
Abstract
Packing problems are np-hard problems with several practical applications. A variant of a 2d Packing Problem (2dpp) was proposed in the gecco 2008 competition session. In this paper, Memetic Algorithms (mas) and Hyperheuristics are applied to a multiobjectivised version of the 2dpp. Multiobjectivisation is the reformulation of a mono-objective problem into a multi-objective one. The main aim of multiobjectivising the 2dpp is to avoid stagnation in local optima. First generation mas refers to hybrid algorithms that combine a population-based global search with an individual learning process. A novel first generation ma is proposed, and an original multiobjectivisation method is applied to the 2dpp. In addition, with the aim of facilitating the application of such first generation mas from the point of view of the parameter setting, and of enabling their usage in parallel environments, a parallel hyperheuristic is also applied. Particularly, the method applied here is a hybrid approach which combines a parallel island-based model and a hyperheuristic. The main objective of this work is twofold. Firstly, to analyse the advantages and drawbacks of a set of first generation mas. Secondly, to attempt to avoid those drawbacks by applying a parallel hyperheuristic. Moreover, robustness and scalability analyses of the parallel scheme are included. Finally, we should note that our methods improve on the current best-known solutions for the tested instances of the 2dpp.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Packing problems are a class of optimisation problems which involve packing a set of objects together as densely as possible. They are highly related to cutting problems, whose main goal is to cut large stock sheets into a set of smaller pieces. In many cases, both problems have been analysed together, being referred to as cutting and packing problems. Both problems have been shown to be combinatorial np-hard problems. Therefore, obtaining high quality solutions is a complex task. However, there is a high interest in solving them because they are related to real life packaging, storage and transportation issues. Therefore, they have many applications and are widely used within more complex systems, e.g. filling containers and trucks, loading pallets, optimising the layout of electrical circuits, etc.
Cutting and packing problems can be classified [29, 40] according to several characteristics: the number of dimensions, the number of available patterns, the shape of the patterns—regular or irregular—, the orientation, and the objective to be optimised, among others. Depending on these features, several variants of the problem can be defined. Some of the most popular ones are 2d strip packing, constrained 2d cutting stock, knapsack problems, and packing with cost. Within each category there are also several different formulations. In the gecco 2008 competition sessionFootnote 1 a variant of a 2d packing problem (2dpp) was proposed. It was a reformulation of a packing problem designed with the aim of hindering the achievement of optimal values and increasing the size of the search space. While it may be difficult to imagine direct practical applications of this particular variant of a 2d packing problem, it is hard and complex enough that it can be used to check the advantages and drawbacks of a given optimisation scheme. This was our main reason for considering this formulation of the problem in our work. Moreover, previous results obtained using different optimisation methods can be used for comparison purposes [27, 35].
Several optimisation algorithms have been defined to deal with complex optimisation problems. Among them, several flavours of metaheuristics have been defined. One of the most promising is the family of Memetic Algorithms (mas) [33]. They are a synergy of Evolutionary Algorithms (eas) or any population-based approach with a separate individual learning process. Considering the classification exposed in [32], mas can be categorised as follows. The first generation mas refers to hybrid algorithms that combine a population-based global search with an individual learning process. The second generation mas include hyperheuristics among other approaches. In this case, different low-level configurations of a metaheuristic—memes—are chosen by the hyperheuristic based on their behaviour to generate local improvements through a reward mechanism. Finally, in third generation mas the pool of memes is dynamically generated during the optimisation process instead of being specified beforehand. In this paper, we consider first and second generation mas. In order to test the second generation mas, a hyperheuristic is considered.
The incorporation of the learning process might lead to stagnation in local optima [34, 35]. Several methods for avoiding stagnation have been proposed [18]. Some of the simplest techniques rely on restarting the approach when stagnation is detected. In other cases, a component is used that inserts randomness or noise into the search. Another possibility is the usage of multiobjectivisation [24]. The term multiobjectivisation refers to the redefinition of originally mono-objective problems as multi-objective ones. Multiobjectivisation usually decreases the selection pressure of the original approach. Therefore, when used in combination with mas, some low quality individuals in the population have a higher probability of surviving. However, if properly configured, these individuals could, in the long term, help to avoid stagnation, thus resulting in high quality solutions.
Another drawback of mas is that the time invested in obtaining high quality solutions could be considerable. With the aim of reducing this time, several paradigms for implementing parallel eas (peas) have been proposed [2]. These paradigms can be extended to mas parallelisation (pmas) by substituting eas by mas. Island-based models have shown good performance and scalability in many areas [2]. Such models conceptually divide the overall pma population into a number of independent and separate populations, i.e. there are separate and simultaneously executing mas—one per processor or island—. Each island evolves in isolation for the majority of the pma execution, but occasionally, some individuals can be migrated among neighbour islands using a predefined migration stage.
The main objective of this work is twofold. Firstly, to analyse the benefits and disadvantages of a set of first generation mas. Such a set of first generation mas is applied to a multiobjectivised version of the 2dpp. Among the proposals, the ones presented in [35] were considered since they yielded the best up-to-date results for the 2dpp. In addition, a novel ma is proposed and an original multiobjectivisation scheme is applied to the 2dpp. We study the effects of the ma applied and of the multiobjectivisation approach utilised on the quality of the solutions obtained. Secondly, in order to avoid the drawbacks of the first generation mas and to enable their usage in parallel environments, a parallel hyperheuristic is applied. This parallel scheme has the added benefit of facilitating the application of the first generation mas from the point of view of the parameter setting. It is a hybrid approach which combines a parallel island-based model with a hyperheuristic. In this case, the pool of memes consists of the aforementioned set of first generation mas. An analysis of the robustness of such a parallel hyperheuristic is performed. The aim is to study the effect caused by different migration stages on the quality of the solutions obtained. In addition, a scalability analysis of this parallel approach is performed. Particularly, we consider the effect that the migration stage has on the scalability of the parallel hyperheuristic. Finally, we should note that our method improves on the current best-known solutions for the tested instances of the 2dpp.
The rest of this paper is organised as follows: In Sect. 2, the background of packing problems, and specifically of the 2dpp, is given. Afterwards, the formal definition of the 2dpp is detailed in Sect. 3. In Sect. 4, the first generation mas applied to the 2dpp are described. The approaches used to multiobjectivise such a problem are also explained at this point. The parallel hyperheuristic is defined in Sect. 5. Then, the experimental evaluation and the results obtained are presented in Sect. 6. Finally, the conclusions and some lines of future work are given in Sect. 7.
2 Background of packing problems
There are many proposals designed to deal with packing problems. Among them, several exact approaches have been proposed [30]. Usually, the time associated with such algorithms is very large. Therefore, in order to reduce the execution time, some parallel exact approaches have also been designed [4, 26]. However, since packing problems usually involve a large search space, exact approaches are practically unaffordable for many real-world instances.
In order to handle large instances, a wide variety of approximation algorithms have been tested. For instance, an approach based on Ant Colony Optimisation (aco) was used to deal with a multi-objective version of a packing problem in [25], while in [31] a Genetic Algorithm (ga) was used for a mono-objective problem. mas have also yielded very promising results for packing problems [41].
Regarding the 2dpp defined in the gecco 2008 competition session, several proposals have also been tested. During the contest, the two best-behaved approaches were based on mas. Prior to the proposals defined in this paper, the approach which had obtained the best results for the competition session instance was a ma that was able to dynamically change its population size (varpop). This approach incorporated an individual learning process specifically designed to deal with the 2dpp. A parallel hybrid model that combines the varpop algorithm and hyperheuristics was proposed in [27] in an effort to obtain high quality results faster. Although high quality solutions were obtained for the contest instance, subsequent studies [35] concluded that stagnation in local optima may appear for other ones. So as to avoid such drawbacks, a parallel homogeneous island-based model was applied to a multiobjectivised version of the 2dpp in [35]. This approach was able to find high quality results for those instances in which the approaches based on the varpop failed. However, for other instances, the time required by the multiobjectivised parallel model was larger than the time invested by the parallel approach based on the varpop algorithm. In addition, it is important to remark that the most suitable multiobjectivisation method depended on the instance to be solved. Therefore, in order to obtain high quality solutions, several multiobjectivisation approaches had to be tested as part of that research.
3 Formal definition of the 2DPP
The problem considered is a variant of a 2d packing problem. It was proposed in the gecco 2008 competition session. Since the problem has been tackled using many different approaches and its search space is vast, it can be used as a benchmark problem. Problem instances are described by the following data:
-
The sizes of a rectangular grid: \(X, Y\).
-
The maximum number which can be assigned to a grid position: \(M\). The value assigned to each grid location is an integer in the range \([0, M]\).
-
The score or value associated with the appearance of each pair \((a, b)\) where \(a, b \in [0, M]\): \(v(a, b)\). Note that \(v(a, b)\) is not necessarily equal to \(v(b, a)\).
A candidate solution is obtained by assigning a number to each grid position. Thus, the search space consists of \({(M + 1)}^{X \cdot Y}\) candidate solutions. The objective of the problem proposed is to best pack a grid so that the sum of the point scores for every pair of adjacent numbers is maximised. Two positions are considered to be adjacent if they are neighbours in the same row, column, or diagonal of the grid. Once a particular pair is collected, it cannot be collected a second time in the same grid.
Mathematically, the problem objective is to find the grid \(G\) which maximises the objective function \(f\):
where
Figure 1 illustrates the objective function assignment for a candidate solution of a \(2 \times 2\) grid. Note that although the pairs \((1, 2)\) and \((2, 1)\) are repeated in the grid, they are only considered once when computing the objective value.

Assignment of the original objective function for the 2DPP
4 First generation multiobjectivised memetic algorithms for the 2DPP
In this section, the first generation mas applied in this paper are described. Since the 2dpp has been multiobjectivised using several approaches, the usage of multi-objective algorithms is required; specifically, two different mas which start from two different Multi-Objective Evolutionary Algorithms (moeas) has been used. Finally, we consider a tailor-made learning process for the 2dpp.
4.1 Multi-objective algorithms
In this paper two different mas are used that are based on two of the most prominent moeas: the Non-dominated Sorting Genetic Algorithm II (nsga-ii) [14], and the Strength Pareto Evolutionary Algorithm 2 (spea2) [42]. Both mas incorporate the tailor-made learning process for the 2dpp presented in Sect. 4.2. Although the ma based on the nsga-ii was considered in a previous work [35], our usage of the spea2 is an original contribution.
The ma based on the nsga-ii (Algorithm 1) uses a fast non-dominated sorting approach with reduced computational complexity. In addition, it applies a selection operator which combines previous populations with new generated ones, ensuring elitism in the approach. The fast non-dominated approach and the selection operator require the definition of a partial order of the individuals. The crowded comparison operator (\(\ge _n\)) is used to establish such an order. This operator assigns two different attributes to every individual \(i\) of the population: the non-domination rank (\(i_{\textit{rank}}\)) and the local crowding distance (\(i_{\textit{distance}}\)).
The non-domination rank makes use of the Pareto Dominance concept. The procedure to calculate it is as follows. First, the set of non-dominated individuals in the population are assigned to the first rank. Then the process is repeated considering only the individuals that do not have a rank assigned. The rank assigned at each step is increased by one. The process ends when every individual in the population has its corresponding rank established.
The local crowding distance is used to estimate the density of solutions surrounding a particular individual. First, the size of the largest cuboid enclosing the individual \(i\) without including any other individual that belongs to its rank is calculated. Then, the crowding distance is given by the mean side-length of the cuboid. Finally, the partial order given by the crowded comparison operator \(\ge _n\) is the following:


The ma based on the spea2 (Algorithm 2) establishes an order among the individuals using a fine-grained fitness assignment strategy. The fitness value of each individual, which has to be minimised, is calculated as the sum of the raw fitness of the individual plus a density estimate. The density information (\(i_{{ density}}\)) is incorporated to discriminate among individuals with identical raw fitness values. In order to calculate the raw fitness, the strength \(i_{strength}\) of each individual \(i\) is calculated as the number of solutions that it dominates, considering the population and the archive:
Then, the raw fitness \(i_{{ raw}}\) is calculated as follows:
In order to complete the definition of the mas considered, other components must be specified. The parent selection operator is the well-known Binary Tournament [17]. Finally, individuals are encoded as two-dimensional arrays of integer values \(G\), where \(G(x, y)\) is the number assigned to the grid position \((x, y)\).
4.2 Learning process for the 2DPP
Multi-objective mas usually incorporate the usage of a multi-objective learning process [22]. However, since the 2dpp is multiobjectivised in this paper, the learning process only considers the original objective function. The process applied can be classified as Lamarckian learning, i.e. the genotype reflects the learning process improvements. It is based on a mono-objective stochastic hill-climbing local search. The local search strategy applied [27] has the following features. For each pair of adjacent grid positions \((i, j)\) and \((k, l)\), a neighbour is considered. This is illustrated in Fig. 2. Each neighbour is constituted by assigning the best possible values to the positions \((i, j)\) and \((k, l)\)—shading positions in Fig. 2—, leaving intact the assignments in any other grid location. In order to assign the best values to both locations, the trivial solution consists of enumerating all possible pairs so that the best one can subsequently be chosen. This approach is computationally too expensive, so a mechanism is used to prune the values explored. First, all the possible assignments \(n \in [0, M]\) to the grid position \((i, j)\) are considered, and the contribution of each assignment \(v_{ij}(n)\), assuming position \((k, l)\) is unassigned, is calculated. The same process is performed for position \((k, l)\), assuming position \((i, j)\) is unassigned, which thus calculates \(v_{kl}(n)\). The contribution to the objective function obtained by assigning a value \(a\) to position \((i, j)\), and a value \(b\) to position \((k, l)\), is given by:
where \(v^{\prime }(a, b) = v(a, b) + v(b, a)\) if the pair \((a, b)\) was not already in the grid, or \(0\) if it was, and \(v_{rep}\) is the value associated with pairs that are constituted by both the assignment of the value \(a\) to \((i, j)\) and the assignment of the value \(b\) to \((k, l)\), which must be considered only once. An upper bound for such a contribution is given by:
where \(bestV(n)\) is the maximum value associated with any pair \((n, m), m \in [0, M]\), i.e.:

Generation of neighbours by the learning process
If \(bestObj\) is the best objective value currently achieved for an assignment of the positions \((i, j)\) and \((k, l)\), the only values \(a^{\prime }, b^{\prime }\) that must be considered are those that satisfy the following inequality:
Omitting the values at which the previous inequality is not satisfied reduces the neighbourhood to be considered considerably, resulting in significant time savings.
Since stochastic hill-climbing is used, the order in which neighbours are analysed is determined randomly. The local search moves to the first new generated neighbour that improves the current solution. Finally, the learning process stops when none of the neighbours improves the current solution.
4.3 Genetic operators
A mutation and a crossover operator are applied during the variation stage of the mas. They are applied with probabilities \(p_m\) and \(p_c\), respectively. Several variation operators were tested in [27]. The best-behaved ones were selected for our work. The crossover operator was the 2D Sub-String Crossover (ssx) [20]. First, a grid cell is selected as the division point. Then, the operator randomly decides to do a vertical or horizontal crossover. ssx is described in Fig. 3. \(H1\) and \(H2\) are generated by means of a horizontal crossover, while \(V1\) and \(V2\) are generated by the application of the vertical one. In both cases, the cell \((3,2)\) is selected as the division point.

Operation of the sub-string crossover (SSX)
The applied mutation operator was the Uniform Mutation with Domain Information (umd). Each gene is mutated with a probability between \({ min}\_p_m\) and \({ max}\_p_m\). In order to make new assignments to the gene, a random value is selected from among those that produce a non-zero increase in the objective value.
4.4 Multiobjectivisation approaches
The term multiobjectivisation was introduced in [24] to refer to the reformulation of originally mono-objective problems as multi-objective ones. There are two main ways to multiobjectivise a problem. The first one decomposes the original objective into several sub-objectives. The Pareto Front of the new definition should contain a solution with the original optimal value. The second one is based on aggregating an auxiliary function as the second objective. This function is used together with the original objective function. Therefore, the Pareto Front always contains a solution with the original optimal value. The main advantage of the second approach is that it can take into account problem-independent information. Thus, general multiobjectivisation approaches useful for several optimisation problems may be designed. In this paper, we consider problem-dependent and problem-independent multiobjectivisations techniques based on aggregation.
Multiobjectivisation usually decreases the selection pressure. Therefore, when used together with mas, some low quality individuals in the population have a higher probability of survival. However, if properly configured, in the long term these individuals could help to avoid stagnation in local optima, thus yielding higher quality solutions.
Several options have been proposed to define the artificial objective function [1, 5, 37]. Some of these are based on the Euclidean distance in the decision space [37]. These functions are a direct measure of the diversity. The following are considered in this work:
-
dcn: The distance to the closest individual has to be maximised.
-
adi: The average distance to all individuals has to be maximised.
-
dbi: The distance to the best individual, i.e. the one with the highest original objective value, has to be maximised.
In the case of the nsga-ii, the aforementioned functions are calculated using the individuals in the population. When the spea2 is applied, however, the individuals in the population and the archive are taken into account.
Other authors propose the usage of objectives that are able to preserve diversity without using a direct measure for it [1]. Among them, the following are used in this work:
-
Random: A random value is assigned as the second objective to be minimised.
-
Inversion: In this case, the optimisation direction of the original objective function is inverted and used as the artificial objective.
In addition, two artificial functions based on the dbi and the dcn multiobjectivisations, which try to avoid the survival of individuals with a very low quality, are also applied. They incorporate the use of a threshold ratio (\(th \in [0, 1]\)) to be specified by the user. These multiobjectivisations are named dbi-thr and dcn-thr, respectively. The dcn-thr approach has never before been used to multiobjectivise the 2dpp. Being \({ bestObjectiveValue}\) the original objective value of the best individual considered by the artificial function, the threshold value (\(v\)) is defined as:
The alternative objective of individuals whose original objective value is lower than \(v\) is assigned to \(0\). Consequently, individuals that are not able to achieve the fixed threshold are penalised. In the special case where \(th = 0\), individuals are never penalised. Thus, dbi-thr and dcn-thr with \(th = 0\) behave as the functions dbi and dcn, respectively. In the case where \(th = 1\), the mas behave as if multiobjectivisation had not been applied.
Figure 4 (left-hand side) shows the behaviour of the dbi and the dcn functions when they are integrated with the mas presented in Sect. 4.1. The maximisation of the original and the artificial objective functions are assumed. Note that every candidate solution is tagged with a label that indicates its corresponding ranking assigned by the ma based on the nsga-ii (left side of every solution). Thus, the label \(Ri\) means that the corresponding candidate solution belongs to the rank number \(i\). Moreover, the corresponding raw fitness assigned by the ma based on the spea2 is also shown on the right-hand side of every candidate solution. The right-hand side of Fig. 4 shows the effect of incorporating the threshold to the dbi and dcn functions. The broken line represents the value of \(v\). We can see that every candidate solution which does not fulfil the minimum quality level established by the threshold ratio is shifted in the objective space. Specifically, a value equal to \(0\) is assigned to the corresponding alternative objective. The effect of the shift is that the corresponding candidate solution will usually belong to a worse rank in the case of the ma based on the nsga-ii. In the case of the ma based on the spea2, a higher raw fitness will be assigned to the corresponding candidate solution. Therefore, the survival probability of the candidate solution will usually decrease.

Behaviour of the MAs without threshold (left-hand side) and with threshold (right-hand side)
Finally, a multiobjectivisation which considers problem-dependent information (Dependent) was also tested. In order to calculate the second objective, the original 2dpp objective function (\(f\)) is decomposed into two separate functions, \(f_0\) and \(f_1\), so that \(f = f_0 + f_1\). The decomposition is performed as follows. First, a table containing all possible pairs whose score is not equal to zero is calculated. Then, this table is sorted based on the score of the appearance of each pair \(\rho \). The resultant position of each \(\rho \), after the sort, is denoted as \(i_{\rho }\). The value associated with each \(\rho \) is taken into account to calculate the function \(f_{obj}\), where \(obj = i_{\rho } \hbox {mod } 2\). Finally, \(f_0\) is used as the additional objective. Likewise, \(f_1\) could have been used as the auxiliary objective function.
5 A parallel hyperheuristic for the 2DPP
This section describes the parallel hyperheuristic applied in this paper. It is a hybrid approach that combines a parallel island-based model with a choice-based hyperheuristic.
5.1 Island-based models
In island-based models, the population is divided into a number of independent subpopulations. Each subpopulation is associated with an island and a configuration of a population-based metaheuristic or meme is executed on each island. In this paper, several configurations of the mas depicted in Sect. 4 are considered as memes. Usually, each available processor constitutes an island which evolves in isolation for the majority of the parallel run. However, collaborative schemes could lead to better behaviour. Therefore, a migration stage that enables the exchange of individuals among islands is generally incorporated.
There are four basic island-based models [10]: all islands execute identical configurations (homogeneous), different configurations are executed on the islands (heterogeneous), each island evaluates different objective function subsets, and each island represents a different region of the genotype or phenotype domains.
Collaboration among islands is handled by means of a migration mechanism. A well designed migration stage can ensure a successful collaboration, meaning the solution search space is better explored. However, if an unsuitable migration stage is introduced in the model, the effect could be similar to, or even worse than, having separate mas simultaneously executing on several processors with no communication among them. Therefore, the migration stage must be carefully defined. To configure the migration stage, the migration topology—where to migrate the individuals—, and the migration rate—how many individuals are migrated and how often—must be established. In addition, those individuals that are going to be migrated and those that are going to be replaced must be selected. This selection is performed by the migration and replacement schemes, respectively.
When applying island-based models, landscapes may be completely different from those produced by the corresponding sequential ma. As a result, the island-based model may find better or equivalent solutions in less time. Depending on the migration stage selected, the landscape is affected in different ways [38]. Consequently, in this paper we test several migration stages.
5.2 Hyperheuristics
A hyperheuristic can be viewed as a heuristic that iteratively chooses among a set of given low-level metaheuristics in order to solve an optimisation problem [6]. Hyperheuristics operate at a higher level of abstraction than heuristics because they have no knowledge of the problem domain. Once a hyperheuristic algorithm is developed, several problem domains and instances can be tackled by just replacing the low-level metaheuristics. Thus, the aim in using a hyperheuristic is “raising the level of generality” [6] at which most current metaheuristics operate. Since the main motivation behind hyperheuristics is to design problem-independent strategies, a hyperheuristic is not concerned with solving a given problem directly, as is the case with most heuristics implementations. In fact, the search is performed in a search space of metaheuristics rather than a search space of potential problem solutions. The hyperheuristic solves the problem indirectly by applying the appropriate solving method at each stage of the optimisation process. Generally, “the goal of raising the level of generality” [6] is achieved at the expense of reduced—but still acceptable—solution quality when hyperheuristics are compared to tailor-made metaheuristic approaches.
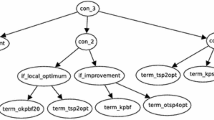
A diagram of a general hyperheuristic framework [6] is given in Fig. 5. It shows a problem domain barrier between the low-level metaheuristics and the hyperheuristic itself. The data flow obtained by the hyperheuristic can include the quality of the solutions—mean, improvement, best, worst—, the resources—time, processors, memory—invested in obtaining such solutions, etc. The hyperheuristic makes its decisions based on this information. The data flow coming from the hyperheuristic can include information about which metaheuristic is to be executed, its parameters, stopping criteria, etc.

Levels and dataflow of a hyperheuristic framework
Several ways for incorporating the ideas of hyperheuristics into an optimisation problem have been proposed. Hyperheuristics which deal with mono-objective optimisation problems are more widespread. A hyperheuristic based on a tabu search was presented in [8]. The same hyperheuristic was used inside a simulated annealing algorithm [16]. Other metaheuristics which have inspired the creation of hyperheuristics include gas [11] and aco [7, 9]. Local search with restart [3] has also been used to implement hyperheuristics. Finally, the choice functions have been used multiple times [12, 13, 23]. In these cases, a scoring function is used to assess the performance of each low-level metaheuristic. All of the resources are allocated to the approach which maximises this function. In [39], a choice function is also used to score each method. However, the resources are assigned using a probability function, which is based on the assigned score. In this paper, we use a hyperheuristic based on the one presented in [39].
5.3 Dynamic-mapped island-based model
In this paper, the dynamic-mapped island-based model (dyn) presented in [28] is used together with different configurations of the mas exposed in Sect. 4 as low-level approaches. It is a hybrid approach that combines a parallel island-based model and a hyperheuristic based on the one presented in [39]. The architecture of the dynamic-mapped model is similar to the parallel island-based model, i.e. it consists of a set of worker islands that evolve in isolation by applying a certain low-level configuration to a given population. In addition, as in the island-based model, a tuneable migration stage allows for the exchange of individuals among neighbouring islands. In this paper we incorporate several migration stages into the dynamic-mapped island-based model. Specifically, four different migration stages, obtained by combining two different migration topologies with two different replacement schemes, are tested.
The migration topologies considered are as follows. The first one is an all to all connected topology (all). In this topology each island connects with and sends its individuals to all of the remaining ones. The second one is a unidirectional ring topology (ring). In such a topology each island connects to exactly two other islands, constituting a logical ring. Considering that there are \(n_p\) islands, labelled from 0 to \(n_p - 1\), each island \(\gamma \) sends its individuals to island \((\gamma + 1)\,\hbox {mod}\,{n_p}\), and receives individuals from island \((\gamma + n_p - 1)\,\hbox {mod}\,{n_p}\). The four migration stages rely on an elitist migration scheme. Specifically, a subpopulation individual is migrated when its original objective value is higher than the original objective value of any member of its previous generations. The migration rate is implicitly defined by the aforementioned migration scheme. Finally, two different replacement schemes are employed. The first one is a novel proposal: the elitist Hamming-based replacement scheme (ham). Firstly, it checks whether or not the immigrant has an original objective value higher than all the individuals of the destination island. If so, the immigrant replaces the individual which has the lowest Hamming distance to it, considering the decision space. Otherwise, the immigrant is discarded. In order to validate the results obtained by the proposal, the elitist ranking scheme (eli) [38] is also applied. It ranks all Pareto fronts and replaces an individual from the worst ranked front with the immigrant. This scheme was specifically designed for the multi-objective field and it provides a high selection pressure. The different migration stages are identified by means of the nomenclature Topology-Replacement_Scheme. For example, the migration stage which uses the unidirectional ring topology and the elitist Hamming-based replacement scheme is referred to as ring-ham.
In the standard island-based model there exists a static mapping among the islands and configurations, i.e. each island executes the same configuration over the course of the complete run. In a homogeneous island-based model, there is only one configuration that is executed by every worker island. In a heterogeneous island-based model, the configurations executed by worker islands are different. However, in the model in question, a dynamic mapping among the islands and configurations is applied. Thus, the configurations executed in each island over the course of the run can vary. This mapping is performed using a hyperheuristic. In order to manage the dynamic mapping, i.e. to apply the hyperheuristic, a new special island, called the master island, is introduced into the scheme. In order to implement it, two kinds of stopping criteria are defined. First, a global stopping criterion is established. When this global stopping criterion is reached, every worker island sends its local solution to the master and the run ends. Moreover, a local stopping criterion is fixed for the execution of the configurations on the worker islands. When a local stopping criterion is reached, the island’s execution is stopped. The local results are then sent to the master island. At this point, the master island applies the hyperheuristic in order to decide which low-level configuration is going to be applied in the idle island. This configuration is applied by taking as the initial population the final population obtained by the previous configuration.
The hyperheuristic selected (hh_imp) is based on using a scoring strategy and a selection strategy for picking the low-level configuration to be executed. The selection of the low-level configuration is as follows. First, the scoring strategy assigns a score to each low-level configuration. This score estimates the improvement that each low-level metaheuristic or configuration can achieve when it starts from the currently obtained solutions. In order to perform this estimate, the previous improvements on the original objective value achieved by each configuration are used. The improvement (\(\textit{imp}\)) is defined as the difference, in terms of the original objective value, between the best achieved individual and the best initial individual. Considering a configuration \(conf\), which has been executed \(j\) times, the score (\(s(conf)\)) is calculated as a weighted average of its latest \(k\) improvements (Eq. 11). In such an equation, \(imp[a][b]\) represents the improvement achieved by configuration \(a\) in execution number \(b\). Depending on the value of \(k\), the adaptation level of the hyperheuristic, i.e. the total amount of historical knowledge that the hyperheuristic considers in order to perform its decisions, can be set. The weighted average assigns a greater importance to the latest executions.
The stochastic behaviour of the low-level metaheuristics involved may lead to variations in the results they obtain. Therefore, it is appropriate to make some selections based on a random scheme. The hyperheuristic can be tuned by means of the parameter \(\beta \), which represents the minimum selection probability that should be assigned to a low-level configuration. If \(n_h\) is the number of low-level configurations involved, a random selection following a uniform distribution is performed in \(\beta \cdot n_h\) percentage of the cases. Therefore, the probability of selecting each configuration \(conf\) is given by:
6 Experimental evaluation
In this section, the experiments performed with the first generation mas described in Sect. 4 and with the parallel hyperheuristic exposed in Sect. 5 are described. The 2dpp is multiobjectivised by the addition of different auxiliary objective functions. However, since the auxiliary function does not represent any practical information—it is only used to preserve the diversity of the population—showing the data for this second objective is of no use. As a result, only data of the 2dpp original objective function is considered when presenting the computational results.
The sequential and parallel optimisation schemes are implemented using the Metaheuristic-based Extensible Tool for Cooperative Optimisation (metco) [28]. Tests were run on hector [19], the uk’s National Supercomputing Service. The Phase 3 (Cray xe6) system of hector is contained in 30 cabinets and comprises of a total of 704 compute blades. Each blade contains four compute nodes, each with two 16-core amd Opteron 2.3 GHZ Interlagos processors. This amounts to a total of 90,112 cores, offering a theoretical peak performance of over 800 tflops. Each 16-core socket is coupled with a Cray Gemini routing and communications chip. Finally, each 16-core processor shares 16 Gb of memory.
Communications among different islands of the dyn model were implemented asynchronously using the Message Passing Interface (mpi) library [36]. We opted to use mpi for two reasons. Firstly, it works on distributed and shared memory architectures. And secondly, since executions of the dyn model with up to 128 cores were carried out, the hector architecture was not suitable for an implementation of the dyn model with openmp. The mpi library version was Cray mpich2 5.6.0, while the compiler was gcc 4.7.2.
Analyses were performed considering two different instances of the 2dpp. The first one is characterised by the following parameters: \(X = 10, Y = 10, M = 99\), and 9032 possible pair scores. The second one is the instance proposed in the competition session. Its parameters are the following: \(X=20, Y=20, M=399\), and 1,5962 possible pair scores.
Since we are dealing with stochastic algorithms, each execution was repeated 24 times. Each experiment was carried out for both instances. So as to be able to present our results with confidence, we ran comparisons applying the following statistical analysis [15]. First, we carried out a Shapiro-Wilk test in order to check whether the values of the results follow a normal (Gaussian) distribution or not. If so, the Levene test was used to check for the homogeneity of the variances. If samples had equal variance, an anova test was done. Otherwise, a Welch test was performed. For non-Gaussian distributions, the non-parametric Kruskal–Wallis test was used to compare the medians of the algorithms. A significance level of 5 % was considered.
6.1 Analysis of the first generation memetic algorithms
The objective of the first experiment was to analyse the behaviour of the first generation mas from the point of view of robustness. Particularly, we studied whether the quality of the solutions depends on the ma applied and/or on the multiobjectivisation approach considered. We also conducted additional analyses with the aim of determining whether the most suitable approach depends on the instance of the 2dpp considered. To do so, we defined 16 different configurations of the first generation mas. They were obtained by combining the two different mas exposed in Sect. 4, with the 8 multiobjectivisation schemes described in Sect. 4.4. In every configuration, the population and the archive sizes were fixed to \(10\) individuals. For the multiobjectivisation approaches that incorporate the usage of a threshold value, this value was set to \(th = 0.99\). Both the umd and the ssx operators were applied in every generation, i.e. the probabilities \(p_m\) and \(p_c\) were set to 1 for every configuration. In addition, the umd operator used the following parameterisation: \({ min}\_p_m = 0.1\) and \({ max}\_p_m = 0.15\). In the case of the first instance, the configurations were executed considering a stopping criterion of 5 h, while for the second one a stopping criterion of 11.5 h was set.
Table 1 shows, for the first instance and for each ma tested, the mean, the median, and the maximum of the original objective values attained. The configurations of the mas were sorted in terms of the mean original objective value. An index based on this order was assigned to each configuration. Thus, the first configuration, i.e. the one which achieved the highest mean of the original objective value, is referred to as seq1, while the last one is referred to as seq16. The differences among the configurations are noticeable and reveal the importance of correctly selecting the appropriate one. In fact, the differences among seq1 and the remaining configurations are statistically significant, except for the configurations seq2–seq4. Statistical tests also confirmed that both the multiobjectivisation approach and the ma used affected the quality of the solutions. For instance, seq1 was significantly different from seq10. Such configurations are based on the same multiobjectivisation approach, but they consider a different ma. Therefore, properly selecting the ma affects the quality of the solutions. Similarly, seq1 and seq5, which are both based on the spea2, are statistically different. Since they only differ in the multiobjectivisation approach used, the importance of properly selecting this component has also been demonstrated. Finally, the incorporation of a threshold value in the multiobjectivisation approaches tested did not affect the quality of the results. The configurations that used a multiobjectivisation approach with threshold were not statistically different from their non-threshold counterparts.
Table 2 shows the same information for the second instance. In this case, differences among the configurations considered are also noticeable. The results obtained by seq1 are statistically different from those obtained by the other configurations, apart from the seq2 and seq3 configurations. In addition, changing the ma used does not yield significant differences in the results. For example, the differences between seq1 and seq2 are not statistically significant. In this case, both configurations applied the same multiobjectivisation method but used different mas. This happened for every pair of configurations in which the multiobjectivisation approach applied was the same and the ma applied was different. However, the multiobjectivisation approach applied did affect the quality of the solutions. For instance, seq1 is statistically different from seq4, and they apply the dcn-thr and the dbi-thr multiobjectivisations, respectively. Finally, configurations applying a multiobjectivisation approach with threshold are statistically different from their non-threshold counterparts.
Considering both tested instances, the most suitable configurations of the mas are different. For example, the configuration seq1 for the first instance is the configuration seq10 for the second instance. Similarly, the configuration seq1 for the second instance is the configuration seq8 for the first one. Thus, the most suitable configurations depend on the features of the instance in question, resulting in some robustness problems. Given a new instance, it is difficult to predict which configuration will provide the best results. In addition, if the number of configurations considered is very large, testing each one of them might not be feasible. Therefore, the application of a hyperheuristic seems very promising. Finally, since the sequential models do not converge even after a very long period of time, the usage of parallel models also seems a promising approach.
6.2 Analysis of the parallel hyperheuristic
The aim of the second experiment was to avoid the robustness problems of the first generation mas by considering a parallel hyperheuristic (dyn). We also analysed the behaviour of the dyn model with respect to the migration stage used. The model was executed with the four migration stages described in Sect. 5.3. A total number of \(n_p = 4\) islands was considered. The global stopping criterion was set to 5 h for the first instance and 11.5 h for the second one. For both instances, the local stopping criterion was set to 10 minutes. The hh_imp hyperheuristic of the dyn model was applied with an adaptation level \(k = \infty \), and the value of \(\beta \) was set in such a way that a 10 % of the decisions performed by the hyperheuristic followed a uniform distribution, i.e. \(\beta \cdot n_h = 0.1\). Finally, the \(n_h = 16\) configurations of the first generation mas applied in the previous experiment (Sect. 6.1) were used for the low-level configurations or memes.
Figure 6 shows, for the first and second instances, the evolution of the mean of the original objective value for the dyn model with the four migration stages. In order to compare the results obtained by the parallel models, also shown are the data of the best sequential configuration (seq1) for each considered instance. For both instances, the parallel models were able to achieve a higher mean of the original objective value than the corresponding best sequential approach. Moreover, the differences among the parallel model which yielded the highest mean objective value and the best sequential approach for each instance considered were statistically significant. In the case of the first instance, the parallel approach relied on the all-ham migration stage, while the second one it used the ring-eli migration stage. Consequently, depending on the features of the instance in question, the most suitable migration stage must be properly selected. The box plots of the dyn model with the different migration stages (Fig. 7) confirm the aforementioned conclusions.

Evolution of the mean of the original objective function resulting from the dyn model with 4 worker islands for the first and second instances

Box plots of the dyn model with 4 islands for the first and second instances
The dyn model avoided the need to check for the most suitable configuration of an algorithm for a given instance. The quality of the solutions obtained from the parallel model applying the best migration stage was higher than the quality obtained by the best sequential approach. Thus, high quality solutions can be achieved by a single execution of this parallel model, resulting in lower use of computational resources. This process thus mitigates the robustness problems of the first generation mas. Lastly, the dyn model facilitates the application of the first generation mas from the point of view of the parameter setting, and enabled their usage in parallel environments.
The objective of the third experiment was to conduct robustness and scalability analyses of the dyn model. Specifically, we studied the relationship between the effect caused by the change in the migration stage and the number of islands. In this case, the dyn model was executed with the same parameterisation as in the previous experiment, but using a total number of 8, 16, and 32 worker islands (\(n_p\)).
Considering the first instance, statistical differences among the different migration stages were not significant when the dyn model was applied with 4 and 8 worker islands. With 16 and 32 islands, however, statistical differences among the migration stages did appear. This means that the importance of properly selecting the migration stage rises with the number of worker islands. Tables 3 and 4 show the statistical significances for the different migration stages considering 16 and 32 worker islands, respectively. Every cell shows whether the row model is statistically better (\(\uparrow \)), not different (\(\leftrightarrow \)), or worse(\(\downarrow \)) than the corresponding column model.
In the case of the second instance, Table 5 shows the results of the statistical tests for the different migration stages considering 4 worker islands. Similarly, Table 6 shows the same information when 8, 16, and 32 islands were used. The amount of significant statistical differences was larger when 8, 16, and 32 islands were applied. As in the first instance, the importance of selecting the appropriate migration stage increases as a higher number of worker islands is used.
In order to better quantify the importance of selecting the appropriate migration stage for the dyn model, we conducted another analysis. Considering the mean of the original objective value achieved by the parallel models with 32 islands, the best and worst were selected for each instance. Figure 8 shows, for the first instance, the box plots of the best and worst parallel models when they were run with up to 32 islands. The same information is shown in Fig. 9 for the second instance. For both cases, the trend towards obtaining better objective values as the number of islands increases is clear when the best migration stage is considered. However, this did not happen when considering the worst stage.

Box plots of the dyn model with the best and worst migration stages for the first instance

Box plots of the dyn model with the best and worst migration stages for the second instance
The above analysis compared different parallel models in terms of the quality achieved at fixed times. However, it is important to quantify the improvement achieved by such parallel approaches in terms of the amount of time saved. To do so, we conducted an additional study that relied on Run-Length Distributions (rld) [21]. rlds show the relationship between success ratios and time. The success ratio of a particular approach is defined as its probability of achieving a certain quality level.
Figure 10 shows, for the first instance, the rlds of the best and worst parallel models with up to 32 worker islands. It also includes the rlds of the sequential configurations seq1 and seq3 to compare the results obtained by the parallel models. The same information is shown in Fig. 11 for the second instance. In order to calculate the rlds for both instances, the quality level was set as the median of the original objective value achieved by the configuration seq3. In the case of the first instance, the parallel models that used the best migration stage clearly outperformed the sequential configurations, obtaining the same or higher success ratios in less time. In addition, not only were high quality solutions yielded by the best parallel model, but they were obtained in less time when the number of worker islands increased. For example, the best parallel models with 16 and 32 worker islands were able to achieve a 100 % success ratio, i.e. every execution reached the set quality level, although the best parallel model with 32 islands obtained this success ratio in less time. The solutions yielded by the parallel models that used the worst-behaved migration stage were of a lower quality than those ones obtained with the best parallel models. Moreover, none of the worst parallel models was able to reach a 100 % success ratio.

RLDs of the dyn model with the best and worst migration stages for the first instance

RLDs of the dyn model with the best and worst migration stages for the second instance
In the case of the second instance, the same conclusions as for the first instance can be extracted for the parallel model using the best migration stage. The behaviour of the parallel models when using the worst migration stage, however, was poor. For example, the parallel model with 4 worker islands obtained a given value for the success ratio in less time than the same model using 32 islands. Summarising, for both instances, selecting the appropriate migration stage does not only affect the quality of the solutions, but also the total amount of time and processors required to achieve said quality level.
In order to quantify the effects that the migration stage has on the scalability of the dyn model, speedup factors were calculated using the data provided by the rlds. Table 7 shows the resulting speedup factors obtained for seq1 by the dyn model applied to the first instance with the best and worst migration stages. In order to calculate these factors the following steps were performed. Firstly, given a model with \(n_p\) worker islands, a relative speedup factor (\(spr_{[n_p]}\)) was calculated for the model with \(n_p \div 2\) worker islands. In the case of the parallel models with \(n_p = 4\) islands, the best sequential configuration (seq1) was used as reference. For this instance, and for each relative speedup factor, the quality level was set as the lowest median of the original objective value achieved in 5 h by both of the models considered. The relative speedup is calculated by dividing the time invested by the model using a lower number of processors by the time invested by the model using a higher amount of processors. These times were obtained by considering a 50 % success ratio. Once the relative speedup factors were calculated, the resulting speedup factor for the model with \(n_p\) processors (\(sp_{[n_p]}\)) was calculated as follows:
The resulting speedup factors for the second instance are shown in Table 8. The aforementioned procedure was used to calculate the factors by setting the time equal to 11.5 h.
For both instances, the speedup factors increased when the parallel model applied had a larger amount of worker islands. For example, in the case of the first instance, the best parallel model with 16 worker islands obtained a speedup factor equal to 6.29, while the same model considering 32 islands achieved a speedup factor equal to 15.73. In this case, the relative speedup factor calculated for both models was greater than one. This means that the model with 32 islands achieved the set quality level in 50 % of the executions in less time than the model with 16 worker islands. However, this was not the case when the corresponding worst parallel model was applied to each instance. For example, in the case of the second instance, the worst parallel model with 8 worker islands obtained a speedup factor equal to 2.57, while the worst parallel model with 16 worker islands yielded a speedup factor equal to 1.36. In this case, the relative speedup factor calculated for both models was lower than one. This means that the model with a lower number of worker islands attained the defined quality level in 50 % of the executions in less time than the model which considered a higher number of islands. Therefore, incorporating a larger amount of processors to the worst-behaved parallel model for each instance in question did not provide good results.
In the fourth experiment, the dyn model using the best-behaved migration stage for each instance was executed using 64 and 128 worker islands, the goal being to study the scalability of the model with a large number of processors. The parameterisation of the dyn model was the same as in previous experiments. However, the global stopping criterion was set to 2 h due to the availability of the computational resources.
Figure 12 shows the box plots of the dyn model with up to 128 worker islands, applying the corresponding best-behaved migration stage for each instance. Even with a large number of worker islands, the quality of the solutions obtained by the dyn model kept increasing as more resources were considered. In general, the larger the number of worker islands, the higher the quality of the solutions obtained. Table 9 shows the speedup factors for seq1 of the parallel model using the best migration stage for each instance, applying 64 and 128 worker islands. Speedup factors were obtained following the same procedure used in the previous experiment. In order to obtain the relative speedup factors for both instances, the quality level was set at the lowest median of the original objective value obtained by the two models in question in 2 h. The calculated speedup factors confirm the benefits of adding a larger amount of processors. The benefits were more noticeable in the case of the first instance. Finally, we should note that using the dyn model avoids the requirement of independently executing each meme. Therefore, the total amount of time that can be saved is greater than the one shown by the calculated speedup factors.

Box plots of the dyn model with the best migration stage for the first and second instances
The executions with \(n_p = 128\) islands were able to provide better results than the best previously known solution for the first instance [35]. The previous best solution was obtained by a multiobjectivised homogeneous parallel island-based model. It was applied considering 4 islands and 12 h of execution. In order to apply this parallel model, the best low-level configuration or meme for a given instance has to be identified, requiring many computational experiments beforehand. A larger amount of resources was invested in our research to improve on the best previous solution. However, this improvement was achieved in only 2 h. Specifically, the original objective value was raised from \(516,202,152\) to \(517,199,441\). Moreover, the use of a larger number of islands was offset by the reduced time and computational resources needed by the dyn model, since the prior analysis to identify the best meme was not necessary.
Since the second instance is harder than the first one, larger executions were required to improve on the best-known solution for this test case. The previous best solution was obtained by combining a mono-objective parallel island-based model with hyperheuristics [27]. Such a model was applied considering 4 islands and 6 h of execution. For this test case it was demonstrated that multiobjectivisation did not provide benefits in the short term [35]. However, it would be interesting to determine whether multiobjectivisation can avoid long-term stagnation. The dyn model was executed with 32 worker islands and considering the same parameterisation as the one applied in the previous experiments. The ring-eli migration stage was used, while the global stopping criterion was set to 15 days. Due to availability of resources, a larger amount of processors was not considered and only one execution was performed. The parallel approach that obtained the previous best result [27] was also executed considering 15 days of execution. Figure 13 shows the evolution of the original objective value for both schemes. It can be noted that in the short-term the mono-objective approach is superior. Then, for a long period of time both approaches obtains similar values. Finally, in the long-term, the multiobjectivised approach provides the best solution. Since only one execution was performed, the superiority of the multiobjectivised scheme can not be ensured. However, results are quite promising. Moreover, the original objective value was raised from \(1,032,619,547\) to \(1,038,329,890\).

Evolution of the original objective function with and without multiobjectivisation in the long term
7 Conclusions and future work
Packing problems are a class of optimisation problems with many practical applications. They are widely used inside more complex systems, e.g. filling containers, loading pallets, optimising the layout of electrical circuits, and scheduling, among others. Since this kind of problem can be classified according to various features, several variants have been defined in the literature. In this paper, we addressed the 2d packing problem (2dpp) defined in the gecco 2008 competition session.
Several approaches have been proposed in order to tackle the 2dpp. During the contest, the two best-behaved approaches were based on first generation mas. Subsequently, a parallel hyperheuristic was proposed in an effort to speed up the process of obtaining high quality results. However, subsequent studies concluded that stagnation in local optima may appear for some instances. So as to avoid this drawback, a parallel island-based model was applied to a multiobjectivised version of the 2dpp. The usage of multiobjectivisation methods avoided stagnation problems, though for some instances, the time required by the parallel model was longer than the time invested by the approaches applied in previous research.
The main contribution of this paper is twofold. Firstly, the advantages and drawbacks of a set of first generation mas were analysed. The first generation mas considered was applied to a multiobjectivised version of the 2dpp. A novel ma based on spea2 was proposed, and a novel multiobjectivisation approach based on the incorporation of a threshold value (dcn-thr) was applied to the 2dpp. The incorporation of a threshold, which must be specified by the user, avoids the survival of low-quality individuals in the population. Computational results demonstrated that, depending on the instance in question, the quality of the results is affected by the ma considered and/or by the multiobjectivisation approach that is applied. In addition, the incorporation of a threshold value in the multiobjectivisation methods also influences the quality of the solutions. Regarding the benefits of the first generation mas, they were able to achieve high quality solutions in both of the instances tested. However, some drawbacks in terms of their robustness were also identified. Particularly, the best configuration of the first generation mas for each of the instances tested was not appropriate for the other one.
Secondly, a parallel scheme whose aim was to avoid the robustness problems of the first generation mas and to improve their behaviour was applied. This parallel scheme (dyn model) combines a parallel island-based model and a hyperheuristic. The different configurations of the first generation mas were used as the low-level configurations, or memes, of the parallel approach. The set of memes was the same for both instances. The experimental evaluation demonstrated that high quality solutions were obtained by the dyn model for both instances of the 2dpp. Consequently, the dyn model avoids the requirement of independently testing every low-level configuration being considered. This thus mitigates robustness problems by avoiding the need to first check the most suitable configuration of an algorithm for a given instance. Moreover, the dyn model facilitates the application of the first generation mas from the point of view of the parameter setting, and enables their use in parallel environments. We also studied the effect that the migration stage has on the quality of the solutions. Differences among the migration stages used were more noticeable when a large number of worker islands was taken into account. Moreover, the addition of extra processors to the dyn model using the appropriate migration stage provided benefits both in terms of saved resources and the quality of the results. Finally, the best-known solutions for the instances considered in this paper were improved. The tests were performed using two instances because no additional data sets were available. We made a considerable effort to carry out a complete analysis using these two instances in order to draw general conclusions. The main strength of using the selected instances is that they were previously analysed with other optimisation schemes. Therefore, they proved quite useful to understanding the advantages of the new proposals.
Several areas of research can be considered for future work. First, it would be desirable to incorporate a larger amount of low-level configurations or memes into the dyn model. Since each low-level configuration might behave differently with different instances, satisfactory results might be achieved if more instances are utilised. However, when a large number of configurations is used, the distribution of the computational resources becomes more difficult, which might affect the performance of the dyn model. It would also be interesting to implement a dyn model suitable for hybrid parallel architectures. Such an implementation would be based on mpi and openmp. Thus, the dyn model might profit from the hybrid architecture of machines like hector. Finally, another interesting area of research would be the design of a model in which the user can specify certain parameters by assigning the ranges that must be used, instead of specifying particular values for them.
References
Abbass, H.A., Deb, K.: Searching under multi-evolutionary pressures. In: Proceedings of the Fourth Conference on Evolutionary Multi-Criterion Optimization, pp. 391–404. Springer (2003)
Alba, E.: Parallel Metaheuristics: A New Class of Algorithms. Wiley-Interscience, Hoboken, NJ (2005)
Araya, I., Neveu, B., Riff, M.C.: An efficient hyperheuristic for strip-packing problems. In: Cotta, C., Sörensen, K. (eds.) Adaptive and Multilevel Metaheuristics, Studies in Computational Intelligence, vol. 136, pp. 61–76. Springer (2008)
Blazewicz, J., Walkowiak, R.: A new parallel approach for multi-dimensional packing problem. In: 4th International Conference on Parallel Processing and Applied Mathematics (PPAM), LNCS, vol. 2328, pp. 194–201. Naleczow, Poland, Springer, Berlin (2002)
Bui, L., Abbass, H., Branke, J.: Multiobjective optimization for dynamic environments. In: Proceedings of the 2005 IEEE Congress on Evolutionary Computation, CEC 2005, vol. 3, pp. 2349–2356 (2005)
Burke, E.K., Kendall, G., Newall, J., Hart, E., Ross, P., Schulenburg, S.: Handbook of Meta-heuristics. Hyper-heuristics: An Emerging Direction in Modern Search Technology. Kluwer, Berlin (2003)
Burke, E.K., Kendall, G., Silva, J.L., O’Brien, R., Soubeiga, E.: An ant algorithm hyperheuristic for the project presentation scheduling problem. In: Proceedings of the 2005 IEEE Congress on Evolutionary Computation, CEC 2005, vol. 3, pp. 2263–2270. Edinburgh, Scotland (2005)
Burke, E.K., Kendall, G., Soubeiga, E.: A tabu-search hyperheuristic for timetabling and rostering. J. Heuristics 9(6), 451–470 (2003)
Chen, P.C., Kendall, G., Vanden Berghe, G.: An ant based hyper-heuristic for the travelling tournament problem. In: Proceedings of IEEE Symposium of Computational Intelligence in Scheduling (CISched 2007), pp. 19–26. Honolulu, Hawaii (2007)
Coello, C.A., Lamont, G.B., Veldhuizen, D.A.V.: Evolutionary Algorithms for Solving Multi-Objective Problems. Genetic and, Evolutionary Computation (2007)
Cowling, P., Kendall, G., Han, L.: An investigation of a hyperheuristic genetic algorithm applied to a trainer scheduling problem. In: Proceedings of the 2002 IEEE Congress on Evolutionary Computation, CEC 2002, vol. 2, pp. 1185–1190. IEEE Computer Society, Washington, DC, USA (2002)
Cowling, P., Kendall, G., Soubeiga, E.: A parameter-free hyperheuristic for scheduling a sales summit. In: Proceedings of 4th Metahuristics International Conference (MIC 2001), pp. 127–131. Porto Portugal (2001)
Cowling, P., Kendall, G., Soubeiga, E.: Hyperheuristics: A robust optimisation method applied to nurse scheduling. In: PPSN, Lecture Notes in Computer Science, vol. 2439, pp. 851–860. Springer (2002)
Deb, K., Pratap, A., Agarwal, S., Meyarivan, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6, 182–197 (2002)
Dems̆ar, J.: Statistical comparison of classifiers over multiple data sets. J. Mach. Learn. Res. 7, 1–30 (2006)
Dowsland, K., Soubeiga, E., Burke, E.: A simulated annealing hyper-heuristic for determining shipper sizes. Eur. J. Oper. Res. 179(3), 759–774 (2007)
Eiben, A.E., Smith, J.E.: Introduction to Evolutionary Computing (Natural Computing Series). Springer, Berlin (2008)
Glover, F.W., Kochenberger, G.A.: Handbook of Metaheuristics (International Series in Operations Research & Management Science). Springer, Berlin (2003)
HECToR: UK National Supercomputing Service. http://www.hector.ac.uk/
Hong, T.P., Tsai, M.W., Liu, T.K.: Two-dimentional encoding schema and genetic operators. In: JCIS. Atlantis Press (2006)
Hoos, H., Stützle, T.: Stochastic Local Search: Foundations and Applications. The Morgan Kaufmann Series in Artificial Intelligence. Morgan Kaufmann Publishers, Burlington (2005)
Jaszkiewicz, A.: Genetic local search for multi-objective combinatorial optimization. Eur. J. Oper. Res. 137(1), 50–71 (2002)
Kendall, G., Cowling, P., Soubeiga, E.: Choice function and random hyperheuristics. In: Proceedings of the 4th Asia-Pacific Conference on Simulated Evolution and Learning (SEAL 2002), pp. 667–671. Singapore (2002)
Knowles, J.D., Watson, R.A., Corne, D.: Reducing local optima in single-objective problems by multi-objectivization. In: Proceedings of the First International Conference on Evolutionary Multi-Criterion Optimization, EMO ’01, pp. 269–283. Springer, London (2001)
Lara, O., Labrador, M.: A multiobjective ant colony-based optimization algorithm for the bin packing problem with load balancing. In: Proceedings of the 2010 IEEE Congress on Evolutionary Computation, CEC 2010, pp. 1–8 (2010)
León, C., Miranda, G., Rodríguez, C., Segura, C.: 2D Cutting stock problem: a New Parallel algorithm and bounds. In: Proceedings of Euro-Par, LNCS, vol. 4641, pp. 795–804. Springer (2007)
León, C., Miranda, G., Segura, C.: A memetic algorithm and a parallel hyperheuristic island-based model for a 2d packing problem. In: Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation, GECCO ’09, pp. 1371–1378. ACM, New York, NY, USA (2009)
León, C., Miranda, G., Segura, C.: METCO: a parallel plugin-based framework for multi-objective optimization. Int. J. Artif. Intell. Tools 18(4), 569–588 (2009)
Lodi, A., Martello, S., Monaci, M.: Two-dimensional packing problems: a survey. Eur. J. Oper. Res. 141(2), 241–252 (2002)
Martello, S., Monaci, M., Vigo, D.: An exact approach to the strip-packing problem. INFORMS J. Comput. 15(3), 310–319 (2003)
Matayoshi, M.: Two dimensional rectilinear polygon packing using genetic algorithm with a hierarchical chromosome. In: Proceedings of the IEEE International Conference on Systems, Man and, Cybernetics, pp. 989–996 (2011)
Nguyen, Q.H., Ong, Y.S., Lim, M.H.: Non-genetic transmission of memes by diffusion. In: Proceedings of the 10th annual conference on Genetic and evolutionary computation, GECCO ’08, pp. 1017–1024. ACM, New York, NY, USA (2008)
Ong, Y.S., Lim, M.H., Zhu, N., Wong, K.W.: Classification of adaptive memetic algorithms: a comparative study. IEEE Trans. Syst. Man Cybern. 36(1), 141–152 (2006)
Segredo, E., Segura, C., León, C.: A multiobjectivised memetic algorithm for the frequency assignment problem. In: Proceedings of the 2011 IEEE Congress on Evolutionary Computation, CEC 2011, pp. 1132–1139 (2011)
Segura, C., Segredo, E., León, C.: Parallel island-based multiobjectivised memetic algorithms for a 2D packing problem. In: Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation, GECCO ’11, pp. 1611–1618. ACM, New York, NY, USA (2011)
Snir, M., Otto, S., Huss-Lederman, S., Walker, D., Dongarra, J.: MPI: The Complete Reference. The MIT Press, Cambridge (1996)
Toffolo, A., Benini, E.: Genetic diversity as an objective in multi-objective evolutionary algorithms. Evol. Comput. 11, 151–167 (2003)
Veldhuizen, D.A.V., Zydallis, J.B., Lamont, G.B.: Considerations in engineering parallel multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput. 7(2), 144–173 (2003)
Vink, T., Izzo, D.: Learning the best combination of solvers in a distributed global optimization environment. In: Proceedings of Advances in Global Optimization: Methods and Applications (AGO), pp. 13–17. Mykonos, Greece (2007)
Wäscher, G., Haußner, H., Schumann, H.: An improved typology of cutting and packing problems. Eur. J. Oper. Res. 183(3), 1109–1130 (2007)
Zhou, Y., Rao, Y., Zhang, G., Zhang, C.: An adaptive memetic algorithm for packing problems of irregular shapes. Adv. Mater. Res. 314–316, 1029–1033 (2011)
Zitzler, E., Laumanns, M., Thiele, L.: SPEA2: Improving the Strength Pareto Evolutionary Algorithm for Multiobjective Optimization. In: Giannakoglou, K.C. et al., (eds.) Evolutionary Methods for Design, Optimization and Control with Application to Industrial Problems (EUROGEN 2001), pp. 95–100. International Center for Numerical Methods in Engineering (CIMNE) (2002)
Acknowledgments
This work was funded in part by the ec (feder) and the Spanish Ministry of Science and Innovation as part of the ‘Plan Nacional de i+d+i’, with contract number tin2011-25448. The work of Carlos Segura was funded by grant fpu-ap2008-03213. The work of Eduardo Segredo was funded by grant fpu-ap2009-0457 The work was also funded by the hpc-europa2 project (project number: 228398) with the support of the European Commission—Capacities Area—Research Infrastructures. Our research made use of the facilities of hector, the uk’s national high-performance computing service, which is provided by uoe hpcx Ltd at the University of Edinburgh, Cray Inc and nag Ltd, and funded by the Office of Science and Technology through the epsrc’s High End Computing Programme.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Segredo, E., Segura, C. & León, C. Memetic algorithms and hyperheuristics applied to a multiobjectivised two-dimensional packing problem. J Glob Optim 58, 769–794 (2014). https://doi.org/10.1007/s10898-013-0088-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-013-0088-4