
Abstract
In air quality modeling, fine-scale daily mapping is generally calculated from dispersion models involving multiple parameters linked in particular to emissions, which require regular updating and a long computation time. The aim of this work is to provide a simpler model, easily adaptable to other regions and capable of estimating nitrogen dioxide concentrations to a good approximation. To this end, we examine the relationship between daily and annual nitrogen dioxide values. We find that this relationship depends on the range of daily values. Then we provide a statistical model capable of estimating daily concentrations over large areas on a fine spatial scale. The model’s performance is compared with standard geostatistical method such as external drift kriging with cross-validation over one year. The reduced computation time means that daily maps can be produced for use by French air quality observatories.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The French law on air quality and rational energy using, dated from December 30th, 1996, specifies that State has to assure, with the supports of local authorities and companies, air quality monitoring. In this way, France gives to AASQA (French Approved Association of Air Quality Monitoring), a survey and information mission about atmospheric pollution. These are the regional air quality observatories. There is an observatory for each region. Over Provence-Alpes-Côte d’Azur Region (PACA region), air quality monitoring network is managed by AtmoSud. It informs the public of any increase in pollution levels and provide data to activate prefectural information-recommendations and alert procedures for the population. To do this, AtmoSud develops modeling tools adapted to these missions.
AZUR is a modelling platform that creates daily high-resolution concentration maps for pollutants such as PM10, PM2.5 and NO2 over millions of grid cells in a reduced calculation CPU time compared with a deterministic model. It produces maps up to day + 2 at 25 m resolution, integrating measurements and forecasts. AZUR has been operating for 3 years at AtmoSud for daily forecasts and has been adapted for hourly forecast (available at www.atmosud.org). The AZUR platform is used for the monitoring missions entrusted to AtmoSud, as well as for studies requiring high-resolution data (Allouche et al. 2022).
Usually, to produce daily air quality maps, chemistry-transport models such as Chimere (Menut et al. 2021) are applied at regional and continental scales. These deterministic models simulate the temporal evolution of 3D concentration fields of gaseous or particulate species. They take into account the complete atmospheric cycle of each species, as well as the chemical transformation of pollutants along their transport path. These models are fed, among other things, by a cadaster of ground-level emissions. It is often difficult to use them with resolutions less than one kilometer. At finer scales, dispersion models such as ADMS (Carruthers et al. 1997, Seaton et al. 2022, Tognet 2015, Tognet 2016) or SIRANE (Soulhac et al. 2011) are used to produce daily maps. For large areas, they require significant computing resources and regular updates of emissions inventories. The AZUR platform uses a statistical approach that is less costly in terms of IT resources. The constraint on input data is lower, since the main data required is an annual map of concentrations of the pollutant studied, updated each year.
To operate, AZUR platform needs two types of data: the first is spatial information provided by maps of annual concentrations from ADMS-Urban model (Carruthers et al. 1997, Seaton et al. 2022, Tognet 2015, Tognet 2016) mixed with a geostatistical method (Malherbe and Cárdenas 2005, Lichternstern 2013). ADMS-Urban's ability to reproduce strong NO2 concentration gradients in the vicinity of major roads at resolutions of 25 m is a major advantage. The ADMS-Urban model is used in preference to a more complex CFD model or those using a Street-in-Grid approach, due to the computational time and machine resources available relative to domain size and grid resolution (Kadaverugu et al. 2019; Silveira et al. 2019; Lugon et al. 2020). The second is the temporal variation provided by punctual measurements or forecast simulated by the Eurlerian Chemistry Transport model CHIMERE (Menut et al. 2021).
This work concerns the spatial part of the modeling platform and focuses on the pollutant NO2 over the whole PACA region. In the first part of the paper, we study the relationships between daily and annual values. Based on these results, we propose a spatial statistical model able of estimating daily concentrations from annual values. In a second section, we demonstrate that the AZUR model is an exact interpolator. In the third part, we compare its estimation quality with a standard kriging method.
Annual maps
Every year, AtmoSud produces annual high-resolution maps, providing an overview of air pollution concentrations across the region at a final resolution of 25 m. They concern the regulatory pollutants nitrogen dioxide (NO2) and fine particles (PM10 and PM2.5). These maps are used to feed the AZUR day and AZUR hour air quality forecasting platforms.
Annual mapping is carried out using the ADMS Urban dispersion model developed by CERC [Cambridge Environmental Research Consultant] (Carruthers et al. 1997, Seaton et al. 2022, Tognet 2015, Tognet 2016). It reproduces the dispersion of pollutants emitted into the atmosphere by different types of sources (industrial, road, residential, etc.) as a function of meteorological conditions. Its Gaussian formulation is suited for studies conducted at fine spatial resolutions, allowing considerable freedom in the positioning of calculation points. It is then possible to distribute these points at greater or lesser distances from the emission sources, to reproduce as faithfully as possible, the variations in concentration in the areas of interest.
The raw ADMS output is then corrected by data assimilation. In order to correct annual spatial variations, we use a large number of temporary campaigns using passive tubes in addition to the 22 fixed stations in the network. The first step is to use a linear regression method, which eliminates the overall bias. A second step consists of kriging with external drift which corrects the mappings locally (Beauchamp et al. 2017 and Gressent et al. 2020).
Air quality data
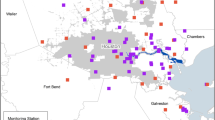
The air quality data produced by AtmoSud are free of charge and available online via our APIs. The NO2 measurement sites are spread throughout the PACA region of France (Fig. 1). They are unevenly distributed over the territory, with the south-west and the coast providing the most data.

Study area and location of traffic stations (red) and background stations (blue) measuring NO2 in the PACA region
Operated by AtmoSud, these stations have several devices measuring at least NO2 and PM10. Depending on their location, they characterise different influences (urban, traffic…). The measurements are transmitted in real-time every 15 min by the on-line measuring devices (NO2: chemiluminescence analyser, O3: photometric analyser and PM10: FIDAS and CPC).
In this study, we worked on all 22 nitrogen dioxide measurement stations in the PACA region. There are 6 stations under the influence of traffic and 16 rural, urban, and suburban background stations. A nitrogen dioxide measuring station is denoted \({s}_{i}\). Its annual average is \(y\left({s}_{i}\right)\). The daily value considered is the daily hourly maximum. It is seen as the \(p\) th percentile within the annual distribution of daily values and will be noted \({q}_{p}({s}_{i})\). Its rank, \(p\), is the proportion of daily values below the \(p\) th percentile. Throughout this article, "annual value" refers to the average annual concentration and "daily value" to the daily hourly maximum concentration.
The study area is based on a regular grid. For a grid point \({s}_{0}\), its annual value is noted \(y({s}_{0})\) and its daily value \({q}_{p}({s}_{0})\) also seen as the \(p\) th percentile in its annual distribution at grid point \({s}_{0}\).
Relationship between annual average and hourly maximum
In this section, we carry out an analysis of the concentration pairs observed at the measuring stations, for which we calculate the ratio of their daily and annual values respectively. On the basis of these results, we show that this relationship depends on the range of daily values considered. This range of values is represented by the rank of the daily measurements when they are considered as percentiles of their annual distribution. In this article, we work with deciles instead of percentiles, as this is sufficient to describe the method and fit the model. But in practice, any percentile can be considered.
Consider an annual history of daily values of nitrogen dioxide concentrations from a measuring station. For all the pairs of stations\({s}_{i}\).and \({s}_{{i}{\prime}}\) and for a fixed rank p (from 0 to 100 by 10), we calculate the ratio of their daily deciles \({q}_{p}\):
As well as the ratio of their annual average \(y\):
The Fig. 2 shows that for the daily deciles \({q}_{80}\) their ratios are lower than the ratios of the means, in fact the spline adjustment (grey curve) is below the bisector represented in dotted line. By calculating these ratios for several deciles, we can observe how these relationships vary (Fig. 3).

Relationship between the ratios of the annual means and the ratios of daily deciles of rank 80 over the years 2016–2017 (grey curve is a spline function fit)

Relationship between the ratios of annual averages and daily deciles for 6 deciles represented by their spline fit (over the years 2016–2017)
The representation of these relationships for different daily deciles (Fig. 3) shows that they evolve as follows:
-
For the deciles of low rank (q {10, 10, 30}) the daily ratios are higher than the annual ratios.
-
For the deciles of higher rank (q {50, 70, 100}) the daily ratios are lower than the annual ratios.
Consider a pair of stations with an annual ratio of 4 (Fig. 3). On days when NO2 levels in the air are high, the daily ratio is equal to 2.5 (q 100 curve). On days when NO2 levels are low, the daily ratio is equal to 6.5 (q 10 curve). It can be seen that as NO2 levels increase, the daily ratios decrease. For two measuring stations, the ratio of their daily deciles, therefore, depends on the ratio of their annual averages as well as the rank p. The following relationship can be written:
We suggest a polynomial of degree n for this function \(f\). Equation (1) then becomes:
With \({\beta }_{j,k}\) coefficients and \(p\in \left[\mathrm{0,100}\right]\).
Fitting model
In Eq. (2), the \({\beta }_{j,k}\) coefficients are calculated from all the pairs \({s}_{i}\) and \({s}_{{i}{\prime}}\) formed by all the stations in the domain. All the pairs thus formed for the 10 deciles considered constitute a sample of 6250 data over a 2-year period (2016 and 2017). Annual values and ranks are calculated over the same years. A training sample representing two-thirds of the data is used to fit the model, while the rest of the data is used to calculate the model's performance: correlation, mean error, standard deviation of error and RMSE (roots mean square error). The estimated coefficients are presented in Table 1. For each term of the polynomial, Table 1 gives the degrees j and k, the estimated coefficients, the standard deviation and the result of Student test.
The Fig. 4 shows estimates of deciles ratios on the test sample. The correlation is 0.93, the mean error—0.001, the standard deviation of error 0.246, and the rmse 0.246. We note that the largest errors are obtained for the lowest ranks and that the mean bias is close to zero for each of the value ranges. We now move on to the estimating of deciles. Equation (2) becomes:

a) Estimation of the daily ratio on the test sample of 2083 observations b) distribution of errors according to the ranges of value. Error is computed by subtracting the observed value from the estimated value
The estimate of the pth decile of station \({s}_{{i}{\prime}}\) is obtained by multiplying the value of the polynomial by the pth decile of station \({s}_{i}\). These results are shown in Fig. 5, where the mean bias per range of values is also close to zero (mean error -0.77, correlation 0.95, standard deviation of error 8.63, rmse 8.66).

a) Estimation of daily NO2 deciles in µg/m3 on the test sample of 2083 observations b) distribution of errors according to value ranges. Error is computed by subtracting the observed value from the estimated value
The degree of the polynomial is set to 3 to reduce the CPU time of the AZUR modeling platform. We compared the difference between using the polynomial of degree 3 and 4. The results are shown in Table 2. The RMSE is 8.66 with the polynomial of degree 3 and 8.54 with the polynomial of degree 4. Increasing the polynomial degree from 3 to 4 does not imply a sufficient gain compared to the increase in CPU time.
Using the model
Let \({s}_{0}\) be a point of the grid. We have an estimate of its annual value \(y({s}_{0})\). The daily value at point \({s}_{0}\) is the unknown to be determined. We note \({\widehat{q}}_{{s}_{i}}\left({s}_{0}\right)\) the estimate of this value made from the station \({s}_{i}\). Equation (3) then becomes:
Thus, for a given grid point \({s}_{0}\), each station \({s}_{i}\) produces an estimate \({\widehat{q}}_{{s}_{i}}\left({s}_{0}\right)\). The rank \(p\) is determined by the concentration measured at station \({s}_{i}\), based on the distribution of its own daily values over previous year. To use Eq. (4), it is necessary to make an assumption about the ranks of the daily values at grid points. An estimate \({\widehat{q}}_{{s}_{i}}\left({s}_{0}\right)\) at grid point \({s}_{0}\) corresponding to the percentile with the same rank as that of the measurement at station \({s}_{{\text{i}}}\). This implies that the concentration at the station and the unknown concentration at the grid point must have the same rank in their own distribution.
This assumption is assumed to be true for the grid points close to the measurement stations. For the other points, we assume that their rank depends on the distance from the surrounding stations (see section discussion). To take these two cases into account, we propose a global estimate at \({s}_{0}\), denoted \(\widehat{z}\left({s}_{0}\right)\), given by Eq. (5), calculated with the inverse distance-weighted average of the estimates \({\widehat{q}}_{{s}_{i}}\left({s}_{0}\right)\).
With:
-
\({E}_{{s}_{0}}\): all stations in the whole domain,
-
\({\lambda }_{i}\): weights depending on the distance of \({s}_{i}\) to \({s}_{0}\)
The weights \({\lambda }_{i}\) are calculated from the inverse square distance between the stations \({s}_{i}\) to the grid point \({s}_{0}\).
Model property
The model has the characteristic of an interpolator passing through the measurement points. To verify this, an estimate is made for each measuring station, at the station itself. With \({s}_{i}\). = \({s}_{0}\), the ratio of annual values being equal to 1, Eq. (4) becomes:
The model is then applied to all deciles, i.e. \(p\in \left[\mathrm{0,100}\right]\) with a step size of 10. The estimated daily values produce errors of less than ± 1 µg/m3 for deciles above q30. For the lower deciles, the average error is 2 µg/m3 and can be as high as 5 µg/m3 (Fig. 6). The largest errors are reached in the lowest deciles (Fig. 6b) and for daily values estimated between 30 µg/m3 and 60 µg/m3 (Fig. 6a). Error is computed by subtracting the observed value from the estimated value, which means that for the lowest deciles, the model overestimates.

a) Auto-estimation of daily NO2 deciles in µg/m3 on the mesurement station points b) distribution of the errors according to the value ranges. Error is computed by subtracting the observed value from the estimated value
Results
In order to assess the performance of the model for NO2, we calculate cross-validation estimates for the 22 measurement stations over the year 2019. To ensure the independence of the test data from the estimated parameters used by the model, the annual values used correspond to the year 2018, and the ranks are calculated from the distribution of daily values from 2016 to 2017 inclusive.
To compare the results obtained with the suggested method, we perform a kriging with external drift using the annual mean (Beauchamp et al. 2017, Gressent et al. 2020, Lichternstern 2013), in global neighbourhood on the same set of stations. The daily variogram is automatically adjusted with a zero-nugget effect. In both methods, the background and traffic stations are used in the same computation.
Table 3 presents the results of the leave-one-out-cross-validation by group of stations, on the one hand the 16 background sites, and on the other the 6 sites under the influence of road traffic. For the background sites, the suggested method has an advantage of 4.8% with an RMSE of 15.0 compared with 15.8 for the kriging method. The correlation coefficient is 0.81 for AZUR method and 0.79 for kriging method.
For the sites under the influence of road traffic, the RMSE is 9.9% better for kriging method with 17.4 compared with 19.1 for AZUR method. The correlation coefficients are close with 0.78 for Azur method and 0.79 for kriging method. The mean error indicates minor differences from the annual values measured.
Background and traffic stations do not have the same range of values. We have therefore calculated the relative error given by the NRMSE (Table 3). The relative error gives the advantage to the traffic station for both methods. This is due to the presence of a background station close to each traffic station. All cities with traffic stations also have a background site.
An example of the visual outputs for the whole region and a zoom on an urban area is shown in Fig. 7 and Fig. 8. With AZUR method, 100 000 000 grid cells are computed for the map below over the whole PACA region (25 m of resolution). 7 min are necessary with 1 CPU (Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10 GHz, 8 cores) with RAM 128 Go.

Example of daily NO2 concentrations computed with AZUR method on 28 February 2019 for the PACA region

Example of daily NO2 concentrations computed with AZUR method on 28 February 2019 zoomed in on the city of Marseille
Discussion
Aera of representativeness
Using the AZUR model imply that the closer a grid point is to a station, the closer its daily rank is to the daily rank of the station. This is reflected in Eq. (5) by a greater weight of the station for the daily estimate at the grid point. This raises the question of the representativeness of the ranks in the neighbourhood of the stations. To study this representativeness, we carried out a variogram analysis of NO2 ranks (Beauchamp et al. 2010, Beauchamp et al. 2018, Kracht and Gerboles 2019). We study the range of the variogram, the distance beyond which measuring stations no longer have any influence on their surroundings. To do this, we calculate the daily variogram of ranks for background sites only, for each day of 2019 (Table 4). The range of the variogram varies from day to day, with a median over 2019 of 16 km. In 90% of cases, the range is greater than 6 km. Most of the time, the cities lie within the zone of representativeness of their measuring station.
Some grid points are most of the time outside the area of representativeness of any station. In this case, several stations have a significant weight in the inverse distance-weighted average given by Eq. (5). To illustrate the quality of the estimation of these grid points, we present the cross-validation results for the most isolated background site in the region, called Manosque, located 45 km from the nearest station (Table 5). The NRMSE is 0.39. It is downgraded by 22% compared to the AZUR NRMSE of all background stations.
Influence of traffic sites
Taking traffic sites into account when calculating the variogram of daily ranks reduces the median range to 8 km (Table 4). This is probably due to the sensitivity of this type of site to variations in road emissions, which implies a reduced area of representativeness for traffic sites (Malherbe and Cárdenas 2005, Minet et al. 2018). To show the sensitivity of the method to the inclusion of traffic sites, we studied the scores for cities with a background site only and cities with a traffic site and a background site (Table 5). The average NRMSE for cities with a traffic site is 0.3, while cities with background sites only is 0.33. There is therefore no significant difference between the two sets of cities as regards the NRMSE for background stations. This score seems even improved where a traffic station is present.
Conclusion
In a first analysis, we showed that daily concentrations between two measurement sites depend not only on the ratio of their annual value but are also linked by their rank in their respective distribution. A variographic analysis enabled us to show that this rank has a spatial correlation over several kilometers around the measurement sites. It makes this approach relevant for spatial estimation.
We therefore proposed a statistical method for high-resolution mapping of ambient air quality over a large area. It constructs daily maps for NO2 from an annual map and a network of measuring stations. The advantage of this method is that it does not consume much CPU time and uses little input data compared to classic dispersion models. Moreover, this estimation method has the property of being an exact interpolator. It allows the calculated map to remain faithful to the measurements used to construct it.
The proposed method was compared to a kriging method with external drift. For background sites, the results are similar. Even if there are differences on traffic stations in terms of standard deviation error, correlations are close. The mean error shows minor differences from annual values measured. AZUR approach compares well to kriging which is a widely used and proven approach.
AZUR was adapted by AtmoSud for forecast mapping. The forecast mode is used by replacing the daily value measured at the stations with the forecast value. The rank is then calculated based on this predicted value in the distribution of measured daily values. AZUR has also been developed for PM10 and PM25. In this case, the daily value to be spatialized is the daily mean. The comparison with external drift kriging was carried out. The results show that the models are suitable to these pollutants.
The definition of the representative zones for measurement stations is currently being improved. This work is carried out by deploying low-cost sensors in large numbers and thus studying their correlation with the stations already in place (Schneider et al. 2017; Gressent et al. 2020). In addition, a tool for detecting outliers has been put in place in order to modulate the representativeness zones of the stations on a day-to-day basis according to measurements from neighbouring stations.
This method has been transposed to the Corsica and Hauts-de-France regions (https://ressources.atmo-hdf.fr/mod_jour/polluants/NO2.html). It is easily transposable for observatories that don’t have high-resolution and operational daily mapping tools.
Data availability
Data will be available on reasonable request. Digital data require considerable disk space and cannot be stored on a simple numerical folder.
References
Allouche J, Cremoni M, Brglez V, Graca D, Benzaken S, Zorzi K, Fernandez C, Esnault V, Levraut M, Oppo S, Jacquinot M, Armengaud A, Pradier C, Bailly L, Seitz-Polski B (2022) Air pollution exposure induces a decrease in type II interferon response: A paired cohort study.https://doi.org/10.1016/j.ebiom.2022.104291
Beauchamp M, Malherbe L, de Fouquet Ch, Létinois L (2018) A necessary distinction between spatial representativeness of an air quality monitoring station and the delimitation of exceedance areas. Environ Monit Assess. https://doi.org/10.1007/s10661-018-6788-y
Beauchamp M, Malherbe L, Létinois L (2010) Application de méthodes géostatistiques pour la détermination de zones de représentativité en concentration et la cartographie des dépassements de seuils. Rapport LCSQA. https://www.lcsqa.org/fr/rapport/2010/ineris/application-methodes-geostatistiques-determination-zones-representativite-concen
Beauchamp M, de Fouquet C, Malherbe L (2017) Dealing with non-stationarity through explanatory variables in kriging-based air quality maps. https://doi.org/10.1016/j.spasta.2017.08.003
Carruthers DJ, Edmunds HA, McHugh CA, Riches PJ, Singles RJ (1997) ADMS Urban – an integrated air quality modelling system for local government, Transactions on Ecology and the Environment, vol. ISSN 15:1743–3541
Gressent A, Malherbe L, Colette A, Rollin H, Scimiab R (2020) Data fusion for air quality mapping using low-cost sensor observations. Environ Int 143(October 2020):105965
Kadaverugu R, Sharma A, Matli C et al (2019) High Resolution Urban Air Quality Modeling by Coupling CFD and Mesoscale Models: a Review. Asia-Pacific J Atmos Sci 55:539–556. https://doi.org/10.1007/s13143-019-00110-3
Kracht O, Gerboles M (2019) Spatial representativeness evaluation of air quality monitoring sites by point-centred variography, pp 229–245. https://doi.org/10.1504/IJEP.2019.101843
Lichternstern A (2013) Kriging methods in spatial statistics, Bachelor’s Thesis, Technische Universität München, Department of Mathematics
Lugon L, Sartelet K, Youngseob K, Vigneron J, Chretien O (2020) Nonstationary modeling of NO2, NO and NOx in Paris using the Street-in-Grid model: coupling local and regional scales with a two-way dynamic approach. ACP 20:7717–7740. https://doi.org/10.5194/acp-20-7717-2020
Malherbe L, Cárdenas G (2005) Application des méthodes géostatistiques pour l’exploitation conjointe des mesures de fond et de proximité. Rapport LCSQA
Menut L, Bessagnet B, Briant R, Cholakian A, Couvidat F, Mailler S, Pennel R, Siour G, Tuccella P, Turquety S, Valari M (2021) The CHIMERE v2020r1 online chemistry-transport model. Geosci Model Dev 14:6781–6811
Minet L, Liu R, Valois M-F, Gehr R, Xu J, Wachenthal S (2018) Development and comparison of air pollution exposure surfaces derived from on-road mobile monitoring and short-term stationary sidewalk measurements. Environ Sci Technol 2018(52):3512–3519
Schneider P, Castell N, Vogt M, Dauge FR, Lahoz WA (2017) Mapping urban air quality in near real-time using observations from low cost sensors and model information. Environ Int 106(2017):234–247. https://doi.org/10.1016/j.envint.2017.05.005
Seaton M, O’Neill J, Bien B, Hood C, Jackson M, Jackson R, Johnson K, Oades M, Stidworthy A, Stocker J, Carruthers D (2022) A Multi-model Air Quality System for Health Research: Road model development and evaluation. Environ Model Softw. https://doi.org/10.1016/j.envsoft.2022.105455
Silveira C, Ferreira J, Miranda AI (2019) The challenges of air quality modelling when crossing multiple spatial scales. Air Qual Atmos Health 12:1003–1017. https://doi.org/10.1007/s11869-019-00733-5
Soulhac L, Salizzoni P, Cierco F-X, Perkins RJ (2011) The model SIRANE for atmospheric urban pollutant dispersion: PART I: presentation of the model. Atmos Environ 45(39):7379–7395
Tognet F (2015) Etude d’intercomparaison des modèles de qualité de l’air à l’échelle de la rue et à l’échelle urbaine. Note technique LCSA. https://www.lcsqa.org/fr/rapport/2015/ineris/etude-intercomparaison-modeles-qualite-air-echelle-rue-echelle-urbaine
Tognet F (2016) Etude comparative des modèles ADMS Urban et SIRANE sur un cas test. Laboratoire central de surveillance de la qualité de l'air. Retrieved December 5, 2018, from: https://www.lcsqa.org/system/files/lcsqa2015-intercomparaison_adms_sirane_drc-16-667152376-12019a_0.pdf
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Morgan Jacquinot, Romain Derain, Alexandre Armengaud, Sonia Oppo. The first draft of the manuscript was written by Morgan Jacquinot and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Declarations
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jacquinot, M., Derain, R., Armengaud, A. et al. Spatial model for daily air quality high resolution estimation. Air Qual Atmos Health (2024). https://doi.org/10.1007/s11869-024-01566-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11869-024-01566-7