
Abstract
Flood disasters have had a devastating effect worldwide over the past century, both in terms of human suffering and material losses. The study of these events and development of more effective adaptation and mitigation policies has become a priority, both in Europe and other parts of the globe. This paper detects and presents the spatial distribution of river flood risks in Europe. The methodology we developed involves an assessment of three key risk components: exposure, vulnerability and hazard. A topography-based flood hazard map of Europe, identifying low-lying areas adjacent to rivers, is presented and used to identify risk, together with land-use data and damage-stage relationship for different land uses. The study covers river flood risk for the entire European continent. This methodology can be used to determine the level of future risk, using the estimations on Hazard, Exposure and Vulnerability from specific climate and economic development models. Annual average flood damage is estimated for European regions, in absolute monetary terms and in % of regional Gross Domestic Product (GDP). The results highlight regions where the threat to the economy from river flood hazard is of major concern.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Floods have been the most reported natural disaster events in many regions. Destructive floods observed in the last decades all over the world have led to record high material damages. Recently, in several individual flood events the material losses exceeded US$ 10 billion, while fatalities in less developed countries have exceeded one thousand every time. Most flood fatalities have occurred outside of Europe, particularly in Asia (being endemic in China, India, and Bangladesh). In the summer of 1998, floods in China caused US$ 30 billion material damage and resulted in over 3000 fatalities, while in 1996, floods in China caused US$ 26.5 billion material damage and approximately 2700 fatalities. In Bangladesh, during the 1998 flood, about 70% of the country’s area was inundated (Kundzewicz et al. 2007).
Europe has also been strongly hit by flood hazards. Indeed, large parts of the continent have been affected by major floods in recent decades, as described in the next chapter.
Although these hazards and disasters are caused by natural phenomena, they are also effects due to interactions between nature and the anthropogenic (social, economical and political) factors, influencing the lives of individuals and communities (Parker 2000; Konrad 2003). A hazard does not automatically lead to a harmful outcome, but identification of a hazard does mean that there is a possibility of harm occurrence. The actual harm depends upon the characteristics of the event, the system’s exposure to the hazard, the characteristics of the exposed system, and its vulnerability, which includes several concepts (sometimes found in literature as synonyms) like, preparedness, adaptation, sensitivity, resilience, resistance (Genovese 2006). The assessment of this resulting harm has been addressed in several ways using different definitions to quantify it, both in semantic and mathematical terms.
The methodology applies an operational implementation of the “risk triangle” approach based on the definition of risk proposed by Crichton (1999) and Kron (2002). According to this proposition, the risk can be modelled by three components: exposure, vulnerability and hazard.
Exposure quantifies the values that are present at the site threatened/affected by the extreme event.
Vulnerability is the hazard-specific lack (or loss) of resistance to damaging/destructive events. Vulnerability depends on the adaptive capacity of the system.
Hazard is the threatening natural event described in terms of its magnitude and probability of occurrence.
Each component is also a function of time, but only Hazard is related to purely natural phenomena, on which it is not yet clear how to relate the effect of human activities. The trend in recent decades has not resulted in a desirable reduction. On the contrary, the number of disastrous weather and climate-related events per year doubled during the 1990s compared with the previous decade, while the number of non-climatic events, such as earthquakes, has remained fairly constant.
In contrast to Hazard, the two remaining components are more directly related to human activities and governmental policies; but once again in recent decades Exposure has been growing as human occupation of floodplains intensifies and when vulnerability comes into play, we notice that dwellings with little resistance and resilience to floods do not decrease, due to the inadequate quality of buildings, lack of adequate flood defenses, weaknesses of the population related to age, gender, and lack of preparednessFootnote 1.
The three components that determine the risk have to be represented by using available geo-referenced datasets in order to be able to produce a risk layer. Spatial analysis techniques using Geographic Information Systems (GIS) are probably the only way to deal with the huge volume of data necessary for the assessment of large regions. The goal of our study is to define an operational approach relying on comparable data throughout Europe in order to assess the direct risk in monetary terms, and to determine the areas where the economic damage from river flood hazard is a major problem.
2 Major flood events in Europe in the last 50 years
Since 1950, there have been 12 flood events in Europe (flash floods and river floods) with the number of fatalities exceeding 100 in each case (Barredo 2007). These included six events in Italy (1951, 1954, 1963, 1985, 1998) and two each in Romania (1970, 1991) and Spain (1962, 1973) (see Fig. 1). The killer-flood in Spain in 1962 was the only event in the last 50 years in Europe that led to more than 1000 fatalities.

Map of the Major Flood Disasters in Europe: 1950–2005 (Barredo and Genovese 2007)
The severe floods in Europe in the first part of this century were mostly caused by heavy rain. The most destructive deluge occurred in August 2002, when in five countries (Czech Republic, Germany, Austria, Hungary, and Romania) the number of flood fatalities reached 55 and the material damage soared to US$ 20 billion (Genovese 2006). Since in September 2002, another major flood (with 23 fatalities and US$ 1.2 billion in material damage) occurred in France, the year 2002 is recognized as holding the record in Europe in the category of highest material damage caused by floods (Kundzewicz 2004). Multiple waves of heavy rains, leading to destructive floods with dozens of fatalities and billions in damage occurred in Romania in 2005 (Munich Re 2006). In June and July 2007, as a result of several waves of intense precipitation, total material flood damage of US$ 8 billion and insured damage of US$ 6 billion were registered in multiple shires (counties) of the U.K (Guy Carpenter & Co Ltd 2007).
3 Direct risk assessment of riverine floods; a macro-scale methodology
When dealing with risk or damage assessment from flood hazard, the “ideal protocol” would require very detailed quantitative information about local morphology and assets of the territory. Although the nature of the hazard is non-deterministic, local communities demand that the knowledge on the potential (or real) losses deriving from a flood event be as detailed as possible. This requires a huge amount of reliable data on the river catchment properties and an accurate quantification of the value of the affected land (Büchele et al 2006; FLOODsite 2006). On the larger European scale, the idea of treating the problem with the same scheme of local catchments is fairly unrealistic, because of a lack of consistent information and also because of the resources needed to process data at high resolution on such a wide geographical extension.
At the European Union (EU) level, the activity on flood related policies is currently focused on the ongoing process of adopting the “Directive on the assessment and management of floods”, which aims to build a common framework of policies and actions on flood prevention and mitigation at the continental level. A systematic knowledge pool, based on territorial mapping (topography, flood hazard, flood risk, land use) and information from past flood events is to be used as the basis of management plans established by Member States. These maps should be ready by the end of 2012. EU-wide flood damage assessment procedures could therefore be developed from a continental flood hazard database, which may include contributions from all nations. This also requires that a correspondingly detailed European database on exposure of assets and on vulnerability to floods be built up. While some nations like the U.K. and Germany (see for example Halcrow 2001 and DWA 2008) are more advanced at flood hazard surveying on a national scale, the time horizon for this to happen across the entire EU is likely to happen later than the above cited 2012.
This work has been carried out within the FP6 integrated project ADAMFootnote 2. During the life of this project, no territorially-based flood risk assessment at the continental scale existed. The methodology outlined here is, therefore, based on what was available in terms of official input data at the EU scale.
The goal is to define an operational approach relying on comparable data throughout Europe in order to assess the direct risk in monetary terms. The methodology should lend itself well to projections of each risk component in the future.
The methodology is based on GIS standard techniques, such as overlay mapping, to combine existing geographical databases that describe, within a certain variance, each of the three components of the “risk triangle”. We now describe the risk components used to implement the model, that we already listed into the introduction.
3.1 Exposure
The main tool for the determination of exposure is the Corine Land Cover (CLC) map for Europe (CEC 1994; EEA 2000). The combination of hazard and land-cover map allows for estimating potential exposure to floods of physical assets (grouped in classes in the land cover map). The CLC map has a nominal scale of 1:100,000, with a minimum mapping unit of 25 ha and has been operationally used in the raster version with 250 m pixel size. Two surveys, for 1990 and 2000 years, have been performed so far and a new version is expected shortly, for the nominal year 2006Footnote 3. This makes it feasible to perform analyses of the change in exposure to flood hazard. Monetary values have been determined by a specific study (HKV 2007 Footnote 4) and expressed as the average land value for each CLC class.
3.2 Vulnerability
In general, the damage caused by floods depends on flood characteristics (e.g. maximum flood depth, velocity and discharge, inundated area, flood duration, season of flood occurrence). However, for the sake of simplicity and operational quantification, only the flood depth can be considered in the present study. Therefore, the vulnerability of the assets under threat is estimated by means of depth-damage functions for each land-use class of CLC for all EU 27 countries. Such functions, also produced within the study mentioned above, are operationally expressed as a multiplying factor V(Δh) (with Δh being the relative flood depth), where 0≤V(Δh)≤1.
3.3 Hazard
This is the crucial component. Flood hazard information is usually obtained through modelling the river flow and the catchment terrain characteristics and expressed as probabilities, by coupling the observed (or calculated) precipitation and the river flow regimes. Flood extent and depth are obtained by superimposing a Digital Terrain Model (DTM).
Throughout this study, flood hazard has been modelled using a raster dataset called Flood Hazard Map (FHM). It is obtained by combining the Pan-European river network database (Vogt et al. 2007) and the so-called GTOPO30 DTM (USGS 1996), with vertical resolution 1 m, resampled to 1 km cell size. This is an orientation map, and there is no hydrological modelling behind it; details on the production of this dataset, along with validation data are published in (De Roo et al. 2007). Simply stated, the five hazard classes are determined by proximity to the river and the difference in elevation between the land and the closest river. Coastal hazards and defence structures (dykes, dams, reservoirs, etc.) are not included. The map is rendered with this qualitative classification in Fig. 2.

Topography-based Flood Hazard Map of Europe. Elevation difference determines the potential flood risk
Although this kind of map was originally developed for use in the qualitative studies and the definition of indicators for EU policies on natural hazards (Barredo et al. 2004, 2005a, 2005b; De Roo et al. 2007; Lugeri et al. 2006; Genovese 2006; CEC 2008), we have expanded its use to more quantitative studies, like those presented here. The map was therefore re-processed to translate the qualitative hazard classes, in terms of probability (frequency or return periods), of flood event occurrences. This was accomplished using expert judgment and a calibration procedure for catchments where a more detailed hazard map, based on the LISFLOOD hydrological model (De Roo 1998; Feyen et al. 2006; Dankers and Feyen, 2008), was availableFootnote 5. The spatial resolution of this map is defined by the DTM, used to calculate water levels of flood events with a given probability, namely the SRTM (Shuttle Radar Topography Mission) DTM (Farr et al. 2007) resampled to 100 m. Both datasets were derived from the same river/catchment information system. Only the DTMs used to estimate water levels and flood extents were different (in addition to the hydrology behind the model). This allowed for calibration according to sub-catchments, down to the smallest structure and taking into account the differences in the DTM resolution.
In this study, the correspondence between the FHM classes and the estimated return periods has been kept constant throughout Europe. The GIS-based method leaves room to introduce spatially variable differences across the continent.
The comparison/calibration procedure was performed in steps. First, we determined a correspondence between hazard class and return period by using the respective information on extent and water levels of the territory, as presented in detail in the interim report of the ADAM Project (Lugeri et al. 2007). For example, Fig. 3 shows the map of a 100-year flood as calculated by the LISFLOOD-based model and as estimated by the topography-based FHM, in the Tisza Basin, part of the Danube catchment in Hungary, Slovakia, Romania, Ukraine and Serbia.

Sketch of the extent and depth of the 100-year flood as predicted by the LISFLOOD-based hazard map with 100-m DEM resolution a and by the topography-based Flood Hazard Map b, in the Tisza basin
Overall, the results of the comparison under the first-step assumptions, showed that the estimate of flood extent from the FHM is higher than that from the LISFLOOD-based map; the latter tends to overestimate the extent of more frequent floods, while changing to a slighter extent for the higher return periods. This is even more evident for shorter return periods (like 5 years), which cannot be defined for the coarser FHM. Conversely, a very steep change in flood extent is observed between the first two return periods in the 1 km FHM. However, such behaviour was expected due to the difference in cell size.
Furthermore, analysis of the distribution of the peak and average flood depths and flood depth difference between two consecutive return periods in the 100 m resolution hazard map, has been performed over the sub-catchments, in order to estimate the flood depths to be assigned to consecutive classes of the 1 km resolution FHM.
An example is provided in Fig. 4, with the distribution of the peak (a) and average (b) flood depths in the third-order subcatchments of the Danube basin for the 20-year flood map, along with the distribution of the flood depth difference for each inundated pixel, between the 50-and 100-year floods (c) and the 100-and 250-year floods (d). The resulting distributions confirm that the LISFLOOD-based map already predicts large values for more frequent floods also in flood depth, in addition to the extent. Similarly to the slight variations in extent observed for longer return periods, the flood depth difference shows a distribution across the small catchments which is rather peaked towards small values, in the order of a few decimetres. Flood depth difference among different classes in the coarse map is limited by the DTM vertical resolution (1 m).

Distribution of the peak a and mean b flood depths in the 20-year flood map, and of depth difference between the 50-and 100-year floods c and the 100-and 250-year floods d in the third-order subcatchments of the Danube basin
The results were considered and discussed by experts at ADAM Project meetings, which led to the conclusion that, given the scale and the purpose of the study, as well as the relatively small requirements in computation performances, the 1-km map could lead to significant results, within an acceptable degree of uncertainty.
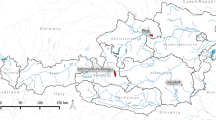
According to the results obtained from the calibration procedure, as well as from the analysis of the aggregation procedure, the “probabilistic translation” of the 1 km FHM was defined as reported in Table 1. In Table 1, the term ∆h represents the elevation difference from the pixel representing a river, as in the definition of the FHM. As a result, a European flood depth map was defined for each return period, where each consecutive map following the first is built by adding the corresponding ∆h depth step to the previous flood zones. A flood depth of 50 cm is defined as the “starting” depth of each flooded pixel that enters the flood map for the first time. Because of the definition of the hazard classes in ranges of ∆h, the monetary risk will also result in a range of values, corresponding to the maximum and minimum values of the flood depth ranges estimated for each return period, thus leading to a set of maps (two per each return period). Figure 5 shows examples of maps for North-East Austria for the return periods of 100 and 500 years, for both maximum and minimum flood depth estimates.

Flood depth maps corresponding to two return periods, 100 years and 500 years, for North-East Austria
After operationally defining the hazard, the following step is to overlay it to the CLC map (year 2000 version), to produce a new set of maps (one map for each return period), where each pixel is coded according to the corresponding land cover and flood depth. The conversion into monetary losses is finally done by the introduction of the land value and damage fraction stored in the aforementioned database, and sketched in Fig. 6, resulting in the final damage maps (Fig. 7). The values are expressed as full-replacement costs after an event; in these maps, each pixel (of 6.25 ha area) bears the damage in absolute terms, i.e. the average damage per square meter stored in the exposure/vulnerability database is already multiplied by the pixel area.

Flood damage as a function of water depth. On the left, are the logical steps for the assessment of monetary damage. The ad hoc survey on land values tabulates the average harmonized value of the five main land-use types across Europe, with a regional breakdown, and is transformed into values per land cover classes, according to the CORINE coding (EEA 2006). This database, representing the Exposure, is eventually combined with the depth-damage curves (synthesizing Vulnerability) to build the region-specific graph on the right-hand side

Distribution of flood damage for return period of 100 and 500 years for North-East Austria
The images clearly demonstrate that the major damage component arises in urban areas, where the most valuable land cover/use types are located.
4 Spatial and temporal aggregation of the results
The aggregation of these pixel-based results into larger spatial units, more suitable for other analyses, is a very important and difficult issue. Larger grids are usually necessary for application of economic models, while administrative units and natural/physical areas (e.g., catchments), are often used in studies supporting policy-making.
The analysis of flood risk (in particular carried out for insurance and re-insurance purposes) is typically based on the statistical/probabilistic analysis of damages related to observed floods and their return periods. The latter is estimated using probability density functions which can be based on the climatology and hydrology points of view. Evaluating the damage can then be performed by standard statistical methods based on the correlation between flood events occurring in different places at different times.
Using simple GIS overlay methods, it is possible to separately calculate the very basic spatial statistics (sums, averages, etc.) over the given boundary, but the main issue is how the FHM was given a probabilistic readout and how to perform the spatial superposition (integration) of the individual potential damage. Two approaches are presented here, with and without taking into account the spatio-temporal correlation of the events.
If no specific spatio-temporal correlation of flood events is introduced, the simplest aggregation method is the simple summation. If we focus on administrative levels e.g. NUTS2 (Nomenclature of Territorial Units for Statistics—CEC 2003), the total damage is the sum of the damage in each “elementary spatial damage unit” (the pixel encoded with its depth-dependent damage), over each administrative unit. Therefore, the damage represents the accumulation of the contributions coming from the exposed portions of land. By focusing just on a single return period, this is expected to lead to an overestimation because the damage value sum relative to the same return period in a NUTS2 region correspond to a situation where the N-year event happened in the whole region at the same time. In fact, in probabilistic terms, one should only look at temporal aggregation in order to build-up a damage-frequency or damage-probability curve (Fig. 8a). The area under the curve itself defines one of the most widely used quantities in flood damage assessment: the Annual Average Damage (AAD), cf. FLOODsite (2006). Nevertheless, since the true probability density functions are unknown, the simple summation, even in the case of time-averaged losses like the AAD, is expected to result in an overestimation.

a Damage-frequency curve—theoretical values. b Damage-frequency curve as estimated for a discrete series of values related to various return periods
In operational terms, the damage-frequency curve is approximated by the damage values recorded or estimated for various return periods, as plotted in Fig. 8b and accordingly calculated as the sum of the trapezoids drawn by the corresponding damage-frequency pairs. Two particular entries in the graph, namely T0 and D∞, represent, respectively, the maximum return period (hence, the frequency 1/T0) when no damage occurs (thus, representing the safety standard—degree of defence from floods), and the maximum possible damage for a catastrophic flood when return period tends to infinity (hence, the frequency tends to 0). The calculation can therefore be expressed as follows:
where D 0 =0, D N =D ∞ and P N =0.
Results of the calculations and their discussion will be shown in the next section.
In addition to the above aggregation method, a new methodology called “hybrid convolution technique”, expressly designed within this work, was used to up-scale the loss distributions from the pixel level to the regional and national levels to obtain one single total loss distribution. The basic idea is that large losses typically come from large scale events. Therefore, depending on the hazard magnitude, losses in different elementary spatial units (clusters) and their aggregation in a certain area may be considered co-monotonic. For example, up to a given hazard magnitude within a given size of the cluster groups, the losses are assumed to be independent, and afterwards they are assumed to be correlated. As the combination of two independent distributions is called “convolution”, and the combination of two dependent distributions is simply the sum, we have called this technique “Hybrid Convolution”.
One of the main issues for this approach was to define the clustering scheme to be used as the basic aggregation frame. As we are addressing river floods caused by rain and snowmelt, the “natural” choice of this scheme was to follow the river catchment structure, provided by the aforementioned European catchments geographic database. In order to achieve a national (NUTS0) or regional (NUTS2) upscaling by this catchment-based aggregation method, the calculations were accordingly performed by selecting the elementary clusters belonging to each administrative unit at the chosen NUTS level. With this method 8 cluster levels were defined, where cluster 1 is the smallest (that is, the smallest sub-catchment, corresponding to a single drainage branch in the river network), and cluster 8 is the largest. Note that the clusters are structured hierarchically, then accordingly coded, with every cluster in each level being disjoint (Fig. 9).

Up-scaling the losses over cluster levels
Therefore, the elementary clusters (the smallest sub-catchments) were used to calculate the “elementary spatial loss”, by summing up the pixel-based losses of the maps of Fig. 7. The next issue was then to upscale the loss distribution. Going from one cluster level (let’s say cluster level n−1) to the next higher cluster level n, one has to aggregate the loss distributions from all clusters in level n−1 within a given cluster in the cluster level n. As previously stated, the simple sum of the loss distributions would overestimate the losses (total dependence between clusters), while the convolution of the distributions would underestimate them (losses in the clusters independent from each other, regardless of the hazard magnitude). Hence, the aggregation of clusters to a higher cluster level must be a co-monotonic transformation. Therefore, for each cluster level we defined an impact threshold in terms of return periods where we assume total independence below this threshold and total dependence above this threshold for each of the subclusters involved in the upscaling process, thus building up the loss distribution for the clusters in level n. This is done iteratively until the country or the regional level of interest is reached. The detailed description of the hybrid convolution method and the algorithm implemented will be addressed in a dedicated paper (Hochrainer et al. 2010).
5 Results and uncertainties
Depending on assumptions of the return periods assigned to the FHM classes, as well as on the convolution steps, a range of possible total loss distributions could be looked at. In addition to the outcomes of the comparison of the flood hazard maps, this analysis was performed comparing the AAD values, as calculated with the present methods, with those published for England and Wales in 2001 (Halcrow 2001) and for Poland (Słota 2000). Also, the case of Austria was used as a benchmark, and loss distributions based on extreme value theory estimation techniques were compared with the losses calculated here. The results of this comparison are shown in Table 2 and discussed thereafter. According to the approach described in Table 1, the AAD for all of Europe was calculated pixel-wise in two versions, for the “maximum” and “minimum” estimated flood depths. For both calculations, the infinite damage has been defined as the damage occurring from a depth distribution estimated as 1000-year flood level (maximum version). As per the second important parameter in the AAD formula, namely, T0, it must be considered that, although the present study is based on potential hazard with no defence structures, in the real world, some natural embankments usually exist, so that a lower estimate for the return period of a flood event must be set. Following the considerations found in literature for similar “macro” scale analysis (Halcrow 2001; Feyen et al. 2008), the return period of first loss was set to the 25-year event. As already suggested, the territorial approach of the present methodology leaves room for the insertion of nation-or region-specific values for this quantity, according to local socio-economic factors like GDP (Feyen et al. 2008); this also allows to take into account adaptation processes as well as future trends.
In order to display how differently the European regions behave in terms of potential flood losses, the AAD raster-based maps have been aggregated over the “regional” European administrative level (NUTS-2), according to both of the above described methods. These values could also be expressed in GDP-relative terms. All values were transformed into standardised Euros for the year 2007, by official Eurostat/OECD data on inflation, currency rate and Purchasing Power Parity. Additionally, only for the “simple summation” method, a spatial arrangement defined by a regular grid with cells of 50 × 50 km was used as the aggregation scheme. In this case, the GDP-relative information could not be displayed, because there is no reliable way to map GDP over abstract grids.
The maps are reported in Figs. 10, 11 and 12, in terms of the mean value of the minimum and maximum damage maps (values in the legends are with full-replacement scheme). It is clearly visible that the hybrid convolution method yields significantly smaller results for the potential AAD than those from the simple summation method. For the time being, it is hard to assess whether the expected overestimation arising from the simple summation approach is now correctly removed or even turned into an underestimation.

Annual Average Damage (AAD) from river floods in Europe: aggregation over NUTS2 level administrative boundaries performed by simple summation. Left: absolute values in standardised Euro (year 2007). Right: share of regional GDP (GDP data from year 2005, except Scotland, 2004, projected into 2007 values by national GDP ratio between respective years)

AAD, as in Fig.10, aggregated by the “hybrid convolution” method

Annual Average Damage (AAD) from river floods in Europe: aggregation by simple summation over a grid with square cells of 50-km size
From Table 2, it seems that the second statement applies; nevertheless, from the reported literature it is hard to decipher how the calculations were actually performed (whether from real events or from potential hazards), how defences were included and so on. In addition, the hybrid convolution method seems to be sensitive to the truncation effect arising when catchment areas are intersected by administrative boundaries. It must be noted that the NUTS2 administrative boundaries represent very heterogeneous territorial units, which sometimes correspond to the whole nation, ranging from 15 to 15,000 square kilometres. We believe that this very diverse degree of fragmentation has an effect on the hybrid convolution process. This issue is currently under investigation.
In Table 2 an absolute error factor (± [AADmax—AADmin]/2) is also included. We have looked at the distribution of this dispersion in relative terms (i.e. divided by the mean AAD) over the regions or grid cells. The result shows that in the simple summation method the distribution is rather peaked around a mean value of about 17%, while with the hybrid convolution it has a mean value of about 14%, but it’s less peaked and, as expected, due to the aforementioned fragmentation issue, it seems to be nation-dependent.
6 Conclusions
We have presented a territorially-based methodology to assess the present river flood risk in Europe, using a topography-based flood hazard map of Europe together with land-use data and damage-stage relationship for different land uses. Although the hazard information is not directly derived from a hydrological model, the method provides a rather simple (with relatively low computation time) tool to analyse—with a regional breakdown—the risk of economic losses for almost all of Europe.
The results, expressed in terms of the Annual Average Damage, highlight regions where the threat to the economy from river flood hazard is of major concern. Although the two aggregation methods used yield slightly different results, Eastern Europe as well as Scandinavia, Austria and the U.K., along with some regions in France and Italy, appear to be under significant threat, especially in terms of regional GDP. The easiest aggregation method, the simple summation over the administrative boundary, is surely overestimating losses. Nevertheless, it is our feeling that—for the time being—it is more stable than the alternative (hybrid convolution). In particular, when dealing with such a delicate matter, where a conservative (“protectionist”) view of the analyst is usually preferable, it is more reliable and draws the attention of policy makers to possible risk “hotspots”.
Furthermore, due to the scale of the study and the corresponding detail level of the database, the overestimation which is intrinsic to the method and arising from the aggregation procedure, compensates to some degree for the lack of consideration of losses from smaller rivers which are not included in the river network.
This methodology can also be used to obtain a risk projection for selected future time horizons, using the estimations on Hazard, Exposure and Vulnerability from specific climate and economic development models. An example of this (which considers hazard change only) is included in another article on this volume (Kundzewicz et al. 2010).
Further work will be focused on the refinement of the hybrid convolution aggregation method and its application to future flood risk scenarios.
Notes
see, e.g. http://www.floodresiliencegroup.org
see http://etc-lusi.eionet.europa.eu/CLC2006/ for the state of the art.
The aim of the study has been to produce flood damage functions relating water depth and economical damage for the assessment of direct damage as a consequence of floods. The flood damage functions have been produced for the CLC2000 classes, interpreted in land-use terms according to the LUCAS survey (EEA 2006). For each land-use class or their combinations, damage functions were produced.
The water depth-damage functions comprise two damage indicators:
-
Damage factor relative to the maximum damage (i.e. between 0 and 1);
-
Absolute damage estimation (in Euros)
The water depth-damage functions include a range of water depths from 0 to 6 m
The approach is summarized as follows:
-
Literature study on flood damage data and damage functions. The study was Internet based and only European sources were considered;
-
Questionnaires were sent to authors to clarify documents found during the Internet search;
-
The collected country-specific quantitative data (comprising damage functions and maximum damage values) were recorded in Excel-spreadsheets;
-
Geographical characteristics of the countries were compared using GIS.
-
Economical characteristics of the countries were compared using statistical economic data from Eurostat and the World Bank;
-
A selection of land use classes was made based on their contribution to maximum damage. The selected classes comprise—on average for all EU countries—at least 80% of the total damage, in order to reduce the number of classes, but still predicting at least 80% of damage.
-
The collected maximum damage values were corrected using average national annual inflation;
-
The corrected maximum damage values were harmonized using statistical data from Eurostat and the World Bank;
-
The collected damage functions were reworked per land use class to one average function to be used for countries without collected functions;
-
Functions and maximum damage values were assigned to member states without collected data;
-
For all (mixed) land use classes of CLC it was identified based on literature (LUCAS survey) which unique land use classes contributed and how much;
-
Country specific functions and values were reworked to be used in relation to CLC datasets;
-
The extension to the entire EU of the LISFLOOD-based hazard map (Feyen et al. 2008) was completed after the end of the work here presented, as related to the ADAM Project.
Abbreviations
- AAD:
-
Annual Average Damage
- CLC:
-
Corine Land Cover
- DTM:
-
Digital Terrain Model
- EU:
-
European Union
- FHM:
-
Flood Hazard Map
- GDP:
-
Gross Domestic Product
- GIS:
-
Geographic Information Systems
- GTOPO30:
-
Global Topography 30″ arc resolution
- NUTS:
-
Nomenclature of Territorial Units for Statistics
- SRTM:
-
Shuttle Radar Topography Mission
References
Barredo JI, Lavalle C, Sagris V, Kasanko M (2004) Climate change impacts on floods in Europe. Toward a set of risk indicators for adaptation, DG-JRC, Ispra, EUR 21472 EN
Barredo JI, Petrov L, Sagris V, Lavalle C, Genovese E (2005a) Toward an integrated scenario approach for spatial planning and natural hazard mitigation, European Communities, DG-JRC, Ispra, EUR 21900 EN
Barredo JI, Lavalle C, De Roo A (2005b) European flood risk mapping, EC DG JRC, 2005 S.P.I.05.151.EN
Barredo JI (2007) Major flood disasters in Europe: 1950–2005. Nat Hazards 42:125–148
Barredo JI, Genovese E (2007) Map of the Major Flood Disasters in Europe: 1950–2005, LB-X1-07-022-EN-N, at http://moland.jrc.ec.europa.eu/publications/MajorFloods1950-2005.pdf last visited 14/12/2009
Büchele B, Kreibich H, Kron A, Thieken A, Ihringer J, Oberle P, Merz B, Nestmann F (2006) Flood-risk mapping: contributions towards an enhanced assessment of extreme events and associated risks. Nat Hazards Earth Syst Sci 6:485–503
CEC (Commission of the European Communities) (1994) CORINE Land Cover. Technical Guide. EUR 12585 EN Office for Official Publications of European Communities, Luxembourg
CEC (2003) Regulation (EC) No 1059/2003 of the European Parliament and of the Council of 26 May 2003 on the establishment of a common classification of territorial units for statistics (NUTS) (Official Journal L 154, 21/06/2003) [available at http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=OJ:L:2003:154:0001:0041:EN:PDF last visited 14/12/2009. see also http://ec.europa.eu/eurostat/ramon/nuts/splash_regions.html]
CEC (2008) DG REGIO; 4th Report on Economic and Social Cohesion [available at http://ec.europa.eu/regional_policy/sources/docoffic/official/reports/cohesion4/index_en.htm last visited 14/12/2009]
Crichton D (1999) The Risk Triangle. In: Ingleton J (ed) Natural Disaster Management. Tudor Rose, London
Dankers R, Feyen L (2008) Climate change impact on flood hazard in Europe: An assessment based on high resolution climate simulations. J Geophys Res 113:D19105. doi:10.1029/2007JD009719
De Roo A. (1998) Modelling runoff and sediment transport in catchments using GIS. In: GIS Applications in Hydrology. Hydrological Processes 12:905–922
De Roo A, Barredo JI, Lavalle C, Bodis K, Bonk R (2007) Potential flood hazard and risk mapping at pan-European scale. In: Peckham R, Jordan G (eds) Digital terrain modelling. Development and applications in a policy support environment. Series: Lecture Notes in Geoinformation and Cartography. Springer-Verlag Berlin
DWA Deutsche Vereinigung für Wasserwirtschaft, Abwasser und Abfall (2008) Arbeitshilfe—Hochwasserschadensinformationen DWA Themen HW 4.4 ISBN:978-3-940173-95-9
EEA (European Environment Agency) (2000) CORINE Land Cover Technical Guide. Tech. Rep. 40. [available at: http://www.eea.europa.eu/publications/tech40add/at_download/file last visited 14/12/2009]
EEA (2006) The thematic accuracy of CORINE Land Cover 2000, Assessment using LUCAS (land use/cover area frame statistical survey), EEA Technical report No. 7/2006 Office for Official Publications of the European Communities, Luxembourg
Farr TG, Rosen PA, Caro E, Crippen R, Duren R, Hensley S, Kobrick M, Paller M, Rodriguez E, Roth L, Seal D, Shaffer S, Shimada J, Umland J, Werner M, Oskin M, Burbank D, Alsdorf D (2007), The Shuttle Radar Topography Mission, Rev. Geophys., 45, RG2004, doi:10.1029/2005RG000183. [available at: http://www2.jpl.nasa.gov/srtm/srtmBibliography.html last visited 14/12/2009]
Feyen L, Dankers R, Barredo JI, Kalas M, Bódis K, de Roo A, Lavalle C (2006) PESETA—Flood risk in Europe in a changing climate. European Commission, 2006 EUR 222313 EN [available at: http://peseta.jrc.ec.europa.eu/docs/EUR%2022313.pdf last visited on 14/12/2009)
Feyen L, Barredo JI, Dankers R (2008) Implications of Global Warming and Urban Land Use Change on Flooding in Europe. In: Water and Urban Development Paradigms—Feyen, Shannon & Neville Eds; CRC Press—Balkema ISBN: 9780415483346; p. 217–225
FLOODsite (2006) Guidelines for socio-economic flood damage evaluation. EU 6th FP Integrated Project Report Number T9-06-01 2006 [available at: http://www.floodsite.net/html/partner_area/project_docs/T09_06_01_Flood_damage_guidelines_D9_1_v2_2_p44.pdf last visited on 14/12/2009)
Genovese E (2006) A methodological approach to land use-based flood damage assessment in urban areas: Prague case study. JRC IES EUR 22497 EN
Guy Carpenter & Co Ltd (2007), Wrong Type of Rain: Impact and Implications of 2007 UK Floods. http://www.guycarp.com/portal/extranet/insights/reportsPDF/2007/UK_Floods_2007.pdf last visited 10/12/2009
Halcrow Group Ltd, HR Wallingford & John Chatterton Associates (2001) National appraisal of assets at risk from flooding and coastal erosion, including the potential impact of climate change. DEFRA Flood Management Division, 64 pp
Hochrainer S, Lugeri N and Radziejewski M (2010) Up-scaling of impact dependent loss distributions: A hybrid convolution approach. European Journal of Operational Research (submitted)
HKV Consultants (2007) Flood damage functions for EU member states. Final Report for Contract n. 382441—F1SC for the European Commission, Joint Research Centre (not for disclosure)
Konrad CP (2003), “Effects of Urban Development on Flood”, U.S. Department of the Interior, U.S. Geological Survey, USGS Fact Sheet FS-076-03
Kron W (2002) Flood risk=hazard x exposure x vulnerability. In: Wu M et al (eds) Flood Defence. Science Press, New York
Kundzewicz ZW (2004) Floods and Flood Protection: Business-as-Usual? In: Rodda JC, Ubertini L (eds) The Basis of Civilization—Water Science? IAHS Publication 286. IAHS Press, Oxfordshire, U.K., pp 201–209
Kundzewicz ZW, Mata LJ, Arnell N, Döll P, Kabat P, Jiménez B, Miller K, Oki T, Şen Z, Shiklomanov I (2007) Freshwater resources and their management. In: Parry ML, Canziani OF, Palutikof JP, Hanson CE, van der Linden PJ (ed.), Climate Change 2007: Impacts, Adaptation and Vulnerability. Contribution of Working Group II to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change. Cambridge University Press, Cambridge, UK and New York, NY, USA [available at http://www.ipcc.ch/pdf/assessment-report/ar4/wg2/ar4-wg2-chapter3.pdf last visited on 14/12/2009]
Kundzewicz ZW, Lugeri N, Dankers R, Hirabayashi Y, Döll P, Pińskwar I, Dysarz T, Hochrainer S, Matczak P (2010) Assessing risk and adaptation to river floods in Europe in a changing climate—projections for the future (this issue)
Lugeri N, Genovese E, Lavalle C, De Roo A (2006) Flood risk in Europe: analysis of exposure in 13 Countries. JRC IES EUR 22525 EN
Lugeri N, Genovese E, Lavalle C, Barredo JI, Bindi M, Moriondo M (2007) An assessment of weather-related risks in Europe. JRC IES EUR 23208 EN
Munich Re (2006). Topics Geo. Annual review: Natural catastrophes 2005. Munich Re, Munich
Parker DJ (2000) Introduction to floods and flood management. In: Parker DJ (ed.), Floods, Vol. I, London & New York
Słota H. (ed.) (2000) Water management in Poland. The Institute of Meteorology and Water Management. Cracow. ISBN 83-912681-1-X
USGS/EROS Data Centre (1996) GTOPO Elevation Database [available at http://eros.usgs.gov/#/Find_Data/Products_and_Data_Available/gtopo30_info last visited on 14/12/2009]
Vogt JV, Soille P, de Jaeger AL, Rimaviciute E, Mehl W (2007) A Pan-European River and Catchment Database. EC-JRC (Report EUR 22920 EN) Luxembourg [available at: http://desert.jrc.ec.europa.eu/action/documents/CCM2-Report_EUR-22920-EN_2007_STD.pdf last visited on 14/12/2009]
Author information
Authors and Affiliations
Corresponding author
Additional information
Guest Editors: Zbigniew W. Kundzewicz and Reinhard Mechler
Rights and permissions
About this article
Cite this article
Lugeri, N., Kundzewicz, Z.W., Genovese, E. et al. River flood risk and adaptation in Europe—assessment of the present status. Mitig Adapt Strateg Glob Change 15, 621–639 (2010). https://doi.org/10.1007/s11027-009-9211-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11027-009-9211-8