
Abstract
Background
Human snores are caused by vibrating anatomical structures in the upper airway. The glottis is a highly variable structure and a critical organ regulating inhaled flows. However, the effects of the glottis motion on airflow and breathing sound are not well understood, while static glottises have been implemented in most previous in silico studies. The objective of this study is to develop a computational acoustic model of human airways with a dynamic glottis and quantify the effects of glottis motion and tidal breathing on airflow and sound generation.
Methods
Large eddy simulation and FW-H models were adopted to compute airflows and respiratory sounds in an image-based mouth-lung model. User-defined functions were developed that governed the glottis kinematics. Varying breathing scenarios (static vs. dynamic glottis; constant vs. sinusoidal inhalations) were simulated to understand the effects of glottis motion and inhalation pattern on sound generation. Pressure distributions were measured in airway casts with different glottal openings for model validation purpose.
Results
Significant flow fluctuations were predicted in the upper airways at peak inhalation rates or during glottal constriction. The inhalation speed through the glottis was the predominating factor in the sound generation while the transient effects were less important. For all frequencies considered (20–2500 Hz), the static glottis substantially underestimated the intensity of the generated sounds, which was most pronounced in the range of 100–500 Hz. Adopting an equivalent steady flow rather than a tidal breathing further underestimated the sound intensity. An increase of 25 dB in average was observed for the life condition (sine-dynamic) compared to the idealized condition (constant-rigid) for the broadband frequencies, with the largest increase of approximately 40 dB at the frequency around 250 Hz.
Conclusion
Results show that a severely narrowing glottis during inhalation, as well as flow fluctuations in the downstream trachea, can generate audible sound levels.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Population-based studies have shown that 60% of adult males are habitual snorers [1]. At least 5% of adults and 1% of children have obstructive sleep apnea (OSA) [2], and there is an increase of sleep disorder occurrence with age [3]. Sleep disorders such as snoring and OSA can have significant adverse health effects such as daytime drowsiness, decrease of cognitive function, hypertension, and in some cases cardiovascular morbidity [4]. New studies also associate snoring sounds with the development of carotid artery atherosclerosis [5], which reduces blood supply to the brain and causes strokes. Snore vibrations can transmit into the carotid artery, causing artery wall damage and atherosclerotic plaque development. Such damages can become worse when resonance happens, and the snore energy is amplified in the carotid lumen. Snoring-associated vibrations of the carotid artery have also been suggested as a cause of plaque rupture and ischemic stroke [6].
The high prevalence of breathing-related sleep disorders and their role in morbidities have stimulated in vivo and in vitro studies to identify their pathology, diagnosis, and treatment [1, 7,8,9,10,11,12,13,14,15,16,17]. However, their effective treatments are still elusive [18, 19]. It is generally acknowledged that irregular airflows or airway vibrations produce the snoring sound; however, to achieve the physiological level control and treatment of snoring symptoms, further investigation is required. There are many sites that can cause snoring or strides [20]. Soft palate, tongue base, and larynx, which have different anatomical and histological structures, cause distinct snore acoustic characteristics. Quinn et al. [21] observed different spectra between palatal and nonpalatal snoring, with the palatal snoring energy concentrating in low frequencies while the tongue-based snoring energy was distributing across high frequencies. The reported values of peak frequencies for palatal vs. nonpalatal snoring differ significantly in the literature: 69 vs. 117 [22], 391 vs. 1094 [9], and 420 vs. 650 [21]. Miyazaki et al. [23] inspected the correlation between the obstructive site and acoustic properties of snoring and reported the fundamental frequency as 103 Hz from the uvula, 250 Hz from the glottis, and 332 Hz from the tongue. Harper et al. [24] measured the sound spectra at different flow rates and reported a 30-dB increase in sound power from 30 to 120 L/min. Based on the analogy between sound-pressure-velocity and electric-voltage-current, Harper et al. [24] developed a dynamic acoustic model that include the turbulent sound source and glottal aperture variation with predefined acoustic point sources, but no attempt was made to accurately model the flow-generated sound sources.
Current clinical snore diagnosis still depends on procedures limited to specialized sleep laboratories, which are usually time-consuming and expensive. Also, it is difficult to wire the test subjects with sensors without disrupting their natural behaviors. Such challenges make the numerical method an ideal tool in studying snoring mechanisms. Compared to experimental investigations, computational fluid dynamics (CFD) and aeroacoustic analysis can provide details of airflow and sound spectrum that are spatially and temporally resolved. By visualizing 3D vortex structures or performing controlled parametric studies of influencing factors, new insights can be gained of the underlying mechanisms that correlate the airflow, airway anatomy and physiology, and snore sound acoustics.
Many numerical investigations have simulated airflows and sound generation in reconstructed respiratory tract reconstructed from medical images of patients with sleep and breathing disorders [25,26,27,28,29,30,31]. Using three patient-specific airway models of children, Xu et al. [20] demonstrated a close relationship between the airway constriction and pharyngeal pressure drop (Fig. 1). Similarly, Yu et al. [30] predicted sharp pressure drops in the flow-limiting regions that were consistent with the apnea-hypopnea index (AHI). Large eddy simulations (LESs) of laryngeal flows included Lin et al. [32] who observed significant effect of turbulent laryngeal jet on tracheal wall shear stress, Xi et al. [33] who emphasized the importance of accurate glottis geometry in predicting airflows in the conducting airways, and Mihaescu et al. [25] who demonstrated the superiority of large eddy simulation over Reynolds-averaged Navier-Stokes (RANS) methods using an image-based airway geometry representing severe OSA. Daily and Thomson [34] simulated the flow-induced vibration of a finite element vocal fold geometry using incompressible and slightly compressible flow models and showed that the compressible model is essential in capturing the acoustic coupling between fluid and solid domains. In a recent study, Xi et al. [31] simulated the flow-induced sounds in a constricted nasopharynx and showed that different anatomies generated unique spectrums with signature peak frequencies and energy distributions.

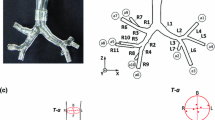
Airway model and outlet boundary conditions. a Upper respiratory airway model with a rhythmically narrowing glottis. The glottal area contraction ratio is 0.62. b There are 23 outlets retained in this study. The boundary conditions at the 23 outlets are specified following the in vitro measurement by Cohen et al. [42]
Even though previous studies improved our understanding of this low-speed vortex-dominated flow phenomenon, they were most limited to rigid-walled airway geometries. The potential influence of compliant walls or moving structures on snoring sounds, however, is unclear. In particular, the glottis, which is the space between the two vocal folds, is highly variable and acts as a critical mechanism in regulating inhaled airflows and sound production. In a series of empirical studies using excised canine larynx modes, Khosla et al. [35,36,37] found that intraglottal vortices could contribute to rapid closing of the glottis by generating negative pressures, which could have important impacts on sound generation. In healthy subjects, the glottis generally widens during inhalation to minimize the breathing work. But for those with laryngomalacia (soft larynx), the upper larynx may collapse inward during inhalation, causing airway constriction [38, 39]. The turbulent flow in and below the glottis can cause creaking breathing sounds (stridor). It is also noted that steady inhalations were often adopted to alleviate the excessive computational cost incurred by tidal breathings. Considering that sound generation is highly sensitive to the airway kinematics and airflows, it is important to quantitatively characterize the effects of airway motions, as well as the incurred flow fluctuations, on the resultant sound acoustics.
The objective of this numerical study is to quantitatively characterize the impacts of glottis motion and tidal breathing on airflows and respiratory sounds in an anatomically accurate mouth-lung model. Specific aims include (1) developing a computational aeroacoustic model of human snoring with a time-varying glottal aperture, (2) characterizing the effects of glottis motion and cyclic breathing on flow topologies, and (3) quantifying the aerodynamically generated sound acoustics under different respiration scenarios.
Methods
Study design
To evaluate the effects of dynamic glottal aperture and tidal breathing on airflow and sound generations, four breathing scenarios were examined, as shown in Fig. 2. The inhalation rate was specified to be either constant or following a sinusoidal profile. Similarly, the glottal aperture was specified to be either rigid (static) or changing its area in phase with the flow (dynamic). Four combinations of breathing scenarios were planned: (1) a constant flow rate and a rigid glottis (constant-rigid), which represents the simplest case in predicting sound generation; (2) a constant flow and a dynamic (expanding) glottis (constant-dynamic), which approximates the sound generation during quasi-steady inhalation but excludes the effects from flow development; (3) a sinusoidal flow and a rigid glottis (sine-rigid), which represents the in vivo condition in subjects with paralyzed glottis; and (4) a sinusoidal flow and a dynamic glottis (sine-dynamic), which represents the in vivo condition for most healthy subjects. By comparing cases 1 and 2 (or cases 3 and 4), the influence of glottis motion can be assessed. Similarly, by comparing cases 1 and 3 (or cases 2 and 4), we can quantify the impacts from flow unsteadiness. Furthermore, the differences between cases 1 and 4 can give us clues on how current computational practices underestimate the life situation, while the differences between cases 3 and 4 will shed lights on how patients with paralyzed glottis sound different from healthy subjects.

Study design. The inhalation rate was specified to be either constant or following a sinusoidal profile. Similarly, the glottal opening was specified to be either rigid (static) or contracting following a sinusoidal function (dynamic). Four breathing scenarios were studied. a A constant flow rate and a rigid glottis (constant-rigid). b A constant flow and a dynamic (expanding) glottis (constant-dynamic). c A sinusoidal flow and a rigid glottis (sine-rigid). d A sinusoidal flow and a dynamic glottis (sine-dynamic). The glottis motion and the transient breathing were controlled by user-defined modules
We first developed a mouth-lung geometry model with controllable glottal apertures. User-defined modules were written to control the glottis motion and transient breathing. We then validated the computational model by comparing predicted pressure distributions to in vitro measurements. The validated computational model was subsequently implemented to predict the airflow and vortex topologies, as well as the flow-induced sound acoustics, under the four breathing scenarios.
Materials and pressure measurement
Multi-sectional hollow mouth-lung casts with different glottal apertures were developed from the airway surface model using Magics (Materialize, Ann Arbor, MI). The cast models were subsequently built using an Stratasys Objet30 Pro 3D printer (Northville, MI), which had a fine layer resolution of 16 μm. Polypropylene (Veroclear, Northville, MI) was used as the printing material, which is transparent and rigid. Three larynx casts were built with different glottal apertures, with the glottis areas shown in Fig. 3a. There was a step-shaped groove at the ends of each section to ensure good sealing and easy assembly. The lung cast was put in a sealed chamber of 5 L and a Robinair 3 CFM vacuum (Warren, MI) was connected to the bottom of the chamber. The inhalation flow rate was controlled by a flow meter (Omega, Stamford, CT). A TSI 9565 VelociCalc ventilation meter (Shoreview, MN) was used to measure the pressures at different sites of the mouth-lung casts.

Experimental measurement of pressure in the upper airway with different glottal openings. a Glottal cross-sectional areas of three in vitro larynx casts. b Pressure distribution in the mouth-lung airway as a function of the axial distance from the mouth. Large pressure gradient occurs at the larynx and is most pronounced for the smallest glottal opening
Airway geometry, dynamic glottis model, and boundary conditions
The intricate respiratory geometrical details can significantly influence the shear layer and vortex coupling behavior, entailing highly accurate airway models for reliable aeroacoustic simulations. An anatomically accurate mouth-lung model that had been previously developed [40] was used in this study. This model geometry was a combination of two components: a mouth-throat model (Fig. 2a) and a tracheobronchial (TB) model that extended to G6 (Fig. 2b). The mouth-throat model geometry was developed from CT images of a 53-year-old healthy adult [41]. The TB geometry was reconstructed from CT scans of a hollow lung cast, which has originally been developed from a cadaver of 34-year-old male [42]. Totally, 44 bronchi and 23 outlets were kept in the TB model. Considering the airway complexity, unstructured elements were generated via ANSYS ICEM 10 (ANSYS, Inc.). To resolve the large gradients within the boundary layer, a body-fitted mesh was developed with fine prismatic cells near the wall.
The kinematics of the glottal aperture was adopted from the measurement by Scheinherr et al. [43, 44] using laryngofibroscopy. The glottis has a wedged shape. The anterior-posterior length is kept constant. The width of the glottis is assumed to vary following a sinusoidal profile, which narrows first and returns to its original state at the end of the inhalation. Such contracting glottal motions often occur in patients with laryngomalacia (soft larynx) during sleep [39, 45], which is opposite to the widening motion of the glottis of healthy awake subjects [43]. In this study, the narrowing ratio is 0.62, with the original area being 100 mm2 and the minimal area being 62 mm2, as displayed in Fig. 1a and Table 2. To ensure a smooth transition from the dynamic glottis to the upstream and downstream airway surfaces, a second sinusoidal function is used connecting the cross sections A and B and the glottis (Fig. 1a). It is noted that this study is not intended to simulate the snoring or phonation process associated with vibrating vocal folds, which has a high frequency of 100–1000 Hz [46, 47], but rather to study the effect of glottis kinematics on airflow and sound generation. It is believed that a narrowing glottis during aspiration, instead of a widening one, is the precursor of the glottal vibration (snoring) and glottal closure (apnea). Therefore, understanding the flow behaviors and induced sound generations can shed lights on the mechanisms of snoring and sleep apnea, about which a quantitative understanding is still lacking.
The inhalation velocity was specified to be either constant or following a sinusoidal profile with an equivalent inhalation flow rate of 15 L/min [48]. A blunt velocity profile was employed at the mouth inlet to account for the upstream conditions:
where u m is the mean velocity, R is the inlet radius, and r is the distance from the center. It is noted that tracheobronchial geometry herein was reconstructed from a cadaver-based lung cast developed by Cohen et al. [42]. Therefore, the outflow distributions among the 23 outlets that were experimentally measured by Cohen et al. [42] was followed in this study, which is listed in Table 1 with the outlet locations being signified in Fig. 1b.
Aeroacoustic model
Large eddy simulations were implemented to compute the transient airflow and vortex behaviors that induce sound generation. The wall-adapted local eddy-viscosity (WALE) model was selected to compute the subgrid-scale viscosity because of its capacity in simulating the transition between laminar and turbulent flow regimes [49]. The breathing sounds are computed using both the Broadband Noise Source model [50] and the Ffowcs Williams and Hawkings (FW-H) model [51]. Only steady turbulent flow solutions are required in the Broadband Noise Source model to predict the surface acoustic power level (SAPL), as follows [52]:
where P A is the acoustic power; l, u′, and a 0 are the turbulent length scale, turbulence velocity, and speed of sound, respectively; and α is a model constant. The SAPL was reported in dB, with the reference acoustic power P ref = 10−12 W/m2.
The FW-H model requires transient airflow solutions to predict the sound generation and propagation, as below [53].
In the equation above, f = 0 denotes the body surface and f > 0 denotes the exterior region. The characters n i , δ(f), and H(f) are the surface normal vector, Dirac delta function, and Heaviside function, respectively; T ij is the Lighthill stress tensor. From left to right, the three terms in the above equation are monopole, dipole, and quadrupole, respectively. In this study, the laryngeal jet is a monopole sound source, the fluctuating pressure on the walls of the anatomical sites is the dipole source, and the unsteady shear stresses and turbulent flows elicit the quadrupole source. Fast Fourier transformation (FFT) was performed to convert the time domains of pressure oscillations at the receivers to frequency domains. The FW-H equation was solved by means of the free-space Green’s function, which transforms the equation into an array of surface and volume integral forms [53,54,55,56].
Wavelet transform and chaos analysis
Wavelet transform decomposes a sound signal into a family of wavelets by means of translation and dilation of a mother wavelet, as given by
where f(t) is a time evolution of the sound signal, ψ(t) is the mother wavelet (analysis window), a is the scale parameter that dilate or compress the analysis window, and b is the time shift. Wavelet transform extracts local irregularities by varying the two parameters a and b [57]. In this study, continuous wavelet transform was used to find the time-frequency spectrum (scalogram) of the signals, while discrete wavelet transform was used to find the multifractal dimensions of the signals. The Morlet wavelet was used as the mother wavelet for both analyses [57].
Hilbert transform was used to compute the instantaneous features (i.e., phase angle and magnitude) of the signal by returning a complex number [58]. The real part is the instantaneous oscillation amplitude (i.e., pressure), while the imaginary part is the time rate of change of the instantaneous phase angle (i.e., frequency). A phase space plot constituted by the oscillation amplitude and frequency can distinguish chaotic responses from periodic or quasi-periodic responses [59]. Both wavelet and Hilbert transforms were conducted using MATLAB.
Numerical methods
ANSYS Fluent was employed to compute the airflow and acoustic equations. A segregated implicit solver was selected that used the Gauss-Seidel method and multigrid approach to achieve optimal performance. The computational mesh was generated using ANSYS ICEM CFD (ANSYS, Inc.). A mesh sensitivity analysis was undertaken by varying mesh densities from very coarse to very fine till the deposition rate reaches mesh-independent [60]. The final computational mesh has approximately 2.2 million cells with the first cell height being 0.05 mm. The time step size Δt was 2.0E−4 s, which gave rise to the highest frequency of 2500 Hz of this acoustic study (f = 1/(2 Δt)). Based on a mesh size of 2.2 million, a time step size of 2.0E−4 s, and 100 iterations per time step, simulation of two inhalation cycles for one test case required 15,000 time steps (1,500,000 iterations), which took approximately 1230 h (51 days) in an Intel 2.27-GHz workstation. The first cycle was intended to establish the unsteady flow field, while pressure sampling and acoustic computation were performed during the second inhalation cycle. Considering the high computational resources required in this study, each breathing condition was simulated once, which was further analyzed using Fourier and wavelet transforms to obtain the flow-induced sound spectrum.
Results
Validation of computational models
To validate the computational airflow model in this study, experimental measurement of pressure in three upper airway cast replicas with different glottal apertures was performed (Fig. 3). The images of the larynx casts are shown in Fig. 3a, along with the cross-sectional areas of the corresponding glottal apertures. Figure 3b shows the experimentally measured pressure distribution in the mouth-lung airway in comparison to the computationally predicted results. For the larynx casts considered, large pressure gradients occur at the larynx and are most pronounced for the smallest glottal opening. Furthermore, good agreement between experimental and computational results for all glottal apertures was considered, indicating that the computational model herein is adequate in capturing the flow characteristics in the human upper respiratory tract.
Validation of the computational acoustic model has been conducted in our previous study [31] by comparing predicted acoustic characteristics from a cylinder flow with benchmark experimental data [61]. A good agreement had been achieved between the experimental results and model predictions, indicating that the current aeroacoustic model is capable of simulating the generation and propagation of flow-excited acoustic sound.
Flow and vortex topologies
Figure 4 depicts the instantaneous velocity contour and vortex topologies in the airway with a rhythmically contracting and expanding glottis subject to a sinusoidal inhalation flow rate (sine-dynamic). Several observations are noted in Fig. 4a. First, the sinusoidal flow and narrowing glottal aperture incite significant flow instabilities in the airway at the peak of the inhalation cycle. The laryngeal jet breaks into many parcels of high-energy flows, which leads to strong turbulence and flow fluctuations (second panel and slice 3 in Fig. 4a). Such high-energy flow parcels are observed to persist through the entire trachea, and even penetrate into the right and left bronchi. Second, highly complex vortex topologies are observed in the upper airway in general, and in the larynx and upper trachea in particular. There are two types of vortex structures: vortex rings shed from constricted airway surfaces and vortex filaments formed from the swirling core flows. During their transportation by the high-speed laryngeal jet, these coherent structures are continuously stretched while interacting with one another. It is observed that the laryngeal jet is not symmetric and oscillates periodically to the right and left, as displayed in the zoomed view of the larynx (third panel in Fig. 4a). Vortex breaking, reformation, and decay occur in the trachea, resulting in highly chaotic flow topologies as shown by the alternating low- and high-intensity vortices (fourth panel in Fig. 4a).

Evolution of flow topologies in the upper airway with a sinusoidal inhalation flow rate and a dynamic glottis. a At peak velocity. b Vortex development
The inhaled flow subjected to a tidal breathing and variable glottis is accompanied by a dynamic transition of laminar flows into highly turbulent flows. To highlight this transition process, the time sequence of the vortex topologies in the sine-dynamic case is shown in Fig. 4b at four instants (T 1 = 1.60 s, T 2 = 1.65 s, T 3 = 1.70 s, T 4 = 1.75 s). At the beginning of the inhalation, well-defined coherent structures are created from the narrowing glottal aperture in phase with an accelerating flow, such as the two vortex filaments and horseshoe-shaped vortex rings (first panel in Fig. 4b). At T 2 = 1.65 s, the flow acceleration and contracting glottis continue to give birth to well-defined vortex filaments and rings, as evidenced by the regular, alternating high- and low-intensity (red and blue) 2D vortices (second panel in Fig. 4b). The transition of flow regime is observed to start from T 3 = 1.70 s when higher flow velocity enhances the interplay among the vortices to point where the vortices are broken into smaller-scale ones and flow instability becomes noticeable. The flow instability and vortex interaction complexity continue to grow. At T 3 = 1.75 s, the complexity vortex topology already looks comparable to that at the peak velocity based on the iso-surfaces of λ 2 criterion = 0.015.
Comparison of the flow and vortex topologies among the four cases is shown in Fig. 5 at the peak flow rates. It is noted that the peak flow velocity of the sinusoidal flow case is twice that of the constant-flow case, while the peak flow velocity in the dynamic glottis case is 1.586 times that of the rigid-glottis case (Fig. 1). Generally, the higher the flow speed is, the stronger the vortex intensity and complexity are. Vortices are concentrated in the larynx and upper trachea for all cases, inducing rigorous mixing and flow oscillation in these regions. Moreover, the flow oscillation shows dependence on glottal flow velocity, which progressively escalates from case 1 to case 4 (Fig. 5). In the sine-dynamic case with the highest peak glottal velocity, the vortices persist throughout the trachea and are still visible in the bronchioles as far as G5 (Fig. 5). Such flow instabilities will incite fluctuations in pressure, which is closely related to sound generations.

Comparison of flow topologies at the peak flow rates among four breathing scenarios. a Constant flow with a rigid glottis (constant-rigid). b Constant flow with a dynamic (widening) glottis (constant-dynamic). c Sinusoidal flow with a rigid glottis (sine-rigid). d Sinusoidal flow with a dynamic (widening) glottis (sine-dynamic). A narrowing glottal aperture destabilizes the flows and enhances the vortex intensity. Compared to the inhalation velocity V 0 in the control case (constant-rigid), the peak velocity is 1.586 V 0 for the case of constant-dynamic, 2.0 V 0 for sine-rigid, and 3.172 V 0 for sine-dynamic
Flow-induced sound analysis
SAPL
Flow-induced sounds under the four breathing scenarios were first examined in Fig. 6 in the form of SAPL, which were predicted using the broadband noise model. Large differences are observed among the four cases. In the first case, the constant flow and static glottis lead to an SAPL of approximately 40 dB around the glottal aperture, where the maximal velocity and flow instability are presented. Since the audible sound has a threshold of 45 dB [62], no detectable sound is generated in this case. In the second case, the narrowing motion of the glottal aperture results in higher acoustic power levels around the aperture as well in the upper trachea. However, only the SAPL around the aperture appears to be larger than 45 dB (the audible sound threshold). In the third case (sine-rigid), the peak velocity is twice that of the constant flow. Audible acoustic sounds originate in both the larynx and upper trachea. In the last case, elevated sound levels are observed in both the larynx and upper trachea. There are substantially more areas with audible sounds in the upper trachea of the last case in comparison to the third case (Fig. 6b). Discrepancies of surface sound levels in other regions (mouth, pharynx, and lung) among the four cases appear less evident, indicating a limited influence of glottal aperture motion on the upstream and far downstream regions. However, careful examination of the pharynx region still reveals some differences, with a slightly elevated surface sound level in this region of the sine-dynamic case than the other three.

Comparison of the surface acoustic power level (SAPL) at the peak velocities between the four breathing scenarios for an equivalent flow rate of 15 L/min
Frequency spectra of different breathing conditions
Figure 7 shows the comparison of the acoustic pressure at peak inhalations (2.15–2.35 s) among the four breathing scenarios for an equivalent flow rate of 15 L/min. The acoustic pressures were recorded at a location 0.3 m ahead of the mouth, with Fig. 7a based on the whole mouth-lung airway geometry and Fig. 7b based on the larynx only. In both figures, the sine-dynamic case gave rise to the highest acoustic pressure. Furthermore, the sine-dynamic case also elicited the highest amplitude of the pressure fluctuations. In contrast, the lowest acoustic pressures were observed in the constant-rigid case in both the absolute magnitude and fluctuation amplitude.

Comparison of the acoustic pressure around the peak velocities between the four breathing scenarios from a all sources (mouth, pharynx, larynx, and trachea) and b larynx only for an equivalent flow rate of 15 L/min
Acoustic pressure from a single anatomical site (larynx) is shown in Fig. 7b. Due to the laryngeal effect, the pressures in the larynx are negative. The fluctuations of the larynx-induced pressure in the sine-dynamic case are significantly higher than the sine-rigid case, even though the averaged pressures in these two cases are similar (Fig. 7b). This difference indicates that the dynamic glottis further enhances the flow instability across the larynx. Elevated pressure fluctuation in the dynamic glottis than the static glottis is also observed in the two constant flow cases but at a much lower level relative to the two sine-flow cases (Fig. 7b).
Comparison of the sound pressure levels (SPLs) among the four cases is displayed in Fig. 8 as a function of the acoustic frequency. The SPL was computed based on the whole airway (all sources) at a distance of 0.3 m from the mouth. Figure 8a, b shows the predicted SPL for a whole breathing cycle (1.5–3.0 s) in the frequency range of 0–2500 and 0–250 Hz, respectively. The smallest time step size was 2.0E−4 s, which was equivalent to a maximum frequency of 2500 Hz. The highest SPL occurs in the range of 0–20 Hz, which is below the audible frequency of human ears. An elevated SPL is found for the sine-dynamics case in the range of 20–300 Hz, which is followed by the sine-rigid, constant-dynamic, with the constant-rigid generating the lowest SPL (Fig. 8a). There were several identifiable (but not significantly high) energy peaks at approximately 75, 150, and 200 Hz (red cycles in Fig. 8b).

Comparison of the breathing mode effects on the generated sound acoustics from the mouth-lung model geometry sampled from one whole cycle at the frequency range of a 0–2500 Hz and b 0–250 Hz, as well as sampled from a certain period: c 1.775–1.975 s and d 2.150–2.350 s
Considering that sound generation is closely associated with flow velocity and pressure fluctuations, the SPL was further sampled at different respiration periods, i.e., around the one-fourth cycle (1.775–1.975 s in Fig. 8c) and half cycle (2.15–2.35 s in Fig. 8d). During the periods of one-fourth cycle 1.775–1.975 s (Fig. 8c), the average flow rates were the same for the four cases. Therefore, by separately comparing the two rigid-glottis cases (or the two dynamic-glottis cases), the effects of flow rate and glottal area variation were excluded and those of the inhalation profile can be evaluated. It is observed that the sinusoidal flow induced higher sound pressure levels than the constant flow regardless of the motion mode of the glottis. This higher SPL is because of the flow development in tidal (sine) breathing that caused augmented flow instability in comparison to a steady (constant) breathing, as illustrated in Fig. 4b (T = 1.75 s) vs. Fig. 5a, b.
A further comparison of the acoustic difference between the two rigid cases vs. the difference between the two dynamic cases is indicative of the effects of the glottis motion. From Fig. 8c, a much lower sound intensity was observed in the constant-rigid case in the range of 0–500 Hz, giving rise to a drastic variation of sound in this range. By contrast, the acoustic responses between the two dynamic glottis cases are more parallel to each other for the whole range of frequencies considered. Therefore, the glottis motion caused additional flow instabilities that contributed to the sound pressure level, which is absent in the two cases with a rigid glottis.
Considering the peak inhalations (2.150–2.350 s) in Fig. 8d, more fluctuations in sound pressure level were observed in the frequency range of 0–500 Hz for all cases except the constant-rigid case. In particular, significantly higher sound pressure levels were predicted for the sine-dynamic case than the sine-rigid case in this frequency range, while for frequencies larger than 500 Hz, similar sound levels were predicted between the two cases. This observation lends further support that the motion of the glottis alters sound characteristics in the low-frequency range (0–500 Hz in this study).
Frequency spectra from different sound sources
To evaluate the anatomical effects on sound generation, the acoustic spectra at the peak inhalation rate (t = 2.150–2.350 s) were decomposed into sound pressure levels from individual respiratory anatomies (sound sources), such as mouth, pharynx, larynx, and lung (Fig. 9). The SPL distribution reveals distinct patterns and amplitudes among the four source sites considered. The pharynx generates the lowest sound level among the four sources, while both the larynx and lung (tracheobronchial region) generate appreciably high levels of sound. Considering the sine-dynamic case which is most approximate to in vivo conditions, much higher sound levels are observed in the range of 100–500 Hz from all source sites except the pharynx. Interestingly, for frequencies from 700 to 2500, the dynamic glottis generates lower sound levels than the static glottis in the lung (Fig. 9d) and, in a lower degree, in the pharynx (Fig. 9b). Observing that intense vortices mostly occur in these two regions (Figs. 4 and 5), it is conjectured that the above reduced sound level is related to the vortex interactions, as well as their time evolution. It is of note that the frequency spectrum herein is an integration of a time series of signals within 1 cycle. Sound behaviors at different instants of the breathing cycle are necessary to better understand the breathing-induced respiratory sounds.

Comparison of the sound source effects on the generated sound at the peak inhalation rate (t = 2.150–2.350 s). a Mouth. b Pharynx. c Larynx. d Lung (tracheobronchial (TB) geometry)
Frequency spectra at different sampling times and locations
Figure 10 shows the comparison of larynx-induced sound spectra sampled at three different times in a breathing cycle. As expected, there are no perceivable discrepancies in SPL among different times for the constant-rigid case (Fig. 10a). In the other three cases, the sound pressure levels at T 1 and T 3 are similar regardless of the breathing modes. Slight higher SPLs were noticed at T 2 than T 1 and T 3 in the constant-dynamic case (Fig. 10b). For the sine-rigid case (Fig. 10c), the sound level at T 2 is similar as that at T 1 and T 3 in the low-frequency range (20–700 Hz) but is higher at high frequencies (>700 Hz). Considering the sine-dynamic case (Fig. 10d), the sound level at T 2 is consistently higher than those sampled at T 1 and T 3 for the whole range of frequency considered. However, it is in the frequency range of 100–500 that the sound level enhancement is most pronounced (Fig. 10d).

Comparison of the sound acoustics generated by the larynx at different times in a breathing cycle for the breathing modes. a Constant-rigid. b Constant-dynamic. c Sine-rigid. d Sine-dynamic
Figure 11 shows the influence of receiver position on the flow-induced sound spectrum for the sine-rigid and sine-dynamic cases. Two receiver positions were considered here: 0.3 and 1.0 m away from the mouth. The decrease in SPL is observed as the receiver is moved away from the mouth. For both cases, the averaged SPL decreases by approximately 10–15 dB moving from 0.3 to 1.0 m ahead of the mouth opening. This is due to the dissipative behavior of the sound through the medium. The larger the distance between the noise source and receiver is, the larger the dissipation of sound is.

Comparison of the sound pressure levels recorded at two receivers for breathing modes. a Sine-rigid. b Sine-dynamic. The sound levels are from the whole mouth-lung geometry at the peak inhalation rate for a duration of 0.2 s (t = 2.150–2.350 s)
Dynamic analysis of sound signals
Considering that the dynamic physiological features could produce dynamic sound characteristics, the flow-induced pressure signals were further analyzed using the continuous wavelet transform to obtain the scalograms of the four breathing scenarios, as shown in Fig. 12. In this manner, the time evolution of the frequency spectrum can be clearly viewed during one inhalation cycle. High-magnitude sound signals at low frequencies (8–32 Hz) were predicted for the sine-dynamic cases, while sound signals with similar magnitudes were absent in the other three cases. Around the peak velocities (t = 0.75 s), the rigid (static) glottis significantly underestimated the sound magnitudes than the dynamic glottis in the frequency range of 100–500 Hz. This is true for both the tidal (Fig. 12a vs. 12b) and constant flow breathings (Fig. 12c vs. 12d), and is consistent with the Fourier analysis results in Fig. 8. For a higher frequency range of 700–2000 Hz, the sine-dynamic case exhibits lower sound intensities than the sine-rigid case at the start and end of breathing cycle (Fig. 12a vs. 12b). This observation also coincides with the reduced sound levels in the lung under the sine-dynamic condition for f = 700–2500, as displayed in Fig. 9d. It is noted that different ranges of the sound magnitude were used for the tidal and constant-flow breathings, with that of the tidal breathing is 2.5 times that of the constant-flow breathing.

Comparison of the scalograms among different breathing conditions. a Constant-rigid. b Constant-dynamic. c Sine-rigid. d Sine-dynamic. The range of scale magnitude for a, b is 2.5 times that for c, d
The pressure fluctuations are displayed in Fig. 13a for the four breathing conditions during one inhalation cycle at a sampling point that is 0.3 m from the mouth opening. Larger amplitudes of pressure fluctuation are observed in the two tidal breathing cases (sine dynamic and sine rigid) than the two constant flow cases (constant dynamic and constant rigid), which agrees with the higher sound magnitudes of the two tidal breathing cases (Fig. 12). The phase space plots for the four cases are shown in Fig. 13b, which exhibit the instantaneous oscillation frequency and amplitude of the signals. Highly irregular patterns are observed for all cases considered, indicating the chaotic characteristics of flow-induced sound signals. In contrast, a pure sinusoidal input is transformed into a smooth ellipse in the phase space (black solid line; Fig. 13b). Considering the sine-dynamic case, the chaotic level varies dramatically throughout the breathing cycle, with the highest chaotic level occurring at the highest velocities (Fig. 13b, right end). However, the lowest level does not occur at the lowest velocity, but at a time approximately 0.4 s after inhalation and 0.4 s before the end, as indicated by the solid arrows in Fig. 13b. These two minimum chaotic levels might be attributed to the transient effects that are significant only at the start and end of the inhalation.

Chaos and multifractal analyses of the sound pressure signals. a Pressures at 0.3 m from the mouth opening. b Phase space based on Hilbert transform. c Multifractal spectrum. d Distribution of scaling exponents
Comparison of the multifractal spectra of the sound pressure signals among the four cases was shown in Fig. 13c. The multifractal spectrum measured the level of time variation in local regularity of a signal [63]. From Fig. 13c, both tidal breathing scenarios (i.e., sine-dynamic and sine-rigid) have a wide range of h scale and appear to be multifractal in nature, regardless of the glottis motion. By contrast, the two constant-flow scenarios appear to be more monofractal with narrow scaling range, exhibiting less variation in time irregularity. Further inspection of the zoomed spectra in Fig. 13c reveals a wider scaling range of the constant-dynamic case than that of the constant-rigid case, which is expected. It is concluded that tidal breathing induces higher levels of chaos than the low-frequency glottis motion considered in this study. As shown in Fig. 13d, large departures in the moment-scale profiles exist between the constant-flow and tidal breathing cases, regardless of the glottis motion.
Discussion
Many efforts have been undertaken in the past years to develop noninvasive techniques to diagnose and monitor breathing disorders. The success of such techniques relies on an accurate knowledge of how the breathing sounds relate to underlying airway shape, motion, airflow, and disease-associated abnormity. In this study, the effects of glottal motion and tidal breathing on airflows and breathing sounds were numerically examined. It was observed that the flow speed in glottis is the predominant factor in dictating the sound intensity, which induced strong turbulence and extensive vortex shedding in and after the larynx. At an equivalent inhalation flow rate of 15 L/min, the glottal velocity is the lowest (2.14 m/s, Re = 2050) for the constant-rigid case and is the highest (6.90 m/s, Re = 6614) for the sine-dynamics case (Table 2). The Reynolds number, Re, was calculated based on a kinematic viscosity of 1.669 × 10−5 m2/s and a characteristic length of 16 mm (the posterior-anterior length of the glottis). The sound intensity in the constant-rigid case was found to be 20–35 dB lower than the sine-dynamic case for all frequencies. In particular, the sine-dynamic case generates a significantly higher sound level (~35 dB) in the range of 20–300 Hz than all other cases (Fig. 8c). Similarly, Harper et al. [24] reported a sound power variation of 15 dB in the bandwidth of 300–600 Hz between different breathing maneuvers at the same flow rate and attributed this difference partially to the glottal aperture variation. However, using a lumped acoustic circuit element model that parallels sound pressure to voltage and air velocity to electric current, they predicted a decrease of 10 dB only for aperture dilation from 64 to 140 mm2, which is much smaller than the 20–35-dB variation predicted in this study. Two factors that have been neglected in the model of Harper et al. [24] may contribute to this disparity: first, the relationship between turbulence and velocity is highly nonlinear. A slight velocity increase in velocity may cause disproportionate enhancement in turbulence, vortex shedding, or flow instability. Secondly, the complex airway anatomical details can elicit earlier onset of turbulence and add to this turbulence enhancement. It is also noted that it is not the volume flow rate but the airflow velocity and turbulence intensity at the glottis, being the critical factor in sound excitation. For a given flow rate, the airflow velocity increases when the glottis narrows and the peak velocity doubles in comparison to the mean velocity.
There are two aspects of the impacts from tidal breathing: the velocity variation and the transient effect. The velocity variation played a substantial role in sound generation. Compared to the constant flow cases, tidal breathing was found to significantly elevate the sound pressure level, i.e., by 10–20 dB, as illustrated in the comparison of Fig. 10a vs. 10c and Fig. 10b vs. 10d. Even for the same breathing cycle, the peak velocity enhanced the sound pressure level by 5–10 dB in the frequency range of 700–2500 Hz than the mean (T 2 vs. T 1 in Fig. 10c). Concerning the transient effect, two dimensionless parameters, the Womersley number α and the Strouhal number St, were calculated and listed in Table 2. The Womersley number (\( \alpha =L\sqrt{2\pi f/v} \)) herein is 5.7 (Table 2) based on a respiration frequency f = 1/3 Hz (20 breaths per minute). Generally, the transient effect is negligible when α < 1 (with mean flow in phase with pressure gradient) and is important when α > 10 (with mean flow lag pressure gradient by 90°). As a result, a perceivable but not significant transient effect was expected, with the airflow lagging the diving pressure by an angle in the range of 0–90°. The Strouhal number (St = fL/V) at the peak aspiration velocity, which is the minimum St during a breathing cycle, is 2.49 × 10−3 for the constant-rigid case and is 7.73 × 10−4 for the sine-dynamics case (Table 2). Therefore, rapid vortex formation is expected, which is shed into the mean flow stream and causes flow instabilities.
Numerical predictions of this study indicated that the larynx-originated snoring might have important implications for promoting the carotid artery atherosclerosis (plaque buildup) and carotid stenosis. The carotid artery atherosclerosis has been shown to be strongly affected by sound frequencies from 652 to 1500 Hz, which accounts for snoring originated at the larynx and tongue base [64, 65]. In this study, relatively high sound pressure energy was predicted over 650 Hz. Considering the proximity of the sound source to the carotid artery, chronic laryngeal snoring can initiate or aggravate the carotid artery wall thickening. Moreover, carotid atherosclerosis is significantly associated with snoring sound energy from 0 to 20 Hz [64]. This study predicted the highest sound pressure levels in this range, which are 10–20 dB higher than those of other frequencies, as shown in Figs. 8, 9, and 10. Even though inaudible, this low-frequency sound energy is much easier to transmit into the surrounding tissues and cause vibrations.
Different values have been reported in previous studies for fundamental frequencies of snores originating at the glottis, for instance, 250 Hz by Miyazaki et al. [23], 652 Hz by Pevernagie et al. [46], and 800 Hz by Saha et al. [47]. However, the predicted sound spectra in this study did not exhibit obvious fundamental frequencies for the four breathing scenarios considered, even though the sound pressure levels remain large and irregular for frequencies larger than 500 Hz (Fig. 8). This finding is consistent with the characteristics of stenotic-typed snoring that generates an irregular sound and peak frequencies over 500 Hz [64]. Considering the sine-dynamic case in particular, the peak frequencies occur in the range of 200–300 Hz (Fig. 8d), which agree with 250 Hz suggested by Miyazaki et al. [23]. It is noted that the FW-H aeroacoustic model is a segregated source-propagation method, which first simulates transient flow field to get the acoustic sources and then analytically solves the wave equation to propagate noise from sources to the receiver [66]. Therefore, sound deflection and absorption by the airway wall were not considered in this study. More realistic models of sound propagation than the FW-H model are needed in future studies to capture the attenuation or amplification of the sounds radiated from the anatomical sources.
The computer model of dynamic glottis developed in this study provides a platform for further studies of pathologies related to glottis dysfunctions. The glottis kinematics was prescribed separately on the two side walls of the glottis; each follows a sinusoidal function at certain amplitude, frequency, and phase angle relative to the inhalation flow rate. For instance, patients with Parkinson’s disease often have symptoms of low-volume and monotonic voice that are associated with abnormal control, coordination, or strength of the vocal fold muscles [67]. Other symptoms include blurred speech, long purse, and tremulous voice. Unilateral and bilateral vocal fold abductor paralysis have been suggested that cause voice dysfunctions in Parkinson’s disease patients [68]. The dynamic glottis model developed herein can be readily adapted to explore such pathological conditions by varying the motion of individual vocal fold with different amplitudes, frequencies, and phase angels. Due to technical challenges in meshing and fluid computations, this model cannot simulate the full glottis closure, which can occur during snoring or phonation. In this study, a glottal area contraction ratio of 62% was investigated.
Other limitations of this study include the assumptions of rigid walls (except the larynx), idealized glottis motion, low glottis vibration frequency, and forced glottis oscillation. Lack of compliance in the airway surface can cause higher sound frequencies in prediction [69]. The sinusoidal motion of the glottal aperture may not accurately simulate in vivo glottis kinematics. Moreover, the glottis motion was assumed to be in phase with the tidal breathing, while during snoring, the glottis vibrates at much higher frequencies [46] and in a flow-excited, self-sustained mode [36]. However, this study was intended to quantitatively examine the effect of glottal motion and tidal breathing, not the actual snoring process, and adopting these assumptions greatly reduce the numerical complexity. In addition, results of this study still have clinical implications on laryngomalacia (soft larynx) and carotid stenosis, as discussed in previous sections. It is also noted that aeroacoustic simulations of breathing sounds are still highly computational demanding. Based on a mesh size of 2.2 million and a time step size of 2.0E−4 s, one test case took approximately 1230 h (51 days) in an Intel 2.27-GHz workstation. Moreover, the airway model herein was based on images of a single subject, which cannot consider intersubject [70] or intrasubject [71] variability.
Conclusion
In conclusion, influences of the glottis motion and tidal breathing were quantitatively examined on airflow and respiratory sounds in an upper airway model using large eddy simulations, as well as Frouier and wavelet analyses. An increase of 25–40 dB in the sound pressure level was predicted for the sine-dynamic case (representing in vivo condition) than the constant-rigid case, which emphasizes the necessity to include the two factors in future aeroacoustic simulations. While in rigid airway models, the tidal breathing intensified the sound in the frequency range of 700–2500 Hz, a narrowing glottal aperture mainly intensified the sound in the frequency range of 100–500 Hz. In vitro airway models with variable glottal apertures are needed to quantify the relative impacts from the glottal motion. Clinically, synchronized recording of the voice and glottis motion using dynamic MR imaging technique may provide new insights into the shape-function relationship of the respiratory tract in general and the glottis in particular.
References
Dalmasso F, Prota R (1996) Snoring: analysis, measurement, clinical implications and applications. Eur Respir J 9:146–159
Young T, Palta M, Dempsey J, Skatrud J, Weber S, Badr S (1993) The occurrence of sleep-disordered breathing among middle-aged adults. N Engl J Med 328:1230–1235
Lindberg E, Elmasry A, Gislason T, Janson C, Bengtsson H, Hetta J, Nettelbladt M, Boman G (1999) Evolution of sleep apnea syndrome in sleepy snorers—a population-based prospective study. Am J Respir Crit Care Med 159:2024–2027
Key APF, Molfese DL, O’Brien L, Gozal D (2009) Sleep-disordered breathing affects auditory processing in 5–7-year-old children: evidence from brain recordings. Dev Neuropsychol 34:615–628
Lee Y-H, Kweon S-S, Choi BY, Kim MK, Chun B-Y, Shin DH, Shin M-H (2014) Self-reported snoring and carotid atherosclerosis in middle-aged and older adults: the Korean Multi-Rural Communities Cohort Study. J Epidemiol 24:281–286
Touboul PJ, Grobbee DE, den Ruijter H (2012) Assessment of subclinical atherosclerosis by carotid intima media thickness: technical issues. Eur J Prev Cardiol 19:18–24
Abeyratne UR, Karunajeewa AS, Hukins C (2007) Mixed-phase modeling in snore sound analysis. Med Biol Eng Comput 45:791–806
Abo-Khatwa MM, Osman EZ, Hill PD, Lee BWV, Osborne JE (2008) Objective evaluation of tongue base snoring after the use of an oral appliance: a prospective case series. Clin Otolaryngol 33:592–595
Agrawal S, Stone P, McGuinness K, Morris J, Camilleri AE (2002) Sound frequency analysis and the site of snoring in natural and induced sleep. Clin Otolaryngol 27:162–166
Beck R, Odeh M, Oliven A, Gavriely N (1995) The acoustic properties of snores. Eur Respir J 8:2120–2128
Beninati W, Harris CD, Herold DL, Shepard JW (1999) The effect of snoring and obstructive sleep apnea on the sleep quality of bed partners. Mayo Clin Proc 74:955–958
Caffier PP, Berl JC, Muggli A, Reinhardt A, Jakob A, Moeser M, Fietze I, Scherer H, Hoelzl M (2007) Snoring noise pollution—the need for objective quantification of annoyance, regulatory guidelines and mandatory therapy for snoring. Physiol Meas 28:25–40
Emoto T, Abeyratne UR, Akutagawa M, Konaka S, Kinouchi Y (2011) High frequency region of the snore spectra carry important information on the disease of sleep apnoea. J Med Eng Technol 35:425–431
Gavriely N, Jensen O (1993) Theory and measurements of snores. J Appl Physiol 74:2828–2837
Hara H, Murakami N, Miyauchi Y, Yamashita H (2006) Acoustic analysis of snoring sounds by a multidimensional voice program. Laryngoscope 116:379–381
Hill PD, Osman EZ, Osborne JE, Lee BWV (2000) Changes in snoring during natural sleep identified by acoustic crest factor analysis at different times of night. Clin Otolaryngol 25:507–510
Jones TM, Ho MS, Earis JE, Swift AC, Charters P (2006) Acoustic parameters of snoring sound to compare natural snores with snores during “steady-state” propofol sedation. Clin Otolaryngol 31:46–52
Lofaso F, Coste A, d’Ortho MP, Zerah-Lancner F, Delclaux C, Goldenberg F, Harf A (2000) Nasal obstruction as a risk factor for sleep apnoea syndrome. Eur Respir J 16:639–643
Atkins M, Taskar V, Clayton N, Stone P, Woodcock A (1994) Nasal resistance in obstructive sleep apnea. Chest 105:1133–1135
Xu HJ, Huang WN, Yu LS, Chen L (2010) Sound spectral analysis of snoring sound and site of obstruction in obstructive sleep apnea syndrome. Acta Otolaryngol 130:1175–1179
Quinn SJ, Huang L, Ellis PD, Williams JEF (1996) The differentiation of snoring mechanisms using sound analysis. Clin Otolaryngol 21:119–123
Saunders NC, Tassone P, Wood G, Norris A, Harries M, Kotecha B (2004) Is acoustic analysis of snoring an alternative to sleep nasendoscopy? Clin Otolaryngol 29:242–246
Miyazaki S, Itasaka Y, Ishikawa K, Togawa K (1998) Acoustic analysis of snoring and the site of airway obstruction in sleep related respiratory disorders. Acta Otolaryngol 537:47–51
Harper VP, Pasterkamp H, Kiyokawa H, Wodicka GR (2003) Modeling and measurement of flow effects on tracheal sounds. IEEE Trans Biomed Eng 50:1–10
Mihaescu M, Murugappan S, Kalra M, Khosla S, Gutmark E (2008) Large eddy simulation and Reynolds-averaged Navier-Stokes modeling of flow in a realistic pharyngeal airway model: an investigation of obstructive sleep apnea. J Biomech 41:2279–2288
Mihaescu M, Mylavarapu G, Gutmark EJ, Powell NB (2011) Large eddy simulation of the pharyngeal airflow associated with obstructive sleep apnea syndrome at pre and post-surgical treatment. J Biomech 44:2221–2228
Powell NB, Mihaescu M, Mylavarapu G, Weaver EM, Guilleminault C, Gutmark E (2011) Patterns in pharyngeal airflow associated with sleep-disordered breathing. Sleep Med 12:966–974
Sittitavornwong S, Waite PD, Shih AM, Koomullil R, Ito Y, Cheng GC, Wang D (2009) Evaluation of obstructive sleep apnea syndrome by computational fluid dynamics. Semin Orthod 15:105–131
Xu C, Sin S, McDonough JM, Udupa JK, Guez A, Arens R, Wootton DM (2006) Computational fluid dynamics modeling of the upper airway of children with obstructive sleep apnea syndrome in steady flow. J Biomech 39:2043–2054
Yu CC, Hsiao HD, Tseng TI, Lee LC, Yao CM, Chen NH, Wang CJ, Chen YR (2012) Computational fluid dynamics study of the inspiratory upper airway and clinical severity of obstructive sleep apnea. J Craniofac Surg 23:401–405
Xi J, Si X, Kim J, Su G, Dong H (2014) Modeling the pharyngeal anatomical effects on breathing resistance and aerodynamically generated sound. Med Biol Eng Comput 52:567–577
Lin C-L, Tawhai MH, McLennan G, Hoffman EA (2007) Characteristics of the turbulent laryngeal jet and its effect on airflow in the human intra-thoracic airways. Respir Physiol Neurobiol 157:295–309
Xi J, Longest PW, Martonen TB (2008) Effects of the laryngeal jet on nano- and microparticle transport and deposition in an approximate model of the upper tracheobronchial airways. J Appl Phys 104:1761–1777
Daily DJ, Thomson SL (2013) Acoustically-coupled flow-induced vibration of a computational vocal fold model. Comput Struct 116:50–58
Khosla S, Muruguppan S, Gutmark E, Scherer R (2007) Vortical flow field during phonation in an excised canine larynx model. Ann Otol Rhinol Laryngol 116:217–228
Khosla S, Murugappan S, Lakhamraju R, Gutmark E (2008) Using particle imaging velocimetry to measure anterior-posterior velocity gradients in the excised canine larynx model. Ann Otol Rhinol Laryngol 117:134–144
Khosla S, Murugappan S, Gutmark E (2008) What can vortices tell us about vocal fold vibration and voice production. Curr Opin Otolaryngol Head Neck Surg 16:183–187
Olney DR, Greinwald JH Jr, Smith RJ, Bauman NM (1999) Laryngomalacia and its treatment. Laryngoscope 109:1770–1775
Awan S, Saleheen D, Ahmad Z (2004) Laryngomalacia: an atypical case and review of the literature. Ear Nose Throat J 83(334):336–338
Xi J, Longest PW (2008) Evaluation of a drift flux model for simulating submicrometer aerosol dynamics in human upper tracheobronchial airways. Ann Biomed Eng 36:1714–1734
Xi J, Longest PW (2007) Transport and deposition of micro-aerosols in realistic and simplified models of the oral airway. Ann Biomed Eng 35:560–581
Cohen BS, Sussman RG, Lippmann M (1990) Ultrafine particle deposition in a human tracheobronchial cast. Aerosol Sci Technol 12:1082–1093
Scheinherr A, Bailly L, Boiron O, Lagier A, Legou T, Pichelin M, Caillibotte G, Giovanni A (2015) Realistic glottal motion and airflow rate during human breathing. Med Eng Phys 37:829–839
Scheinherr A, Bailly L, Boiron O, Legou T, Giovanni A, Caillibotte G, Pichelin M (2012) Glottal motion and its impact on the respiratory flow. Comput Methods Biomech Biomed Eng 15:69–71
Lane RW, Weider DJ, Steinem C, Marin-Padilla M (1984) Laryngomalacia. A review and case report of surgical treatment with resolution of pectus excavatum. Arch Otolaryngol 110:546–551
Pevernagie D, Aarts RM, De Meyer M (2010) The acoustics of snoring. Sleep Med Rev 14:131–144
Saha S, Bradley TD, Taheri M, Moussavi Z, Yadollahi A (2016) A subject-specific acoustic model of the upper airway for snoring sounds generation. Sci Rep 6:25730
Douglas NJ, White DP, Pickett CK, Weil JV, Zwillich CW (1982) Respiration during sleep in normal man. Thorax 37:840–844
Nicoud F, Ducros F (1999) Subgrid-scale stress modeling based on the square of the velocity gradient tensor. Flow Turbul Combust 62:183–200
Proudman I (1952) The generation of noise by isotropic turbulence. Proceedings of the Royal Society of London Series A—Mathematical and Physical. Sciences 214:119–132
Ffowes Williams JE, Hawkings DL (1969) Sound generation by turbulence and surfaces in arbitrary motion. Philosophical Transactions of the Royal Society of London A (Mathematical and Physical Sciences) 264:321–342
Lilley GM (1993) The radiated noise from isotropic turbulence revisited. NASA Contract Report 93–75, NASA Langley Research Center, Hampton, VA
Brentner KS, Farassat F (2003) Modeling aerodynamically generated sound of helicopter rotors. Prog Aerosp Sci 39:83–120
Bregraves GA, Peacuterot F, Freed D (2010) A Ffowcs Williams-Hawkings solver for Lattice-Boltzmann based computational aeroacoustics. 16th AIAA/CEAS Aeroacoustics Conference 2010. 31st AIAA Aeroacoustics Conference:145–159
Khelladi S, Bakir F (2010) A consistency test of thickness and loading noise codes using Ffowcs Williams and Hawkings equation. Advances in Acoustics and Vibration: 174,361 (174,366 pp.)–174,361 (174,366 pp.)
Spalart PR, Shur ML (2009) Variants of the Ffowcs Williams-Hawkings equation and their coupling with simulations of hot jets. Int J Aeroacoustics 8:477–491
Grossmann A, Morlet J (1984) Decomposition of Hardy functions into square integrable wavelets of constant shape. SIAM J Math Anal 15:723–736
Subbu A, Ray A (2008) Space partitioning via Hilbert transform for symbolic time series analysis, pp. 084,107–084,107
Jubran BA, Hamdan MN, Shabanneh NH, Szepessy S (1998) Wavelet and chaos analysis of irregularities of vortex shedding. Mech Res Commun 25:583–591
Xi J, Yuan JE, Yang M, Si X, Zhou Y, Cheng YS (2016) Parametric study on mouth-throat geometrical factors on deposition of orally inhaled aerosols. J Aerosol Sci 99:94–106
Revell JD, Prydz RA, Hays AP (1977) Experimental study of airframe noise vs. drag relationship for circular cylinders. Lockheed Report 28074, Final Report for NASA Contract NAS1–14403. Final Report for NASA Contract NAS1–14403
Larrosa F, Hernandez L, Morello A, Ballester E, Quinto L, Montserrat JM (2004) Laser-assisted uvulopalatoplasty for snoring: does it meet the expectations? Eur Respir J 24:66–70
Xi J, Si XA, Kim J, Mckee E, Lin E-B (2014) Exhaled aerosol pattern discloses lung structural abnormality: a sensitivity study using computational modeling and fractal analysis. PLoS One 9:e104682
Lee GS, Lee LA, Wang CY, Chen NH, Fang TJ, Huang CG, Cheng WN, Li HY (2016) The frequency and energy of snoring sounds are associated with common carotid artery intima-media thickness in obstructive sleep apnea patients. Sci Rep 6:30559
Hu FB, Willett WC, Manson JE, Colditz GA, Rimm EB, Speizer FE, Hennekens CH, Stampfer MJ (2000) Snoring and risk of cardiovascular disease in women. J Am Coll Cardiol 35:308–313
Ffowcs Williams JE, Hawkings DL (1969) Sound generation by turbulence and surfaces in arbitrary motion. Philos Trans Royal Soc A264:321–342
Ramig LO, Fox C, Sapir S (2008) Speech treatment for Parkinson’s disease. Expert Rev Neurother 8:297–309
Blumin JH, Berke GS (2002) Bilateral vocal fold paresis and multiple system atrophy. Arch Otolaryngol–Head Neck Surg 128:1404–1407
Pasterkamp H, Kraman SS, Wodicka GR (1997) Respiratory sounds—advances beyond the stethoscope. Am J Respir Crit Care Med 156:974–987
Pickering DN, Beardsmore CS (1999) Nasal flow limitation in children. Pediatr Pulmonol 27:32–36
Ohki M, Ogoshi T, Yuasa T, Kawano K, Kawano M (2005) Extended observation of the nasal cycle using a portable rhinoflowmeter. J Otolaryngol 34:346–349
Funding
NSF provided financial support in the form of Grants CBET 1605434 (Xi) and 1605232 (Dong). This work was partially supported by NIH R01 CA204189 (Glide-Hurst). The supporters have no role in the design or conduct of this research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Informed consent
For this type of study, formal consent is not required.
Rights and permissions
About this article

Cite this article
Xi, J., Wang, Z., Talaat, K. et al. Numerical study of dynamic glottis and tidal breathing on respiratory sounds in a human upper airway model. Sleep Breath 22, 463–479 (2018). https://doi.org/10.1007/s11325-017-1588-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11325-017-1588-0