
Abstract
Convolutional neural networks (CNN) have been widely used in image scene classification and have achieved remarkable progress. However, because the extracted deep features can neither focus on the local semantics of the image, nor capture the spatial morphological variation of the image, it is not appropriate to directly use CNN to generate the distinguishable feature representations. To relieve this limitation, a global-local feature adaptive fusion (GLFAF) network is proposed. The GLFAF framework extracts multi-scale and multi-level features by using a designed CNN. Then, to leverage the complementary advantages of the multi-scale and multi-level features, we design a global feature aggregate module to discover global attention features and further learn the multiple deep dependencies of spatial scale variations among these global features. Meanwhile, a local feature aggregate module is designed to aggregate the multi-scale and multi-level features. Specially, multi-level features at the same scale are fused based on channel attention, and then spatial fused features at different scales are aggregated based on channel dependence. Moreover, spatial contextual attention is designed to refine spatial features across scales and different fisher vector layers are designed to learn semantic aggregation among spatial features. Subsequently, two different feature adaptive fusion modules are introduced to explore the complementary associations of global and local aggregate features, which can obtain comprehensive and differentiated image scene presentation. Finally, a large number of experiments on real scene datasets coming from three different fields show that the proposed GLFAF approach can more accurately realize scene classification than other state-of-the-art models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Scene classification has been extensively studied in the field of computer vision due to the increasing demand of scene-centric technologies. Scene classification can help people understand the content of images, which has brought great convenience to people’s lives in many applications such as smart cities, autonomous driving, video surveillance, and remote sensing detection. However, there are complex intra-class differences and inter-class similarities of objects in actual scenes, which increases the difficulty of information integration and logical reasoning in each scene. Therefore, how to extract semantic cues for image feature representation is still a challenging research topic in the field of scene classification.
To classify a scene image, the image is first characterized by a feature encoder and then can be classified by a classifier [11, 43, 65]. Generally, there are inconsistencies and differences between the information extracted from visual data and people’s comprehension of the same data in a given situation, which leads to the semantic gap between feature representation and high-level understanding [48]. A lot of work has been conducted to improve the representation ability of images. Among them, constructing scene feature representations with stronger descriptive capabilities is the most critical step to bridge the semantic gap between high-level scene understanding and low-level visual attributes [67]. Early, the traditional methods mainly focus on the research of hand-crafted visual features. The descriptors such as scale invariant feature transform (SIFT) [29], speed up robust features (SURF) [3], oriented brief (ORB) [37] are mainly used to extract visual feature points from the image, and then these features are input into the classifier for classification. Subsequently, researchers have further abstracted local visual features using bag of visual words(BOVW) [69], vector of locally aggregated descriptors (VLAD) [23], or latent dirichlet allocation (LDA) [8] for image classification. However, the abovementioned features are easy to understand and implement, but are highly dependent on the prior knowledge of the designer. Therefore, these features have low semantic level and limited representation ability, making it difficult to effectively describe the high-level semantic information of complex images.
Recently, there are many deep feature-based methods trying to apply excellent CNNs to build an effective feature representation for image scene classification [17, 44, 50]. Since the CNN is a notably hierarchical network structure, there are two types of features in the CNN: convolutional features and fully connected(FC) features. Among them, convolutional features that contain different spatial structure information of image, while FC features that contain abstract semantic information. In general, it’s believed that the shallow features of CNN are closer to the texture information of the image, while the middle-level and high-level features are more inclined to the semantic information of the image [6], that is, higher-level features are more discriminative in semantics. Moreover, recent works demonstrate that aggregating the intermediate features (convolutional features and FC features) [30, 42, 51] and integrating diverse features [21, 41, 71] can significantly improve the classification performance of scene image. However, these related studies usually aggregate different features directly and do not explore their multiple inter-dependencies among different features. Although different feature fusions can improve the discriminative ability of feature representations, most of which focus on global information exploration while ignoring some key local knowledge.
The local information representation is of great importance to image scene classification. Some attention mechanisms [5,6,7, 26, 31, 57] have been introduced into CNN architecture to consider the relative importance of different channels and spatial regions in the feature maps for improving the performance of scene classification. Different from CNNs that only explores the relationships between neighboring pixels, transformer models can directly capture the long-range correlation of the local information by the use of a self-attention mechanism [15, 28], which provides a new approach for image scene classification. In addition, multi-modal/view data objects have attracted substantial research attention because of their heterogeneous and complementary feature spaces [53, 55, 75]. Some researchers represent images as multi-view data in different feature spaces and exploit the complementary information in multi-view data for computer vision [16, 31,32,33, 62, 63, 66, 68, 70]. For example, Wu et al. [62, 63] and Feng et al. [16] explored associations in multi-source data for image recognition. Xiong et al. [66], Ma et al. [32] and Xu et al. [68] proposed multi-modal network structures including global and local networks from different perspectives to extract visual features for image scene classification. While Lv et al. [31], Ni et al. [33] and Zeng et al. [70] extracted multi-modal features from a global and local perspective based on the high-level feature map from a same backbone network, and then further aggregated multi-modal features for image scene classification. However, these mentioned methods do not focus on the diversity association of multi-view features in different network layers and different spatial scales.
Based on the above discussions and aforementioned limitations, an end-to-end global-local feature adaptive fusion (GLFAF) network is proposed for image scene classification. Specially, we learn the global dependence of multi-scale and multi-level features from the CNN structure to discover globally shared texture information and semantic information. Meanwhile, a cross-scale progressive aggregation strategy is designed to enhance local semantics and generate the local aggregate features. Subsequently, the global and local features are merged to learn the multi-modal collaborative feature of the image. However, it is worth considering how to explore the fusion advantages between global aggregate features and local aggregate features. In general, it is not appropriate to merge these two features directly. Therefore, the adaptive feature fusion strategy is designed to learn the relationship between the multi-modal features and thus fuse their features rationally. All in all, the global and local aggregate features are extracted from multi-scale and multi-level spatial features generated by the same CNN. Meanwhile, the global and local aggregate features are assigned with optimal weights to get the fused features in an adaptive manner. Specially, the fusion strategy is to assign adaptive weights to confidence scores from the global aggregate features and the local aggregate features, respectively. The optimal weights of the features are trained by the overall model and is optimized in an end to end fashion.
In general, the major contributions of our paper are as follows:
-
1.
An end-to-end global-local multi-modal feature adaptive fusion network is proposed for image scene classification. It can simultaneously simulate the scale and rotation changes of images from both global and local perspectives, and can enhance the global and local semantic representation of images. Consequently, the advantages of adaptive fusion of global aggregate features and local aggregate features can be fully utilized.
-
2.
A global feature aggregate module with multiple spatial dependence is proposed to leverage the complementary advantages of the multiple different spatial feature maps from a global perspective. It first learns spatial global attention features from multi-scale and multi-level spatial feature maps. Then, bidirectional recurrent dependencies and long-range contextual dependencies of these global attention features are learned sequentially to discover their deep correlations.
-
3.
A local feature aggregate module with cross-scale local semantic enhancement is proposed to leverage the complementary advantages of the multiple different spatial feature maps from a local perspective. It first learns channel attention dependencies between multi-level features in the same scale space. The spatial features of different scales are then aggregated across layers to generate rich local features. Next, spatial contextual attention is designed to refine spatial region features and different fisher vector layers are introduced to learn compact associations of spatial local features.
-
4.
Two different adaptive feature fusion strategies are investigated to take full advantage of respective features. Different from the commonly used feature fusion methods, the feature adaptive fusion strategy is designed to learn the relationship between the global aggregate features and the local aggregate features with the optimal combination.
2 Related works
Our proposed image scene classification network is highly related to the following aspects.
2.1 Image scene classification methods
Early studies on the traditional features were generally low-level features developed based on the prior knowledge about images, such as lights, colors, textures, and shapes. These low-level features include not only global feature descriptors such as generalized search trees (GIST) [34] and census transform histogram (CENTRIST) [61], but also local feature descriptors such as SIFT [29], histogram of oriented gradient (HOG) [12], local binary pattern (LBP) [39] and SURF [3]. These methods are easy to implement, but their main disadvantage is that a single feature is not enough to represent high-level semantic information, resulting in low classification accuracy. These features are usually combined to integrate multiple kinds of information to yield improved performance [14]. However, these methods based on hand-crafted features are not suitable for classifying scenes with complex backgrounds due to their limited representational ability. Then, the mid-level methods that rely on unsupervised feature learning are developed to bridge the semantic gap between low-level features and semantic information. Specially, these raw pixel values or low-level local features(e.g., SIFT [29]) are used to construct a middle-level representation through BoVW [69], probabilistic latent semantic analysis (PLSA) [18], and sparse coding [40], etc. Compared to methods with hand-crafted features, mid-level based methods can obtain image representations that are more suitable for scene classification [78]. Since unsupervised mid-level methods do not use label information, the feature extraction ability is limited, which is not conducive to further improving the classification performance.
With the development of CNN, it has achieved impressive performance in image scene classification. Due to their powerful feature extraction capabilities and end-to-end learning mechanism, the performance of these methods is much better than methods based on low-level features or middle-level features. Some researchers have focused on designing the structure of the neural network for image scene classification. They designed different methods to change the network layers to add various information. For example, Cheng et al. [10] introduced a new rotation invariant layer on the basis of the existing CNN architecture for improving the performance of scene classification. Li et al. [26]proposed a multi-vector VLAD method based on CNN features for scene classification. Lu et al. [30]aggregated spatial feature maps of different scales by fusing the multi-layer features in the neural network to improve the image scene classification. Shi et al. [42] proposed a lightweight CNN architecture based on branch feature fusion (LCNN-BFF) for scene classification, which uses a lightweight branch fusion strategy to improve the computational efficiency. In order to better retain spatial information, Zhang et al. [73] replaced the original FC layer architecture in CNN with the capsule network architecture. Wang et al. [58] first utilized enhanced feature pyramid network to extracts multi-scale and multi-level features, and then designed a deep semantic embedding module to learn the complementary advantages of these features. Besides, a two-branch deep feature fusion module is introduced to aggregate the features at different levels for image scene classification.
In addition, some researchers have focused on integrating different features for image scene classification. They focused on fusing different neural networks or different features. In general, fusing different information together can add scale and rotation invariant information. For example, Zhang et al. [71] proposed a gradient boosting random convolutional network framework for scene classification, which can effectively combine multiple deep neural networks. Combining these basic neural networks can fuse scale and rotation invariant information into the deep model. Shen et al. [41] proposed a group-attention-fusion strategy to merge two different CNNs to generate refined multi-scale features for scene classification. Huang et al. [21] utilized a pre-trained CNN as a feature extractor to obtain three different features, including multi-layer convolutional features, FC features and LBP-based FC features. Then, these features are fused to fully exploit the discriminative power of the pre-trained CNN for scene classification.
Although the feature representations generated by the abovementioned CNN methods can improve the performance of scene classification tasks compared to traditional methods, they focus on the integration of global features and ignore the extraction of some key local features. However, our method can not only focus on learning global features of images, but also mine and aggregate more informative local features in an adaptive manner.
2.2 Attention mechanism
To further improve the discriminative ability of CNN features, the attention mechanism has been proposed, which aims to focus on some key component to obtain the detailed information during CNN feature learning. For example, Hu et al. [19] introduced a squeeze-and-excitation (SE) block to construct the interdependence among feature channels and adaptively readjusted the channel feature response, thereby significantly improving the performance of existing CNNs. Furthermore, Woo et al. [60] proposed a simple and effective convolutional block attention module(CBAM) that can sequentially infer attention maps along channel and spatial dimensions, and then apply the attention maps to the input feature map for adaptive feature refinement. Wang et al. [57]proposed a novel end-to-end attention recurrent convolutional network (ARCNet) to process and fuse the series of attention representation with a long short-term memory (LSTM)-based sequential processor to select a series of attention regions for scene classification. Bi et al. proposed an attention pooling-based dense connected CNN (APDC-Net) [5] and a residual attention based densely connected CNN(RADC-Net) [6] for scene classification, respectively, which have the potential to strengthen local semantic information and to preserve discriminative CNN features. Similarly, they also proposed a multiple instance densely connected CNN (MIDC-Net) [7] for scene classification, which can strengthen the local semantic representation and multi-instance feature learning. Sun et al. [51] designed gated bidirectional network based on SE block [19] to aggregate multi-layer convolutional features for image scene classification. Obviously, these methods based on regular attention aim to obtain discriminative spatial local information and key channel feature information from image scenes.
Inspired by the great success of transformer in natural language processing [52], researchers have proposed to apply transformer to solve computer vision tasks [15, 28, 59, 74]. Transformer can capture long-range contextual information through multi-head attention, which can be regarded as an enhanced version of the attention mechanism. Recently, Dosovitskiy et al. [15] proposed a fully-transformer model named vision transformer(ViT) for image classification. ViT first divides the image into fixed-size patches, and then learns effective visual features by mining the relationships among image patches. Despite the success of ViT, the transformer architecture with full attention mechanism [52] is computationally inefficient. To improve efficiency, Liu et al. [28] proposed swin transformer for various image recognition tasks. This method designs a window-based multi-head attention mechanism, which divide the image into multiple windows and only interact inside the windows. Unlike the ViT model, which can only generate outputs of low-resolution features, Wang et al. [59]proposed the pyramid vision transformer (PVT) model for dense vision prediction tasks. Specifically, they design a progressive reduction pyramid and a spatial reduction attention layer to obtain multi-scale and higher-resolution outputs with limited resources. Similarly, Zhang et al. [74] proposed a transformer-based encoder-decoder segmentation architecture, which not only introduced a pyramidal transformer structure to encode multi-scale feature representations, but also designed a transformer parsing module to perform dual decoding of multi-scale features. Clearly, these transformer-based methods aim to obtain long-range contextual associations of local features in images.
Our method designs various strategies based on regular attention [19, 60] to learn channel attention in cross-layer fusion features at the same scale and spatial attention in multi-scale fusion features, and also design different soft attention to learn associative aggregation of spatial local features. Furthermore, inspired by the transformer’s ability to learn long-range contextual dependencies, but different from these methods [15, 28, 59, 74] learn long-range dependencies of local region features in images, we utilize the self-attention mechanism to learn long-range association dependencies among multi-scale and multi-level spatial aggregation features.
2.3 Multi-modal learning
Recently, multi-modal or multi-view data has surged as a major stream of big data, where each modal/view encodes individual property of data objects. In general, different modalities are complementary to each other. Therefore, the research of fusing multi-modal features for comprehensive representation of data objects has received extensive attention, such as social recommendation [75], spectral clustering [55], and image retrieval [53], etc. Moreover, deep multi-view learning methods are widely employed in the field of image recognition. Ding et al. [13] first employed multiple CNNs to extract features from face images, and then concatenated all these features. Next, an auto-encoder is used to compress the merged features. Wu et al. [62, 63] proposed different deep metric learning methods for multi-spectral face recognition. Feng et al. [16] presented a cross-modality graph reasoning method for RGB-Infrared person re-identification. Their method can globally model the inter-dependency between modalities and context, and to keep semantic identity consistency between global and local representation. Xiong et al. [66] designed a global modality-specific feature learning module and a local modality-consistent feature learning module, both of which were combined to learn the specificity and consistency of multi-modal features simultaneously for scene classification. Ma et al. [32] obtained intermediate feature maps from pre-trained CNNs and built a global and local integrated model by introducing a visual attention mechanism. They also designed attention consistency model to eliminate the negative impact of attention inconsistency problems on the classification. Xu et al. [68] designed a global-local bi-branch structure to explore discriminative features of raw images and key regions, and adopted a decision-level fusion strategy to improve the image scene classification. Lv et al. [31] proposed a local-global feature fusion network for scene classification, which first utilized ResNet50 to extract the high-level feature map of the image, and then learned the local and global features of the high-level feature map from the channel dimension and the spatial dimension, respectively. Ni et al. [33] proposed a compact global-local convolutional network based on multi-feature fusion learning, which can take full advantage of local feature distribution learning and the global cross-correlations of multi-feature statistics. Zeng et al. [70] proposed a multi-branch scene classification structure that simultaneously extracts features of global context and local small objects, which can learn robust abstract feature representations of scene images by integrating the features of both. Sun et al. [49] proposed a comprehensive scene classification representation method, which fuses three deep features of target semantic information, global appearance information and contextual appearance information. Sitaula et al. [46] introduced hybrid deep features to represent images by aggregating four types of features that include scene-based and object-based features at the whole image and part image levels.
To sum up, the abovementioned multi-modal learning methods are used for image classification by fusing deep features of multi-source data [13, 16, 62, 63] or different deep features of the same data [31,32,33, 46, 49, 66, 68, 70]. Unlike their methods that only use the high-level features of the network for multi-modal learning, and mostly adopt the strategy of direct feature fusion. Our method first uses multi-scale and multi-level spatial features in the same network to generate multi-modal features from different perspectives, and then designs different attention mechanisms to fuse these multi-modal features.
3 Method description
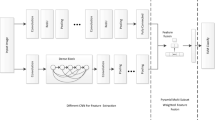
This section mainly introduces the network structure of GLFAF, as shown in Fig. 1. A deep convolutional network is designed as the backbone network for generating multi-scale and multi-level spatial features. Based on these spatial features, we first learn the global attention features, and then mine bidirectional recurrent dependencies and arbitrary pair-wise dependencies of scale variations in spatial sequence features to obtain global aggregate features. Meanwhile, channel attention is used to fuse the multi-level spatial features at the same scale, and cross-scale channel dependencies is used to progressively generate the multi-scale aggregated spatial features. Then, spatial contextual attention is introduced to enhance spatial local features. Moreover, the learnable FisherVector layer is further designed to obtain the local aggregate features. Finally, two different adaptive fusion mechanisms are designed to merge global and local aggregate features. Next, the details of the network structure will be elaborated.

The flowchart of the global-local feature adaptive fusion network for image scene classification
3.1 Backbone network
The backbone network of our proposed GLFAF model is consists of the five convolutional blocks, as shown Conv1-Conv5 of Fig. 1. Since each convolutional block contains several convolution layers and a maximum pooling layer, multi-level feature maps with different spatial resolutions can be generated in turn. In order to make the learned feature maps contain both high-level semantic information and sufficient spatial information, more network layers containing features of different resolutions are used to learn more spatial feature maps. It is obviously different from the previous studies of only using the features from last convolutional layer or pool layer to produce the spatial feature map. Specifically, three different convolutional blocks (Conv3-Conv5) are selected, each of which consists of four convolutional layers, can be used to generate multi-scale and multi-level spatial features. Given the input image I, the feature map Xl with different layers at each spatial resolution is obtained, and its size is H × W × C. Xl is a 3D tensor with height H, width W, and channel C, l indicates any scale space. In short, the image is input into the designed backbone network, and the multi-resolution features of different layers can be learned. These multi-scale and multi-level spatial features from different network layers can represent different visual meanings such as lines, textures, and objects. Then, we learn the relationship among the multi-scale and multi-level spatial features from the perspective of the global view and the local view to explore the discriminative feature representation.
3.2 Global feature aggregation
Based on the Conv3-Conv5 of the backbone network in Section 3.1, the three convolutional blocks can extract global information in multi-scale and multi-level feature spaces. Specifically, the global features are learned by global average pooling (GAP) of the first and last layers of the convolutional feature maps in each convolutional block. The feature values of different channels are learned by GAP, which can represent the global contextual information of the image, as follows:
where \({\text {X}}_{l}^{c} \in {R^{H \times W}}\) is the spatial feature map of the c-th channel extracted from a certain layer of the backbone network in GLFAF, and its width is W and height is H. \({Z_{l}} = \left \{ {{z_{l}^{c}}|c = 1,...C} \right \} \in {R^{c}}\) is the global feature representation of Xl.
Then, after the GAP, two FC layers are constructed, and W1 ∈ RF/r×F, W2 ∈ RF×F/r and b1 ∈ RF, b2 ∈ RF/r are the corresponding weight matrices and bias vectors, respectively. In order to capture the channel-wise dependencies, a weight factor oc for the c-th channel can be learned via a sigmoid layer using an attention mechanism after training the two FC layers.
where W1c, W2c and b1c, b2c represent weight matrices and bias vectors of two FC layers corresponding to the c-th channel, respectively. δ(⋅) denotes the ReLU activation function, and σ(⋅) is the sigmoid function. The equation (2) can learn to assign different weights to different channels. The higher weight, the more important of that channel.
Subsequently, the weight factor acts on the global contextual feature map, then global attention feature \({g_{l}^{c}}\) for the c-th channel is obtained via the GAP layer:
where ⋅ denotes the channel-wise multiplication operation. Finally, the features of global attention can be described as follows :
As shown in a of Fig. 1, the above operations of GAP and attention are simultaneously applied to the feature maps generated by Conv3_1, Conv3_4, Conv4_1, Conv4_4, Conv5_1 and Conv5_4 of the backbone network for learning the global attention features Gaf3_1, Gaf3_4, Gaf4_1, Gaf4_4, Gaf5_1, and Gaf5_4 at different spatial resolutions and at different levels in the same spatial resolution. Based on equation (4), the above series of features can be formally expressed as G3 − 1,G3 − 4, G4 − 1,G4 − 4,G5 − 1, G5 − 4.
In order to learn the global correlation among spatial features at different scales, a bidirectional recurrent neural network (RNN) [2] approach is exploited to mine the dependence of cross-scale spatial sequence features. It can simultaneously learn global dependencies across scales in two directions which are from low spatial resolution to higher spatial resolution and from high spatial resolution to lower spatial resolution.
Specifically, when dealing with a spatial sequence of length L, we uncover the globally associative shared features of the spatial sequence from the varying spatial scales in different directions, i.e., the global aggregate features \(h_{l}^ \leftrightarrow \) in the network layer of l ∈ [1,⋅⋅⋅,L] can be expressed as:
the symbols → and \( \leftarrow \) represent the spatial sequence from low spatial resolution to higher spatial resolution and the spatial sequence from high spatial resolution to lower spatial resolution, respectively. Gl represents the spatial features of the l-th layer, and hl represents the hidden layer unit. Wih and Whh denote the shared conversion matrices from the input state to the hidden layer state, and from the previous hidden layer to the current hidden layer, respectively. bh is the bias term, and φh is the nonlinear ReLU activation function.
In a bidirectional recurrent model, the spatial sequence information needs to be recursively acquired. Although bidirectional RNNs can mine sequence information of multi-scale and multi-level features in two different directions, they ignore the semantic dependencies between different layers in the same scale space and between any two scale spaces. Usually, such dependencies are essential to understand the arbitrary invariance among global features. Since the self-attention(SA) mechanism [52] in transformer has the advantage of performing global computation on the input sequence and summarizing the information for an update. Therefore, the SA mechanism is exploited to further learn the arbitrary dependence among sequence features from multi-scale and multi-level spatial bidirectional dependencies. That is, SA can not only mine the context information in spatial sequence features, but also capture the dependence of scale changes in spatial sequences by calculating the correlation between each pairs of global features in parallel. Specifically, SA uses the dot product operation to calculate the pair-wise relations of global features in spatial sequences, and the calculation formula is as follows:
where \({W_{q}} \in {R^{L \times {d_{q}}}}\), \({W_{k}} \in {R^{L \times {d_{k}}}}\), and \({W_{v}} \in {R^{L \times {d_{v}}}}\) are three learnable projection matrices, which are used to project \(h_{l}^ \leftrightarrow \) into the spaces of query Q, key K, and value V, respectively. QKT uses the dot product operation to calculate the pair-wise similarity from multi-scale and multi-level global spatial sequence features. dk and dv are two hyperparameters. \(\sqrt {{d_{k}}} \) is used to scale the attention based on the dot product and prevent the result of the dot product of Q and K from being too large. softmax(⋅) denotes a normalization function, which make the calculated value become a probability distribution with the sum of weights being 1.
The relationship among spatial features can be captured regardless of the scale difference between global features because the self-attention mechanism calculates the similarity between any two global features in the spatial sequence. Therefore, the output SA(⋅) of the self-attention learns not only the contextual relationships of the sequences, but also the long-term dependencies of the spatial sequences.
Then, the self-attention features in the spatial sequence are aggregated to generate a multi-scale dependent feature representation hSA. Subsequently, a FC layer is used to further learn the association among the features, thus generating the final global aggregate features \({y_{_{SA}}}\), as follows:
where WSA and bSA denote the weight matrix and the bias vector, respectively, and Max(0,⋅) implements the ReLU activation function.
3.3 Local feature aggregation
Section 3.2 obtains global aggregate information by learning the overall dependence of multi-scale and multi-level spatial features. Different from Section 3.2, this section progressively enhance and aggregate local feature information based on these same spatial features to obtain discriminative feature representation, as shown in b of Fig. 1. Generally, the extraction of visual local features (e.g., SIFT [29]) can learn the scale invariance of images well. Therefore, inspired by SIFT features, CNN is used to extract rich multi-scale and multi-level local features and learn the semantic context of local features.
3.3.1 Cross-scale spatial local feature learning
Generally, convolution features of different levels contain spatial structure information of different image scenes. Shallow convolutional layers have small receptive fields, which can capture the appearance information of each detailed scene unit. However, deep convolutional layers have large receptive fields, which can harvest the spatial structure information among different scene units. It obviously provides a basis for the aggregation of different intermediate convolutional layers. However, some existing methods [56, 65] usually use traditional feature coding (e.g., VLAD [23]) methods to encode the local features generated by each convolutional layer separately. However, such traditional feature coding methods cannot explore the complementarity among convolutional features from different levels.
In order to aggregate the intermediate convolutional layers to generate richer local features, a convolutional feature fusion module is designed to convert the features of intermediate convolutional layers into an aggregated convolutional representation. It consists of three parts: 1) multi-level spatial feature fusion in the same scale; 2) multi-scale spatial feature fusion; 3) attention-enhanced spatial feature learning. Unlike traditional feature coding methods that encode each layer of features separately, our proposed convolutional feature coding module simultaneously takes all intermediate convolutional features as input to generate a convolutional representation.
The main idea of the feature encoding module is to learn the convolutional representation using nonlinear convolution. First, a channel attention fusion method is designed to merge the multi-level convolutional features in the same scale space. Then the pooling operation is used to unify the sizes of the convolutional features in different scale spaces. Next, the concatenation operation is used to merge different convolutional features, and the convolution of 1 × 1 with ReLU is used to explore the complementarity among all convolutional features on the channel because the convolutional operation based on ReLU is a simple and efficient operation to increase the nonlinear interaction across the channel features. Finally, the spatial contextual attention is designed to generate discriminative spatial feature map. Next, the convolutional feature fusion module will be described.
As shown in b of Fig. 1, the lowest-level convolutional feature map Conv_L_1 and the highest-level convolutional feature map Conv_L_4 in each scale space are combined in the dimension of the channel to obtain the multi-level aggregated spatial feature map Conv_L_1-4, denoted as U. Since the above operations all merge multi-level features in the channel dimension, we further explore the feature dependence among channels to better aggregate the multi-level features in the same spatial resolution. In recent years, channel attention modules such as SE block [19] and ACNet [20]have been designed to make the network focus on more informative channels. More precisely, the proposed channel attention fusion module (as shown in Fig. 2) is inspired by channel attention mechanism in CBAM [60]. Specially, the maximum pooling fmax and average pooling favg are applied to spatial feature map U to generate one-dimensional global channel representations vm and va. Subsequently, vm and va are learned through multi-layer perceptron (MLP) to analyze their channel dependencies. Therefore, the different deep channel-dependent representations are fused by summing and activated with sigmoid to obtain the channel attention representation Zc(U). The final channel attention map Uc is generated by performing element-wise multiplication between Zc(U) and U. The expression of channel attention is as follows:
where fc represents the MLP operation, W1 ∈ RC/r×C and W2 ∈ RC×C/r denote the learning weights of the two FC layers in the MLP, δ(⋅) denotes the ReLU activation function, and σ(⋅) is the sigmoid function.

Channel attention fusion
The abovementioned multi-level channel attention fusion operation is applied to spatial maps of different scales to construct three-scale multi-level aggregated spatial feature maps, namely Conv3_1_4, Conv4_1_4 and Conv5_1_4. The maximum pooling operation in the backbone network in GLFAF will sequentially generate convolutional feature maps of different sizes, which can help increase the receptive field. Obviously, the sizes of the three different spatial convolution feature maps, Conv3_1_4, Conv4_1_4, and Conv5_1_4, are different.
In order to aggregate convolution features of different sizes, the width and height of all intermediate convolution features need to be unified to the same size. Specifically, average pooling operations with different strides are used to unify the width and height of the three different multi-level aggregated spatial feature maps, and keep the number of spatial channels unchanged. In addition, the l2-normalization is employed to normalize the multi-level aggregated convolutional features across the channel. Since the magnitude of values in different convolutional feature is completely different, the l2-normalization can effectively avoid numerical problems. Then, the formula of the l2-normalization across the channel is expressed as follows:
where r ∈ RH,W,C denotes the convolutional feature, \(\overline r \in {R^{H,W,C}}\) denotes the normalized convolutional feature, H denotes the height of r and \(\overline r \), W denotes the width of r and \(\overline r \), C denotes the number of channels of r and \(\overline r \), and ε denotes used to avoid the divisor, 0. After the l2-normalization, the proposed GLFAF can converge more steadily.
After a series of pooling and normalization operations, three convolutional feature maps of uniform size are generated. To avoid introducing weight parameters, a concatenation operation is used to merge different convolutional features. That is, the three uniform convolutional features are directly stacked in the channel dimension. Finally, the convolutional operation of 1 × 1 with ReLU is used to further explore the complementarity among channels in the convolutional feature. It not only increases the nonlinear interaction of cascading features among channels [50], but also keeps the width and height of the features unchanged. Therefore, a multi-scale deep aggregated spatial feature map Um ∈ RN×N×D is generated. In summary, multi-level spatial feature in the same scale and multi-scale spatial feature are both progressively fused from the channel dimension of the convolutional feature map to obtain rich features. However, there is no reinforcement learning about the differences in different positions of spatial features in the spatial (width and height) dimensions. Therefore, the spatial attention mechanism should be further designed to highlight meaningful spatial feature units.
Spatial attention is used to make the network focus on more informative regions. The CBAM [60] utilizes a 7 × 7 convolution to learn the spatial attention mask after concatenating the max-pooled and average-pooled spatial features. In order to better capture the spatial context-aware information, we modified the original spatial attention sub-module in CBAM. That is, the convolutions with different receptive fields are used to generate intermediate feature masks, rather than using a 7 × 7 convolution only. Then, these intermediate masks are concatenated and a 1 × 1 convolution is used to learn weights.
The spatial attention map can be considered as the weighted sum of feature masks. An illustration of our spatial context attention sub-module is shown in Fig. 3. The S ∈ RN×N×2 is generated by concatenating squeezed feature masks \(f_{{\max \limits } }^{c}({U_{m}})\) and \(f_{avg}^{c}({U_{m}})\). Here, \(f_{{\max \limits } }^{c}\) and \(f_{{\max \limits } }^{c}\) represent max-pooling and average-pooling along the channel dimensions, respectively. To exploit the spatial contextual information, four different scales of context filters (3 × 3, 5 × 5, 7 × 7, and 9 × 9 ) are used. The feature mask is produced by concatenating these channel masks generated by the 3 × 3, 5 × 5, 7 × 7, and 9 × 9 context filters. Then, a 1 × 1 convolution is used to learn and accumulate weights. The spatial contextual attention can be computed as:
where fn×n denotes a n × n convolution. Consequently, the modulated spatial feature map Ud is obtained by element-wise multiplication between the multi-scale aggregated spatial feature map Um and the final spatial attention mask Zs(Um).

Spatial attention fusion
3.3.2 Fisher vector network layer
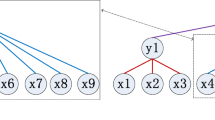
The discriminative spatial feature map Ud is aggregated into an visual feature representation with local invariance, which is specifically implemented by the designed fisher layer. The traditional fisher vector(FV) [35] is hard-assigned and non-differentiable, so it cannot be learned end-to-end through deep networks. Therefore, we modify the traditional non-differentiable learning method in FV [35] to an end-to-end learning method, and call it the fisher layer, as shown in Figs. 4 and 5.

Schematic diagram of FisherNet layers

Schematic diagram of FisherNext layers
In fisher’s aggregation learning, Ud ∈ RN×N×D can be decomposed into N × N number of D-dimensional local region features Ud = {ui,j|ui,j ∈ RD,i,j = 1,2,⋅⋅⋅,N}, where each ui,j represents a local feature at a specific location of the input image. Then, FisherNet and FisherNext are proposed by using two different designs of spatial region ui,j as the smallest unit and grouped ui,j as the smallest unit.
FisherNet
For a series of inputable spatial local features ui,j ∈ RD, a soft-assigned learnable probability function is as follows:
where Wk and bk are learnable parameters. In other words, the soft assignment of the local features ui,j to the semantic centers ck uses the interval range of 0 to 1 to measure the correlation weight of the local feature ui,j to the semantic center ck. In the traditional hard allocation method, if the local feature ui,j and the semantic centers ck are closely related, then ak(ui,j) is equal to 1; otherwise, it is equal to 0.
In order to be able to integrate into the deep network end-to-end, ak(ui,j) will define the soft assignment between the local region features ui,j and the learnable K semantic centers {c1,c2,⋅⋅⋅,cK|ck ∈ RD}. As shown in (a) of Fig. 4, the differentiable fisher vector can be expressed as follows:
where V1(:,q,k) and V2(:,q,k) capture the first-order and second-order FisherNet aggregation representation, respectively. ck,k ∈ [1,K] is the learnable semantic center, and δk,k ∈ [1,K] is the diagonal covariance of the semantic center. To define δk,k ∈ [1,K] as positive, a gaussian noise with unit mean and small variance is first used to initialize their values randomly, and then square their values during the training process to keep them positive.
As shown in (b) of Fig. 4, the matrix V1 and V2 is L2-normalized column-wise (intra-normalization) first, and stretch it into a vector, L2-normalized again in its entirety, batch-normalized again, and finally, different orders of spatial aggregation features \({V_{1}^{n}}\) and \({V_{2}^{n}}\) are obtained. Subsequently, the two features are fused and a non-linear FC layer is used to explore the internal associations among the fused features to obtain the final feature representation of local invariance. Its calculation is as follows:
where ⊕ denotes the operation of feature splicing, Wnet and bnet are the weight matrix and the bias vector respectively, and Max(0,⋅) realizes the ReLU activation function.
FisherNext
Unlike FisherNet, which takes the generated image local region as the smallest unit, FisherNext further divides the image local region into groups. It can also calculate the association among spatial local features, and can greatly reduce the network parameters of the fisher layer.
Specifically, as shown in (a) of Fig. 5, a FC layer is first used to expand the feature vector ui,j in each spatial region, as shown in the following equation:
where Wfc ∈ RD×2D and bfc ∈ RD denote the weight matrix and the bias vector, respectively, and Max(0,⋅) implements the ReLU activation function. This operation relearns the spatial region feature ui,j ∈ RD as \(u_{i,j}^{m} \in {R^{2D}}\).
Then, in order to finely discover the contribution of the features in each spatial region to the overall semantics, all spatial region features are divided into {G— g ∈{1,⋅⋅⋅,G}} groups, each of which contains mD/G-dimensional feature vectors. That is, the spatial region feature map \(U_{N,N}^{m}\) with a shape of (N2,mD) is divided into G lower dimensional feature vectors \(U_{N,N}^{mg}\) with a shape of (N2,G,mD/G).
Different from the idea of soft assignment in FisherNet, we try to design a hierarchical soft assignment idea to adaptively learn higher-order related information in the semantic centers. Formally, take the given \(u_{i,j}^{m}\) in \(U_{N,N}^{m}\) and the corresponding \(u_{i,j}^{mg}\) in \(U_{N,N}^{mg}\) as inputs, K semantic centers \(c_{k}^{mg}\) as learnable parameters over groups. FisherNext-based adaptive aggregation means that the compact association of local features \(u_{i,j}^{mg}\) in all groups from learnable semantic centers \(c_{k}^{mg}\) in the same grouped lower-dimensional space. The calculation is as follows:
where \({V_{1}^{g}}(:,q,k)\) and \({V_{2}^{g}}(:,q,k)\) capture the first-order and second-order FisherNext aggregation representation, respectively. \({\text {\{ }}c_{k}^{mg}{{|}}k \in [1,K]{\text {\} }}\) is the learnable semantic center, and \(\{ \delta _{k}^{mg}{{|}}k \in [1,K]\} \) is the diagonal covariance of the semantic center. To define \(\{ \delta _{k}^{mg}{{|}}k \in [1,K]\} \) as positive, we first use a gaussian noise with unit mean and small variance to initialize their values randomly, and then square their values during the training process to keep them positive.
Among them, \({a_{g}^{m}}(u_{i,j}^{m})\) denotes the attention function over groups G, and the calculation process is as follows:
where Wg ∈ RmD×G and bg ∈ RG denote the weight matrix and bias vector, respectively, while σ(⋅) implements the sigmoid function with an output scale of 0 to 1. Thus, we can obtain probability values to measure the importance of each subgroup g.
In addition, \(\overline a_{gk}^{m}(u_{i,j}^{m})\) denotes the soft assignment of grouped local feature \(u_{i,j}^{mg}\) to K different semantic center \(c_{k}^{mg}\). The attention function of the learnable soft-assignment is denoted as follows:
where Wgk ∈ RmD×Gk and bgk ∈ RGK denote the weight matrix and the bias vector, respectively. BN(⋅) implements the batch normalization function, and the conversion process of batch normalization is as follows:
where h is the vector passing through FC layer over a complete minibatch, γ and β are model parameters that determine the mean and standard deviation of the normalized activation, ε is a regularization hyperparameter. The statistics Mean[h] and V ar[h] are estimated by the sample mean and sample variance of the current minibatch.
As shown in (b) of Fig. 5, the matrix \({V_{1}^{m}}\) and \({V_{2}^{m}}\) are L2-normalized column-wise (intra-normalization) first, and stretch it into a vector, L2-normalized again in its entirety, batch-normalized again, and finally, different orders of spatial aggregation features \(V_{1n}^{m}\) and \(V_{2n}^{m}\) are obtained. Subsequently, the two features are fused and a non-linear FC layer is used to explore the internal associations among the fused features to obtain the final feature representation \({V_{n}^{m}}\) of local invariance. Its calculation is as follows:
where ⊕ denotes the operation of feature splicing, WV and bV are the weight matrix and the bias vector respectively, and Max(0,⋅) realizes the ReLU activation function.
3.4 Adaptive feature fusion
In general, fusing features from different modal spaces can provide superior performance over a single modality. However, direct cascading of different modal features [21, 30, 41] often does not provide the best performance. In order to alleviate this limitation, two adaptive fusion networks are constructed: 1) weighted adaptive feature fusion; 2) bidirectional adaptive feature fusion. For ease of representation, the global aggregate features are denoted as \({h_{f}^{g}}\), and the local aggregate features are denoted as \({h_{f}^{l}}\). Then the two fusion models are introduced as follows:
3.4.1 Weighted adaptive feature fusion
The attention model is designed to calculate the optimal fusion weight for each feature \({h_{f}^{g}}\) and \({h_{f}^{l}}\), which can adaptively weigh the importance of \({h_{f}^{g}}\) and \({h_{f}^{l}}\). Figure 6 shows the schematic diagram of weighted adaptive feature fusion. Specifically, according to the content of the respective characteristics, the respective attention weights λg and λl are adaptively learned to generate the optimal solution to satisfy λg + λl = 1. The learned attention is subsequently applied to the input features \({h_{f}^{g}}\) and \({h_{f}^{l}}\) respectively, and the calculation process is as follows:
where W* and b∗ are the parameters of learnable weight matrix and bias vector, respectively, and hg and hl are the global aggregate features and local aggregate features after single-layer perceptron transformation, respectively. δ(⋅) implements the ReLU activation function, σ(⋅) is the sigmoid activation function of logistic regression, and ⊕ is the connection operation. λg represents the attention weight applied to the global invariant features, and 1 − λg represents the attention weight applied to the local aggregate features. Therefore, hgl represents the global-local features of weighted adaptive fusion. In addition, o represents the final output features of exploring the internal associations in hgl.

Schematic diagram of weighted adaptive feature fusion
3.4.2 Bidirectional adaptive feature fusion
Inspired by the recurrent neural network [2], a bidirectional adaptive feature fusion method from “global-local” and “local-global” is proposed to merge global aggregate features and local aggregate features. The framework of bidirectional adaptive feature fusion is shown in Fig. 7.

Schematic diagram of bidirectional adaptive feature fusion
In the global to local direction, there are two input nodes in the model. The first input feature is the global aggregate feature \({h_{f}^{g}}\), and the second input feature is the local aggregate feature \({h_{f}^{l}}\). The reset ratio and the update ratio are calculated by Eqs.(34) and (35), respectively. The primary fusion feature \({h_{f}^{p}}\) is calculated by Eq.(36). The primary fusion feature and the global aggregate feature are used as the two input features to calculate the intermediate fusion feature \({h_{f}^{i}}\) by Eq.(37).
In the local to global direction, the first input feature is the local aggregate feature \({h_{b}^{l}}\) and the second input feature is the global aggregate feature \({h_{b}^{g}}\). The reset ratio and the update ratio are also calculated by Eqs.(38) and (39), respectively. The primary fusion feature \({h_{b}^{p}}\) is calculated by Eq.(40). The primary fusion feature and the local aggregate feature are used as the two input features to calculate the intermediate fusion feature \({h_{b}^{i}}\) by Eq.(41).
In bidirectional feature fusion, \({h_{b}^{i}}\) and \({h_{f}^{i}}\) are calculated together to get the final fusion feature o. The formula is show as follows:
In all these formula Eqs.(34)-(42). Wz, Wr, Uz,Ur, W , U, Wf, Wb, bo are all the weight parameters that need to be learned during the training phase. σ(⋅) is the sigmoid activation function of logistic regression.
3.5 Classification
In summary, an end-to-end network structure is proposed to learn the global-local features, and to explore the adaptive fusion of global aggregate features and local aggregate features. As shown in Fig. 1, the scene image I is input to the proposed GLFAF model, and the softmax classifier is used to obtain the semantic label of the scene image I . The goal of training the GLFAF is to minimize the cross entropy loss of the classifier. The formula of cross entropy loss is as follows:
where o is the adaptive fusion feature representation extracted from the scene image, m is the label corresponding to the image, 𝜃 is the weight parameter of softmax, {c|c ∈{1,...,K}} is the total number of semantic labels in the training database, and M is the number of scene images trained in a batch, and 1{⋅} denotes the indicator function. Obviously, all operations of multi-scale and multi-level spatial features extraction, the learning of global aggregate features and local aggregate features, the adaptive fusion of global-local features and softmax classifier in the proposed GLFAF are optimized under the supervision of cross-entropy loss J.
4 Experimental analyses
In this section, extensive experiments are conducted to evaluate the effectiveness of the proposed GLFAF. First, the data sets to be used for our experiments are introduced. Second, the experimental settings are then described. Third, the performance of GLFAF is compared with other state-of-the-art methods. Next, we study model ablation analysis to evaluate the contribution of each model component. Finally, the running time and the weight parameters of different network are reported and discussed.
4.1 Dataset description
We use three datasets from different fields, including the infrared maritime scene (IMS) dataset [14], UIUC-Sports(UIUC) dataset [24] and UC Merced Land-Use (UCM) dataset [69] to conduct a series of experiments. As shown in Table 1, the basic information of the three datasets is introduced. The IMS dataset contains 5 marine environment categories such as backlit sea, calm sea, foggy sea, rough sea and sea-sky-line. And it has a total of 2066 images with at least 200 images in each category. Scene examples of IMS dataset are shown in Fig. 8. The UIUC dataset contains 1579 images covering 8 categories of sports activity scenes, and each category contains 137-250 images. Scene examples of UIUC dataset are shown in Fig. 9. The UCM dataset contains 2100 images belonging to RGB images of 0.3 m spatial resolution. It covers 21 land-use categories, and each category contains 100 scene images. Scene examples of UCM dataset are shown in Fig. 10.

Sample diagram of the scene classification in IMS dataset

Sample diagram of the scene classification in UIUC dataset

Sample diagram of the scene classification in UCM dataset
4.2 Experimental settings
All images are adjusted to the same size of 224 × 224 × 3. In particular, VGG19-Net [44] is selected as the backbone network, and the subsequent global and local aggregation features are learned based on the 3-5 blocks in VGG19-Net. We adjust the output of the first convolution feature and the fourth convolution feature in these blocks to a feature map with the same channel size using a convolution operation with the kernel size of 3*3 and the filters number of 128, respectively. The stochastic gradient descent (SGD) method with small batch sizes and weight decay is used to optimize the entire network, where the weight decay value is 0.0001, the momentum value is 0.9, and the learning rate in the training phase is 0.001. The batch-size of the proposed GLFAF network is 16, and we exploit real-time data augmentation(e.g., random rotation, flip, and cropping) on the training dataset. The computer configuration is as follows: RAM: 32GB; processor: Intel (R) Core(TM)i7-9750H CPU @2.60 GHz; GPU: Nvidia GeForce GTX 1660Ti.
For the IMS dataset, 50% and 90% of the images in each category are randomly selected for training, and the remaining 50% and 10% are used for testing. For each train/test set in the UIUC dataset, 70 images per category are involved in the train set and 60 images are involved in the test set, as done by previous studies [45,46,47, 65]. We randomly selected 50% of the images in each scene class from the UCM dataset as the training set, and the rest are divided into the test set, as employed in previous studies [5,6,7, 31, 58].
We select the Precision, Recall, F1 score, and Accuracy as indicators to analyze and compare the experimental results, which are defined as follows:
the TP (True Positive), TN (True Negative), FP (False Positive), and FN (False Negative) represent the relationship between the predicted authenticity and the actual scene, respectively. It is known from equation (46) that F1 score is related to recall and precision, and is their harmonic mean. The higher the F1 score, the higher the precision and recall, and the better the performance.
In addition, the confusion matrix is also used to evaluate classification performance quantitatively. It is a specific table layout that allows to visualize directly the performance of each category, which reports errors and confusions among different categories by calculating the correct and incorrect classification of the test images for each category and accumulating the results in a table.
4.3 Comparison with state-of-the-arts
This section will compare the performance of the proposed GLFAF method with other recently proposed image scene classification methods on the three different datasets.
4.3.1 Experiment 1: IMS dataset
In this experiment, we use the IMS dataset under the training ratios of 50% and 90% to evaluate the effectiveness of the proposed method. Table 2 lists the overall accuracy results of the comparative experiment of the respective methods. As shown in Table 2, the proposed GLFAF method achieves overall accuracy of 90.61%, 91.58%, 90.51%, 90.80% under training ratios of 50%, and 94.69%, 96.14%, 94.20%, 95.65% under training ratios of 90%, respectively. Obviously, the classification performance of the proposed GLFAF method is higher than other comparison methods. Among them, the overall accuracy of the proposed methods are better than those of classical networks such as VGG-16, VGG-19 and ResNet50. Moreover, the proposed GLFAF method also shows better overall accuracy compared to the current state-of-the-art methods (e.g., FACNN, VGG16-CapsNet and GBNet+global feature). Compared with the multi-branch feature fusion network LCNN-BFF, the performance of the proposed GLFAF-NetFV-w and GLFAF-NextFV-w is roughly comparable to the LCNN-BFF method, while the proposed GLFAF- NetFV-b and GLFAF-NextFV-b significantly outperform the LCNN-BFF method. In terms of adaptive fusion of global and local features of GLFAF, our bidirectional adaptive fusion method works slightly better than the weighted adaptive fusion method. In addition, for the two different configurations of the fisher vector layer, the effect of using the NetFV configuration is slightly better than that of NextFV. Overall, the effect of the approach based on NetFV and the effect of the approach based on NextFV is almost equivalent. Moreover, with the increase of trainable infrared maritime data, the recognition accuracy of scene classification is higher. It shows that a larger number of training data sets are more conducive to the accurate classification of infrared maritime scenes.
Table 3 shows the performance of the GLFAF-NetFV-b method for each class in the IMS dataset under the 90% training rate. It can be seen that the proposed GLFAF-NetFV-b method achieves more than 90% performance on the three evaluation metrics(i.e., precision, recall and F1 score) for all categories. In addition, to more intuitively visualize the performance of the proposed GLFAF-NetFV-b method, the confusion matrix of our method on different categories is further plotted. Figure 11 shows the confusion matrix of GLFAF-NetFV-b at a training ratio of 90% on the IMS dataset. As shown in Fig. 11, the proposed method achieves more than 95% classification accuracy on the four categories of ’calm sea’, ’foggy sea’, ’rough sea’, and ’sea-sky-line’, while 93% classification accuracy in the category of ’backlit sea’. It can be seen that our global-local feature adaptive fusion method based on multi-scale spatial features can mine discriminative infrared sea surface features in the category-unbalanced infrared maritime scene dataset. Of course, the value of the diagonal line in Fig. 11 also represent recall of each scene category. The appearance of tiny ripples in the calm sea is similar to texture in backlit sea, which causes confusion between the ’backlit sea’ category and the ’calm sea’ category. Meanwhile, the rough textures in the ’rough sea’ category are similar to the ’backlit sea’ category, which makes some samples in it be incorrectly classified as ’backlit sea’. Furthermore, the background of the sea and fog segmentation generated by the foggy sea surface is similar to the scene of the sea and sky segmentation, which makes some samples of the ’foggy sea’ category be incorrectly identified as the ’sea-sky-line’ category.

Confusion matrix of GLFAF-NetFV-b under the 90% training ratio on the IMS dataset
4.3.2 Experiment 2: UIUC dataset
Table 4 tabulates the comparison results on the UIUC dataset. The UIUC dataset is sport event scenes, which is different from the general scenes. It is an understanding of sports scenes, and it pays more attention to the action of the prominent target and semantic context in the image. Since UIUC dataset is a class imbalanced dataset, we choose 70 samples from each class for training and 60 samples from each class for testing. As shown in Table 4, the overall accuracy of the four variants of the proposed GLFAF method has reached more than 95%. Moreover, the overall accuracy of GLFAF-NetFV-w is the highest, which is better than that of the WS-AM method that focuses on spatial relationship aggregation, and is equal to the overall accuracy of the DF method that focuses on deep content features. As far as the four variants of our model are concerned, the effect based on NetFv configuration is better than that based on NextFv configuration, and the effect based on weighted adaptive feature fusion is also significantly better than that based on bidirectional adaptive feature fusion.
Table 5 shows the performance of GLFAF-NetFV-w method in each category on UIUC dataset. It can be seen that the proposed method achieves better than 90% performance on precision, recall and F1 score on all categories except ’bocce’. The confusion matrix of the UIUC dataset is indicated in Fig. 12. It can be seen that the classification performance of six different categories (e.g., RockClimbing, badminton, polo, rowing, sailing, and snowboarding) can reach more than 95%, and even the classification performance of three categories such as’RockClimbing’, ’badminton’ and ’sailing’ reaches 100%. The distinction between the ’bocce’ category and the ’croquet’ category is the most confusing, especially for the ’bocce’ category, due to the similar body movements and spheres between the ’bocce’ category and the ’croquet’ category.

Confusion matrix of GLFAF-NetFV-w on the UIUC dataset
4.3.3 Experiment 3: UCM dataset
We further perform experiment 3 on the UCM dataset to evaluate the performance of our proposed method. As discussed in Section 4.1, this dataset is challenging due to its small data size and many categories. As shown in Table 6, four variants of proposed GLFAF method is compared with some novel networks based on VGG16, ResNet50, and attention mechanism. The best performance is 97.52% obtained by our method GLFAF-NetFV-w, which is 0.56% higher than the original best performance acquired by VGG-VD16 + RIR. Moreover, the overall accuracy of the GLFAF-NetFV-w method is also better than the global-local feature fusion method ResNet_LGFFE with resnet50 as the backbone network. Compared with the multi-scale and multi-level feature aggregation network EFPN-DSE-TDFF, our methods GLFAF-NetFV-w and GLFAF-NetFV-b also improve by 1.33% and 0.95%, respectively. This is because our method not only extracts multi-scale and multi-level features, but also enriches the feature representation of images based on global and local multi-modal learning. From the perspective of spatial local aggregation, the NetFv-based configuration performs better than the NextFv-based configuration. From the perspective of multimodal fusion, the method based on weighted adaptive feature fusion is also slightly better than the method based on bidirectional adaptive feature fusion, but the performance of these two fusion methods is generally comparable on the UCM dataset.
Table 7 shows the performance of the GLFAF-NetFV-w method on each scene category in the UCM dataset. It can be seen that the proposed method achieves better than 90% performance on precision, recall and F1 score on all categories except ’intersection’ and ’storagetanks’. Figure 13 shows the confusion matrix of GLFAF-NetFV-w on the UCM dataset. When the training rate is 50%, the classification accuracy of 20 scene categories reaches more than 90%. The ’storagetanks’ category has the worst classification performance compared to the other 20 scene categories. This is due to the fact that the distribution of circular landmark buildings in the ’storagetanks’ category is very similar to that of street intersections, rooftops, and round courts, which makes the samples in the ’storagetanks’ category prone to misclassification. Besides, some images of the ’mediumresidential’ category may be incorrectly identified as ’denseresidential’ and ’sparseresidential’. The main features of the three scene categories (’denseresidential’, ’mediumresidential’, ’sparseresidential’) are buildings, the only difference is the density of buildings in the image.

Confusion matrix of GLFAF-NetFV-w on the UCM dataset
4.4 Ablation experiments
In order to study the impact of different modules in the proposed method on scene classification, we use the proposed GLFAF-NetFV-w as the benchmark and Accuracy as the evaluation metric to conduct ablation experiments on the IMS dataset, UIUC dataset and UCM dataset, as shown in Table 8. Furthermore, different methods designed in our ablation experiments exploit the same parameter settings, optimization strategies, and training settings. To simplify the representation, we call the global feature aggregation learning branch as GFA_Net, the local feature aggregation learning branch as LFA_Net, and the GLFAF-NetFV-w as GLFA_Net. As can be seen from Table 8, when only GFA_Net or LFA_Net is used, the overall accuracy on the IMS dataset are 93.75% and 94.12%, respectively; the overall accuracy on the UIUC dataset are 96.46% and 96.88%, respectively; the overall accuracy on the UCM dataset is 96.95% and 96.38%, respectively. GLFA_Net combines the advantages of both, and the overall accuracy on the three datasets reach 94.69%, 97.29%, and 97.52%, respectively. Additionally, to verify that the channel attention module(as shown in Fig. 2) and spatial contextual attention module(as shown in Fig. 3) in the proposed GLFA_Net method are effective, we remove different types of attention modules and verify their performance. As can be seen from Table 8, the effects of removing channel attention (GLFA_Net_without_channel attention), removing spatial attention (GLFA_Net_without_spatial attention), and removing channel-spatial attention (GLFA_Net_without_channel&spatial attention) have all decreased to varying degrees, which indicates that the attention module in the proposed method is effective in mining discriminative features.
In order to better demonstrate the intermediate process of the attention module in GLFA_Net, we select images of six scenes of rough sea, sea-sky-line, polo, rockclimbing, storagetanks and tenniscourt as experimental data to visualize the output of the attention model. In Fig. 14, channel attention fusion_1, channel attention fusion_2, and channel attention fusion_3 respectively represent the visualization results of multi-level channel attention fusion in the three scale spaces of Block3-Block5, while spatial context attention represents the visualization results of spatial context attention. The visualization experiments on the six scene images demonstrated that different attention modules in the proposed method could extract different detailed features in scene images, which is helpful to solve the problems of within-class differences and between-class similarities in the classification of scene images.

The visualization results of different attention modules in the proposed method
4.5 Computational efficiency analysis
The training and testing time can directly reflect the computational efficiency of our proposed method. The backbone network of our proposed GLFAF model is modified based on the VGG-19 network. Therefore, the VGG-19 network is exploited as the model benchmark to analyze the running time of four variants of GLFAF, namely GLFAF-NetFV-w, GLFAF-NetFV-b, GLFAF-NextFV-w and GLFAF-NextFV-b. The training time, test time and weight parameters of different networks are shown in Table 9. The data divided by different configurations in each data set are trained on their respective models for 150 epochs. As shown in Table 9, the running time of different variants of GLFAF is very close to the running time of VGG-19 network. Among them, the VGG-19 network contains approximately 139.6 million weight parameters, most of which are introduced by the FC layers. In GLFAF, the FC layers of VGG-19 network are removed, but the global and local invariant features in multi-scale and multi-level spatial maps are learned. Next, global and local features are aggregated in an adaptive manner for image scene classification. Specifically, GLFAF-NetFV-w has 43.7 million weight parameters, GLFAF-NetFV-b has 44.3 million weight parameters, GLFAF-NextFV-w has 31.8 million weight parameters and GLFAF-NextFV-b has 32.5 million weight parameters. Obviously, the weight parameter of the four variants of GLFAF is significantly smaller than that of VGG-19 network. In GLFAF network, the weight parameters of our methods based on NetFV are larger than our methods based on NextFV, and the weight parameters of our methods using bidirectional adaptive feature fusion are slightly larger than our methods using weighted adaptive feature fusion under the same configuration of NetFV or NextFV.
Although the weight parameters of the GLFAF network are significantly smaller than those of the VGG-19 network, the running time of the GLFAF network is not significantly reduced. That is, compared to the VGG-19 network, the GLFAF network requires slightly less running time on the UIUC dataset, but slightly more running time on the IMS and UCM datasets. In terms of the neural networks, the computational efficiency of FC layers is very high, while the computational efficiency of convolutional layers is relatively low. Compared with the VGG-19 network, some additional convolutional layers, recursive learning mechanism, different attention mechanisms, different association aggregation mechanisms of spatial region features, and different feature adaptive fusion mechanisms are introduced in our GLFAF network. Although these added components make the GLFAF network richer in feature representation, these different mechanisms reduce its computational efficiency to varying degrees. More specifically, NextFV-based methods have significantly smaller weight parameters than NetFV-based methods, but the running time of NextFV-based methods is not reduced compared to NetFV-based methods. It is due to the fact that grouped attention mechanism in NextFV is more complex than the attention mechanism in NetFv, which greatly reduces the computational efficiency of the NextFV-based method. Meanwhile, the running time of the bidirectional adaptive feature fusion method based on the same NetFV or NextFV configuration is slightly longer than that of the weighted adaptive feature fusion method. This is because the gated attention mechanism in bidirectional adaptive feature fusion is more complex than that in weighted adaptive feature fusion, which reduces the computational efficiency of the model.
5 Conclusions
In this paper, an end-to-end global-local feature adaptive fusion network is proposed for image scene classification. The global aggregate features and the local aggregate features can be extracted respectively based on the multi-scale and multi-level spatial features acquired from the same backbone network. Specifically, the global aggregate features are generated by exploring the multiple relationships of global features at different scales. Meanwhile, the local aggregate features are generated by gradually fusing spatial features of different scales, and mining the relationship of spatial local features based on multiple attentions. Furthermore, assuming the different roles of global aggregate features and local aggregate features, two different adaptive feature fusion strategies are proposed to merge global-local features together. Overall, our approach can explore the complementary nature of global and local features to comprehensively describe the image scene. Finally, the proposed method is comprehensively evaluated on three datasets with different characteristics. The experimental results demonstrate that the proposed method achieves better image scene classification performances than other related methods.
We show that there is a best-performing value for our proposed approach. As a final remark we would like to note that through the experimental results that discussed in Section 4.3 we also observed that our method still suffers from some misclassifications for scene images that are highly similar in appearance. This is due to the fact that although our method studies the high-order correlation of spatial local features, it does not focus on the spatial positional relationship of local features. In the future, we will incorporate local positional relationships in higher-order associations of local features, and explore metric learning method to integrate local and global information.
Data Availability
The UC Merced Land-Use dataset that support the findings of this study are available in the ucmerced repository: http://weegee.vision.ucmerced.edu/datasets/landuse.html. The UIUC Sports dataset that support the findings of this study are available in the stanford repository: http://vision.stanford.edu/lijiali/event_dataset/. The infrared maritime scene dataset that support the findings of this study are available from the corresponding author on reasonable request.
References
Anwer RM, Khan FS, van de Weijer J et al (2018) Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J Photogrammetry Rem Sens 138:74–85
Basiri ME, Nemati S, Abdar M et al (2021) ABCDM: an attention-based bidirectional CNN-RNN deep model for sentiment analysis. Futur Gener Comput Syst 115:279–294
Bay H, Tuytelaars T, Van Gool L (2006) Surf: speeded up robust features, European conference on computer vision. Springer, Berlin, pp 404–417
Bi Q, Qin K, Li Z et al (2019) Multiple instance dense connected convolution neural network for aerial image scene classification. In: 2019 IEEE International conference on image processing (ICIP). IEEE, pp 2501–2505
Bi Q, Qin K, Zhang H et al (2019) APDC-Net: attention pooling-based convolutional network for aerial scene classification. IEEE Geosci Rem Sens Lett 17(9):1603–1607
Bi Q, Qin K, Zhang H (2020) RADC-Net: a residual attention based convolution network for aerial scene classification. Neurocomputing 377:345–359
Bi Q, Qin K, Li Z et al (2020) A multiple-instance densely-connected ConvNet for aerial scene classification. IEEE Trans Image Process 29:4911–4926
Blei DM, Ng AY, Jordan MI (2003) Latent Dirichlet allocation. J Mach Learn Res 3:993–1022
Chen Y (2015) Convolutional neural network for sentence classification. University of Waterloo
Cheng G, Ma C, Zhou P et al (2016) Scene classification of high resolution remote sensing images using convolutional neural networks. In: 2016 IEEE International geoscience and remote sensing symposium (IGARSS). IEEE, pp 767–770
Cheng G, Xie X, Han J et al (2020) Remote sensing image scene classification meets deep learning: challenges, methods, benchmarks, and opportunities. IEEE J Selected Topics Appl Earth Observ Rem Sens PP(99):1–1
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: IEEE computer society conference on computer vision and pattern recognition (CVPR’05), vol 1. IEEE, pp 886–893
Ding C, Tao D (2015) Robust face recognition via multimodal deep face representation. IEEE Trans Multimed 17(11):2049–2058
Dong L, Zhang T, Ma D et al (2020) Maritime background infrared imagery classification based on histogram of oriented gradient and local contrast features. Journal of Infrared and Millimeter Waves 39:5
Dosovitskiy A, Beyer L, Kolesnikov A et al (2020) An image is worth 16x16 words: transformers for image recognition at scale, arXiv:2010.11929
Feng Y, Chen F, Ji Y, et al. (2021) Efficient cross-modality graph reasoning for RGB-infrared person re-identification. IEEE Signal Process Lett 28:1425–1429
He K, Zhang X, Ren S et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Hofmann T (2001) Unsupervised learning by probabilistic latent semantic analysis. Mach Learn 42(1):177–196
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7132–7141
Hu X, Yang K, Fei L et al (2019) Acnet: attention based network to exploit complementary features for rgbd semantic segmentation. In: IEEE International conference on image processing (ICIP). IEEE, pp 1440–1444
Huang H, Xu K (2019) Combing triple-part features of convolutional neural networks for scene classification in remote sensing. Remote Sens 11(14):1687
Jiang Y, Yuan J, Yu G (2012) Randomized spatial partition for scene recognition, European conference on computer vision. Springer, Berlin, pp 730–743
Jgou H, Douze M, Schmid C et al (2010) Aggregating local descriptors into a compact image representation. In: 2010 IEEE computer society conference on computer vision and pattern recognition. IEEE, pp 3304–3311
Li LJ, Li FF (2007) What, where and who? Classifying events by scene and object recognition Computer Vision. In: Proc.of IEEE International conference on computer vision, pp 1–8
Li Q, Wu J, Tu Z (2013) Harvesting mid-level visual concepts from large-scale internet images. In: 2013 IEEE Conference on computer vision and pattern recognition, pp 851–858
Li Q, Peng Q, Yan C (2018) Multiple VLAD encoding of CNNs for image classification. Comput Sci Eng 20(2):52–63
Lin D, Lu C, Liao R et al (2014) Learning important spatial pooling regions for scene classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3726–3733
Liu Z, Lin Y, Cao Y et al (2021) Swin transformer: hierarchical vision transformer using shifted windows. International Conference on Computer Vision, 10012-10022
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis 60(2):91–110
Lu X, Sun H, Zheng X (2019) A feature aggregation convolutional neural network for remote sensing scene classification. IEEE Trans Geosci Remote Sens 57(10):7894–7906
Lv Y, Zhang X, Xiong W et al (2019) An end-to-end local-global-fusion feature extraction network for remote sensing image scene classification. Rem Sens 2019 11(24):3006
Ma J, Ma Q, Tang X et al (2020) Remote sensing scene classification based on global and local consistent network, IGARSS 2020-2020. In: IEEE International geoscience and remote sensing symposium. IEEE, pp 537–540
Ni K, Liu P, Wang P (2021) Compact global-local convolutional network with multifeature fusion and learning for scene classification in synthetic aperture radar imagery. IEEE J Selected Topics Appl Earth Observ Rem Sens 14:7284–7296
Oliva A, Torralba A (2001) Modeling the shape of the scene: a holistic representation of the spatial envelope. Int J Comput Vis 42(3):145–175
Perronnin F, Snchez J, Mensink T (2010) Improving the fisher kernel for large-scale image classification, European conference on computer vision. Springer, Heidelberg, pp 143–156
Qi K, Yang C, Hu C et al (2021) Rotation invariance regularization for remote sensing image scene classification with convolutional neural networks[J]. Remote Sens 13(4):569
Rublee E, Rabaud V, Konolige K et al (2011) ORB: an efficient alternative to SIFT or SURF. In: 2011 International conference on computer vision. IEEE, pp 2564–2571
Sadeghi F, Tappen M F (2012) Latent pyramidal regions for recognizing scenes, European conference on computer vision. Springer, Berlin, pp 228–241
Satpathy A, Jiang X, Eng HL (2014) LBP-based edge-texture features for object recognition. IEEE Trans Image Process 23(5):1953–1964
Sheng G, Wen Y, Tao X et al (2012) High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int J Remote Sens 33(8):2395–2412
Shen J, Zhang T, Wang Y et al (2010) A dual-model architecture with grouping-attention-fusion for remote sensing scene classification. Remote Sens 13(3):433
Shi C, Wang T, Wang L (2020) Branch feature fusion convolution network for remote sensing scene classification. IEEE J Selected Topics Appl Earth Observ Rem Sens 13:5194–5210
Shrinivasa SR, Prabhakar CJ (2022) Scene image classification based on visual words concatenation of local and global features. Multimed Tools Appl 81 (1):1237–1256
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. Computer Science
Sitaula C, Xiang Y, Basnet A et al (2019) Tag-based semantic features for scene image classification. In: International conference on neural information processing. Springer, Cham, pp 90–102
Sitaula C, Xiang Y, Basnet A et al (2020) Hdf: hybrid deep features for scene image representation. International Joint Conference on Neural Networks (IJCNN) IEEE 2020:1–8
Sitaula C, Aryal S, Xiang Y et al (2021) Content and context features for scene image representation[J]. Knowl-Based Syst 232:107470
Smeulders AWM, Worring M, Santini S et al (2000) Content-based image retrieval at the end of the early years. IEEE Trans Pattern Anal Mach Intell 22(12):1349–1380
Sun N, Li W, Liu J et al (2018) Fusing object semantics and deep appearance features for scene recognition. IEEE Trans Circuits Syst Video Technol 29 (6):1715–1728
Szegedy C, Liu W, Jia Y et al (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1–9
Sun H, Li S, Zheng X et al (2019) Remote sensing scene classification by gated bidirectional network. IEEE Trans Geosci Rem Sens PP(99):1–15
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need[J]. Advances in Neural Information Processing Systems, 30
Wang Y (2021) Survey on deep multi-modal data analytics: collaboration, rivalry, and fusion. ACM Trans Multimed Comput Commun Appli (TOMM) 17 (1s):1–25
Wang D, Mao K (2019) Task-generic semantic convolutional neural network for web text-aided image classification. Neurocomputing 329:103–115
Wang Y, Zhang W, Wu L et al (2016) Iterative views agreement: an iterative low-rank based structured optimization method to multi-view spectral clustering. arXiv:1608.05560
Wang G, Fan B, Xiang S et al (2017) Aggregating rich hierarchical features for scene classification in remote sensing imagery. IEEE J Selected Topics Appl Earth Observ Rem Sens 10(9):4104–4115
Wang Q, Liu S, Chanussot J et al (2018) Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans Geosci Remote Sens 57(2):1155–1167
Wang X, Wang S, Ning C et al (2021) Enhanced feature pyramid network with deep semantic embedding for remote sensing scene classification. IEEE Trans Geosci Rem Sens 59(9):7918–7932
Wang W, Xie E, Li X et al (2021) Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. International Conference on Computer Vision, 568–578
Woo S, Park J, Lee JY et al (2018) Cbam: convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV), pp 3–19
Wu J, Rehg JM (2010) Centrist: a visual descriptor for scene categorization. IEEE Trans Pattern Anal Mach Intell 33(8):1489–1501
Wu F, Jing XY, Dong X et al (2018) Intraspectrum discrimination and interspectrum correlation analysis deep network for multispectral face recognition. IEEE Trans Cybern 50(3):1009–1022
Wu F, Jing XY, Feng Y et al (2021) Spectrum-aware discriminative deep feature learning for multi-spectral face recognition. Pattern Recogn 111:107632
Xia GS, Hu J, Hu F (2017) AID: a benchmark data set for performance evaluation of aerial scene classification. IEEE Trans Geosci Remote Sens 55(7):3965–3981
Xia S, Zeng J, Leng L et al (2019) Ws-am: weakly supervised attention map for scene recognition. Electronics 8(10):1072
Xiong Z, Yuan Y, Wang Q (2020) MSN: modality separation networks for RGB-D scene recognition. Neurocomputing 373:81–89
Xu K, Huang H, Deng P et al (2020) Two-stream feature aggregation deep neural network for scene classification of remote sensing images[J]. Inform Sci 539:250–268
Xu K, Huang H, Deng P (2021) Remote sensing image scene classification based on global-local dual-branch structure model. IEEE Geoscience and Remote Sensing Letters
Yang Y, Newsam S (2010) Bag-of-visual-words and spatial extensions for land-use classification. In: Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems, pp 270–279
Zeng D, Chen S, Chen B et al (2018) Improving remote sensing scene classification by integrating global-context and local-object features. Remote Sens 10(5):734
Zhang F, Du B, Zhang L (2015) Scene classification via a gradient boosting random convolutional network framework. IEEE Trans Geosci Remote Sens 54(3):1793–1802
Zhang C, Zhu G, Huang Q et al (2017) Image classification by search with explicitly and implicitly semantic representations. Inform Sci 376:125–135
Zhang W, Tang P, Zhao L (2019) Remote sensing image scene classification using CNN-CapsNet. Remote Sens 11(5):494
Zhang J, Yang K, Constantinescu A et al (2021) Trans4Trans: efficient transformer for transparent object segmentation to help visually impaired people navigate in the real world. International Conference on Computer Vision, 1760–1770
Zhang C, Wang Y, Zhu L et al (2021) Multi-graph heterogeneous interaction fusion for social recommendation. ACM Trans Inform Syst (TOIS) 40 (2):1–26
Zheng Y, Jiang YG, Xue X (2012) Learning hybrid part filters for scene recognition, European conference on computer vision. Springer, Berlin, pp 172–185
Zhou B, Khosla A, Lapedriza A et al (2016) Places: an image database for deep scene understanding, arXiv:1610.02055
Zhu Q, Zhong Y, Liu Y et al (2018) A deep-local-global feature fusion framework for high spatial resolution imagery scene classification. Remote Sens 10(4):568
Funding
This paper was supported in part by the Fundamental Research Funds for the Central Universities of China under Grant 3132019340 and 3132019200. This paper was supported in part by high tech ship research project from ministry of industry and information technology of the people’s republic of China under Grant MC-201902-C01.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare no conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lv, G., Dong, L., Zhang, W. et al. A global-local feature adaptive fusion network for image scene classification. Multimed Tools Appl 83, 6521–6554 (2024). https://doi.org/10.1007/s11042-023-15519-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15519-2