
Abstract
Sign language is the only means of communication for speech and hearing impaired people. Using machine translation, Sign Language Recognition (SLR) systems provide medium of communication between speech and hearing impaired and others who have difficulty in understanding such languages. However, most of the SLR systems require the signer to sign in front of the capturing device/sensor. Such systems fail to recognize some gestures when the relative position of the signer is changed or when the body occlusion occurs due to position variations. In this paper, we present a robust position invariant SLR framework. A depth-sensor device (Kinect) has been used to obtain the signer’s skeleton information. The framework is capable of recognizing occluded sign gestures and has been tested on a dataset of 2700 gestures. The recognition process has been performed using Hidden Markov Model (HMM) and the results show the efficiency of the proposed framework with an accuracy of 83.77% on occluded gestures.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Sign language is a form of visual language that uses grammatically structured manual and non-manual sign gestures for communication [45]. Manual gestures include hand shape, palm’s orientation, location and movements, whereas non-manual gestures are represented by various facial expressions including head tilting, lip pattern, and mouthing [5, 38]. The language forms one of the natural means of communication among hearing impaired people. The goal of a Sign Language Recognition (SLR) system is to translate sign gestures into a meaningful text that helps persons without any speech or hearing disability can to understand sign language [24], hence, provides a natural interface for communication between humans and machines. A simple way to implement a SLR systems is based on tracking the position of hand and identifying relevant features to classify a given sign. This process of detecting and tracking the hand movements is relatively easier when compared with articulated or self occluded gestures and hand movements [18]. In literature, there exists a number of SLR systems proposed by various researchers for multiple sign languages including American [45], Australian [35], Indian [18], Spanish [15], and Greek [33], etc. However, most of the existing SLR systems require a signer to perform sign gestures in front of the capturing device, i.e., camera or sensor. These systems fail to recognize sign gestures correctly (i) when there is a change in the signer’s relative position with respect to the camera or (ii) when the signer performs the gestures in a different plane leading to some change in Y-axis orientation. Such a scenario is depicted in Fig. 1, where a signer performs a sign gesture with a rotation along Y-axis in the camera coordinate system that results into self occlusion and a distorted view of the gestures being acquired. Therefore, pose and position invariant hand gesture tracking and recognition system can be very much helpful to improve the overall performance of the SLR systems and makes them usable for real life scenario including real time gesture recognition involving multiple signers, sign word spotting, etc.

Body occlusion occurs when a signer performs (a) sign gesture with rotation along Y-axis (b) a distorted human torso of the performed sign
With the advancement in low-cost depth sensing technology and emergence of sensors such as Leap motion and Microsoft Kinect, new possibilities in Human-Computer-Interaction (HCI) are evolving. These devices are designed to provide 3D point cloud of the observed scene. Kinect provides a 3D skeleton view of the human body through its rich Software Development Kit (SDK) [39]. 3D skeleton tracking can successfully address the body part segmentation problem, therefore, it is considered highly useful in hand gesture recognition. Illumination variation related problems that are usually encountered in images captured using traditional 2D cameras, can be avoided using such systems. Kinect has been successfully used in various applications including 3D interactive gaming [4], robotics [28], rehabilitation [13] and hand gesture recognitions [18, 25, 30]. Zafrulla et al. [45] have developed an automatic SLR system using Kinect based skeleton tracking. The authors have utilized 3D points of the upper body skeletal joints and fed these features to Hidden Markov Model (HMM) for recognition purpose. However, their system suffers from tracking errors when the users remain seated. In such cases, the main challenge is to extract self occluded, articulated or noisy sign gestures that can be used to perform recognition. In this paper, we propose a new framework for SLR using 3D points of body skeleton that can be used to recognized gestures independently irrespective to the signer’s position or rotation with respect to the sensor. The main contributions to the paper are as follows:
-
(i)
Firstly, we present a position and rotation invariant sign gesture tracking and recognition framework that can be used for designing SLR. Our system observes all gestures independently by transforming the 3D skeleton feature points with respect to one of the coordinate axes.
-
(ii)
Secondly, we demonstrate the robustness of the proposed framework for recognition of self-occluded gestures using HMM. A comparative gesture recognition performance has also been presented using the HMM and SVM (Support Vector Machine) classifiers.
Rest of the paper is organized as follows. In Section 2, a chronological review of recent works in this field of study, is presented. System setup along the preprocessing and feature extraction are presented in Section 3. Experimental results are discussed in Section 4. Finally, we conclude with the future possibilities of the work in Section 5.
2 Related work
Hand gesture recognition is one of the basic steps of SLR systems. Handful of research work are being carried out in locating and extracting the hand trajectories. These work vary from vision-based skin color segmentation to depth-based analysis. To overcome the self-occlusion problem in hand gesture recognition, researchers have used multiple cameras to estimate 3D hand pose. Athitsos et al. [2] have proposed an estimation of 3D hand poses by finding the closest match between the input image and a large image database. The authors have used a database indexed with the help of Chamfer distance and probabilistic line matching algorithms by embedding binary edge images into a high dimensional Euclidean space. In [6], the authors have proposed a Relevance Vector Machine (RVM) based 3D hand pose estimation method to overcome the problem of self-occlusion using multiple cameras. The authors have extracted multiple-view descriptors for each camera image using shape contexts to form a high dimensional feature vector. Mapping between the descriptors and 3D hand pose has been done using regression analysis on RVM.
Recent development in depth sensor technology allows the users to acquire images with depth information. Depth cameras such as time-of-flight and Kinect have been successfully used by researchers for 3D hand and body estimation. Liu et al. [27] have proposed hand gesture recognition using time-of-flight camera to acquire color and depth images, simultaneously. The authors have extracted shape, location, trajectory, orientation and speed as features from the acquired 3D trajectory. Chamfer distance has been used to find the similarity between two hand shapes. In [34], the authors have proposed a gesture recognition system using Kinect. Three basic gestures have been considered in the study using skeleton joint positions as features. Recognition of gestures has been performed using multiple classifiers namely, SVM, Backpropagation Neural Network (NN), Decision Tree and Naive Bayes where an average recognition rate of 93.72% was recorded in their work. Monir et al. [32], have proposed a human posture recognition system using Kinect 3D skeleton data points. Angular features of the skeleton data are used to represent the body posture. Three different matching matrices have been applied for recognition of postures where a recognition rate of 96.9% has been observed with priority based matching. Another study of hand gesture recognition using skeleton tracking has been proposed in [31] using torso-based coordinate system. The authors have used angular representation of the skeleton joints and SVM classifier to learn key poses, whereas a decision forest classifier has been used to recognize 18 gestures. Almeida et al. [1] have developed one SLR system for Brazilian Sign Language (BSL) using Kinect sensor. The authors have extracted seven vision-based features that are related to shape, movement and position of the hands. An average accuracy of 80% has been recorded on 34 BSL signs with the help of SVM classifier. In [26], the authors have proposed a covariance matrix based serial particle filter to track the hand movements in isolated sign gesture videos. Their methodology has been applied on 50 isolated ASL gestures with an accuracy of 87.33%.
Uebersax et al. [41] have proposed the SLR system for ASL using time-of-flight (TOF) camera. The authors have utilized depth information for hand segmentation and orientation estimation. Recognition of letters is based on average neighborhood margin maximization (ANMM), depth difference (DD), and hand rotation (ROT). Confidences of the letters are then combined to compute a word score. In [37], the authors have utilized Kinect sensor to develop gesture based arithmetic computation and rock-paper-scissors game. They have utilized depth maps as well as color images to detect the hand shapes. Recognition of gestures has been carried out using a distance metric to measure the dissimilarities between different hand shapes known as Finger-Earth Mover’s Distance (FEMD). A Discriminative Exemplar Coding (DEC) based SLR system is proposed in [40] using Kinect. The authors have used background modeling to extract human body and hand segmentation. Next, multiple instance learning (MIL) has been applied to learn similarities between the frames using SVM, and AdaBoost technique has been used to select the most discriminative features. An accuracy of 85.5% was recorded on 73 sign gestures of ASL. Keskin et al. [17] have proposed a real time hand pose estimation system by creating a 3D hand model using Kinect. The authors have used Random Decision Forest (RDF) to perform per pixel classification and the results are then fed to a local mode finding algorithm to estimate the joint locations for the hand skeleton. The methodology has been applied to recognize 10 ASL digits, where an accuracy of 99.9% has been recorded using SVM. A Multi-Layered Random Forest (MLRF) has been used to recognize 24 static signs of ASL [23]. The authors have used Ensemble of Shape Function (ESF) descriptor that consist of a set of histograms to make the system translation, rotation and scale invariant. An accuracy of 85% has been recorded when tested on gestures of 4 subjects.
Chai et al. [5] have proposed the SLR and translation framework using Kinect. Recognition of gestures has been performed using a matching score computed with the help of Euclidean distance. The methodology has been tested on 239 Chinese Sign Language (CSL) words, where an accuracy of 83.51% has been recorded with top 1 choice. A hand contour model based gesture recognition system has been proposed in [44]. Their model simplifies the gesture matching process to reduce the complexity of gesture recognition. The authors have used pixel’s normal and the mean curvature to compute the feature vector for hand segmentation. The methodology has been applied to recognize 10 sign gestures with an accuracy of 96.1%. A 3D Convolutional Neural Network (CNN) has been utilized in [14] to develop a SLR system. The model extracts both spatial and temporal features by performing 3D convolutions on the raw video stream. The authors have used multi-channels of video streams, i.e., color information, depth data, and body joint positions, and these features have been fed as input to the 3D CNN. Multilayer Perceptron (MLP) classifier has been used to classify 25 sign gestures performed by 9 signers with an accuracy of 94.2%. In [43], the authors have used hierarchical Conditional Random Field (CRF) to detect candidate segments of signs using hand motions. A BoostMap embedding approach has been used to verify the hand shapes and segmented signs. However, their methodology requires a signer to wear a wrist-band during data collection. In [8], the authors have proposed one SLR system for 24 ASL alphabet recognition using Kinect. Per-pixel classification algorithm has been used to segment human hand into parts. The joint positions are obtained using a mean-shift mode-seeking algorithm and 13 angles of the hand skeleton have been used as the features to make the system invariant to the hand’s size and rotational directions. Random Forest based classifier has been used for recognition of ASL gestures with an accuracy of 92%. In this work, we have used Affine transformation based methodology on 3D human skeleton to make the proposed SLR system position and rotation invariant.
To the best of our knowledge, all of the existing gesture recognition systems require the users to perform in front of the Kinect sensor. Therefore, such systems suffer when the users perform gestures that are recorded from side views. This creates occlusion, especially in the joints of the 3D skeleton. In the proposed framework, we present a solution to the self-occluded sign gestures. Our solution is position and rotation independent of the signer within the sensor’s viewing field. A summary of the related work in comparison to the proposed methodology is presented in Table 1.
3 System setup
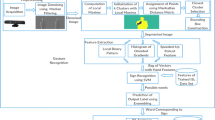
In this section, we present a detailed description of the proposed framework of the SLR system. It offers position and rotation independent sign gesture tracking and recognition. Since the displacement in signer’s position with respect to the Kinect can change the origin of the coordinate system in the XZ-plane, it may cause difficulty in recognition. Similarly, when the signer performs a sign and the side view of the gesture is captured by the sensor, it may cause self-occlusion. A block diagram of the proposed framework is shown in Fig. 2, where the acquired 3D skeleton represents gesture sequences that undergoes Affine transformation. After transformation, the hands are segmented from the skeleton to extract gesture sequence and it is followed by feature extraction and recognition.

Block diagram of the proposed framework for SLR
3.1 Affine transformation
After capturing the signer’s skeleton information through Kinect, skeleton data are then processed through affine transformation. Affine transformation has been used to cancel out the effect of signer’s rotation and position while performing the gestures. Two different 3D transformations , namely rotation and translation as given in (1) and (2), have been applied,
where \(R_{y}^{\theta }\) is the rotation matrix for rotating a 3D vector by an angle of 𝜃 about Y-axis, and T(t x , t y , t z ) is the translation vector for translating the points in 3D.
3.1.1 Rotation invariant
If the signer does not perform sign in parallel to the Kinect sensor, then the torso makes an angle (𝜃 z ) with the Z-axis of the sensor’s coordinate system. For calculating 𝜃 z , we have used three specific 3D points of the skeleton, i.e., left shoulder (L), right shoulder (R) and the spine center (C) that constitute the torso-plane (TP) as shown in Fig. 3.

Computation of the plane TP using three 3D points on skeleton as representative (a) with front view (b) side view-1 (45 degree approx. with Z-axis) (c) side view-2 (90 degree approx. with Z-axis)
TP has been used as the representative of the 3D skeleton. Next, two vectors \(\overrightarrow {CL}\) and \(\overrightarrow {CR}\) are computed on TP as shown in Fig. 4a.

Computation to cancel out the rotation effect (a) computation of 𝜃 z before rotation (b) After rotation of 𝜃 z about Y-axis
Finally, a normal vector (\(\hat {n}\)) is estimated from TP with the help of \(\overrightarrow {CL}\) and \(\overrightarrow {CR}\), and it can be computed using (3). In our study, we made a zero-degree (0o) angle between Z-axis and \(\hat {n}\) for all gestures. Thus, while testing, 𝜃 z is calculated using (4) by taking the projection of \(\hat {n}\) in the XZ-plane,
where \(\hat {k}\) is an unit vector < 0, 0, 1 > along Z-axis. After estimating the value of 𝜃 z , torso is rotated across Y-axis using (1) to cancel the effect of rotation of the signer as depicted in Fig. 4b.
3.1.2 Position invariant
After canceling out the rotational effect, we have used another heuristic to make the gesture recognition system independent of the position while the gestures are performed in the XZ-plane. To accomplish this, coordinates of the torso have been transformed from the sensor’s frame of reference to a new frame of reference with respect to the signer. This is performed by translating the 3D point (C) of the skeleton to the center and shifting the rest of the data points with respect to this new origin using (2) as illustrated Fig. 5.

Computation of position invariant by translating the 3D spine point C to center
An alignment of all gestures improves recognition performance. Also, this makes the system position invariant. Rotation and position invariant steps have been applied on a typical gesture performed on three different angles as shown in Fig. 6, where first column shows the raw gesture captured using Kinect, second column shows the outcome of the rotation invariant step, whereas the third column shows the translation of the torso to the center for making the position invariant.

Applying rotation and position invariant steps to a gesture captured at three different viewing angles: Figures in first column show a gesture performed in front, side view-1 and side view-2; Figures in second column show the gestures after applying rotation invariant step that rotates the torso about Y-axis; Figures in third column shows the outcome of the position invariant step that translates the torso to the origin with respect to spine
3.1.3 Hand segmentation
Since gestures are performed either using single hand or both hands, both left (H L ) and right (H R ) hands are segmented from the 3D torso. For each hand, two 3D points, namely, wrist and hand-tip have been segmented from the torso that can be obtained using (5) and (6). This makes H L and H R of 6 dimensions each by concatenation of two 3D points,
where [W L | T L ] and [W R | T R ] are the wrist and hand-tips of left and right hands, respectively.
3.2 Feature extraction
Three different features have been extracted from the 3D segmented hands H L and H R , namely angular features (A L and A R ), velocity (V L and V R ) and curvature features (C L and C R ). The details are as follows.
3.2.1 Angular direction
Angular features have been considered by various researchers in gesture recognition problems [7, 21, 29]. Angular direction corresponding to a 3D gesture sequence point M(x, y, z) is computed with the help of two neighbor points, i.e., L(x 1, y 1, z 1) and N(x 2, y 2, z 2) as depicted in Fig. 7.

Computation of the angular features of a 3D gesture sequence
Neighboring points are selected in such a way that all points are non-collinear. In this work, N and L are the third neighboring points that lies on either side of M. By doing this, we have ensured that all three points are collinear. A gesture sequence is shown in the Fig. 7 that forms a vector \(\overrightarrow {LN}\) making α, β and γ angles with the coordinate axes. These angles can be calculated using (7) and (8). These angles are taken as the three angular direction features of the feature set. Both H L and H R consist of two 3D sequences. Therefore, 6 dimensional angular features A L and A R have been computed corresponding to H L and H R , respectively.
3.2.2 Velocity
Velocity features are based on the fact that, each gesture is performed at different speeds [46]. For example, certain gestures may include simple hand movements, thus, having uniform speed, whereas complex gestures may have varying speeds. Velocity (V) can be computed by measuring the distance between two successive points of the 3D gesture sequence, say (x t , y t , z t ) and (x t+1, y t+1, z t+1), and it can be computed using (9).
In this study, the velocity has been computed for both hands that results into a 6-dimensional feature vector V L and V R , each corresponds to one hand.
3.2.3 Curvature
Curvature feature represents a shape’s curve and they are used to reflect the structural feature such as concavity and convexity. This has been successfully utilized in various gesture recognition tasks [7]. Curvature of a 3D point B(x, y, z) on the gesture sequence is estimated using its two neighboring points A(x 1, y 1, z 1), C(x 2, y 2, z 2) and a circle is drawn if the points are non-collinear. This is accomplished with the help of two perpendicular bisectors \(\overrightarrow {OM}\) and \(\overrightarrow {ON}\) as depicted in Fig. 8, where the gesture sequence is marked using dashed line.

Computation of the curvature features of a 3D gesture sequence
The center of the circle is calculated using (10). We have extracted five curvature related features, namely, the center (O), radius (r) of the circle, \(\angle {AOC}\) marked as (𝜃) in the figure, and two normal vectors \(\overrightarrow {OM}\) and \(\overrightarrow {ON}\) that comprises of 11 dimensions.
In this study, curvature has been computed for both hands which results into a 22-dimensional feature vector C L and C R each hand, respectively. Thus, by applying all three features, a new multi-dimensional feature vector (F T ) of 68-dimension is constructed as given in (11).
3.3 HMM guided gesture recognition
HMM is used for modeling the temporal sequences and it has been used by researchers in sign gesture and handwriting recognition systems [20, 21, 45]. HMM can be defined using { π, A, B}, with π as the initial probability distribution, A = [a i j ], i, j = 1, 2, …N as the state transition matrix that has transition probability from state i to state j, and B defines the probability of observations with b j (O k ) as a density function from state j and observing a sequence O k [19, 36]. For each state of the model, a Gaussian Mixture Model (GMM) is defined. The output probability density of the state j can be computed using (12),
where M j defines the number of Gaussian components assigned to j, and ℵ(x, μ, Σ) denotes the Gaussian with mean (μ) and co-variance matrix (\(\sum \)) and a weight coefficient (c j k ) of the Gaussian for component k of the state j. The observation probability of the sequence O = (O 1, O 2, …O T ) has been assumed to be generated by a state sequence Q = Q 1, Q 2, …Q T of length T. This can be computed using (13), where \(\pi _{q_{1}}\) denotes the initial probability of start state.
HMM has been used for recognition of sign gestures and a set of HMMs are trained using the feature vector F T defined in (11).
3.3.1 Dynamic context-independent feature
For boosting the sign gesture recognition system, we have included contextual information from neighboring windows by adding time derivatives in every feature vector. Such type of contextual and dynamic information in the current window helps to enhance the performance of recognition process [3]. The first and second-order dynamic features are known as delta and acceleration coefficients, respectively. Computation of delta coefficients is done with the help of first order regression of the feature vector using (14),
where d t is a delta coefficient at time t that has been computed in terms of static coefficients c t−Θ to c t+Θ. Value of Θ is set according to the window size. Likewise, the acceleration coefficients can be obtained using second order regression. A temporal information has been captured by these derivative features at each frame that represents the dynamics of the features around the current window. In this study, the 68-dimensional feature vector (F T ) has been used along with the dynamic features discussed earlier to create a 204-dimensional feature vector for classification.
4 Results
We first present the dataset that has been prepared to test our proposed system. Next, we present gesture recognition results. We have carried out experiments in such a way that the training and test sets include gestures of different users.
4.1 Dataset description
A dataset of 30 isolated sign gestures of Indian Sign Language (ISL) has been prepared. The sign gestures have been performed by 10 different signers, where each sign has been performed 9 times by every signer. Hence, in total 2700 (i.e. 30 × 9 × 10) gestures have been collected. Out of these 30 sign words, 16 words have been performed using single hand (right hand only), whereas remaining 14 words have been performed by both hands. Few examples of single and double-handed gestures are shown in Fig. 9.

Pictorial representation of sign gestures: (a) single-handed (b) double-handed. Note: Two instances of each gesture have been shown where one depicts the starting pose and the other is towards ending of gesture
In order to show the robustness of the proposed framework, all sign gestures have been performed at three different rotational angles as shown in Fig. 10, where a signer has performed sign gestures in three different directions, that make approximately 0°, 45°, and 90° angles between torso plane (TP) and Z-axis, respectively.

Figure shows a gesture made by a signer in different view angles. a front view with zero-degree b side view 1 with 45o approx. c side view 2 with 90o approx
All these gestures from different view-angles were considered in our dataset. Similarly, signers have also changed their positions in the XZ-plane of the sensor’s view field when performing different gestures. The 3D visualization of the gesture shows the variations when a gesture is performed by different signers. A 3D plot of the tip points during single-handed sign gesture ‘bye’ is shown in Fig. 11 (first row) the gesture has been performed at different angles.

Figure shows the variation of the same gesture in our dataset. First row: 3D plot for the sign word ‘bye’ (1-handed) performed at different viewing angles (column 1: front view, column 2: side view 1, column 3: side view-2); Second row: 3D plot for sign word ‘dance’ (2-handed) performed at different viewing angles by different signers
Different colors distinguish amongst various signers. Similarly, a 3D plot for the sign word ‘dance’ is shown in Fig. 11 (second row), where large variations in the input sequence can be seen. We have made the dataset public for the research community.Footnote 1
4.2 Experimental protocol
Experiments have been carried out using user-independent training of the gesture sequences. Our proposed methodology does not require a signer to enroll any gestures in the system for testing the system. HMM models are trained such that they do not depend on users. The results have been recorded using Leave-One-Out Cross-Validation (LOOCV) scheme. According to this scheme, the number of folds are equal to the number of instances. The learning algorithm is applied once for each instance, using all other instances as training set. In our experiments, we have kept gestures of 9 persons in training and test the gestures of 10th person. The process is repeated for every person. Finally, an average of the results is recorded and reported. Recognition of gestures has been carried out in three modes, namely, for single hand, double hand, and using a combination of both.
4.3 HMM based gesture recognition
Gesture recognition has been performed without dynamic features as well as with dynamic features. The experiments have been carries out by varying HMM states, S t ∈ {3, 4, 5, 6} and by varying number of Gaussian mixture components per state from 1 to 256 with an incremental step of power of 2. Results using the framework by varying GMM components and HMM states are shown in Figs. 12 and 13, respectively using single, double and both hands gestures.

Gesture recognition rate by varying Gaussian mixture components

Gesture recognition rate by varying HMM states
An accuracy of 81.29% has been recorded for single handed gestures at 64 Gaussians components and 3 HMM states, whereas accuracies of 84.81% and 83.77% have been recorded on double handed gestures and combined gestures with 4 HMM and 5 HMM states and 128 Gaussians, respectively, when tested with dynamic features. Similarly, recognition of gestures have also been tested without using the dynamic features, where recognition rate of 75.29%, 78.56% and 73.54% have been recorded for single, double and combination modes, respectively. A comparison between the recognition rate of gesture with and without using dynamic features, is shown in Table 2.
It can be observed that the dynamic feature based gesture recognition outperforms non-dynamic set. The confusion matrix, using dynamic features in the form of heat map is shown in Fig. 14.

Gesture recognition performance in the form of confusion matrix
4.4 Rotation-wise results
In this section, we present the results obtained using different rotations as shown in Fig. 10. HMM classifier has been trained with the gestures that have been performed in the front view of the signer, whereas the gestures from side-views are kept for testing. Recognition has been carried out jointly on single as well as double-handed gestures. Performance has been compared with raw data and the results are presented in Fig. 15.

Rotation wise gesture recognition in comparison to raw data when trained with only front view gestures
An accuracy of 86.67% has been obtained on front-view setup. We have obtained accuracies of 78.45% and 64.39% respectively on side view data. In all views, the proposed feature outperforms recognition using raw data.
In addition, the rotation-wise performance has also been computed by training the system with the complete preprocessed gestures including front and side views. Recognition results are depicted in Fig. 16, where the performance of the system has been increased in comparison to the accuracies obtained using front gestures based training.

Rotation wise gesture recognition when trained with all gestures (including front, side view 1 and side view 2)
4.5 Scalability test
A scalability test has also been performed by varying the training data, e.g. by varying number of signers (2,4,6,8) and by keeping the test data fixed during the experiments. These experiments have been carried out to test user-independence on the combined data for single as well as double-handed gestures and testing them on gestures of two signers while varying the training data. The recognition results are shown in Fig. 17, where an accuracy of 83% was recorded with 8 number of signers participated in training of the HMM classifier.

Gesture recognition performance by varying training signers
4.6 Comparative analysis
A comparative analysis of the proposed framework has been performed using SVM guided sign gesture recognition system. For this purpose, two different features, i.e., Mean and Standard Deviation have been extracted from the feature vector F T . SVM classifier directly uses a hypothesis space for estimating the decision surface instead of modeling probability distribution of the training samples [16, 22]. The basic idea is to search an optimal hyperplane such that it maximizes the margins of the decision boundaries such that the worst-case generalization errors are minimized. For a set of M labeled training samples (x i , y i ), where x i ∈ R d and y i ∈ {+1, −1}, the SVM classifier maps it into higher dimensional feature space using a non-linear operator ϕ(x). The optimal hyperplane is computed by the decision surface defined in (15),
where K(x i , x) is the kernel function. In this study, Radial Basis Function (RBF) kernel has been used to train the SVM model. Performance has been evaluated using the complete setup, i.e., preprocessed gestures in training and then applying the user-independent test mode. Finally, average results are reported. The value of the γ is kept fixed at 0.0049, whereas the regularization parameter C has been varied from 1 to 99 as shown in Fig. 18.

Gesture recognition performance using SVM by varying regularization parameter
Accuracies of 71.75%, 77.77% and 70.91% have been recorded on three different values of C, i.e., 98, 87, and 91 for single-handed, double-handed and combined gestures, respectively.
Rotation-wise results have been computed by training the system with front gestures as well as with complete dataset. Recognition results are depicted in Fig. 19.

Rotation-wise results by training with front view and all gestures (including front and side views) using SVM
In addition, the accuracies of all views have also been computed in user-dependent training using 9-fold cross validation scheme. The dataset has been divided into 9 equal parts and 8 parts of them have been kept in training and test the remaining part. Similarly, all the parts have been tested and average results are computed. Recognition accuracies of all views are shown in Fig. 20, where an average performance of 90.26% is recorded.

Recognition results of all views in user-dependent training
To the best of our knowledge, no other method exists with which we can compare our method directly. However, viable comparisons of the front-view gestures are performed with two publicly available datasets, namely, GSL20 [33] and CHALEARN [10]. The dataset GSL20 consist 20 sign gestures of Greek Sign Language (GSL), whereas the CHALEARN dataset consist of 20 Italian sign gestures recorded with Kinect sensor. In CHALEARN dataset, the accuracy is reported on the validation set due to non-availability of labels in test data [12]. The authors in [11] have considered 7 joints of the 3D skeleton, namely, shoulder center (SC), elbow right (ER), elbow left (EL), hand right (HR), hand left (HL), wrist right (WR) and wrist left (WL) whereas in our methodology we have considered only 4 joints, i.e. hand right (HR), hand left (HL), wrist right (WR) and wrist left (WL). Therefore, achieved lower accuracy in comparison to [11]. The comparative performance is presented in Table 3.
4.7 Error analysis
This section presents an analysis on failure cases. We show a confusion matrix in Fig. 14 for such results. Some gestures have not been recognized because of the presence of distortions in the data even after the affine transformation. Moreover, some gestures share similar movements, shape and hand orientation that creates some confusion within the set. Hence, they have been recognized falsely. For examples, the single-handed sign gesture representing ‘name’ and ‘no’ have similar hand movements except the speed and position of hand. Similarly, two-handed sign gestures for the word ‘wind’ and ‘go’ also share similar characteristics in terms of movements and positions of the hands.
5 Conclusion and future work
In this paper, we have proposed a rotation and position invariant framework for SLR that provides an effective solutions to recognize self-occluded gestures. Our system does not require a signer to perform sign gestures in front of the sensor. Hence, provides a natural way of interaction. The proposed framework has been tested on a large dataset of 2700 sign words of ISL that have been collected with varying rotations and positions of the signer in the field of view of the sensor. Recognition has been carried out using HMM classifier in three modes using single-handed, double-handed and combined setup. Results show the robustness of the proposed framework with an overall accuracy of 83.77% using the combined setup. In future, the work can be extended to the recognition of interaction between multiple persons. Vision based approaches in combination with depth sequences and 3D skeleton could also help in boosting recognition performance. Additionally, more robust features and classifiers such as Recurrent Neural Network (RNN) could also be explored to improve the performance further.
References
Almeida S G M, Guimarães F G, Ramírez J A (2014) Feature extraction in Brazilian sign language recognition based on phonological structure and using rgb-d sensors. Expert Syst Appl 41(16):7259–7271
Athitsos V, Sclaroff S (2003) Estimating 3d hand pose from a cluttered image. In: Computer Vision and Pattern Recognition, volume 2, pp II–432
Bianne-Bernard A-L, Menasri F, Mohamad R A-H, Mokbel C, Kermorvant C, Likforman-Sulem L (2011) Dynamic and contextual information in hmm modeling for handwritten word recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 33(10):2066–2080
Bleiweiss A, Eshar D, Kutliroff G, Lerner A, Oshrat Y, Yanai Y (2010) Enhanced interactive gaming by blending full-body tracking and gesture animation. In: ACM SIGGRAPH ASIA Sketches, p 34
Chai X, Li G, Lin Y, Xu Z, Tang Y, Chen X, Zhou M (2013) Sign language recognition and translation with kinect. In: Conference on Automatic Face and Gesture Recognition
de Campos T E, Murray D W (2006) Regression-based hand pose estimation from multiple cameras. In: International Conference on Computer Vision and Pattern Recognition, vol 1, pp 782–789
Dominio F, Donadeo M, Zanuttigh P (2014) Combining multiple depth-based descriptors for hand gesture recognition. Pattern Recogn Lett 50:101–111
Dong C, Leu M C, Yin Z (2015) American sign language alphabet recognition using microsoft kinect. In: Conference on Computer Vision and Pattern Recognition Workshops, pp 44–52
Elliott R, Cooper H, Ong E-J, Glauert J, Bowden R, Lefebvre-Albaret F (2011) Search-by-example in multilingual sign language databases. In: Sign Language Translation and Avatar Technologies Workshops
Escalera S, Gonzàlez J, Baró X, Reyes M, Lopes O, Guyon I, Athitsos V, Escalante H (2013) Multi-modal gesture recognition challenge 2013: Dataset and results. In: 15th International conference on multimodal interaction, pp 445–452
Escobedo-Cardenas E, Camara-Chavez G (2015) A robust gesture recognition using hand local data and skeleton trajectory. In: International Conference on Image Processing, pp 1240–1244
Fernando B, Efstratios G, Oramas J, Ghodrati A, Tuytelaars T (2016) Rank pooling for action recognition. IEEE transactions on pattern analysis and machine intelligence
García Incertis I, Gomez Garcia-Bermejo J, Zalama Casanova E (2006) Hand gesture recognition for deaf people interfacing 18th International Conference on Pattern Recognition, vol 2, pp 100–103
González-Ortega D, Díaz-pernas F J, Martínez-Zarzuela M, Antón-Rodríguez M (2014) A kinect-based system for cognitive rehabilitation exercises monitoring. Comput Methods Prog Biomed 113(2):620–631
Huang J, Zhou W, Li H, Li W (2015) Sign language recognition using 3d convolutional neural networks. In: International Conference on Multimedia and Expo, pp 1–6
Jiaxiang W U, Cheng J, Zhao C, Hanqing L U (2013) Fusing multi-modal features for gesture recognition. In: 15th International conference on multimodal interaction, pp 453–460
Kaur B, Singh D, Roy P P A novel framework of eeg-based user identification by analyzing music-listening behavior. Multimedia Tools and Applications
Keskin C, Kıraç F, Kara Y E, Akarun L (2013) Real time hand pose estimation using depth sensors. In: Consumer Depth Cameras for Computer Vision. Springer, pp 119–137
Kumar P, Gauba H, Roy P P, Dogra D P (2016) A multimodal framework for sensor based sign language recognition. Neurocomputing
Kumar P, Gauba H, Roy P P, Dogra D P (2016) Coupled hmm-based multi-sensor data fusion for sign language recognition. Pattern Recognition Letters
Kumar P, Saini R, Roy P, Dogra D (2016) Study of text segmentation and recognition using leap motion sensor. IEEE Sensors Journal
Kumar P, Saini R, Roy P P, Dogra D P (2016) 3d text segmentation and recognition using leap motion. Multimedia Tools and Applications
Kumar P, Saini R, Roy P P, Dogra D P (2017) A bio-signal based framework to secure mobile devices. Journal of Network and Computer Applications
Kuznetsova A, Leal-Taixé L, Rosenhahn B (2013) Real-time sign language recognition using a consumer depth camera. In: International Conference on Computer Vision Workshops, pp 83–90
Lang S, Block M, Rojas R (2012) Sign language recognition using kinect. In: International Conference on Artificial Intelligence and Soft Computing, pp 394–402
Li Y (2012) Hand gesture recognition using kinect. In: International Conference on Computer Science and Automation Engineering, pp 196–199
Lim K M, Tan A W C, Tan S C (2016) A feature covariance matrix with serial particle filter for isolated sign language recognition. Expert Syst Appl 54:208–218
Liu X, Fujimura K (2004) Hand gesture recognition using depth data. In: Automatic Face and Gesture Recognition, pp 529–534
Machida E, Cao M, Murao T, Hashimoto H (2012) Human motion tracking of mobile robot with kinect 3d sensor. In: Annual Conference of The Society of Instrument and Control Enginners, pp 2207–2211
Marin G, Dominio F, Zanuttigh P (2015) Hand gesture recognition with jointly calibrated leap motion and depth sensor. Multimedia Tools and Applications
Martínez-Camarena M, Oramas M J, Tuytelaars T (2015) Towards sign language recognition based on body parts relations. In: International Conference on Image Processing, pp 2454–2458
Miranda L, Vieira T, Martinez D, Lewiner T, Vieira A W, Campos M F M (2012) Real-time gesture recognition from depth data through key poses learning and decision forests. In: Conference on graphics, Patterns and Images, vol 25, pp 268–275
Monir S, Rubya S, Ferdous H S (2012) Rotation and scale invariant posture recognition using microsoft kinect skeletal tracking feature. In: International Conference on Intelligent Systems Design and Applications, vol 12, pp 404–409
Ong E-J, Cooper H, Pugeault N, Bowden R (2012) Sign language recognition using sequential pattern trees. In: Conference on Computer Vision and Pattern Recognition, pp 2200–2207
Patsadu O, Nukoolkit C, Watanapa B (2012) Human gesture recognition using kinect camera. In: International Joint Conference on Computer Science and Software Engineering, pp 28–32
Potter L E, Araullo J, Carter L (2013) The leap motion controller: a view on sign language. In: 25th Australian computer-human interaction conference: augmentation, application, innovation, collaboration, pp 175–178
Rabiner L (1989) A tutorial on hidden markov models and selected applications in speech recognition. Readings in Speech Recognition 77(2):257–286
Ren Z, Meng J, Yuan J, Zhang Z (2011) Robust hand gesture recognition with kinect sensor. In: 19th International Conference on Multimedia, pp 759–760
Starner T, Weaver J, Pentland A (1998) Real-time american sign language recognition using desk and wearable computer based video. IEEE Transactions on Pattern Analysis and Machine Intelligence 20(12):1371–1375
Suarez J, Murphy R R (2012) Hand gesture recognition with depth images: A review. In: International Symposium on Robot and Human Interactive Communication, vol 21, pp 411–417
Sun C, Zhang T, Bao B-K, Changsheng X U, Mei T (2013) Discriminative exemplar coding for sign language recognition with kinect. IEEE Transactions on Cybernetics 43(5):1418–1428
Uebersax D, Gall J, Van den Bergh M, Gool L V (2011) Real-time sign language letter and word recognition from depth data. In: International Conference on Computer Vision Workshops, pp 383–390
Yang H-D (2014) Sign language recognition with the kinect sensor based on conditional random fields. Sensors 15(1):135–147
Yao Y, Yun F U (2014) Contour model-based hand-gesture recognition using the kinect sensor. IEEE Transactions on Circuits and Systems for Video Technology 24 (11):1935–1944
Zafrulla Z, Brashear H, Starner T, Hamilton H, Presti P (2011) American sign language recognition with the kinect. In: International conference on multimodal interfaces, vol 13, pp 279–286
Zhang X U, Chen X, Li Y, Lantz V, Wang K, Yang J (2011) A framework for hand gesture recognition based on accelerometer and emg sensors. Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans 41(6):1064–1076
Acknowledgments
The authors would like to thank the anonymous reviewers for their constructive comments and suggestions to improve the quality of the paper. We are also thankful to our signers who are the students of an intermediate school ‘Anushruti’ at IIT Roorkee, India.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kumar, P., Saini, R., Roy, P.P. et al. A position and rotation invariant framework for sign language recognition (SLR) using Kinect. Multimed Tools Appl 77, 8823–8846 (2018). https://doi.org/10.1007/s11042-017-4776-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4776-9