
Abstract
Machine learning methods have been deployed widely in Internet traffic classification, which identify encrypted traffic and proprietary protocols effectively based on statistical features of traffic flows. Among these methods, support vector machines (SVMs) have attracted increasing attention as it achieves the state of art performance in traffic classification compared with other machine learning methods. However, traditional SVMs-based traffic classifier also has its limitations in real application: high training complexity and computation cost on both memory and CPU, which leads to the frequent and timely updating of traffic classifier being impractical. In this paper, incremental SVMs (ISVM) model is first introduced to reduce the high training cost of memory and CPU, and realize traffic classifier’s high-frequency and quick updates Besides, a modified version of ISVM model with attenuation factor, called AISVM, is further proposed to utilize valuable information in the previous training data sets. The experimental results have proved the effectiveness of ISVM and AISVM models in traffic classification.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Internet traffic classification has attracted lots of research interests in the recent years. The ability to identify flows and their relevant protocols is required for many applications, such as security and Quality of Service (QoS). The traditional methods of traffic classification are based on well-known port numbers and deep packets identifications [1]. However, these methods became ineffective when dealing with dynamic port numbers, encrypted payloads, unknown protocols, and even variants of known protocols.
Later on, machine learning methods were introduced to tackle the above problems, which mainly exploited the network behaviors and statistical characteristics of traffic flows [2, 3]. Many supervised machine learning models have been applied in traffic classification, such as Naive Bayes (NB) [4], SVMs [5, 6], Bayesian networks [7], k-nearest neighbor (k-NN) [8], C4.5 decision tree [9] and neural networks [10], etc. Among these methods, SVMs have attracted considerable interests for its high accuracy. Proved by the experiments, SVMs obtain an average accuracy over 95%, 2.3% higher than the best performance of other machine learning methods on the same data sets [5]. In this paper, SVMs are adopted as the baseline method in traffic classification.
Although SVMs are able to achieve satisfactory performance, it has two main limitations in practice in traffic classification task.
-
(1)
High training cost on both memory and CPU: As SVMs have a high training complexity, the training of SVMs itself is time-consuming, especially in dealing with noisy data [11]. In addition, the more statistical features and training data adopted to achieve higher accuracy, the more occupations of memory and CPU resources needed.
-
(2)
Hardly realizing the frequent and timely updating: In real scenario of traffic classification, when adding the new training data, the entire traffic classifier has to be retrained in order to adapt to the new change by combining the old training data with the new training data. This updating method is costly and time-consuming which causes the frequent and timely updating of traffic classifier to be impractical. But in real application, the timely updating of the model is critical for traffic classification.
In order to tackle these problems, ISVM model is firstly introduced in traffic classification, which realizes the incremental updating of the classification model by utilizing the new training data set and the Support Vectors (SVs) produced in the last training process. The thought of incremental learning based on SVMs was first presented by Syed et al. in 1999 [11]. The method is known as the SV-incremental model in some situations. The application of ISVM model is due to the following reasons: first, SVs are the only parameters in SVMs model that the resulting decision depends on. That is, results got by training SVMs model with SVs are the same as those with the whole training data set. Therefore, an incremental result is equivalent to non-incremental result, when all the SVs in each non-incremental training case are included.
When being used in practice, however, ISVM model also has its limitations. As it only utilizes the new training data set and the SVs produced in the last updating process, other previous training data will be discarded directly. It could result in the loss of potential valuable information contained in the previous training data, which plays an important role in determining the classification boundary. AISVM is proposed for traffic classification to address this issue. The key point of AISVM model is to give per SV a weight value. If a training sample is SV in the current updating process, but not SV in the next updating process, it will not be discarded directly. Its weight value will be attenuated instead, until the weight value declines below a certain value. Then, the sample will be discarded from the set of the SVs.
The major contributions of this paper include:
-
ISVM model is firstly applied to traffic classification, and the experimental results proved its effectiveness in classifying traffic flows.
-
The high training cost of memory and CPU is dramatically reduced by deploying ISVM model, in order to realize traffic classifier’s high-frequency and quick updates.
-
AISVM model is proposed to overcome the drawback of ISVM itself in real application of traffic classification, which further improves the traffic classification accuracy without the updating cost increasing.
The remainder of this paper is organized as follows. Section 2 reviews related work. In Section 3, ISVM model is introduced for traffic classification and AISVM model is further proposed. Section 4 discusses the experimental results. Section 5 concludes the paper and presents the future work.
2 Related work
Internet traffic classification is a task of classifying the network flows which are a mixture of various flows with different application protocols. Traditional technologies of traffic classification mainly incorporate two categories: port-based method and payload-based method [1].
In port-based method, TCP or UDP port numbers are used to inspect and identify the application protocols according to the Internet Assigned Numbers Authority (IANA) list of the registered ports or well-known ports. It is simple and fast. But it became less effective as more new applications (such as P2P) started implementing dynamic port numbers in order to hide their identity [12]. Later on, payload-based methods were developed to inspect packet payloads based on specific string patterns of known applications. Though this method is more accurate, it does not work on encrypted traffic, and causes serious privacy and legal concerns.
More recently, machine learning methods have been applied in many fields [13, 14]. They also have received more attention in traffic classification [15]. Using the statistical features of traffic flows, machine learning techniques are able to avoid the above problems of port-based and payload-based methods. Machine learning models used in traffic classification are divided into two branches: unsupervised learning and supervised learning methods [3]. The former clusters traffic flows into groups that have similar traffic characteristics, while the latter classifies the traffic flow into a predefined category. The drawback of the unsupervised traffic classification is that without the real traffic classes, it is difficult to build an application-oriented traffic classifier by only using the clustering results. In contrast, the supervised learning methods require priori knowledge (also known as pre-labeled data) to train the classification model and the corresponding parameters. Then the trained model can be used in traffic classification [16]. This paper mainly focuses on supervised machine learning models for their popularity and wide usage.
They also have been received more attention in traffic classification. In 2005, Moore and Zuev [17] applied NB model to classify application protocols. In 2006, Williams et al. [18] compared five supervised learning models including NB with discretization, NB with kernel density estimation (NBKDE), C4.5 decision tree, Bayesian network and Naive Bayes tree, from the aspects of classification accuracy and computational performance. In 2009, Este et al. [5] applied SVMs on three well-known data sets and obtained an average accuracy over 95%, which is 2.3% higher than the best performance of other machine learning methods on the same data sets. In 2011, Finamore et al. [19] further presented statistical characterization of payload as features used in traffic classification based on SVMs. In 2012, Nguyen et al. [20] trained the machine learning models with a set of sub-flows and investigated different sub-flow selection strategies. In 2014, Ye and Cho [21] proposed an improved two-step hybrid P2P traffic classification framework with heuristic rules and REPTree model. In 2015, Li et al. [22] utilized logistic regression model to classify the traffic flows with the non-convex multi-task feature selection method. Peng et al. [23] verified that 5-7 packets are the best packet numbers for early stage traffic classification based on 11 well-known supervised learning models.
3 Traffic classification based on incremental SVMs model
3.1 Problem setting
We first discuss how to transform traffic classification into a classification problem. Consider a set of traffic flows{x1, x2, …, xn}, each flow xi ∈ Rd, in which d dimension of features correspond to d attributes of the traffic flow, such as packet size, TCP window size, etc. Each xi is tagged as one of the application protocols{y1, y2, …, ym}, such as P2P, WWW, and FTP, etc. By training with the mapping pairs <xi, yj> in the training data set, the goal is finding a discriminative function y = f(x), which can make accurate prediction about what application protocol the unlabeled traffic flow belongs to. In this paper, we start with the simple binary classification problem. As the application protocols usually contains more than two types of protocols, the one-against-all strategy is utilized to expand the binary SVMs model into multi-class SVMs model for traffic classification.
3.2 Traditional SVMs model
SVMs are first introduced in a binary classification task with batch learning setting, assuming the training data and their labels are given as follows: {(x1, y1), (x2, y2), …, (xn, yn)},xi ∈ Rd,yi ∈ {+1, −1}.
SVMs separate the training samples by maximizing the margin between the SVs and the classification hyperplane. The hyperplane is defined by the equation: w ⋅ x + b = 0, where w is a coefficient vector, b is a scalar offset, and the symbol “⋅” denotes the inner product in Rd, defined as:
Samples lying on each side of the hyperplane are labeled as −1 or 1, respectively. The training samples falling on the margin of classification hyperplane are called SVs.
Through the Mercer kernel function K(xj, xk) = Φ(xj) ⋅ Φ(xk), e.g. linear, polynomial and RBF kernel, SVMs map the original training samples in space X to a higher dimensional space F to make them be separated. The new discriminative function is:
where \( w=\sum \limits_{i=1}^n{\alpha}_i{y}_i\Phi \left({x}_i\right) \), \( b=-\raisebox{1ex}{$1$}\!\left/ \!\raisebox{-1ex}{$2$}\right.\left(\sum \limits_{x_a,{x}_b\in \left\{{x}_i\right\}}\sum \limits_{i=1}^n{\alpha}_i{y}_i\Phi \left({x}_a\right)\Phi \left({x}_b\right)\right) \),
Φ(x) is the mapping function.
SVMs optimize the coefficients w and b by applying the sequential minimal optimization algorithm, which is the direct reason why the training cost of SVMs model is so high. However, not all the samples but SVs (whose coefficients are not equal to zero) decide the classification hyperplane and the discriminative function. SVs can absolutely replace the whole training samples to present the characteristics of the data distribution, when kernel function and other coefficients are confirmed [24]. That is why ISVM model could get an incremental result that is equal to the non-incremental result, by utilizing the new training data set and the SVs produced in the last updating process.
3.3 Incremental SVMs model for traffic classification
As the new training data occur, the data distribution also changes with the time going. The classification model is required to be updated, in order to fit the new data and to make the accurate prediction. The traditional updating method of SVMs-based traffic classifier is to retrain the model by combining the old training data with the new one. The main drawback of this strategy is the cost of the model updating is too high, both in the occupation of updating time and computational resources. In this paper, ISVM model is implemented to tackle this problem, which realizes the incremental updating of the traffic classifier.
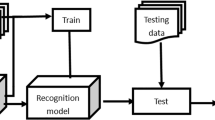
ISVM model discards the original training data, and retains the SVs which are produced in the last updating process of SVMs model [25]. When a new training data join, ISVM classifier trains a new discriminative function by combining the new data with the retained SVs [26, 27]. The updating procedure will be repeated, when an additional new data join. Figure 1 shows the primary updating steps of ISVM model.

The sketch map of ISVM updating steps
3.4 ISVM model with attenuation factor for traffic classification
Although ISVM model could accelerate the speed of model updating, it decreases the traffic classification accuracy. In the original setting of ISVM model, if the SVs in the last updating process cannot maintain its status and become the member of Not-SVs, it will be discarded directly in the next updating process. From the global perspective, this discarding strategy will result in the loss of potential valuable information contained in the previous SVs. Further, these SVs should play a critical role in determining the classification hyperplane continuously.
AISVM model gives each SV a weight value. In the continuous updating process of the traffic classifier, AISVM model retains all the previous SVs until its weight value is reduced below a certain value. Compared with the simply strategy of direct discarding, this method tries best to make use of the previous training samples. The algorithm is as the following:

From the algorithm, the initial SVMs model is trained in Step1 to Step6, when the first training data occurs. All the SVs are assigned with 1. From Step7, the updating process of SVMs model is described. The new model is trained by the new data and the remaining SVs. The new SVs are generated after the model updating in Step8. In Step10 to Step 15, the set of the remaining SVs is updated. In Step16 to Step17, the value set of the remaining SVs is updated.
4 Experimental results and discussions
4.1 Experimental data sets, metrics and setting
-
(1)
Data sets
The traffic data set of Cambridge’s Nprobe Project is used to train and test SVMs in this paper. The data set has been widely deployed in traffic classification such as the experiments based on Bayesian methods by Moore and Zuev [17]. It provides a wide variety of features to characterize traffic flows, which includes simple statistics about packet length, inter-packet timing, and information derived from traffic flows [28]. The total data set contains ten subsets, in which per subset has 256 attributes (seen in Table 1). In all the experiments of this paper, Entry1 data set is adopted as the training data, and Entry2 to Entry10 data sets as the test data.
-
(2)
Evaluation metrics
The main metric used to evaluate the performance of traffic classification is accuracy value, which is the percentage that the number of traffic flows correctly classified accounts for of the total number of traffic flows. The accuracy values are obtained for the whole system instead of per class. Besides, the training time in each updating process is taken into account.
-
(3)
Experimental setting
In order to verify the fact that the traditional SVMs achieve the best performance in traffic classification, a comparative experiment is firstly conducted which adopts NB and NBKDE as the comparison methods. Then, the traditional SVMs model is directly deployed in incremental learning setting. To observe the variation trend of the accuracy value, training time and the SVs number during the incremental updating process of traffic classifier, Entry1 data set is divided into ten parts by the sequence of generating time. The statistics of each training part is listed in Table 2. N/A means no sample of this application protocol occurs. Then, ten parts of Entry1 data sets are added to the training process one by one. ISVM model and AISVM are further utilized in traffic classification. The division of training data set and the adding strategy of training data are the same as the above experiments.
4.2 Experimental results and discussions
-
(1)
The batch learning based on the traditional SVM model
From Table 3, the performance of Naive Bayes model is much lower than the other two models. Besides, although the NBKDE model achieves a fairly high accuracy, it is impractical in real application because its classification process is very time-consuming. For example, it spends more than thirty minutes in identifying the flows in Entry9 data set, while SVMs only use 69.364 s. Considering the average accuracy, the SVMs model also achieves the accuracy over 2.3% higher than that of the NBKDE model. Therefore in this paper, SVMs are adopted as the baseline model in traffic classification.
-
(2)
The incremental learning results based on the traditional SVMs model
Table 4 presents the experimental results of incremental learning based on the traditional SVMs model by progressively increasing the training data. The result in the 10th line is the point that all parts of the Entry1 are added to the training process. The Entry1 column belongs to the close test, as Entry1 itself is training data set. The other columns are the results of the open test. The Average column is calculating the average accuracy value from Entry2 to Entry10 column.
From Table 4, the accuracy value is not always increasing along with the increasing size of training data. The performance of the SVMs model does not absolutely depend on the size of training data, but on the number of SVs [11]. In general, the more SVs are, the higher classification accuracy that the SVMs model can achieve. From the global sense, the performance of traffic classification based on SVMs will increase with the size of the training data set growing.
However, with the increasing of the training data, the computing complexity and the occupation of the computing resources will also grow significantly, which posts a great challenge to the frequent and timely updating of the model in traffic classification. For example, in the 10th line, when the size of training data set grows to 24,863, its corresponding training time is 86 h, 44 min and 51 s, which reaches the peak value of training time during the entire incremental training process.
-
(3)
The incremental learning results based on ISVM models
From the experiments above, it is confirmed that it is hard to deploy the traditional SVMs model in incremental learning setting, because it leads to a long updating period and high occupation of memory and CPU. So ISVM model is applied to tackle this problem. Table 5 lists the classification results based on ISVM model.
In the continual process of model updating, the training time are reduced dramatically in each step compared with the traditional SVMs model in the same incremental learning pattern, which powerfully proves the effectiveness of ISVM model in realizing the frequent and timely updating of the traffic classifier. But in the 10th line which is the end step of incremental updating process, the average accuracy value is over 1.5% lower than the traditional SVMs in the same phrase. The decreasing of the traffic classification accuracy is due to that ISVM model ignores the previous data except the SVs produced in the last updating process. This method could result in the loss of potential valuable information contained in all the previous training data.
-
(4)
The incremental learning results based on AISVM models
ISVM model only retains the SVs in each updating process, resulting in the loss of much information. AISVM model is proposed to tackle this problem, in order to make use of more information in previous training data. Table 6 shows the results based on AISVM model with all data sets. The parameter β is set as 1, the attenuation factor as 0.4. That is, if a training sample is not selected as SV in three continual updating steps, it will be discarded. Compared with ISVM model, AISVM model improves the classification accuracy by 1.2 percentages without the obvious increment of updating time.
-
(5)
Comparison with three models
To intuitively show the effectiveness of ISVM and AISVM models in traffic classification, Fig. 2 shows the accuracies of the final results with the test data sets. Table 7 shows the average performance comparison of these three models. The final result is the point that all the training data were used during the entire incremental learning process.

The final results based on the three Models
As Fig. 2 shown, three models have got the similar trends in the accuracy with test data sets from Entry2 to Entry10. But from Table 7, SVMs consume more than 86 h during the entire increasing updating process, 14 times more than ISVM and AISVM models. It significantly is proved that ISVM and AISVM models are effective to reduce the updating time. Compared the proposed AISVM model with ISVM model, the former one achieves 1.2 percentages improvement of the average classification accuracy without the obvious increment of the updating time. Besides, the number of SVs has a significant impact on the classification performance of the traffic classifier. More SVs usually mean high classification accuracy.
5 Conclusions
SVMs model is an effective discriminative learning model with high classification performance. However, traditional SVMs do not adapt to incremental updating in traffic classification, because of its high requirement of both time and computing resources. Aiming to tackle the problem, this paper first uses ISVM model in traffic classification. To overcome the drawback of ISVM model, AISVM model is further proposed to effectively make use of potential valuable information contained in the previous training data. The experimental results have proved that the proposed models are more effective than the traditional SVMs model in reducing the high training cost of memory and CPU with high classification performance in the same incremental updating setting.
Future work will include further implementation in online traffic classification. Extensions to applying more incremental learning modes in traffic classification, such as learning for un-supervised and semi-supervised learning, are being considered.
References
Kim H, Claffy K C, Fomenkov M, et al (2008) Internet traffic classification demystified: myths, caveats, and the best practices[C]//Proceedings of the 2008 ACM CoNEXT conference. ACM, 1-12
Karagiannis T, Papagiannaki K, Faloutsos M (2005) BLINC: multilevel traffic classification in the dark[C]//ACM SIGCOMM Computer Communication Review. ACM 35(4):229-240
Nguyen T T T, Armitage G (2008) A survey of techniques for internet traffic classification using machine learning[J]. IEEE Commun Surveys Tutor 10(4):56-76
Wang Y, Yu S Z (2008) Machine learned real-time traffic classifiers[C]. Intelligent Information Technology Application, 2008. IITA’08. Second International Symposium on IEEE, 3 p 449-454
Este A, Gringoli F, Salgarelli L (2009) Support vector machines for TCP traffic classification[J]. Comput Netw 53(14):2476–2490
Yuan R, Li Z, Guan X et al (2010) An SVM-based machine learning method for accurate internet traffic classification[J]. Inf Syst Front 12(2):149–156
Bashar A, Parr G et al (2014) Application of Bayesian networks for autonomic network management. J Netw Syst Manag 22(2):174–207
Zhang J, Xiang Y et al (2013) Network traffic classification using correlation information. IEEE Trans Parallel Distrib Syst 24(1):104–117
Monemi A, Zarei R, Marsono MN (2013) Online NetFPGA decision tree statistical traffic classifier[J]. Comput Commun 36(12):1329–1340
Auld T, Moore AW, Gull SF (2007) Bayesian neural networks for internet traffic classification[J]. IEEE Trans Neural Netw 18(1):223–239
Syed NA, Liu H, and Sung KK (1999) Handling concept drifts in incremental learning with support vector machines. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM Press, New York, NY, pages 272-276
A. Moore and K. Papagiannaki. Toward the Accurate Identification of Network Applications. In Proceedings of PAM Workshop, 2005
Pan Z, Liu S, Fu W (2017) A review of visual moving target tracking[J]. Multimed Tools Appl 76(16):16989–17018
Liu S, Cheng X, Fu W et al (2014) Numeric characteristics of generalized M-set with its asymptote[J]. Appl Math Comput 243:767–774
Dainotti A, Pescape A, and Claffy KC (2012) Issues and future directions in traffic classification. IEEE Netw 26(1):35-40
Perera P, Tian Y C, Fidge C, et al (2017) A Comparison of Supervised Machine Learning Algorithms for Classification of Communications Network Traffic[C]//International Conference on Neural Information Processing. Springer, Cham, 445-454
Moore A and Zuev D (2005) Internet traffic classification using Bayesian analysis techniques[C]. ACM SIGMETRICS-2005, Banff, Alberta, p 50-60
Williams N, Zander S, Armitage G (2006) A preliminary performance comparison of five machine learning algorithms for practical IP traffic flow classification[J]. ACM SIGCOMM Comput Commun Rev 36(5):5–16
Finamore A, Mellia M, Meo M, et al (2010) Kiss: Stochastic packet inspection classifier for udp traffic[J]. IEEE/ACM Trans Netw (TON) 18(5):1505-1515
Nguyen TTT, Armitage G, Branch P, et al (2012) Timely and continuous machine-learning-based classification for interactive IP traffic[J]. IEEE/ACM Trans Netw (TON) 20(6):1880-1894
Ye W, Cho K (2014) Hybrid P2P traffic classification with heuristic rules and machine learning[J]. Soft Comput 18(9):1815–1827
Li D, Hu G, Wang Y et al (2015) Network traffic classification via non-convex multi-task feature learning[J]. Neurocomputing 152:322–332
Peng L, Yang B, Chen Y (2015) Effective packet number for early stage internet traffic identification[J]. Neurocomputing 156:252–267
Ruping S. (2001) Incremental learning with support vector machines[C]. Data Mining, 2001. ICDM 2001, Proceedings IEEE International Conference on. IEEE, p 641-642
Laskov P, Gehl C, Kruger S, Muller K (2006) Incremental support vector learning: analysis, implementation and applications[J]. J Mach Learn Res 7:1909–1936
Shilton A, Palaniswami M, Ralph D et al (2005) Incremental training of support vector machines[J]. IEEE Trans Neural Netw 16(1):114–131
Tsai C H, Lin C Y, Lin C J. (2014) Incremental and decremental training for linear classification[C]. Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, p 343-352
Moore AW and Zuev D (2005) Discriminators for use in flow-based classification [R]. Technical report, Intel Research, Cambridge
Acknowledgements
This work was partly financially supported through grants from the National Natural Science Foundation of China (No. 60903083 and 61502123), Scientific planning issues of education in Heilongjiang Province (No. GBC1211062), and the research fund for the program of new century excellent talents (No. 1155-ncet-008). The authors thank the anonymous reviewers for their helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sun, G., Chen, T., Su, Y. et al. Internet Traffic Classification Based on Incremental Support Vector Machines. Mobile Netw Appl 23, 789–796 (2018). https://doi.org/10.1007/s11036-018-0999-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11036-018-0999-x