
Abstract
In this paper, we propose an energy-efficient joint video encoding and transmission framework for network lifetime extension, under an end-to-end video quality constraint in the Wireless Video Sensor Networks (WVSN). This framework integrates an energy-efficient and adaptive intra-only video encoding scheme based on the H.264/AVC standard, that outputs two service differentiated macroblocks categories, namely the Region Of Interest and the Background. Empirical models describing the physical behavior of the measured energies and distortions, during the video encoding and transmission phases, are derived. These models enable the video source node to dynamically adapt its video encoder’s configuration in order to meet the desired quality, while extending the network lifetime. An energy-efficient and reliable multipath multi-priority routing protocol is proposed to route the encoded streams to the sink, while considering the remaining energy, the congestion level as well as the packet loss rates of the intermediate nodes. Moreover, this protocol interacts with the application layer in order to bypass congestion situations and continuously feed it with current statistics. Through extensive numerical simulations, we demonstrate that the proposed framework does not only extend the video sensor lifetime by 54%, but it also performs significant end-to-end video quality enhancement of 35% in terms of Mean Squared Error (MSE) measurement.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the recent developments in CMOS technology, tiny low-cost imaging sensors have been developed. As a result, the sensor nodes are able to capture visual information, which enhance all the previous sensor-based applications, especially those that are monitoring-oriented. Hence, a new derivative of the Wireless Sensor Networks (WSN), which is the Wireless Video Sensor Network (WVSN) [6, 28], has been introduced. The sensor nodes are constrained in terms of memory, processing, and the most important resource: the energy. In a WVSN, the generated visual information is huge, compared to the case of WSN, and needs to be processed prior to transmission. This operation is commonly called the compression or the encoding. The energy consumed during this processing has to be taken into account [6]. According to the literature [21], the video compression task can consume about 2/3 of the total power for video communications over wireless channels. For these reasons, energy-efficient compression schemes adapted to the WVSNs are needed.
Another important issue in the WVSNs that is strongly recommended [28], for efficient data communication, is the differentiated service paradigm. For example, based on the relevance of the video data, the routing protocol may provide differentiated treatments to the packets, by achieving high reliability only to the most significant packets. In general, achieving more reliability in a WVSN means consuming more energy. Therefore, thanks to this paradigm, significant amount of energy may be conserved. In fact, this feature should be first introduced at the application layer and is afterwards respected at the lower layers. This interaction between layers is formally called the Cross-Layering. It is considered as the most efficient solutions’ design to deal with the stringent constraints of the WVSN [11], and to meet the application’s requirements with a low complexity.
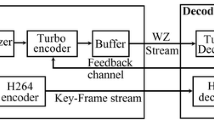
In this paper, a novel energy-efficient and cross-layer designed framework for video delivery over WVSN is proposed. This approach involves three layers: application, routing and MAC. We adopt an energy-efficient and adaptive intra-only video compression scheme dedicated to the WVSNs, in the application layer. Actually, this video compression scheme, which was first proposed in our previous work [7], is based on the H.264/AVC standard using intra-only coding mode. In this scheme, when an event occurs, the video encoder switches to a so called rush mode, adopts a higher Frame Rate (FR) and produces two service differentiated Macroblocks (MB) categories, namely the Region of Interest (ROI) and the Background (BKGD). Afterwards, a simple bit rate adaptation technique, called the Frequency Selectivity (FS), is applied to the BKGD in order to decrease the energy consumed during the transmission process. This operation is controlled by the Frequency Selectivity Parameter (FSP) that represents the number of the retained coefficients after the transform. A block diagram of the proposed video compression scheme in [7] is given in Fig. 1. This solution has proven that considerable energy is saved during the transmission process. However, the consumed energy during the encoding process was not considered.

Block diagram of the proposed video compression scheme [7]
The novelty of the paper compared to this previous work is that we propose here empirical models in line with the physical behavior of the energies and the distortions measured during the video encoding and transmission phases. The proposed models are expressed as functions of three controlling parameters of the video encoder [7] which are the FR, the Quantization Parameter (QP) and the FSP. To the best of our knowledge, this is the first work that proposes models considering this particular combination of controlling parameters. Using the proposed models, the video source node may predict these energies and distortions and then adapt its video encoder’s configuration in order to decrease the global energy consumption, while meeting the desired video quality. In addition, as second major original contribution, we propose a novel Energy-efficient and Reliable Multipath Multi-priority routing protocol (ERMM) to handle the encoded video streams. In fact, ERMM considers the neighboring nodes whose the Remaining Energy (RE) is above the average, then estimates their reliability using a proposed metric, in order to deliver High Priority (HP) and Low Priority (LP) packets (i.e. ROI and BKGD) according to the desired reliability. Moreover, this protocol interacts with the application layer (i.e. video encoder) in order to bypass congestion situations and continuously feed it with current statistics. In addition, this protocol relies on the cooperation of the MAC layer as well, in order to guarantee the differentiated service, by giving the high priority packets higher chances to access the shared medium and to keep track of the current loss rates.
The main contributions of this paper can be summarized as follows: (i) empirical models for predicting the energy consumption and the distortion during the video encoding and the transmission phases are derived and evaluated, (ii) a new energy-efficient and reliable multipath multi-priority routing protocol that serves each packet according to the region which its payload data belongs (i.e. ROI or BKGD) is proposed, (iii) a novel framework that integrates and defines the interactions between all of the presented components, for network lifetime extension under a desired end-to-end video quality distortion, is described and (iv) an extensive evaluation of the proposed framework in terms of energy-efficiency, reliability, delay, and video quality is exposed.
The remainder of this paper is organized as follows. Section 2 presents a review of the cross-layer approaches and frameworks dedicated to the WVSNs. In Section 3, empirical models for predicting the energy consumption and the distortion caused by the encoding and the transmission phases are derived then validated. These models are used by the video encoder representing the first component of our framework. In Section 4, the second component of the framework, namely the proposed ERMM routing protocol is detailed. Section 5 explains the interactions between the different proposed components of the framework. In Section 6, the proposed framework is evaluated in terms of energy consumption, reliability, delay and video quality. Finally, the paper is concluded in Section 7.
2 Related works
We investigate in this section the most relevant and recent works proposing cross-layer approaches for WVSNs. In [23], Politis et al. propose a cross-layer approach involving the application and the routing layers. In the application layer, they adopt the classical implementation of the H.264/AVC standard for the video compression at the source node. In order to compensate the energy drained during this phase, the well known LEACH [18] protocol for clustering is first used. In addition, they introduce two packet scheduling algorithms, namely Baseline and Power aware, that selectively drop packets and track the video distortion generated by this drop by a proposed recursive distortion prediction model. However, the authors in [23] did not consider the energy consumed during the compression phase, especially when inter-prediction is performed.
Aghdasi et al. [4] present a cross-layer approach influencing the application, the transport and the network layers. The authors introduce the prioritization paradigm by generating two service differentiated frames using a proposed encoder called Modified-MPEG. The transport protocol uses inter-layer command messages to be aware of the network status. The packets’ retransmissions are prohibited to perform real-time video transmission. A single path routing protocol based on hop-by-hop negotiation with a selected parent is adopted. However, there is no clear distinction between the energy consumed for the transmission and the encoding. Moreover, prohibiting retransmissions as well as multipath routing have a negative impact on the reliability performances, especially in the WVSN.
A framework for image transmission with priority routing is presented by Felemban et al. [14]. In the application layer, they perform data prioritization using a bit planes based separation. For routing, the authors choose as the next hop, the neighbour whose the number of hops from the sink is the least. In MAC layer, a priority based enqueuing/dequeuing procedure is introduced. However, choosing the next hop following only one dimension metric with no load balancing mechanisms, results in concentrating the load on specific nodes, leading to their quick death. Additionally, no energy consumption evaluation of the framework is presented.
In [26], the authors propose a cross-layer framework that interconnects the application, network and MAC layers. In the application layer, the Wyner-Ziv lossy distributed source coding is used at the sensor node with variable group of pictures size. The models for predicting the distortion caused by the encoding and the packet loss are also provided. Then, the generated frames are routed using a source directed multipath routing. For service differentiation, the IEEE 802.11e MAC [3] layer is adopted and packets containing I-Frames data are given the HP, while those containing W-Frames data are processed with LP. This work is quite similar to our proposal in large, but the specific objective is different. Our work aims to extend the network lifetime under a video quality constraint, while the authors in [26] aim to maximize the capacity of the deployed network. Nevertheless, they do not provide a model for video encoding energy consumption.
The issue of network lifetime extension under a video quality constraint is addressed in [15] and [30]. In [15], the authors present a distributed algorithm for maximizing the network lifetime by jointly optimizing the source rates, the encoding powers, and the routing scheme. In fact, they first consider the energies consumed as well as the distortions of both transmission and encoding phases in the formulation of the optimization problem. Then, Lagrangian duality is used to solve this problem. The authors in [30] propose a framework for source and channel rate adaptation, where the energy consumption of source and network encoding, error control and data communication are considered. In fact, models for predicting these quantities are proposed. Thereafter, a weighted convex optimization problem is formulated to be decomposed into a two-level optimization procedure. The Lagrangian duality is also used for solving this problem.
3 Video encoder’s prediction models
This section focuses on the mathematical tools used by the framework’s first component (i.e. the video encoder). Actually, these tools are empirical models enabling the video encoder to dynamically select the appropriate configuration, with the concern of decreasing the energy consumption while meeting a desired end-to-end video quality. The unique mathematical model that describes well the energy consumption and the video distortion is used in [15] and [30], and was first proposed in [17]. Nevertheless, the authors in [16] highlight that their analytical approach described in [17] cannot be easily extended to other video encoders such as H.264/AVC standard. Hence, they propose in [16] an operational approach for off-line energy consumption analysis and modelling, which can be applied to generic video encoders. It consists on the consideration of the parameters that are responsible for consuming more or less energy during the video signal compression. In our case, these parameters are the FR, the QP and the FSP.
In the present work, we adopt an intra-only encoder based on the H.264/AVC standard. Motivations behind this choice are twofolds. First, it is well-known that motion estimation and compensation are highly complex procedures. In fact, according to the experiments presented in [5], conducted on Stargate/Telos video sensor nodes, the computational energy depletion constitutes the major portion (more than 90%) of the total energy consumption as compared to the bit transmission energy. In addition, the inter coding with motion estimation consumes more than 10 times the energy drained by the intra coding. Hence, choosing intra-only coding mode significantly limits energy consumption of ressource-limited video nodes. In order to decrease the high bit rate generated by this mode, we compensate it by using the frequency selectivity and adopting lower frame rate. Second, intra-only coding avoids error propagation across successive frames, hence preserving video quality. Therefore, there is no temporal losses propagations. Moreover, the Flexible Macroblock Ordering (FMO) tool [20], which is provided by the H.264/AVC standard, is used to separately encode two regions in each frame. Hence, the ROI is protected from spatial losses propagations occurred in the BKGD and vice-versa.
To the best of our knowledge, no prior work has proposed models for energy and distortion prediction for the encoding and transmission phases, considering this particular combination of controlling parameters, for an intra-only H.264/AVC based video encoder. Therefore, in order to derive appropriate models, extensive tests were carried out for energy and distortion measurements using several video sequences, on a PC with an Intel 2.93 GHz Core 2 Duo processor. The ITU-T recommends for the selection of appropriate test sequences to consider the Spatial Information (SI) and the Temporal Information (TI) of the scenes [19]. In fact, these parameters reflect the compression difficulty as well as the level of impairment that is suffered when the scene is transmitted. Furthermore, it is important to choose sequences that span a large portion of the spatial-temporal information plane [19]. Specifically, we use eight video sequences, Hall, Foreman, Soccer, Ice in QCIF resolution (176 × 144), and Bus, City, Stefan and News in CIF resolution (352 × 288). Figure 2 illustrates the distribution of the test video sequences over the spatial-temporal information plane. As can be seen, the considered set of sequences covers a large area, showing its SI-TI diversity. In fact, according to Fig. 2, this set includes video sequences representing contents with a moderate TI and SI ranging from low to high (i.e. City, Foreman, Ice, News, Stefan and Bus), while others represent contents with a moderate SI and TI ranging from low to high (i.e. Soccer, Foreman, Ice and Hall). One can expect that only the SI index is relevant since intra-only coding is performed. However, the TI index also matters since error concealment at the decoder is performed by slice copy from the previous decoded frame, as further discussed in Section 3.2.

The coverage of the considered video sequences over the spatial-temporal information plane
Each sequence is encoded at 14 different QPs and 16 different FSPs at 30 fps using our modified JM18.4 implementation of the H.264/AVC standard, as illustrated by the Fig. 1, in its baseline profile. In the rest of the paper, the curves represent the models and the points correspond to the measurements. Due to the lack of space and for the sake of visibility, only four sequences and eight QPs are shown.
3.1 Energy consumption modelling
The video source node spends its lifetime encoding and transmitting the video streams. Therefore, the energy drained by a node E T o t a l can be approximated by:
where E E n c and E T r a n s refer to the consumed energy for encoding and transmitting the video stream respectively.
In our previous work [8], we only address the impact of FR and QP variations, on the encoding energy consumption of an intra-only H.264/AVC encoder. We have shown that the energy decreases by about the half when the Frame skip (Fskip) is increased by one (i.e. decreasing the FR by the half), which is an obvious behaviour. In this Section 3.1, we extend this approach by investigating and modelling the joint effect of QP and FSP variations on the consumed energy, for both video encoding and transmission phases.
3.1.1 Encoding energy modelling
The consumed energy for processing a specific task can be approached, as presented in [24], by a number of clock cycles dependent function, given as follows:
where N c y c is the number of clock cycles, C t o t a l is the average capacitance switched per cycle, V d d is the supply voltage, I 0 is the leakage current, freq is the clock speed, V T is the thermal voltage and n a processor dependant constant. On the other hand:
where T P r o c is the processing time of the task, which is in our case the encoding time returned by the encoder.
For reliable and accurate measurements, we control the running of the encoder to be in a real-time fashion and make it the only executed process in one microprocessor. Once the measurements are converted to energies, using the model of (2), they are normalized by the maximal consumed energy. The different coefficients of (2) are available on Intel’s website [1].
Points in Fig. 3 show the behaviour of the average normalized measured energy consumption during the encoding process for different QPs and FSPs over 200 realisations. For a given FSP, the normalized measured energy decreases when the QP increases. The same behaviour is observed when the FSP decreases for a given QP. Those behaviours can be explained by the fact that when increasing the QP and decreasing the FSP, more zero coefficients are generated, leading to a simple entropy coding scheme. Actually, the points in Fig. 3 illustrate the behaviour of (QP,FSP)-dependent coefficients that reduce the maximal energy reached for (QP m i n , FSP m a x ). For each QP, the maximal value of the coefficients is reached at FSP= F S P m a x , then decreases toward the minimal value reached at FSP= F S P m i n . These observations suggest that the (QP,FSP)-dependent coefficients, noted C E E (.), can be modelled by:

Measured (points) and predicted (curves) normalized encoding energy C E E (Q P,F S P). Curves are predicted values by the proposed model of (4)
Points in Fig. 4 report the measured α E E (Q P,F S P m a x ) that expresses the effect of the quantization on the normalized consumed energy during the encoding process. Actually, this was investigated in detail in our previous work [8], where all of the coefficients were kept, which corresponds to the (QP,FSP m a x ) configuration. We have seen that α E E (.) can be predicted by the following model:
where a is a content-dependent coefficient obtained by minimizing the Root Mean Squared Error (RMSE) between measured and predicted data. As shown in Fig. 4, the proposed model in (5) can predict the reduction coefficients α E E (.) accurately.

Measured (points) and predicted (curves) α E E (Q P,F S P m a x ). Curves are predicted values by the proposed model of (5)
Points in Fig. 5 reports the measured β E E (Q P,F S P), representing the introduced energy consumption reduction when decreasing the FSP for a given QP. According to the measured data in Fig. 5, the appropriate functional form for β E E (.) has to meet some conditions.

Measured (points) and predicted (curves) β E E (Q P,F S P). Curves are predicted values by the proposed model of (6)
First, when the FS is applied with the maximal FSP, no energy consumption reduction should be observed. Hence, the unique energy consumption reduction should be the one achieved by the quantization (5). Second, the more coefficients are retained in the FS phase, the less energy-efficiency there is. Finally, when the quantization becomes more severe, the effect of the FS becomes less important. Based on the above mentioned arguments, we propose the following functional form for β E E (.):
where \(QP_{norm}=\frac {QP}{QP_{max}}\), F S P ∗ is the dual of FSP (F S P ∗ = F S P m a x − F S P) and \(FSP^{*}_{norm}=\frac {FSP^{*}}{FSP^{*}_{max}}\). According to several tests, we conclude that c can be fixed to -1 and f fixed to 1.2. The parameters b and d are content dependent.
As can be seen in Fig. 5, the proposed model in (6) describes well the behaviour of β E E (QP,FSP). The overall model for estimating the energy consumed during the video encoding process, considering the QP and the FSP, can be formulated by:
Note that E E (Q P m i n ,F S P m a x ) depends mainly of the video content, the Q P m i n , the F S P m a x , the FR, as well as the microprocessor’s features. Curves in Fig. 3 show that the model, proposed in (4), describes well the consumed encoding energy during the encoding process with an average prediction error of 6% in terms of RMSE.
3.1.2 Transmission energy modelling
The energy consumed per bit during the transmission process is given by the well-known model proposed in [18]:
where 𝜖 f s is the energy consumed by the amplifier to transmit at short distance, E e l e c is the energy dissipated in the electronic circuit to transmit and receive the signal and d is the distance between the transmitter and the receiver. Based on this model, the energy consumed for transmitting, at a given distance d at a fixed 𝜖 f s and E e l e c , depends directly of the data rate generated by the encoder.
Points in Fig. 6 represent the collected normalized energy consumed during the transmission phase of the conducted tests. The first observation is that the joint effect of the quantization and the FS on the energy drained for encoding is approximately the same as the one of the energy drained for the transmission. The second one is that the achievable energy-efficiency by increasing the QP and decreasing the FSP is more important in the transmission than in the encoding, which is a logical result. The reason is that during the encoding process, even if the zero coefficients makes the CAVLC simpler, there is some energy that is dissipated for their processing (comparing, counting, …). Moreover, for transmitting the encoded signal, considerable energy-efficiency is observed due to the efficient encoding.

Measured (points) and predicted (curves) normalized transmission energy C T E (Q P,F S P). Curves are predicted values by the proposed model of (9)
Similar to Section 3.1, the points in Fig. 6 can be seen as the behaviour of (QP,FSP)-dependent coefficients that reduce the maximal energy reached also for (QP m i n ,FSP m a x ). For each QP, the maximal value of the coefficients is reached at FSP= F S P m a x , then decreases toward the minimal value reached at FSP= F S P m i n . These observations suggest that these (QP,FSP)-dependent coefficients, noted C T E (.), can be modelled by:
Points in Fig. 7 report the measured α T E (Q P,F S P m a x ), representing the effect of the quantization on the normalized consumed energy during the transmission process. As can be seen, α T E (.), similar to α E E (.), reaches its maximum at QP=QP m i n and its minimum at QP=QP m a x . However, α T E (.) decreases faster than α E E (.) and reaches minimal values approaching 0. Therefore, we propose to model α T E (.) as an exponentially decreasing function of QP, as follows:
where k is a content-dependent coefficient obtained by minimizing the RMSE between measured and predicted data. As shown in Fig. 7, the proposed model given by (10) can predict the reduction coefficients α T E (Q P,F S P m a x ) accurately.

Measured (points) and predicted (curves) α T E (Q P,F S P m a x ). Curves are predicted values by the proposed model of (10)
Points in Fig. 8 report the measured β T E (Q P,F S P) that introduce energy consumption reduction when decreasing the FSP for a given QP. According to the measured data on this figure, the appropriate functional form for β T E (.) has to meet the same conditions stated before, regarding the β E E (.). For these reasons, we have:
According to several tests, we conclude that c can be fixed to -0.1 and f fixed to 2. The parameters b and d are content dependent. From Fig. 8, we observe that the proposed model in (11) describes well the behaviour of β T E (.).

Measured (points) and predicted (curves) β T E (Q P,F S P). Curves are predicted values by the proposed model of (11)
The overall model for estimating the energy consumed during the video transmission process, considering the QP and the FSP, can be formulated by:
As shown in Fig. 6, the proposed model in (9) describes well the coefficients C T E (Q P,F S P), and hence the consumed energy during the transmission process with an average prediction error of 4% in terms of RMSE. The E T (Q P m i n ,F S P m a x ) depends of the radio module features, Q P m i n , F S P m a x , and FR.
3.2 Video distortion modelling
In the following, we derive models for video distortion prediction mainly caused by both the encoding and the transmission processes. The end-to-end video distortion D T o t a l can be approximated by:
where D E and D T refer to the distortion caused by encoding and transmitting the video stream respectively. Note that since intra-only coding is used, error propagation does not occur across frames. The distortion is expressed in terms of Mean Squared Error (MSE), and is given by:
where X is the frame of original video sequence, Y is the frame of compressed or received video sequence, m and n are frame width and height respectively.
3.2.1 Encoding distortion modelling
The distortion introduced by the encoding process can be expressed as a function of the QP and the FSP. Since we adopt a pixel level measure, the FR does not affect the video quality.
Points in Fig. 9 report the normalized measured encoding distortion. Unlike the encoding energy, increasing the QP and decreasing the FSP lead to an increase of the video distortion, which is an obvious behaviour. In fact, when the quantization and the FS are severe, more relevant information is lost. This affects directly the measured quality that drops dramatically. Note that the normalization is done by the maximal encoding distortion value, reached for (QP m a x ,FP m i n ).

Measured (points) and predicted (curves) C E D (Q P,F S P). Curves are predicted values by the proposed model of (15)
Points in Fig. 9 can be seen as the behaviour of (QP, FSP)-dependent coefficients that reduce the maximal distortion reached for (QP m a x ,FSP m i n ). For each QP, the maximal value of the coefficients is reached at FSP= F S P m i n , then decreases toward the minimal value reached at FSP= F S P m a x . These observations suggest that the coefficients C E D (.) can be modelled by:
Points in Fig. 10 report the measured α E D (Q P,F S P m i n ), containing the effect of the quantization on the normalized distortion caused by the encoding process. Unlike α E E (.), α E D (.) reaches its maximum at QP= QP m a x and its minimum at QP= QP m i n . In addition, α E D (.) observes a quasi-stationary phase until a given QP is reached, where α E D (.) sharply increases. Therefore, we propose to model α E D (.) by:
where a 0 is the normalized measured encoding distortion for (QP,FSP)= (0,1) and n is a content-dependent coefficient obtained by minimizing the RMSE between measured and predicted data. As shown in Fig. 10, the proposed model in (16) can predict the reduction coefficients α E D (Q P,F S P m i n ) accurately.

Measured (points) and predicted (curves) α E D (Q P,F S P m i n ). Curves are predicted values by the proposed model of (16)
Points in Fig. 11 report the measured β E D (Q P,F S P) that introduce encoding distortion reduction when increasing the FSP for a given QP. According to the measured data on this figure, the appropriate functional form for β E D (.) has to meet the following conditions. First, when the FS is applied with the minimal FSP, no encoding distortion reduction should be observed. Hence, the unique encoding distortion reduction should be the one due to the quantization, given by (16). Second, the more coefficients are retained in the FS phase, the less encoding distortion there is. Finally, when the quantization becomes more severe the effect of the FS becomes less important. Based on these observations, we propose the following functional form of β E D (.):
where p, g and h are model parameters. According to several tests, h can be set to 0.41.

Measured (points) and predicted (curves) β E D (Q P,F S P). Curves are predicted values by the proposed model of (17)
The overall model for estimating the video distortion due to the encoding process, considering the QP and the FSP, can be formulated by:
As can be observed in Fig. 9, the proposed model in (15) can generate the coefficients C E D (Q P,F S P) and thus estimate the encoding distortion with an average prediction error of 4% in terms of RMSE.
3.2.2 Transmission distortion modelling
Another factor affecting the video quality is the packet loss during the transmissions. The introduced distortion, D T , is mainly dependent on the adopted encoding methodology (e.g. inter or intra) as well as the Packet Loss Rate (PLR). The PLRs are continuously provided by the network layer.
The introduced distortion due to the loss of a packet k can be estimated by the following widespread model [29]:
where E[D (R,k)] and E[D (L,k)] are the expected distortions when the packet k is either correctly received or lost, respectively. ρ k is the loss probability of the packet k.
In the earlier video coding standards, intra pixels are coded directly using transform coding. In the H.264/AVC standard, intra-prediction is applied by first predicting the current MB using previously coded neighbouring pixels in the current frame, then the prediction error is coded using transform coding. Therefore, when a packet belonging to a given slice is lost, the next MBs cannot be retrieved. For this purpose, in this paper, we perform partially or entire past frame slice copy loss concealment at the decoder, depending on the number of lost MBs.
Accordingly, when any packet is lost, the expected distortion E[D (L,k)] is caused by the frame loss concealment E[D (C o n,k)]. This last can be easily approximated at the encoder by the average difference between two successive frames, which is directly related to the inherent TI of the video sequence. When the packet is received, the distortion E[D (R,k)] is caused by the channel errors. In the present work, we assume that the packets are either lost or correctly received, hence E[D (R,k)] = 0. Thereafter, (19) becomes:
Finally, the frame level distortion can be approximated by:
where D n refers to the distortion at frame n, and N is the number of the frame’s packets. We introduce a temporal loss effect propagation factor λ that represents the introduced distortion caused by the concealment from previous concealed frames.
For model validation, since none of the few H.264/AVC real trace datasets available in the literature use the intra-only prediction mode, we adopt a two-state Markov chain model to generate bursty packet loss patterns, characterizing the WVSN [15]. This model is widely used to simulate the packet loss patterns in wireless sensor networks [10, 12, 15]. The average PLR is given by [15]:
where P G B and P B G correspond to the transition probability from the Good to the Bad state, and from the Bad to the Good state, respectively [15].
Using this model, we generate 200 packet loss patterns for each PLR . The results are reported in Fig. 12. The proposed model approaches well the measured average distortions with an average prediction error of 9% in terms of RMSE.

Measured (points) and predicted (curves) D T . Curves are predicted values by the proposed model of (21)
4 ERMM routing protocol
This section focuses on the second component of the proposed framework, which acts at the network and MAC layers. Actually, we propose an energy-efficient routing protocol integrating the differentiation service paradigm, to efficiently handle the encoded video stream. The proposed routing protocol performs a hop-by-hop routing decision strategy that offers more scalability and flexibility to network topology and traffic changes. This protocol is actually inspired by the well known MMSPEED [13] protocol, that is considered as a reference routing protocol for the Wireless Multimedia Sensor Networks in general [6] and is used in many recent research works in both WSN and WVSN communities [22, 25]. Therefore, we aim in this section to revisit the MMSPEED protocol in order to improve its reliability and energy-efficiency, and introduce interactions with the application layer to suit the context of the WVSN. The proposed ERMM protocol operates under the same assumptions as the MMSPEED protocol [13].
4.1 Reliability measure enhancement
In the following, we first define some terms that will further be used, then propose an enhanced reliability measure. Table 1 lists the relevant notations and variables for this algorithm. The first one is the Next-Hop Candidates (NHC) set, regrouping the nodes within the communication range and closer to the sink S than the current node i, and it is formulated as follows:
where d i s t(i,S) and d i s t(j,S) are Euclidean distances between i and S, j and S respectively, and N S i is the neighbourhood set that contains the one-hop reachable neighbours. The reliability of a candidate node j is defined in [13] by:
where P L R i j is the average rate of the lost packets sent to j. Equation (24) expresses the probability that the packet reaches the node j, then the sink S after \(\frac {dist(j,S)}{dist(i,j)}\) approximative hops separating j and S. Usually, the radio conditions vary along the path. However, in order to operate in a decentralized architecture, where the node has information about only its neighborhood, the P L R i j is assumed to be constant over the needed hops to reach the sink S.
We propose here an enhancement of this reliability measure of (24) by considering the \(PLR^{l}_{ij}\), referring to the achieved average loss rate regarding a given packet priority l, in addition to the Available Buffer Size (ABS) A B S l of the node j. In fact, the A B S l gives an information about the chances of the packet to be buffered in the next-hop node, independently of the success or not of the transmission. Therefore, in ERMM, the node’s reliability is expressed as follows:
where E R M(j) is the Enhanced Reliability Measure (ERM) of the node j for the packet priority l given by:
where I B S l is the Initial Buffer Size (IBS) of the priority queue l.
The Total Reaching Probability (TRP) as presented in [13], allows to estimate the chances that a packet has to reach the sink, when it is relayed over multiple paths from a given source i and it is formulated as follows:
4.2 Neighbouring tables establishment and maintenance
The proposed routing protocol is stateless and operates on the basis of local information to dynamically construct paths toward the destination. For neighbouring tables establishment, the nodes broadcast packets during a given period NE (i.e. Neighbouring Establishment) after network deployment. These packets contain their unique identifier (ID) and the three-dimensional coordinates referring to their respective location. Upon the reception of these messages, each node stores the ID and the coordinates of its neighbours. For neighboring tables maintenance, the nodes periodically broadcast control packets containing their respective ID, three-dimensional coordinates, RE and ABS in each level of the priority queue.
Upon the reception of each control packet, the node updates the entry of the concerned node and checks the validity of all of its entries. Thanks to the adopted IEEE 802.11e MAC layer [3], the nodes have also local statistics about the achieved PLR for each packet priority level P L R l.
4.3 The routing algorithm
Figure 13 presents the flowchart of the proposed routing algorithm. The first step is the establishment of the NHC set, knowing the sink’s coordinates. Selecting candidates in such a manner allows the convergence of the packet toward the destination. Afterwards, the Average RE (A v g R E) among the NHC set is computed as follows:
where N is the size of NHC set and the RE is obtained from the neighbouring table. Accordingly, two subsets are created on the basis of the so estimated A v g R E, namely the N H C H A v g and the N H C L A v g , which contain the nodes with RE higher and lower than the A v g R E respectively. Next, for each node j of the N H C H A v g subset, a score considering its reliability \(RP^{S}_{ij}\) and its distance from the current node i is calculated as follows:
where \(RP^{S}_{ij}\) is obtained by (25) and τ is a control coefficient obtained through simulations. Considering at first stage the nodes with residual energy higher than the average (i.e. the N H C H A v g subset) aims to select the best neighbouring nodes in terms of energy, hence performing higher energy efficiency and load balancing. Taking the d i s t(i,j) into account allows to consider neighbours close to the node i. Hence, shorter delays can be performed since the congestion level, represented by the ABS, is also taken into consideration. The nodes are then sorted according to these scores. The nodes are then selected according to their score and injected one by one in (27) until the TRP reaches the desired reliability that depends on the packet’s priority. The packet is then sent to these nodes.

ERMM routing algorithm’s flowchart
Whenever the nodes belonging to N H C H A v g are not sufficient to overcome the specified PLR, the N H C L A v g subset is used. In this situation, it is of greater importance to seek reliability than the timeliness. Therefore, the nodes belonging to N H C L A v g subset are sorted according to their \(RP^{S}_{ij}\), then injected one by one in (27) to enhance and reach the desired reliability. If all the nodes in N H C L A v g are used and the TRP is still lower than the desired reliability (i.e. 1 − P L R D e s i r e d ) by a given Percentage Threshold PT, the packet is discarded. Here, the node detects a congestion situation and notifies the source node in order to decrease the packet rate until the TRP becomes reachable for the following packets. In addition, the video source node decreases its video encoder’s FR in accordance. When PT of the desired reliability is achieved, the packet is sent to the considered nodes.
4.4 Underlying MAC layer
Now that the next-hops are selected, the packet is relayed to the MAC layer to be further transmitted. If the MAC layer is already receiving or sending a packet, the current packet is enqueued according to its priority in the appropriate queue. The MAC layer continuously reports the ABS as well as the average PLR of each priority to the network layer.
In order to efficiently report the event to the sink during the rush mode, the event’s data has to be prioritized across the network. This is achieved using the Enhanced Distributed Coordination Function (EDCF) provided by IEEE 802.11e standard. In the following, we assign the ROI in the rush mode to the HP, while the BKGD and the standby mode are assigned to the LP access categories. We denote the \(PLR^{HP}_{Current}\) and \(PLR^{LP}_{Current}\) the last stored PLR for the HP and LP packets respectively.
5 Framework overview
In this section, we introduce the proposed framework which concern is to reduce the overall energy consumption while meeting a user’s desired end-to-end video quality. Actually, the proposed framework is designed with respect to the WVSN constraints (i.e. energy efficiency, video quality, reliability, bandwidth) and hence could be adopted for video surveillance applications using the WVSN, in energy-constrained environments such as the wildlife and the Smart Cities. We deem for a practical realization of the framework, a camera such as the LILIN IPD2220ES [2] could be used, since it adopts the H.264/AVC standard with ROI/BKGD separation and offers controllable multiple Frame Rates and bit rates (QP). Hence, given a video quality constraint and the observed node’s remaining energy, the video encoder of our framework begins by estimating the actual transmission distortion, then it seeks the appropriate configuration in terms of the triplet (FR,QP,FSP), using the models of Section 3. Afterwards, the encoded video stream is routed with service differentiation and energy-efficiency towards the destination, using the proposed routing protocol in Section 4. The relevant notations and variables for the framework are listed in Table 1.
Specifically, during the standby mode, each frame is encoded with intra-only prediction following a given initial FR denoted by F R S t a n d . Given the \(PLR^{LP}_{Current}\), the node could approach the transmission video distortion using the model in (21). Consequently, the allowed encoding distortion is deduced. Afterwards, thanks to the encoding distortion model of (18), a solution set of QPs and their corresponding FSPs is constructed. Now, each couple is evaluated in terms of energy consumption, by using the models of (7) and (12). Afterwards, the node chooses the couple (QP,FSP) minimizing the energy consumption. On the basis of the estimated total energy consumption of the selected configuration, denoted Q P + and F S P +, the node decides whether it could compress and transmit the stream or not. If the RE in the node is greater than the required energy by a given threshold ET, the node may encode the video stream and relay it to the network layer. In the opposite case, the node decreases the adopted F R S t a n d and re-evaluate the required encoding and transmission energies in an iterative manner. When the lower permitted F R m i n is reached, the node increases the selected Q P +, then re-evaluates the encoding and transmission energies until the maximal permitted Q P m a x is attained. If the node is still incapable of performing the encoding, it turns-off the video module and remains as a relaying node.
In the rush mode, a higher initial F R R u s h is adopted. In Fig. 14, the flowchart explains the adopted procedure when two priorities coexist. This procedure is similar to the one proposed for the standby mode, with a minor adaptation. In fact, in the rush mode, the ROI and the BKGD are encoded using the same QP. By using the models of (18) and (21), in addition to the respective PLRs (i.e. \(PLR^{HP}_{Current}\) and \(PLR^{LP}_{Current}\)), the node separately deduces the couples (QP,FSP) satisfying the distortion constraint of each region. Afterwards, the node selects the shared QPs and their respective FSPs. Finally, by using the models of (7) and (12), the node evaluates the energy consumption of each couple and selects those minimizing the total energy consumption. The selected configuration is denoted Q P +, \(FSP^{+}_{ROI}\) and \(FSP^{+}_{BKGD}\).

Rush Mode flowchart
Once the video stream is encoded, the data is relayed to the network layer. The ERMM routing is then preformed as explained in Section 4.
6 Performance evaluations
In order to validate the proposed cross-layer framework, we conduct several tests using our modified JM18.4 implementation of the H.264/AVC standard. The video sequence Coastguard is used, in QCIF spatial resolution at 30 fps, with (SI,TI)=(126,34). This QCIF format is composed of 99 MBs of 16x16 pixels. Since we choose to simulate the transmission of a fixed number of 3 MBs per packet, each frame is split into 33 packets.
The proposed cross-layer designed framework is composed of two major elements: (i) a video encoder performing dynamic encoding parameter selection via the prediction models of Section 3 and (ii) the ERMM routing protocol of Section 4. Therefore, we divide the current section into two subsections. In Section 6.1, we provide a view at the scale of one video source node by evaluating the impact of the dynamic selection of the video encoding parameters in terms of energy efficiency and video quality. Section 6.2 provides a view at the scale of a WVSN deployed to perform video surveillance of a given field, with the concern of delivering video streams to the sink, under a given quality constraint while extending the network lifetime as much as possible. Therefore, the overall framework is evaluated in terms of delay, reliability, energy-efficiency and video quality.
In this paper, we propose off-line models for the prediction of energy consumption and distortion, for which some parameters are content dependent. We propose as a first approach to select the models’ parameters values on the basis of the (SI,TI) index. Consequently, the corresponding models parameters values of the nearest training video sequence in terms of SI and TI are selected, which corresponds in this case to News video sequence.
In Table 2, we report the different parameters used for the simulations.
6.1 Video source node evaluation
In this Subsection, we evaluate the behaviour of the video source node implementing our proposed encoding scheme. Therefore, we compare this last against a basic one. The basic encoding scheme consists in using the H.264/AVC intra-only encoder with FMO option to generate the ROI and the BKGD. The QP is set to 40 and the FR for standby and rush mode are set to 3.75 and 7.5 respectively. The initial F R s t a n d and F R R u s h for the proposed framework are also set to 3.75 and 7.5 respectively. The targeted maximal distortion, in terms of MSE, is fixed at 500. In this evaluation, we alternate three standby modes and three rush modes, as illustrated in Figs. 15, 16 and 17. In these figures, a round consists in collecting the current PLR regarding the packet priority P L R C u r r e n t , encoding the video signal, then transmitting it. For fair comparison, for each round the encoding schemes are subject to the same randomly generated P L R C u r r e n t .

Total energy consumption

Average end-to-end distortion after loss concealment

Runtime parameter values
Figure 15 shows the energy consumed by the video source node for encoding and transmitting the video signal. The proposed encoding scheme outperforms the basic one and extends the source node lifetime. In fact, this behaviour can be explained by the fact that the proposed encoding scheme adapts its configuration according to the available energy. Hence, when needed, the node decreases the encoder’s FR and progressively increases the QP in order to decrease the energy consumption and meet the desired quality. In addition, as can be seen in the end of our scheme’s Standby mode3, when the RE reaches the specified threshold ET, the node turns off its video module and remains as a relay node. In fact, this is done in order to maintain the network connectivity as long as possible. The observed average source node lifetime extension over these rounds is about 54%. This extension is of great interest specially to avoid as much as possible critical situations, such as node death during reporting an event (i.e. Fig. 15 in Rush mode2).
Figure 16 shows the average end-to-end video distortion after concealment for both schemes. While the basic scheme uses constants QP and FR values, the proposed scheme adapts its configuration according to the current PLR, desired end-to-end video distortion and the node’s RE. We observe that, for the proposed scheme, considering node’s RE during the encoding process allows the node to remain available for more video encodings and transmissions. Moreover, when the RE becomes lower, the node tends to increase the distortion, while meeting the targeted video quality, to save energy as illustrated in Fig. 16 during the Standby mode3.
In Fig. 17, we report the adopted configuration by the proposed scheme at runtime. This encoding scheme selects, during the standby modes, higher Q P + to save energy while providing acceptable video quality. During the rush modes, the \(FSP^{+}_{BKGD}\) are lower than the \(FSP^{+}_{ROI}\) to compensate the energy drained for the selected Q P + in order to meet the desired quality.
6.2 Framework evaluation
In the following, we evaluate the proposed framework in terms of energy-efficiency, reliability, delay and end-to-end video quality. The used protocols and the proposed models are implemented in the JSIM [27] simulator. We use the energy model of a wireless AT&T Wavelan PCMCIA card implemented in the simulator.
In Table 2, we report the different parameters used for the simulations. We consider 100 nodes randomly deployed in an area of interest where a given number of them are video nodes. The evaluation consists in a sequence of two standby modes separated by one rush mode, under a distortion constraint of 300. We study the impact of the number of video source nodes on the framework performance over 100 realizations. In each realization, the number of the video source nodes is fixed while their positions and the instants when they start sending are randomly chosen. We make sure that the sending periods overlap in order to evaluate the reaction of the framework in presence of a congestion situation. In addition, the proposed framework is compared against a basic one composed of the above described basic encoding scheme and the MMSPEED [13] routing protocol.
In Fig. 18, we present the average Packet Delivery Ratio (PDR) over the 100 realizations. Both frameworks are able to provide service differentiation to the HP and LP packets, thanks to the adopted 802.11e MAC layer. However, by considering the congestion level information estimated by the neighbour’s average loss rate in addition to its current ABS, the proposed ERMM protocol integrated in our framework provides higher PDR for HP and LP packets. Moreover, when needed, our framework decreases the packet generation rate (i.e. P R S M or P R R M ) to relieve the network. Nevertheless, our approach provides the desired PDR up to 12 video source nodes for the LP stream, against 8 video source nodes for the basic framework. For the HP stream, the desired PDR of 75% is achieved up to 20 video source nodes, while it is provided only up to 10 video source nodes for the basic framework. In average, the PDR provided by our framework exceeds the one obtained by the basic framework by about 12% and 20% for the HP stream and LP stream respectively.

Average packet delivery ratio while varying the number of video source nodes
Figure 19 exposes the average remaining energy of the network over the 100 realizations. This energy decreases while the number of video source nodes increases, which is an obvious behaviour. As shown in Section 6.1, our framework saves a significant amount of energy at the video source node level. When combining our encoding scheme to the ERMM protocol, additional energy is saved during the routing process. Hence, the overall network lifetime is extended by about 15%.

Average remaining energy while varying the number of video source nodes
In Fig. 20, we report the obtained results in terms of delay over the 100 realizations. We observe that the basic framework offers a delay reduction of 3% for the HP stream and 15% for the LP stream. This behaviour is mainly caused by including the delay metric in the MMSPEED protocol, while the ERMM protocol aims to provide energy-efficiency and reliability. Nevertheless, the maximal delay of our framework does not exceed 1.2 s, which is bearable in a video-surveillance application.

Average delay while varying the number of video source nodes
The average end-to-end video distortion, over the 100 realizations, after concealment is given by Fig. 21. The proposed framework provides video quality with respect to the maximal distortion constraint, while the basic one offers this quality up to 10 video source nodes. In average, the video quality enhancement is about 35%, expressed by the decrease of the measured MSE for the proposed framework. This decrease is achieved thanks to the enhanced reliability of the proposed ERMM protocol, in addition to its interactions with the video encoder, that dynamically adapts its configuration to remain below the defined distortion threshold while extending the network lifetime.

Average end-to-end distortion after concealment while varying the number of video source nodes
Finally, for guidance, we report in Table 3 a comparative study between our proposed framework and some of the existing ones in the literature. In fact, performances comparison is not always obvious due to the fact that the simulation environment (i.e node’s initial energy budget, network density, number of video source nodes, available bandwidth, considered video distortions, considered consumed energies) varies from an approach to another.
Therefore, in Table 3, we present the average performance in terms of the considered energies, delay, PDR, number of video source nodes, the consumed energy for encoding and transmitting a video frame and the received video quality. As can be seen on Table 3, the proposed framework in average handles the tradeoff between network energy-efficiency and received video quality.
7 Conclusion
This paper proposed a novel framework for network lifetime extension under an end-to-end video distortion constraint, for video delivery over a WVSN. The proposed framework relies on the cooperation of an energy-efficient encoding scheme, based on the H.264/AVC standard, and an Energy-efficient and Reliable Multipath Multi-priority routing protocol. First, we derived empirical models for energy consumption and distortion prediction during the encoding and the transmission phases. Second, we integrated them to our proposed video encoding scheme to dynamically adapt its configuration on the basis of the underlying network layer’s feedbacks and the information about the remaining energy. Third, we proposed a routing protocol that considers the remaining energy, the packet loss rate and the available buffer size in nodes’ multi-priority queues, in order to perform differentiated service, reliable and energy-efficient routing. Simulation results, in terms of energy, reliability, video quality and delay proved the efficiency of the proposed framework. In fact, our framework achieves 35% of end-to-end video quality enhancement, expressed in terms of MSE decrease, and 54% of video source node lifetime extension, resulting in increasing by 15% the overall network lifetime.
References
Aghdasi H, Abbaspour M, Moghadam M, Samei Y (2008) An energy-efficient and high-quality video transmission architecture in wireless video-based sensor networks. Sensors 4529–4559. doi:http://dx.doi.org/10.3390/s8074529 10.3390/s8074529
Ahmad JJ, Khan HA, Khayam SA (2009) Energy efficient video compression for wireless sensor networks 43rd annual conference on information sciences and systems (CISS). doi:10.1109/CISS.2009.5054795. IEEE, pp 629–634
Akyildiz IF, Melodia T, Chowdury K (2007) Wireless multimedia sensor networks: A survey, vol 51
Alaoui-Fdili O, Coudoux F, Fakhri Y, Corlay P, Aboutajdine D (2013) Energy efficient adaptive video compression scheme for WVSNs The European signal processing conference. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6811596
Alaoui-Fdili O, Fakhri Y, Corlay P, Coudoux FX, Aboutajdine D (2014) Energy consumption analysis and modelling of a h.264/AVC intra-only based encoder dedicated to WVSNs The IEEE international conference on image processing. doi:10.1109/ICIP.2014.7025237, pp 1189–1193
Boluk PS, Baydere S, Harmanci AE (2011) Perceptual quality-based image communication service framework for wireless sensor networks. Wirel Commun Mob Comput 14(1):1–18. doi:10.1002/wcm.1218 10.1002/wcm.1218
Costa D, Guedes L, Vasques F, Portugal P (2014) Relevance-based partial reliability in wireless sensor networks. EURASIP J Wirel Commun Netw 2014(1):142. doi:10.1186/1687-1499-2014-142
Costa DG, Guedes LA (2011) A survey on multimedia-based cross-layer optimization in visual sensor networks. Sensors 11(5):5439–5468. doi:10.3390/s110505439
Costa DG, Guedes LA (2012) A discrete wavelet transform (dwt)-based energy-efficient selective retransmission mechanism for wireless image sensor networks. Journal of Sensor and Actuator Networks 1(1):3–35. doi:10.3390/jsan1010003
Felemban E, Chang-Gun L, Ekici E (2006) MMSPEED: multipath multi-speed protocol for QoS guarantee of reliability and. timeliness in wireless sensor networks. IEEE Trans Mob Comput 5(6):738–754. doi:10.1109/TMC.2006.79
Felemban E, Sheikh AA, Manzoor MA (2014) Improving response time in time critical visual sensor network applications. Ad Hoc Netw 23:65–79. doi:10.1016/j.adhoc.2014.06.003
He Y, Lee I, Guan L (2009) Distributed algorithms for network lifetime maximization in wireless visual sensor networks. IEEE Trans Circuits Syst Video Technol 19(5):704–718. doi:10.1109/TCSVT.2009.2017411
He Z, Eggert J, Cheng W, Zhao X, Millspaugh J, Moll R, Beringer J, Sartwell J (2008) Energy-aware portable video communication system design for wildlife activity monitoring. IEEE Circuits Syst Mag 8(2):25–37. doi:10.1109/MCAS.2008.923007
He Z, Liang Y, Chen L, Ahmad I, Wu D (2005) Power-rate-distortion analysis for wireless video communication under energy constraints. IEEE Trans Circuits Syst Video Technol 15(5):645–658. doi:10.1109/TCSVT.2005.846433
Heinzelman W, Chandrakasan A, Balakrishnan H (2000) Energy-efficient communication protocol for wireless microsensor networks The annual Hawaii international conference on system sciences. doi:10.1109/HICSS.2000.926982
IEEE std 802.11e/D3.3 draft supplement to IEEE standard for telecommunications and information exchange between systems – LAN/MAN specific requirements. part 11: Wireless lan medium access control (MAC) and physical layer (PHY) (2002). http://www.ece.virginia.edu/~mv/edu/el604/references/P802_11E-D1_3.pdf
Intel core2 duo processor. http://support.intel.co.jp/pressroom/kits/core2duo/
ITU-T RECOMMENDATION P (1999) Subjective video quality assessment methods for multimedia applications
Lambert P, Neve WD, Dhondt Y, de Walle RV (2006) Flexible macroblock ordering in H.264/AVC. J Vis Commun Image Represent 17(2):358–375. doi:10.1016/j.jvcir.2005.05.008 Introduction: Special Issue on emerging H.264/AVC video coding standard
LILIN IPD2220ES. http://www.ttsys.com/pdf/RFID/IPD2220ES-EN_TTS_v4.pdf
Lu X, Wang Y, Erkip E (2002) Power efficient H.263 video transmission over wireless channels The international conference on image processing. doi:10.1109/ICIP.2002.1038078, vol 1, pp 533–536
Macit M, Gungor VC, Tuna G (2014) Comparison of QoS-aware single-path vs. multi-path routing protocols for image transmission in wireless multimedia sensor networks. Ad Hoc Netw 19:132–141. doi:10.1016/j.adhoc.2014.02.008
Politis I, Tsagkaropoulos M, Dagiuklas T, Kotsopoulos S (2008) Power efficient video multipath transmission over wireless multimedia sensor networks. Mob Netw Appl :274–284. doi:10.1007/s11036-008-0061-5
Rui D, Pu W, Akyildiz I (2012) Correlation-aware QoS routing with differential coding for wireless video sensor networks. IEEE Trans Multimed 14(5):1469–1479. doi:10.1109/TMM.2012.2194992
Sahin D, Gungor VC, Kocak T, Tuna G (2014) Quality-of-service differentiation in single-path and multi-path routing for wireless sensor network-based smart grid applications. Ad Hoc Netw 22:43–60. doi:10.1016/j.adhoc.2014.05.005
Shah G, Liang W, Akan O (2012) Cross-layer framework for QoS support in wireless multimedia sensor networks. IEEE Trans Multimed 14(5):1442–1455. doi:10.1109/TMM.2012.2196510
Sobeih A, Hou J, Kung L, Li N, Zhang H, Chen W, Tyan H, Lim H (2006) J-sim: a simulation and emulation environment for wireless sensor networks. IEEE Wirel Commun 13(4):104–119. doi:10.1109/MWC.2006.1678171
Soro S, Heinzelman W (2009) A survey of visual sensor networks Adv Multimed. doi:10.1155/2009/640386
Zhai F, Eisenberg Y, Pappas T, Berry R, Katsaggelos A (2006) Rate-distortion optimized hybrid error control for real-time packetized video transmission. IEEE Trans Image Process 15(1):40–53. doi:10.1109/TIP.2005.860353
Zou J, Xiong H, Li C, Zhang R, He Z (2011) Lifetime and distortion optimization with joint source/channel rate adaptation and network coding-based error control in wireless video sensor networks. IEEE Trans Veh Technol 60(3):1182–1194. doi:10.1109/TVT.2011.2111425
Acknowledgements
This research was supported by the excellence fellowships program of the National Center for Scientific and Technical Research (CNRST) of Morocco (G01/003) and the Franco-Moroccan cooperation program in STICs for the research project “RECIF”.
The authors would also like to thank the editorial office Christian Malan, the editor-in-chief, the guest editors as well as the anonymous reviewers for their efforts and valuable comments and suggestions that have led to improvements in this paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Driss Aboutajdine died before publication of this work was completed.
Rights and permissions
About this article

Cite this article
Alaoui-Fdili, O., Coudoux, FX., Fakhri, Y. et al. Energy-efficient joint video encoding and transmission framework for WVSN. Multimed Tools Appl 77, 4509–4541 (2018). https://doi.org/10.1007/s11042-017-4904-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4904-6