
Abstract
The paper describes the procedure employed for developing a new earthquake zone map of India as part of the seventh revision of the Indian Earthquake Standard IS 1893 (Part 1). This new zone map is based primarily on a probabilistic earthquake hazard analysis performed at a grid spacing of 0.1°×0.1° in longitudes and latitudes of the entire country. But, for grid locations with small probabilistic hazard estimates, a minimum level of hazard has been estimated deterministically for the most likely maximum magnitude of an earthquake on the nearest mapped fault. Based on the results, the Indian landmass is grouped into five zones, designated as ‘earthquake zones II, III, IV, V, and VI.’ The peak ground accelerations corresponding to a return period of 2475 yr in these zones are estimated as 0.15, 0.30, 0.45, 0.60, and 0.75g, which also include the site amplification effect. Common normalized response spectra are recommended for all five zones, one for each of the three different site soil conditions, as an interim measure.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
The Indian plate can be divided into three main tectonic domains, namely: (a) the Himalayas in the north, (b) the Indo-Gangetic Plains adjoining the Himalayas (to its south), and (c) the peninsular India in the south. Each of these broad geographical regions of India is characterized by distinctly different levels of earthquake hazard and the associated earthquake risks. Thus, the first earthquake regionalization map of India prepared in 1935 by the Geological Survey of India (Auden 1959), which has demarcated landmass into heavy, moderate, and light-to-no damage, conforms closely to these three geographical divisions of India. The entire Himalayan region is vulnerable to high-magnitude earthquakes due to the building up and release of stresses by the continuing movement of the Indian Plate towards the Eurasian Plate at a pace of ~50 mm/yr, of which ~20 mm/yr is exhibited in the form of contraction across the Himalaya (Jade et al. 2017). Since the late 1800s, the Himalayan region has a recorded history of four great earthquakes, namely the 1897 Shillong (M8.1) earthquake, the 1905 Kangra (M7.9) earthquake, the 1934 Bihar–Nepal (M8.3) earthquake, and the 1950 Assam–Tibet (M8.6) earthquake; three of which (other than the 1897 Shillong earthquake) are associated directly with the Himalayan plate boundary. Moreover, many of the Himalayan segments have been identified as seismic gaps, where disastrous earthquakes are suspected to occur anytime in the future (Khattri 1987; Bilham et al. 2001).
The densely populated Indo-Gangetic Plains adjoining the Himalayan collision zone are highly vulnerable to the major Himalayan as well as the strong local earthquakes due to thick sediments amplifying the ground motions. Also, isolated parts of peninsular India are prone to moderate-magnitude earthquakes that may cause significant loss of life and property. These corroborations have been amply demonstrated by several more recent damaging earthquakes between the years 1988–2015 in different parts of the country and the neighbouring areas. These include the 1988 Bihar–Nepal (M6.8), the 1991 Uttarkashi (M6.8), the 1993 Killari (M6.3), the 1997 Jabalpur (M6.1), the 1999 Chamoli (M6.5), the 2001 Bhuj (M7.7), the 2002 Diglipur (M6.5), the 2004 Indian Ocean (M9.3), the 2005 Kashmir (M7.6), the 2011 Sikkim (M6.9) and the 2015 Nepal (M7.9) earthquakes. The reconnaissance studies following these earthquakes revealed that most deaths were caused primarily by the collapse of buildings and structures that did not comply with provisions of earthquake-resistant design. A similar magnitude of earthquakes in many other parts of the world did not lead to such enormous losses of lives, where the buildings and structures were built with virtues for earthquake resistance and under the supervision of strict techno-legal regimes. Thus, it is prudent to make earthquake risk mitigation an integral part of the development process in India through the earthquake-resistant design of buildings and infrastructure facilities based on quantitatively derived, more realistic zone maps of the country.
The need for earthquake-resistant structures was felt strongly at the beginning of the 20th century as an aftermath of several destructive earthquakes in different parts of the world. The development of building design codes began in Italy following the 1908 Messina disaster, in Japan following the 1923 Kanto disaster, and in California after the 1925 Santa Barbara earthquake. The first design code that was introduced in Japan in 1924 proposed to define the earthquake effects by an equivalent static horizontal force equal to a small fraction (termed as seismic coefficient) of the weight of the building. In India, the values of seismic coefficients first suggested were in the range of 0.05–0.15 (Kumar 1933) after the 1931 M7.4 Mach earthquake. However, the recommendations for earthquake loads were not formulated in India till the first code for earthquake-resistant design of structures was published in 1962 (IS 1893–1962), which proposed the values of seismic coefficients for different types of structures in each zone. Since then, the zone map and the seismic coefficients in the Indian code have been revised three times in 1966, 1970, and 2002. The original map of 1962, as well as the subsequent revisions, was based mainly on the distribution of the epicenters and the associated macro-seismic intensity levels due to significant past earthquakes with only limited use of the tectonic and geological setup of the country (ISI 1982). Due to the inadequacy of the required input data so far, no formal earthquake hazard analyses have been adopted to develop these zone maps of India.
Many of the international earthquake design codes (e.g., Eurocode 8, European Commission et al. 2012; and ASCE 07-16, ASCE 2017) also started with zone maps based on the historical occurrence of damaging earthquakes. But, over the years, they updated the zones to reflect the resulting relative hazard based on a stated quantitative method. For instance, Eurocode 8 sub-divides the national territories into zones based on the local seismicity and describes the hazard in terms of a single parameter, namely PGA (peak ground acceleration) on Site Class A, corresponding to a reference return period of the earthquake action. On the other hand, ASCE 07-16 and IBC (international building code, IBC 2015) evolved from zone maps to spectral acceleration maps for periods of 0.2 and 1 sec, all corresponding to a 2475-yr return period. The existing zone map of India is based mainly on the observed MSK64 intensity levels of earthquake ground shaking at different locations during past earthquakes. The earthquake zones II, III, IV, and V correspond to the intensity of VI (or less), VII, VIII, and IX (and above) and are assigned PGA values of 0.1, 0.16, 0.24, and 0.36g, respectively. These PGA values are not derived based on any quantitative earthquake hazard assessment and are abysmally low, especially for the higher earthquake zones. For example, the regions of the Himalayan plate boundary and northeast India with the potential to produce earthquakes exceeding magnitude 8.0 are covered by earthquake zones IV and V with design PGA values of 0.24 and 0.36g, respectively, whereas the 1897 Great Shillong Plateau earthquake in northeast India is reported to have resulted in PGA values more than 1.0g. The design accelerations in similar areas worldwide are taken to be two times (or more) compared to that in the existing zone map of India. Therefore, there is a need to revise India's current earthquake-resistant design code on the basis of an adept quantitative technique such as hazard analysis.
Though several probabilistic earthquake hazard analysis studies had been attempted in India since the late 1970s till the last revision of the zone map in 2002 (e.g., Basu and Nigam 1977; Khattri et al. 1984; Bhatia et al. 1999), these were mainly of academic interest, and none could be utilized to have a quantitative zone map for Indian code. But, a sufficiently comprehensive database on past seismicity, tectonic as well as geologic setup, and strong motion acceleration records has become available in India since 2002, which in turn facilitated better practices of probabilistic earthquake hazard analysis in several recent studies (e.g., Jaiswal and Sinha 2007; NDMA 2010; Nath and Thingbaijam 2012; Mandal et al. 2013; Sitharam and Sreevalsa 2013; Sreejaya et al. 2022). Currently, over 79% of India’s population lives on ~57% of its land, i.e., under the threat of moderate to severe earthquake hazard. Also, by 2046, the urban population in India is estimated to cross the rural population, which is only 30% at present. The growing population and the rural-to-urban migration pose extreme pressure for a fast pace of development in urban India, especially because of the large infrastructure requirement. If all these developments are to be sustainable, the revision of earthquake hazards is an urgent need.
Therefore, the current article focuses on how a new zone map has been derived using the results of our recent probabilistic earthquake hazard assessment (PEHA) study for India and the neighbouring regions (Sreejaya et al. 2022). The more common current practice is to present the results of earthquake hazard analysis as contour maps of a ground motion parameter, say PGA or response spectral acceleration (Sa), at specific natural periods of interest (0.2, 0.5, and 1 sec). But, for ease of use by practicing engineers, the results of the detailed earthquake hazard analysis have been judiciously optimized into a single zone map similar to the existing one rather than the multiple contour maps. The present study provides the reader with a clear illustration of the procedure involved in obtaining the zone map, especially the qualitative aspects (like the considerations adopted, the negotiations undertaken, and the broad-brush approximations made to address the absence of needed data, like the thickness of sediment deposits). The zone map presented herein has been accepted by the BIS (Bureau of Indian Standards) for inclusion in the new revision of IS 1893 (Part 1).
2 Brief history of zone maps
Understanding the earth, its varying attributes, complexity, and seismicity pattern are foci of worldwide research. To differentiate the areas of risk for the common man, the concept of earthquake zones was implemented. Many countries worldwide have captured past earthquake activity to produce earthquake zone maps. Several different systems are developed, ranging from numerical zones to coloured zones, where numbers or colours represent different levels of earthquake shaking intensity expected therein.
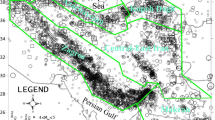
India, too, has diverse geology spread over its 3.287 million km2 land area. Initial attempts to prepare an earthquake hazard zone map of the country date back to the 1930s. These were subjective and based on deterministic assessments. Based on the history of earthquake events on its landmass, India began to demarcate land areas to reflect the likelihood of damaging earthquakes. The early efforts of earthquake safety in India were motivated by two great earthquakes, namely the 1897 Assam and the 1934 Bihar–Nepal earthquakes, whose damage was reported in literature through intensity maps. Another devastating event occurred in 1931 near Quetta (now in Pakistan) with an intensity of VIII on the Rossi Forel (RF) scale. The aftermath of this event resulted in a new project entailing the design of earthquake-resistant housing quarters for the railways. The outcome of the project was the first-ever earthquake zone map for India (Kumar 1933). According to this zone map (figure 1), the region was divided into violent, strong, and weak earthquake regions. The early ‘Earthquake Zone Map of India’ by a government agency was developed in 1935 through the Geological Survey of India (GSI) after the event of the great Bihar–Nepal (M8.3) earthquake of 15th January 1934. It reflected the damages incurred during the 1897 Assam and the 1931 Quetta earthquakes. It placed India in three zones, which demarcate land areas where slight, moderate, and severe damages are expected. The area demarcated as severe experienced earthquake shaking corresponding to intensity VIII or more on the Modified Mercalli Intensity (MMI) scale, where significant damages are expected.

Early Zone Map of India by a Railway Engineer (Kumar 1933).
The early zone maps of India proposed by several different investigators (e.g., West 1937; Tandon 1956; Krishna 1959; Mithal and Srivastava 1959; Guha 1962; Srivastava 1969; Gubin 1971) were all concerned with delineating the regions prone to different levels of damage on a qualitative basis or the expected levels of a selected non-instrumental macro-seismic intensity scale (Gupta and Todorovska 1995; Mohapatra and Mohanty 2010). Later, between 1977 and 1999, three important studies (Basu and Nigam 1977; Khattri et al. 1984; Bhatia et al. 1999) attempted to prepare PGA maps using a probabilistic earthquake hazard approach. The first probabilistic zone map of India (Basu and Nigam 1977) presented PGA contours for a 100-year return period. This work was improved by considering India’s landmass in 24 tectonic source zones, and a zone, PGA contour map, was proposed corresponding to a 10% probability of exceedance in 50 yr (Khatri et al. 1984). In another effort, 86 tectonic source zones were considered, and a different map was proposed based on probabilistic considerations of major tectonic features and seismic trends (Bhatia et al. 1999). However, both of these studies were based on meager data on past seismicity, and the attenuation relations used were not calibrated for the Indian condition. Another important study on the seismic zoning of India (Parvez et al. 2003) was based on the deterministic computation of the synthetic seismograms by dividing the country into 15 regional polygons based on structural models, seismogenic source zones, Q-structure, focal mechanism, and earthquake catalogue, which had not been adequately validated with the recorded strong motion data.
In 2007, the National Disaster Management Authority (NDMA) of India commissioned a study to examine all the past studies and update the country on earthquake hazards. The study proposed the probabilistic design of PGA values for the nation by dividing the country into 32 seismogenic source zones (NDMA 2010). In 2019, NDMA commissioned another study under the umbrella of the BIS to improve and finalize the earthquake hazard in India based on consultations with the organizations estimating earthquake hazard in India. Two important studies carried out in the meantime (Nath and Thingbaijam 2012; Sitharam and Sreevalsa 2013) were also considered, and the most updated probabilistic zone maps of India were evolved (Sreejaya et al. 2022). The outcome of that study has been used in this paper to arrive at the latest version of the zone map of India included in the Indian Earthquake code – IS 1893.
The first formal ‘Earthquake Zone Map of India’ was published by the BIS in 1962 as part of its standard IS 1893, titled ‘Recommendations for Earthquake Resistant Design of Structures’ (IS:1893 1962). This map was produced through a committee of experts from various organizations based mainly on the observed intensity values during the major past earthquakes. It placed India in ‘seven’ zones, namely zones 0, I, II, III, IV, V, and VI, corresponding to expected MMI levels of V (or less), V, VI, VII, VIII, IX, and X (and above), respectively. ‘Zone 0’ was considered to be a non-seismic zone (where no damage is expected) and zone VI an active region (where extensive damages are expected) (figure 2a). Most of the northeast India and the Kutch region of Gujarat were sorted under zone VI, and most of the peninsular shield was classified as zone 0.

Formal Earthquake Zone Maps of India since 1962 (Jain 2016) (a) 1962 edition, (b) 1966 edition, (c) 1970 version, and (d) 2002 edition (redrawn based on IS 1893:1962, IS 1893:1966, IS 1893:1984 and IS 1893:2002).
The second ‘Earthquake Zone Map’ was published in 1966 (IS:1893 1966) with some modifications in the peninsular region but did not digress significantly from the 1962 version. The revision of 1966 followed the same general approach as that in the 1962 map, except that some weight was given to the tectonic features. It moved only the margins between these zones; and the broad features of the 1962 version were retained (figure 2b). It attempted to address the gap of the previous map, namely the presence of zones around the Gujarat region with narrow land masses having MMI of V, VI, and VII; the modification was made without changing the zones and method.
The third ‘Earthquake Zone Map’ was released in 1970 (IS:1893 1970), based on the levels of intensities sustained during damaging earthquakes in the interim period in regions considered to be low seismic areas (e.g., 1967 M6.5 Koyna and 1969 M5.7 Bhadrachalam earthquakes). It reduced the number of zones from seven to five (namely I, II, III, IV, and V) (figure 2c). Significant changes were made in the peninsular region along the western and eastern coastal margins, where these 1967 and 1969 earthquakes occurred. Zone 0 abolished the concept of a zone with no likelihood of occurrence of earthquakes. Moreover, due to the devastating 1967 earthquake, the Koyna region was upgraded to zone III. Parts of the Himalayan boundary in the north and northeast and the Kachchh area in the west were classified as zone V. The maximum Modified Mercalli Intensity (MMI) of earthquake shaking expected in the five zones I, II, III, IV, and V were stated to be V (or less), VI, VII, VIII, and IX (and above), respectively. The 1975 revision of the standard did not change the zone map but introduced the concepts of seismic zone factor and importance factor. No change in the zone map was made in the 1984 revision.
The fourth ‘Earthquake Zone Map’ was released in 2002, immediately after the devastating 2001 Bhuj (M7.7) earthquake (figure 2d). Also, public uproar following the 1993 Killari (Maharashtra, Central India) earthquake that occurred in the erstwhile earthquake zone I, with about 8000 fatalities, again raised questions on the validity of the earthquake zone map in peninsular India. The 2001 Bhuj earthquake in the most severe earthquake zone V of the country caused about 13,805 fatalities. These two events, in particular, pressured the Bureau of Indian Standards to revise the earthquake zone map again in 2002. It involved three major modifications. Firstly, it reduced the total number of seismic zones from five to four by merging areas with zone I in the 1970 map with those in zone II. Secondly, the region of zone III in Maharashtra was extended to reflect the devastating damage caused by the 1993 M6.3 Killari earthquake; this was the major reason for the revision of the zone map. Earlier, Killari village was in zone I, where the likelihood of earthquake shaking was the least, but ~8000 lives were lost owing to the collapse of houses. Thirdly, Chennai city was placed in seismic zone III, as against zone II in the 1970 version of the map. The four zones II, III, IV, and V were stated to expect Medvedev–Sponheuer–Karnik (MSK) Intensity levels of VI (or lower), VII, VIII, and IX (and above), respectively. For design, the peak ground accelerations considered in earthquake zones II, III, IV, and V are 0.10, 0.16, 0.24, and 0.36g, respectively. This map is based on deterministic considerations (with no probabilities assigned to the exceedance of shaking levels during earthquakes expected in the zones). This current earthquake zone map places ~59% of India’s land area to be susceptible to MSK intensity VII and above, representing moderate to severe earthquake ground shaking (Mohapatra and Mohanty 2010).
The revision of IS 1893 in 2016 did not make any change in the zone map from its 2002 version. Six decades after 1962 saw the development of the Indian Earthquake Codes, and along with it, the earthquake zones and earthquake zone maps were changed (table 1). The first four earthquake zone maps were based on maximum earthquake intensities likely to be experienced at different locations. These maps attempted, in a qualitative sense, to reflect the regions of varying damage, which are governed significantly by geology in addition to the earthquake magnitude. Recently, the BIS has approved a new fifth ‘Earthquake Zone Map of India’ as part of the seventh revision of IS 1893, developed using the probabilistic hazard analysis method, which accounts for the effects of the expected seismicity and the local site condition quantitatively, to obtain the PGA estimates throughout the country for a return period of 2475 yr. The current paper presents the procedure adopted to arrive at the said map, using the results of a thorough hazard analysis that was carried out over the entire country (Sreejaya et al. 2022).
3 Probabilistic earthquake hazard analysis (PEHA)
The detailed probabilistic earthquake hazard analysis (PEHA) carried out for generating the new zone map of India comprises four basic elements, namely: (i) identifying and defining seismic sources; (ii) characterizing source probability; (iii) characterizing ground motion probability; and (iv) deriving hazard in terms of exceedance probabilities (Yu et al. 2011).
3.1 Identifying and defining seismic sources
Seismic sources are generally defined by an analysis of the seismotectonic features and the association of past seismicity with them. India has diverse seismotectonic features across its large landmass and complex interaction at the junction of Indian and neighbouring tectonic plates. The Indian plate (on which the Indian subcontinent lies) is moving in a northeast direction concerning the Eurasian plate at the rate of 3–28 mm/yr (Jade et al. 2017). This junction between the two plates (called the Himalayas) is an active tectonic region of the world. The major faults identified in this region include the Main Frontal Thrust (MFT), the Main Central Thrust (MCT), and the Main Boundary Thrust (MBT). Most earthquakes in this region occurred in the active shallow crust; these include the 1897 M8.1 Shillong Plateau, the 1905 M7.9 Kangra, the 1934 M8.3 Bihar–Nepal, the 1950 M8.6 Assam, the 1991 M6.8 Uttarkashi, the 1999 M6.5 Chamoli, the 2011 M6.9 Sikkim, and the 2015 M7.9 Nepal earthquakes. The peninsular India (called the Indian Shield) is separated from the Himalayas by the deep alluvial basin of Gangetic Plains. Most of peninsular India is considered to be a stable continental region owing to its relatively limited earthquake activity. Major faults in this region include a system of almost E–W trending faults of regional extent in the Kutch and the Son–Narmada–Tapti rift basins with several isolated faults of local nature in the rest of the area. The most devastating (intraplate) earthquakes that occurred in this region include the 1967 M6.5 Koyna, the 1993 M6.3 Killari, the 1997 M6.1 Jabalpur, and the 2001 M7.7 Bhuj earthquakes.
The eastern boundary of the Indian mainland is characterized by an active inland subduction zone termed the Indo-Burmese subduction zone, which forms part of the great Burma–Andaman–Nicobar–Sunda arc (Gupta 2006) that resulted in the 2004 M9.3 Sumatra earthquake and is the major source of the high level of seismicity in Andaman–Nicobar area. The Indo-Burmese subduction plate boundary has resulted in many deep subduction earthquakes in northeast India. All the major faults in the foregoing tectonic domains of India are mapped in the seismo-tectonic Atlas of India (GSI 2000). In addition, the faults in Sri Lanka and the Himalaya–Tibet region (Styron et al. 2010) are included in the database for better analysis in Southern India and trans-Himalaya, respectively (Sreejaya et al. 2022). The fault map of India thus obtained constitutes 1838 faults in total (figure 3). However, information on the maximum earthquake potential and the average recurrence times of the largest earthquakes possible on these faults is lacking, to model these faults properly as individual seismic sources. Therefore, hazard analysis was based on using area types of seismic sources only.

Based on a study of the historical seismic activity and of the tectonic and geological settings, India is identified to have 33 area-type seismic source regions: Source Zones (SZ) 1–4 in the active regions of the Himalayas; SZs 10–15 and 32 in the Andaman and Nicobar Island regions; SZs 5–8 in the northeast India region; SZs 21–26 in the Chaman Fault region; SZ 30 in the Hindukush–Pamir region; SZs 17, 20 and 29 in the peninsular region of South India; SZs 16, 18 and 19 in the peninsular region of Central India; SZ 27 in the Kutch region; and SZ 33 in the Tibet region (to provide a well-rounded analysis of the Himalayan zones). All these 33 seismic source zones are shown in figure 3.
The past seismicity of the region was compiled in the form of an updated earthquake catalogue based on the NDMA (2010) earthquake register, which consisted of 69,519 earthquakes for the period from 2600 BC to December 2019. The compiled catalogue was homogenized to moment magnitude (Mw) (Scordilis 2006; Yenier et al. 2008; Baruah et al. 2012) and declustered to make sure that the considered catalogue follows Poisson distribution. The Gardner–Knopoff algorithm (Gardner and Knopoff 1974) with the Urhammer space-time window was adopted for declustering the catalogue. This identified a large number of events (40,749) as the dependent events, leaving behind only 28,770 as the main shocks for the present hazard analysis. The epicenters of the main shocks in the resulting declustered catalogue are superimposed over the major tectonic features in figure 4, which indicates that the identified area sources conform well to the tectonic features as well as the observed past seismicity.

Epicentral map of the homogenized and declustered catalogue showing the 33 seismogenic source zones along with some cities with a population exceeding one million.
3.2 Characterizing source probability
Since fault recurrence characteristics of all the mapped faults are not available readily, seismic recurrence characteristics are quantified source zone-wise (33 seismogenic source zones) using the truncated Gutenberg Richter’s (G–R) relation:
where
wherein the controlling seismicity parameters include the upper bound of source magnitude Mmax and the recurrence parameter \(\beta = b\ln_{10}\), and \(N(m_{0} )\) represent the cumulative occurrence rate of earthquakes with magnitude greater than or equal to \(m_{0}\). The quantity within the parenthesis in equation (2) represents the probability distribution \(F_{M} (m)\), of magnitude having values greater than or equal to a specified value \(m\). The associated probability density function \(f_{M} (m)\) is given by \(- dF_{M} (m)/dm\).
In characterizing the source probability for all 33 source zones, the available data on the main shocks within each seismic source were analyzed for periods of completeness over different magnitude intervals using approaches proposed in the literature (Stepp 1972; Tinti and Mulargia 1985). A detailed description of this analysis is available elsewhere (Dhanya et al. 2022; NDMA 2022). The data reported as ‘complete’ in different magnitude intervals were used to estimate the parameter b of the Gutenberg–Richter (G–R) recurrence relation equation (1) for each source zone using two popular maximum likelihood methods proposed in the literature (Weichert 1980; Kijko and Graham 1998).
For use in equation (2), the Mmax estimates for most of the seismogenic source zones have been obtained by suitable increments in the observed maximum magnitude values from the earthquake catalogue. But, as the magnitudes of many past earthquakes have been fixed based on historical transcripts and other geological evidence, there is a large variation in them. Therefore, in addition to assigning the Mmax values using the above principle, some of the source zones with very large observed earthquake magnitudes have been subdivided further to provide reasonable Mmax values that can be concurrent with the recently recorded data. Accordingly, the source zones 27, 28, and 8 are subdivided further with a higher Mmax for the Kutch, Aravalli ranges, and Shillong Plateau subzones, respectively. Further, the Mmax value obtained for the Himalayan region was Mw 8.8. But, in the past ~700 yr, the highest magnitude event that the Himalayas experienced is Mw 8.2 in Nepal. In general, the great magnitude Himalayan earthquakes are not expected to have a recurrence period larger than about 250–500 yr. Therefore, based on expert elicitation, the Mmax value for Himalayan source zones is fixed at 8.3. Based on these parameters, the probability density function for Mw is obtained. The estimates of the b-value and the maximum magnitude Mmax obtained for all 33 source zones are given in table 2.
For the present hazard analysis, the activity rate \(N(m_{0} )\) in equation (2) has been defined for a grid of size 0.1°×0.1° covering the entire study region. The observed number of earthquakes greater than or equal to a threshold magnitude (m0) of 4.0 is counted in each grid cell from the homogenized and declustered catalogue. These are used along with the respective effective periods of completeness to obtain the cumulative occurrence rate per cell, with the rate for the ith cell denoted by \(n_{i} (m_{0} )\). The activity rates \(n_{i} (m_{0} )\) for the entire grid cells in each of the 33 area sources are smoothed spatially using fault-oriented elliptical Gaussian distribution (Lapajne et al. 2003) to get the smoothed activity rate \(\tilde{n}_{i} (m_{0} )\) for the ith grid cell, which is taken to represent the activity rate \(N(m_{0} )\) for this grid cell. Thus, the activity rates of earthquakes in the present study are distributed non-uniformly over the area of each source zone in a physically realistic manner.
3.3 Characterizing ground motion probability
The probability density function for the ground motion intensity parameter is derived using several local and global ground motion models (GMMs) applicable to the region using a logic tree approach to account for epistemic uncertainties. Since the Indian subcontinent constitutes different tectonics, such as the active and subduction regions in the north and north-east and the stable continental region in the south, appropriate GMMs are selected, and the analysis is carried out for B-C type Site Classes (as per National Earthquake Hazards Reduction Program, Vs30 = 760 m/s). Local GMMs include SSSA17 (Singh et al. 2017) for the Indo-Gangetic Plains, GT18 (Gupta and Trifunac 2018), and DR20 (Dhanya and Raghukanth 2020) for the Himalayan regions. However, due to the unavailability of local GMMs for other tectonic regions, global GMMs are considered for peninsular India. Since the Himalayan and Indo-Gangetic Plains are considered active tectonic regions, NGA-West 2 models are considered, namely: ASK14 (Abrahamson et al. 2014), BSSA14 (Boore et al. 2014), CB14 (Campbell and Bozorgnia 2014), and CY14 (Chiou and Youngs 2014). In addition, subduction GMMs are used for North-East India, namely KNMF06 (Kanno et al. 2006), ZJSX06 (Zhao et al. 2006), Y97 (Youngs et al. 1997), AB03 (Atkinson and Boore 2003), and BCHydro16 (Abrahamson et al. 2016). Further, GMMs that are applicable to the stable continental regions are used for peninsular India, namely AB06 (Atkinson and Boore 2006) and NGA-East characterization model (Goulet et al. 2021). Further, the weights of the logic tree were obtained using the normalized ranking method proposed by Kale et al. (2019). A detailed explanation regarding the logic trees considered for the analysis is available elsewhere (Sreejaya et al. 2022). After obtaining all the necessary probability density functions, the exceedance probability is calculated for Sa, corresponding to a particular return period. The probability of a ground motion intensity exceeding a particular level was calculated based on the probability of that intensity level occurring at a site for a magnitude-distance combination \(P\left[ {PGA > y*|R_{i} ,M_{w} } \right]\) and the probability of occurrence of the same magnitude event within the vicinity of the site.
3.4 Hazard estimation
After obtaining the probability density functions for magnitude as well as PGA, integration is performed to obtain the final probability of exceedances concerning the required return periods. Here, the Cornell–McGuire procedure (Cornell 1968; McGuire 1974) assumes the earthquake occurrences as independent Poisson processes. According to this approach, the probability that the PGA exceeds a particular level ‘y*’ in a return period of ‘T’ yr is given by:
Here \(\mu_{y*}\) is the mean annual rate of exceedance of ground motion parameter \(y*\); \(\tilde{n}_{i} \left( {m_{0} } \right)\) is the elliptically smoothed seismic activity rate for the ith grid cell; \(P\left[ {PGA > y*|R_{i} ,M_{w} } \right]\) is the conditional probability that the parameter \(y*\) would be exceeded for distance \(R_{i}\) and magnitude \(M_{w}\); and \(f_{{M_{i} }} \left( {M_{w} } \right)\) is the probability density function for source magnitude. Thus, the mean annual rate of exceedances and the resulting uniform hazard response spectrum (UHRS) curves are obtained for the entire country on a 0.1° × 0.1° grid. A detailed description of this method is given in the literature (NDMA 2022; Sreejaya et al. 2022). The resulting hazard map, derived for PGA for a return period of 2475 yr is reported in figure 5. The site-specific PGA values thus obtained from the above analysis are almost twice to that of the zone factors specified by the current earthquake code (IS1893 2016) for some of the cities in Himalaya and northeast India.

PEHA contour map of PGA corresponding to 2475 yr return period.
4 Lower-bound deterministic hazard estimates
The PEHA performed to prepare the PGA contour map of figure 5 is based on the spatially smoothed distribution of the past seismicity only because the information required to use individual faults as seismic sources is lacking. Therefore, the probabilistic PGA estimates given in figure 5 are seen to be unrealistically small at many of the locations with little or no past seismicity despite the existence of mapped faults in the vicinity. In order to improve the situation, the deterministic earthquake hazard assessment (DEHA) method was applied to determine the due weightage of the mapped faults.
The DEHA method is intended traditionally to arrive at the upper bound of the earthquake hazard at a site by identifying a controlling maximum credible earthquake (MCE) magnitude and assuming it to occur at the shortest possible distance on the associated fault. The likelihood of realizing the MCE magnitude during life periods of engineering interest is expected to be extremely small. However, it is not possible to define MCE magnitudes for most of the faults in the region in a widely accepted way without strong personal judgement. Therefore, it is proposed to use the DEHA method using maximum frequent earthquake (MFE) magnitude for each area source, which can unquestionably be assumed to occur at any time in the future on any of the mapped faults in the source zone. In general, the MFE magnitude in a source zone may be lower than even the observed maximum magnitude in the source zone. The estimates of MFE magnitudes for all the area sources considered in this study are arrived at from elicitation as listed in table 3, along with their focal depths.
For estimating the lower-bound deterministic estimate of PGA at each grid point, the MFE magnitudes listed in table 3 are assumed to occur on the nearest fault to the grid point in the respective source. If no fault exists within 25 km of the grid point, the MFE is assumed to occur at a minimum distance of 25 km, following the concept of a floating earthquake. The MFE magnitude and distance combinations for all the source zones are used to identify the controlling M and R combination. The controlling M and R pairs for all the grid points are used to compute the hazard, using all the GMMs that were used in PEHA. Finally, the weighted average hazard values are computed in a logic tree framework (Sreejaya et al. 2022). The hazard map thus obtained for median estimates (50% confidence levels) is shown in figure 6. This DEHA map is governed mainly by the contributions of the specific faults, which have not been included in the PEHA map of figure 5 due to the prior mentioned reasons.

DEHA contour map of PGA for the median estimate (50% confidence level).
5 Finalizing the earthquake hazard map
The final hazard map is obtained by using the larger of the deterministic, and the probabilistic hazard analysis estimates at each of the grid sites; and the resulting hazard contour map is shown in figure 7. As the deterministic estimates are made only at the 50th percentile level and are based on the MFE magnitude in each area type of sourcezone, the deterministic estimates control the hazard over limited areas where a fault exists with no past seismicity associated with it. Thus, the map in figure 7 is dominated by the probabilistic hazard only, except for at some isolated locations. This map provides the PGA values estimated corresponding to the assumed engineering bedrock type (B-type) of surface site condition. Therefore, the amplifications at sites with other soil categories, as well as basin characteristics, need to be evaluated.

Final contour map (max of DEHA and PEHA) of PGA corresponding to 2475 yr return period.
5.1 Hazard map with site amplification accounted
The PGA values given in the map of figure 7 correspond to the engineering bedrock type of surface site condition characterized by shear wave velocity – Vs ~760 m/s, hereinafter called Site Class B. But, many of the sites would, in reality, be characterized by lower Vs values towards the surface, which would amplify the PGA estimates. The effects of site amplification are expected to be prominent in all basins (including those along the Himalayas), the Indo-Gangetic Plains, and the river estuaries in peninsular India. However, the depths are unavailable for the quaternary deposits on the Indian landmass; even the digitized map showing the contour plan of the land area with the lateral extent and depth of quaternary deposits is not available yet. Because of this, though theoretically viable, the site amplification could not be incorporated straight away into the hazard estimate. Hence, as a first approximation, the lithological map of India given in figure 8 is used to assign site amplification factors to the PGA estimates at four major lithological units, namely metamorphic and volcanic rocks, sedimentary rocks, laterite, and alluvium. It is well recognized that the various lithological units do not necessarily reflect the thickness of soils at those locations but are used as proxies to various site classes to be used in this version of the PEHA of India, for want of any better information.

Principal lithological groups in India digitized as per GSI (2000).
Towards estimating the expected amplification in earthquake waves, we have gathered multiple base-soil profiles for different regions of India from various sources such as published literature (Boominathan 2004; Anbazhagan and Sitharam 2008; Muthuganeisan et al. 2015; Bajaj and Anbazhagan 2019, etc.,) and other MASW studies conducted for real-life projects (~45 studies in total). The one-dimensional velocity profiles as well as the SPT-N borehole test data from these sources are used to calculate the respective site classes (NEHRP A-type: Hard rock, Vs30 > 1500 m/s; B-type: Rock, 760 ≤ Vs30 < 1500; C-type: Very dense soil/soft rock, 360 ≤ Vs30 < 760; D-type: Stiff soil, 180 ≤ Vs30 < 360; and E-type: Soft clay, Vs30 ≤ 180). Further, site amplifications for each of these sites are derived by performing a one-dimensional site response analysis w.r.t. the bedrock strata using DEEPSOIL software (Hashash et al. 2020). Since a few of the soil profiles do not have detailed information on the soil variation up to bedrock depth, the shear wave velocities and soil properties, such as G/Gmax (Seed and Idriss 1970) and dynamic density, are randomized throughout the depth of the soil column. During the analysis, three standard bedrock time histories are considered from the PEER NGA database. The original time histories are scaled to generate 30 samples of time histories, such that the considered scenarios cover the range of input PGAs (say 0.1 to 1g). Further, the analysis is performed, and the surface-level time histories are obtained for each of the 30-time history samples, totaling 250 soil profiles. Figure 9 shows the histogram of the average shear wave velocity and depth of column for the 250 profiles generated by randomization of the limited number of actual profiles. These have been used to obtain the amplification factors for site classes C and D for different levels of PGA at the bedrock, as given in table 4. Further, the lithological group – metamorphic and volcanic rocks, sedimentary rocks, laterite, and alluvium corresponding to each of these soil profiles is determined, and the respective amplification factors (table 5) are derived for each lithologic group as well, based on the respective results as well as expert judgment. For alluvium/soil sites, similar values are reported in the literature (e.g., Idriss 1991). This approximation is considered to absorb the effects of thick deposits overlying the bedrock, i.e., the effects of site period on the PGA values. Understandably, this will lead to higher PGA even in those areas where there are no quaternary deposits, as well as in those structures founded on engineering rock.

Variations in average shear wave velocity and depth of soil column in 250 profiles considered with soil strata having (a) 180 ≤ Vs ≤ 360 m/s and (b) 360 ≤ Vs ≤ 760 m/s.
The PGA estimates at the grid sites with different lithological units in the map of figure 7 are scaled by the corresponding amplification factors as given in table 5 to obtain the final hazard map reported in figure 10. This contour map with site amplification effects accounted is used as the basis for developing the new zone map of India.

Hazard map of India after multiplying the rock level PGA values with the amplification factors deduced for the various lithological units.
5.2 Smoothening and removal of islands
After accounting for soil amplification, the finalized contour map of figure 10, is used to prepare a raw zone map by enclosing areas with PGA values in five ranges of 0.0–0.15g (zone II), 0.15–0.30g (zone III), 0.30–0.45g (zone IV), 0.45–0.60g (zone V) and 0.60g and higher (zone VI). This zone map is given in figure 11, which is seen to be characterized by several inliers of adjacent higher or lower zones. Therefore, the zone map obtained is smoothed out as per the following considerations:
-
(1)
Zone boundaries are rounded to have smooth transitions between the five zones. Also, the boundaries of the higher zones are enlarged to include the major cities in the adjacent lower zone, provided they were within 50 km from the boundaries of the higher zone.
-
(2)
A land strip of ~50 km width along the southwest coast of India is upgraded to earthquake zone III, even though the PEHA work indicated this area to be ideally in earthquake zone II. This is adopted to account for possible hazards due to offshore faults.
-
(3)
At zone boundaries, inliers of smaller zones are, in general, merged into the higher zone, but the very small size of inliers of the higher zone is merged into, the lower zone only if no past seismicity is noted at those locations.

The raw zone map of India, which is based on the hazard map shown in figure 10.
The smoothed zone boundaries thus arrived at are shown in figure 12, which resulted in the new zone map of India with five seismic zones, as given in figure 13. In addition, the new zone map is plotted against the seismicity and fault maps of India in figures S1 and S2 of the Supplementary material, respectively. This map is found to be adequately consistent with the past seismicity as well as the mapped faults in the region of study.

Earthquake Zone Map of India with (dark lines) and without (coloured areas) smoothening.

The finalized new zone map of India with smoothed zone boundaries.
6 Zone factors
The new zone map of India in figure 13 is based on the five intervals of the PGA hazard for the return period of 2475 yr. Though the earthquake zone VI with the highest seismic hazard in the country is defined for PGA estimates greater than 0.6g and encompasses areas with PGA values up to about 1.0g, it is proposed to consider an optimum value of 0.75g as the design PGA for this zone. Further, to overcome the peculiarities due to uncertainties in the various input parameters to the hazard analysis, the range of PGAs in the other four zones is replaced with the upper bound values to represent the PGA value at all the locations in that zone. The PGA values for earthquake zones II, III, IV, V, and VI thus become 0.15, 0.30, 0.45, 0.60, and 0.75g, respectively. These values represent the reference zone factors for a return period (TRP) of 2475 yr, as listed in table 6.
The Earthquake Design Philosophy adopted in the 2023 revision of the Indian Standards related to earthquake safety, namely, IS 1893 on ‘Design Earthquake Hazard and Criteria for Earthquake Resistant Design of Structures’, IS 13920 on ‘Specifications for Earthquake Resistant Design and Detailing of Structures’, and IS 13935 on ‘Principles for Earthquake Safety Assessment and Retrofit of Structures’, required structures to be placed under five categories, namely: (a) Normal structures, (b) important structures, (c) critical and lifeline structures, (d) special structures, and (e) nuclear power plant structures. The basis for the choice of these five categories is the risk associated with them, especially the negative consequence of their collapses. These include losses of life and property, disruptions in businesses and governance, post-earthquake functionality, and indirect losses owing to their non-performance.
The relative hazard levels for the design of these different categories of structures are proposed to be differentiated as per the return periods listed in table 7. Thus, it is necessary to know the values of the zone factors for seven different TRPs of 73, 225, 475, 975, 2475, 4995, and 9975 (say) yr in all. Under the assumption of Poisson distribution, these return periods correspond to different probabilities of exceedance during a design life of 50 yr, as given in table 8. In principle, it could have been possible to obtain the zone factors for all the return periods by computing the hazard directly for those return periods, similar to that of the 2475 yr. However, a more convenient/practical approach is recommended for use in IS 1893 (Part 1) in which the zone factors for other return periods are obtained from the 2475 yr by developing an empirical relationship. The reference return period TRP,ref of 2475 yr is taken to reflect the best estimate possible from the earthquake hazard assessment undertaken. This is because of the aleatoric and epistemic uncertainties that may have crept in during the first-cut effort towards PEHA that we embarked on in India. Also, if higher reference return periods TRP, ref of 4995 or 9975 yr are considered, the PGA values (especially in the lower zones II and III) would be much higher than that are realistic in the Gondwanaland in the peninsular India, which is stated and understood to be seismically stable. The PEHA may be based on the larger values and may draw more criticism than what we are facing with the reference return period TRP, ref of 2475 yr.
Following the approach adopted by the Eurocode 8, the scaling factor \(s\) to get the zone factor \(Z_{{T_{RP} }}\) for a desired return period \(T_{RP}\) from the zone factor \(Z_{2475}\) corresponding to a reference return period of 2475 yr is defined as
Here, factor k is estimated empirically by carrying out the PEHA for several different \(T_{RP}\) values. The parameter k is found to vary over a wide range: 0.28–0.60, with higher values in areas of low seismicity and vice-versa. When k is high, s <1.0 for \(T_{RP}\) lower than 2475 yr and more than 1.0 for \(T_{RP}\) higher than 2475 yr. On the other hand, when k is small, s is comparatively higher for lower \(T_{RP}\) and lower for higher \(T_{RP}\). Thus, the use of a k-value that is too high for low seismicity areas may unduly underestimate and overestimate the PGA values for lower and higher return periods, respectively. Similarly, the effect of using a k-value that is too low will unduly overestimate and underestimate the PGA values for lower and higher return periods than 2475 years, respectively. The thin curves in figure 14 for k-values of 0.26 and 0.42 can be considered to approximate well the scale factors for the higher three zones (IV, V, and VI) and the lower two zones (II and III), respectively. These k-values provide balanced estimates of the scaling factors for different return periods and are in line with values cited in classical literature (Lubkowski 2010). The scale factors based on these k-values for seven different return periods rounded off to the nearest fractions are given in table 9. The values of the zone factors for the same return periods for all five seismic zones are given in table 10.

Scaling factor of earthquake zone factors adopted by IS 1893 (Part 1) in 2023, showing the approximated fractions: Blue – zones II and III; red – zones IV, V and VI; as well as actual k values (equation 5): Black – zones II and III; pink – zones IV, V and VI.
The zone factors with different return periods for the five earthquake zones in the new zone map of India provide the basic horizontal PGA estimates for use in earthquake-resistant design or safety evaluation of different categories of structures in each of these zones. The code has also proposed the normalized design response spectral shapes for three different site classes, which are used along with the zone factor to get the design earthquake coefficient required for earthquake-resistant design.
7 Tasks ahead
Despite the very good general understanding of the spatial locations of occurrence of earthquakes and the possible upper limit of their magnitude at the inter-plate boundaries, specific prediction in terms of the exact time, location, and magnitude by earth scientists is still elusive. On the other hand, a similar broad understanding of the earthquake-prone locations and possible maximum magnitudes is, in general, lacking for the intra-plate environment. Hence, over the last three decades, the emphasis worldwide has been on earthquake hazard assessment, which provides an effective basis for risk mitigation by way of earthquake-resistant design of buildings and infrastructure facilities. Due to the random and stochastic nature of the processes involved in the generation of earthquakes in a seismic source and the resulting ground motion intensities at a site, the earthquake hazard is commonly estimated currently using the PEHA method; the same has been used for the first time to prepare a zone map for India in this study. In this method, the seismicity at the earthquake sources and the expected ground motion at a site are both defined using suitable probabilistic models developed using the data and information available at any given point in time. Due to limited data and information available compared to the ideal requirement, any hazard analysis is considered to have only short-term validity and is required to be updated periodically (say, every 5–10 yr) by collecting additional data and developing improved models for the input to the hazard analysis.
In reality, surprise earthquakes will continue to be witnessed in areas with no past seismicity and active fault known to exist, and the damaging earthquake may not happen where expected (e.g., postulated seismic gap areas along plate boundaries) even much after the contemplated natural period (Geller 2011). Nevertheless, the PEHA also provides a method to account for the effects of such eventualities in a balanced way by taking the uncertainties into account. To improve upon the situation further, even after having sufficiently large databases available, more intensified data collection is being continued in many parts of the world, and the hazard maps are being updated frequently using new data. For example, the first version of the United States National Seismic Hazard Map in 1996 has been revised four times over a short period of 22 yr (Petersen et al. 2020). Though the proposed quantitative zone map of India developed using the PEHA method can be considered a significant update over the existing qualitative map, further updating is essential by identifying the specific faults as the seismic sources for the occurrence of the largest possible magnitudes in different tectonic domains and by selecting the GMMs representative of different regions of the country and updating those further using the available recorded strong motion acceleration data.
The PEHA performed to prepare the proposed zone map of India is based solely on the area type of seismic sources, the results of which are dominated by the available data on past earthquakes. Also, the GMMs used are based on only limited validation using the recorded strong-motion data. In enhancing the reliability of this zone map, it is necessary to supplement the area sources of background seismicity with the fault sources of the largest possible earthquakes collate all the strong-motion data available in the country, and initiate a comprehensive program for strong-motion data recording at the national level and to develop region-specific GMMs.
The tasks ahead to have the next updating of the hazard zoning of India in the future and the subsequent regular revisions in a consistent manner are:
-
(i)
The earthquake catalogue to be used in PEHA has to meet the requirements of comprehensiveness, quality, and uniformity. In meeting these requirements, it is necessary to compile a critically scrutinized earthquake catalogue for India and neighbouring regions from all available indigenous and international sources of instrumental as well as historical earthquakes. Also, the catalogue should be extended as much as possible in the past to the pre-historical earthquakes using available publications on paleo-seismic studies and the non-technical ancient literature.
-
(ii)
The catalogue compiled under (i) should be homogenized to moment magnitude using region-specific conversion relations with standard deviations taken into account and then be declustered judiciously to avoid excessive removal of the dependent events. This homogenized and declusterd catalogue should be used in the earthquake hazard analysis.
-
(iii)
The PEHA requires accurate information on all the tectonic and geological features that may be the sources of the earthquakes. A comprehensive geotectonic map of India and neighbouring areas should thus be prepared by starting with the tectonic map of India by the Geological Survey of India (GSI 2000) and incorporating additional tectonic features from the published literature. Available focal mechanism solutions from the GCMT catalogue (Ekström et al. 2012) and various published papers should be superimposed over the tectonic map to infer the dominant focal mechanisms of the earthquakes associated with the potentially active known faults.
-
(iv)
As it will not be possible generally to identify all the active faults and their maximum seismic potential in all parts of the country, and as all the past earthquakes are not seen to be associated with the known faults only, the use of area type of seismic sources of diffused seismicity will continue to play an important role in PEHA for all times to come. Thus, a physically plausible set of area types of seismic source zones must be identified by interpretation of the correlation between past earthquakes and tectonic features, following the process of expert elicitation so that it may need only minor changes in the future.
-
(v)
For each area source, a realistic estimate of the maximum earthquake magnitude should be arrived at by applying all possible methods commonly used worldwide for the purpose. A suitable earthquake recurrence model should be defined for each source using available data on past seismicity, with the completeness of the data in different magnitude ranges taken into account. Before finalization, the recurrence model should be validated by the GPS-based strain rate data, if available.
-
(vi)
The magnitudes within a small interval close to the largest possible earthquake in an area source are expected to be associated with specific faults only. Thus, each area source must identify the active faults with their detailed geometry, possible maximum magnitude, slip rate, and average recurrence period of the maximum magnitude to be used as independent seismic sources. A project on active fault mapping in earthquake zones IV and V of the existing seismic zone map (zones V and VI in the new map) is already being executed by the Ministry of Earth Sciences, Government of India, which may be extended to vulnerable areas in lower zones in the future. As the active fault mapping project is going to be long-term in nature, in the interim, active faults for earthquake hazard mapping must be finalized by expert elicitation.
-
(vii)
Realistic hazard assessment requires developing GMMs specific to different source-to-site path characteristics as a minimum for prediction of ground motion due to (a) local earthquakes in the Himalayan plate boundary region, (b) local earthquakes in the plate vicinity region of northeast India, (c) local earthquakes in the intraplate area of Indo-Gangetic Plains, (d) Himalayan earthquakes in the Indo-Gangetic Plains, (e) Indo-Burmese subduction zone earthquakes in northeast India, and (f) local earthquakes in the intraplate region of peninsular India. In collecting the necessary data for this purpose, a centrally coordinated multi-organization national program for installing and recording strong motion data in all parts of the country must be initiated immediately. Ensuring the continued operational readiness of an already installed strong motion network is also of the essence.
-
(viii)
Deep sediments can amplify or deamplify the earthquake shaking induced at the basement rock level, depending upon the intensity and frequency of the shaking. Detailed soil columns above the bedrock should also be characterized at every strong motion recording site to develop realistic amplification factors for the ground motion at different types of site soil conditions. In quantifying the basin effects realistically in the ground motion prediction, the thickness of sediments up to the basement rock and its stratification is required to be collected underneath each strong motion recording site. Additionally, there is an urgent need to plan and implement the work for a collection of soil column characteristics, including stratification and depth to bedrock for the entire Indian land mass at a closer grid spacing. This would enable the implementation of soil amplification in PEHA in a more realistic manner.
-
(ix)
As the studies under items (vii) and (viii) above are of a long-term nature, an attempt must be made in the meantime to create a strong motion database by collating the data available with different organizations and individual researchers in the country. This database is expected to be significantly large and can be used in combination with suitably selected limited data from other regions of the world to develop the required GMMs for many regions of the country. Reasonably realistic GMMs may also be developed using a hybrid empirical method (Campbell 2003) or the referenced empirical approach (Atkinson 2008) with the limited data available. Alternatively, data-driven methods may be used with the available database to select appropriate GMMs from other data-rich regions of the world.
The implementation of the short-term components of the foregoing tasks may be initiated right away to improve the characterization of seismic sources using a combination of area and fault sources, to improve earthquake recurrence models for area sources by validation with the GPS-based strain rate data and for the fault sources by literature review and expert elicitation, and to have improved GMMs by making use of the available strong motion data. Over about five years, this should enable the updated probabilistic seismic hazard maps of India in terms of the contour maps for PGA and response spectrum amplitudes at selected natural periods as per the current international practice.
8 Summary and conclusion
In the current study, a detailed methodology is provided, demonstrating the procedure involved in deriving a new earthquake zone map of India. The zone map is developed based on PGA values corresponding to a return period of 2475 yr from the state-of-the-art PEHA with a lower threshold value in areas of no past seismicity determined by a deterministic analysis. The landmass of the entire country is divided into five seismic zones (zone II: 0–0.15g; III: 0.15–0.3g; IV: 0.3–0.45g; V: 0.45–0.6g; VI: 0.6–0.75g) with the upper bound of the PGA value as the earthquake zone factor of that zone. Amplification corresponding to different soil and lithologic groups is also taken into account while deriving the final zone map. Moreover, scaling factors are also derived to obtain the zone factors corresponding to other return periods – 73, 225, 475, 975, 4995, and 9975 yr. The new zones and their zone factors can be considered to represent the level and spatial distribution of earthquake hazards more realistically, vis-à-vis what can be experienced during the expected maximum magnitudes of future earthquakes in different parts of the country.
A major limitation of the current map is that the effect of the active faults could not be modeled explicitly due to a lack of knowledge about the fault recurrence characteristics. However, this has been compensated to a very good extent by using an elliptical gridded seismicity model over all the area source zones of high seismicity. This method has been adopted for regions elsewhere in the world, and sometimes with even coarser quality of data. Further, it was a compulsion to use global ground motion prediction models in the parameter estimation setup due to the lack of sufficient strong motion records and robust ground motion models. Also, due to a lack of basin structure and site soil information, the site amplification factors could be accounted for only approximately with slight conservatism. As discussed in the previous section, substantial improvements in infrastructure for data collection, apart from processing and easy dissemination, are needed before future revisions of earthquake hazards to upscale the quality of the next edition of earthquake hazard estimate of India. Additionally, physics-based earthquake hazard estimates coupled with realistic measured slip rates may become necessary, especially to capture the effects of characteristics of near-fault ground motions at distances away from the fault.
References
Abrahamson N A, Silva W J and Kamai R 2014 Summary of the ASK14 ground motion relation for active crustal regions; Earthq. Spectra 30(3) 1025–1055.
Abrahamson N A, Gregor N and Addo K 2016 BC Hydroground motion prediction equations for subduction earthquakes; Earthq. Spectra 32(1) 23–44.
Anbazhagan P and Sitharam T G 2008 Mapping of average shear wave velocity for Bangalore region: A case study; J. Environ. Eng. Geophys. 13(2) 69–84.
ASCE/SEI 7-16 2017 Minimum design loads and associated criteria for buildings and other structures; ASCE, https://doi.org/10.1061/9780784414248.
Atkinson G M and Boore D M 2003 Empirical ground-motion relations for subduction-zone earthquakes and their application to Cascadia and other regions; Bull. Seismol. Soc. Am. 934 1703–1729.
Atkinson G M and Boore D M 2006 Earthquake ground-motion prediction equations for Eastern North America; Bull. Seismol. Soc. Am. 966 2181–2205.
Atkinson G M 2008 Ground-motion prediction equations for eastern North America from a referenced empirical approach: Implications for epistemic uncertainty; Bull. Seismol. Soc. Am. 983 1304–1318.
Auden J B 1959 Earthquakes in relation to the Damodar Valley project; Proc. Symp. Earthq. Eng., Univ. Roorkee, Roorkee, India.
Bajaj K and Anbazhagan P 2019 Seismic site classification and correlation between VS and SPT-N for deep soil sites in Indo-Gangetic Basin; J. Appl. Geophys. 163 55–72.
Baruah S, Baruah S, Bora P K, Duarah R, Kalita A, Biswas R and Kayal J R 2012 Moment magnitude MW and local magnitude ML relationship for earthquakes in Northeast India; Pure Appl. Geophys. 169(11) 1977–1988.
Basu S and Nigam N 1977 Seismic risk analysis of Indian peninsula; In: Proceedings of 6th World Conference on Earthquake Engineering, New Delhi, pp. 782–790.
Bhatia S C, Ravi Kumar M and Gupta H K 1999 A probabilistic seismic hazard map of India and adjoining regions; Ann. Geofis. 42 1153–1164.
Bilham R and England P 2001 Plateau ‘pop-up’ in the great 1897 Assam earthquake; Nature 410 806–809.
Boominathan A 2004 Seismic site characterization for nuclear structures and power plants; Curr. Sci.1388–1397.
Boore D M, Stewart J P, Seyhan E and Atkinson G M 2014 NGA-West2 equations for predicting PGA PGV and 5% damped PSA for shallow crustal earthquakes; Earthq. Spectra 303 1057–1085.
Campbell K W 2003 Prediction of strong ground motion using the hybrid empirical method and development of ground motion attenuation relations in eastern North America; Bull. Seismol. Soc. Am. 933 1012–1033.
Campbell K W and Bozorgnia Y 2014 NGA-West2 ground motion model for the average horizontal components of PGA PGV and 5% damped linear acceleration response spectra; Earthq. Spectra 303 1087–1115.
Chiou B S J and Youngs R R 2014 Update of the Chiou and Youngs NGA model for the average horizontal component of peak ground motion and response spectra; Earthq. Spectra 303 1117–1153.
Cornell C A 1968 Engineering seismic risk analysis; Bull. Seismol. Soc. Am. 585 1583–1606.
Dhanya J, Sreejaya K P and Raghukanth S T G 2022 Seismic recurrence parameters for India and adjoined regions; J. Seismol. 26 1051–1075.
Dhanya J and Raghukanth S T G 2020 Neural network-based hybrid ground motion prediction equations for Western Himalayas and North-Eastern India; Acta Geophys. 68 303–324.
Ekström G, Nettles M and Dziewonski A M 2012 The global CMT project 2004–2010: Centroid-moment tensors for 13017 earthquakes; Phys. Earth Planet Inter. 200–201 1–9.
European Commission, Joint Research Centre, Aucun B, Fajfar P and Franchin P 2012 Eurocode 8: Seismic design of buildings – Worked examples (eds) Aucun B, Carvalho E, Pinto P and Fardis M, Publications Office, https://doi.org/10.2788/91658.
Gardner J K and Knopoff L 1974 Is the sequence of earthquakes in Southern California with aftershocks removed Poissonian?; Bull. Seismol. Soc. Am. 645 1363–1367.
Geller R 2011 Shake-up time for Japanese seismology; Nature 472 407–409.
Goulet C A, Bozorgnia Y, Kuehn N, Al Atik L, Youngs R R, Graves R W and Atkinson G M 2021 NGA-East ground-motion characterization model Part I: Summary of products and model development; Earthq. Spectra 371_suppl 1231–1282.
GSI 2000 Seismotectonic Atlas of India and its Environs; Geological Survey of India.
Gubin I E 1971 Multi-element seismic zoning considered on the example of the Indian Peninsula; Earth Phys. 12 10–23.
Guha S K 1962 Seismic regionalization of India; Proceedings of Symposium Earthquake Engineering, 2nd edn, Roorkee, India, pp.191–207.
Gupta I D and Todorovska M I 1995 Seismic Zoning Chapter V; In: Selected Topics in Probabilistic Seismic Hazard Analysis (eds) Todorovska M I, Gupta I D, Gupta V K, Lee V W and Trifunac M D, Report No CE 95-08 Dept of Civil Eng., Univ. Southern California, Los Angeles, USA.
Gupta I D 2006 Delineation of probable seismic sources in India and neighborhood by a comprehensive analysis of seismotectonic characteristics of the region; Soil Dyn. Earthq. Eng. 76 766–790.
Gupta I D and Trifunac M D 2018 Empirical scaling relations for pseudo relative velocity spectra in western Himalaya and northeastern India; Soil Dyn. Earthq. Eng. 106 70–89.
Hashash Y M A, Musgrove M I, Harmon J A, Ilhan O, Xing G, Numanoglu O, Groholski D R, Phillips C A and Park D 2020 DEEPSOIL 7.0 User Manual; Urbana IL Board of Trustees of University of Illinois at Urbana-Champaign, USA.
IBC 2015 International building code; International Code Council Inc.
Idriss I M 1991 Earthquake ground motions at soft soil sites; In: Proceedings of the Second International Conference on Recent Advances in Geotechnical Earthquake Engineering and Soil Dynamics, March 11–15, 1991, St Louis Missouri, Invited Paper LP01.
ISI 1982 Explanatory Handbook on Codes for Earthquake Engineering IS: 1893-1975 & IS: 4326-1976 Special Publication SP: 22 S&T – 1982, Indian Standards Institute ISI, New Delhi, pp. 47–57.
IS: 1893 2016 Criteria for Earthquake Resistant Design of Structures; Bureau of Indian Standards, Manak Bhawan, New Delhi.
Jade S, Shrungeshwara T S, Kumar K, Choudhary P, Dumka R K and Bhu H 2017 India plate angular velocity and contemporary deformation rates from continuous GPS measurements from 1996 to 2015; Sci. Rep. 7 11439.
Jain S K 2016 Earthquake safety in India: Achievements challenges and opportunities; Bull. Earthq. Eng. 14(5) 1337–1436, https://doi.org/10.1007/s10518-016-9870-2.
Jaiswal K and Sinha R 2007 Probabilistic seismic-hazard estimation for peninsular India; Bull. Seismol. Soc. Am. 971(B) 318–330.
Kale O 2019 Some discussions on data-driven testing of ground-motion prediction equations under the Turkish ground-motion database; J. Earthq. Eng. 231 160–181.
Kanno T, Narita A, Morikawa N, Fujiwara H and Fukushima Y 2006 A new attenuation relation for strong ground motion in Japan based on recorded data; Bull. Seismol. Soc. Am. 963 879–897.
Khattri K N, Rogers A M, Perkins D M and Algermissen S T 1984 A seismic hazard map of India and adjacent areas; Tectonophys. 1081(2) 93–134.
Khattri K N 1987 Great earthquakes seismicity gaps and potential for earthquake disaster along the Himalaya plate boundary; Tectonophys. 138 79–92.
Kijko A and Graham G 1998 Parametric-historic procedure for probabilistic seismic hazard analysis Part I: Estimation of maximum regional magnitude Mmax; Pure Appl. Geophys. 1523 413–442.
Krishna J 1959 Seismic zoning map of India; Curr. Sci. 62 17–23.
Kumar S L 1933 Theory of earthquake resisting design with a note on earthquake resisting construction in Baluchistan; Punjab Engineering Congress.
Lapajne J, Motnikar B S and Zupancic P 2003 Probabilistic seismic hazard assessment methodology for distributed seismicity; Bull. Seismol. Soc. Am. 936 2502–2515.
Lubkowski Z A 2010 Deriving the seismic action for alternative return periods according to Eurocode 8; In: Proceedings of the 14th European conference on earthquake engineering.
Mandal H S, Shukla A K, Khan P K and Mishra O P 2013 A new insight into probabilistic seismic hazard analysis for Central India; Pure Appl. Geophys. 170 2139–2161.
McGuire R K 1974 Seismic structural response risk analysis incorporating peak response regressions on earthquake magnitude and distance; Report R74-51, Structures Publication, 399.
Mithal R and Srivastava S 1959 Geotectonic position and earthquakes of Ganga–Brahmaputra region; First Symposium on Earthquake Engineering, University of Roorkee, India.
Mohapatra A K and Mohanty W K 2010 An overview of seismic zonation studies in India; Indian Geotechnical Conference, IGS Mumbai Chapter & IIT Bombay, Dec 16–18, 2010.
Muthuganeisan P, Gade M, Raghukanth S T G and Dodagoudar G R 2015 Seismic site classification and response analysis for Shimla, Himachal Pradesh; 6th International Geotechnical Symposium on Disaster Mitigation in Special Geoenvironmental Conditions.
NDMA 2010 Development of probabilistic seismic hazard map of India; The National Disaster Management Authority, Government of India, New Delhi.
NDMA 2022 Probabilistic seismic hazard map of India; The National Disaster Management Authority, Government of India, New Delhi, https://ndma.gov.in/sites/default/files/PDF/Technical%20Documents/NDMA_PSHMI.pdf.
Nath S K and Thingbaijam K K S 2012 Probabilistic seismic hazard assessment of India; Seismol. Res. Lett. 83 135–149.
Parvez I A, Vaccari F and Panza G F 2003 A deterministic seismic hazard map of India and adjacent areas; Geophys. J. Int. 155(2) 489–508.
Petersen M D, Shumway A M and Powers P M et al. 2020 The 2018 update of the US National seismic hazard model: Overview of model and implications; Earthq. Spectra 361 5–41.
Scordilis E M 2006 Empirical global relations converting MS and mb to moment magnitude; J. Seismol. 102 225–236.
Seed H B and Idriss I M 1970 Soil moduli and damping factors for dynamic response analysis; Rep No EERC 75-29, Berkeley, CA: Earthquake Engineering Research Center, University of California.
Singh S, Srinagesh D, Srinivas D, Arroyo D, Perez-Campos X, Chadha R, Suresh G and Suresh G 2017 Strong ground motion in the Indo-Gangetic plains during the 2015 Gorkha Nepal earthquake sequence and its prediction during future earthquakes; Bull. Seismol. Soc. Am. 107(3) 1293–1306.
Sitharam T and Sreevalsa K 2013 Seismic hazard analysis of India using areal sources; J. Asian Earth Sci. 62 647–653.
Sreejaya K P, Raghukanth S T G, Gupta I D, Murty C V R and Srinagesh D 2022 Seismic hazard map of India and neighboring regions; Soil Dyn. Earthq. Eng. 163 107505.
Srivastava L S 1969 A note on the seismic zoning map of India; Bull. Ind. Soc. Earthq. Technol. 64 185–194.
Stepp J C 1972 Analysis of completeness of the earthquake sample in the Puget Sound area and its effect on statistical estimates of earthquake hazard; In: Proceedings of the 1st Int. Conf. on Microdonation, Seattle 2 897–910.
Styron R, Taylor M and Okoronkwo K 2010 Database of active structures from the Indo-Asian collision; EOS Trans. Am. Geophys. Union 91(20) 181–182.
Tandon A N 1956 Zones of India liable to earthquake damage Indian; J. Meteorol. Geophys. 10 137–146.
Tinti S and Mulargia F 1985 Completeness analysis of a seismic catalogue; Ann. Geophys. 3 407–414.
Weichert D H 1980 Estimation of the earthquake recurrence parameters for unequal observation periods for different magnitudes; Bull. Seismol. Soc. Am. 704 1337–1346.
West W D 1937 Earthquakes in India presidential address; In: Proceedings of the Indian Science Congress, Hyderabad, pp. 189–227.
Youngs R R, Chiou S J, Silva W J and Humphrey J R 1997 Strong ground motion attenuation relationships for subduction zone earthquakes; Seismol. Res. Lett. 681 58–73.
Yenier E, Erdoğan O and Akkar S 2008 Empirical relationships for magnitude and source-to-site distance conversions using recently compiled Turkish strong-ground motion database; In: The 14th World Conference on Earthquake Engineering 18p.
Yu Y, Gao M and Xu G 2011 Seismic zonation; In: Encyclopedia of Solid Earth Geophysics, Encyclopedia of Earth Sciences Series (ed.) Gupta H K, Springer, Dordrecht, pp. 1224–1230.
Zhao J X, Zhang J, Asano A, Ohno Y, Oouchi T, Takahashi T, Ogawa H, Irikura K, Thio H K and Somerville P G et al. 2006 Attenuation relations of strong ground motion in Japan using site classification based on predominant period; Bull. Seismol. Soc. Am. 963 898–913.
Author information
Authors and Affiliations
Contributions
Raghukanth S T G, Gupta I D and Murty C V R conceptualized and supervised the work. Chaudhary J K and Arun Kumar S coordinated the discussions and documentation related to the project. Srinagesh D provided data on soil profiles and strong motion data. Ramjivan Singh provided data related to GSI maps. Sreejaya K P contributed to the overall analysis of PEHA and drawing the figures for the manuscript. Mandal H S and Chopra S contributed to the amplification study. Roshan A D and Gupta I D contributed to the deterministic analysis. Raghukanth S T G, Murty C V R, Goswami R, Gupta I D, Sinha R and Sheth A R contributed to the methodology involved in finalizing the zones and zone factors. Bhargavi P wrote the original draft, reviewed the comments received, and prepared base replies. Raghukath S T G, Murty C V R and Gupta I D edited the manuscript before submission and finalized the replies to the comments received.
Corresponding author
Additional information
Communicated by Sagarika Mukhopadhyay
Supplementary material pertaining to this article is available on the Journal of Earth System Science website (http://www.ias.ac.in/Journals/Journal_of_Earth_System_Science).
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Raghukanth, S.T.G., Podili, B., Sreejaya, K.P. et al. Draft Earthquake Zone Map of India. J Earth Syst Sci 133, 158 (2024). https://doi.org/10.1007/s12040-024-02368-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12040-024-02368-2