
Abstract
Named Data Networking (NDN) is a promising architecture that aims to natively satisfy emerging applications such as the Internet of Things (IoT). Therefore, enabling NDN in real-world IoT deployments is becoming essential in order to benefit from Information Centric Networking (ICN) features. To design realistic NDN-based communication solutions for IoT, revisiting mainstream technologies such as low-power wireless standards may be the key. In this paper, we explore NDN forwarding over IEEE 802.15.4 following two steps. First, we mathematically model a broadcast-based forwarding strategy for NDN over constrained networks with the IEEE 802.15.4 technology in mind. The model estimates the number of frames transmitted and the mean round-trip time per request, under content popularity considerations. Second, based on mathematical and experimental observations of the broadcast-based forwarding at network level, we elaborate Named-Data Carrier-Sense Multiple Access (ND-CSMA), an adaptation of the Carrier-Sense Multiple Access (CSMA) algorithm used in IEEE 802.15.4. Results show that adaptations such as ND-CSMA may be reasonably envisioned to improve NDN efficiency with current IoT technologies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
IoT systems are built with battery-powered devices that have limited computational power and memory capacity. These devices are often mobile and massively deployed through houses, fields of crops, etc. Device interconnection is achieved with low-rate wireless technologies that allow communication with a satisfactory data rate, payload size and distance range, all with a long-lasting battery lifetime. One of these technologies, the IEEE 802.15.4 [1], greatly contributes to make IoT possible. Sensors and wireless equipment use 802.15.4-capable modules to exchange data in most IoT systems. The wide adoption of this standard proves its suitability for the IoT.
It was then necessary to create 6LoWPAN [2] to support IPv6 communication over the IEEE 802.15.4 standard, and the Constrained Application Protocol (CoAP) [3] to handle data exchange in constrained environments. More generally, Internet Engineering Task Force (IETF) Working Groups are devoting great efforts to adapt the TCP/IP stack to suit IoT systems. These efforts have extended the TCP/IP stack and created various other protocols acting as middleware between the application layer and the network layer. Nevertheless, the limits of IP-based protocols are still a reality [4]. For example, host-based IP addressing can not express device identity, data naming and content security within the same network layer protocol. Important requirements such as caching, mobility and multicast further complicate the IoT support. Therefore, IP-based solutions support the IoT at application level using the Representational State Transfer (REST) architecture, which indicates that the TCP/IP stack has reached its limit to support these new requirements. Moreover, most of these solutions are converging to the principles of the Information Centric Networking (ICN) [5] paradigm; by considering data names and object-based security as design principles.
Unlike host-based networking, Named Data Networking (NDN) [6] operates with named content. In NDN, every piece of content is identified by a unique name which applications use to request data. Content names are independent from the host location; that is, each content item keeps the same name everywhere at producers, caches and consumers. This feature is combined with cryptographic operations to provide self-secured packets. Since packets are independent from their source and destination hosts, NDN natively supports in-network caching. NDN is an evolved L3 protocol, as it includes some of the relevant operations traditionally provided by higher network layers such as security and flow control. With these features, NDN can match most IoT applications that focus on the content regardless of where it is located or how it is transported. Current efforts regarding NDN for the IoT consist in supporting applications in a simpler, more efficient, and more elegant way [7]. Lightweight design in constrained wireless networks can be considered as a major step towards enabling NDN in IoT. However, in NDN’s journey to real-world IoT deployments, we believe that adaptations of current IoT-related technologies will be required. One of these adaptations concerns link layer technologies, and particularly the IEEE 802.15.4, as investigated in this paper.
In this context, we first model a broadcast-based NDN forwarding strategy for wireless constrained networks. The model estimates the average number of frames transmitted per request (i.e., Interest-Data exchange) and the mean round-trip time (RTT) under content popularity considerations. After that, based on mathematical and experimental observations, we consider an adaptation of the Carrier-Sense Multiple Access (CSMA) algorithm to achieve a trade-off between the Interest satisfaction, the number of transmissions, and the round-trip time. The designed adaptation, Named-Data CSMA (ND-CSMA), is derived from the CSMA algorithm to provide a better support for the broadcast-based forwarding approach.
The rest of the paper is organized as follows. Section 2 briefly reports on some ICN/NDN models formulated so far and some NDN-802.15.4 related studies. Section 3 gives an overview of the basic NDN forwarding in wired networks. In Section 4, the deployment of NDN in wireless networks is discussed through different approaches. Section 5 details the wireless forwarding strategy considered in this study, and Section 6 presents the model formulation and evaluation. Section 7 describes and evaluates the proposed ND-CSMA scheme. Section 8 concludes the paper with some future perspectives.
2 Related work
Most of the models on ICN/NDN are conducted exclusively around caching, such as cache deployment, cache decision and cache replacement. Some studies manage to model ICN/NDN transport and routing performance, with comparison to TCP/IP [8].
Only few analytical models consider the interaction between caching and transport in ICN/NDN protocols. Furthermore, these models exclusively consider wired networks [9,10,11]. In the cache modeling area, some studies have been presented in the context of Web caching with ICN under the Least Recently Used (LRU) replacement policy. A noticeable work [12] is used as a basis in our model to compute cache miss rate probabilities.
To the best of our knowledge, no model has been explicitly formulated on NDN in wireless networks with cache consideration, whether for constrained or traditional wireless networks such as MANETs.
We also believe that no proposals do exist for adapting the CSMA algorithm to improve wireless forwarding with ICN/NDN.
Concerning real-world deployments, an NDN integration with IEEE 802.15.4 (ZigBee) is proposed in [13] and other aspects of IEEE 802.15.4 have been investigated before, such as addressing and name-to-address mapping [14].
3 Named data networking
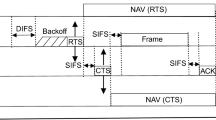
NDN protocol operates using Interest and Data packets that carry content names instead of source and destination addresses. To forward packets based on names, each node maintains two data structures: the Forwarding Information Base (FIB) and the Pending Interest Table (PIT). Optionally, a Content Store (CS) is used to provide in-network caching.
In wired networks, a typical NDN communication operates according to the following steps (see Fig. 1):
-
1)
The communication is initiated by the consumer that requests a content item by sending an Interest carrying the corresponding name (e.g., /building1/room1/ temperature).
-
2)
Upon receiving an Interest, a router (relay node) checks its local CS. If a corresponding Data exists, it is sent back without forwarding the Interest any further. If there is no matching content in the CS, the router checks the PIT.
-
3)
If an Interest for the same content item is present, the new Interest is not forwarded but its originating interface is added to the existing PIT entry. The new Interest is forwarded only if no similar Interest is already waiting in the PIT.
-
4)
Interest packets are forwarded according to the FIB using the longest prefix match (LPM). After that, the router records the Interest and its originating interface in the PIT until a matching Data is received or the Interest expires.
-
5)
When the Interest reaches the producer of the content item or an intermediate cache, the corresponding Data packet is sent back.
-
6)
Usingthe PIT, the Data packet follows the reverse path of the Interest(s) until the consumer(s). When the Data reaches a router, it is forwarded to every interface from which a corresponding Interest was received. Then, the router discards the PIT entry and caches a copy of the Data in its CS.
-
7)
When a Data packet is received and no matching Interest is present in the PIT, its considered unsolicited by the node and the packet is discarded.

Interest and Data processing at an NDN node
4 Named data networking in wireless networks
Some wireless network features, particularly in ad hoc networks, can be intuitively related to ICN/NDN principles. Therefore, the following benefits can be expected from a deployment of NDN in wireless environments [15,16,17]. First, with a connection-less and consumer-driven communication model, NDN can cope well with intermittent connectivity and dynamic topologies of wireless environments. Moreover, satisfactory data delivery can be expected thanks to native caching and location-independent data security. Second, NDN does not require any logical identification of nodes, since content items are retrieved using their names. This is more natural regarding current applications where the content (i.e., its name) is more relevant than the host address. Third, in emerging applications, content is usually published from servers (e.g., news, weather information) or it can be shared between groups of consumers (e.g., road traffic and safety) or it can be created by one user and published into a group of consumers (e.g., social media). These communication scenarios can be efficiently supported with multicast and broadcast data delivery. With Interest aggregation and Data caching, NDN natively supports multicast and has a powerful data dissemination capability. This helps NDN to take advantage of the broadcast nature of wireless and support these required communication patterns.
To design an NDN-based wireless network, an overlay of NDN on top of IP should be avoided for three main reasons [15]: First, discover and maintain end-to-end routes between nodes require recurrent communications; which may lead to high control overhead due to the multiple protocols involved. Second, using IP as the underlying protocol forces point-to-point communications, without exploiting broadcast, multicast, and in-network caching. Third, the protocol stack becomes larger, requiring more device resources which is already a constraint in the IP stack itself.
Therefore, the most efficient approach for deploying NDN in wireless networks is to run NDN directly over the link layer.
However, the forwarding decision in wireless networks is slightly different than in wired networks. The main reason is that a wireless radio corresponds to only one network interface; thus a node cannot distinguish between different next-hops using network interfaces. Thus, without a mechanism such as source/destination address to control packet transmissions, only broadcast communication is available at the link layer. This basic approach is designated here as Blind Flooding (BF). BF is the simplest way to forward packets with broadcast in NDN wireless networks. It is straightforward and efficient in finding content, even with node mobility and intermittent connectivity. However, flooding packets on a wireless medium generates large network overhead, and high resource consumption, which is not acceptable in IoT environments.
To attenuate the broadcast effect, a mapping between NDN names and MAC addresses can be envisioned [18]. The purpose is to use unicast communications when a destination address is available. For example, when an Interest is forwarded (using broadcast), the relay node stores the MAC address of the source node in the PIT alongside the Interest. When the Data is received, it is forwarded to the source node only, using the unicast address corresponding to the Interest. Similarly, the relay node can store the MAC address of the Data source in its FIB, which will be used as a next-hop for the corresponding content name to forward further Interests.
That being said, mapping NDN names to MAC addresses may achieves different performances regarding Data availability, memory usage, network overhead, and packet redundancy. An experimental comparison of these mappings is reported in [18]. In short, unicast usually improves the battery lifetime of devices by keeping CPU usage and control overhead to a minimum, and can benefit from MAC layer acknowledgment and frame retransmission. However, additional memory is required to maintain the name-to-MAC mappings, and a mechanism to extract and aggregate prefixes from names is also needed [19]. Furthermore, using unicast (i.e., point-to-point) is not inline with the NDN vision, which uses content naming alone.
To keep using broadcast while reducing resource consumption and network overhead is to enhance the Network Interface Controller (NIC) with an appropriate frame filtering mechanism. Therefore, the NIC hardware can be adapted consequently to support frame filtering based on names rather than MAC addresses [20]. Although good improvements can be expected, the solution implies re-engineering a part of the hardware, which makes it non realistic regarding current IoT equipment.
One software-based approach to efficiently use broadcast is to reduce the risks of collision and packet redundancy [21]. This is achieved by delaying its own transmissions and overhearing neighbors’ communications, as detailed in the next section. This approach is designated here as Controlled Flooding (CF). Although this approach is not always efficient for IoT devices and wireless technologies, it is simple to implement and is one of the most realistic solutions.
The approaches described above are summarized in Table 1.
5 Controlled flooding strategy
As mentioned above, using host addresses to transmit NDN packets decreases its data dissemination power, and limits the NDN benefits expected in mobile wireless networks. Moreover, mapping names to addresses requires transmission overhead to discover and maintain routes in resource-constrained environments, and needs more memory for the FIB.
To keep the benefits of flooding/broadcast while reducing overhead and redundancy, Controlled Flooding (CF) can be envisioned. With CF, relay-nodes exploit broadcast communications to overhear neighbors’ communications and possibly avoid forwarding some packets. To do so, every relay node defers its transmissions with a random delay during which it keeps listening on the shared wireless medium. While waiting, if the node overhears a communication (i.e., Interest or Data) with the same name, it cancels its transmission.
In practice, Interest and Data transmissions are deferred for ΔI and ΔD periods of time respectively. Both ΔI and ΔD are computed based on an interval, defer window (dw), from which an integer value is randomly chosen to generate the waiting delays as follows [22]:
where DeferSlotTime is a short period of time.
Here, ΔI and ΔD are selected in disjoint intervals with ΔI > ΔD to give higher priority to Data packet transmissions and avoid useless Interest broadcasts. During the ΔI waiting time, the node listens to the channel: if it overhears an Interest or a Data with the same name, it cancels its own transmission. Although the CF strategy is designed for IEEE 802.11 technologies, it can be envisioned over IEEE 802.15.4 when low latency is not required.
In order to study the applicability of CF over constrained wireless networks such as IEEE 802.15.4, in the next section, we formulate an analytical model of the CF strategy considering content popularity.
6 Controlled flooding model
6.1 Assumptions and notation
We consider a typical IoT deployment with consumer applications requesting content produced by end-devices. Consumers requests are transmitted through a gateway. The gateway and the end-devices have a single IEEE 802.15.4 interface.
We assume a wireless physical layer with no transmission errors. The network topology is a full binary tree of depth N, in which the root corresponds to the gateway, and the leaves represent the end-devices. The other nodes in the tree act as relay-nodes (see Fig. 2). Nodes are not mobile. Sibling nodes overhear each other’s communications but no packet is actually forwarded between them. Hence, only one path is possible to reach an end-device (i.e., producer) from the gateway.

Tree topology example with N = 3
We consider that relay-nodes located at the same level in the tree have caches of the same size. The gateway has the largest cache among all nodes, and end-devices have the smallest cache size. We believe that such configuration is a realistic IoT scenario. Nodes manage their caches according to the LRU replacement policy.
The following metrics are considered in the model:
-
Cost-per-request (CPR). The number of packets transmitted to retrieve a content requested by the gateway.
-
Round-trip time per request (RPR). The mean delay time (in ms) measured by the gateway from sending an Interest to receiving a matching Data.
6.2 Content popularity
We consider a set of M content items equally divided into K classes, each one containing m = M/K content items. Each class represents a different popularity, and has a probability qk to be requested, where k = 1,2,...,K.
The content consumed in our scenario can be considered as Web content, which typically follows Zipf distribution [23]. Hence, a Zipf distribution is used to model the popularity of content classes as follows:
qk = c/kα with α > 1 and \(c = 1 / {\sum }_{k=1}^{K} 1/k^{\alpha }\).
We consider that each content item is transmitted in one Data packet. For the sake of simplicity, we assume that each end-device produces the same amount of content items of each class.
The Interest arrival process is modeled using a Markov Modulated Rate Process (MMRP) of intensity λ. Hence, Interest packets for class k content are issued following a Poisson process of intensity λk = λqk. Within each class, the content item to request is uniformly chosen among the m different content items in the given class. Consequently, a content item in class k is requested with probability qk/m. The notations and their meanings are summarized in Table 2.
6.3 Model formulation
We first define pk, pk(i) and pt as follows. According to the above assumptions, there is no data duplication among caches at the same level. This allows us to consider all the caches at each level i as one cache. Given this, at the first level (i.e., gateway), the stationary miss probability pk, for content of class k, is defined and proven in [12] as follows:
for relatively large x, where \(1/g = \lambda c \sigma ^{\alpha } m^{\alpha -1} {\Gamma }(1-\frac {1}{\alpha })^{\alpha }\).
Considering a tree with N levels, an MMRP content request process with rate λ(i), and under the popularity distribution given above, the miss probability at level i ∈ [2,N) is also defined and proven in [12] as follows:
For more details on Eqs. 3 and 4, including proof and discussions, readers may refer to [12].
When none of the two sibling nodes has the requested content item, both of them try to forward the Interest according to the CF strategy described in Section 5.
According to the random delays computation (see Eq. 1), an Interest is forwarded by both nodes if they choose random numbers with a difference smaller than s = rI/τ. Hence, the probability that two sibling nodes transmit the same Interest is equivalent to the probability that two random numbers chosen from the interval of length S = dw + 1 have a difference smaller than s. This can be formulated as follows:
Here, we can define the CPR for retrieving a class k content item as follows:
where:
Note that Eq. 6 models the CPR only for the requests that have been satisfied. That is, pk(N) = 0.
Equation 6 is obtained based on the following approach. As the content can be found at any level from 1 to N, the cost is defined as a weighted sum of the transmitted packets associated to each level i. The weights correspond to the cache hit probability (1 − pk(i)) at level i given that a cache miss occurred at all the previous levels. For every possible level i, the number of packets is composed of two parts: 2(i − 1) corresponds to the number of packets transmitted along the path from the gateway to the level-i device, plus the number of packets transmitted if the sibling of each previous node (from level 2 to i − 1) has also transmitted the Interest, which has a probability pt of occurring for each pair of siblings.
Here, Eq. 7 assumes that when the sibling of a node (at level l) transmits an Interest, the cost can be recursively computed using the same approach as Eq. 6 in its sub-tree (from level l + 1 to N). The only difference is that, on this side of the network, we directly consider the path from level l to the leaf level N, since the requested content has already been found elsewhere and there is no data duplication. However, in each sub-tree, the first Interest is always transmitted, but the number of transmissions recursively computed is subject to the probability that no collision occurs between the first sibling nodes of the sub-tree (pf).
Following the same approach, we define the mean RPR for a class k content item as follows:
where Ri = (i − 1)(rI + rD + δI + δD).
Similarly to CPR, as the content can be found at any level from 1 to N, the mean RPR is a weighted sum of the total time Ri required to send the Interest and get the Data associated to each level i. The weights correspond to the cache hit probability (1 − pk(i)) at level i given that a cache miss occurred at all the previous levels (i.e., 1 to i − 1).
Here, Ri is obtained by multiplying the number of hops (i − 1) for level i by the total delay needed to send an Interest and get Data; which includes waiting delays (δI + δD) and time-on-air (rI + rD).
When two sibling nodes delay their transmissions, the node with the shortest delay will transmit the packet first. Furthermore, the round-trip delay measured by the consumer (e.g., gateway) will be affected by the shortest waiting delay computed at each level. Hence, the global estimation of δI and δD is not halfway between the lowest and the highest values (e.g., dw/2τ). To approximate the values of δI and δD, we consider the mean of the lowest half of [dw,2dw] and [0,dw − 1] intervals respectively. This gives us δI = (9dw/8)τ and δD = ((dw − 1)/8)τ.
6.4 Model evaluation
To evaluate our model, we use the CF strategy implemented by the NDNOMNeT++ simulation framework [24]. In the following evaluation we consider a tree of depth N = 4. The gateway requests content from a total of M = 3000 items, distributed in K = 50 classes of decreasing popularity, each one with m = 60 items. The request rate at the gateway is λ = 1 request/s. We set up a cache of size x = 300 packets at each level of the tree. Interest and Data packets have a size of 30 bytes and 90 bytes respectively.
Three content popularity distributions are tested with α ∈ {1.5, 2, 2.5}. Two configurations of the CF strategy are tested with dw = 127 and dw = 255.
Preliminary simulations have been used to set τ = 0.032μs. We also measured rI = 1.36ms, rD = 3rI and pf = 0.8 with preliminary simulations.
Every simulation has run for 10 hours. Results are reported and discussed in the following.
First, the Interest satisfaction rate is reported in Table 3. We observe that dw = 127 always achieves better Interest satisfaction rate than 255. The reason is that 127 is low enough to make relay nodes transmit more packets and explore the network without being too low to create a lot of collisions. However, the remaining results show that this Interest satisfaction rate is achieved at the cost of many more transmissions than dw = 255. This is confirmed in both simulation results and model.
Figure 3a, b and c show the CPR for dw = 127, under α = 1.5, 2 and 2.5 respectively. Similarly, Fig. 3d, e and f show the CPR for dw = 255, with α = 1.5, 2 and 2.5 respectively. According to the results, the value of α has in impact on the efficiency of NDN. In fact, small values of α reduce the popularity difference between classes, which introduces more diversity in the requests, increases the cache miss rate and thus the CPR. Inversely, when α is high (e.g., > 2) applications frequently request content items of the most popular classes, which takes advantage of caching and reduces the CPR.

Model evaluation results
We observe that CPR becomes better when a higher value of dw is used. For example, up to two transmissions per request are saved for the least popular content when using dw = 255 instead of dw = 127.
The model fits well for the different values of dw and α, and accurately predicts the CPR according to the content popularity. However, higher discrepancies between the model and simulations are observed when the value of α increases. The reason is that a cache miss is more likely to occur when α is higher which leads to more transmissions. The behavior of the nodes becomes then more dependent on the link layer, which is not included in the model.
To study the efficiency of CF, we represent the CPR for a perfect-unicast scenario. Perfect-unicast refers to the best CPR expected if a host-based routing protocol with unicast is used instead of NDN. We note that NDN with CF outperforms perfect-unicast for the most popular content. This shows that transmission overhead induced by broadcast can be attenuated by small caches in the presence of popular content.
Figure 3g, h, and i report on the RPR for dw = 127, under α = 1.5, 2 and 2.5 respectively. Figure 3j, k, and l report on the RPR for dw = 255, under α = 1.5, 2 and 2.5 respectively. The model catches the simulation behavior, and the same observations can be made as for CPR. However, a higher dissimilarity is observed between the model and simulations. The reasons are the same as for CPR with an additional fact related to medium access time. As dw values are not high enough to avoid redundant packet transmissions, the link layer has to resolve more medium access contentions, leading to less accuracy in our model. This can be confirmed by observing raw simulation results (i.e., blue dots) which present higher scatter as α gets higher.
RPR performance show that the CPR attenuation observed above with dw = 255 comes at the cost of a higher RPR. The reason is that random waiting delays also increase when dw increases. For example, with dw = 255 an increase of 15ms of round-trip delay per request is observed for the least popular content than with dw = 127.
Overall, we find that a trade-off between cost and round-trip delays is difficult to achieve with the CF mechanism. On the one hand, trying to reduce waiting delays by reducing dw increases the number of transmissions and collisions as the nodes do not have enough time to listen to each other. We should note that this situation becomes even worse in a complex topology when more than two forwarders are available. On the other hand, reducing cost with higher values of dw will induce higher waiting delays. Moreover, the nodes are still listening to transmissions when waiting, which is not helpful for energy consumption.
An ideal improvement one may look for is to reduce the round-trip time and energy consumption by eliminating waiting delays while keeping the lowest number of frame transmissions (i.e., CPR). Since eliminating waiting delays will significantly impact the CPR, we have to question whether a trade-off theoretically exists that may achieve reasonable CPR, low RTT and a reasonable Interest satisfaction rate.
According to the CF strategy, the tree is explored depending on whether both sibling nodes forward the Interest or only one of them does. In the model evaluation, we find that the best overall performance for CF is achieved with dw = 127. Let the corresponding forwarding probability for each sibling node-pair be \(p_{t}^{*}\). Then, we can easily observe that there is no value of pt lower than \(p_{t}^{*}\) that can achieve the same or better satisfaction rate, which is confirmed by Table 3. That is, a compromise at L3 level that achieves optimal performance is not possible in our configuration.
In fact, overhearing transmissions at L3 requires packets to be entirely received in order to access the name. Moreover, in our configuration every node can overhear only its sibling node transmissions. Therefore, by shifting the forwarding decision to the L2 level (with some modifications) instead of using deferred transmissions, one may expect better performances since the CSMA algorithm natively considers multiple-access contention. The following section presents the design and evaluation of our L2-based approach.
7 A named data CSMA for IEEE 802.15.4
As mentioned before, eliminating waiting delays will inevitably increase the number of unnecessary packet transmissions and channel access contention. To handle that, we consider pt = 1, which corresponds to dw = 0, and we modify the CSMA algorithm of the IEEE 802.15.4 in such a way that the number of attempts to access the channel is lower when transmitting an Interest than when transmitting a Data. In practical terms, we replace the waiting delays by a priority-based CSMA scheme designed for NDN. In this section, we describe the legacy CSMA algorithm followed by the design and evaluation of the ND-CSMA scheme.
7.1 Legacy CSMA
IEEE 802.15.4 [25] defines a standard for the physical and MAC layers of low-rate wireless networks. The standard uses slotted or unslotted CSMA as a medium access mechanism. In this section, we consider the unslotted version of CSMA.
The CSMA algorithm works with a set of default parameters and each node maintains two values when running the algorithm: Number of Back-offs (NB) and Back-off Exponent (BE). NB is always initialized to 0 for a new packet transmission, and it denotes the number of access attempts for the current packet transmission. BE is used to compute the random back-off period that a device should wait before attempting to assess the channel. Default parameter values are shown in Table 4.
The CSMA algorithm operates as follows:
-
1)
Step 1. The values of NB and BE are initialized according to the IEEE 802.15.4 standard.
-
2)
Step 2. The delay of the random back-off period is selected in the range from 0 to 2BE− 1.
-
3)
Step 3. After the waiting time, the node performs a Clear Channel Assessment (CCA). If the channel is idle, the node starts transmission. If the channel is busy, the algorithm increments NB by 1 and updates BE as follows: BE = min(BE + 1,aMaxBE). Then, if NB is lower than the maximum number of back-offs (i.e., macMaxCSMABackoffs) the algorithm goes to Step 2; if not, the transmission is canceled and considered to have failed.
7.2 The named data CSMA scheme
In legacy CSMA, all the nodes access the shared channel with a fair chance. However, priority-based CSMA [26] uses the difference in traffic type to introduce differentiated channel access for nodes. Therefore, the priority-based CSMA mechanism is designed to make nodes with high priority traffic have a greater chance of accessing the channel. The ND-CSMA algorithm we propose is inspired by the priority-based CSMA approach.
The frames are classified into two priority classes according to the packet type they transmit: (i) frames that contain a Data packet at any node, and frames that contain a locally issued Interest (i.e., consumer node) are assigned a priority 0. (ii) frames that contain an Interest packet to forward (i.e., at relay nodes) are assigned a priority 1. The other CSMA parameters and values are kept the same in ND-CSMA.
By distinguishing between Interest and Data frames, the ND-CSMA algorithm operates in the same way as legacy CSMA described above, but with one difference. When the channel is assessed to be busy, retrying another back-off depends on the priority class of the frame to transmit. If the frame has a priority 1, the number of back-off attempts is limited by a threshold value th. Then, the transmission is canceled if the number of attempts reaches th. The algorithm operates as usual for the frames of priority 0. According to the number of back-offs allowed by the CSMA parameters, the values of th should be between 1 and 4, while th = 5 makes ND-CSMA equivalent to the legacy CSMA.
ND-CSMA scheme is summarized in Fig. 4.

ND-CSMA algorithm
7.3 Evaluation
To evaluate the ND-CSMA scheme, we simulate three scenarios.
-
CF. The Controlled Flooding strategy as described in Section 5 with the legacy CSMA algorithm.
-
BF. The Blind Flooding approach presented in Section 4, also using the legacy CSMA. Notice that this scenario is equivalent to the CF strategy without waiting delays.
-
ND-CSMA-x. The BF strategy using the ND-CSMA mechanism with th = x ∈ {1,2,3,4}.
In the BF strategy, upon receiving an Interest or Data, a node immediately tries to forward the packet and lets the link layer medium access algorithm (i.e., legacy CSMA or ND-CSMA) resolve the contention.
All the scenarios are simulated under the same conditions and parameters as those used in Section 6: a tree topology with depth N = 4, M = 3000 content items distributed in K = 50 classes, each one with m = 60 items, and a cache of size x = 300 packets at each level. For the CF strategy, we use dw = 127 and τ = 0.032μs. Two content popularity configurations are evaluated: a low popularity difference with α = 1.2, and a high popularity difference with α = 2.0.
The following metrics are measured in the simulation:
-
Mean round-trip time. The mean time needed for the gateway to retrieve a content item from a device.
-
Transmitted frames. The total number of frames successfully transmitted. We also refer to this metric as the cost.
-
Interest satisfaction rate. This corresponds to the number of Data packets received by the gateway over the number of Interests it sent.
-
Mean back-off time. The average time the nodes spent in back-off to access the wireless medium. This is also used as an indicator for energy consumption.
Figure 5 shows the results obtained for the low (α = 1.2) and the high (i.e., α = 2.0) popularity rate respectively.

ND-CSMA evaluation
We observe that for both popularity configurations, ND-CSMA-1 achieves better RPR compared to the CF and BF scenarios. The mean back-off time with ND-CSMA-1 is the smallest among the evaluated scenarios, while BF achieves the highest back-off time due to the large number of forwarding decisions generated after eliminating waiting delays. This means that legacy CSMA without delays has to resolve medium access contention with more back-off periods whereas ND-CSMA has the possibility to cancel some Interest transmissions when the channel is busy rather than waiting for other back-off periods. For this reason, the round-trip time achieved in with BF is slightly higher than ND-CSMA.
The CF strategy is also capable of canceling scheduled transmissions using deferred transmissions. However, it achieves that with a wait-and-listen mechanism which induces higher round-trip delays, and a relatively high back-off time is required when the chosen random delays are not different enough.
Moreover, the results show that ND-CSMA-1 can ensure necessary packet transmissions while keeping the total cost at a minimum compared to the two other schemes.
For content with high popularity differences (i.e., α = 2.0), the Interest satisfaction rate is quite similar for all the approaches. This indicates that even with a reduced medium access attempts, ND-CSMA does not reduce the efficiency of the broadcast. When content items have quite similar popularity (i.e., α = 1.2), ND-CSMA-1 achieves lower Interest satisfaction rate. This means that more medium access attempts are needed to provide a good Interest satisfaction rate. This is achieved by ND-CSMA-2. ND-CSMA-2 has a higher frame transmission and back-off time than ND-CSMA-1, but it is the second best scenario after ND-CSMA-1. That is, ND-CSMA-2 may be more suitable than ND-CSMA-1 in some situations.
Overall, ND-CSMA-1 and ND-CSMA-2 seem to be the best compromise in the evaluated configuration.
For the same value of α, ND-CSMA-3 and ND-CSMA-4 achieve merely the same results. This is because 3 or 4 attempts to access the medium does not prevent nodes from transmitting Interests as they would do it in legacy CSMA. The behavior of ND-CSMA becomes then close to the legacy CSMA where the number of attempts to access the medium is 5.
To return to our theoretical expectations, the results confirm that a link layer adaptation is able to keep the benefits of a broadcast-based forwarding strategy in terms of satisfaction rate, while reducing medium access contention and frame transmissions. It then achieves the trade-off we were looking for.
8 Conclusion and future work
In this paper, we modeled Controlled Flooding, a simple broadcast-based forwarding strategy for NDN in wireless networks. One objective of the model is to show that caching can attenuate the number of transmissions generated by broadcast while keeping the data dissemination power of NDN. The second objective dealt with in the second part of the paper is to study the relevance of investigating the link layer to design a forwarding strategy that achieves a satisfactory compromise. Based on a simple modification of the IEEE 802.15.4 MAC layer, preliminary results shed light on the need to rethink typical link layer schemes for ICN/NDN such as the CSMA algorithm.
However, we can easily foresee that the ND-CSMA adaptation is specific to the topology and scenario under consideration, and thus can not be applied as a general solution to all network configurations. As future work, we aim to explore more complex CSMA adaptations for lightweight forwarding to take the most of NDN and design a general-purpose Named-Data CSMA. Another envisioned direction for future work is to formulate a more realistic model based on the one presented in this paper.
Abbreviations
- ICN :
-
Information Centric Networking
- NDN :
-
Named Data Networking
- RTT :
-
Round-Trip Time
- CSMA :
-
Carrier-Sense Multiple Access
- ND-CSMA :
-
Named-Data Carrier-Sense Multiple Access
- LRU :
-
Least Recently Used
- MANET :
-
Mobile Ad hoc Network
- FIB :
-
Forwarding Information Base
- PIT :
-
Pending Interest Table
- CS :
-
Content Store
- BF :
-
Blind Flooding
- NIC :
-
Network Interface Controller
- CF :
-
Controlled Flooding
- dw :
-
defer window
- CPR :
-
Cost-per-request
- RPR :
-
Round-trip time per request
- NB :
-
Number of Back-offs
- BE :
-
Back-off Exponent
- CCA :
-
Clear Channel Assessment
References
IEEE (2016) Ieee standard for information technology—telecommunications and information exchange between systems local and metropolitan area networks—specific requirements - part 11, Wireless lan medium access control (mac) and physical layer (phy) specifications. IEEE Std 802.11-2016 (Revision of IEEE Std 802.11-2012), pp 1–3534
Montenegro G, Hui J, Culler D, Kushalnagar N (2007) Transmission of IPv6 Packets over IEEE 802.15.4 Networks, RFC 4944
Shelby Z, Hartke K, Bormann C (2014) The Constrained Application Protocol (coAP), RFC 7252
Shang W, Yu Y, Droms R, Zhang L Challenges in IoT networking via TCP/IP architecture, NDN, Tech. Rep. NDN-0038, February 2016. [Online]. Available: https://named-data.net/wp-content/uploads/2016/02/ndn-0038-1-challenges-iot.pdf
Ahlgren B, Dannewitz C, Imbrenda C, Kutscher D, Ohlman B (2012) A Survey of Information-Centric Networking. IEEE Commun Mag 50(7):26–36
Zhang L, Afanasyev A, Burke J, Jacobson V, claffy kc, Crowley P, Papadopoulos C, Wang L, Zhang B (2014) Named Data Networking. ACM SIG-COMM Comput Commun Rev 44(3):66–77
Shang W, Bannisy A, Liangz T, Wangx Z, Yu Y, Afanasyev A, Thompsonx J, Burkex J, Zhangz B, Zhang L (2016) Named Data Networking of Things (Invited paper). In: The 1st IEEE intl. Conf. on internet-of-things design and implementation, Berlin, pp 117–128
Carofiglio G, Morabito G, Muscariello L, Solis I, Varvello M (2013) From content delivery today to information centric networking. Comput Netw 57(16):3116–3127. Information Centric Networking
qing G, WANG T, LIU J, ya J, Chen H, Jie Liu Y (2013) Modeling in-network caching and bandwidth sharing performance in information-centric networking. J China Univ Posts Telecommun 20 (2):99–105
Ren Y, Li J, Li L, Shi S, Zhi J, Wu H (2017) Modeling content transfer performance in information-centric networking. Futur Gener Comput Syst 74:12–19
Udugama A, Palipana S, Goerg C (2013) Analytical characterisation of multi-path content delivery in content centric networks. In: 2013 Conference on Future Internet Communications (CFIC), pp 1–7
Carofiglio G, Gallo M, Muscariello L, Perino D (2011) Modeling data transfer in content-centric networking. In: 2011 23rd International Teletraffic Congress (ITC), pp 111–118
Abane A, Daoui M, Bouzefrane S, Muhlethaler P (2019) Ndn-over-zigbee: a zigbee support for named data networking. Futur Gener Comput Syst 93:792–798
Kietzmann P, Gündogan C, Schmidt TC, Hahm O, Wählisch M (2017) The need for a name to MAC address mapping in NDN towards quantifying the resource gain. In: ACM ICN 2017 - 4Th ACM conference on information-centric networking, Berlin
Amadeo M, Campolo C, Molinaro A, Ruggeri G (2014) Content-centric wireless networking: A survey. Comput Netw 72:1–13. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1389128614002497http://www.sciencedirect.com/science/article/pii/S1389128614002497
Ren Z, Hail MA, Hellbrück H (2013) CCN-WSN - A lightweight, flexible content-centric networking protocol for wireless sensor networks. In: 2013 IEEE eighth international conference on intelligent sensors. Sensor Networks and Information Processing, pp 123–128
Amadeo M, Campolo C, Molinaro A, Mitton N (2013) Named data networking: a natural design for data collection in wireless sensor networks. in: 2013 IFIP wireless days (WD), pp 1–6
Kietzmann P, Gündogan C, Schmidt TC, Hahm O, Wählisch M (2017) The Need for a Name to MAC Address Mapping in NDN: Towards Quantifying the Resource Gain. In: ACM ICN 2017 - 4th ACM Conference on Information-Centric Networking, Berlin. [Online]. Available: https://hal.inria.fr/hal-01666601
Shi J, Newberry E, Zhang B (2017) On broadcast-based self-learning in named data networking. In: 2017 IFIP networking conference, IFIP Networking) and Workshops, pp 1–9
Shi J, Liang T, Wu H, Liu B, Zhang B (2016) Ndn-nic: Name-based filtering on network interface card. In: ICN
Wang L, Afanasyev A, Kuntz R, Vuyyuru R, Wakikawa R, Zhang L (2012) Rapid traffic information dissemination using named data. In: Proceedings of the 1st ACM Workshop on Emerging Name-Oriented Mobile Networking Design - Architecture, Algorithms, and Applications, ser. NoM ’12. ACM, New York, pp 7–12. [Online]. Available: https://doi.org/10.1145/2248361.2248365
Amadeo M, Campolo C, Molinaro A (2015) Forwarding strategies in named data wireless ad hoc networks: Design and evaluation. J Netw Comput Appl 50(Supplement C):148–158
Breslau L, Cao P, Fan L, Phillips G, Shenker S (1999) Web caching and zipf-like distributions: evidence and implications. In: IEEE INFOCOM ’99. Conference on Computer Communications. Proceedings. Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies. The Future is Now (Cat. No.99CH36320), vol 1, pp 126–134
Abane A, Muhlethaler P, Bouzefrane S, Daoui M, Battou A (2018) Towards evaluating named data networking for the iot: A framework for omnet++ 09
IEEE (2011) Ieee standard for local and metropolitan area networks–part 15.4: Low-rate wireless personal area networks (lr-wpans). IEEE Std 802.15.4-2011 (Revision of IEEE Std 802.15.4-2006), pp 1–314
ZHAO L, wei G, BAI H, min Z (2013) SHEN TANG, Priority-based ieee 802.15.4 csma/ca mechanism for wsns. J China Univ Posts Telecommun 20(1):47–53
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Abane, A., Muhlethaler, P. & Bouzefrane, S. Modeling and improving named data networking over IEEE 802.15.4. Ann. Telecommun. 76, 839–850 (2021). https://doi.org/10.1007/s12243-021-00848-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12243-021-00848-w