
Abstract
Barren lands are being transformed into agricultural fields with the growing demand for agriculture-based products. Hence, monitoring these regions for better planning and management is crucial. Surveying with high-resolution RS (remote sensing) satellites like Worldview-2 provides a faster and cheaper solution than conventional surveys. In the study, the arid region comprising cropland and barrenlands are efficiently and autonomously delineated using its spectral and textural properties using state-of-the-art random forest (RF) ensemble classifiers. The textural information window size is optimized and at a GLCM (gray-level co-occurrence matrix) window size of 13, a stable trend in classification accuracy was observed. A further rise in window sizes did not improve the classification accuracy; beyond GLCM 19, a decline in accuracy was observed. Comparing GLCM-13 RF with the no-GLCM RF classifier, the GLCM-based classifiers performed better; thus, the textural information assisted in removing isolated crop-classified outputs that are falsely predicted pixel groups. Still, it also obscured information about barren lands present within croplands. Delineation accuracy was 93.8 % for the no-GLCM RF classifier, whereas, for the GLCM-13 RF classifier, an accuracy of 97.3 % was observed. Thus, overall, a 3.5 % improvement in accuracy was observed while using the GLCM RF classifier with window size 13. The textural information with proper calibration over high-spatial resolution datasets improves crop delineation in the present study. Henceforth, a more accurate cropland identification will provide a better estimate of the actual cropland area in such an arid region, which will assist in formulating a better resource management policy.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
There has been a rise of agricultural activities in arid and semi-arid regions throughout the globe. The primary reason is the growing population’s high demand for agricultural products. The terraforming of deserts and wastelands into arable lands using modern technologies (Marasco et al., 2012; Muniasamy, 2020; Patil et al., 2015; Singh, 1998; Tanwar et al., 2018) has its consequences. The arid lands were never designed to sustain heavy agricultural activities, and human terraforming abilities are in their infancy. So, there have been new challenges in the drylands, such as unprecedented farming activities and environmental changes (El-Beltagy & Madkour, 2012; Sivakumar et al., 2005). An effective monitoring strategy must be implemented to collect data and observe these phenomena for better planning and management. Field surveys for these vast wastelands are one solution, but they are slow, time-consuming, and costly. On the other hand, remote sensing satellites (Hazaymeh & Hassan, 2017; Johansen et al., 2008; Tueller, 1987) and unmanned aerial systems (UAS) (Ahmad et al., 2022; Sankey et al., 2018) provide a cost-efficient and rapid alternative for mapping and surveying such surfaces.
With the availability of the high temporal frequency and spatial resolution of remote sensing data from satellite constellations like the Dove satellite sensor constellation etc., it is still a challenge to extract helpful information from the enormous amount of data available. The information from the huge collection of raster datasets can be autonomously extracted with statistical and machine learning classification algorithms. The classification algorithms efficiently delineate the phenomenon or classes by segregating information from noise with minimal human interaction once properly trained. The use of machine learning algorithms to extract features in agricultural fields is an ongoing research area as algorithms’ ability to delineate features varies from case to case and needs to be calibrated uniquely for the feature and region. A few studies have used remote sensing classification for these arid regions (Chen et al., 2020; Jabal et al., 2022; Krisnayanti et al., 2021; Ram & Kolarkar, 1993; Saha et al., 2018; Sharma et al., 2015). In those studies, the satellite data had moderate resolution for mapping various natural and anthropogenic activities. With modern technology, high-resolution satellites like Worldview-2 (Alabi et al., 2016; Nouri et al., 2013; Rahman et al., 2018; Upadhyay et al., 2012; Zhang et al., 2019) provide data for measuring these parameters with better accuracy. However, at such a high-resolution, small objects that were previously invisible behave as noise and hinder classification accuracy (Adhikari et al., 2021). Hence, more refined automated machine learning (ML)-based classification methods and better algorithms are needed to provide enhanced results.
The proper selection of ML algorithms plays a vital role in the process of feature extraction. The random forest (RF) (Breiman, 2001) is a widely used and well-tested ML algorithm in the field of remote sensing (Belgiu & Drăguţ, 2016; Pal, 2005) feature extraction and classifcaiton. RF algorithm is an ensemble-based ML algorithm consisting of many independent decision tree classifiers trained on subsets of training samples. The combined results of all trees are aggregated to summarize the result. It can take large data sets with higher dimensionality, provides variable importance that informs about the impact of the variable on the output quality, is immune to overfitting, and handles bulk quantities of variables efficiently. Hence, it is used as the primary ML model for the current case study. Another major factor that decides the model’s classification accuracy is the input parameters (or variables) and training samples used for classification. Image textures (Bharati et al., 2004) are the derived visual interpretation features from the pixels themselves. Image textures are spatial patterns or a specific arrangement of pixels that distinguishes them from the background or other features. The textural image information takes the surrounding pixels into consideration, thus adding more context to the features. In the current study, the texture of various classes are visually distinct and using a textural mathematical descriptor can further enhance the classification accuracy. Here one such innovative approach is discussed for an arid cropland delineation from similar barren land using textural information.
Materials and methods
Study area and datasets
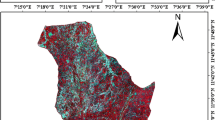
The northwestern Rajasthan in India is a dryland; most of it is covered in sand and xerophytic vegetation. These regions suffer from severe erosion, low rainfall, and severe droughts. In the late 1960s, the green revolution influenced agricultural practices throughout the nation. The geography of northwestern Rajasthan has seen a dynamic shift in its land use and land cover since then and is still undergoing transformation. The combination of vast unhabitable areas, extreme climatic conditions and regional data complexities have resulted in poor monitoring of these regions. The region (as shown in Fig. 1) is situated at Bhaluri village in Bikaner district, Rajasthan, India. It has an arid climate and has water dependency on canals or seasonal rainfall. The region encounters extreme temperature variations and poor soil quality in terms of nutrients and the terrain is highly erosive. The soil taxonomy of the area falls under Torripsamments (aridic Psamment). It consists of unconsolidated sand deposits, often found near shifting sand dunes. It has no distinct soil horizons, has low water-holding capacities, and must consist entirely of loamy sand or coarser texture material. Seasonal farming (Kharif) is performed in small patches in the region.

Study area in Bhaluri village
The image (shown in Fig. 1) is a subset of satellite imagery taken in October 2019 from Worldview-2, a high-resolution remote sensing satellite. Worldview-2 satellite is a commercial Earth Observation satellite by DigitalGlobe (Launch date 8/Oct/2009). The PAN band has ground sample distance (GSD) of 0.46 m while the eight-band multispectral (MUS) has 1.84 m and radiometric resolution is 11 bits/pixel. It is a sun-synchronous satellite with an altitude of 770 km and a revolution period of 100 min. For this study, the Worldview-2 eight-band multispectral dataset was available. The bands are shown in Table 1.
Most of the data analysis work was done using open-source libraries of R in Rstudio (raster) (Hijmans et al., 2021), Rgdal (Bivand et al., 2021), ggplot2 (Wickham, 2016), GGally (Schloerke et al., 2021), caret (Kuhn, 2021), random forest (Liaw & Wiener, 2002), RStoolbox (Leutner et al., 2021), python gdal (GDAL/OGR Contributors, 2021), cv2 (Bradski, 2000), numpy (Harris et al., 2020), matplotlib (Hunter, 2007), seaborn (Waskom, 2021), pandas, and Scikit-image (van der Walt et al., 2014). For map publishing and data visualization, ArcGIS and ArcGIS Pro were used.
Reference data generation
Furthermore, to explore the validity of the classified results, the cropland was manually digitized (as shown in Fig. 2), and was used as a reference for the automated random forest classification approach. It will provide insight into the similarity between manual delineation and automated strategies discussed above. It is to be noted that, in the manual delineation approach, small green patches and tree canopies were not marked as croplands but considered whole as a parcel distinctively visible in the image.

Manually delineated croplands
Methodology
The study area selected is a subset from an arid region which depicts current scenario of arid croplands. The study was designed to analyze the automatic cropland feature extraction for aridlands. Figure 3 explains the methodology followed for the paper. First, the atmospherically and terrain-corrected Worldview-2 data was collected. It was observed for radiometric and geometric corrections, and finally, the desired study area was cropped out. OSAVI (optimized soil-adjusted vegetation index) (Rondeaux et al., 1996) was derived, which is similar to NDVI (normalized difference vegetation index) (Tucker, 1979), but the influence of background soil is reduced effectively (Xue & Su, 2017). Here band B7 and band B5 were taken as the NIR band and red band respectively to calculate OSAVI, as shown in Eq. (1).
where ρ is reflectance in the respective band.

Methodological flowchart
The GLCM (gray level co-occurrence matrix) is one of the image’s textural mathematical descriptors to differentiate various textures and has been widely used in remote sensing applications (Dhumal et al., 2019; Iqbal et al., 2021; Jia et al., 2012; Wickham, 2016). GLCM is created from a grayscale image. It is estimated by taking a pixel and building a relative window size around it. Within the window, the intensity of each pixel is compared with the central pixel and different combinations of gray levels that co-occur window are recorded in a matrix, which gives the measure of variance in gray level intensity concerning the central pixel. Finally, as discussed below, various statistical methods are applied to derive the different GLCM variables. Thus, GLCM might provide helpful information on separating crop patterns (dense) and wild vegetation (sparse) when combined with random forests. In few previous works (Adhikari et al., 2021; Wickham, 2016), GLCM indeed improved the accuracy but the present work investigates the ability of GLCM to delineate croplands in an arid ecosystem. It will highlight their application for the semi-arid cropland automatic delineation, which assists in better and more convenient monitoring of the region.
The OSAVI was used to calculate the GLCM (Hall-Beyer, 2017; Haralick et al., 1973) and the seven textural bands (mean, variance, homogeneity, contrast, dissimilarity, entropy, and second moment) as shown in the following equations (Eqs. (2) to (8)), which were used as an input parameters for classifcation. The following GLCM bands were used in the study:
-
1.
Mean (B10):
$${M}_{ij}= \sum_{i}^{N}\sum_{i}^{N}i*P(i,j)$$(2) -
2.
Variance (B11):
$$VA{R}_{ij}= \sum_{i}^{N}\sum_{i}^{N}{\left(i-\mu \right)}^{2}*P(i,j)$$(3) -
3.
Homogeneity (B12):
$$HO{M}_{ij}= \sum_{i}^{N}\sum_{i}^{N} \frac{1}{1+{\left(i-j\right)}^{2} }*P(i,j)$$(4) -
4.
Contrast (B13):
$$CO{N}_{ij}= \sum_{i}^{N}\sum_{i}^{N}{\left(i-j\right)}^{2}*P(i,j)$$(5) -
5.
Dissimilarity (B14):
$$DI{S}_{ij}= \sum_{i}^{N}\sum_{i}^{N}|i-j|*P(i,j)$$(6) -
6.
Entropy (B15):
$$EN{T}_{ij}= -\sum_{i}^{N}\sum_{i}^{N}P\left(i,j\right)*\mathrm{log}(p(i,j))$$(7) -
7.
Second Moment (B16):
$$S{M}_{ij}= \sum_{i}^{N}\sum_{i}^{N}P{\left(i,j\right)}^{2}$$(8)
where,
\(P(i,j)\) = GLCM value on element (i, j)
N = number of gray levels used
\(\mu = {\sum }_{i,j}^{N}i*P(i,j)\), is the GLCM mean
These GLCM features statistically describe the texture of the objects in the image. The Gray level is quantized to 16 levels and in all directions, but one parameter remains unknown, which is the window size, which determines the range over which gray level co-occurrence is observed. Hence, multiple GLCM datasets are generated by varying bin (or window) sizes. The various sample sizes were tested with respect to the classifcation accuracy, and at about six thousand samples, the accuracy was getting consistent and was taken as the sample size. Then, all 16 bands are normalized and six thousand samples (fifteen hundred each from all four classes) are sampled from the population using stratified random sampling and manually validating the pixels through visual inspection. Defining the number of samples for RF machine learning algorithm has been an issue. We worked on samples from 25 samples per class (the total number of classes is 4) to 2000 samples per class keep all other parameter constant and examined the model’s accuracy. It was observed that model accuracy increased with sample size but as it approached 2000 samples per class the acuuracy curve became almost flat. Hence, 1500 samples per class was taken for current model. From the literature (Corcoran et al., 2013; Izquierdo-Verdiguier & Zurita-Milla, 2020; Rodriguez-Galiano et al., 2012), it was observed that around 1:2 ratio for dividing their training and testing dataset. During the empirical comparison of the accuracies of results using different ratios of training and testing data (for 6000 samples), we found 1:2 worked best for us. Two-thirds (66.67 % approx.) samples are taken for training data and the rest are used for testing data.
The random forest (Breiman, 2001) classifiers are run multiple times by varying GLCM textural bin sizes, which are applied in order to analyze and optimize the model with respect to bin size. The window sizes used were 0, 3, 5, 7, 9, 11, 13, 15, 19, and 23. The classifiers are labeled as no-GLCM (only nine (B1 to B9) bands are used as input parameters), GLCM-3, GLCM-5, GLCM-7, GLCM-9, GLCM-11, GLCM-13, GLCM-15, GLCM-19, and GLCM-23, respectively. Finally, testing data is used to validate the classification. Then, the final crop delineations (from all classifiers) are compared with the manual classification to observe the similarity between manual and automated approaches.
The study area is broadly classified into two major categories (croplands) (a), where active agriculture is being practised and the barrenlands. The barrenlands are further classified into three sub-categories: (b) dense xerophytic vegetation (wildland) are undisturbed passive sandy region with major vegetation patches, the sandy textured with minor vegetation patches (sparse vegetation land) (c), and actively disturbed (bright soil patches) (d) that are most likely formed due to human agricultural activities in past and currently unused as shown in Fig. 4. A few pixels of cropland and wildland share vegetation cover and spectra similarly; bright patches and sparse vegetation wildland pixels are pretty similar in terms of pixel values. Moreover, similar spectral properties lead to higher chances of misclassification. The cropland vegetation and tree canopies are denser in OSAVI band than the rest of the region, but specific patches within cropland boundaries are bright due to soil degradation or poor crop health.

a Cropland, b dense xerophytic vegetation (wildland), c the sandy textured soil with minor vegetation patches, and d bright soil patches
The improper agricultural practices might have resulted in the removal of wild vegetation and making the soil surface prone to erosion, leading to further degradation of barrenlands. Most of the barrenlands of class (d) might be caused due to removal of natural vegetation for croplands and are now abandoned with minimal vegetation growth leading to more land degradation and sparser vegetation. The tree canopies’ spectral signature behave quite similar to croplands which add more complexity as tree canopies are small features that adds ambiguity at the borders. In the following Worldview-2 data, delineating these regions becomes challenging as most bands are highly positively or negatively correlated (as shown in Fig. 5). Hence, the information they offer might overlap a lot. The bands B11 and B16 showed the least (positive) correlation, whereas B7 and B8 have a minimal correlation.

Correlation table between different bands (GLCM bin size is 13)
The correlogram was plotted using a small sample (twenty thousand samples selected with stratified random sampling from four classes) from manually classified datasets for all sixteen bands, but due to its large size (16 bands), a subset (only bands B1, B6, and B9) is presented in Fig. 6. Band B1 class (d) (in purple) seems to have a bimodal histogram, and as the wavelength increases (or the band number), the bimodal gets closer, they approach SWIR wavelengths. The class (d) which represents the bright patches, from the histogram, it was observed there are twin peaks within the bright patches class, one slightly brighter than the other, and as the wavelength increases, the twin peaks converge. This shows the possibility of two subtypes of bright patches or might be noise (or misrepresentation) within labelled samples. The OSAVI (B9) is a vegetation index; it highlights class (a) (in peach), which is rich in chlorophyll and represents healthy plants. It is noticeable that the OSAVI is quite spread for class (a), which indicates the overall varying condition of crops and bimodal histogram and also could be due to the minor presence of tree canopies in class (a) samples.

Correlogram of 4 classes samples (peach (crop/class a), lime green (poor vegetation/class b), cyan (sparse wild vegetation/class c), and purple (bright patches/class d) to bands (B1 (coastal), B6 (red edge), and B9 (OSAVI))
It would appear that for the sample, the delineation between barrenlands (b, c, d) and cropland is possible using B9. Still, it is a sample and does not highlight small spatial classes like tree canopies at the delineation border and various random locations that distort accuracy. Furthermore, for a better study of land degradation, the delineation between different classes of barrenlands is also required, so ML algorithm RF was implemented to provide better analysis. In Fig. 4, the texture of each barrenlands and cropland is different due to vegetation pattern; thus, using GLCM (of OSAVI) might improve the classification accuracy.
The seven normalized GLCM-13 (with a window size of 13) images, generated from the OSAVI band, are shown in Fig. 7 as grayscale images. The GLCM is used for the quantification of heterogenous surface patterns and roughness. Since OSAVI was used for GLCM generation, the soil-adjusted vegetation surfaces were highlighted from the rest of the characters. The seven GLCM textural images, mean, variance, homogeneity, contrast, dissimilarity, entropy, and second moment cover individual aspect of the matrix-based statistical texture features. The mean and variance act as the low pass filter and the elements that vary from the average value are re-adjusted to give an averaging look to the image. The averaging effects tend to eliminate the speckles generated by tree canopies. Homogeneity or inverse difference moment (IDM) value appraises the tightness of the distribution of the components.

GLCM-13 textural images a mean, b variance, c homogeneity, d contrast, e dissimilarity, f entropy, g second moment, and h OSAVI of the study area
Thus, the IDM tends to be significant for images with constant or near-constant patches. The contrast is more prominent for a GLCM with larger off-diagonal values and its weight values are the opposite of IDM weight. The first-order GLCM entropy for homogeneous scenes highlights higher entropy. It will highlight the zones of a sudden change in pixel values which are mostly boundary lines with abrupt change in classes. Thus, a near-random or noisy image will have a larger entropy. In the dataset, the boundaries are visually distinct and focused on homogeneity, contrast, entropy, and dissimilarity, although only entropy inhibits tree canopy information to a certain extent. Second moment (SM) measures the homogeneity by the sum of squares of entries. A near-random or noisy image will have an evenly distributed GLCM with a low SM. In the image, the large uniform regions appear brighter, while complex regions with smaller field patches appear darker. Overall, the mean and variance highlight the significant agricultural croplands with vegetation. In contrast, entropy highlights various boundaries between different classes with minimal interference from the tree canopyies and SM emphasizes image uniformity. The visual inspection of data provides a glimpse of dataset parameters and further statistical analysis needs to be conducted.
Similarly, the rasters were analyzed for each of the seven GLCM parameters and represented in Fig. 8 as the density plot. The density plots, or kernel density estimates (KDE), are the smoothened version of the histogram representing a continuous variation in the values. The samples from the normalized GLCM-13 are extracted and plotted for analysis. The KDE of B11 (mean) and B12 (variance) tends to conveniently segregate out cropland from the rest of the Bands. Since they are random samples from population and do not represent the exact distribution of classes, the appropriate boundary delineation of the croplands might not be attained but samples provide an approximate information on classes behavior. While in rest of the bands, the delineation of each class is visible, but the overlap between classes b, c, and d is dominant, showing similarity in classes in the particular bands.

Density plot of a GLCM bands (B10 to B16) with four class samples (a (crop), b (poor vegetation), c (sparse wild vegetation), and d (bright patches) for GLCM-13 textural bands (B10 to B16)
On further analysis, the mean GLCM KDE at different bin sizes (3, 5, 7, 9, 11, 13, 15, 17, and 19) are represented in Fig. 9 for all four class samples. The KDE from the sample provides a deeper insight into the behavior of classes concerning bin size and the seven GLCM parameters. The mean GLCM KDE for different bin sizes highlights values shifting in four classes. Classes (a) cropland and (d) bright patches are on the distinct opposite side of the graphs but are mostly adjacent in the image. It also highlights the average OSAVI values of each class and classes b, c, and d have similar OSAVI values. Overall, as the bin size increases, the mean GLCM KDE tends to flatten, and most are multimodal.

Density plot of a different band with four class samples (a (crop), b (poor vegetation), c (sparse wild vegetation), and d (bright patches) for GLCM mean textural Bin sizes (3, 5, 7, 9, 11, 13, 15, 17, and 19)
Overall, the band ratios could not fully delineate all classes optimally. In order to improve results, machine learning classifiers (MLC) were implemented. The RF classifiers have high accuracy with limited training samples and were used in the study (Belgiu & Drăguţ, 2016; Feng et al., 2015). The RF uses multiple parallel decision trees with input samples selected through bootstrap aggregation. The output classified image is the combination of results from multiple decision trees fed with slightly different training samples; this results in higher classification accuracy. The multiple samples are obtained by Bootstrap aggregation (bagging function). Suppose input training samples are X = x1, x2, x3…, xn and output are Y = y1, y2, y3 …, yn. The bagging process is repeated N times with changing training sets using the fitting function (fn), as given in Eq. 9. Unseen x′ is fitted by fn, and then, the result is averaged by N. This process reduces the bias and strong cumulative predictor trees has a higher chance of designating accurate classes to input datasets.
Results and discussion
The major results of the RF classification are for all the bin sizes and textural parameters are collectively discussed in the following section. Table 2 represents the confusion matrix of RF classification using the nine bands only (no-GLCM). The overall accuracy and kappa coefficient observed were 96.3 % and 94.8 % respectively, when run with testing datasets. Overall the distinction between crop and other classes was observed with high accuracy. Classes b, c, and d seem to have a more significant overlap. Higher overlap between classes is because of both are barrenlands with difference in vegetation cover and the OSAVI band used for GLCM highlights vegetation. Hence, using OSAVI band for generating GLCM texture bands highlights vegetation-barren textures and improves the classification accuracy with additional textural details. The final organized map is shown in Fig. 10. Most of the misclassifications are due presence of chlorophyll-rich tree canopies in the midst of barrenlands which are on the higher end of OSAVI and closer to class cropland (class a) leading to decrease in classification accuracy.

RF no-GLCM cropland classification of the study area
Table 3 represents the confusion matrix of classified results with the GLCM-13 (input is nine bands and GLCM-13 bin-sized seven textural bands) approach. The training and testing data used were the same in all approaches. Clearly, GLCM-13 has higher accuracy than no-GLCM approach. The overall accuracy of 99.5 % and the kappa coefficient of 99.3 % was observed. GLCM improved the accuracy by adding textural information. The accuracy also depends upon the properties of training and testing samples taken. Even though the overall accuracy is high, it should be noted that the relative accuracy of the no-GLCM compared with GLCM-13 is lower; hence, it has improved the classification model. Figure 11 represents the classified map with the GLCM-13 approach. The presence of lesser speckles is also a bonus using textural information.

RF 13-GLCM classification of study area
The random nature of classifiers comes from the row and column subsampling. Each tree takes random sub-samples, which are split based on a random subset of input data variables. The split-criterion importance is measured across all classification and regression trees (CART) for each input variable as variable importance is calculated for the GLCM-13 and no-GLCM classifier, shown in Table 4. The more significant the variable responsible for classification higher it is ranked. On further comparison of the first few variables’ importance for no-GLCM approach, B2 (blue) seems to be the most significant variable, followed by B9 (OSAVI) and B7 (NIR-1), while bands B6 (red edge) and B4 (yellow) had a minimal role in the splitting of data.
Similarly, the most significant variable for the GLCM-13 classification observed was B12 (variance), followed by B11 (mean) and B7 (NIR-1), while B3 (green), B4 (yellow), and B6 (red edge) had a minimal contribution. Now the variable importance may increase or decrease by altering varying input combinations. As most bands are highly correlated (as seen in Fig. 5), thus bands B3, B4, B5, and B6 seem to have a lower contribution. At the same time, NIR and OSAVI-based bands play a vital role in classification as the texture is primarily due to vegetation patterns. OSAVI, NIR, and most of the GLCM bands highlight the vegetation more from background objects, thus improving the accuracy.
In further analysis, the cropland was delineated, and a morphological operator (erosion) was applied to remove noise. The same filter was used in both cases and the border areas were trimmed and finally compared with manual delineation. Figure 12 represents the binary image output of no-GLCM and GLCM-13 approaches. The noise is reduced but not eliminated using morphological operators. It is then compared with manual delineation (Fig. 2). The resultant output is represented in Table 5 (here, the reference is manual delineation and predicted is the output of GLCM-13 RF).

a Delineation of the crop from no-GLCM classifiers, b delineation of the crop from GLCM-13 classifiers
The overall accuracy of 96.3 % and kappa coefficient of 94.8 % were observed for the no-GLCM RF classifier. For GLCM-13, RF classifier accuracy of 99.5 % and kappa coefficient of 99.3 % were observed. As the GLCM bin size increases, reference crop and predicted barren-land error tend to increase during anticipated crop and reference barren error decreases. Also the minor barren region within the cropland is obscured with increase in GLCM bin size. On the nine bands, the Maximum Likelihood Classifier (MLC) model (no-GLCM MLC) was also applied with similar conditions and even though the classification accuracy observed was almost similar to no-GLCM RF, the delineation accuracy of no-GLCM MLC was 89 %. Hence, RF-based models were preferred over it.
As the GLCM bin size increases, overall accuracy tends to go higher until it stagnates at bin size 19; no further improvement in accuracy is observed, as seen in Fig. 13. Figure 13 also compares bin sizes and both accuracies (RF-GLCM classifier and manual delineation), which show an increment in the accuracy with an increment in bin sizes. The graph at bin size 13 for RF-GLCM tends to stagnate for RF-GLCM and delineation accuracy. While for bin size nine, the delineation accuracy tends to stall to a straight line and then slowly decline after bin size 19. Lower delineation accuracy is observed for no-GLCM because of the presence of tree canopies and green vegetation in barren region classes. In GLCM RF-based approach, the influence of these object noises (tree canopies in barrenlands) is somewhat reduced, but it also nullifies the small patches of barrenlands present between the croplands.

Comparison of accuracy with different bin sizes
The vegetation texture was distinctively visible for different classes at current very high satellite data resolution. The work supported using GLCM-based RF MLC for automated classification of arid regions by showing improved classification accuracy over non-GLCM datasets. It was observed that OSAVI-based GLCM-13 gave the optimal results when delineating crops for the present study. The delineation of croplands using texture seems to blur the minor barren land inside the cropland while also removing little vegetation patches in the barren fields. The tree canopy at the edges of cropland and barren land contributes to the delineation error. As bin sizes increases, the classifiers can compensate. Hence depending upon the application, the GLCM-based classification must be used cautiously.
Conclusions
The current paper explored the utility of advanced high-resolution remote sensing satellite datasets for monitoring and characterizing arid croplands activities from the background. The addition of textural properties overall enhanced the delineation process as the boundary delineation accuracy has improved with 16 parameters by 3.5 %. Overall monitoring the ever-changing agricultural patches to estimate the barren land, cropland, and natural vegetation area for various applications (mapping LU/LC (land use/land cover), biomass estimation, anthropogenic mapping activities, cereals harvest predictions, and modeling for desertification, deforestation, soil erosion, desert greening to name a few is a cumbersome process) is essential for arid zone environment monitoring and assessment. Using the textural information and ML processes for auto delineation between these classes will save lot of time and provide better results, assisting in environmental management decisions. Furthermore, the present work improves monitoring accuracy by emphasizing the potential of high-spatial resolution satellite imageries, artificial intelligence, and textural information. Automating the classification process to properly delineate croplands with high accuracy will result in a much better and faster analysis of the region. It will eventually make environmental and agricultural remote sensing surveys faster and economical for vast dryzone areas. It is a more frequent and cost-efficient survey with better accuracy that will result in better environmental policies and planning leading to a more sustainable developement (Pathak et al., 2013; Ram & Kolarkar, 1993; Shakoor et al., 2011).
The segmentation and object-based image analysis approaches can be further implemented for better boundary delineation challenges in arid zone for high-resolution remote sensing monitoring. Further research over data dimensionality, development of hyperspectral indices, data integration from multiple sensors, and resolving data complexity over higher spatial resolution data might improve the model quality further, leading to better analysis and hence better mapping. The delineation of zones may further be used with time series data to study the vegetation trends. The application of high-resolution RS satellites and RS-UAS (Unmanned Aerial System) with automatic class delineation procedures opens multiple avenues for tracking fauna, anthropogenic activities, and precision mapping of vegetation dynamics might revolutionize the environmental mapping paradigms. The application of artificial intelligence for the classification and delineation of high-resolution remote sensing datasets for environmental monitoring has a huge potential.
Data availability
The data that support the findings of this study are available from DGRE-DRDO. Still, restrictions apply to the availability of these data, which were used under license for current research, and so are not publicly available. Datasets were available for the concerned work only. Data are, however, available from the authors upon reasonable request and with permission of the Director, DGRE-DRDO, and with the approval of the competent authority.
References
Adhikari, A., Kumar, M., Agrawal, S., & Raghavendra, S. (2021). An integrated object and machine learning approach for tree canopy extraction from UAV datasets. Journal of the Indian Society of Remote Sensing, 49(3), 471–478. https://doi.org/10.1007/s12524-020-01240-2
Ahmad, N., Iqbal, J., Shaheen, A., et al. (2022). Spatio-temporal analysis of chickpea crop in arid environment by comparing high-resolution UAV image and LANDSAT imagery. International Journal of Environmental Science and Technology, 19, 6595–6610. https://doi.org/10.1007/s13762-021-03502-z
Alabi, T., Haertel, M., & Chiejile, S. (2016). Investigating the use of high resolution multi-spectral satellite imagery for crop mapping in Nigeria - crop and landuse classification using WorldView-3 high resolution multispectral imagery and LANDSAT8 data. GISTAM 2016 - Proceedings of the 2nd International Conference on Geographical Information Systems Theory, Applications and Management, 2, 109–120. https://doi.org/10.5220/0005767301090120
Belgiu, M., & Drăguţ, L. (2016). Random forest in remote sensing: A review of applications and future directions. ISPRS Journal of Photogrammetry and Remote Sensing, 114, 24–31. https://doi.org/10.1016/j.isprsjprs.2016.01.011
Bharati, M. H., Liu, J. J., & MacGregor, J. F. (2004). Image texture analysis: Methods and comparisons. Chemometrics and Intelligent Laboratory Systems, 72(1), 57–71. https://doi.org/10.1016/j.chemolab.2004.02.005
Bivand, R., Keitt, T., Rowlingson, B., Pebesma, E., Sumner, M., Hijmans, R., Baston, D., Rouault, E., Warmerdam, F., Ooms, J., & Rundel, C. (2021, November 20). rgdal: Bindings for the “Geospatial” Data Abstraction Library. Retrieved from https://cran.r-project.org/package=rgdal
Bradski, G. (2000). The openCV library. Dr. Dobb’s Journal: Software Tools for the Professional Programmer, 25(11), 120–123.
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324
Chen, Y., Zhang, X., Fang, G., Li, Z., Wang, F., Qin, J., & Sun, F. (2020). Potential risks and challenges of climate change in the arid region of northwestern China. Regional Sustainability, 1(1), 20–30. https://doi.org/10.1016/j.regsus.2020.06.003
Corcoran, J. M., Knight, J. F., & Gallant, A. L. (2013). Influence of multi-source and multi-temporal remotely sensed and ancillary data on the accuracy of random forest classification of wetlands in Northern Minnesota. Remote Sensing, 5(7), 3212–3238. https://doi.org/10.3390/RS5073212
Dhumal, R. K., et al. (2019). A spatial and spectral feature based approach for classification of crops using techniques based on GLCM and SVM. In G. Panda, S. Satapathy, B. Biswal, R. Bansal (Eds.), Microelectronics, electromagnetics and telecommunications. Lecture notes in electrical engineering (Vol. 521). Singapore: Springer. https://doi.org/10.1007/978-981-13-1906-8_5
El-Beltagy, A., & Madkour, M. (2012). Impact of climate change on arid lands agriculture. Agriculture and Food Security, 1(1), 1–12. https://doi.org/10.1186/2048-7010-1-3/FIGURES/6
Feng, Q., Liu, J., & Gong, J. (2015). UAV remote sensing for urban vegetation mapping using random forest and texture analysis. Remote Sensing, 7(1), 1074–1094. https://doi.org/10.3390/rs70101074
GDAL/OGR Contributors. (2021, November 20). Geospatial data abstraction software library. Open Source Geospatial Foundation. Retrieved from https://gdal.org
Hall-Beyer, M. (2017). Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. International Journal of Remote Sensing, 38(5), 1312–1338. https://doi.org/10.1080/01431161.2016.1278314
Haralick, R. M., Dinstein, I., & Shanmugam, K. (1973). Textural features for image classification. IEEE Transactions on Systems, Man and Cybernetics, SMC-3(6), 610–621. https://doi.org/10.1109/TSMC.1973.4309314
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del Río, J. F., Wiebe, M., Peterson, P., …, Oliphant, T. E. (2020). Array programming with NumPy. Nature, 585(7825), 357–362. https://doi.org/10.1038/s41586-020-2649-2
Hazaymeh, K., & Hassan, Q. K. (2017). A remote sensing-based agricultural drought indicator and its implementation over a semi-arid region, Jordan. Journal of Arid Land, 3(9), 319–330. https://doi.org/10.1007/S40333-017-0014-6
Hijmans, R. J., van Etten, J., Mattiuzzi, M., Sumner, M., Greenberg, J. A., Lamigueiro, O. P., Bevan, A., Racine, E. B., & Shortridge, A. (2021, November 20). Raster: Geographic data analysis and modeling. https://cran.r-project.org/package=raster
Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), 90–95. https://doi.org/10.1109/MCSE.2007.55
Iqbal, N., Mumtaz, R., Shafi, U., & Zaidi, S. M. H. (2021). Gray level co-occurrence matrix (GLCM) texture based crop classification using low altitude remote sensing platforms. PeerJ Computer Science, 7, 1–26. https://doi.org/10.7717/PEERJ-CS.536/TABLE-21
Izquierdo-Verdiguier, E., & Zurita-Milla, R. (2020). An evaluation of guided regularized random forest for classification and regression tasks in remote sensing. International Journal of Applied Earth Observation and Geoinformation, 88, 102051. https://doi.org/10.1016/J.JAG.2020.102051
Jabal, Z. K., Khayyun, T. S., & Alwan, I. A. (2022). Impact of climate change on crops productivity using MODIS-NDVI time series. Civil Engineering Journal, 8(6), 1136–1156. https://doi.org/10.28991/CEJ-2022-08-06-04
Jia, L., Zhou, Z., & Li, B. (2012). Study of SAR image texture feature extraction based on GLCM in Guizhou karst mountainous region. International Conference on Remote Sensing, Environment and Transportation Engineering. https://doi.org/10.1109/RSETE.2012.6260741
Johansen, K., Roelfsema, C., & Phinn, S. (2008). High spatial resolution remote sensing for environmental monitoring and management preface. Journal of Spatial Science, 53(1), 43–47. https://doi.org/10.1080/14498596.2008.9635134
Krisnayanti, D. S., Bunganaen, W., Frans, J. H., Seran, Y. A., & Legono, D. (2021). Curve number estimation for ungauged watershed in semi-arid region. Civil Engineering Journal, 7(6), 1070–1083. https://doi.org/10.28991/CEJ-2021-03091711
Kuhn, M. (2021, November 21). Classification and regression training. Retrieved from https://cran.r-project.org/package=caret
Leutner, B., Horning, N., & Schwalb-Willmann, J. (2021, November 21). RStoolbox tools for remote sensing data analysis. Retrieved from https://cran.r-project.org/package=RStoolbox
Liaw, A., & Wiener, M. (2002). Classification and regression by random forest. R New, 2(3), 18–22. https://CRAN.R-project.org/doc/Rnews/, https://cran.r-project.org/web/packages/randomForest/citation.html
Marasco, R., Rolli, E., Ettoumi, B., Vigani, G., Mapelli, F., Borin, S., Abou-Hadid, A. F., El-Behairy, U. A., Sorlini, C., Cherif, A., Zocchi, G., & Daffonchio, D. (2012). A drought resistance-promoting microbiome is selected by root system under desert farming. PLOS ONE, 7(10), e48479. https://doi.org/10.1371/JOURNAL.PONE.0048479
Muniasamy, A. (2020). Machine learning for smart farming: a focus on desert agriculture. 2020 International Conference on Computing and Information Technology (ICCI-1441). https://doi.org/10.1109/ICCIT-144147971.2020.9213759
Nouri, H., Beecham, S., Anderson, S., & Nagler, P. (2013). High spatial resolution WorldView-2 imagery for mapping NDVI and its relationship to temporal urban landscape evapotranspiration factors. Remote Sensing, 6(1), 580–602. https://doi.org/10.3390/rs6010580
Pal, M. (2005). Random forest classifier for remote sensing classification. International Journal of Remote Sensing, 26(1), 217–222. https://doi.org/10.1080/01431160412331269698
Pathak, P., Chourasia, A. K., Wani, S. P., & Sudi, R. (2013). Multiple impact of integrated watershed management in low rainfall semi-arid region: A case study from Eastern Rajasthan, India. Journal of Water Resource and Protection, 05(01), 27–36. https://doi.org/10.4236/jwarp.2013.51004
Patil, V. C., Al-Gaadi, K. A., Madugundu, R., Tola, E. H. M., Marey, S., Aldosari, A., Biradar, C. M., & Gowda, P. H. (2015). Assessing agricultural water productivity in desert farming system of Saudi Arabia. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 8(1), 284–297. https://doi.org/10.1109/JSTARS.2014.2320592
Rahman, M., Robson, A., Bristow, M., Rahman, M., Robson, A., & Bristow, M. (2018). Exploring the potential of high resolution WorldView-3 imagery for estimating yyield of mango. RemS, 10(12), 1866. https://doi.org/10.3390/RS10121866
Ram, B., & Kolarkar, A. S. (1993). Remote sensing application in monitoring land-use changes in arid Rajasthan. International Journal of Remote Sensing, 14(17), 3191–3200. https://doi.org/10.1080/01431169308904433
Rodriguez-Galiano, V. F., Ghimire, B., Rogan, J., Chica-Olmo, M., & Rigol-Sanchez, J. P. (2012). An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS Journal of Photogrammetry and Remote Sensing, 67(1), 93–104. https://doi.org/10.1016/J.ISPRSJPRS.2011.11.002
Rondeaux, G., Steven, M., & Baret, F. (1996). Optimization of soil-adjusted vegetation indices. Remote Sensing of Environment, 55(2), 95–107. https://doi.org/10.1016/0034-4257(95)00186-7
Saha, A., Patil, M., Goyal, V. C., & Rathore, D. S. (2018). Assessment and impact of soil moisture index in agricultural drought estimation using remote sensing and GIS techniques. Proceedings, 7(1), 2. https://doi.org/10.3390/ecws-3-05802
Sankey, T. T., McVay, J., Swetnam, T. L., McClaran, M. P., Heilman, P., & Nichols, M. (2018). UAV hyperspectral and lidar data and their fusion for arid and semi-arid land vegetation monitoring. Remote Sensing in Ecology and Conservation, 4(1), 20–33. https://doi.org/10.1002/RSE2.44
Schloerke, B., Cook, D., Larmarange, J., Briatte, F., Marbach, M., Thoen, E., Elberg, A., & Crowley, J. (2021, November 21). GGally: Extension to “ggplot2.” Retrieved from https://cran.r-project.org/package=GGally
Shakoor, U., Saboor, A., Ali, I., & Mohsin, A. Q. (2011). Impact of climate change on agriculture: Empirical evidence from arid region. Pakistan Journal of Agricultural Sciences, 48(4), 327–333.
Sharma, H., Burark, S. S., & Meena, G. L. (2015). Land degradation and sustainable agriculture in Rajasthan. India. Journal of Industrial Pollution Control, 31(1), 7–11.
Singh, H. P. (1998). Sustainable development of the Indian desert: The relevance of the farming systems approach. Journal of Arid Environments, 39(2), 279–284. https://doi.org/10.1006/JARE.1998.0405
Sivakumar, M. V. K., Das, H. P., & Brunini, O. (2005). Impacts of present and future climate variability and change on agriculture and forestry in the arid and semi-arid tropics. In J. Salinger, M. Sivakumar, R. P. Motha (Eds.), Increasing climate variability and change. Dordrecht: Springer. https://doi.org/10.1007/1-4020-4166-7_4
Tanwar, S. P. S., Singh, Akath, Bhati, T. K., Patidar, M., Mathur, B. K., Kumar, Praveen, & Yadav, O. P. (2018). Rainfed integrated farming system for arid zone of India: resilience unmatched. Indian Journal of Agronomy, 63(4), 403–414.
Tucker, C. J. (1979). Red and photographic infrared linear combinations for monitoring vegetation. Remote Sensing of Environment, 8(2), 127–150. https://doi.org/10.1016/0034-4257(79)90013-0
Tueller, P. T. (1987). Remote sensing science applications in arid environments. Remote Sensing of Environment, 23(2), 143–154. https://doi.org/10.1016/0034-4257(87)90034-4
Upadhyay, P., Kumar, A., Roy, P. S., Ghosh, S. K., & Gilbert, I. (2012). Effect on specific crop mapping using WorldView-2 multispectral add-on bands: Soft classification approach. Journal of Applied Remote Sensing, 6(1), 063524–063531. https://doi.org/10.1117/1.JRS.6.063524
van der Walt, S., Schönberger, J. L., Nunez-Iglesias, J., Boulogne, F., Warner, J. D., Yager, N., Gouillart, E., Yu, T., & the scikit-image contributors. (2014). scikit-image: image processing in Python. PeerJ, 2, e453. https://doi.org/10.7717/peerj.453
Waskom, M. L. (2021). seaborn: Statistical data visualization. Journal of Open Source Software, 6(60), 3021. https://doi.org/10.21105/joss.03021
Wickham, H. (2016). ggplot2: Elegant graphics for data analysis. New York: Springer-Verlag. ISBN 978-3-319-24277-4. https://ggplot2.tidyverse.org, https://cran.r-project.org/web/packages/ggplot2/citation.html
Xue, J., & Su, B. (2017). Significant remote sensing vegetation indices: A review of developments and applications. Journal of Sensors, 2017, 1–17. https://doi.org/10.1155/2017/1353691
Zhang, K., Gann, D., Ross, M., Robertson, Q., Sarmiento, J., Santana, S., Rhome, J., & Fritz, C. (2019). Accuracy assessment of ASTER, SRTM, ALOS, and TDX DEMs for Hispaniola and implications for mapping vulnerability to coastal flooding. Remote Sensing of Environment, 225, 290–306. https://doi.org/10.1016/j.rse.2019.02.028
Acknowledgements
We thank the Director, DGRE-DRDO, Chandigarh, and the Project Director of the WISDOM project for providing us with the necessary resources and support to conduct this research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Adhikari, A., Garg, R.D., Pundir, S.K. et al. Delineation of agricultural fields in arid regions from Worldview-2 datasets based on image textural properties. Environ Monit Assess 195, 605 (2023). https://doi.org/10.1007/s10661-023-11115-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10661-023-11115-x