
Abstract
Identifying the set of available alternatives in a choice process after considering an individual’s bounds or thresholds is a complex process that, in practice, is commonly simplified by assuming exogenous rules in the choice set formation. The Constrained Multinomial Logit (CMNL) model incorporates thresholds in several attributes as a key endogenous process to define the alternatives choice/rejection mechanism. The model allows for the inclusion of multiple constraints and has a closed form. In this paper, we study the estimation of the CMNL model using the maximum likelihood function, develop a methodology to estimate the model overcoming identification problems by an endogenous partition of the sample, and test the model estimation with both synthetic and real data. The CMNL model appears to be suitable for general applications as it presents a significantly better fit than the MNL model under constrained behaviour and replicates the MNL estimates in the unconstrained case. Using mode choice real data, we found significant differences in the values of times and elasticities between compensatory MNL and semi-compensatory CMNL models, which increase as the thresholds on attributes become active.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Within the framework of discrete choice models, one of the main tools used in predicting the transportation demand are random utility maximization (RUM) models (McFadden 1968). These models are usually applied assuming that individuals exhibit a compensatory behaviour regarding attributes and that the set of alternatives is known and fixed. An important problem arises when the value of one or more attributes are excessively high or low, lying out of the domain in which choices are considered to be feasible by the consumer. This problem is present whenever there are bounds (upper or lower) on attributes, representing either individuals’ self-imposed thresholds or exogenous constraints (e.g., income, time or physical limitations), which are not explicitly represented in the model. For example, in a residential choice context, individuals cannot choose units which price is greater than their income (that is an exogenous constraint), but they can also limit their choices to units with a minimum square footage (self-imposed threshold), based on their personal preferences or unobserved limitations or requirements. Models that ignore the presence of bounds can lead to inconsistent parameter estimation and, thus, forecasting errors (Swait 2001). In the transportation field, models that account for thresholds on attributes, called semi-compensatory models, have gain great interest in the last decade, being applied to modal (Cantillo and de Ortúzar 2005), location (Martínez and Hurtubia 2006, Kaplan et al. 2012), destination (Zheng and Guo 2008) and route choice (Kaplan and Prato 2010).
The microeconomic theory recognizes that the consumers’ choice domain should be explicitly defined by all the constraints, such as income and time budgets, but also physical and psychological constraints. Once these constraints are introduced into the utility function, the theory defines the so-called indirect utility function (IUF). However, the standard theory provides little information to modellers about the actual functional form of the IUF. This function is usually inferred from observed behaviour by applying econometric methods, in too many cases using a linear utility function due to limited data. Hence, while the theoretical IUF must be a complex non-linear function able to encapsulate constraints, the scarcity of data and the difficulty in identifying the full set of constraints complicate the estimation of appropriate utility functions; the result is that constraints are largely ignored. Thus, the compensatory (non-constrained utility) model may predict demands outside of the consumer’s domain, even if the point estimates of the model parameters are sufficiently accurate.
The role of domains has been emphasized by the elimination-by-aspects approach (Tversky 1972), which focuses on thresholds of attributes to describe individuals’ choices. In the search for a practical solution to obtain a realistic representation of the choice process under constrained domains, a handful of models have been proposed that include an explicit definition of the set of alternatives available to each individual (see, for instance, Swait 2009). For example, in transportation demand, constraints may be activated when the travel time is too long, making an activity at a given destination infeasible (e.g. walking a long distance), or when the travel cost is so high that the user cannot finance the trip.
Two approaches are found in the literature attempting to reconcile the advantages of RUM models with the need to model choice-set formation. First, the two-stages approach (Manski 1977) proposes that the choice probability of a given alternative is the joint probability of choosing that alternative conditional on the choice set, summed over all choice sets. Applications of this approach are in Cantillo and de Ortúzar (2005) and in Kaplan et al. (2012). The main problem with this approach is the great computing costs involved in enumerating the usually very large number of choice sets (Swait and Ben-Akiva 1987). The second approach is a single-stage (or implicit) method that includes the availability of alternatives implicitly in the IUF by reflecting disutility when attributes violate thresholds, so they are not chosen. This approach has the advantage of higher efficiency by avoiding the combinatorial number of choice sets; see applications in Cascetta and Papola (2001) and Swait (2001). However, Cascetta and Papola’s model is difficult to estimate particularly in complex specifications with multiple constraints, while Swait’s model does not allow randomness in penalizations, nor is the utility function derivable at the threshold, which may create instability when the model is used in equilibrium analysis.
The Constrained Multinomial Logit (CMNL) model (Martínez et al. 2009) is a one-stage closed-form model with utility penalizations, which allows the modeller to represent multiple constraints on individuals’ choices. The penalizations (also referred as cut-offs) are specified as binomial Logit functions, which may indistinctively represent the two sources affecting choice-set formation: exogenous constraints on attributes faced by individuals and endogenous (self-imposed) thresholds on attributes. Given its potential benefits, the CMNL has attracted some attention to applications and some preliminary estimations have been made, e.g. for location choice (Martínez and Hurtubia 2006), mode choice (Bierlaire et al. 2010), school choice (Martínez et al. 2010) and hunter site choice (Truong 2010). However, these applications are limited to the case where a variable represent only a threshold without playing a role in the compensatory utility.
In this paper we study the more general case where the constrained attribute is also a variable in the compensatory utility, raising problems of identification between the compensatory parameters and those of the cut-offs. The nature of this problem is of more general interest as it is likely to appear whenever behaviour adapts to different contexts, therefore, for a given individual, a different utility function applies depending on the context. To overcome this problem we developed a novel endogenous method to partition the data affected by compensatory and constrained behaviour, so we estimate parameters using the relevant sub-set of data where the correct behaviour applies. This method avoids the exogenous partition, based on the modeller’s intervention in revealed preference data, or on declared bounds as proposed by Swait (2001) in a case of a stated preference study.
The relevance of studying the estimation of the CMNL’s model is that the probability functional form differs from traditional Logit models, and its complexity prevents us from extrapolating conclusions from previous studies. Therefore, in this paper, the log-likelihood function is specified and the optimal conditions are derived and interpreted, the identification conditions of parameters are discussed, and the method to partition the estimation sample is tested. The model parameters are estimated using synthetic data, as a way to build up experience on estimating this new model in a controlled environment, as well as using real databases to analyse empirically the implications on the parameter estimates and prediction capabilities.
The paper is organized as follows. In “The CMNL model” section, we describe the model; in “Estimation method” section we discuss the estimation method and analyse identification issues; in “Empirical analysis and results” section, we present estimation results using simulated and real data; and we present the endogenous method to partition the estimation sample using a maximum likelihood procedure; we finalize with a “Conclusions and final comments” section.
The CMNL model
The model is based on the RUM approach, which assumes that the indirect utility, \( U_{ni} \), provided by an alternative i, to the individual n, is known by the decision-maker but not by the modeller. This is represented in the choice model by the sum of two components: a deterministic component, \( V_{ni} , \) known by the modeller and represented by a function of the vector of attributes of the alternative, and a random component \( \varepsilon_{ni} , \) that represents the analyst’s inability to appreciate all attributes and variations in tastes that govern the actual behaviour of individuals, as well as errors in measurement and imperfections in the information available. Therefore, the indirect utility function is as follows:
Within the RUM approach, one of the most frequently used models is the Multinomial Logit (MNL) (McFadden 1974). The MNL model, assumes that the random component \( \varepsilon_{ni} \) follows an identical and independent (iid) Gumbel distribution, offering a closed form for the choice probabilities. The MNL probability that individual n, chooses alternative i within the set of alternatives available, denoted by \( C_{n} , \) is given by
where µ is the scale parameter of the Gumbel distribution.
The Constrained Multinomial Logit (CMNL) model is proposed by Martínez et al. (2009) as a generalization of the above formulation that combines, in a one-stage model, a traditional compensatory deterministic component (called V) plus a non-compensatory component; this is termed a semi-compensatory approach. The non-compensatory component is activated when one or more attributes of the relevant choice alternative approach their respective threshold values. In this model, the utility function is defined as
where \( x_{i} \) is the vector of attributes of alternative i, and \( \phi_{ni} \) is a deterministic penalization function or cut-off for alternative i. An attribute cut-off is the minimum/maximum acceptable level that an individual sets for an attribute. In Martínez et al. (2009) this utility function is not derived from a theoretical argument; instead, the inclusion of a cut-off factor and its functional form is instrumental, and several convenient features for modelling purposes justify the specific formulation given above. We also remark, following Swait (2001), that making different assumptions on the stochastic term in Eq. (3) would lead to a family of extreme value models with cut-off, including Nested Logit, Mixed Logit and other discrete choice models. The analysis that follows is developed for the iid Gumbel case, but it can be extended to a wider family of constrained models.
Multiple constraints are allowed in the CMNL model, allowing for upper and lower bounds on one or more attributes. For that purpose and assuming that elementary cut-offs are independent both within and between constraints, the aggregated cut-off is defined by the multiplication of the set of upper restrictions, \( \phi_{nik}^{U} , \) and lower restrictions, \( \phi_{nik}^{L} \), on the corresponding attribute, k, as follows:
Each elementary cut-off in Eq. (4) is defined as a binomial Logit on a given attribute k and alternative i, thus representing a “soft” restriction, meaning that it may be trespassed by the decision-maker at the cost of a penalization in the utility function. The elementary cut-offs on attribute k for individual n on alternative i are:
where \( b_{nk} \) and \( a_{nk} \) are the upper and lower bounds, respectively, that restrict the choice; \( \omega_{k} \) is the scale parameter of the binomial Logit \( \left( {\omega_{k} > 0} \right);\rho_{k} \) is a position parameter defined below and \( x_{ik} \) is the value of the restricted attribute for the corresponding choice. For notation simplicity, we have omitted the superscript U and L in the upper and lower bound for the scale and position parameters, \( \omega \;{\text{and}}\; \rho \). We note that the binomial Logit model [Eqs. (5), (6)] cannot completely eliminate the choice probability when a constrained attribute is beyond its bounds. Instead, the CMNL model considers a soft constraint imposing a limit on the probability of violating the bounds, which is expressed by an implicit condition \( \phi_{nik} (a_{nk} )=\eta_{k} \) (similarly for the upper bound), with a model parameter \( \eta_{k} \in (0,1). \) This condition is equivalently and more conveniently expressed by the definition of a position parameter \( \rho_{k} \) as:
As stated above, both parameters \( (\rho ,\eta ) \) may be different for the upper and lower bounds.Footnote 1
Note that the elementary binomial Logit cut-offs defined by Eqs. (5) and (6) and the composite cut-off defined by Eqn. (4) belong to (0,1); if the constrained attribute takes values beyond the upper or lower bounds, then \( \phi \epsilon \left( {\eta ,0} \right) \) and utilities decrease by factor ln(ϕni) in Eq. (3); consequently, the choice probability of alternative i vanishes. For realistic values of attributes, i.e., \( x \ll |\infty |, \) the cut-off does not reproduce a deterministic behaviour, that is, \( \phi_{ni} (x) \ne \{ 0,1\} . \)
Figure 1 shows the behaviour of the upper cut-off function with \( \omega_{k} \) and \( \eta_{k} \) for the particular case of a linear utility function V. Observe that ln(ϕ ni ) approximates a bilinear function, similar to Swait (2001) linear penalization term, but instead of having a kink at the threshold (point b nk − x nk = 0 in the figure), the CMNL cut-off is differentiable at that point. The functional form defined for the cut-off reaches its maximum \( \left( {\phi_{nik} \sim 1} \right) \) when the attribute moves away from the bound towards the interior of the feasible domain; conversely, when the value of the constrained attribute exceeds the threshold, the cut-off value tends to zero, penalizing the utility function in a non-linear way. Therefore, \( \phi_{nik} \) may be understood as the probability that individuals consider alternative i within their choice sets.

Penalization of the utility function
By assuming that the random component in the utility function follows an iid Gumbel distribution, the choice probability of alternative i is as follows:
which is a closed functional form similar to that of the MNL. This form differs, however, on the set of alternatives \( C_{n}^{\prime } , \) which is individual specific only due to unfeasible options (like no car in the house); otherwise considers all alternatives. It is also convenient to write the probability as:
This expression highlights that choice probabilities depend on the difference between utilities and the ratio between cut-offs. The dependence on utilities differences is relevant for the identification of parameters, just like in the case of the MNL model. The dependence on the cut-offs ratio is relevant when the cut-offs tend to zero, because their logarithm is undefined but their ratio may be defined. Identification considerations are discussed in detail in “Estimation method” section.
One property of Eq. (8a), highlighted by Martínez et al. (2009), is that in equilibrium it preserves the convenient convergence properties of the MNL model under choice externalities or consumer interactions such as congestion or mutual attraction between consumers. In this case, the utility function contains endogenous attributes that depend on other consumers’ choices, either in the compensatory part or in the cut-off of the utility function; thus, a fixed-point problem is generated to predict demand. The authors prove that this fixed-point problem under the CMNL model has a unique solution and that the fixed-point iteration algorithm converges to that solution. This property, highly useful in forecasting equilibrium, is not proven to exist by Cascetta and Papola (2001) and Swait (2001) in their respective models; hence, the performance of these models in finding stable equilibrium is unknown.
The cut-off function may be defined for an exogenous constraint, where \( a_{nk} \) and \( b_{nk} \) are known by the modeller, as well as for endogenous thresholds self-imposed by the choice maker, where these parameters are unknown. For the latter case, we discuss below whether these parameters can be identified in the estimation process. To simplify the analysis, in what follows only upper bounds, \( b_{nk} \), will be imposed on the attributes because they are most commonly found in transportation studies (for example, time and cost upper bounds).
Estimation method
The method proposed for the estimation of the CMNL model is the maximum likelihood method. The likelihood of each observation is built considering the probability function of Eq. (8a). The parameter estimates are determined from the solution of the following maximum likelihood problem:
where \( \delta_{ni} = 1 \) if individual n chooses alternative i, 0 if not, P ni is the probability of Eq. (8a), and \( \theta_{n} \) is the vector of parameters of the compensatory utility function such that \( \theta_{n} = \left( {\theta_{nk} \in \Re ,k = 1 \ldots K} \right). \) Hereafter, for simplicity in the exposition, utility is assumed to be linear in attributes x: \( V_{ni} = \theta_{n0} + \sum\limits_{k} {\theta_{nk} \cdot x_{ik} } . \) We use the logarithm of Eq. (9), i.e. l = ln(L), to simplify calculations and we consider only upper bounds for simplicity. It is worth noting that Eq. (9) assumes endogenous bounds, b, although it can be simplified by assuming exogenous bounds. More generally, the estimation problem could combine both types of bounds in the same choice problem.
The first-order conditions (FOC) of Eq. (9) for each \( \theta_{n} ,\,\omega_{k} ,b_{nk} \) and \( \rho_{k} \) parameters are the following:
with \( \overline{\phi }_{nik} = 1 - \phi_{nik} \) as the constraint compliance probability and \( \Upphi_{nik} = \left( {1 - \phi_{nik} } \right) \cdot \left( {x_{nik} - b_{nik} } \right) \) as the expected magnitude of the constraint compliance.
These FOC have interpretations that are consistent with the theory on which the CMNL model is founded. Equation (10) verifies the FOC for the MNL model in the linear utility case,Footnote 2 and the alternative specific constants, \( \theta_{n0} \), reproduce the market shares in the estimation sample; as in the MNL model, all but one of them are identifiable. The rest of the parameters guarantee that the expected (predicted) average values of attributes are equal to the average values observed in the sample. As in the case of MNL, the scale parameter, \( \mu \), is not identifiable but this fact does not affect the cut-off parameters. Equation (11) states that the estimation of parameters, \( b_{nk} \), guarantee that the predicted and observed compliance of each constraint matches for each cluster of individuals. Equation (12) is similar but aggregated across the whole population; hence, it is redundant if Eq. (11) holds for all n, although it is relevant for exogenous bounds when (11) does not hold. It is important to underline here an identification problem that may arise to estimate \( b_{nk} \) and \( \rho_{k} \) when bounds are endogenous; under exogenous constraints, \( \rho_{k} \) can always be identified. In Eq. (13), \( \Upphi_{nik} \) represents the expected magnitude of the violation of bounds, the estimate of \( \omega \) imposes that the predicted magnitude of the constraint violations matches with that observed in the data. It is worth noting that when attribute k is in the compensatory domain, then ϕ nik = 1 and \( \Upphi_{nik} = 0, \) which implies that the relevant information to estimate parameter ω k comes from observations near the threshold. From these conditions it can be seen that the CMNL model is a generalization of the MNL because, if the individuals present a pure compensatory behaviour, the cut-off parameters are irrelevant, and the FOCs of the MNL model are recovered.
Note that, as in the MNL model, the scale parameter, \( \mu \), cannot be identified, so we estimate \( \mu V_{ni} (x_{i} ) + \ln \left( {\phi_{ni} (x_{i} )} \right) \), where \( \ln \phi_{ni} (x_{i} ) = - \ln [1 + \exp \,\omega_{k} (x_{ik} - b_{nk} + \rho_{k} )] \). We also note that \( \ln \phi_{ni} (x_{i} ) \) is close to a bilinear form, as depicted in Fig. 1, approximated by \( \ln \phi_{ni} (x_{i} \to b_{nk} ) \approx - \omega_{k} (x_{ik} - b_{nk} + \rho_{k} ) \). The quasi-bilinear form of the cut-off combined with the linear compensatory utility induces a potential correlation problem between the parameters θ nk and ω k , both associated with the restricted attribute, x ik ; this problem will occur if an attribute is present both in the compensatory component and the cut-off of the utility function. In this case an approach to identify parameters is to partition the sample between observations subject to compensatory behaviour and those affected by constraints. We propose a partitioning approach in “Empirical analysis and results” section.
When the bounds are endogenous variables, such as, for example, thresholds on walking time or travel time in a mode choice, only a combined parameter, \( \widetilde{\rho }_{nk} = \rho_{k} - b_{nk} , \) can be identified in addition to \( \omega_{k} \). This observation has practical importance because it implies that, when it is convenient, the CMNL model can be estimated assuming endogenous bounds, thus eliminating the need to provide exogenous parameters to the model.
When the bounds are exogenous, for example when income is observed, then both \( b_{nk} \) and \( a_{nk} \) are known, and \( \rho_{nk} \) and \( \omega_{k} \) can be estimated in addition to the θ n parameters in the compensatory part. In this case, all parameters are identifiable and, since the proportion of people violating the restriction can be obtained directly from the database, \( \rho_{k} \cdot \omega_{k} \) can be obtained from Eq. (7); it follows that only the parameter \( \omega_{k} \) needs to be estimated.
Empirical analysis and results
Estimation with synthetic data
To evaluate the estimation of the CMNL model, we used the simulation method suggested by Williams and de Ortúzar (1982), also applied by Munizaga et al. (2000). The idea of this method is to test the model in a controlled situation, where the choice process and all the parameters are known. This method allows for testing whether the model parameters are well recovered when using a database obtained from known choice rules. It also helps to check if the model recognizes the correct behaviour with and without constraints. Finally, the prediction capabilities can also be checked: parameters should be recovered if the model is correctly specified and not subject to any identification problems; conversely, in over specified models parameters should not be identifiable.
We generated a dataset assuming a behaviour by which individuals make their choices following a compensatory utility function, but they penalize some attributes after certain thresholds, just as the CMNL assumes. Mode choice data was generated for four hypothetical alternatives: Car, Bus, Shared-Taxi and Metro, with a utility function that depended on four attributes: Travel Time, Walking Time, Waiting Time and Cost, simulating the choices of 10,000 individuals. The attributes of each mode were generated as normal variables with fixed means and variances. Given the number of observations, there is no need to make several repetitions of the simulation experiments for each particular case (the results won’t be different).
The iid Gumbel terms were generated with a variance such that the scale factor, μ, equals one. The following linear utility function was evaluated for each alternative i and observation n:
The parameters used to simulate the data are reported in Table 1.
Finally, the choice of each individual is computed as the alternative that yields the simulated maximum utility. In this process, the values of the attributes and the choice parameters presented in Table 1 were carefully chosen to represent a real choice situation, but also to have an adequate balance between the deterministic and random components. This is important because a purely deterministic or a purely random experiment would not allow for the estimation of a random utility (CMNL or MNL) model. For these experiments, a homogenous population of individuals is assumed; therefore, a single set of parameters was considered for the entire sample.
In Table 2, we present results for a case in which travel time (tt) was penalized. The model was estimated assuming an exogenous bound, according to Eq. (15), and an endogenous bound, as shown in Eq. (16). As mentioned above, in the case of an endogenous bound, ω tt , b tt and ρ tt cannot be separately identified; therefore, an aggregate B tt = ω tt · (−b tt + ρ tt ) parameter is estimated instead. Note that in this case η tt can be directly calculated from the dataset as the percentage of observations in which the constraint is violated, which defines ρ tt according to Eq. (7).
The estimation results show that in both cases, endogenous and exogenous bounds, the scale parameter of the penalization term, ω tt , is correctly estimated. The parameters estimation is analysed in terms of the t test, checking whether the parameters are significantly different from zero and whether they are significantly different from the known design value. All parameters’ estimates are significantly different from zero (t0 > 1.96), and none of them is significantly different from the corresponding design values used to generate the data (see [td] < 1.96). Comparing the results of both cases, parameters are not significantly different and the slight difference in log-likelihood is not surprising, as the model with an exogenous bound has been fed with the true (design) value of the bound. This basically proves that the CMNL model is capable of capturing the true parameters, in a case where the “real” behaviour is constrained.
We also studied what would happen if we used an incorrect model regarding the simulated behaviour. For that purpose, we generated an additional database using a compensatory utility function (MNL database), and estimated the parameters from a CMNL model. The results, presented in Table 3, show that for all parameters in the compensatory function the true value lye within the estimated confidence interval, even though the cost parameter is in the lower limit of its rather large confidence interval. On the other hand, the parameters associated with the cut-off were not statistically significant. These results are not surprising, given the fact that the simulated behaviour is indeed compensatory. However, the merit of these results is that they show that a modeller with no clue about the behaviour of the decision-makers, can assume a constrained behaviour and calibrate a CMNL model and the resulting parameters should indicate whether the behaviour is compensatory or not.
Then we proceeded inversely: using a database generated assuming a constrained behaviour (CMNL database) we estimated a MNL model. Two different databases were used, one generated with bounds on travel costs and the other on travel times. The results of these experiments are shown in Table 4. It can be seen that the MNL model only recovers the parameters of non-penalized variables, and also that the model fit is significantly worse than that of the correct CMNL model. The values of the likelihood ratio test show that in this case the modeller would clearly choose the CMNL specification. This again suggests that it is safe to try the CMNL specification, because if the behaviour captured with the data is indeed constrained, the CMNL model should appear superior, while if it is not, the model should be not significantly better than the MNL.
To estimate the potential error of not considering constrained behaviour when it is present in reality, we conducted a prediction analysis. This is necessary because it might argue that even though the parameters are different, the MNL model could somehow compensate and predict correctly. Therefore, we tested several policy scenarios where the penalized attribute value changes. The predictions of both models were compared with the real (simulated) behaviour to calculate the following χ2 error index (see Munizaga et al. 2000), originally proposed by Gunn and Bates (1982) to take into account the relative magnitude of the observations: \( \chi^{2} = \sum\nolimits_{i} {\frac{{\left( {\widehat{N}_{i} - N_{i} } \right)^{2} }}{{N_{i} }},} \) where and \( \widehat{N}_{i} \) and N i are the model estimate and actual (simulated) the number of individuals choosing option i. The results are summarized in Table 5, where values above 7.81 imply significant differences between the prediction and the simulated behaviour.
The results in Table 5 are for constrained travel time and cost on different modes (one column for each mode) predicted with the corresponding model on each case. As expected, the CMNL model predictions are generally correct, i.e. they present a χ2 error index bellow 7.81, and the MNL model fails to reproduce changes of behaviour in the majority of cases. The larger errors are concentrated in the cases of 50 % cost reduction of shared taxi, bus and metro, and travel time reduction of the same percentage for metro. These results are valid for this case, and we don’t have a general explanation of them. However, regarding the concentration of errors in specific policies and modes, there might be a relation between thresholds and potential biases of the MNL predictions.
In summary, these tests using simulated data indicate that the CMNL model captures correctly the constrained behaviour when it is present and would lead the modeller to a MNL when there are not active constrains. Also, we have shown that MNL predictions could be severely biased when constrained behaviour is present and it is not considered in the model.
Estimation with real data
The estimation of the CMNL with real data needs to overcome the identification problem found in “Estimation method” section , which arises when the variable is subject to a threshold but it is also included in the compensatory utility. In this paper we propose and test the following approach: define an endogenous method to partition the sample between compensatory and constrained behaviour and estimate the each set of parameters using the corresponding subset of data. The novelty here is the endogenous partition, which differs from previous approaches that circumvent the partition problem by adding exogenous information, e.g. exogenous partition by analysing the data or use stated preference data to identify thresholds (Swait 2001).
We used the Las Condes–Downtown database (Donoso 1982), recognized as a good quality source of revealed preferences data previously used in several studies. The database contains a detailed description of the available alternatives for each individual (cost, travel time, and walking time, among others), several socio-demographic variables to characterize the individual (income, gender, and working hours, among others), and the option chosen. The average values of the explanatory variables are described in Table 6. A potential drawback of this data set is the exogenous definition of the choice set and that the level of service variables are only available for the alternatives belonging to the choice set of each individual. This is a limitation on the quality of the test we carried out.
Exogenous partition approach
Prior to estimating the CMNL model, we conducted a statistical analysis to identify attributes that may be subject to a non-compensatory behaviour, thus determining likely ranges for the relevant bounds, shown as ranges b tt for travel and b wt for waiting time in Fig. 2. In both cases, there is a clear slope change at a certain point, indicating a possible threshold effect and the likely range for the bound.

Level of service variables, cumulative histograms
A preliminary study about the performance this exogenous partition method is shown in Fig. 3. The log-likelihood of models with the same specification of utility (see Table 4) and a cutoff on walking time is presented for different partitions of the sample given by parameter d% and for several exogenous values of bounds, b nk , selected from Fig. 2. The sample is ordered for increasing values of walking time and d is the percentage of the sample assumed not affected by the threshold. Therefore, d = 0 is equivalent to estimating the original CMNL model without partition and with identification problems, while d = 100 represents the MNL model and ω k = 0. Figure 3a shows that for partition d between 0 and 15 the CMNL performs better than the MNL, independently of the exogenous bound chosen, and for all bounds the best likelihood is obtained at the same d point (approximately at d = 10). Figure 3b shows that the scale parameter is sensitive to d and b. Hence we conclude that the partition affects both the log-likelihood and the estimated ω k . Therefore, how to select the partition is a relevant question. In this particular application, the maximum likelihood was found at a very small d, which implies that 90 % the observations are affected by the walking time threshold. This is not a general result, as different maximum likelihood partitions were found in other cases not reported here. Additionally, we empirically verified that there is no relevant correlation between parameters in this partitioned version of the model, thus the partition method comply with the objectives.

Results of CMNL estimation with exogenous partition and penalization of walking time. Las Condes–Downtown database: morning trip to work
Additionally, to complement this empirical analysis, and given the complexity of the model CMNL model (Fig. 1), we also studied the alternative of estimating the approximated model that linearly penalizes the attributes, in line with the formulation of Swait (2001). Swait’s model is shown in Eq. (17), where \( \beta_{nk} \) is the parameter that accompanies the penalized attribute k in the partition of the domain defined by \( g \) (equal to 0 if x ik belongs to the partition d% affected by the cut-off; 1 otherwise):
Notice that this bilinear model can be seen as a linear approximation of Eqs. (15) and (16), as shown in Fig. 1. The results using the Las Condes–Downtown database show that the log-likelihood of the CMNL model for all values of g is always larger than that of the MNL model and Swait’s model. Therefore, we conclude that the partitioned estimation method allows estimating the penalization parameters and shows a better fit than simpler models, such as the MNL and the bilinear Swait’s model. Moreover, despite the similarity between the CMNL and the bilinear models (Fig. 1), the difference in likelihood is significant.
Endogenous partition approach
In this section we develop and analyze a method to estimate the CMNL model without an ex-ante exogenous partition of the sample. The idea is to replace the costly and inaccurate inspection methodology depicted in Fig. 3 by an optimization procedure able to identify the partition of the sample that yields the maximum likelihood. For that end we redefine the utility function in Eqs. (15) and (16) as:
where the g is defined as a continuous and differentiable partition factor \( g_{nik} = \frac{1}{{1 + e^{{x_{ik} - b_{nk} - \tau_{k} }} }} \) which penalizes each attribute x k . The new position parameter τ k defines at what point of the attribute’s value the observations switch from compensatory to non-compensatory behaviour, which is identified simultaneously with all other parameters. The roles of \( \delta \) in Eq. (9) and factor g in Eq. (18) can be understood as similar and complementary: while the former assigns individuals’ observations to choices, the latter assigns choices to a specific utility function.
The estimation for the Las Condes–Downtown database, was performed considering walking and travel times constrained by thresholds common to all individuals. The best model obtained, considering that \( \omega_{k} \) must be nonnegative and taking into account the significance of the estimators, is presented in Table 7. In the CMNL specification walking time is subject to a threshold of \( b = 5 \) min and \( \rho = 3,42 \) min. All variables in the compensatory utility are specified in linear form, and their parameters are not significantly different than those of the MNL, except for the constrained variable (walking time).
We also explored the effect of adding nonlinear terms on walking time in the compensatory utility. In this case, the threshold parameters become non significant. This was tested for several non-linear exponents. These exercises suggest that the nonlinear term competes with the cut-off, making both models potentially similar. However, there is an advantage on using the CMNL model in predicting demand, because it provides a model of the feasible choice set for scenarios with different thresholds, while the MNL with nonlinear terms ignores the existence of such thresholds.
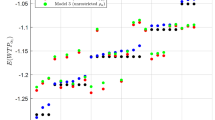
In Fig. 4 we present the elasticities and subjective values of time (SVT) for the models presented in Table 7. We observe that the elasticities perform similarly up to 5 min of walking time, beyond that threshold the estimates are significantly different. The SVT are constant up to the 5 min walking time threshold but different between CMNL and MNL and, as expected, the gap between MNL and CMNL increases with the walking time. These results highlight the potential negative repercussions for both model forecasting performance and policy evaluation when assuming that individuals follow a compensatory behaviour.

Elasticities and subjective values of time walking time constrained model
Conclusions and final comments
The CMNL model is a generalization of the MNL model that has a more complex probability formulation; this generalization can be extended to the family of Logit models (nested, Mixed, etc.). Using a non-linear function, it includes the possibility of penalizing the utility of alternatives not available or discarded by the decision maker because the value of one or more attributes (or indeed a function of the attributes) approaches or exceeds a threshold. This paper has confirmed that, despite the augmented complexity, it is feasible to implement the CMNL model by estimating the parameters using the maximum likelihood method. The first-order conditions are consistent with the models’ underpinning theory of behaviour, that is, they reproduce the MNL conditions within the domain of the variables, while at the edge (near the threshold) they define new conditions, allowing for the estimation of the parameters associated with the penalization.
It has been shown that the CMNL model is capable of making reliable predictions. In the case of real data, we found statistically significant evidence of threshold effects, where the CMNL model fits the data better than the MNL model. Additionally, we found that the CMNL predictions are different from those of the MNL model when behaviour is constrained. The modeller faces the a priori question of which variables are subject to thresholds. From our results, the modeller could assume thresholds for all variables, or proceed with a stepwise approach adding cut-offs one by one. In both cases, the likelihood ratio test will help finding the best specification.
We have observed that the parameters of the restricted variables in the model may, under certain circumstances, present an identification problem, due to the correlation with their corresponding parameters in the compensatory component of the utility function. This problem does not always appear, as shown in the simulation analysis. We proposed a method to deal with this identification problem without requiring an a priori assumption regarding the data. The method consists in the endogenous partition of the attributes domain into two sub-domains defined by a critical value: an interior in which behaviour is assumed to be compensatory (trade-off between attributes) and the edge of the domain where the cut-off applies; thus, in each domain, an appropriate utility function applies. The method estimates the compensatory and the cut-off parameters, identifying the best partition by maximum likelihood.
The CMNL model belongs to a family of non-linear utility Logit models. Although all of them might be considered as alternatives to model constrained behaviour, we note that the CMNL model allows the modeller to specify the utility function as composed by two distinctive terms, which introduces the flexibility to differentiate between the compensatory and the restrained behaviour in the corresponding sub-domains. This offers the advantage that the cut-off term vanishes in the compensatory sub-domain, thus not affecting the utility function in that domain. Moreover, the CMNL model can further differentiate the utility function for cases of several attributes subject to thresholds by simply specifying the corresponding cut-off functions.
Finally, we conclude that both theoretically and empirically, the CMNL model does reproduce the MNL model, while the inverse does not hold. This means that the modeller may assume a non-compensatory behaviour and estimate a CMNL model, and the results will let her/him know whether the assumption is supported by the data; if not, the estimated parameters are the MNL model parameters. Moreover, the CMNL model provides a straightforward method for modelling the choice-set availability without imposing arbitrary rules, and we have shown that this model is also easy to implement. Additionally, we have shown that the estimation of the subjective value of time varies significantly from the compensatory assumption of the behaviour of the MNL model to the constrained behaviour of the CMNL specification; even in the compensatory domain, the former underestimates the results of the latter.
All the conclusions obtained have a more significant impact on demand forecasting in contexts in which behaviour is subject to constraints: the tighter the domain and the more constraints, the larger the impact, which is a more common case in developing countries.
Notes
Empirical evidence shows that, although cutoffs are part of the decision-making process, some individuals chose alternatives that are outside their feasible domain (see Huber and Klein 1991). This effect is allowed in the CMNL by the introduction of the parameter η.
References
Bierlaire, M., Hurtubia, R., Flötteröd, G.: An analysis of the implicit choice set generation using the constrained multinomial Logit model. Transp. Res. Rec. 2175, 92–97 (2010)
Cantillo, V., de Ortúzar, J.D.: A semi-compensatory discrete choice model with explicit attribute thresholds of perception. Transp Res. 39B, 641–657 (2005)
Cascetta, E., Papola, A.: Random utility models with implicit availability/perception of choice alternatives for the simulation travel demand. Transp. Res. 9C, 249–263 (2001)
Donoso, P.: Calibración de modelos Logit simple para el corredor Las Condes–Centro. Civil Engineering Thesis, Pontificia Universidad Católica de Chile (1982)
Gunn, H.H., Bates, J.J.: Statistical aspects of travel demand modelling. Transp. Res. 16A, 371–382 (1982)
Huber, J., Klein, N.M.: Adapting cutoffs to the choice environment: the effects of attribute correlation and reliability. J Consum Res 18, 346–357 (1991)
Kaplan, S., Prato, C.G.: Joint modeling of constrained path enumeration and path choice behaviour: a semi-compensatory approach. In: Proceedings of the European Transport Conference, 11–13 Oct, Glasgow (2010)
Kaplan, S., Shiftan, Y., Bekhor, S.: Development and estimation of a semi-compensatory model with a flexible error structure. Transp. Res. 46B, 291–304 (2012)
Manski, C.: The structure of random utility models. Theory Decis 8, 229–254 (1977)
Martínez, F., Hurtubia, R.: Dynamic model for the simulation of equilibrium status in the land use market. Netw Spat Econ 6, 55–73 (2006)
Martínez, F., Aguila, L., Hurtubia, R.: The Constrained Multinomial Logit: a semi-compensatory choice model. Transp. Res. 43B, 365–377 (2009)
Martínez, F., Tamblay, L., Weintraub, A.: School locations and vacancies: a constrained logit equilibrium model. Environ. Plan. 43A, 1853–1874 (2010)
McFadden, D.: The revealed preferences of government bureaucracy. Bell. J. Econ. Manag. Sci. 6, 401–416 (1968)
McFadden, D.: Conditional Logit analysis of qualitative choice behaviour. In: Zarembka, P. (ed.) Frontiers in econometrics, pp. 105–142. Academic Press, New York (1974)
Munizaga, M.A., Heydecker, B., de Ortúzar, J.D.: Representation of heteroskedasticity in discrete choice models. Transp. Res. 34B, 219–240 (2000)
Swait, J.: A non-compensatory choice model incorporating attribute cutoffs. Transp. Res. 35B, 903–928 (2001)
Swait, J.: Choice models based on a mixed discrete/continuous PDFs. Transp. Res. 43B, 766–783 (2009)
Swait, J., Ben-Akiva, M.: Incorporating random constraints in discrete models of choice set generation. Transp. Res. 21B, 91–102 (1987)
Truong, T., Adamowicz, W.L., Boxall, P.: Health risk perception, hunting site choice and chronic wasting disease: modeling the effect of risk on preferences and choice set formation over time. Presented at Association of Environmental and Resource Economists, 9–10 June, Seattle (2010)
Tversky, A.: Elimination by aspects: a theory of choice. Psychol. Rev. 79, 281–299 (1972)
Williams, H.C.W.L., de Ortúzar, J.D.: Behavioural theories of dispersion and the misspecification of travel demand models. Transp. Res. 16B, 167–219 (1982)
Zheng, L., Guo, J.Y.: Destination choice model incorporating choice set formation. In: Proceedings of the 87th TRB Annual Meeting, 13–17 Jan, Washington DC (2008)
Acknowledgments
Funding: Fondecyt (1110124, 1120288), ISCI (ICM P-05-004-F, CONICYT FBO16), FONDEF D10I-1002. A previous version of this paper was presented in the International Choice Modelling Conference. The authors wish to thank the comments of anonymous referees.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Castro, M., Martínez, F. & Munizaga, M.A. Estimation of a constrained multinomial logit model. Transportation 40, 563–581 (2013). https://doi.org/10.1007/s11116-012-9435-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11116-012-9435-4