
Abstract
Risk identification on hydropower project, the first step of risk management process, is an extremely complex issue and has a significant impact on the efficiency of the following risk assessment and control. On the other hand, finding out some more possible risk factors among many risk ones is a multi-criteria decision making problem. This paper develops an evaluation model based on the interval analytic hierarchy process (IAHP) and extension of technique for order preference by similarity to ideal solution (TOPSIS), to identify exactly the more possible risk factors under a complex and fuzzy environment. In this paper, the IAHP is used to analyze the structure of risk identification problems in hydropower project and to determine weights of the criteria and decision makers, and extension of TOPSIS method with interval data is used to obtain final ranking of potential risk factors in hydropower project. Risk identification on an earth dam is conducted to illustrate the utilization of the model proposed in this paper. The application could be interpreted as demonstrating the effectiveness and feasibility of the proposed model.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The concept of hydropower project management in China has changed gradually from “project safety” to “project risk” (Li 2009) since twenty-first century. Risk management on hydropower project has been developed for nearly three decades, but in China it is still in its infancy. As the first step of risk management process, risk identification is an extremely complex and important issue. This issue is the foundation and an important component of risk analysis, assessment and control and describes the possible negative impact on systems, such as risk factors, the way of risk occurrence and risk scope. Its primary aim is to find out where risks are and what induces risks, and to make a qualitative analysis of the consequence. Besides in hydropower project, it identifies potential failure geneses, failure modes and failure paths and has a significant impact on the efficiency of the following risk decision making and control. Since hydropower project is a large-scaling and complex system, risk identification is very complicated and requires a large amount of human resources, material resources and financial resources. Although there are a large number of conventional methods for risk identification, none of them is perfect in finding out risk factors exactly. And most conventional approaches tend to separate risk identification and risk assessment and can only deal with certain problems other than uncertain ones, which are widely existed in the real circumstance. Thus, this paper develops a new evaluation model based on the interval analytic hierarchy process (IAHP) and extension of technique for order performance by similarity to ideal solution (TOPSIS) with interval data to improve the reliability of risk identification on hydropower project.
The remainder of this paper is structured as follows: First, the literature review on risk, risk management and risk identification is given, and the methods of IAHP and extension of TOPSIS with interval data adopted in this paper are introduced in detail. Then, the proposed model for risk identification on hydropower project is presented, and the stages of the proposed approach are explained in detail. Next, risk identification on an earth dam is conducted and discussed to illustrate the utilization of the model proposed in this paper. Finally, conclusions and suggestions are discussed.
2 Literature review and methods
2.1 Risk, risk management and risk identification
As every coin has two sides, risk has a two-edged nature and is known as “a threat and a challenge” (Flanagan and Norman 1993), or “the chance of something happening that will have an impact on objectives; may have a positive or negative impact” (Smith et al. 2006). But its negative impact must be emphasized in projects, especially in hydropower project. In the field of hydropower project, the risk, defined by ICOLD on the 20th Congress in 2000, is a measure of the likelihood and severity of adverse consequences on life, health, property and environment, and the product of the probability of adverse events and harmful consequences (Kreuzer 2000). Risk management is “a system which aims to identify and quantify all risks to which the business or project is exposed so that a conscious decision can be taken on how to manage the risks” (Flanagan and Norman 1993), or “the processes concerned with conducting risk management planning, identification, analysis, responses, and monitoring and control on a project” [PMI (Project Management Institute) 2004], or “the culture, processes and structures that are directed towards realizing potential opportunities whilst managing adverse effects” (Standards Association of Australia, AS/NZS 4360 2004). A systematic process of risk management on hydropower project is normally divided into (1) risk identification, (2) risk assessment and (3) risk control and treatment (e.g., Mojtahedi et al. 2010; Brandsater 2002; Duijne et al. 2008).
At present, risk management on hydropower project develops rapidly, especially in the USA, Canada, Australia and Western Europe. Guidelines for Risk Assessment was issued by ANCOLD in 1994 and then revised (ANCOLD 2003) in 2003; the risk analysis and management techniques have been brought into dam safety management by BC Hydro Company in Canada (Lou 2000) since the 1990s; “Dam Safety Decisions and Management based on risk analysis” was researched and discussed as an issue on the 20th Congress in 2000; the bulletin on Risk Assessment in Dam Safety Management (ICOLD Bulletin 2003), issued by ICOLD in 2003, is mainly about the principles and glossaries of terms on risk assessment and describes briefly the application of risk assessment in dam safety. But in China, risk management on hydropower project lags far behind other countries. There are only a few literatures on it (e.g., Jin 2008; Sun 2010; Yan 2011; Li 2011; Li et al. 2006; Ma 2006). Now, accelerating the application of risk management on hydropower project is an important and urgent task in China.
Risk identification is the first and most important step of risk management process. Potential risk factors associated with hydropower projects are identified and ranked in this process. As an intermediate process between risk identification and risk control and treatment, risk assessment is to analyze the probability of failure induced by potential risk factors in hydropower projects through qualitative or quantitative methods and to evaluate the potential loss of risk. Once the risk factors of the project have been identified and evaluated, proper risk control and treatment strategies must be made to deal with the potential risks in the project implementation. The aim of risk control and treatment is to remove as many negative impacts as possible and to assure the risk is as low as reasonably practicable (ANCOLD 2003). However, it has been recognized that risk management cannot eliminate all risks but only can identify appropriate strategies to assist project stakeholder to manage them (Zou et al. 2007; Mojtahedi et al. 2010).
Belonging to project risk identification, risk identification on hydropower project is considered as the most difficult problem in engineering for its systemic complexity and intense uncertainty. There are a large number of techniques for risk identification, such as brainstorming, Delphi groups, questionnaires and interviews, scenarios analysis, fault tree method analysis, analytic hierarchy process and checklists. However, as stated by Hillson (2002), there is no “best method” for risk identification, and an appropriate combination of techniques should be used.
Generally speaking, hydropower project is huger and more complex than other projects, so its reliability of risk identification is lower than that in other projects. However, the disaster caught by its failure is severer than others. As a result, it may be helpful to develop a new approach to risk identification on hydropower project. And the application of a new approach in risk identification will be favorable to bring the maximum benefits of hydropower project.
2.2 The AHP/IAHP method
The AHP method (Saaty 1980) is a systemic analysis method proposed by Saaty in the mid-1970s. It is an approach to determine the relative importance of a set of activities in a multi-criteria decision problem and is possible to incorporate judgments on intangible qualitative criteria alongside tangible quantitative criteria (Badri 2001). In order to resolve these uncertain problems existed widely in the real circumstance, recent research tends to focus on interval and/or fuzzy hierarchy process (Lipovetsky and Tishler 1999; Buckley et al. 2001; Mikhailov 2002). In the literature, AHP/IAHP has been widely used for solving many complicated decision-making problems including risk identification on hydropower project (Dağdeviren and Yüksel 2008; Kahraman et al. 2003; Kular and Kahraman 2005). The IAHP method adopted in this paper consists of the following steps (Zhu 2005):
Step 1: A complex multi-attribute decision making problem is broken down and structured as a hierarchy of interrelated decision elements (criteria, decision alternatives). A hierarchy has at least three levels: overall goal of the problem at the top, multiple criteria that define alternatives in the middle and decision alternatives at the bottom (Albayrak and Erensal 2004).
Step 2: Make a comparative judgment of the alternatives and the criteria. After the hierarchy is constructed, prioritization procedure starts in order to determine the relative importance of the criteria within each level. The pairwise judgment starts from the second level and finishes in the lowest level alternatives. In each level, the criteria are compared pairwise according to their levels of influence and based on the specified criteria in the higher level (Albayrak and Erensal 2004). In AHP/IAHP, multiple pairwise comparisons are based on a standardized comparison scale of nine levels (Table 1).
Let \( C = \{ C_{j} |j = 1,2, \ldots ,n\} \) be the set of criteria. The result of the pairwise comparison on n criteria can be summarized in an (n × n) interval evaluation matrix A in which every element [a l ij , a u ij ] (i, j = 1,2, ··· ,n) is the quotient of weights of the criteria, as shown:
Step 3: Check the consistency of the interval comparison matrix. N judgment matrices are randomly generated from the interval comparison matrix A. Then the final consistency ratio (CR) of each judgment matrix, usage of which let someone to conclude whether the evaluations are sufficiently consistent, is calculated as the ratio of the consistency index (CI) and the random index (RI), as indicated
The consistency index (CI) is
where λ max denotes the largest eigenvalue of the judgment matrix.
The random index (RI), determined by n, is given in Table 2.
The number 0.1 is the accepted upper limit for CR. If the final consistency ratio exceeds this value, the judgment matrix is not a consistent matrix. After the final consistency ratios (CR) of all judgment matrices are calculated, the degree of consistency (η) (Zhu 2005; Zhu et al. 2005) of the interval comparison matrix is calculated as the ratio of the m and the N, as indicated.
where m denotes the number of the inconsistent certain matrices whose final consistency ratio (CR) is less than 0.1.
The number 60 % is the accepted lower limit for η (Zhu et al. 2005). If the η is less than this value, the evaluation procedure has to be repeated to improve consistency. A mathematical method for finding the improper elements is proposed by Zhu et al. (2005). Interested readers can check the content of (Zhu et al. 2005) for more details.
Step 4: Determine the weights of the criteria. There are a lot of methods for solving interval comparison matrix and the method proposed by Zhu et al. (2005) is adopted in this paper. The method defines three kinds of weights: w l i , w u i and w g i .w l i is the minimum one of the weights for judgment matrices generated randomly from the interval comparison matrix A and its calculation model is expressed as follows:
where I denotes the Ith judgment matrix, I = 1,2, ··· ,N; IN = {1,2, ··· ,N}; \( \overline{a}_{ij} \) denotes the element in the interval matrix; A I denotes the certain matrix generated randomly from the interval comparison matrix A.w u i is the maximum one of the weights for judgment matrices generated randomly from the interval comparison matrix A and its calculation model is expressed as follows:
w g i is the most possible one of the weights for judgment matrices generated randomly from the interval comparison matrix A and its calculation model is expressed as follows:
The final weights for the interval comparison matrix A are given as (Chen 1996)
All the three calculation models are highly nonlinear and can be solved by PSO or GA using MATLAB (Zhu 2005, Zhu et al. 2005). Interested readers can check the content of (Zhu 2005, Zhu et al. 2005) for more details of the method in solving weights of interval comparison matrix.
This method can be used to determine the weights of decision makers as well as that of criteria.
2.3 Extension of TOPSIS method with interval data
The TOPSIS (technique for order performance by similarity to idea solution) was first developed by Hwang and Yoon (1981). Its basic principle is that the chosen alternative should have the shortest distance from the ideal solution and the farthest distance from the negative-ideal solution (Ertugrul and Karakasoglu 2009). In order to resolve lots of existed uncertain problems in the real circumstance, the fuzzy TOPSIS method (Chen 2000; Dağdeviren et al. 2009) and extension of TOPSIS method with interval data (Jahanshahloo et al. 2009) are presented and developed. TOPSIS is a rational, understandable and straightforward method for the solution of multi-attribute group decision-making problems. The extension of TOPSIS method with interval data is adopted in this paper. It consists of the following steps (Jahanshahloo et al. 2009):
Step 1: Establish a matrix D p, (p = 1,2, ··· ,m) for each decision maker. The structure of the matrix can be depicted as:
where A i denotes the alternative j, j = 1,2, ··· ,J; F i represents the i th attribute or criterion, i = 1,2, ··· ,n; \( \left[ {\mathop f\nolimits_{ij}^{pl} ,\mathop f\nolimits_{ij}^{pu} } \right] \) is an interval value indicating the performance rating of each alternative A i with respect to each criterion F j ; by Dp (p = 1,2, ··· ,m). Note that there should be m decision matrices for the m decision makers.
Step 2: Calculate the normalized decision matrix \( {\mathbf{R}}^{{\mathbf{p}}} \left( { = \left[ {\mathop r\nolimits_{ij}^{pl} ,\mathop r\nolimits_{ij}^{pu} } \right]} \right) \) for each decision maker. The normalized value \( \left[ {\mathop r\nolimits_{ij}^{pl} ,\mathop r\nolimits_{ij}^{pu} } \right] \) is calculated as follows:
The interval \( \left[ {\mathop r\nolimits_{ij}^{pl} ,\mathop r\nolimits_{ij}^{pu} } \right] \) is the normalized form of interval \( \left[ {\mathop f\nolimits_{ij}^{pl} ,\mathop f\nolimits_{ij}^{pu} } \right] \).
Step 3: Construct the group decision matrix (G) as follows:
The grouping value for criterion j can be:
WD p is the weight of each decision maker where
Step 4: Construct the weighted normalized appraisal matrix. It can be calculated by multiplying the normalized matrix by its associated weights. The weighted normalized value \( \left[ {\mathop v\nolimits_{ij}^{l} ,\mathop v\nolimits_{ij}^{u} } \right] \) is calculated as:
where w j represents the weight of the j th attribute or criterion.
Step 5: Determine the positive-ideal and negative-ideal solutions. Now suppose alternative k,to define the ideals as:
where I′ is associated with the benefit criteria, and I′′ is associated with the cost criteria.
Step 6: Calculate the separation measures, using the n-dimensional distance. The separations of alternative k from the positive-ideal solution \( \left( {\mathop A\nolimits_{k}^{ + l} ,\mathop A\nolimits_{k}^{ + u} } \right) \) are given as
Similarly, the separations of alternative k from the negative-ideal solution (\( \mathop A\nolimits_{k}^{ - l} ,\mathop A\nolimits_{k}^{ - u} \)) are given as
Step 7: Calculate the relative closeness to the idea solution and rank the performance order. The relative closeness of the alternative k can be expressed as
where the R k index value lies between 0 and 1. The larger the index value is, the better the performance of the alternatives will be.
3 The proposed model for risk identification on hydropower project
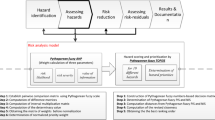
A systematic process of risk management on hydropower project consists of three steps and each step is complex and relatively independent. In this paper, we mainly propose a new model for the first step, that is, risk identification. The proposed model for risk identification, composed of IAHP and extension of TOPSIS methods, is designed in four main sections (Fig. 1). The initial phase of the proposed model is establishing a group for risk identification on hydropower project. The planning and executing phase consists of four sections: gathering potential risk data of hydropower project, structuring decision hierarchy and assigning weights via IAHP, making decisions by extension of TOPSIS and ranking potential risk factors. This phase should be iterated in specific time intervals through hydropower project life cycle. The closing phase of the model is documenting results and compiling lessons learned for the following two steps (risk assessment and risk control) of risk management on hydropower project.

Schematic diagram of the proposed model for risk identification on hydropower project
3.1 Section 1: gathering potential risk data of hydropower project
This section is mainly to determine potential risk factors based on historical information, documentations of similar hydropower projects, monitoring data and so on. This section is the base of planning and executing phase, so the information should be detailed and complete in order to determine potential risk factors correctly.
3.2 Section 2: structuring decision hierarchy and assigning weights via IAHP
After potential risk factors are determined, the decision hierarchy should be structured. Then the criteria to be used for evaluation are determined, and decision makers are chosen. Finally weights of criteria and decision makers are assigned using IAHP. The criteria of risk identification on hydropower project and their definitions are given in Table 3. And all criteria are considered beneficial. Decision makers in hydropower project are composed of dam owners, discipline engineers, experts with specific knowledge in particular areas of concern, stakeholders and so on.
3.3 Section 3: making decisions by extension of TOPSIS with interval data
Before executing extension of TOPSIS with interval data, some assumptions should be considered: (1) Criteria are the same for all decision makers. (2) Criteria may have different weights but criteria’s weights are the same for all decision makers. (3) Decision makers have different weights. The process of extension of TOPSIS with interval data is explained in detail in Sect. 2.3.
3.4 Section 4: ranking potential risk factors
This section is to rank potential risk factors and to select the top five (generally) at the end process of extension of TOPSIS. The top five will be analyzed carefully in the following two steps of risk management.
4 An application of proposed model
4.1 Introduction of the hydropower project
Located in the Chuhe River, lower reaches of Yangtze River, the reservoir is large-scaled and comprehensively utilized. It can contain 18.55 million m3 of water, and its normal high water level, dead water level and check flood level are, respectively, 40.50, 31.60 and 43.20 m. It has comprehensive functions of flood control, irrigation, navigation, power generation, cultivation, etc. Its flood control standards are designed for a 500-year event and checked for a 1000-year event. The hydroproject mainly consists of a dam, a spillway, an emergency spillway and a plant downstream of the dam.
A safety appraisal is held for the influence of natural erosion, damage by human and animals and aging after the dam has been in operation for many years. According to the result of safety appraisal, the prevailing problems are listed below.
-
(1)
Dam foundation:
It is suspected that constructed diversion channel and natural blanket have been destroyed, and dam foundation is vulnerable to damage by seepage. Cutoff trench, which ranges from 0 + 580 to 0 + 670, is not sealed off, hence leading to a hidden danger due to bypass seepage. Due to substandard grouting, severe bypass seepage prevails at the right dam abutment during operational stage.
-
(2)
Dam body:
Dam body is made of combination of materials which are high permeable and have low dry densities. Those materials may leads to settlement cracks during operational stage.
-
(3)
Normal spillway:
The height of wing wall at upstream sluice and back filled soil behind the wing wall are lower than required level. Hoist room is poor, in which the gate has a serious leakage, the hoisting equipment is out of the service period, and the bridge head is cracked and tilted. The cracks in the downstream are cress-crossing. Energy dissipation is imperfect. Scour protection is not provided, and flow is highly turbulent. The flood embankment on the right bank has been destroyed for many times.
-
(4)
Emergency spillway:
It has not been constructed since last failure.
-
(5)
There are no management systems in the dam yard, such as safety inspection & monitoring.
4.2 Decision hierarchy of potential failure modes of the dam
Based on the historical statistic data of earth dam failures and the engineering safety appraisal materials, the decision hierarchy of potential failure modes of the earth dam is constructed as Fig. 2. X j (j = 1,2, ··· ,15) in Fig. 2 denotes potential failure mode.

The decision hierarchy of potential failure modes of the earth dam
4.3 Weights determination and relevant provisions
In order to rank these potential failure modes of the reservoir, some provisions should be set first. Table 4 shows the conversion from decision makers’ descriptive scales to related measures. Table 5 and 6 show the interval pairwise comparison matrices for criteria and decision makers, respectively. Table 7 shows the results obtained with IAHP. Table 8 shows a suitable measure of risk identification criteria which can be changed in different countries and regions.
4.4 Evaluation of potential failure modes and determination of the final rank
By considering above information, each decision maker is asked to establish a decision matrix by comparing potential failure modes under each of the criteria separately. Considering the weights of criteria and decision makers, the interval weighted group decision matrix is presented in Table 9. Potential failure modes are specified by their codes. Then we deal with formula (22)–(31) to calculate the separations and closeness for each potential failure mode. Table 10 represents the final rank of the potential failure modes. Based on the rank of potential failure modes, we choose the top five as the main failure modes of the dam. And then risk assessment and corresponding measures will be carried out in order to prevent possible potential dam failure in the following two steps of risk management in hydropower project.
5 Conclusion
Risk identification on hydropower project is an important issue and has a significant impact on the efficiency of the subsequent risk assessment, control and decision making. However, there are a large number of potential risk factors and a large set of subjective or ambiguous data in the process of risk identification. Therefore, this paper presents a new and effective evaluation approach to improve decision quality.
The IAHP and extension of TOPSIS methods are used in the proposed model. IAHP is used to assign weights to the criteria and decision makers, while extension of TOPSIS with interval data is employed to determine the priorities of the potential risk factors. With the above-mentioned structure, the proposed model differs from the present risk identification models. Its criteria contain risk identification and risk assessment simultaneously. Also the weights of criteria and decision makers are considered during the process of decision. Meanwhile, interval judgments are adopted to adapt the real and fuzzy environment. Additionally, the effectiveness and feasibility of the proposed model are shown in the application. Based on the above, one can draw a conclusion that the proposed method is prior and more accurate than conventional methods.
Although the model is developed and tested for risk identification on hydropower project, it can also be used with slight modifications in risk identification on other projects. In order to gain more accurate and reasonable results, some new models should be proposed and used simultaneously to improve the quality of risk identification in the future.
References
Albayrak E, Erensal YC (2004) Using analytic hierarchy process (AHP) to improve human performance: an application of multiple criteria decision making problem. J Intell Manuf 15(4):491–503
ANCOLD (Australian National Committee on Large Dams). Guidelines on Risk Assessment, 2003
Badri MA (2001) A combined AHP-GP model for quality control systems. Int J Prod Econ 72(1):27–40
Brandsater A (2002) Risk assessment in the offshore industry. Saf Sci 40(1–4):231–269
Buckley J, Feuring T, Hayashi Y (2001) Fuzzy hierarchical analysis revisited. Eur J Oper Res 129(1):48–64
Chen S (1996) Evaluating weapon systems using fuzzy arithmetic operations. Fuzzy Sets Syst 77(3):265–276
Chen CT (2000) Extensions of the TOPSIS for group decision-making under fuzzy environment. Fuzzy Sets Syst 114(1):1–9
Dağdeviren M, Yüksel İ (2008) Developing a fuzzy analytic hierarchy process (AHP) model for behavior-based safety management. Inf Sci 178(6):1717–1733
Dağdeviren M, Yavuz S, Kılınç N (2009) Weapon selection using the AHP and TOPSIS methods under fuzzy environment. Expert Syst Appl 36(4):8143–8151
Duijne FHV, Aken DV, Schouten EG (2008) Consideration in developing complete and quantified methods for risk assessment. Saf Sci 46(2):245–254
Ertugrul Ī, Karakasoglu N (2009) Performance evaluation of Turkish cement firms with fuzzy analytic hierarchy process and TOPSIS methods. Expert Syst Appl 36(1):702–715
Flanagan R, Norman G (1993) Risk management and construction. Blackwell Science Pty. Ltd., Victoria
Hillson D (2002) Use a risk breakdown structure to understand your risks. Project Management Institute Annual Seminars, Texas
Hwang CL, Yoon K (1981) Multiple attribute decision making: methods and applications, A state of the art survey. Springer-Verlag, New York
ICOLD Bulletin (2003) Risk assessment in dam safety management
Jahanshahloo GR, Lotfi FH, Davoodi AR (2009) Extension of TOPSIS for decision-making problems with interval data: interval efficiency. Math Comput Model 49(5–6):1137–1142
Jin Y (2008) Study on the analysis approach for the dangerous situations of dam breach. Hohai University, Nanjing
Kahraman C, Ruan D, Doğan I (2003) Fuzzy group decision-making for facility location selection. Inf Sci 157:135–153
Kreuzer H (2000) The use of risk analysis to support dam safety decisions and management. ICOLD 20th Congress, Beijing
Kular O, Kahraman C (2005) Fuzzy multi-attribute selection among transportation companies using axiomatic design and analytic hierarchy process. Inf Sci 170(2–4):191–210
Li L (2009) Risk management of large dams and emergency plan: modern dam safety concept. China Water Resour 22:63–66
Li S (2011) Key technology research and system development of dam safety risk management. Tianjin University, Tianjin
Li L, Wang R, Sheng J et al (2006) Risk assessment and risk management of large dam. WaterPower Press, Beijing
Lipovetsky S, Tishler A (1999) Interval estimation of priorities in the AHP. Eur J Oper Res 114(1):153–164
Lou J (2000) Dam safety risk management of BC Hydro Company in Canada. Large dam saf 4:7–11
Ma F (2006) Risk analysis and early-warning methods for reservoir dams. Hohai University, Nanjing
Mikhailov L (2002) Fuzzy analytical approach to partnership selection in formation of virtual enterprises. Omega 30(5):393–401
Mojtahedi SMH, Mousavi SM, Makui A (2010) Project risk identification and assessment simultaneously using multi-attribute group decision making technique. Saf Sci 48(4):499–507
PMI (Project Management Institute), 2004. A guide to the project management body of knowledge, PMBOK Guide, 3rd ed. Project Management Institute Inc, USA. Chapter 11 on project risk management
Saaty T (1980) Analytical hierarchy process. McGraw-Hill, NewYork
Smith NJ, Merna T, Jobling P (2006) Managing risk in construction projects. Blackwell, Oxford
Standards Association of Australia, AS/NZS 4360 (2004) Standard for risk management
Sun Y (2010) Study on characteristic of dam disaster complex adaptive system and model for dam break threshold value. Tianjin University, Tianjin
Yan L (2011) Study on operation safety risk analysis method of dam. Tianjin University, Tianjin
Zhu J (2005) Research on some problems of the analytic hierarchy process and its application. Northeastern University, Shenyang
Zhu J, Liu S, Wang M (2005) Novel weight approach for interval numbers comparison matrix in the analytic hierarchy Process. Syst Eng-Theor Pract 4:29–34
Zou PXW, Zhang G, Wang J (2007) Understanding the key risks in construction projects in China. Int J Proj Manag 25(6):601–614
Acknowledgments
The study was funded by the Innovative Research Groups of the National Natural Science Foundation of China (Grant no. 51021004).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Zhang, S., Sun, B., Yan, L. et al. Risk identification on hydropower project using the IAHP and extension of TOPSIS methods under interval-valued fuzzy environment. Nat Hazards 65, 359–373 (2013). https://doi.org/10.1007/s11069-012-0367-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-012-0367-2