
Abstract
MP3Stego is a typical steganographic tool for MP3 audio. Once the cover audio is unavailable, it is hard to distinguish between background noise and steganographic distortion. In this work, the MP3Stego algorithm has been analyzed from a warden’s perspective. It is observed that the number of bits in the bit reservoir will be disturbed when the secret message is embedded. In addition, a reliable estimation of cover audio is obtained by the proposed recompression calibration. The calibrated features are classified with support vector machine technique. Experimental results show that the proposed scheme is effective and gets good performance, especially when the embedding rate is not less than 0.01 %. The results also shows that the proposed scheme can achieve lower false positive rate comparing to the existing algorithms.
Similar content being viewed by others

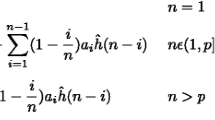
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Steganography is the art of hiding the present of communication by embedding secret messages into innocent looking covers, such as digital images, videos, and audios [7]. Its aim is to avoid drawing suspicion to the transmission of hidden information. Steganalysis is the art of detecting secret messages hidden using steganography [17]. The goal of steganalysis is to reveal the presence of embedded message and to break the covert communication.
Due to the prevalent usage of MP3 audios, the competition between MP3 steganography and MP3 steganalysis has escalated over the past few years. Several stego tools for MP3 audios have been arisen, such as MP3Stego [15], MP3Stegz [16], Under MP3Cover [1]. In our early works, we also have proposed two novel steganographic methods for MP3 audios [21, 22]. As far as MP3 steganography tools are concerned, MP3Stego is the most typical one. In MP3Stego, with the benefit of the distortion adjustment mechanism of the MP3 codec, the sum of the distortion caused by quantization and MP3Stego is effectively controlled below the masking threshold which is the minimum sound level that human can perceive. Once the cover audio is unavailable, it is hard to distinguish whether the test audio has been operated by MP3Stego or not.
In order to defeat MP3Stego, some steganalytic methods have been proposed in recent years. Since MP3Stego changes the behavior of quantization in MP3 encoding, Westfeld [3, 20] proposed an attack method based on the variance of the block length which is a parameter related to quantization. Similarly, Dittmann [6, 12] considered that there would be more different block lengths after MP3Stego embedding. Hence, the number of different block lengths is taken as a steganalytic feature in their method. However, the performance of this method can be still improved especially at low embedding rates. Qiao [18] introduced a detection method based on an inter-frame feature set which contains the moment statistical features on the second derivatives, as well as Markov transition features and neighboring joint density of MDCT coefficients. In his another work [19], the statistical moments of GGD (Generalized Gaussian Distribution) shape parameters for MDCT coefficients are also taken as the steganalytic features. Ozer et al. [2, 14] presented a method for detecting audio steganography based on audio quality metrics. Although this method can expose the presence of MP3Stego, relatively high false positive rate is one of the limitations. Additionally, the dimensionality of the feature space is the main inconvenience of Qiao’s and Ozer’s methods.
Generally, the steganalytic detector will be more straightforward and effective if the features can be extracted directly from the position where the steganography takes place. Since MP3Stego happens during quantization, more attentions should be paid to the parameters associated with the quantization. In this work, the number of bits in bit reservoir which is an important component of quantization is introduced into steganalysis to attack MP3Stego. In order to weaken the influence of the audio content and expose the stego noise, the calibrated feature is extracted by recompression. The results demonstrate that the proposed method can achieve a good discriminatory ability for MP3Stego.
The rest of this paper is organized as follows. The basic operations of MP3Stego algorithm are briefly covered in Section 2. Section 3 focuses on the main idea of the proposed method. We verify the effectiveness of the proposed method under various conditions with experimental results in Section 4. Finally, conclusions are drawn in Section 5.
2 Background
In this section, the fundamental operations of the MP3Stego algorithm are first reviewed. Then, the impact caused by the MP3Stego operations is also analyzed.
2.1 Fundamental operations of MP3Stego
The embedding of MP3Stego is integrated with the inner loop function that controls the bit rate of MP3 encoder [9]. The pseudo-code for the inner loop function with MP3Stego is given in Fig. 1. The inner loop quantizes the MDCT coefficients and increases the quantization step until the quantized coefficients can be coded with the available number of bits. The variable P 32 contains the number of the bits used for scalefactors and Huffman code data for current granule, which is also called block length. Without embedding, the inner loop will be finished when the P 32 is within the range of the number of bits available. In MP3Stego, the inner loop will continue to iterate until the parity of the P 32 is equal to the hidden bit b and the bit demand for Huffman coding is met. Once the inner loop is done, another loop, namely outer loop, will check the distortions introduced by the quantization operation. If the allowed distortion is exceeded, the inner loop will be called again. The above process will be iterated until the bit rate and distortion requirements are both met. It will only be considered that the hidden bit b has been embedded until the two-nested iterations are done.

Pseudo-code for inner loop function with MP3Stego
2.2 Impact of MP3Stego
Since the hiding process of MP3Stego takes place during the quantization process, it is natural and reasonable to pay more attention on the parameters related to the quantization if we want to capture the trace of the MP3Stego operations. As described in Subsection 2.1, the artifacts introduced to the MP3 encoder by MP3Stego are attributed that the embedding operation changes the termination condition of the inner loop function. It is obvious that the condition of ending loop in MP3Stego is more rigorous than that in non-stego case, which means that more iterations are required to exit the inner loop due to the embedding. It is noted that the quantization step will be incremented by one in each inner loop (See Fig. 1). Consequently, a larger quantization step will be appeared at the end of the loop in stego case. The larger the quantization step, the smaller the value of the quantized coefficients. Finally, the number of the actual allocation bits for quantization will be smaller than the number of bits that the MP3 codec has assigned to current granule.
MP3 allows coding different frames with a different number of bits, though achieving a target average bit rate should still be necessary. So a bit reservoir has been adopted during MP3 coding to control the bit variation among the encoded frames. This mechanism provides the space to loan or deposit bits to control the audio quality under a bit rate constraint. If a frame does not need all the bits allocated to it, it can put the spare ones into this reservoir. A more complex frame that requires more bits than it is given, can then take bits from the reservoir. Thus, in the stego case, the extra bits will be added to the bit reservoir after the inner and outer loops finish their jobs. It means that the number of bits in the reservoir will be larger than that in non-stego case. If that’s the case, we could just calculate the mean of the bit number in bit reservoir to detect MP3Stego. That is,
where b i (i ∈ {1,2,⋯, N}) is the size of bit reservoir in the i-th granule. Figure 2 shows the value of μ for 10 different audios under various cases. Here, the embedding rate (er) is defined as the ratio of the secret message length to the length of the stego MP3 file. It can be seen that, for the given audio, the mean value always keeps in a stable value between nature version and stego-version. So it is not a suitable steganalytic feature for MP3Stego. The reason is mainly that, in order to meet the desired target bit rate, the encoder will allocate more bits to the next granule, while the extra bits required can be borrowed from the bit reservoir. Therefore, the number of bit in the bit reservoir will be reduced correspondingly.

Mean of the number of bits in bit reservoir before and after embedding for 10 audios from different sources
Although there are no dramatic changes in the mean value between nature version and stego version, it can be expected that the fluctuation in value of the number of bits in bit reservoir between adjacent granules will become larger. Hence, the standard deviation which can reflect the fluctuation of data may be a good feature to attack MP3Stego. That is,
However, the experimental results show that the detector based on the standard deviation feature performs poorly. The reason is illustrated in Fig. 3, plotting the classifier σ for 50 audios, before and after embedding. The audios came from five different sources. It can be seen that the value of standard deviation depends on the source of cover audio. So the effect of the cover audio should be removed during feature extraction.

Standard deviation before (circles) and after (triangles) embedding (embedding rate is at 0.01 %) for 50 audios under 128 kbps
3 Proposed steganalytic method
In order to eliminate the impact of the audio content, recompression calibration scheme is used to obtain the estimation of cover audio from the stego audio. The main idea of the proposed algorithm is to extract the statistic of bit number of bit reservoir as steganalytic feature, and measure the similarity between the features of the estimated audio and the stegoed audio. The proposed steganalysis algorithm is mainly composed of four parts: recompression calibration, features extraction, classifier training and stego audio detection. Details of the proposed steganalysis scheme will be address in the following subsection.
3.1 Cover estimation by recompression calibration
In steganalysis, it is almost impossible to have access to the cover. If we can obtain the estimation of the cover from the suspect one as effectively as possible, the steganalytic performance will be improved. In recent years, several methods for cover estimation have been arisen, such as filtering [11], down-sampling [10], reembedding [13], and recompression [8]. One of the most famous approaches for creating an estimate of the cover image is the model proposed by Fridrich in [8] known as JPEG recompression calibration. Similarly, we conjectured that the steganographic effect on bit reservoir would be removed through recompression calibration.
Denote M d as an MP3 audio under scrutiny and it is in the form of bitstream and contains totally N granules. M e is the MP3 audio that M d is decompressed to the time domain and then compressed back to MP3 with the same compression ratio. That is,
where C and D denote the MP3 compression and decompression algorithm respectively, and cr is the compression ratio.
In order to evaluate the validity the proposed calibrated scheme, the histogram of the bit reservoir is investigated. Figure 4 shows the histograms at the compression ratio of 128 kbps and at the embedding rate of 0.01 %. It can be seen that the histogram outlines of the estimated audios (Fig. 4b and d) are both quite close to the cover one (Fig. 4a) while the histogram outline of the stego audio (Fig. 4c) is quite different. For quantitative evaluation, some distance functions, such as Manhattan, Euclidean, Chebyshev, Bhattacharyya, and Kullback–Leibler, are adopted to evaluate the similarity of the histograms [4]. The experimental results at the embedding rate of 0.01 % and compression ratio of 128 kbps are shown in Table 1. The smaller the distance, the greater the similarity of histograms. It can be seen that the proposed calibrated scheme can eliminate the effect of the steganographic operation.

Histograms of number of bits in reservoir (a) Cover audio, cr = 128 kbps (b) Estimated audio from the cover (c) Stego audio, er = 0.01 % (d) Estimated audio from the stego
3.2 Feature extraction and classifier training
The essence of steganalysis is the sensitive feature that can easily determine whether an audio contains secret message. In this paper, the calibrated feature of bit reservoir used for steganalysis are extracted.
After the recompression calibration, we will have the testing audio and estimated audio. From these two audios, the values of μ (mean) and σ (standard deviation) can be calculated respectively according to Eqs. 1 and 2. Then, we define the reciprocal of the coefficient of variance as,
From the testing audio and the estimated audio, SNR d and SNR e can be obtained respectively. The final calibrated feature F for steganalysis can be defined as,
Steganalysis can be regarded as a simple two class classification problem. A standard classification usually includes training and testing steps. In the training step, the extracted features from training data are fed into a classifier to train a model. In the testing step, the trained model is applied to classify testing data into its corresponding class. Many classifiers, such as artificial neural network, Fisher’s linear discriminant, Bayesian discriminant analysis and support vector machine can be used to steganalysis classification. The proposed scheme uses a simple two class SVM as a classifier.
3.3 Detecting MP3Stego
Denote M d as an MP3 audio under scrutiny and it is in the form of bitstream and contains totally N granules. The process of detecting MP3Stego is described as follows.
-
Step 1:
Obtain the cover estimation M e by decoding M d and compressing again.
-
Step 2:
For the i-th granule in M d , get the side information by parsing the bitstream. Then extract the number of bits in reservoir (b d,i ) which can be obtained directly from the parameter (main_data_end i ) of the side information. That is,
$$ {b_{d,i }}=main\_data\_en{d_i}\times 8 $$(6) -
Step 3:
Repeat the Step 1 and Step 2 until reach the end of the bitstream. Finally, we can get the sequence B d of b d,i . Similarly, we can get the sequence B e from M e .
-
Step 4:
Calculate the mean (μ d , μ e ) and standard variance (σ d , σ e ) by Eqs. 1 and 2.
- Step 5:
-
Step 6:
Take the F as the input for the trained SVM classifier. Apply SVM classifier and determine whether the testing MP3 audio has been deal with MP3Stego or not.
4 Experimental results
To evaluate the performance of the proposed method on detecting the MP3Stego algorithm, a total number of 1200 mono audios from 6 different sources are used as cover audios and each audio is sampled at 44.1 kHz, 16 bits/sample and has the duration of 10 s. They have never been MP3 compressed. Before embedding, the secret message is always compressed and then encrypted just as MP3Stego does. The embedding rate is defined as the ratio of message length to the stego MP3 file length. All audios are embedded with 0.001 %, 0.002 %, 0.005 %, 0.01 %, 0.02 % secret messages.
In the experiment, half of the cover and stego audios are randomly selected to train the SVM classifier and the rest are used for testing. A Matlab version for LIBSVM [5] package implementing C-SVM classifier, with its default parameters and kernel (RBF), is employed in the experiment. Classification results are averaged by 10 times of randomly selecting the training and testing audios.
The performance of the proposed algorithm is compared with the state-of-the-art approaches for detecting MP3Stego [6, 18, 20]. These algorithms are implemented in Microsoft’s Visual Studio 2010 under Windows environment. The detection results of MP3Stego with the uncalibrated and calibrated features are listed in Table 2. Accuracy in Table 2 is defined as follow,
where TP is the occurrence that a stego audio is classified as stego, TN is the occurrences that a nature audio is classified as nature, FP is the occurrences that a nature audio is classified as stego and FN is the occurrences that a stego is classified as nature. From the results, it is observed that the calibrated feature produces better classification results than that by the uncalibrated feature. It indicates that the calibration with recompression does increase the feature’s sensitivity to the MP3Stego operation while suppressing the influence of the audio content. Additionally, the classification performance decreases as the embedding rate decreases. Especially when the embedding rate is less than 0.002 %, the performances are not good. This shows that the steganalysis of MP3Stego is still very challenging in cases with low embedding rates.
In steganalysis, a false positive corresponds to classifying a cover as a stego. Similarly, a false negative corresponds to classifying a stego as a cover. For an effective detection system, keeping the false positive and false negative rates as low as possible is important. Figure 5 gives the results about false negative rates for the above features under different compression ratios and different embedding rates. For the calibration feature, it is obvious that either the false positive rate or the false negative rate decreases when the embedding rate increases. Moreover, the graphs show that the false positive and false negative rates for the calibrated feature are both less than 20 % when the embedding rate is greater than 0.01 %. These results also reveal that the calibration improves the discriminatory power of the proposed feature. Table 3 shows the false positive rates at the true positive rates of 50 % (noted as FP_50) and 80 % (noted as FP_80) when the compression ratio is at 192 kbps and the embedding rate is at 0.02 %. The closer to 0 the two indicators, the better the performance of the detection algorithm. As can be seen from Table 3, the proposed method has the same performance as the algorithm proposed by [20], and is better than the other two detection algorithms.

False alarm rate for uncalibrated (solid lines) and calibrated (dash lines) features (a) false positive rate (b) false negative rate
While the ROC curve contains most of the information about the accuracy of the classifier, it is sometimes desirable to produce quantitative summary measures of the ROC curve. Figure 6 gives the ROC curves using calibrated feature under different compression ratios. The curves indicate that the proposed scheme is able to reliably detect the trace of MP3Stego. For instance, in Fig. 6a, a probability of detection of approximately 90 % is achieved at a false positive rate of 10 %, when the embedding rate is as low as 0.01 %.

ROC curves of detector using calibrated feature under different compression ratios (a) 128 kbps (b) 192 kbps (c) 256 kbps
The most commonly used such measure is the area under the ROC curves (AUC). In this paper, the detection reliability [8] is adopted to evaluate the detection performance, which is defined as,
where A is the AUC. A is scaled to obtain ρ = 1 for a perfect detection and ρ = 0 for a random guessing. The results for detection reliabilities under different embedding rates and different compression ratios are shown in Table 4. The results in Table 4 also show that the calibrated feature outperforms the uncalibrated feature. Meanwhile, it can be seen that the detection performance depends on the embedding rate. The less the embedding rate, the more difficult it is to detect.
5 Conclusions
In this paper, we have investigated the steganalysis of MP3 audios, especially for MP3Stego algorithm. The effect on the bit reservoir, which is caused MP3Stego embedding, is utilized. By re-compression calibration, the cover audio is effectively estimated. The steganalytic features is obtained from the detecting and estimated audios. The extraction of the features is simple and rapid because they can be obtained directly from the MP3 bitstream without fully decoding. The experimental results show that the proposed method is effective to detect MP3Stego and the calibration can improve the reliability of detection. In future, we will aim to find some more sensitive features and more refined methods of calibration for attacking MP3Stego and other MP3 steganography tools such as UnderMP3Cover and Stego-Lame.
References
Achmad Z (2002) Stego-Lame, http://sourceforge.net/projects/mp3stegz
Avcibas I (2006) Audio steganalysis with content-independent distortion measures. IEEE Signal Process Lett 13(2):92–95
Bohme R, Westfeld A (2004) Statistical characterisation of MP3 encoders for steganalysis. Proceedings of ACM Workshop on Multimedia and Security, ACM, New York, USA, p 25–34
Cha SH (2007) Comprehensive survey on distance/similarity measures between probability density functions. Int J Math Models Methods Appl Sci 1(4):300–307
Chang CC, Lin CJ (2001) LIBSVM: A library for support vector machines. http://www.csie.ntu.edu.tw/~cjlin/libsvm
Dittmann J, Hesse D (2004) Network based intrusion detection to detect steganographic communication channels: on the example of audio data. Proceedings of IEEE International Workshop on Multimedia Signal Processing, IEEE, Siena, Italy, p 343–346
Dumitrescu S, Wu X, Wang Z (2003) Detection of LSB steganography via sample pair analysis. IEEE Trans Signal Process 51(7):1995–2007
Fridrich J (2004) Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes. Proceedings of International Conference on Information Hiding, Vol. 3200, Springer, Berlin, LNCS, p 67–81
ISO/IEC 11172–3 (1993) Information technology—coding of moving pictures and associated audio for digital storage media at up to about 1.5 M bit/s—part3: audio
Ker AD (2005) Steganalysis of LSB matching in grayscale images. IEEE Signal Process Lett 12(6):441–444
Ker AD, Bohme R (2008) Revisiting weighted stego-image steganalysis. Proceedings of SPIE on Security, Forensics, Steganography, and Watermarking of Multimedia Contents X, SPIE, Vol. 6819, p 5–17
Kraetzer C, Dittman J (2007) Pros and cons of mel-cepstrum based audio steganalysis using SVM classification. Proceedings of International Conference on Information Hiding, Vol. 4567, Springer, LNCS, p 359–377
Malik H (2008) Steganalysis of qim steganography using irregularity measure. Proceedings of ACM Workshop on Multimedia and Security, ACM, New York, USA, p 149–158
Ozer H, Sankur B, Memon N, Avcibas I (2006) Detection of audio covert channels using statistical footprints of hidden messages. Digit Signal Process 16(4):389–401
Petitcolas FAP (2002) MP3Stego. http://www.cl.cam.ac.uk/~fapp2/steganography/mp3stego
Platt C (2004) UnderMP3Cover. http://sourceforge.net/projects/ump3c
Provos N, Honeyman P (2003) Hide and seek: an introduction to steganography. IEEE Secur Priv 1(3):32–44
Qiao M, Sung A, Liu Q (2009) Steganalysis of MP3Stego. Proceedings of International Joint Conference on Neural Networks, IEEE, New Jersey, USA, p 2566–2571
Qiao M, Sung A, Liu Q (2009) Feature mining and intelligent computing for MP3 steganalysis. Proceedings of International Joint Conference on Bioinformatics, Systems Biology and Intelligent Computing, IEEE, Washington, DC, USA, p 627–630
Westfeld A (2003) Detecting low embedding rates. Proceedings of International Conference on Information Hiding, Vol. 2578, Springer, LNCS, p 324–339
Yan D, Wang R (2011) Huffman table swapping-based steganography for MP3 audio. Multimedia Tools Appl 52(2–3):291–305
Yan D, Wang R, Zhang L (2009) Quantization step parity-based steganography for MP3 audio. Fundam Inform 97(1–2):1–14
Acknowledgment
This work was supported by the National Natural Science Foundation of China (Grant No. 6117037), Doctoral Fund of Ministry of Education of China (Grant No. 20103305110002), Ningbo University Fund (Grant No. XK1087, XYL10002), Zhejiang Scientific and Technical Key Innovation Team of New Generation Mobile Internet Client Software (Grant No. 2010R50009), Scientific Research Fund of Zhejiang Provincial Education Department (Grant No. Y201119434) and K.C. Wong Magna Fund in Ningbo University.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Yan, D., Wang, R. Detection of MP3Stego exploiting recompression calibration-based feature. Multimed Tools Appl 72, 865–878 (2014). https://doi.org/10.1007/s11042-013-1406-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-013-1406-z