
Abstract
In this work we propose and analyze a weighted proper orthogonal decomposition method to solve elliptic partial differential equations depending on random input data, for stochastic problems that can be transformed into parametric systems. The algorithm is introduced alongside the weighted greedy method. Our proposed method aims to minimize the error in a \(L^2\) norm and, in contrast to the weighted greedy approach, it does not require the availability of an error bound. Moreover, we consider sparse discretization of the input space in the construction of the reduced model; for high-dimensional problems, provided the sampling is done accordingly to the parameters distribution, this enables a sensible reduction of computational costs, while keeping a very good accuracy with respect to high fidelity solutions. We provide many numerical tests to assess the performance of the proposed method compared to an equivalent reduced order model without weighting, as well as to the weighted greedy approach, in both low and high dimensional problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Many physical models and engineering problems are described by partial differential equations (PDEs). These equations usually depends on a number of parameters, which can correspond to physical or geometrical properties of the model as well as to initial or boundary conditions of the problem, and can be deterministic or subject to some source of uncertainty. Many applications require either to compute the solutions in real time, i.e. to compute them almost instantaneously given certain input parameters, or to compute a huge number of solutions corresponding to diverse parameters. The latter is for example the case when we want to evaluate statistics of some features associated to the solution. In both cases it is necessary to have methods to get very fast, and still reliable, numerical solutions to these equations.
Reduced order models [7, 18, 23, 33] were developed to face this problem. The main idea of these methods is that in many practical cases the solutions obtained for different values of the parameters belong to a lower-dimensional manifold of the function space they naturally belong to. Therefore, instead of looking for the solution in a high-dimensional approximation subspace of this function space, one could look for it in a low-dimensional, suitably tailored, reduced order space. Obviously, this considerably reduces the computational effort, once the reduced spaces are available. Different methods have been developed to construct these sub-spaces in an efficient and reliable way: two popular techniques are the greedy method and the Proper Orthogonal Decomposition (POD) method. Other possibilities include rational interpolation methods, balanced truncation [6], tensor methods, system balancing [5], discrete empirical interpolation methods [10].
As said above, many of the parameters describing the problem at hand can be subject to uncertainties. In several applications, keeping track of these uncertainties could make the model more flexible and more reliable than a deterministic model. In this case we consider PDEs with random inputs, or stochastic PDEs. Many different methods are available to solve such problems numerically, such as stochastic Galerkin [36], stochastic collocation [1, 28, 41], as well as Monte-Carlo [36], multi-level [17, 25, 38], importance sampling [32] and polynomial chaos techniques [42]. More recently, methods based on reduced order models have been developed [11,12,13, 16, 34, 35, 39]. In practice, they aim to construct low-dimensional approximation subspaces in a weighted fashion, i.e. more weight is given to more relevant values of the parameters, according to an underlying probability distribution.
Our proposed weighted POD method corresponds to a weighted principal component analysis [19], where the data is represented by the snapshot PDE solutions. Such algorithm has already been successfully applied to various uncertainty quantification problems [20, 22, 37], also in the context of POD [8]. Nevertheless, to our knowledge, no reduced order method for stochastic PDEs based completely on the POD algorithm has been proposed so far.
In this paper we consider the case of linear elliptic PDEs with the same assumption as in [12]. We briefly discuss the framework and introduce the weighted greedy algorithm. The rest of the work is devoted to define a weighted proper orthogonal decomposition method, which is the original contribution of this work. While the greedy algorithm aims to minimize the error in a \(L^\infty \) norm over the parameter space, the POD method looks instead at the \(L^2\) norm error, which, in the stochastic case, is the mean square error. The integral of the square error is discretized according to some quadrature rule, and the reduced order space is found by minimizing this approximation error. From the algorithmic point of view, this corresponds to applying a principal component analysis to a weighted (preconditioned) matrix. The main difference from the greedy algorithm is that our method does not require the availability of an upper bound on the error. Nevertheless, our method requires an Offline computation of an high number of high-fidelity solutions, which may be costly. Therefore, to keep the computational cost low, we adopted sparse quadrature rules. These methods allow to get the same accuracy at a sensibly lower computational cost, especially in the case of high dimensional parameter space. The resulting weighted POD method shows the same accuracy as long as the underlying quadrature rule is properly chosen, i.e. accordingly to the distribution. Indeed, since the reduced order space will be a subspace of the space spanned by the solutions on the parameter nodes given by the quadrature rule, these training parameters need to be representative of the probability distribution on the parameter space. Thus the choice of a proper quadrature rule plays a fundamental role.
The work is organized as it follows. An elliptic PDE with random input data is set up with appropriate assumptions on both the random coefficient and the forcing term in Sect. 2. In Sect. 3 we describe the affinity assumptions that must be made on our model to allow the use of the reduced basis methods; the greedy algorithm is presented in its weighted version. Our proposed method is then described as based on the minimization of an approximated mean square error. Sparse interpolation techniques for a more efficient integral approximation in high dimensions are also presented. Numerical examples (Sect. 4) for both a low-dimensional (\(N=4\)) problem and its high dimensional counterpart (\(N=9\)) are presented as verification of the efficiency and convergence properties of our method. Some brief concluding remarks are made in Sect. 5.
2 Problem Setting
Let \((\Omega ,\mathcal {F},P)\) be a complete probability space, where \(\Omega \) is the set of possible outcomes, \(\mathcal {F}\) is the \(\sigma \)-algebra of events and P is the probability measure. Moreover, let \(D\subseteq \mathbb {R}^d\) (\(d=1,2,3\)) be an open, bounded and connected domain with Lipschitz boundary \(\partial D\). We consider the following stochastic elliptic problem: find \(u: {\overline{D} \times \Omega } \rightarrow \mathbb {R}\), such that it holds for P-a.e. \(\omega \in \Omega \) that
Here a is a strictly positive random diffusion coefficient and f is a random forcing term; the operator \(\nabla \) is considered w.r.t. the spatial variable x. Motivated by the regularity results obtained in [12], we make the following assumptions:
-
i.
The forcing term f is square integrable in both variables, i.e.
$$\begin{aligned} {||}f{||}^2_{L^2_P(\Omega )\otimes L^2(D)} \doteq \int _{{D \times \Omega }} {f^2(x; \omega )}\,dP(\omega )dx < \infty . \end{aligned}$$ -
ii.
The diffusion term is P-a.s. uniformly bounded, i.e. there exist \(0<a_{\text {min}}<a_{\text {max}}<\infty \) such that
$$\begin{aligned} P({a(x; \cdot )}\in (a_{\text {min}},a_{\text {max}}) \,\forall \, x \in D)=1. \end{aligned}$$
If we introduce the Hilbert space \(\mathbb {H} = {H^1_0(D) \otimes L^2_P(\Omega )}\), we can consider the weak formulation of problem (1): find \(u\in \mathbb {H}\) s.t.
where \(\mathbb {A}:\mathbb {H}\times \mathbb {H}\rightarrow \mathbb {R}\) and \(\mathbb {F}:\mathbb {H}\rightarrow \mathbb {R}\) are, respectively, the bilinear and linear forms
The above is called weak-weak formulation. Thanks to assumption i.-ii., the Lax-Milgram theorem [9] ensures us the existence of a unique solution \(u\in \mathbb {H}\).
More than the solution itself, we will be interested in statistics of values related to the solution, e.g., the expectation \({{\mathrm{\mathbb {E}}}}[s(u)]\), where s(u) is some linear functional of the solution. In particular, the numerical experiments in the following are all performed for the computation of \({{\mathrm{\mathbb {E}}}}[u]\).
2.1 Weak–Strong Formulation
To numerically solve problem (2) we first need to reduce \((\Omega ,\mathcal {F},P)\) to a finite-dimensional probability space. This can be accomplished up to a desired accuracy through, for example, the Karhunen-Loéve expansion [26]. The random input is in this case characterized by K uncorrelated random variables \(Y_1(\omega ),\dots ,Y_K(\omega )\) so that we can write
and hence (thanks to the Doob-Dynkin lemma [30])
where \(\mathbf {Y}(\omega ) = (Y_1(\omega ),\dots ,Y_K(\omega ))\). We furthermore assume that \(\mathbf {Y}\) has a continuous probability distribution with density function \(\rho :\mathbb {R}^K\rightarrow \mathbb {R}^+\) and that \(Y_k(\Omega ) \subseteq \varGamma _k\) for some \(\varGamma _k\subset \mathbb {R}\) compact sets, \(k=1,\dots ,K\). In case the initial probability density is not compactly supported, we can easily reduce to this case by truncating the function \(\rho \) on a compact set up to a desired accuracy. Our problem can be reformulated in terms of a weighted parameter \(y\in \varGamma \doteq \prod _{k=1}^K\varGamma _k\): find \(u:\varGamma \rightarrow \mathbb {V} \doteq H_0^1(D)\) such that
for a.e. \(y\in \varGamma \), where \(A(\cdot ,\cdot ;y)\) and \(F(\cdot ;y)\) are, respectively, the parametrized bilinear and linear forms defined as
for \(k=1,\dots ,K\). The parameter y is distributed according to the probability measure \(\rho (y)dy\). Problem (3) is called the weak-strong formulation of problem (2). Again, the existence of a solution is guaranteed by the Lax-Milgram theorem.
Given an approximation space \(\mathbb {V}_\delta \subseteq \mathbb {V}\) (typically a finite element space), with \(\text {dim}(\mathbb {V}_\delta ) = N_\delta < \infty \), we consider the approximate problem: find \(u_{N_\delta }:\varGamma \rightarrow \mathbb {V}_\delta \) such that
for a.e. \(y\in \varGamma \). We refer to problem (4) as the truth (or high dimensional) problem and \(u_{N_\delta }\) as the truth solution. Consequently we approximate the output of interest as \(s_{N_\delta } = s(u_{N_\delta }) \simeq s(u)\) and its statistics, e.g. \({{\mathrm{\mathbb {E}}}}[s_{N_\delta }] \simeq {{\mathrm{\mathbb {E}}}}[s(u)]\).
2.2 Monte-Carlo Methods
A typical way to numerically solve problem (3) is to use a Monte-Carlo simulation. This procedure takes the following steps:
-
1.
generate M (given number of samples) independent and identically distributed (i.i.d.) copies of \(\mathbf {Y}\), drawn from \(\rho \), and store the obtained values \(y^j\), \(j=1,\dots ,M\);
-
2.
solve the deterministic problem (3) with \(y^j\) and obtain solution \(u_j=u(y^j)\), for \(j=1,\dots ,M\);
-
3.
evaluate the solution statistics as averages, e.g.,
$$\begin{aligned} \mathbb {E}[u] \simeq \langle u \rangle = \frac{1}{M}\sum _{j=1}^M u_j \qquad \text {or} \qquad \mathbb {E}[s(u)] \simeq \langle s(u) \rangle = \frac{1}{M}\sum _{j=1}^M s(u_j) \end{aligned}$$for some suitable output function s.
Although the convergence rate of a Monte Carlo method is formally independent of the dimension of the random space, it is relatively slow, typically \(1/\sqrt{M}\). Moreover, the \(1/\sqrt{M}\) scaling comes with a lot of important caveats for high dimension problems. In fact, this ignores the multipliers of the scalings, which can be quite large for basic Monte Carlo for some integrands. Also, for a given problem class, the multiplier (the variance of the integrand) itself may grow with dimension, which means the \(1/\sqrt{M}\) scaling is misleading when considering high dimensions. Thus, one requires to solve a large amount of deterministic problems to obtain a desired accuracy, which implies a very high computational cost. In this framework reduced order methods turn out to be very useful in order to reduce the computational cost, at cost of a (possibly) small additional error. We mention that other alternatives exist. For example, the number of samples needed to recover a certain accuracy could be recuced by adopting variance reduction tecniques (see e.g. [31], Chapter 8).
3 Weighted Reduced Order Methods
Given the truth approximation space \(\mathbb {V}_\delta \), reduced order algorithms look for an approximate solution of (4) in a reduced order space \(\mathbb {V}_N\subseteq \mathbb {V}_\delta \), with \(N\ll N_\delta \). Reduced order methods consist of an offline phase and an online phase.
During the offline phase, an hierarchical sequence of reduced order spaces \(\mathbb {V}_1\subseteq \cdots \subseteq \mathbb {V}_{N_{\text {max}}}\) is built. These spaces are sought in the subspace spanned by the solutions for a discrete training set of parameters \(\varXi _t = {\lbrace }y^1,\dots ,y^{n_t}{\rbrace }\subseteq \varGamma \), according to some specified algorithm. In this work we focus on the greedy and POD algorithm, as we will detail in Sects. 3.2 and 3.3, respectively.
During the online phase, the reduced order problem is solved: find \(u_N:\varGamma \rightarrow \mathbb {V}_N\) such that
for a.e. \(y\in \varGamma \). At this point, we can approximate the output of interest as \(s_N = s(u_N) \simeq s(u)\) and its statistics, e.g. \({{\mathrm{\mathbb {E}}}}[s_N] \simeq {{\mathrm{\mathbb {E}}}}[s(u)]\). In the stochastic case, we would also like to take into account the probability distribution of the parameter \(y\in \varGamma \). Weighted reduced order methods consist of slight modifications of the offline phase so that a weight\(w(y_i)\) is associated to each sample parameter \(y_i\), according to the probability distribution \(\rho (y)dy\). As we will discuss, another crucial point is the choice of the training set \(\varXi _t\).
For sake of simplicity, from now on we omit the index \(\delta \), \(N_\delta \) and we assume that our original problem (3) coincides with the truth problem (4).
3.1 Affine Decomposition Assumption
In order to ensure efficiency of the online evaluation, we need to assume that the bilinear form \(A(\cdot ,\cdot ;y)\) and linear form \(F(\cdot ;y)\) admit an affine decomposition. In particular, we require the diffusion term a(x; y) and the forcing term f(x; y) to have the following form:
where \(a_k\in L^\infty (D)\) and \(f_k\in L^2(D)\), for \(k=1,\dots ,K\), and \(y = (y_1,\dots ,y_K)\in \varGamma \). Thus, the bilinear form \(A(\cdot ,\cdot ;y)\) and linear form \(F(\cdot ;y)\) can be written as
with
for \(k={0},\dots ,K\). In the more general case that the functions \(a(\cdot ; y)\), \(f(\cdot ; y)\) do not depend on y linearly, one can reduce to this case by employing the empirical interpolation method [3]. A weighted version of this algorithm has also been proposed in [14].
3.2 Weighted Greedy Algorithm
The greedy algorithms ideally aims to find the N-dimensional subspace that minimizes the error in the \(L^\infty (\varGamma )\) norm, i.e. \(\mathbb {V}_N\subseteq \mathbb {V}\) such that the quantity
is minimized. The reduced order spaces are built hierarchically as
for \(N=1,\dots ,N_{\text {max}}\), where the parameters \(y^N\) are sought as solution of an \(L^\infty \) optimization problem in a greedy way:
To actually make the optimization problem above computable, the parameter domain \(\varGamma \) is replaced with the training set \(\varXi _t\). The greedy scheme is strongly based on the availability of an error estimator \(\eta _N(y)\) such that
Such an estimator needs to be both sharp, meaning that there exists a constant c (possibly depending on N) as close as possible to 1 such that \({||}u(y)-u_N(y){||}_\mathbb {V} \ge c\cdot \eta _N(y)\), and efficiently computable. An efficient way to compute \(\eta _N\) is described in detail e.g. in [23] (the affine decomposition (6) plays an essential role here). The greedy scheme actually looks for the maximum of the estimator \(\eta _N\) instead of the quantity in (7) itself. In the case of stochastic parameter \(y\in \varGamma \), the idea is to modify \(\eta _N(y)\), multiplying it by a weight w(y), chosen accordingly to the distribution \(\rho (y)dy\). The estimator \(\eta _N(y)\) is thus replaced by \(\widehat{\eta }_N(y) \doteq w(y)\eta _N(y)\) in the so called weighted scheme. Weighted greedy methods have been originally proposed and developed in [11,12,13, 15, 16]. An outline of the weighted greedy algorithm for the construction of the reduced order spaces is reported in Algorithm 1.

A greedy routine with estimator \(\widehat{\eta }_N\) hence aims to minimize the distance of the solution manifold from the reduced order space in a weighted \(L^\infty \) norm on the parameter space. Now, depending on what one wants to compute, different choices can be made for the weight function w. For example, if we are interested in a statistics of the solution, e.g., \(\mathbb {E}[u]\), we can choose \(w(y)=\rho (y)\). Thus, for the error committed computing the expected value using the reduced basis, the following estimates holds:
If we are interested in evaluating the expectation of a linear output s(u), \(\mathbb {E}[s(u)]\), using the same weight function, we get the error estimate:
Instead, taking \(w(y)=\sqrt{\rho (y)}\) one gets the estimate for the quadratic error:
3.3 Weighted POD Algorithm
The Proper Orthogonal Decomposition is a different method to build reduced order spaces, which does not require the evaluation of an error bound. The main idea in the deterministic (or uniform, i.e. when \(\rho \equiv 1\)) case is to find the N-dimensional subspace that minimizes the error in the \(L^2(\varGamma )\) norm, i.e. \(\mathbb {V}_N\subseteq \mathbb {V}\) such that the quantity
is minimized. As with the greedy algorithm, the method does not aim to minimize the quantity (9) directly, but a discretization of it, namely
where \(\varphi _i = u(y^i)\), \(i=1,\dots ,n_t\), and \(P_N:\mathbb {V}\rightarrow \mathbb {V}_N\) the projection operator associated with the subspace \(\mathbb {V}_N\). One can show (see e.g. [23]) that the minimizing N-dimensional subspace \(\mathbb {V}_N\) is given by the subspace spanned by the N leading eigenvectors of the linear map
where \({\langle }\cdot , \cdot {\rangle }_\mathbb {V}\) denotes the inner product in \(\mathbb {V}\). Computationally, this is equivalent to find the N leading eigenvectors of the symmetric matrix \(C\in \mathbb {R}^{n_t\times n_t}\) defined as \(C_{ij} = {\langle }\varphi _i,\varphi _j{\rangle }_\mathbb {V}\). In the case of stochastic inputs we would rather like to find the N-dimensional subspace that minimizes the following error
Based on this observation, we propose a weighted POD method, which is based on the minimization of a discretized version of (10), namely
where \(w:\varXi _t \rightarrow [0,\infty )\) is a weight function prescribed according to the parameter distribution \(\rho (y)dy\), and \(w_i=w(y^i)\), \(i=1,\dots ,n_t\). Again, this is computationally equivalent to finding the N leading eigenvectors of the preconditioned matrix \(\hat{C} \doteq P \cdot C\), where C is the same as defined before and \(P=\text {diag}(w_1,\dots ,w_{n_t})\). We note that the matrix \(\hat{C}\) is not symmetric in the usual sense, but it is with respect to the scalar product induced by the matrix C (i.e. it holds that \(\hat{C}^TC = C\hat{C}\)). Thus, spectral theorem still holds and there exists an orthonormal basis of eigenvectors, i.e., \(\widehat{C}\) is diagonalizable with an orthogonal change of basis matrix. The discretized parameter space \(\varXi _t\) can be selected with a sampling technique, e.g., using an equispaced tensor product grid on \(\varGamma \) or taking M realizations of a uniform distribution on \(\varGamma \). Note that if we build \(\varXi _t\) as the set of M realizations of a random variable on \(\varGamma \) with distribution \(\rho (y)dy\), and we put \(w\equiv 1\), the quantity (11) we minimize is just a Monte Carlo approximation of the integral (10). Following this observation, a possible approach would be to select \(\varXi _t\) and w as the nodes and the weights of a quadrature rule that approximates the integral (10). That is, if we consider a quadrature operator \(\mathcal {U}\), defined as
for every integrable function \(f:\varGamma \rightarrow \mathbb {R}\), where \({\lbrace }x^1,\dots ,x^{n_t}{\rbrace }\subset \varGamma \) are the nodes of the algorithm and \(\omega _1,\dots ,\omega _{n_t}\) the respective weights, then we can take \(\varXi _t = {\lbrace }x^1,\dots ,x^{n_t}{\rbrace }\) andFootnote 1\(w_i = \omega _i\rho (x^i)\). Therefore, varying the quadrature rule \(\mathcal {U}\) used, one obtain diverse ways of (at the same time) sampling the parameter space and preconditioning the matrix C. An outline of the weighted POD algorithm for the construction of the reduced order spaces is reported in Algorithm 2.

Since the proposed weighted POD method requires to perform \(n_t\) truth solve and compute the eigenvalues of a \(n_t\times n_t\) matrix, the dimension \(n_t\) of \(\varXi _t\) should better not be too large. A possible way to keep the sample size \(n_t\) low is to adopt a sparse grid quadrature rule, as we describe in the following.
3.4 Sparse Grid Interpolation
In order to make the weighted POD method more efficient as the dimension of the parameter space increases, we use Smolyak type sparse grid instead of full tensor product ones for the quadrature operator \(\mathcal {U}\). These type of interpolation grids have already been used in the context of weighted reduced order methods [11, 13] as well as of other numerical methods for stochastic partial differential equations, like e.g. in stochastic collocation [28, 41]. Full tensor product quadrature operator are simply constructed as product of univariate quadrature rules. If \(\varGamma = \prod _{k=1}^K \varGamma _k\) and \({\lbrace }\mathcal {U}_i^{(k)}{\rbrace }_{i=1}^\infty \) are sequences of univariate quadrature rules on \(\varGamma _k\), \(k=1,\dots ,K\), the tensor product multivariate rule on \(\varGamma \) of order q is given by
where we introduced the differences operators\(\varDelta _0^{(k)}=0\), \(\varDelta _{i+1}^{(k)}=\mathcal {U}_{i+1}^{(k)}-\mathcal {U}_i^{(k)}\) for \(i\ge 0\). Given this, the Smolyak quadrature rule of order q is defined as
Therefore, Smolyak type rules can be seen as hierarchical sum of ordinary full tensor product rules. One of their main advantage is that the number of evaluation points is drastically reduced as K increases. Indeed, if \(X^{(k)}_i\) is the set of evaluation points for the rule \(\mathcal {U}_i^{(k)}\), then the set of evaluation points for the rule \(\mathcal {U}_q^K\) is given by
while the set of evaluation points for the rule \(\mathcal {Q}_q^K\) is given by
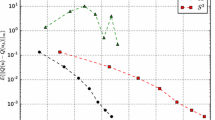
In practice, for K large, one has that \({|}\varTheta _S^{q,K}{|}\) grows much slower as q increases w.r.t. \({|}\varTheta _F^{q,K}{|}\), which has an exponential behavior (see Fig. 1 for a comparison using a Clenshaw–Curtis quadrature rule). This implies that the adoption of Smolyak quadrature rules has a much lower computational cost than common full tensor product rules for high dimensional problem. Moreover, the performance of Smolyak quadrature rules are comparable with standard rules. For more details about error estimates and computational cost of Smolyak rules we refer e.g. to [4, 21, 24, 29, 40].

Two dimensional grids based on nested Clenshaw–Curtis nodes for \(q=6\). The left one is based on a Smolyak rule (145 nodes), while the right one on a full tensor product rule (1089 nodes)
4 Numerical Tests
We tested and compared the weighted greedy algorithm and the weighted POD algorithm for the solution of problem (1) on the unit square domain \(D = [0,1]^2\). To solve the below problems we used the \(\mathtt {RBniCS}\) library [2], built on top of \(\mathtt {FEniCS}\) [27].
4.1 Thermal Block Problem
In this section we describe the test case we considered to assess the numerical performance of the diverse algorithms. Let \(D = [0,1]^2 =\cup _{k=1}^K \Omega _k\) be a decomposition of the spatial domain. We consider problem (1) with \(f \equiv 1\) and

and \(y=(y_1,\dots ,y_K)\in \varGamma = [1,3]^K\). In other words, we are considering a diffusion problem on D, where the diffusion coefficient is constant on the elements of a partition of D in K zones. We study the case of a stochastic parameter \(\mathbf {Y}=(Y_1,\dots ,Y_K)\) where \(Y_k\)’s are independent random variables with a shifted and re-scaled Beta distribution:
for some positive distribution parameters \(\alpha _k,\beta _k\), \(k=1,\dots ,K\). We consider a uniform decomposition of the domain D for either \(K=4\) (low-dimensional case) or \(K=9\) (high-dimensional case), as illustrated in Fig. 2.

The considered decompositions of the spatial domain \(D = [0,1]^2\)
4.2 Weighted Reduced Order Methods
We implemented the standard (non-weighted) and the weighted greedy algorithm for construction of reduced order spaces. We took \(\omega = \sqrt{\rho }\) in the weighted case (this choice being motivated by (8)) and we sampled \(\varXi _t\) using diverse techniques:
-
sampling from uniform distribution;
-
sampling from equispaced grid;
-
sampling from the (Beta) distribution.
We choose \(y^1 = (2,\dots ,2)\in \mathbb {R}^K\) as the first parameter in Algorithm 1 (the mode of the distribution \(\mathbf {Y}\)). The size of the training set was chosen to be \(n_t = 1000\) for the case \(K = 4\) and \(n_t = 2000\) for the case \(K = 9\).
Furthermore, we implemented diverse versions of the weighted POD algorithm and we compared their performance. As explained above, different version of the weighted POD algorithm are based on different quadrature formulae. Each formula is specified by a set of nodes \(\varXi _t = {\lbrace }y_1,\dots ,y_{n_t}{\rbrace }\) and a respective set of weights \(w_i\) (note that these can be different from the weights \(\omega _i\) of the quadrature formula; below we also denote \(\rho _i=\rho (y_i)\)). In particular, we experimented the following weighted variants of the POD algorithm with non-sparse grids:
-
Uniform Monte-Carlo: the nodes are uniformly sampled and the weights are given by \(w_i = \rho _i/n_t\);
-
Monte-Carlo: the nodes are sampled from the distribution of \(\mathbf {Y}\) and uniformly weighted;
-
Clenshaw–Curtis (Gauss–Legendre, respectively): the nodes are the ones of Clenshaw–Curtis (Gauss–Legendre, resp.) tensor product quadrature formula and the weights are given by \(w_i = \rho _i\omega _i\);
-
Gauss–Jacobi: the nodes are the ones of the Gauss–Jacobi tensor product quadrature formula and the weights are given by \(w_i = \omega _i\).
In the low-dimensional case (\(K=4\)) we tested the methods for two different values of the training set size, \(n^1_t\) and \(n^2_t\). In the first test we chose \(\varXi _t=\varXi _t^1\) to be the smallestFootnote 2 possible set such that \({|}\varXi _t^1 {\setminus } \partial \varGamma {|}\ge 100\) and in the second test we chose \(\varXi _t=\varXi _t^2\) to be the smallest possible set such that \({|}\varXi _t^2 {\setminus } \partial \varGamma {|}\ge 500\). For the high-dimensional case (\(K=9\)), the sizes of the sets of nodes of Gauss–Legendre and Gauss–Jacobi rules was \(n_t=2^9=512\); indeed, the next possible choice \(n_t=3^9=19683\) was computationally impracticable. Moreover, Clenshaw–Curtis formula was not tested, because a very large training set would have been required as \({|}\varXi _t \cap \mathring{\varGamma }{|}=1\) for (the already impracticable choice) \(n_t=3^9\). In this case, the use of sparse Gauss–Legendre/Gauss–Jacobi quadrature rules provided a more representative set of nodes consisting of just \(n_t = 181\) nodes. A summary of the formulae and training set sizes used is reported in Table 1.
4.3 Results
We compared the performance of the weighted greedy and weighted POD algorithms for computing the expectation of the solution. In particular, we computed the error (10) using a Monte Carlo approximation, i.e.,
where \(y^1,\dots ,y^M\) are M independent realizations of \(\mathbf {Y}\) drawn from a Beta distribution. For truth problem solutions, we adopted \(\mathbb {V}_\delta \) to be the classical \(\mathbb {P}^1\)-FE approximation space. Three cases were carried out:
-
1.
distribution parameters \((\alpha _i,\beta _i)=(10,10)\), for \(i = 1, \ldots , K = 4\);
-
2.
distribution parameters \((\alpha _i,\beta _i)=(10,10)\), for \(i = 1, \ldots , K = 9\);
-
3.
distribution parameters \((\alpha _i,\beta _i)=(75,75)\), for \(i = 1, \ldots , K = 9\), resulting in a more concentrated distribution than case 2.
Figures 3, 4, 5, 6, 7, 8, 9, 10 and 11 show the graphs of the error (12) (in a \(\log _{10}\) scale), as a function of the reduced order space dimension N, for different methods. In particular, Figs. 3, 4 and 5 collect the results for case 1, as well as Figs. 6, 7, 8, 9, 10 and 11 those of cases 2 and 3. From these plots, we can gather the following conclusions:
-
Weighted vs standard The weighted versions of the POD and greedy algorithms outperform the performance of their standardFootnote 3 counter-parts in the stochastic setting, see Figs. 3 (POD) and 5 (Greedy) for case 1. Such a difference is even more evident in for high parametric dimension (compare Fig. 3 to Fig. 6 for the POD case) or in presence of higher concentrated parameters distributions (compare Fig. 6 to Fig. 9 for the POD case, and see Figs. 10 and 11 for the greedy case).
-
Importance of representative training set The Monte-Carlo and Gauss–Jacobi POD algorithms outperform the other weighted POD variants (Fig. 4 for case 1, as well as Figs. 6 and 7 for case 2). In the low-dimensional case 1, we can still recover the same accuracy also with the other weighted variants, at the cost of using a larger training set \(\varXi _t\) (Fig. 4). However, for the high dimensional case 2, the choice of the nodes plays a much more fundamental role (see Figs. 6 and 7). Monte-Carlo and Gauss–Jacobi methods perform significantly better because the underlying quadrature rule is designed for the specific distribution \(\rho (y)\,dy\) (a Beta distribution). For more concentrated distributions, methods lacking a representative training set may eventually lead to a very inaccurate sampling of the parameter space, even resulting in numerically singular reduced order matrices despite orthonormalization of the snapshots. This is because the subspace built by the reduced order methods is a subspace of \({\lbrace }u(y) {{\mathrm{\,:\,}}}y \in \varXi _t {\rbrace }\). Thus, if \(\varXi _t\) contains only points y with low probability \(P{\lbrace }Y = y{\rbrace }\), adding a linear combination of solutions \({\lbrace }u(y) {{\mathrm{\,:\,}}}y \in \varXi _t {\rbrace }\) to the reduced space does not increase the accuracy of the computed statistics. Instead the weighting procedure tends to neglect such solutions, resulting in linearly dependent vectors defining the reduced order subspace. This can also be observed for the weighted greedy algorithm (Fig. 10).
-
Breaking curse of dimensionality through sparse grids The presented algorithms also suffer from the fact that for increasing parameter space dimensions K, the number of nodes, \(n_t\), increases exponentially. In the weighted POD algorithm we can mitigate this problem by adopting a sparse quadrature rule. Figure 8 shows the performances of the (tensor product) Gauss–Jacobi POD versus its sparse version. Not only does the use of sparse grids make the method much more efficient, reducing significantly the size of the training set used (in our specific case, from \(n_t = 512\) to \(n_t=181\)), but it also results in a negligibly higher accuracy. On the other hand, the importance of a well-representative training set is highlighted by the use of sparse grids. Sparse Gauss–Legendre results in numerically singular matrices at lower N (than its tensor product counter-part); sparsity makes its associated training set less representative. For this reason, the plots of the error obtained with this method were not reported.
-
Weighted POD vs weighted greedy The weighted POD seems to work slightly better than the weighted greedy (see Fig. 5 (right) for case 1 and Fig. 11 for case 3). This is because weighted POD is designed to minimize (in some sense) the quantity (10); however, the difference in terms of the error is practically negligible. The main difference in the two algorithms lies in the different training procedure. Thanks to the availability of an inexpensive error estimator, we are able to use large training sets for greedy algorithms, while still requiring a moderate computational load during the training phase. On the flip side, the availability of different techniques for the POD algorithms also allows control of the computational cost of this algorithm, which does not require the construction of an ad-hoc error estimator, making it more suitable to study problems for which such error estimation procedure is not yet available.

Low-dimensional case (\(K=4\)) Plots of the error (12) obtained using standard (POD—uniform), uniform Monte-Carlo (Weighted POD—Uniform) and Monte-Carlo (POD—distribution) POD algorithms. Left: \(\varXi _t^1\). Right: \(\varXi _t^2\)

Low-dimensional case (\(K=4\)) Plots of the error (12) obtained using Clenshaw–Curtis, Gauss–Legendre and Gauss–Jacob POD algorithms. Left: \(\varXi _t^1\). Right: \(\varXi _t^2\)

Low-dimensional case (\(K=4\)) Left: Plots of the error (12) obtained using standard greedy algorithm and weighted greedy algorithm with uniform sampling and sampling of the distribution. Right: Plots of the error (12) obtained using standard and weighted greedy and standard and Gauss–Jacobi POD algorithms. Results in this plot are obtain using the second training set \(\varXi _t^2\)

High-dimensional case (\(K=9\)) Plots of the error (12) obtained using standard, uniform Monte-Carlo and Monte-Carlo POD algorithms. Left: \(\alpha _i=\beta _i=10\). Right: \(\alpha _i=\beta _i=75\)

High-dimensional case (\(K=9\)) Plots of the error (12) obtained using (tensor product) Gauss–Legendre and Gauss–Jacobi POD algorithms. Left: \(\alpha _i=\beta _i=10\). Right: \(\alpha _i=\beta _i=75\)

High-dimensional case (\(K=9\)) Plots of the error (12) obtained using Gauss–Legendre POD and sparse Gauss–Legendre POD algorithms. Left: \(\alpha _i=\beta _i=10\). Right: \(\alpha _i=\beta _i=75\)

High-dimensional case (\(K=9\)) Plots of the error (12) obtained using standard, Monte-Carlo and Gauss–Jacobi POD algorithms. Left: \(\alpha _i=\beta _i=10\). Right: \(\alpha _i=\beta _i=75\)

High-dimensional case (\(K=9\)) Plots of the error (12) obtained using standard and weighted greedy algorithms with uniform sampling and from the distribution. Left: \(\alpha _i=\beta _i=10\). Right: \(\alpha _i=\beta _i=75\)

High-dimensional case (\(K=9\)) Plots of the error (12) obtained using standard and weighted Greedy and standard and Monte-Carlo POD algorithms. Left: \(\alpha _i=\beta _i=10\). Right: \(\alpha _i=\beta _i=75\).
5 Conclusion and Perspectives
In this work we developed a weighted POD method for elliptic PDEs. The algorithm is introduced alongside the previously developed weighted greedy algorithm. While the latter aims to minimize the error in the \(L^\infty \) norm, the former minimizes an approximation of the mean squared error, which is of better interpretation when weighted. Differently from the weighted greedy method, the introduced weighted POD algorithm does not require the availability of error estimation; indeed, such error estimator may not be readily available in general (e.g. for nonlinear problems). The weighted POD approach is based instead on a quadrature rule, which can be chosen accordingly to the parameter distribution. In particular, this allows to implement sparse quadrature rules to reduce the computational cost of the offline phase as well.
A numerical example on a thermal block problem was carried out to test the proposed reduced order method, for either a low dimensional parametric space or two high dimensional space of parameters. For this problem, we assessed that the weighted POD method is an efficient alternative to the weighted greedy algorithm. The numerical tests also highlighted the importance of a training set which is representative of the underlying parameter distribution. In case of a representative rule, the sparse quadrature rule based algorithm showed to perform better for what concerns accuracy and a lower number of training snapshots.
Possible future investigations could concern applications to problems with more involved stochastic dependence, as well as non-affinely parametrized problems. The latter ones could require the use of an ad-hoc weighted empirical interpolation technique [14]. Another extension, especially in the greedy case, would be that of providing accurate estimation for the error. Such estimation were obtained for linear elliptic coercive problems in [12], but it would be useful to generalize them to different problems. Finally, the proposed tests and methodology could also be used as the first step to study nonlinear problems.
Notes
We assume that \(\mathcal {U}\) is a quadrature rule for integration with respect to dy. If a quadrature rule \(\mathcal {U}_{\rho }\) for integration with respect to the weighted measure \(\rho dy\) is used instead, that is suffices to take \(w_i = \omega _i\).
When using tensor product quadrature rule, we can not impose the cardinality of \(\varXi _t\) a priori. We also note that when we use the Clenshaw–Curtis approximation, the majority of the points in \(\varXi _t\) lies on \(\partial \varGamma \): these point are completely negligible, since \(\rho |_{\partial \varGamma } \equiv 0\). So, in this case, we need to take a considerably larger value for \(n_t\) to reach the desired cardinality of nodes in the interior \(\mathring{\varGamma }\).
The standard algorithms are obtained imposing unitary weights and sampling from uniform distribution.
References
Bäck, J., Nobile, F., Tamellini, L., Tempone, R.: Stochastic spectral galerkin and collocation methods for pdes with random coefficients: a numerical comparison. In: Hesthaven, J.S., Rønquist, E.M. (eds.) Spectral and High Order Methods for Partial Differential Equations: Selected Papers from the ICOSAHOM ’09 conference, June 22–26, Trondheim, Norway, pp. 43–62. Springer, Berlin (2011)
Ballarin, F., Sartori, A., Rozza, G.: RBniCS—reduced order modelling in FEniCS. http://mathlab.sissa.it/rbnics (2015)
Barrault, M., Maday, Y., Nguyen, N., Patera, A.: An ‘empirical interpolation’ method: application to efficient reduced-basis discretization of partial differential equations. Comptes Rendus Mathematique 339(9), 667–672 (2004)
Bathelmann, V., Novak, E., Ritter, K.: High dimensional polynomial interpolation on sparse grids. Adv. Comput. Math. 4(12), 273–288 (2000)
Benner, P., Cohen, A., Ohlberger, M., Willcox, K.: Model Reduction and Approximation: Theory and Algorithms, vol. 15. SIAM (2017)
Benner, P., Gugercin, S., Willcox, K.: A survey of projection-based model reduction methods for parametric dynamical systems. SIAM Rev. 57(4), 483–531 (2015)
Benner, P., Ohlberger, M., Patera, A., Rozza, G., Urban, K.: Model Reduction of Parametrized Systems. Springer, Berlin (2017)
Bistrian, D., Susan-Resiga, R.: Weighted proper orthogonal decomposition of the swirling flow exiting the hydraulic turbine runner. Appl. Math. Model. 40(5–6), 4057–4078 (2016)
Brezis, H.: Functional Analysis, Sobolev Spaces and Partial Differential Equations. Springer, Berlin (2010)
Chaturantabut, S., Sorensen, D.C.: Nonlinear model reduction via discrete empirical interpolation. SIAM J. Sci. Comput. 32(5), 2737–2764 (2010)
Chen, P.: Model order reduction techniques for uncertainty quantification problems. Ph.D. thesis, École polytechnique fédérale de Lausanne EPFL (2014)
Chen, P., Quarteroni, A., Rozza, G.: A weighted reduced basis method for elliptic partial differential equations with random input data. SIAM J. Numer. Anal. 51(6), 3163–3185 (2013)
Chen, P., Quarteroni, A., Rozza, G.: Comparison between reduced basis and stochastic collocation methods for elliptic problems. J. Sci. Comput. 1(59), 187–216 (2014)
Chen, P., Quarteroni, A., Rozza, G.: A weighted empirical interpolation method: a priori convergence analysis and applications. SESAIM. Math. Model. Numer. Anal. 4(48), 943–953 (2014)
Chen, P., Quarteroni, A., Rozza, G.: Multilevel and weighted reduced basis method for stochastic optimal control problems constrained by stokes equations. Numerische Mathematik 1(133), 67–102 (2016)
Chen, P., Quarteroni, A., Rozza, G.: Reduced basis methods for uncertainty quantification. SIAM/ASA J. Uncertain. Quantif. 5(1), 813–869 (2017)
Cliffe, K.A., Giles, M.B., Scheichl, R., Teckentrup, A.L.: Multilevel monte carlo methods and applications to elliptic pdes with random coefficients. Comput. Visual. Sci. 14(1), 3 (2011)
Dahmen, W.: How to best sample a solution manifold? In: G.E. Pfander (ed.) Sampling Theory, a Renaissance: Compressive Sensing and Other Developments, pp. 403–435. Springer, Berlin (2015)
Fan, Z., Liu, E., Xu, B.: Weighted principal component analysis. In: International Conference on Artificial Intelligence and Computational Intelligence, pp. 569–574. Springer, Berlin (2011)
Gabriel, K.R., Zamir, S.: Lower rank approximation of matrices by least squares with any choice of weights. Technometrics 21(4), 489–498 (1979)
Gerstner, T., Griebel, M.: Numerical integration using sparse grids. Numer. Algorithms 3–4(18), 209–232 (1998)
Haber, M., Gabriel, K.: Weighted Least Squares Approximation of Matrices and Its Application to Canonical Correlations and Biplot Display. Tech. rep. Department of Statistics, University of Rochester, Rochester (1976)
Hesthaven, J., Rozza, G., Stamm, B.: Certified Reduced Basis Methods for Parametrized Partial Differential Equations. Springer, Berlin (2016)
Holtz, M.: Sparse Grid Quadrature in High Dimensions with Applications in Finance and Insurance. Springer, Belrin (2010)
Lang, J., Scheichl, R.: Adaptive multilevel stochastic collocation method for randomized elliptic PDEs. Preprint 2718 (2017)
Loève, M.: Probability Theory. Springer, Berlin (1978)
Logg, A., Mardal, K.A., Wells, G.: Automated Solution of Differential Equations by the Finite Element Method: The FEniCS Book, vol. 84. Springer, Berlin (2012)
Nobile, F., Tempone, R., Webster, C.G.: A sparse grid stochastic collocation method for partial differential equations with random input data. SIAM J. Numer. Anal. 5(46), 2309–2345 (2008)
Novak, E., Ritter, K.: High dimensional integration of smooth functions over cubes. Numerische Mathematik 1(75), 79–97 (1996)
Oksendal, B.: Stochastic Differential Equations. An Introduction with Applications. Springer, Berlin (1998)
Owen, A.B.: Monte Carlo theory, methods and examples (2013). http://statweb.stanford.edu/~owen/mc/
Peherstorfer, B., Cui, T., Marzouk, Y., Willcox, K.: Multifidelity importance sampling. Comput. Methods Appl. Mech. Eng. 300, 490–509 (2016)
Quarteroni, A., Rozza, G., Manzoni, A.: Certified reduced basis approximation for parametrized partial differential equations and applications. J. Math Ind. 1(1), 3 (2011)
Spannring, C.: Weighted reduced basis methods for parabolic PDEs with random input data. Ph.D. thesis, Graduate School CE, Technische Universität Darmstadt (2018)
Spannring, C., Ullmann, S., Lang, J.: A weighted reduced basis method for parabolic PDEs with random data. arXiv preprint arXiv:1712.07393 (2017)
Sullivan, T.: Introduction to Uncertainty Quantification. Springer, Berlin (2015)
Tamuz, O., Mazeh, T., Zucker, S.: Correcting systematic effects in a large set of photometric light curves. Mon. Notices R. Astron. Soc. 356(4), 1466–1470 (2005)
Teckentrup, A.L., Jantsch, P., Webster, C.G., Gunzburger, M.: A multilevel stochastic collocation method for partial differential equations with random input data. SIAM/ASA J. Uncertain. Quantif. 3(1), 1046–1074 (2015)
Torlo, D., Ballarin, F., Rozza, G.: Stabilized weighted reduced basis methods for parametrized advection dominated problems with random inputs. arXiv preprint arXiv:1711.11275 (2017)
Wasilkowski, G.W.: Explicit cost bounds of algorithms for multivariate tensor product problems. J. Complex. 1(11), 1–56 (1995)
Xiu, D., Hesthaven, J.S.: High-order collocation methods for differential equations with random inputs. SIAM J. Sci. Comput. 3(27), 1118–1139 (2006)
Xiu, D., Karniadakis, G.E.: The Wiener–Askey polynomial chaos for stochastic differential equations. S. J. Sci. Comput. 24(2), 619–644 (2002)
Acknowledgements
We acknowledge the support by European Union Funding for Research and Innovation—Horizon 2020 Program—in the framework of European Research Council Executive Agency: H2020 ERC Consolidator Grant 2015 AROMA-CFD project 681447 “Advanced Reduced Order Methods with Applications in Computational Fluid Dynamics”. We also acknowledge the INDAM-GNCS projects “Metodi numerici avanzati combinati con tecniche di riduzione computazionale per PDEs parametrizzate e applicazioni” and “Numerical methods for model order reduction of PDEs”. The computations in this work have been performed with RBniCS [2] library, developed at SISSA mathLab, which is an implementation in FEniCS [27] of several reduced order modelling techniques; we acknowledge developers and contributors to both libraries.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Venturi, L., Ballarin, F. & Rozza, G. A Weighted POD Method for Elliptic PDEs with Random Inputs. J Sci Comput 81, 136–153 (2019). https://doi.org/10.1007/s10915-018-0830-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10915-018-0830-7