
Abstract
Artificial intelligence and mechanical engineering are two mature fields of science that intersect more and more often. Computer-aided mechanical analysis tools, including multibody dynamics software, are very versatile and have revolutionalized many industries. However, as shown by the literature presented in this review, combining the advantages of multibody system dynamics and machine learning creates new and exciting possibilities. For example, the multibody method can assist machine learning by providing synthetic data, while machine learning can provide fast and accurate subsystem models. The intersection of both approaches results in surrogate and hybrid modeling techniques, advanced control algorithms, and optimal design applications. A notable example is the development of autonomous systems for vehicles, robots, and mobile machinery. In our review we have found nontrivial, innovative, and even surprising applications of machine learning and multibody dynamics. This review focuses on applying neural networks, mainly deep learning, in connection with the multibody system method. Over one hundred and fifty papers are covered, and three main research areas are identified and introduced: data-driven modeling, model-based control and estimation, and data-driven control. The paper starts with a primer on machine learning and concludes with future research directions. The main goal is to provide a comprehensive and up-to-date review of existing literature to inspire further research.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Rapid growth in Artificial Intelligence (AI) has radically altered a number of mechanical engineering applications. Autonomous vehicles, automated harbor cranes, robotic systems, and unmanned mining are examples of applications that have been significantly impacted. The development of sufficient artificial intelligence for autonomy is critically dependent on the capability of the machinery to describe its actions and to percept its environment. This pathway will lead to machines capable of autonomous operation (e.g., performing tasks automatically, individually, or as a fleet) enabled by wireless machine communication. A critical step towards autonomously-operated systems relates to fully or partly automated actions, which can be accomplished by employing AI-based solutions. The aim of automated actions is to simplify the control and operation of the machines with semiautonomous operator assistance systems. This can be used to enhance safe operation of a machine and to reduce cognitive stress on the operator and consequently improve an operator’s well-being. Simplifying the control and operation also reduces stress on the machine, which will extend machine life, availability, and productivity.
AI can be connected to Multibody System Dynamics (MSD) such that a well-trained neural network can describe a submodel such as friction. In this way, AI-based technologies in the form of hybrid models can take multibody simulations to another level in terms of computational efficiency and accuracy. This surrogate model can be based on practical experiments and/or detailed models. Surrogate models can also be used to replace an entire multibody model. This makes it possible to combine data from experiments with data obtained from multibody-based simulations. The combination of measured and simulated data could also evolve over a machine’s lifetime as more is learned about its usage.
A critical bottleneck in the widespread implementation of AI in mechanical engineering and autonomy, in particular, relates to data production. Many AI-based technologies, such as deep and reinforcement learning, rely on large amounts of training data to function well. For example, more than ten million work cycles are needed to teach an excavator to operate autonomously for a single work cycle using a reinforced learning procedure [1]. Although in some cases the data can be obtained from measurements, in general cases it may be cumbersome to obtain [2]. The use of high-efficiency multibody system simulation can be connected to AI, and multibody system dynamics can offer data for AI training. To achieve this end, physics-based multibody simulation can produce data for AI needs accurately and efficiently. Multibody tools will then encourage more effective and more extensive AI implementations. As multibody system simulation can produce data more quickly than experiments on prototypes, it is possible to efficiently evaluate, tune, and select an AI-based algorithm for each application.
This paper presents AI technologies in the framework of multibody system dynamics. In particular, the objective is to provide a comprehensive, up-to-date review of existing literature that explores the combination of AI and multibody system dynamics. The paper also discusses the enormous potential of an AI and multibody system dynamics combination in terms of hybrid models. This combination has been investigated for more than a decade. Well over 100 journal articles covering this topic are discussed here. There is a myriad of AI, Machine Learning (ML), and Deep Learning (DL) methods applied to multibody dynamics and control. However, this paper considers only the application of shallow and deep neural networks to multibody system dynamics.
2 Primer on machine learning
Artificial intelligence, a term which was coined in 1956 [3], refers to any technique that enables a machine to mimic human behavior. The definition applies to any rule-based or data-driven approach. Machine learning, which is a subset of AI, includes using mathematics, statistics, and optimization rules to come up with a data-driven approach for the previous goal; in this sense, ML does not consider rule-based approaches. Lastly, deep learning utilizes a Deep Neural Network (DNN) to empower ML data-driven methods to solve more complex problems (Fig. 1). It should be noted that shallow neural networks also provide good solutions in particular problems, and these classes of solutions are considered under the category of ML.

AI vs ML vs DL
DL has recently gained the spotlight in the fields of science and engineering. With improved sensor technology and massive computer storage capabilities, large-scale acquisition of data has been made possible. This amount of data, coupled with advanced computing powers and recently developed complex algorithms, has been offering practical solutions to big real-world problems. The “learning” component in DL is the process of training the underlying algorithms to perform a desirable task.
2.1 Different neural network structures
A Neural Network (NN) is a nonlinear function approximator formulated by a group of parameters . The optimal set of parameters is obtained by optimization algorithms. Researchers have come up with different structures of NNs for solving various problems.
2.1.1 Artificial neural networks
The structure of an Artificial Neural Network (ANN) is inspired by the human brain. It includes artificial neurons arranged as multiple layers; the ANN consists of three types of layers: the input layer (which includes the input of the network), the output layer (which includes the network output), and the hidden layers (which include the middle layers of the network between input and output). The input is fed through these layers and processed by multiple mathematical operations. The output of each layer acts as the input to the next layer; the operation continues until the final output, see Fig. 2. Networks with up to three hidden layers are often called shallow and the ones with more than three hidden layers are often called deep neural networks. Furthermore, the network with a feed-forward structure, i.e., with no loops or recurrent connections, is called Feed-Forward Neural Network (FFNN). A vanilla NN, often called Multilayer Perceptron (MLP), has a feed-forward structure and is fully connected with the nodes in one layer being connected to all nodes in adjacent layers. The input of each layer goes through an initial linear filter, consisting of multiplication by a weight matrix and summation with a bias matrix; the weights and biases compose the overall parameters of the NN. The filter is followed by a nonlinear activation function acting on the result:
where and are the input and output vectors to the \(i\)th layer. In equation (1), and denote the weight matrix and the bias vector for the \(i\)th layer, respectively. Note that the ANN’s input should always be arranged as a 1-dimensional (1D) vector. In equation (1), is the nonlinear activation function; various functions including but not limited to the sigmoid, Rectified Linear Unit (ReLU) (zero output for negative input and a linear function for positive input), and tangent hyperbolic have been used in the deep learning community based on the specific purpose of the network [4].

The scheme of an ANN. The inputs go through the hidden layers where they are linearly transformed by weights and biases and nonlinearly transformed by the activation functions to generate the outputs. Note that all the nodes in hidden layers are fully connected to the inputs to that layer in a conventional ANN
2.1.2 Convolutional neural networks
Convolutional Neural Network (CNN) is one of most common NNs currently used in research and industry [5]. Firstly introduced by LeCun et al. [6], this structure has an advantage in that the feature extraction is automatically done by the network, meaning that no human knowledge/supervision is required for the determination of the features. In addition, CNNs include the weight sharing characteristic; multiple parts of the network have the same parameters. This important distinction from MLPs results in fewer overall parameters and simplified training, which makes CNNs applicable to larger datasets. The CNN has been applied in many fields including object detection and face recognition [7], [8], image classification [9], environment recognition [10], pose detection [11], and speech processing [12].
The structure of a CNN consists of convolution filters (kernels) with size \(n_{K} \times n_{K}\). This filter convolves with a small part of an \(n_{I} \times n_{I}\) input at a time:
where \(S_{I}\) is a scalar filtered part of the data after each convolution, is the filter parameters, is the part of the input on which the filter is acting, and ∗ denotes convolution operation. Then, depending on the chosen stride (which determines the number of input elements that the filter passes after each move), the filter slides on the other parts of the input. Given the structure of the filter, the output after the filter has a smaller size than the input. This limits the use of many kernels in deeper networks as the input size turns to zero. Plus, the standard convolution implementation uses edge and corner data values less than middle values and the final network may lose performance. To solve these problems, a padding technique is applied before the filter, in which a zero layer is added to the edge of the data, hence preserving the size of the output. The last layers include multiple fully connected (FC) layers for the classification purpose. The scheme of a CNN can be seen in Fig. 3.

The scheme of a CNN. The feature extraction layers are responsible for obtaining meaningful groups from raw input data; for instance, feature extractors in a face recognition CNN extract face components like eyes, nose, etc. The classification layers map the extracted features to the desired classes (in the face recognition example, the features are mapped to the corresponding individual). The input goes through multiple convolution layers (here, one is depicted) where a filter is swept through the input to generate smaller data. Often, a pooling layer is also added to take the maximum (or average in case of average pooling) of neighboring data elements and make the data even more compact. The final filtered data are then fed through a fully-connected network to generate the output
2.1.3 Recurrent neural networks
A Recurrent Neural Network (RNN) is tailored towards sequential data or time series. This networks is designed for applications in which the temporal characteristics of data is a necessary factor for the success of DL algorithms. Its unique format makes it applicable for speech segmentation [13] and natural language processing [14]. Also, due to its temporal aspect and hidden implementation of feedback in their network, RNN is a good candidate for modeling and control of dynamical systems [15], [16]. Unlike other structures, in RNN there is no assumption that the inputs and outputs are independent, meaning that each input does not only contribute to one output. In RNN, the outputs are divided into time-steps. The output of the time-step \(t\) is dependent on the inputs from previous time-steps \(t-1\), \(t-2\), \(t-3\), etc. (Fig. 4). While this structure facilitates the implementation of networks that can predict the next word in a sentence (or similar applications), it imposes a major problem, commonly known as vanishing/exploding gradients [17]. As the gradients backpropagate through the hidden layers (the gradient is calculated backward through the layers using the chain rule), depending on their initial values, they can get very large or small for the previous time-step weights. In the former case, the training becomes unstable. In the latter case, the weights of the previous time-steps are updated much slower than the later time-steps, making the training much slower for those sections of the network. As the previous time-step information is used in later time-step layers, the untrained parts of the network affect the training of the faster parts as well. Long Short-Term Memory (LSTM) and gate recurrent units have been developed to solve this problem [18], [19], [20].

The scheme of RNN. , , , refer to the input, hidden state, weight, and output vector, respectively. \(i\) denotes the time step at which the vectors are represented. When an input sequence is fed through the network, each input element is used to generate the output while going through a hidden state. The hidden state from previous input elements is then fed into the next layers. This way, the inputs will have information about previous input/outputs
2.2 Optimization algorithms for ML/DL
To find the parameters of a neural network, namely weights and biases that determine the mapping between the input and output, an optimization problem is solved to minimize (or maximize in some cases) an objective function. Generally speaking, a logarithmic/cross-entropy cost function is used for classification problems, and mean squared error or similar functions are utilized for regression problems. Depending on the convexity of the optimization problem, the solution might have one (global) or multiple (local) optima. Gradient-based methods [21] are one of the main approaches for solving optimization problems. Stochastic gradient descent [22] along with adaptive momentum optimizer [23] have been used extensively in the literature. While gradient-based methods are a common solution in the deep learning community, they are susceptible to converging to local optima and saddle points. In addition, the performance of these methods degrades considerably with noisy gradients, a common feature in dynamical system and controls applications. Streams of research have focused on combining evolutionary algorithms with gradient-based approaches for solving optimization problems, especially in reinforcement learning applications, semisupervised data-driven methods, where the aforementioned problems have larger impact on the performance of the algorithm [24].
2.3 Important issues in NN training
2.3.1 Overfitting
In the ML research, the data are split in three sections: the training data are used to train the network for a given task; the validation data are used to tune the network hyperparameters (number of layers, number of hidden units, etc.) for the highest performance; and finally, the test data are used to evaluate the performance of the network on unseen data. A successfully-trained network offers good accuracy on all data. Although a high training accuracy is valued on the training data, fitting an NN exactly to this sample data is not desired. Overfitting results in very good accuracy on the training data and poor performance on the test data. In other words, the model only memorizes the structure of the training data and cannot generalize well to new unseen data, which is ultimately the goal of using data-driven approaches. Overfitting stems from multiple factors; usually, if the model is trained too much or the algorithm is too complex for the sample data, the NN even learns the irrelevant structures on the data, like the noise, and hence loses it generalizability. Various methods exist for avoiding overfitting, including but not limited to:
-
Simplifying the network structure by reducing the number of layers or the number of hidden units.
-
Stopping the training earlier whenever a certain training/testing accuracy is reached; also known as “early stopping”.
-
Adding a regularization term to the cost function to penalize high weight and bias values.
-
Adding dropout layers, which randomly disable part of the network by setting the corresponding weights and biases to zero during training.
2.3.2 Underfitting
Underfitting has the opposite effect to overfitting and happens when the model has a poor performance on the training and test samples. It usually occurs when the model is not complex enough for the structure of the data or the model is not trained enough. As a result, adding more layers/units to the model and/or adding more training epochs are common solutions. Based on the previous section, there is an optimum complexity of the model and the training epochs (a measure for the number of times the training vectors are used once before updating the weights) for each problem. Using validation and test sets and trying different network settings is therefore of utmost importance. Moreover, a stream of research is focused on optimization-based hyperparameter tuning [25].
2.4 Learning schemes in ML/DL
Depending on the application, DL algorithms make use of three general learning schemes: supervised learning, unsupervised learning, and semisupervised learning, which differ in terms of whether the true outputs are available and how they are used.
2.4.1 Supervised learning
Supervised learning is a suitable method when the true outputs (also called expert labels) are available for a set of inputs. An approximate mapping between input-output pairs is of interest to replace the experiments or computationally intractable models. To this end, NNs act as parameterized nonlinear function approximators, and the mapping is found by acquiring a suitable set of parameters . Hence, supervised learning obtains the following approximate function:
where is the approximate output to replace the real output , is the overall NN function, which depends on the input and parameter . Broadly speaking, studies that use supervised learning can be classification or regression problems; the former predicts a discrete output, like whether an image is a cat or a dog, and the latter predicts a continuous quantity, like the exoskeleton assistive torque for a given human pose.
Supervised learning is the dominant method used in the DL community. Many applications, like object detection, image segmentation, and natural language processing, make use of this approach. Moreover, most of the DL research in multibody dynamics takes advantage of this method since the true labels are usually available from physical models or experiments.
2.4.2 Unsupervised learning
In some applications, the labels are not available and only a set of input data exists. However, it is of interest to find/change the underlying structure of data, for example, to group the emails into spam and nonspam categories from the data or to reduce the dimension of the input data for faster training. Unsupervised learning algorithms are utilized for this purpose. Depending on the structure of data, different subcategories of unsupervised learning can be used. If the goal is to categorize the data into distinct groups, the problem is considered as a clustering. K-means, mean-shift, DBSCAN, mixture models, and hierarchical clustering are among the most common clustering algorithms [26]. Another category of unsupervised learning problems is called embedding, where the data have a continuous distribution. The linear versions of this approach lead to the quite well-known singular value decomposition and principal component analysis methods [27]. The nonlinear versions include AutoEncoder networks [28]. Embedding algorithms are a powerful tool for model and dimensionality reduction.
2.4.3 Semisupervised learning
There are two categories to this method. Semisupervised learning can be associated with the class of learning methods where the expert labels are not available prior to the training but are generated (approximated) during the training; a function approximator is responsible for generating/correcting the labels and another approximator is responsible for creating the correct output based on the approximate labels. The second category looks into the ways to improve accuracy where the amount of labeled data is substantially smaller than the unlabeled data. The two most well-known methods that are based on semisupervised learning are reinforcement learning and generative adversarial networks.
2.4.4 Reinforcement learning
Reinforcement Learning (RL) is based on the first category of semisupervised learning. In this method, the agent (the algorithm, controller, or the brain) interacts with an environment by generating an action and observing the environment’s next state. Each agent interaction with the environment is evaluated; being in the state and executing the action , where the subscript \(t\) is the time index, obtains an immediate reward from the environment (see Fig. 5). The goal of the RL algorithm is to maximize the cumulative reward, i.e., the reward obtained starting from the initial state and proceeding until the terminal state is met. This is achieved by obtaining the value function for each state, which determines the quality of a given state. This value can be considered as the true label, which is usually not known before the training. As a result, it is estimated; the algorithm aims to make the estimations close to the true values. The value functions are updated at each iteration by the Bellman equation [29]
where is the value function for the state at the iteration \(t\); \(R_{t+1}\) is the immediate reward for being in the state, and is the value of the successor state. \(\gamma \) is the discount factor used to emphasize on short-term rewards. This formulation can also be rewritten for state-action pairs instead of just the states.

The schematic of RL. The agent refers to the component that does the decision-making based on a policy, which is the algorithm that defines the mapping between the states and actions. Based on the current policy , the current state , and the current reward signal \(R_{t}\), the agent calculates the current action and applies it to the environment. It then receives the next state and reward signal \(R_{t+1}\) for the next iteration
Multiple function approximators have been utilized to estimate the value functions. For instance, linear functions have been selected as follows:
In this representation, can be any nonlinear function of the states; however, the value function approximation with the parameters is linear. A common RL method in control applications that uses linear approximation is least square policy iteration [30]. The specific use of DNNs as a nonlinear function approximation has led to the emergence of Deep Reinforcement Learning (DRL) research, which dominates the current studies in the field of computer science and engineering.
RL has recently gained the spotlight with the seminal work of David Silver, in which an agent beat a human master in the game of AlphaGo [31]. The use of deep neural networks as function approximators has been popularized in RL by the introduction of deep Q networks [32]. Recently, modifications to actor-critic methods have been proposed to work with continuous state-action environments; these approaches use an actor to approximate the policy (the controller), which is updated based on the value function approximate value coming from the critic. Deep deterministic policy gradient and twin-delayed policy gradient methods are among these approaches [33], [34]. This achievement has made RL algorithms directly applicable to continuous physical domains, like multibody dynamic systems, without the need for state-action discretization.
Generally speaking, RL can be categorized into model-free and model-based methods, both of which rely on interactions with the environment. Having said that, model-based methods use a model of the environment for prediction/planning, while model-free methods do not require a model representation of the environment and depend solely on environment interactions. Both variations will be discussed in more detail in future sections.
2.4.5 Generative adversarial networks
Developed by Ian Goodfellow [35], Generative Adversarial Network (GAN) is an interesting category of deep learning algorithms that is used for generative modeling. At its core, GAN is an unsupervised learning task with unlabeled data. There are no expert labels provided with the input data. Having said that, an updated version of GANs adds a small amount of labeled data and uses the second category of semisupervised learning. The goal is to extract patterns of the input data and generate new data containing the same pattern; the first part fits well with the unsupervised learning scheme previously discussed. Having said that, this problem is posed as a supervised learning problem in GANs. There are two networks in any GAN, namely a generator network and a discriminator network; as the name suggests, the generator network is trained to produce new examples that are similar to the input data. The discriminator network is responsible for determining whether the output of the generator network is a real example (sampled from the input distribution) or a fake example. Drawing inspiration from game theory, these two networks are trained together as a zero-sum game in an adversarial manner, i.e., the generator network keeps improving on generating good fake examples and the discriminator network keeps improving on detecting fake examples. A well-trained GAN contains a discriminator network that labels fake outputs as real examples half the time erroneously. This means that the generator is capable of producing examples that are highly similar to the input data. GANs have shown potential in MSD community. They have been used, for example, to decrease the computation for data-driven inverse-kinematics and inverse-dynamics approximation [36].
3 AI-powered high-fidelity multibody modeling
This section examines studies in which data-based models are incorporated into multibody formulations to enhance computational efficiency and/or accuracy. Data required to create such models are generated synthetically or acquired by measurements. A data-driven model made with simulation-based, synthetic data trades intensive precomputations and a large memory footprint for the improved efficiency of the data-driven solution. Correspondingly, real-life measurement data allow for improved accuracy by model identification. A neural network based on a trained data set can provide accurate solutions for multibody applications. This makes it ideal for building surrogate representations of a submodel within the multibody framework, or for building entire multibody models. A global approximation procedure that covers points from the whole domain of interest can be used in the multibody framework. This chapter introduces studies where a multibody model or its submodel is replaced by surrogate models based on the NN representation.
Firstly, some overview works on data-driven modeling will be presented in Sect. 3.1. Next, papers devoted to black-box data-driven surrogate submodels are discussed in Sect. 3.2. Following, work dedicated to the data-driven representation of complete multibody system models in inverse and forward dynamic simulations is shown in Sects. 3.3 and 3.4, respectively. Finally, Sect. 3.5 presents hybrid methods, combining the deep learning technique with a physics-based modeling approach. Table 1 reviews some paper examples of data-driven modeling of multibody systems.
3.1 Thematic reviews
ML has a long history in computational mechanics, and several domain-specific reviews are already available. As shown below, this ranges from personalized medicine [61], through aerospace applications [62], to autonomous driving [63].
Saxby et al. [61] reviewed personal musculoskeletal modeling that employs the data-driven approach. Their study targeted the personalized medicine domain—to match the individual and the biomechanical model. To this end, the investigation has taken the AI-based approach, which has resulted in fast, personalized computational models for a human neuromusculoskeletal system. In addition, the study has discussed types of computational models, a framework for customized model generation and operation, ML applications in model personalization, and implementation details.
Brunton et al. [62] introduced a comprehensive literature review on data-driven approaches in aerospace applications. Their study taught concept-based strategies for various production processes, including design and design optimization. They highlighted multiple possibilities on how ML can enhance the solution of engineering optimization problems. Similarly, they explained how ML can be applied in aerospace design, manufacturing, service, and the concept of digital twins. The paper offered several case studies.
Similarly, the paper by Hashemi et al. [63] discussed the application of various artificial learning techniques. The study focused on “black-box” modeling, model-based control (including deep reinforcement learning), and vision-based systems (including human pose recognition) in autonomous driving and biomechatronics.
3.2 Surrogate subsystem models in the multibody framework
This section presents papers that utilize black-box ML techniques to approximate multibody model subsystems. Condition monitoring studies were also included under the surrogate model category as they must internally represent the main characteristic of the monitored system. Studies have shown good accuracy and efficiency in their domains.
Ardeh et al. [37] and Han et al. [40] reported that their surrogates trained on synthetic data offered high accuracy and efficiency compared to the full, nonlinear simulation models. Ardeh et al. [37] built a surrogate of a tire using a feed-forward neural network. The surrogate model was designed for use in a quarter-car vehicle model. Han et al. [40] proposed a deep learning approach to flexible multibody simulations. However, massive data are required to achieve high-fidelity models for deformable bodies, mainly due to fine model discretization in time and space. To solve the issue, the authors proposed a two-stage learning procedure. In the first stage, the training was performed using small-size, randomly selected data. In the second stage, data-driven model performance was improved by training a second network designed to provide error corrections. The new approach was tested on several models. In addition, Han et al. [40] reports on the computational time of trained data-driven models in comparison with physics-based simulations. It is noted that the efficiency of the data-driven solution depends mostly on the number of prediction points (nodes) requested. All analyzed data-driven models have lower execution times than classical simulations. For the most complex model (excavator’s arm) and prediction for 10 nodes, the data-driven model was 80 times faster than classical simulation on average.
Ma et al. [42] introduced a deep learning model based on experimental data for the normal contact force. The proposed solution can approximate contact forces on complex surfaces and offers high accuracy and good generalization properties. The study, motivated by the lack of an appropriate physics-based model for such an application, analyzed contact between a gun barrel and a bourrelet projectile.
Multibody simulations often generate synthetic data for training ML-based condition monitoring systems. Monitored systems include bearing fault detection (Sobie et al. [43], Kahr et al. [41]), wind turbine gearbox (Azzam et al. [38]), flexible rotors (García Peyrano et al. [39]), and diagnosis of wheel out-of-roundness in high-speed trains (Ye et al. [44]). The main reason to use synthetic data instead of measurements for model learning is the difficulty in data acquisition for various failure scenarios.
Sobie et al. [43] developed a detailed bearing simulation model to generate training data for a given physical realization. The study compares feature-based methods (such as random forests, shallow neural networks, and logistic regression) with deep learning convolutional neural networks and the nearest-neighbor classifier using dynamic time warping. The nearest-neighbor classifier is a supervised learning method that classifies data based on what class the known data points nearest to it belong to. The algorithm relies on distance for classification, and to consider the varying speed of the time series, a dynamic time warping similarity measure is employed. The trained models were verified using measurements of the speed faults. Simulation data make it possible to build a classifier for any model and bearing configuration, giving good classification results. However, as the authors pointed out, experimental data should be included to improve classification accuracy. Moreover, the traditional feature-based data-driven models were outperformed by newly introduced models that lacked features.
Similarly, Karh et al. [41] used a three-dimensional multibody model of the bearing to simulate various failure scenarios. The failure classification was based on CNN fed with an image of wavelet transform generated from the data. The model was verified on measurement data. The trained network easily distinguished between healthy and defective bearings, but the source of failure was not always appropriately identified.
Azzam et al. [38] created a virtual sensor to estimate all six components of loads on a wind turbine gearbox because an actual sensor is costly. All data for training and verifying neural network-based virtual sensors were generated in multibody simulation. Six networks were designed, one for each gearbox’s load component.
García Peyrano et al. [39] analyzed the mechanical imbalance of the flexible rotor of a steam turbine. The multibody model considers various imbalance conditions and bearing stiffness. In addition, two ML models were trained based on synthetic data: a feed-forward neural network and a support vector machine. Support vector machine is a robust supervised learning model for classification and regression analysis. Both methods have shown accurate predictions of the system imbalance.
Ye et al. [44] studied the problem of the train’s wheel out-of-roundness. Traditional out-of-roundness measurement is laborious and time-consuming. Therefore, the authors presented a concept of an ML-based online monitoring system of wheel out-of-roundness. Axle box acceleration is used as the input. Proposed network architectures include five neural networks, convolutional and fully connected, to process time and frequency domain signals. The solution has shown good accuracy in condition monitoring of wheel out-of-roundness.
3.3 Inverse dynamics applications
ML methods applied to inverse dynamics problems are mostly related to the modeling of robotic manipulators. The works of Polydoros et al. [46], Zhou and Schoellig [48], and Ren and Ben-Tzvi [36] fall into this category. Various ML techniques are used in this context.
The solution by Polydoros et al. [46] was based on a network architecture with a self-organized layer (which employs the generalized Hebbian learning algorithm—a learning rule for linear FFNN in unsupervised learning primarily used to approximate principal components of the input) and a recursive layer. Self-organizing unsupervised learning is a type of FFNN used to produce a discrete, low-dimensional representation of a higher-dimensional data set while preserving the relative distance between the points. Moreover, the Bayesian linear regression was applied to update the weights between the recursive layer and the outputs. Validation was performed on five measurement data sets from four robots. The proposed approach illustrated a state-of-the-art generalization ability and better adaptability than the existing real-time state-of-the-art learning solutions. Moreover, it robustly adapted to changes in the robot and its environment due to, e.g., mechanical wear or moving objects.
Similarly, Zhou and Schoellig [48] introduced a framework for trajectory generation for a robotic manipulator to train deep learning inverse dynamics models. The authors discussed the problem of insufficient coverage of experimental data for data-driven model training. They proposed an adaptive approach for data collection to train deep neural networks. The introduced procedure was based on an ML technique called active learning (not to be confused with the method of automatic label generation), closely related to optimal experimental design, which makes it possible for the learner to query the training data to increase information content actively. Their data-driven model’s data efficiency and training quality were superior to those obtained using a trial-and-error methodology where the trajectories are selected manually.
Ren and Ben-Tzvi [36] recognized that data collection for data-driven inverse kinematics and dynamics models is the most time-consuming task in model development. Therefore, they proposed an algorithm based on generative adversarial networks (consult Sect. 2.4) already widely applied in the computer vision community to overcome this concern. The authors used several GAN architectures to aid data creation in inverse kinematics and dynamics problems and performed experimental validation on two robotic manipulators.
Rane et al. [47] used deep learning techniques to compute internal forces during motion in musculoskeletal models based on kinematic inputs. In musculoskeletal modeling, data-driven models offer three main advantages: low computational cost (once the model is trained), recognition of the most significant model inputs (which may reduce the number of required measurements), and development of a data-driven model that makes it possible to assess relationships at the population level. The positions of the lower limb markers (18 in total) and ground reaction forces with center of pressure data from a force plate served as input for the network. Internal forces for the network labels were computed using existing modeling software. Moreover, the electromyographic signal of an electrical activity produced by skeletal muscles was also used as network output based on processed raw data. As a result, the final model showed good accuracy and superior efficiency. However, the authors emphasized that limited data decreases the performance of the data-driven model in scenarios where subject information was used only in the testing phase and not in training.
Similarly, Nasr et al. [45] used deep learning to approximate inverse muscle activation dynamics. In their black-box model called InverseMuscleNet, biomechanical kinematic (joint angle, joint velocity, joint acceleration) and dynamic (joint torque, activation torque) variables are fed into an RNN, which estimates the electromyographic signals. To decrease the number of inputs and find the most dominant ones, a sensitivity analysis on the input space is done using a backward selection algorithm. Moreover, the network configuration is optimized by trying different input sets and model weights. The resulting RNN can replace the inefficient static optimization that is often used for this purpose and is computationally efficient enough for real-time applications like rehabilitation and sports engineering. Also, this model bypasses the need for time-consuming and invasive electromyographic electrode setup on subjects.
3.4 Forward dynamic applications
Studies in this section focus on time-varying responses of complete multibody systems without directly solving the equations of motion. The primary motivation behind those papers is increased efficiency compared to the original simulation model. The works of Urda et al. [56] and Byravan and Fox [49] build the system-level model from experimental data. Compared with surrogates in Sect. 3.2, those models represent the whole system.
The development of ML models has had a long history in railway applications. In 2007, Martin et al. [53] proposed substituting the multibody model with a neural network to approximate the forces on a wheel-rail interface based on track geometry and train characteristics. The study used a recurrent neural network and multibody simulation software to generate synthetic training data. Good agreement was observed between simulation results and neural network computations.
Similarly, Kraft et al. [52] studied the possibility of using black-box modeling in railway vehicle simulation in the presence of track irregularities. The authors evaluated several linear and nonlinear models against multibody simulation responses and measurements. While all models have reproduced vertical (primarily linear) motion, the highly nonlinear lateral movement required nonlinear modeling; the recurrent neural networks provided the most accurate results. Moreover, relative to the standard multibody simulation, computational times were shorter for the data-based model. The study emphasized that the performance of the data-driven model depends on the availability of training data.
Urda et al. [56] introduced a neural network-based estimation method for lateral wheel–rail contact forces. Their findings have shown that deep learning techniques are computationally efficient and easy to apply to the description of wheel–rail contact forces. They have compared two methods for lateral force estimation: the classical approach based on a harmonic elimination technique and the application of a deep neural network. The paper also offered an experimental validation of the data-driven model compared to simulation results. The authors concluded that the deep learning approach, compared with the classical harmonic elimination technique, is computationally more efficient and requires fewer sensor inputs.
Alternatively, Choi et al. [50] proposed a method to replace the multibody-based equations of motion of arbitrary systems using a deep neural network-based modeling technique. As for other findings, the main goal of their procedure was to improve computational efficiency. In addition, the authors emphasized the smoothness of the solution at the displacement, velocity, and acceleration levels. Trained data-driven models are valid for the range of design variables and initial configurations of the system under consideration. The study applied the procedure to three simple academic examples and one practical case.
An interesting perspective was introduced by Byravan and Fox [49], where rigid body motion was predicted based on point cloud data from a depth camera. The motivation for this work was to observe physics rather than derive it from first principles. The study represents the kinematics of the rigid bodies as a SE(3) (special Euclidean group representing 3D rotations and translations) transformation. The authors used a deep learning architecture with convolutional, fully connected, and deconvolutional layers (deconvolutional neural networks, often called transposed convolutional networks, use convolution to perform upsampling to find lost features) to predict how the environment changes due to applied forces. This results in higher accuracy and is more general than solutions obtained from data-driven models developed with no assumptions regarding the motion under investigation. The ML solution was verified with experimental data.
Hegedüs et al. [51] and Pan et al. [55] proposed a neural-network-based road vehicle model that can substitute a classic road vehicle model. In both studies, the data-driven solution was based on standard deep neural networks and showed good agreement with the full multibody model. Adequate efficiency and accuracy made the vehicle model suitable for real-time model-based motion planning and control. Hegedüs et al. [51] modeled a single-track vehicle and used ML to predict the overall behavior of the car, whereas Pan et al. [55] modeled a complete vehicle but predicted only fundamental quantities like the distance traveled and output velocity.
Nasr et al. [54] developed MuscleNet for fast approximation of forward muscle models. Taking electromyographic signals and delayed joint kinematics as input, MuscleNet estimates the current joint kinematics (angle, velocity, acceleration) and joint/muscle dynamics (net joint torque, joint activation torque). Multiple network structures including ANNs, CNNs, RNNs, and recurrent CNNs are tested for this purpose. Two configurations of electromyographic inputs (raw, filtered) are also considered to evaluate the filtering capabilities of networks. RNNs with filtered electromyographic inputs showed the best performance among all network structures. MuscleNet represents muscle activation dynamics, muscle contraction dynamics, musculoskeletal geometry, and skeletal dynamics; it bypasses complex muscle modeling and model parameter identification and is computationally feasible for real-time application.
One of the main reasons for using data-driven models instead of classical simulations is a decrease in computational time. Therefore, it is worth pointing out that Choi et al. [50] and Hegedüs et al. [51] introduced computational time comparisons between physics-based simulations and data-driven models. Choi et al. [50] reports on computational time for their most complicated mechanical system (vibrating transmission with bearing contact) as it is not expected to note the computational advantage of the data-driven model for very simple mechanical systems. However, for the reported example, the data-driven model was over 110 times faster than the physics-based simulation. Hegedüs et al. [51] also reported that their data-driven models (of a planar, rigid, single-track vehicle) are faster than physics-based simulation. The computational advantage of the data-driven models depends on total simulation times. It ranges from around 3 times speedup for 1 s simulation to 1.3 speedup for 20 s.
3.5 Hybrid modeling techniques
Including expert knowledge of the system results in so-called gray-box or hybrid models. When available and applicable, specialist knowledge can enhance the model’s properties and allow for easier ML model creation. Expert knowledge can be included as a regularization term (like in the work of Angeli et al. [57]), as a part of the model (as in Hosking and McPhee [58]), or can be exploited to design an appropriate structure for the ML model (as was done by Ye et al. [60] and Oishi and Yagawa [59]). This section presents a variety of applications and modeling designs.
Angeli et al. [57] proposed a deep learning architecture to reduce the dimensionality of the multibody system from full to minimal coordinates to enable the use of space observers. While the description of the system in minimal coordinates has many advantages, obtaining suitable representation is generally challenging and depends critically on the multibody formulation used. Therefore, the authors have proposed using a recurrent auto-encoder deep learning architecture to approximate the mapping between full system coordinates and a minimal set of coordinates. Recurrent auto-encoder implements an auto-encoder for sequential data using an encoder–decoder recurrent neural network. The encoder structure compresses (encodes) input into a fixed-length vector. The original sequence can then be reconstructed through the decoder structure. A critical characteristic of the proposed solution is that the learning process uses the multibody model directly. Therefore, it was not based only on data. Moreover, the authors selected sigmoid activation functions for their network instead of the more commonly used ReLU because the sigmoid functions provide smooth first- and second-order derivatives. Their proposed solution was verified using two numerical examples. It showed good accuracy for the range of motion within the training data.
Hosking and McPhee [58] proposed a mixed approach to model the powertrain of a hybrid passenger car (Lincoln MKZ Hybrid). The car uses a complex power-split powertrain, which is challenging to model robustly using analytic modeling or experimental identification. Therefore, the authors proposed combining analytical and experimental approaches. The drivetrain model was physics-based, while the control system and power source were approximated using neural networks, and parameters were obtained from measurements. The model was developed with limited knowledge of the system, and identification was made end-to-end based on vehicle road testing. The proposed solution proved to be an adequate approximation of the actual vehicle and supported the development of model-based controllers for the autonomous vehicle.
Nasr et al. [64] used InverseMuscleNet [45] (see Sect. 3.3) as part of the high-fidelity model to which a Model Predictive Control (MPC) is applied. In this paper, MPC acts as the human central nervous system controller. The human model is coupled with an upper-limb exoskeleton, which uses a mid-level controller based on model-based and fuzzy logic techniques to adjust the exoskeleton assistance. InverseMuscleNet estimates the approximated electromyographic signals in the high-fidelity model.
Ye et al. [60] proposed a general deep learning model for multibody systems. Their solution comprises three parts: a 3D convolutional neural network, a recurrent Long Short-Term Memory (LSTM) network, and a standard MLP feed-forward, fully connected network. The design of their networks was physics-informed, that is, based on the fact that the system is described with second-order differential equations and that the resulting state depends on previous states and external interference. The resulting DL model was applied to a vehicle-track system in which the vehicle had ten degrees of freedom, and no constraints were present in the system.
Oishi and Yagawa [59] proposed a general framework for extracting rules inherent to computational mechanics. The introduced procedure was based on deep learning techniques. While interesting and applicable to phenomena existing in multibody systems, the authors have demonstrated their method by developing a new numerical quadrature for a finite element stiffness matrix calculation. The number and placement of the quadrature points were optimized for each finite element in the model to achieve superior efficiency as compared with a classical approach.
4 Control-oriented DL models for model-based control and estimation
Model-based controllers have been extensively used in multibody dynamics research. These controllers utilize a model internally, usually referred to as the “control-oriented” model. The performance and stability of model-based controllers rely heavily on the accurate representation of the system dynamics. For complex multibody systems, obtaining an accurate physical model is not always feasible. Even in cases when a model can be acquired, it may not be utilized for real-time control due to computational complexity. Moreover, the inherent dynamics and model parameters may change over time, for example, in different control scenarios. While obtaining a physics-based model requires doing extensive experiments to find the model parameters, for each scenario and for each system (when modeling vehicles for example, each vehicle portrays a different dynamic behavior which necessitates individual tests on each vehicle [65]), online estimation algorithms suffer from high computation for complex systems. Given that a great amount of data is available when these systems are operated by human experts, ML methods offer a viable solution to approximate the control-oriented model offline/online. These approaches are capable of extracting hidden patterns in the data and hence can capture higher-order and varying dynamics.
In this section, we will discuss how ML has been used to approximate the control-oriented model. Different controllers that have used AI-driven internal models will be reviewed. In addition, research on data-driven models for estimation will be studied.
4.1 Model-based reinforcement learning
Model-Based Reinforcement Learning (MBRL) is one of the main categories of RL. This method is dependent on the interactions with the environment but also uses an internal model to predict state trajectories (often called “rollouts”) and plan future action sequences [66]. A powerful method to facilitate this prediction and planning is to use receding horizon control; the optimal sequence of future actions is calculated in a defined horizon window, but only the first action is applied to the environment, after which the same procedure is continued for future horizons. This is achieved by solving the following optimization for each prediction horizon:
where is the action sequence in the horizon window and is the reward function. This optimization can be solved using derivative-free and sample-based approaches like random shooting [67] and cross entropy method [68]; it can also be tackled using ideas from optimal control and trajectory optimization [69], where the first- and second-order derivative of the reward function and the internal model are utilized [70], [71]. This idea is the main structure used in Linear Quadratic Regulator (LQR) [72], iterative LQR [73], and MPC [74]. While MPC is sometimes interchangeably used with MBRL, it is not the only method for applying model-based planning. It should be noted that the aforementioned methods can be, and have been, integrated. More information on the MBRL can be found in the review papers [70], [71], and [75].
As discussed, a crucial component of MBRL is the use of an internal model; this model can be known a priori using physical rules. It can also be learned using ML, where a surrogate model is used for planning (similar to the discussions in Sect. 3.2). In addition, only part of the model can be approximated, like an aerodynamic drag coefficient or a static friction term (refer to Sect. 3.5). In this section, we discuss the MBRL research in the field of multibody dynamics.
To develop a variable impedance controller for efficient human-robot interaction, Roveda et al. [76] used a neural network approach to approximate the human-robot dynamics. To avoid overfitting in low-data regimes and capture the uncertainty in the data, an ensemble of ANNs was utilized to learn the model; the ANNs will produce different outputs in data regimes where there is uncertainty. The model is trained offline based on previously gathered data, but it is also updated online to account for human motor adaptation. The resulting human–robot interaction model is utilized within an MPC optimized by cross entropy method to dynamically obtain the stiffness and damping parameters of the impedance controller by minimizing the human effort.
Model-free approaches, which we review in Sect. 5.2, do not require a mathematical representation of the system dynamics. While these approaches can obtain the optimal policy based on data patterns, they are highly sample-inefficient. On the other hand, MBRL uses model information, rendering better sample-efficiency but less accurate controllers. To combine the capabilities of these two methods, Nagabandi et al. [77] used MBRL with model-free fine-tuning. First, a deep neural network-based surrogate model is trained to approximate the dynamics. Then, an MBRL algorithm is utilized to obtain an acceptable policy. This policy is then used as the initial solution of a model-free learner to compute the near-optimal solution. The integrated method achieved high tracking accuracy and sample-efficiency on multiple complex locomotion tasks of the openAI gym environment [78].
MPC was utilized for real-time aggressive driving maneuvers in [79]. The model predictive path integral approach, which is usually applied with a control-affine assumption, was combined with general nonlinear dynamics with the aid of information-theoretic control. As this approach requires a model of the system, a multi-layered NN is used to approximate the dynamics. While the NN-approximated multibody dynamics is initially trained using random policies, it is later retrained by the data gathered from applying model predictive path integral to the current dynamic model. The process is repeated until no further improvement is observed in the model accuracy. The resulting model-based controller achieves good empirical tracking for a complex mobile robot driving task.
4.2 Other model-based controllers
Aside from learning the control-oriented models (surrogate models) for MBRL (MPC in particular), a limited stream of research has focused on other controllers. Richards et al. [80] used a feed-forward neural network in a meta-learning scheme to approximate an integrated model and adaptive controller. The approximate multibody model of a planar fully actuated rotorcraft includes the uncertain dynamic terms; it also comprises the aerodynamic disturbance. The learning is done on past data in an offline manner. The meta-learning (or the colloquially used term “learning how to learn”) tracks several trajectories with desirable performance. Each trajectory is assigned to a base-learner, which learns the specific task. The meta-learner is then defined to minimize the average trajectory error in all tasks.
In [81], the model of a helicopter was obtained using a ReLU network, which combines a quadratic lag model (mapping the current state and multiple past inputs to the current helicopter linear/angular acceleration) and a two-layer neural network with ReLU activation functions. This multibody model has been successful in capturing the nonlinear dynamic terms, aerodynamic terms, engine model, vibration, and external disturbances. State-action pairs from expert demonstrations were used for training the network. Contrary to simple linear models, the NN-based model is able to handle complex aerobatic maneuvers. The DL-based model has enabled the use of model-based controllers.
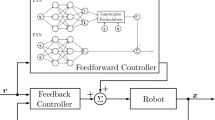
A simple two-layer fully-connected NN was used to approximate the translational and rotational components of a quadrotor dynamics [82]. To collect the training data, the quadrotor moved along multiple trajectories using an LQR with a low-level proportional-derivative controller. The LQR controller uses a near-hover linear approximate model to derive the feedback control law. The trained NN model was utilized within a sequential convex optimization to calculate the open-loop control signal. The authors showed that the combination of the feedforward controller (with an NN-based control-oriented model) with the feedback LQR-proportional-derivative controller works better than only the feedback term on the test trajectories (unseen in training). Moreover, the simple structure of NN enables the high online computation of sequential convex optimization.
Researchers have implemented a nonlinear auto-regressive with exogenous input (NARX) network to approximate nonlinear vehicle dynamics [83]. Instead of using an internal feedback signal, as in recurrent neural networks, NARX feeds the delayed control inputs and outputs as extra inputs to a classic multi-layer perceptron. They studied the effect of initial weights and the optimum network size on the network accuracy. Both offline and online training schemes are tested and it is concluded that it is possible, with the addition of a greater online computational cost, to use NNs for online system identification and control of complex vehicle systems.
The same problem was studied in [65] but for changing vehicle dynamics at the limit of multiple friction surfaces; these conditions affect the vehicle stability and controllability and must be captured in the model to ensure good controller performance in all driving scenarios. A two-layer NN was trained to approximate vehicle dynamics. Exploiting the data from both low- and high-friction driving scenarios, this model was able to perform well on different road surfaces and bypass the need for explicit friction estimation. The NN-based model was utilized within a feedforward–feedback controller, rendering better control results than with a physics-based alternative.
4.3 Model-based estimators
A subset of estimation techniques requires a model of the system. Kalman Filter (KF) and Extended Kalman Filter (EKF) are among these approaches. ML approaches are then utilized when obtaining a model is not possible or convenient. The work of Angeli et al. [57] on obtaining minimal coordinates using AutoEncoders was presented in Sect. 3.5. The minimal ordinary differential equations obtained from this method were used in an EKF to estimate the states of a slider-crank mechanism [84].
KFs are limited to linear systems and assume Gaussian distributions for the noise, disturbance, and state estimates. Also EKFs, the nonlinear version of KFs, require iterative local linearization of the plant around the new mean and covariance estimates. To overcome these issues, researchers have been developing the Moving Horizon Estimator (MHE) [85], [86]. While KFs are the reformulation of LQRs, MHEs are the reformulation of MPCs; using the past states in a finite horizon window, MHEs estimate the current state by solving an optimization problem. Similar to MPC, MHE enables the use of a nonlinear plant model and explicit inclusion of constraints. To approximate the control-oriented model in the MHE estimator, Sun et al. [87] used a type 2 Fuzzy neural network. In this research, MHE estimates the external force/torque in a bilateral telerobotic system. The output of the estimator is used in a Sliding Mode Controller (SMC) for nonlinear control of the plant. Type 2 fuzzy neural network enables the application of model-based estimators on a complex robotic system without the need to derive an accurate mathematical model.
5 Data-driven control
An alternative to using model-based controllers with learned models (as mentioned in Sect. 3) is directly using model-free data-driven control approaches that do not explicitly require a dynamics model for design. This method is applicable to situations in which learning a model requires an extensive and challenging data acquisition.
5.1 ML-based MPC optimization
In Sect. 4.1, we discussed how ML methods can be used to train a control-oriented model for MPC implementation. There exists another challenging problem in real-time application of this controller; the online optimization of the MPC may be computationally intensive, and hence solving it on embedded systems and micro-controllers may not be feasible, especially for high-state dynamic systems. Some of the derivative-free and sample-based methods for MPC optimization are mentioned in Sect. 4.1. Here, however, we discuss the research on approximating the optimization solution specifically using neural networks.
Inspired by explicit MPC [88], where the feedback policy is obtained offline by solving the optimization problem for various ranges of operation, neural networks have been used to train a controller that mimics an MPC controller based on synthetic data generated from an offline MPC. Winqvist et al. [89] presented a general framework for training and validation of neural networks for MPC. They proposed using PyTorch with the CVXPY optimization tool [90] for constrained explicit MPC. They also offered a hit-and-run sampler to systematically generate the input data for the network. Lastly, the authors explore the idea of adding domain knowledge to the network training.
In [91], Varshney et al. presented DeepControl: a two-layer fully connected neural network that replaces a Nonlinear Model Predictive Control (NMPC) for online quadrotor control. The training synthetic data are generated from a simulated model of the quadrotor using Gazebo. This model is obtained by matching the simulation transfer function with that of the real physical system for some manual movements of the quadrotor. Offline MPC is used in simulation as the high-level controller to generate the corresponding roll, pitch, yaw rate, and thrust commands for following a given desired trajectory. A low-level Proportional Integral Derivative (PID) is then applied to obtain motor speed commands. The DNN controller has a close performance to NMPC for three different desired trajectories; on the other hand, it has a much lower online computation compared to NMPC. As a result, the DNN controller was applied in real-time, which led to less power consumption for computations and more flight time, compared to NMPC implementation.
Data-driven NMPC has been applied to other dynamic systems and the same ideas can be implemented in MSD. Pan et al. [92] iteratively linearized the nonlinear system model and changed the optimization problem from nonconvex nonlinear to convex quadratic programming; they then used a recurrent neural network to approximate the solution to the new optimization. This controller was applied to a polymerization reaction problem. Cao et al. [93] presented the idea of “optimize and train” for NMPC approximation with deep feed-forward networks. In this approach, the process of generating the training data by offline NMPC and training the network is done simultaneously. As they discussed, the conventional “optimize then train” methods tend to lead to divergent (or inaccurate) networks when there exist multiple solutions for a given initial state. The data-driven controller is applied to a quadtank system for numerical case study.
5.2 Model-free reinforcement learning
Model-Free Reinforcement Learning (MFRL) has been recently studied for the control of multibody systems. As mentioned in Sect. 2.4.4, MFRL finds the optimal policy based on the interaction with the environment and does not require an internal model. Therefore, if the environment reflects the changing dynamics, then the DRL controller can generalize to multiple situations.
To review, RL formulates the problem as a Markov decision process (MDP), in which the transition dynamics to the next state depend only on the previous state. Mathematically speaking:
where is the transition probability function, which is a general formulation for stochastic systems. and are the states and actions in the corresponding time indexes, respectively. The same formulation can be applied to deterministic dynamics.
DRL has been recently suggested for feedback control systems [94], [95], and has been applied to robotic applications [96], [97], [98].
A stream of research has focused on using DRL for the purpose of controlling musculoskeletal systems. In particular, a team of researchers at Stanford University have integrated an openSim musculoskeletal environment with DRL-based controller platforms. The resulting platform has been used in NeuralIPS 2019 challenge: “Learn to Move-Walk Around” [99]. Multiple researchers have since studied DRL algorithms to control a full musculoskeletal system with 8 Degree of Freedom (DOF) and 22 muscles.
Combining RL with imitation learning, which we discuss in later sections, has enabled realistic human movements on a complex musculoskeletal system with 346 muscles [100]. This data-driven controller has led to predictive simulations of various human movements. In addition, multiple anatomical conditions, including bone deformity, muscle weakness, and contracture, were studied. This method has successfully simulated pathological gait patterns and human-prosthetic movement. In [101], DRL was coupled with curriculum learning [102] for simulating natural human gait. This approach splits the overall reward function into smaller portions and trains the agent sequentially; hence, it is highly applicable to human movement problems in which the human (is assumed) to optimize a different function at each stage of movement (standing up, walking, picking up objects for example). In this manner, curriculum learning is similar to the general multi-stage optimization method.
DRL has also been used in autonomous vehicle research. In [103], DRL was applied to an autonomous vehicle for adaptive cruise control. The results show comparable performance with MPC when there are no uncertainties and better performance in the presence of delays, disturbances, and unmodeled dynamics.
From the control-theoretic perspective, the focus is mostly on stability; however, the computer science community has concentrated on convergence properties [104]. This is one of main research gaps between the control-theoretic approach to reinforcement learning, often categorized as approximate dynamic programming, and the conventional RL used in the computer science community. Moreover, there is no explicit constraint handling in MFRL formulation. As a result, there are still safety concerns for MFRL, mainly on safety-critical applications. Recent studies have examined the possibility of combining MPC and MFRL to address this issue. For instance, the idea of safe learning-based MPC was presented in a recent review by Hewing et al. [105]. Based on this idea, the optimal control input is calculated based on MFRL and another optimization is solved in series. This optimization minimizes the deviation between the solution and the MFRL output; the problem constraints are included in this optimization to ensure safety.
MFRL is a powerful method as it can operate without a system transition model and can learn a policy from experiments. However, the main drawback is that a reward function should be defined; in some cases, this function is not straightforward to acquire, i.e., it is not clear what metric is being optimized to perform a certain task. Fortunately, two other research streams can offer a solution: imitation learning (Sect. 5.3) and inverse reinforcement learning (Sect. 5.4).
5.3 Imitation learning
Imitation Learning (IL) attempts to learn a policy from human demonstrations. In contrast to MFRL, which generates the training data using random (and partially-trained) policies as the experience, IL uses the data from a human expert performing a task so as to mimic that behavior [106]. Having access to optimal human demonstration bypasses the need to set a reward function.
Wu et al. [107] used imitation learning for robot impedance regulation. They stated that the problem of Cartesian impedance control can be formulated as an LQR with the stiffness coinciding with the LQR weighting matrix. Inspired by how humans dynamically regulate their arm impedance while interacting with the environment, IL was utilized with human demonstration data to learn to adaptively modify the stiffness parameter.
In [108], researchers utilized IL to increase the adaptive capacity of robots to unseen situations. Human demonstrations can be used to teach the robots various motor skills. Invariant motion patterns in the data are then extracted and reproduced in new unseen scenarios. This method was used for trajectory modulation in various unseen situations.
Similarly, Finn et al. [109] used IL to improve the generalizability of robots to unstructured complex environments. As it is impractical to train a DL for each specific task, they proposed training a meta-imitation learning scheme to teach the robots how to learn new skills more efficiently. They used a one-shot learning approach, which is learning a policy from a single demonstration. The authors used a CNN structure, which takes camera data and robot configuration as inputs and outputs the actions (robot torques) for reaching scenarios. Meta-learning has resulted in faster and more efficient learning of new skills by robots.
Kebria et al. [110] used imitation learning on an autonomous vehicle vision problem. Using the simulation data from three different camera views of a vehicle controlled by a human, a CNN structure was trained to map the raw image data to the final steering angle. Since the configuration of CNNs has a great impact on their performance, the researchers on this study compared 96 CNN configurations with different layers, number of filters, and filter sizes in terms of mean squared error to find the best configuration and explore the effect of each parameter. Finally, an ensemble of CNN models was used for steering angle prediction.
5.4 Inverse reinforcement learning
So far, the bulk of research has focused on obtaining accurate and fast controllers that can minimize or maximize the intuitively-defined metrics. Recent advances in optimization-based control and deep learning, however, have led to posing a new question: What is the underlying metric that an expert minimizes or maximizes to do a certain task? This research direction aspires to obtain more accurate cost/reward functions. Inverse Reinforcement Learning (IRL), which is the model-free version of inverse optimal control, has been utilized for this purpose [111]. This approach follows a reverse methodology of RL; the already running policy is considered as an optimal controller and the input-output tuples generated from this policy are used to find the reward/cost function that is optimized to find the policy.
Autonomous driving can take good advantage of IRL. To design reliable controllers for autonomous vehicles, it is imperative to mimic human behavior in driving by deriving the human reward function. Nevertheless, this function is complex, stochastic, and varies greatly between drivers [112], [113], [114]. To remedy this, IRL has been used based on gathered human expert data. You et al. [112] used a DNN to approximate the reward function that humans minimize in driving using an IRL setting. The optimal DNN parameters were obtained by gradient-based optimization and maximum entropy principle (MEP). Wu et al. [113] improved upon previous IRL algorithms for autonomous driving by introducing a continuous trajectory sampler, which uses prior knowledge on vehicle kinematics and motion planning algorithms. This addition enables the use of IRL in a continuous formulation, making it applicable to large-scale continuous problems. In addition, this study has used real traffic data; while previous research has assumed optimal (near-optimal) policies for real data, this study considers the uncertainty in the human demonstrations to account for the terms that interfere with ideal human driving.
Woodworth et al. [115] took advantage of IRL to find the preferences of different users to an assistive robot. While previous applications of robots in healthcare had focused on imposing a certain task, like finishing a certain exercise by the user, this research focused on finding a user-specific preference while performing each task. The underlying algorithm should be able to adapt to a multitude of tasks and subjects. This research used observational repeated inverse reinforcement learning to perform long-term, task-independent preference learning in scenarios with incomplete information (only partial knowledge about the task and the environment was available). The algorithm observed each subject’s data while doing multiple rehabilitation exercises to infer their motor learning scheme. This study enabled the subject-specific control of these devices and their compatibility to each subject.
IRL is applied to a very complex and highly redundant snake-like robot in [116]. An RL controller was first used to find energy-efficient and realistic gait at various velocities. An adversarial IRL was then trained based on the demonstrations from the RL controller using a GAN. By improving upon the initial reward function, the IRL controller is able to preserve the efficiency and natural gait resulting from the RL controller while adapting to changing dynamics due to damaged body parts. In this sense, the IRL controller outperforms both the RL and model-based controllers.
5.5 Other applications
So far, the papers in Sect. 5 have discussed data-driven methods to substitute a control policy. The summary of these approaches are provided in Table 2. There are, however, other sections that complete/augment the closed-loop system; controller tuners, state observers, and disturbance observers are among the important components of a closed-loop system. In this section, we discuss the ML research on these components.
5.5.1 Data-driven controller weights adjustment
In many cases, existing control approaches are sufficient for obtaining the desired performance in multibody dynamics systems. However, every control method has multiple parameters (gains) that require meticulous tuning. This process is usually done manually, which results in a time-intensive manual trial and error adjustment; moreover, the manual tuning does not achieve the optimal set of weights. Current tuning techniques are limited to simple controllers and cannot generalize to all approaches. Plus, they still suffer from repetitive trial and error iterations [117]. Recently, automatic tuning methods have been studied; general data-driven methods are exploited for this purpose. In [118], the bees algorithm was used to tune an LQR controller on an inverted pendulum control problem. Researchers in [119] took advantage of Gaussian optimization, namely simultaneous perturbation stochastic approximation, to tune the same controller for a robot arm balancing an inverted pole. Particle swarm optimization was also investigated to tune a PID controller [120]. The resulting controller was applied to a ball on plate trajectory tracking system. Recently, a genetic algorithm was integrated with an SMC for rehabilitation robot control [121].
While the above approaches work on a variety of problems, more complex approximators are usually required for large-scale problems. In addition, most of the above data-driven approaches utilize static optimization, which cannot be used for adaptive dynamic weight adjustment. DL, and more specifically DRL, methods have been used to remedy these issues. Several works have taken advantage of DRL for tuning a PID controller in single-agent [122], [123], [117], and multi-agent problems [124]. DRL has also been applied to more advanced controllers. Specifically, a learning automata RL algorithm has been integrated with a linear MPC for autonomous vehicle control and mobile robotics. The resulting controller has been tested in simulation [125] and experiments [126], [127]. An NMPC has also been automatically tuned using incremental DRL for unmanned aerial vehicle control [128]. Liu et al. [129] used an NN approach to dynamically approximate the switching gain of an SMC for an uncertain robot control. The neural network SMC adapts to unknown dynamics and disturbance and can resolve the chattering and high-input issue of SMC.
The cited papers have focused on low-level controller tuning. On the other hand, several studies have used DRL for tuning mid-level controllers. These controllers are extensively used in rehabilitation robotics and assistive devices as they directly adjust the compliance in human-robot interactions. In particular, online tuning of mid-level controllers are investigated in the form of impedance [98], [130], [131] and admittance [132] controllers. These intelligent controllers have enabled online personalization of assistive devices and exoskeletons to different subjects, resulting in less muscle effort from the subject and more comfort during use.
5.5.2 NN-based observers and estimators
Various issues may arise in real-time control of multibody dynamics systems. First, exact kinematic and dynamic parameters are usually not available; the uncertainty around the parameter values can degrade the performance of the controller. Moreover, the values of some of the parameters may vary during system operation. Second, external disturbances can affect the system stability (and performance). In the control community, robust control methods are utilized to mitigate this issue. The controller is usually augmented with a disturbance estimator, which usually requires some knowledge about the disturbance characteristics (e.g., its model). NN-based estimators rely solely on the sensor data to approximate the disturbance and are advantageous when no knowledge about the disturbance model can be obtained. Third, while most controllers work with system states (state-feedback controllers for example), measured outputs cannot obtain all the states in a variety of problems. As a solution, state observers are developed to approximate some (or all) of the states. We talked about state-based observers using DL-based AI models in Sect. 3.5 with the work of [57]. This work is applicable to problems where an approximate system model can be acquired. Researchers have also worked on complete data-driven observers, discussed below, that do not require a model.
Wu et al. [133] presented the idea of using neural-network-based observers in rehabilitation robotics. Radial Basis Function (RBF) network was used as a disturbance observer. The network was also utilized to account for robot modeling errors. Using this scheme, the authors were able to implement an adaptive admittance controller on the rehabilitation robot without concerns about closed-loop stability.
A recurrent neuro-adaptive state observer was proposed in [134]. This RNN-based scheme was applied to a flexible-joint manipulator and was trained by modified backpropagation; to ensure the stability of the observer, an e-modification term was added to the optimization; this term is derived from robust adaptive control theory for systems with bounded disturbances. The advantage of the RNN-based observer is the fact that it does not require a model; hence it is applicable to complex nonlinear systems for which an accurate representation of the system is not easy to acquire.
RBF networks were also utilized to estimate the unknown parameters of cooperative multiple manipulators [135]. They were also incorporated as the disturbance observers when the torques reach their upper-bounds. Almost all actuated systems are susceptible to input saturation. As a result, this research proposed a data-driven approach to resolve this problem.
5.5.3 Adaptive data-driven controllers
In most real-time control applications, both the dynamics of the plant and the environment change during system operation. We previously discussed how data-driven approaches can estimate the change in the dynamics. Alternatively, the changing conditions can be taken into consideration by using an adaptive controller, therefore improving the performance of the closed-loop system. Here, we discuss the research on data-driven adaptive controllers.
Luan et al. [136] applied an RBF network adaptive controller to a SCARA robot. This controller was combined with SMC to guarantee robustness against uncertainties and disturbance. The same idea was also applied to three-link industrial robot manipulators [137]. The resulting controller outperformed PID and fuzzy controllers both in terms of tracking accuracy and input expenditure. An adaptive NN tracking controller was designed in [138] for robotic manipulators with dead-zones. An RBF neural network was used to augment a back-stepping controller by approximating the intermediate control functions. Neural networks were also used in [139] for adaptive control of a 2-DOF helicopter with input dead-zone and output constraint. Adaptive control theory was used to update the NN weights and hence introduce adaptivity to the closed-loop system. The integral barrier Lyapunov function was utilized to ensure output constraint satisfaction. Another study focused on robotic manipulators with external disturbances and time-varying outputs [140]. A model-based backstepping controller was augmented to an adaptive NN-based controller.
6 Future directions and ideas
Although there has been a myriad of recent research in using deep learning in multibody dynamics and control, many opportunities exist for future studies. In this section, we examine two promising research paths that can be explored by the multibody dynamics community. These areas have been investigated in other fields; we believe they have the potential to advance the field of multibody system dynamics.
6.1 Physics-informed neural networks
Raissi et al. [142] have recently introduced physics-informed neural networks, in which laws of physics are considered in the training of a neural network as the surrogate model. They showed that the neural network-based approximation of any physical system that is described by a nonlinear partial differential equation (PDE) can exploit the physics of the system (as prior knowledge) in the training. To this end, they proposed a second neural network with the same weights as the primary network that approximates the system variable. The second neural network enforces the right-hand side of the PDE to be zero. In other words, the same weights that approximate the system variable enforce the PDE equation.
As any multibody system follows certain dynamic laws, we suggest using the system physics (model equations) as a regularization scheme; the additional constraint would avoid unrealistic networks and would enable the training with fewer samples. The idea of physics-informed models has already been tested in MSD, and it has shown potential opportunities for future research. Lutter et al. [143] introduced Deep Lagrangian Network (DeLaN), which imposed Lagrangian mechanics on the training. The augmentation led to more robust neural networks, capable of generalizing to new samples with fewer training cases; the resulting network was also physically plausible. DeLaN has been used to represent the inverse dynamics of a robot for a trajectory tracking problem; the lower-triangular matrix composing the inertia matrix is represented by a deep neural network as follows:
where is the robot joint angle and are the NN parameters. An optimization problem is then solved to find the best set of parameters while ensuring the positive-definiteness of the inertia matrix. The inertia matrix, resulting from the matrix , is utilized to generate the system equations. The optimization then aims to minimize the error between the multibody model and torque sample data.
DeLaN is one example of general physics-informed networks, and many other solutions exist. For example, Hamiltonian neural networks presented by Greydanus et al. [144] can learn an arbitrary conservation law based on Hamiltonian mechanics. While DeLaN requires existence of the mass matrix , Cranmer et al. [145] provided a neural network architecture for learning arbitrary Lagrangians. However, as pointed out by Krishnapriyan et al. [146], special learning techniques may be required for accurate training of physically-informed neural networks in many real-life scenarios.
6.2 More complex networks
Most research in data-driven multibody dynamics and control has used common network structures: ANNs, CNNS, RNNs, and autoencoders. With recent advances in network configurations, we believe that the MSD community can benefit from new structures. In this section, we present the application of new neural networks to multibody dynamic modeling and control.
6.2.1 Temporal convolutional neural networks
To combine the feature extraction and expression capabilities of CNNs with the temporal modeling capabilities of RNNs, temporal convolutional neural networks have recently been developed [147]. While solving the gradient vanishing/explosion problem (similar to LSTM networks), temporal CNNs also introduce more efficiency by adding more parallel computations; unlike the conventional dependency on previous timesteps for current timestep calculation (as in RNNs, LSTMs, gate recurrent units), temporal CNNs use the same filter for the whole sequence, hence enabling parallel computations. Temporal CNNs have been investigated for system identification in [148]. The resulting data-driven approach has been successfully used for the Silverbox dataset, which is the electronic version of the Duffing oscillator, and to identify an F-16 ground vibration test.
6.2.2 Transformers
With more focus on the attention mechanism, recently developed transformer networks have added considerable improvements to machine translation, computer vision, and other applications [149], [150]. While LSTM networks solve the problem of vanishing/exploding gradients to some extent, for some applications, like machine translation where longer output dependency to earlier elements in the sequence is observed, this issue is not completely resolved. To this end, the attention mechanism utilizes all the hidden states, instead of only the last one, and decides what elements of the hidden states are relevant to generating the output; roughly speaking, the attention mechanism learns where to focus when given a long sequence of data (hence the name). In addition to resolving the long-dependency issue, similar to TCNNs, the unique structure of transformers allows for parallelization of computations on sequential data. Due to their temporal component, transformers have the potential to improve the previous work on ML-based MSD modeling and control, especially in cases where the output from the current timestep has a high dependency on input/output from timesteps in the past.
6.2.3 Graph network-based simulators
Modeling challenges are expected as the number of components in a multibody system increases. Hence, solutions with more expressive capabilities should be used. For complex physical systems, like MSD systems with many DOF and components, finding an accurate model is difficult and simulating it is computationally expensive. Using NN-based surrogate models (Sect. 3) with conventional network structures may still lead to high computations during inference.
Hence, a network with an inherent structure to handle higher input components is preferred. Recently, an interesting class of networks called graph network-based simulator (GNS) has been developed for modeling complex physical systems with very high input size [151]. These networks are a special kind of graph neural networks. A unique feature of graph neural networks is that they can accept an unstructured graph as input, i.e., no constraint on the topology or size of the input is imposed. This enables structuring the physical system as a graph and feeding it to the network. In the GNS network, the physical states are represented as graphs of interacting particles structured as nodes and the message-passing between nodes is learned using data. GNS has been implemented on a range of complex physical systems, including fluid dynamics, rigid solids, and deformable materials. We believe GNS has potential for modeling complex multibody dynamics with higher states and components.
7 Conclusions
The use of ML in multibody system dynamics is growing rapidly. In this paper, we discussed the multiple streams of research on the integration of these two fields and the ways in which data-driven solutions can provide improvements to MSD research.
Neural networks may provide surrogate dynamic models with comparable accuracy to multibody models but with higher computational efficiency. Moreover, they can be utilized in hybrid models where part of the system is difficult to model analytically and is replaced with a data-driven blackbox alternative.
ML-based solutions can also improve the controllers applied to multibody systems. Efficient control-oriented models within a model-based controller can be obtained from data. In addition, the control policy itself can be approximated using data-driven approaches. Other aspects of control design can also be improved by ML. Neural networks can replace the conventional state/disturbance estimators. They can also be used for online controller parameter adjustment, facilitating the use of adaptive controllers.
Although ML methods have improved the accuracy/efficiency of multibody system models and controllers, there is a huge potential for further integration of these two fields. While new network structures and data-driven solutions can potentially improve the current state of this integration, physical models can also be used to improve the network learning. More research is needed to move towards the optimal combination of physics-based and data-driven solutions in MSD systems.
Availability of data and materials
Not applicable (review paper).
References
Kurinov, I., Orzechowski, G., Hamalainen, P., Mikkola, A.: Automated excavator based on reinforcement learning and multibody system dynamics. IEEE Access 8, 213998–214006 (2020)
Kalashnikov, D., Varley, J., Chebotar, Y., Swanson, B., Jonschkowski, R., Finn, C., Levine, S., Hausman, K.: MT-Opt: continuous multi-task robotic reinforcement learning at scale (2021). arXiv:2104.08212 [cs]
Cordeschi, R.: AI turns fifty: revisiting its origins. Appl. Artif. Intell. 21(4–5), 259–279 (2007)
Nwankpa, C., Ijomah, W., Gachagan, A., Marshall, S.: Activation functions: comparison of trends in practice and research for deep learning, pp. 1–20 (2018)
Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., Liu, T., Wang, X., Wang, G., Cai, J., Chen, T.: Recent advances in convolutional neural networks. Pattern Recognit. 77, 354–377 (2018)
LeCun, Y., Haffner, P., Bottou, L., Bengio, Y.: Object recognition with gradient-based learning. In: Shape, Contour and Grouping in Computer Vision, pp. 319–345. Springer, Berlin (1999)
Dhillon, A., Verma, G.K.: Convolutional neural network: a review of models, methodologies and applications to object detection. Prog. Artif. Intell. 9(2), 85–112 (2020)
Li, H.C., Deng, Z.Y., Chiang, H.H.: Lightweight and resource-constrained learning network for face recognition with performance optimization. Sensors (Switzerland) 20(21), 1–20 (2020)
Salman, H., Singhal, P., Shankar, T., Yin, P., Salman, A., Paivine, W., Sartoretti, G., Travers, M.: Learning to sequence robot behaviors for visual navigation (2018). arXiv:1907.02057
Laschowski, B., McNally, W., Wong, A., McPhee, J.: Preliminary design of an environment recognition system for controlling robotic lower-limb prostheses and exoskeletons. In: IEEE International Conference on Rehabilitation Robotics, vol. 2019–June, pp. 868–873 (2019)
McNally, W., Vats, K., Wong, A., McPhee, J.: EvoPose2D: pushing the boundaries of 2D human pose estimation using neuroevolution (2020)
Palaz, D., Magimai-Doss, M., Collobert, R.: End-to-end acoustic modeling using convolutional neural networks for HMM-based automatic speech recognition. Speech Commun. 108, 15–32 (2019)
Batur Dinler, Ö., Aydin, N.: An optimal feature parameter set based on gated recurrent unit recurrent neural networks for speech segment detection. Appl. Sci. (Switzerland) 10(4), 1273 (2020).
Yin, W., Kann, K., Yu, M., Schütze, H.: Comparative study of CNN and RNN for natural language processing (2017)
Chandar, S., Sunder, H.: Dynamic systems simulation and control using consecutive recurrent neural networks. Commun. Comput. Inf. Sci. 1290, 92–103 (2020)
Trischler, A.P., D’Eleuterio, G.M.: Synthesis of recurrent neural networks for dynamical system simulation. Neural Netw. 80, 67–78 (2016)
Hu, Y., Huber, A., Anumula, J., Liu, S.-C.: Overcoming the vanishing gradient problem in plain recurrent networks, Sect. 2, pp. 1–20 (2018)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Gao, C., Yan, J., Zhou, S., Varshney, P.K., Liu, H.: Long short-term memory-based deep recurrent neural networks for target tracking. Inf. Sci. 502, 279–296 (2019)
Hewamalage, H., Bergmeir, C., Bandara, K.: Recurrent neural networks for time series forecasting: current status and future directions. Int. J. Forecast. 37(1), 388–427 (2021)
Wright, S., Nocedal, J., et al.: Numerical optimization. Springer Sci. 35(67–68), 7 (1999)
Bottou, L.: Stochastic gradient descent tricks. In: Neural Networks: Tricks of the Trade, pp. 421–436. Springer, Berlin (2012)
Zhang, Z.: Improved Adam optimizer for deep neural networks. In: 2018 IEEE/ACM 26th International Symposium on Quality of Service, IWQoS 2018, pp. 1–2 (2019)
Such, F.P., Madhavan, V., Conti, E., Lehman, J., Stanley, K.O., Clune, J.: Deep neuroevolution: genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning (2017)
Snoek, J., Larochelle, H., Adams, R.P.: Practical bayesian optimization of machine learning algorithms, pp. 1–9
Wu, X., Kumar, V., Ross, Q.J., Ghosh, J., Yang, Q., Motoda, H., McLachlan, G.J., Ng, A., Liu, B., Yu, P.S., Zhou, Z.H., Steinbach, M., Hand, D.J., Steinberg, D.: Top 10 algorithms in data mining. Knowl. Inf. Syst. 14, 1–37 (2008)
Xu, X., Liang, T., Zhu, J., Zheng, D., Sun, T.: Review of classical dimensionality reduction and sample selection methods for large-scale data processing. Neurocomputing 328, 5–15 (2019)
Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Science 313(5786), 504–507 (2006)
Bellmann, R.: The theory of dynamic programming. Bull. Am. Math. Soc. 60, 503–515 (1954)
Lagoudakis, M.G., Parr, R.: Least-squares policy iteration. J. Mach. Learn. Res. 4(6), 1107–1149 (2004)
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T., Hassabis, D.: Mastering the game of Go with deep neural networks and tree search. Nature 529(7587), 484–489 (2016)
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A.A., Veness, J., Bellemare, M.G., Graves, A., Riedmiller, M., Fidjeland, A.K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., Hassabis, D.: Human-level control through deep reinforcement learning. Nature 518(7540), 529–533 (2015)
Hunt, J.J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., Wierstra, D.: Continuous learning control with deep reinforcement (2016)
Fujimoto, S., Van Hoof, H., Meger, D.: Addressing function approximation error in actor-critic methods. In: 35th International Conference on Machine Learning ICML 2018, vol. 4, pp. 2587–2601 (2018)
Goodfellow, I.J., Pouget-abadie, J., Mirza, M., Xu, B., Warde-farley, D.: Generative adversarial nets, pp. 1–9
Ren, H., Ben-Tzvi, P.: Learning inverse kinematics and dynamics of a robotic manipulator using generative adversarial networks. Robot. Auton. Syst. 124, 103386 (2020)
Ardeh, H.A., Tupy, M., Negrut, D.: On the construction and use of surrogate models for the dynamic analysis of multibody systems. In: Volume 13: New Developments in Simulation Methods and Software for Engineering Applications; Safety Engineering, Risk Analysis and Reliability Methods; Transportation Systems, ASMEDC, vol. 13, pp. 17–26 (2009)
Azzam, B., Schelenz, R., Roscher, B., Baseer, A., Jacobs, G.: Development of a wind turbine gearbox virtual load sensor using multibody simulation and artificial neural networks. Forsch. Ingenieurwes./Eng. Res. 85, 241–250 (2021)
García Peyrano, O., Vignolo, J., Mayer, R., Marticorena, M.: Online unbalance detection and diagnosis on large flexible rotors by SVR and ANN trained by dynamic multibody simulations. J. Dyn. Mon. Diag. 1(3) (2022). https://doi.org/10.37965/jdmd.2022.58
Han, S., Choi, H.S., Choi, J., Choi, J.H., Kim, J.G.: A DNN-based data-driven modeling employing coarse sample data for real-time flexible multibody dynamics simulations. Comput. Methods Appl. Mech. Eng. 373, 113480 (2021)
Kahr, M., Kovács, G., Loinig, M., Brückl, H.: Condition monitoring of ball bearings based on machine learning with synthetically generated data. Sensors 22(7), 2490 (2022)
Ma, J., Dong, S., Chen, G., Peng, P., Qian, L.: A data-driven normal contact force model based on artificial neural network for complex contacting surfaces. Mech. Syst. Signal Process. 156, 107612 (2021)
Sobie, C., Freitas, C., Nicolai, M.: Simulation-driven machine learning: bearing fault classification. Mech. Syst. Signal Process. 99, 403–419 (2018)
Ye, Y., Zhu, B., Huang, P., Peng, B.: Oornet: a deep learning model for on-board condition monitoring and fault diagnosis of out-of-round wheels of high-speed trains. Measurement 199, 111268 (2022)
Nasr, A., Inkol, K.A., Bell, S., McPhee, J.: InverseMuscleNET: alternative machine learning solution to static optimization and inverse muscle modeling. Front. Comput. Neurosci. 15 (2021). https://doi.org/10.3389/fncom.2021.759489
Polydoros, A.S., Nalpantidis, L., Kruger, V.: Real-time deep learning of robotic manipulator inverse dynamics. In: IEEE International Conference on Intelligent Robots and Systems, vol. 2015–Decem, no. October, pp. 3442–3448 (2015)
Rane, L., Ding, Z., McGregor, A.H., Bull, A.M.: Deep learning for musculoskeletal force prediction. Ann. Biomed. Eng. 47(3), 778–789 (2019)
Zhou, S., Schoellig, A.P.: Active training trajectory generation for inverse dynamics model learning with deep neural networks. In: Proceedings of the IEEE Conference on Decision and Control, vol. 2019–Decem, no. i, pp. 1784–1790 (2019)
Byravan, A., Fox, D.: SE3-nets: learning rigid body motion using deep neural networks. In: 2017 IEEE International Conference on Robotics and Automation, ICRA, pp. 173–180. IEEE, Singapore (2017)
Choi, H.S., An, J., Han, S., Kim, J.G., Jung, J.Y., Choi, J., Orzechowski, G., Mikkola, A., Choi, J.H.: Data-driven simulation for general-purpose multibody dynamics using Deep Neural Networks. Multibody Syst. Dyn. 51(4), 419–454 (2021)
Hegedüs, F., Gáspár, P., Bécsi, T.: Fast motion model of road vehicles with artificial neural networks. Electronics 10, 928 (2021)
Kraft, S., Causse, J., Martinez, A.: Black-box modelling of nonlinear railway vehicle dynamics for track geometry assessment using neural networks. Veh. Syst. Dyn. 57(9), 1241–1270 (2019)
Martin, T.P., Zaazaa, K.E., Whitten, B., Tajaddini, A.: Using a multibody dynamic simulation code with neural network technology to predict railroad vehicle-track interaction performance in real time. In: Volume 5: 6th International Conference on Multibody Systems, Nonlinear Dynamics, and Control, Parts A, B, and C, ASMEDC, vol. 5 PART C, pp. 1881–1891 (2007)
Nasr, A., Bell, S., He, J., Whittaker, R.L., Jiang, N., Dickerson, C.R., McPhee, J.: Musclenet: mapping electromyography to kinematic and dynamic biomechanical variables by machine learning. J. Neural Eng. 18(4), 0460d3 (2021)
Pan, Y., Nie, X., Li, Z., Gu, S.: Data-driven vehicle modeling of longitudinal dynamics based on a multibody model and deep neural networks. Measurement 180, 109541 (2021)
Urda, P., Aceituno, J.F., Muñoz, S., Escalona, J.L.: Artificial neural networks applied to the measurement of lateral wheel-rail contact force: a comparison with a harmonic cancellation method. Mech. Mach. Theory 153, 103968 (2020)
Angeli, A., Desmet, W., Naets, F.: Deep learning for model order reduction of multibody systems to minimal coordinates. Comput. Methods Appl. Mech. Eng. 373, 113517 (2021)
Hosking, B.A., McPhee, J.: Powertrain modeling and model predictive longitudinal dynamics control for hybrid electric vehicles. In: SAE Technical Papers, vol. 2018–April, pp. 1–10 (2018)
Oishi, A., Yagawa, G.: Computational mechanics enhanced by deep learning. Comput. Methods Appl. Mech. Eng. 327, 327–351 (2017)
Ye, Y., Huang, P., Sun, Y., Shi, D.: MBSNet: a deep learning model for multibody dynamics simulation and its application to a vehicle-track system. Mech. Syst. Signal Process. 157, 107716 (2021)
Saxby, D.J., Killen, B.A., Pizzolato, C., Carty, C.P., Diamond, L.E., Modenese, L., Fernandez, J., Davico, G., Barzan, M., Lenton, G., da Luz, S.B., Suwarganda, E., Devaprakash, D., Korhonen, R.K., Alderson, J.A., Besier, T.F., Barrett, R.S., Lloyd, D.G.: Machine learning methods to support personalized neuromusculoskeletal modelling. Biomech. Model. Mechanobiol. 19(4), 1169–1185 (2020)
Brunton, S.L., Kutz, J.N., Manohar, K., Aravkin, A.Y., Morgansen, K., Klemisch, J., Goebel, N., Buttrick, J., Poskin, J., Blom-Schieber, A.W., Hogan, T., McDonald, D.: Data-driven aerospace engineering: reframing the industry with machine learning. AIAA J. 59(8), 1–26 (2021)
Hashemi, A., Lin, Y., McNally, W., Laschowski, B., Hosking, B., Wong, A., McPhee, J.: Integration of machine learning with dynamics and control: from autonomous cars to biomechatronics. Canadian Society for Mechanical Engineering (CSME) Bulletin, 9–10 (2019)
Nasr, A., Hashemi, A., McPhee, J.: Model-based mid-level regulation for assist-as-needed hierarchical control of wearable robots: a computational study of human-robot adaptation. Robotics 11(1), 20 (2022)
Spielberg, N.A., Brown, M., Kapania, N.R., Kegelman, J.C., Gerdes, J.C.: Neural network vehicle models for high-performance automated driving. Sci. Robot. 4(28) (2019). https://doi.org/10.1126/scirobotics.aaw1975
Bertsekas, D.: Reinforcement Learning and Optimal Control. Athena Scientific, United States (2019)
Richards, A.G.: Robust constrained model predictive control. PhD thesis, Massachusetts Institute of Technology (2005)
De Boer, P.-T., Kroese, D.P., Mannor, S., Rubinstein, R.Y.: A tutorial on the cross-entropy method. Ann. Oper. Res. 134(1), 19–67 (2005)
Kelly, M.: An introduction to trajectory optimization: how to do your own direct collocation. SIAM Rev. 59(4), 849–904 (2017)
Pal, C.-V., Leon, F.: Brief survey of model-based reinforcement learning techniques. In: 2020 24th International Conference on System Theory, Control and Computing, ICSTCC, pp. 92–97. IEEE, Romania (2020)
Wang, T., Bao, X., Clavera, I., Hoang, J., Wen, Y., Langlois, E., Zhang, S., Zhang, G., Abbeel, P., Ba, J.: Benchmarking model-based reinforcement learning (2019). arXiv preprint. arXiv:1907.02057
Kwakernaak, H., Sivan, R., Tyreus, B.N.D.: Linear Optimal Control Systems (1974)
Tassa, Y., Erez, T., Todorov, E.: Synthesis and stabilization of complex behaviors through online trajectory optimization. In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 4906–4913. IEEE, Portugal (2012)
Lee, J.H.: Model predictive control: review of the three decades of development. Int. J. Control. Autom. Syst. 9(3), 415–424 (2011)
Schwenzer, M., Ay, M., Bergs, T., Abel, D.: Review on model predictive control: an engineering perspective. Int. J. Adv. Manuf. Technol. 117(5), 1327–1349 (2021)
Roveda, L., Maskani, J., Franceschi, P., Abdi, A., Braghin, F., Molinari Tosatti, L., Pedrocchi, N.: Model-based reinforcement learning variable impedance control for human-robot collaboration. J. Intell. Robot. Syst. 100(2), 417–433 (2020)
Nagabandi, A., Kahn, G., Fearing, R.S., Levine, S.: Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. In: Proceedings - IEEE International Conference on Robotics and Automation, pp. 7579–7586 (2018)
Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., Zaremba, W.: OpenAI Gym, pp. 1–4 (2016)
Williams, G., Wagener, N., Goldfain, B., Drews, P., Rehg, J.M., Boots, B., Theodorou, E.A.: Information theoretic MPC for model-based reinforcement learning. In: Proceedings - IEEE International Conference on Robotics and Automation, pp. 1714–1721 (2017)
Richards, S., Azizan, N., Slotine, J.-J., Pavone, M.: Adaptive-control-oriented meta-learning for nonlinear systems (2021)
Punjani, A., Abbeel, P.: Deep learning helicopter dynamics models. In: 2015 IEEE International Conference on Robotics and Automation, ICRA, pp. 3223–3230 (2015)
Bansal, S., Jiang, F.J., Tomlin, C.J., Oct, S.Y.: Learning quadrotor dynamics using neural network for flight control, no. 0931843
Rutherford, S.J., Cole, D.J.: Modelling nonlinear vehicle dynamics with neural networks. Int. J. Veh. Des. 53(4), 260–287 (2010)
Angeli, A., Desmet, W., Naets, F.: Deep learning of multibody minimal coordinates for state and input estimation with Kalman filtering. Multibody Syst. Dyn. 53(2), 205–223 (2021)
Alessandri, A., Baglietto, M., Battistelli, G., Zavala, V.: Advances in moving horizon estimation for nonlinear systems, pp. 5681–5688 (2010)
Jin, C., Maitland, A., McPhee, J.: Hierarchical Nonlinear Moving Horizon Estimation of Vehicle Lateral Speed and Road Friction Coefficient. Letters Dyn. Sys. Control. 1(1), 011005 (2021)
Sun, D., Liao, Q., Stoyanov, T., Kiselev, A., Loutfi, A.: Bilateral telerobotic system using Type-2 fuzzy neural network based moving horizon estimation force observer for enhancement of environmental force compliance and human perception. Automatica 106, 358–373 (2019)
Alessio, A., Bemporad, A.: A survey on explicit model predictive control. Lect. Notes Control Inf. Sci. 384, 345–369 (2009)
Winqvist, R., Venkitaraman, A., Wahlberg, B.: On training and evaluation of neural network approaches for model predictive control (2020)
Diamond, S., Boyd, S.: Cvxpy: a python-embedded modeling language for convex optimization. J. Mach. Learn. Res. 17(1), 2909–2913 (2016)
Varshney, P., Nagar, G., Saha, I.: DeepControl: energy-efficient control of a quadrotor using a deep neural network. In: IEEE International Conference on Intelligent Robots and Systems, pp. 43–50 (2019)
Pan, Y., Wang, J.: Nonlinear model predictive control using a recurrent neural network. In: Proceedings of the International Joint Conference on Neural Networks, no. July, pp. 2296–2301 (2008)
Cao, Y., Gopaluni, R.B.: Deep neural network approximation of nonlinear model predictive control. IFAC-PapersOnLine 53(2), 11319–11324 (2020)
Roberts, J.W., Manchester, I.R., Tedrake, R.: Feedback controller parameterizations for reinforcement learning. In: IEEE SSCI 2011: Symposium Series on Computational Intelligence - ADPRL 2011: 2011 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, pp. 310–317 (2011)
Lewis, F.L., Vrabie, D.: Adaptive dynamic programming for feedback control. In: Proceedings of 2009 7th Asian Control Conference ASCC 2009, pp. 1402–1409 (2009)
Kober, J., Bagnell, J.A., Peters, J.: Kober_IJRR_2013, pp. 1–73 (2013)
Sun, C., Orbik, J., Devin, C., Yang, B., Gupta, A., Berseth, G., Levine, S.: Fully autonomous real-world reinforcement learning for mobile manipulation, pp. 1–16 (2021)
Li, M., Wen, Y., Gao, X., Si, J., Huang, H.: Toward expedited impedance tuning of a robotic prosthesis for personalized gait assistance by reinforcement learning control. IEEE Trans. Robot. 38(1), 407–420 (2021)
Song, S., Kidziński, Ł., Peng, X.B., Ong, C., Hicks, J., Levine, S., Atkeson, C.G., Delp, S.L.: Deep reinforcement learning for modeling human locomotion control in neuromechanical simulation. J. NeuroEng. Rehabil. 18(1), 1–17 (2021)
Lee, S., Park, M., Lee, K., Lee, J.: Scalable muscle-actuated human simulation and control. ACM Trans. Graph. 38(4), 73 (2019)
Weng, J., Hashemi, E., Arami, A.: Natural walking with musculoskeletal models using deep reinforcement learning. IEEE Robot. Autom. Lett. 6(2), 4156–4162 (2021)
Bengio, Y., Louradour, J., Collobert, R., Weston, J.: Curriculum learning. In: Proceedings of the 26th Annual International Conference on Machine Learning, pp. 41–48 (2009)
Lin, Y., McPhee, J., Azad, N.L.: Comparison of deep reinforcement learning and model predictive control for adaptive cruise control. IEEE Trans. Intell. Veh. 6(2), 221–231 (2021)
Buşoniu, L., de Bruin, T., Tolić, D., Kober, J., Palunko, I.: Reinforcement learning for control: performance, stability, and deep approximators. Annu. Rev. Control 46, 8–28 (2018)
Hewing, L., Wabersich, K.P., Menner, M., Zeilinger, M.N.: Learning-based model predictive control: toward safe learning in control. Annu. Rev. Control Robot. Auton. Syst. 3(1), 269–296 (2020)
Hussein, A., Gaber, M.M., Elyan, E., Jayne, C.: Imitation learning: a survey of learning methods. ACM Comput. Surv. 50(2), 1–35 (2017)
Wu, Y., Zhao, F., Tao, T., Ajoudani, A.: A framework for autonomous impedance regulation of robots based on imitation learning and optimal control. IEEE Robot. Autom. Lett. 6(1), 127–134 (2020)
Huang, Y., Rozo, L., Silverio, J., Caldwell, D.G.: Non-parametric imitation learning of robot motor skills. In: Proceedings - IEEE International Conference on Robotics and Automation, vol. 2019–May, pp. 5266–5272 (2019)
Finn, C., Yu, T., Zhang, T., Abbeel, P., Levine, S.: One-shot visual imitation learning via meta-learning. In: CoRL, pp. 1–12 (2017)
Kebria, P.M., Khosravi, A., Salaken, S.M., Nahavandi, S.: Deep imitation learning for autonomous vehicles based on convolutional neural networks. IEEE/CAA J. Autom. Sin. 7(1), 82–95 (2020)
Azar, N.A., Shahmansoorian, A., Davoudi, M.: From inverse optimal control to inverse reinforcement learning: a historical review. Annu. Rev. Control 50, 119–138 (2020)
You, C., Lu, J., Filev, D., Tsiotras, P.: Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning. Robot. Auton. Syst. 114, 1–18 (2019)
Wu, Z., Sun, L., Zhan, W., Yang, C., Tomizuka, M.: Efficient sampling-based maximum entropy inverse reinforcement learning with application to autonomous driving. IEEE Robot. Autom. Lett. 5(4), 5355–5362 (2020)
Sharifzadeh, S., Chiotellis, I., Triebel, R., Cremers, D.: Learning to drive using inverse reinforcement learning and deep Q-networks. In: Nips, pp. 1–7 (2016)
Woodworth, B., Ferrari, F., Zosa, T.E., Riek, L.D.: Preference learning in assistive robotics: observational repeated inverse reinforcement learning. Proc. Mach. Learn. Res. 85, 1–19 (2018)
Bing, Z., Lemke, C., Cheng, L., Huang, K., Knoll, A.: Energy-efficient and damage-recovery slithering gait design for a snake-like robot based on reinforcement learning and inverse reinforcement learning. Neural Netw. 129, 323–333 (2020)
Okafor, E., Udekwe, D., Ibrahim, Y., Mu’azu, M.B., Okafor, E.G.: Heuristic and deep reinforcement learning-based PID control of trajectory tracking in a ball-and-plate system. J. Inf. Telecommun. 5(2), 179–196 (2021)
Bilgic, H.H., Sen, M.A., Kalyoncu, M.: Tuning of LQR controller for an experimental inverted pendulum system based on the bees algorithm. J. Vibroeng. 18(6), 3684–3694 (2016)
Marco, A., Hennig, P., Bohg, J., Schaal, S., Trimpe, S.: Automatic LQR tuning based on Gaussian process global optimization. In: Proceedings - IEEE International Conference on Robotics and Automation, vol. 2016–June, pp. 270–277 (2016)
Hussein, S.U., Muhammed, B.M., Sikiru, T.H., Umoh, I.J., Salawudeen, A.T.: Trajectory tracking control of ball on plate system using weighted artificial fish swarm algorithm based PID. In: 2017 IEEE 3rd International Conference on Electro-Technology for National Development, NIGERCON 2017, vol. 2018–Janua, no. June 2018, pp. 554–561 (2018)
Hashemi, A., McPhee, J.: Assistive sliding mode control of a rehabilitation robot with automatic weight adjustment. In: 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society, EMBC, pp. 4891–4896 (2021)
Shipman, W.J., Coetzee, L.C.: Reinforcement learning and deep neural networks for PI controller tuning. IFAC-PapersOnLine 52(14), 111–116 (2019)
Carlucho, I., De Paula, M., Acosta, G.G.: An adaptive deep reinforcement learning approach for MIMO PID control of mobile robots. ISA Trans. 102, 280–294 (2020)
El Hakim, A., Hindersah, H., Rijanto, E.: Application of reinforcement learning on self-tuning PID controller for soccer robot multi-agent system. In: Proceedings of the 2013 Joint International Conference on Rural Information and Communication Technology and Electric-Vehicle Technology, rICT and ICEV-T 2013 (2013)
Ure, N.K., Yavas, M.U., Alizadeh, A., Kurtulus, C.: Enhancing situational awareness and performance of adaptive cruise control through model predictive control and deep reinforcement learning. In: IEEE Intelligent Vehicles Symposium, Proceedings, vol. 2019–June, no. IV, pp. 626–631 (2019)
Jardine, P.T., Givigi, S.N., Yousefi, S.: Experimental results for autonomous model-predictive trajectory planning tuned with machine learning. In: 11th Annual IEEE International Systems Conference, SysCon 2017 - Proceedings (2017)
Jardine, P.T., Kogan, M., Givigi, S.N., Yousefi, S.: Adaptive predictive control of a differential drive robot tuned with reinforcement learning. Int. J. Adapt. Control Signal Process. 33(2), 410–423 (2019)
Mehndiratta, M., Camci, E., Kayacan, E.: Automated tuning of nonlinear model predictive controller by reinforcement learning. In: IEEE International Conference on Intelligent Robots and Systems, no. October, pp. 3016–3021 (2018)
Liu, C., Wen, G., Zhao, Z., Sedaghati, R.: Neural-network-based sliding-mode control of an uncertain robot using dynamic model approximated switching gain. IEEE Trans. Cybern. 51(5), 2339–2346 (2021)
Wen, Y., Si, J., Brandt, A., Gao, X., Huang, H.H.: Online reinforcement learning control for the personalization of a robotic knee prosthesis. IEEE Trans. Cybern. 50(6), 2346–2356 (2020)
Wu, W., Saul, K.R., Huang, H.: Using reinforcement learning to estimate human joint moments from electromyography or joint kinematics: an alternative solution to musculoskeletal-based biomechanics. J. Biomech. Eng. 143(4), 1–9 (2021)
Tu, X., Li, M., Liu, M., Si, J., Huang, H.: A data-driven reinforcement learning solution framework for optimal and adaptive personalization of a hip exoskeleton (2020)
Wu, Q., Chen, B., Wu, H.: Adaptive admittance control of an upper extremity rehabilitation robot with neural-network-based disturbance observer. IEEE Access 7, 123807–123819 (2019)
Abdollahi, F., Talebi, H.A., Patel, R.V.: A stable neural network observer with application to flexible-joint manipulators. In: ICONIP 2002 - Proceedings of the 9th International Conference on Neural Information Processing: Computational Intelligence for the E-Age, vol. 4, no. 1, pp. 1910–1914 (2002)
He, W., Sun, Y., Yan, Z., Yang, C., Li, Z., Kaynak, O.: Disturbance observer-based neural network control of cooperative multiple manipulators with input saturation. IEEE Trans. Neural Netw. Learn. Syst. 31(5), 1735–1746 (2020)
Luan, F., Na, J., Huang, Y., Gao, G.: Adaptive neural network control for robotic manipulators with guaranteed finite-time convergence. Neurocomputing 337, 153–164 (2019)
Yen, V.T., Nan, W.Y., Van Cuong, P.: Robust adaptive sliding mode neural networks control for industrial robot manipulators. Int. J. Control. Autom. Syst. 17(3), 783–792 (2019)
Zhou, Q., Zhao, S., Li, H., Lu, R., Wu, C.: Robotic manipulators with dead zone. IEEE Trans. Neural Netw. Learn. Syst. PP(12), 1–10 (2018)
Ouyang, Y., Dong, L., Xue, L., Sun, C.: Adaptive control based on neural networks for an uncertain 2-DOF helicopter system with input deadzone and output constraints. IEEE/CAA J. Autom. Sin. 6(3), 807–815 (2019)
Wu, Y., Huang, R., Li, X., Liu, S.: Adaptive neural network control of uncertain robotic manipulators with external disturbance and time-varying output constraints. Neurocomputing 323, 108–116 (2019)
Pan, Y., Cheng, C.-A., Saigol, K., Lee, K., Yan, X., Theodorou, E., Boots, B.: Agile autonomous driving using end-to-end deep imitation learning (2018)
Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019)
Lutter, M., Ritter, C., Peters, J.: Deep Lagrangian networks: using physics as model prior for deep learning. In: 7th International Conference on Learning Representations, ICLR 2019, pp. 1–17 (2019)
Greydanus, S., Dzamba, M., Yosinski, J.: Hamiltonian neural networks. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 32. Curran Associates, Red Hook (2019)
Cranmer, M., Greydanus, S., Hoyer, S., Battaglia, P., Spergel, D., Ho, S.: Lagrangian neural networks (2020). arXiv:2003.04630 [physics, stat]
Krishnapriyan, A., Gholami, A., Zhe, S., Kirby, R., Mahoney, M.W.: Characterizing possible failure modes in physics-informed neural networks. In: Advances in Neural Information Processing Systems, vol. 34, pp. 26548–26560. Curran Associates, Red Hook (2021)
Lea, C., Flynn, M.D., Vidal, R., Reiter, A., Hager, G.D.: Temporal convolutional networks for action segmentation and detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 156–165 (2017)
Andersson, C., Ribeiro, A.H., Tiels, K., Wahlstrom, N., Schon, T.B.: Deep convolutional networks in system identification. In: Proceedings of the IEEE Conference on Decision and Control, vol. 2019–Decem, pp. 3670–3676 (2019)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Lin, T., Wang, Y., Liu, X., Qiu, X.: A survey of transformers (2021). arXiv preprint. arXiv:2106.04554
Sanchez-Gonzalez, A., Godwin, J., Pfaff, T., Ying, R., Leskovec, J., Battaglia, P.: Learning to simulate complex physics with graph networks. In: International Conference on Machine Learning, PMLR, pp. 8459–8468 (2020)
Funding
The first and last authors gratefully acknowledge funding provided by the Canada Research Chairs program and the Natural Sciences and Engineering Research Council of Canada. The second and third authors gratefully acknowledge funding provided by Business Finland’s “Kumppanuusmalli – SANTTU – LUT” project under grant 8859/31/2021.
Author information
Authors and Affiliations
Contributions
Arash Hashemi: conceptualization, visualization, writing (Sects. 2, 4, 5, 6, 7), review and editing. Grzegorz Orzechowski: conceptualization, visualization, writing (Abstract, Sects. 1, 3), review and editing. Aki Mikkola: conceptualization, funding acquisition, supervision, writing (Abstract, Sects. 1, 3), review and editing. John McPhee: conceptualization, funding acquisition, supervision, writing (Sects. 2, 4, 5, 6, 7), review and editing.
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Hashemi, A., Orzechowski, G., Mikkola, A. et al. Multibody dynamics and control using machine learning. Multibody Syst Dyn 58, 397–431 (2023). https://doi.org/10.1007/s11044-023-09884-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11044-023-09884-x