
Abstract
This study assessed the effect of adjectives and noun premodifiers on L2 noun phrase comprehension and error types among English Language Learners. We also examined the correlation between L2 noun phrase comprehension and L2 reading comprehension, as well as the contribution of L2 noun phrase comprehension to L2 reading comprehension. One hundred and one Hebrew-speaking 11th graders were tested on the English noun phrase comprehension task, indexing cross-language effects (from L1 to L2). The task included sentences in four conditions, each representing a different noun phrase structure at the syntactic subject position: NN, NNN, AdjNN, and AdjNNN. Participants also completed L1 reading comprehension and L2 vocabulary tests that were controlled for in the correlation and regression analyses. Overall, the results indicate that sentences with noun premodifiers and no adjective premodifiers were more challenging and more susceptible to L1 interference. Partial correlation analyses showed that participants’ performance on all four conditions of the noun phrase comprehension test was significantly and positively correlated with their L2 reading comprehension. Multiple regression analyses revealed that higher accuracy and low error rates in the NN and AdjNNN conditions made a unique contribution to L2 reading comprehension, when we controlled for L1 reading comprehension and L2 vocabulary. This study confirmed the significant effects L1 has on L2 syntactic knowledge, which relates significantly and contributes to L2 reading comprehension abilities among adolescent students.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Cross-language transfer
Native speakers develop a deep understanding of language structure through exposure. This understanding includes lexical knowledge, word categories, syntactic structures and grammatical rules, as well as an understanding of the relative frequencies with which these different elements co-occur (MacDonald, 2013; MacDonald et al., 1994; Tabor & Tanenhaus, 1999). English language learners (ELLs) sometimes use such previously acquired knowledge about their first language (L1) to cope with the linguistic demands of the target language (L2, Bardovi-Harlig & Sprouse, 2018; Patel et al., 2022; Verbeek et al., 2022). This phenomenon is known as Cross-Language Transfer. While cross-language transfer has been found more commonly in beginning learners (e.g., Schwartz & Sprouse, 1996), even as learners develop their interlanguage, they may persist in occasionally employing linguistic patterns from their L1 (e.g., Choi & Ionin, 2021). These occurrences of cross-language transfer effects that influence comprehension and production are propelled by a “grammar competition” scenario, whereby the grammatical structures of another language become active simultaneously, resulting in a competition for activation between the grammatical structures of all the different languages spoken by the individual (e.g., Amaral & Roeper, 2014; Smith & Truscott, 2014).
The influence of a learner’s L1 on L2 comprehension can be positive, e.g., when knowledge of the first language leads to faster and easier mastery of the target language due to high similarity, or negative, where differences between these languages occur, thus leading to more L2 errors (Baker, 2008; Borer, 1984; Chomsky, 1995; Slabakova, 2008, 2013). Positive or negative cross-language transfer can be manifested in different linguistic domains such as accent, lexicon, grammar (MacWhinney, 2005; Prior et al., 2017) or syntax (Booth et al., 2018). For example, when ELLs are required to process a syntactic structure in L2, they may rely on the L1 syntactic structure (König & Gast, 2008; Lipka et al., 2005; Ringbom, 2007). When the syntactic structure of the first language is different or does not exist in the foreign language, syntactic errors in oral and written production may arise, as well as difficulties in L2 reading comprehension (Hatzidaki et al., 2011; Lemhöfer et al., 2010; Robertson, 2000; Świątek, 2018).
Various studies have examined cross-language transfer. However, findings have not been consistent due to variations in the linguistic aspect under investigation, the L1-L2 language combinations and the grammatical differences between these languages, and the type of task employed to study the effects (Ellis, 2005). The present study focuses on the effect of adjective and noun premodifiers, which are constructed differently in Hebrew and English, on L2 Noun Phrase (NP) comprehension and error types among Hebrew-speaking English Language Learners (ELLs), as well as the connection and contribution to L2 reading comprehension.
L2 syntactic knowledge, syntax transfer, and reading comprehension
Syntactic knowledge involves incorporating individual words into structures and making predictions about the syntactic structure, word category, or specific word that is likely to come next (Altmann & Mirkovic, 2009; Jaeger & Snider, 2013; Kutas et al., 2011; Levy, 2008; MacDonald, 2013; Pickering & Garrod, 2013; Van Petten & Luka, 2012). In the context of bilingualism and L2, studies provide two main perspectives on how bilinguals process syntax: the Shared Syntax account and the separate syntax account (Hartsuiker & Pickering, 2008). These two approaches differ in their assumptions about whether L1 and L2 syntactic knowledge are integrated or separate. The Shared Syntax account proposes that bilinguals have a shared set of syntactic representations for both languages, and that the grammatical rules of one language can influence the other language (e.g., Bernolet et al., 2013; Hartsuiker et al., 2004). Conversely, the separate syntax account (e.g., de Bot, 1992; Ullman, 2001) suggests that bilinguals maintain separate stores of syntactic information for each language and access them independently.
Various studies have shown that bilinguals can rely on previously acquired L1 resources to support the development of L2 skills (Koda, 2007, 2008). This reliance appears to be related to the level of similarity between grammatical constructions (e.g., Hwang et al., 2017). Research examining the influence of L1 syntax on L2 sentence processing remains limited and inconclusive. Some evidence suggests that L1 syntax may affect L2 processing, particularly in tasks involving complex word order and online reading (Hopp, 2006, 2010; Jackson, 2008). According to constraint-based theories of language, during L2 sentence processing, individuals consider multiple syntactic analyses simultaneously and ultimately adopt the interpretation with the strongest support (MacDonald et al., 1994; Trueswell et al., 1994).
Several studies have suggested that for similar constructions in both languages, bilinguals share syntactic representations (e.g., Bernoletet al., 2007; Bernolet et al., 2013; Hartsuiker et al., 2004; Hartsuiker & Bernolet, 2017; Kantola & van Gompel, 2011). A study by Tokowicz and Warren (2010) has shown that English-speaking beginning adult L2 learners of Spanish showed sensitivity to grammatical violations in the L2 only in structures that are similar to those of the L1, but not in L2-unique structures. Similarly, Hwang et al. (2017) found that Korean-English bilinguals may have native-like syntactic skills for similar constructions, but not necessarily for different constructions. Hwang et al. (2017) reported an increase in transfer errors, possibly because participants had difficulty suppressing a competing first language structure due to shared syntactic processes.
Certain studies propose that L2 readers do not consistently rely on L1 syntax during L2 sentence comprehension, demonstrating similar or no preference for syntactic attachment regardless of differences between their L1 and L2 preferences (Felser et al., 2003; Papadopoulou & Clahsen, 2003). Nonetheless, some conflicting findings suggest otherwise (Hopp, 2014; Witzel et al., 2012). Against this diverse background, it is not clear whether the finding extends to other syntactic constructions (e.g., NPs) and typologically different languages (e.g., Hebrew and English). Do Hebrew-speaking ELLs draw upon linguistic elements and structures from their first language during NP comprehension? These conflicting findings suggest that more research is needed.
Syntactic knowledge is closely related to reading comprehension in both L1 and L2 (e.g., Cain, 2007; Guo & Roehrig, 2011; Hung, 2021; Sarbazi et al., 2021; Tong et al., 2014; Zhang, 2012), as a reader’s ability to anticipate the syntactic categories of the following words may impact the capacity and speed of deriving meaning from the sentence (Folk & Morris, 2003; Tunmer & Bowey, 1984) and the whole text (Kintsch, 1998). In studies that involved different languages, knowledge of syntactic structures in L2 has been found to be a strong predictor of reading comprehension in both children (Taşçı & Turan, 2021) and adults (Gottardo & Mueller, 2009; Shiotsu & Weir, 2007; Van Gelderen et al., 2003). However, the effect of L2 NP structures and their difference from L1 structures on L2 reading comprehension has yet to be investigated. The current study investigated whether Hebrew-English bilingual adolescents rely on their L1 syntactic representations when coping with L2 NP structures at the subject position of the sentence in their L2, i.e., whether they rely on word order conventions in Hebrew while reading sentences in English, and whether this ability is related to and explains English reading comprehension.
Word order in L2
One critical aspect of syntactic knowledge is understanding how the words are arranged canonically in the sentence. This understanding helps the reader derive meaning from written or spoken input, decipher ambiguous words (Folk & Morris, 2003), predict the next word, and anticipate its syntactic category (Tunmer & Bowey, 1984). Studies have shown that second language learners can process L2 input word-by-word by gradually interpreting the input and reacting to semantic information (Dussias & Cramer, 2008; Dussias & Piñar, 2010; Juffs & Harrington, 1996; Williams, 2006; Williams et al., 2001). However, they do not predict the next word to the same extent as native speakers, although they may be familiar with the L2 word order rules (Dussias et al., 2013; Grüter et al., 2012; Grüter & Rohde, 2013; Hopp, 2013; Lew-Williams & Fernald, 2010; Martin et al., 2013). It has been found that in sentences that include the movement of words or the use of long-distance dependencies, word order can be a bottleneck in the meaning making process (Clahsen & Felser, 2006).
Various studies have revealed that language learners present word order errors that are influenced by the L1 during sentence comprehension and production. For example, Spanish and Dutch ELLs encounter difficulty in creating indirect questions in English (L2), as they present word order errors that are influenced by their L1 (Hatzidaki et al., 2018). Similar findings were also found among French children who reversed word order when composing sentences in English due to the influence of their L1 word order; in French, the adjective typically follows the noun, but commonly used adjectives can appear before the noun (Nicoladis, 2006).
The effect of word order has been observed in adult ELLs as well (Yuan, 2017). For instance, in a study that tested Chinese-speaking students, a longer reaction time was observed in English sentence comprehension, compared to native English-speaking students. The longer reaction time may be attributed to the fact that in Chinese, the sentence begins with a word that represents the theme of the sentence rather than the subject (Yuan, 2017). This study indicates that despite adequate exposure and proficiency, performance on sentence comprehension tasks can be affected by the linguistic difference between the languages.
NPs: Hebrew vs. English
NP is considered the largest expansion of the maximal projection of the noun (Omachonu, 2016). Smaller than a clause or sentence, NPs play roles in both the internal structure of clauses, serving as subjects or objects, and in the syntactic connection between clauses through the use of relative clauses (Ravid & Berman, 2010). An NP may contain more than one noun, but only one noun in the NP can function as its head (Jackendoff, 1977). The distinction between the head and the additional elements of the NP is that the head noun is obligatory, while the other elements are optional (Attabor, 2019; Mathews, 2003). In complex NPs, which include a head noun that functions as the subject and the related descriptors, the position of the premodifiers, their number and their type, affect the language learner’s ability to process the sentence (Priven, 2020; Trimble, 1985).
NPs possess well-defined syntactic boundaries and generally adhere to a fixed ordering of internal components, making them resistant to syntactic extraction (Ravid & Berman, 2010; Siloni, 1997). However, word order within the NP can vary across languages. While in some languages, the modifiers can precede the head noun (e.g., English, German, or Turkish), in other languages modifiers follow it (for example in Hebrew, Arabic, or Spanish). In Russian, for example, both options are possible (Dryer, 2007). The processing of NPs is considered a meaning construction process (Gagné & Spalding, 2011; Ji et al., 2011; Koester et al., 2007) which goes beyond mere word recognition and entails the activation and integration of semantic, syntactic, and pragmatic information to form a coherent mental representation of the phrase. Such a process may be challenging for L2 learners who may have difficulty comprehending sentences in which the position of the head noun’s modifiers is different than in their L1. For example, Spanish-speaking ELLs have been found to have difficulty translating complex NPs appearing in medical research articles from English to Spanish (Pastor, 2008). Each additional premodifier in the English sentence altered the position of the subject compared to its position in Spanish, thereby increasing the level of difficulty in translating the sentence. This difficulty translates into syntactic transfer errors (Hwang et al., 2017) during comprehension of L2 sentences.
Hebrew and English exhibit typological differences in NP usage and structure (Berman, 1988, 2009; Ravid & Shlesinger, 1995; Ravid & Zilberbuch, 2003a, b). Nominal elements assume a more central role in Hebrew syntax compared to English; Hebrew shows a propensity for more nominal elements within clause structures. Unlike English, Hebrew lacks features that contribute to the complexity of the verb phrase, relying instead on adverbial prepositional phrases to convey similar meanings. The relative “nominality” of Hebrew compared to English is manifested in a diverse range of nominal constructions linking two nouns, such as “construct state” bound compounds, periphrastic noun plus noun constructions, and the use of the genitive particle “shel” or other prepositions, alongside the complex “double construct” linking and denominal adjective modification. Consequently, Hebrew NPs are typically longer than their English counterparts (Berman, 1988, 2009; Ravid & Shlesinger, 1995; Ravid & Zilberbuch, 2003a, b).
Word order within the NP is constructed differently in Hebrew and English; in Hebrew, modifiers follow nouns (Wintner & Ornan, 1995), whereas in English, modifiers precede the noun. Consider the following four sentences and the NP structure used in each one.
-
(1)
English: The ‘team leader’ was highly impressive. (NN)
Hebrew: ‘Leader the team’ was highly impressive.
-
(2)
The ‘new team leader’ was highly impressive. (AdjNN)
Hebrew: ‘Leader the team the new’ was highly impressive.
-
(3)
The ‘debate team leader’ was highly impressive. (NNN)
Hebrew: ‘Leader team the debate’ was highly impressive.
-
(4)
The ‘new debate team leader’ was highly impressive. (adjNNN)
Hebrew: ‘Leader team the debate the new’ was highly impressive.
We tested our participants’ ability to identify the head noun in each of these 4 types of NPs, which can be challenging for Hebrew-speaking ELLs. In Sentences 1 and 3 which do not include an adjective, Hebrew-speaking ELLs can be affected by the NP structure in Hebrew (in which the head noun appears first) and mistakenly identify the word ‘team’ (in Sentence 1) or the word ‘debate’ (in Sentence 3) as the head noun. Because Hebrew often employs a “head-first” structure in NPs, where the head noun precedes its modifiers, Hebrew-speaking ELLs do not look for the head noun of an NP after already seeing a noun at the beginning of the sentence (except that it’s a premodifier). This is what we call an L1-based error (Pichette & Leśniewska, 2018) which results from syntactic transfer. Any other noun that is identified by Hebrew-speaking ELLs as the head noun of the NP does not directly derive from activation of L1 syntax and may stem from inadequate mastery of the L2.
Hebrew-speaking ELLs are also more likely to anticipate the head noun after they encounter an adjective (in Sentences 2 and 4, the word “new” would signal to them that they should keep reading to find the head noun). In other words, due to cross-language influence, Hebrew-speaking ELLs may display a preference for “head noun first”, which results from an L1-based rather than L2-based parsing mechanism. In addition to the change of the location of the head noun, note that in Hebrew the prefixal “The” attaches not to the head element in the construction, which is sequentially the first nominal in the expression (the head noun generally preceding its modifiers in Hebrew NP’s), but rather to the modifying noun. If the definite marker “The” is attached to the modifying noun, the expression as a whole is definite (as seen in Sentences 1 and 3). In NPs that include an adjective, the prefixal “The” is also added to the adjective (as seen in Sentences 2 and 4; Berman, 1978).
While most studies have explored the production of NPs as a measure of syntactic complexity in both L1 (Ansarifar et al., 2018; Biber & Gray, 2011; Lan et al., 2019; Parkinson & Musgrave, 2014) and L2 writing (Hesamoddin et al., 2018; Lan et al., 2019, 2022; Laufer & Waldman, 2011; Rørvik, 2022; Siyanova & Schmitt, 2007), some studies have compared the processing of NPs in native and second language users. Evidence from these studies indicates that second language (L2) learners tend to process NPs word by word, which differs fundamentally from the chunk-like processing observed in native speakers (Conklin & Schmitt, 2012; Wray, 2002). L2 language users typically analyze NPs on a word-by-word basis and then infer the combined meanings of the modifier and head element (Connelly et al., 2007; Hamada, 2024). Recent studies also suggest that the congruence between multiword expressions in the L1 and L2 can facilitate NP processing among L2 users in a manner similar to that of native speakers (e.g., Carrol et al., 2016; Wolter & Gyllstad, 2013; Yamashita & Jiang, 2010). However, limited research has compared the comprehension of NPs in the context of L1-L2 syntactic transfer (Snape et al., 2023). Such comparative studies could assist in delivering customized grammar instruction to address the diverse needs of L2 students.
The present study
Language learning depends on the nature of the input that is acquired and the extent to which input properties resemble or differ from the first language, thus facilitating or hindering the process. Even subtle L1 influence can sometimes affect L2 parsing and comprehension (Kaan, 2014; Roberts, 2012). While previous studies have posited that for similar constructions in the two languages, bilinguals share syntactic representations (e.g., Bernolet et al., 2007; Bernolet et al., 2013; Hartsuiker et al., 2004; Kantola & van Gompel, 2011), fewer studies have investigated cross-language transfer of different grammatical structures. In addition, several studies have found that ELLs are challenged by sentences that include complex NPs (Ansarifar et al., 2018; Lan et al., 2022; Lan & Sun, 2019; Staples et al., 2016). However, it is not clear to what extent they are disrupted by the number of noun premodifiers and the existence of an adjective premodifier. By testing the participants on 4 different types of NPs, we can identify the effect of different NP structures and the extent to which a decline in NP comprehension is attributed to the cross-language transfer. While previous offline studies have primarily utilized grammaticality judgment tasks (Choi et al., 2018; Hua & Lee, 2005; Snape, 2008), this study uses an NP comprehension task that was designed in accordance with the different characteristics of NP structures in Hebrew and English, in an attempt to address the following hypotheses:
-
1.
The Number of Noun premodifiers (NNpM) and the existence of an Adjective premodifier (ApM) would affect NP comprehension.
Considering the typological differences in NPs between Hebrew and English (Berman, 1978; Ravid & Berman, 2010; Siloni, 1997) and the observation that the comprehension of NPs involves meaning construction (Gagné & Spalding, 2011; Ji et al., 2011; Koester et al., 2007), we hypothesize that comprehension would be greater for NPs that include two noun premodifiers (NNpM) and lack an Adjective premodifier (ApM) than for NPs that include one noun premodifier (NNpM) and an Adjective premodifier (ApM).
-
2.
The NNpM and ApM would affect L1- and L2- based error rates in the NP comprehension test.
Considering the observation that L2 learners may display cross-language transfer as a function of the syntactic structures’ complexity, we hypothesize that the errors exhibited in sentences containing only noun modifiers and no adjectives will result from incorrect cross-linguistic activation of the L1 (Hartsuiker & Pickering, 2008), compared with errors exhibited in sentences containing two nouns which will be explained by the lack of language-specific representations for their L2.
-
3.
NP comprehension would uniquely contribute to the explained variance of English (L2) reading comprehension beyond Hebrew(L1) reading comprehension and English (L2) vocabulary.
This hypothesis is based on the prediction that the comprehension of NPs involves more than syntactic parsing; it entails actively constructing meaning by integrating semantic elements (Folk & Morris, 2003; Kintsch, 1998; Tunmer & Bowey, 1984). During NP comprehension, comprehenders synthesize linguistic knowledge and contextual cues to derive nuanced meanings. This relies on a dynamic process of understanding the structure of the head noun, the relationship between head nouns and modifiers and integrating individual word meanings into a coherent whole (Berman, 1978; Gagné & Spalding, 2013; Siloni, 1997). L2 reading comprehension has been associated with L2 vocabulary (Pasquarella et al., 2012; Taşçı & Turan, 2021) and L1 reading comprehension (Pae, 2018; Proctor et al., 2006; Shum et al., 2016; Van Gelderen et al., 2007; Yamashita, 2001). Therefore, we controlled these variables to examine the unique contribution of NP comprehension.
Method
Participants
The sample size was determined a priori using the G*power software. For an ANOVA with repeated measures (within factors) analyses and the test parameters (low effect size = 0.15, α error = 0.05, power = 0.90, and moderate correlation among repeated measures = 0.40), the total sample size required is 96 participants. In order to increase power and sensitivity, the present study comprised 101 eleventh-grade Hebrew-speaking students (59 boys and 42 girls). The students’ ages ranged between 16 and 17 (M = 16.14, SD = 0.35). All participants were students at Israeli public high schools and had studied English as a foreign language in lessons since the 2nd grade.
To ensure all participants understood sentences in English, the inclusion criteria for the current study were intact English vocabulary and reading comprehension. Therefore, we administered both an English (L2) vocabulary test and an English (L2) reading comprehension test. Students who scored less than 55 (55 is considered the minimum passing grade according to the Israeli Ministry of Education) on both tests (3 students) were excluded from the study. We also administered a Hebrew (L1) reading comprehension test for the purpose of measuring students’ L1 reading comprehension abilities in their L1. Students who scored less than 55 (out of 100) on both tests (2 students) were excluded from the study.
Materials
All participants were administered a battery of four tests: Hebrew (L1) reading comprehension, English (L2) reading comprehension, English (L2) vocabulary, and English (L2) NP comprehension.
The Hebrew (L1) reading comprehension test included a passage from published Hebrew matriculation tests. The passage was a 294-word narrative text. Participants were asked to read the text and answer 8 comprehension questions. We used both multiple-choice and open-ended questions to create a comprehensive assessment. There were 3 factual questions, 2 main idea questions, 1 inference question, 1 reference question, and 1 reasoning question. The internal consistency of the test items was high (α = 0.88).
The English (L2) reading comprehension test included a 332-word narrative text which was adapted from previously published English matriculation tests. Participants were asked to read the text and answer 8 comprehension questions. Both multiple-choice and open-ended questions were used. There were 3 factual questions, 2 main idea questions, 1 inference question, 1 reference question and 1 reasoning question. The internal consistency of the test items was high (α = 0.87).
The English (L2) vocabulary test was developed based on the English matriculation test (Module E). We selected English words at the B1 level according to the Common European Framework of Reference for Languages (CEFR). Participants were required to match 25 words in English to their definitions in English. The internal consistency of the test items was high (α = 0.92).
The English (L2) NP comprehension test was designed to assess participants’ ability to understand complex NPs in English and the extent to which their NP comprehension skills are affected by Hebrew syntax (L1). Prior to developing the experimental sentences that differed in the number of noun premodifiers and the premodifier type that preceded the subject, we wanted to ensure that sentences did not differ in level of difficulty. 32 basic sentences (including a single noun in the subject position) were divided randomly into 4 lists, each consisting of 8 sentences, followed by a question about the head noun. A repeated measures ANOVA was conducted with 30 students to establish that the lists were equivalent in difficulty. Similar to the study sample, these students were native Hebrew speakers who studied English as a foreign language (none were native English speakers). In order to verify that sentences in the 4 lists were equally difficult, a one-way ANOVA with repeated measures was conducted. Results indicate no significant differences between the lists F(3,87) = 0.54, p = .654, ηp² = 0.02 [List 1: M = 88.33%, SD = 14.66, List 2: M = 85.42%, SD = 20.78, List 3: M = 84.17%, SD = 20.74 and List 1: M = 86.25%, SD = 21.61]. These basic sentences were then used to build the 4 experimental conditions that differed in the number of noun premodifiers that preceded the subject and the premodifier type (noun and/or adjective) that preceded the subject, resulting in four sentence types (See Appendix 1): (1) sentences whose subject included an NP with one noun premodifier (NN), (2) sentences whose subject included an NP with two nouns (NNN), (3) sentences whose subject included an NP with one adjective premodifier and one noun premodifier (Adj. NN), and (4) sentences whose subject included an NP with one adjective premodifier and two noun modifiers (Adj. NNN).
It should be noted that the same 30 students also completed the Hebrew reading comprehension, English vocabulary, and English reading comprehension tests. T test analyses indicated that this group of students in the pilot did not differ significantly in their performance on the Hebrew reading comprehension, English vocabulary, and English reading comprehension tests [t(129) = 0.43, p = .670, t(129) = 0.62, p = .538 and t(129) = 0.47, p = .639, respectively].
In order to ensure that participants would be less likely to rely solely on technical strategies, such as choosing the last word before the verb as the head noun without reading the sentence, 32 control sentences were added. To reduce the chance of bias in their responses, the control items were virtually the same as the other 32 sentences, but lacked the specific constructs being investigated – premodifiers. These filler items were included to prevent participants from discerning the true purpose of the experiments and to ensure that participants would remain uncertain about the location of the head noun. The test was randomized to ensure that a sentence with no premodifiers would never appear before or immediately following the same sentence with premodifiers.
All the questions were formed similarly: “Who\What + verb”. For example: “The debate team leader was highly impressive. Who was highly impressive?” For each question three answers were presented: (1) the correct answer (in the above example, it would be ‘the leader’); (2) an L1-based error: an answer based on structure of NPs in Hebrew, i.e., the first noun the reader encountered in the sentence (in the above example, it would be ‘the debate’); Hebrew-speaking ELLs can be affected by the NP structure in Hebrew (in which the head noun appears first) and may mistakenly identify the first noun they encounter in the sentence as the head noun. (3) an L2-based error: an answer that may result from inadequate L2 mastery, i.e., one of the other premodifiers or any other word from the sentence that could semantically function as the head noun of the NP. See Appendix 2 for more examples.
A correct answer was awarded 1 point, and an incorrect response received 0 points. The incorrect responses were classified into two types: L1-based errors and L2-based errors. We counted the number of each error type in each one of the NP conditions. We then converted the scores to percentages by dividing the number of errors in each type by the total number of errors.
The internal consistency of the NP comprehension test was high (α = 0.88). Test sentences were of equal length across all four conditions (M = 9.36 words, SD = 2.03). The internal consistency of the NP comprehension test was high (α = 0.88).
-
(1)
sentences whose subject included an NP with two nouns (NNN, M = 9.38 words, SD = 2.73).
-
(2)
sentences whose subject included an NP with one noun premodifier (NN, M = 9.31 words, SD = 2.08).
-
(3)
sentences whose subject included an NP with one adjective premodifier and one noun premodifier (Adj. NN, M = 9.19 words, SD = 2.75).
-
(4)
sentences whose subject included an NP with one adjective premodifier and two noun modifiers (Adj. NNN, M = 9.38 words, SD = 2.73).
Procedure
The Hebrew (L1) reading comprehension, English (L2) reading comprehension, English (L2) vocabulary were presented and recorded on paper. Each task was administered on a different day in order to keep the participants focused. Testing took place in small groups of 14–15 participants. Overall, the participants took approximately 120 min to complete the whole battery of tasks, with no time limit for any part.
The NP comprehension test was administered on Quizizz (https://quizizz.com/?lng=en), an internet-based learning platform. Sentences were presented on a computer screen one at a time on each page of the test, using the Ariel 18 pt font. The participants were asked to read each sentence and answer a multiple-choice question that appeared after the sentence (See Appendix 2). Once participants had read each sentence and answered the following question, they moved on to the next page and were not able to return to the previous pages. Thus, they were not able to change any of their previous answers. Instructions for the NP comprehension test were given in Hebrew. No time limit was set on the test.
Results
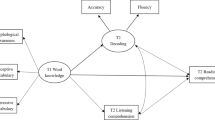
In order to examine the first research question regarding the effect of the Number of Noun premodifiers (NNpM) and the existence of an Adjective pre-Modifier (ApM) on NP comprehension performance, a two-way (2 × 2) ANOVA with repeated measures was conducted. The independent variables creating the four conditions were NNpM and ApM as the within-subjects factors. The dependent variable was NP comprehension performance in percentages for each condition (See Table 1).
As Table 1 shows, the interaction of NNpM and ApM was not significant, F(1,100) = 0.76, p = .384, ηp² = 0.01. Nevertheless, the main effect of NNpM was significant, indicating a higher NP comprehension performance when the sentence contained one rather than two noun premodifiers F(1,100) = 65.22, p < .001, ηp² = 0.40. In addition, the main effect of ApM was significant, indicating a higher NP comprehension performance in a sentence containing an adjective as compared with a sentence that did not contain an adjective F(1,100) = 22.08, p < .001, ηp² = 0.18. The non-significant interaction indicated a higher NP comprehension performance when the sentence contained one rather than two noun premodifiers, in sentences containing an adjective and sentences that did not contain an adjective.
In order to examine the second research question regarding the effect of the Number of Noun premodifiers (NNpM) and the existence of an Adjective premodifier (ApM) on L1- and L2- based errors in the NP comprehension test, a three-way (2 × 2 × 2) ANOVA with repeated measures was conducted. The independent variables were the NNpM, ApM and Error type as the within-subjects factors. The dependent variable was the percentage of errors in the NP comprehension test (See Table 2).
The two-way interaction of NNpM and Error type was significant, F(1,100) = 71.16, p < .001, ηp² = 0.42 (See Fig. 1).

Mean (and SE) of the Percentage of Errors in the NP Comprehension Test by NNpM and Error Type
In order to examine the source of the interaction between NNpM and Error type, paired samples t-test analyses were conducted in order to explore the simple effect of NNpM in each error type. The simple effect of NNpM was significant in both error types [L1 error: t(100) = 3.32, p < .001; L2 error: t(100) = 11.05, p < .001]. The results indicated that while the L1 error rate was significantly higher in sentences that contained one noun premodifier, the L2 error rate was significantly higher in more complex sentences that contained two noun premodifiers.
The two-way interactions of NNpM and ApM and ApM and Error type as well as the three-way interaction of NNpM, ApM and Error type were not significant, [F(1,100) = 0.76, p = .384, ηp² = 0.01, F(1,100) = 0.83, p = .364, ηp² = 0.01 and F(1,100) = 0.02, p = .895, ηp² = 0.00, respectively]. Finally, the main effects of NNpM, ApM and Error type were significant [F(1,100) = 65.22, p < .001, ηp² = 0.40, F(1,100) = 22.08, p < .001, ηp² = 0.18 and F(1,100) = 11.91, p < .001, ηp² = 0.11, respectively]. The results indicated that error rates were significantly higher in sentences that contained two noun premodifiers than in sentences that contained one noun premodifier, as well as in sentences that did not contain an adjective as compared with sentences that contained an adjective, and the L1 error rate was significantly higher than the L2 error rate.
In order to examine the third research question and hypothesis regarding the unique contribution of students’ performance on the NP comprehension test to the EPV of their performance on the English reading comprehension test, beyond their performance on the Hebrew reading comprehension test and the English vocabulary test, two hierarchical regression analyses were conducted, one for performance and one for error type.
Prior to examining this hypothesis, we examined the correlation between NP comprehension performance and English reading comprehension performance, while controlling for Hebrew reading comprehension and English vocabulary, by conducting partial correlation analyses (See Table 3).
As Table 3 shows, significant positive correlations were found between the four NP comprehension conditions and performance on the English reading comprehension test. These results indicate that as students’ performance on the NP comprehension test increased, their performance on the English reading comprehension test increased, respectively.
Regression results regarding performance on the NP comprehension test: Students’ performance on the Hebrew reading comprehension and the English vocabulary tests were entered in the first step of the analysis and students’ performance on the different sentence types in the NP comprehension test were entered in the second step of the regression model. The variables in both steps were entered into the regression in a stepwise manner. Thus, only variables that contributed significantly to the EPV were entered into the regression model. The order variables were entered into the model in accordance with their level of significance to the contribution of the EPV (see Table 4).
As seen in Table 4, students’ performance on the Hebrew reading comprehension and the English vocabulary tests contributed significantly, 66.5% to the EPV of students’ performance on the different sentence types in the NP comprehension test. The positive β coefficients indicate that students who scored higher on the Hebrew reading comprehension and on the English vocabulary tests tended to score higher on the English reading comprehension test.
A unique contribution of students’ performance was found in the different sentence types in the NP comprehension test, to the EPV of their performance on the English reading comprehension test, beyond their performance on the Hebrew reading comprehension and English vocabulary tests (∆R2 = 14.1%, p < .001). The positive β coefficients indicated that students who performed better in sentences containing one noun premodifier and no adjective and sentences containing two noun premodifiers and an adjective, performed better on the English reading comprehension test. It should be noted that students’ performance on sentences containing one noun premodifier and no adjective contributed the most EPV of their performance on the English reading comprehension test (11.8% out of 14.1%).
Regression results regarding the Error type: Students’ performances on the Hebrew reading comprehension and on the English vocabulary tests were entered in the first step of the analysis and students’ error types on the different sentence conditions in the NP comprehension test were entered in the second step of the regression model. The variables in both steps were entered into the regression in a stepwise manner (see Table 5).
The results in the first step of the regression model were similar to the results of the previous regression analysis.
A unique contribution of the error types on the different sentences in the NP comprehension test was found for the EPV of students’ performance on the English reading comprehension test, beyond their performance on the Hebrew reading comprehension and English vocabulary tests (∆R2 = 14.6%, p < .001). The negative β coefficients indicated that students who made fewer L1 and L2 errors in sentences containing one noun premodifier and no adjective and in sentences containing two noun premodifiers and an adjective, performed better on the English reading comprehension test. It should be noted that the percentage of L1 errors in sentences containing one noun premodifier and no adjective contributed the most EPV of their performance on the English reading comprehension test (9% out of 14.6%).
Discussion
Although ELLs have been reported to be challenged by complex NPs (Pastor, 2008), it is unknown whether NNpM and the existence of an ApM impact this difficulty. The first goal of the present study was to examine whether English NP comprehension is affected by NNpM and the existence of ApM among Hebrew-speaking high-school students learning English as a foreign language. To find evidence of cross-language transfer, we also investigated whether the percentage of L1- and L2-based error rates is affected by the NNpM and the existence of ApM. An additional goal was to determine whether NP comprehension performance as measured by NNpM and the existence of an ApM correlates with English reading comprehension performance, while controlling for Hebrew reading comprehension and English vocabulary. Finally, we examined the uniquely significant contribution of students’ performance on the NP comprehension test (performance and error type) to the EPV of English reading comprehension beyond Hebrew reading comprehension and English vocabulary. Overall, our results confirmed the significant effect L1 has on L2 NP comprehension, and the connection and contribution of NP comprehension to L2 reading comprehension among adolescent students.
This study broadens the preceding research literature in two central ways. Firstly, investigating the differences in NP processing between Hebrew and English provides insights into crosslinguistic influence, i.e., how learners transfer knowledge between these typologically dissimilar languages. This sheds light on the extent to which linguistic differences impact second language acquisition, and the extent to which NP processing patterns are influenced by general cognitive principles or by language-specific grammatical rules. Such findings can inform language pedagogy by identifying potential areas of difficulty for learners transitioning between Hebrew and English, thus guiding the development of tailored teaching strategies.
The effect of NNpM and the existence of an ApM on NP comprehension
In terms of our first research question, the study’s results indicate that NP comprehension was greater in sentences including one premodifier than those with two premodifiers. This confirms the complexity that additional premodifiers can pose in syntactic processing, as proposed by Priven (2020). We speculate that for Hebrew speakers, NPs in sentences that included a triple noun train were the most difficult to process as they are quite rare in Hebrew. Previous research has shown that the movement of words in the sentence compared to the L1 and the use of long-distance dependencies word order can be a bottleneck in L2 sentence comprehension (Clahsen & Felser, 2006). The results also yielded evidence of a significant effect of modifier type on NP comprehension performance. Namely, sentences containing an adjective premodifier were processed more accurately compared to sentences without adjective premodifiers. It is likely that the existence of an adjective prompts the reader to search for the head noun in the NP as compared with NPs that include 2 or more nouns.
The greater difficulty posed by noun premodifiers for Hebrew speakers may be attributed to syntactic transfer, i.e., the activation of L1 syntactic strictures and the linguistic difference in NP structures between the languages (Hartsuiker & Pickering, 2008). Unlike in English, in Hebrew modifiers follow nouns. Thus, it is possible that when Hebrew speakers encounter such NPs, they interpret the first noun as the head noun rather than the modifier. This suggests that the type of premodifier may play a role in NP comprehension and may indicate that when ELLs are engaged in a challenging NP comprehension task, the presence of the competing L1 structure may also prompt them to activate L1 grammar (Amaral & Roeper, 2014; Smith & Truscott, 2014).
The effect of NNpM and the existence of an ApM on L1- vs. L2- based errors
With regard to the second research question, our error analysis reveals that participants exhibited more errors for sentences with two, as compared to one, noun premodifiers. Errors were also more prominent in sentences without an adjective premodifier, compared with sentences that included an adjective. A possible reason for the lower error rate in the presence of an adjective may be that the adjective provided a very strong cue to premodification and may have triggered students to attend more closely to the NP structure and search for the head noun. Moreover, an interaction between the NNpM and error type was found, indicating that there were more L1-based errors in sentences containing one noun and more L2-based errors in sentences containing two nouns. This pattern of findings supports the hypothesis that syntactic transfer of L1 structures plays a role in NP comprehension among ELLs (Bardovi-Harlig & Sprouse, 2018; Patel et al., 2022; Verbeek et al., 2022). In Hebrew, the first noun encountered in a sentence is the syntactic subject, so that when participants encountered two nouns, their initial reaction may have been to choose the first noun as the subject rather than the premodifier, which may have led to the increase in L1 errors in these sentences.
Interestingly, L2 errors increased when sentences contained two noun modifiers, possibly indicating NP comprehension difficulties might also stem from the increased complexity of the L2 structure (Clahsen & Felser, 2006; Tan & Foltz, 2020). These findings may be connected to the concept of the Shared Syntax account, which proposes that bilinguals use common syntactic representations from both languages (Hartsuiker & Pickering, 2008). According to this conceptual framework, instances of cross-language transfer might arise among novice learners who lack language-specific representations for their L2 and consequently rely on their L1’s grammar. Similarly, advanced learners could also exhibit cross-language influences by extending similarities between L1 and L2 syntax to features specific to a shared structure, like applying L1 word order conventions to L2 syntactic structures (Hwang et al., 2017). Given that the participants in our study can be categorized as advanced learners, the discovery that such learners display syntactic transfer as a function of the structures’ complexity suggests that the errors exhibited in sentences containing only noun modifiers result from cross-linguistic activation of the L1 which interacts with L2 grammar knowledge (Hartsuiker & Pickering, 2008).
The unique contribution of NP comprehension to the EPV of L2 reading comprehension
As NP comprehension has been shown to be related to reading comprehension processes (Folk & Morris, 2003; Gagné & Spalding, 2013; Kintsch, 1998; Tunmer & Bowey, 1984), our third research question explored the unique contribution of performance and errors on the NP comprehension test to the explained variance of students’ performance in the L2 reading comprehension test beyond L1 reading comprehension and L2 vocabulary. Prior to this examination, we presented the correlation between NP comprehension and L2 reading comprehension while controlling for Hebrew (L1) reading comprehension and English (L2) vocabulary. A significant correlation between how well the participants performed on the four NP comprehension test conditions, i.e., NN, NNN, AdjNN, and AdjNNN sentences and their L2 reading comprehension abilities was found. This finding concurs with existing research that highlights the role of syntactic knowledge in reading comprehension (Cain, 2007; Guo & Roehrig, 2011; Shiotsu & Weir, 2007; Siu & Ho, 2020). These correlations suggest that strong skills in NP comprehension can facilitate performance in reading comprehension, and that an individual’s ability to comprehend complex NPs may have beneficial effects upon comprehending L2 input.
The first hierarchical regression analysis indicated that students’ performance on sentences including one noun premodifier and those including two noun premodifiers and an adjective had a unique contribution of 11.8% and 3% (respectively) to their English reading comprehension beyond the contribution of L1 reading comprehension and vocabulary performance (66.5%). We believe that this NN structure is crucial in explaining L2 reading comprehension, as they mark the difference between L1 and L2, while the AdjNNN structure represents a long NP that is rare in Hebrew. This finding concurs with previous studies highlighting the role of L2 syntactic knowledge in reading comprehension (Jeon & Yamashita, 2014; Taşçı & Turan, 2021; Van Gelderen et al., 2003). The findings also strengthen the importance of a strong foundation in L1 reading comprehension abilities (Pae, 2019) and L2 vocabulary (see Zhang & Zhang, 2022 for a meta-analysis). Being familiar with certain words might have helped the participants decide whether it can be considered a noun or a verb.
A complementary perspective is also provided by the second hierarchical regression analysis which indicated that students’ lower rates on sentences including one noun premodifier and sentences including two nouns and an adjective offered a unique contribution of 9% and 5.6% (respectively) to students’ English reading comprehension, beyond the contribution of L1 reading comprehension and vocabulary performance. These findings reinforce the important role of NP comprehension in L2 reading comprehension in typologically different languages and the value of a strong foundation in L2 syntactic structures in text comprehension.
Taken together, the overall pattern of results offers several novel contributions. First, findings from this study indicate that the number and type of premodifier(s) affect L2 NP comprehension among Hebrew-speaking ELL high school students. Secondly, our study provides evidence for the cross-language transfer of syntactic knowledge between Hebrew and English which differs in NP structure. Finally, the unique contribution of acquiring the NN and AdjNNN NP structures to reading comprehension abilities in L2 is another novel feature of this study, in that it emphasizes the specific NP structures that Hebrew-speaking ELLs face in English as an L2. Although L1 reading comprehension and L2 vocabulary account for approximately 66% of the variance, our findings emphasize the importance of focusing on syntactic skills from a contrastive analysis approach, as it plays a role in reading comprehension. This insight can help practitioners understand the relative importance of various factors that explain L2 reading comprehension development.
When interpreting the results of this present study, it’s important to consider some limitations. First, the results are limited to high-school level Hebrew-English ELLs. We know from previous studies that speakers of different languages do not acquire English as L2 in the same way (Choi & Ionin, 2021). Therefore, it is important to examine whether the results would be similar or different across learners of different ages and other languages that vary syntactically from English. In addition, the verification of the difficulty level of the 4 research conditions was done with a group of 30 students which is considered a relatively small number. Future replication studies should verify equivalent item difficulty across the 4 conditions with a larger sample, or alternatively use professional judgement from subject-matter experts. Furthermore, exploring the effect of syntactic structure on L2 reading comprehension using both online and offline paradigms would allow a clearer understanding of how differences in L1 and L2 syntactic structures impact reading comprehension. Finally, researching the impact of NP on L2 reading comprehension in other syntactic positions beyond the subject of the sentence, could provide a wider understanding of how NP comprehension influences L2 reading comprehension. These insights may further enhance our theoretical understanding as well as the practical implications of L2 knowledge and its influence on reading comprehension.
These findings have practical implications for the foreign-language classroom and the incorporation of L2 syntactic knowledge in foreign-language teaching. Earlier research has demonstrated that providing explicit instructions regarding the cross-language distinctions between L1 and L2 can have positive effects on foreign language learning (as seen in studies like Hopp & Thoma, 2021; McManus & Marsden, 2019). Our findings regarding the type of errors (L1 based vs. L2 based) readers may also help in the design of more effective teaching strategies and intervention programs. In this regard, the study introduces a fresh perspective to the integration of adjectival and NPs in English-as-a foreign-language instruction. The finding that specific NP syntactic knowledge is related to L2 reading comprehension and contributes to L2 reading comprehension beyond L1 reading comprehension and L2 vocabulary, suggests that developing syntactic knowledge skills may be an effective way to improve reading comprehension in L2.
References
Altmann, G. T., & Mirković, J. (2009). Incrementality and prediction in human sentence processing. Cognitive Science, 33(4), 583–609. https://doi.org/10.1111/j.1551-6709.2009.01022.x.
Amaral, L., & Roeper, T. (2014). Multiple grammars and second language representation. Second Language Research, 30(1), 3–36. https://doi.org/10.1177/0267658313519017.
Ansarifar, A., Shahriari, H., & Pishghadam, R. (2018). Phrasal complexity in academic writing: A comparison of abstracts written by graduate students and expert writers in applied linguistics. Journal of English for Academic Purposes, 31, 58–71. https://doi.org/10.1016/j.jeap.2017.12.008.
Attabor, O. T. (2019). Syntactic interference: A study of Ígálá and English noun phrases in Malachai 1: 6 and Mathew 2. Journal of Literature Languages and Linguistics, 60, 40–46. https://doi.org/10.7176/JLLL.
Baker, B. A. (2008). L2 writing and L1 composition in English: Towards an alignment of effort. Articles, 43(2), 139–155. https://doi.org/10.7202/019579ar.
Bardovi-Harlig, K., & Sprouse, R. A. (2018). Negative versus positive transfer. The TESOL Encyclopedia of English Language Teaching, 1–6. https://doi.org/10.1002/9781118784235.eelt0084.
Berman, R. A. (1978). Early verbs: Comments on how and why a child uses his first words. International Journal of Psycholinguistics, 5, 21–39.
Berman, R. A. (1988). Language knowledge and language use: Binominal constructions in Modern Hebrew. General Linguistics, 28(4), 261.
Berman, R. A. (2009). Trends in research on narrative development. Language Acquisition, 294–318. https://doi.org/10.1057/9780230240780_13.
Bernolet, S., Hartsuiker, R. J., & Pickering, M. J. (2007). Shared syntactic representations in bilinguals: Evidence for the role of word-order repetition. Journal of Experimental Psychology: Learning Memory and Cognition, 33(5), 931–949. https://doi.org/10.1037/0278-7393.33.5.931.
Bernolet, S., Hartsuiker, R. J., & Pickering, M. J. (2013). From language-specific to shared syntactic representations: The influence of second language proficiency on syntactic sharing in bilinguals. Cognition, 127(3), 287–306. https://doi.org/10.1016/j.cognition.2013.02.005.
Biber, D., & Gray, B. (2011). Grammatical change in the noun phrase: The influence of written language use. English Language & Linguistics, 15(2), 223–250. https://doi.org/10.1017/s1360674311000025.
Booth, P., Clenton, J., & Van Herwegen, J. (2018). L1 – L2 semantic and syntactic processing: The influence of language proximity. System, 78, 54–64. https://doi.org/10.1016/j.system.2018.07.011.
Borer, H. (1984). Restrictive relatives in modern Hebrew. Natural Language & Linguistic Theory, 2(2), 219–260. https://doi.org/10.1007/BF00133282.
Cain, K. (2007). Syntactic awareness and reading ability: Is there any evidence for a special relationship? Applied Psycholinguist, 28, 679–694. https://doi.org/10.1017/S0142716407070361.
Carrol, G., Conklin, K., & Gyllstad, H. (2016). Found in translation: The influence of the L1 on the reading of idioms in a L2. Studies in Second Language Acquisition, 38(3), 403–443.
Choi, S. H., & Ionin, T. (2021). Plural marking in the second language: Atomicity, definiteness, and transfer. Applied Psycholinguistics, 42(3), 549–578. https://doi.org/10.1017/S0142716420000569.
Choi, S. H., Ionin, T., & Zhu, Y. (2018). L1 Korean and L1 Mandarin L2 English learners’ acquisition of the count/mass distinction in English. Second Language Research, 34, 147–177. https://doi.org/10.1177/0267658317717581.
Chomsky, N. (1995). Language and Nature. Mind, 104(413), 1–61. https://doi.org/10.1093/mind/104.413.1.
Clahsen, H., & Felser, C. (2006). Grammatical processing in language learners. Applied Psycholinguistics, 27(1), 3–42. https://doi.org/10.1017/S0142716406060024.
Conklin, K., & Schmitt, N. (2012). The processing of formulaic language. Annual Review of Applied Linguistics, 32, 45–61.
Connelly, V., Gee, D., & Walsh, E. (2007). A comparison of keyboarded and handwritten compositions and the relationship with transcription speed. British Journal of Educational Psychology, 77(2), 479–492. https://doi.org/10.1348/000709906X116768.
de Bot, K. (1992). Applied Linguistics. Applied Linguistics, 13(1), 1–24. https://doi.org/10.1093/applin/13.1.1.
Dryer, M. S. (2007). Word order. Language Typology and Syntactic Description, 1, 61–131. https://doi.org/10.1017/CBO9780511619427.002.
Dussias, P. E., & Cramer Scaltz, T. R. (2008). Spanish–English L2 speakers’ use of subcategorization bias information in the resolution of temporary ambiguity during second language reading. Acta Psychologica, 128(3), 501–513. https://doi.org/10.1016/j.actpsy.2007.09.004.
Dussias, P. E., & Piñar, P. (2010). Effects of reading span and plausibility in the reanalysis of wh-gaps by chinese-english second language speakers. Second Language Research, 26(4), 443–472. https://doi.org/10.1177/0267658310373326.
Dussias, P. E., Valdés Kroff, J. R., Tamargo, G., R. E., & Gerfen, C. (2013). When gender and looking go hand in hand. Studies in Second Language Acquisition, 35(2), 353–387. https://doi.org/10.1017/S0272263112000915.
Ellis, R. (2005). Measuring implicit and explicit knowledge of a second language: A psychometric study. Studies in Second Language Acquisition, 27, 141–172. https://doi.org/10.1017/S0272263105050096.
Felser, C., Roberts, L., Marinis, T., & Gross, R. (2003). The processing of ambiguous sentences by first and second language learners of English. Applied Psycholinguistics, 24(3), 453–489.
Folk, J. R., & Morris, R. K. (2003). Effects of syntactic category assignment on lexical ambiguity resolution in reading: An eye movement analysis. Memory & Cognition, 31(1), 87–99. https://doi.org/10.3758/BF03196085.
Gagné, C. L., & Spalding, T. L. (2011). Inferential processing and meta-knowledge as the bases for property inclusion in combined concepts. Journal of Memory and Language, 65(2), 176–192. https://doi.org/10.1016/j.jml.2011.03.005.
Gagné, C. L., & Spalding, T. L. (2013). Conceptual composition: The role of relational competition in the comprehension of modifier-noun phrases and noun–noun compounds. Psychology of Learning and Motivation, 59, 97–130. https://doi.org/10.1016/B978-0-12-407187-2.00003-4.
Gottardo, A., & Mueller, J. (2009). Are first- and second-language factors related in predicting second-language reading comprehension? A study of spanish-speaking children acquiring English as a second language from first to second grade. Journal of Educational Psychology, 101(2), 330–344. https://doi.org/10.1037/a0014320.
Grüter, T., & Rohde, H. (2013). L2 processing is affected by RAGE: Evidence from reference resolution. In the 12th conference on Generative Approaches to Second Language Acquisition (GASLA).
Grüter, T., Lew-Williams, C., & Fernald, A. (2012). Grammatical gender in L2: A production or a real-time processing problem? Second Language Research, 28(2), 191–215. https://doi.org/10.1177/0267658312437990.
Guo, Y., & Roehrig, A. D. (2011). Roles of general versus second language (L2) knowledge in L2 reading comprehension. Reading Foreign Language, 23, 42–64.
Hamada, M. (2024). Multiword expressions: Understanding the meanings of Noun-Noun compounds in L2. English Teaching & Learning, 1–19. https://doi.org/10.1007/s42321-024-00169-w.
Hartsuiker, R. J., & Bernolet, S. (2017). The development of shared syntax in second language learning. Bilingualism: Language and Cognition, 20(2), 219–234. https://doi.org/10.1017/S1366728915000164.
Hartsuiker, R. J., & Pickering, M. J. (2008). Language integration in bilingual sentence production. Acta Psychologica, 128(3), 479–489. https://doi.org/10.1016/j.actpsy.2007.08.005.
Hartsuiker, R. J., Pickering, M. J., & Veltkamp, E. (2004). Is syntax separate or shared between languages? Cross-linguistic syntactic priming in spanish-english bilinguals. Psychological Science, 15(6), 409–414. https://doi.org/10.1111/j.0956-7976.2004.00693.x.
Hatzidaki, A., Branigan, H. P., & Pickering, M. J. (2011). Co-activation of syntax in bilingual language production. Cognitive Psychology, 62(2), 123–150. https://doi.org/10.1016/j.cogpsych.2010.10.002.
Hatzidaki, A., Santesteban, M., & Duyck, W. (2018). Is language interference (when it occurs) a graded or an all-or-none effect? Evidence from bilingual reported speech production. Bilingualism: Language and Cognition, 21(3), 489–504. https://doi.org/10.1017/S1366728917000736.
Hesamoddin, S., Farzaneh, S., & Ahmad, A. (2018). An examination of relative clauses in argumentative essays written by EFL learners. Journal of Language and Education, 4(4 (16), 77–87. https://doi.org/10.1016/j.jeap.2017.12.008.
Hopp, H. (2006). Syntactic features and reanalysis in near-native processing. Second Language Research, 22(3), 369–397. https://doi.org/10.1191/0267658306sr272oa.
Hopp, H. (2010). Ultimate attainment in L2 inflection: Performance similarities between non-native and native speakers. Lingua, 120(4), 901–931. https://doi.org/10.1016/j.lingua.2009.06.004.
Hopp, H. (2013). Grammatical gender in adult L2 acquisition: Relations between lexical and syntactic variability. Second Language Research, 29(1), 33–56. https://doi.org/10.1177/0267658312461803.
Hopp, H. (2014). Working memory effects in the L2 processing of ambiguous relative clauses. Language Acquisition, 21, 250–278.
Hopp, H., & Thoma, D. (2021). Effects of Plurilingual Teaching on Grammatical Development in Early Foreign-Language Learning. The Modern Language Journal, 105(2), 464–483. https://doi.org/10.1111/modl.12709.
Hua, D., & Lee, T. H. T. (2005). Chinese ESL learners’ understanding of the English count-mass distinction. In Proceedings of the 7th generative approaches to second language acquisition conference (GASLA 2004) (pp. 138–149).
Hung, C. O. Y. (2021). The role of executive function in reading comprehension among beginning readers. British Journal of Educational Psychology, 91, 600–616. https://doi.org/10.1111/bjep.12382.
Hwang, H., Shin, J. A., & Hartsuiker, R. J. (2017). Late bilinguals share syntax unsparingly between L1 and L2: Evidence from cross-linguistically similar and different constructions. Language Learning, 68(1), 177–205. https://doi.org/10.1111/lang.12272.
Jackendoff, R. (1977). X syntax: A study of phrase structure. MIT Press.
Jackson, C. (2008). Proficiency level and the interaction of lexical and morphosyntactic information during L2 sentence processing. Language Learning, 58(4), 875–909. https://doi.org/10.1111/j.1467-9922.2008.00481.x.
Jaeger, T. F., & Snider, N. E. (2013). Alignment as a consequence of expectation adaptation: Syntactic priming is affected by the prime’s prediction error given both prior and recent experience. Cognition, 127(1), 57–83. https://doi.org/10.1016/j.cognition.2012.10.013.
Jeon, E. H., & Yamashita, J. (2014). L2 reading comprehension and its correlates: A meta-analysis. Language Learning, 64(1), 160–212. https://doi.org/10.1111/lang.12034.
Ji, H., Gagné, C. L., & Spalding, T. L. (2011). Benefits and costs of lexical decomposition and semantic integration during the processing of transparent and opaque English compounds. Journal of Memory and Language, 65(4), 406–430. https://doi.org/10.1016/j.jml.2011.07.003.
Juffs, A., & Harrington, M. (1996). Garden path sentences and error data in second language sentence processing. Language Learning, 46(2), 283–323. https://doi.org/10.1111/j.1467-1770.1996.tb01237.x.
Kaan, E. (2014). Predictive sentence processing in L2 and L1. Linguistic Approaches to Bilingualism, 4(2), 257–282. https://doi.org/10.1075/lab.4.2.05kaa.
Kantola, L., & van Gompel, R. P. G. (2011). Between- and within-language priming is the same: Evidence for shared bilingual syntactic representations. Memory & Cognition, 39(2), 276–290. https://doi.org/10.3758/s13421-010-0016-5.
Kintsch, W. (1998). Comprehension: A paradigm for cognition. Cambridge University Press.
Koda, K. (2007). Reading and language learning: Crosslinguistic constraints on second language reading development. Language Learning, 57, 1–44. https://doi.org/10.1111/0023-8333.101997010-i1.
Koda, K. (2008). Impacts of prior literacy experience on second-language learning to read. In K. Koda, & A. M. Zehler (Eds.), Learning to read across languages: Cross-linguistic relationships in first- and second-language literacy development (pp. 68–96). Routledge.
Koester, D., Gunter, T. C., & Wagner, S. (2007). The morphosyntactic decomposition and semantic composition of German compound words investigated by ERPs. Brain and Language, 102(1), 64–79.
König, E., & Gast, V. (2008). Reciprocity and reflexivity–description, typology and theory. Reciprocals and Reflexives: Theoretical and Typological Explorations, 1–32. https://doi.org/10.1515/9783110199147.1.
Kutas, M., DeLong, K. A., & Smith, N. J. (2011). A look around at what lies ahead: Prediction and predictability in language processing. In M. Bar (Ed.), Predictions in the brain: Using our past to generate a future (pp. 190–207). Oxford University Press.
Lan, G., & Sun, Y. (2019). A corpus-based investigation of noun phrase complexity in the L2 writings of a first-year composition course. Journal of English for Academic Purposes, 38, 14–24. https://doi.org/10.1016/j.jeap.2018.12.001.
Lan, G., Liu, Q., & Staples, S. (2019). Grammatical complexity:‘What does it mean’and ‘so what’for L2 writing classrooms? Journal of Second Language Writing, 46, 100673. https://doi.org/10.1016/j.jslw.2019.100673.
Lan, G., Zhang, Q., Lucas, K., Sun, Y., & Gao, J. (2022). A corpus-based investigation on noun phrase complexity in L1 and L2 English writing. English for Specific Purposes, 67, 4–17. https://doi.org/10.1016/j.esp.2022.02.002.
Laufer, B., & Waldman, T. (2011). Verb-noun collocations in second language writing: A corpus analysis of learners’ English. Language Learning, 61(2), 647–672. https://doi.org/10.1111/j.1467-9922.2010.00621.x.
Lemhöfer, K., Schriefers, H., & Hanique, I. (2010). Native language effects in learning second-language grammatical gender: A training study. Acta Psychologica, 135(2), 150–158. https://doi.org/10.1016/j.actpsy.2010.06.001.
Levy, R. (2008). Expectation-based syntactic comprehension. Cognition, 106(3), 1126–1177. https://doi.org/10.1016/j.cognition.2007.05.006.
Lew-Williams, C., & Fernald, A. (2010). Real-time processing of gender-marked articles by native and non-native Spanish speakers. Journal of Memory and Language, 63(4), 447–464. https://doi.org/10.1016/j.jml.2010.07.003.
Lipka, O., Siegel, L. S., & Vukovic, R. (2005). The literacy skills of English language learners in Canada. Learning Disabilities Research and Practice, 20(1), 39–49. https://doi.org/10.1111/j.1540-5826.2005.00119.x.
MacDonald, M. C. (2013). How language production shapes language form and comprehension. Frontiers in Psychology. https://doi.org/10.3389/fpsyg.2013.00226. 4.
MacDonald, M. C., Pearlmutter, N. J., & Seidenberg, M. S. (1994). The lexical nature of syntactic ambiguity resolution. Psychological Review, 101(4), 676–703. https://doi.org/10.1037/0033-295X.101.4.676.
MacWhinney, B. (2005). The emergence of linguistic form in time. Connection Science, 17(3–4), 191–211. https://doi.org/10.1080/09540090500177687.
Martin, C. D., Thierry, G., Kuipers, J. R., Boutonnet, B., Foucart, A., & Costa, A. (2013). Bilinguals reading in their second language do not predict upcoming words as native readers do. Journal of Memory and Language, 69(4), 574–588. https://doi.org/10.1016/j.jml.2013.08.001.
Mathews, P. H. (2003). Linguistics: A very short introduction. Oxford University Press Inc. https://doi.org/10.1093/actrade/9780192801487.001.0001.
McManus, K., & Marsden, E. (2019). Signatures of automaticity during practice: Explicit instruction about L1 processing routines can improve L2 grammatical processing. Applied Psycholinguistics, 40(1), 205–234. https://doi.org/10.1017/S0142716418000553.
Nicoladis, E. (2006). Cross-linguistic transfer in adjective–noun strings by preschool bilingual children. Bilingualism: Language and Cognition, 9(1), 15–32. https://doi.org/10.1017/S136672890500235X.
Omachonu, G. S. (2016). 8. Headedness & demarcation between nominal compounds & noun phrases in Ígálà. Issues in Contemporary African Linguistics: A Festschrift for Oladele Awobuluyi, 11, 103.
Pae, T. I. (2018). Effects of task type and L2 proficiency on the relationship between L1 and L2 in reading and writing: An SEM approach. Studies in Second Language Acquisition, 40(1), 63–90. https://doi.org/10.1017/s0272263116000462.
Pae, T. I. (2019). A simultaneous analysis of relations between L1 and L2 skills in reading and writing. Reading Research Quarterly, 54(1), 109–124. https://doi.org/10.1002/rrq.216.
Papadopoulou, D., & Clahsen, H. (2003). Parsing strategies in L1 and L2 sentence processing: A study of relative clause attachment in Greek. Studies in Second Language Acquisition, 25(4), 501–528.
Parkinson, J., & Musgrave, J. (2014). Development of noun phrase complexity in the writing of English for Academic purposes students. Journal of English for Academic Purposes, 14, 48–59. https://doi.org/10.1016/j.jeap.2013.12.001.
Pasquarella, A., Gottardo, A., & Grant, A. (2012). Comparing factors related to reading comprehension in adolescents who speak English as a first (L1) or second (L2) language. Scientific Studies of Reading, 16(6), 475–503. https://doi.org/10.1080/10888438.2011.593066.
Pastor, M. L. C. (2008). English complex noun phrase interpretation by Spanish learners. Revista Española De Lingüística Aplicada, 21, 27–44.
Patel, N., Peterson, K. A., Ingram, R. U., Storey, I., Cappa, S. F., Catricala, E., Halai, A., Patterson, K. E., Rowe, M. L. R., J. B., & Garrard, P. (2022). A ‘Mini linguistic state ExaminatioN’to classify primary progressive aphasia. Brain Communications, 4(2), fcab299. https://doi.org/10.1093/braincomms/fcab299.
Pichette, F., & Leśniewska, J. (2018). Percentage of L1-based errors in ESL: An update on Ellis (1985). International Journal of Language Studies, 12(2), 1–16. http://www.ijls.net/pages/volume/vol12no2.html.
Pickering, M. J., & Garrod, S. (2013). How tightly are production and comprehension interwoven? Frontiers in Psychology, 4. https://doi.org/10.3389/fpsyg.2013.00238.
Prior, A., Degani, T., Awawdy, S., Yassin, R., & Korem, N. (2017). Is susceptibility to cross-language interference domain specific? Cognition, 165, 10–25. https://doi.org/10.1016/j.cognition.2017.04.006.
Priven, D. (2020). All these nouns together just don’t make sense! An investigation of EAP students’ challenges with complex noun phrases in first-year college-level textbooks. Canadian Journal of Applied Linguistics, 23(1), 93–116. https://doi.org/10.37213/cjal.2020.28700.
Proctor, C. P., August, D., Carlo, M. S., & Snow, C. (2006). The intriguing role of Spanish language vocabulary knowledge in predicting English reading comprehension. Journal of Educational Psychology, 98(1), 159–169. https://doi.org/10.1037/0022-0663.98.1.159.
Ravid, D., & Berman, R. A. (2010). Developing noun phrase complexity at school age: A text-embedded cross-linguistic analysis. First Language, 30(1), 3–26. https://doi.org/10.1177/0142723709350531.
Ravid, D., & Shlesinger, Y. (1995). Factors in the selection of compound-types in spoken and written Hebrew. Language Sciences, 17(2), 147–179. https://doi.org/10.1016/0388-0001(95)00007-I.
Ravid, D., & Zilberbuch, S. (2003a). Morphosyntactic constructs in the development of spoken and written Hebrew text production. Journal of Child Language, 30(2), 395–418.
Ravid, D., & Zilberbuch, S. (2003b). The development of complex nominals in expert and non-expert writing: A comparative study. Pragmatics & Cognition, 11(2), 267–296. https://doi.org/10.1075/pc.11.2.05rav.
Ringbom, H. (2007). Cross-linguistic similarity in foreign language learning (Vol. 21). Multilingual Matters. https://doi.org/10.21832/9781853599361.
Roberts, L. (2012). Individual differences in second language sentence processing. Language Learning, 62, 172–188. https://doi.org/10.1111/j.1467-9922.2012.00711.x.
Robertson, D. (2000). Variability in the use of the English article system by Chinese learners of English. Second Language Research, 16(2), 135–172. https://doi.org/10.1191/026765800672262975.
Rørvik, S. (2022). Noun-phrase complexity in the texts of intermediate-level Norwegian EFL writers: Stasis or development? Nordic Journal of Language Teaching and Learning, 10(2), 298–326. https://doi.org/10.46364/njltl.v10i2.987.
Sarbazi, M., Khany, R., & Shoja, L. (2021). The predictive power of vocabulary, syntax and metacognitive strategies for L2 reading comprehension. Southern African Linguistics and Applied Language Studies, 39(3), 244–258. https://doi.org/10.2989/16073614.2021.1939076.
Schwartz, B. D., & Sprouse, R. A. (1996). L2 cognitive states and the full transfer/full access model. Second Language Research, 12(1), 40–72. https://doi.org/10.1177/026765839601200103.
Shiotsu, T., & Weir, C. J. (2007). The relative significance of syntactic knowledge and vocabulary breadth in the prediction of reading comprehension test performance. Language Testing, 24(1), 99–128. https://doi.org/10.1177/0265532207071513.
Shum, K. K. M., Ho, C. S. H., Siegel, L. S., & Au, T. K. F. (2016). First-language longitudinal predictors of second‐language literacy in young L2 learners. Reading Research Quarterly, 51(3), 323–344. https://doi.org/10.1002/rrq.139.
Siloni, T. (1997). Noun phrases and nominalizations: The syntax of DPs (Vol. 31). Springer Science & Business Media.
Siu, T. S. C., & Ho, S. H. C. (2020). A longitudinal investigation of syntactic awareness and reading comprehension in chinese-english bilingual children. Learning and Instruction, 67, 101327. https://doi.org/10.1016/j.learninstruc.2020.101327.
Siyanova, A., & Schmitt, N. (2007). Native and nonnative use of multi-word vs. one-word verbs. International Review of Applied Linguistics in Language Teaching, 45(2), 119–139. https://doi.org/10.1515/IRAL.2007.005.
Slabakova, R. (2008). Meaning in the second language. Mouton de Gruyter.
Slabakova, R. (2013). Adult second language acquisition. Linguistic Approaches to Bilingualism, 3(1), 48–72. https://doi.org/10.1075/lab.3.1.03sla.
Smith, M. S., & Truscott, J. (2014). The multilingual mind: A modular processing perspective. Cambridge University Press.
Snape, N. (2008). Resetting the nominal mapping parameter in L2 English: Definite article use and the count–mass distinction. Bilingualism: Language and Cognition, 11(1), 63–79. https://doi.org/10.1017/S1366728907003215.
Snape, N., Hosoi, H., & Umeda, M. (2023). Second language processing of English definite noun phrases by Spanish speakers and Japanese speakers. Journal of Second Language Studies, 6(2), 319–347. https://doi.org/10.1075/jsls.22010.sna.
Staples, S., Egbert, J., Biber, D., & Gray, B. (2016). Academic writing development at the university level: Phrasal and clausal complexity across level of study, discipline, and genre. Written Communication, 33(2), 149–183. https://doi.org/10.1177/0741088316631527.
Świątek, A. (2018). The use of selected English determiners by Polish users of English at different proficiency levels. Applied Linguistics Papers, 3/2018(25), 79–88. https://doi.org/10.32612/uw.25449354.2018.3.pp.79-88.
Tabor, W., & Tanenhaus, M. K. (1999). Dynamical models of sentence processing. Cognitive Science, 23(4), 491–515. https://doi.org/10.1207/s15516709cog2304_5.
Tan, M., & Foltz, A. (2020). Task sensitivity in L2 English speakers’ syntactic processing: Evidence for good-enough processing in self-paced reading. Frontiers in Psychology, 11, 575847. https://doi.org/10.3389/fpsyg.2020.575847.
Taşçı, S., & Turan, Ü. D. (2021). The contribution of lexical breadth, lexical depth, and syntactic knowledge to L2 reading comprehension across different L2 reading proficiency groups. English Teaching & Learning, 45(2), 145–165. https://doi.org/10.1007/s42321-020-00065-z.
Tokowicz, N., & Warren, T. (2010). Beginning adult L2 learners’ sensitivity to morphosyntactic violations: A self-paced reading study. European Journal of Cognitive Psychology, 22(7), 1092–1106. https://doi.org/10.1080/09541440903325178.
Tong, X., Tong, X., Shu, H., Chan, S., & McBride-Chang, C. (2014). Discourse-level reading comprehension in Chinese children: What is the role of syntactic awareness? Journal of Research in Reading, 37(S1), S48–S70. https://doi.org/10.1111/1467-9817.12016.
Trimble, L. (1985). English for science and technology: A discourse approach. Cambridge University Press.
Trueswell, J. C., Tanenhaus, M. K., & Garnsey, S. M. (1994). Semantic influences on parsing: Use of thematic role information in syntactic ambiguity resolution. Journal of Memory and Language, 33(3), 285–318. https://doi.org/10.1006/jmla.1994.1014.
Tunmer, W. E., & Bowey, J. A. (1984). Metalinguistic awareness and reading acquisition. In W. E. Tunmer, C. Pratt, & M. L. Herriman (Eds.), Metalinguistic awareness in children: Theory, research, and implications (pp. 144–168). Springer Berlin Heidelberg.
Ullman, M. T. (2001). A neurocognitive perspective on language: The declarative/procedural model. Nature Reviews Neuroscience, 2(10), 717–726. https://doi.org/10.1038/35094573.
van Gelderen, A., Schoonen, R., de Glopper, K., Hulstijn, J., Snellings, P., Simis, A., & Stevenson, M. (2003). Roles of linguistic knowledge, metacognitive knowledge and processing speed in L3, L2 and L1 reading comprehension. International Journal of Bilingualism, 7(1), 7–25. https://doi.org/10.1177/13670069030070010201.
Van Gelderen, A., Schoonen, R., Stoel, R. D., De Glopper, K., & Hulstijn, J. (2007). Development of adolescent reading comprehension in language 1 and language 2: A longitudinal analysis of constituent components. Journal of Educational Psychology, 99(3), 477–491. https://doi.org/10.1037/0022-0663.99.3.477.
Van Petten, C., & Luka, B. J. (2012). Prediction during language comprehension: Benefits, costs, and ERP components. International Journal of Psychophysiology, 83(2), 176–190. https://doi.org/10.1016/j.ijpsycho.2011.09.015.
Verbeek, L., Vissers, C., Blumenthal, M., & Verhoeven, L. (2022). Cross-language transfer and attentional control in early bilingual speech. Journal of Speech Language and Hearing Research, 65(2), 450–468. https://doi.org/10.1044/2021_JSLHR-21-00104.
Williams, J. N. (2006). Incremental interpretation in second language sentence processing. Bilingualism: Language and Cognition, 9(1), 71–88.
Williams, J. N., Mobius, P., & Kim, C. (2001). Native and non-native processing of English wh- questions: Parsing strategies and plausibility constraints. Applied Psycholinguistics, 22(4), 509–540. https://doi.org/10.1017/S0142716401004027.
Wintner, S., & Ornan, U. (1995). Syntactic analysis of hebrew sentences. Natural Language Engineering, 1(3), 261–288. https://doi.org/10.1017/s1351324900000206.
Witzel, J., Witzel, N., & Nicol, J. (2012). Deeper than shallow: Evidence for structure-based parsing biases in second-language sentence processing. Applied Psycholinguistics, 33(2), 419–456.
Wolter, B., & Gyllstad, H. (2013). Frequency of input and L2 collocational processing: A comparison of congruent and incongruent collocations. Studies in Second Language Acquisition, 35(3), 451–482. https://doi.org/10.1017/S0272263113000107.
Wray, A. (2002). Formulaic language and the lexicon. Cambridge University Press.
Yamashita, J. (2001). Transfer of L1 reading ability to L2 reading: An elaboration of the linguistic threshold. Studies in Language and Culture, 23(1), 189–200.
Yamashita, J., & Jiang, N. A. N. (2010). L1 influence on the acquisition of L2 collocations: Japanese ESL users and EFL learners acquiring English collocations. Tesol Quarterly, 44(4), 647–668. https://doi.org/10.5054/tq.2010.235998.
Yuan, B. (2017). Can L2 sentence processing strategies be native-like? Evidence from English speakers’ L2 processing of Chinese base-generated-topic sentences. Lingua, 191, 42–64.
Zhang, D. (2012). Vocabulary and grammar knowledge in second language reading comprehension: A structural equation modeling study. Modern Language Journal, 96(4), 558–575. https://doi.org/10.1111/j.1540-4781.2012.01398.x.
Zhang, S., & Zhang, X. (2022). The relationship between vocabulary knowledge and L2 reading/listening comprehension: A meta-analysis. Language Teaching Research, 26(4), 696–725. https://doi.org/10.1177/1362168820913998.
Funding
This research received no specific grant from any funding agency.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study was approved by the ethics committee of the Israeli Ministry of Education. Informed consent was obtained from all participants.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1 types of NP structures in the English (L2) NP comprehension test
Set | premodifiers type | number of premodifiers | Examples |
|---|---|---|---|
1 | NN | 0 | Medicine promotes healthier athlete lifestyle |
1 | Sportsmedicine promotes healthier athlete lifestyle | ||
2 | NNN | 0 | The doll fell on the floor and broke |
2 | The porcelain babydoll fell on the floor and broke | ||
3 | Adj. NN | 0 | The barks make my cat very stressed |
2 | The loud dogbarks make my cat very stressed | ||
4 | Adj. NNN | 0 | The book is classically designed |
3 | The old office phonebook is classically designed |
Appendix 2 types of answers
Answer type | Example 1 | Example 2 | Explanation |
|---|---|---|---|
Sentence | The art fair received rave reviews from the attendants of the event. | The police department collaboration made the man’s arrest easier? | Premodifier(s) + head noun |
The equivalent sentence in Hebrew | The fair art received rave reviews from the attendants of the event | The collaboration department police made the man’s arrest easier? | Head noun + premodifiers |
Question | what received rave reviews? | What made the arrest easier? | |
Correct | The fair | The collaboration | |
L1-based error | The art | The police | Because in Hebrew the head noun appears first, this answer represents activation of L1 syntax |
L2-based error | The attendants | The department | This type of error represents any other incorrect answer that doesn’t indicate syntactic transfer of the L1 NP structure. |
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sasson, A., Schiff, R. & Zluf, B. Syntactic knowledge in a foreign language: examining cross-language transfer effects in L2 noun phrase comprehension. Read Writ (2024). https://doi.org/10.1007/s11145-024-10569-w
Accepted:
Published:
DOI: https://doi.org/10.1007/s11145-024-10569-w