
Abstract
Independence and normality of observations for each level of the classification variables are two fundamental assumptions in traditional analysis of variance (ANOVA), whereas in many real applications the data violate seriously from these assumptions. Accordingly, in these situations using this traditional theory leads to unappealing results. We consider time series ANOVA by assuming a skew normal distribution for innovations. We provide iterative closed forms for the maximum likelihood estimators and construct asymptotic confidence intervals for them. A simulation study and a real data example are used to evaluate the efficiency and applicability of the proposed model for analyzing skew-symmetric time series data.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The ANOVA is a frequently used statistical methodology for analyzing data in which one or more response variables are considered under various situations specified by one or more factors (explanatory classification variables). The aim of this technique is to discover and model the significant differences between the means of three or more independent populations by splitting total variability of response observations into the systematic (between the classification variables) and non-systematic variability (within the classification variables). As it is highlighted by some authors, e.g., Gelman [13], ANOVA is an extremely important method in exploratory and confirmatory data analysis. It is often the starting step for many statistical surveys about different populations that helps researcher to verify the effective factors on response variables. There are numerous applications for ANOVA in various disciplines such as agriculture, engineering, economics, public health and social sciences. This seminal technique was firstly developed by Fisher in 1920s. Reitz [25] was the first who used ANOVA in educational researches. The seminal books of Fisher [12], Cochran and Cox [11], Cox [10], Snedecor and Cochran [29] and Montgomery [24], among others, have been provided a set of comprehensive useful references about ANOVA. Regarding the above-mentioned references, the validity of ANOVA depends on some fundamental assumptions where the most important of them are: (i) independence of observations for each group, (ii) independence of groups under consideration, (iii) normality of observations for each group and (iv) homogeneity of observations variance for different groups. Lund et al. [22] studied the problem of dependency in ANOVA for time series data and also proposed a new test statistic for autocorrelated data to use one-way ANOVA. Senoglu and Tiku [27] showed the effect of non-normality on the test statistic while working with two-way classification model. A number of studies take a part in the literature which are based on time series data in ANOVA. See, for example, Górecki and Smaga [14] and Liu et al. [21]. The idea in this article is to use a flexible skew-symmetric distribution, to handle the non-normality of data in ANOVA when the observations are timely dependent. In this direction, we used a member of the Skew Normal (SN) distribution which is a class of skew-symmetric distributions with highly flexibility for analyzing abnormal observations and includes the normal as a special case. Since Azzalini [2] where the first univariate version of the distribution introduced, much research effort has been focused on developing similar new families of distributions or generalizing an existing one. See, for example, Azzalini [3] and Henze [17] for discussion on univariate and Azzalini and Dalla-Valle [5], Azzalini and Capitanio [4], Branco and Dey [8] and Sahu et al. [26] for multivariate case. In addition, various applications of SN distribution have been discussed in the literature; for example, Cancho et al. [9] and Arellano-Valle et al. [1] discussed SN regression analysis, Lin and Lee [20] considered the SN mixed effect model and Lachos et al. [18] demonstrated analyzing censored data under SN distribution. In the context of the time series data, there has been a progressive interest in using SN distribution for data analysis. A non-Gaussian autoregressive (AR) model with epsilon skew normal innovations has been introduced by Bondon [7] and also the method of moments and maximum likelihood (ML) estimators of the model parameters and their corresponding limiting have been provided in it. Following Bondon [7], Sharafi and Nematollahi [28] considered SN distribution for the innovations. The semiparametric analysis of the nonlinear AR(1) model with skew-symmetric innovations has been investigated by Hajrajabi and Fallah [15]. Hajrajabi and Fallah [16] discussed the classical and Bayesian estimation of the AR(1) model with skew-symmetric innovations from a parametric point of view. More recently, Maleki et al. [23] provided the expectation conditional maximization either (ECME) algorithm for multivariate scale mixture of skew normal (SMSN) distributions in vector autoregressive (VAR) models. In this paper, we develop a time series ANOVA model under the SN distribution. We have used a version of the SN distribution which introduced by Sahu et al. [26] and Azzalini [2]. This family of SN distributions is more tractable than others specially in maximum likelihood (ML) estimation of the parameters via expectation–maximization (EM) algorithm. This paper is organized as follows. The theoretical foundation of the proposed model is presented in Sect. 2. We also discuss the maximum likelihood estimation of the model, in this section. In Sect. 3, we use the asymptotic properties of the maximum likelihood estimators to construct the confidence interval for the model coefficients. A simulation study is worked out in order to assess the model in various situations, in Sect. 4. In Sect. 5, real world data are analyzed to explain the applicability and performance of the proposed theory.
2 The Proposed Model
There are many designs for an ANOVA model such as complete random design, randomized complete block design, split plot, Latin squares and Greco-Latin. On the other hand, the factors in an ANOVA model may indicate to fixed or random effects. For a fixed effect model, the levels of factors are all the levels of interest, while for a random effect model a subset of randomly selected levels from all possible levels are considered in order to generalize the results to the whole levels. In what follows, for the sake of brevity, we assume that there are a single factor and a single response variable. We also assume that the factor indicates fixed effects. Consider an autoregressive time series one-way ANOVA model, for R treatment and T observations, of the form
where \(Y_{it}\) denotes the t-th observation in the i-th treatment, p is order of autoregressive model, \(\mu _0\) is the overall mean of the observations and \(\tau _i\) is the specific effect of the i-th treatment. The constraint \(\sum _{i=1}^{R}\tau _i=0\) is imposed to the effects of treatments. The main purposes of the ANOVA are usually to estimate the treatment means and to test hypotheses about them. In traditional theory of the ANOVA, the model innovations and consequently the responses are assumed to be normal and mutually independent random variables, whereas these assumptions does not appear to be feasible in many situations especially when the observations indicate to asymmetry and dependent data.
Considering the Sahu et al. [26] skew normal (SSN) distribution with scale parameter \(\sigma ^2\) and skewness parameter \(\lambda \) for the innovations, \(a_{it}\), the model (1) could be written as
where
Hence, the conditional distribution of response variable is of the form
where \({\varvec{\nu }}=({\varvec{\theta }}, {\varvec{\tau }}, {\varvec{\Phi }})\) with \({\varvec{\theta }}=(\mu _0,\sigma ^2,\lambda )\), \({\varvec{\tau }}=(\tau _1,\ldots ,\tau _{R-1})\) and \({\varvec{\Phi }}=({\varvec{\Phi }}_1,\ldots ,{\varvec{\Phi }}_{R})\) such that \({\varvec{\Phi }}_i=(\Phi _{i1},\ldots ,\Phi _{ip}),\ i=1,\ldots ,R\). Also \(\phi (\cdot )\) and \(\Phi (\cdot )\) denote the density and cumulative distribution function of the normal distribution, respectively. Given data \({\varvec{y}}=(y_{p+1},\ldots ,y_n)\), the conditional likelihood function of the model (2) is given by
As it can be seen, due to the complexity of likelihood function (4), there are no analytical form for the ML estimators of the model parameters. Therefore, we provide an EM algorithm to compute the numerical values of these estimators. For this purpose we used the following lemma about stochastic representation of the skew normal distribution as a mixture of half-normal (HN) and normal distribution. We refer the reader to Barr et al. [6] for more details.
Lemma 1
If \(Y_t|U_t=u_t\sim N(\mu +\lambda u_t,\sigma ^2)\) and \(U_t\sim HN(0,1)\), then \(Y_t\) distributed as \(SSN(\mu , \sigma ^2,\lambda )\). Also, the joint density of \((Y_t,U_t)\) and conditional distribution of \(U_t|Y_t\) are given, respectively, by
and
Also, we have
where \(\eta _{t}=\frac{\lambda }{\sigma ^2+\lambda ^2}(y_{t}-\mu )\), \(\jmath ^2 =\frac{\sigma ^2}{\sigma ^2+\lambda ^2}\) and \(\delta _{t} =\frac{\phi (\frac{\eta _{t}}{ \jmath })}{\Phi (\frac{ \eta _{t}}{\jmath })}\).
By using Lemma 1, the model (2) can be written as a mixture of half-normal (HN) and normal distribution as: \(Y_{it}|U_{it}=u_{it}\sim N(\mu _{it}-{\sqrt{\frac{2}{\pi }}}\lambda +\lambda u_{it},\sigma ^2)\) with considering \(U_{it}\sim HN(0,1)\). Therefore, the joint distribution of incomplete and missing data \((Y_{it},U_{it})\) as the complete data are
Considering (5), the complete likelihood and log-likelihood functions are obtained to be
and
respectively, where
2.1 The EM Algorithm
In this section, an EM algorithm is developed to estimated the proposed model parameters. In E step, the conditional expectation of complete data log likelihood given incomplete data are obtained to be
where
with, according to Lemma 1,
where \(\eta _{it}=\frac{\lambda }{\sigma ^2+\lambda ^2}(y_{it}-\mu _{it}+{\sqrt{\frac{2}{\pi }}}\lambda )\), \(\jmath ^2=\frac{\sigma ^2}{\sigma ^2+\lambda ^2}\) and \(\delta _{it}=\frac{\phi (\frac{\eta _{it}}{ \jmath })}{\Phi (\frac{ \eta _{it}}{\jmath })}\). In M step, the algorithm finds values in parameter space that maximize the conditional expectation (6). Given the values of parameters in iteration j, the updated estimates of the model parameters in \((j+1)\)-th iteration are obtained to be:
The E and M steps are repeated alternately until a convergence rule holds. See Hajrajabi and Fallah [15] for more details.
3 Asymptotic Confidence Intervals
Since there is no closed form expression for the ML estimators of parameters in proposed model, computing the exact distribution of these estimators is not possible. In this section, the asymptotic distribution of ML estimators are used to construct asymptotic confidence intervals for the parameters.
According to the fundamental asymptotic properties of ML estimators (see, for example, Lehmann [19], p. 525), we have asymptotically normal (AN) distribution as follows,
where
and
with
for \( i=1,\ldots ,R\). Letting \({\varvec{\nu }}=({\varvec{\theta }},{\varvec{\tau }},{\varvec{\Phi }})\), the general Fisher information matrix of model given by
could be written as
where
with \(Q^{'}=\sigma ^2+\lambda ^2\) and
Also, the second-order derivations of the log-likelihood function with respect to the parameters are given by
where
with \(\delta _{\Phi (s)}=\dfrac{\phi (s)}{\Phi (s)}\) and \(\Delta _{\phi }(s)=\delta _{\Phi (s)}(s+\delta _{\Phi (s)})\). The computational details of the second-order derivation of parameters in Eq. (8) are straightforward, see Appendix A. For example, we have
Thus, the asymptotic \((1-\alpha )\%\) confidence intervals for the model parameters are given by:
As it can be seen in Eq. (9), in Fisher information matrices the ML estimators of parameters are substituted by their corresponding consistent estimators according to large sample theory. See, for example, Lehmann [19] for more details.
4 Simulation Study
In this section, we perform a simulation study to evaluate the proposed methodology. We simulated the data from the model in Eq. (2) where
with \(R=3\), \((\mu _0, \sigma ^2)=(0.1, 0.1)\), \((\tau _1, \tau _2, \tau _3)=(1, 2, -3)\) and \((\Phi _{11}, \Phi _{21}, \Phi _{31})=(0.1, 0.9, 0.3)\). In order to evaluate the ability of the proposed model with both symmetric and asymmetric structures, time series data are simulated by considering different values for the skewness parameter \(\lambda \) in the set of \(\{-2, 0, 2\}\). For assessing the effects of number of observations on ML estimators, we consider a range of variations for T in the set of \(\{50, 100, 200, 400\}\). The expected value, relative bias, \(\hbox {RB}=E(\frac{{\hat{{\varvec{\nu }}}}}{{\varvec{\nu }}})-1\), and the root of mean squares error (RMSE) of the ML estimator under the above conditions are computed and the results are presented in Table 1. In all computations, the number of repetitions is fixed in 1000. As it can be seen, there exist some negligible biases in estimates of parameters. Also the values of RMSE decreases when the number of observations increases indicating to consistency of the ML estimators.
We also considered a situation in which one may vanish the skewness of the data and use a usual normal model. In Table 2, the relative efficiency (RE) of the estimators for the normal (N) model to their counterparts for the skew normal model for different number of observations is computed as \(\hbox {RE}({\hat{{\varvec{\nu }}}}_\mathrm{N},{\hat{{\varvec{\nu }}}}_\mathrm{SSN})=\frac{\text {MSE}({\hat{{\varvec{\nu }}}}_\mathrm{SSN})}{\text {MSE}({\hat{{\varvec{\nu }}}}_\mathrm{N})}\). The results indicate the considerably more efficiency of the skew normal in comparison with the normal model, due to the skewed structure of the simulated data for (\(\lambda =-\,2, 2\)). As it is expected, for \(\lambda =0\), there are no significant differences between the values of MSE for the normal and skew normal models.
5 Real Example
In this section, we report some empirical results based on the analysis of the daily returns of the Mellat, Saderat and Ansar bank stock of Iran from 01/01/2014 to 01/14/2015 for 222 observations. These data are available at www.tsetmc.com. The descriptive statistics of the daily returns presented for the observations of each bank in Table 3 indicate to the negative skewness of data.
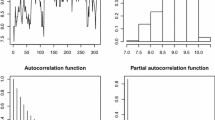
The box plot and the histogram of the observations for three banks presented in Fig. 1 (left and middle panels) indicate unimodality and left-skewed structure of data. Also, partial autocorrelation function (PACF) for three banks is shown in Fig. 1 (right panel) that indicate the dependency degree of observations in order one.

Box plot (right), the histogram (middle) and the PACF (left) for the Mellat bank (up), Saderat bank (middle) and Ansar bank (down)
The ML estimates of model parameters and their asymptotic confidence interval (ACI) are presented in Table 4.
As given in Table 4, the estimates of \(\Phi _{11}\) appear to be statistically nonsignificant at the 5% level based on the ACI in both skew normal and normal models. Therefore, the model can be simplified by dropping this nonsignificant parameter. The ML estimates of the reduced model parameters and their asymptotic confidence intervals are presented in Table 5. It is seen that all the estimates are significant at the 5% level.
We compute the RMSE of prediction defined by \(\hbox {RMSEP}={\sqrt{\frac{1}{n-1}\sum _{t=2}^{n}(y_t-\hat{y_t}})^2}\) in order to assess the predictive power of the models and also the AIC and BIC criteria for two models that are provided in Table 6.
The results indicate that the skew normal model has better fit to the data than the normal model. We also check the residuals of model by using Ljung–Box goodness-of-fit test for significant serial correlations. The results show the model appears to be adequate in describing the data.
6 Conclusion
We proposed an ANOVA time series model with assuming the skew normal distribution for innovations in situations that the observations show a serious violation from normality assumption. In these cases, the skew normal family of distributions due to its flexibility can be used for data analysis. The ML approach is used to estimate the parameters of proposed model via the EM algorithm. The simulation results and the empirical application on the daily returns of the Mellat, Saderat and Ansar bank stock of Iran indicated the performance of the proposed method. Also, proposed methodology could be extended to multivariate ANOVA models (MANOVA).
References
Arellano-Valle, R.B., Genton, M.G.: On fundamental skew distributions. J. Multivar. Anal. 96, 93–116 (2005)
Azzalini, A.: A class of distribution which includes the normal ones. Scand. J. Stat. 12, 171–178 (1985)
Azzalini, A.: Further results on a class of distributions which includes the normal ones. Statistica (Bologna) 12, 199–208 (1986)
Azzalini, A., Capitanio, A.: Statistical applications of the multivariate skew-normal distributions. J. R. Stat. Soc. B 12, 579–602 (1999)
Azzalini, A., Dalla Valle, A.: The multivariate skew-normal distribution. Biometrika 83, 715–726 (1996)
Barr, R., Donald, E., Sherril, T.: Mean and variance of truncated normal distribution. Am. Stat. 53, 357–361 (1999)
Bondon, P.: Estimation of autoregressive models with epsilon-skew-normal innovations. J. Multivar. Anal. 100, 1761–1776 (2009)
Branco, M.D., Dey, D.K.: A general class of multivariate skew-elliptical distributions. J. Multivar. Anal. 79, 99–113 (2001)
Cancho, V.G., Lachos, V.H., Ortega, E.M.: A nonlinear regression model with skew-normal errors. Stat. Pap. 51, 547–558 (2010)
Cox, D.R.: Planning of Experiments. Wiley, New York (1966)
Cochran, W.G., Cox, G.M.: Experimental Design, 2nd edn. Wiley, New York (1957)
Fisher, R.A.: The Design of Experiments. Oliver Boyd, Edinburgh (1935)
Gelman, A.: Analysis of variance: why it is more important than ever (with discussion). Ann. Stat. 33, 1–53 (2005)
Górecki, T., Smaga, Ł: A comparision of tests for the one-way ANOVA problem for functional data. Comput. Stat. 30, 987–1010 (2015)
Hajrajabi, A., Fallah, A.: Nonlinear semiparametric AR(1) model with skew symmetric innovations. Commun. Stat. Simul. Comput. 47, 1453–1462 (2017)
Hajrajabi, A., Fallah, A.: Classical and Bayesian estimation of the autoregressive model with skew symmetric innovations. J. Iran. Stat. Soc. 18, 157–175 (2019)
Henze, N.A.: A probabilistic representation of the skew-normal distribution. Scand. J. Stat. 13, 271–275 (1986)
Lachos, V.H., Bandyopadhyay, D., Dey, D.K.: Linear and nonlinear mixed-effects models for censored HIV viral loads using skew-normal/independent distributions. Biometrics 67, 1594–1604 (2011)
Lehmann, E.L.: Elements of Large Sample Theory. Springer, New York (1999)
Lin, T., Lee, J.: Estimation and prediction in linear mixed models with skew-normal random effects for longitudinal data. Stat. Med. 27, 1490–1507 (2008)
Liu, G., Shao, Q., Lund, R., Woody, J.: Testing for seasonal means in time series data. Environmetrics 27, 198–211 (2016)
Lund, R., Liu, G., Shao, Q.: A new approach to ANOVA methods for autocorrelated data. Am. Stat. Assoc. 70, 55–62 (2016)
Maleki, M., Wraith, D., Mahmoudi, M.R., Contreras-Reyes, J.E.: Asymmetric heavy-tailed vector auto-regressive processes with application to financial data. J. Stat. Comput. Simul. 90, 324–340 (2020)
Montgomery, D.C.: Design and Analysis of Experiments. Wiley, New York (2012)
Reitz, W.: Statistical techniques for the study of institutional differences. J. Exp. Educ. 3, 11–24 (1934)
Sahu, S., Dey, D., Branco, M.: A new class of multivariate distributions with applications to Bayesian regression models. Can. J. Stat. 29, 129–150 (2003)
Senoglu, B., Tiku, M.: Analysis of variance in experimental design with nonnormal error distributions. Commun. Stat. Theory Methods 30, 1335–1352 (2001)
Sharafi, M., Nematollahi, A.R.: AR(1) model with skew-normal innovations. Metrika 79, 1011–1029 (2016)
Snedecor, G.W., Cochran, W.G.: Statistical Methods, 8th edn. Iowa State University Press, Ames (1989)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Rafiqul I. Chowdhury.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
In this appendix, we provide details of the computation for the second-order derivation of parameters in Eq. (8). Letting \(a_{it}=y_{it}-m_{it}+{\sqrt{\frac{2}{\pi }}}\), we have:
The second-order derivations correspond to \(\mu _0\):
The second-order derivations correspond to \(\lambda \):
The second-order derivations correspond to \(\sigma ^2\):
The second-order derivations correspond to \(\tau _i\):
The second-order derivations correspond to \(\phi _{ik},~~~~k=1,\ldots ,p\):
Rights and permissions
About this article

Cite this article
Hajrajabi, A., Fallah, A. Autoregressive Time Series Analysis of Variance with Skew Normal Innovations. Bull. Malays. Math. Sci. Soc. 45 (Suppl 1), 121–138 (2022). https://doi.org/10.1007/s40840-022-01258-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40840-022-01258-4