
Abstract
Nowadays, with the development of cyber-physical systems (CPS), there are an increasing amount of applications deployed in the CPS to connect cyber space with physical world better and closer than ever. Furthermore, the cloud-based CPS bring massive computing and storage resource for CPS, which enables a wide range of applications. Meanwhile, due to the explosive expansion of applications deployed on the CPS, the energy consumption of the cloud-based CPS has received wide concern. To improve the energy efficiency in the cloud environment, the virtualized technology is employed to manage the resources, and the applications are generally hosted by virtual machines (VMs). However, it remains challenging to meet the Quality-of-Service (QoS) requirements. In view of this challenge, a QoS-aware VM scheduling method for energy conservation, named QVMS, in cloud-based CPS is designed. Technically, our scheduling problem is formalized as a standard multi-objective problem first. Then, the Non-dominated Sorting Genetic Algorithm III (NSGA-III) is adopted to search the optimal VM migration solutions. Besides, SAW (Simple Additive Weighting) and MCDM (Multiple Criteria Decision Making) are employed to select the most optimal scheduling strategy. Finally, simulations and experiments are conducted to verify the effectiveness of our proposed method.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, cyber-physical systems (CPS) which emerge as a novel computing system have gained a lot of popularity in many critical areas such as health care, manufacturing and traffic control [29]. Plenty of enterprises utilize CPS to implement distributed computing resources. In CPS, physical systems work as sensors to collect information of real-world and send the sensory information to computation platforms for further analysis. Computation platforms analyze and process the information and then return a feedback or command to physical systems [16]. The real-time information brought by CPS is critical to make efficient decision. With the development of mobile devices, the integration of CPS and mobile devices bring more opportunities to attain more information. However, the complex applications in CPS (i.e. industrial applications and monitor applications) often require massive storages and computing resources to meet the performance requirements of users. Due to the storage and computing capacity limit of mobile devices, the performance of CPS applications is not capable of filling the bill. To meet the resource and storage requirements of applications in CPS, cloud computing emerges as a novel computing paradigm to provision rich computing resources [2, 20].
By virtue of the resource-rich cloud, cloud-based CPS improves the computing capacity of CPS to conduct resource-hungry applications. In order to provision the physical resources dynamically, virtualized technology is extensively used for resource management in the cloud platforms [13], which provides an effective manner to improve the resource efficiency of the cloud-based CPS. Running applications on the virtual machines (VMs) makes it possible for high resource utilization and low energy consumption. By virtue of integrating cloud with CPS, numerous systems like cloud-integrated vehicles which are unachievable due to the resources limit are able to be deployed efficiently [36].
With the aim of providing better service experience of cloud-based CPS, reasonable scheduling strategies are necessary to migrate applications to cloud more efficiently [3, 7]. Despite the advantages of VM migration, the VM migration operations also generate certain transmission delay, and the transmission of VM images leads to additional energy consumption of the switches in the datacenter [26]. Therefore, it is necessary to consider both the negative and the positive aspects of the VM migrations and determine the reasonable scheduling strategy due to the different requirements of users. Currently, the energy consumption of cloud-based CPS has received wide concerns since it not only augments the operating cost of the cloud providers, but also dramatically decreases battery life [4]. Thus, how to reduce energy consumption of the cloud datacenters becomes a key restrict for better user experience of resource intensive applications in cloud-based CPS [22, 27].
Meanwhile, owing to the rapid growth of multiple service demands, it remains challenging to meet the quality-of-service (QoS) requirements with the data traffic increasing [30]. It is troublesome to meet the global QoS requirement by virtue of the different users’ preferences for a certain QoS. In view of this challenge, a QoS-aware VM scheduling method is proposed in this paper. By offloading various applications to other physical machines (PMs), the workloads on some under-load physical servers are migrated out, and these servers could be set to idle mode for energy saving [8, 14]. By reasonable offloading method, the requisite computing resources are provisioned and the QoS of applications in CPS can be ensured at the same time. Our work is to find an optimal VM scheduling strategy in cloud-based CPS with QoS enhancement. In view of this, a QoS-aware VM scheduling method for energy conservation, named QVMS, in cloud-based CPS is proposed. The main contributions are as follows.
First, we define some basic concepts and present the system model. Then, we formalize the objective function and present the constraints.
Besides, Non-dominated Sorting Genetic Algorithm (NSGA-III) is adopted to find the optimal VM scheduling strategies and achieve the goal of QoS enhancement including energy consumption, downtime and resource utilization.
SAW (Simple Additive Weighting) and MCDM (Multiple Criteria Decision Making) are adopted to select the most optimal scheduling strategy.
Finally, we conduct the extensive experimental evaluations to verify the effectiveness of our proposed VM scheduling method.
The rest of this paper is organized as follows. Section 2 presents the problem definition. Section 3 elaborates our proposed method. In Section 4, performance evaluation is illustrated. Section 5 summarizes the related work. Section 6 concludes the paper and presents the future work.
2 Problem definition
In this section, we introduce some formalized concepts in the QoS-aware VM scheduling method in cloud-based CPS. Quality of Service (QoS) includes a group of nonfunctional requirements like energy consumption, response time, availability, resource utilization, and throughput, etc. We analyze and quantify the energy consumption and resource utilization, and model the QoS-aware problem as a multi-objective optimization problem. Some key notations and descriptions used in the paper are listed in the Table 1.
2.1 Basic concepts
Suppose there are N PMs in the cloud environment used during the application execution, denoted as P = {p1,p2,…,pN}. Besides, there are M CPS applications running on the PMs in P, denoted as V = {v1,v2,…,vM}. We model the applications as special VMs which consist of multiple VM instances. Besides, we model the QoS indicators of the VM scheduling like energy consumption, downtime, resource utilization rate to quantify the QoS requirements. Let X = {x1,x2,…,xM} be the VM scheduling policy for the VMs in V, where xm ∈ P (m = {1,2,…,M}) is the PM which the VM vm is migrated to. Let Y = {y1,y2,…,yM} be the VM original deployment for the VMs in V, where ym ∈ P (m = {1,2,…,M}) is the PM which the VM vm is originally deployed on.
2.2 Energy consumption analysis
The VMs which are occupied by tasks are running, and let AE(X) be the VM execution energy consumption caused by the task execution with the scheduling policy X. The energy consumption of active VMs with X for the m-th VM vm in V is calculated by
where 𝜃m is the requested number of VM instances for vm, am(X) is the energy consumption rate of running VM instances, and Tm(X) is the running time of vm.
\({I_{m}^{n}}(X)\) is a binary variable to determine whether vm is placed on pn with policy X, and its calculation expression is
According to the condition of vm, we calculate the energy consumption of idle VMs by
where βm(X) is the energy consumption rate of vm in idle mode, τn (X) isthe maximum of VMs running time.
The PM in operation has basic energy consumption regardless of whether it is idle or running. The calculation expression of PM basic energy consumption is
where γn (X) is the basic energy consumption rate of pn.
Faced with the emergence of network hotspots and problem of overloading, the switches and hosts are arranged by the fat-tree topology in the cloud data center. Owing to the fat-tree topology, the loads that aggregate at the core layer are processed and diverted timely by the multiple links to the core layer.
The switches in the fat-tree topology are classified in three layers including core, aggregation and edge. The fat-tree topology is displayed in Figure 1. The topology rules of fat-tree are as follows: the number of pods contained in the topology is k, the number of connected server per pod is \({\left ({\frac {k}{{\mathrm {2}}}} \right )^{2}}\), the number of edge switches and aggregate switches within each pod is \(\frac {k}{2}\), the number of core switches is \({\left ({\frac {k}{{\mathrm {2}}}} \right )^{2}}\), and the number of ports per switch in the network is k.

The fat-tree topology
Let pa be the source PM and pb be the goal PM. Denote la,b as a binary variable to judge whether pa needs to access pb, which is measured by
Let fa,b be the frequency for pa to access pb, and the total access time is denoted by
In the fat-tree topology, the access time between PMs depends upon the distributed locations among the PMs. Let ES(X), AS(X) and CS(X) be the corresponding switch that need to be accessed according to the scheduling strategy X in the edge layer, aggregation layer and core layer respectively. The accommodating situations in the fat-tree are classified into four conditions. First, The application is processed in the same PM due to the scheduling strategy, which is denoted as ya≠xa. Then, xa and ya are linked to the same edge switch and different hosts, which is denoted as ya≠xa, ES(ya)≠ES(xa). Besides, xa and ya are connected to the same aggregation instead of the same edge switch and host, which is denoted by ya≠xa, ES(ya)≠ES(xa), AS(ya)≠AS(xa). At last, xa and ya are linked to the same core switch instead of hosts, edge and aggregation switch, which is denoted by ya≠xa,ES(ya)≠ES(xa),AS(ya)≠AS(xa),CS(ya)≠CS(xa). After analyzing all the possible accommodating situation, the access time for xa to access yb is calculated as
where Dm is the memory used by vm, and BSE is the available network bandwidth between hosts and edge switches, BEA is the available network bandwidth between edge switches and aggregation switches, and BAC is the available network bandwidth between aggregation switches and core switches. The number of switches for pa accessing pb in the topology is denoted by
During the scheduling process, each switch employed in the fat-tree has a base energy comsumption SEbase which is calculated by
Then, the transmission energy consumption is calculated by accommodation situation in the above analysis. Based on the different scheduling strategy, the transmission energy SEex consumption is calculated by
Then, the switch energy consumption is calculated by
where β is the baseline energy consumption rate for each switch, and γ is the energy consumption rate for each port, ta,b(X) is the access time for pa to access pb, and δa,b(X) is the total number of switches in the topology.
In this way, the total energy consumption denote as E(X) is calculated by
2.3 Downtime analysis
The downtime in the VM migration operation contains switch time and the access time of the log file. Suppose in the migration operation of vm with X, the memory image is transmitted Im(X) times. Let the access time of all the remaining log files be \(MT_{m}^{{i_{m}}}(X)\) when the log file transfers at im(X) time. The downtime when vm is migrated from pn with X is calculated by
where \(D_{m}^{{i_{m}}}(X)\) is the size of dirty page transferred by vm, and Bm,n is the bandwidth between ym and pn. In order to keep the consistency of VM memory condition before and after the migration, the dirty pages produced in the process of memory transmission are sent to the goal PM during the next transmission. Hence, the size of dirty page transferred by vm could be calculated by
where Sm(X) is the size of the mirror memory of vm, and Rm(X) is the producing rate of memory dirty page. The switch time of vm is calculated by
Similarly, the computation latency is dismissed because of the same number and computing rate of occupied VMs. Then, the total downtime is calculated by
2.4 Resource utilization analysis
In the cloud data center, multiple VM instances are created to allocate resources. The resource requirements could be quantified by the number of VM instances. Let cn be the capacity of n-th PM. The resource utilization with Xun(X) is calculated by
Let Kn be the flag to judge whether the pn is running, which is measured by
where Lm is a binary variable to determine where vm hosts a load, and its calculation expression is
So, the total number of running PMs is calculated by
The resource utilization rate is calculated by
2.5 Problem definition
In this paper, we focus on the QoS-aware VM scheduling method to reduce the energy consumption, downtime and the resource utilization, and the VM scheduling problem is defined by
3 A QoS-aware VM scheduling method for energy conservation in cloud-based CPS
As we discuss in the Section 2, the QoS-aware VM scheduling problem is a multi-objective optimization problem. NSGA-III is adopted for its efficient and accurate performance when solving optimization problem with multiple objectives ranging from three to fifteen. First in this section, the VM scheduling strategies are encoded and the fitness functions are given. Then, NSGA-III algorithm is adopted to find the optimal solution. Finally, a method overview is described.
3.1 Encoding
In this section, we encode for the VM scheduling strategies. In the genetic algorithm (GA), a gene represents a scheduling strategy of an application. A chromosome which represents a set of scheduling strategy of VMs is composed of a group of genes. The value of the scheduling strategy which is the location of PMs encodes as 1, 2, 3,…, N. An encoding example of scheduling method for VMs in V with N PMs is displayed in Figure 2. As is shown in Figure 2, v1 is migrated from p1 to p2, and v2 is migrated from p3 to p1, and v3 is migrated from pN to p4, and vm is migrated from p4 to pN.

An instance of encoding
3.2 Fitness function
In GA, fitness function is used to determine whether a solution is efficient. A chromosome is the scheduling strategy of all the VMs in a schedule. In the paper, the NSGA-III algorithm utilizes the energy consumption and resource utilization as the fitness functions to find the optimal scheduling strategies. The fitness functions are given by (11), (15) and (21) respectively.
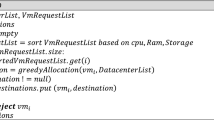
The energy consumption is the first fitness function, Algorithm 1 specifies the procedure of calculating the total energy consumption. In this algorithm, we input the fat-tree network topology, the number of VMs M, the number of PMs N, the encoding result of VM scheduling strategy cs, the VM original deployment Y and the scheduling strategy X. We calculate the total energy consumption including the energy consumption of active VMs, the energy consumed by the idle VMs, the basic energy consumption of PMs, and the switch energy consumption in the algorithm. Finally, the outputs are the total energy consumption for the scheduling strategy.

The downtime of VM migrations is another fitness function, Algorithm 2 specifies the procedure of calculating the downtime of VM migration. In this algorithm, the inputs are the number of VMs M, the number of PMs N, the VM scheduling strategy X, and the VM original deployment Y. The downtime in the VM migration operation contains switch time and the access time of the log file. The access time of the log file is calculated (Lines 1-5), and the switch time is calculated (Lines 6-10).Then we get the total downtime (Line 10).

The resource utilization of PMs is also a fitness function, algorithm 3 specifies how to calculate the average resources utilization of PMs used. The inputs are M VMs to be scheduled, N PMs, the VM scheduling strategy X, and the VM original deployment Y. In this algorithm, we first calculate the total resource utilization, then calculate the resource utilization rate of PMs used.

According to what we discuss in the Section 2, in order to achieve QoS enhancement, we are supposed to reduce the energy consumption and downtime and optimize the resource utilization with the constraints given by (23), (24) and (25). The fitness function optimization problem is a multi-objective optimization problem, and NSGA-III algorithm is used to select the best scheduling policy in the paper.
3.3 Optimize the VM scheduling strategy using NSGA-III algorithm
First, the parameters of the GA are initialized, such as the size of the population The crossover is to combine the two parental chromosomes in the population, trying to get better spring chromosomes., the number of iterations IT, the possibility of crossover and mutation are denoted by Pc, Pd.Each chromosome consists of the VM scheduling policies which are denoted by cs. The chromosome in the s-th schedule is denoted as Cs,e = {cs,e ∣ 1≤s≤ Npop, 1≤ e≤ M}.
The parent population Pt of size Npop is randomly initialized in the specified value range, and then an offspring population Qt which has a size of Npop is generated by crossover and mutation operators. The crossover is to combine the two chromosomes in the parent population to generate new pair of chromosomes. As is shown in Figures 2 and 3, the crossover point is determined firstly, and the genes around the crossover points are changed.

An instance of crossover
The mutation is to modify some genes of chromosome and generate new individuals with the aim of preventing early convergence. Figure 4 shows a instance of mutation operation in one schedule strategy.

An instance of mutation
Then, populations Pt and Qt are combined as population Rt of size 2Npop. Similar to the basic framework of the NSGA-II algorithm, the non-dominated sorting is used to divide the population Rt by non-domination levels. Then, each chromosome is added to a new population St, until the size of St is equal to Npop. For further selection, the ideal points and extreme points are determined first to normalize the objective value, and compute the reference points accordingly. The ideal points are calculated by the minimum for three fitness functions (Emin, Dmin, RUmin) in St. The objective value is translated by subtracting the minimum from the fitness function and then the ideal points of St become a zero vector. The process could be denoted by
The extreme points are identified by the solutions that make the achievement scalarizing function minimum. Let 𝜖E, 𝜖D and 𝜖R be the extreme values of energy consumption, downtime and resource utilization. The extreme values are calculated by
where WE, WD and WRU are the weight factors of the three fitness functions. For each objective function, we could get an extreme vector to construct a hyper-plane. Hence, the intercept of each objective axis could then be computed as aE, aD, aRU. The objective functions are normalized as
According to the new constructed hyper-plane, the reference points are simply placed onto the normalized hyper-plane. Each axis has an intercept of 1 and is divided into g parts along each objective. The total number of reference points is \({C^{g}_{2M+g-1}}\).
After normalizing each objective function adaptively, we need to associate population individuals with reference points. We count the number of population members are associated with reference points. The solutions in the non-dominated front Fl are sorted by the number of reference points associated with solutions. A solution is selected randomly from the solutions that associated with the maximum reference points each time. The selection procedure is repeated until the size of St is equal to Npop for the first time. Finally, the Npop strategies for the child population are selected.
3.4 Selecting scheduling strategy using MCDM and SAW
Our method is aimed at realizing the trade-off among energy consumption, downtime and resource utilization. Each child population selected above contains Npop chromosomes which represent scheduling strategies of VMs. To select the relatively optimal scheduling strategy, MCDM and SAW are employed. The higher energy consumption of scheduling strategy means the solution is worse. Therefore, energy consumption is a negative criterion for our scheduling strategy. We normalize the energy consumption as
where Emax and Emin are the maximum and minimum of energy consumption of Xi scheduling strategy. Similarly, the downtime and resource utilization can be normalized by
In addition, to calculate the utility value of each solution, the weight of each objective function requires determination. The utility value in the scheduling strategy Xi is calculated by
where V (X) represents the utility value of the X scheduling strategy and wE, wD, wRU are the weight of three objectives relatively. After calculating all the utility values of Npop solutions, the maximum utility value is calculated by
The solution Xop with the maximum utility value Vop is selected as the most optimal scheduling strategy.
3.5 Method overview
Our goal is to minimize the downtime and the energy consumption in this paper. The VM scheduling problem is defined as a multi-objective optimization problem and NSGA-III is utilized to find the optimal scheduling strategy. The overview of our method is displayed in Algorithm 4. The input of the algorithm 4 are the initial population Pt and the number of iterations IT. The algorithm outputs the optimal VM scheduling strategy. We generate the population Rt of size 2Npop by combining Pt and Qt. (Lines 2 and 3). Then, we primarily select the child population by non-dominated sorting (Lines 4 to 9). Moreover, we select the strategies further by reference points. (Lines 10 to 15) Finally, we obtain the optimal scheduling strategy Xn.

4 Experimental evaluation
4.1 Simulation setup
In our simulation, four datasets with different scales of the applications are applied, and the number of applications is set to 50, 100, 150 or 200. The specified parameter settings in this experiment are illustrated in Table 2.
4.2 Performance analysis of QVMS
As displayed in Figure 5, when the number of applications is 50, 100, 150, or 200, the number of generated solutions by QVMS is 3, 3 ,3 and 4 respectively. After comparing the utility value given in (36), we obtain the most optimal schedule strategy among all the generated solutions. The solution with the maximum utility value is regarded as the most optimal schedule strategy. For example, the solution 2 in Figure 5b has a obviously higher utility value than the other two solutions and is the optimal solution in all 3 solutions.

Comparison of utility value of the solutions generated by QVMS with different application sets
4.3 Comparison analysis
In this subsection, the comparisons before and after employing our proposed QVMS method with the same experimental context are analyzed in detail. The resource utilization, the downtime and the energy consumption are the main metrics for evaluating the performance of the VM scheduling method. To analyze the advantage of QVMS, several scheduling methods are employed to contrast with. The contrast methods are introduced as follows.
Benchmark: The applications are scheduled to the nearest PM by the shortest path algorithm until the current PM cannot satisfy the resource requirement of the application to be scheduled. Then, the remaining applications are offloaded to the next close PM. The process is repeated until all the applications are offloaded.
ESM (Energy-aware VM scheduling method): ESM is an energy-aware dynamic VM scheduling method in clouds presented by Dou et al. [8]. The method includes two VM offloading phases where applications are offloaded with lower energy consumption or higher performance.
4.3.1 Comparison of resource utilization
Figure 6 shows the comparison of the resource utilization of the PMs among Benchmark, ESM and QVMS with different application scales. It is intuitive from Figure 6 that our proposed strategy QVMS achieves high and stable resource utilization. That is, QVMS reduces the number of idle VMs and wastes less resources.

Comparison of average resource utilization with Benchmark and ESM
4.3.2 Comparison of energy consumption
In the experiment, the energy consumption consists of four parts, active energy consumption of VMs, the idle energy consumption of VMs, the basic energy consumption of PMs and the energy consumption of switches. The energy consumption of VMs, PMs and switches are displayed in Figures 7, 8 and 10 relatively. As is shown Figure 7, the energy consumption of VMs of all the three method is nearly the same. Besides, QVMS has an obvious advantage in the energy consumption of switches. Figure 8 shows that QVMS consume less energy than Benchmark and ESM. Figure 9 shows the comparison of running PMs, our QVMS only has fewer than half of PMs in Benchmark, which means QVMS save more energy consumption and the basic energy consumption of PM is illustrated in Figure 10. The difference between QVMS and ESM in energy consumption of PMs is nearly the same as the number of running PMs. Finally, Figure 11 displays the total energy consumption. With the increase of the application scale, the gap between with or without the employment of QVMS is enlarged, which may because the QVMS employs less PMs and reduce the basic energy consumption of PMs, which save the total energy consumption to a great extent. ESM takes the better performance into consideration at times, which lead to a little bit higher energy consumption than QVMS on some conditions.

Comparison of the energy consumption of running VMs with Benchmark and ESM

Comparison of the energy consumption of switches with Benchmark and ESM

Comparison of the number of running PMs with Benchmark and ESM

Comparison of the energy consumption of running PMs with Benchmark and ESM

Comparison of the total energy consumption with Benchmark and ESM
4.3.3 Comparison of downtime
To improve the resource utilization, VM migrations are necessary between PMs, which results in the cost of downtime. According to the model, network topological distance is the key factor affecting the cost of downtime. We calculate the downtime consumption of all the migration compositions, based on the four application scales. From Figure 12, simulation results show that the downtime fluctuates around 35 seconds in the simulation environment and the downtime of ESM and Benchmark is a little longer than QVMS.

Comparison of the downtime with Benchmark and ESM
5 Related work
With the development of manufacturing industry, CPS are systematically utilized to monitor and process the information between the physical factory layer and the cyber computing layer [1, 19, 21, 34]. In [19], a CPS architecture is proposed as an implement of CPS to improve efficiency, reliability and quality. The proposed CPS structure consists of two components including advanced connectivity and intelligent data management. Besides, to address the complexity, heterogeneity and multidisciplinary nature of industrial CPS, Akkaya et al. using aspect-oriented modeling to segregate aspects of expertise and manage the complexity [1]. In [34], Yu et al. analyze the potential of CPS that makes contributions to the development of smart grid. By virtue of CPS, the efficiency of monitoring, controlling and communication is advanced. However, CPS are lack in real-time performance and dynamic conditions which pose great challenges to monitor industrial applications successfully. Lu et al. surveyed advances in real-time wireless network for industrial CPS including real-time scheduling algorithm, wireless cyber-physical simulation and cyber-physical co-design of wireless control systems [21].
Furthermore, offloading resource intensive applications to cloud has been a popular method to overcome the capacity limit of mobile devices [31, 33]. When offloading the applications, the characteristics of applications and quality of network should be taken into consideration. In [38], Zhou et al. presented an offloading framework which is called mCloud consisting of nearby cloudlets and remote public cloud. By offloading to the mCloud, the context of mobile devices is used to provide an adaptive code offloading decision. However, when many users offloading their tasks to the cloud, they could produce interference to each other and cause long latency. Zheng et al. present a multi-user dynamic computation offloading method using game theory to make efficient and reasonable offloading decision [37]. Similarly, Hong et al. improved the Quality of Experience (QoE) from the perspective of users’ context. To solve the problem of scheduling the offloaded data and selecting offloading services, a energy-latency-price trade-off is presented [15].
Combining CPS with cloud computing is an alternative approach for enhancing performance of CPS applications [9, 11, 18, 25, 35]. In [9], to address the challenge of resource management in cloud system, Gai et al. proposed a smart cloud-based optimizing workload model to assign tasks in heterogeneous clouds taken the sustainable factors into consideration. To reply to the emerging ”Industry 4.0”, the integration of cloud computing and CPS becomes significant. In [35], Yue et al. present a service-oriented industrial cyber-physical model. With the support of cloud and service application, the CPS enable a sustainable system and environmental friendly business. However, as the number of applications increasing, there are operational risks that CPS being attacked. Rahman et al. proposed a forensic-by-design framework for cloud-based CPS to protect CPS cloud system from being attacked [25]. Moreover, with the propose of addressing the lack of applications supporting monitoring and analysis of dynamic human activity in cloud-based CPS, Gravina et al. proposed activity as a service to support human activity recognition [11]. Kumar et al. proposed an intelligent and energy-efficient scheme in smart grid CPS by cloud-based control using game theory to realize efficient energy management [18].
In recent years, many researches focus on efficient approaches to reducing cloud datacenters’ energy consumption [7, 23, 32, 39]. To address this problem, Chiang et al. proposed an efficient green control (EGC) algorithm which solves constrained optimization problems to improve the performance [7]. Zhu et al. proposed an energy-aware scheduling method named EARH for real-time and independent tasks [39]. EARH utilizes a rolling-horizon and is able to be integrated with other scheduling method. In [23], an energy and monetary cost-aware task scheduling model is proposed to offload multiple tasks to cloud. The scheduling model first find the optimal scheduling strategy for tasks, and then offer a reduction in the cost.
Dynamic VM integration is also a way to reduce energy consumption. A feasible way proposed by Chen et al. to handle this problem is reducing search space by selecting a suitable VM composition in the first step, and then abandoning on worse compositions. What’s more, it can ensure optimality of VM integration [5, 20, 24].
In many cases, cloud data centers need service composition mechanisms because single VM can hardly meet all users’ needs [6, 10, 12, 17, 28]. Jiang et al. proposed to choose the top k service composition because it can avoid the emergency such as the unavailability of best service composition [17]. Chen et al. think that QoS-aware service composition need to be formulated as a multi-objective optimization problem due to the requirements of QoS attributes. To find the optimal composition solutions, Chen et al. also proposed an approach based on Pareto set model which adjust the weight of different QoS attributes [6]. In [28], Shah et al. analyze the challenge of realizing QoS of health care service, and using CPS to combine real-time patient monitoring with data processing to enable QoS requirement.
To the best of our knowledge, there are few investigations, focusing on preserving QoS requirement as well as optimizing energy consumption when combining CPS with cloud computing. The efficient VM scheduling method is needed to meet the QoS requirement when offloading CPS applications to the cloud.
6 Conclusion and future work
In this paper, a QoS-aware VM scheduling method for energy conservation in cloud-based CPS is proposed. First, we construct a systematic model with parameters such as downtime, resource utilization and energy consumption. Then, we see this model as a multi-objective optimization and solve it based on NSGA-III. Furthermore, the most optimal scheduling strategy is selected by MCDM and SAW. The method can be used to minimize downtime, energy consumption and maximize resource utilization. Through experimental evaluation, our method is proved to be effective. In the future, more QoS standards will be taken into consideration to meet multiple users’ requirements. Furthermore, our proposed method will be adjusted ulteriorly to make it more practical for real life scenario.
References
Akkaya, I., Derler, P., Emoto, S., Lee, E.: Systems engineering for industrial cyber–physical systems using aspects. Proc. IEEE 104(5), 997–1012 (2016)
Alam, K., Saddik, A.: C2ps: a digital twin architecture reference model for the cloud-based cyber-physical systems. IEEE Access 5, 2050–2062 (2016)
Canali, C., Chiaraviglio, L., Lancellotti, R., Shojafar, M.: Joint minimization of the energy costs from computing, data transmission, and migrations in cloud data centers. IEEE Trans. Green Commun. Netw. 2(2), 580–595 (2018)
Chen, X.: Decentralized computation offloading game for mobile cloud computing. IEEE Trans. Parallel Distrib. Syst. 26(4), 974–983 (2015)
Chen, Y., Huang, J., Lin, C., Hu, J.: A partial selection methodology for eficient QoS-aware service composition. IEEE Trans. Serv. Comput. 8(3), 384–397 (2015)
Chen, Y., Huang, J., Lin, C., Shen, X.: Multi-objective service composition with QoS dependencies. IEEE Trans. Cloud Comput. (2016)
Chiang, Y., Ouyang, Y., Hsu, C.: An efficient green control algorithm in cloud computing for cost optimization. IEEE Trans. Cloud Comput. 3(2), 249–262 (2015)
Dou, W., Xu, X., Meng, S., Zhang, X., Hu, C., Yu, S., Yang, J.: An energy-aware virtual machine scheduling method for service QoS enhancement in clouds over big data. Concurrency and Computation: Practice and Experience, 29(14), e3909 (2017)
Gai, K., Qiu, M., Zhao, H., Sun, X.: Resource management in sustainable cyber-physical systems using heterogeneous cloud computing. IEEE Transactions on Sustainable Computing 3(2), 60–72 (2018)
Garcia-Valls, M., Bellavista, P., Gokhale, A.: Reliable software technologies and communication middleware: a perspective and evolution directions for cyber-physical systems, mobility, and cloud computing. Futur. Gener. Comput. Syst. 71, 171–176 (2017)
Gravina, R, Ma, C, Pace, P, Aloi, G, Russo, W, Li, W, Fortino, G.: Cloud-based activity-aaservice cyber–physical framework for human activity. Futur. Gener. Comput. Syst. 75, 158–171 (2017)
Gu, L., Zeng, D., Guo, S., Barnawi, A., Xiang, Y.: Cost efficient resource management in fog computing supported medical cyber-physical system. IEEE Trans. Emerg. Top. Comput. 5(1), 108–119 (2017)
Hasan, M., Kouki, Y., Ledoux, T., Pazat, J.: When Green SLA becomes a possible reality in cloud computing. IEEE Trans. Cloud Comput. 5(2), 249–262 (2017)
Hasan, M., Kouki, Y., Ledoux, T., Pazat, J.: When Green SLA becomes a possible reality in cloud computing. IEEE Trans. Cloud Comput. 5(2), 249–262 (2017)
Hong, H., El-Ganainy, T., Hsu, C., Harras, K., Hefeeda, M.: Disseminating multilayer multimedia content over challenged networks. IEEE Trans. Multimedia 20 (2), 345–360 (2018)
Hossain, M., Malhotra, J.: Cloud-supported cyber–physical localization framework for patients monitoring. IEEE Syst. J. 11(1), 118–127 (2017)
Jiang, W., Hu, S., Liu, Z.: Top K query for QoS-aware automatic service composition. IEEE Trans. Serv. Comput. 7(4), 681–695 (2014)
Kumar, N., Zeadally, S., Misra, S.: Mobile cloud networking for efficient energy management in smart grid cyber-physical systems. IEEE Wirel. Commun. 23 (5), 100–108 (2016)
Lee, J., Bagheri, B., Kao, H.: A cyber-physical systems architecture for industry 4.0-based manufacturing systems. Manufacturing Letters 3, 18–23 (2015)
Liu, Y., Liu, A., Guo, S., Li, Z., Choi, Y., Sekiya, H.: Context-aware collect data with energy efficient in Cyber–physical cloud systems, Futur. Gener. Comput. Syst. (2017)
Lu, C., Saifullah, A., Li, B., Sha, M., Gonzalez, H., Gunatilaka, D., Wu, C., Nie, L., Chen, Y.: Real-time wireless sensor-actuator networks for industrial cyber-physical systems. Proc. IEEE 104(5), 1013–1024 (2016)
Nir, M., Matrawy, A., St-Hilaire, M.: Economic and energy considerations for resource augmentation in mobile cloud computing. IEEE Trans. Cloud Comput. 6(1), 99–113 (2018)
Nir, M., Matrawy, A., St-Hilaire, M.: Economic and energy considerations for resource augmentation in mobile cloud computing. IEEE Trans. Cloud Comput. 6(1), 99–113 (2018)
Qi, L., Meng, S., Zhang, X., Wang, R., Xu, X., Zhou, Z., Dou, W.: An exception handling approach for privacy-preserving service recommendation failure in a cloud environment. Sensors 18(7), 2037 (2018)
Rahman, N., Glisson, W., Yang, Y., Choo, K.: Forensic-by-design framework for cyber-physical cloud systems. IEEE Cloud Computing 3(1), 50–59 (2016)
Rodriguez-Mier, P., Mucientes, M., Lama, M.: Hybrid optimization algorithm for large-scale QoS-aware service composition. IEEE Trans. Serv. Comput. 10(4), 547–559 (2017)
Sadooghi, I., Martin, J., Li, T., Brandstatter, K., Maheshwari, K., Ruivo, T., Garzoglio, G., Timm, S., Zhao, Y., Raicu, I.: Understanding the performance and potential of cloud computing for scientific applications. IEEE Trans. Cloud Comput. 5(2), 358–371 (2017)
Shah1, T., Yavari, A., Mitra, K., Saguna, S., Jayaraman, P., Rabhi, F., Ranjan, R.: Remote health care cyber-physical system: quality of service (QoS) challenges and opportunities. IET Cyber-Physical Systems 1(1), 40–48 (2016)
Shu, Z., Wan, J., Zhang, D., Li, D.: Cloud-integrated cyber-physical systems for complex industrial applications. Mobile Netw. Appl. 21(5), 865–878 (2016)
Wang, S., Lei, T., Zhang, L., Hsu, C., Yang, F.: Offloading mobile data traffic for QoS-aware service provision in vehicular cyber-physical systems. Futur. Gener. Comput. Syst. 61, 118–127 (2016)
Xu, X., Dou, W., Zhang, X., Chen, J.: Enreal: an energy-aware resource allocation method for scientific workflow executions in cloud environment. IEEE Trans. Cloud Comput. 4(2), 166–179 (2016)
Xu, X., Dou, W., Zhang, X., Hu, C., Chen, J.: A traffic hotline discovery method over cloud of things using big taxi GPS data. Software: Practice and Experience 47(3), 361–377 (2017)
Xu, X., Zhao, X., Ruan, F., Zhang, J., Tian, W., Dou, W., Liu, A.: Data placement for privacy-aware applications over big data in hybrid clouds. Secur. Commun. Netw. 2017, 1–15 (2017)
Yu, X., Xue, Y.: Smart grids: a cyber–physical systems perspective. Proc. IEEE 104(5), 1058–1070 (2016)
Yue, X., Cai, H., Yan, H., Zou, C., Zhou, K.: Cloud-assisted industrial cyber-physical systems: an insight. Microprocess. Microsyst. 39(8), 1262–1270 (2015)
Zhang, Y., Qiu, M., Tsai, C., Mehedi Hassan, M., Alamri, A.: Health-CPS: healthcare cyber-physical system assisted by cloud and big data. IEEE Syst. J. 11(1), 88–95 (2017)
Zheng, J., Cai, Y., Wu, Y., Shen, X.: Dynamic computation offloading for mobile cloud computing, A stochastic game-theoretic approach. IEEE Trans. Mobile Comput. 18(4), 771–786 (2018)
Zhou, B., Dastjerdi, A., Calheiros, R., Srirama, S., Buyya, R.: A context-aware offloading framework for heterogeneous mobile cloud. IEEE Trans. Serv. Comput. 10(5), 797–810 (2017)
Zhu, X., Yang, L., Chen, H., Wang, J., Yin, Shu, Liu, X.: Real-time tasks oriented energy-aware scheduling in virtualized clouds. IEEE Trans. Cloud Comput. 2 (2), 168–180 (2014)
Acknowledgements
This research is supported by the National Science Foundation of China under grant no. 61702277 and no. 61872219.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article belongs to the Topical Collection: Special Issue on Smart Computing and Cyber Technology for Cyberization
Guest Editors: Xiaokang Zhou, Flavia C. Delicato, Kevin Wang, and Runhe Huang
Rights and permissions
About this article

Cite this article
Qi, L., Chen, Y., Yuan, Y. et al. A QoS-aware virtual machine scheduling method for energy conservation in cloud-based cyber-physical systems. World Wide Web 23, 1275–1297 (2020). https://doi.org/10.1007/s11280-019-00684-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11280-019-00684-y