
Abstract
The aim of this paper is to describe the development of a speaker-independent continuous automatic Amazigh speech recognition system. The designed system is based on the Carnegie Mellon University Sphinx tools. In the training and testing phase an in house Amazigh_Alphadigits corpus was used. This corpus was collected in the framework of this work and consists of speech and their transcription of 60 Berber Moroccan speakers (30 males and 30 females) native of Tarifit Berber. The system obtained best performance of 92.89 % when trained using 16 Gaussian Mixture models.
Similar content being viewed by others



Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Automatic Speech Recognition (ASR) means a process that inputs human speech and tries to convert to its corresponding set of words based on a specific algorithm (Al-Zabibi 1990). ASR has attracted a huge amount of interest in the last decades, mainly due to a wide area of applications involving such technology. ASR can be used in industrial and civilareas such as; hands free operations, mobile voice application, human-computer interaction, automatic translation, automated telephone services and can help handicapped people to control equipments or navigate on internet. It is a technology which makes life easier and very promising (Haton et al. 2006). Recently, ASR systems have played important roles in several areas and different ASR systems are found in literature. ASR systems are highly dependent on: the language spoken (English, French), the way to recognize speech (isolated words, continuous speech) and the speaker characteristics (speaker dependent, speaker independent). These categories of systems are used depending on the type of users’ application (Huang et al. 2001; Alotaibi and Shahshavari 1998; Satori et al. 2007, 2009; Abushariah et al. 2012).
In general, spoken alphabets and digits for different languages were targeted by ASR researchers. A speaker-independent spoken English alphabet recognition system was developed by Cole et al. (1990). That system was trained on one token of each letter from 120 speakers. Their performance was 95 % when tested on a new set of 30 speakers, but it was increased to 96 % when tested on a second token of each letter from the original 120 speakers. An artificial neural networks based speech recognition system was designed and tested with automatic Arabic digits recognition by Ajami Alotaibi (2005). The system was an isolated word speech recognizer and it was implemented both as a multi-speaker (i.e., the same set of speakers were used in both the training and testing phases) mode and speaker-independent (i.e., speakers used for training are different from those used for testing) mode. This recognition system achieved 99.5 % correct digit recognition in the multi-speaker mode, and 94.5 % in speaker-independent mode for clean speech. The Arabic speech recognition system developed by Hyassat and Zitar (2006) used CMU Sphinx4 engine based on HMM, which obtained a word recognition rate of 92.21 % for about 35 min of training and 7 min of testing speech data. Their system was trained using different Gaussian mixture models and they obtained best performance with eight Gaussians. Recently, Silva et al. (2012) investigated the speech recognition system digit in Portuguese language using Line Spectral Frequencies (LSF). They demonstrate that LFS provides best results in compared to those obtained by using Mel-Frequency Cepstrum Coefficients (MFCC).
The domain of ASR technologies is an expensive process and requires a considerable amount of resources. That is why only a small part of the world’s languages can benefit of this kind of technologies and related tools (Le and Besacier 2009). The Amazigh language is considered as an African resource poor or less-resourced language (Boukous 1995; Greenberg 1966). To the best of our knowledge, there is a few speech recognition research works on less-resourced language as Amazigh. In this paper we describe our experience to design Amazigh speech recognition system based on HMM.
The paper is organized as follows: Sect. 2 presents a brief description of the Amazigh language. In Sect. 3, we describe the Amazigh speech recognition system and our investigations to adapt the system to Amazigh language. Section 4 investigates the experimental results. Finally, in Sect. 5, we provide our conclusions and future directions.
2 Amazigh language
The Amazigh language, known as Berber or Tamazight, is a branch of Hamito-Semitic (Afro-Asiatic) languages. It is, spoken in a vast geographical area of North Africa. Amazigh covers the northern part of Africa which extends from the Red Sea to the Canary Isles and from the Niger and Mali (Tuareg) in the Sahara to the Mediterranean Sea (Boukous 1995; Greenberg 1966); Amazigh Languages 2013; Galand 1988).
In Morocco, the Amazigh language is spoken by some 28 % of the population, grouped in three main regional varieties, depending on the area and the communities: Tarifit spoken in northern Morocco, Tamazight in Central Morocco and South-East, and Tachelhit spoken in southern Morocco (Ouakrim 1995; Chaker 1984).
Since 2003, Tifinaghe-IRCAM has become the official graphic system for writing Amazigh in Morocco. This system contains: (Outahajala and Zenkouar 2011; Boukous 2009; Fadoua and Siham 2012).
-
27 consonants including: the labials (
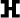
,
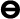
,
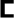
), the dentals (
,
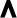
,
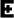
,
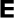
,

,

,
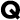
,
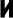
), the alveolars (

,
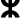
,
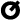
,
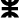
), the palatals (
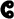
,
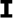
), the velar (
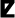
,
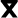
), the labiovelars (
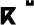
,
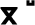
), the uvulars (
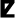
,
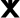
,
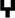
), the pharyngeals (
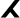
,
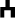
) and the laryngeal (
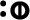
);
-
2 semi-consonants
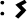
and
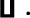
;
-
4 vowels: three full vowels:

,
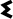
and
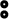
and neutral
vowel (or schwa) which has a rather special status in Amazigh phonology.

































3 Amazigh speech recognition system
This section describes our experience to create and develop an Amazigh voice recognition system using CMU Tools [cmu sphix web]. Figure 1 illustrates the main components that are usually found in a typical ASR system.
3.1 System overview

Block diagram of ASR system
All of our experiments, both training and recognizing were based on CMU Sphinx system, which is HMM-based, speaker-independent, continuous recognition system capable of handling large vocabularies (CMU Sphinx Open Source Speech Recognition Engines 2013; Huang 1989; Lee 1989). Our approach for modeling Amazigh sounds in The CMU Sphinx system consisted of generated and trained acoustic and language models with Amazigh speech data. The dictionary adopted in the experiments was made using 43 Amazigh words and their transcriptions. The allowed syllables in Amazigh language are: V, CV, VC, CVC, C, CC and CCC where V indicates a vowel while C indicates a consonant (Ridouane 2003). Table 1 represents the Amazigh 10 first digits and 34 alphabets along with the way of how to pronounce them, type of syllable, their transcription using English Arabic and Amazigh scripts, and number of syllables in every spoken word.
3.2 Speech database preparation
The database Amazigh_Alphadigits was created in the framework of this work and it contains a corpus of speech and their transcription of 60 Berber Moroccan speakers.Footnote 1 The corpus consists of spoken 10 Amazigh firsts’ digits (0–9) and 33 Amazigh alphabets collected from 60 Moroccan speakers native of Tarifit Berber (30 males and 30 females) aged between 12 and 45 years-old. The audio files were generated by speakers pronouncing the digits in numerical order and alphabets in alphabetical order. Thus, the task of labeling speech signals after segmentation is easy. The sampling rate of the recording is 16 kHz, with 16 bits resolution. Table 2 shows more speech corpus technical details.
During the recording sessions, speakers were asked to utter the 10 digits and 33 alphabets sequentially starting with digits followed by alphabets. Audio recordings for a single speaker were saved into one “.wav” file and sometimes up to four “.wav” files depending on number of sessions the speaker spent to finish recording. It is time consuming to save every single recording once uttered.
Hence, the corpus consists of 10 repetitions of every digit and alphabets produced by each speaker. Depending on this, the corpus consists of 25,800 tokens. During the recording session, the waveform for each utterance was visualized back to ensure that the entire word was included in the recorded signal see Fig. 2. Therefore, there was a need to segment manually these bigger “.wav” files into smaller ones each having a single recording of a single word and manual classification of those “.wav” files into the corresponding directories was done. Wrongly pronounced utterances were ignored and only correct utterances are kept in the database.

Waveform for the ten firsts Amazigh digits recording session (speaker moel) before cutting it manually into separated single utterance.
3.3 Training
Training is the process of learning the Acoustic Model and Language Model to construct the knowledge base used by the system. The knowledge base contains: Acoustic Model, Language Model and Pronunciation Dictionary.
3.3.1 Feature extraction
The purpose of this sub-system (see fig. 1) is to extract speech features which play a crucial role in speech recognition system performance.
As seen in Table 2, the parameters used in our system, were 16 KHz sampling rate with a 16 Kbit sample, 25.6 ms Hamming Window with consecutives frames overlap by 10 ms and Mel-Frequency Cepstral Coefficients (MFCC).
3.3.2 Acoustic model
The acoustic model provides a mapping between the observed features of basic speech units (phonemes) provided by the front-end of the system and the Hidden Markov Models (HMMs) (Huang et al. 1990). In the HMM based technique words in the target vocabulary are modeled as a sequence phonemes, while each phoneme is modeled as a sequence of HMM states. The basic HMM model used in this work is a 5-states HMMs architecture for each Amazigh phoneme, three emitting sates and two non emitting ones as entry and exit which join models of HMM units together in the ASR engine, as shown in Fig. 3. Each emitting state consists of Gaussian mixtures trained on 13 dimensional Coefficients MFCC, their delta and delta delta vectors, which are extracted from the signal.

The 5-states HMM model.
In this study, the acoustic model was performed using speech signal from the Amazigh Alphadigits training database. Table 4 shows a description database subsets used in the training. Every recording in the training corpus are transformed into a sequence of feature vectors. For each recording, a set of features files are computed using the front-end provided by Sphinxtrain (CMU lmtool 2013). In this stage, the engine looks into the phonetic dictionary (see Table 3) which maps every used Amazigh word to a sequence of phonemes. During the training, all 44 Amazigh phonemes are used by means of a phone list (Satori et al. 2009). The Amazigh phonemes are further refined into Context-Dependent (CD) tri-phones and added to the HMM set.
3.3.3 Language model
The n-gram language model used by the ASR system guide the search for correct word sequence by predicating the likelihood of the nth word, using the \(n-1\) preceding words. The common feasible n-gram models are uni-gram, bi-gram and tri-gram. Creating of a language model consists of computing the word uni-gram counts, which are then converted into a task vocabulary, with word frequencies, generating the b-grams and tri-grams from the training text based on this vocabulary. In this work, The CMU-Cambridge statistical language modeling toolkit is used to generate Language model of our system (CMU lmtool 2013).
3.3.4 Pronunciation dictionary
The pronunciation dictionary called also lexicon it contains all Amazigh words we want to train followed by their pronunciation. Table 3, shows the phonetic dictionary list used in the training of our system. The alternate transcriptions marked with parenthesis like (2) stand for second pronunciation. The pronunciation dictionary serves as an intermediary between the Acoustic Model and Language Model.
4 Experimental results
In order to evaluate the performances of the system we had performed three experiments (Exp.1–Exp.3) and obtained results shown in the tables below. The experiments included the training and testing the system using different subsets of the Amazigh_Alphadigits corpus. In the first experiment the system was trained and tested by using only the Amazigh digits, second experiment working on the Amazigh alphabets, third the combination of the Amazigh digits and alphabets together. Table 4 shows the database subsets used in the three experiments their descriptions, Number of words, Number of speakers, Token number.
In all experiments corpus subsets were disjointed and partioned to training 70 % and testing 30 % in order to assure the speaker independent aspect. Also, the system was trained using different Gaussian mixture models. The numbers of Gaussian mixtures per model were 4, 8, and 16. Each of 43 digits and alphabets were considered separately.
In the case of the first experiment, Table 5 shows the accuracy rate of the system in addition to the system total accuracy rate using all digits. Depending on the testing corpus subset, the system had to recognise 1,800 token for the all 10 digits. The system performances are 91.01, 91.50 and 92.89 % was found for using 4, 8 and 16 Gaussian mixture distributions, respectively. It is found that 16 GMMs obtained the best recognition rate of 92.89 %.
By considering the digits recognition analysis, the most frequently misrecognized Amazigh digits are SA and KOZ. Both of these words are monosyllabic and the modelling process of such one syllable words is more difficult than two or more syllable words.
In the second experiment, the systems try to recognize 5,940 samples of all 33 amazigh alphabets. Table 6 shows the accuracy rate of the system. The performances are 87.90, 88.50 and 89.28 % for using 4, 8 and 16 GMMs, respectively. Also, in the case of alphabets the best results was found with 16 GMMs. The most frequently misrecognized Amazigh alphabets are YA and YO.
In the last experiment, all alphabets and digits are combined in order to use a maximum available dataset. In testing, the system was programmed to test total of 7,740 alphabets and digits tokens. The system correct rates in this case were 88.07, 88.88 and 89.07 % for 4, 8 and 16 GMMs, respectively. This confirms our previous observation that 16 GMMs performs better as compared to 4 and 8 GMMs. Also, it is noted that he system performance was better for alphabets but lower for digits (Tables 7, 8).
5 Conclusion
In this paper, we investigated the speaker independent alphadigits ASR system using a database of sounds corresponding to digits and alphabets spoken in Moroccan Amazigh language. This system was implemented by using Carnegie Mellon University Sphinx tools based on HMMs. This work includes creating the speech database amazigh alphadigits, which consist of many subsets covering alldigits and alphabets of Berber language used in the training and testing phase of the system. Recognition results show that our Amazigh ASR system is speaker independent and its performance is comparable to that reported (Hyassat and Zitar 2006) Arabic recognition results.
Notes
The Amazigh Speech Corpus was collected by students during two periods of three month: (Mars to Mai 2011 and 2012), within the framework of the graduate programs of the faculty Polydisciplinary of Nador, Morocco.
References
Abushariah, M. A. A. M., Ainon, R. N., Zainuddin, R., Elshafei, M., & Khalifa, O. O. (2012). Arabic speaker-independent continuous automatic speech recognition based on a phonetically rich and balanced speech corpus. International Arab Journal of Information Technology, 9(1), 84–93.
Ajami Alotaibi, Y. (2005). Investigating spoken Arabic digits in speech recognition setting. Information and Computer Science, 173, 115–139.
Alotaibi, Y. A., & Shahshavari, M. M. (1998). Speech recognition—What it takes for a computer to understand your commands. IEEE Potentials.
Al-Zabibi, M. (1990) An acoustic-phonetic approach in automatic Arabic Speech Recognition. The British Library in Association with UMI.
Amazigh Languages. (2013). Encyclopædia Britannica Online. Retrieved 23 June, 2013, from http://www.britannica.com/EBchecked/topic/61496/Amazigh-languages.
Boukous, A. (1995). Société, langues et cultures au Maroc: Enjeux symboliques (No. 8). Faculté des Lettres et des Sciences Humaines.
Boukous, A. (2009). Phonologie de l’amazighe. Rabat: Institut royal de la culture amazighe.
Chaker, S. (1984). Textes en linguistique berbère: introduction au domaine berbère. Paris: Ed. du C.N.R.S.
CMU lmtool. (2013). Retrieved June 23, 2013, from http://www.speech.cs.cmu.edu/tools/lmtool-new.html.
CMU Sphinx Open Source Speech Recognition Engines. (2013). Retrieved February 10, 2013, from http://www.cmusphinx.sourceforge.net/html/cmusphinx.php.
Cole, R., Fanty, M., Muthusamy, Y., & Gopalakrishnan, M. (1990). Speaker-independent recognition of spoken English letters. In International joint conference on neural networks (IJCNN) (Vol. 2, pp. 45–51).
Fadoua, A. A., & Siham, B. (2012). Natural language processing for Amazigh language: Challenges and future directions. Language Technology for Normalisation of Less-Resourced Languages, 19.
Galand, L. (1988). Le berbère. In J. Perrot (Ed.), Les langues dans le monde ancien et moderne. Part 3: Les langues chamito-sémitiques (pp. 207–242). Paris: CNRS.
Greenberg, J. H. (1966). The languages of Africa. Mouton: The Hague.
Haton, M.-C., Cerisara, C., Fohr, D., & Laprie, Y., & Smaili, K. (2006). Reconnaissance automatique de la parole du signal a son interpretation. Paris: Universciens Dunod.
Huang, X., Acero, A., & Hon, H. (2001). Spoken language processing a guide to theory, algorithm and system design. Upper Saddle River: Prentice Hall.
Huang, X. D. (1989). The SPHINX-II Speech Recognition System: An overview. Computer Speech and Language, 7(2), 137–148.
Huang, X. D., Ariki, Y., & Jack, M. A. (1990). Hidden Markov models for speech recognition. Edinburgh: Edinburgh University Press.
Hyassat, H., & Zitar, R. A. (2006). Arabic speech recognition using SPHINX engine. International Journal of Speech Technology, 9(3–4), 133–150.
Le, V. B., & Besacier, L. (2009). Automatic speech recognition for under-resourced languages: Application to Vietnamese language. IEEE Transactions on Audio, Speech, and Language Processing, 17(8), 1471–1482.
Lee, K. F. (1989). Automatic Speech Recognition the development of the SPHINX system. Boston: Kluwer.
Ouakrim, O. (1995). Fonética y fonología del Bereber. Survey: University of Autònoma de Barcelona.
Outahajala, M., Zenkouar, L., & Rosso, P. (2011). Building an annotated corpus for Amazighe. In Proceedings of 4th international conference on Amazigh and ICT, Rabat, Morocco.
Ridouane, R. (2003). Suites de consonnes en berbère: phonétique et phonologie. Doctoral Dissertation, Université de la Sorbonne nouvelle-Paris III.
Satori, H., Harti, M., & Chenfour, N. (2007). Arabic Speech Recognition system based on CMUSphinx. In Proceedings of ISCIII2007, 3rd international symposium on computational intelligence and intelligent informatics, Agadir, Morocco, pp. 31–35.
Satori, H., Hiyassat, H., Harti, M., & Chenfour, N. (2009). Investigation Arabic Speech Recognition using CMU Sphinx System. The International Arab Journal of Information Technology, 6(2), 186–190.
Silva, D. F., de Souza, V. M., Batista, G. E., & Giusti, R. (2012). Spoken digit recognition in Portuguese using line spectral frequencies. In Advances in artificial intelligence—IBERAMIA 2012 (pp. 241–250). Berlin: Springer.
Acknowledgments
We would like to thank people involved in the development of the Carnegie Mellon University Sphinx system and making it available as open source.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Satori, H., ElHaoussi, F. Investigation Amazigh speech recognition using CMU tools. Int J Speech Technol 17, 235–243 (2014). https://doi.org/10.1007/s10772-014-9223-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-014-9223-y