
Abstract
Recently, most existing learning-based fusion methods are not fully end-to-end, which still predict the decision map and recover the fused image by the refined decision map. However, in practice, these methods are hard to predict the decision map precisely. Inaccurate prediction further degrades the performance of fusing, resulting in edge blurring and artefacts. This paper proposes an end-to-end multi-focus image fusion model based on conditional generative adversarial network (MFFGAN). In MFFGAN, we introduce a pioneering use of the conditional generative adversarial network to the field of image fusion. Moreover, we introduce the simple and efficient relativistic discriminator to our network, so the network converges faster. More importantly, MFFGAN is fully trained in this adversarial relationship to produce visually perceptive images that contain rich texture information and avoid the post-processing phase. Considering the detailed information of source images, we introduce the widely used perceptual loss to improve fused image performance. Thanks to the element-wise fusion criterion, our model can conveniently and efficiently fuse multiple images. Additionally, extensive experimental results show that the proposed model achieves excellent performance in subjective and objective evaluations.
Similar content being viewed by others
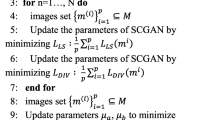
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Multi-focus images are different images of the same scene captured with a different focus in the cameras, which cannot have all information of the scene [37]. The multi-focus image fusion is an effective way to integrate the clear parts of multiple input images into one comprehensive all-in-focus image. Therefore, the fused image is more appropriate for human or machine perception. Vast researchers for multi-focus image fusion have been studied in the recent years and can be roughly classified into two categories of spatial-based domains and transform domain-based methods [18, 21, 23, 40, 47, 50].
In the transform domain-based methods, Discrete Cosine Transform (DCT) [37] and Multi-Scale Transform (MST) [22, 51] are most often employed. In general, these methods first utilize a transform tool to decompose the source images into other domains, then integrate all decomposition coefficients by selecting different fusion rules, and finally reconstruct the fused image by implementing a reverse transform. The image decomposition schemes and fusion rules matter in transform domain-based methods. In the past two decades, this kind of methods achieved great success and widely applied to the multi-focus image fusion. However, the hand-crafted fusion rules or decomposition schemes of the transform domain-based methods are often hard to optimize and are not robust, and thus could not achieve the optimal fusion result when selecting an unsuitable fusion rule or decomposition scheme.
Compared with the transform domain-based methods, the spatial domain-based methods produce the fused image directly by merging the clear pixels, blocks or regions from the source images in the spatial domain. These parties avoid the complex and time-consuming step of decomposition and reconstruction, thereby protecting the information of the input images from being lost. Several methods are introduced for spatial domain in recent years, including guided filtering-based (GFF) [21] and homogeneity similarity-based (HS) [17]. All of them detect the focused regions from the pixel perceptive to generate an initial decision map and then refine it to obtain the final decision map. However, many of these methods always fail to develop an ideal decision map, especially in the boundary between focus and defocus regions, which create artifacts and image blurring.
In recent years, deep learning has received widespread attention and profound success in various fields [7, 19, 25]. In the area of image fusion, Liu et al. [23] constructed a two-layer decomposition image fusion algorithm using convolutional sparse representation (CSR). Convolutional neural networks (CNNs), an important role in deep learning, were first used to fuse multi-focus images [24]. Liu et al. used labelled patches to train the Siamese CNN [45] framework to predict the decision map (MFCNN). In [4], Du et al. extend MFCNN [24] to the multi-scale CNN framework. The authors first used multi-scale input to train the CNN and then applied morphological operations and a watershed algorithm to generate decision maps. More recently, Wen et al. [40] presented a two-channel CNN combined with smoothing filtering for the fusion task. In [8], Guo et al. performed multi-focus image fusion through the conditional generative adversarial networks [28]. This work employed the generator G to construct initial decision maps and used the discriminator D to distinguish the generator-produced decision map from the human-annotated decision map. They also introduced convolutional conditional random fields (ConvCRFs) [36] to refine the initial decision map. However, they all require complex post-processing procedures to refine the initial decision map. Figure 1 illustrate the fusion process diagram of these methods.

The fusion process diagram of other methods
To solve the problem, Zhang et al. [48] proposed a general end-to-end image fusion framework based on CNN (IFCNN). This work first adopted a well-trained convolutional layer to extract a large number of low-level features and used a subsequent convolutional layer to adjust the feature properties. The features of the two source images were directly fused by the element-wise fusion rules. In the end, the fused image is reconstructed from two convolutional layers. In [42], Xu et al. present a unsupervised and unified densely connected network (FusionDN) for image fusion task. The three-channel image (usually RGB) first converted them from RGB to YCbCr color space and then fed the Y channel (luminance channel) into the model. However, these CNN-based fusion methods lack additional constraints that yield some blurred and color shifting effects.
Recently, the generative adversarial network (GAN) presented by Goodfellow et al. [6] has achieved great success in various computer vision task,such as image super-resolution [15], image synthesis [2] and image-to-image translation [49]. Original GAN [6] consists of two components: a generator G and a discriminator D. G aims to capture the data distribution while D tries to distinguish the sample generated by the generator rather than the ground-truth data. This model corresponds to a minimax two-player game optimized simultaneously. In order to control the mode of the generating data, Mirza et al. proposed the conditional generative adversarial nets (cGAN) [28], where both the G and D are conditioned on some additional information. This modification can increase the stability in training and enhance the descriptive power of G.
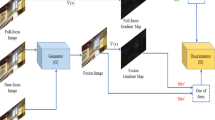
In this paper, in order to avoid the complicated post-processing procedure and produce high-quality fused results, we propose an end-to-end multi-focus image fusion model based on conditional generative adversarial network (MFFGAN), the architecture of which has been shown in Fig 2. As far as we know, this is the first time an end-to-end generative adversarial network has been used for multi-focus image fusion. We designed the generator network with convolutional layers and residual blocks and built the discriminator network based on VGG11 [35]. First, we use one well-trained convolutional layer and two residual blocks to extract extensive low-level features of the source images. Then the low-level features directly fuse by the element-wise fusion rule. Finally, we reconstruct the fused image in subsequent convolutional and residual blocks.
Moreover, we perform numerous experiments to verify the validity of the proposed model without any post-processing phase. Meanwhile, experimental results show that the proposed model achieves state-of-the-art performance in subjective and objective evaluations. To sum up, this thesis has three main contributions:
-
1.
We present an end-to-end cGAN-based method for multi-focus images fusion (MFFGAN), where the additional label and adversarial learning can facilitate the generator to produce high-quality fused results.
-
2.
We introduce relative discriminators and perceptual loss in the model to obtain better fusion performance and stable training procedures.
-
3.
To fully train the model, we synthesis a large-scale multi-focus image dataset, which is more natural and diverse than the pairs of entirely focused and thoroughly blurred patches.
The remainder of this paper is organized as follows. We detail our GAN model, loss function and training set in Section 2. In Section 3, we illustrate extensive experiments results and analysis. Finally, Section 4 present the conclusion.
2 Proposed method

The proposed multi-focus image fusion model via the residual generative adversarial network. Figure 2(a) illustrates the architecture of our generator network, consisting of convolutional layers and residual blocks. Figure 2(b) shows our discriminator network based on VGG11. These two form our MFFGAN model
2.1 Architecture
The proposed MFFGAN framework is shown in Fig. 2. We design a simple and effective conditional generative adversarial network (cGAN) to utilise the representative information of multi-focus images fully. Like original GAN [6], Our model includes a generator G and a discriminator D. In this part, the components of the proposed network architecture are described in details.
2.1.1 Generator
As shown in Fig. 2(a), the generator G has three components: feature extraction module, feature fusion module and image reconstruction module. G takes a pair of multi-focus images as input and outputs a fused result. The feature extraction module has two branches, each of which contains one convolutional layer and two residual blocks.
As known, feature extraction is an essential step in image fusion algorithms. However, it required a large number of computational resources to train a good feature extraction layer. To save training time and to extract valuable feature information, transferring a well-trained classification network parameter into our regression model would be a suitable approach [44]. Therefore, in the generator G, we use the first convolutional layer of ResNet101 [9] as our first layer Conv1 to extract low-level features. In ResNet101, the kernel size of the first convolutional layer is \(7 \times 7\), which aims to extract the feature roughly. To avoid affecting the performance of Conv1 during the training process, we fix its parameters. Nevertheless, there are some problems, such as we know that ResNet101 was initially used for classification tasks. The features extracted by Conv1 might be inappropriate to use for feature fusion directly, so we added two residual blocks (Block2, Block3) to tune the features to fit feature fusion better. Both residual blocks have a smaller filter size of \(3 \times 3\), padding of 1 and stride of 1. To couple the two branches together, the weights of the feature extraction module are shared. By adopting weight sharing among the feature extraction module, the number of parameters can be significantly reduced.
This paper aims to propose a residual GAN-based multi-focus image fusion model that can fuse dual-input or multi-input images. In general, many methods usually concatenated the convolutional features of multiple images in the channel dimension. However, when the number of input images varies, the feature fusion module parameters vary as well.
Therefore, when the fusion model structure is fixed, the model can only handle a fixed number of input images. To solve this issue, following [48], we use the elementwise fusion rule in feature fusion module, which contains no parameters and can fuse arbitrary input images. We expect sharp and precise edges and excellent perceptual quality in the final fused image for multi-focus image fusion. These salient objects manifest as sharp features (maximum values) in the feature maps [48]. Therefore, we choose the elementwise-maximum fusion rule for feature fusion.
where \(\phi ^{j}_{i}\) is the j-th feature map of the i-th image and \(\widehat{\phi ^j}\) is the fused feature map of the j-th channel by the elementwise-maximum fusion strategy. In the feature extraction phase, we used a convolutional layer and two residue blocks. Therefore, in the image reconstruction module, we also used two residual blocks and a convolutional layer to reconstruct the generated image of the fused features.
In the original GAN [6] model, the input features were restructured with downsampling layers to reduce redundancy and get more practical information. However, the downsampling layer inevitably loses the necessary information of the input image for image fusion, which affects the quality of the final fused image. Therefore, to keep the feature map size as the input image size, there is no downsampling layer in our end-to-end model. In both to satisfy the above conditions and to generate excellent fusion images, the detailed parameters of G are listed in Table 1. It should be noted that, unlike the typical residual block in other networks, according to [39], the batch normalization (BN) layer is prone to introduce artifacts during GAN model training. Hence, we remove BN layers from the residual blocks and use the better-performing parametric rectified linear unit (PReLU) [27] instead of the typical ReLU [29].
2.1.2 Discriminator
The architecture of our discriminator is shown in Fig. 2(b). The fused image \(I_f\) and the ground-truth image \(I_g\) are input for the discriminator. During the training procedure, the discriminator tries to calculate how the fused image relatively close to the ground-truth image and distinguish ground-truth images from images fused by the generator G.
Since image classification tasks require fewer computational resources than image generation, the discriminator structure is less complicated than that of the generator. We build our discriminator network based on VGG11 [35]. For the design of the discriminator, we make some changes based on VGG11. Five convolutional layers and five maximum pooling layers are used in the proposed network, with a BN layer after each convolutional layer. The BN layer can effectively speed up network training. All convolutional layers have the same parameter settings as VGG-11. For the activation function, we use the more efficient PReLU to adjust the degree of backpropagation leakage. We use a convolutional layer with a convolutional kernel size of \(1 \times 1\) to replace the VGG-11 network’s full connection layer for dimensionality reduction in the output layer. Thus, both the generator and the discriminator can be considered as fully convolutional networks that can accommodate different sizes of input images.
2.2 Loss function

Schematic illustration of building the training set according to Section 2.3. (a) is an RGB image in the PASCAL VOC 2012 [5], and (b) is the corresponding labelled segmented image. (c) is the decision map from the labelled segmented image. (d) is the all blurred image by the Gaussian kernel, (e) and (f) are a pair of multi-focus images
Loss functions are a vital part of deep learning, and setting up a proper loss function contributes to improved model performance and faster convergence. l2 loss is widely used in network training. However, it tends to produce images that are too smooth and lose high-frequency details. Compared with l2 loss, l1 loss can be chosen for more significant features but is challenging to optimize. In this work, to obtain a satisfactory fused image and accelerate convergence, we perform the robust Charbonnier loss [14] to train our model. We employ image loss to constrain the pixel intensity distribution between the fused image and the ground truth image. The image loss function \(Loss_i\) can be expressed as
where \(I_{f}\) and \(I_{g}\) indicate the fused image and corresponding ground-truth image, respectively, based on experience, the penalty coefficient \(\varepsilon\) is set as \(10^{-3}\).
Moreover, we introduce the perceptual loss [11] to add mored high-level global features into the fused image. The perceptual loss is defined as the difference of the high-level feature map between the fused image \(I_f\) and the ground-truth image \(I_g\). the perceptual loss \(Loss_p\) is expressed as
where \(\psi _{f}\) and \(\psi _{g}\) denote the feature maps of \(I_f\) and \(I_g\), respectively. Here, the feature map extracted from the 5-th max-pooling layer is used to calculate the perceptual loss.

The Lytro dataset [31], a public test set widely used for multi-focus image fusion evaluation
In [11, 48], the authors used features extracted from a pre-trained VGG-net [35] or ResNet101 [9] to calculate the perceptual loss. However, VGG-net and ResNet101 were pre-trained on the ImageNet [3], without containing multi-focus images. In this work, we expect the discriminator to distinguish between high-level features of fused images and ground truth images (i.e., fuzzy image information and clear texture information). Thus, using the pre-trained VGG-net for target detection and image classification as our discriminator network is problematic. We used generated and ground-truth images to train the discriminator to extract relatively efficient high-level features compared to the pre-trained VGG-Net. This is the reason why the discriminator, instead of VGG-Net, is used to extract high-level features. Therefore, the perceptual loss computed by feature maps of our discriminator.
The adversarial loss function is essential for the GAN model. We adopt the simple relativistic discriminator [12] as our adversarial loss to improve fusion performance. The adversarial loss \(Loss_{ad}\) as follows
where \(C(\cdot )\) denote the non-linear transformation of the discriminator, \(D\big (I_{real},I_{fake}\big )\) is the probability that the fake image relatively close to the real image, in which the real data is labelled as 1. The adversarial loss for discriminator \(Loss_D\) is in a symmetrical form
Then, the total loss of the generator \(Loss_G\) is given by
where we use the weight parameters \(\alpha\) and \(\beta\) to balance the different items in \(Loss_G\).

2.3 Training set
It is well known that the GAN models’ training process is data-driven and requires a great deal of data. For the multi-focus image fusion task, only nine pairs of multi-focus images exist in the publicly labelled dataset [34] that we know of, which is inadequate for training the GAN model.
However, manually labelling datasets is time-consuming and inefficient. According to previous reports in the literature, multi-focus image datasets are more accessible to generate than other types of image datasets, which can be viewed as a simulation of a focus-to-defocus scene. Due to optical imaging principles, the focal length of the lens is fixed in the case of a set of images, the focus region is sharp, and the defocus region is blurry. Therefore, combining a focused foreground region with a defocused background region is a reasonable way to obtain multi-focus images. In contrast, we use a focused background region and a defocused foreground region to form another one.
According to the above approach, we must resolve the separation of foreground and background in natural RGB images and simulate the defocus situation to make it as close as possible to the real defocused image. In [48], sing random blurring and dynamic thresholding, Zhang et al. generated a high-resolution multi-focus image dataset online on the NYU-D dataset [30] in the training phase. In [8], Guo et al. created a dataset containing about 6,000 pairs multi-focus images in the PASCAL VOC 2012 dataset [5] using manually labeled segmented images and ground-truth images. However, the NYU-D dataset contains only indoor images, missing natural images of outdoor, animal, and other scenes. So in our study uses the PASCAL VOC 2012 dataset to generate a sizeable multi-focus image dataset more rationally and intuitively.
Our multi-focus image generation process is as follows. First, we select the manually segmented image and convert it into a binary image which is the decision map \(I_d\). The pixel value of the object is set to 1, and the remaining pixel value is set to 0. To balance the ratio of focused and defocus areas, we set the dynamic threshold of the focus area and the defocus area in the image to 0.4-0.6. Second, to simulate a realistic defocus scene, we use the Gaussian filter to blur the source image randomly, expressed as
where \(*\) indicates the convolutional operator and G is the Gaussian filter. G can be expressed as
where \(\sigma\) denotes the standard deviation of the Gaussian filter and ksize is a parameter to control the kernel size. In order to simulate all defcous scenes, we set the kernel size ksize ranges from 3 to 17. \(\sigma = 0.6 \times (ksize -1 ) + 0.8\) and \(i = 1 \cdots (ksize -1 )\), \(\alpha\) is the scale factor chosen for achieving \(\sum G(i) = 1\). Third, according to Eq. 11, we generate a pair of foreground-focused and background-focused images from the source image \(I_s\), the Gaussian blur image \(I_b\), and the decision image \(I_d\).
In Eq. 11, \(\odot\) denotes the dot multiplication operator and \(\mathbf {1}\) is a all-ones matrix which has the same size with \(I_d\).
Finally, we randomly crop and flip the multi-focus image pair \(I_1\), \(I_2\) and the source image \(I_s\) to expand the training set. For each collection of images, we randomly crop on a scale of 0.5 to 1, then resize to \(224 \times 224\). In the end, these resized images are randomly flipped.
Compared to the previous synthetic dataset, we generate a more natural multi-focus image dataset. Our dataset has more diverse multi-focus images sufficient to cover all focus-to-defocus scenarios due to random cropping and flipping. During the training process, we use the corresponding source image \(I_s\) as the ground truth image \(I_g\), which is beneficial for achieving better results with our model. In Fig. 3 shows an example from our training set with its source image and manually segmented image. Furthermore, we summarize the multi-focus image data set generation method in Algorithm 1. Overall, we build a multi-focus image training set with higher resolution, more blurring styles, and fused images with ground-truth images compared to previous datasets. Thus, our MFFGAN model can be trained sufficiently well under the training set.
2.4 Training details
To improve fusion performance and keep the training process stable, we set up the training process differently for the generator and the discriminator. The details of the training process we summarize in Algorithm 2. Under our large-scale high-resolution dataset, the generator G per-trains 200 epochs under the image loss \(Loss_i\), and the batch size is set to 16. At this point, the generator G is already able to produce better fusion images. We introduce the discriminator D to form the MFFGAN model. At this stage, we use \(Lss_G\) and \(Loss_D\) to optimize the model’s parameters G for 600 epochs. Due to the enormous computational resources required during fine-training, the minibatch was reduced from 16 to 8. The pre-training phase consumed about 12 hours and the follow-up training took about 40 hours during the whole training process. Adam [13] optimizer is used to update parameter, and its momentum set as 0.9. For the learning rate setting, the basic learning rate for generator and discriminator are respectively set to \(4 \times 10^{-4}\), \(8 \times 10^{-4}\) and decays exponentially. In the loss function, the parameters \(\alpha\) and \(\beta\) are empirically set as 0.1 and 0.01. PyTorch [32] was used to implement our model with a RTX 2080Ti GPU.

3 Experimental results and analysis
In this section, we have done extensive experiments to validate the performance of the proposed image fusion model. Firstly, the experimental settings are briefly described, then qualitative and quantitative results are illustrated and discussed, and more analysis of our model is made in the end.

Visual comparison on the first pair of Lytro dataset. In this and following figures, at the bottom right of each subfigure, we show the highlighted image in red box
3.1 Experimental setup
To validate the efficacy of the proposed model, We compare our MFFGAN wtih nine state-of-art fusion methods (i,e, NSCT [46], NSCT-SR [20], CSR [23], FusionDN [42], GFF [21], LPSR [22], GCF [41], DenseFuse [16], and IFCNN-baseline [48]. In these methods, NSCT, NSCT-SR, GFF and LPSR are traditional methods. CSR, FusionDN, GCF, DenseFuse and IFCNN are deep learning methods. Specifically, IFCNN and FusionDN are end-to-end image fusion models. All the fusion methods test on the Lytro dataset [31], shown in Fig. 4.
To objectively evaluate the quality of fused images, many evaluation metrics have been proposed in recent years. In this paper, we employ six metrics to evaluate the performance of different methods, including normalized mutual information (NMI) [10, 26], nonlinear correlation information entropy (NCIE) [38], gradient-based fusion metric (G) [43], spatial frequency (SF) [33], standard deviation (SD), and the sum of the correlations of differences (SCD) [1]. \(Q_{NMI}\) is an index based on information entropy to reflect the information correlation between the original image and the fused image. \(Q_{NMI}\) and \(Q_{NCIE}\) are information entropy-based metrics that reflect the information correlation between the source image and the fused image. \(Q_G\) and \(Q_{SF}\) assesses the feature information transferred from source image pairs to the fused image. \(Q_{SD}\) and \(Q_{SCD}\) reflect the information distribution and contrast of the fused images, respectively. For all metrics, larger values mean better image quality.

Visual comparison on the fifth pair of Lytro dataset
3.2 Subjective evaluation of the methods
In this section, we exhibit three multi-focus images pairs from the Lytro dataset [31] to examine our approach versus other methods performance visually. The fusion results of different results are shown in Figs. 5, 6 and 7.
In Fig. 5(a) and (b) are the source image pairs, which captured a man playing golf on the grass. (c)-(l) show the results of the nine fusion algorithms and our MFFGAN. Ideally, we would like to combine the foreground-focused clear man’s hair and cloth in Fig. 5(a) and background-focused clear grass and flagship court in Fig. 5(b) into the fusion image. The results of NSCT, NSCT-SR and CSR show many burrs around the edges of the stripes. It is possible that the processing of the decomposition coefficients in the image reconstruction has led to the introduction of some noise. In Fig. 5(e) and (i), GFF and GCF fail to fuse the precise edges into the fusion image in the highlighted image. In Fig. 5(h), the result of FusionDN suffers from severe color distortion, which might be caused by the model trained with infrared images. Figure 5(j) shows that the DenseFuse result is fuzzy and lacking texture information. Through careful observation, LPSR, IFCNN and our MFFGAN present better visual quality and more salient features.
Figure 6(a) and (b) show a pair of multi-focus images of a female volleyball player observing from outside the fence. We expect to integrate the chain edge in the foreground, and the people detail in the background into the fusion image. In Fig. 6(c), (d), (g), (e), (j) and (i) we can see some noise on the boundaries between the chain link and people. In DenseFuse, we can see that there present evidence blur and loss of detail. Figure 6 shows FusionDN integrates the salient features into fused result, but the color shift is noticeable. In the end, LPSR, IFCNN and proposed method show the sharp edge and achieve better performance.
In Fig. 7, NSCT and DenseFuse still reveal the weak performance while other methods provide better-fused results. Also, in Fig. 7(d)-(g), there is some blurring effect around the koala (see the closeups). In Fig. 7(h), FusionDN also has a color shift problem in the sea and fails to fuse the background information into the fusion image. Compared to other methods, IFCNN and our MFFGAN blends the foreground and background images into the fused image well and maintains better texture information.

Visual comparison on the 14th pair of Lytro dataset
3.3 Objective evaluation of the methods
The six metrics mentioned in section 3.1 are used to evaluate fusion performance qualitatively. The average evaluation scores for ten methods on the public dataset are listed in Table 2. In this and the following tables, the values in blod font indicate the best results for the corresponding metric rows and the underlined values denote the second-best outcome. It fully demonstrates the effectiveness of the proposed method on multi-focus image fusion in quantitative analysis.
3.4 More analysis
1) Ablation study on the number of residual blocks: It is well known that the representational ability of the network grows stronger as the network deepens. However, the deepening of the network leads to an enormous amount of parameters, which affects the model’s running time. Table 3 presents the objective metrics and runtime of the MFFGAN model with different numbers of residual blocks on the public dataset. Obviously, MFFGAN with two blocks and three blocks outperforms MFFGAN with one block in terms of all metrics. Also, MFFGAN with three is only slightly improved over MFFGAN with two blocks but consumes the most average fusion time. To balance performance and runtime, we adopt two residual blocks in the feature extraction module and image reconstruction module to build the proposed MFFGAN model.
2) Dual-image and multi-image runtimes: When the sensor acquires information about the scene, it usually gets multiple images instead of two images. In industry and vehicles, we want to get fused images quickly and accurately. So the runtime is a significant indicator for multiple input image fusion. This section calculates the average runtime on Lytro datasets [31] and list them in Table 4. All experiments are performed on the platform with Intel i7-8700 CPU and NVIDIA 2080Ti GPU. The first row of the table represents the average fusion time of two images for each method, and the second row represents the average fusion time of three images. Except for GFF, IFCNN and our MFFGAN, all other methods have to fuse multi-input images sequentially. Runtime increases linearly with the number of images, which seriously affects the industrial application of image fusion. Our method gets the second-fastest running time of all methods and can fuse multiple images quickly due to the elementwise fusion rule.
3) Ablation study on batch normaliztion: It is well known that the batch normalization (BN) layer plays a critical role in CNNs. The BN layer accelerates the network training process and avoids overfitting problems. In GAN networks, however, the BN layer tends to introduce artifacts [39]. To demonstrate the negative effect of the BN layer on GAN networks, we conduct an experiment to test the MFFGAN (without BN layer), compared with the MFFGAN with BN layer. We can observe from Table 5 that the MFFGAN without BN layer outperforms model with BN layer in terms of all metrics.
4) Validation of perceptual loss: In this section, we experiment to confirm the perceptual loss that can improve the fusion performance in our model. Note that “Without perceptual loss” refers to MFFGAN without perceptual loss and BN layer. As shown in Table 5, MFFGAN with perceptual loss outperforms MFFGAN without perceptual loss in all metrics.
5) Validation of GAN: In this subsection, we designed an experiment to prove the GAN model’s superiority. In Sect. 2.4, we introduce discriminators into the model during fine-training to form a GAN model. Then, we train the generator network separately and compute the perceptual loss in the fine-training phase with a pre-trained VGG11. In this way, we prepare a CNN model train with the same settings as the generator G. The results are shown in Table 6, where our GAN model exceeds the CNN model on all metrics. The superiority of the GAN model in the image generation direction is demonstrated.
4 Conclusion
This paper proposes an end-to-end image fusion model based on generative adversarial networks (MFFGAN). The proposed model cloud computing to provide fast and efficient image fusion algorithms. We use elementwise-max fusion rules to fuse image features, so our model can easily fuse multiple input images. In the model training phase, we fully trained our MFFGAN using a large-scale high-resolution diverse training set. Introducing perceptual loss and relative discriminators into our model improves training stability and visual quality of fused images. The experimental results show that our MFFGAN outperforms state-of-the-art algorithms in qualitative and quantitative evaluation and runtime. The proposed model is designed to fuse the multi-focus images, thus designing the specific architecture and feature fusion rule might enable the image fusion module to deal with the different target image dataset.
References
Aslantas V, Bendes E (2015) A new image quality metric for image fusion: The sum of the correlations of differences. AEU Int J Electron Commun 69(12):1890–1896
Chen J, Luo S, Xiong M, Peng T, Zhu P, Jiang M, Qin X (2020) Hybridgan: hybrid generative adversarial networks for mr image synthesis. Multimed Tools Appl Applications 79(37), 27615–27631
Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L (2009) Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conf Compu Vis Pattern Recognit pp 248–255
Du C, Gao S (2017) Image segmentation-based multi-focus image fusion through multi-scale convolutional neural network. IEEE Access 5(99):15750–15761
Everingham M, Eslami S, Gool L, Williams C, Winn J, Zisserman A (2015) The pascal visual object classes challenge: A retrospective. Int J Comput Vision 111(1):98–136
Goodfellow I (2016) Nips 2016 tutorial: Generative adversarial networks
Goodfellow I, Bengio Y, Courville A (2016) Deep learning. MIT press
Guo X, Nie R, Cao J, Zhou D, Mei L, He K (2019) Fusegan: Learning to fuse multi-focus image via conditional generative adversarial network. IEEE Trans Multimedia 21(8):1982–1996
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: 2016 IEEE Conf Comput Vis Pattern Recognit (CVPR) vol 2016-, pp 770–778
Hossny M, Nahavandi S, Creighton D (2008) Comments on’information measure for performance of image fusion’. Electron Lett 44(18):1066–1067
Johnson J, Alahi A, Li FF (2016) Perceptual losses for real-time style transfer and super-resolution. arXivorg
Jolicoeur-Martineau A (2018) The relativistic discriminator: a key element missing from standard gan. arXivorg
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. arXiv preprint arXiv:14126980
Lai WS, Huang JB, Ahuja N, Yang MH (2019) Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans Pattern Anal Mach Intell 41(11):2599–2613
Ledig C, Theis L, Huszar F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z, Shi W (2017) Photo-realistic single image super-resolution using a generative adversarial network. arXivorg
Li H, Wu X (2019) Densefuse: A fusion approach to infrared and visible images. IEEE Trans Image Process 28(5):2614–2623
Li H, Chai Y, Yin H, Liu G (2012) Multifocus image fusion and denoising scheme based on homogeneity similarity. Opt Commun 285(2):91–100
Li Q, Yang X, Wu W, Liu K, Jeon G (2018) Multi-focus image fusion method for vision sensor systems via dictionary learning with guided filter. Sensors 18(7):2143
Li Q, Lu L, Li Z, Wu W, Liu Z, Jeon G, Yang X (2019) Coupled gan with relativistic discriminators for infrared and visible images fusion. IEEE Sens J
Li S, Yang B, Hu J (2011) Performance comparison of different multi-resolution transforms for image fusion. Information Fusion 12(2), 74–84
Li S, Kang X, Hu J (2013) Image fusion with guided filtering. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society 22(7), 2864–75
Liu Y, Liu S, Wang Z (2015) A general framework for image fusion based on multi-scale transform and sparse representation. Information Fusion 24:147–164
Liu Y, Chen X, Ward RK, Wang ZJ (2016) Image fusion with convolutional sparse representation. IEEE Signal Process Lett 23(12):1882–1886
Liu Y, Chen X, Peng H, Wang Z (2017) Multi-focus image fusion with a deep convolutional neural network. Information Fusion 36:191–207
Liu Y, Chen X, Wang Z, Wang ZJ, Ward RK, Wang X (2018) Deep learning for pixel-level image fusion: Recent advances and future prospects. Information Fusion 42:158–173
Liu Z, Blasch E, Xue Z, Zhao J, Laganiere R, Wu W (2011) Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: a comparative study. IEEE Trans Pattern Anal Mach Intell 34(1):94–109
Maas AL, Hannun AY, Ng AY (2013) Rectifier nonlinearities improve neural network acoustic models. In: Proc ICML vol 30, p 3
Mirza M, Osindero S (2014) Conditional generative adversarial nets
Nair V, Hinton GE (2010) Rectified linear units improve restricted boltzmann machines. In: ICML
Nathan Silberman PK Derek Hoiem, Fergus R (2012) Indoor segmentation and support inference from rgbd images. In: ECCV
Nejati M, Samavi S, Shirani S (2015) Multi-focus image fusion using dictionary-based sparse representation. Information Fusion 25:72–84
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L et al (2019) Pytorch: An imperative style, high-performance deep learning library. arXiv preprint arXiv:191201703
Qu G, Zhang D, Yan P (2002) Information measure for performance of image fusion. Electron Lett 38(7):313–315
Saeedi J, Faez K (2013) A classification and fuzzy-based approach for digital multi-focus image fusion. Pattern Analysis and Applications 16(3), 365–379
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings, International Conference on Learning Representations, ICLR
Teichmann MT, Cipolla R (2018) Convolutional crfs for semantic segmentation. arXiv preprint arXiv:180504777
Vakaimalar E, Mala K et al (2019) Multifocus image fusion scheme based on discrete cosine transform and spatial frequency. Multimed Tools Appl 78(13):17573–17587
Wang Q, Shen Y, Jin J (2008) Performance evaluation of image fusion techniques. Image Fusion: Algorithms and Applications 19:469–492
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Qiao Y, Change Loy C (2018) Esrgan: Enhanced super-resolution generative adversarial networks. In: The European Conference on Computer Vision (ECCV) Workshops
Wen Y, Yang X, Celik T, Sushkova O, Albertini MK (2020) Multifocus image fusion using convolutional neural network. Multimed Tools Appl
Xu H, Fan F, Zhang H, Le Z, Huang J (2020a) A deep model for multi-focus image fusion based on gradients and connected regions. IEEE Access 8:26316–26327
Xu H, Ma J, Le Z, Jiang J, Guo X (2020b) Fusiondn: A unified densely connected network for image fusion. In: AAAI, pp 12484–12491
Xydeas C, Petrovic V (2000) Objective image fusion performance measure. Electron Lett 36(4):308–309
Yan H, Yu X, Zhang Y, Zhang S, Zhao X, Zhang L (2019) Single image depth estimation with normal guided scale invariant deep convolutional fields. IEEE Trans Circuits Syst Video Technol 29(1):80–92
Zagoruyko S, Komodakis N (2015) Learning to compare image patches via convolutional neural networks. In: Proc IEEE Conf Comput Vis Pattern Recognit vol 07-12-, pp 4353–4361
Zhang Q, Long Guo B (2009) Multifocus image fusion using the nonsubsampled contourlet transform. Signal Process 89(7):1334–1346
Zhang Y, Bai X, Wang T (2017) Boundary finding based multi-focus image fusion through multi-scale morphological focus-measure. Information Fusion 35:81–101
Zhang Y, Liu Y, Sun P, Yan H, Zhao X, Zhang L (2020) Ifcnn: A general image fusion framework based on convolutional neural network. Information Fusion 54:99–118
Zhao Y, Zheng Z, Wang C, Gu Z, Fu M, Yu Z, Zheng H, Wang N, Zheng B (2020) Fine-grained facial image-to-image translation with an attention based pipeline generative adversarial framework. Multimed Tools Appl pp 1–20
Zhou Z, Li S, Wang B (2014) Multi-scale weighted gradient-based fusion for multi-focus images. Information Fusion 20:60–72
Zhou Z, Wang B, Li S, Dong M (2016) Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with gaussian and bilateral filters. Information Fusion 30:15–26
Acknowledgements
This work was supported in part by the Sichuan University under grant 2020SCUNG205.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mao, Q., Yang, X., Zhang, R. et al. Multi-focus images fusion via residual generative adversarial network. Multimed Tools Appl 81, 12305–12323 (2022). https://doi.org/10.1007/s11042-021-11278-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11278-0