
Abstract
The volume of data being gathered every day is large and health care societies correspondingly generate a large volume of information daily. Although health care industry is rich in information but it requires discovering concealed relationships and patterns in data. The aim of this paper is employing data mining methods to find out knowledge in a dataset that was provided by a research center. By analyzing the drugs that were bought by each patient, our proposed method aims to predict the type of physician each patient has referred to and the type of disease he is suffering from. Our collected dataset contains details such as sex, age and the names of the drugs prescribed for each patient. For labeling the instances, a group of pharmacy students and professors has determined each patient’s disease. A number of experiments have been performed to compare the performance of different data mining techniques for predicting the diseases and the results illustrate that the proposed Stacking Model has higher accuracy compared to other data mining techniques such as k-Nearest Neighbor (kNN).
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Data mining helps to discover hidden patterns, as well as descriptive, predictive, and comprehensible models in all kinds of data [1]. The most common kinds of data for applying data mining techniques are data warehouse data and database data. Other forms of data such as data streams, spatial data, or network data can also be used [2]. In other words, its purpose is to analyze data from different aspects and extracting knowledge from it. The data mining techniques have been developed in recent years and include generalization, characterization, classification, clustering, association mining, pattern matching, data visualization and meta-rule guided mining [3]. The discovered knowledge by data mining approaches can be applied for different applications in various sectors such as the healthcare industry. It is a fact that most of the information which are available at this sector is unstructured, massive and high dimensional. Consequently, a good approach can bring a remarkable opportunity to assist physician deal with this large amount of data [4]. The main aim of this sector is to promote, enhance, and protect the population’s health, which needs to be quantified first. As a result, data mining can identify patterns, relationships and models, which support predictive and decision-making processes for diagnosis and treatment planning. The discovered models can be called predictive models, which can be integrated in hospitals’ information systems as models that are able to decrease the time of decision-making [5]. Automatic medical diagnosis systems tend to benefit from collected datasets and decision support systems.
This study proposes a method for predicting the patients’ diseases regardless of their medical and medicinal records. The dataset comes from a survey conducted by Non-Communicable Diseases Research Center (NCDRC)Footnote 1 in the province of Markazi, enlisting the drugs prescribed for each patient according to their insurance record. Different classification methods are employed to predict the diseases based on the drugs in the prescription. Experiments illustrate that the results of predictions are acceptable. The remainder of this paper is organized as follows: Section 2 provides a review on relevant studies. Section 3 explains the basis of the employed classification method, i.e. stacking. The proposed method is explained in Section 4. Section 5 presents the experimental results and discussions. At last, Section 6 concludes the paper.
2 Problem statement
Data mining techniques are applied in health systems to scientifically use data and analytics in order to detect inadequacies and the best practices, which guide them to cut down extra costs. This requires information on the health status of the population. However, an organization that usually registers clinical diagnoses does not have available information all the time. While pharmacy-based data, which usually covers a large population, is available information to identify chronic conditions (CCs) in populations, which is mostly known as “Burden of Disease” [6]. Although estimating the global burden of disease has been done in many countries such as USA [7], in other countries, which do not have a connected hospital systems, it is such a difficult task. Besides, using pharmacy data is a reliable source for these countries to help estimate the burden of disease. From the medical point of view, different factors such as valuable chronic diseases, the results of treatment, the current improvements, or conflicting deterioration, subjective and objective evaluation of the patient, and also other valuable data can highly effect on the diagnosis and decision-making in patients’ treatment [8]. These are the reasons why prescription-based data can have a vital role in each society in order to help them promote the community health.
3 Literature survey
In recent years, numerous studies have been conducted on predicting different diseases, disease treatment, and drug discovery in many hospitals. Different data mining techniques have been applied for diagnosis and gained different results. In the following, a short literature survey regarding data mining techniques and evaluation in healthcare have been developed.
Chen et al. applied usages of big data analytics in hospitals’ historical data. In their research, Patient Treatment Time Prediction (PTTP) algorithm was used in order to predict the waiting time for each treatment task for a patient. PTTP model was best fitted by a random forest optimization algorithm. Each patient’s requested treatment tasks were asks and a Hospital Queuing-Recommendation (HQR) system recommends an efficient and suitable treatment plan with the least waiting time for the patient [9].
Bellaachia and Gauven used data mining techniques such as Naïve Bayes, C4.5 decision Tree and Back Propagated Neural Network in order to perform a study to predict the survivability rate of breast cancer patients. The dataset, which is used in this study, is from the SEER Public-Use Data. It consists of 151,886 records, which have all the accessible 16 fields from the SEER database. They reached the conclusion that the model created by C4.5 has a vastly improved performance with 93.6% accuracy compared to other methods [10].
Palaniappan and Awan proposed a classification method for an Intelligent Heart Disease Prediction System (IHDPS) using data mining techniques, which included Naïve Bayes and Neural Network. They used medical profiles such as age, sex, blood pressure, and blood sugar, which could help them predict the likelihood of heart disease among patients. IHDPS is a dependable Web-based and user-friendly system [11].
Repalli built a model to predict how likely it was for the people of different age groups to be affected by diabetes following their activities. The medical data had 50,784 records with 37 variables. The selected model for the prediction of the binary target variable was a decision tree with a low misclassification rate. The results demonstrated that 34% of the population under the age of 20 were not affected by diabetes, 33.9% of the population whose age were above 20 and below 45 were not affected by diabetes and 26.8% of those aged over 45 were not diabetic [12].
4 Algorithm: Stacking
The increased accuracy of an ensemble, which is due to a reduction in the model’s variance and its bias, is based on the simple but powerful process of group averaging or majority vote [13]. In other words, it is a collective decision-making system, which is able to combine the predictions of learned classifiers in order to create prediction of new instances. Stacking is one of the ensemble methods, which is similar to Boosting and Bagging (Bootstrap aggregating). Boosting is a machine-learning ensemble algorithm used to reduce variance and bias. It is based on turning a set of weak learners into strong learners. Robert Schapire’s answer was based on “hypothesis boosting problem” [14] that had significant contributions in machine learning and statistics, most remarkably the development of boosting; therefore, they finally formulated Adaboost (Adaptive Boosting). On the other hand, Bagging was designed to improve the stability and accuracy of machine learning algorithms, which are applied in statistical classification and regression. Not only does it reduce variance but also it helps to avoid over-fitting.
There are two approaches for combining models. The first one is voting, in which the class predicted by the majority of the models is selected, while in stacking the predictions by each different model is given as input for a meta-level classifier whose output is the final class.
Stacking which sometimes called stacked generalization, is an approach to combine several machine learning techniques into one predictive model in order to improve the predictive force. It generates a global classifier by training a meta-level learner for combining the predictions of the base-level classifiers [15]. At first, the available data is used to train all of the other algorithms, then a combiner algorithm is trained in order to make a final prediction. In this step, all the predictions of the other algorithms are used as additional inputs. Stacking had also lead to great results on both supervised learning tasks like regression, classification and distance learning and unsupervised learning such as neural networks and density estimation. Table 1 compares bagging, boosting, and stacking techniques:
5 The proposed method
In this section, in the first part, the way of collecting data is explained and then in the second part, a suitable model for disease prediction is presented.
5.1 Data collection
The dataset consists of drug information of 600 patients, which is provided by specialists in the medical field. Each instance has 388 attributes namely; sex, age and the name of 386 drugs that were prescribed to them. Only the drug names were selected and then they were put in different columns as different attributes. After that, “1” was set to an instance who had bought that drug and “0” to the one who had not.
The first purpose of this research is to predict what kind of physician each instance has referred to. The class of data consists of 34 different doctors. Since the frequencies of each physician were not significant, a different processing was used by statistical methods and a decision to divide the labels into two classes was made, “general practitioner (G)” and “other specialists (NG)”. Table 2 shows a brief summary of attributes in the dataset.
The second goal of this research, which is more important, is to predict what kind of disease each instance is suffering from. A group of people, which consisted of three pharmacy students and two professors, were gathered to predict each patient’s disease only by the name of the drugs given to each instance in the dataset. Their predictions did not have any errors since the results were checked twice by each professor. The number of classes (number of different diseases) is 70. Therefore, each instance in the dataset has a label of 70 different diseases. According to frequencies of each class, the first nine classes in descending order are as follow. The abbreviation of each disease is shown in parentheses. Common Cold (C), Vaginal infection (VI), Poisoning (P), Stomach disorders (S), Depression (D), Gastrointestinal distress (GI), Allergy (A), Infection (IN) and Other diseases (O).
It is also good to mention that the number of patients who suffered from common cold was almost more than twice the other groups and consequently the data set was biased. Table 2 describes the attributes, which are used in the dataset. Label 1 is the type of doctor as general or specialist. Label 2 is the name of the disease.
5.2 Modeling
The main methods of data mining are categorized into two classes, predictive and descriptive methods. In this paper, predictive methods are used in order to predict two different labels, which were explained in the previous part. Classification, regression, and deviation detection methods are three learning methods of the model in data mining with a predictive nature [16]. In this section, the stacking model, which was designed to reach the highest accuracy, will be described. As it was shown in Table 2, there are a large number of attributes regarding the number of instances. As a result, there were too many pairwise correlations between the variables to be considered and the accuracy of prediction model would suffer if they were included. In addition, overfitting can occur as well. To prevent overfitting, applying ensemble methods which are one of the most common solutions are used. Besides, in order to escape the curse of dimensionality, Principle Components Analysis (PCA) was employed on the input attributes. PCA is a dimension reduction method that uses orthogonal linear projections to reduce the number of parameters. In other words, a set of correlated variables will be transferred into a new set of uncorrelated variables. Generally, a vector space transform is used to reduce the dimensionality of large data sets [17].
5.2.1 Model 1
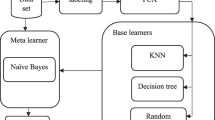
A Stacking algorithm is proposed to model the dataset. This Stacking algorithm has three base learners including kNN [16], Decision tree, and Support Vector Machine (SVM). Naïve Bayes is the Meta learner of the Stacking model. Fig. 1 shows the stacking model for predicting the type of physician, general practitioner and other specialists. In the proposed stacking model, Meta features, which are the results of the prediction of the three used classifiers, are added to the original features of the instances. Consequently, the Meta learner, which is the Naïve Bayes (NB) classifier, models the instances with 388 + 3 features. After applying PCA, the maximum number of components, which led to the best result, was 15 attributes.

Stacking model 1
5.2.2 Model 2
The stacking model for predicting Label 2 of this dataset includes four classifiers: kNN [18], Decision tree, Generalized linear model and Random Forest(RF) as base learners and Naïve bayes as the meta learner. In this case, the Meta learner, which is a Naïve Bayes classifier, models the instances with 388 + 4 features. PCA was applied in this version of the dataset as well to reduce the dataset to a lower dimension and the maximum number of component was 13. Fig. 2 shows the stacking model for the classification of diseases based on the patients’ prescriptions.

Stacking model 2
6 Experiments
The dataset consists of 600 records. Two attributes were considered as labels and separate experiments have done on each of them. The first one is the type of physician each patient referred to and the second one is the disease he suffers from. The data-mining tool RapidMinerFootnote 2 is used for doing experiments. The parameters of base learners and their values are shown in Tables 3 and 4.
In the Table 5, it is shown that the accuracy of other ensemble methods with 15 and 13 attributes for the first and second Labels of the dataset is less than stacking method. The learner for both Adaboost and Bagging methods is Decision Tree and its parameters are shown in Table 5.
However, the results of the experiments would have been worse if PCA had not been used. In fact, the use of PCA has significantly improved the results. Table 6 shows the accuracies for two stacking models without applying PCA.
Tables 7 and 8 compare the accuracy of both stacking models, using various base learners and Meta learners which led to best three results.
The confusion matrices of the models for predicting Label 1 and Label 2 are shown in Table 9 and Table 10 respectively. For predicting Label 1 (G or NG), there are two classes, and therefore a 2 × 2 confusion matrix can be obtained. While for the second version of the dataset, there are nine classes with a 9 × 9 confusion matrix.
According to Table 10, the prediction for four classes “D”, “GI”, “A” and “IN” is mistaken with class “O”. As it can be seen, the final model failed to predict class “D” disease (Depression) and its class recall is equal to zero, although this disease had a large enough distribution in the original dataset. Considering class “D” in class “O”, there will be 8 classes. Besides, this change has made the accuracy of the model 61.83%. Table 11 shows the confusion matrix for these experiments.
Table 12 shows a short summary of different accuracies for different data mining techniques, which were discussed above.
Finally, Tables 13 and 14 are provided to demonstrate that the proposed ensemble method has a higher accuracy compared to single classifiers like kNN, Naïve Bayes, decision tree etc. in the first and second label of dataset. According to Section 4, a collective decision-making system gives the opportunity to reach a better result.
7 Conclusion
The overall objective of this paper was to predict what kind of physician each patient has referred to and what kind of diseases- among nine classes- each instance is suffering from. Three data mining classifications were used, which were Decision tree, Naïve Bayes, and kNN. However, none of them worked properly. Therefore, a Stacking classifier was applied, which was shown that has higher accuracy than single classifiers. In the first version of the dataset, three different base learners include kNN, Decision Tree and SVM were applied for classifying while in the second version, four diverse base learners including kNN, Decision Tree, Generalized Linear Model, and Random Forest were used in the stacking operator. This system can be further developed and it can use a larger number of drugs as input attributes. Predicting patients’ disease is the first step. Health care industry can use this information to identify persons with chronic conditions, which is an indirect method to estimate prevalence. Pharmacy drug data may be a valuable source for measuring population’s burden of disease, when clinical data are missing. In addition, Other data mining techniques like Association Rules can be used. Clearly, association rules are in the category of descriptive methods and only some descriptive rules can be obtained out of the dataset.
References
Zaki MJ, Meira W Jr. Data mining and analysis: fundamental concepts and algorithms. Cambridge: Cambridge University Press; 2014.
Han, Jiawei, Kamber, Micheline, “data mining: concepts and techniques”, Morgan Kaufmann; 2012.
Liao SH, Chu PH, Hsiao PY. Data mining techniques and applications - a decade review from 2000 to 2011. Expert Syst Appl. 2012;39(12):11303–11.
E. Barati et al., “A Survey on Utilization of Data Mining Approaches for Dermatological (Skin) Diseases Prediction,” Cyber Journals: Multidisciplinary Journals in Science and Technology, Journal of Selected Areas in Health Informatics (JSHI). 2011;March Edition.
Taranu I. Data mining in healthcare: decision making and precision. Database Systems Journal. 2015;VI(4)
Dean CA, Geneus CJ, Rice S, Johns M, Quasie-Woode D, Broom K, et al. Assessing the significance of health information seeking in chronic condition management. PEC J. 2017;100:1519–26.
Muellera N, Rojas-Ruedaa D, Basagañaa X, Cirach M, Cole-Hunter T, Dadvand P, et al. Health impacts related to urban and transport planning: a burden of disease assessment. Environ Int J. 2017;107:243–57.
Metsker O, Bolgova E, Yakovlev A, Funkner A, Kovalchuk S. Pattern-based Mining in Electronic Health Records for complex clinical process analysis. Procedia Computer Science Journal. 2017;119:197–206.
Chen J, Li K, Tang Z, Bilal K, Li K. A parallel patient treatment time prediction algorithm and its applications in hospital queuing-recommendation in a big data environment. IEEE ACCESS. 2016;4:1767–83.
B. Abdelghani and E. Guven, “Predicting breast Cancer survivability using data mining techniques”, Ninth Workshop on Mining Scientific and Engineering Datasets in conjunction with the Sixth SIAM International Conference on Data Mining”, 2006.
S. Palaniappan, R. Awang, “Intelligent Heart Disease Prediction System Using Data Mining Techniques”. IJCSNS. 2008;Vol. 8, No. 8.
Repalli P. Prediction on diabetes using data mining approach, Oklahoma State University. Texas: Oklahoma State University, SCSUG Educational Forum Agenda; 2011.
Michael A. King, “ensemble learning techniques for structured and unstructured data”, dissertation for the degree of doctor of philosophy in business information technology, chapter 1, Virginia, United States, 2015.
Schapire RE. The strength of weak learnability. J Mach Learn. 1990;5:197–227.
J. Sulzmann, J. Fürnkranz, “Rule stacking: an approach for compressing an ensemble of rule sets into a single classifier”, Discovery Science. 2011;pp 323–334. Springer Berlin Heidelberg.
M. Kantardzic, “Data Mining: Concepts, Methods¸ Models and Algorithms,” 2nd ed, Wiley; 2011.
Jolliffe IT. Principal component analysis. New York: Springer-Verlag; 1986.
Zhang SC. KNN-CF approach: incorporating certainty factor to kNN classification. IEEE Intelligent Informatics Bulletin. 2010;11(1):24–33.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Electronic supplementary material
ESM 1
(XLSX 1976 kb)
Rights and permissions
About this article

Cite this article
Dehkordi, S.K., Sajedi, H. Prediction of disease based on prescription using data mining methods. Health Technol. 9, 37–44 (2019). https://doi.org/10.1007/s12553-018-0246-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12553-018-0246-2