
Abstract
The pathways that regulate energy homeostasis, the mechanisms of damage repair, and the signaling response to internal environmental changes or external signals have been shown to be critical in modulating lifespan of model organisms and humans. In order to investigate whether genetic variation of genes involved in these pathways contribute to longevity, a two-stage case–control study in two independent sets of long-lived individuals from Calabria (Italy) was performed. In stage 1, 317 SNPs in 104 genes were analyzed in 78 cases (median age 98 years) and 71 controls (median age 67 years). In stage 2, 31 candidate SNPs identified in stage 1 (π markers = 0.1) were analyzed in an independent sample composed by 288 cases (median age 92 years) and 554 controls (median age 67 years). Two SNPs, rs282070 located in intron 1 of the MAP3K7 gene, and rs2111699 located in intron 1 of the GSTZ1 gene, were significantly associated (after adjustment for multiple testing) with longevity in stage 2 (p = 1.1 × 10−3 and p = 1.4 × 10−3, respectively). Interestingly, both genes are implicated in the cellular response to internal and external environmental changes, playing a crucial role in the inflammation processes that accompany aging. Our data confirm that long-lived subjects are endowed with genetic variants that allow them to optimize these cellular responses and to better deal with environmental and internal stresses.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Over the past decades, developed societies have experienced a gradual increase in life expectancy which sharply increased the percentage of elderly people in the population and, at the same time, increased the number of subjects who are not autonomous and are affected by invalidating pathologies (Vaupel 2010). Since this has important implications, especially from a social point of view, there is at present a considerable interest in understanding how individuals achieve a long and healthy life.
Family-based studies demonstrated the existence of an important familial and genetic component of longevity. Indeed, parents, siblings, and offspring of long-lived subjects have a significant survival advantage and a higher probability to have been or to became long-lived (Gudmundsson et al. 2000; Kerber et al. 2001; Cournil and Kirkwood 2001; Perls et al. 2000, 2002; Schoenmaker et al. 2006; Willcox et al. 2006; Montesanto et al. 2011). Furthermore, the offspring of centenarians show a lower incidence of age-related diseases and a higher degree of physical functioning and autonomy, when compared to appropriately selected controls (Terry et al. 2003, 2004; Atzmon et al. 2006). Twin studies have found that approximately 25 % of the overall variation in human lifespan can be attributed to genetic factors (Herskind et al. 1996; Ljungquist et al. 1998; Skytthe et al. 2003), which becomes more relevant at advanced ages (Hjelmborg et al. 2006).
In the past years, there has been a surge of activity aimed at unraveling the effects of genetic variability on aging and lifespan. Specific mutations in single genes (age-1, daf2, sir2, methuselah, and p66) that extend or decrease lifespan in nematode worms (Caenorhabditis elegans), fruit flies (Drosophila), and mice have revealed evolutionary, often interconnected, conserved pathways for aging which are related to nutritional sensing, stress response signaling, and DNA repair/maintenance (Kenyon 2010; Fontana et al. 2010). The insulin/insulin-like growth factor-I (IGF-1) signaling pathway and downstream effectors such as the forkhead box O group (FoxO) family, the sirtuin family, the target of rapamycin (TOR) kinase, are perhaps the best studied pathways involved in aging and longevity.
Research in human longevity mainly focused on the orthologues of such candidate loci. Studies of centenarians or long-lived subjects have been successful in identifying specific genes and genotypes that influence human lifespan (for reviews see Christensen et al. 2006; Bonafè and Olivieri 2009; Chung et al. 2010; Slagboom et al. 2011). Particular striking examples include GH/IGF-1/insulin signaling (GHR, IGF1R, and FOXO3A), antioxidant (SOD1, SOD2, PON1, and FOXO3A), and inflammatory (IL6, CETP, and Klotho) pathways, silencing genes (SIRT1 and SIRT3), and elements of lipid metabolism (APOE, APOB, ACE, and APOC3).
Most of gene-longevity association studies have so far focused on a single or a few candidate genes. However, given the complexity of the longevity trait, a single-locus approach may not be suitable, as each locus is likely to exert a small, if any, effect on the trait. Thus, approaches have been developed that take into account that complex traits can be caused by an intricate pattern of genetic variants, where the epistatic effects may be not negligible. Recent technological improvements in genotyping technology have made whole genome genotyping (>100,000 SNPs) more accessible. Indeed, genome-wide association studies (GWAS) are at present widely used to find genetic variants contributing to variation in human lifespan (Puca et al. 2001; Lunetta et al. 2007; Newman et al. 2010; Walter et al. 2011; Deelen et al. 2011; Nebel et al. 2011; Malovini et al. 2011). Along with GWAS, studies that consider candidate biochemical pathways consisting of many biologically related genes, and a minimal number of “tagging” SNPs that efficiently capture all the common genetic variation in the assayed genomic region, are also being routinely used (Passarino et al. 2006; Nebel et al. 2009; Pawlikowska et al. 2009; Flachsbart et al. 2010).
Here, for testing the association of a number of polymorphic genes with longevity, we used a two-stage design, an approach that has proven to be useful for the identification of a number of genetic variants associated with pathological phenotypes such as cancer, Crohn’s disease, and migraine (Milne et al. 2006; Beckly et al. 2008; Corominas et al. 2009). We analyzed 317 SNPs in 104 selected genes involved in longevity pathways (DNA repair, apoptosis and cell cycles regulation, metabolism of xenobiotics, insulin/IGF-1, and neuromodulation). A first sample (stage 1) was used to test all selected SNPs, and only those showing some hint of association were subsequently retested in a second sample (stage 2), thus reducing the number of association tests (Zuo et al. 2006; Satagopan and Elston 2003; Satagopan et al. 2004; Thomas et al. 2004; Skol et al. 2007; Zheng et al. 2008).
Materials and methods
Study population
Stage 1 sample was recruited between 1994 and 1997 in Calabria (southern Italy) and included 149 unrelated subjects of which 78 were considered as cases (≥90 years; median age, 98 years; 36 males and 42 females) and 71 as controls (<90 years; median age, 67 years; 39 males and 32 females). Stage 2 sample was recruited subsequently between 2005 and 2008, also in Calabria, and included 842 unrelated subjects of which 288 are cases (≥90 years; median age, 92 years; 125 males and 163 females) and 554 are controls (<90 years; median age, 67 years; 277 males and 277 females). Study participants, their parents, and grandparents were all born in Calabria, as ascertained from population registers.
Younger subjects were contacted through general physicians. Subjects older than 90 years were identified by screening of population registers in different municipalities distributed across the entire Calabria region. Subjects who were eligible for the study were contacted and invited to participate in the study. A written informed consent was obtained from all participants before enrolling in the study. The healthy status was ascertained by medical visit carried out by a geriatrician who also administered a structured questionnaire validated within European recruitment projects (available at the following web site: http://biologia.unical.it/echa/results.htm). The questionnaire was aimed to the collection of sociodemographic information, evaluation of physical and cognitive status, medications, and information on common diseases that occurred in the past. Subjects with dementia and/or neurologic disorders were not included. At the time of the visit, peripheral venous blood samples were also obtained. White blood cells from blood buffy coats were used as source of DNA.
Candidate genes and SNP selection
Candidate genes were chosen from genetic pathways related to DNA repair, apoptosis and cell cycle regulation, metabolism of xenobiotics, insulin/IGF-1, and neuromodulation. The selection was based on their biological relevance and on published reports indicating their involvement in aging and longevity in either model organisms or humans. Using keywords as “aging AND longevity”, “human aging”, “human longevity”, “aging AND model organism”, a range of online databases were employed including Pubmed (http://www.ncbi.nlm.nih.gov/pubmed/) and GenAge (http://genomics.senescence.info/genes)/. Additionally, pathway analysis tools, such as “Biocarta” (http://cgap.nci.nih.gov/Pathways/BioCarta_Pathways) and “Kegg” (http://www.genome.jp/kegg/) were used for identification of pathway-specific genes.
The chromosomal region encompassing the candidate genes were identified through the databases http://www.ncbi.nlm.nih.gov/ (gene and mapview) and http://www.ensembl.org/index.html. The gene region was defined as the region from up to 5 kbp upstream of the transcription start site to up to 5 kbp downstream of the transcription stop site, allowing no overlap with the neighboring genes. In the choice of candidate SNPs, we used different online databases (eg., http://www.ncbi.nlm.nih.gov/projects/SNP; http://www.ensembl.org/index.html; and http://www.hapmap.org/cgi-perl/gbrowse/hapmap).
SNPs selection was based on the following criteria: minor allele frequency (MAF) >10 % in Caucasians, coding SNPs and SNPs having potential functional impact (non-synonymous SNPs, SNPs located in potential regulatory region), and SNPs previously identified in relevant association studies. Tagging SNPs were selected with the use of the Tagger program within Haploview (http://www.broad.mit.edu/mpg/haploview/; http://www.broad.mit.edu/mpg/tagger/; de Bakker et al. 2005), using pair wise tagging with a minimum r 2 of 0.8.
In total we identified 317 SNPs in 104 genes which are involved in the above-mentioned pathways. The complete list of genes, SNPs, and other relevant information is provided in Supplementary Table S1.
Genotyping
Genotyping of the samples in stage 1 was carried out using a microarray technique based on the arrayed primer extension (Kurg et al. 2000). Genotyping of samples in stage 2 was carried out using an allele-specific PCR-based KASPar SNP genotyping system (KBiosciences, Hoddesdon, UK) (Cuppen 2007). Genotyping quality control procedures consisted of inclusion of duplicates and inclusion of both positive and negative (water blanks) controls in each assay reaction.
Quality control
After genotype calling, in order to check errors at genotypic level, the datasets were subjected to a battery of quality control (QC) tests. In particular, SNPs were excluded if they had (1) a significant deviation from Hardy–Weinberg equilibrium (HWE, p < 0.001) in the control group; (2) a Missing Frequency (MiF) higher than 20 %; and (3) a frequency of rare allele (MAF) <1 %.
Statistical analyses
Single SNP analysis
In both stages, the chi-square test was used to assess the association between the variability of the analyzed polymorphisms and human longevity. Before to apply the test, each genotypic variable was first coded with respect to dominant, recessive, and heterozygote disadvantage/advantage model. For each of these models, the corresponding chi-square value was then obtained. The maximum of these three chi-square values \( \left( {{\chi^{{2}}}_{\text{MAX}}} \right) \) was used as a measure of association between the polymorphism and the analyzed phenotype:
where\( {{\chi }^{2}}_{{{\text{DOM}}}},{{\chi }^{2}}_{{{\text{REC}}}} \) and \( {{\chi }^{2}}_{{{\text{HET}}}} \) represent the three chi-square statistics assuming a dominant, recessive and an heterozygote disadvantage/advantage model of inheritance of the analyzed polymorphism. The p value of the proposed test statistics was obtained by the Monte-Carlo procedure described in Ziegler and König (2010). The procedure of ranking the SNPs not according to a single p value but to the minimum of different test statistics allows to obtain more robust results, as reported in Zheng et al. (2007).
In the present study, the \( {\chi^{{2}}}_{\text{MAX}} \) test (maximum of three different chi-square tests) was used to assess the associations between the selected markers (M = 317) and the analyzed phenotype. In the stage 1 the \( {\chi^{{2}}}_{\text{MAX}} \) values were ranked, and a proportion π markers equal to 0.1 (top 10 %) of the initial set of SNPs corresponding approximately to a p value <0.15 was selected for stage 2 analysis. By following the standard strategy to consider the stage 2 data as a replication study, the same test was used to assess the association between the selected polymorphism and longevity, adopting the Bonferroni-corrected significance level α/(π markers·M).
Interaction analysis
In order to capture second-order SNP–SNP interactions, we used the model-based multifactor dimensionality reduction (MB-MDR) method recently developed by Calle et al. (2010). It is an extension of the popular multifactor dimensionality reduction (MDR) method in which risk categories are defined using a regression model that also allows adjustments for main effects and covariates. By this approach, first, logistic regressions analyses are performed to define the nine possible genotypic combinations as high (H), low (L), or no risk (0). Then, these multilocus genotypes of the same risk category are merged and two Wald statistics (WH and WL, one for each risk) with the relevant p values (PH and PL) are obtained. The significance for the epistatic effect is based on the minimum between PH and PL (MIN.P). Finally, the significance of a specified model is assessed through a permutation test on the maximum Wald statistic, implemented in the function mbmdr.PermTest of MB-MDR package.
In the present study we applied the MB-MDR algorithm to the stage 2 dataset. The permutation procedure (10,000 permutations) was applied to the interaction models with a MIN.P < 0.05.
Results
Dataset stage 1
Initially, 317 SNPs from 104 candidate genes (see Supplementary Table S1) were genotyped in 78 cases and 71 controls. After the QC phase, the final number of analyzed polymorphisms in stage 1 was 235. In particular, 49 SNPs were excluded from the analysis because of a significant deviation from HWE. Thirty SNPs were excluded from the analysis because of a MiF value higher than 20 %. Finally, three SNPs were excluded on the basis of MAF criterion (<1 %). The cleaned dataset was then analyzed for association with longevity by using the \( {\chi^{{2}}}_{\text{MAX}} \) test.
Single-locus analysis
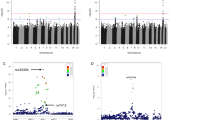
The plot reported in Fig. 1 displays the p values computed on the basis of the \( {\chi^{{2}}}_{\text{MAX}} \) test with respect to the analyzed polymorphisms. Supplementary Table S2 reports the list of the top-ranked SNPs (π markers = 0.1) obtained according to the association results and corresponding approximately to a p value <0.15.

Plot of the stage 1 association results using the \( {\chi^{{2}}}_{\text{MAX}} \) test (maximum of three different chi-square tests). Red line represents the p value corresponding approximately to the π markers value (0.1) for the definition of the top-ranked SNPs (p < 0.15)
Dataset stage 2
The 31 selected SNPs were genotyped in the additional 288 cases and 554 controls in the subsequent stage 2. Two SNPs were excluded from the following association analysis because of a MiF value higher than 20 %. The cleaned dataset was then analyzed for association with longevity by using the \( {\chi^{{2}}}_{\text{MAX}} \) test. Table 1 reports the SNPs which we found to have a significant effect on the phenotype in the \( {\chi^{{2}}}_{\text{MAX}} \) test with the most likely best model. The complete list of the results obtained for the 29 SNPs of stage 2 is reported in Supplementary Table S3. After the Bonferroni’s correction (p value threshold <0.05/29), two of the observed associations remained statistically significant: rs282070 (p value equal to 1.1 × 10−3) and rs2111699 (p value equal to 1.4 × 10−3). In particular, for the SNP rs282070, located in MAP3K7 gene, the subjects carrying the C allele showed an increased chance to attain longevity; for the SNP rs2111699 located in GSTZ1 gene, the subjects carrying two copies of the G allele showed an increased chance to survive at very old age.
Interaction analysis
Supplementary Table S4 reports the significant second-order interactions results (p < 0.05) in the stage 2 dataset from the MB-MDR analysis. In this table for each interaction model, a permutation testing was performed for each of the top-ranked models (MIN.P < 0.05) by permuting the outcome variable calling the mbmdr.PermTest function of the mbmdr package (10,000 permutations). By this approach, we found that all these interactions resulted to be significant (p ≤ 0.05). However, after a Bonferroni’s correction for multiple testing no significant differences remained.
Discussion
In the present study, we investigated possible associations between longevity and 317 SNPs in 104 candidate genes involved in the regulation of aging-related biological pathways by using a two-stage approach. To improve the efficiency of this study design, we used a robust test that is powerful when the underlying genetic model is unknown and that was successfully applied to genome-wide association studies (Zheng et al. 2007; Sladek et al. 2007). We found that two SNPs, rs282070 on intron 1 of MAP3K7 gene and rs2111699 on intron 1 of GSTZ1 gene, were significantly associated with survival at advanced age after Bonferroni’s correction.
MAP3K7 (also known as transforming growth factor-β activated kinase-1) is a serine/threonine kinase, member of the mitogen-activated protein kinase kinase kinase family, which plays a crucial role in interleukin 1, tumor necrosis factor, and Toll-like receptor signaling pathways. Various stressors and inflammatory cytokines trigger the activation of MAP3K7 which in turn activates key intracellular kinases such as the p38 MAPK, c-jun N-terminal kinase, and I-kappa B kinase complex. These pathways ultimately activate transcription factors nuclear factor-kappa B and activator protein-1 which are critical regulators of genes of the immune-inflammatory responses (Ninomiya-Tsuji et al. 1999; Sato et al. 2005; Chen et al. 2006; Landström 2010). Studies have also demonstrated that the oxidative stress caused by reactive oxygen species (ROS) may induce or mediate the activation of the MAPK pathways, including the one mediated by MAP3K (Son et al. 2011 for a review). In particular, Omori et al. (2008) reported that MAP3K7 regulates the levels of ROS and prevent inflammation. Thus, MAP3K7 may be considered as a crucial factor in the cascade of intracellular events initiated by environmental and/or physiological stressors that induce cells to survive or to die and therefore may be important for regulating aging. However, although several components of MAPK signaling pathways play important roles in the regulation of cellular senescence (Maruyama et al. 2009; Debacq-Chainiaux et al. 2010) and have been also implicated in the pathogenesis of many human diseases (Kim and Choi 2010), no data have been documented so far about the influence of MAP3K7 on human aging and longevity. The results of our study provide the first evidence of such an influence with the rs282070-C allele positively affecting longevity in a dominant manner.
Also GSTZ1 is implicated in the cellular response to environmental insults. GSTZ1 is a member of the glutathione S-transferase (GSTs) superfamily of multifunctional enzymes which are involved in the cellular detoxification, via conjugation with glutathione (GSH) of a wide range of endogenous and exogenous toxic compounds, and various reactive products generated under oxidative stress. Diverse cellular functions, ranging from apoptosis to cell survival, are also modulated by GSTs (Nebert and Vasiliou 2004; Hayes et al. 2005; Laborde 2010). The GSTs comprise three families of genes designed as cytosolic, mitochondrial, and microsomal transferase. The cytosolic GSTZ class of GSTs is expressed in many eukaryotic species, including fungi, plants, insects, and mammals (Board et al. 1997). Human GSTZ1, which is identical to maleylacetoacetate isomerase, catalyses two distinct reactions: the biotransformation of a range of α-haloacids, including dichloroacetic acid, a drinking water contaminant, and the GSH-dependent isomerization of maleylacetoacetate to fumarylacetoacetate, the penultimate step in the phenylalanine–tyrosine catabolic pathway (Board and Anders 2005; Board and Anders 2011). Analysis of Gstz1-knockout mice provided more insight about the physiological role of Gstz1. Besides a range of pathological changes, Gstz1 −/− mice display the induction of some of the cytosolic GST isoenzymes, and the constitutive expression of genes that are regulated by antioxidant-response elements (AREs) and that respond to oxidative stress via the Keap1/Nrf2 signaling pathway, which regulates the expression of numerous detoxifying and antioxidant genes (Lim et al. 2004; Lee and Johnson 2004). All of these findings support the view that the lack of GSTZ1 may induce oxidative stress (Blackburn et al. 2006). The antioxidant role of GSTs is well known and derives essentially from their ability to regulate the concentration of GSH, the most powerful cellular antioxidant, in different cellular compartments including mitochondria, the principal source and target of ROS. For instance, specific mitochondrial GST isoforms are able to protect mitochondria from oxidative insults either indirectly by maintaining appropriate levels of GSH or directly by reducing cellular peroxides and reactive aldehydes, such as 4-hydroxynonenal, generated from lipid peroxidation (Raza 2011). The recent discovery that GSTZ1 also localizes in mitochondria (Li et al. 2011) leads to assume that GSTZ1 may also contribute to the cellular redox status and then may be relevant to aging and longevity. Interestingly, Starr et al. (2008) showed that the GSTZ1 R42G variant affects both telomere length, a biomarker of stress and physical aging, and suggest that this may occur through oxidative stress. Moreover it has been shown that the GSTZ1-1002 G>A variant influences cognitive ability in the elderly, probably because of its effect on dopamine production and dopamine by-product disposal (Starr et al. 2008). In our study, the rs2111699 resulted to be significantly associated to the longevity phenotype. It seems to act in a recessive manner, with the rs2111699-G allele favoring survival at very old age. To our knowledge, this is the first study reporting an association between GSTZ1 genetic variability and human survival.
Overall, based on our data, it can be concluded that MAP3K7 and GSTZ1 are longevity genes whose variability actually affects the organism’s chances of reaching advanced age. As the rs282070 in MAP3K7 and the rs2111699 in GSTZ1 are intronic, their functional significance is unclear. It is possible that these SNPs are located in regions containing cis-regulatory elements essential for gene expression, and that the allelic variants differently affect the transcriptional rate, but linkage disequilibrium of these SNPs with other functional variants is also possible. This is an interesting issue that needs to be investigated in future research. Nevertheless, we believe that our results reinforce the view (synthesized in the oxidation inflammatory theory of aging, see De la Fuente and Miquel 2009) that the immune, inflammatory, and stress responses, which are essential components of the body’s network of defense against external and internal damaging agents, play an essential role in life span and in age-related phenotypes.
References
Atzmon G, Rincon M, Schechter CB, Shuldiner AR, Lipton RB, Bergman A, Barzilai N (2006) Lipoprotein genotype and conserved pathway for exceptional longevity in humans. PLoS Biol 4(4):e113
Beckly JB, Hancock L, Geremia A, Cummings JR, Morris A, Cooney R, Pathan S, Guo C, Jewell DP (2008) Two-stage candidate gene study of chromosome 3p demonstrates an association between nonsynonymous variants in the MST1R gene and Crohn’s disease. Inflamm Bowel Dis 14(4):500–507
Blackburn AC, Matthaei KI, Lim C, Taylor MC, Cappello JY, Hayes JD, Anders MW, Board PG (2006) Deficiency of glutathione transferase zeta causes oxidative stress and activation of antioxidant response pathways. Mol Pharmacol 69(2):650–657
Board PG, Anders MW (2005) Human glutathione transferase zeta. Methods Enzymol 401:61–77
Board PG, Anders MW (2011) Glutathione transferase zeta: discovery, polymorphic variants, catalysis, inactivation, and properties of Gstz1−/− mice. Drug Metab Rev 43(2):215–225
Board PG, Baker RT, Chelvanayagam G, Jermiin LS (1997) Zeta, a novel class of glutathione transferases in a range of species from plants to humans. Biochem J 328:929–935
Bonafè M, Olivieri F (2009) Genetic polymorphism in long-lived people: cues for the presence of an insulin/IGF-pathway-dependent network affecting human longevity. Mol Cell Endocrinol 299(1):118–123
Calle ML, Urrea V, Malats N, Van Steen K (2010) mbmdr: an R package for exploring gene–gene interactions associated with binary or quantitative traits. Bioinformatics 26(17):2198–2199
Chen ZJ, Bhoj V, Seth RB (2006) Ubiquitin, TAK1 and IKK: is there a connection? Cell Death Differ 13:687–692
Christensen K, Johnson TE, Vaupel JW (2006) The quest for genetic determinants of human longevity: challenges and insights. Nat Rev Genet 7(6):436–448
Chung WH, Dao RL, Chen LK, Hung SI (2010) The role of genetic variants in human longevity. Ageing Res Rev 9(Suppl 1):S67–S78
Corominas R, Ribases M, Camiña M, Cuenca-León E, Pardo J, Boronat S, Sobrido MJ, Cormand B, Macaya A (2009) Two-stage case–control association study of dopamine-related genes and migraine. BMC Med Genet 10:95
Cournil A, Kirkwood TB (2001) If you would live long, choose your parents well. Trends Genet 17(5):233–235
Cuppen E. Genotyping by allele-specific amplification (KASPar) (2007) CSH Protoc 2007:pdb.prot4841. doi: 10.1101/pdb.prot4841
de Bakker PI, Yelensky R, Pe’er I, Gabriel SB, Daly MJ, Altshuler D (2005) Efficiency and power in genetic association studies. Nat Genet 37:1217–1223
De la Fuente M, Miquel J (2009) An update of the oxidation-inflammation theory of aging: the involvement of the immune system in oxi-inflamm-aging. Curr Pharm Des 15(26):3003–3026
Debacq-Chainiaux F, Boilan E, Dedessus Le Moutier J, Weemaels G, Toussaint O (2010) p38(MAPK) in the senescence of human and murine fibroblasts. Adv Exp Med Biol 694:126–137
Deelen J, Beekman M, Uh HW, Helmer Q, Kuningas M, Christiansen L, Kremer D, van der Breggen R, Suchiman HE, Lakenberg N, van den Akker EB, Passtoors WM, Tiemeier H, van Heemst D, de Craen AJ, Rivadeneira F, de Geus EJ, Perola M, van der Ouderaa FJ, Gunn DA, Boomsma DI, Uitterlinden AG, Christensen K, van Duijn CM, Heijmans BT, Houwing-Duistermaat JJ, Westendorp RG, Slagboom PE (2011) Genome-wide association study identifies a single major locus contributing to survival into old age; the APOE locus revisited. Aging Cell 10(4):686–698
Flachsbart F, Franke A, Kleindorp R, Caliebe A, Blanché H, Schreiber S, Nebel A (2010) Investigation of genetic susceptibility factors for human longevity—a targeted nonsynonymous SNP study. Mutat Res 694(1–2):13–19
Fontana L, Partridge L, Longo VD (2010) Extending healthy life span—from yeast to humans. Science 328(5976):321–326
Gudmundsson H, Gudbjartsson DF, Frigge M, Gulcher JR, Stefansson K (2000) Inheritance of human longevity in Iceland. Eur J Hum Genet 8(10):743–749
Hayes JD, Flanagan JU, Jowsey IR (2005) Glutathione transferases. Annu Rev Pharmacol Toxicol 45:51–88
Herskind AM, McGue M, Holm NV, Sorensen TI, Harvald B, Vaupel JW (1996) The heritability of human longevity: a population based study of 2872 Danish twin pairs born 1870 ± 1900. Hum Genet 97:319–323
Hjelmborg VBJ, Iachine I, Skytthe A, Vaupel JW, McGue M, Koskenvuo M, Kaprio J, Pedersen NL, Christensen K (2006) Genetic influence on human lifespan and longevity. Hum Genet 119:312–321
Kenyon CJ (2010) The genetics of ageing. Nature 464(7288):504–512
Kerber RA, O’Brien E, Smith KR, Cawthon RM (2001) Familial excess longevity in Utah genealogies. J Gerontol A Biol Sci Med Sci 56(3):B130–B139
Kim EK, Choi EJ (2010) Pathological roles of MAPK signaling pathways in human diseases. Biochim Biophys Acta 1802(4):396–405
Kurg A, Tõnisson N, Georgiou I, Shumaker J, Tollett J, Metspalu A (2000) Arrayed primer extension: solid-phase four-color DNA resequencing and mutation detection technology. Genet Tes 4(1):1–7
Laborde E (2010) Glutathione transferases as mediators of signaling pathways involved in cell proliferation and cell death. Cell Death Differ 17:1373–1380
Landström M (2010) The TAK1–TRAF6 signalling pathway. Int J Biochem Cell Biol 42:585–589
Lee JM, Johnson JA (2004) An important role of Nrf2-ARE pathway in the cellular defense mechanism. J Biochem Mol Biol 37(2):139–143
Li W, James MO, McKenzie SC, Calcutt NA, Liu C, Stacpoole PW (2011) Mitochondrion as a novel site of dichloroacetate biotransformation by glutathione transferase zeta 1. J Pharmacol Exp Ther 336(1):87–94
Lim CE, Matthaei KI, Blackburn AC, Davis RP, Dahlstrom JE, Koina ME, Anders MW, Board PG (2004) Mice deficient in glutathione transferase zeta/maleylacetoacetate isomerase exhibit a range of pathological changes and elevated expression of alpha, mu and pi class glutathione transferases. Am J Pathol 165:679–693
Ljungquist B, Berg S, Lanke J, McClearn GE, Pedersen NL (1998) The effect of genetic factors for longevity: a comparison of identical and fraternal twins in the Swedish Twin Registry. J Gerontol A Biol Sci Med Sci 53(6):M441–M446
Lunetta KL, D’Agostino RB Sr, Karasik D, Benjamin EJ, Guo CY, Govindaraju R, Kiel DP, Kelly-Hayes M, Massaro JM, Pencina MJ, Seshadri S, Murabito JM (2007) Genetic correlates of longevity and selected age-related phenotypes: a genome-wide association study in the Framingham Study. BMC Med Genet 8(Suppl 1):S13
Malovini A, Illario M, Iaccarino G, Villa F, Ferrario A, Roncarati R, Anselmi CV, Novelli V, Cipolletta E, Leggiero E, Orro A, Rusciano MR, Milanesi L, Maione AS, Condorelli G, Bellazzi R, Puca AA (2011) Association study on long-living individuals from Southern Italy identifies rs10491334 in the CAMKIV gene that regulates survival. Proteins Rejuvenation Res 14(3):283–291
Maruyama J, Naguro I, Takeda K, Ichijo H (2009) Stress-activated MAP kinase cascades in cellular senescence. Curr Med Chem 16(10):1229–1235
Milne RL, Ribas G, González-Neira A, Fagerholm R, Salas A, González E, Dopazo J, Nevanlinna H, Robledo M, Benítez J (2006) ERCC4 associated with breast cancer risk: a two-stage case-control study using high-throughput genotyping. Cancer Res 66(19):9420–9427
Montesanto A, Latorre V, Giordano M, Martino C, Domma F, Passarino G (2011) The genetic component of human longevity: analysis of the survival advantage of parents and siblings of Italian nonagenarians. Eur J Hum Genet, In Press
Nebel A, Flachsbart F, Till A, Caliebe A, Blanché H, Arlt A, Häsler R, Jacobs G, Kleindorp R, Franke A, Shen B, Nikolaus S, Krawczak M, Rosenstiel P, Schreiber S (2009) A functional EXO1 promoter variant is associated with prolonged life expectancy in centenarians. Mech Ageing Dev 130(10):691–699
Nebel A, Kleindorp R, Caliebe A, Nothnagel M, Blanché H, Junge O, Wittig M, Ellinghaus D, Flachsbart F, Wichmann HE, Meitinger T, Nikolaus S, Franke A, Krawczak M, Lathrop M, Schreiber S (2011) A genome-wide association study confirms APOE as the major gene influencing survival in long-lived individuals. Mech Ageing Dev 132(6–7):324–330
Nebert DW, Vasiliou V (2004) Analysis of the glutathione S-transferase (GST) gene family. Hum Genomics 1:460–464
Newman AB, Walter S, Lunetta KL, Garcia ME, Slagboom PE, Christensen K, Arnold AM, Aspelund T, Aulchenko YS, Benjamin EJ, Christiansen L, D’Agostino RB Sr, Fitzpatrick AL, Franceschini N, Glazer NL, Gudnason V, Hofman A, Kaplan R, Karasik D, Kelly-Hayes M, Kiel DP, Launer LJ, Marciante KD, Massaro JM, Miljkovic I, Nalls MA, Hernandez D, Psaty BM, Rivadeneira F, Rotter J, Seshadri S, Smith AV, Taylor KD, Tiemeier H, Uh HW, Uitterlinden AG, Vaupel JW, Walston J, Westendorp RG, Harris TB, Lumley T, van Duijn CM, Murabito JM (2010) A meta-analysis of four genome-wide association studies of survival to age 90 years or older: the Cohorts for Heart and Aging Research in Genomic Epidemiology Consortium. J Gerontol A Biol Sci Med Sci 65(5):478–487
Ninomiya-Tsuji J, Kishimoto K, Hiyama A, Inoue J, Cao Z, Matsumoto K (1999) The kinase TAK1 can activate the NIK-IκB as well as the MAP kinase cascade in the IL-1 signalling pathway. Nature 398:252–256
Omori E, Morioka S, Matsumoto K, Ninomiya-Tsuji J (2008) TAK1 regulates reactive oxygen species and cell death in keratinocytes, which is essential for skin integrity. J Biol Chem 283(38):26161–26168
Passarino G, Montesanto A, Dato S, Giordano S, Domma F, Mari V, Feraco E, De Benedictis G (2006) Sex and age specificity of susceptibility genes modulating survival at old age. Hum Hered 62(4):213–220
Pawlikowska L, Hu D, Huntsman S, Sung A, Chu C, Chen J, Joyner AH, Schork NJ, Hsueh WC, Reiner AP, Psaty BM, Atzmon G, Barzilai N, Cummings SR, Browner WS, Kwok PY, Ziv E (2009) Association of common genetic variation in the insulin/IGF1 signaling pathway with human longevity. Aging Cell 8(4):460–472
Perls T, Shea-Drinkwater M, Bowen-Flynn J, Ridge SB, Kang S, Joyce E, Daly M, Brewster SJ, Kunkel L, Puca AA (2000) Exceptional familial clustering for extreme longevity in humans. J Am Geriatr Soc 48(11):1483–1485
Perls TT, Wilmoth J, Levenson R, Drinkwater M, Cohen M, Bogan H, Joyce E, Brewster S, Kunkel L, Puca A (2002) Lifelong sustained mortality advantage of siblings of centenarians. Proc Natl Acad Sci USA 99(12):8442–8447
Puca AA, Daly MJ, Brewster SJ, Matise TC, Barrett J, Shea-Drinkwater M, Kang S, Joyce E, Nicoli J, Benson E, Kunkel LM, Perls T (2001) A genome-wide scan for linkage to human exceptional longevity identifies a locus on chromosome 4. Proc Natl Acad Sci U S A 98(18):10505–10508
Raza H (2011) Dual localization of glutathione S-transferase in the cytosol and mitochondria: implications in oxidative stress, toxicity and disease. FEBS J 278(22):4243–4251. doi:10.1111/j.1742-4658.2011.08358.x
Satagopan JM, Elston RC (2003) Optimal two-stage genotyping in population based association studies. Genetic Epidemiol 25:149–157
Satagopan JM, Venkatraman ES, Begg CB (2004) Two-stage designs for gene disease association studies with sample size constraints. Biometrics 60:589–597
Sato S, Sanjo H, Takeda K, Ninomiya-Tsuji J, Yamamoto M, Kawai T, Matsumoto K, Takeuchi O, Akira S (2005) Essential function for the kinase TAK1 in innate and adaptive immune responses. Nat Immuno l6:1087–1095
Schoenmaker M, de Craen AJ, de Meijer PH, Beekman M, Blauw GJ, Slagboom PE, Westendorp RG (2006) Evidence of genetic enrichment for exceptional survival using a family approach: the Leiden longevity study. Eur J Hum Genet 14(1):79–84
Skol AD, Scott LJ, Abecasis GR, Boehnke M (2007) Optimal designs for two-stage genome-wide association studies. Genet Epidemiol 31:776–788
Skytthe A, Pedersen NL, Kaprio J, Stazi MA, Hjelmborg JV, Iachine I, Vaupel JW, Christensen K (2003) Longevity studies in GenomEUtwin. Twin Res 6(5):448–454
Sladek R, Rocheleau G, Rung J, Dina C, Shen L, Serre D, Boutin P, Vincent D, Belisle A, Hadjadj S, Balkau B, Heude B, Charpentier G, Hudson TJ, Montpetit A, Pshezhetsky AV, Prentki M, Posner BI, Balding DJ, Meyre D, Polychronakos C, Froguel P (2007) A genome-wide association study identifies novel risk loci for type 2 diabetes. Nature 445(7130):881–885
Slagboom PE, Beekman M, Passtoors WM, Deelen J, Vaarhorst AA, Boer JM, van den Akker EB, van Heemst D, de Craen AJ, Maier AB, Rozing M, Mooijaart SP, Heijmans BT, Westendorp RG (2011) Genomics of human longevity. Philos Trans R Soc Lond B Biol Sci 366(1561):35–42
Son Y, Cheong YK, Kim NH, Chung HT, Kang DG, Pae HO (2011) Mitogen-activated protein kinases and reactive oxygen species: how can ROS activate MAPK pathways? J Signal Transduct 2011:792639. doi:10.1155/2011/792639
Starr JM, Fox H, Harris SE, Deary IJ, Whalley LJ (2008) GSTz1 genotype and cognitive ability. Psychiatr Genet 18(4):211–212
Terry DF, Wilcox M, McCormick MA, Lawler E, Perls TT (2003) Cardiovascular advantages among the offspring of centenarians. J Gerontol A Biol Sci Med Sci 58(5):M425–M431
Terry DF, Wilcox MA, McCormick MA, Perls TT (2004) Cardiovascular disease delay in centenarian offspring. J Gerontol A Biol Sci Med Sci 59(4):385–389
Thomas D, Xie R, Gebregziabher M (2004) Two-stage sampling designs for gene association studies. Genet Epidemiol 27:401–414
Vaupel JW (2010) Biodemography of human ageing. Nature 464(7288):536–542
Walter S, Atzmon G, Demerath EW, Garcia ME, Kaplan RC, Kumari M, Lunetta KL, Milaneschi Y, Tanaka T, Tranah GJ, Völker U, Yu L, Arnold A, Benjamin EJ, Biffar R, Buchman AS, Boerwinkle E, Couper D, De Jager PL, Evans DA, Harris TB, Hoffmann W, Hofman A, Karasik D, Kiel DP, Kocher T, Kuningas M, Launer LJ, Lohman KK, Lutsey PL, Mackenbach J, Marciante K, Psaty BM, Reiman EM, Rotter JI, Seshadri S, Shardell MD, Smith AV, van Duijn C, Walston J, Zillikens MC, Bandinelli S, Baumeister SE, Bennett DA, Ferrucci L, Gudnason V, Kivimaki M, Liu Y, Murabito JM, Newman AB, Tiemeier H, Franceschini N (2011) A genome-wide association study of aging. Neurobiol Aging 32(11)):2109.e15–28
Willcox BJ, Willcox DC, He Q, Curb JD, Suzuki M (2006) Siblings of Okinawan centenarians share lifelong mortality advantages. J Gerontol A Biol Sci Med Sci 61(4):345–354
Zheng G, Joo J, Lin JP, Stylianou M, Waclawiw MA, Geller NL (2007) Robust ranks of true associations in genome-wide case–control association studies. BMC Proc 1(Suppl 1):S165
Zheng G, Meyer M, Li W, Yang Y (2008) Comparison of two-phase analyses for case–control genetic association studies. Stat Med 27:5054–5075
Ziegler A, König IR (2010) Front matter. In: Second Edn A statistical approach to genetic epidemiology: with access to E-learning platform by Friedrich Pahlke. Wiley, Weinheim. doi: 10.1002/9783527633654
Zuo YJ, Zou GH, Zhao HY (2006) Two-stage designs in case–control association analysis. Genetics 173:1747–1760
Acknowledgments
The research leading to these results has received funding from the European Union’s Seventh Framework Programme (FP7/2007-2011) under grant agreement no. 259679 and from “Fondi di Ateneo” of the University of Calabria.
Author information
Authors and Affiliations
Corresponding author
Additional information
Fausta Di Cianni and Daniele Campa, and Stefano Landi and Giuseppina Rose have equal contribution to the study.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Table S1
Loci and polymorphisms analyzed in stage 1 (DOC 729 kb)
Table S2
Top-ranked SNPs (π markers = 0.1) obtained according to \( {\chi^{{2}}}_{\text{MAX}} \) test in the stage 1 sample (DOC 104 kb)
Table S3
Association results of the 29 selected SNPs ranked on the basis of their estimated p values obtained according to \( {\chi^{{2}}}_{\text{MAX}} \) test in the stage 2 sample (DOC 88 kb)
Table S4
Interaction analysis results obtained using the Model-Based Multifactor Dimensionality Reduction approach proposed by Calle et al. (2010) (DOC 71 kb)
About this article
Cite this article
Di Cianni, F., Campa, D., Tallaro, F. et al. MAP3K7 and GSTZ1 are associated with human longevity: a two-stage case–control study using a multilocus genotyping. AGE 35, 1357–1366 (2013). https://doi.org/10.1007/s11357-012-9416-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11357-012-9416-8