
Abstract
Preventing secret from being suspicious during transferring over Internet has become an emergent issue in the past decades. Several protecting data methods such as cryptographic techniques, watermarking or steganography techniques, etc. have been proposed to conceal secrets from being discovered. In this paper, we introduce the Minima-Maxima Preserving (MMP) data hiding algorithm for absolute moment block truncation coding (AMBTC) compressed images, which preserves the high and low values in each block to reversibly extract secret and recover host images during the extracting procedure. As a result, image quality is maintained that makes the secret messages hidden and avoids suspicion from attackers. Experimental results show that the scheme has better performance compared to state-of-the-art schemes in terms of visual quality and embedding rate. Besides, with the high embedding rate, the scheme can be widely used in practice.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Sharing and transferring digital data over the Internet has been popular during the past decade. In practice, in order to transfer data, the following issues can be considered. Firstly, the most important issue is security since users require their secrets to be transferred safely in an imperceptible way. Secondly, we might be concerned about the accuracy of the methods in which these secrets can be completely and exactly extracted. Finally, the efficiency of these methods allows users to send a large amount of secret information at the same time. Among several highly secure approaches, data hiding is adopted as a simple, secure and efficient way.
Data hiding is the art of concealing a large amount of secret data into host files. Host covers can be text files or multimedia files such as images, audios and videos. Among them, images have been widely used as host covers since they have more space to embed secrets. Data hiding schemes are basically developed in three domains—the spatial domain, the frequency domain and the compression domain. In general, data hiding can be categorized into two groups—reversible data hiding (RDH) [2–5, 12, 14–18, 20, 21, 25, 29, 31–33] and irreversible data hiding (IDH) [6–11, 13, 19, 22, 24, 28, 30, 34]. RDH allows one to embed secret data into an image in such a way that the original image can be reconstructed from the marked image.
One well-known RDH scheme in the spatial domain is the histogram-shifting-based RDH (HSRDH), which was proposed by Ni et al. in 2006 [21]. The main drawback of Ni et al.’s scheme is its extremely low payload, which is not efficient and practical since the demand of transferring data is getting higher and higher in the digital era. Since then, a lot of literature related to histogram modification have been proposed to improve the capacity of this scheme [17, 18, 25]. In [14], Jung et al. proposed an improvement of Ni et al.’s method [21], whereby unlike Ni et al.’s, Jung et al.’s scheme exploited predicted values from a pixel, an edge of image and image’s joint noticeable difference (JND) to embed data. Therefore, the scheme achieves better capacity than that of Ni et al.; however, its capacity is still very low. To further improve the embedding payload of this approach, in 2013, Li et al. [17] proposed another RDH scheme by using frequency of difference values of pixel-pairs to form a two-dimension histogram, instead of the conventional one-dimension histogram methods. Although, the scheme significantly enhances the number of embedded bits (from 0.02 bpp of Ni et al. to 0.19 bpp for smooth images), it is not efficient since there are a lot of unused space remaining in an image. Also in 2013, Li et al. [18] proposed a generalized-HSRDH method. In their generalized scheme, the authors figured out that several HSRDHs proposed in the literature are special cases of their generalized construction. Using this scheme, we can embed up to 0.9 bit into per pixel. Up to now, it is the highest capacity for HSRDH-based methods.
In the frequency-domain RDH, the host image is transformed into frequency coefficients via various integer transforms [23] such as discrete Fourier transform (DFT), discrete cosine transform (DCT), and discrete wavelet transform (DWT). The primary property of frequency coefficients is that low frequency coefficients contain more important information whereas in high frequency area information is less significant. Thus, the matrix of frequency coefficients are divided into non-overlapping blocks and the secret data will be embedded in those blocks with low mean values.
While RDH schemes focus on how to recover the original host images, IDH schemes usually aim to construct marked images as natural as possible and avoid large-sized carrier images, but still can carry more secret bits. To reduce the size of host images, there are several compression methods adopted as a preprocessing step before creating marked images [34]. Then, the embedding and the extracting procedures will be processed to generate high quality marked images with high payload. The frequently employed common compression methods are vector quantization/side-match vector quantization (VQ/SMVQ) compression [22], joint photographic experts group (JPEG) compression [24] or block truncation/absolute moment block truncation (BTC/AMBTC) compression [6–8, 26] and so on. The major drawback of most of these data hiding schemes for compression domain is the extremely low embedding capacity. Qin et al. [22] employed image inpainting to embed secret into SMVQ indices. The scheme aims to reduce visual distortion and error diffusion caused by the progressive compression; however, the capacity of the scheme is not more than 0.1 bpp. Guo et al. [7] proposed a data hiding method for BTC, which exploits the concept of secret sharing to enhance the security of the method. The authors used two host images to embed secret data to achieve good visual quality, but embedding rate still needs to be improved. Among these data compression methods, AMBTC is an improvement of BTC in terms of performance and complexity.
In this paper, our goal is to propose a reversible data hiding scheme with high embedding rate while preserving good visual quality. We introduce an algorithm for AMBTC compressed images named Minima-Maxima Preserving algorithm (MMP). In this algorithm, one high-mean value and one low-mean value of each block are kept unchanged to be the information to recover the host image during the extracting procedure. By doing so, our proposed MMP algorithm results in the following advantages, which are: first, it achieves higher payload and better image quality, thus satisfying the requirements of the data hiding method; second, the scheme can reversibly reconstruct the original AMBTC compressed image. The above contributions show the technical merits of our proposed algorithm.
The rest of the paper is organized as follows. In Section 2, we briefly introduce the concept of AMBTC compression method. The MMP algorithm is described in detail in Section 3. Section 4 is our implementation and discussion. Finally, conclusions are made in Section 5.
2 AMBTC compression algorithm
Block truncation coding (BTC) [4] is an efficient lossy compression method, which requires a very low computational complexity. BTC method quantizes the pixels in each block of gray-level image into a two-level bitmap while reserving statistical moments of blocks to maintain an acceptable visual quality of BTC compressed image. To improve the performance of BTC technique, Lema and Mitchell [15] proposed a variant of BTC, called absolute moment block truncation coding (AMBTC). AMBTC preserves the first absolute moment along with the mean. The main difference between BTC and AMBTC is the computation of quantization levels during the encoding phase. With simpler computation, AMBTC is more suitable for real-time applications.
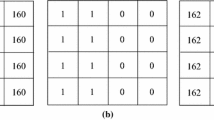
In AMBTC compression, the original image is first divided into non-overlapping blocks. For each block, we compute its mean value and absolute value. After that, two quantization values called low-mean value (a) and high-mean value (b) are calculated. Then, pixels which are lower than the mean value are replaced by a, and pixels, and which are higher than or equal to the mean value are replaced by b. Meanwhile, a bitmap is recorded based on a and b. Figure 1 is an example of the compression (encoding) procedure when the block size of the host image is 4 × 4. The details of AMBTC compression method are described in the following subsections.

AMBTC encoding procedure (a) Original 4 × 4 Image, (b) Corresponding Bitmap, and (c) Compressed Image
2.1 Encoding procedure
In Fig. 1, we briefly describe the process of encoding. Figure 1(a) is the original image block with 16 pixels. By applying the AMBTC encoding procedure which is introduced below, we get the bitmap shown in Fig. 1(b) and two values: low-mean value a and high-mean value b. The compressed image is constructed by replacing the value “0” of the bitmap with a and the value “1” of the bitmap with b. The result of the compressed image is shown in Fig. 1(c). Hereafter, we introduce the encoding procedure in details.
Input gray-level image is first divided into non-overlapping blocks sized M × M. We suppose that the number of pixels in each block is N b = M × M, and \( {x}_1,{x}_2,\ldots,{x}_{N_b} \)denote the pixels in a block. The mean value of each block is calculated by Eq. (1) :
Then, the image block can be compressed by two quantization levels and one bitmap as below:
where q represents the number of pixels whose grey-level are greater than or equal to the mean value\( \overline{x} \). Bitmap B of the block represents the pixels, each of which is formed from the grey value by the rule: if the pixel value x i is greater than or equal to the mean value \( \overline{x} \), the corresponding bitmap’s element is set to 1; otherwise, it is set to 0.
2.2 Decoding procedure
To decode and reconstruct the block of image, two quantization levels a and b and the bitmap are obtained. All the values “0” of the block are replaced by a, and values “1” are replaced by b:
After all the blocks of images are decoded, the original image is decompressed.
3 Proposed minima-maxima preserving (MMP) algorithm
To achieve higher payload and better image quality, in this section, a novel Minima-Maxima Preserving (MMP) Algorithm based on least-significant-bit (LSB) substitution is proposed. Originally, the LSB-substitution method cannot be used to recover the host image since whenever we modify these bits, the receiver might not have any information about the original pixels to recover the host image. To achieve reversibility, the proposed MMP algorithm embeds secret data into AMBTC compressed image by the following way: the first high-mean and low-mean values are kept unchanged for each block of compressed image; for the rest of the pixels in the block, we embed secret data by adaptively replacing one or two LSBs. Therefore, the embedding capacity is significantly enhanced and the marked images have good visual quality.
Figure 2 represents the overall flow of the MMP algorithm that has two main procedures: image compression and secret embedding procedure which is introduced in Subsection 3.1, and secret extraction and host restoration procedure which is introduced in Subsection 3.2, respectively.

Overall flow of the proposed algorithm
3.1 Image compression and secret embedding procedure
Figure 3 briefly describes the process of image compression and secret embedding procedure.

Flowchart of secret embedding procedure
In our algorithm, we assume that I is the original grayscale image of H × W pixels represented as
S is the n-bit secret message such that S = {s i | 0 ≤ i < n, s i ∈ {0, 1}}. The secret message S is further arranged to be a k-bit virtual image S' which is represented as \( {S}^{\prime }=\left\{{s}_i^{\prime }|0\le i<{n}^{\prime },{s}_i^{\prime}\in \left\{0,1,\dots, {2}^k-1\right\}\right\} \), where n ′ < H × W. The secret message S and its corresponding embedded message S' are mapped as follows:
The host image is divided into non-overlapping blocks sized β. Then, we compress this image by employing AMBTC which was introduced in Section 2 to get the AMBTC compressed image C sized H × W:
For each block, the pixels are scanned in raster-scan order and the first high-mean value and low-mean value are recorded and kept unchanged. The message S' will be embedded into k-rightmost LSBs of the remained pixels of the block. The pixel of AMBTC block \( {c}_{B_i} \) storing the k-bit message \( {s}_i^{\prime } \)is modified to create the marked pixel by using (6):
After all the blocks of image are processed, the marked image is obtained.
The pseudo code of the image compression and secret embedding procedure is demonstrated by Algorithm 1 as follows.

After receiving the marked image C ′, to extract the secret and recover the host image, the receiver performs the secret extraction and host restoration procedure which is described in Subsection 3.2.
3.2 Secret extraction and host restoration procedure
In this subsection, we describe the process of extracting phase of MMP algorithm. An overview of secret extraction and host restoration procedure is shown in Fig. 4.

Flowchart of secret extraction procedure
In the extraction procedure, the marked image C ′is collected. The marked image is first divided into non-overlapping blocks as same as the embedding procedure. The embedded message can be extracted without requiring of the original host image. For each block, the k-LSBs of the selected pixels are extracted by using (7) and combined to reconstruct the original secret message sequence.
Since the high-mean value and low-mean value of each block are unmodified, their values can be used to reconstruct the original AMBTC compressed image C.
The following Algorithm 2 demonstrates the pseudo code of the extraction and host restoration procedure.

After all the steps are processed, we exactly obtain the original secret and the reconstructed compressed image.
In the following section, we implement our method to demonstrate that the proposed scheme is efficient and achieves a good performance.
4 Experimental results
In the performed experimental evaluation, we focus on three principal aspects. Firstly, we validate the MMP embedding algorithm to confirm that the high capacity feature is reached. Secondly, we demonstrate that the marked images generated by the MMP algorithm are in good quality. Finally, we evaluate the reconstruction efficiency to illustrate the reversibility of the algorithm. All the experiments are implemented by Matlab on Window 7 OS, platform Intel Core i7, 8GB RAM. Figure 5 is a set of standard grayscale test images which are downloaded from databases [26, 27]. Moreover, in order to objectively evaluate the scheme, we compare our scheme with several schemes which have recently been proposed.

Host images for testing
4.1 Fundamental parameters for validation
We adopt peak-signal-to-noise (PSNR) to measure the image quality generated by the scheme. The PSNR parameter is defined as below:
where H × W is the image size, O i,j and WI i,j are the pixels of an original image and its watermarked image, respectively.
Besides, to evaluate the visibility error between the original watermark image and the extracted one using properties of human visual system, we use the Structural Similarity (SSIM) parameter [28], which is defined by (14). According to [28], human visual perception is exceedingly sensitive for extracting structural information from a scene. Therefore, SSIM measurement is a task of three comparisons - luminance, contrast and structure.
To compare the luminance of each image, we first compute its mean intensity:
where H × W is the size of watermark image, wi i and ew i are pixel values of the original watermark and extracted watermark images, respectively. The luminance comparisons function l(wi, ew) is a comparison of μ wi and μ ew :
where C 1 = (K 1, L), L ∈[0,255], and constant K < 1.
To estimate the contrast of the image, the standard deviation is adopted as (11):
The contrast comparisons c(wi, ew)is the comparison of μ wi and μ ew :
The structure comparison is computed by:
The structural similarity measurement is computed by combining (10), (12) and (13) to yield:
Finally, we use the mean SSIM (MSSIM) to evaluate the image quality:
4.2 Results and discussions
The original image is processed block by block during the compression procedure. Next, this compressed image is considered as a host image to carry the secret message. Therefore, the size of block β has a major effect on the quality of marked image. We illustrate our scheme with various sizes of β, where β ∈ {4, 8, 16, 32}. For each block-size, the highest number of embedded bits is calculated as follows.
-
Since the image’s block size is β × β pixels, the number of blocks is:
$$ N=\frac{H\times W}{\beta^2}. $$ -
For each block, we keep two values - low-mean value and high-mean value – to recover the original compressed image. Therefore, the number of remained pixels is β 2–2.
-
For each pixel of a block, we embed k bits. The embedding capacity of each block is (β 2–2) × k.
-
Thus, the embedding capacity of the proposed MMP algorithm is defined as below:
$$ C a p a c i t y=\frac{H\times W}{\beta^2}\times \left({\beta}^2-2\right)\times k. $$
Table 1 shows the performance of the MMP algorithm in term of embedding capacity and structural similarity on different test images under different block sizes.
Furthermore, Tables 2, 3 and 4 show that our proposed method can work well on different types of images, i.e. smooth images and complex images. Tables 2, 3 and 4 demonstrate the performance of the MMP algorithm on the image of Lena, Baboon and Cameraman, respectively. Tables 2, 3 and 4 results illustrate that the embedding rate increases when the block-size is larger. Since the larger the block-size is, the lesser the number of un-embedded high and low mean values achieves.
For example, when block-size, β = 4, the highest embedding rate is 1.75 bpp. This means that we can embed at most \( \frac{512\times 512}{4^2}\times \left({4}^2-2\right)\times 2=458752 \) bits into a 512 × 512 host image.
The results in Tables 2, 3 and 4 also show that the scheme generates a good visual quality of images, which is higher than 40 dB in average. Moreover, when the block size β = 32, the SSIM values are significantly decreased. It is obvious that the number of unchanged high and low mean values is smaller when the block size is larger. Therefore, there are more spaces for embedding secrets. Thus, the similarity of the structure might be decreased.
Figure 6 shows the correlation between the visual image quality and embedding rate. In general, both visual quality and embedding rate are trade-off. It means that the more bits we embed in the image, the lower image quality we will get. It can be seen from Fig. 6(a-d) that a good tradeoff between embedding rate and image quality is achieved since even the embedding rate increases significantly, the quality of the marked image decreases slightly.

PSNR versus embedding rate of the proposed scheme
In the following, we evaluate the undetectability performance of the proposed scheme by analyzing that it can withstand the enhancing LSBs attack. The enhancing LSBs attack produces a pattern image in which k LSBs of the marked image are extracted and (8 − k) “0” bits are appended to these k LSBs. The pattern image can be used for the detection of LSB substitution because a regular pattern will appear when LSB substitution is used for data hiding. For example, Fig. 7(b) shows an enhancing LSBs attack (k = 2) on Fig. 7(a) that is a marked image created by LSB substitution. From the regular pattern in Fig. 7(b), the LSB substitution can be easily detected. In contrast, the proposed scheme can resist the enhancing LSBs attack as shown in Fig. 7(c) and (d).

The enhancing LSBs attack for “Lena”
Finally, Table 5 compares the performance of some previous schemes [1, 7, 22, 34] and our proposed scheme under block size β = 4 in Table 5. Zhang et al.’s method [34], which was proposed in 2013, has a very good quality of the marked images. However, since it is based on histogram modification technique, which embeds secret according to the frequencies of the image sequence instead of pixels themselves, the embedding rate of the scheme is quite low (not more than 1 bpp). Qin et al.’s method [22] is a new idea for data hiding technique since they combine image inpainting technique with data hiding for compression domain. The scheme embeds secret into the VQ/SMVQ compression code, thus, to make the marked image imperceptible, the user should carefully control the compression rate. Therefore, the embedding rate of the scheme cannot be enlarged. Table 5 shows that our scheme achieves better quality and higher embedding rate than that of other schemes.
5 Conclusions
In this paper, a novel reversible data hiding method called MMP algorithm for AMBTC compressed images is proposed. Our MMP algorithm can embed a large amount of secret bits while maintaining a good visual quality of the marked image. Compared to those existing data hiding methods for compressed images, our proposed scheme achieves a good performance in terms of embedding rate, image quality as well as reversibility.
References
Chang CC, Lin CY, Fan YH (2008) Lossless data hiding for color images based on block truncation coding. Pattern Recogn 41:2347–2357
Coatrieux G, Pan W, Boulahia NC, Cuppens F, Roux C (2013) Reversible watermarking based on invariant image classification and dynamic histogram shifting. IEEE Trans Inf Forensics and Secur 8:111–120
Coltuc D (2011) Improved embedding for prediction-based reversible watermarking. IEEE Trans Inf Forensics Secur 6:873–882
Delp EJ, Mitchell OR (1979) Image compression using block truncation coding. IEEE Trans Commun 27:1335–1341
Fallahpour M, Megias D, Ghanbari M (2011) Reversible and high-capacity data hiding in medical image. IET Image Process 5:190–197
Guo JM, Liu YF (2010) Joint compression/watermarking scheme using majority-parity guidance and halftoning-based block truncation coding. IEEE Trans Image Process 19:2056–2069
Guo JM, Liu YF (2012) High capacity data hiding for error-diffused block truncation coding. IEEE Trans Image Process 21:4808–4818
Guo JM, Tsai JJ (2011) Data-hiding in halftone images using adaptive noise-balanced error diffusion. IEEE Multimedia 18:48–59
Guo JM, Su CC, Liu YF, Lee H, Lee JD (2012) Oriented modulation for watermarking in direct binary search halftone images. IEEE Trans Image Process 21:4117–4126
Hamghalam M, Mirzakuchaki S, Akhaee MA (2013) Robust image watermarking using dihedral angle based on maximum-likelihood detector. IET Image Process 7:451–463
Hong W, Chen TS (2012) A novel data embedding method using adaptive pixel pair matching. IEEE Trans Inf Forensics 7:176–184
Hong W, Chen TS, Wu HY (2012) An improved reversible data hiding in encrypted images using side match. IEEE Signal Process Lett 19:199–202
Hou CL, Lu CC, Tsai SC, Tzeng WG (2011) An optimal data hiding scheme with tree-based parity check. IEEE Trans Image Process 20:880–886
Jung SW, Ha LT, Ko SJ (2011) A new histogram modification based reversible data hiding algorithm considering the human visual system. IEEE Signal Process Lett 18:95–98
Lema MD, Mitchell OR (1984) Absolute moment block truncation coding and its application to color images. IEEE Trans Commun 32:1148–1157
Li X, Yang B, Zeng T (2011) Efficient reversible watermarking based on adaptive prediction-error expansion and pixel selection. IEEE Trans Image Process 20:3524–3533
Li X, Zhang W, Gui X, Yang B (2013a) A novel reversible data hiding scheme based on two-dimensional difference-histogram modification. IEEE Trans Inf Forensics Secur 8:1091–1100
Li X, Li B, Yang B, Zeng T (2013b) General framework to histogram-shifting-based reversible data hiding. IEEE Trans Image Process 22:2181–2191
Liu YF, Guo JM, Lee JD (2011) Inverse halftoning based on the Bayesian theorem. IEEE Trans Image Process 20:1077–1084
Ma K, Zhang W, Zhao X, Yu N, Li F (2013) Reversible data hiding in encrypted images by reserving room before encryption. IEEE Trans Inf Forensics Secur 8:553–562
Ni Z, Shi YQ, Ansari N, Su W (2006) Reversible data hiding. IEEE Trans Circuits Syst Video Technol 16:354–362
Qin C, Chang CC, Chiu YP (2014) A novel joint data-hiding and compression scheme based on SMVQ and image inpainting. IEEE Trans Image Process 23:969–978
Shi YQ, Li X, Zhang X, Wu H, Ma B (2016) Reversible data hiding: advances in the past two decades. Special Section in IEEE Access: Latest Advances and Emerging Applications of Data Hiding 4:3210–3237
Subramanyam AV, Emmanuel S, Kankanhalli MS (2013) Robust watermarking of compressed and encrypted JPEG2000 images. IEEE Trans Multimedia 14:703–716
Tai WL, Yeh CM, Chang CC (2009) Reversible data hiding based on histogram modification of pixel differences. IEEE Trans Circuits Syst Video Technol 19:906–920
The test image database. (2012) [Online]. Available: http://msp.e.ntust.edu.tw/publicfile/ImageSet.rar
The USC-SIPI image database (1997) [Online]. Available: http://sipi.usc.edu/database/
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13:600–612
Wang SY, Li CY, Kuo WC (2013) Reversible data hiding based on two-dimensional prediction errors. IET Image Process 7:805–816
Zareian M, Tohidypour HR (2013) Robust quantization index modulation-based approach for image watermarking. IET Image Process 7:432–441
Zhang X (2011) Reversible data hiding in encrypted image. IEEE Signal Process Lett 18:255–258
Zhang X (2012) Separable reversible data hiding in encrypted image. IEEE Trans Inf Forensics Secur 7:826–832
Zhang W, Chen B, Yu N (2012) Improving various reversible data hiding schemes via optimal codes for binary covers. IEEE Trans Image Process 21:2991–3003
Zhang W, Hu X, Li X, Yu N (2013) Recursive histogram modification: establishing equivalency between reversible data hiding and lossless data compression. IEEE Trans Image Process 22:2775–2785
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Huynh, NT., Bharanitharan, K., Chang, CC. et al. Minima-maxima preserving data hiding algorithm for absolute moment block truncation coding compressed images. Multimed Tools Appl 77, 5767–5783 (2018). https://doi.org/10.1007/s11042-017-4487-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4487-2