
Abstract
The aim of this study is to analyze the trends in sugarcane output in Bangladesh, China, India, Nepal, Pakistan, and Sri Lanka by employing three different models, i.e., the autoregressive integrated moving average (ARIMA), ARIMAX, and the last one Holt linear trend. The study based on secondary data spanning from FAO 1961 to 2020 was utilized for forecasting up to 2030. Comparative analysis revealed that the ARIMAX model outperformed the other models, exhibiting higher R2values and lower values of MAPE, MPE, RMSE, and MAE. The findings indicated that the ARIMAX model (1,1,5) was most suitable for forecasting sugarcane production in Bangladesh, China, India, Nepal, Pakistan, and Sri Lanka with a 95% accuracy level. By the year 2030, the projected sugarcane production is expected to be 3806.84 thousand tonnes in Bangladesh, 124,936.77 thousand tonnes in China, 421,559.43 thousand tonnes in India, 4467.87 thousand tonnes in Nepal, 78,084.75 thousand tonnes in Pakistan, and 943.67 thousand tonnes in Sri Lanka. Furthermore, the study observed a decreasing trend in instability across all countries, except for China where instability was found to be increasing. This research is of utmost importance as it contributes to understanding the future dynamics between sugarcane production and demand, thereby addressing the potential gap in the coming years.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Belonging to the grass family, sugarcane is a perennial plant growing mostly in the hot to tropical temperate region of Asia. The plant’s mass composition consists of 57 percent water and the remaining being straw, bagasse, and sugar (Matos et al. 2020). About 8 percent of world’s sugarcane production comes from Southeast Asia (FAOSTAT, 2021). Economy of Southeast Asian countries depends heavily on agriculture with sugarcane being one of the most significant cash crops grown (Zhai and Zhuang 2012). Since ancient times, conventional uses of sugarcane include production of sugar and alcohol fermented from its juice (de Souza et al. 2014). Ethanol produced from sugarcane is used to produce low-carbon biofuel (Formann et al. 2020). Ethanol produced from sugarcane has substituted over one percent of gasoline used in the world (Goldemberg and Guardabassi 2009). This has led to improvement in air quality as unlike gasoline, ethanol does not produce lead, thereby reducing the harmful emissions (Goldemberg et al. 2008). Sugar prices witness maximum fluctuations among all agricultural commodities throughout the world (Elobeid and Beghin 2006; Maitah and Smutka 2019). The market forces of demand and supply mainly govern the prices of sugar (Kotyza et al. 2021). Having the demands for sugar nearly stable, the fluctuation in supply or production of sugar makes the prices volatile. Predicting sugarcane production in upcoming years will act instrumental in controlling sugarcane prices as well as ensuring continuous supply of bioethanol.
If past data are available, then future statistics can be predicted. Many studies have been carried out to forecast sugarcane production by employing varied methodology. In a study carried out in Pakistan, five distinct yield models were industrialized for sugarcane area forecasting and one model for yield forecasting by using ordinary least square technique. Sugarcane production was further predicted by multiplying yield and area forecasts (Masood and Javed 2004). Ali et al., (2015) attempted to forecast production and yield of sugarcane by employing both autoregressive moving average (ARMA) and autoregressive integrated moving average (ARIMA) and found ARMA (1,4) and ARMA (1,1) as most suitable for predicting sugarcane production and yield, respectively. Hossain and Abdulla (2015) predicted sugarcane production in Bangladesh by employing ARIMA (0,2,1) model. Vishwajith et al. (2016) used data from 1950–2012 to forecast sugarcane area, production and yield and found ARIMA (2,1,1) model as most appropriate for the same. ARIMA (2,1,1) model was used to predict sugarcane production data in Pakistan from 2019–2030 by utilizing data from 1947–2017 (Mehmood et al. 2019). Hussain (2023) predicted sugarcane production in Pakistan by employing ARIMA model and found ARIMA (2,1,6), ARIMA (1,1,2), ARIMA (4,1,8), ARIMA (1,0,3), and ARIMA (4,1,2) as most suited models for Punjab, Sindh, KP, Baluchistan, and Pakistan, respectively. Forecasting in sugarcane has also been done by using data mining approaches (Everingham et al. 2009; Beulah and Punithavalli 2016) and crop simulation models (Hammer et al. 2020).
Many researchers have used hybrid ARIMA and ANN models to predict sugar cane production (Bhardwaj and Sanjeev 2022; Paswan et al. 2022). Joint prediction model of Markov and the logistic growth curve has been used to forecast sugarcane production of Guangxi province in China (Li and Qiu 2012). Mishra et al. (2022) applied ARIMA and ETS (exponential smoothing) models for forecasting sugarcane production in South Asian countries. Tyagi et al. (2023) employed various models such as to forecast yearly sugarcane production in India using 63 years of data from 1960 to 2022, and five different models were used: the mean forecast model, the nave model, the basic exponential smoothing model, Holt’s model, and the ARIMA time series models. The current study employs hybrid time series analysis and instability analysis in sugarcane production in South East Asia. For this purpose, sugarcane production data of Bangladesh, China, India, Nepal, Pakistan, and Sri Lanka from 1961 to 2020 have been used.
Materials and Methods
The primary approaches to the research problem, together with their methodologies, are as follows:
Source of Data
The information gathered is entirely secondary. The FAO was consulted for information on sugarcane production from 1961 to 2020 (www.fao.org).
Descriptive Statistics
A rational and understandable framework for numerical data is provided by descriptive statistics. To evaluate a big number of participants in a research study, we may use a variety of procedures or only one measure. Large volumes of data can be interpreted more easily with descriptive statistics. Each descriptive statistic condenses a lot of data into a manageable quantity of language. Researchers employed maximum, minimum, mean, skewness, and kurtosis studies to describe the pattern of the series across India, Bangladesh, China, Nepal, Pakistan, and Sri Lanka.
Instability and Its Measure
For assessing the instability in the production, the index certain by Cuddy and Della (1978) and Srivastava et al., (2022) was used: CVt = (CV) x \(\sqrt{1-{R}^{2}}\).
where σ = standard deviation; \(\overline X = mean\); R2 = coefficient of determination for linear trend model; and CVt = CV around trend
Modeling and Forecasting
The statistics in this paper relate to the production of sugarcane in six distinct South Asian countries: Bangladesh, China, India, Nepal, Pakistan, and Sri Lanka from 1961 to 2020. For modeling and predicting sugarcane production, Holt’s model, ARIMA, and ARIMAX were utilized. Because they are straightforward to use and generate precise estimates, these three models are the most frequently employed for modeling and forecasting. ARIMAX used FAO data to compile information on fertilizer use for sugarcane farming in a number of South Asian region.
(ARIMA) Autoregressive Integrated Moving Average Model
The (ARIMA) model, often known as the Box–Jenkins approach, was put forth by Box and Jenkins in 1976. An autoregressive (AR) and a moving average (MA) model (ARMA) is combined to form the ARIMA model. While the other models work well with stationary data, the ARIMA model is used with non-stationary data (Tekindal et al. 2020). The data differences for the stabilization process are subtracted from the d degree to create the ARIMA (p, d, q) model, which is then added. In the ARIMA (p, d, q) model, p denotes the degree of the AR model, q the degree of the MA model, and d the number of differences that must be taken into account in order to stabilize the data (Supriya et al. 2023). The ARIMA(p, d, q) model equation is as follows:
where ϕp denotes the AR operator’s parameters, including their values; αq denotes error term coefficient; θq denotes the parameter value for the MA operator, and Yt represents the data with dth differences of the actual data (Brockwell et al. 2016; Gujarati and Porter 2012). The steps listed below can be used to fit time series data to an ARIMA model (Ahmadzai et al. 2019)
Identification Stage
The series’ seasonality was identified, the variables’ stationary nature was established, and the autoregressive or moving average was calculated using the augmented Dickey–Fuller (ADF), the auto-correlation function (ACF), and the partial auto-correlation function (PACF) of the series.
Estimation Stage
Using computer methods, find the coefficients that match the chosen ARIMA model the best.
Diagnostic Stage
One way to determine whether the projected model satisfies the requirements of a stationary univariate process is to look at the residuals’ independence from one another and their persistence in mean and variance over time. Insufficient assessment forces us to start over and attempt to build a more precise model.
Estimation of Parameter of ARIMAX Model
The ARIMAX model is a generalization of the ARIMA model, and it has the capability of including an additional input variable. Estimation of the ARIMAX model parameters was accomplished using the non-linear least square method. The preceding equation can be rewritten as follows if one refers to Bierens (1987);
Diagnostic Checking
ARIMAX model diagnostic checking is the same as ARIMA model diagnostic testing by visualizing ACF and PACF residual graphs. If the residuals calculated from this model are white noise, one can accept the particular estimate fit.
Holt’s Linear Trend Method
A smoothing random variability average, the exponentially weighted moving average, offers the following advantages: It was highly noteworthy that (1) the weight of older data was reduced; (2) the assessment was quite simple; and (3) most critically for the data set, only a little amount of data were needed. The following is a summary of these advantages: A reduction in the weight of older data was highly significant, rather straightforward to quantify, and—most significantly for the data set—only required a little amount of data. For determining level, trend, and forecast, Holt (1957) used the model of his three equations (Mishra et al. 2021a, b a and b).
Level Equation: \({L}_{t}=\alpha {Y}_{t}+(1-\alpha )({L}_{t-1}+{T}_{t-1})\)
Trend Equation: \({T}_{t}=\beta \left({L}_{t}-{L}_{t-1}\right)+(1-\beta ){T}_{t-1}\)
Forecast Equation: \({Y}_{t+1}={L}_{t}+(h){T}_{t}\)
where Lt is an estimate of the level of series at time t, Tt denotes for an estimate of its trend at time t, α is the smoothing value for level, ranging from 0 to 1, and β is the smoothing parameter for trend also ranging from 0 to 1.
Model Selection Criteria
On the basis of maximum R2, minimum RMSE, minimum mean absolute percentage error (MAPE), and minimal mean percentage error (MPE), the optimal Box–Jenkins ARIMA model is chosen above ARIMAX and Holt’s model. Any model that has largely complied with the aforementioned requirements is chosen. In this section, the goodness-of-fit metrics used in time series modeling are defined.
The data sets were split into two parts: 80 percent for model training and 20 percent for model testing, respectively. The Gretl software and Microsoft Excel were used to model, validate, and project the data.
Augmented Dickey–Fuller Test
The augmented Dickey–Fuller test is a type of unit root test, which is a statistical evaluation. When using time series models, the statistical inference procedure may be hampered by unit root test, a characteristic of various stochastic walks (such as random processes) in probability concept and statistics. Simply expressed, the unit root process had non-stationary but not always trend-driven. When doing an ADF test, the following assumptions are made:
Null Hypothesis (HO): The series with unit root process.
Alternative Hypothesis (HA): The series had no unit root process.
This test may show that the series is not stationary if the null hypothesis cannot be proved.
Conditions for Rejecting the Null Hypothesis. If the p value is less than 0.05 and the time series does not have a unit root, this suggests that the time series is stationary. Its structure does not change constantly.
Results and Discussion
In the initial stage, we conducted an exploratory analysis of the data to gain insights into the predicted sugarcane production across different countries. Table 1 presents descriptive statistics outlining key observations. It is evident that India leads in sugarcane production, producing approximately 3.5 times more than China, the second-largest producer. Notably, Nepal and Sri Lanka experienced the most significant changes in sugarcane production during the period 1961–2020, as indicated by the maximum and minimum values. In terms of average production, India stands out with the highest value of 225,367.76, whereas Sri Lanka has the lowest average production at 640.48. Analyzing the standard deviations of sugarcane output reveals that India exhibits the highest variability with a standard deviation of 91,219.14. The positive skewness observed in all countries, except for Bangladesh, along with the difference between the maximum and minimum values, suggests a consistent increase in sugarcane production from 1961 to 2020. Moreover, the kurtosis values in all countries indicate a platykurtic distribution, implying that the presence of outliers in the data is insignificant. The measures of central tendency, specifically the order of mean > median > mode for positive skewness and mean < median < mode for negative skewness, further support the asymmetric nature of the data. Similar results were reported by Mishra et al. 2022.
Measure the Instability of Sugarcane Production
Then, assess the volatility of the sugarcane crop over the period depicted in Table 2. In this analysis, nonlinearity had to be introduced into the trend model. The R2 (coefficient of determination) that was derived from the model that fit the data the best was used to determine the CVt value for each of the sequences. We refer to the model that was used by Srivastava et al., 2022 as the improved Cuddy and Della model. During the process of analyzing instability, the de-trend coefficient of variation is computed for three unique time periods: period 1, which spans the years 1961 to 1980; period 2, which spans the years 1981 to 2000; period 3, which spans the years 2001 to 2020; and overall period, which spans the years 1961 to 2020 in its entirety.
With the exception of China, Period I showed the most instability in another country. The coefficient variance around trend (CVt) decreased slightly in Bangladesh, India, Nepal, Pakistan, and Sri Lanka, from 16.79 in Period I to 6.35 in Period III, 11.11 in Period I to 9.08 in Period III, and 12.72 in Period I to 12.76 in Period III. Therefore, the production of sugarcane is now more unstable as a result of the introduction of new technology. It affects farmers’ incomes and choices to invest in lucrative agricultural technologies by raising the risk of farm production. In addition to this, it has an effect on the general level of price stability and the susceptibility of households with low incomes. Agriculture production is at greater risk due to instability, which has an effect on farmers’ income and choice to invest in high-paying tools (Chand and Raju, 2009).
Modeling and Forecasting
Before employing the ARIMA (autoregressive integrated moving average) model, it is essential to ensure that the time series data are stationary, meaning its statistical properties do not depend on the specific time point. Stationarity can be associated with a white noise series with a constant mean (µ) and constant variance (σ). Therefore, in this study, the first step involved conducting the augmented Dickey–Fuller (ADF) test on the sugarcane production time series data from different South Asian countries. The results of the ADF test indicated that almost all series were non-stationary (p > 0.05), implying the need for further processing. To address this, first differencing was applied to the original data, which successfully transformed all the series into stationary ones, with constant mean and variance, as evidenced in Table 3. Subsequently, different ARIMA models ranging from (0, 1, 0) to (1, 1, 5) were considered suitable for modeling and forecasting the behavior of sugarcane production. However, to ensure the adequacy of the selected models, a diagnostic check was performed on the residuals using the ACF and PACF graphs, as depicted in Fig. 1. This step aimed to verify the models’ appropriateness and identify any remaining patterns or autocorrelations in the residuals.

ACF and PACF graphs of residuals for the best-fitted models of sugarcane production for South Asian countries
After that, we used three different techniques—ARIMA, ARIMAX, and Holt’s linear trend—to model and predict the time series data for sugarcane output in South Asian nations. The model was chosen after the performance was assessed using a variety of metrics, including the highest value of R2 (coefficient of determination) criteria for each country and the lowest value of root mean squared error (RMSE), mean absolute error (MAE), mean percentage error (MPE), and mean absolute percentage error (MAPE).
Upon fitting the models for each series, we compared the results to determine the best forecasting model. The analysis revealed that the ARIMAX model outperformed the other approaches in all six South Asian countries, as presented in Table 4. Having identified the best forecasting model, we proceeded to estimate the values of sugarcane production from 2017 to 2020, as displayed in Table 5.
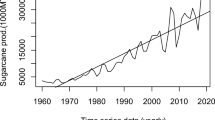
Based on these forecasts, sugarcane production is anticipated to witness an upward trend in Bangladesh, China, India, Nepal, Pakistan, and Sri Lanka in the coming years. By the year 2030, the projected sugarcane production is expected to be 3806.84 thousand tonnes in Bangladesh, 124,936.77 thousand tonnes in China, 421,559.43 thousand tonnes in India, 4467.87 thousand tonnes in Nepal, 78,084.75 thousand tonnes in Pakistan, and 943.67 thousand tonnes in Sri Lanka, as shown in Table 6. These predictions are further supported by the forecast visuals presented in Fig. 2. The key factors contributing to this positive trend in sugarcane production include agricultural finance, price support programs, improved management practices, and research advancements, among others. These factors collectively contribute to the long-term sustainability and growth of sugarcane production in the region.

Observed and forecasting of production of sugarcane in South Asian countries
The results of this research have important repercussions for the agriculture sector and the various parties involved in that sector. The projected increase in sugarcane production highlights the importance of implementing appropriate measures to support and sustain this growth. Factors such as agricultural finance, price support programs, improved management practices, and research initiatives will play crucial roles in maintaining the upward trend in sugarcane production. It is important to note that the forecasts are based on historical data and the assumption that current trends and factors influencing sugarcane production will continue in the future. However, unforeseen events, changes in agricultural policies, and other external factors can influence actual production levels. Therefore, regular monitoring, evaluation, and adjustment of strategies based on updated information are necessary to make sure the accuracy and relevance of these forecasts. Overall, this study delivers valuable understandings into the future dynamics of sugarcane production in South Asian countries. The use of advanced forecasting models like ARIMAX can assist policymakers, researchers, and agricultural stakeholders in making informed decisions to meet the growing demand for sugarcane and address potential gaps in the coming years.
Conclusion
The findings to antedate sugarcane production from 2021 to 2030 reveal that production will increase in all six countries. India would have the highest predicted value in 2030, according to the study’s findings, which are conclusive. ARIMA, ARIMAX, and Holt’s linear trend models were employed to model and forecast sugarcane production in South Asian countries. The models were evaluated based on various metrics such as RMSE, MAE, MPE, MAPE, and R2 values. The ARIMAX model was initiated to be the best-performing model for forecasting sugarcane production based on fertilizer consumption in all six countries, and various factors such as agricultural finance, price support programs, and improved management practices will play crucial roles in sustaining this growth. However, it is important to continually monitor and adapt strategies to account for potential changes and uncertainties in the agricultural sector.
This study delivers valuable understandings into the future dynamics of sugarcane production in South Asian countries. The use of advanced forecasting models like ARIMAX can assist policymakers, researchers, and agricultural stakeholders in making informed decisions to meet the growing demand for sugarcane and address potential gaps in the coming year. Also, the examination of sugarcane production instability across various periods and states yielded noteworthy outcomes. Instability was assessed using the coefficient of variance around the trend (CVt), where lower values denoted higher stability. The findings indicated a slight decline in CVt over time in Bangladesh, India, Nepal, Pakistan, and Sri Lanka, except for China, which displayed the highest instability during Period III.
Implications and Policies
Agricultural Finance
Ensuring access to adequate financial resources and investment opportunities for farmers and agricultural enterprises is vital. Establishing financial mechanisms that support sugarcane cultivation, such as loans, subsidies, and credit facilities, can enable farmers to expand their operations and adopt modern farming techniques.
Price Support Programs
Implementing price support programs can provide stability and incentives for sugarcane farmers. Guaranteeing minimum prices for their production or offering subsidies during periods of market fluctuation can encourage farmers to increase production and invest in the crop.
Improved Management Practices
Promoting and disseminating best practices in sugarcane cultivation, including efficient irrigation methods, integrated pest management, and soil conservation techniques, can enhance productivity and sustainability. Training programs and extension services should be developed to educate farmers on these practices.
Research Initiatives
Continued research and development efforts are essential to address challenges in the sugarcane sector. Investing in research to develop disease-resistant varieties, enhance crop productivity, and improve post-harvest technologies can contribute to long-term growth. Collaboration between research institutions, agricultural experts, and industry stakeholders is crucial in driving innovation and finding solutions.
Data availability
Data will be available upon request from the corresponding author.
References
Ahmadzai, M.K., M. Eliw, and andD. Zhou. 2019. Descriptive and econometric analysis of wheat production in Afghanistan (A case study in Paktia province). South Asian Journal of Social Studies and Economics 5 (3): 1–10.
Ali, S., N. Badar, and H. Fatima. 2015. Forecasting production and yield of sugarcane and cotton crops of Pakistan for 2013–2030. Sarhad Journal of Agriculture 31 (1): 1–10.
Beulah, R., and M. Punithavalli. 2016. Prediction of sugarcane diseases using data mining techniques. IEEE International Conference on Advances in Computer Applications, Coimbatore, India, pp. 393–396.https://doi.org/10.1109/ICACA.2016.7887987.
Bharadwaj, N., and Sanjeev. 2022. Time series prediction using hybrid ARIMA-ANN models for sugarcane. International Journal of Plant and Soil Science 34 (23): 772–782.
Bierens, H.J. 1987. ARMAX model specification testing, with an application to unemployment in the Netherlands. Journal of Econometrics 35 (1): 161–190.
Box, G.E., and G.M. Jenkins. 1976. Time series analysis, control, and forecasting. San Francisco, CA: Holden Day 3226 (3228): 10–12.
Brockwell, P.J., P.J. Brockwell, R.A. Davis, and R.A. Davis. 2016. Introduction to time series and forecasting, 202–221. Singapore: Springer.
Chand, R., and S.S. Raju. 2009. Dealing with effects of Monsoon Failures. Economic and Political Weekly 29–34.
Cuddy, J.D.A., and P.A. Della. 1978. Measuring the instability of time series data. Oxford Bulletin of Economics Statistics 40 (1): 79–85.
De Souza, A.P., A. Grandis, D.C.C. Leite, and M.S. Buckeridge. 2014. Sugarcane as a Bioenergy source: History, performance, and perspectives for second-generation bioethanol. BioEnergy Research 7 (1): 24–35.
Elobeid, A., and J. Beghin. 2006. Multilateral trade and agricultural policy reforms in sugar markets. Journal of Agricultural Economics 57 (1): 23–48.
Everingham, Y.L., C.W. Smyth, and N.G. Inman-Bamber. 2009. Ensemble data mining approaches to forecast regional sugarcane crop production. Agricultural and Forest Meterorology 149 (3–4): 689–696.
FAOSTAT, 2021. Food Outlook. FAO, Rome.
Formann, S., A. Hahn, L. Janke, W. Stinner, H. Strauber, W. Logrono, and M. Nikolausz. 2020. Beyond sugar and ethanol production: Value generation opportunities through sugarcane residues. Frontiers in Energy Research 8: 579577.
Goldemberg, J., and P. Guardabassi. 2009. The potential for first generation ethanol production from sugarcane. Biofuels, Bioproducts and Biorefining 4 (1): 17–24.
Goldemberg, J., S.T. Coelho, and P. Guardabassi. 2008. The sustainability of ethanol production from sugarcane. Energy Policy 36 (6): 2086–2097.
Gujarati, D.N., D.C. Porter, and S. Gunasekar. 2012. Basic econometrics. New York: Tata McGraw-Hill Education.
Hammer, R.G., P.C. Sentelhas, and J.C.Q. Mariano. 2020. Sugarcane yield prediction through data mining and crop simulation models. Sugar Tech 22: 216–225.
Holt, C.E. 1957. Forecasting seasonals and trends by exponentially weighted averages; (ONR Memorandum No. 52). Carnegie Institute of Technology, Pittsburgh.
Hossain, M.M., and F. Abdulla. 2015. Forecasting the sugarcane production in Bangladesh by ARIMA model. Journal of Statistics Applications and Probability 4 (2): 297–303.
Hussain, N. 2023. Predicting forecast of sugarcane production in Pakistan. Sugar Tech 25: 681–690.
Kotyza, P., K. Czech, M. Wielechowski, L. Smutka, and P. Prochazka. 2021. Sugar prices versus financial market uncertainty in the time of crisis: Does COVID-19 induce structural changes in the relationship. Agriculture 11 (2): 93.
Li, D., and M. Qiu. 2012. The application of joint model for sugarcane production forecast of Guangxi province. Procedia Engineering 31: 1083–1088.
Maitah, M., and L. Smutka. 2019. The development of world sugar prices. Sugar Tech 21: 1–8.
Masood, M.A., and M.A. Javed. 2004. Forecast models for sugarcane in Pakistan. Pakistan Journal of Agricultural Science 41 (1–2): 80–85.
Matos, M.D., F. Santos, and P. Eichler. 2020. Chapter 1- sugarcane world scenario. In Sugarcane biorefinery, technology and perspectives, ed. F. Santos, S.C. Rabelo, M.D. Matos, and P. Eichler. Amsterdam: Academic Press.
Mehmood, Q., M.H. Sial, M. Riaz, and N. Shaheen. 2019. Forecasting the production of sugarcane crop of Pakistan for the year 2018–2030, using Box Jenkin’s methodology. The Journal of Animal and Plant Science 29 (5): 1396–1401.
Mishra, P., A.M.G. Al Khatib, I. Sardar, J. Mohammed, K. Karakaya, A. Dash, and A. Dubey. 2021a. Modeling and forecasting of sugarcane production in India. Sugar Tech 23 (6): 1317–1324.
Mishra, P., A. Matuka, M.S.A. Abotaleb, W.P.M.C.N. Weerasinghe, K. Karakaya, and S.S. Das. 2021b. Modeling and forecasting of milk production in the SAARC countries and China. Modeling Earth Systems and Environment 8 (1): 947–959.
Mishra, P., K.M. Alakkari, A. Lama, S. Ray, C. Shoko, M. Abotaleb, A.M.G.A. Khatib, and K. Karakaya. 2022. Modeling and forecasting sugarcane production in South Asian countries. Current Applied Science and Technology 23 (1): 1–15.
Paswan, S., A. Paul, and A.S. Noel. 2022. Time series prediction for sugarcane production in Bihar using ARIMA & ANN model. The Pharma Innovation Journal 11 (4): 1947–1956.
Srivastava, A.B., P. Supriya, K.K. Singh. Mishra, and H.P.S. Choudhari. 2022. Instability and production scenario of wheat production in Uttar Pradesh using ARIMA model and its role in food security. Indian Journal of Economics and Development 18 (1): 181–188.
Supriya, A.B., Y.S. Srivastava, M. Raghav, P. Devi, S. Kumari, P. Yadav, R. Mishra, B.K. Gautam, S.K. Verma. Gupta, and D. Bohra. 2023. Modelling and forecasting of lentil production in india and its instability. Journal of Animal, Plant and Science 33 (4): 817–828.
Tekindal, M.A., H. Yonar, A. Yonar, M. Tekindal, M.B. Çevrimli, H. Alkan, Z.S. Inanç, and B. Mat. 2020. Analyzing COVID-19 outbreak for Turkey and eight country with curve estimation models, boxjenkins (ARIMA), brown linear exponential smoothing method, autoregressive distributed lag (ARDL) and SEIR models. Eurasian Journal of Veterinary Science 36: 304. https://doi.org/10.15312/EurasianJVetSci.2020.304.
Tyagi, S., S. Chandra, and G. Tyagi. 2023. Statistical modelling and forecasting annual sugarcane production in India: Using various time series models. Annals of Applied Biology 182 (3): 371–380.
Vishwajith, K.P., P.K. Sahu, B.S. Dhekale, and P. Mishra. 2016. Sugarcane and sugar production in India. Indian Journal of Economics and Development 12 (1): 71–80.
Zhai, F., and J. Zhuang. 2012. Agricultural impact of climate change: A general equilibrium analysis with special reference to Southeast Asia. Climate change in Asia and the Pacific: How can countries adapt 12: 17–35.
Author information
Authors and Affiliations
Contributions
S. and A.B.S. were involved in conceptualization. S., A.B.S., B.K., and S.Y. carried out the formal analysis and investigation. A.S. wrote and prepared the original draft. S., A.S., S.Y., and M.P.N. took part in reviewing and editing. S. was responsible for the supervision.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Supriya, Srivastava, A.B., Kumari, B. et al. Comparative Analysis of Sugarcane Production for South East Asia Region. Sugar Tech 26, 264–273 (2024). https://doi.org/10.1007/s12355-023-01346-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12355-023-01346-0