
We report heritabilities for individual differences in female pubertal development at the age of 12. Tanner data on breast and pubic hair development in girls and data on menarche were obtained from a total of 184 pairs of monozygotic and dizygotic twins. Genetic correlations were estimated to determine to what extent the same genes are involved in different aspects of physical development in puberty. A Bayesian estimation approach was taken, using Markov-chain Monte Carlo simulation to estimate model parameters. All three phenotypes were to a significant extent heritable and showed high genetic correlations, suggesting that a common set of genes is involved in the timing of puberty in general. However, gonadarche (menarche and breast development) and adrenarche (pubic hair) are affected by different environmental factors, which does not support the three phenotypes to be regarded as indicators of a unitary physiological factor.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
INTRODUCTION
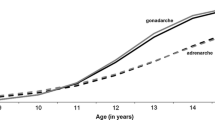
Entering puberty, children undergo large changes in their physiology and physical appearance which will turn them into adults. All these changes can be related to the endocrine system, specifically the hypothalamic-pituitary-gonadal (HPG) and the hypothalamic-pituitary-adrenal (HPA) axes. Gonadarche, or reproductive puberty, results from a reactivation of the gonadotropin-releasing hormone (GnRH) pulse generator, which in girls leads to the stimulation of the ovaries producing estradiol. Breast tissue is the primary target for estradiol and therefore breast development is usually the first sign of puberty. Menarche most often occurs in middle or late puberty.
Puberty actually consists of two independent but overlapping endocrine processes. As opposed to gonadarche, adrenarche is the result of the activation of the HPA axis which leads to increased concentrations of the three adrenal androgens DHEA, DHEAS and androstenedione. These lead to pubic hair, body odour and often acne. Adrenarche is a much more gradual process which may start at an age as early as six years in girls or even earlier and continues well into the third decade of life (Dorn and Rotenstein, 2004).
There is quite some variability in the timing of the overt onset of puberty: it may start at an age even as young as seven years. To some extent this variability is related to pathologies that make some children enter puberty either very early (precocious puberty) or relatively late (delayed puberty). What is called precocious, normal or delayed is based on statistical considerations (Palmert and Boepple, 2001). Usually a deviance of 2–2.5 times the standard deviation from the mean in the population is regarded as abnormal. Precocious puberty may be the result of a lesion in the central nervous system, but often it is the result of the same increase of GnRH secretion that is also the start of puberty in children within the normal age-range; the only difference being its early start. Also with delayed puberty onset, in most cases there seems to be no underlying pathology. Therefore, most of the variation in puberty onset remains largely unexplained, except that it is the direct result of increases in GnRH and androgen secretion that start off a whole array of physiological changes. One motivation for studying individual differences in pubertal timing and their aetiology is that early puberty onset has consistently been shown to be associated with psychosocial problems (Johansson and Ritzen, 2005).
In most countries the median age of puberty onset has been decreasing for a long time but seems to have stabilized during the nineties of last century. There still seems to be some decrease in the US (Herman-Giddens et al., 1997, 2004), although this is disputed by some (Coleman and Coleman, 2002; Styne, 2004). Precocity has been associated with migrating children: children adopted from other countries mature faster when compared with both foster country and country of origin (Parent et al., 2003). In addition, there are reports that menarche is earlier in girls in homes with absent fathers (e.g., Maestripieri et al., 2004). It is uncertain however to what extent these environmental correlations are indeed attributable to non-genetic causes. For instance, the absent-father effect could be partially explained by the transmission of a particular allele of the androgen receptor gene inherited from the father (Comings, et al., 2002, but see Jorm et al., 2004). Other (environmental) factors are nutrition-related, particularly to food substances such as phyto-oestrogens and lignans (Muinck Keizer-Schrama and Mul, 2001) and malnutrition in early and prenatal life (Da Silva Faria et al., 2004; Veening et al., 2004). There also seems to be a relation between the amount of body fat and delayed menarche (Frisch, 1996). But again, genetic factors responsible for this association cannot be ruled out.
Be that as it may, these factors together explain only a small portion of the total variability. There seem to be significant yet unexplained genetic influences on pubertal timing, with heritability estimates up to 50 to 80% (Fischbein, 1977; Sklad, 1977; Meyer et al., 1991; Loesch et al., 1995; Palmert and Hirschhorn, 2003; Eaves et al., 2004) depending on phenotype definition and mode of assessment. Molecular studies have found more direct evidence for the influence of genes. The Oct-2 transcription factor, a homeodomain gene of the POU family, and the thyroid transcription factor-1 (TTF-1) have been associated with the onset of puberty in female mammals (Ojeda et al., 1999, 2000).
It is unknown to what extent the genes that explain individual differences in age at menarche are the same genes as those involved in other processes related to pubertal development, such as breast development and pubic hair growth. There have been two recent reports on the heritability of different indicators of puberty (Mustanski et al., 2004; Eaves et al., 2004) but both are based on common factor models that explicitly postulate one latent trait underlying several indicator variables and do not allow for extra covariance between a subset of indicators. Thus, the fact that there are two distinguishable endocrinological processes is not taken into account in these models. This study therefore aims at estimating the extent to which the same genes and the same environmental factors are involved in individual differences in menarche, the timing of breast development and pubic hair in females. Low genetic/environmental correlations would indicate that timing of two pubertal phenotypes is influenced by different genes/environmental factors. High correlations would indicate that, even though the underlying processes may be different, their timing is influenced by the same genetic/environmental factors. Since gonadarche and adrenarche are determined by independent physiological processes, it is hypothesised that both genetic and environmental correlations between menarche and breast development are high, but their respective correlations with pubic hair development are low.
A Bayesian approach (Gelman et al., 2004) was taken to estimate heritabilities and genetic correlations, using Markov-chain Monte Carlo (MCMC) simulation (Gilks et al., 1996) for numerical implementation. This approach is flexible in that it handles practically any kind of model. Instead of point estimates and confidence intervals, it yields posterior marginal distributions for the parameters of interest. If desired, it can also incorporate information from earlier, similar studies through the specification of so-called prior distributions.
METHOD
Subjects
Female twins came from two cohorts. The first cohort was 12 years old in 1998, when data on pubertal status were obtained from female twins who participated in a longitudinal study on hormone levels, cognition and behaviour problems in children (Bartels et al., 2002). All participants were registered with the Netherlands Twin Registry (NTR; Boomsma et al., 2002). There were 102 twin pairs with at least one data point on a female twin (mean age: 12.2 years, SD=0.2, range=11.7–12.8). There were 35 monozygotic pairs with complete data on both twins, and two monozygotic pairs with complete data on one twin but incomplete data on the other twin. There were 33 same-sex dizygotic pairs with complete data on both twins, one pair with data complete on only one twin and incomplete data on the other, and one pair with incomplete data on both twins. From the female twins with a male co-twin, 28 females had complete data, and only two had incomplete data. Zygosity status of same-sex twins was based on either DNA (15%) or blood polymorphisms (61%) or, if no DNA or blood was available, questionnaire data (24%).
The second cohort consists of female twins who were 12 years old in 2003 and participated in a similar study. All twins were registered with the NTR and were selected on the basis of age, zygosity and geography: children were selected at the age of five and only if they lived within a 100 km radius from Amsterdam (Groot et al., 2004). The parents of the twins were invited by mail to participate in a study on neuropsychological development and attention. None of the children suffered from severe physical or mental handicaps. Parents and children signed an informed consent before participation. There were 82 twin pairs with at least one data point on a female twin (mean age: 12.4 years, SD=0.1, range=12.1–12.9). There were 39 pairs of monozygotic female twins with complete data on both twins, one pair with complete data on only one twin, and three pairs with incomplete data on both twins. There were 11 pairs of same-sex dizygotic female twins with complete data on both twins, two pairs with complete data on only one twin, and one pair with incomplete data on both twins. There were 22 female twins with a male co-twin on whom we had complete data; on three others we had incomplete data. Zygosity was determined from DNA polymorphisms.
Materials
In the first cohort, female twins filled out an extended Tanner questionnaire (based on Marshall and Tanner, 1969) asking about their menarche (no/yes), breast development (5 ordered categories), and pubic hair development (5 categories). The categories consisted of drawn figures showing all stages of development. In the second cohort, female twins filled out an extended Tanner questionnaire asking about their menarche (no/yes), breast development (5 categories), and pubic hair development (6 categories). The categories were indicated by photographs showing all stages of development. Tanner self-reports correlate 0.82 with GP (physician) ratings (Coleman and Coleman, 2002).
Statistical Analysis
To obtain estimates for heritabilities and genetic correlations based on categorical data, some assumptions need to be made. It was assumed that for each variable, the frequencies in the different categories reflected a continuous underlying normally distributed trait with a number of thresholds (Crittenden, 1961; Falconer, 1965; Lynch and Walsh, 1998). When there were very few observations in one category, adjacent categories were collapsed (for the first cohort we had three categories for breast development and three for pubic hair; for the second cohort, two and four respectively). Polychoric correlations were estimated for the three phenotypes, separately for monozygotic and dizygotic twins and for both cohorts. Modelling these correlations on the latent continuous traits in monozygotic and dizygotic twins would then allow estimation of heritabilities (based on within-trait, cross-twin correlations) and genetic correlations (based on cross-trait, cross-twin correlations).
It was assumed that, even though slightly different measurement instruments were used (i.e., photographs and drawings), heritabilities and genetic correlations were similar for the two cohorts. The model was implemented in the freely obtainable WinBUGS~1.4 package that allows MCMC simulation using the Gibbs sampler (for a review on WinBUGS~1.4 and an example, see Cowles, 2004). The fully specified model is described below.
MCMC
MCMC is often used to fit Bayesian statistical models. For a proper understanding of the MCMC method, it is therefore necessary to know the basics of Bayesian inference. In Bayesian statistics, inference is based on the posterior marginal density of a parameter value, P(θ|Y), where θ represents a model parameter and Y the observed data. By Bayes’ theorem, the density P(θ|Y) is proportional to the product of the likelihood of the data given the model parameter P(Y|θ) and the marginal density for θ, P(θ). In formula form
The marginal distribution of θ is termed the prior distribution (prior in the sense of before the data have been taken into account), and must be specified by the user. The model provides us with the likelihood function P(Y|θ), as usual, and hence the posterior distribution of θ is determined (posterior in the sense of after the data have been taken into account). The posterior distribution is a description of the probabilities of possible values for θ given the observed data and forms the basis for statistical inference. We may for example take the mean or the median of this distribution as our point estimate for θ. The interval between the 2.5th and the 97.5th percentile of the posterior distribution is known as the central 95% credibility region. Under some conditions, and given sufficient data, it can be interpreted as a 95% confidence interval.
Sometimes it is easy to compute the posterior distribution analytically, but very often this is not possible. One can then use computer simulation to draw a sample of θ-values from the posterior distribution. The mean or median of the posterior distribution can then be approximated by the mean or median of the sampled θ-values, and approximate credibility intervals can be determined in a similar way. In practice, exact simulation from the posterior distribution may not be feasible either and one replaces this with MCMC-methods. These methods involve drawing from a Markov chain with the posterior distribution as the stationary distribution. Although the initial draws cannot be considered to be sampled from the posterior distribution, the chain eventually approximates stationarity sufficiently closely to consider, after discarding the initial draws (‘burn-in’), the remaining draws as sampled from the posterior distribution. These are then used to calculate means or percentiles. For an introduction to Bayesian data analysis and MCMC, see Gelman et al. (2004).
One of the advantages of Bayesian methods is that it is possible to incorporate prior knowledge into the modelling. This is particularly useful when the amount of observed data is limited. For example, suppose we have data on menarche in 20 MZ twins and 20 DZ twins. We then have very little statistical power to estimate heritability. But menarche has been found to be heritable before and earlier reported estimates hover around 0.60. We can use this a priori information by using an informative prior distribution for our heritability parameter, and use a distribution with mean 0.6 and a standard deviation of 0.1, indicating the degree of our uncertainty. The result will be that our estimate from the data will be biased towards 0.60 and will show smaller posterior credibility intervals. Of course, the danger is that we might capitalize too much on earlier reports and that our resulting posterior credibility interval is too optimistic. This is a problem when the assessment method of menarche used in the earlier studies differed in an important way from the assessment method used in the present study. Often then, a non-informative or ‘vague’ prior is specified so that the posterior distribution depends mostly on the observed data. For not too small data sets, the inference will then typically be similar to inference based on maximum likelihood. For the modelling reported here, only vague priors were specified so that inference is not based on prior knowledge.
Modelling Genetic and Environmental Contributions to the (co-)variance of the Phenotypes
In order to estimate models using WinBUGS, it is necessary to specify, apart from the prior distributions of the parameter values, the conditional distribution of the data given all current parameter values. It was assumed that the observed proportions in the different answer categories were dependent on scores on normally distributed latent continuous traits with a number of thresholds (Crittenden, 1961; Falconer, 1965). These latent scores were decomposed into additive genetic effects, shared environmental effects and nonshared environmental effects. In order to speed up the MCMC estimation, the nonshared environmental effects were further decomposed into two parts. See the appendix for technical details.
RESULTS
Descriptives
In the first cohort, 86% of the girls had not yet had their first menses. In 22% of the girls breast development had not yet started (they indicated the first of four ordered categories) and in 27% pubic hair was still absent (first of five categories). In the second cohort the respective percentages were 74%, 5% (first of five categories) and 10% (first of 6 categories). Highest degree of breast development was indicated by 12% in the first cohort and 4% in the second cohort. Highest degree of pubic hair development was indicated by 2% in the first cohort and 4% in the second cohort.
Polychoric Correlations
Polychoric correlations within and between individuals and within and between traits were first estimated separately in WinBUGS and are reported in Table I. Order of twins within pairs was of no importance here and therefore the relevant correlations were equated by design. The polychoric correlations in Table I do not suggest any non-additive genetic factors underlying phenotypic variability since the DZ twin correlations are about half the MZ twin correlations or more.
Heritability and Genetic Correlations
Table II presents the Bayesian estimates for the variance components. The point estimates are the medians of the posterior distributions and also the 2.5th and 97.5th percentile of the posterior distributions are given. Note that the interpretation of the intervals is different from the more commonly reported confidence intervals in the frequentist tradition (although Bayesian credibility intervals can be shown to approximate confidence intervals for large numbers of data). For example, given these data, the probability that the heritability of menarche lies between 0.22 and 0.40 is 95%. It is therefore highly unlikely that menarche is not heritable. All three phenotypes are in fact heritable.
Table III presents the estimates for the genetic and non-genetic correlations. The point estimates are the medians of the posterior distributions and are presented together with the 2.5th and 97.5th percentiles. For example, given these data, the probability that the genetic correlation between breast development and pubic hair development lies between 0.63 and 0.90 is 95%. It is therefore highly unlikely that there is no genetic relationship between these two phenotypes. In fact, all phenotypes are genetically related. In addition, breast development is clearly related to menarche through non-genetic factors that are shared by twins.
DISCUSSION
Variation in pubertal development is known to be heritable in girls and also shows substantial common environmental influences. The stages of development were assessed in twin girls of age 12 and the variability was significantly heritable. Furthermore, our three indicators of development, breasts, pubic hair, and menarche, were genetically correlated, meaning that to a large extent, the genes that explain variability in one phenotype also explain the variability in the other puberty-related phenotypes. To some extent, particularly for menarche, there seem to be important environmental factors, shared by twin siblings, that influence pubertal timing. The estimates for the environmental correlations were lower than the genetic correlations, half of them not even significantly different from zero, so that it seems that different aspects of the environment affect different indicators of puberty. The correlation between breast development and menarche is a notable exception, as these are closely related through environmental factors shared by twins.
These results have important implications for the modelling of pubertal development: when different environmental factors affect different indicators of puberty, pubertal developmental stage cannot be regarded as a unitary concept and one can therefore not assume that different phenotypes are indicators of the same underlying construct. The common pathway models of Eaves et al. (2004) and Mustanski et al. (2004) should therefore be extended to allow for extra correlation between indicators of gonadarche through the shared environment, or, preferably, to allow for two latent variables for puberty: gonadarche and adrenarche with their respective indicators.
The findings are in line with the fact that puberty entails two independent but overlapping processes: gonadarche, which affects breast development and menarche, and adrenarche, which affects pubic hair development. Although the genetic correlations among all three phenotypes were high (>0.70), the only important environmental correlation was that between breast development and menarche (0.72). These findings suggest that both the timing of adrenarche and the timing of gonadarche are affected largely by the same set of genes, but there are environmental factors shared by twins that have unique effects on the timing of adrenarche and gonadarche. This non-genetic familial clustering suggests that pubertal timing might be affected by specific nutrients (Muinck Keizer-Schrama and Mul, 2001), malnutrition in early life (Da Silva Faria et al., 2004; Veening et al., 2004), and/or other factors that are related to socio-economic status (Parent et al., 2003).
An obvious limitation of this study is its sole focus on female puberty. Mustanski et al. (2004) included twin boys in their study and estimated the extent to which the factors that are responsible for male puberty are the same as those responsible for female puberty. However, this is tricky since the indicator variables necessarily differ across the sexes, violating the assumption of measurement invariance. In addition, one is necessarily forced to either model the shared environmental factors to be partly different or the genetic factors: there is too little information using the classical twin design to estimate both. The relevant information comes from the observed correlation between twins of opposite sex: when a twin correlation is smaller for opposite sex twins than for dizygotic same sex twins, this is an indication that the genetic factors and/or the shared environmental factors differ across sexes. With only correlations in twins raised in the same family to go on, one must choose between estimation of a genetic correlation and estimation a shared environmental correlation. A possible solution for this non-identifiability would be to use an extended twin design where genetically unrelated opposite sex siblings that have grown up in the same home (e.g., foster children) or genetically related opposite sex siblings grown up elsewhere are included in the study.
In this study, an MCMC approach was used to estimate heritabilities and genetic and environmental correlations. Much has already been said about the advantages of this approach in the context of twin studies (Eaves and Erkanli, 2003; Eaves et al., 2004). Nevertheless, the reader should realise that the use of this method requires more than some experience with statistical modelling. It requires basic knowledge of Bayesian statistics in general and knowledge concerning problems that are specific to MCMC estimation. Convergence is affected by the choice of initial values and the number of burn-in samples. Other important decisions in MCMC estimation are (1) how many samples are needed from the posterior distributions in order to be confident about an estimate, because the samples are correlated, (2) how many independent chains one should run using different starting points, (3) how best to parametrise the model and (4) which priors to use. Using appropriate priors is essential to avoid simulation problems and is particularly important when estimating variance components and correlations, since variances are bounded at zero. Moreover, assessing model fit using MCMC and model comparison are issues that still require a lot of theoretical work. For more on these and other issues, see Cowles (2004) and Gilks et al. (1996).
REFERENCES
Bartels M., Rietveld M. J. H., Van Baal G. C. M., Boomsma D. I. (2002). Genetic and environmental influences on the development of intelligence. Behav. Genet. 32:237–249
Boomsma D. I., Vink J. M., Beijsterveldt C. E. M., De Geus E. J. C., Beem A. L., Mulder E. J. C. M., Riese H., et al. (2002). Netherlands Twin Register: A focus on longitudinal research. Twin Res. 5:401–406
Coleman L., Coleman J. (2002). The measurement of puberty: A review. J. Adolescence 25:535–550
Comings D. E., Muhleman D., Johnson J. P., MacMurray J. P. (2002). Parent–daughter transmission of the androgen receptor gene as an explanation of the effect of father absence on age of menarche. Child Dev. 73:1046–1051
Cowles M. K. (2004). Review of WinBUGS 1.4. Am. Stat. 58:330–336
Crittenden L. B. (1961). An interpretation of familial aggregation based on multiple genetic and environmental factors. Ann. New York Acad. Sci. 91:769–780
Da Silva Faria T., Fonte Ramos C., Sampaio F. J. B. (2004). Puberty onset in the female offspring of rats submitted to protein or energy restricted diet during lactation. J. Nutr. Biochem. 15:123–127
Dorn L. D., Rotenstein D. (2004). Early puberty in girls: The case of premature adrenarche. Wom. Health Iss. 14:177–183
Eaves L. J., Erkanli A. (2003). Markov Chain Monte Carlo approaches to analysis of genetic and environmental components of human developmental change and G X E interaction. Behav. Genet. 33:279–299
Eaves L., Silberg J., Foley D., Bulik C., Maes H., Erkanli A., Angold A., Costello E. J., Worthman C. (2004). Genetic and environmental influences on the relative timing of pubertal change. Twin Res. 7:471–481
Falconer D.S. (1965). The inheritance of liability to certain diseases, estimated from the incidence among relatives. Ann. Hum. Genet. 29:51–71
Fischbein S. (1977). Intra-pair similarity in physical growth of monozygotic and of dizygotic twins during puberty. Ann. Hum. Biol. 4:417–430
Frisch R. E. (1996). The right weight: Body fat, menarche, and fertility. Nutrition 12:452–453
Gelman A., Carlin J. B., Stern H. S., Rubin D. B. (2004). Bayesian Data Analysis. (2nd ed.). Boca Raton FL, Chapman & Hall/ CRC
Gilks W. R., Richardson S., Spiegelhalter D. J. (1996). Markov Chain Monte Carlo Methods in Practice. Boca Raton FL, CRC Press
Groot A. S., de Sonneville L. M. J., Stins J. F., Boomsma D. I. (2004). Familial influences on sustained attention and inhibition in preschoolers. J. Child Psychol. Psychiatry 45:306–314
Herman-Giddens M. E., Kaplowitz P. B., Wasserman R. (2004). Navigating the recent articles on girls’ puberty in Pediatrics: What do we know and where do we go from here? Pediatrics 113:911–917
Herman-Giddens M. E., Slora E. J., Wasserman R. C., Bourdony C. J., Bhapkar M. V., Koch G. G., Hasemeier C.M. (1997). Secondary sexual characteristics and menses in young girls seen in office practice: A study from the pediatric research in office settings network. Pediatrics 99:505–512
Johansson T., Ritzen E. M. (2005). Very long-term follow-up of girls with early and late menarche. Endocr. Dev. 8:126–136
Jorm A. F., Christensen H., Rodgers B., Jacomb P. A., Easteal S. (2004). Association of adverse childhood experiences, age of menarche, and adult reproductive behavior: Does the androgen receptor gene play a role? Am. J. Med. Genet. B 125:105–111
Loesch D. Z., Hopper J. L., Rogucka E., Huggins R. M. (1995). Timing and genetic rapport between growth in skeletal maturity and height around puberty: similarities and differences between girls and boys. Am. J. of Hum. Genet. 56:753–759
Lynch M., Walsh B. (1998). Genetics and Analysis of Quantitative Traits. Sunderland MA, Sinauer
Marshall W. A., Tanner J. M. (1969). Variations in pattern of pubertal changes in girls. Arch. Dis. Child. 44:291–303
Maestripieri D., Roney J. R., DeBias N., Durante K. M., Spaepen G. M. (2004). Father absence, menarche and interest in infants among adolescent girls. Dev. Sci. 7:560–566
Meyer J. M., Eaves L. J., Heath A. C., Martin N. G. (1991). Estimating genetic influences on the age-at-menarche: a survival analysis approach. Am. J. Med. Genet. 39:148–154
Muinck Keizer-Schrama S. M. P. F., Mul D. (2001). Trends in pubertal development in Europe. Hum. Reprod. Update 7:287–291
Mustanski B. S., Viken R. J., Kaprio J., Pulkkinen L., Rose R. J. (2004). Genetic and environmental influences on pubertal development: Longitudinal data from Finnish twins at ages 11 and 14. Dev. Psychol. 40:1188–1198
Ojeda S. R., Hill J., Hill D. F., Costa M. E., Tapia V., Cornea A., Ma Y. J. (1999). The Oct-2 POU domain gene in the neuroendocrine brain: A transcriptional regulator of mammalian puberty. Endocrinology 140:3774–3789
Ojeda S. R., Ma Y. J., Lee B. J., Prevot V. (2000). Glia-to-neuron signaling and the neuroendocrine control of female puberty. Recent Prog. Horm. Res. 55:197–223; discussion 223–4
Palmert M. R., Hirschhorn J. N. (2003). Genetic approaches to stature, pubertal timing, and other complex traits. Mol. Genet. Metab. 80:1–10
Palmert M. R., Boepple P. A. (2001). Variation in the timing of puberty: Clinical spectrum and genetic investigation. J. Clin. Endocr. Metab. 86:2364–2368
Parent A. S., Teilmann G., Juul A., Skakkebaek N. E., Toppari J., Bourguignon J. P. (2003). The timing of normal puberty and the age limits of sexual precocity: Variations around the world, secular trends, and changes after migration. Endocr. Rev. 24:668–693
Sklad M. (1977). The rate of growth and maturing of twins. Acta Genet. Med. Gemel. 26:221–237
Styne D. M. (2004). Puberty, obesity and ethnicity. Trends Endocrin. Met. 15:472–478
Veening M. A., van Weissenbruch M. M., Roord J. J., Delemarre-Van Waal H. A. (2004). Pubertal development in children born small for gestational age. J. Pediatr. Endocr. Met. 17:1497–1505
ACKNOWLEDGMENTS
This study was supported by grants from the Netherlands Organisation for Scientific Research NWO, numbers 575-25-012, 904-57-94, and 051-02-060,668-772. AS was supported by the Evangelischer Entwicklungsdienst, Bonn, Germany.
Author information
Authors and Affiliations
Corresponding author
APPENDIX
APPENDIX
Estimating Heritabilities and Genetic and Environmental Correlations using MCMC
The phenotypes were measured using ordinal scales. In order to estimate heritabilities and genetic and environmental correlations, we assumed three underlying latent normally distributed variables using the so-called threshold model (Crittenden, 1961; Falconer, 1965; Lynch and Walsh, 1998). Latent traits were decomposed into additive genetic (A), shared environmental (C) and nonshared environmental (F) parts. In order to implement the model in WinBUGS, it is most efficient to parametrise the model in such a way that the nonshared environmental vector F is further decomposed into vectors U and E, where U incorporates nonshared environmental correlations between the traits and E is a vector with uncorrelated coordinates:
Here, the first index i denotes the phenotype and the second j the individual in a twin pair. More precisely, we modelled the nonshared environmental vector as F=U + E with U and E independent and marginally distributed as follows:
The parameters in this specification are not individually identifiable from the data, but can be used to specify a prior distribution on the model used. The Bayesian approach yields a posterior distribution for all parameters, but we only report the part of the posterior distribution that concerns identifiable parameters, as the remaining part of the posterior is a result of prior specification only, without intervention of the data. For instance, the unshared environmental coefficient of correlation between the latent variables for the first and second phenotypes is given by
Thus, although the parameters χ,ρ7,δ,γ, and κ are individually not identifiable given the data, a function of them (ρ) is. Using the MCMC method it is straightforward to calculate the posterior distribution for this function from the sampled values of the full parameter set.
The vectors for the additive genetic effects (A) and shared environmental effects (C) were modelled in the usual way:
for MZ twin pairs and
for DZ twin pairs, and
Here, inference is more straightforward. For instance, ρ1 stands for the correlation between the additive genetic effects on the first and second latent trait and ρ4 stands for the correlation between the shared environmental effects on the first and second latent trait.
Implementation of the model in WinBUGS requires the specification of prior distributions for the parameters as well as the conditional distribution of the observed data given the model parameters. Given the genetic and non-genetic random effects A iik C ik and U ijk for both individual twins from a twin pair k, the probability of a particular phenotypic state in a twin is not dependent on the respective phenotype in her co-twin nor on the other phenotypes. The conditional probability of a response in the first category for a phenotype is then
with Y ijk denoting the the i-th phenotype in the j-th twin from the k-th twin pair, Φ(.) denoting the cumulative standard normal distribution function and t i1 denoting the first threshold for the i-th phenotype. For the conditional probability of observing a response in the second category we have
All other conditional probabilities can be written out analogously. These conditional probabilities can be used in a Gibbs sampling algorithm as implemented in WinBUGS in order to estimate the thresholds and other parameters of interest. Its implementation in WinBUGS consists of a rather large script. Contact SvdB or AS for a copy.
Rights and permissions
About this article
Cite this article
van den Berg, S.M., Setiawan, A., Bartels, M. et al. Individual Differences in Puberty Onset in Girls: Bayesian Estimation of Heritabilities and Genetic Correlations. Behav Genet 36, 261–270 (2006). https://doi.org/10.1007/s10519-005-9022-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-005-9022-y