
Abstract
In today's era, the embedded system plays a very keen role in every field. However, the possibilities of errors occur in that system is so common, due to which the degradation of the system takes place or the system gets crash. The various types of errors that can be occurred in the embedded system are deliberated in its mathematical modelling. The interaction of the software with each system’s component and interaction of system software to application software are also considered. In this study, Markov process, Laplace Transformation and supplementary variable technique have been used to analyse the reliability measures of embedded system with its sensitivity and also discussed the effects of various failure rates on system performance. At last, a numerical example has been take to illustrate the results and their graphical representation are also given.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the current scenario, it is impossible to imagine work without a computer system. The embedded system plays a diverse role in a different field. For example, it is used in weather forecasting, controlling rockets etc. It also have a great importance in business, education and automated things. Therefore, a system should be error-free, more efficient and reliable. The tolerance of the system should be more to handle more and more work at a time.
If any system develops, then its software and hardware components are tested very carefully to make the system error-free. But, then also, there exist some probability of accident. There can be either degradation of the system or crash. Generally, the error occurs more in softwares than hardwares. In different fields, for various types of work, many software have to be installed in the system [Lyu (1996), Goyal and Ram (2016), Kumaresan and Ganeshkumar (2020)].
Reliability of the system is the probability of its adequate performance during a predefined period given that the system behavior is completely characterized in context of probability measures [Ram and Goyal (2016); Goyal et al. (2017), Cao et al. (2019)]. At most of the places, distributed system approach has been used which consists of multiple autonomous computer systems communicating through a network. A computer program running in a distributed system is called distributed program and the writing of such programs is called distributed programming [Goyal and Ram (2014), Rajaraman (2010), McCluskey and Mitra (2004)].
Many authors have worked on the reliability of various systems such as hardware systems, software systems but they did not study about the errors in embedded system. Soi and Aggarwal (1980) presented a model which described the future trends in the digital communication system and analyzed the availability behavior of next-generation digital communication system. Goel et al. (1993) designed a model for a satellite-based computer communication networks system in which a master station is connected with the remote micro earth stations in the country. Pham (1992) analyzed the reliability and mean time to failure of a high voltage system with two transmitters in addition to a power supply and addressed that the working of the system is affected by any failed component. The authors explained these analyses through numerical examples. In this study, they did not integrate human error and common-cause failure. Ram et al. (2013) developed a stochastic model of a complex repairable system by introducing the concept of the standby unit with the incorporation of distinct failures namely human error, minor failure, waiting time to repair, and unit failure, and obtained the various reliability measures by employing two types of the repair strategy.
Liu (1998) calculated the reliability of a load-sharing k-out-of-n system for arbitrary distribution by presenting a generalized model without considering human error and common-cause failure. Singh et al. (2013) modeled a series system with two units in which each unit is controlled by its controller and analyzed the cost–benefit of the system including the service cost but they did not consider the warranty period. Dhillon and Yang (1996) developed Markov models to perform reliability analysis of a repairable and non-repairable robot and its safety system and presented an expression for robot reliability, mean time between failure, and state probabilities but they did not obtain the expected profit. Pham and Wang (1996) developed the concept of imperfect maintenance and discussed several methods and optimal policies on imperfect maintenance for estimating the reliability measures. In this study, the authors did not analyze the effect of failure rates on reliability.
Billinton and Wang (1999) present a technique for system reliability distribution to evaluate the expected value of the system reliability measures. They also present a Monte Carlo simulation for system evaluation and compared the results found by both techniques. Qureshi (2008) provided a review of key traditional accident modeling approaches and their limitation and described new system theoretic approaches to the modeling and analysis of accidents in the safety–critical systems. Musa and Okumoto (1984) developed a software reliability model that predicts expected failure and better than existing software reliability models and is simpler than any of the models that approaches it in predictive validity. Goseva-popstojanova and Trivedi (2001) designed and detailed state of the architecture –based approaches to the reliability of component-based software and explained how it can be used to examine the software behavior.
Zhu and Pham (2019) proposed a model in which failures are categorized into three types such that hardware failure, software failure, hardware-software interaction failure. Hardware-software interaction failure is also divided into a software-induced hardware failure and hardware-induced software failure. They provide a Markov model and compared the result with and without hardware-software interaction failure. Teng et al. (2006) proposed a Markov model to analyze hardware-software interaction failure and apply the approach to a real telecommunication system. Zeng et al. (2019) proposed an approach to analyze the reliability of a non-repairable system based on path and integrals and explain the case studies with and without warm standby systems. Gertsbakh and Shpungin (2016) described various types of network reliability including static and dynamic reliability with Monte Carlo approach. Some importance measures for network reliability models has also been discussed in their book. While Zhang and Mahadevan (2017) evaluated the network reliability problem using game theory. In their study they design the problem of router and attacker as a two player game and optimized using Dijkstra and FW algorithm.
1.1 Research gaps
After the review of some papers related to embedded system, authors identify the following research gaps-
-
(i)
To develop the mathematical models for embedded systems.
-
(ii)
To analyse the reliability indices for the embedded system including human error and network failure.
-
(iii)
To investigate the mean time to failure and mean time to repair.
-
(iv)
To discussed the maintenance cost for the system.
-
(v)
To analyse the expected profit in the system.
-
(vi)
To study about the sensitivity of the system due to its component.
-
(vii)
To determine the effects of multi failures on it.
1.2 Objectives
The multiplicity of mathematical models developed so far considered reliability, cost analysis and MTTF of a complex system, with different types of failures and one type of repairs. But they did not consider one of the important aspects, role of human failure at the reliability of embedded system. In this paper, authors discussed the following points-
-
To design the mathematical model of embedded system with context of different types of errors such as human error, errors due to networking, due to intolerance of software, hardware errors, and errors due to the interaction of hardware and software.
-
To determine the system’s reliability by considering human error and network failure.
-
This paper details the effect of each failures on system’s working and provided that how these errors can be reduced or enhance the system reliability as MTTF and sensitivity study.
-
To analyse the expected profit in the system.
2 Mathematical model details
2.1 Assumptions
In the proposed model, the following assumptions have been made:
-
(i)
The system has probabilistic behaviour i.e. characterized by the constant hazard rate.
-
(ii)
Future states depend only on the current state not on the past state.
-
(iii)
In the initial state, the embedded system is in a good state.
-
(iv)
The system covers three types of states—good, degraded, and failed.
-
(v)
Only one change is allowed at a time in the transition states.
-
(vi)
The system has two types of failures- partial failure, complete failure.
-
(vii)
When the failed component is repaired, the system is consider as good as new.
-
(viii)
The failure and repair rates follow general distribution.
3 Notations
Notations associated with this work are described in Table 1.
3.1 System description
Authors have designed the mathematical model of embedded system (hardware and software combinatory system) under the consideration multi-failures such as such as human error, errors due to networking, due to intolerance of software, hardware errors, and errors due to the interaction of hardware and software. The system consists of hardware components and softwares to perform the task. System’s performance depends upon the working of its each component and software updation, and it also affected by the human interaction with the system. Unfortunately, many researchers avoided the human error in reliability analysis. Human error is a tag given to an achievement that has negative consequences or fails to achieve the desired task. Human error can be classified into two types non-critical (Type 1) and critical human error (Type 2) based on their action [Dhillon and Yang, 1993].
Human Error Type-1: Either an action that is not intended or desired by the human to perform a prescribed function within the specified limits of accuracy, sequence, or time that fails to produce the expected result and has led or has the potential to lead to an unwanted Consequence. For example, If pilot in command's improper decision to takeoff into deteriorating weather conditions (including turbulence, gusty winds, and an advancing thunderstorm and associated precipitation) when the airplane was overweight and when the density altitude was higher than he was accustomed to, resulting in an a stall caused by failure to maintain airspeed. (NTSB 1997, p. 53).
Human Error Type-2: A generic term to encompass all those actions in which a planned sequence of mental or physical activities fails to achieve its intended task, and when these failures cannot be attributed to some chance agency (Reason 1990). For example, Bhopal gas tragedy on 3 December, 1984.
Hardware Error Type-1: It can be corrected by the time limit. Due to this error, system achieves the degraded state and can be improved. Therefore, no data is lost or lost data can be retrieved.
Hardware Error Type-2: It cannot be corrected by the time limit. Due to this error, system failed completely and cannot be improved easily. Comprehensive data is lost by this error.
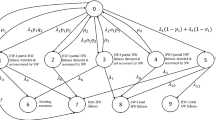
The proposed embedded system is divided into states, which are shown in the state transition diagram (Fig. 1). As per our assumption, initially, the system is in good working condition i.e. free from error. However, due to existence of several errors, system either goes to the degraded state or gets crash that means goes to a completely failed state. In the degraded state, system works with reduced efficiency but when it gets crashes or completely failed then system stop working. Mathematical model of the embedded system based on the states shown in Fig. 1 and described in Table 2, is derived with the help of Markov process. Markov process has a specific property of memoryless. So, failures allow the transition of the system memoryless. Markov process is completely characterized by its transition probability matrix. In a Markov model, authors associate with the state of the system of a probability Pij, indicating the probability of the system moving from state i to state j. This probability is called the transition probability. A matrix of transition state probabilities is called transition matrix.

State transition diagram
3.2 Formulation of the model
By the probability of consideration and continuity of arguments, one can obtain the following set of differential equations possesses the present mathematical model
Boundary conditions
Initial condition
Taking Laplace transformation of Eqs. (1) to (11) using Eq. (12)
Boundary conditions
3.3 Solution of the model
By solving Eqs. (13) to (18) using (19) to (22), we get
where, \(A_{1} = \alpha_{1} + \lambda_{N} + \beta_{1} + \lambda_{S1} + \beta_{2} + \lambda_{SIT} + \alpha_{2} + \lambda_{C}\); \(A_{2} = \frac{{\lambda_{N} }}{{s + \lambda_{C} + \mu }}\); \(A_{3} = \frac{{\alpha_{1} }}{{S + \lambda_{C} + \alpha_{2} + \mu }}\); \(A_{4} = \frac{{\beta_{1} }}{{S + \beta_{2} + \mu }}\); \(A_{5} = \frac{{\lambda_{S1} }}{{S + \lambda_{S2} + \lambda_{SIT} + \mu }}\).
3.4 Probabilities of the upstate and downstate of the system
4 Particular cases and numerical computations
4.1 Availability analysis
Cogitate that the repair facility is available. Setting the value of various parameters as \(\lambda_{SIT} = 0.15\), \(\alpha_{1} = 0.5\), \(\alpha_{2} = 0.1\), \(\lambda_{N} = 0.4\), \(\beta_{1} = 0.2\), \(\beta_{2} = 0.1\), \(\lambda_{C} = 0.1\), \(\lambda_{S1} = 0.1\), \(\lambda_{S2} = 0.3\), \(\mu = 1\), \(\varphi (x) = 1\) [Zhang and Mahadevan (2017); Gertsbakh and Shpungin (2016); Ram and Goyal (2016)] and taking the inverse Laplace transformation of Eq. (23), one can obtain availability of the system in terms of time t as
Now varying the time t from 0 to 50 unit in Eq. (25), one obtains the availability of the designed system as shown in Table 3 and corresponding Fig. 2 respectively.

Availability vs Time
4.2 Reliability Analysis
The system is how much reliable, can be calculated by taking the inverse Laplace transformation of Eq. (23) and setting the value of various parameters as \(\lambda_{SIT} = 0.15\), \(\alpha_{1} = 0.5\), \(\alpha_{2} = 0.1\), \(\lambda_{N} = 0.4\), \(\beta_{1} = 0.2\), \(\beta_{2} = 0.1\), \(\lambda_{C} = 0.1\), \(\lambda_{S1} = 0.1\), \(\lambda_{S2} = 0.3\), \(\mu = 0\), \(\varphi (x) = 0\)[Zhang and Mahadevan (2017); Gertsbakh and Shpungin (2016); Ram and Goyal (2016)], one can obtain the reliability of the system in terms of time t as
Now, varying the time t from 0 to 15 in Eq. (26), one acquires the reliability of the designed system as shown in Table 4 and corresponding Fig. 3 respectively.

Reliability vs Time
4.3 Mean time to failure (MTTF)
MTTF helps to analyse the effects of each failure on the system independently. One may get it by setting the repair rates equals to zero in Eq. (23) as:
Varying input parameters one by one at 0.1, 0.2,……………..,0.9 respectively and setting the other failure rates as \(\lambda_{SIT} = 0.15\), \(\alpha_{1} = 0.5\), \(\alpha_{2} = 0.1\), \(\lambda_{N} = 0.4\), \(\beta_{1} = 0.2\), \(\beta_{2} = 0.1\), \(\lambda_{C} = 0.1\), \(\lambda_{S1} = 0.1\), \(\lambda_{S2} = 0.3\) authors can get the MTTF concerning the variation of failure rates that signify in Table 5 and graphical representation shown in Fig. 4.

MTTF vs Variation in failure rates
4.4 Expected profit
Expected profit has great importance to maintain system reliability. Let the service facility be always available, the expected profit during the interval [0, t) is given as:
Let us cogitate the value of \(K_{1} = 1\), the value of K2 varies as 0.1, 0.3, and 0.5 respectively, one obtains Table 6 and Fig. 5, which epitomizes the graph of expected profit concerning time.

Expected Profit vs Time
4.5 Sensitivity analysis
It is a very important analysis to predict the rate of change of parameters with respect to the particular variables [Henley and Kumamoto (1992), Andrews and Moss (1993)]. Sensitivity to a factor is defined as the partial derivative of the function concerning that factor [Goyal and Ram (2018)]. Here, these factors are the failure rates of the embedded system.
4.5.1 Sensitivity of reliability
The reliability of the embedded system is how much sensitive concerning each failure rate, can be analyzed by partial differentiation of inverse Laplace transform of Eq. (23), concerning the failure rates of each state. Reliability sensitivity can be calculated by putting the values of failure and repair rates as \(\lambda_{SIT} = 0.15\), \(\alpha_{1} = 0.5\), \(\alpha_{2} = 0.1\), \(\lambda_{N} = 0.4\), \(\beta_{1} = 0.2\), \(\beta_{2} = 0.1\), \(\lambda_{C} = 0.1\), \(\lambda_{S1} = 0.1\), \(\lambda_{S2} = 0.3\), \(\mu = 0\), \(\varphi (x) = 0\), in the partial derivatives of reliability function. Varying time t from 0 to 20 units and failure rates from 0.1 to 0.9, the sensitivity of reliability graphically revealed in Fig. 6. In Fig. 6, a1 stands for \(\alpha_{1}\), l1 stands for \(\lambda_{SIT}\), a2 stands for \(\alpha_{2}\), ln stands for \(\lambda_{N}\), b1 stands for \(\beta_{1}\), b2 stands for \(\beta_{2}\), lc stands for \(\lambda_{C}\), ls1 stands for \(\lambda_{S1}\), ls2 stands for for for \(\lambda_{S2}\).

Reliability sensitivity of the embedded system
4.5.2 Sensitivity of MTTF:
The sensitivity in MTTF of the embedded system can be studied through the partial differentiation of Eq. (27) concerning the failure rates of the embedded system. By applying the set of parameters as \(\lambda_{SIT} = 0.15\), \(\alpha_{1} = 0.5\), \(\alpha_{2} = 0.1\), \(\lambda_{N} = 0.4\), \(\beta_{1} = 0.2\), \(\beta_{2} = 0.1\), \(\lambda_{C} = 0.1\), \(\lambda_{S1} = 0.1\), \(\lambda_{S2} = 0.3\), in partial differentiation of MTTF, one can calculate the MTTF sensitivity as shown in Table 7 and corresponding graphs shown in Fig. 7.

MTTF Sensitivity concerning failure rates
5 Result discussions
In this research work, the authors have studied the numerous reliability characteristics such as availability, reliability, MTTF and profit concerning the service rate of the system. Through the overall study of the system, the following observations have been made:-
Figure 2 representing the graph of availability of system decreases with a high rate in the first five months reaches 70% and in the next five months its availability decreases to 70% to 65% but the rate is slow from the first five months. Availability continuously decreases with the same rate from 10 to 15 months and 15 to 20 months and till 50 months and after 50 months availability is only 30%.
Reliability of system decreases to 32% in first five months and it decreases to 12% in 10 months and 10% in 15 months and 8% in 20 months and it decreases uniformly and reaches 1% in 40 months and 0.21%in 45 months and reliability approach to almost 0% after 50 months (Fig. 3).
MTTF (Fig. 4) of software error due to intolerance, hardware error (type-2), and human error (type-2) decreases smoothly. MTTF of catastrophic failure decreases at a high rate.
MTTF of networking error increases because in starting possibilities of networking error is more and then it occurs very rarely.
MTTF of hardware error also increases because in starting if hardware error is removed then failure rate decreases after that hardware error occurs very rarely.
Figure 5 shows that the expected profit of the system increases with the increment in time but decreases as service cost increases. After a long time, profit decreases as time increase.
Reliability Sensitivity first increases concerning time and after some time it decreases in case of human error type-1, networking error, hardware error type-1 as shown in Fig. 6. It also decreases these errors. Reliability sensitivity decreases for a short period and after that increases in case of human error type 2, hardware type-2, catastrophic failure, error due to intolerance, software error type-1 and type-2. Reliability sensitivity increases in case of increment in these errors.
The sensitivity of MTTF (Fig. 7) is increasing rapidly for some time concerning the human error type 2, hardware type-2, catastrophic failure, and after a fixed period it increases slightly concerning time. MTTF sensitivity increases slightly and after some time it will be constantly concerning the error due to intolerance, software error type-1 and type-2, human error type-1. The sensitivity of MTTF decreases very slightly concerning time in case of networking error and hardware error type-2.
6 Conclusions
While the technical world existing, embedded system plays a pivotal role everywhere. This study focused on the mathematical model of embedded system under multiple failures using Markov process, to predict the effect of each failures on system’s working and provided some results that helps to get highly reliable system. As Dhillon and Yang (1993) have shown that the human error can affect the system working upto 70%, so, it must not be avoided in the evaluation of system reliability. Markov process provided the best result about the reliability evaluation of embedded system because multiple errors specially human error are depend only the current transition. Many researchers [Narayanan and Xie, 2006; Wattanapongsakorn and Levitan, 2004] have analysed the reliability of embedded system but they did not consider human error and networking error. Through the overall study, it is determined that the availability of the system decreases greatly in starting, and then it decreases uniformly. Similarly, in starting five months, the reliability of the system decreases straightly and after that, it decreases smoothly. After a fixed time the system’s reliability is constant. As months pass profit decreases and service rate increases. With the vital examination of the proposed system, the authors find that the system is more sensitive in concerning the networking error and human error type 2. Human error type 1 has the almost equivalent effect throughout the working but human error type 2 has big changes with time. These results are very beneficial for software engineers and system engineers. Embedded system is more appropriate then the externally software based system because it has less probability of human error as compare to externally software based system. As a direction for future work, we will try to study the designed model with the presence of common cause failure and find out the meantime to repair the system.
References
Andrews JD, Moss TR (1993) Reliability and risk assessment, Longman Scientific and Technical
Billinton R, Wang P (1999) Teaching distribution system reliability evaluation using Monte Carlo simulation. IEEE Trans Power Syst 14(2):397–403
Cao X, Hu L, Li Z (2019) Reliability analysis of discrete-time series-parallel systems with uncertain parameters. J Ambient Intell Humaniz Comput 10(7):2657–2668
Dhillon BS, Yang N (1996) Reliability analysis of a repairable robot system. J Qual Maint Eng 2(2):30–37
Dhillon BS, Yang N (1993) Availability of a man-machine system with critical and non-critical human error. Microelectron Reliab 33(10):1511–1521
Gertsbakh IB, Shpungin Y (2016) Models of network reliability: analysis, combinatorics, and Monte Carlo. CRC Press
Goel LR, Gupta R, Rana VS (1993) Reliability analysis of a satellite-based computer communication network system. Microelectron Reliab 33(2):119–126
Goševa-Popstojanova K, Trivedi KS (2001) Architecture-based approach to reliability assessment of software systems. Perform Eval 45(2–3):179–204
Goyal N, Ram M (2014) Software development life cycle testing analysis: a reliability approach. Math Eng Sci Aerosp 5(3):313–329
Goyal N, Ram M (2018) Bi-directional system analysis under Copula-Coverage approach. Commun Stat Simul Comput 47(6):1831–1844
Goyal N, Ram M, Dua AK (2016) An approach to investigating reliability indices for tree topology network. Cybernet Syst Int J 47(7):570–584
Goyal N, Rawat S, Ram M (2017) Software reliability growth model for non-homogenous poisson process (NHPP) under agile process. Int J Appl Math Comput Sci 27(4):777–783
Henley EJ, Kumamoto H (1992) Probabilistic Risk Assessment. IEEE Press, New York
Kumaresan K, Ganeshkumar P (2020) Software reliability prediction model with realistic assumption using time series (S) ARIMA model. J Ambient Intell Human Compu 11:5561–5568
Liu H (1998) Reliability of a load-sharing k-out-of-n: G system: non-iid components with arbitrary distributions. IEEE Trans Reliab 47(3):279–284
Lyu MR (1996) Handbook of software reliability engineering, vol 3. IEEE Computer Society Press, CA
McCluskey EJ, Mitra S (2004) Fault tolerance. In: Tucker AB (ed) Computer science handbook, 2nd edn, Chapter 25. Chapman and Hall/CRC Press, London, UK
Musa JD, Okumoto K (1984) A logarithmic Poisson execution time model for software reliability measurement. In Proceedings of the 7th international conference on Software engineering 230–238
Narayanan V, Xie Y (2006) Reliability concerns in embedded system designs. Computer 39(1):118–120
NTSB (1997) Aircraft accident report, NTSB/AAR-97102. National Transportation Safety Board, Washington, DC
Pham H, Wang H (1996) Imperfect maintenance. Eur J Operation Res 94(3):425–438
Pham H (1992) Reliability analysis of a high voltage system with dependent failures and imperfect coverage. Reliab Eng Syst Saf 37(1):25–28
Qureshi ZH (2008) A review of accident modeling approaches for complex critical sociotechnical systems (No. DSTO-TR-2094). Defence Science and Technology Organisation Edinburgh (Australia) Command Control Communications and Intelligence Div
Rajaraman V (2010) Fundamentals of computers. PHI Learning Pvt. Ltd., Delhi
Ram M, Goyal N (2016) ATM network inspection under stochastic modelling. J Eng Sci Technol Rev 9(5):1–8
Ram M, Singh SB, Singh VV (2013) Stochastic analysis of a standby system with waiting repair strategy. IEEE Trans Syst Man Cybernet Syst 43(3):698–707
Reason J (1990) Human error. Cambridge University Press
Singh VV, Ram M, Rawal DK (2013) Cost analysis of an engineering system involving subsystems in a series configuration. IEEE Trans Autom Sci Eng 10(4):1124–1130
Soi IM, Aggarwal KK (1980) On human reliability trends in digital communication systems. Microelectron Reliab 20(6):823–830
Teng X, Pham H, Jeske DR (2006) Reliability modeling of hardware and software interactions, and their applications. IEEE Trans Reliab 55(4):571–577
Wattanapongsakorn N, Levitan SP (2004) Reliability optimization models for embedded systems with multiple applications. IEEE Trans Reliab 53(3):406–416
Zeng Y, Xing L, Zhang Q, Jia X (2019) An analytical method for reliability analysis of hardware-software co-design system. Qual Reliab Eng Int 35(1):165–178
Zhang X, Mahadevan S (2017) A game theoretic approach to network reliability assessment. IEEE Trans Reliab 66(3):875–892
Zhu M, Pham H (2019) A novel system reliability modeling of hardware, software, and interactions of hardware and software. Mathematics 7(11):1049
Funding
Funding is not taken for this work from any agency.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There are no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Goyal, N., Roy, V.K. & Ram, M. Mathematical modelling of embedded systems under network failures. Int J Syst Assur Eng Manag 13, 604–614 (2022). https://doi.org/10.1007/s13198-021-01313-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-021-01313-6