
Abstract
This study extends our understanding of what makes an online review useful by examining the effects of review quality (i.e., as a composite variable of review comprehensiveness and review topic consistency) on review usefulness, and the moderating effects of source credibility on the relationship between review quality and review usefulness. The Elaboration Likelihood Model, convergence theory, and cueing effect literature are used to define the variables of review comprehensiveness and review topic consistency. Analyses of 27,517 restaurant reviews from Yelp show that review topic consistency has a positive effect on review usefulness, but, contrary to our hypothesis, review comprehensiveness has a negative effect on review usefulness. We also found source credibility positively moderates the effect of review comprehensiveness on review usefulness, but negatively moderates the effect of review topic consistency on review usefulness. Theoretical and practical implications are discussed.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Online review websites allow consumers to share their opinions about and experiences with products and services with other consumers. Grimes (2012) reports that, after family members and friends, consumer reviews are perceived as the most influential source of information when making a purchasing decision. Fullerton (2017) reports that 82% of consumers read online reviews before making a purchasing decision. However, a challenge faced by consumers is to extract the most useful reviews from an overwhelming volume of online reviews (Choi et al., 2019; Choi & Leon, 2020; Huang et al., 2018). To address this issue, many websites such as Yelp and Amazon have implemented a social voting system that allows consumers to assess and vote on the helpfulness or usefulnessFootnote 1 of online reviews (Kuan et al., 2015).
Understanding the factors that affect the usefulness of online reviews has been an important topic in e-commerce research (Huang et al., 2018; Li & Huang, 2020). This is because online reviews that are perceived to be useful affect online consumers to enter into an online transaction (Choi & Leon, 2020; Kuan et al., 2015; Sun et al., 2019). Also, prior research reports a positive interaction effect of review usefulness and review content on new product sales and firms’ revenue (Mariani & Borghi, 2020; Topaloglu & Dass, 2019). Moreover, online retailers that display useful reviews are known to gain a strategic advantage in consumer attention and “stickiness” (Yin et al., 2014). For example, when Amazon implemented a social voting feature in its product review system, it increased its revenue by $2.7 billion, clearly demonstrating the importance of social voting systems in online marketplaces (Spool, 2009).
Early review usefulness research attempted to measure review usefulness and its antecedents using psychometric-based latent variables by conducting a survey or experiment (e.g., Cheung et al., 2009; Cheung et al., 2012; Filieri et al., 2018; Li et al., 2013). While such measures helped us understand what makes online reviews perceived to be useful, they also revealed three limitations. First, decaying memory or a lack of familiarity with online review activities may prevent respondents from providing accurate or unbiased responses or may cause them to answer the questions in a way that appears favourable to others (Krumpal, 2013). Second, it could not explain the inherent heterogeneity of products or service features that is an important determinant of review usefulness (Aghakhani et al., 2018; Ghose et al., 2012; Ghose & Ipeirotis, 2010; Qiu et al., 2012; Sun et al., 2019). For instance, a consumer reading laptop reviews may be interested in topics related to battery life, gaming capabilities, and screen resolutions, whereas a consumer reading restaurant reviews may be interested in topics such as food quality, ambiance, and service quality. Third, such measures may not accurately reflect reality in the sense that consumers compare multiple reviews of the same product or service before casting “useful votes” for a particular review (Qahri-Saremi & Montazemi, 2019; Zhou et al., 2018).
In this regard, advances in text mining methods have assisted us in overcoming the limitations of survey-based psychometric measures by allowing us to analyze online review texts directly downloaded from online review websites such as Yelp or Amazon. Indeed, thanks to the advancement of text mining methods and the availability of online review texts, researchers were able to quantitatively identify the textual characteristics that influence online review usefulness in terms of review length, readability scores, review ratings, linguistic styles, or review sentiment (Aghakhani et al., 2021; Li & Huang, 2020; Mousavizadeh et al., 2020; Ren & Nickerson, 2019; Siering et al., 2018; Sun et al., 2019). To our knowledge, however, online review research using text mining approaches has not progressed to the point of examining the textual qualities in terms of topical coverage and their consistency being discussed in online reviews. While some research has quantified the consistency of online reviews in terms of the congruence between a product review rating and the average rating of the focal product (Baek et al., 2012; Choi & Leon, 2020; Kuan et al., 2015), it has not progressed far enough to measure the consistency or comprehensiveness of actual review contents expressed in online review texts. As a result, in order to broaden our understanding of what constitutes useful online review, our study contributes to this line of research by answering the following questions:
-
RQ1) Does review comprehensiveness (i.e., the number of topics covered in a review) affect review usefulness?
-
RQ2) Does review topic consistency (i.e., the consistency between the main topic discussed in a review and the main topic discussed across all other reviews for the same product or service) affect review usefulness?
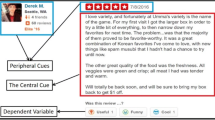
After Amazon implemented its “top reviewer” rank and Yelp implemented its elite-badge as platform generated signals to endorse the credibility of good reviewers, many researchers have examined the independent effect of source credibility (i.e., top reviewer rank or elite-badge) and content of reviews on review usefulness (Baek et al., 2012; Choi & Leon, 2020; Filieri et al., 2018; Kuan et al., 2015). However, according to the Elaboration Likelihood Model (ELM), human communication involves joint, not independent, processing of peripheral cues (e.g., source credibility signal like a top-reviewer badge) and central cues (e.g., the textual contents of a review). Reflecting on this research gap, a few researchers have examined how simultaneous processing of multiple cues affects review usefulness. For instance, Aghakhani et al. (2021) report that rating inconsistency moderates the effect of review content on review usefulness. Huang et al. (2018) maintain that temporal cues (e.g., the time when the review is written) and social cues (e.g., who wrote the review) moderate the effect of review content on review usefulness. We follow this line of research that examines the joint processing of multiple information cues in online reviews. Drawing upon the important but less-explored tenet of ELM that emphasizes the joint processing of central and peripheral cues in human communications, our study purposes to elucidate the moderating effect of source credibility (as a peripheral cue) on the relation between review content (as a central cue) and review usefulness. Therefore, our third research question is as follows:
-
RQ3) Does source credibility moderate the effects of review comprehensiveness and review topic consistency on the review usefulness?
To answer the three research questions, we employ the theoretical lens of the ELM (Petty & Cacioppo, 1986), convergence theory (Moscovici, 1980), the cueing effect (Sniezek & Buckley, 1995), and previous research on review usefulness. We build and operationalize two measures of review quality—review comprehensiveness and review topic consistency— using the topic modeling method of text data analytics. For this exploration, we analyzed restaurant reviews collected from Yelp. To empirically test our hypothesis, negative binomial regression analyses and a series of robustness checks are performed.
The next section synthesizes prior review usefulness research to specify the research gap and introduce the ELM as the main theoretical foundation of this study. We define review comprehensiveness and review topic consistency as important variables to measure review quality. Following that, we introduce our research model and hypotheses. The research methodology section discusses the data collection method, measurement methods, and econometric models. After that, the results of our data analyses are presented followed by the theoretical and practical implications of our research. The paper concludes with the limitations of our research and directions for further research.
2 Theoretical Foundation
2.1 Review Usefulness
The social voting feature in online consumer review platforms is a technological component that allows users to express their views on the reviews by casting votes on whether they found a review useful (Baek et al., 2012; Kuan et al., 2015). Review usefulness is among the most important topics in e-commerce research, as reviews with more useful votes are perceived as credible, leading to a greater influence on the purchase decision (Cheung et al., 2012; Choi & Leon, 2020; Sun et al., 2019).
Previous review usefulness studies are classified into two streams depending on the effect of reviewer-related factors and review-related factors on review usefulness (Hong et al., 2017). In terms of the reviewer-related factors, past research maintains that disclosure of personal information by a reviewer (e.g., his/her real name, photo, location, and identity) has a positive effect on review usefulness (Forman et al., 2008; Ghose & Ipeirotis, 2010; Karimi & Wang, 2017; Sun et al., 2019). Past research also reports the positive effect of the reviewer’s expertise on review usefulness where expertise is measured as the total number of reviews posted by a reviewer (Baek et al., 2012; Guo & Zhou, 2017; Kuan et al., 2015) or the cumulative useful votes that a reviewer received (Choi & Leon, 2020). Other reviewer-related factors, such as the number of friends or followers, are also reported to have a positive effect on review usefulness (Guo & Zhou, 2017; Racherla & Friske, 2012).
In terms of review-related factors, past research has examined how non-textual features of reviews, such as review rating and review age (i.e., the time elapsed since the review was posted), affect review usefulness (Baek et al., 2012; Racherla & Friske, 2012). However, most studies show a greater interest in examining the effect of textual features of online reviews on review usefulness. The advances in text mining contribute significantly to this line of research.
Research on the effect of review text on review usefulness is divided into two streams. The first stream of research examines how the content and style of review text affect review usefulness. For instance, factors such as readability score (Ghose & Ipeirotis, 2010; Korfiatis et al., 2012), review length (Choi & Leon, 2020; Sun et al., 2019), and review objectivity (Ghose et al., 2012; Ghose & Ipeirotis, 2010) tend to show a positive effect on review usefulness. The second stream of research considers the effect of emotion-bearing words expressed in online reviews on review usefulness, where the sentiment mining methods are frequently used (Aghakhani et al., 2021; Craciun et al., 2020; Mousavizadeh et al., 2020; Siering et al., 2018). Key factors that are reported to affect review usefulness include review sentiment (Mousavizadeh et al., 2020; Salehan & Kim, 2016), consistency between review sentiment and review rating (Aghakhani et al., 2021), the intensity of emotions expressed in a review (Ren & Nickerson, 2019) and the interaction between emotional tones in a review and reviewer gender (Craciun et al., 2020).
2.2 Elaboration Likelihood Model and Review Usefulness
According to the ELM (Petty & Cacioppo, 1986), the persuasiveness of a message can be explained by the function of central and peripheral cues. Central cues prompt a message recipient to think critically about the meaning elaborated in the message. To understand the intended meaning of central cues, a message recipient carefully inspects the related facts and relevance of the message before responding to the message. For this reason, processing the central cues of a message requires deliberate thinking and high cognitive effort. By contrast, processing a message expressed through peripheral cues tends to be automatic and involves less cognitive effort, as it uses the heuristic knowledge gained through habitual experience (Angst & Agarwal, 2009). When processing messages with peripheral cues, people tend to rely on general impressions, their moods, and/or the credibility of the message’s sender. Therefore, message processing with peripheral cues is less costly, almost automatic, and requires low cognitive effort in assessing messages. However, it often contributes to bias due to reinforcement of one’s previous knowledge and habitual tendencies.
The ELM has been widely used in prior review usefulness studies to investigate how the central and peripheral cues of online reviews affect review usefulness. Appendix Table 1 summarizes prior research that has examined the effects of central and peripheral cues on review usefulness. Additionally, the ELM has been used to investigate the effect of textual features of reviews on review usefulness (Choi & Leon, 2020; Ren & Nickerson, 2019; Siering et al., 2018; Sun et al., 2019; Zhao et al., 2018). In part, this signifies the usefulness of the ELM in explaining the stronger effect of semantic features of textual reviews (ELM’s central cues), compared to non-textual features (ELM’s peripheral cues), on review usefulness.
This study addresses two important tenets of the ELM that received less attention in prior research. First, most prior review usefulness research has examined the independent effect of textual or non-textual features of online reviews on review usefulness (Baek et al., 2012; Kuan et al., 2015; Mousavizadeh et al., 2020; Racherla & Friske, 2012; Siering et al., 2018; Zhao et al., 2018). However, according to the ELM, the central and peripheral cues simultaneously, not separately, affect review usefulness (Bhattacherjee & Sanford, 2006; Petty & Cacioppo, 1986). For example, in face-to-face communication with another person, people tend to use verbal messages to convey semantic meaning (i.e., central cues), together with facial expressions, voice tone, etiquette, tidy clothes, etc. (i.e., peripheral cues). Further, if a communication partner is referred to as a close friend of a socially respected figure, the effect of verbal communication tends to be amplified as being more trustworthy. Wittingly or not, we always communicate using both central and peripheral cues. In practice, it is difficult to separate verbal cues from peripheral ones to assess the implied meaning and intention of communications.
A few studies highlight this limitation by stressing that review usefulness should be evaluated by considering both textual and other cues together (Hu et al., 2008; Li et al., 2013). For example, recent research investigates the joint effect by examining how social and temporal factors, as well as other peripheral cues (e.g., rating inconsistency), moderate the effect of review content on review usefulness (Aghakhani et al., 2021; Huang et al., 2018). Continuing this line of research, our study intends to advance our understanding of the joint effect of central and peripheral cues by testing the moderating effect of source credibility (i.e., a peripheral cue) on the relationship between review content (i.e., a central cue) and review usefulness. We are particularly interested in the moderating role of source credibility (e.g., the moderating effects of elite badge members on Yelp) because it has been identified as a significant driver of information adoption (Angst & Agarwal, 2009; Bhattacherjee & Sanford, 2006; Sussman & Siegal, 2003), eWOM credibility (Cheung et al., 2009; Cheung et al., 2012), and review usefulness (Hong et al., 2017).
According to the information processing literature, the information quality of a textual message (as the central cue of the ELM) is one of the most important drivers of information system adoption in various contexts such as the adoption of electronic health records (Angst & Agarwal, 2009; Sussman & Siegal, 2003), document management systems (Bhattacherjee & Sanford, 2006), and knowledge management system adoption in an organization (Sussman & Siegal, 2003). In the eWOM adoption context, information quality expressed in an eWOM message has been reported as a key dimension of eWOM credibility (Cheung et al., 2009; Cheung et al., 2012). Information processing and information quality literature suggest information comprehensiveness and information consistency as two dimensions that compose the information quality and their effects can be empirically measured (Kahn et al., 2002; Sussman & Siegal, 2003).
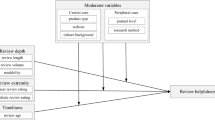
Employing and modifying the information processing literature, we define the two dimensions of review quality (i.e., review comprehensiveness and review topic consistency) that have been under-explored in review usefulness research, to investigate if and how they affect review usefulness. We define review comprehensiveness as the breadth of detail that elaborates various aspects of a focal product or service covered by an online review. We define review topic consistency as the consistency between the main content of a product or service covered in a review and the aggregate topic covered in all other reviews. We propose our research model (refer to Appendix Fig. 1) that hypothesizes the direct and positive effect of review comprehensiveness (H1) and review topic consistency (H2) on review usefulness. We also hypothesize that source credibility positively moderates the relationship between review comprehensiveness and review usefulness (H3), whereas it negatively moderates the relationship between review topic consistency and review usefulness (H4). We control for other important factors related to reviews, reviewers, and products/services (i.e., restaurants in this study). The following section details our hypotheses.
3 Hypotheses Development
3.1 Review Comprehensiveness
Prior research has measured the comprehensiveness of online reviews in terms of their length (i.e., the number of words in a review) (Baek et al., 2012; Kuan et al., 2015; Mousavizadeh et al., 2020). Review length has been studied as an important predictor of review usefulness, with most studies reporting its positive effect on review usefulness (Baek et al., 2012; Hong et al., 2017; Kuan et al., 2015; Mousavizadeh et al., 2020; Salehan & Kim, 2016). This stream of research maintains that longer reviews are more diagnostic in consumers’ purchase decision-making process because they are likely to contain more comprehensive information about products, leading to an increase in their likelihood of receiving useful votes.
Other studies, however, have reported the nonsignificant (Huang et al., 2015) or negative effect (Racherla & Friske, 2012) of review length on review usefulness. Huang et al. (2015) report that increasing review length beyond 144 words diminishes its positive effect on review usefulness. Chua and Banerjee (2015) maintain that long reviews increase consumers’ information search cost, decreasing the likelihood of receiving useful votes. Sun et al. (2019) argue that review length is a less determinant predictor of review usefulness for search products in comparison to experience products in that search product features are more easily compared and evaluated than experience products.
Beyond review length, consumers are more inclined to search for reviews that cover various attributes of products and services (Aghakhani et al., 2018; Qiu et al., 2012; Sun et al., 2019). A plausible explanation is that because sellers rarely include all aspects of products in their product description, reviews that cover various aspects of products reduce the information asymmetry problem that is prevalent in e-commerce platforms (Siering et al., 2018). The comprehensiveness of topics covered in reviews becomes important especially for online reviews of service products due to the heterogeneous interests of various consumers (Bailey, 2005; Yüksel & Yüksel, 2003). For instance, in the case of restaurant reviews, some customers are interested in information about the ambiance of restaurants whereas others are interested in the service or food quality. Therefore, it is likely that consumers ignore unidimensional reviews if the topic discussed in the review does not include enough information they are looking for. Acknowledging the importance of review comprehensiveness as a dimension of review quality, we propose the following hypothesis:
-
H1: Review comprehensiveness (i.e., the number of topics covered in a review) has a positive effect on review usefulness.
3.2 Review Topic Consistency
According to the convergence theory, the convergence of thoughts and opinions is formed through people’s tendency to follow existing beliefs, values, and widespread popular feelings (Moscovici, 1980). The convergence in a group is reinforced and intensified when the majority of a group holds consistent beliefs, opinions, or attitudes about a topic (Mannes, 2009; Nemeth, 1986). Therefore, a new member’s opinion tends to either assimilate into the majority’s topic or differentiate into a new topic, possibly forming a new group of topics (Baker & Petty, 1994; Mannes, 2009; Zhao et al., 2018).
Consistent with the convergence theory, prior review usefulness research maintains that the inconsistency between a numerical review rating and the average product rating has a negative effect on review usefulness (Baek et al., 2012; Kuan et al., 2015). We, however, need to consider the limitation of the rating-consistency perspective that stems from the J-shaped distribution of star ratings. The J-shaped distribution speaks to the tendency that most product reviews receive five stars and very few products receive one or two stars (Hu et al., 2009). Especially, Hu et al. (2009) point out that people tend to post online reviews when they are extremely happy (i.e., 4 or 5 stars) or extremely unhappy (i.e., 1 or 2 stars), but might not bother to post reviews when they feel an average level of satisfaction with purchased products or services. This has led researchers to question the reliability of the online review system itself (Adomavicius et al., 2019; Gao et al., 2017). This suggests that “people should not solely rely on the simple average [star rating] that is readily available” (Hu et al., 2009). Reflecting on this limitation, some studies propose other measures for review consistency. For instance, Mudambi et al. (2014) and Aghakhani et al. (2021) report that the consistency between the sentiment expressed in a review text and the star rating has a positive effect on review usefulness.
However, what remains unexplored is the idea that consumers have limited time and cognitive resources available to process a large number of review texts (Mudambi et al., 2014; Sun et al., 2019). Therefore, as explained by the convergence theory, consumers may primarily read reviews that elaborate on the main features of products or services that have been discussed by the majority of reviewers. Therefore, we examine review consistency in terms of the consistency between the main topic discussed in most other reviews and the major topic discussed in a focal review. We submit the following hypothesis:
-
H2: Review topic consistency has a positive effect on review usefulness.
3.3 The Moderating Role of Source Credibility
Source credibility, as a peripheral cue, has been considered an important reviewer-related factor in eWOM adoption studies (Cheung et al., 2009; Cheung et al., 2012). These studies maintain that an eWOM from a highly credible source affects the perceived credibility of the eWOM, increasing the likelihood of the eWOM adoption by consumers. Baek et al. (2012) and Kuan et al. (2015) report that those reviewers who are recognized by Amazon’s “top reviewer” badge are perceived more credible than other reviewers. Recent meta-analysis studies, however, show inconsistent findings related to the effect of source credibility on review usefulness. While Ismagilova et al. (2020) report a positive effect of source credibility on review usefulness, Qahri-Saremi and Montazemi (2019) report the opposite result. These inconsistent findings may signify the interplay of central and peripheral cues as indicated by the ELM.
The ELM maintains that the central and peripheral cues of a message jointly, not independently, influence the message recipient’s evaluation of a message (Aghakhani et al., 2021; Bhattacharyya et al., 2020; Sussman & Siegal, 2003). It suggests that the credibility of an author (i.e., the peripheral cue) should be examined together with the message content (i.e., the central cue) to better understand the eWOM adoption process. Past research calls attention to the complex mechanism underlying the role of source credibility in information adoption. For instance, Luo et al. (2013) report that source credibility positively moderates the effect of recommendation completeness on recommendation credibility, whereas it negatively moderates the effect of recommendation persuasiveness on recommendation credibility.
The effect of review comprehensiveness and review topic consistency (i.e., as a central cue) together with source credibility (i.e., as a peripheral cue) on review usefulness can be better understood when we heed the temporal dynamics of information processing. According to the ELM, peripheral cues tend to function in the early stage of message processing, especially when a message recipient is to process complex information (Petty & Cacioppo, 1986). This means that a positive peripheral cue (e.g., elite badge member sign), which is attached to a central message, primes the message recipient to quickly form an initial general impression of a review text before scrutinizing its key messages.
Processing topics in a lengthy and comprehensive review requires a high cognitive cost. We, therefore, argue that a source credibility signal (i.e., elite badge symbol as a peripheral cue) is likely to interact with review comprehensiveness (i.e., the number of topics in a review text as a central cue), especially during the initial information scanning process. It implies that consumers might try to peripherally estimate if a review is contributed by a trustworthy elite badge member, before investing cognitive effort to interpret the topics covered in a review text (Mousavizadeh et al., 2020). Thus, we argue that the presence of an elite badge symbol attached to a review text is likely to exert a stronger effect as a review text gets longer because it can alleviate the cost associated with time and cognitive effort required to read a comprehensive and lengthy review (Mudambi et al., 2014). We thus argue that the presence of an elite badge symbol in a review text is more likely to prompt online consumers to read and evaluate topics expressed in a review text, and this interacting dynamic increases the likelihood of receiving useful votes. Therefore, we put forth the following hypothesis:
-
H 3 : Source credibility positively moderates the effect of review comprehensiveness on review usefulness.
However, when we try to understand the interaction between source credibility and review topic consistency, the influence of source credibility (e.g., an elite badge symbol as a peripheral cue) should be interpreted with caution. According to the cueing effect mechanism, a sequence of cues may help an individual diagnose a problem. When an alternative or less diagnostic cue precedes the main cue to solve a problem, it reduces individuals’ attention and effort to process the main cue (Sniezek & Buckley, 1995; Yin et al., 2020). We, therefore, argue that the positive impression of source credibility signal can attenuate consumers’ information processing effort to evaluate review topic consistency. In reverse, when cues for source credibility (e.g., an elite badge symbol as a peripheral cue) are absent, the effect of review topic consistency (as a central cue) stands out. In other words, when a review is posted by a non-elite badge member, review topic consistency becomes a more determinant factor in consumers’ evaluation of review usefulness. Therefore, we suggest the following hypothesis:
-
H4: Source credibility negatively moderates the effect of review topic consistency on review usefulness.
4 Research Methodology
4.1 Data Collection
In order to test our hypotheses, we focus on restaurants, which are service products. It is because consumers tend to rely heavily on online reviews, due to the high level of experiential variation at restaurants, compared to search products (e.g., a digital camera) (Racherla & Friske, 2012). Data were collected from yelp.com. Yelp has been widely recognized as one of the major online consumer review sites for service industries like restaurants. Following the suggestion of Salehan and Kim (2016), we selected restaurants that had received at least 100 reviews. In total, 27,517 reviews from 100 restaurants that do business in major metropolitan cities in the United States were gathered.
4.2 Measures
The dependent variable in this study is review usefulness. It is measured as the number of “useful” votes a review received from Yelp users. Source credibility, which refers to the credibility of a reviewer, is operationalized as a binary variable. If a reviewer is an elite badge member, the source credibility is assigned as 1; otherwise, 0. In the following sections, we explain how the two independent variables (i.e., review comprehensiveness and review topic consistency) and the control variables are measured.
4.2.1 Measure of Review Comprehensiveness
We define review comprehensiveness as the number of topics covered in a review. To measure review comprehensiveness, we used topic modeling, which is a probabilistic model frequently used to uncover the underlying semantic structure of a document collection (Blei et al., 2003). Latent Dirichlet Allocation (LDA) and Latent Semantic Analysis (LSA) are two popular topic modeling methods (Slof et al., 2021). Among these two models, we choose LDA over LSA, because it is built upon underlying generative probabilistic semantics that is appropriate for the type of data we have (Blei et al., 2003). Moreover, LDA has been widely used in recent studies as the preferred model for assessing user-generated content (Chunmian et al., 2021; Costello & Lee, 2021; Jung & Suh, 2019; Lee, 2022; Slof et al., 2021). That means LDA follows the assumption closer to the reality that authors (i.e., reviewers in our study) create documents (i.e., reviews in our study) by choosing a variety of topics and drawing words from the vocabulary for each topic (Debortoli et al., 2016; Vakulenko et al., 2014).
Following the steps outlined by Gjerstad et al. (2021) and Lee (2022), we used “GENSIM”, “NLTK”, and “spaCy” packages in Python to pre-process the review texts before applying LDA. Using “NLTK”, we split each review text into tokens (i.e., words). Following Gjerstad et al. (2021), we used the Gensim package in Python to create both unigrams (i.e., individual words) and bigrams (i.e., a sequence of two words). We used the NLTK stop words dictionary to remove unnecessary functional words (e.g., stop words such as “a,” “all,” “the,” “to,” “with” and so on), which might not be useful in identifying topics from our review texts. We also removed the punctuations using the “GENSIM” package. Following Gjerstad et al. (2021) we used the Porter stemmer in the NLTK package to reduce the inflected word forms (e.g., “was,” “were,” “is,” “are,” “been”) to their root form (e.g., “be”). Since English is an inflectional language with multiple inflected forms for a single word (or lemma), we used “spaCy” to perform lemmatization to resolve the words to their dictionary forms.
We used the term frequency-inverse document frequency (TF-IDF) weighting algorithm to parse the entire review documents. Given that we extract and classify online review texts into a set of topics, we used TF-IDF over the Word2Vec model which is known to show a better performance for text classification tasks (Cahyani & Patasik, 2021). The TF-IDF weighting value increases proportionally to the number of times a word appears in a review. However, this increase is offset by the number of documents that contain the word across entire review documents (Cao et al., 2011). By using the TF-IDF weighting method, we created a matrix for the reviews and fed it into the LDA algorithm. Before running the LDA model, we reviewed prior literature and similar websites to find the upper bound value of parameter K (i.e., the number of underlying topics). They suggest that restaurant reviews are characterized by 11 dimensions (Pettijohn et al., 1997). These dimensions include service quality and staff attitude, product/food quality, menu diversity, hygiene/cleanliness, convenience and location, noise, service speed, price and value, facilities/special features, and atmosphere/ambiance. Also, by examining similar restaurant review websites, we found that Opentable (an online restaurant-reservation service) allows reviewers to rate restaurants based on four categories (i.e., food, service, ambiance, and value). Setting the upper bound value of parameter K as 11, we experimented to run 10 different LDA models with the parameter K ranging from 2 to 11.
Since LDA is an unsupervised topic modeling method, not many evaluation metrics can be used to assess its outcome performance (Blei et al., 2003). Prior literature suggests that perplexity score and topic coherence score are reasonable choices for evaluating the LDA model performance (Gjerstad et al., 2021; Lee, 2022; Liu et al., 2021; Slof et al., 2021; Zhang et al., 2020). Although previous studies report that optimizing the topic model with perplexity score yields less semantically meaningful topics than topic coherence score (Chang et al., 2009; Röder et al., 2015), we report the results of both metrics that evaluate the performance of our ten LDA-generated topic models. As presented in Appendix Fig. 2, both the topic coherence scoreFootnote 2 and perplexity score indicate that the model with four underlying topics produces the best performance. Therefore, we used the four-topic model to assess the review comprehensiveness.
For each review, the LDA model assigns the probability that a review belongs to one of the four identified topicsFootnote 3 of “food”, “service”, “ambiance”, and “value”. To operationalize review comprehensiveness, we set the topic cut-off probability to 25%, assuming that the four topics are equally distributed across all reviews. This means that, if a review had at least a 25% association with any of the identified topics, it was coded as 1 to indicate that the topic was discussed in the review text; otherwise, it was coded as 0. Based on this approach, review comprehensiveness was scored in the range of 0 to 4, depending on the number of topics covered in a review.
4.2.2 Measure of Review Topic Consistency
We operationalized review topic consistency as a binary variable representing the consistency between a major topic discussed in a review (i.e., the topic with the highest percentage of coverage) and the major topic discussed in all other reviews of a particular restaurant. For instance, if a review mainly elaborates on the service and most of the other reviews describe the service as well, the review topic consistency will be coded as 1; otherwise, 0.
4.2.3 Measures of Control Variables
After using the same text pre-processing steps described above, we used the Textblob package in Python to measure review sentiment and review subjectivity (Loria, 2020). Textblob calculates the sentiment polarity of text at the sentence level. It then aggregates the sentence-level polarity scores at the review level, with values ranging from −1 (very negative) to +1 (very positive). Textblob also counts the number and intensity of sentiments in a review text to examine whether a sentence is more subjective (having more sentiment) or more objective (having less sentiment). Textblob produces subjectivity scores ranging from 0 to 1, with 0 being the least subjective and 1 being the most subjective (Sahni et al., 2017).
Review longevity was measured by the number of months that had elapsed from the date when a review was posted. Review length was measured as the number of words in a review. Rating inconsistency was measured as the absolute distance between the average restaurant rating and the numerical rating of a review. Appendix Table 2 shows the descriptive statistics of the variables used in our analysis. Also, Appendix Table 3 shows the correlation among variables.
4.3 Empirical Analysis
In our data, many reviews (54%) did not receive a single useful vote, which indicates the over-dispersed variance of the dependent variable. Taking this into account, we used a negative binomial regression, one of the Poisson model variations, for analysis (Greene, 2003; Schindler & Bickart, 2012). To ensure that a negative binomial regression is suitable over the Poisson model, we tested whether the over-dispersion parameter α is significantly different from zero. Our results had a p value of <0.001, which confirms the existence of over-dispersion in our dataset. This validates that it is appropriate to use the negative binomial regression over the Poisson model. We built five models (refer to Appendix Table 4); model 1as a base model containing only control variables, model 2 containing control variables and independent variables, model 3 containing control variables and independent variables as well as the interaction effect of review comprehensiveness and source credibility, model 4 containing the control variables and the independent variables as well as the interaction effect of review topic consistency and source credibility and, model 5 which is a full model containing all the direct and interaction effects.
5 Results
Model 5 in Appendix Table 4 is used to describe the analysis results. Our first hypothesis (H1) examines the effect of review comprehensiveness on review usefulness. Appendix Table 4 shows that, contrary to our hypothesis, review comprehensiveness has a significant negative effect on the usefulness of online reviews (B = −0.062, p < 0.05). One possible explanation for this opposite result relates to the cognitive cost that consumers should invest to process reviews encompassing many topics (Aghakhani et al., 2021; Mudambi et al., 2014; Sun et al., 2019). This cost leads consumers to focus on more targeted reviews that include only the topic they are searching for (e.g., food or service, but not both) so that they can reduce the cognitive effort required to find the information they need. A second possible explanation is that reviews covering many topics may not have enough details on any of the focal topics that consumers are interested in. A third possible explanation is that reviews containing many topics tend to be lengthy, and the longer review text might decrease focus and increase the cognitive cost to process the review contents.
Our second hypothesis examines the effect of review topic consistency on review usefulness. As model 5 shows, review topic consistency has a positive effect on review usefulness (B = 0.153, p < 0.01), supporting H2. Employing the convergence theory (Mannes, 2009; Zhao et al., 2018), prior studies have examined review topic consistency in terms of the agreement between a numeric review rating and the average product rating (Baek et al., 2012;Kuan et al., 2015 ; Mousavizadeh et al., 2020). However, under-explored has been the possibility that consumers compare one review with other reviews, and the common topics presented by many other reviews are more likely to be assessed as credible (Qahri-Saremi & Montazemi, 2019). Thus, our finding expands the previous studies by providing evidence that the consistency between the main topics in a review and the major topics discussed across all the reviews is a significant predictor of review usefulness.
Our results also show that source credibility has a moderating effect on the relationship between review comprehensiveness and review usefulness. Also, source credibility has a moderating effect (different than the previous one) on the relationship between review topic consistency and review usefulness. While processing online reviews, the elite-badge source credibility signal offsets the cognitive cost of processing lengthy and comprehensive reviews, and it amplifies their likelihood of receiving useful votes. Therefore, H3 is supported. In contrast, when consumers devote their cognitive effort to evaluate the consistency between reviews, the prevailing effect of elite-badge credibility (i.e., peripheral cue) attenuates the importance of review topic consistency (i.e., central cue) in consumers’ evaluation of the usefulness of a review. This implies that review topic consistency becomes a more determinant predictor of review usefulness if a review is posted by a non-elite-badge member, validating H4.
5.1 Robustness Checks
To ensure the validity of our results, we ran a series of robustness checks. We used the Zero-inflated negative binomial regression to account for the excessive number of zero useful votes (54%) in our data. We assumed that the zero useful votes in our data can be determined by two different behavioral processes of online consumers. First, consumers might not cast a useful vote simply, because they did not read a review. Second, although consumers read a review, they might not cast a vote, because they find it not useful (Greene, 1994; Jin et al., 2015). The Zero-inflated negative binomial regression generates two separate models, a logit model and a negative binomial model (Kyriakou et al., 2017). Following Jin et al. (2015), we used the negative binomial model instead of the logit model, because we are interested in reviews that receive zero useful votes with the presupposition that they are not perceived as useful.
Second, we also checked if our model is robust to alternative measures of review comprehensiveness. To start, we used review length as a measure of review comprehensiveness, because previous studies have shown that longer reviews are likely to contain more comprehensive information about products or services (Kuan et al., 2015; Mousavizadeh et al., 2020). Next, to operationalize review comprehensiveness, we initially assumed an equal distribution of the weights of four different topics (i.e., in terms of “Food Quality,” “Service Quality,” “Value,” and “Ambience”), which led us to use a topic cut-off value of 25% to determine whether a specific topic is discussed in reviews. This assumption raised the concern that, while extracting topics from review documents, some topics might be algorithmically downgraded than other topics. To address this concern, we randomly selected 300 sample reviews – i.e., 75 reviews from each group of reviews that have the topic cut-off values of 25%, 20%, 15%, and 10%, respectively – from our raw review database (refer to Appendix 3 for details). The first two authors independently read and analyzed those reviews to qualitatively evaluate if review texts in each group are assigned with adequate topics in comparison to another group of reviews. The first two authors then discussed the findings and concluded that the topic cut-off value of 10% appears to best represent topic coverage expressed in review texts. As a result, the review comprehensiveness was re-analyzed using the new data generated from the topic cut-off value of 10%.
As reflected in Appendix Table 5, we have built 5 models. In model 1, we re-estimate the full model with the default measure of review comprehensiveness using the Zero-inflated negative binomial regression. In models 2 and 3, we used review length as the measure of review comprehensiveness and re-estimate the full model using the negative binomial regression and the Zero-inflated negative binomial, respectively. Finally, in model 4 and model 5, we used the new measure of review comprehensiveness (i.e., with 10% topic coverage) and re-estimate the full model using the negative binomial regression and the Zero-inflated negative binomial, respectively.
As presented in Appendix Table 5, our findings are consistent with those in Appendix Table 4 in terms of the sign and significance of coefficients, validating the robustness of our empirical findings. Particularly, the results of model 2 and model 3 show that review length as a measure of review comprehensiveness has a negative effect on review usefulness, but its interaction with source credibility has a positive effect on review usefulness. However, when review comprehensiveness is measured as the number of topics in a review (i.e., models 1, 4, and 5), the effect of review length as the control variable on review usefulness becomes insignificant. We underline this finding as an important contribution of our study since it indicates that the number of topics covered in a review is a superior measure of review comprehensive than review length.
6 Theoretical and Practical Contributions
This study contributes to the online review literature by developing and validating the antecedents that affect review usefulness. Our main contribution is that, while past research indirectly measured review quality with psychometric latent variables (e.g., perceived review quality) or proxy variables (e.g., review length) (Cheung et al., 2009; Cheung et al., 2012; Eslami et al., 2018; Karimi & Wang, 2017; Kuan et al., 2015; Li & Huang, 2020), we developed two review quality-related variables (i.e., review comprehensiveness and review topic consistency) to directly measure their effects on review usefulness. In particular, we developed the review comprehensiveness variable to measure the topical coverage of product or service features expressed in online reviews (Aghakhani et al., 2018; Ghose et al., 2012; Ghose & Ipeirotis, 2010; Qiu et al., 2012; Sun et al., 2019), and the variable of review topic consistency to consider the reality that consumers might compare a focal review with many other reviews to vote for review usefulness (Baek et al., 2012; Kuan et al., 2015; Qahri-Saremi & Montazemi, 2019; Salehan & Kim, 2016). The contributions of this research are not trivial in that we directly measure the effects of review quality on its usefulness by going beyond the traditional survey-based latent variables or other proxy variables (Cheung et al., 2012; Craciun et al., 2020; Filieri et al., 2018).
Another contribution is that we take into account a lesser-known aspect of ELM for review usefulness research. We built and tested hypotheses 3 and 4 to highlight that central and peripheral cues are processed simultaneously, not independently, for persuasive communications (Bhattacherjee & Sanford, 2006). In the context of review usefulness research, we tested their plausibility with the moderating effect of the elite badge symbol that engages in consumers’ processing of review comprehensiveness and review topic consistency. Our use of ELM goes beyond the prior review usefulness research that has solely focused on independent effects of central or peripheral factors on review usefulness without considering their joint effects (Eslami et al., 2018; Filieri et al., 2018; Mousavizadeh et al., 2020; Siering et al., 2018). In that regard, our study contributes to this line of research that examines the moderating effect of peripheral cues (e.g., star rating, and social or temporal cues) on the relationship between review quality cues on review usefulness. Also, our findings on the different moderating effects of source credibility (i.e., elite badge symbol) enrich our understanding of the ELM in that heuristic peripheral cues can bring about bias effect in deciding whether or not a review is useful (Luo et al., 2013).
This study makes a few practical contributions. Currently, Yelp allows users to sort online reviews by the order of posting dates, consumer rating scores, reviewers’ status (i.e., elite badge status), and their proprietary ranking algorithm (i.e., Yelp sort). Implementing semantics-based sorting algorithms might be particularly useful for service-oriented businesses (e.g., restaurants) where consumers have diverse interests (e.g., ambiance, cleanness, service quality, price, etc.) to search through. We believe that review comprehensiveness and review topic consistency variables can be implemented into sorting algorithms of online review platforms to help online users in sorting through online reviews according to topical coverage and their interests.
Our study also informs online review platform service providers about the importance of hosting useful reviews that can help other online consumers. They can educate online review contributors to read a handful of other reviews so that they can compose and post topical reviews of interest to other consumers. This strategy is particularly important, given that long reviews with multiple topics contributed by elite or non-elite badge members tend to show opposite effects on review usefulness.
7 Limitations
Our study has a few limitations. First, previous studies have shown that platforms (Lee & Youn, 2009) and product types (Kuan et al., 2015; Mousavizadeh et al., 2020) influence the rate of eWOM adoption. Thus, our study needs to be repeated on other product/service types and other platforms. Also, our study has limitations associated with using cross-sectional data to examine causal effects. Future researchers can collect a panel dataset to examine if temporal effects of online reviews exist to receive usefulness votes.
8 Conclusions
Provided that online consumer reviews are important for consumers’ purchase decisions and trustful online transactions, understanding the determinants of review usefulness is important. By using the ELM as a main theoretical lens and adapting the topic modeling method, we measured review comprehensiveness and review topic consistency as two important dimensions that compose review quality. Consistent with the convergence theory, our analyses show that online reviews become more useful when the main topic in a review is consistent with the main topic discussed in other reviews. Also, we found that describing too many topics with a long review does not necessarily improve its usefulness. Our results also show that source credibility interacts with these two dimensions of review quality to affect review usefulness. Particularly, source credibility positively moderates the relationship between review comprehensiveness and review usefulness. However, it has a negative moderating effect on the relationship between review topic consistency and review usefulness. Our study also provides practical guidelines useful for online consumer review sites and their members in terms of designing a better social voting system and writing better reviews, respectively.
Notes
Review usefulness in Yelp and review helpfulness in Amazon essentially serve the same function of expressing online review quality. Therefore, for ease of reading, we use the term “usefulness” henceforth.
We used topic coherence score, which is built upon pointwise mutual information (PMI), because it tends to show the highest correlations with human ratings (Röder et al., 2015)
We manually assign the labels of “food”, “service”, “ambiance”, and “value” to the four topics based on the determinant keywords that appear in each topic with the highest probability.
References
Adomavicius, G., Bockstedt, J., Curley, S., & Zhang, J. (2019). Reducing recommender systems biases: An investigation of rating display designs. Forthcoming, MIS Quarterly, 43(4), 1321–1341.
Aghakhani, N., Karimi, J., & Salehan, M. (2018). A unified model for the adoption of electronic word of mouth on social network sites: Facebook as the exemplar. International Journal of Electronic Commerce, 22(2), 202–231.
Aghakhani, N., Oh, O., Gregg, D. G., & Karimi, J. (2021). Online review consistency matters: An elaboration likelihood model perspective. Information Systems Frontiers, 23, 1287–1301. https://doi.org/10.1007/s10796-020-10030-7
Angst, C. M., & Agarwal, R. (2009). Adoption of electronic health records in the presence of privacy concerns: The elaboration likelihood model and individual persuasion. MIS Quarterly, 33(2), 339–370.
Baek, H., Ahn, J., & Choi, Y. (2012). Helpfulness of online consumer reviews: Readers' objectives and review cues. International Journal of Electronic Commerce, 17(2), 99–126.
Bailey, A. A. (2005). Consumer awareness and use of product review websites. Journal of Interactive Advertising, 6(1), 68–81.
Baker, S. M., & Petty, R. E. (1994). Majority and minority influence: Source-position imbalance as a determinant of message scrutiny. Journal of Personality and Social Psychology, 67(1), 5.
Bhattacharyya, S., Banerjee, S., Bose, I., & Kankanhalli, A. (2020). Temporal effects of repeated recognition and lack of recognition on online community contributions. Journal of Management Information Systems, 37(2), 536–562.
Bhattacherjee, A., & Sanford, C. (2006). Influence processes for information technology acceptance: An elaboration likelihood model. MIS Quarterly, 30(4), 805–825.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3(Jan), 993–1022.
Cahyani, D. E., & Patasik, I. (2021). Performance comparison of TF-IDF and Word2Vec models for emotion text classification. Bulletin of Electrical Engineering and Informatics, 10(5), 2780–2788.
Cao, Q., Duan, W., & Gan, Q. (2011). Exploring determinants of voting for the “helpfulness” of online user reviews: A text mining approach. Decision Support Systems, 50(2), 511–521.
Chang, J., Boyd-Graber, J., Wang, C., Gerrish, S., & Blei, D. M. (2009). Reading tea leaves: How humans interpret topic models. In: Advances in Neural Information Processing Systems- Proceedings of the 2009 conference (pp. 288–296).
Cheung, M. Y., Luo, C., Sia, C. L., & Chen, H. (2009). Credibility of electronic word-of-mouth: Informational and normative determinants of on-line consumer recommendations. International Journal of Electronic Commerce, 13(4), 9–38.
Cheung, C. M.-Y., Sia, C.-L., & Kuan, K. K. (2012). Is this review believable? A study of factors affecting the credibility of online consumer reviews from an ELM perspective. Journal of the Association for Information Systems, 13(8), 2.
Choi, H. S., & Leon, S. (2020). An empirical investigation of online review helpfulness: A big data perspective. Decision Support Systems, 139, 113403.
Choi, A. A., Cho, D., Yim, D., Moon, J. Y., & Oh, W. (2019). When seeing helps believing: The interactive effects of previews and reviews on E-book purchases. Information Systems Research, 30(4), 1164–1183.
Chou, Y.-C., Chuang, H. H.-C., & Liang, T.-P. (2021). Elaboration likelihood model, endogenous quality indicators, and online review helpfulness. Decision Support Systems, 153, 113683.
Chua, A. Y., & Banerjee, S. (2015). Understanding review helpfulness as a function of reviewer reputation, review rating, and review depth. Journal of the Association for Information Science and Technology, 66(2), 354–362.
Chunmian, G., Haoyue, S., Jiang, J., & Xiaoying, X. (2021). Investigating the demand for Blockchain talents in the recruitment market: Evidence from topic modeling analysis on job postings. Information & Management, 103513. https://doi.org/10.1016/j.im.2021.103513
Costello, F. J., & Lee, K. C. (2021). Exploring investors' expectancies and its impact on project funding success likelihood in crowdfunding by using text analytics and Bayesian networks. Decision Support Systems, 154, 113695.
Craciun, G., Zhou, W., & Shan, Z. (2020). Discrete emotions effects on electronic word-of-mouth helpfulness: The moderating role of reviewer gender and contextual emotional tone. Decision Support Systems, 130, 113226.
Debortoli, S., Müller, O., Junglas, I., & vom Brocke, J. (2016). Text mining for information systems researchers: An annotated topic modeling tutorial. Communications of the Association for Information Systems, 39(1), 7.
Eslami, S. P., Ghasemaghaei, M., & Hassanein, K. (2018). Which online reviews do consumers find most helpful? A multi-method investigation. Decision Support Systems, 113, 32–42.
Filieri, R., McLeay, F., Tsui, B., & Lin, Z. (2018). Consumer perceptions of information helpfulness and determinants of purchase intention in online consumer reviews of services. Information & Management, 55(8), 956–970.
Forman, C., Ghose, A., & Wiesenfeld, B. (2008). Examining the relationship between reviews and sales: The role of reviewer identity disclosure in electronic markets. Information Systems Research, 19(3), 291–313.
Fullerton, L. (2017). Online reviews impact purchasing decisions for over 93% of consumers, report suggests. Retrieved from https://www.thedrum.com/news/2017/03/27/online-reviews-impact-purchasing-decisions-over-93-consumers-report-suggests. Accessed 20 Mar 2022.
Gao, B., Hu, N., & Bose, I. (2017). Follow the herd or be myself? An analysis of consistency in behavior of reviewers and helpfulness of their reviews. Decision Support Systems, 95, 1–11.
Ghose, A., & Ipeirotis, P. G. (2010). Estimating the helpfulness and economic impact of product reviews: Mining text and reviewer characteristics. IEEE Transactions on Knowledge and Data Engineering, 23(10), 1498–1512.
Ghose, A., Ipeirotis, P. G., & Li, B. (2012). Designing ranking systems for hotels on travel search engines by mining user-generated and crowdsourced content. Marketing Science, 31(3), 493–520.
Gjerstad, P., Meyn, P. F., Molnár, P., & Næss, T. D. (2021). Do president Trump's tweets affect financial markets? Decision Support Systems, 147, 113577.
Greene, W. H. (1994). Accounting for excess zeros and sample selection in Poisson and negative binomial regression models. Working paper EC-94-10, Department of Economics, Stern School of Business, New York University, New York.
Greene, W. (2003). Econometric analysis (4th ed.). Prentice-Hall.
Grimes, M. (2012). Global Consumers’ Trust in ‘Earned’Advertising Grows in Importance. Retrieved from (https://www.nielsen.com/us/en/insights/article/2012/consumer-trust-in-online-social-and-mobile-advertising-grows/). Accessed 20 Mar 2022.
Guo, B., & Zhou, S. (2017). What makes population perception of review helpfulness: An information processing perspective. Electronic Commerce Research, 17(4), 585–608.
Hong, H., Xu, D., Wang, G. A., & Fan, W. (2017). Understanding the determinants of online review helpfulness: A meta-analytic investigation. Decision Support Systems, 102, 1–11.
Hu, N., Liu, L., & Zhang, J. J. (2008). Do online reviews affect product sales? The role of reviewer characteristics and temporal effects. Information Technology and Management, 9(3), 201–214.
Hu, N., Zhang, J., & Pavlou, P. A. (2009). Overcoming the J-shaped distribution of product reviews. Communications of the ACM, 52(10), 144–147.
Huang, A. H., Chen, K., Yen, D. C., & Tran, T. P. (2015). A study of factors that contribute to online review helpfulness. Computers in Human Behavior, 48, 17–27.
Huang, L., Tan, C.-H., Ke, W., & Wei, K. K. (2018). Helpfulness of online review content: The moderating effects of temporal and social cues. Journal of the Association for Information Systems, 19(6), 3.
Ismagilova, E., Slade, E., Rana, N. P., & Dwivedi, Y. K. (2020). The effect of characteristics of source credibility on consumer behaviour: A meta-analysis. Journal of Retailing and Consumer Services, 53, 101736.
Jin, Q., Animesh, A., & Pinsonneault, A. (2015). First-mover advantage in online review platform. Proceedings of 36th International Conference on Information Systems. https://aisel.aisnet.org/icis2015/proceedings/eBizeGov/26
Jung, Y., & Suh, Y. (2019). Mining the voice of employees: A text mining approach to identifying and analyzing job satisfaction factors from online employee reviews. Decision Support Systems, 123, 113074.
Kahn, B. K., Strong, D. M., & Wang, R. Y. (2002). Information quality benchmarks: Product and service performance. Communications of the ACM, 45(4), 184–192.
Karimi, S., & Wang, F. (2017). Online review helpfulness: Impact of reviewer profile image. Decision Support Systems, 96, 39–48.
Korfiatis, N., García-Bariocanal, E., & Sánchez-Alonso, S. (2012). Evaluating content quality and helpfulness of online product reviews: The interplay of review helpfulness vs. review content. Electronic Commerce Research and Applications, 11(3), 205–217.
Krumpal, I. (2013). Determinants of social desirability bias in sensitive surveys: A literature review. Quality & Quantity, 47(4), 2025–2047.
Kuan, K. K., Hui, K.-L., Prasarnphanich, P., & Lai, H.-Y. (2015). What makes a review voted? An empirical investigation of review voting in online review systems. Journal of the Association for Information Systems, 16(1), 1.
Kyriakou, H., Nickerson, J. V., & Sabnis, G. (2017). Knowledge reuse for customization: Metamodels in an open design community for 3D printing. arXiv preprint arXiv:1702.08072.
Lee, C. K. H. (2022). How guest-host interactions affect consumer experiences in the sharing economy: New evidence from a configurational analysis based on consumer reviews. Decision Support Systems, 152, 113634.
Lee, M., & Youn, S. (2009). Electronic word of mouth (eWOM) how eWOM platforms influence consumer product judgement. International Journal of Advertising, 28(3), 473–499.
Li, M., & Huang, P. (2020). Assessing the product review helpfulness: Affective-cognitive evaluation and the moderating effect of feedback mechanism. Information & Management, 57(7), 103359.
Li, M., Huang, L., Tan, C.-H., & Wei, K.-K. (2013). Helpfulness of online product reviews as seen by consumers: Source and content features. International Journal of Electronic Commerce, 17(4), 101–136.
Liu, F., Lai, K.-H., Wu, J., & Duan, W. (2021). Listening to online reviews: A mixed-methods investigation of customer experience in the sharing economy. Decision Support Systems, 149, 113609.
Loria, S. (2020). textblob Documentation. Available at: https://buildmedia.readthedocs.org/media/pdf/textblob/latest/textblob.pdf. Accessed 10 Mar 2022.
Luo, C., Luo, X. R., Schatzberg, L., & Sia, C. L. (2013). Impact of informational factors on online recommendation credibility: The moderating role of source credibility. Decision Support Systems, 56, 92–102.
Mannes, A. E. (2009). Are we wise about the wisdom of crowds? The use of group judgments in belief revision. Management Science, 55(8), 1267–1279.
Mariani, M. M., & Borghi, M. (2020). Online review helpfulness and firms’ financial performance: An empirical study in a service industry. International Journal of Electronic Commerce, 24(4), 421–449.
Moscovici, S. (1980). Toward a theory of conversion behavior. Advances in Experimental Social Psychology, 13, 209–239.
Mousavizadeh, M., Koohikamali, M., Salehan, M., & Kim, D. J. (2020). An investigation of peripheral and central cues of online customer review voting and helpfulness through the Lens of elaboration likelihood model. Information Systems Frontiers. https://doi.org/10.1007/s10796-020-10069-6
Mudambi, S. M., Schuff, D., & Zhang, Z. (2014). Why aren't the stars aligned? An analysis of online review content and star ratings. 47th Hawaii International Conference on System Sciences.
Nemeth, C. J. (1986). Differential contributions of majority and minority influence. Psychological Review, 93(1), 23.
Pettijohn, L. S., Pettijohn, C. E., & Luke, R. H. (1997). An evaluation of fast food restaurant satisfaction: Determinants, competitive comparisons and impact on future patronage. Journal of Restaurant & Foodservice Marketing, 2(3), 3–20.
Petty, R. E., & Cacioppo, J. T. (1986). The elaboration likelihood model of persuasion. Advances in Experimental Social Psychology, 19(1), 123–205.
Qahri-Saremi, H., & Montazemi, A. R. (2019). Factors affecting the adoption of an electronic word of mouth message: A Meta-analysis. Journal of Management Information Systems, 36(3), 969–1001.
Qiu, L., Pang, J., & Lim, K. H. (2012). Effects of conflicting aggregated rating on eWOM review credibility and diagnosticity: The moderating role of review valence. Decision Support Systems, 54(1), 631–643.
Racherla, P., & Friske, W. (2012). Perceived ‘usefulness’ of online consumer reviews: An exploratory investigation across three services categories. Electronic Commerce Research and Applications, 11(6), 548–559.
Ren, J., & Nickerson, J. V. (2019). Arousal, valence, and volume: How the influence of online review characteristics differs with respect to utilitarian and hedonic products. European Journal of Information Systems, 28(3), 272–290.
Röder, M., Both, A., & Hinneburg, A. (2015). Exploring the space of topic coherence measures. Proceedings of the eighth ACM international conference on Web search and data mining,
Sahni, T., Chandak, C., Chedeti, N. R., & Singh, M. (2017). Efficient twitter sentiment classification using subjective distant supervision. Proceedings of 9th International Conference on Communication Systems and Networks (COMSNETS),
Salehan, M., & Kim, D. J. (2016). Predicting the performance of online consumer reviews: A sentiment mining approach to big data analytics. Decision Support Systems, 81, 30–40.
Schindler, R. M., & Bickart, B. (2012). Perceived helpfulness of online consumer reviews: The role of message content and style. Journal of Consumer Behaviour, 11(3), 234–243.
Siering, M., Muntermann, J., & Rajagopalan, B. (2018). Explaining and predicting online review helpfulness: The role of content and reviewer-related signals. Decision Support Systems, 108, 1–12.
Slof, D., Frasincar, F., & Matsiiako, V. (2021). A competing risks model based on latent Dirichlet allocation for predicting churn reasons. Decision Support Systems, 146, 113541.
Sniezek, J. A., & Buckley, T. (1995). Cueing and cognitive conflict in judge-advisor decision making. Organizational Behavior and Human Decision Processes, 62(2), 159–174.
Spool, J. M. (2009). The magic behind amazon’s 2.7 billion dollar question. User Interface Engineering http://www.uie.com/articles/magicbehindamazon/. Accessed 10 Mar 2022.
Sun, X., Han, M., & Feng, J. (2019). Helpfulness of online reviews: Examining review informativeness and classification thresholds by search products and experience products. Decision Support Systems, 124, 113099.
Sussman, S. W., & Siegal, W. S. (2003). Informational influence in organizations: An integrated approach to knowledge adoption. Information Systems Research, 14(1), 47–65.
Topaloglu, O., & Dass, M. (2019). The impact of online review content and linguistic style matching on new product sales: The moderating role of review helpfulness. Decision Sciences. https://doi.org/10.1111/deci.12378
Vakulenko, S., Müller, O., & Brocke, J. V. (2014). Enriching iTunes App Store categories via topic modeling. Proceedings of 35th International Conference on Information Systems (pp. 1–11).
Yin, D., Bond, S. D., & Zhang, H. (2014). Anxious or angry? Effects of discrete emotions on the perceived helpfulness of online reviews. MIS Quarterly, 38(2), 539–560.
Yin, J., Ngiam, K. Y., & Teo, H. H. (2020). Work design in healthcare artificial intelligence applications: The role of advice provision timing. Proceedings of 41st International Conference on Information Systems. https://aisel.aisnet.org/icis2020/is_health/is_health/10
Yüksel, A., & Yüksel, F. (2003). Measurement of tourist satisfaction with restaurant services: A segment-based approach. Journal of Vacation Marketing, 9(1), 52–68.
Zhang, L., Yan, Q., & Zhang, L. (2020). A text analytics framework for understanding the relationships among host self-description, trust perception and purchase behavior on Airbnb. Decision Support Systems, 133, 113288.
Zhao, K., Stylianou, A. C., & Zheng, Y. (2018). Sources and impacts of social influence from online anonymous user reviews. Information & Management, 55(1), 16–30.
Zhou, L., Wang, W., Xu, J. D., Liu, T., & Gu, J. (2018). Perceived information transparency in B2C e-commerce: An empirical investigation. Information & Management, 55(7), 912–927.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
All authors declare that they are not affiliated with or involved in any organizations, entities, or individuals with a financial or non-financial interest in the subject matter or materials discussed in this manuscript.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1 Figures

Theoretical model

Topic coherence and perplexity scores
Appendix 2 Tables
Appendix 3: Qualitative Analyses of Sample Review Texts
A topic cut-off value of 25% assumes equal distributions of the four different topics (i.e., the topics of “value,” “food,” “ambiance,” and “service”) across a review text. This assumption ignores the possibility that some topics might be more importantly described than other topics. As a result, we generated a random sample of 300 reviews using four different topic cut-off values of 25%, 20%, 15%, and 10%. After reading and qualitatively examining the 300 sample reviews, we determined that a topic cut-off value of 10% best represents the number of topics contained in a review text. Review comprehensiveness was accordingly re-estimated with the new 10% topic cut-off value. The four tables below show exemplary review texts with the topic of “value” (first table), “food” (second table), “ambiance” (third table), and “service” (fourth table) having different topic cut-off values of 25%, 20%, 15%, and 10%
Review | The score for the Topic of “Value” |
|---|---|
Phenomenal value. The team that runs this place really has a winner in their hands and I hope they hold the course with excellent food at a reasonable price. I’ve tried most the dishes and all have been well executed. The staff treats everyone very well and even offers up an occasional beer or wine tasting, which is a nice touch. Go, eat, enjoy | 0.25 |
Breakfast review. The breakfast here is a little pricy but you should know that before coming in. There are cheaper options like potato pancakes for 5$ or new York egg sandwich for $8. I tried the eggs Benedict and the NY egg sandwich. Both delicious NY egg sandwich was a big portion. Came with two fried eggs and two big slices of bacon. Eggs Benedict was cooked to perfection. The spinach made it different and the holidase sauce made well. Coffee was strong for those coffee lovers. Yum. | 0.2 |
My cousin decided to treat me to dinner, courtesy of EY, and I decided to choose the one place that I’ve always wanted to come, Bottega Louie! The ambiance is definitely extremely beautiful with high ceilings and low light candles. The open kitchen is also a nice touch. They don’t take reservations but we were seating immediately (not sure how that happened but I’m not complaining!). We were put in a corner seat, which was a terrible place to sit because you can’t see anything but that was perfectly fine with me. Also, the menu is extensive BUT IS SO SMALL. I could barely read it! They start you off with a leaf shaped bread and butter, which was a bit hard but had great flavor. We started with the portobello fries, which are ACTUALLY MUSHROOMS. For some reason I thought it would just be oil, like truffle fries. The flavor wasn’t bad but I actually dislike mushrooms so I wouldn’t order that again... We ordered the Louie Salad, which was SO delicious. It was tangy and fresh and the jumbo shrimp was extremely flavorful. Definitely my favorite salad and I don’t even like salad. We also ordered the Hanger steak as well as the Trenne Pasta? I’m not sure if if that’s what the pasta was called but it’s the pasta that they’re known for that’s crunchy. The steak was extremely flavorful and I wasn’t too big of a fan of the pasta. In the end we got a DELICIOUS creme brulee and some macarons from the front. The service was great but they were a bit on the slow side. Overall, I want to come back and try brunch. I loved the ambiance and the fact that the meal was free (because it’s expensive!).. But I wasn’t WOWed and it didn’t meet my expectations. | 0.15 |
There’s nothing really wrong with Quartino, but I haven’t found any particular reason to pick it. The food is modestly priced and modestly good. Each trip, one dish usually ends up being terrible though, and there’s nothing excellent to offset it. Add the cramped space, the poor quality of the bread (that bread “Q” is such a tease), and the indifferent service, and I’m just not into the experience. I am docking a star for shared plates, since enough is enough of this trend. I’d like to have dinner when I go out for dinner. I’ve been here at least a half dozen times, and one trip stands out as excellent. This was for a large group -- for which Quartino’s is perfect. But if you have a smaller party you might as well go elsewhere. My girlfriend loves this place, and she’s going to hate this | 0.1 |
Review | The score for the Topic of “Food” |
|---|---|
I hear the sandwiches here are the bomb. I wouldn’t know. What I do know is that the Mac N′ Cheese will knock your socks off with it’s creamy cheesiness. | 0.25 |
Nice restaurant. Busy on the weekends and they do not take reservations, Walk in Only. Clam pasta dish was wonderful and of course the portobello Mushroom fries. DO NOT order the lobster soup. It is the worst, It tasted like fishy water and was salty and VERY FISHY. I was very disappointed by the dish. I wish I could have sent it back or said something about it because it was terrible. | 0.2 |
Been there at least 4 times now, my friends and I love it. Amazing food, cozy space, great service. They have a great oyster happy hour special too. Seafood is delicious- what’s offered changes over time- and the rotating assortment of beer on tap keeps the experience fresh and exciting. Out of what I had the most recent time, I’d most recommend the marlin crudo. But everything else was tasty too. | 0.15 |
Wasn’t terribly impressed. Sangria was delicious. Unfortunately, my brother and I both thought the food was particularly bland. The short rib was nice and tender, just needs more flavor. The tortellini with prosciutto and peas was alright, also bland tasting. Shrimp risotto was watery and very bland. Kind of disappointed. The atmosphere is busy and loud, which was okay for us, would be a good place for a first date where there’s action happening. Great place to people watch. I doubt I will return though. Much better Italian food in the city. Our server was friendly and outgoing, which is always appreciated. | 0.1 |
Review | The score for the Topic of “Ambience” |
|---|---|
complimentary drink, which wasn’t necessary, but we accepted:) Once we were seated, our waitress was great. She was attentive, friendly, and knowledgeable. When we were about to order dessert, the same manager came to our table and asked us to move tables to accommodate a handicapped guest as our table was wheelchair accessible. We gladly moved, no problem. For our “trouble” we were given more free drinks and the manager brought 4 complimentary desserts to our table. He was so attentive and we truly felt valued and appreciated. Overall, food was delicious, service was outstanding, and atmosphere was cozy and authentic. Will absolutely be back! | 0.25 |
I lived down the street from this joint which was a blessing and a curse in so many ways... Loved the pizza, hate the next morning workout, loved the market dessert choices, hate the guilt I feel the next day... I like taking out of town visitors to this place for the ambiance, but the wait can be insane on weekends. Overall, the menu offers a good selection, and pricing is very reasonable! | 0.2 |
Went here for a late dinner and was quite impressed. There are two locations in the Chicago area, and it’s a great place to go if you’re looking for some quality American food. From fried chicken to kale salad, there’s something here for everyone. The restaurant itself has a casual feel, and it set up like an upscale diner. It’s spacious and it a good option for groups. I made a reservation for three and we were seated right away upon arriving. The beer selection on tap was interesting, and I hadn’t heard of many of them. We ended up getting a round of the Yumyum, which was a decent IPA. I was in the mood for something light and healthy, so I ordered the quinoa kitchen salad, which was made from fresh, unique ingredients {romain lettuce, quinoa, almonds, radish, mint, feta, leeks, topped with crispy onion flakes} that complemented each other well! I was surprised at how filling it ended up being - I was only able to make it through half of it. The rest of the table decided on burgers (turkey and backyard) which they enjoyed. I tried the sweet potato fries, which were on the thicker side so they tasted healthier and ended up being a generous amount of potato. The prices here are decent, and are comparable to others restaurants in the area {$14 burgers and salads}. I would definitely be back for another visit next time I’m in the area. | 0.15 |
I’m in Atlanta for the week and had to get some good southern food that I can’t get in AZ and I can definitely say that Poor Calvin’s was the right choice. We came on an early Wednesday night so luckily there was no wait to be seated. We got the special appetizer for the day, salmon hush puppies. This was AMAZING (my mouth is watering just thinking about it). Our group also got the fried chicken with lobster mac & cheese + collard greens. This was a good choice. The serving was also large so I had some to-go. The atmosphere is classy yet cozy here. I enjoyed my first time and I’ll keep this place in mind when I’m back in Atlanta. | 0.1 |
Review | The score for the Topic of “Service” |
|---|---|
I’ve been here several times and have enjoyed every meal. Bottega Louie is well priced, and the food is consistently good. Waiters are friendly and deliver excellent service. I like ordering several small plates and sharing them with the table. | 0.25 |
Believe the hype! We chose Upstate based on location then read the reviews. You guys...so right! Very organized wait list with text notification system. The hour wait, spent at a friendly dive across the street, was worth it! The smell of the food at the next table had us drooling in anticipation as soon as we sat down. Excellent service -- casual and friendly, great menu and the food was spectacular. Prices are very reasonable -- $11 small plate/$15 main -- and portions are generous. I couldn’t finish the house favorite clams with fettuccine and lord knows, I tried. I would marry that fettuccine if NY ever passed human/food equality laws. Thinly sliced buttery whisky cake was the perfect finish. I will be back. | 0.2 |
We decided to try this place due to good reviews and were a bit disappointed. The food was presented to a good standard and the taste was great. It has been just a little expensive for what we get and the portions are on the smaller side. The server was very helpful and extremely knowledgeable on the menu choices so we were able to enjoy both the food and drinks selected. Highly recommend this to anyone wanting a wonderful dining experience. | 0.15 |
Sooo expensive, mediocre desert.. on top of that, terrible customer service! Oh theres No free parking.. 38 for 5 macaroons and 2 pastries.. We got there and there’s no parking on the streets so we had to park in a nearby structure for $5.. Once we walked in it was a market place.. Super noisy and packed.. We stood infront of their counter for 15 mins waiting for help.. Oh there’s no line so whoever is the rudest gets the service.. Sorry other reviewers.. But this place is terrible.. I like the decorations though.. Macaroons everywhere.. But the macaroon themselves were not good for that price.. | 0.1 |
Rights and permissions
About this article

Cite this article
Aghakhani, N., Oh, O., Gregg, D. et al. How Review Quality and Source Credibility Interacts to Affect Review Usefulness: An Expansion of the Elaboration Likelihood Model. Inf Syst Front 25, 1513–1531 (2023). https://doi.org/10.1007/s10796-022-10299-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10796-022-10299-w