
Abstract
Big data analytics has simplified processing complexity of large dataset in a distributed environment. Many state-of-the-art platforms i.e. smart grid has adopted the processing structure of big data and manages a large volume of data through MapReduce paradigm at distribution ends. Thus, whenever a wireless IoT edge node bundles a sensor dataset into storage media, MapReduce agent performs analytics and generates output into the grid repository. This practice has efficiently reduced the consumption of resources in such a giant network and strengthens other components of the smart grid to perform data analytics through aggregate programming. However, it consumes an operational latency of accessing large dataset from a central repository. As we know that, smart grid processes I/O operations of multi-homing networks, therefore, it accesses large datasets for processing MapReduce jobs at wireless IoT edge nodes. As a result, aggregate MapReduce at wireless IoT edge node produces a network congestion and operational latency problem. To overcome this issue, we propose Wireless IoT Edge-enabled Block Replica Strategy (WIEBRS), that stores in-place, partition-based and multi-homing block replica to respective edge nodes. This reduces the delay latency of accessing datasets for aggregate MapReduce and increases the performance of the job in the smart grid. The simulation results show that WIEBRS effective decreases operational latency with an increment of aggregate MapReduce job performance in the smart grid.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Big data processing has resolved large dataset management challenges in a distributed parallel environment [1]. We find many large dataset management systems i.e. Cloudera [2], MapR [3] and Hadoop [4] in todays market that support multihoming aggregate MapReduce processing. Apache Hadoop is an open-source data management system that processes large-scale datasets in distributed environment. It consists of four main components i.e. Hadoop-common, YARN [5], HDFS [6] and MapReduce [7]. Hadoop-common is a library that provides environment functions for cluster processing. Yet Another Resource Negotiator (YARN) is the brain of Hadoop that schedules tasks and allocate resources into them. Hadoop Distributed File System (HDFS) is a file system that manages I/O operations of files and blocks in the cluster. MapReduce is an open-source programming model that processes large-scale datasets in the distributed parallel environment. HDFS comprises of three components i.e. client, Namenode, and Datanode. A client submits an input of MapReduce job and requests Namenode to allocate resources and schedules tasks over a Datanode. The Datanode processes job and generates an output into storage media of HDFS [8, 9] as shown in Fig. 1.

HDFS architecture
The smart grid is an evolution in traditional power grid architecture and adopts processing structure of big data to manage and process large volumes of data into distributed ends [10]. The grid supports aggregate programming and facilitates MapReduce paradigm to run aggregate functions for evaluating jobs in distributed ends [11]. This shifts consumption of resources i.e. computing capacity and memory usage from the level of the central grid to individual edge nodes and effectively performs data analytics in smart grid [12]. However, a network of the grid pays trade-off to this benefit and consumes huge bandwidth in transporting enormous size datasets for aggregate MapReduce processing [13]. Moreover, aggregate function consumes an operational latency Latencyn = Networki (Pathdistance/(Processing Time)) in receiving data blocks through multi-homing environment [14]. Thus, aggregate MapReduce produces operational latency problems and network congestion issues in smart grid.
To resolve this issue, we propose Wireless IoT Edge-enabled Block Replica Strategy (WIEBRS), that stores data block replicas into in-place wireless IoT edge node, partition-based group of nodes and multi-homing based network of nodes and perform aggregate MapReduce job over them. This tremendously reduces network workload of moving large datasets and reduces operational latency in the smart grid.
The main contribution of the WIEBRS is:
-
A novel in-place replica generation strategy that manages blocks with-in the workstation.
-
A novel partition-based replica generation strategy that places blocks into multiple storage medias of the workstations
-
A novel multi-homing based replica strategy that processes block into multiple network nodes of the cluster
The remaining paper is organized as follows. Section 2 describes related work of similar fashion. Section 3 briefly explains proposed strategy WIEBRS. Section 4 presents experimental environment and evaluation result. Finally, Sect. 5 describes conclusion and future research directions.
2 Related Work
Several researchers have presented their contributions in IoT-enabled data analytics such as processing large-scale IoT datasets in the distributed big data environment [15], urban IoT edge analytics [16], Iot devices used as edge nodes over road networks [17], an IoT converging technique for processing large-scale big data analytics in mobile edge computing [18], deep learning techniques to use IoT datasets in edge computing [15] and live large-scale streaming analytics in wireless IoT edge nodes [19]. To this extent and best of authors’ knowledge, research related to processing large-scale data blocks placement over IoT-enabled edge-node has not much explored.
This paper introduces a novel concept of processing in-place, partition-based and multi-homing based data block replica management using edge-nodes into a large-scale data analytics environment.
3 Wireless IoT Edge-Enabled Block Replica Strategy (WIEBRS)
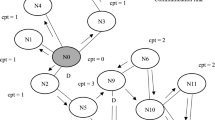
WIEBRS is an adaptive block replica strategy that purposefully addresses block replication in three ways i.e. (1) In-place replica management, (2) Partition-based replica management and (3) multi-homing based replica management and stores \('n+1'\) replica into in-place storage media, exchanges \('n+2\left( n\right) '\) replicas into partition k and \('n+3\left( n\right) '\) replicas to multi-homing partition of smart grid as shown in Fig. 2.

WIEBRS replica management
3.1 In-Place Replica Management
When an edge node processes an aggregate MapReduce job j, Namenode generates in-place input splits of program m based on number of edges and performs map operation map \(\left( M \right)\). The edge node produces a map result and returns combiner task for reduce operation. Unlike the default approach, Namenode then assigns reduce operation to same edge node and produces an output into storage media. This aggregate MapReduce job processing generates an in-place output into storage media of node c. The number of in-place replicas can be obtained as,
where the term in-place expresses a collection of storage media such as RAM, SSD and Disk. The precise replica production of in-place management can be represented as,
3.2 Partitioned-Based Replica Management
Partitions separate the storage and accessibility of same block copies in a single group of edge nodes. The partitions of wireless IoT edge nodes are designed to support the idea of aggregate MapReduce job processing. Therefore, when an edge node produces an in-place replica \(Replica_{in-place}\), partition k receives a copy of it and exchange that with other edge nodes of the same partition. The number of partitioned-based replicas can be obtained as,
The heterogeneous storage media in partition-based replica management simplifies complexity of storing \(k\times Replica_{in-place}\) in respective medias and edge nodes exchange block copies onto multiple storage media as,
3.3 Multi-Homing Based Replica Management
The term multi-homing represents an exchange of block copies over \(2\left( w \right)\) networks. When an in-place edge node produces a replica, it is exchanged with two or more than two multi-homing w networks that are capable to handle replica partitions. With this posture of properties, a multi-homing network can handle replicas as,
where w represents the number of multi-homing networks available in a cluster. Keeping the fact in view, that a multi-homing may belong to multiple class of IPs [20], WIEBRS exchange the block copies onto trusted storage media of respective edge nodes as,
where E represents an edge node of a multi-homing networking having trusted tag T.
4 Experimental Evaluation
In this section, we simulate WIEBRS approach over a multi-homing cluster configuration.
4.1 Environment
The cluster configuration consists of Intel Xeon processor with 8 CPUs, 32 GB memory, and storage device i.e. 1 TB Hard disk drive. In addition to that, we use Intel core i5 with 4 Core, 16 GB memory and storage device i.e. 1 TB Hard disk drive. We install 5 virtual machines having VirtualBox 5.0.16, as seen from Tables 1 and 2.
4.2 Experimental Dataset
The experimental dataset consist of 25 data blocks of 64 MB (1.56 GB size) [21].
4.3 Experimental Results
The simulations performed for evaluating proposed approach are: (1) In-place aggregate MapReduce, (2) Partitioned-based aggregate MapReduce, and (3) Multi-homing based aggregate MapReduce processing.
4.3.1 In-Place Aggregate MapReduce Processing
MapReduce generates a single input split program due to operations being carried into single wireless IoT edge node ‘c’ [22]. WIEBRS observes that single edge node consumes in-place computing capacity, memory usage and network I/O between \(65 \le resources \ge 75\) node percentile and in-place bandwidth between \(0.2 \le Bandwidth \ge 0.8\) GB/s for generating an output of the aggregate MapReduce job. The in-place block placement function stores 1.56 GB of the replica as shown in Fig. 3.

Aggregate MapReduce performance in single wireless IoT edge node
4.3.2 Partitioned-Based Aggregate MapReduce Processing
MapReduce generates \(n+2\left( n\right)\) input split programs for processing a job into partition k [23]. WIEBRS observes that partition k divides input split programs into \(k\times \left\{ n+2\left( n\right) \right\}\) configuration and consumes computing capacity, memory usage and network I/O between \(78 \le resource \ge 87\) partition percentile and partition network bandwidth between \(0.3 \le Bandwidth \ge 0.7\) GB/s for generating an output of the aggregate MapReduce job. The partitioned-based block placement function stores 1.56 GB of the replica to each node of partition k as shown in Fig. 4.

Aggregate MapReduce performance in partition k
4.3.3 Multi-Homing Based Aggregate MapReduce Processing
MapReduce generates \(n+3\left( n\right)\) input split programs for processing a job into multi-homing network w. WIEBRS observes that multi-homing network divides input split programs into \(w\times \left\{ n+3\left( n\right) \right\}\) configuration and consumes computing capacity, memory usage and network I/O between \(80 \le resource \ge 88\) multi-homing network percentiles and a multi-homing network bandwidth \(0.6 \le Bandwidth \ge 10\) GB/s for generating output of aggregate MapReduce job. The multi-homing network based block placement function stores 1.56 GB of the replica to each node of network G, as shown in Fig. 5.

Aggregate MapReduce performance in multi-homing network w
5 Conclusion
This paper proposes Wireless IoT Edge-enabled Block Replica Strategy (WIEBRS), that stores block replicas onto in-place, partition-based and multi-homing network based storage media and perform the aggregate MapReduce job in respectively. WIEBRS is evaluated through simulations and observed that Wireless IoT Enabled-Edge nodes effectively increases aggregate MapReduce block replica placement performance in a multi-homing distributed computing environment. In future, we focus to work over inter-media replica management of Hadoop cluster in smart grid environment.
References
LaValle, S., et al. (2011). Big data, analytics and the path from insights to value. MIT Sloan Management Review, 52(2), 21.
Cloudera. (2016). The modern platform for data management and analytics. Cloudera. http://www.cloudera.com/. Accessed April 27, 2016.
M. Technologies. (2016). Featured customers. https://www.mapr.com/. Accessed April 27, 2017.
Welcome to Apache Hadoop!. (2014). http://hadoop.apache.org/. Accessed April 27, 2017.
Apache Hadoop 2.7.2 Apache Hadoop YARN. (2016). https://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html. Accessed April 27, 2017.
Apache Hadoop 2.7.2 HDFS users guide. (2016). https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html. Accessed April 27, 2017.
Apache Hadoop 2.7.2 MapReduce Tutorial. (2016). https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html. Accessed April 27, 2017.
Karun, A. K., & Chitharanjan, K. (2013). A review on hadoopHDFS infrastructure extensions. In 2013 IEEE conference on information and communication technologies (ICT). IEEE.
Tsuruoka, Y. (2016). Cloud computing-current status and future directions. Journal of Information Processing, 24(2), 183–194.
Tuballa, M. L., & Abundo, M. L. (2016). A review of the development of Smart Grid technologies. Renewable and Sustainable Energy Reviews, 59, 710–725.
Gungor, V. C., et al. (2011). Smart grid technologies: Communication technologies and standards. IEEE transactions on Industrial Informatics, 7(4), 529–539.
Bera, S., Misra, S., & Rodrigues, J. J. P. C. (2015). Cloud computing applications for smart grid: A survey. IEEE Transactions on Parallel and Distributed Systems, 26(5), 1477–1494.
Spivak, A., & Nasonov, D. (2016). Data preloading and data placement for MapReduce performance improving. Procedia Computer Science, 101, 379–387.
Maheshwari, N., Nanduri, R., & Varma, V. (2012). Dynamic energy efficient data placement and cluster reconfiguration algorithm for mapreduce framework. Future Generation Computer Systems, 28(1), 119–127.
Li, H., Ota, K., & Dong, M. (2018). Learning IoT in edge: Deep learning for the internet of things with edge computing. IEEE Network, 32(1), 96–101.
Chowdhery, A., et al. (2018). Urban IoT edge analytics. In A. Rahmani, P. Liljeberg, J.-S. Preden & A. Jantsch (Eds.), Fog computing in the internet of things (pp. 101–120). Cham: Springer.
Zhang, D., Shou, Y., & Xu, J. (2018). A mapreduce-based approach for shortest path problem in road networks. Journal of Ambient Intelligence and Humanized Computing, 9(46), 1–9.
Lu, Z., et al. (2017). IoTDeM: An IoT Big Data-oriented MapReduce performance prediction extended model in multiple edge clouds. Journal of Parallel and Distributed Computing, 118, 316–327.
Sharma, S. K., & Wang, X. (2017). Live data analytics with collaborative edge and cloud processing in wireless IoT networks. IEEE Access, 5, 4621–4635.
José, M., & Hutchison, D. (2018). Game theory for multi-access edge computing: Survey, use cases, and future trends. In IEEE Communications Surveys & Tutorials.
Qureshi, N. M. F., Shin, D. R., Siddiqui, I. F., & Chowdhry, B. S. (2017). Storage-tag-aware scheduler for hadoop cluster. IEEE Access, 5, 13742–13755.
(2016) RDP: A storage-tier-aware Robust Data Placement strategy for Hadoop in a Cloud-based Heterogeneous Environment. KSII Transactions on Internet and Information Systems 10(9)
Abbas, A., Farah Siddiqui, I., Lee, S. U., Kashif Bashir, A., Ejaz, W., & Qureshi, N. M. F. (2018). Multi-objective optimum solutions for IoT-based feature models of software product line. IEEE Access, 6, 12228–12239.
Acknowledgements
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2016R1A6A3A11932892).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Qureshi, N.M.F., Siddiqui, I.F., Unar, M.A. et al. An Aggregate MapReduce Data Block Placement Strategy for Wireless IoT Edge Nodes in Smart Grid. Wireless Pers Commun 106, 2225–2236 (2019). https://doi.org/10.1007/s11277-018-5936-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-018-5936-6