make it more appropriate than discriminant analysis. The minus point of LR is no guidelines available for the selection of covariates and between studies, the covariates selected varying significantly. In future logistic regression studies, covariates inventories associated with land sliding produced from global can act as a useful aid in the selection of covariates.
Globally this approach is widely used by the researchers and Indian researchers also used this method for landslide hazard zonation with high success rates [11, 14].
2.2.3 Artificial neural network (ANN) method
According to Lees et al. [31] “Neural network is a processing device, implemented as an algorithm or in hardware, whose design was motivated by the design and function of mammalian brains; they react to training data input in such a way as to alter their initial state, something no conventional algorithm does: they can learn” (Fig. 5). ANN has over three layers of neurons which are connected by weights. This model uses Backpropagation learning algorithm’ which defines rules for assignment of weights. The weight of each variable is then adjusted to minimise errors. Artificial Neural Network (ANN) is a non-linear model and proved to be more effective in landslide hazard assessment [32, 33]. It produces a more accurate result than other multivariate method [34]. An important merit of the ANN is that for specific statistical variables are not required since ANN is independent of the statistical distribution of the data [31]. In comparison with other statistical methods, ANN permits the target classes to be defined, by accounting the distribution of classes in the corresponding domain of each data source ANN requires fewer training data with respect to statistic methods for carrying out accurate analysis [35].

Architecture of Neural network geometry consists of input, hidden and output layers
2.3 Geotechnical or physically based models (slope stability methods)
This method focuses stability of a particular site or a slope. The input data for this method is obtained from laboratory tests and can be used to determine safety factor for particularly considered slope. In this method the accuracy is high and it depends on provided input data and the methods utilised for the analysis. This method usually ignores a causative factor like climate and human-induced factors, drainage and vegetation. This method only provides the stability of a slope that means a factor of safety at the particular time of data collection. It does not account other factors that are mainly responsible for the changes of causes of landslides, the temporal and spatial frequencies of the landslides, and the magnitudes of the landslides.
3 Case reviews
Academic research has been expanded from bivariate to multivariate modelling. There are some examples of landslide studies throughout India.
3.1 Bivariate models
The application of WofE method has been applied for the Himalayan region [25, 35]. Among these studies, Guri et al. [35], carried out bivariate statistical approach to assess the two-fold benefit of WofE model in landslide hazard zonation. Firstly, in the scarcity of data, we can derive critical parameters related to landslide and in another hand, WofE allows variables to evaluate their cumulative consequences on a landslide. The outcome was generated within a short period of time. Similar kind of studies has been reported from the southern part of India [36, 37] with very high accuracy in posterior landslide occurrences.
Sarkar et al. [38] used indirect IVM model for the assessment of landslide susceptibility in the part of Darjeeling Himalaya. Thematic layers were assigned weight through information value method. Success- prediction rate curve and receiver operator characteristic (ROC) curve were used to examine the analysis and assess the performance of model respectively. Sharma et al. [39, 40] developed the application Shannon’s entropy with aid of bivariate statistical method i.e., IVM for Sikkim Himalaya in India.
Vijith et al. [41], Kannan et al. [8] used FR to estimated landslide potential zone and landslide vulnerability of Western Ghats’s and Theni district of Tamil Nadu respectively. The result shows the high accuracy of landslide potential zone. The model was authenticated/affirmed with relative landslide density index where it showed good performance of map. Several studies involving comparative evaluation of FR with different statistical method like likelihood ratio [42], fuzzy logic [43] has been done.
3.2 Multivariate models
Kumar and Anbalagan [43] has applied binary LR model for the landslide susceptibility zonation in the part of rim region of Tehri reservoir in Garhwal district, India. On the basis of cell-by-cell technique landslide occurrence of probability was measured in the GIS environment. The study revealed that area near reservoir side slope was highly susceptible to landslide hazard and the result showed the acceptable accuracy of 80.2% when it was validated with ROC curve.
Kundu et al. [44] prepared landslide zonation map for Ganeshganga Watershed area of Himalayas through a binary LR model. Several causative factors like land use/land cover, slope, relative relief, aspect, tectonic structures, lithology, lineaments, drainage density, distance to drainage, distance to the road were taken into consideration for the landslide susceptibility mapping and weights were assigned to each factor through LR analysis. The final probability map was categorised into four classes of landslide susceptible zone from high to low. The resultant map showed 95.2% accuracy through ROC curve.
Several studies for landslide susceptibility mapping using ANN have been carried out in India. Arora et al. [34] produced a landslide hazard zonation (LHZ) map using Artificial Neural Network (ANN) black box approach in the Bhagirathi Valley, Himalayas, and India. The accuracy of the LHZ map produced by the ANN is around 80% with a very small training dataset. The distribution of landslide hazard zones derived from ANN shows similar trends as that observed with the existing landslides locations in the field. A comparison of the results with an earlier produced GIS-based LHZ map of the same area by the authors (using the ordinal weight rating method) indicates that ANN results are much better than those obtained from an ordinal method-based LHZ classification (based on subjective rating) of the same area as reported in Saha et al. [45]. Socio-economic impact and susceptibility mapping are also done within Nilgiris district of Tamil Nadu state [46].
Kuriakose et al. [47] used the physically based model to develop shallow landslide model in the upper basin of Tikovil river, Kerala. With limited data input, the final output expresses the spatial and temporal pattern of the uncertainty of slope in the region.
4 Discussion
The systematic literature studies show that there are several statistical modelling for landslide susceptibility. Landslide types like shallow, debris and earth slide were mostly found in the research work. The literature is widely associated with multivariate statistical modelling. The bivariate statistical method is a good learning tool for the analyst to find out factors or combination of factors that play a role in the initiation of landslides. This method is used as direct and also serves as the initial stage for starting the multivariate analysis, whereas, the multivariate technique is able to find out the actual and potential landslide susceptibility. This method’s success is relying on quality, quantity and reliability of the data. The finding on methodologies suggests that multivariate gives more accurate result than conventional methods. Over the past few years research on landslide hazard is increased but still, there are some gaps in the research work. The first and most important problem is data scarcity in terms of the record of landslide occurrence with date and time, numbers of landslide happened and their administrative location. These data are no longer maintained which seriously threatens to their persistent. PostgresSQL/PostGIS is a new approach which stores millions of date set in the form of landslide documentation and this is a good data sharing and knowledge transfer approach for research world. In India aerial photographs and topographical data is not available for border region/entire Himalayan region as restricted for security purposes. However Indian remote sensing satellite data has stood as a standard data input for landslide studies but sometimes required data has cloud cover, which hampered landslide studies. Globally, there have two main eras of landslide studies i.e. empirical and modelling era. The empirical era (1958–1990) is concerned with past landslide losses with respect to cost estimation whereas modelling era (1990–2014) is focused on future scenario of landslide occurrence and losses. From the 1990s, GIS and remote sensing evolved as a powerful tool in landslide modelling. Cost estimation and risk analysis are missing in both eras. At present time, few studies are developed to overcome with above-stated approaches [31, 32] but still cost estimation faces major challenges. A critical step for integrating risk assessment is to analyse what type of landslide damage affected people and property in which way, and how people respond and contributed to them. Early warning system for landslide prone areas is still missing in research practices.
5 Conclusion
The study presents a critical review of different methods adopted for landslide hazard zonation and susceptibility mapping in India context during a time framework of 1980–2015. The study reveals that recently Indian scientist is mostly using multivariate statistical analysis as it gives the more appropriate result as compared to heuristic and bivariate method. Remote sensing and GIS with the aid of aerial photography/high-resolution satellite data emerge as a powerful tool for landslide hazard zonation mapping. There is a limited study in the geotechnical aspect in landslide hazard zonation in India. Combining the effect of geospatial and geotechnical method will definitely give a significant result in landslide susceptibility. Indian Government needs to modify and reconstruct the BIS codes and National Disaster Management Authority (NDMA) guidelines for landslide hazard zonation and management. Central and state Govt. should prepare the user-friendly community level early warning system for landslide hazard.
References
Burton, I., Kates, R., & White, G. (1978). The environment as hazard. New York: Oxford University Press.
Varnes, D., & IAEG. (1984). Landslide hazard zonation: A review of principles and practice (pp. 1–6). Paris: United Nations Scientific and Cultural Organization.
Abella, E. A. C. (2008). Multi-scale landslide risk assessment in Cuba. ITC, Netherlands, Dissertation Number 154.
Anbalagan, R. (1992). Landslide hazard evaluation and zonation mapping in mountainous terrain. Engineering Geology, 32, 269–277.
National Remote Sensing Agency. (NRSA). (2001). Landslide hazard zonation mapping along the corridors of the pilgrimage routes in Uttaranchal Himalaya. Technical document, NRSA, Department of Space, India.
Rawat, S. J., & Joshi, C. R. (2012). Remote-sensing and GIS-based landslide susceptibility zonation using the landslide index method in Igo River Basin, Eastern Himalaya, India. International Journal of Remote Sensing, 33(12), 3751–3767.
Lallianthanga, R. K., Laltanpuia, R. D., & Sailo, R. L. (2013). Landslide hazard zonation of Lawngtlai town, Mizoram, India using high resolution satellite data. Research Inventy: International Journal of Engineering and Science, 3(6), 36–46.
Kannan, M., Saranathan, E., & Anbalagan, R. (2015). Comparative analysis in GIS-based landslide hazard zonation-a case study in Bodi–Bodimettu Ghat section, Theni District, Tamil Nadu, India. Arabian Journal of Geoscience, 8, 691–699. doi:10.1007/s12517-013-1259-9.
Anbalagan, R., & Singh, B. (1996). Landslide hazard and risk assessment mapping of mountainous terrain—A case study from Kumaun Himalaya, India. Engineering Geology, 43, 237–246.
Sikkim State Disaster Management Authority. (2012) Multi-hazards risk vulnerability assessment Gangtok, East Sikkim. Land Revenue and Disaster Management Department. Government of Sikkim. http://www.ssdma.nic.in/CMS/GetPdf?MenuContentID=10201. Accessed 7 April 2015.
Marrapu, B. M., & Jakka, R. S. (2014). Landslide Hazard Zonation methods: A critical review. International Journal of Civil Engineering and Research, 5(3), 215–220.
Aleotti, P., & Chowdhury, R. (1999). Landslide Hazard assessment: Summary. Review and New Perspectives, Bulletin of Engineering Geology and the Environment, 58, 21–44.
Mondal, S., & Maiti, R. (2013). Integrating the Analytical Hierarchy Process (AHP) and the Frequency Ratio (FR) model in landslide susceptibility mapping of Shiv-khola watershed, Darjeeling Himalaya. International Journal of Disaster Risk Science, 4(4), 200–212. doi:10.1007/s13753-013-0021-y.
Ghosh, S., Carranza, E. J. M., Van Westen, C. J., Jetten, V. G., & Bhattacharya, D. N. (2011). Selecting and weighting spatial predictors for empirical modelling of landslide susceptibility in the Darjeeling Himalayas (India). Geomorphology, 131, 35–56.
Kampa, U., Growleya, B. J., Khattak, G. A., & Owenb, A. L. (2008). GIS-based landslide susceptibility mapping for the 2005 Kashmir earthquake region. Geomorphology, 101(4), 631–642.
Sharma, M., & Kumar, R. (2008). GIS-based landslide hazard zonation: a case study from the Parwanoo area, lesser and outer Himalaya, H.P., India. Bulletin of Engineering Geology and Environment, 67, 129–137. doi:10.1007/s10064-007-0113-2.
van Westen, C. J. (2000). The modelling of landslide hazards using GIS. Surveys In Geophysics, 21, 241–255.
Bonham-Carter, G. F., Agterberg, F. P. & Wright, D. F. (1989). Weights of evidence modeling: A new approach to mapping mineral potential. In F. P. Agterberg, & G. F. Bonham-Carter (Eds.), Statistical applications in the earth sciences. Geological Survey of Canada, 89(9):171–183.
Yin, K. L., & Yan, T. Z. (1988). Statistical Prediction Model for Slope Instability of etamorphosed rocks. In C. Bonnard (Ed.), Proceeding fifth international symposium on landslides, Lausanne (Vol. 2, pp. 1269–1272). Rotterdam: Balkema.
van Westen, C. J. (1993). Application of geographical information system to landslide hazard zonation. Doctoral thesis. ITC, International institute for Survey and Earth Sciences (ITC). Enschede: ITC Publication. uuid:a59d2eca-ab58-41e6-91c9-01e4e090cf81.
Kannan, M., Saranathan, E., & Anabalagan, R. (2013). Landslide vulnerability mapping using frequency ratio model: A geospatial approach in Bodi–Bodimettu Ghat section, Theni district, Tamil Nadu, India. Arabian Journal of Geoscience, 6, 2901–2913. doi:10.1007/s12517-012-0587-5.
Bureau of Indian Standards. (1998). Preparation of landslide hazard zonation maps in mountainous terrain—Guidelines (Part2-Macrozonation) (2nd ed., Vol. 14496, pp. 1–19). New Delhi: BIS.
van Westen, C. J., Rengers, N., Terlien, M. T. J., & Soeters, R. (1997). Prediction of the occurrence of slope instability phenomenal through GIS based hazard zonation. Geologische Rundschau, 86(2), 404–414.
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Human Genetics, 7(2), 179–188. doi:10.1111/j.1469-1809.1936.tb02137.x.
Lee, C., Huang, C., Lee, J., Pan, K., Lin, M., & Dong, J. (2008). Statistical approach to storm event—Induced landslides susceptibility. Natural Hazards Earth System Science, 8, 941–960.
Guzzetti, F., Reichenbach, P., Cardinali, M., Galli, M., & Ardizzone, F. (2005). Probablistic landslide hazard assessment at the basin scale. Geophysics Journal of Royal Astronomical Society, 72, 272–299.
Kleinbaum, D. G. & Klein, M. (2010). Logistic regression: A self-learning text. 3rd edn. doi:10.1007/978-1-4419-1742-3.
Pardeshi, S. D., Autade, S. E., & Pardeshi, S. (2013). Landslide hazard assessment: Recent trends and techniques (Vol. 2, p. 523). Springer Plus. http://www.springerplus.com/content/2/1/523.
Mathew, J., Jha, V. K., & Rawat, G. S. (2007). Weights of evidence modelling for landslide hazard zonation mapping in part of Bhagirathi valley, Uttarakhand. Current Science, 92(5), 628–638.
Mathew, J., Jha, V. K., & Rawat, G. S. (2009). Landslide susceptibility zonation mapping and its validation in part of Garhwal Lesser Himalaya, India, using binary logistic regression analysis and receiver operating characteristic curve method. Landslides, 6, 17–26. doi:10.1007/s10346-008-0138-z.
Lee, S., Ryu, J. H., Won, J. S., & Park, H. J. (2004). Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Engineering Geology, 71, 289–302.
Pradhan, B., & Lee, S. (2009). Landslide risk analysis using artificial neural network model focussing on different training sites. International Journal of Physical Sciences, 4, 001–015.
Pradhan, B., & Lee, S. (2010). Regional landslide susceptibility analysis using back-propagation neural network model at Cameron Highland, Malaysia. Landslides, 7, 13–30.
Arora, M. K., Das Gupta, A. S., & Gupta, R. P. (2004). An artificial neural network approach for landslide hazard zonation in the Bhagirathi (Ganga) Valley, Himalayas. International Journal of Remote Sensing, 25(3), 559–572.
Guri, P. K., Champati Ray, P. K., & Patel, R. C. (2015). Spatial prediction of landslide susceptibility in parts of Garhwal Himalaya, India, using the weight of evidence modelling. Environmental Monitoring and Assessment, 187, 324. doi:10.1007/s10661-015-4535-1.
Prasannakumar, V., & Vijith, H. (2012). Evaluation and validation of landslide spatial susceptibility in the Western Ghats of Kerala, through GIS-based weights of evidence model and Area under curve technique. Journal of the Geological Society of India, 80, 515–523.
Sujatha, E. R., Kumaravel, P., & Rajamanickam, G. V. (2014). Assessing landslide susceptibility using Bayesian probability-based weight of evidence mode. Bulletin of Engineering Geology and the Environment, 73(1), 147–161.
Sarkar, S., Roy, A. K., & Martha, T. R. (2013). Landslide susceptibility assessment using information value. Journal Geological Society of India, 82, 351–362.
Sharma, L. P., Patel, N., Ghose, M. K., & Debnath, P. (2012). Influence of Shannon’s entropy on landslide-causing parameters for vulnerability study and zonation—A case study in Sikkim, India. Arabian Journal of Geoscience, 5, 421–431. doi:10.1007/s12517-010-0205-3.
Sharma, L. P., Patel, N., Ghose, M. K., & Debnath, P. (2015). Development and application of Shannon’s entropy integrated information value model for landslide susceptibility assessment and zonation in Sikkim Himalayas in India. Natural Hazards, 75, 1555–1576. doi:10.1007/s11069-014-1378-y.
Vijith, H., Rejith, P. G., & Madhu, G. (2009). Using InfoVal method and GIS techniques for the spatial modelling of landslide susceptibility in the upper catchment of River Meenachil in Kerala. Journal of the Indian Society of Remote Sensing, 37, 241–250.
Sharma, L. P., Patel, N., Ghose, M. K., & Debnath, P. (2014). Application of frequency ratio and likelihood ratio model for geo-spatial modelling of landslide hazard vulnerability assessment and zonation: a case study from the Sikkim Himalayas in India. Geocarto International, 2(92), 128–146. doi:10.1080/10106049.2012.748830.
Kumar, R., & Anbalagan, R. (2015). Landslide susceptibility zonation in part of Tehri reservoir region using frequency ratio, fuzzy logic and GIS. Journal of Earth System Science, 124(2), 431–448.
Kundu, S., Saha, A. K., Sharma, D. C., & Pant, C. C. (2013). Remote sensing and GIS based landslide susceptibility assessment using binary logistic regression model: A case study in the Ganeshganga Watershed, Himalayas. Journal of the Indian Society of Remote Sensing, 41(3), 697–709. doi:10.1007/s12524-012-0255-y.
Saha, A. K., Gupta, R. P., & Arora, M. K. (2002). GIS-based landslide hazard zonation in a part of the Himalayas. International Journal of Remote Sensing, 23, 357–369.
Prabu, S., & Ramakrishnan, S. S. (2009). Combined use of socio economic analysis, remote sensing and GIS data for landslide hazard mapping using ANN. Journal of Indian Society of Remote Sensing, 37, 409–421.
Kuriakose, S., & van Beek, L. P. H. (2009). Parameterizing a physically based shallow landslide model in a data poor region. Earth Surface Process and Landforms, 34, 867–881.
Acknowledgements
The authors highly thank full to the Department of Science and Technology, Government of India for providing INSPIRE Fellowship for carrying out the research work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Rights and permissions
About this article

Cite this article
Kaur, H., Gupta, S. & Parkash, S. Comparative evaluation of various approaches for landslide hazard zoning: a critical review in Indian perspectives. Spat. Inf. Res. 25, 389–398 (2017). https://doi.org/10.1007/s41324-017-0105-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41324-017-0105-7