
Abstract
Introduction
There are limited data available regarding the connection between heavy metal exposure and mortality among hypertension patients.
Aim
We intend to establish an interpretable machine learning (ML) model with high efficiency and robustness that monitors mortality based on heavy metal exposure among hypertension patients.
Methods
Our datasets were obtained from the US National Health and Nutrition Examination Survey (NHANES, 2013–2018). We developed 5 ML models for mortality prediction among hypertension patients by heavy metal exposure, and tested them by 10 discrimination characteristics. Further, we chose the optimally performing model after parameter adjustment by genetic algorithm (GA) for prediction. Finally, in order to visualize the model’s ability to make decisions, we used SHapley Additive exPlanation (SHAP) and Local Interpretable Model-Agnostic Explanations (LIME) algorithm to illustrate the features. The study included 2347 participants in total.
Results
A best-performing eXtreme Gradient Boosting (XGB) with GA for mortality prediction among hypertension patients by 13 heavy metals was selected (AUC 0.959; 95% CI 0.953–0.965; accuracy 96.8%). According to sum of SHAP values, cadmium (0.094), cobalt (2.048), lead (1.12), tungsten (0.129) in urine, and lead (2.026), mercury (1.703) in blood positively influenced the model, while barium (− 0.001), molybdenum (− 2.066), antimony (− 0.398), tin (− 0.498), thallium (− 2.297) in urine, and selenium (− 0.842), manganese (− 1.193) in blood negatively influenced the model.
Conclusions
Hypertension patients’ mortality associated with heavy metal exposure was predicted by an efficient, robust, and interpretable GA-XGB model with SHAP and LIME. Cadmium, cobalt, lead, tungsten in urine, and mercury in blood are positively correlated with mortality, while barium, molybdenum, antimony, tin, thallium in urine, and lead, selenium, manganese in blood is negatively correlated with mortality.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Since 1990, the prevalence of hypertension has seen a twofold increase, with current estimates indicating that 1.28 billion adults worldwide are affected by this condition [1,2,3]. Established risk factors for hypertension include genetics, diet, and lifestyle [4]. Additionally, emerging evidence suggests a potential role of metal exposure in influencing both the risk and mortality associated with hypertension [5]. Metals can enter the human body through various pathways, including inhalation, dermal contact, and ingestion [6]. Essential elements play a critical role in numerous physiological processes such as immunity, metabolism, and development [7]. However, both deficiencies and excesses of these elements can adversely affect human health [7, 8]. Toxic metals, in particular, can disrupt bodily homeostasis and organ function [9]. A substantial body of epidemiological research has been dedicated to examining the impact of metal exposure on hypertension [10]. Nevertheless, there is a paucity of studies investigating the relationship between heavy metal levels and the increased risk of premature death in individuals with hypertension, underscoring the importance of identifying modifiable risk factors to mitigate adverse health outcomes in this population.
Research on the health effects of metal mixtures has typically focused on isolated exposures, utilizing conventional statistical or machine learning (ML) analyses [5, 9, 11,12,13,14]. This highlights the need for novel analytical methodologies to elucidate the link between heavy metal exposure and mortality among those suffering from hypertension more effectively.
Traditional approaches to disease prediction or mortality risk assessment require stringent data preparation standards [15,16,17]. However, advancements in computer science and the proliferation of data sources pose significant challenges in extracting actionable insights from large datasets [18]. Machine learning, with its capacity to handle less rigorously pre-processed data, offers a promising avenue for exploring vast information landscapes, potentially enhancing hazard identification and health-related decision-making [19].
In our study, we utilized datasets from the National Health and Nutrition Examination Survey (NHANES) for the years 2013–2018, which include specific information on metal exposure not available in other data release cycles. Our aim was to explore the relationship between heavy metal exposure and mortality among individuals with hypertension. We employed five ML models to predict mortality based on heavy metal exposure, assessed the performance of these models, and subsequently applied GA to optimize the performance of the most effective model. Additionally, our study incorporated advanced EMR mining techniques, such as SHapley Additive exPlanation (SHAP) [20] and local interpretable model-agnostic explanations (LIME) [21], to evaluate the contribution of heavy metals to mortality risk, potentially facilitating earlier interventions for hypertension patients.
2 Methods
2.1 Participants
The NHANES study in the United States employed diverse survey methodologies to gather demographic, dietary, clinical examination, laboratory, questionnaire, and mortality data on the US population. This data is accessible on the website of American Centers for Disease Control and Prevention (https://www.cdc.gov/nchs/nhanes). Our analysis includes data from three consecutive NHANES cycles, spanning from 2013 to 2018, augmented by mortality data from 2019.
Inclusion criteria for our study population were: age above 18 years; completion of blood and urine tests for heavy metals; provision of hypertension status in NHANES questionnaire data; and hypertension information derived from the multi-cause mortality data. Exclusion criteria were: participants with over 10% missing data and those with inconsistent information. Our final cohort for follow-up analysis comprised 2347 individuals.
3 Data Collection
3.1 Demographics Characteristics of the Study Participants
The NHANES database provided demographic and other pertinent characteristics of participants, including gender, age (in years at screening), Race/Hispanic origin w/NH Asian, education level (college or above, high school or equivalent, and less than high school), poverty-to-income ratio (PIR) (≤ 1, 1–4, and ≥ 4) [22], and body mass index (BMI, kg/m2).
3.2 Heavy Metals
Our analysis included urinary and blood concentrations of 13 heavy metals, measured at the National Center for Environmental Health using stringent quality control procedures [23].
3.3 Mortality Ascertainment
Mortality status was acquired from the NHANES 2019 Public-use Linked Mortality File (LMF), linked to the National Death Index. Disease-specific mortality was identified according to the International Statistical Classification of Diseases and Related Health Problems, Tenth Revision (ICD-10), with hypertension diagnosed using code I10 since the 2013-2014 data cycle [24].
3.4 Pre-processing of Features
For machine learning applications, with the involvement of medical experts, we selected 22 variables (also known as features in ML field), 19 continuous and 3 categorical. We excluded data with more than 10% missing values. Missing values for continuous variables were imputed with medians, and modes were used for unordered categorical variables [25]. Standard Scaler was utilized for normalizing features, and one-hot encoding was applied to categorical variables. Feature extraction employed principal component analysis (PCA) and select K best (SKB) algorithms [26], discarding variables with minimal model impact to mitigate overfitting.
3.5 Model Establishment
The dataset was partitioned into training and test sets via repeated K-fold cross-validation. We evaluated five machine learning algorithms: deep neural networks (DNN), support vector machine (SVM), Gaussian Naive Bayes (GNB), decision tree (DT), and extreme gradient boosting (XGB), to predict mortality among hypertension patients exposed to heavy metals, each with distinct characteristics and advantages. The DNN method is usually more accurate with simple structure for data training; meanwhile, it also has strong black-box characteristics, that is, it is more difficult for people to understand its discrimination principle [28]. SVM is data-insensitive, but can process nonlinear, multidimensional datasets [29]. GNB performs well on small-scale data, can handle multiple classification tasks, and is suitable for incremental training, but there will be noise and redundancy [30, 31]. Visual analytics are supported by DT, which is easy to comprehend and interpret, but it is susceptible to problems with over-fitting [32]. XGB is a library optimized to increase distributed gradient and designed to be highly efficient, flexible, and portable [33]; however, XGB's model parameters are too many to adjust for the optimal efficiency [34].
After assessing each model's discriminative ability, we selected the most appropriate model for mortality prediction, optimizing parameters using genetic algorithms (GA) [35]. genetic algorithms (GA) are used in our study to optimize model parameters, ensuring the highest possible accuracy and robustness. GA not only explores a wide parameter space but also helps infer the importance of risk factors by optimizing model performance. The SHAP and LIME methods were employed for model interpretation, assessing risk factors for hypertension-associated mortality from 2013 to 2018.
3.6 Statistical Analysis
Continuous variables were summarized as medians (interquartile range), and categorical variables as counts (percentage). Group-specific characteristics were compared using chi-square tests, and heavy metal levels were described using geometric means (standard deviations). Trends over the 6-year period (3 data release cycles) were analyzed with the Mann–Kendall test.
The indicators used for model effectiveness testing included average area under the curve (AAUC) [36] and 95% confidence intervals (95% CI), best area under the curve (BAUC), average precision score (APS), average recall, average f1 score, average accuracy, average brier score loss, average cross-entropy loss, average Jaccard index, and average Cohen’s kappa of each model by repeated K-Fold cross validation.
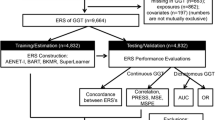
Analyses were performed using Python 3.9.7, with a significance threshold set at P < 0.05. A schematic overview of our methodology is presented in Fig. 1.

Overview plot
4 Results
4.1 Participants’ Demographics Characteristics
Table 1 presents a summary of the demographic characteristics of the 2347 study participants, all of whom were diagnosed with hypertension. Of these participants, 2003 were alive at the conclusion of the study. The cohort consisted of 1167 men, with an average age of 64.15 years. Deceased participants were more likely to be female, older, have a higher BMI, be of Hispanic ethnicity, possess a higher level of education, and have a lower family income, with all observed differences being statistically significant (P < 0.05).
4.2 Heavy Metals’ Concentrations
Table 2 delineates the concentrations of heavy metals detected in the urine and blood samples across different data release cycles. Significant trends in the concentrations of barium, cadmium, cobalt, cesium, manganese, molybdenum, lead, antimony, tin, thallium, and tungsten in urine, and lead, cadmium, mercury, selenium, and manganese in blood were identified (all Pfor trend < 0.05).
4.3 Models’ Preprocessing
In the process of feature selection, PCA revealed that a minimum of 19 variables were necessary to retain over 95% of the original dataset's information content. Feature scores determined by SKB ranged from 4.23 to 148.73. The top 19 features were selected based on these scores to tailor our ML models. Subsequently, 5 ML algorithms were applied to the NHANES dataset using repeated K-Fold cross-validation for training purposes.
4.4 Models' Performance
The XGB model has the optimal AAUC (AUC 0.943; 95% CI 0.937–0.948), BAUC (1), and APS (0.946) performance which were significantly higher than the AUC values of the other 4 models (P < 0.05). To enhance the AAUC and APS in mortality prediction, parameters were refined using GA, resulting in the GA-XGB model achieving the best performance of AAUC (AUC 0.959; 95% CI 0.953–0.966), and APS (0.996). The best receiver operating characteristic (ROC) curve and precision-recall curve of 6 ML models (including GA-XGB) are shown in Fig. 2. DNN (93.6%), XGB (96.9%), and GA-XGB (96.8%) showed good accuracy when predicting mortality.

The best receiver operating characteristic curve and precision-recall curve for models
4.5 Models’ Comparison
Table 3 shows the performances' comparison of the ML models. The AAUC, BAUC, APS, average recall, average f1 score, average accuracy, average brier score loss, average cross-entropy loss, average Jaccard index, and average Cohen's kappa for all 5 ML models are shown in Table 3. XGB reached the best of the 5 models in 8 of the 10 performance indicators. Typically, the AAUC (AUC 0.943; 95% CI 0.937–0.948), BAUC (1), and APS (0.946) of XGB performed the best of all 5 ML models. The comparison results demonstrate that XGB has the best performance of the five for mortality prediction among hypertension patients. After parameter optimization using GA, the XGB model's effectiveness further improved, as detailed on the right side of Table 3.
4.6 Feature Importance Visualization
SHAP and LIME were used to visualized features' influence on mortality prediction among hypertension patients of the GA-XGB model. The SHAP and LIME summary plot demonstrates the impact of each selected feature of the model to predict hypertension (Fig. 3).

The SHAP and LIME-GA-XGB summary plot
The SHAP value plot on the left side of Fig. 3 globally indicates that cadmium (0.094), cobalt (2.048), lead (1.12), tungsten (0.129) in urine, and lead (2.026), mercury (1.703) in blood positively influence the model, while barium (− 0.001), molybdenum (− 2.066), antimony (− 0.398), tin (− 0.498), thallium (− 2.297) in urine, and selenium (− 0.842), manganese (− 1.193) in urine negatively influence the model. Additionally, the SHAP and LIME summary plot shows that being old, non-Hispanic, having a lower education level, having a higher PIR, and having a higher BMI are related to higher hypertension risk. The SHAP interaction value plot on the upper right side of Fig. 3 demonstrates the interaction between main features. The LIME value plot on the lower right side of Fig. 3 locally indicates the feature importance of single sample discrimination (the 2088th sample). SHAP values illustrate features’ contributions to mortality prediction of the model.
4.7 Prediction Interpretation
The SHAP decision plot, illustrated in Fig. 4, represents individual participant predictions with lines converging at a decision point of 0.968, ordered by feature importance based on the observations plotted. Additionally, the tree plot reveals the optimal discrimination logic, serving as a foundational element of the decision-making process.

The SHAP-GA-XGB decision plot
5 Discussions
In our study, for predicting mortality among hypertension patients in 2013–2018 NHANES data, we developed a ML strategy that can be understood in relation to heavy metal exposure. The GA-XGB model was chosen to predict mortality because it performed the best of the 5 ML algorithms. The GA-XGB model performed well with an average AUC of 0.959, and an accuracy of 0.968. To address the limitations of these algorithms, we integrated the SHAP game theory method with LIME, enhancing the interpretation of model features on both global and local scales through summary and decision plots. Our findings suggest that the SHAP and LIME-GA-XGB model shows promising potential for predicting mortality in hypertension patients exposed to heavy metals.
This research builds upon prior studies that employed ML algorithms for disease prediction [27, 33, 35], underscoring the benefits of advanced classification algorithms in improving prediction accuracy. ML, a branch of artificial intelligence, utilizes mathematical algorithms to identify patterns in diverse data sets, facilitating decision-making processes [18, 37]. However, the complexity of ML algorithms often hampers their understandability, posing challenges to medical decision-making [38].
Our SHAP and LIME-GA-XGB model leverages multi-source NHANES data, including demographics, examinations, laboratory results, and questionnaires, avoiding the need for new data collection efforts. Since 2013, significant attention has been directed towards heavy metal exposure in the United States [39], coinciding with the adoption of the ICD-10 for recording NHANES disease data [40]. We employed extensive data, particularly focusing on the concentration of heavy metals in participants' urine and blood samples. The GA-XGB model demonstrated high efficiency, and among 6 ML algorithms tested, it provided the best performance in terms of classification robustness, aided by strategies such as repeated K-Fold cross-validation to prevent overfitting [41]. SHAP and LIME analyses offered comprehensive interpretability of the GA-XGB model, highlighting the significance of various features in hypertension mortality prediction.
The findings of SHAP were comparable to those of previous studies, which primarily focused on determining how heavy metal exposure affects mortality. Exposure to heavy metals has been linked to increased mortality rates, particularly from cancer and cardiovascular disease [42]. This is a significant concern given the prevalence of heavy metal contamination in drinking water and its potential health impacts [43]. The toxic effects of heavy metals, including oxidative damage and DNA modification, can lead to a range of health issues, from brain damage to cancer [44]. On the positive correlation with mortality, Chen [45] found that higher blood cadmium levels were associated with increased all-cause, cardiovascular, and Alzheimer's disease mortality in these patients. Obeng-Gyasi [46] revealed that the combined effect of lead exposure and chronic physiological stress significantly increased the likelihood of cardiovascular disease mortality. Fardin [47] found that chronic mercury exposure can accelerate the development of hypertension, potentially increasing the risk of cardiovascular diseases. On the negative correlation with mortality, Kuria [48] and Al‐Mubarak [49] found that high selenium levels were associated with a reduced risk of cardiovascular disease (CVD) incidence and mortality. Dietary manganese intake has been associated with a reduced risk of mortality from cardiovascular disease in the Japanese population [50]. The specific impact of other metals’ exposure on mortality among hypertension patients was not directly addressed in previous studies. Further research is needed to explore these potential relationships.
Future research should continue to monitor and analyze key features, aiding experts in drawing informed conclusions rather than relying solely on algorithmic predictions. Expanding the database and incorporating clinician insights could further validate the model's performance [51].
Our study faces several limitations. First, due to computational limits, we were unable to disaggregate other potentially dynamic correlations within the limited data. Secondly, the self-reported nature of hypertension diagnoses in NHANES questionnaire data, despite adherence to ICD-10 standards, may introduce information bias [52]. Third, the strict inclusion criteria for study participants led to significant data missing, potentially introducing bias. Lastly, the complexity of model interpretation may affect the reproducibility of our findings.
6 Conclusions
In our study among US NHANES 2013–2018 participants, the SHAP and LIME-GA-XGB model was found to be an interpretable ML model with high efficiency and robustness that predicts mortality among hypertension patients based on heavy metal exposure. Cadmium, cobalt, lead, tungsten in urine, and mercury in blood positively contribute to mortality among hypertension patients, while barium, molybdenum, antimony, tin, thallium in urine, and lead, selenium, manganese in blood negatively contributes to mortality among hypertension patients.
References
Wang T, Cai X, Zhang L, Li Y, Chen Z, Zhao H, Liu J. Development and validation of a nomogram for arterial stiffness. J Clin Hypertens (Greenwich). 2023;25(10):923–31. https://doi.org/10.1111/jch.14723.
Mills KT, Stefanescu A, He J. The global epidemiology of hypertension. Nat Rev Nephrol. 2020;16(4):223–37. https://doi.org/10.1038/s41581-019-0244-2.
Zheng K, Zeng Z, Tian Q, Huang J, Zhong Q, Huo X. Epidemiological evidence for the effect of environmental heavy metal exposure on the immune system in children. Sci Total Environ. 2023;868: 161691. https://doi.org/10.1016/j.scitotenv.2023.161691.
NCD Risk Factor Collaboration (NCD-RisC). Worldwide trends in hypertension prevalence and progress in treatment and control from 1990 to 2019: a pooled analysis of 1201 population-representative studies with 104 million participants [published correction appears in Lancet. 2022 Feb 5;399(10324):520]. Lancet. 2021;398(10304):957–80. https://doi.org/10.1016/S0140-6736(21)01330-1.
Garner RE, Levallois P. Associations between cadmium levels in blood and urine, blood pressure and hypertension among Canadian adults. Environ Res. 2017;155:64–72. https://doi.org/10.1016/j.envres.2017.01.040.
Kerkadi A, Alkudsi DS, Hamad S, Alkeldi HM, Salih R, Agouni A. The association between zinc and copper circulating levels and cardiometabolic risk factors in adults: a study of Qatar biobank data. Nutrients. 2021;13(8):2729. https://doi.org/10.3390/nu13082729. (published 2021 Aug 9).
Messaoudi M, Begaa S. Dietary intake and content of some micronutrients and toxic elements in two Algerian spices (Coriandrum sativum L. and Cuminum cyminum L.). Biol Trace Elem Res. 2019;188(2):508–13. https://doi.org/10.1007/s12011-018-1417-8.
Arnaud J, van Dael P. Selenium interactions with other trace elements, with nutrients (and drugs) in humans. Selenium. 2018. https://doi.org/10.1007/978-3-319-95390-8_22.
Lee MS, Park SK, Hu H, Lee S. Cadmium exposure and cardiovascular disease in the 2005 Korea National Health and Nutrition Examination Survey. Environ Res. 2011;111(1):171–6. https://doi.org/10.1016/j.envres.2010.10.006.
Aramjoo H, Arab-Zozani M, Feyzi A, Saeedi R, Safari H, Mirza-Aghazadeh-Attari M, Khazaei S. The association between environmental cadmium exposure, blood pressure, and hypertension: a systematic review and meta-analysis. Environ Sci Pollut Res Int. 2022;29(24):35682–706. https://doi.org/10.1007/s11356-021-17777-9.
Yim G, Wang Y, Howe CG, Romano ME. Exposure to metal mixtures in association with cardiovascular risk factors and outcomes: a scoping review. Toxics. 2022;10(3):116. https://doi.org/10.3390/toxics10030116. (published 2022 Mar 1).
Shi P, Jing H, Xi S. Urinary metal/metalloid levels in relation to hypertension among occupationally exposed workers. Chemosphere. 2019;234:640–7. https://doi.org/10.1016/j.chemosphere.2019.06.099.
Qian H, Li G, Luo Y, Zhang W, Wang Y, Wang X, Song Y. Relationship between occupational metal exposure and hypertension risk based on conditional logistic regression analysis. Metabolites. 2022;12(12):1259. https://doi.org/10.3390/metabo12121259. (published 2022 Dec 14).
Zhong Q, Jiang CX, Zhang C, Chen H, Li R, Zhao Y, Yu G. Urinary metal concentrations and the incidence of hypertension among adult residents along the Yangtze River, China. Arch Environ Contam Toxicol. 2019;77(4):490–500. https://doi.org/10.1007/s00244-019-00655-4.
Xu S, Sun M. The interpretable machine learning model associated with metal mixtures to identify hypertension via EMR mining method. Journal of Clinical Hypertension. 2024;26.2:187–196. https://doi.org/10.1111/jch.14768. (published 2024 Jan 14).
Xu S, Zhang T, Sheng T, Liu J, Sun M, Luo L. Cost supervision mining from EMR based on artificial intelligence technology. Technol Health Care. 2023;31(3):1077–91. https://doi.org/10.3233/THC-220608.
Xu S, Sun M. Covid-19 vaccine effectiveness during Omicron BA.2 pandemic in Shanghai: a cross-sectional study based on EMR. Medicine (Baltimore). 2022;101(45):e31763. https://doi.org/10.1097/MD.0000000000031763.
Stafford IS, Kellermann M, Mossotto E, Beattie RM, MacArthur BD, Ennis S. A systematic review of the applications of artificial intelligence and machine learning in autoimmune diseases. NPJ Digit Med. 2020;3:30. https://doi.org/10.1038/s41746-020-0229-3. (published 2020 Mar 9).
Alber M, Buganza Tepole A, Cannon WR, De S, Dura-Bernal S, Garikipati K, Karniadakis GE, Lytton WW, Perdikaris P, Petzold L, Kuhl E. Integrating machine learning and multiscale modeling-perspectives, challenges, and opportunities in the biological, biomedical, and behavioral sciences. NPJ Digit Med. 2019;2:115. https://doi.org/10.1038/s41746-019-0193-y. (published 2019 Nov 25).
Nordin N, Zainol Z, Mohd Noor MH, Chan LF. An explainable predictive model for suicide attempt risk using an ensemble learning and Shapley Additive Explanations (SHAP) approach. Asian J Psychiatr. 2023;79: 103316. https://doi.org/10.1016/j.ajp.2022.103316.
Peng K, Menzies T. Documenting evidence of a reuse of ‘“why should I trust you?”: explaining the predictions of any classifier’. In: Proceedings of the 29th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering. 2021. p. 1600. https://doi.org/10.1145/3468264.3477217.
Odutayo A, Gill P, Shepherd S, Akingbade A, Hopewell S, Tennant A, Lown M, Marston L, Perera R, Tomlinson LA, Heneghan C. Income disparities in absolute cardiovascular risk and cardiovascular risk factors in the United States, 1999–2014. JAMA Cardiol. 2017;2(7):782–90. https://doi.org/10.1001/jamacardio.2017.1658.
NHANES. NHANES 2013–2014 laboratory methods. https://wwwn.cdc.gov/nchs/nhanes/ContinuousNhanes/. Accessed 20 Oct 2023.
Mou C, Ren J. Automated ICD-10 code assignment of nonstandard diagnoses via a two-stage framework. Artif Intell Med. 2020;108: 101939. https://doi.org/10.1016/j.artmed.2020.101939.
Rodríguez P, Bautista MA, Gonzalez J, Escalera S. Beyond one-hot encoding: lower dimensional target embedding. Image Vis Comput. 2018;75:21–31. https://doi.org/10.1016/j.imavis.2018.04.004.
Desyani T, Saifudin A, Yulianti Y. Feature selection based on naive bayes for caesarean section prediction. IOP Conf Ser Mater Sci Eng. 2020;879(1):012091. https://doi.org/10.1088/1757-899X/879/1/012091.
Barile C, Casavola C, Pappalettera G, Kannan VP. Damage progress classification in AlSi10Mg SLM specimens by convolutional neural network and k-fold cross validation. Materials (Basel). 2022;15(13):4428. https://doi.org/10.3390/ma15134428. (published 2022 Jun 23).
Du X, Liu M, Sun Y. Cell recognition using BP neural network edge computing. Contrast Media Mol Imaging. 2022;2022:7355233. https://doi.org/10.1155/2022/7355233. (published 2022 Jul 12).
Kim M, Kim YJ, Park SJ, Bae J, Lee K, Seo Y, Kim Y. Machine learning models to identify low adherence to influenza vaccination among Korean adults with cardiovascular disease. BMC Cardiovasc Disord. 2021;21(1):129. https://doi.org/10.1186/s12872-021-01925-7. (published 2021 Mar 9).
Ding X, Zhang H, Ma C, Zhang X, Zhong K. User identification across multiple social networks based on Naive Bayes model [published online ahead of print, 2022 Sep 14]. IEEE Trans Neural Netw Learn Syst. 2022. https://doi.org/10.1109/TNNLS.2022.3202709.
Yang S, Taylor D, Yang D, He M, Liu X, Xu J. A synthesis framework using machine learning and spatial bivariate analysis to identify drivers and hotspots of heavy metal pollution of agricultural soils. Environ Pollut. 2021;287: 117611. https://doi.org/10.1016/j.envpol.2021.117611.
Zweck E, Spieker M, Horn P, Vogt C, Westermann D, Plicht B, Zimmer S, Taborski U, Dreger H, Schmitt J, Rudolph TK, Lehmkuhl L, Bauersachs J, Landmesser U, Kremer J, Schueler R. Machine learning identifies clinical parameters to predict mortality in patients undergoing transcatheter mitral valve repair. JACC Cardiovasc Interv. 2021;14(18):2027–36. https://doi.org/10.1016/j.jcin.2021.06.039.
Xia F, Li Q, Luo X, Wu J. Identification for heavy metals exposure on osteoarthritis among aging people and Machine learning for prediction: a study based on NHANES 2011–2020. Front Public Health. 2022;10:906774. https://doi.org/10.3389/fpubh.2022.906774. (published 2022 Aug 1).
Deng J, Fu Y, Liu Q, Chang L, Li H, Liu S. Automatic cardiopulmonary endurance assessment: a machine learning approach based on GA-XGBOOST. Diagnostics (Basel). 2022;12(10):2538. https://doi.org/10.3390/diagnostics12102538. (published 2022 Oct 19).
El Bilali A, Abdeslam T, Ayoub N, Lamane H, Ezzaouini MA, Elbeltagi A. An interpretable machine learning approach based on DNN, SVR, extra tree, and XGBoost models for predicting daily pan evaporation. J Environ Manag. 2023;327: 116890. https://doi.org/10.1016/j.jenvman.2022.116890.
Pruessner JC, Kirschbaum C, Meinlschmid G, Hellhammer DH. Two formulas for computation of the area under the curve represent measures of total hormone concentration versus time-dependent change. Psychoneuroendocrinology. 2003;28(7):916–31. https://doi.org/10.1016/s0306-4530(02)00108-7.
Akyea RK, Qureshi N, Kai J, Weng SF. Performance and clinical utility of supervised machine-learning approaches in detecting familial hypercholesterolaemia in primary care. NPJ Digit Med. 2020;3:142. https://doi.org/10.1038/s41746-020-00349-5. (published 2020 Oct 30).
Srour B, Fezeu LK, Kesse-Guyot E, Allès B, Debras C, Druesne-Pecollo N, Chazelas E, Deschasaux M, Esseddik Y, Latino-Martel P, Hercberg S, Touvier M, Galan P, Baudry J. Ultraprocessed food consumption and risk of type 2 diabetes among participants of the NutriNet-Santé prospective cohort. JAMA Intern Med. 2020;180(2):283–91. https://doi.org/10.1001/jamainternmed.2019.5942.
Guney M, Zagury GJ. Contamination by ten harmful elements in toys and children’s jewellery bought on the North American market. Environ Sci Technol. 2013;47(11):5921–30. https://doi.org/10.1021/es304969n.
Yin R, Yin L, Li L, Liu S, Zhan Y, Zheng X, Zhang X, Jiang X, Xu J. Hypertension in China: burdens, guidelines and policy responses: a state-of-the-art review. J Hum Hypertens. 2022;36(2):126–34. https://doi.org/10.1038/s41371-021-00570-z.
Rajkomar A, Oren E, Chen K, Dai AM, Hajaj N, Liu PJ, Liu X, Marcus J, Sun M, Sundberg P, Yee H, Zhang K, Duggan GE, Irvin J, Laird D, Shpanskaya K, Glenn DA, Shine B, McConnell MV, Chung S, Baiocchi M, Dean J. Scalable and accurate deep learning with electronic health records. NPJ Digit Med. 2018;1:18. https://doi.org/10.1038/s41746-018-0029-1. (published 2018 May 8).
Wang M, Xu Y, Pan S, Zhang J, Zhong A, Song H, Ling W. Long-term heavy metal pollution and mortality in a Chinese population: an ecologic study. Biol Trace Elem Res. 2010;142(3):362–79. https://doi.org/10.1007/s12011-010-8802-2.
Rehman K, Fatima F, Waheed I, Akash MS. Prevalence of exposure of heavy metals and their impact on health consequences. J Cell Biochem. 2019;119(1):157–84. https://doi.org/10.1002/jcb.26234.
Lawal KK, Ekeleme IK, Onuigbo CM, Ikpeazu VO, Obiekezie SO. A review on the public health implications of heavy metals. World J Adv Res Rev. 2021;10(3):255–65. https://doi.org/10.30574/wjarr.2021.10.3.0249.
Chen S, Shen R, Shen J, Lyu L, Wei T. Association of blood cadmium with all-cause and cause-specific mortality in patients with hypertension. Front Public Health. 2023;11:1106732. https://doi.org/10.3389/fpubh.2023.1106732.
Obeng-Gyasi E, Ferguson AC, Stamatakis KA, Province MA. Combined effect of lead exposure and allostatic load on cardiovascular disease mortality—a preliminary study. Int J Environ Res Public Health. 2021;18(13):6879. https://doi.org/10.3390/ijerph18136879.
Fardin PBA, Simões RP, Schereider IRG, Almenara CCP, Simões MR, Vassallo DV. Chronic mercury exposure in prehypertensive SHRs accelerates hypertension development and activates vasoprotective mechanisms by increasing NO and H2O2 production. Cardiovasc Toxicol. 2020;20(3):197–210. https://doi.org/10.1007/s12012-019-09545-6.
Kuria A, Tian H, Li M, Wang Y, Aaseth JO, Zang J, Cao Y. Selenium status in the body and cardiovascular disease: a systematic review and meta-analysis. Crit Rev Food Sci Nutr. 2021;61(21):3616–25. https://doi.org/10.1080/10408398.2020.1803200.
Al-Mubarak AA, Beverborg NG, Suthahar N, Gansevoort RT, Bakker SJ, Touw DJ, Hillege HL, de Boer RA, van der Meer P, van der Velde AR, de Borst MH, Verweij NG, Hoenderop JG, de Vries AP, Gans RO, Rienstra M, van Veldhuisen DJ, Schalkwijk CG, Voors AA, van der Harst P, van der Veen AJ, van der Meer P, Hillege HL. High selenium levels associate with reduced risk of mortality and new-onset heart failure: data from PREVEND. Eur J Heart Fail. 2022;24(2):299–307. https://doi.org/10.1002/ejhf.2405.
Meishuo O, Eshak ES, Muraki I, Cui R, Shirai K, Iso H, Tamakoshi A. Association between dietary manganese intake and mortality from cardiovascular disease in Japanese population: the Japan collaborative cohort study. J Atheroscler Thromb. 2022;30(2):152–63. https://doi.org/10.5551/jat.63195.
Choi DJ, Park JJ, Ali T, Lee S. Artificial intelligence for the diagnosis of heart failure. NPJ Digit Med. 2020;3:54. https://doi.org/10.1038/s41746-020-0261-3. (published 2020 Apr 8).
NHANES. National health and nutrition examination survey. https://wwwn.cdc.gov/Nchs/Nhanes/2017-2018/RXQ_RX_J.htm#RXDRSC1. Accessed 20 Oct 2023.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics statement
We did not take part in the participant recruiting since this analysis was based on the US NHANES’s already-available data. As far as we are aware, no patients were involved in the planning, selection, or execution of the study.
Consent for publication
Informed consent was obtained from all individual participants included in the study.
Data availability statement
The datasets that support the findings of this study are available publicly. Full lists of records identified through database searching are available on reasonable request from the corresponding author. Correspondence: schuster_ter@163.com.
Conflict of interest statement
The authors declare that they have no competing interests.
Funding statement
No funds are involved in the research project.
Author contributions
All authors contributed to designing the study. Xu S was responsible for data collection and analysis. Xu S was responsible for writing the manuscript. The corresponding author Sun attested that all listed authors meet authorship criteria. No other individuals meeting the criteria have been omitted. Sun is the guarantor. All authors have read and approved the final manuscript.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Xu, S., Sun, M. Assessment of EMR ML Mining Methods for Measuring Association between Metal Mixture and Mortality for Hypertension. High Blood Press Cardiovasc Prev (2024). https://doi.org/10.1007/s40292-024-00666-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40292-024-00666-w