
Abstract
In this paper, a network model named DCC-Net based on infrared image sensor is developed for sports data management. Optical imaging plays an important role in the collection and analysis of sports data, but the traditional methods have limitations in the aspects of illumination change and motion blur. To solve these problems, we propose a DCC-net network model based on infrared image sensor. The background of this study is to improve the efficiency of collection and management of sports data in order to promote the improvement of athletes' training and competitive performance. We use a combination of convolutional neural networks and recurrent neural networks to extract and understand motion information in infrared images. The experimental results show that the DCC-net network model has better performance than the traditional optical method in the aspects of illumination variation and motion blur, and provides more accurate and stable motion data. Therefore, DCC-net network model based on infrared image sensor is an effective sports data management tool, which can provide more comprehensive and accurate training and competitive support for athletes and coaches.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image semantic segmentation has always been an important task that is difficult to solve in the field of image processing, and it has a pivotal significance in understanding images (Garcia-Garcia et al. 2018). Image semantic segmentation is a combination of two fields: image semantic segmentation and image recognition. Its purpose is to accurately segment the target object and assign a semantic label to each pixel in the image. In recent years, deep learning has played a very important role in image processing. It has an efficient function of extracting automatic features, combining low-level functions to form high-level functions, and switching between different functions (Peng et al. 2019). Because of this spatial correlation, deep learning algorithms have great advantages in extracting global and local feature information of an image. With the rapid development of embedded systems, there are more and more types of embedded operating systems, and their functions are becoming more and more perfect. Some of these systems need to be paid for, and some have open source codes that are easy for developers to use. Among these operating systems, FreeRTOS is one of the leading micro systems (Guan et al. 2016). It occupies a large part of the microprocessor MCU (microcontroller unit) application market (Mazzi et al. 2021). Its most striking feature is that there are different task scheduling methods that provide options and the source code is completely open, can be freely changed, and can also run on more processor platforms. In this article, we focus on the research on the student's physical exercise data management platform, as well as the research methods of the student's physical testing work, such as the literature data method, questionnaire survey method and Delphi method, and the different functions from the exercise data management platform (Belton et al. 2019). The modules are selected, focusing on the analysis of the theoretical construction of the functional modules of the data platform of the student's physical fitness test (Zhang and Min 2020). In the traditional physical education model, the dissemination of knowledge and skills and the improvement of students' physical and psychological qualities mainly depend on the teaching and use of books, activities and other media (Bertills et al. 2018). This not only increases the economic cost of venues and equipment, but also the scope of knowledge dissemination is very limited, and the dissemination speed is relatively slow (Pence et al. 2019). Therefore, physical education teachers can prepare courses online through a networked educational environment, upload PPT and technical videos, publish homework, and publish exam standards and results through the Internet (Harris and Metzler (Harris and Metzler 2019). Participants can refer to the course materials on the server at any time to avoid the problem of not having a complete grasp of sports technical activities during the physical education process (Zhao et al. 2021).
Traditional optical methods are limited in some aspects. These include sensitivity to changes in illumination and blurring during high-speed motion. In order to overcome these problems, a new technology, sports data management scheme based on infrared image sensor (DCC-Net network model), is proposed. Infrared image sensors can capture the infrared radiation emitted by human movement, providing a means to overcome the illumination changes and blurring phenomena. Compared to traditional optical imaging, infrared image sensors can also provide higher image quality in low light conditions. The progress of sensor technology has gradually reduced the cost of infrared image sensors and gradually expanded the scope of use. It is widely used in the collection and analysis of sports data, which provides more accurate and stable data support for athletes and coaches. Therefore, the research of sports data management scheme based on infrared image sensor (DCC-Net network model) is of great significance. Through this program, the accurate tracking and analysis of athletes' movements can be realized, and more comprehensive and accurate training and competitive support can be provided. This will further promote the development of sports science and improve the performance level of athletes.
2 Related work
The literature introduces the Deeplabv3 + semantic segmentation algorithm based on the encoding–decoding structure, analyzes the problems of using it as a lightweight algorithm and the defects of the algorithm itself, and then proposes a solution: using the basic network DF1 that takes into account both speed and accuracy; Lightweight ASPP with horizontal dense connection is adopted; two low-level features are merged in the decoding stage and an attention mechanism is introduced. Finally, the effectiveness of the algorithm is verified (Zhou et al. 2022). The literature introduces the realization of street view image semantic segmentation algorithm based on AM5749. First, the Cityscapes data set was reorganized, and a lightweight segmentation algorithm was designed on the basis. Then the hardware composition and software framework of AM5749 were introduced. Then the algorithm was sparse and quantified. Finally, a pipeline was built on the embedded platform to achieve Fast processing of algorithms (Heide et al. 2016). The literature introduces the overall design of the data acquisition recorder, analyzes the task requirements of the data acquisition recorder software, determines the functional indicators, describes the embedded development process, gives the overall design plan, and details the functions of each component module (Dodero et al. 2017). The literature introduces the design of the control software of the data acquisition recorder, and divides the control software into modules. Each module is independent of each other and does not affect each other, which reduces the program coupling. Detailed description of the design of human–computer interaction interface, data transmission design, data management design (digital filtering, data calibration, real-time display, real-time storage) and other data calibration and real-time display, Real-time storage), etc. The literature introduces the influence of the state frequency adaptive technology on the system power consumption, and analyzes the low power consumption mode at the same time. The FreeRTOS scheduling process for various tasks is combined with the principle of task state transmission to design low power consumption strategies and optimize system power consumption without affecting its performance (Ramegowda and Lin 2022).
3 Theoretical basis of image semantic segmentation
3.1 Basic theory
3.1.1 Structure of convolutional neural network
Convolutional neural networks can process data with a variety of spatial structures through unique convolutional operations, such as one-dimensional arrays representing time series signals, two-dimensional arrays representing image or speech data, and three-dimensional arrays representing video data. In this study, we focus on sports data management based on infrared image sensors and use convolutional neural networks to process these 2D image data. Infrared image sensor plays a key role in this research. The introduction of infrared light allows us to capture the infrared radiation emitted by human movement, which can provide more details and information than visible images. Especially under low light conditions, infrared image sensors can still provide high image quality, helping to accurately capture the athlete's motion state. Using the data obtained from infrared image sensor, convolutional neural network technology is applied to extract and understand the motion information in the image. Convolutional neural networks can effectively learn feature representations in images through multi-layer convolution and pooling operations. For example, the convolution operation is used to detect the key parts of the human body, such as arms, legs, etc., so as to realize the recognition and analysis of movement posture. In the DCC-Net network model of this study, we input the data obtained by infrared image sensor into the network, and use the structure of convolutional neural network to extract features and learn motion information. Through multi-layer convolution and pooling operation, we can obtain the motion key points and details in the image, and apply them to the management and analysis of sports data.
The traditional convolutional neural network consists of a convolutional layer, an activation layer, a pooling layer and a fully connected layer. Usually in addition to these general architectures, an additional normalization layer is used to improve network performance. These components will be discussed in detail in this article.
The convolutional neural network extracts the features on the image by moving the convolution kernel. Each time a feature is extracted, it only affects the area covered by the current convolution kernel, and the number of convolution kernels is artificially determined. When extracting low-level features, the convolution operation mainly extracts the edge features of the image. When extracting the high-level features, the convolution operation is performed on these edge features, so that the convolutional neural network can extract the rich semantics from the low-level features High-level characteristics of information. This multi-layer convolution method deepens the neural network's ability to abstract image information. The specific convolution operation process can be expressed as:
The pooling layer plays its role in three aspects: (1) Gradually reduce the dimensionality of the input data, extract more representative features from the input, remove the noise data of the input part, and greatly reduce the amount of calculation of the network model; (2) The purpose of increasing the neuron's receptive field is achieved by reducing the dimensions of the input data by downsampling; (3) reducing the parameters of the network, improving the generalization of the model, and preventing over-fitting. To a certain extent, the pooling layer has excellent performance, such as: scale invariance, rotation invariance and translation invariance. After a pooling operation, the size of the output feature map is:
The activation layer contains a large number of activation functions, whose function is to perform a nonlinear transformation on the input to improve the expressiveness of the feature. The weighted average is a linear sum operation, and the deepening of the network layer is only a combination of linear operations, and the final network adjustment is still a linear function. By adding nonlinear transformations, various nonlinear problems can be described and the versatility of neural networks can be improved. Commonly used activation functions include sigmoid function, hyperbolic function (tanh) and linear normalized unit (ReLU).
The mathematical expression of the sigmoid function is:
The advantage of the function is that the output value is mapped to (0,1), and it is continuous and differentiable everywhere. But there are also disadvantages. The output of sigmoid is limited to a small range and most of the area is easily saturated. When it is in the saturated area, the gradient of the function is about 0. If you continuously multiply the smaller gradient, the gradient will gradually shrink until disappear. Since the sigmoid function 0 is not the center of the output, all the inputs in the next network layer can be positive, and the gradient shows that the sawtooth wave decays and converges very slowly.
The mathematical expression of the tanh function is:
The Tanh function has a gradient vanishing condition. However, since the initial average is 0, it is easier to converge than sigmoid during training.
The mathematical expression of the ReLU function is:
The fully connected layer is usually equivalent to a classifier in the network level. That is, each neuron in the front layer is connected to all neurons in the back layer, and the number of neurons in the back layer is equal to the number of output categories. The fully connected layer contains the prestressing term and weight parameters. In the calculation, the input value is weighted and a deviation term is added. Calculated as follows:
When training the network, the parameters of all network layers will participate in the update, and the distribution of the data will continue to change. During the training process, the data distribution gradually approaches the saturation region of the activation function, causing the gradient to disappear. In order to cope with this change in data distribution, each level of the network needs to be adjusted accordingly to adapt to the unstable data distribution, but this also prolongs the convergence time. To solve this problem, batch normalization (BatchNormlization, BN) is proposed. BN normalizes the output value of the network layer to a normal distribution. The batch standardization formula is:
However, standardization will destroy the properties of the original data. In addition to standardization, it is important to know where the data feature value should be. In order to restore the ability to characterize data, BN introduces two learnable parameters γ and β to perform normalized value translation and scaling. The formula for the recovery process is:
3.1.2 Key technologies of image segmentation
Compared with ordinary convolution, expanded convolution mainly introduces the parameter of expansion coefficient. Ordinary convolution is equivalent to the expansion convolution with the expansion coefficient of 1. The expansion convolution inserts a value of 0 in the convolution kernel under the premise of the same input, and finally achieves the purpose of increasing the receptive field.
For the dilated convolution with the expansion coefficient of d and the size of the convolution kernel of k, the calculation of the receiving field is as follows:
Perform linear interpolation on the x-axis to calculate the point P, as shown in the formula:
Then linearly interpolate on the y axis:
Finally, the above three formulas are combined to get the value of point P:
3.2 Image semantic segmentation based on DCCNet
As shown in Fig. 1, this paper proposes the DCCNet + DenseCRF combined model structure.

DCCNet + DenseCRF model structure diagram
According to the changes to the VGG16 network, the DCCNet network structure is proposed. It consists of four basic layers: convolutional layer, ReLU layer (activation layer), maximum merging layer (down-sampling layer) and unfolding layer (up-sampling layer). The backbone framework of DCCNet refers to the model framework of FCN, and converts the last fully connected layer into the corresponding convolutional layer. The DCCNet backbone layer consists of six modules. Each module has several repetitive convolutional layers with 3 × 3 filters. Each convolutional layer is followed by the ReLU activation layer and finally the downsampling of the maximum pooling layer. You can see that DCCNet looks like FCN, but in fact the network structure is quite different. In essence, FCN relies on incremental learning from lower layers to restore more complex functions. Each training of the network depends on the initialization model of the previous stage. This structure allows the multi-scale capabilities of the network context to be independent of each other, and does not have the effect of multi-layer one-step fusion. In contrast, the DCCNet proposed in this article uses a single-layer structure that combines contextual functions with multi-layer functions that interact with the final output. In addition, our network is more effective than FCN in terms of training.
The first pixel is connected to all other pixels in the figure. The full connection of other pixels and the observed variables are not shown in the figure. This fully connected approach raises the complexity of the model to the highest level. DenseCRF can be represented by an energy function:
The binary energy term is:
The entire training and testing process of this experiment is completed on the Cafe platform. This experiment uses two data sets, namely PASCAL VOC 2019 and SIFT Flow. The data set contains not only the original image, but also the corresponding artificially labeled tag card (Ground Truth, GT). The current PASCAL VOC 2019 dataset has been expanded to 10,582 training images with some other annotations.
The cross entropy function is used as a loss function during model training:
Select the stochastic gradient descent (SGD) algorithm. As follows:
The initial training parameters of DCCNet select the VGG-16 model trained in the ImageNet dataset in advance, and use the training verification set in the PASCA LVOC2019 dataset and the 2488 images of SIFT Flow as the test set for DCCNet model training.
During training, the learning rate γ decreases as follows:
During training, the DCCNet network first reads training images (original images) from the data set in the data layer during training. The training image extracts features from the convolutional layer and performs down-sampling in the maximum pooling layer. Then, the feature resolution of the image is extended by the up-sampling layer. Finally, we will enter the softmax level. The Softmax layer calculates the loss based on DCCNet image prediction and GT read from the data layer, and uses the SGD + pulse optimization algorithm to update the weights. Repeat the above steps until the final loss converges, that is, until the network training is completed.
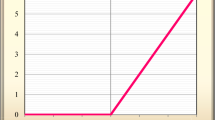
Figure 2 shows the iterative graph of DCCNet loss during the training process of data records PASCAL VOC 2019 and SIFTF Low. The loss value will fluctuate according to the number of iterations, but the loss in these two values will generally decrease, and finally the loss will converge as the number of iterations increases. It also shows that the model is trained iteratively to achieve the best results.

Loss-iteration diagram
During the experiment, we choose standard pixel accuracy, average pixel accuracy or commonly used semantic image segmentation level to evaluate the model. Nmn indicates that the pixels in category m are divided into category n, and C represents the total number of categories in the dataset. PA is the ratio of correctly predicted pixels to the total number of pixels. As shown in the formula:
mPA is to calculate the average of the proportion of correct classifications in all categories, as shown in the formula:
MIoU is to calculate the ratio of the intersection of the true value and the predicted value, as shown in the formula:
Table 1 shows the output of the test set after merging the various branches (DCCNet-32, DCCNet-16 and DCCNet-8). The table shows that by merging branches, compared with DCCNet-32 s, MioU has increased by almost 10%, but when two modules that do not include DCCNet-8 are merged, it only accounts for 66.8% of MIoU. This shows that DCCNet-8 contains a lot of image space pixel information.
A similar experiment was carried out using the SIFT Flow data set to prove the diversity of the designed DCCNet network. Table 2 shows the test results of the data set SIFT Flow on different models. It can be seen that whether it is MioU, PA or mPA, DCCNet + CRF is better than other models.
Figure 3 shows DCCNet-8, DCCNet-16 and DCCNet-32, which are obtained by testing two images using the trained DCCNet and testing the visual output after merging. Each small image in the illustration has 21 functional maps, representing the 21 categories in PASCAL VOC 2012.

Visualization results of the middle layer feature map
Figure 4 shows a comparison of partial segmented images recorded by DCCNet and other network models in the data set PASCALVOC 2019. As shown in the figure, select the tag card (GT column) as a reference, the segmentation effect of DCCNet is better than that of FCN and DeepLab. For example, FCN and DeepLab mistakenly identified all small target objects in the last line of the visualized image.

The segmentation results of some pictures in the PASCAL VOC2019 verification set
Figure 5 shows the visualization results of the SIFTFlow data set. For target objects such as buildings, cars, and windows, it is found that after DenseCRF processing, the segmentation effect of details such as object shape and boundary has been further enhanced.

Segmentation results of some pictures in the SIFTFlow test set
3.3 Image semantic segmentation based on DDN
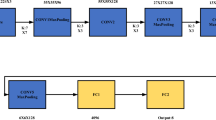
Figure 6 shows the overall structure of the sports data management DCC-Net network model (hereinafter referred to as DDN) based on infrared image sensor. In DDN, infrared image sensor plays an important role. It can capture the motion state of the human body in sports by receiving infrared radiation, and pass this information to the network for processing. DDN consists of two parts: convolutional network and deconvolution network. The convolutional network is responsible for extracting image features, which includes the steps of convolutional operation on infrared image data. This part can extract key information related to sports from infrared images, such as movement posture and key parts of the body. The convolutional network section describes the shape boundary of the segmented object output of the convolutional network section. With the support of infrared image sensor, deconvolution network can restore the shape boundary of object in sports more accurately, and provide more accurate segmentation results. Ultimately, the output of the DDN is a 21-dimensional probability graph with the same size and resolution as the input image. This means that for each pixel in the input image, the DDN can give a probability value that it belongs to one of the predefined categories. Through such output, we can understand the distribution of sports data provided by the infrared image sensor in different categories, and then carry out more in-depth data management and analysis..

DDN network structure diagram
The design concept of BN is relatively intuitive. This is because as the network is training, the deep network activation input will gradually move or change before the nonlinear changes. The reason for the slow exercise is that the overall distribution is usually loose. The BN layer uses a normalization technique to force the output value of each layer to be mapped to a standard normal distribution with an average value of 0 and a variance of 1. Essentially, the non-standard issuance distribution will be redistributed.
Enter a batch of data:
Find the mean of the input data:
Find the variance of the input data:
Output:
Using the BN layer can not only speed up the network training, but also significantly speed up the fusion process, and can also improve the classification effect. Second, it simplifies the process of adjusting network parameters, reduces the need for parameter initialization, and enables learning at a higher learning speed.
Figure 7 shows the visualization results of the PASCAL VOC 2019 validation set from top to bottom in the original image, including Ground Truth, FCN, DeepLab, SegNet, LDN, and DDN. It can be seen from the figure that the DDN segmentation result is more accurate and smooth. Compared with the segmentation results of other models, the target contour with a more accurate profile is closer to Ground Truth. In short, DDN has the best segmentation effect.

The segmentation results of some pictures in the PASCAL VOC2012 verification set
This chapter mainly designs the DDN network, examines the contextual information between different layers of the network, and proposes the network structure of EDN in order to accurately reconstruct the spatial information of the image lost from the pooling layer. It connects the convolutional and non-convolutional network parts of DDN through EDN, so that DDN can combine the attributes of different receiving fields. At the same time, connecting DDN through EDN can also integrate the local and global information of the image well, providing a large amount of image information for the final result of semantic image segmentation. Finally, we conducted experimental verification on the PASCAL VOC 2019 data set, and verified that DDN is superior to most segmentation frameworks based on FCN and traditional EDN.
4 Application of embedded sports data management in physical education
4.1 Demand analysis of physical education auxiliary system
This system is a teaching assistant system based on the DCC-Net network model of sports data management based on infrared image sensor. It aims to make up for the deficiency of traditional sports by using infrared image sensor according to the current situation of sports in a certain university. In addition to providing classroom teaching, the system also has online real-time question-and-answer function, student online discussion function, question collection function and online learning function, which can not only be used as a supplement to classroom education, but also a part of students' open management tool. Through the application of infrared image sensor, the system can be run on the campus network or other departments' local area network, or even the Internet, to provide students with convenient and fast learning and communication environment, improve the effect of physical education. The application of DCC-Net network model of sports data management based on infrared image sensor can provide teachers and students with more targeted teaching and learning support, help to optimize the content and methods of physical education, and provide more accurate data analysis and guidance for students' sports training and development. Whether on campus or online, this system is able to create a better physical education learning and management environment for students and teachers.
When designing an online sports teaching system, it is essential to consider the educational design principles to ensure that the system meets the business needs of the users. The first principle is to pay attention to the analysis of educational goals and content, which involves understanding the learning objectives and developing content that meets those objectives. This requires careful consideration of the target audience and their learning needs, as well as the learning outcomes that need to be achieved. Another important principle is to create situations in the design of educational activities, which involves designing activities that are relevant and engaging for the learners. This can include using real-world examples, simulations, and interactive exercises to help learners apply their knowledge and skills in practical settings. Emphasizing the important role of educational activities is also critical for effective online education design. This involves designing activities that are challenging, meaningful, and relevant to the learners' goals, and that encourage active participation and engagement. In addition, the design of information resources related to independent learning is an important aspect of online education design. This involves providing learners with access to a range of resources, such as readings, videos, and online forums, to support their independent learning and help them achieve their learning goals.
Collaborative learning is another important aspect of online education design, which involves designing activities that promote collaboration and interaction among learners. This can include group projects, peer review activities, and online discussions, which encourage learners to share their ideas and perspectives and learn from each other's experiences.Finally, the use of various information resources is critical for effective online education design. This involves providing learners with access to a range of resources, such as multimedia content, online articles, and interactive simulations, to support their learning and help them achieve their learning goals.
The diversity of student backgrounds and learning needs poses a significant challenge to traditional classroom teaching, particularly in the context of sports education. To address this challenge, it is essential to establish a sports network support system that can provide students with a more personalized and adaptive learning experience. By creating an environment where students can learn knowledge outside of sports classes, the sports network support system can help to supplement and enhance classroom instruction. This can be particularly beneficial for students who may lack physical exercise or who have limited access to sports facilities and equipment. In addition, the sports network support system can also provide teachers with valuable tools for organizing and managing their education. This can include features such as online assessments, progress tracking, and personalized learning plans, which can help teachers tailor their instruction to the specific needs and abilities of each student. The sports network support system can also serve as a platform for collaborative learning and knowledge sharing among students. By allowing students to interact and collaborate with each other, the system can help to foster a sense of community and engagement, and promote the development of important social and communication skills.
The interactive network education model offers a promising approach to designing a PE network support system that can support and enhance physical education. By leveraging the benefits of online education, the system can provide students with a more personalized and adaptive learning experience, while also allowing teachers to guide and support their learning in a flexible and responsive way.One key goal of the system design is to fully demonstrate the benefits of online education and the importance of independent learning. By giving students more control over their learning and providing them with access to a range of resources and tools, the system can help to foster a sense of ownership and responsibility for their own learning process. In addition, the system can facilitate interaction between teachers and students, providing a networked educational environment that allows for more frequent and meaningful exchanges of information. Another important goal is to fully demonstrate the benefits of physical education and the important role that teachers play in guiding and supporting students' learning. By providing students with clear learning goals and objectives, and helping them to understand the key and difficult points of each lesson, teachers can help to ensure that students are able to achieve their learning outcomes and develop important physical and cognitive skills. In addition, the system can also help to promote collaboration and knowledge sharing among students, by providing opportunities for group projects, peer review, and online discussions. This can help to foster a sense of community and engagement, and promote the development of important social and communication skills.
(3) Make full use of the online education environment and make the most of multimedia education. Integrate symbols, language, text, sound, graphics, animation, video and other information media, and use graphical interactive surfaces and interactive window operations to benefit people. Prompt the computer interactive function to be greatly improved, the content of the physical education class is clearly displayed, and the teaching effect and quality are improved.
(4) The physical education teacher prepares courses online through the networked education environment, uploads PPT and technical videos through the network, and publishes homework, test standards and results. Participants can access the course materials on the server at any time to avoid the problem of not mastering certain technical movements in sports, and to make them listen to the class more carefully.
4.2 Embedded system hardware selection
Embedded microprocessor and infrared image sensor are important components of DCC-Net network model of sports data management based on infrared image sensor. As the core component of embedded system, embedded microprocessor provides the basis for intelligent operation of the system. Through the effective management and control of the infrared image sensor, the embedded microprocessor makes the operation of the system more intelligent, and the design is more flexible, powerful and easy to develop. In the case of normal operation of the system, the embedded microprocessor provides powerful multi-task concurrency, so that the system can handle multiple tasks at the same time, and realize efficient data management and processing. It also has a wealth of functions to meet the needs of different sports data management. The embedded microprocessor also provides reliable system performance to ensure the stable operation of the system, and has functions such as low cost, low power consumption and memory protection, so that the system can achieve an efficient energy consumption ratio during operation, reducing cost and extending the service life of the system.
In actual use, not every microprocessor can meet the specific requirements of R&D equipment, and it needs to be selected according to functional requirements. After all, every microprocessor has its advantages and disadvantages. Some high-performance microcomputers The processor is fast, has good performance, is not difficult to develop, and has a high probability of success, but it is usually expensive and cannot be widely used. Although some low-end microprocessors are cheap, the main frequency is too low, the running speed is slow, the development is more difficult, and it is difficult to meet the needs of system development, so this involves the issue of reasonable selection.
There are already a huge number of embeddable microprocessors on the market, including ARM, MIPS, PowerPC, X86, EMPU, EDSP, MCU, SoC and other architectures. The development of embedded systems requires hardware as support. Before mass production of the final hardware, it is best to choose a hardware development platform according to actual needs, implement most of the functions on the development board, and conduct preliminary functional research and debugging.
4.3 System management database design
The system management database stores user information, such as teacher information, student information, and class information. The system defines four authorization types. These four permissions represent four login IDs: system administrators, teachers, students, and general visitors.
Among them, the curriculum design is shown in Table 3, which analyzes the upcoming courses in detail. The information of teachers and students is shown in Table 4
The table presented in the context of the discussion clearly illustrates the organizational structure of the online sports teaching system. According to the table, teachers can teach multiple classes, and each class has its own unique class password. This structure offers several advantages, including greater flexibility in scheduling and greater efficiency in managing multiple classes.Moreover, the teacher ID number and the class ID number serve as unique identifiers for each teacher's class. This enables the system to accurately track and manage the progress of each student, and ensure that they are assigned to the correct class with the correct teacher.Additionally, this structure allows for greater security and privacy, as each class is assigned a unique password that only authorized students can access. This helps to prevent unauthorized access and protect the sensitive information of both teachers and students.
4.4 Analysis of the implementation results of the system implementation
The system is based on the Browser/Web Sever/DBMS Severs structure, with a precisely defined structure and a friendly interface. Teachers and students can directly access the system through a browser, which is very convenient and practical. System users are mainly teachers and students. Educational resource modules, coursework modules, and exam-related modules are all open modules. You can browse and learn by simply clicking the browser and entering the appropriate function items, which promotes the search and sharing of educational resources between teachers and students.
5 Conclusion
The DCC-Net network model of sports data management based on infrared image sensor has brought important innovation and progress in the field of physical education. By capturing and analyzing movement data using infrared image sensors, the model is able to monitor and evaluate students' athletic performance in real time, providing targeted guidance and feedback to teachers and students. The model combines the intelligent operation of embedded microprocessors, making the system more flexible, powerful, and easy to develop and operate. The model's online real-time question-and-answer function, student online discussion function, question collection function and online learning function not only provide a comprehensive complement to classroom teaching, but also serve as a part of student autonomous learning and management tools. It can run on the campus network or the Internet to provide students with a convenient learning and communication environment. The application of DCC-Net network model of sports data management based on infrared image sensor not only provides accurate data analysis and guidance, but also promotes the optimization of the content and methods of sports education. Teachers can adjust teaching strategies based on real-time feedback and data analysis from students to provide more personalized instruction for individual differences. Through systematic learning function and online discussion function, students can actively participate in sports learning and communication, and obtain more comprehensive knowledge and skills. Therefore, the sports data management DCC-Net network model based on infrared image sensor has a broad application prospect in the field of physical education. It not only improves the effectiveness and efficiency of physical education, but also provides students with a better learning and management experience. Through continuous innovation and improvement, this model will make a greater contribution to the development of physical education.
Data availability
The data will be available upon request.
Change history
09 September 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s11082-024-07436-x
References
Belton, I., MacDonald, A., Wright, G., Hamlin, I.: Improving the practical application of the Delphi method in group-based judgment: A six-step prescription for a well-founded and defensible process. Technol. Forecast. Soc. Chang. 147, 72–82 (2019)
Bertills, K., Granlund, M., Dahlstrom, O., Augustine, L.: Relationships between physical education (PE) teaching and student self-efficacy, aptitude to participate in PE and functional skills: with a special focus on students with disabilities. Phys. Educ. Sport Pedagog. 23(4), 387–401 (2018)
Dodero, J.M., Gonzalez-Conejero, E.J., Gutierrez-Herrera, G., Peinado, S., Tocino, J.T., Ruiz-Rube, I.: Trade-off between interoperability and data collection performance when designing an architecture for learning analytics. Futur. Gener. Comput. Syst. 68, 31–37 (2017)
Garcia-Garcia, A., Orts-Escolano, S., Oprea, S., Villena-Martinez, V., Martinez-Gonzalez, P., Garcia-Rodriguez, J.: A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 70, 41–65 (2018)
Guan, F., Peng, L., Perneel, L., Timmerman, M.: Open source FreeRTOS as a case study in real-time operating system evolution. J. Syst. Softw. 118, 19–35 (2016)
Harris, M.T., Metzler, M.: Online personal fitness course alignment with national guidelines for online physical education. J. Teach. Phys. Educ. 38(3), 174–186 (2019)
Heide, F., Diamond, S., Nießner, M., Ragan-Kelley, J., Heidrich, W., Wetzstein, G.: Proximal: efficient image optimization using proximal algorithms. ACM Trans. Gr. (TOG) 35(4), 1–15 (2016)
Li, Y., Shi, T., Zhang, Y., Chen, W., Wang, Z., Li, H.: Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote. Sens. 175, 20–33 (2021a)
Li, A., Jiao, L., Zhu, H., Li, L., Liu, F.: Multitask semantic boundary awareness network for remote sensing image segmentation. IEEE Trans. Geosci. Remote Sens. 60, 1–14 (2021b)
Mazzi, Y., Gaga, A., Errahimi, F.: Benchmarking and comparison of two open-source RTOSs for embedded systems based on ARM Cortex-M4 MCU. Indian J. Sci. Technol. 14(16), 1261–1273 (2021)
Pence, J., Sakurahara, T., Zhu, X., Mohaghegh, Z., Ertem, M., Ostroff, C., Kee, E.: Data-theoretic methodology and computational platform to quantify organizational factors in socio-technical risk analysis. Reliab. Eng. Syst. Saf. 185, 240–260 (2019)
Peng, C., Li, Y., Jiao, L., Chen, Y., Shang, R.: Densely based multi-scale and multi-modal fully convolutional networks for high-resolution remote-sensing image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 12(8), 2612–2626 (2019)
Ramegowda, D., Lin, M.: Energy efficient mixed task handling on real-time embedded systems using FreeRTOS. J. Syst. Architect. 131, 102708–102713 (2022)
Zhang, Z., Min, H.: Analysis on the construction of personalized physical education teaching system based on a cloud computing platform. Wirel. Commun. Mob. Comput. 2020, 1–8 (2020)
Zhao, L., Liu, X., Su, Y.S.: The differentiate effect of self-efficacy, motivation, and satisfaction on pre-service teacher students’ learning achievement in a flipped classroom: a case of a modern educational technology course. Sustainability 13(5), 2888–2895 (2021)
Zhou, W., Jin, J., Lei, J., Yu, L.: CIMFNet: Cross-layer interaction and multiscale fusion network for semantic segmentation of high-resolution remote sensing images. IEEE J. Sel. Top. Signal Process. 16(4), 666–676 (2022)
Funding
This article was supported by the (1) Humanities and Social Sciences Project of Chongqing Municipal Education Commission (Research on Collaborative Empowerment of School Sports under the Background of Double Reduction Policy), with the content being a series of research paper results, numbered (23SKGH005); (2)the Doctoral Student Support Project of Southwest University of Political Science and Law (Research on University Campus Network Construction), with the content being a series of research paper results, numbered (XZZX2019153).
Author information
Authors and Affiliations
Contributions
WY has contributed to the paper’s analysis, discussion, writing, and revision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s11082-024-07436-x
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yong, W. RETRACTED ARTICLE: DCC-net network model for motion data management based on infrared light sensor. Opt Quant Electron 56, 600 (2024). https://doi.org/10.1007/s11082-023-06249-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11082-023-06249-8