
Abstract
Adaptability to change is one of the essential requirements of the supply chain for organizations in a competitive environment. Development of resilience strategies is the key to achieving this goal. Another issue in supply chains is the necessity for a way of dealing with uncertainty. Therefore, fuzzy logic and numbers have been widely used to model the uncertainty in the problems. The purpose of this paper is to facilitate supply chain management by developing a new approach in resilient supplier selection problem. In this study, after gathering the judgment of decision makers (DMs) as linguistic variables and converting them to interval-valued intuitionistic fuzzy (IVIF) numbers, the weight of each criterion is determined based on an entropy index; then, the complex proportional assessment (COPRAS) method based on IVIF numbers is used for ranking the suppliers. Objective and subjective weights are calculated to determine weights of DMs. Finally, due to the advantages of the last aggregation approaches, weights of DMs and COPRAS scores are aggregated by the weighted aggregated sum product assessment method (WASPAS). Finally, the effectiveness of the proposed method is shown by using the method in two case studies from the literature.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Supplier selection is considered as an important part of supply chain management (SCM). One of the most important actions for creating and protecting a strong relationship between customers and organization is the process of evaluation, selection and continuous improvement to the suppliers. Selection of suppliers as a complex multi-criteria decision-making (MCDM) problem addresses both qualitative and quantitative criteria [1,2,3,4,5]. It is worth noting that one of the challenges in this area is uncertainty and limitations of information and data. In recent years in the SCM, the performance of potential suppliers has been evaluated against multiple criteria rather than considering a single factor cost [6]. Despite the importance of decision-making techniques for the construction of effective decision models for supplier selection, there are very few developments in the selection of suppliers by considering resilient criteria in the SCM. However, in previous studies there have been multiple attempts on using MCDM techniques for supplier selection. Resilience, which is the ability of the system to return to its original state or a better one after being disturbed, assumes great significance in this context [7]. Resilience has become an important concept in organizational management due to the importance of investigating effects of a disaster on an organization and its reversal to the normal state [8]. In summary, resilience strategies must be developed since it is a solution to overcome disruptions.
There are limited studies on the resilient supplier selection problem. Tang [9] regarded flexible supply base as one of the primal enablers of supply chain resilience. Hamel and Valikangas [10] viewed resilience as a distinct source of sustainable competitive advantage for suppliers. Haldar et al. [11] developed a quantitative approach for strategic supplier selection under a fuzzy environment in a disaster scenario. Using this method, organizations could design resiliency plans to mitigate the vulnerability of a supply chain system. Sahu et al. [12] adapted an efficient decision support system (DSS) to facilitate evaluation and selection of resilient suppliers in fuzzy context with VIKOR approach. Haldar et al. [13] incorporated an analytic framework with technique for order of preference by similarity to ideal solution (TOPSIS) and analytic hierarchy process (AHP) for supply chain design to help decision makers (DMs) in selecting the most ideal resilient supplier under a disruption scenario.
It can be concluded from the above that resilient supplier selection has been addressed by several scholars in recent years. However, several issues are not properly considered in it. One aspect is using the right tools to address uncertainty. Classic fuzzy sets are able to address the judgments of experts in the process, but they cannot address aspects, such as disagreements and hesitancy. Moreover, addressing the membership degrees by intervals rather than crisp values is more practical under uncertain environments [14, 15]. Also, determining the weights of DMs for increasing the performance of the methodology has not been well addressed.
Given the existing gaps in resilient suppler selection, the purpose of this paper is to provide a method that effectively addresses uncertainty in supplier selection. For this reason, interval-valued intuitionistic fuzzy (IVIF) numbers have been used. Due to the difference in DMs in terms of expertise and knowledge, the importance of them based on objective and subjective weights is considered by introducing a new approach. Weights of criteria are addressed by using a mathematical approach based on the concept of entropy. Also, to use information in a more effective way, the method applies a last aggregation approach.
The rest of this paper is organized as follows. In Sect. 2, IVIFSs concepts are briefly reviewed. In Sect. 3, the proposed decision-making approach is presented and Sect. 4 presents the application of the proposed approach. To conclude the paper, Sect. 5 depicts the concluding remarks of this paper.
2 Preliminaries
Atanassov and Gargov [16] introduced the implication of IVIFSs, which are an extension of intuitionistic fuzzy sets introduced by Atanassov [17]. IVIF numbers express membership degree, non-membership degree and hesitation degree by using intervals rather than crisp values. These numbers have received increased attention in real-world applications [18]. This is due to the enhancement in management of uncertainty over some other methods that prefers definite numbers to confidence intervals. In this section, some definitions and concepts of IVIF numbers are described.
Definition 1
Let \(\tilde{\alpha }=\left( \left[ a_{1},b_{1} \right] ,\left[ c_{1},d_{1} \right] \right) , \tilde{\beta }=\left( \left[ a_{2},b_{2} \right] ,\left[ c_{2},d_{2} \right] \right) \) where \(\left[ a_{\mathrm {i}},b_{\mathrm {i}} \right] \subseteq \left[ 0,1 \right] , \left[ c_{\mathrm {i}},d_{\mathrm {i}} \right] \subseteq \left[ 0,1 \right] \) and \(0\le b_{i}+d_{i}\le 1\; \forall i\) be two IVIF numbers. Therefore, the followings are defined [16]:
The extension division operator can be defined as follows [19]:
Also, subtraction operator is defined as follows [20]:
Definition 2
Let \(\tilde{\alpha }=\left( \left[ a_{1},b_{1} \right] ,\left[ c_{1},d_{1} \right] \right) , \tilde{\beta }=\left( \left[ a_{2},b_{2} \right] ,\left[ c_{2},d_{2} \right] \right) \) be two IVIF numbers. To compare these numbers, a generalized improved score (GIS) function based on unknown degree is defined as follows [21]:
where \(\kappa _{1}+\kappa _{2}=1\) and \(\kappa _{1},\kappa _{2}\mathrm {\ge 0}\) show attitudinal characters of the GIS function. Finally, the comparison between IVIF numbers is obtained based on the following logic:
Definition 3
Let \(\tilde{A} \left\langle \left( x,\left[ {\mu _{{\tilde{A} l}} \left( x \right) ,\mu _{{\tilde{A} u}} \left( x \right) } \right] ,\left[ {\vartheta _{{\tilde{A} l}} \left( x \right) ,} { \left( x \right) } \right] ,\left[ {\pi _{{\tilde{A} l}} \left( x \right) ,\pi _{{\tilde{A} u}} \left( x \right) } \right] \right) :xX \right\rangle \) and \( \tilde{B} \left\langle \left( x,\left[ {\mu _{{\tilde{B} l}} \left( x \right) ,\mu _{{\tilde{B} u}} \left( x \right) } \right] ,\right. \right. \left. \left. \left[ {\vartheta _{{\tilde{B} l}} \left( x \right) ,\vartheta _{{\tilde{B} u}} \left( x \right) } \right] ,\left[ {\pi _{{\tilde{B} l}} \left( x \right) ,\pi _{{\tilde{B} u}} \left( x \right) } \right] \right) :xX \right\rangle \) be two IVIF numbers, while \( X\in \left\{ x_{1},x_{2},\ldots ,x_{n} \right\} ; \) then, the normalized Hamming distance operator can be defined as [22]:
Definition 4
Let \(\tilde{x_{j}}=\left( \left[ a_{j},b_{j} \right] ,\left[ c_{j},d_{j} \right] \right) (j\in N)\) be a collection of IVIFNs and \(w_{j}={(w_{1},w_{2},\ldots ,w_{n})}^{T}\) be the weight vector that \(\lambda _{j}\) implying importance degree of \(\tilde{x_{j}}\), with limitations \(w_{j}\ge 0~(j\in N)\) and \(\sum _{j=1}^n {w_{j}=1}\), and let interval-valued intuitionistic fuzzy weighted averaging (IVIFWA): \(\Phi ^{{\varvec{n}}}\rightarrow \Phi \) if [22]:
3 Proposed Method of Resilient Supplier Selection
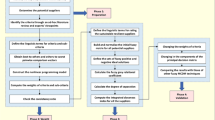
In this section, the introduced method of resilient supplier selection is presented. The method has the following main steps. First, the required data and judgments are gathered. Then, weights of criteria are computed by introducing a novel method. IVIF-COPRAS is presented to rank the suppliers based on [14]. Then, the subjective and the objective weights of DMs are computed. Finally, the scores and weights are used in an aggregation process to reach a final ranking of suppliers based on the resilience concept.
3.1 Description of Making IVIF Decision Matrices
The first step of the method consists of creating decision matrices based on experts opinions, while all matrix components are IVIF numbers. The procedure begins by forming a decision matrix that consists of criteria and alternatives for each DM. Let \(X=\left\{ x_{1},x_{2},\ldots ,x_{s} \right\} \) be a set of suppliers and \(C=\left\{ c_{1},c_{2},\ldots ,c_{n} \right\} \) be a set of criteria. Let \(D=\left\{ d_{1},d_{2},\ldots ,d_{g} \right\} \) be a set of DMs. Suppose that \(\tilde{M}^{(k)}{=\left( \tilde{m}_{ij}^{(k)} \right) }_{s\mathrm {\times }n}\)is an IVIF decision matrix, where \(\tilde{m}_{ij}^{(k)}\) is score of supplier \(x_{i}\) with respect to criterion \(c_{j}\) that is expressed by the \(d_{k}\mathrm {. }\tilde{m}_{ij}^{(k)}\) is displayed as follows:
In Eq. (12), \(\tilde{\mu }_{ij}^{\left( k \right) },\tilde{\vartheta }_{ij}^{\left( k \right) }\;\text {and}\;\tilde{\pi }_{ij}^{\left( k \right) }\) are closed intervals and represent membership degree, non-membership degree and hesitation degree, respectively. For each element \(\tilde{m}_{ij}^{(k)}\), the hesitation degree is obtained as follows:
3.2 Description of Computing Criteria Weights
Step 1: Normalize the decision matrix
The first step is to normalize the \( \tilde{M}^{(k)}{=\left( \tilde{m}_{ij}^{(k)} \right) }_{s\times n}\) matrix with a linear method. The criteria are categorized into two sections of profit criteria (subset B) and cost criteria (subset C). Normalized matrix \(\tilde{N}^{(k)}{=\left( \tilde{n}_{ij}^{(k)} \right) }_{s\times n}\)can be determined as follows:
where \(\tilde{n}_{ij}^{(k)}\) is obtained based on Eqs. (15)–(19).
The lower bound of membership degree for \(\tilde{n}_{ij}^{(k)}\) is denoted by \(\dot{\mu }_{ij}^{-(k)}\) and calculated based on Eq. (16).
The upper bound of membership degree for \(\tilde{n}_{ij}^{(k)}\) is denoted by \(\dot{\mu }_{ij}^{+(k)}\) and calculated based on Eq. (17).
The lower bound of membership degree for \(\tilde{n}_{ij}^{(k)}\) is denoted by \(\dot{\vartheta }_{ij}^{\mathrm {-(}k)}\) and calculated based on Eq. (18).
The upper bound of membership degree for \(\tilde{n}_{ij}^{(k)}\) is denoted by \(\dot{\vartheta }_{ij}^{\mathrm {+(}k)}\) and calculated based on Eq. (19).
Step 2: Calculate the entropy matrix.
Entropy is used to measure uncertainty in the system. This concept, as an objective approach, can be used instead of subjective approaches (e.g., AHP) for determining weights. However, its output includes more realistic results. In many studies, entropy method has been used to determine the weights [23, 24]. This method is used to compute uncertainty in information in terms of probability theory.
\(E\left( \tilde{m}_{ij}^{\left( k \right) } \right) \) is the entropy of \(\tilde{m}_{ij}^{\left( k \right) }\) and is defined based on Eq. (20) [25].
where \(\pi _{F_{Q}\left( \tilde{n}_{ij}^{(k)} \right) }=1-F_{Q}\left( \tilde{\dot{\mu }}_{ij}^{\left( k \right) } \right) -F_{Q}\left( \tilde{\dot{\vartheta }}_{ij}^{\left( k \right) } \right) \); \(F_{Q}\left( \tilde{\dot{\mu }}_{ij}^{\left( k \right) } \right) =F_{Q}\left( \left[ \dot{\mu }_{ij}^{-(k)},\dot{\mu }_{ij}^{+(k)} \right] \right) =\lambda \dot{\mu }_{ij}^{-(k)}+(1-\lambda )\dot{\mu }_{ij}^{+(k)}\); \(\lambda \) is the attitudinal character of Q [26].
Equation (20) can also be calculated as follows:
Step 3: Calculate the divergence index.
According to the entropy theory, if the entropy value for a criterion is smaller across alternatives, the criterion should be assigned a bigger weight; thereupon, the higher value of divergence index shows more importance of relevant criterion [25, 27].
Divergence index is computed in Eq. (22).
Step 4: Calculate the normalized weights.
In cases where DMs have incomplete information about weights, the following linear programming model is used.
Otherwise, if no information is available, weights of the criteria are obtained by Eq. (27).
3.3 Description of Ranking Based on IVIF-COPRAS Method
Since the method is last aggregation, the following is applied for each DM separately. This approach avoids information loss caused by early aggregations.
Step 1: Calculate the weighted normalized IVIF assessment matrix \(\tilde{\hat{N}}^{(K)}\).
where
Step 2: Calculate the \(B_{i}^{(k)}\) index for each supplier and DM, while incorporating criteria are benefit ones.
where p represents the number of profit criteria.
Step 3: Calculate \(C_{i}^{(k)}\) index for each supplier and DM, while incorporating criteria are cost ones.
where \(n-p\) represents the number of cost criteria.
Step 4: Calculate the relative weight of each alternative based on the following formula.
where \(\hbox {GIS}\left( \tilde{C}_{i}^{(k)} \right) \) and \( \hbox {GIS}\left( \tilde{B}_{i}^{(k)} \right) \) are scores of \(\tilde{C}_{i}^{(k)}\) and \(\tilde{B}_{i}^{(k)}\), respectively. The formula for calculating the GIS function is shown in Eq. (7).
Step 5: Choose a supplier with the highest priority over others; in other words, determine the maximum \(Q_{i}\) for each DM (\(Q_{max}^{(k)}=\mathop {\max }\limits _{i}Q_{i}^{(k)})\). As a result, the above alternative may vary for each DM.
Comparison of IVIF numbers is performed by the method of Garg [21] presented in Eq. (7).
Step 6: Calculating the utility degree of each alternative.
It is worth noting that an alternative that has a higher \(D_{i}^{(k)}\) has a higher priority than others.
As a result, the following matrix is obtained
3.4 Calculate Weights of the DMs
In the presented approach, the DMs’ weight computations proposed by Liu and Li [28] are extended under an interval-valued intuitionistic fuzzy environment.
3.4.1 Calculate Subjective Weights of the DMs
Weights of DMs can be divided into subjective and objective weights. Subjective weights are related to known information, like the level of familiarity with the issue at hand. The subjective weights are obtained by comparing the scores of each alternative by each DM against the criteria.
\(T_{fr}\) is defined as relative importance index of \(d_{f}\) from the point of view of \(d_{r}\) and its calculation is expressed in Eq. (34).
The overall importance index is obtained from the sum of relative importance indicators. The overall importance index for fth DM is represented by \(T_{f}\) and is calculated based on Eq. (35).
The larger the index \(T_{fr}\), the closer the two DMs (f and r) to each other and hence the larger the index \(\mathrm {T}_{f},\) implying a higher subjective weight. Eventually, the normalized subjective weights for fth DM are calculated based on Eq. (36).
3.4.2 Calculate Objective Weights of the DMs
The quality of each DM’s judgment is related to objective weight. In other words, the intensity of the DMs agreement with the group determines its objective weight. The weighted average matrix is defined as the ideal matrix, and the judgment information of each DM is compared with it [29]. The weighted average matrix is defined as \(\tilde{A}=\left( \tilde{a}_{ij} \right) _{s\mathrm {\times }n}\) and is calculated in Eq. (37):
Based on the above matrix, \(\gamma _{f}\) is defined as the degree of similarity index of fth DM to the group of DMs.
The normalized objective weight for fth DM is calculated in Eq. (39).
Let \(\rho _{f}\) be the fth DM’s integrated weight, while \(\alpha ,\beta >0\) and \(\alpha \mathrm {+}\beta \mathrm {=1}\). These values can be varied according to the type of each problems. The integrated weight of fth DM is computed in Eq. (40).
Finally, normalized integrated weight is obtained according to Eq. (41).
3.5 Description of Aggregation Based on WASPAS Method
The aim of this step is to rank suppliers based on the computed values of D utility degrees and weights of DMs, using WASPAS method [30]. Aggregated rankings are obtained in Eq. (42).
where \(\varGamma \in \left[ 0,1 \right] \)
The higher \(\zeta _{i}\) for each supplier expresses the higher priority of the supplier in the assessment process.
4 Applying the Introduced Resilient Supplier Selection
In this section, the effectiveness of the proposed method in the field of selection of resilient suppliers is shown, and the results of the proposed method are compared with the results of the study by Haldar et al. [11] and Sahu et al. [12] in two case studies, respectively. Table 1 is used to convert the linguistic variables to IVIF numbers for creating decision matrix. It should be noted that these values are also applied by Zavadskas et al. [30].
4.1 The First Case Study
An automobile giant wishes to develop a proactive resiliency strategy to rank suppliers as its commitment to the global market. As a result based on study of Haldar et al. [11], four DMs have assessed candidate suppliers according to five criteria, and the results are shown in Table 2.
Existing criteria include: product quality (C1), reliability of the product (C2), functionality of the product (C3), customer satisfaction (C4) and cost of the product (C5). C5 is a cost criterion, and C1, C2, C3 and C4 are profit criteria.
The results of the implementation of the algorithm for the general criteria are shown in Tables 3, 4 and 5, while the values of the parameters are: \( \kappa _{1}=\kappa _{2}=0.5,\alpha =\beta =0.5,\lambda =0.6,\varGamma =0.4.\)
Table 3 shows the information related to determining the weight of each DM according to general criteria. In Table 4, weights of general criteria are shown.
Also, the choice of suppliers according to three strategic planning criteria under flexible strategy is the next step. Three strategic planning criteria are considered in developing resiliency in the supply chain systems. These resiliency criteria include:
-
Investment in capacity buffers (R1)
-
Responsiveness (R2)
-
Capacity for holding strategic inventory stocks for crises (R3)
The judgments of DMs in order to rank suppliers based on the resiliency criteria are shown in Table 6.
The final output of the proposed method for the resiliency criteria is shown in Tables 7, 8 and 9. The ranking of suppliers under the resiliency strategy is shown in Table 9. Table 7 shows the information related to determining the weight of each DM according to resiliency criteria. In Table 8, weights of resiliency criteria are presented.
Comparing the results of Table 10 shows that \( A_{2}\) is a the best supplier. Haldar et al. [11] have used the linear combination of normalized rates for ranking suppliers. Sensitivity analysis shows that \({ A}_{2}\) is the best supplier which has a greater closeness coefficient for both strategies. The proposed method presents similar results without the matrix of the importance of criteria from DMs. The parameters of the problem do not have an excessive impact on the results which indicates that this method is more efficient.
4.2 The Second Case Study
In this subsection, the case study presented by Sahu et al. [12] is used. This section includes five DMs, three criteria and five suppliers. The suppliers’ assessment matrix is shown in Table 11.
The results of the suppliers’ ranking with two methods of Sahu et al. [12], and the proposed method are shown in Table 12.
The results of both methods are exactly the same. In addition, based on the \({{\hbox {OSI}}}_{{\hbox {NRi}}}\) index, \(S_{2}\) and \(S_{5}\) are close together, and their difference is less than 0.05. The similarity of these two suppliers is confirmed based on \(\zeta _{i}\) index as their difference is 0.04. In other words, both methods indicate that \(S_{2}\) and \(S_{5}\) are in the same group as \(S_{{2}}\) has little precedence over \(S_{5}\).
5 Conclusion
Supplier selection is an important task in supply chain management. Numerous individual and integrated approaches were proposed to solve the supplier selection problem. Disruptions and delays are big threats for the success of supply chains. One approach to address disruptions in supply chains is considering resilience. Resilient supplier selection is a new research and application direction. In this paper, a new method of resilient supplier selection was introduced. The presented method applied IVIFSs to address uncertainty in supply chain environments. Moreover, the suggested method applied entropy measure and a new mathematical model to address weights of criteria. Moreover, IVIF-COPRAS was used to rank the suppliers for each expert. Weight of each expert was computed by considering the subjective and the objective approach. In order to display the applicability of this approach, two case studies from the literature were adopted and solved. For future studies, applying this method in other real-world applications, such as project selection and strategy selection, could be interesting.
References
Rajesh, R.; Ravi, V.: Supplier selection in resilient supply chains: a grey relational analysis approach. J. Clean. Prod. 86, 343–359 (2015)
Gitinavard, H.; Foroozesh, N.; Mousavi, S.M.; Mohagheghi, V.: Soft computing based on a selection index method with risk preferences under uncertainty: applications to construction industry. Int. J. Comput. Syst. Eng. 4(4), 238–247 (2018)
Vahdani, B.; Mousavi, S.M.; Tavakkoli-Moghaddam, R.; Hashemi, H.: A new enhanced support vector model based on general variable neighborhood search algorithm for supplier performance evaluation: a case study. Int. J. Comput. Intell. Syst. 10, 293–311 (2017)
Foroozesh, N.; Gitinavard, H.; Mousavi, S.M.; Vahdani, B.: A hesitant fuzzy extension of VIKOR method for evaluation and selection problems under uncertainty. Int. J. Appl. Manag. Sci. 9(2), 95–113 (2017)
Foroozesh, N.; Tavakkoli-Moghaddam, R.; Mousavi, S.M.: Sustainable-supplier selection for manufacturing services: a new failure mode and effects analysis model based on interval-valued fuzzy group decision-making. Int. J. Adv. Manuf. Technol. 95(9–12), 3609–3629 (2018)
Ho, W.; Xu, X.; Dey, P.K.: Multi-criteria decision making approaches for supplier evaluation and selection: a literature review. Eur. J. Oper. Res. 202(1), 16–24 (2010)
Christopher, M.; Peck, H.: Building the resilient supply chain. Int. J. Logist. Manag. 15(2), 1–14 (2004)
Azadeh, A.; Abdollahi, M.; Farahani, M. H.; Soufi, H.R.: Green-resilient supplier selection: an integrated approach. In: International IEEE Conference, Istanbul. July 26 (Vol. 28) (2014)
Tang, C.S.: Perspectives in supply chain risk management. Int. J. Prod. Econ. 103(2), 451–488 (2006)
Hamel, G.; Valikangas, L.: The quest for resilience. Revista Icade. Revista de las Facultades de Derecho y Ciencias Económicas y Empresariales 62, 355–358 (2004)
Haldar, A.; Ray, A.; Banerjee, D.; Ghosh, S.: Resilient supplier selection under a fuzzy environment. Int. J. Manag. Sci. Eng. Manag. 9(2), 147–156 (2014)
Sahu, A.K.; Datta, S.; Mahapatra, S.S.: Evaluation and selection of resilient suppliers in fuzzy environment: exploration of fuzzy-VIKOR. Benchmark. Int. J. 23(3), 651–673 (2016)
Haldar, A.; Ray, A.; Banerjee, D.; Ghosh, S.: A hybrid MCDM model for resilient supplier selection. Int. J. Manag. Sci. Eng. Manag. 7(4), 284–292 (2012)
Mohagheghi, V.; Mousavi, S.M.; Vahdani, B.: A new multi-objective optimization approach for sustainable project portfolio selection: a real world application under interval-valued fuzzy environment. Iranian J. Fuzzy Syst. 13(6), 41–68 (2016)
Mohagheghi, V.; Mousavi, S.M.; Aghamohagheghi, M.; Vahdani, B.: A new approach of multi-criteria analysis for the evaluation and selection of sustainable transport investment projects under uncertainty: a case study. Int. J. Comput. Intell. Syst. 10, 605–626 (2017)
Atanassov, K.; Gargov, G.: Interval-valued intuitionistic fuzzy sets. Fuzzy Sets Syst. 31, 343–349 (1989)
Atanassov, K.T.: Intuitionistic fuzzy sets. Fuzzy Sets Syst. 20(1), 87–96 (1986)
Chen, T.Y.: IVIF-PROMETHEE outranking methods for multiple criteria decision analysis based on interval-valued intuitionistic fuzzy sets. Fuzzy Optim. Decis. Mak. 14(2), 173–198 (2015)
Li, D.F.: Extension principles for interval-valued intuitionistic fuzzy sets and algebraic operations. Fuzzy Optim. Decis. Mak. 10(1), 45–58 (2011)
Zhao, H.; Xu, Z.; Yao, Z.: Interval-valued intuitionistic fuzzy derivative and differential operations. Int. J. Comput. Intell. Syst. 9(1), 36–56 (2016)
Garg, H.: A new generalized improved score function of interval-valued intuitionistic fuzzy sets and applications in expert systems. Appl. Soft Comput. 38, 988–999 (2016)
Zhang, X.; Xu, Z.: Soft computing based on maximizing consensus and fuzzy TOPSIS approach to interval-valued intuitionistic fuzzy group decision making. Appl. Soft Comput. 26, 42–56 (2015)
Dorfeshan, Y.; Mousavi, S.M.: A new interval type-2 fuzzy decision method with an extended relative preference relation and entropy to project critical path selection. Int. J. Fuzzy Syst. Appl. 8(1), 19–47 (2019)
Chou, Y.C.; Yen, H.Y.; Sun, C.C.: An integrate method for performance of women in science and technology based on entropy measure for objective weighting. Qual. Quant. 48(1), 157–172 (2014)
Jin, F.; Pei, L.; Chen, H.; Zhou, L.: Interval-valued intuitionistic fuzzy continuous weighted entropy and its application to multi-criteria fuzzy group decision making. Knowl. Based Syst. 59, 132–141 (2014)
Yager, R.R.: OWA aggregation over a continuous interval argument with applications to decision making. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 34(4), 1952–1963 (2004)
Shemshadi, A.; Shirazi, H.; Toreihi, M.; Tarokh, M.J.: A fuzzy VIKOR method for supplier selection based on entropy measure for objective weighting. Expert Syst. Appl. 38(10), 12160–12167 (2011)
Liu, W.; Li, L.: An approach to determining the integrated weights of decision makers based on interval number group decision matrices. Knowl. Based Syst. 90, 92–98 (2015)
Yue, Z.: A method for group decision-making based on determining weights of decision makers using TOPSIS. Appl. Math. Model. 35(4), 1926–1936 (2011)
Zavadskas, E.K.; Antucheviciene, J.; Hajiagha, S.H.R.; Hashemi, S.S.: Extension of weighted aggregated sum product assessment with interval-valued intuitionistic fuzzy numbers (WASPAS-IVIF). Appl. Soft Comput. 24, 1013–1021 (2014)
Acknowledgements
The authors would like to thank anonymous referees for their valuable comments that have led to improvements.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Davoudabadi, R., Mousavi, S.M., Mohagheghi, V. et al. Resilient Supplier Selection Through Introducing a New Interval-Valued Intuitionistic Fuzzy Evaluation and Decision-Making Framework. Arab J Sci Eng 44, 7351–7360 (2019). https://doi.org/10.1007/s13369-019-03891-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-019-03891-x