
Abstract
In clinical treatment, deep learning plays a pivotal role in medical image classification. Deep learning techniques provide opportunities for radiologists and orthopedic to ease out their lives with faster and more accurate results. The traditional deep learning approach nevertheless reached its performance ceiling. Therefore, in this paper, we investigate different enhancement techniques to boost the deep neural networks performance and provide a solution as BoostNet. The experiment is categorized into four different phases. We have selected ChampNet from benchmark deep learning models (EfficientNet: B0, MobileNet, ResNet18, VGG19). This phase helps to obtain the best model. In the second phase, The ChampNet evaluates with different resolution datasets. This phase helps to finalize the dataset resolution to enhance the performance of ChampNet. In the third phase, Champ-Net merges with image enhancement techniques, Contrast Limited Adaptive Histogram Equalization (CLAHE), High-frequency filtering (HEF), and Unsharp masking (UM). This phase helps to obtain Boost-Net with enriched performance. The last phase helps us to verify BoostNet results with Lightness Order Error. The presented research work fuses the image enhancement technique with ChampNet to generate BoostNet models. An assessment was performed on the Musculoskeletal Radiograph Bone Classification using classification schemes to demonstrate the proposed model's performance. The Classification accuracy of BoostNet was for the train a test dataset with and without enhancement techniques. The proposed model ChampNet + CLAHE, ChampNet + HEF, ChampNet + UM approach achieved 95.88%, 94.99%, and 94.18% accuracy, respectively. This experiment leads to a more accurate and efficient classification model. The main aim of this paper is to enhance techniques to boost the deep neural networks performance and provide a solution as BoostNet.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In medical imaging, a wide variety of studies have been conducted using different models of deep neural networks (DNNs) to classify or diagnose diseases. Technologies such as DNNs and computer vision have already demonstrated the ability to recognize images and exceed human accuracy. Beside, the remarkable success in recent years of deep learning models (DLMs) in image classification, segmentation, and detection tasks, connects to an era of significant use for diagnostic medical imaging. However, the availability of large datasets with reliable ground-truth analysis is a major issue in medical imaging.
DLMs have contributed to a series of breakthroughs in the task of image classification (Krizhevsky et al. 2009, 2012). The DLMs utilities low, mid, and high-level features (Zeiler and Fergus 2014). Bundy A., & Wallen, L. et al. shows that the depth of a network model is of critical importance for challenging datasets. The issue of shallow vs. deep networks has long been argued for a long time in DLMs. Training of very deep learning models raises the issue of diminishing feature reuse (Zagoruyko and Komodakis 2017). This makes the training process cumbersome to train these models. González-Villà, S., Oliver et al. design a deep learning model with a perfect balance between resolution, depth, and width to achieve better accuracy and less error in training loss.
The public health sector is a highly critical sector where health professionals perform most interpretations of medical data. Advanced study of deep learning models reduced the complexity of the analysis of various medical images (Razzak et al. 2018). Image enhancement is an essential component of preprocessing. It is therefore important to examine the association between image improvement and the deep learning approach. He, K., Zhang, X., Ren et al. the authors employed on grayscale ImageNet dataset to pretrain, the Inception-V3 model tested on single-channel medical chest X-ray dataset outperformed both in terms of accuracy and speed. The DLMs ResNet-50 and DenseNet-161 approach a transfer learning methodology for the histopathology Kimia Path24 dataset, color, and grayscale image dataset. The DenseNet-161 uses a grayscale dataset, and the ResNet-50 uses a color dataset (Talo 2019). A novel DLMS implements split-transform-merge block (STM) and RE-based feature extraction to detect COVID-19 pneumonia (Shereen et al. 2020). Deep learning automated detection of medical imaging has shown promising results (Dou et al. 2021).
We propose a BoostNet DLM approach to improve the performance of musculoskeletal radiographs X-ray images. The highlight of this research is to assess the impact of three different image enhancement techniques (CLAHE, HEF, and UM) on DLMs for medical musculoskeletal radiographs X-ray images so that it helps to provide better opportunities for radiologists and orthopedic to ease out their lives with faster and more accurate results. The paper is organized into six different sections as follows: the most crucial related works described in the second section. In the third section, we have discussed the materials and methods used for the proposed model. In the fourth section, we have elaborated on the proposed model. In the fifth section, we have explained the simulation results and validation in detail. In the last section, we have discussed the conclusion and future scope.
2 Related work
Howard, A. G. et al. DLM is to investigate the efficiency of the model by increasing the depth (16–19 layers) on dataset ImageNet Challenge 2014. As the model layer extends to the 19th layer, the error rate of the deep learning model is saturated. To ease out the training of substantially deeper networks, the authors have developed a residual learning model (He et al. 2016a). The model has achieved an error rate of 3.57 % on the ImageNet test dataset (He et al. 2016b). In (He et al. 2016a) authors have suggested the propagation formulation for a deep learning model to transmit backward and forward pass directly from block to block. In Howard et al. (2017) two hyper-parameter resolution and width multiplier, the model creator can develop the best size model based on the problem, that is, a constraint. In (Tan and Le 2019) the authors suggested an appropriate scaling approach, which uniformly scales all three parameters width/depth/resolution dimensions using a compound coefficient (Jairath et al. 2021).
The authors have applied a transfer learning approach to both the deep learning models DenseNet-161 and ResNet-50 without a fully connected layer (Talo 2019). The research work was carried out on the Kimia Path24 dataset, both grayscale and colored format. The DenseNet-161 utilizes a grayscale dataset to achieve a classification accuracy of 97.89%, and the ResNet-50 utilizes a color dataset to achieve a classification accuracy of 98.87%. The authors Jaderberg, M. et al. Jaderberg, M. et al. presented a new version of the ResNet model. In this model, the authors have eliminated the global average pooling layer and added an adaptive drop-out. The Montgomery County Chest X-ray to achieve a classification accuracy of 87.71%, NIH X-ray set to achieve a classification accuracy of 62.9%, and the Shenzhen chest X-ray to attain a classification accuracy of 81.8%.
The authors Triwijoyo et al. (2020) have worked on the STARE dataset. The dataset is resized into three different datasets 31 × 35, 46 × 53, and 61 × 70 pixels classified with 15 different eye diseases. The studies have shown that input datasets with size 31 × 35 and 61 × 71 pixels have achieved the highest training accuracy and the input test dataset with size 31 × 35 with an accuracy of 80.93%. The authors Mahbod et al. (2020) study dermoscopic image dataset with different resolution sizes ranging from 64 × 64 to 768 × 768 pixels. Various deep learning models trained on DenseNet-121, ResNet-50, and ResNet-18. The author Dorffner, G., & Ellinger, I. et al. concludes the work as the classification performance significantly reduced on small-sized dataset 64x64 pixels and shows significant improvement with the dataset with size 128×128 pixels.
In Shin and Jung (2013) the edge area was improved by applying a high-frequency pass (emphasis) filter to the X-ray medical imaging field. To enhanced the edge and contrast of the X-ray image, the Gaussian high-pass filter is used with the optimized value offseta = 0.5 and cutoff frequencya = 0.05. In González-Villà et al. (2020) author has proposed a two-stage fusion approach (m-NLSS and m-JLF) for improving brain segmentation performance. In Sahu et al. (2019) author has designed a model to remove the noise (Wiener Filter, Median Filter, Average Filter, Weighted Median Filter, Gaussian Filter) and enhance (CLAHE) the color fundus image. The Weighted Median filter combines with the CLAHE technique gives a 7.85% improvement in Peak Signal to Noise Ratio (PSNR). P. K., & Yadav, D. et al. author has discussed a new nonlinear UM enhancement technique (NLUM). NLUM can help boost the diagnosis and treatment by increasing fine details in mammograms.
3 Materials and methods for the proposed model
3.1 Bone X-ray image dataset
The musculoskeletal radiograph (MURA) is a collection of a total of 40561 image and bone X-ray images. The dataset contains 55.63% normal and 44.36 % abnormal X-ray images. This dataset was published by Rajpurkar et al. (2017) the most popular X-ray dataset (Rakhra et al. 2021). We have reorganized the MURA dataset into musculoskeletal radiograph bone classification (MURA-BC) for our experiments. The data set is organized into two folders (train and test), and each folder contains seven subfolders for each study, shoulder, elbow, humerus, finger, wrist, and hand. Only normal X-rays were extracted from the MURA dataset. The MURA-BC X-ray dataset details listed in Table 1.
3.2 Deep learning benchmark models
The key technical points about benchmark deep learning models are discussed below:
-
Efficientnet B0: In Tan and Le (2019) author has proposed the efficientnet model based on the scaling theory for deep learning models. The three scaling factors taken into account are depth, width, and resolution. We have implemented this efficientnet (efficientnet: B0) baseline model for our research purposes.
-
MobileNet: MobileNet is a lightweight and effective model (Howard et al. 2017). This model is designed to overcome challenges on the hardware level, such as limited memory, energy, and power. The model was designed for depth-wise separable convolution. These hyper-parameters help the model builder to select the appropriate DLM size for the framework depending on the problem constraints.
-
ResNet18: In He et al. (2016a) author have submitted the ResNet model to the ImageNet Competition (ILSVRC) in 2015, and 152 layers 8 × deeper VGG nets were a winner in the Image NetChallenge. Two essential features implemented are dropout and batch normalization. At the network edge, the architecture also lacks fully connected layers.
-
VGG-19: The VGG-19 model contains 19 trainable layers including convolutional and fully connected layers as well as max pooling, and dropout (Simonyan and Zisserman 2014). The DLMs classify 1000 different object categories (mice, keyboards, pencils, and various animals, etc.). As a result, the DLM has mastered the rich features of classification for a wide range of images (Setiawan et al. 2019). The network has an image scale of 224-by-224. The research shows that network depth is an essential component for improved performance (Zhang et al. 2015). The drawback of VGGNet is that the assessment is costly higher and requires much more memory to handle 19.6 billion FLOPs and approx. 143 million parameters.
3.3 Image enhancement techniques
The mathematical strength of different types of image enhancement techniques is discussed below:
-
CLAHE: CLAHE image enhancement technique (Zuiderveld 1994), Input image (\(I_{Orignal}\)) is divided into non-overlapping \({ }(R_{{\text{contextual }}}\)) regions called sub image, titles, and blocks (Setiawan et al. 2019). The CLAHE method has primarily two key parameters: Clip limit (\(C_{limit}\)) and non-overlapping regions \({ }(R_{{\text{contextual }}} )\). These two parameters mainly control the enhanced image quality. \({\text{N}}_{{{\text{av}}}}\) is average number of pixels in each gray level calculated as depicted in (1).
$$N_{av} = \frac{{N_{crX} \times { }N_{crY} }}{{N_{g} }}$$(1)
where \({\text{N}}_{{\text{g}}} = { }\) Gray levels number in the \({ }R_{{\text{contextual }}}\), \(N_{crX} =\) Pixels number in the x dimensions of \({ }R_{{\text{contextual }}}\), \({\text{N}}_{{{\text{crY}}}} =\) Pixels number in the y dimensions of \(R_{{\text{contextual }}}\).the actual clip limit \((C_{limit}\)) is computes as depicted in
where \(N_{c} = { }\) maximum multiple of average pixels in gray level of \({ }R_{{\text{contextual }}}\), \(N\sum c\) = total number of clipped pixels. The number of pixels distributed averagely at each gray level is computed as depicted in (3).
The \({\text{Pd}}\) distributed pixel is computed as depicted in (4).
where \(N_{lp}\) denotes the remaining number of clipped pixels.
-
HEF: HEF is an enhancement technique that employs a Gaussian filter to enhance the edges in the input image (Bundy and Wallen 1984). The edges emerge presented in the high-frequency variety as they have more shifts that are dramatic in intensity (Deshmukh et al. 2021). This enhancement technique generates a low contrast-enhanced image and implements the Histogram Equalization method to improve contrast and sharpness. In the algorithm, the radius represents sharpness intensity. The original image is implemented through the Fourier transformation and the filter function. After the inverse transformation, we will have a filtered image. Secondly, the contrast of the image is in tune with histogram equalization. The Gaussian high pass filter is calculated as depicted in (5)
$${\text{Gau}}_{{\_{\text{filter}}\left( {{\text{x}},{\text{y}}} \right)}} = 1 - {\text{e}}^{{ - {\text{D}}^{2} \left( {{\text{x}},{\text{y}}} \right)/2{\text{D}}_{0}^{2} }}$$(5)where D0 denotes the cut-off distance, and the \({\text{F}}\left( {{\text{i}},{\text{j}}} \right)\) denotes Fourier transform computed as depicted in (6)
$${\text{F}}\left( {{\text{i}},{\text{j}}} \right) = \mathop \sum \limits_{{{\text{x}} = 0}}^{{{\text{h}} - 1}} \mathop \sum \limits_{{{\text{y}} = 0}}^{{{\text{w}} - 1}} {\text{f}}\left( {{\text{x}},{\text{y}}} \right){\text{e}}^{{ - {\text{j}}2{\uppi }\left( {\frac{{{\text{ix}}}}{{\text{h}}} + \frac{{{\text{jy}}}}{{\text{w}}}} \right)}}$$(6)where x and i = 0, 1,2, ……h-1 and y and j = 0,1,2, ……w-1, \({\text{F}}\left( {{\text{x}},{\text{y}}} \right)\) denotes inverse Fourier transform computed as depict in (7):
$${\text{F}}\left( {{\text{x}},{\text{y}}} \right) = \frac{1}{{{\text{hw}}}}\mathop \sum \limits_{{{\text{x}} = 0}}^{{{\text{h}} - 1}} \mathop \sum \limits_{{{\text{y}} = 0}}^{{{\text{w}} - 1}} {\text{f}}\left( {{\text{i}},{\text{j}}} \right){\text{e}}^{{ - {\text{j}}2{\uppi }\left( {\frac{{{\text{ix}}}}{{\text{h}}} + \frac{{{\text{jy}}}}{{\text{w}}}} \right)}}$$(7)
-
UM: UM is an image enhancement technique that sharpens the original image (Polesel et al. 2000). The sharp details are calculated as the difference between the original and its Gaussian blur image. These collected details are then scaled and added back to the original image. At the beginning of this technique, Gaussian blur is applied to the input image (Shin and Jung 2013; Simonyan and Zisserman 2014). The radius and amount are two important parameters for Gaussian blur (Ramponi 1998). The size of the edge to be increased is affected by the radius. The amount is a factor of lightness or darkness contrast is added to the edges obtained through the equation as depicted in (8).
$$G\left( {x,y} \right) = \frac{1}{{2\pi \sigma^{2} }}e^{{ - \frac{{x^{2} + y^{2} }}{{2\sigma^{2} }}}}$$(8)where x and y denote the horizontal and vertical distance from the source, σ denotes the Gaussian distribution standard deviation. \({\text{I}}_{{\_{\text{enhanced}}}}\) is an enhanced image obtained through the equation as depicted in (9)
$${\text{I}}_{{\_{\text{enhanced}}}} = {\text{ I}}_{{\_{\text{orignal}}}} + {\text{contrast}}\_{\text{value*}}\left( {{\text{I}}_{{\_{\text{blur}}}} } \right)$$(9)where \({\text{I}}_{{\_{\text{orignal}}}} { }\) the original image, and \({\text{I}}_{{\_{\text{blur}}}}\) unsharp image.
4 Proposed work
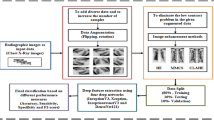
There are four major phases of the proposed model: Image preprocessing, benchmark DLMs training from scratch & validation, ChampNet processed with different resolution datasets and applied image enhancement techniques. The highlights of the proposed model are to select the ChampNet from the benchmark deep learning model and implement image enhancement techniques to boost the ChampNet performance. Lightness Order Error (LoE) validates the performance of BoostNet = ChampNet + image enhancement technique. Figure 1 depicts the block design of our suggested paradigm.

Block design of our suggested paradigm
4.1 Research environment
The research work is carried out in the virtual environment. The host virtual machine is equipped with Ubuntu operating system, 12 GB RAM, and six virtual CPUs from the Intel Xeon silver 2.10 GHZ processor server. Python 3.0 is used for the implementation of the proposed model.
4.2 Image preprocessing
The Pre-processing X-ray images improve the key details of the raw image. The image-preprocessing two-step process dataset generation and transformation.
4.3 Dataset generation
In this phase, The MURA-BC X-ray dataset has been used in various pixel estimation dataset generation such as 32 × 32, 40 × 40, 48 × 48, 56 × 56, 64 × 64, 72 × 72, 80 × 80, 88 × 88 pixels. The MURA-BC X-ray dataset arranges in two folders: train and test. The train folder contains a total no of 21,935 and the test folder contains a total no of 630 X-ray images from seven different classes.
4.4 Transformation
In this phase, the training dataset is randomly cropped with 4 padding and X-ray images are randomly flipped horizontally. This technique provides an edge on the test dataset. The unseen X-ray image dataset captured for the test set can be in a random fashion. The normalization method is used to reduce unwanted noise or distortion signals. The X-ray image captured through the image modality system may be incomplete and devoid of essential details, such as irregular staining and poor contrast (Q et al. 2020).
4.5 Benchmark deep learning models training
The training of the benchmark deep learning model (EfficientNet: B0, MobileNet, ResNet18, VGG19) has been performed from scratch. The MURA-BC 32 × 32 X-ray image dataset has been used for training, validation, and testing purposes. This phase will help us to determine the best model from the benchmark is deep learning model (Mahajan et al. 2021).
4.6 ChampNet processed with different resolution datasets
In this phase, we have determined the performance of the deep learning model processed with different resolution datasets 40 × 40, 48 × 48, 56 × 56, 64 × 64, 72 × 72, 80 × 80, 88 × 88 pixels. The experiment performed in this phase is to select the resolution of the dataset for which the model performance gets stable in terms of training time and accuracy.
4.7 Image enhancement techniques
The Image enhancement phase is an essential aspect of our proposed model. The main aim of this phase is to boost the performance of the deep learning model and figure out the best enhancement techniques for the bone X-ray images. In this paper, total three enhancement techniques, CLAHE, HEF, UM are implemented. Table 2 contains the detailed parameters of the enhancement techniques. In Fig. 2, we demonstrate the outcomes of enhancement techniques implemented on some of the original X-ray images and Fig. 3 shows a histogram of randomly selected elbow images from the MURA-BC dataset.

Enhancement technique outcomes

Histogram of randomly Elbow image from MURA-BC
5 Simulation, results, and validation
From the above applied methodologies, it can be seen that the histogram for randomly Elbow image from MURA-BC for different models shows some variation which can be detected by simulating the above results and then comparing the results to find best one. The simulation of the proposed model is categorized in three major phases: benchmark deep learning model training & validation, ChampNet processed with different resolution dataset, implementation of image enhancement techniques on ChampNet, and the simulation of these three phases has been performed on Python 3.0. The model evaluation and validation explained in subsections.
5.1 Model evaluations
The performance of our model evaluated using accuracy \(\left( {A_{cc} } \right)\) and Cross-entropy error rate (\(E_{r} )\). Validation is performed through Lightness Order Error (LoE).
-
Accuracy
The accuracy is the total number of correctly classified images out of the total number of the images in the dataset (Mall et al. 2019). The ‘Accuracy’ computes as depicted in (10) are as follows:
The ‘total number’ of the images in the dataset is computed as depicted in (11) as follows:
where TP denotes True positives, TN denotes True negative, FP denotes False positive, False denotes negative FN.
-
Cross-entropy Cross-entropy is widely used in the deep learning training process (Zhang and Sabuncu 2018). The Cross-entropy function is computed as depicted in (12):
$$E_{r} = \left( {ylog\left( p \right) + \left( {1 - y} \right)\log \left( {1 - p} \right)} \right) - \left( {ylog{ }\left( p \right) + \left( {1 - y} \right)\log \left( {1 - p} \right)} \right)$$(12)
Losses calculated separated for each class per observation and sum of the result computed as depicted in (13):
where M > 2 denotes multiclass classification, log is the natural log, y is a binary indicator (0 or 1), c is the correct classification for observation, p denotes the predicted probability for observation of class c.
-
Lightness Order Error The naturalness is crucial for image enhancement technique, but most of the techniques cannot maintain the naturalness effectively. We have considered the well-known image quality assessment (IQA) technique as Lightness Order Error (LoE) (Wang et al. 2013). This IQA technique provides the foremost solution among the methods (HEF, UM, and CLAHE) tested. LoE measure is based on the differences between the original input image (\(I_{\_input}\)) and enhanced image (\(I_{\_enhanced} )\).the low LoE score indicates best solution and preserves the naturalness in enhanced images. The LoE is computed as depict in (14):
$${\text{LoE}} = \frac{1}{{\text{h * w}}}\mathop \sum \limits_{{{\text{i}} = 1}}^{{\text{h}}} \mathop \sum \limits_{{{\text{j}} = 1}}^{{\text{w}}} {\text{RD}}\left( {{\text{i}},{\text{j}}} \right)$$(14)
When h and w are the height and the width of RD, (x,y) is the relative order difference. In equation (15), the relative order difference is defined for the original image and the enhanced image.
where \({\text{L}}\left( {{\text{x}},{\text{y}}} \right)\) lightness is computed as depicted in (16) and U (x, y), the unit step method computes as depicted in (17):
5.2 Experiment results for ChampNet selection
We have implemented our proposed model in Python, which provides the pathway to boost the performance of DLMs to classify bone X-ray images, we have performed a sequence of different experiments to analyze and confirm the effectiveness of our proposed model on the benchmark medical image dataset. To verify the efficiency of our model on MURA-BC medical imaging dataset, first, the training of the benchmark deep learning model (EfficientNet: B0, MobileNet, ResNet18, VGG19) has been performed from scratch (Rizwan et al. 2008). The MURA-BC 32 × 32 X-ray image dataset has been used for model training, validation, and testing purposes. The model training was performed for 20 epochs. Table 3 contains the results of training accuracy of benchmark deep learning model EfficientNet: B0, MobileNet, ResNet18, VGG19. We have obtained max training accuracy values of 92.12%, 91.64%, 92.05%, and 91.96%, respectively.
The test accuracy of EfficientNet: B0, MobileNet, Resnet18, and VGG19 benchmark models are depicted in Table 4. The max test accuracy achieved 92.12%, 91.64%, 92.05%, and 91.96%, respectively.
Table 5 contains the training error rate of benchmark deep learning model EfficientNet: B0, MobileNet, ResNet18, and VGG19. We obtain min training error rate values of 0.2814, 0.402656, 0.276089, and 0.3524966, respectively.
The test accuracy of EfficientNet: B0, MobileNet, Resnet18, and VGG19 benchmark models are depicted in Table 6. The min test error rate achieved 0.276527, 0.291593, 0.293466, and 0.324585, respectively.
The ChampNet selection is based on two standards: the max accuracy and the min error rate. The ChampNet is selected based on the training and test accuracy indicated in Fig. 4. Maximum training and test accuracy are 92.15 and 91.30, respectively.

Max train and test accuracy of different DLMs
With the help of Fig. 5, based on the training and testing error rates of various deep learning models. We have estimated the minimum training and testing error rates as 0.242 and 0.277, respectively. Through Figs. 4 and 5, we can easily determine EfficientNet: B0 as our ChampNet from the benchmark DLMs.

Train and test error rate of different DLMs
5.3 Experiment results for ChampNet processed with different resolution datasets
First, this experiment contributes to finding out the relationship between deep learning model performance and different dataset resolutions (Prasanalakshmi and Farouk 2019). Second, estimate the training time at different resolutions. The results in Tables 7 and 8 show the different resolution X-ray image dataset with the classification performance based on train and test accuracy, respectively. Table 9 contains estimate training time on different resolution datasets. However, the performance of DLMs improves with the growth in dataset resolution. As we increase the dataset resolution, the training time also increases. Thus, it is evident that from Tables 7, 8, and 9 that the 64 × 64-pixel resolution dataset is the best in terms of accuracy and training duration. Due to this reason, we have selected a 64 × 64-pixel X-ray image dataset, further investigating the performance of the model in the next phase.
5.4 Experiment results for ChampNet processed with different image enhancement
In this phase of research, the main objective is to boost the performance of DLMs. We have processed the dataset finalized from the previous phase with different image enhancement techniques, namely, CLAHE, HEF, and UM. The results in Table 10 and Fig. 6 show the classification performance of ChampNet with enhancement techniques on the train the test dataset with and without enhancement techniques applied (Awotunde et al. 2021; Munirathinam et al. 2021). All three techniques of image enhancement on the training dataset perform approximately the same in the range of 95.88%. The difference was examined during the test dataset with and without enhancement techniques (Zaman et al. 2018). From Table 10, it is clear that the CLAHE technique outperforms the other two techniques on both the test dataset with and without enhancement techniques. The CLAHE technique achieved 94.99% and 94.18% accuracy on the test dataset with and without enhancement techniques, respectively (Tang and Shabaz 2021). HEF achieved 94.79% and UM achieved 94.61% for the test dataset with enhancement techniques. HEF achieved only 40.13% and UM achieved 84.58% for the test dataset without enhancement techniques (Sathya et al. 2019).

Train and test accuracy on the train, test (with and without enhancement) dataset
5.5 Experiment result validation with LoE
In the last phase, the LoE method is used to validate the result of the previous phase of the experiment as depicted in Fig. 7. The LoE score for different bone X-ray images is shown in Table 11. The low LoE score indicates the best solution and preserves the naturalness in enhanced images (Manzoor et al. 2018). The CLAHE LoE score is 96.72, which is the lowest among the other two techniques. The HEF LoE score is 403.68 and the UM LoE score is 115.68. The low LoE score of CLAHE validates the result of the previous phase.

LoE score for different X-ray studies
6 Conclusion
The proposed design of BoostNet can enhance the performance of the MURA-BC dataset. The BoostNet plays a dynamic role in advancing the state-of-art performance of the musculoskeletal radiograph datasets. In this paper, we have introduced a model to improve DLMs in the medical imaging domain. Specifically, we have executed a series of experiments to enhance the accuracy of the model and authenticate the results using LoE techniques. The obtained findings are interesting for a wide variety of reasons:
-
Benchmark DLMs (EfficientNet: B0, MobileNet, ResNet18, VGG19). The EfficientNet: B0 (ChampNet) outperforms other deep learning models, MobileNet, ResNet18, VGG19 in terms of high accuracy and low error rate. The EfficientNet: B0 provides high performance with minimum hardware resources. The experiment was performed in a virtual environment with 12 GB RAM and six virtual CPUs from an Intel Xeon Silver 2.10 GHZ processor server.
-
The ChampNet performance improves gradually as we increase the dataset resolution, but the performance of the model gets stable. The EfficientNet: B0 with 64 × 64 resolution achieves stable accuracy (Tables7 and 8). This finding helps to improve the model accuracy.
-
The ChampNet with 64 × 64 resolution dataset is implemented with three different enhancement techniques (CLAHE, HEF, and UM). The CLAHE outperforms the other two enhancement techniques, HEF and UM (Table 10). The ChampNet with CLAHE technique is referred to as BoostNet.
-
The outcome of the ChampNet (64 × 64 resolution) with different enhancement techniques (CLAHE, HEF, and UM) experiment is verified with the LoE technique (Table 11 and Fig. 6).
The outcome of the research is musculoskeletal radiograph X-ray images processed with CLAHE enhancement technique with DLMs. The BoostNet can be implemented on several other medical imaging problems. In the future, the experiment could be processed with a higher resolution dataset and high-performance hardware resources. This model provides an immediate, complete tool to guide medical professionals in the treatment process in multiple medical domains. The practical deployments and application order to respond to resource constraints. In future it helps to provide better opportunities for radiologists and orthopedic to ease out their lives with faster and more accurate results.
References
Awotunde JB, Chakraborty C, Adeniyi AE (2021) Intrusion detection in industrial internet of things network-based on deep learning model with rule-based feature selection. Wirel Commun Mobile Comput
Bundy A, Wallen L (1984) High-emphasis filtering. In: Catalogue of artificial intelligence tools. Springer, Berlin, Heidelberg. pp 47–47
Deshmukh S, Thirupathi Rao K, Shabaz M (2021) Collaborative learning based straggler prevention in large-scale distributed computing framework. In: Kaur M (ed) Security and communication networks. Hindawi Limited. Vol. 2021. pp 1–9. https://doi.org/10.1155/2021/8340925
Dou C, Zheng L, Wang W, Shabaz M (2021) Evaluation of urban environmental and economic coordination based on discrete mathematical model. In: Singh D (ed) Mathematical problems in engineering. Hindawi Limited. Vol. 2021. pp 1–11. https://doi.org/10.1155/2021/1566538
González-Villà S, Oliver A, Huo Y, Lladó X, Landman BA (2020) A fully automated pipeline for brain structure segmentation in multiple sclerosis. NeuroImage: Clin 27:102306
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 770–778
He K, Zhang X, Ren S, Sun J (2016) Identity mappings in deep residual networks. In: European conference on computer vision. Springer, Cham. pp. 630–645
Howard AG et al (2017) Mobilenets: efficient convolutional neural networks for mobile vision applications, arXiv preprint http://arxiv.org/abs/1704.04861
Jaderberg M et al (2015) Spatial transformer networks, arXiv preprint http://arxiv.org/abs/1704.04861
Jairath K, Singh N, Jagota V, Shabaz M (2021) Compact ultrawide band metamaterial-inspired split ring resonator structure loaded band notched antenna. In: Kumar V (ed) Mathematical problems in engineering. Hindawi Limited. Vol. 2021. pp 1–12. https://doi.org/10.1155/2021/5174455
Krizhevsky A, Hinton G (2009) Learning multiple layers of features from tiny images
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 25:1097–1105
Mahajan K, Garg U, Shabaz M (2021) CPIDM: a clustering-based profound iterating deep learning model for HSI segmentation. In: Shanmuganathan V (ed) Wireless communications and mobile computing. Hindawi Limited. Vol. 2021. pp 1–12. https://doi.org/10.1155/2021/7279260
Mahbod A, Schaefer G, Wang C, Ecker R, Dorffner G, Ellinger I (2021) Investigating and exploiting image resolution for transfer learning-based skin lesion classification. In: 2020 25th international conference on pattern recognition (ICPR). IEEE. pp 4047–4053
Mall PK, Singh PK, Yadav D (2019) Glcm based feature extraction and medical x-ray image classification using machine learning techniques. In: 2019 IEEE conference on information and communication technology. IEEE. pp 1–6
Manzoor U, Rizwan A, Demirbas A, Hafiz NAS (2018) Analysis of perception gap between employers and fresh engineering graduates about employability skills: a case study of Pakistan. Int J Eng Educ 34(1):248–255
Munirathinam R, Ponnan S, Chakraborty C, & Umathurai S (2021) Improved performance on seizure detection in an automated electroencephalogram signal under evolution by extracting entropy feature. Multimed Tools Appl, 1–16
Panetta K, Zhou Y, Agaian S, Jia H (2011) Nonlinear unsharp masking for mammogram enhancement. IEEE Trans Inf Technol Biomed 15(6):918–928
Polesel A, Ramponi G, Mathews VJ (2000) Image enhancement via adaptive unsharp masking. IEEE Trans Image Process 9(3):505–510
Prasanalakshmi B, Farouk A (2019) Classification and prediction of student academic performance in king Khalid University-A machine learning approach. Indian J Sci Technol 12:14
Q et al (2020) Zhan A GPU-based residual network for medical image classification in smart medicine. Inf Sci 536:91–100
Rajpurkar P, Irvin J, Bagul A, Ding D, Duan T, Mehta H, Ng AY (2017) Mura: Large dataset for abnormality detection in musculoskeletal radiographs. arXiv preprint arXiv:1712.06957
Rakhra M, Singh R, Lohani TK, Shabaz M (2021) Metaheuristic and machine learning-based smart engine for renting and sharing of agriculture equipment. In: Singh D (ed) Mathematical problems in engineering. Hindawi Limited. Vol. 2021. pp 1–13. https://doi.org/10.1155/2021/5561065
Ramponi G (1998) A cubic unsharp masking technique for contrast enhancement. Signal Process 67(2):211–222
Razzak MI, Naz S, Zaib A (2018) Deep learning for medical image processing: overview, challenges and the future. Classification in BioApps, pp 323–350
Rizwan A, Alvi MS, Hammouda MM (2008) Analysis of factors affecting the satisfaction levels of engineering students. Int J Eng Edu 24(4):811–816
Sahu S et al (2019) An approach for de-noising and contrast enhancement of retinal fundus image using CLAHE. Opt Laser Technol 110:87–98
Sathya D, Ganesh Kumar P, Prasanalakshmi B (2019) Enhancement of data security with reduced energy consumption in WMSN
Setiawan F, Yahya BN, Lee S-L (2019) Deep activity recognition on imaging sensor data. Electron Lett 55(17):928–931
Shereen MA, Khan S, Kazmi A, Bashir N, Siddique R (2020) COVID-19 infection: origin, transmission, and characteristics of human coronaviruses. J Adv Res 24:91
Shin CH, Jung CY (2013) An enhancement of medical image using optimized high-frequency emphasis filter. J Korea Inst Inf Commun Eng 17(3):698–704
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition, arXiv preprint http://arxiv.org/abs/1704.04861
Talo M (2019) Automated classification of histopathology images using transfer learning. Artif Intell Med 101:101743
Tan M, Le Q (2019) Efficientnet: rethinking model scaling for convolutional neural networks. In: International conference on machine learning. pp 6105–6114. PMLR
Tang S, Shabaz M (2021) A new face image recognition algorithm based on cerebellum-basal ganglia mechanism. In: Chakraborty C (ed) Journal of healthcare engineering. Hindawi Limited. Vol. 2021. pp 1–11. https://doi.org/10.1155/2021/3688881
Triwijoyo BK, Sabarguna BS, Budiharto W, Abdurachman E (2020) Deep learning approach for classification of eye diseases based on color fundus images. In: Diabetes and fundus OCT. Elsevier. pp 25–57
Wang S, Zheng J, Hu HM, Li B (2013) Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans Image Process 22(9):3538–3548
Zaman S, Chakraborty C, Mehajabin N, Mamun-Or-Rashid M, Razzaque MA (2018) A deep learning based device authentication scheme using channel state information. In: 2018 International conference on innovation in engineering and technology (ICIET). IEEE. pp 1–5
Zeiler MD, Fergus R (2014) Visualizing and understanding convolutional networks. Springer, Cham, pp 818–833
Zhang X et al (2015) Accelerating very deep convolutional networks for classification and detection. IEEE Trans Pattern Anal Mach Intell 38(10):1943–1955
Zhang Z Sabuncu MR (2018) Generalized cross entropy loss for training deep neural networks with noisy labels’. arXiv preprint http://arxiv.org/abs/1704.04861
Zuiderveld K (1994) Contrast limited adaptive histogram equalization. Graphics gems, pp 474–485
Funding
This research received no external funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest and all ethical issues including human or animal participation has been done. No such consent is applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mall, P.K., Singh, P.K. BoostNet: a method to enhance the performance of deep learning model on musculoskeletal radiographs X-ray images. Int J Syst Assur Eng Manag 13 (Suppl 1), 658–672 (2022). https://doi.org/10.1007/s13198-021-01580-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-021-01580-3