
Abstract
TIFR-ARIES Near Infrared Spectrometer (TANSPEC) instrument provides simultaneous wavelength coverage from 0.55 to 2.5 \(\mu \)m, mounted on India’s largest ground-based telescope, 3.6-m Devasthal Optical Telescope at Nainital, India. The TANSPEC offers three modes of observations, imaging with various filters, spectroscopy in the low-resolution prism mode with derived \(R\sim 100\)–400 and the high-resolution cross-dispersed mode (XD-mode) with derived median \(R\sim 2750\) for a slit of width 0.5 arcsec. In the XD-mode, 10 cross-dispersed orders are packed in the \(2048 \times 2048\) pixels detector to cover the full wavelength regime. As the XD-mode is most utilized as well as for consistent data reduction for all orders and to reduce data reduction time, a dedicated pipeline is essential. In this paper, we present the code for the TANSPEC XD-mode data reduction, its workflow, input/output files and a showcase of its implementation on a particular dataset. This publicly available pipeline pyTANSPEC is fully developed in Python and includes nominal human intervention only for the quality assurance of the reduced data. Two customized configuration files are used to guide the data reduction. The pipeline creates a log file for all the fit files in a given data directory from its header, identifies correct frames (science, continuum and calibration lamps) based upon the user input, offers an option to the user for eyeballing and accepting/removing of the frames, does the cleaning of raw science frames and yields final wavelength calibrated spectra of all orders simultaneously.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction

Raw images of an object frame, cont1 lamp, Ar-lamp and Ne-lamp (from left to right). The color bar represents counts and its scale is from \(m -2\sigma \) to \(m +30\sigma \), where m and \(\sigma \) are the sigma clipped median and standard deviation, respectively. All 10 orders of the TANSPEC XD-mode, from the XD-order 3 (wavelength \(\sim \)1.9–2.5 \(\mu \)m) at the bottom, to the XD-order 12 (wavelength \(\sim \)0.55–0.61 \(\mu \)m) at the top, are marked in the object frame.
TIFR-ARIES Near Infrared Spectrometer (TANSPEC) is developed in collaboration with Tata Institute of Fundamental Research (TIFR), Mumbai, India; Aryabhatta Research Institute of Observational Sciences (ARIES), Nainital, India and Mauna Kea Infrared LLC (MKIR), Hawaii. The TANSPEC was installed on India’s largest ground-based telescope, 3.6-m Devasthal Optical Telescope (DOT) at Nainital, India, on 2 April 2019. It is one of the few instruments in the world having simultaneous continuous wavelength coverage from 0.55 to 2.5 \(\mu \)m with median resolving power, \(R\sim 2750\) in the cross-dispersed mode (XD-mode) and \(R\sim 100\)–400 in the low-resolution prism mode (LR-mode) for a slit of width 0.5 arcsec. However, it has slits of different widths ranging from 0.5 to 4.0 arcsec for observations. In addition, it has an independent imaging camera consisting of several broadbands and narrowband filters with a pixel scale of 0.25 arcsec per pixel. Therefore, the TANSPEC provides three modes of observations, XD-mode and LR-mode spectroscopies and imaging-mode using two Teledyne HgCdTe Astronomical Wide Area Infrared Imager (HAWAII) detectors (H1RG: \(1024 \times 1024\) pixels for imaging as well as slit-viewing and H2RG: \(2048 \times 2048\) pixels for spectroscopy). The estimated peak gain value for H1RG is \(4.3 \pm 0.2\) e\(^-\) per ADU, while H2RG offers observations in two gain-modes: low-gain and high-gain modes with peak values \(4.5 \pm 0.2\) e\(^-\) per ADU and \(1.12 \pm 0.03\) e\(^-\) per ADU, respectively (Sharma et al. 2022). The detectors read out in Sample-Up-The-Ramp (SUTR) mode. In SUTR mode, the voltage in each pixel reads out during the exposure without impacting the ongoing photon collection. Hence, we get a time series of measurements for each pixel, which linearly increases proportionally to the flux falling on the pixel. To generate the final image, the flux in each pixel is calculated by the linear slope fitting along the time axis. The estimated upper limits of the linear regime for H2RG and H1RG detectors are 26,000 ADU (57,000 ADU for high gain) and 30,000 ADU, respectively (Sharma et al. 2022). We refer to the TANSPEC documentFootnote 1 and instrument paper (Sharma et al. 2022) for additional details.
Among all observation modes, the XD-mode is one of the most efficient ways of studying celestial sources by acquiring spectroscopic data in a broad wavelength range in a single exposure. So, it is the most commonly used mode by the observers. Images in XD-mode observations typically consist of object frames (science target) with corresponding continuum lamps (cont1) and arc lamps (Ar and Ne) for the continuum correction and the wavelength calibration, respectively. The observed frames in the TANSPEC XD-mode, for instance, are shown in Figure 1. As presented in Figure 1, the raw images show multiple cross-dispersed orders (10 orders from grating order 3–12) in \(2048 \times 2048\) pixels detector to cover the full-wavelength regime of the TANSPEC. As a result, the data reduction of the XD-mode is a bit more complex and time-consuming than the other two modes (imaging and LR-mode). In addition, the spectral orders are curved and thus, the dispersion axis is not aligned with the detector columns, which makes the extraction of XD-mode spectra particularly challenging (Cushing et al. 2004). Hence, a dedicated automated pipeline is essential for consistent data reduction over the night and for reducing the data reduction time.
To provide a set of semi-automatic scripts for reducing TANSPEC XD-mode data, we have developed a spectral reduction package, pyTANSPEC (version 0.0.1) keeping in mind that the coding language Python is used nowadays by the largest fraction of users among the astronomical community and the development and maintenance of well-known astronomical data reduction software, IRAF is discontinued since 2013. The current version supports data reduction for slits of width 0.5 and 1.0 arcsec and it embarks on slope-fitted images.
In this paper, we illustrate pyTANSPEC and provide an example of spectra reduced with it. We describe the pyTANSPEC package and its workflow in Section 2. Section 3 deals with the reduction and discussion of an A-type star, and the future aspects of pyTANSPEC are given in Section 4. Finally, we summarize in Section 5.
2 Description of the package
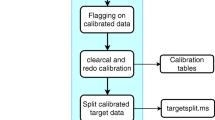
The purpose of the pyTANSPEC_v0.0.1 pipeline is to extract the XD-mode spectra consistently over the night by minimizing human errors that can be introduced during manual reduction as well as reducing the required time of manual data analysis. The pipeline works for object images obtained in either one or two positions of the slit. The data reduction pipeline is solely written in Python 3 and has a modular setup. The numpy (Harris et al. 2020), astropy (Astropy Collaboration et al. 2013, 2018), scipy (Virtanen et al. 2020), scikit-image (van der Walt et al. 2014), ccdproc (Craig et al. 2015) and matplotlib (Hunter 2007) packages of Python are used for most calculations. Instead of full-scale automation, the pipeline is made semi-automated with minimal human intervention for the quality assurance of the reduced data. The interface of the pipeline has been designed a lot alike the TIFR Near Infrared Spectrometer and Imager (TIRSPEC) pipelineFootnote 2 (Ninan et al. 2014), so the users of it can operate the TANSPEC pipeline with ease. Each step of the pipeline can be run independently or simultaneously. The metadata for the pipeline is passed on from one step to the next step via human-readable text files. This helps the users to control the flow of pipeline. The pyTANSPEC can be downloaded from Github.Footnote 3 In this paper, we describe the essential steps carried out by the pipeline and for practical implication, we refer to the documentation. The flow chart of the pipeline is displayed in Figure 2 and has been described in this section.

Flow diagram of the TANSPEC XD-mode data reduction pipeline. Users need to create a directory and copy all the data and pipeline-related requirements into it. Users can name the directory according to their whims. Here, we have named it as MotherTANSPEC.
2.1 Preparation
All configurations can be done in configuration files. Two configuration files,Footnote 4 TANSPECscript.config and spectrum_extractor_TANSPEC.config are used to define the required parameters for running the pipeline. There are several parameters, and some of them are redundant. A description of the available parameters can be found in the configuration file itself. The redundant parameters are kept in the configuration files for future developments of the pipeline. TANSPECscript.config is the main configuration file running the pipeline, while spectrum_extractor_TANSPEC.config is used during the spectrum extraction. In Table 1, we list the most important parameters in the TANSPECscript.config file to be modified to set up the extraction of a new target. However, the default values of parameters can be adopted for the second config file. Thus, two configuration files are used in the pipeline for easing out complexity and making it friendlier to users. After customizing configuration files, the pipeline runs end-to-end to convert raw spectroscopic images into wavelength-calibrated spectra.
2.2 Log file generation
In the first step, the pipeline automatically creates an observational log file of the raw frames for a given data directory, based on the header information. It lists name of all files, their corresponding selected header keywords and auto-generated file number in an ascending order starting from ‘0’ in a text file inside the given data directory. The auto-generated file number should be used during the pipeline run, where required. Creating a log file is an important step for the TANSPEC pipeline to nullify the complexity of running the pipeline because of the user-defined random naming and numbering of files. The users can discard any frame by prepending ‘#’ to the line of that particular image in the log file if required.
2.3 Selection, visualization and acceptance of image frames
In the next three steps, the pipeline yields options to the users for selecting objects as well as continuum and calibration (Ar and Ne lamps) frames, displays all the selected frames and accepts or discards frames based on the user input. These are important steps as the users get another opportunity to discard unwanted frames if they are uncertain, which frame to prefix ‘#’ in the created log file as discussed above as well as to cross-check desired frames for reduction with selected ones.

Generation of a final continuum image. Left: Normalized median combined image in each night (\(F_{\text{each-night}}\)), middle: Average of normalized median images over several weeks (\(F_{\text{avg-several-weeks}}\)), and right: A final continuum image (\(F_{\textrm{Final}}\)), where the upper portion of \(F_{\text{each-night}}\) (an imaginary curved line that connects two marked lines in red color) is replaced by \(F_{\text{avg-several-weeks}}\) to form \(F_{\textrm{Final}}\), are shown.
2.4 Identification of dither frames
The conventional way of near-infrared (NIR) observation is to observe the target at two different positions of the slit to counter the sky background. The pipeline is capable of identifying and separating dithered frames. To detect the dithered frames, a small region (\(80 \times 42\) pixels) of a certain continuum window is selected. The continuum window can be customized through the main configuration file by providing the starting and ending pixels of that window along the cross-dispersed axis. Pixel values of cross-dispersed order 5 are provided for this purpose by default. The difference between the starting and ending pixels (80 pixels) serves as the height of the region, while a fixed width of 42 pixels is selected along the dispersion axis centered at the middle of the cross-dispersed axis. Background subtracted median counts (\(F_\mathrm {BS_i}\), where \(i = 1,\ldots ,80\) pixels) are estimated for the defined region along the dispersion axis. We consider only those pixels (\(y_{i}\)) having counts (\(F_{\textrm{BST}_i}\)) greater than the threshold value to derive the center pixel of the dispersion axis for the region following the equation,
The threshold value is defined as the summation of background and 6\(\sigma \) counts, where \(\sigma \) is the calculated standard deviation using the median absolute deviation of \(F_\textrm{BS}\). If centers of the raw spectra are >6 pixels apart from each other along the dispersion axis, they are identified as the dither pair by the pipeline.
2.5 Combining image frames
The combined images (e.g., science frames at each dither and continuum) are created by the pipeline to improve the SNR. The images are median-combined on a pixel-by-pixel basis. However, the user can also combine images using the sum or average. The combined frames are used for further reduction.
2.6 Image processing
Image processing includes multiple steps, such as correction with dark, bias and continuum images as well as the removal of cosmic rays and correction with bad-pixel mask for dead pixels, however, processing steps depend on the instrument used for the observations. In the case of TANSPEC, the dark current is small (\(\approx \)0.1 e\(^-\) s\(^{-1}\) in the high-gain setting) and bad pixels are negligible in numbers and the majority of them lie along the edges of the H2RG array (Sharma et al. 2022), which is used for spectroscopy. Thus, the pyTANSPEC package allows the user to implement flat and cosmic ray corrections.
2.6.1 Flat correction
The combined continuum frame is smoothened by implementing a median filter. Each pixel of the frame will be replaced by the median value of the surrounding pixels, using a user-defined box (default size: \(25 \times 51\)) around the pixel. The box size of the filter can be customized through the main configuration file. The combined continuum frame is divided by the smoothened version of it to get the normalized continuum image (see the left image in Figure 3). It can be found that the signal-to-noise ratio (SNR) for higher orders (specifically for orders 10, 11 and 12) of the image is poor. The region lying above the curved line that can be drawn through the marked regions in red color in Figure 3 is our concern. We call this imaginary curved line as the line-of-control (LoC). To improve the SNR at higher orders, a final continuum image is created (see the right image of Figure 3), where the upper portion of the LoC of the normalized continuum image in each night as described above is replaced by the previously generated normalized master continuum image (see the middle image of Figure 3). The normalized master continuum images come with the pyTANSPEC package and are created by averaging the median filtered continuum data over several weeks of continuum images (a total of 55 images used). They can be found at Github.Footnote 5 It is found that the SNR above the LoC for the final continuum image is improved by approximately a factor of 4. Using this image, the pipeline does the flat correction.
2.6.2 Removal of cosmic rays
Removal of cosmic rays is an optional step in the pipeline. It is performed based on a variation of the Laplacian edge detection algorithm using the Python package astrocrappy (McCully et al. 2018), which can identify cosmic rays of arbitrary shape and size by the sharpness of their edges. We refer to van Dokkum (2001) for additional details.
2.6.3 Subtraction of dither pair
Dither pair (A and B) is subtracted from each other (i.e., A–B and B–A) to remove the bright NIR sky if the object is observed in two positions of the slit. The subtraction is carried out on a pixel-by-pixel basis. The subtraction of dither pair also removes the dark current and background signal from the telescope, if any. It was made an optional step in the pipeline and depends on the user input during the pipeline run.
2.7 Spectrum extraction and wavelength calibration
2.7.1 Extracting science spectra
Owing to the large curvature in the blue traces of the XD-mode spectrum, it is difficult to trace the blue orders in the 2D image for faint stars. Hence, we took a different approach for the order tracing. We first traced the order positions of a bright star observation and designated that as the template trace. Depending on the position of the star in the slit during the observation, the trace location will shift in the XD direction. Due to atmospheric dispersion as well as spectrograph optics, this will not be a pure linear translation of the trace locations in the XD direction. Hence, to match the trace of any given target observations, we need to allow the template traces to be non-linearly shifted and stretched in the XD direction. This is done by fitting the cut profiles along the XD direction for all the orders simultaneously using a 2nd order polynomial. Even if there is no significant blue light in a particular target’s spectrum, the brighter infrared orders will be sufficient to accurately transform the template trace to the location of the stellar spectrum. We have tested the effect of template fitting on determining the dispersion axis towards the edges and found that our method traces the dispersion axis at the edge approximately identical to the center.
Once the trace is matched to the target’s spectrum in the 2D image, then the pipeline extracts the spectrum inside user-specified aperture window via sum extraction. The sum extraction takes care of the boundary pixel effect by sub-pixel interpolation to sum the light consistently within the exact aperture window size. The sky background spectrum is also extracted from both sides of the stellar spectrum based on user-specified window sizes. In future, we will add an option for optimal extraction as well, which basically scales the spatial profile of an imaged spectrum during its sum extraction by applying non-uniform pixel weights and reduces the statistical noise to a minimum. For additional details, we refer to Horne (1986).
2.7.2 Wavelength solution
The TANSPEC uses a combination of Ar and Ne lamps for wavelength calibration of all the orders. The exact same aperture window used for the targets’ spectrum extraction is used to extract Ar and Ne lamps data via sum extraction. For XD-orders 3–9 (i.e., wavelength range from 0.65 \(\mu \)m to 2.5 \(\mu \)m), Ar-lamp data is used, and for the rest (i.e., from 0.55 \(\mu \)m to 0.75 \(\mu \)m), Ne-lamp is used. Good lines to use for the fits were manually identified and stored in the pipeline. Without any user input, the pipeline will refit those selected lines from the database with the Gaussian profile model and derive a wavelength dispersion solution. The current version of the pipeline provides Chebyshev and Legendre functions for the wavelength solution, which can be customized through the main configuration file. The default value for the wavelength solution is the Legendre polynomial of order 4. Users can verify the goodness of the fit and residuals (derived in terms of radial velocity) from the output directory (we refer to the documentation for details), and accordingly, the order of the fit can be adjusted. However, it is to note that over-fitting can occur on the use of orders >4, especially for spectra of higher XD-orders.
3 Results and discussion
We have tested the package with various different data sets for various nights. These include data taken with both slits of width 0.5 and 1.0 arcsec as well as with different gain setups. We will present the reduced spectra of an A-type (HIP 14431) star as an example. It is essential to mention that the reduction procedure as well as the quality of the reduction depend on, in part, the typical approach in which observations were carried out with the TANSPEC.
The star was observed in two dithered positions with a slit of 1.0 arcsec width in a high-gain setting. Two frames (each with an exposure of 180 s) were obtained in each dither along with three frames of cont1 and one frame each for Ar and Ne lamps.
The data were reduced using the pyTANSPEC pipeline with the parameters described in the manual. Flat correction and cosmic rays removal were implemented to the raw images after the median combined all frames in each dither position. For instance, one median combined, flat corrected and cosmic rays removed image is shown in Figure 4. Dither pair was also subtracted to make A–B and B–A frames. After the preparation for the science extraction, the wavelength calibrated spectra of the star were extracted for A–B and B–A frames (see Figure 5 for A–B image). Extracted spectra were then averaged out to get the final spectra. The final spectra are displayed in Figure 6. The full spectral coverage of TANSPEC from 0.55 \(\mu \)m to 2.5 \(\mu \)m can be seen. Several spectral features (mainly H-line as it is an A-type star) are identified and marked. Most of the unmarked features are due to terrestrial atmospheric O\(_2\) and H\(_2\)O absorptions. Figure 6 also shows the lower flux (hence lower SNR) in the blue side (i.e., higher orders) in comparison with the red side (i.e., lower orders). It is expected as the grating efficiency falls away significantly towards higher orders from the center (i.e., zeroth order).

Median combined, flat corrected and cosmic rays removed image for the first dither position. The color bar represents counts and its’ scale is from \(m - 2\sigma \) to \(m + 30\sigma \), where m and \(\sigma \) are the sigma-clipped median and standard deviation, respectively.

Dither pair subtracted (A–B) image. Color bar is similar to Figure 4.

Wavelength calibrated spectra of HIP 14431, an A-type star. Several important spectral lines of the target are also marked. For reduction, we considered two different cases. In the first case, the dither pairs subtraction was performed and extracted spectra are shown in blue color. For the other case, no dither pairs subtraction was executed and the extracted spectra are overplotted in red color. In both cases, spectra look similar.
One of the key aspects of the pipeline is that even when the star is observed in only one position of the slit (which is not followed commonly in NIR observations), the pipeline is capable of extracting spectra effectively. To counter the background counts, the pipeline itself estimates the background using the regions on both sides of the star aperture during the spectrum extraction. As mentioned earlier, the widths of the stars’ aperture of x pixels and the background of 2y pixels (y pixels on each side of the star aperture) can be customized through the main configuration file. The estimated backgrounds are then averaged and scaled by the aperture width. Thus, the scaling factor is x/y. The scaled averaged background is subtracted from star flux to remove the same.
For example, we used the same star, HIP 14431 and followed the similar reduction procedures as mentioned above except for the dither pair subtraction (which is an optional step in the pipeline as mentioned earlier). Thus, it can be considered that the star was observed in one position of the slit as we did not subtract dither pair and performed the averaging of extracted spectra of dither pair images. The spectra is overplotted in Figure 6 in red color. The extracted spectra for the two cases (with and without the dither pair subtraction) look alike. Thus, the pipeline can extract the spectra efficiently if the star was observed in one position of the slit. The advantage of observing the star in one position of the slit is that it reduces the overhead time during the observation to some extent. In addition, it is important to note that if the star was observed in two dither positions of the slit and the user wants to do dither pair subtraction, the background subtraction has been done twice. The first one is during dither pair subtraction and the second is during the spectrum extraction. We have investigated the possible shift in the dispersion solution by degrees 4 and 6 for both Legendre and Chebyshev functions on this dataset and found that the possible error in wavelength solution is <10 Å.
Using a Linux machine (Ubuntu 22.04.1 LTS installed), with a 1.60 GHz Intel Core i5 (10th Gen) processor with 8 Gb DDR4 RAM, we found that the pipeline typically takes \(\sim \)7 min to complete all the tasks (i.e., from TASK 0 to TASK 6) for this dataset.
4 Future improvements
Several areas for future improvement have been identified. The current version of pyTANSPEC only offers the XD-mode data reduction for slits of width 0.5 and 1.0 arcsec. We plan to include data reduction capability for all available slits in the XD-mode. For that, normalized master continuum images and lists of previously identified Ar and Ne lines against pixels are only needed to be included for the remaining slits. We expect to release it in the next update. Also, the pipeline does not currently support telluric correction or any form of photometric calibration. We are currently in the process of implementing these features into the pipeline. For spectrum extraction, the pipeline uses a conventional method, but the background calculation already performed could be used to implement optimal extraction to maximize SNR. Other areas for improvement are to include the use of continuum lamp (cont2) and the scope of reduction for imaging mode as well as LR-mode.
5 Summary
The pyTANSPEC, the data reduction package was developed solely in Python for the TANSPEC instrument on 3.6-m DOT to help its users. The pipeline currently supports spectroscopic data reduction for slits of 0.5 and 1.0 arcsec widths for the XD-mode. It is made semi-automated with minimum human interaction for the assurance of quality data reduction. It starts with the generation of a log of observation file that summarizes all the information needed about images to run the pipeline. In the following steps, the standard spectroscopic reduction procedures were executed and the pipeline yields wavelength-calibrated spectra. Two configuration files that contain several user-defined parameters are used to get control over the pipeline as well as the spectrum reduction. The pipeline typically takes \(\sim \)7 min to provide wavelength-calibrated spectra of all orders simultaneously from a raw dataset when a Linux machine (Ubuntu 22.04.1 LTS installed), with a 1.60 GHz Intel Core i5 (10th Gen) processor with 8 Gb DDR4 RAM is in use. The pipeline was tested for different data sets over various nights and is performing as per our expectations. Thus, it has been released publicly on 18 March 2022.
Notes
References
Astropy Collaboration, Robitaille T. P., Tollerud E. J., et al. 2013, A &A, 558, A33
Astropy Collaboration, Price-Whelan A. M., Sipőcz B. M., et al. 2018, AJ, 156, 123
Craig M. W., Crawford S. M., Deil C., et al. 2015, ccdproc: CCD data reduction software ascl:1510.007
Cushing M. C., Vacca W. D., Rayner J. T. 2004, PASP, 116, 362
Harris C. R., Millman K. J., van der Walt S. J., et al. 2020, Nature, 585, 357
Horne K. 1986, PASP, 98, 609
Hunter J. D. 2007, Computing in Science & Engineering, 9, 90
McCully C., Crawford S., Kovacs G., et al. 2018, Astropy/Astroscrappy: V1.0.5 Zenodo Release https://doi.org/10.5281/zenodo.1482019
Ninan J. P., Ojha D. K., Ghosh S. K., et al. 2014, Journal of Astronomical Instrumentation, 3, 1450006
Sharma S., Ojha D. K., Ghosh A., et al. 2022, PASP, 134, 085002
van der Walt S., Schönberger J. L., Nunez-Iglesias J., et al. 2014, arXiv e-prints, arXiv:1407.6245
van Dokkum P. G. 2001, PASP, 113, 1420
Virtanen P., Gommers R., Oliphant T. E., et al. 2020, Nature Methods, 17, 261
Acknowledgements
This work is supported by the Tata Institute of Fundamental Research, Mumbai, under the Department of Atomic Energy, Government of India. SG, JPN and DKO acknowledge the support of the Department of Atomic Energy, Government of India, under project identification no. RTI 4002. We also thank all the members of the IR Astronomy group at TIFR for their support during observations. The authors would like to thank the staff at the 3.6-m DOT, Devasthal and ARIES, for their cooperation during the observation using TANSPEC. SG is thankful to Koshvendra Singh and Arpan Ghosh for running the code before its public release. We are very much thankful to the referee for their insightful comments, which helped us to improve the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
This article is part of the Special Issue on “Star formation studies in the context of NIR instruments on 3.6m DOT”.
Rights and permissions
About this article

Cite this article
Ghosh, S., Ninan, J.P., Ojha, D.K. et al. pyTANSPEC: A data reduction package for TANSPEC. J Astrophys Astron 44, 30 (2023). https://doi.org/10.1007/s12036-023-09926-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12036-023-09926-y