
Abstract
Purpose of this review
Alcohol-induced mortality has been increasing in the USA for over a decade, but whether increases are specific to particular birth cohorts remains inadequately understood, in part because estimating age–period–cohort (APC) models is methodologically controversial. The present study compares four different age–period–cohort models for alcohol-induced death in the USA from 1999 to 2020.
Recent findings
We utilized US vital statistics data from 1999 to 2020; alcohol-induced deaths included those fully attributable to alcohol excluding poisoning. Age–period–cohort models included first derivatives, intrinsic estimator (IE), hierarchical APC, and Bayesian estimation. APC models were convergent in demonstrating that alcohol-induced death peak between age 45 and 60 in the USA. Models were also convergent in demonstrating a positive period effect, with deaths increasing across age groups particularly since 2010–2012. Models were divergent, however, in the presence and magnitude of cohort effects. The first derivative approach demonstrated that the peak positive cohort effect was for individuals born in the 1950s and peaking in the 1960s, which have higher risks of death across the lifecourse compared with other cohorts. This effect was less observable in other APC models. The IE model did not generate a cohort effect for those born in the 1950s–1960s, but did show a positive cohort effect for those born in the early to mid 1980s. Hierachical and Bayesian models also demonstrated a positive cohort effect for those born in the late 1970s and early 1980s, birth cohorts who are beginning to enter the peak age of risk for alcohol-related deaths.
Summary
Age–period–cohort models can provide useful quantitative framing in unpacking and understanding trends in alcohol-induced deaths, yet there are differences across methods in assumptions and modeling strategies, and thus some differences in results. First-derivative methods most closely approximated data visualizations and may provide the most robust statistical model of APC processes in alcohol-related death in the USA, especially given consistency with several other models. Comparison across methods is a critical strategy for triangulating evidence. Emerging evidence of a cohort effect for those born 1970s–1980s suggests an increased burden of alcohol-induced mortality as they enter the age band of highest risk in the next decade.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Peak alcohol consumption was in 1981 at 2.76 gallons of ethanol per capita, and after almost two decades of decline, per capita consumption in the USA has increased from 2.15 gallons per capita in 1998 to 2.38 gallons per capita 2019 [1]. Increases in consumption are concentrated among US adults in mid-life [2], approximately age 30–45, and are especially apparent among women [3]. The consequences of increased consumption have a predictable increase in alcohol-related deaths [4,5,6,7] Since 1999, deaths fully attributable to alcohol in the USA have increased by 51%, with faster increases among women than men, and with the majority of deaths due to liver disease and poisoning [4]. Deaths attributed to alcohol on death certificates underestimate the total mortality in the US caused by alcohol, given under ascertainment, and the contribution of alcohol to injuries, cardiovascular disease, cancer, and other major drivers of US mortality [8,9,10]. As such, it is critical to continue surveillance of these trends and implement interventions to reduce consumption.
Alcohol consumption and deaths induced by alcohol use differ substantially by age. Consumption and death have decreased substantially among adolescents and young adults [11], but accelerated during the transition to adulthood and in midlife [12, 13], and remained a central contributor to morbidity and mortality through the adult lifecourse [4, 14]. The variation in alcohol-related deaths by age, and the differential variation in trends in death across time, suggests that there may be important age, period (temporal variation that is independent of age), and cohort (temporal variation that is age specific, i.e., an age-by-period interaction) effects in alcohol-related deaths, the identification of which can improve surveillance and intervention [15].
Understanding patterns of mortality by age, period, and cohort is critically important to surveillance efforts [16]. Variation in mortality rates over time are reflections of temporal trends in causes of mortality, which may shift over time sufficiently to observe temporal variation [17]. In addition, the presence of strong birth cohort effects can obscure assessments of trends over time, even age-adjusted trends, given that birth cohort effects arise due to an interaction of age with time [18]. Further, the identification of at-risk cohorts implies that some groups have higher alcohol-attributable deaths through the lifecourse, and should be especially targeted for intervention and additional support. Such approaches have proven to be valuable for public health for other outcomes [19, 20].
Yet methodological assessments of age, period, and cohort effects, through age–period–cohort models, has been a source of controversy for decades [21, 22]. Considering mortality through age, period, and cohort perspectives is at core a technique of data visualization [23], as it essentially involves a series of rates arrayed alongside a two- to three-dimensional space in which variation across time-related dimensions can be observed. Variation in the same series of rates can be equally attributed across age, period, and cohort when they are linearly aligned, because cohort = period − age. As such, modeling age, period, and cohort categories to generate estimates of the linear associations between age, period, and cohort with any outcome, including mortality, are inevitably subject to numerous assumptions.
The inability to generate a model that assigns variation in linear effects of age, period, and cohort is termed “the identification problem” [24]. Throughout the past six decades, efforts to generate models of age, period, and cohort effects have focused on various aspects of the underlying data generating process, including non-linear variation [25, 26], variance and covariance matrix constraints [27, 28], mechanisms [29], multi-level nesting [30, 31], and other approaches [32, 33]. Each provides one way to further visualize data, but inevitably requires assumptions that will privilege some aspect of the model and result in influence on study results (e.g., true period effects will be modeled as cohort effects, or vice versa, etc.). The assumptions required for model identification mean that for any particular outcome, we can, often do, obtain different results based on the model that we apply to it. Therefore, it is often recommended to have strong a priori or theoretical hypotheses and background information to inform modeling decisions when conducting age–period–cohort estimation.
In this paper, we present an overview of four different age–period–cohort models estimating alcohol-induced mortality in the USA from 1999 through 2020 in order to compare and contrast the various modeling assumptions underlying each approach, and the resulting estimates. In doing so, we provide readers with a centralized guide to age–period–cohort models and assumptions that underlie them. Our data and code are available as an appendix to the paper (available at https://github.com/caroruth/alcohol-apc.git).
Methods
We utilized US vital statistics data from 1999 to 2020. We focused on deaths from age 16 to 74; deaths outside of this range were sparse data and could be influenced by selective survival at the upper tail of the age distribution. Following the approach of Shiels et al. [7], Spencer et al. [6], and Spilane [5], we included the following underlying cause of death ICD-10 code mortality from conditions that are fully attributable to alcohol: E24.4, alcohol-induced pseudo-Cushing syndrome; F10.0, mental and behavioral disorders due to alcohol use, acute intoxication; G31.2, degeneration of nervous system due to alcohol; G62.1, alcoholic polyneuropathy; G72.1, alcoholic myopathy; I42.6, alcoholic cardiomyopathy; K29.2, alcoholic gastritis; K70, alcoholic liver disease; K85.2, alcohol-induced acute pancreatitis; K86.0, alcohol-induced chronic pancreatitis; R78.0, finding of alcohol in blood. We did not include external cause codes in our analysis due to a major change in the coding of alcohol poisonings beginning with 2007 mortality data [34] that limited the utility of cross-year comparison.
Shown in Fig. 1 is the unadjusted age-specific alcohol-induced death rates by year using this coding schema, smoothed using LOESS regression. These mortality rates indicate a general increase over time, especially in 2020, and peaks of alcohol-induced death in approximately age 45–65. We first present a method to array and visualize age, period, and cohort variation. We then present four different age–period–cohort models: first derivatives, intrinsic estimator, hierarchical, and Bayesian APC. We present methodological details of each model, and their results, together in order to provide a comprehensive overview of how age–period–cohort modeling generates results. The details of each model and key references are provided in Table 1.

Unadjusted age-specific alcohol-induced death rates by period (year of data), smoothed using LOESS regression
Results
Data visualization of alcohol-induced mortality in the USA
The most central contribution of considering age, period, and cohort simultaneously when conceptualizing causes of variation in mortality or other health outcomes over time is through data visualization. Application of statistical models beyond data visualization often formalize (sometimes problematically) what we see visually when rates are arrayed in two and three dimensions. Numerous approaches to data visualization of age, period, and cohort effects have been developed and implemented across the literature, including basic two-dimensional descriptive approaches [23, 35, 47] to three-dimensional mapping and lexis surface visualizations and Lexis diagrams. We used the hexagonal visualization approach (hexmaps) developed by Jalal et al. [48] which visually arrays rates at equal 60° angles across age, period, and cohort axes. Results are shown in Fig. 2.

Hexagonal visualization of alcohol-induced death rates in the USA from 1999 to 2020, across age (A), period (P), and cohort (C). Eeach hexagon represents the alcohol-induced mortality rate for a specific age group in a specific year. Equations for the center coordinates of each hexagon are calculated as \(x=\frac{p\sqrt{3}}{2}\) and \(y=a-\frac{p}{2}\) where \(a={\text{ag}}{\text{e}}\) and \(p={\text{period}}\)
By age, the hexmaps indicate substantial age effects; across period and cohort, deaths peak in the mid-life, from approximately age 45 to 60 as indicated by color gradient with red the highest rates. We can see this in the hexmap, because the hexagons are in a lighter blue color at those ages for early periods, moving to yellows, oranges, and reds in later period which is indicative of higher rates in those age groups. The movement from blue to yellow, to orange and red, however, is also indicative of a cohort effect that is visible on the hexmaps. The color of the hexagons become richly concentrated for certain cohorts; the increase in the cohort effect begins with those born in the late 1930s, and peaks among those born in approximately 1960s. Another cohort effect is emergent in this hexmap as well; for those younger cohorts born in the late 1970s and early 1980s, the lighter blue colors begin to emerge and descend vertically beginning after approximately 2010–2012, indicating that increasingly younger age groups are evidencing higher rates of alcohol-induced mortality than their previous born cohorts. Note that younger cohorts are not yet in the peak age of alcohol-induced death risk; the hexmaps indicate that deaths even before peak age are more rapidly accelerating than for cohorts at the same age in previous time periods.
Method 1: first-derivative approach to the age–period–cohort model
All modeling strategies to attribute specific variation to age, period, and cohort effects involve a series of assumptions that are not necessarily based on the observed data, given that the linear effects of age, period, and cohort cannot be identified in the same model. Holford [17, 26] and others [35] have used an approach to handle the identification problem by first estimating linear effects of age as well as the general linear trend over time (not attributable to specific period or cohort effects). This general linear trend is termed “drift.” Then, the first derivatives of the drift parameter are fit to the model for which variation is attributable to period and cohort. Thus, this model essentially uses the non-linearity of the magnitude of change of overall temporal variation to assess the relative increase and decrease in linear variation over time that is associated with period and cohort. Model decisions can be maximized by assessing the change in model fit as the number of parameters in the model increases. For alcohol-induced deaths, model fit statistics, generated in the Epi package in R developed by Cartensen [36], are shown in Online Appendix Table 2.
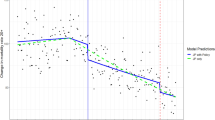
The full age–period–cohort model provided the best fit to the data; we proceeded with generating estimates of age, period, and cohort effects for alcohol-induced deaths in these data, shown in Fig. 3. The age effect is graphed on the left axis per 100,000 population, and indicates that alcohol-induced deaths peak approximately age 45–60 in the USA. The next line is the cohort effect, which indicates that cohorts born approximately around 1960 (thus, in their 20 s in the 1980s during the peak per capita alcohol consumption in the USA in recent history) have higher alcohol-induced deaths compared with other cohorts, averaged across the lifespan. These estimates are rate ratios, and the axis for the rate ratios is on the right-hand axis of the graph. Finally, the period effect is the last line in the figure, and indicate that alcohol-induced deaths have been increasing across age and cohort relatively rapidly after approximately 2010–2012. In summary, these data indicate a substantial congruence with the descriptive data in Fig. 2, showing that alcohol-induced deaths peak in middle age. Yet alcohol-related deaths are also increasing across age in the last decade as well (i.e., a period effect), and especially for those cohorts born approximately around 1960, thus in the peak age of alcohol-related death in ~ 2005–2015 (i.e., a cohort effect).

Age (left line), period, cohort (middle line), and period (right line) effects on alcohol-induced mortality in the USA from 1999 to 2020 as modeled by the first-derivative approach (model 1). Age effects are depicted on the far left, and scale is on the left axis and expressed as the rate per 10,000 population. Cohort effects are depicted on the middle line, and scale is on the right axis and expressed as the risk ratio compared to a reference cohort (1960). Period effects are depicted as the far right line, and scale is on the right axis and expressed as the risk ratio compared to the reference period (2010)
While the first-derivative approach is a classical approach to APC estimation, limitations abound. The models can be sensitive to sparse data and outlier rates at both extremes of the cohort distribution, and interactions between age, period, and cohort cannot be readily or routinely incorporated. It also is currently parameterized only for some data types and distributions, and is most stable for rare outcomes.
Method 2: intrinsic estimator (IE) model
Developed by Yang and colleagues [27, 37] and applied throughout the epidemiological literature [49, 50], the IE is among a suite of APC methods that focus on using principal component regression analysis in order to identify unbiased constraints that can be placed on the model that do not affect parameter estimates of age, period, and cohort effects. In the IE formulation, parameter space of the age–period–cohort regression design matrix is decomposed into two additive components, one of which corresponds to the unique zero eigenvalue of the regression design matrix and is independent of the underlying age, period, and cohort effects as it is only determined by the number of age groups and period groups. It is a fixed vector that does not affect parameter estimation, and this property makes it a suitable candidate for a constraint on model estimation. The parameter estimates for age, period, and cohort effects are then identified through the Moore–Penrose generalized inverse [51].
For alcohol-induced deaths, results using the IE estimator are shown in Fig. 4. Results for age and period effects are consistent with the results from the first-derivative approach. Specifically, the age effect indicates a peak of alcohol-related mortality around age 45–60, and a period effect indicating gradual increase across age in alcohol-induced deaths that begins accelerating around 2010–2012. However, the cohort effect is not consistent with the first-derivative approach. There is no peak in cohort deaths for those cohorts that have the highest mortality rate as observed visually in the hexmaps (those born in the 1950s and 1960s), and the model generates an estimate consistent with a major drop in alcohol-induced deaths for the youngest cohorts (who have not yet entered the central risk period for alcohol-induced alcohol-related deaths). There is a suggestion of a potential positive cohort effect for those born in the early to mid 1980s, which is consistent with the emergent cohort effect for those born in the late 1970s and early 1980s observed in the hexmaps.

Age, period, and cohort effects on alcohol-induced mortality in the USA from 1999 to 2020, as modeled by the intrinsic estimator (IE) model (model 2). Each panel represents age (left panel), period (center panel), and cohort (right panel). Effect parameter estimates in each panel are identified through the Moore–Penrose generalized inverse
The intrinsic estimator, and aligned methods that reply on principal components for constraints, have been criticized in the literature as relying not only on unverifiable assumptions, but assumptions that become hidden in the model estimation process [38,39,40]. Results can be especially biased when underlying true age, period, and cohort are linear, and the choice of model constraints still leads to non-unique solutions that may impact the results. Given that the estimates of the cohort effect are not aligned with the visual graphs that we see in the hexmaps, the cohort effect estimates as estimated by the IE model may indeed be biased, and attributing a residual age effect (i.e., that those in ages younger than 45 have lower overall alcohol-induced deaths) to a cohort effect.
Method 3: hierarchical age–period–cohort model
The hierarchical age–period–cohort model purportedly resolves the identification problem by conceptualizing age, period, and cohort effects as two-level random effect models [24, 41]. In this model, age is most often conceptualized as an individual-level fixed effect, modeled as appropriate (e.g., categorial, linear, quadratic, cubic, etc.). Period and birth cohort are modeled as intercept- or slope-varying cross-classified (i.e., non-nested) random effects. As such, one way to conceptualize the multi-level APC model is to first envision an age distribution with respect to the outcome, and for the intercept of that age distribution, consider that entire distribution as shifting across time and birth cohort. For the slope, consider the shape of the age distribution shifting across time and birth cohort [30]. Within the multi-level model, considering a random intercept cross-classified model, there are thus three error distributions with mean and standard deviation: the distribution of outcomes clustered with respect to time periods, the distribution of outcomes clustered with respect to birth cohort, and the individual-level differences between observed and predicted outcome after accounting for mean differences by age. The nature of these distributions will differ based on the distributional assumptions made regarding the outcome. For alcohol-induced deaths, we assumed a Poisson-distributed outcome distribution with cross-classified random intercept effects for period and cohort. Age, period, and cohort were all included in the model as single-year categorical variables. The results are shown in Fig. 5. Similar to all other APC models, the peak of the age distribution for alcohol-induced deaths was approximately age 45–60. Period effects were remarkably similar to the IE estimator, with a gradual increase that accelerates around approximately 2010–2012, suggesting that there is a positive period effect in the past decade of alcohol-induced deaths that is independent of age. Cohort effects from the multi-level model indicate a positive cohort effect for those born in the early 1980s, as well as a suggestion of a cohort effect for those born in and around the 1960s, although not as strongly observed.

Age, period, and cohort effects on alcohol-induced mortality in the USA from 1999 to 2020, as modeled by the hierarchical age–period–cohort model (model 3). Each panel represents age (left panel), period (center panel), and cohort (right panel). Effect parameter estimates in each panel are identified through a cross-classified random intercept model where period and cohort are cross-classified random effects and age is an individual-level fixed effect
While the multi-level model has provided a useful analytic framework to estimate and visualize age, period, and cohort effects, there are limitations. In particular, Bell and colleagues [42, 43] and others [44] have critiqued the assumptions that underlie the multi-level age, period, cohort model as untenable. The multi-level model only models age as a fixed effect, which may apportion variance to random effects that may be inappropriate depending on the actual (unknowable) underlying data generating structure. This is especially true for linear or near-linear effects, and indicate that strong assumptions are needed for inference from the multi-level model. These assumptions are further stretched when the error terms for individual and period–cohort effects are assumed to be independent, which is unlikely for years and cohorts that are adjacent.
Method 4: Bayesian APC
Rather than placing constraints on model parameters themselves as a solution to the identification problem, the Bayesian approach to APC model achieves this through specifying prior probability distributions. For alcohol-induced deaths, we specified first-order autoregressive random walk smoothing priors for age, period, and cohort. The first-order differences of an effect are then restricted to zero to ensure the APC effects are identifiable. These first-order random walk priors assume a constant time trend rather than linear as with second-order random walk priors. Like the first-derivative approach to APC modelling, the Bayesian APC organizes population and mortality data on the Lexis diagram. Markov chain Monte Carlo simulation methods are then used to estimate a hierarchical model with a binomial model in the first stage [45]. Results for this model are shown in Fig. 6. Once again, age effects peak around age 45–60 and we see a major increase in period effects around 2010–2012. The cohort effect displays a pattern with two peaks, one for the cohorts born approximately around 1960 and the second, larger peak for the cohorts born in the early- to mid-1980s. Additional extensions to the Bayesian approach also recommend using published results and theoretical claims to clarify resolution to the identification problem [46], as well as collecting primary data from a subject-area experts, to inform the prior distributions, which may be difficult to obtain. Bayesian models are sensitive to the choice of the prior distributions placed on parameters, and “non-informative” priors (such as random walks, as specified by the models presented here) may have a bias if time trends are not constant.

Age, period, and cohort effects on alcohol-induced mortality in the USA from 1999 to 2019, as modeled by the Bayesian age–period–cohort model (model 4). Effects are estimated from posterior samples generated from a hierarchical model with a binomial model in the first-stage and first-order random walks as smoothing priors for the age, period, and cohort parameters
Discussion
In the present analysis, we visualized age, period, and cohort variation in alcohol-induced deaths in the USA from 1999 through 2020 and compared four models for estimating age–period–cohort effects. There was convergence as well as divergence across method in various associations. Methods were convergent in demonstrating that alcohol-induced deaths peak between age 45 and 60 in the USA, and that there is a positive period effect in the last decade, with accelerating deaths across age groups especially after 2010–2012. Models diverged in estimates of the cohort effect, however. The first-derivative approach detected that those born around the 1950s and 1960s had a higher rate of alcohol-induced death compared to previous and later born cohorts, consistent with the hexmap visualizations. These people would be in their 20 s at the time of peak alcohol consumption in the USA which was 1977–1986. This would also be consistent with the evidence that drinking pattens at younger ages increase the risk of developing an alcohol use disorder. Other methods produced estimates indicative of a cohort effect for those born in the late 1970s and early 1980s, which is also consistent, although to a lesser extent, in the data visualization. Nevertheless, the cohort effect for those born in the 1970s and 1980s, if true, is particularly concerning given that these cohorts are just entering the maximum age of risk for alcohol-induced deaths in the coming years. This last cohort would also have been in their 20 s around the period 1995–2000 which was a period of one of the lowest per capita alcohol consumptions in since the 1970s [1]. In summary, age–period–cohort models can provide useful quantitative framing in unpacking and understanding trends in alcohol-induced deaths, yet there were differences across methods in assumptions and modeling strategies, and thus differences in results. First-derivative methods most closely approximated data visualizations and may provide the most robust statistical model of APC processes in alcohol-related death in the USA, especially given consistency with several other models.
The methodological and substantive literature on age, period, cohort estimation remains controversial, without explicit guidance on the specific methods to apply to specific types of data and questions. One reason why such controversy remains is that there is still considerable ambiguity on the conceptualization and operationalization of birth cohort as a social category or construct [52, 53]. Numerous sociological theories and analyses have positioned the role of birth cohorts as fundamentally cohesive to social and political experiences [54]. It is clearly meaningful to come of age and develop into adulthood in a time of war or peace, economic insecurity versus prosperity, and other broad population-level exposures. Such experiences shape worldviews, political party affiliations and participations, opportunities, and resources in ways that Glen Elder describes as our “interconnected lives” as members of the same birth cohort [55, 56]. Health researchers have discussed birth cohort effects as “phenotypes,” positioning mortality autocorrelations by birth cohort as potentially the result of early life exposures that result in variation in immunological markers of stress response and potentially driven by trends in prenatal nutrition [57]. Yet these different theories about the emergence of cohort effects as the intertwining of biological and social also reflect the need for additional theorical development; cohort categorizations do not have distinct boundaries or markers, and it is unclear whether cohort is a “social class” like other demographic categories [54].
More broadly, there is concern that because different results can be obtained based on the modeling strategy used, it limits the usefulness of age–period–cohort models to public health. Indeed, in the example of alcohol-induced death, based on the model used, we could conclude that the highest risk group is the oldest adults (IE model), currently middle-age adults (first-derivative approach), or young adults (hierarchical APC and Bayesian models). This would greatly impact the advice or recommendations that we as epidemiologists provide to guide public health efforts in terms of messaging, outreach, and clinical support. While that may seem discouraging, it should also be noted that the validity of all scientific results are subject to the appropriateness of assumption of the statistical models that generate them. APC is not unique compared to any other area of health science, as long as we remember that all statistical models should be guided by theory and close examination of descriptive patterns before the selection of a model. In other areas of temporal trends, APC models may be much more closely aligned than we see here for alcohol-induced death; thus, it is not true in the absolute that APC models will generate different results. Rather, we note that it can occur; thus, model choice should be made carefully.
Cohort effects in alcohol-induced mortality documented here reflect trends in beverage consumption patterns and co-occurring morbidity and mortality in the USA. Cohort effect models suggest an increase in mortality for 1960s cohorts, and there are suggestive increases in some models for those born in the early 1980s. The reasons for the inconsistencies across models are due to how underlying variation is partitioned, as well as how relative effects are presented. That is, the models that demonstrate a stronger cohort effect for those born in the late 1970s and early 1980s compared to those born in the 1960s may generate those associations because they are displaying relative increases rather than absolute; given that the cohorts born in the late 1970s and 1980s are younger, the relative increase in recent years is, on a multiplicative scale, higher than those in previous cohorts. However, caution should be taken in interpreting some results as they may be indicative of residual bias. In the IE estimate in particular, there was a strong negative cohort effect for those in the youngest cohorts, which could be indicative of residual confounding of the age effect, given that these young cohorts have not had sufficient lifecourse to generate estimates for appreciable alcohol-induced mortality.
The reasons for these increases may be distinct by cohort group. Increases in mortality due to injury among cohorts born around the 1960s are well documented, termed “deaths of despair” by Case and Deaton [14] and extending to outcomes such as drug poisoning, suicide, and other alcohol-related outcomes such as liver disease as well [58]. Among those born in the 1980s, however, available evidence has demonstrated clear cohort effects in heavy drinking for these cohorts [59, 60], especially among women, with higher levels of consumption and binge drinking during the transition to adulthood and into mid-life [2] which may portend increased rates of alcohol-induced death given gender differences in susceptibility to chronic effects of alcohol [61]. Indeed, per capita consumption has been increasing in the USA since approximately 1997–2000, which would fit the time period of when these cohorts (born in the early 1980s) would be accelerating their drinking during the transition to adulthood [1]. The reasons why these cohorts have accumulated unique consumption patterns and comorbid mortality outcomes remain under-investigated. The deaths of despair cohorts are associated with the declining robustness of middle-class earnings and status, and declining returns on education for the current cohorts of those in early and late middle age. Those born in the 1980s, on the other hand, especially women, are increasingly occupying higher status positions and education [3, 62], and thus, increases in alcohol consumption may be linked to more discretionary leisure spending and fewer social sanctions on heavy drinking. Long-term trends that contribute to changes over time in alcohol consumption, including the erosion of public health protections such as alcohol taxes [63], likely have contributed to the increases in consumption over time, coupled with concentration of advertising to women in middle age that may potentiate sale of alcohol to particular birth cohorts and contribute to risk.
Trends in alcohol-induced morality are the product of social factors that interact with alcohol consumption and vary across generations, given that alcohol availability, preferences, and norms are highly variable across generation, country, and social class [64, 65]. Substance use more generally has strong cohort effects, as each generation uses alcohol and other additive substances differently as information about health harms, access, and acceptability shift over time [66, 67]. For alcohol use, available evidence indicates that cohorts born in the late 1970s and early 1980s have particularly heavy use of alcohol throughout the lifecourse, which may be reflected in the emerging cohort as they enter the highest period for risk of alcohol-related deaths. Further, per capita alcohol sales as well as self-reported alcohol consumption on national surveys has been increasing in recent years [1], especially among women, which coincides with the emerging period effect that is observed in several of the age–period–cohort models generated to account here for temporal patterns in alcohol-related death.
In summary, age–period–cohort visualization and modeling remains critical for surveillance and informing public health interventions; generally, modeling should be guided by data visualization given that the underlying assumptions of any one model are not verifiable. No age–period–cohort model will be appropriate in all circumstances; the choice should be based on the particular data structure and hypothesis. For example, rare outcomes such as mortality may be better suited for the first-derivative or Bayesian approaches, rather than IE or hierarchical age–period–cohort model, unless cross-level interactions or mediation tests are indicated or hypothesized. Hierarchical age–period–cohort models are flexible to a wide range of outcome distributions, but are biased when age, period, and cohort effects are linear (as are other APC models); however, they may be the only model suitable for complex longitudinal structures (as described in this paper) or when mediation tests are indicated. We recommend always confirming results with multiple age–period–cohort models for a robustness check; when results diverge, they should be interpreted with more caution. Visually inspecting and understanding the descriptive patterns of results remains a critical part of the APC modeling process and model selection decision; just like with any analysis, moving straight to a regression or other statistical model without fully understanding the descriptive nature of the trends over time can lead researchers astray.
References
Slater ME, Alpert HR. Surveillance report #117: Apparent per capita alcohol consumption: national, state, and regional trends, 1977-2019. Natl Inst Alcohol Abus Alcohol. Published online 2020. Available online: https://pubs.niaaa.nih.gov/publications/surveillance117/SR-117-Per-Capita-Consumption.pdf. Accessed 16 July 2022.
Keyes KM, Jager J, Mal-Sarkar T, Patrick ME, Rutherford C, Hasin DS. Is there a recent epidemic of women’s drinking? A critical review of national studies. Alcohol Clin Exp Res. 2019;43(7):1344–59. https://doi.org/10.1111/acer.14082.
McKetta SC, Prins SJ, Bates LM, Platt J, Keyes KM. US trends in binge drinking by gender, occupation, and work structure among adults in the midlife, 2006–2018. Ann Epidemiol. 2021;62:22–9.
White A, Castle I-J, Hingson R, Powell P. Using death certificates to explore changes in alcohol-related mortality in the United States, 1999 to 2017. Alcohol Clin Exp Res. 2020;44(1):178–87. https://doi.org/10.1111/acer.14239.
Spillane S, Shiels MS, Best AF, et al. Trends in alcohol-induced deaths in the United States, 2000–2016. JAMA Netw Open. 2020;3(2):e1921451–e1921451. https://doi.org/10.1001/jamanetworkopen.2019.21451.
Spencer M, Curtin SC, Hedegaard H. Rates of alcohol-induced deaths among adults aged 25 and over in rural and urban areas: United States, 2000–2018. NCHS Data Br No 383. Published online 2020. Available online: https://www.cdc.gov/nchs/products/databriefs/db383.htm#:~:text=Age%2Dadjusted%20rates%20of%20alcohol,rural%20compared%20with%20urban%20areas. Accessed 16 July 2022.
Shiels MS, Tatalovich Z, Chen Y, et al. Trends in mortality from drug poisonings, suicide, and alcohol-induced deaths in the United States from 2000 to 2017. JAMA Netw Open. 2020;3(9):e2016217–e2016217. https://doi.org/10.1001/jamanetworkopen.2020.16217.
Rehm J, Shield KD, Weiderpass E. Alcohol consumption. A leading risk factor for cancer. Chem Biol Interact. 2020;331:109280. https://doi.org/10.1016/j.cbi.2020.109280.
Rehm J, Shield KD, Roerecke M, Gmel G. Modelling the impact of alcohol consumption on cardiovascular disease mortality for comparative risk assessments: an overview. BMC Public Health. 2016;16:363. https://doi.org/10.1186/s12889-016-3026-9.
Reynolds K, Lewis B, Nolen JDL, Kinney GL, Sathya B, He J. Alcohol consumption and risk of stroke: a meta-analysis. JAMA. 2003;289(5):579–88. https://doi.org/10.1001/jama.289.5.579.
Platt JM, Jager J, Patrick ME, et al. Forecasting future prevalence and gender differences in binge drinking among young adults through 2040. Alcohol Clin Exp Res. 2021;45(10):2069–79. https://doi.org/10.1111/acer.14690.
Jager J, Keyes KM, Schulenberg JE. Historical variation in young adult binge drinking trajectories and its link to historical variation in social roles and minimum legal drinking age. Dev Psychol. 2015;51(7):962–74. https://doi.org/10.1037/dev0000022.
Patrick ME, Terry-McElrath YM, Lanza ST, Jager J, Schulenberg JE, O’Malley PM. Shifting age of peak binge drinking prevalence: historical changes in normative trajectories among young adults aged 18 to 30. Alcohol Clin Exp Res. 2019;43(2):287–98.
Case A, Deaton A. Rising morbidity and mortality in midlife among white non-Hispanic Americans in the 21st century. Proc Natl Acad Sci. 2015;112(49):15078–83. https://doi.org/10.1073/pnas.1518393112.
Keyes KM. Age, period, and cohort effects in alcohol use in the United States in the 20th and 21st centuries: implications for the coming decades. Alcohol Res Curr Rev. 2022;42(1):2. https://doi.org/10.35946/arcr.v42.1.02.
Yang Y, Land KC. Chapter 1. Why cohort analysis? In: Age-period-cohort analysis: New models, methods, and empirical applications. 1st ed.; Published February 25, 2013 by Chapman and Hall/CRC.
Holford TR. Understanding the effects of age, period, and cohort on incidence and mortality rates. Annu Rev Public Health. 1991;12:425–57. https://doi.org/10.1146/annurev.pu.12.050191.002233.
Keyes KM, Utz RL, Robinson W, Li G. What is a cohort effect? Comparison of three statistical methods for modeling cohort effects in obesity prevalence in the United States, 1971–2006. Soc Sci Med. 2010;70(7):1100–8. https://doi.org/10.1016/j.socscimed.2009.12.018.
Susser M. Period effects, generation effects and age effects in peptic ulcer mortality. J Chronic Dis. 1982;35(1):29–40. https://doi.org/10.1016/0021-9681(82)90027-3.
Smith B, Morgan RL, Beckett G, et al. Recommendations for the identification of chronic hepatitis C virus infection among persons born during 1945–1965. Morb Mortal Wkly Rep. 2012;61(RR04):1–18.
Glenn ND. Cohort analysts’ futile quest: statistical attempts to separate age, period and cohort effects. Am Sociol Rev. 1976;41:900.
Bell A. Age period cohort analysis: a review of what we should and shouldn’t do. Ann Hum Biol. 2020;47(2):208–17. https://doi.org/10.1080/03014460.2019.1707872.
Minton J. The Lexis surface: a tool and workflow for better reasoning about population data. In: Age, period and cohort effects: Statistical analysis and the identification problem. 1st ed.; 2020. Published November 6, 2020 by Routledge.
Yang Y, Land KC. Age-period-cohort analysis: new models, methods, and empirical applications. 1st ed.; 2013. Published November 6, 2020 by Routledge.
Fannon Z, Monden C, Nielsen B. Modelling non-linear age-period-cohort effects and covariates, with an application to English obesity 2001–2014. J R Stat Soc Ser A. 2021;184(3):842–67. https://doi.org/10.1111/rssa.12685.
Holford TR. Age–period–cohort analysis. Wiley StatsRef Stat Ref Online. Published online February 15, 2016:1–25. https://doi.org/10.1002/9781118445112.stat06122.pub2
Yang Y, Schulhofer-Wohl S, Fu WJ, Land KC. The intrinsic estimator for age-period-cohort analysis: what it is and how to use it. Am J Sociol. 2008;113(6):1697–736. https://doi.org/10.1086/587154.
Tu Y-K, Krämer N, Lee W-C. Addressing the identification problem in age-period-cohort analysis: a tutorial on the use of partial least squares and principal components analysis. Epidemiology. 2012;23(4):583–93. https://doi.org/10.1097/EDE.0b013e31824d57a9.
Winship C, Harding DJ. A mechanism-based approach to the identification of age-period-cohort models. Sociol Methods Res. 2008;36(3):362–401. https://doi.org/10.1177/0049124107310635.
Reither EN, Hauser RM, Yang Y. Do birth cohorts matter? Age-period-cohort analyses of the obesity epidemic in the United States. Soc Sci Med. 2009;69(10):1439–48. https://doi.org/10.1016/j.socscimed.2009.08.040.
Yang Y, Land KC. Age–period–cohort analysis of repeated cross-section surveys: fixed or random effects? Sociol Methods Res. 2008;36(3):297–326. https://doi.org/10.1177/0049124106292360.
Chen W-Q, Zheng R-S, Zeng H-M. Bayesian age-period-cohort prediction of lung cancer incidence in China. Thorac Cancer. 2011;2(4):149–55. https://doi.org/10.1111/j.1759-7714.2011.00062.x.
Robertson C, Gandini S, Boyle P. Age-period-cohort models: a comparative study of available methodologies. J Clin Epidemiol. 1999;52(6):569–83. https://doi.org/10.1016/s0895-4356(99)00033-5.
Xu J, Kochanek KD, Murphy SL, Tejada-Vera B. Deaths: final data for 2007. Natl Vital Stat Reports. 2010;58(19):119.
Carstensen B. Age-period-cohort models for the Lexis diagram. Stat Med. 2007;26(15):3018–45. https://doi.org/10.1002/sim.2764.
Carstensen B, Plummer M, Hils M, Laara E. Epi: a package for statistical analysis in epidemiology (R package version 1.1.34). Published online 2012. Available online: https://cran.r-project.org/web/packages/Epi/Epi.pdf. Accessed 16 July 2022.
Yang Y, Fu WJ, Land KC. A methodological comparison of age-period-cohort models: the intrinsic estimator and conventional generalized linear models. Sociol Methodol. 2004;34(1):75–110. https://doi.org/10.1111/j.0081-1750.2004.00148.x.
Luo L. Assessing validity and application scope of the intrinsic estimator approach to the age-period-cohort problem. Demography. 2013;50(6):1945–67. https://doi.org/10.1007/s13524-013-0243-z.
Pelzer B, te Grotenhuis M, Eisinga R, Schmidt-Catran AW. The non-uniqueness property of the intrinsic estimator in APC models. Demography. 2015;52(1):315–27. https://doi.org/10.1007/s13524-014-0360-3.
te Grotenhuis M, Pelzer B, Luo L, Schmidt-Catran AW. The intrinsic estimator, alternative estimates, and predictions of mortality trends: a comment on Masters, Hummer, Powers, Beck, Lin, and Finch. Demography. 2016;53:1245–52.
Yang Y, Land KC. A mixed models approach to the age-period-cohort analysis of repeated cross-section surveys, with an application to data on trends in verbal test scores. Sociol Methodol. 2006;36(1):75–97. https://doi.org/10.1111/j.1467-9531.2006.00175.x.
Bell A, Jones K. Should age-period-cohort analysts accept innovation without scrutiny? A response to Reither, Masters, Yang, Powers, Zheng and Land. Soc Sci Med. 2015;128:331–3. https://doi.org/10.1016/j.socscimed.2015.01.040.
Bell A, Jones K. The hierarchical age-period-cohort model: why does it find the results that it finds? Qual Quant. 2018;52(2):783–99. https://doi.org/10.1007/s11135-017-0488-5.
Luo L, Hodges JS. Constraints in random effects age-period-cohort models. Sociol Methodol. 2020;50(1):276–317. https://doi.org/10.1177/0081175020903348.
Schmid V, Held L. Bayesian age-period-cohort modeling and prediction: BAMP. J Stat Softw. Published online 2007. Available online: https://www.jstatsoft.org/article/view/v021i08. Accessed 16 July 2022.
Fosse E. Bayesian age-period-cohort models. In: Age, period and cohort effects: Statistical analysis and the identification problem.; 2020. Published November 6, 2020 by Routledge.
Keyes KM, Li G. A multiphase method for estimating cohort effects in age-period contingency table data. Ann Epidemiol. 2010;20(10):779–85. https://doi.org/10.1016/j.annepidem.2010.03.006.
Jalal H, Burke DS. Hexamaps for age–period–cohort data visualization and implementation in R. Epidemiology. Published online 2020. https://journals.lww.com/epidem/Fulltext/9000/Hexamaps_for_Age_Period_Co_ort_Data_Visualization.98384.aspx. Accessed 16 July 2022.
Masters RK, Hummer RA, Powers DA, Beck A, Lin S-F, Finch BK. Long-term trends in adult mortality for U.S. Blacks and Whites: an examination of period- and cohort-based changes. Demography. 2014;51(6):2047–73. https://doi.org/10.1007/s13524-014-0343-4.
Keyes KM, Miech R. Age, period, and cohort effects in heavy episodic drinking in the US from 1985 to 2009. Drug Alcohol Depend. 2013;132(1–2):140–8. https://doi.org/10.1016/j.drugalcdep.2013.01.019.
Searle SR, Gruber MHJ. Linear models. Hoboken: Wiley; 2016.
Smith HL. Advances in age–period–cohort analysis. Sociol Methods Res. 2008;36(3):287–96. https://doi.org/10.1177/0049124107310636.
Suzuki E. Time changes, so do people. Soc Sci Med. 2012;75(3):452–8. https://doi.org/10.1016/j.socscimed.2012.03.036.
Ryder NB. The cohort as a concept in the study of social change. Am Sociol Rev. 1965;30(6):843–61. https://doi.org/10.2307/2090964.
Elder GH. The life course as developmental theory. Child Dev. 1998;69(1):1–12. https://doi.org/10.2307/1132065.
Elder GH. Children of the Great Depression: 25th Anniversary Edition.; 1998. Published September 11, 1998 by Routledge.
Finch CE, Crimmins EM. Inflammatory exposure and historical changes in human life-spans. Science (80-). 2004;305(5691):1736–9. https://doi.org/10.1126/science.1092556.
Masters RK, Tilstra AM, Simon DH. Explaining recent mortality trends among younger and middle-aged White Americans. Int J Epidemiol. 2018;47(1):81–8. https://doi.org/10.1093/ije/dyx127.
Kerr WC, Greenfield TK, Bond J, Ye Y, Rehm J. Age-period-cohort modelling of alcohol volume and heavy drinking days in the US National Alcohol Surveys: divergence in younger and older adult trends. Addiction. 2009;104(1):27–37. https://doi.org/10.1111/j.1360-0443.2008.02391.x.
Kerr WC, Greenfield TK, Ye Y, Bond J, Rehm J. Are the 1976–1985 birth cohorts heavier drinkers? Age-period-cohort analyses of the National Alcohol Surveys 1979–2010. Addiction. 2013;108(6):1038–48. https://doi.org/10.1111/j.1360-0443.2012.04055.x.
White AM. Gender differences in the epidemiology of alcohol use in the United States. Alcohol Res Curr Rev. 2020;40(2):1–13. https://doi.org/10.35946/arcr.v40.2.01.
McKetta SC, Keyes KM. Trends in U.S. women’s binge drinking in middle adulthood by socioeconomic status, 2006–2018. Drug Alcohol Depend. 2020;212:108026. https://doi.org/10.1016/j.drugalcdep.2020.108026.
Blanchette JG, Ross CS, Naimi TS. The rise and fall of alcohol excise taxes in U.S. states, 1933–2018. J Stud Alcohol Drugs. 2020;81(3):331–8. https://doi.org/10.15288/jsad.2020.81.331.
Skog O-J. The collectivity of drinking cultures: a theory of the distribution of alcohol consumption. Br J Addict. 1985;80(1):83–99. https://doi.org/10.1111/j.1360-0443.1985.tb05294.x.
Room R. The idea of alcohol policy. Nord Stud Alcohol Drugs. 1999;16(1_suppl):7–20. https://doi.org/10.1177/145507259901601S17.
Jalal H, Buchanich J, Roberts MS, Balmert L, Zhang K, Burke DS. Changing dynamics of the drug overdose epidemic in the United States, 1979–2016. Science (80-). 2018;361(6408):eaau1184.
Keyes KM, Hamilton A, Kandel DB. Birth cohorts analysis of adolescent cigarette smoking and subsequent marijuana and cocaine use. Am J Public Health. 2016;106(6):1143–9. https://doi.org/10.2105/AJPH.2016.303128.
Acknowledgements
The authors wish to thank Dr. Timothy Naimi for feedback on earlier versions of the manuscript.
Funding
Funding was provided by R01-AA026861 and 2U54GM104942.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
K. Keyes, C. Rutherford, and G. Smith have been compensated for expert witness work in litigation.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Injury Epidemiology
Appendix
Appendix
Table 2
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Keyes, K.M., Rutherford, C. & Smith, G.S. Alcohol-Induced Death in the USA from 1999 to 2020: a Comparison of Age–Period–Cohort Methods. Curr Epidemiol Rep 9, 161–174 (2022). https://doi.org/10.1007/s40471-022-00300-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40471-022-00300-0