
Abstract
In classification problems, the data samples belonging to different classes have different number of samples. Sometimes, the imbalance in the number of samples of each class is very high and the interest is to classify the samples belonging to the minority class. Support vector machine (SVM) is one of the widely used techniques for classification problems which have been applied for solving this problem by using fuzzy based approach. In this paper, motivated by the work of Fan et al. (Knowledge-Based Systems 115: 87–99 2017), we have proposed two efficient variants of entropy based fuzzy SVM (EFSVM). By considering the fuzzy membership value for each sample, we have proposed an entropy based fuzzy least squares support vector machine (EFLSSVM-CIL) and entropy based fuzzy least squares twin support vector machine (EFLSTWSVM-CIL) for class imbalanced datasets where fuzzy membership values are assigned based on entropy values of samples. It solves a system of linear equations as compared to the quadratic programming problem (QPP) as in EFSVM. The least square versions of the entropy based SVM are faster than EFSVM and give higher generalization performance which shows its applicability and efficiency. Experiments are performed on various real world class imbalanced datasets and compared the results of proposed methods with new fuzzy twin support vector machine for pattern classification (NFTWSVM), entropy based fuzzy support vector machine (EFSVM), fuzzy twin support vector machine (FTWSVM) and twin support vector machine (TWSVM) which clearly illustrate the superiority of the proposed EFLSTWSVM-CIL.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Support vector machine (SVM) [2, 36, 39] has been extensively used in the past few decades for solving classification and regression problems in many applications [31, 33, 44, 45]. It gives a global solution to the optimization problem by solving a convex optimization problem using quadratic programming and provides a relatively robust and sparse solution. Other techniques like artificial neural networks (ANNs) are based on empirical risk minimization (ERM) principle which suffer from the problem of local minima. SVM has been used in various applications such as face recognition [11, 27, 29], pattern recognition [10, 21], speaker verification [23], intrusion detection [20], sentiment classification [38] and various other classification problems [6, 7, 19].
SVM has its roots in statistical learning theory and it is based on the principle of structural risk minimization (SRM). It finds the optimal hyperplane separating the different classes using a set of data points known as support vectors. Due to this it has a very low Vapnik-Chervonenkis (VC) dimension as compared to other techniques like ANN. One of the drawbacks of SVM is that its training cost is very high i.e. O(m3) where m is the total number of training samples [14]. Recently, an efficient approach twin support vector machine (TWSVM) is proposed by Jayadeva and Chandra [14] to decrease the training cost of SVM. In TWSVM two quadratic programming problems (QPPs) of smaller size are solved to find the classifying hyperplane rather than solving a single large problem as in standard SVM. A least squares variant of SVM has been proposed by Suykens and Vandewalle [15] to decrease the training cost, called as least squares support vector machine (LSSVM). In LSSVM one solves a set of system of linear equation instead of a QPP of large size. To further reduce the training cost, a twin version of LSSVM is proposed by Kumar and Gopal [21], termed as least square twin support vector machine (LS-TWSVM) where it solves a pair of set of linear equations.
In the training of SVM, same importance is given to all the training points in constructing the classifier. Due to this, the hyperplane gets biased towards the majority class samples. Since, the class of interest is the minority class so more weight needs to be given to the minority class samples to generate the unbiased classifier. In applications like fault detection, disease detection and many other related applications, the task is to correctly identifying the faults and disease from the data. Usually the data contains a lot less number of data samples with the abnormality. For assigning the weights many fuzzy based membership techniques have been proposed in the recent years. Lin and Wang [3] have proposed support vector machine based on fuzzy membership values (FSVM). Similar to SVM, FSVM also suffers in accuracy in case of class imbalanced data. To handle the problem of class imbalance, Batuwita and Palade [32] have presented a new model as FSVMs for class imbalance learning (FSVM-CIL). FSVM-CIL reduces the effect of outliers and noise in the training data. Here, the smaller fuzzy membership values are assigned to support vectors to reduce the effect of support vectors on the resultant decision surface based on class centres. Similarly, a new efficient approach fuzzy support vector machine for non-equilibrium data is proposed [9] to reduce the misclassification accuracy of positive class as compared to the negative class in FSVM. Bilateral-weighted FSVM (B-FSVM) is proposed [45] where membership of each sample is calculated by considering the samples on the basis of membership values for the positive and negative class. To solve bankruptcy prediction problem, a new fuzzy SVM is proposed by Chaudhuri and De [1]. In weighted least squares support vector machines (WLSTSVM) [16] the authors have obtained a sparse model for least squares support vector machine which is obtained by a pruning method where weights are given to the data points based on the error distribution to take care of the non-gaussian distributions which results in better accuracy.
For multiclass problems, a fuzzy least squares support vector machine is proposed by Tsujinishi and Abe [8]. In a similar way, Zhang et al. [37] have proposed a fuzzy least squares support vector machine for object tracking. Least squares recursive projection twin support vector machine (LSPTSVM) is proposed in Shao et al. [42] for classification. It generates projection planes for better classification on the basis of projection twin support vector machine (PTSVM) [40] by solving two modified primal problems in the form of linear equations whereas PTSVM needs to solve two quadratic programming problems along with two systems of linear equations. Weighted linear loss twin support vector machine (WLTSVM) for large-scale classification is proposed in Shao et al. [43] where the authors have considered twin support vector machine with weighted linear loss function to construct the two hyperplanes and use the weights on the linear loss function to take care of the differences in the data distribution. It is solved by using conjugate gradient algorithm to deal with large-scale datasets. Mehrkanoon and Suykens [22] have developed a method to solve partial differential equations using least squares support vector machine (LS-SVM). The partial differential equations are solved using LS-SVM using a set of linear equations rather than by non-linear equations as in ANN.
To further reduce the training cost of SVM, fuzzy least squares twin support vector machine is proposed by Sartakhti et al. [18] to deal with class imbalance datasets. Recently, Rastogi and Saigal [34] have proposed a new approach termed as tree-based localized fuzzy twin support vector clustering with square loss function. Further, Chen and Wu [40] have proposed a new fuzzy twin support vector machine (NFTWSVM) for pattern classification. For the work on the variants of TWSVM, we refer the reader to Shao et al. [41], Tanveer et al. [24] and Balasundaram et al. [35].
Entropy is used by Chen and Wu [40] to get the uncertainty measurement in neighbourhood systems. The information entropy based weights are more suited to imbalance problems as they take into account the probability distribution of the data which helps in determining the weights according to the class certainty. Further, it helps in giving less weight to the noisy data points which have less class certainty. Recently, Fan et al. [30] have proposed an entropy based fuzzy support vector machine (EFSVM) for class imbalance problem in which fuzzy membership is computed based on the entropy of the class samples where it solves a large size QPP to find the final decision classifier. Motivated by the work of Fan et al. [30], Lin and Wang [3] and Suykens and Vandewalle [15], we have proposed a new approach termed as entropy based fuzzy least squares support vector machine (EFLSSVM-CIL) for class imbalanced data. In EFLSSVM-CIL, we solve a set of linear equations through matrix operations resulting in less training time as compared to SVM where a large size QPP is solved to find the resultant classifier. Further, we have also proposed another method called entropy based fuzzy least squares twin support vector machine (EFLSTWSVM-CIL) to further improve the generalization ability and reduce the training cost. To justify the usability and applicability of our proposed methods, we have performed numerical experiments on several real-world datasets and compared the results with twin support vector machine (TWSVM), fuzzy twin support vector machine (FTWSVM), entropy based fuzzy support vector machine (EFSVM) and new fuzzy twin support vector machine (NFTWSVM) in terms of accuracy and training cost. One can notice that the proposed method EFLSTWSVM-CIL has outperformed the other existing fuzzy based techniques by a significant margin.
In this paper, all vectors are taken as column vectors. The inner product of two vectors is denoted as: xtz where x and z are the vector of n −dimensional real spaceRn and xt is the transpose of x. ||x|| and ||Q|| will be the 2-norm of a vector x and a matrix Q respectively. The vector of ones of dimension m and the identity matrix of appropriate size is denoted by e and I respectively.
The paper is organized as follows: Section 2 is to give a review on the work related to variants of support vector machine like Least squares support vector machine (LSSVM), Twin support vector machine (TWSVM), Least squares twin support vector machine (LSTWSVM), Fuzzy twin support vector machine (FTWSVM) and New fuzzy twin support vector machine (NFTWSVM) for pattern classification. The proposed methods EFLSSVM-CIL and EFLSTWSVM-CIL are discussed in Sections 3 and 4 respectively. Several numerical experiments have been performed on well known real world datasets to check the effectiveness and applicability of proposed methods in Section 5. In Section 6, we have concluded the paper with future work.
2 Related work
In this section, we have briefly discussed the formulations of least squares support vector machine (LSSVM), twin support vector machine (TWSVM), least squares twin support vector machine (LSTWSVM), fuzzy twin support vector machine (FTWSVM) and new fuzzy twin support vector machine (NFTWSVM).
2.1 Least squares support vector machine (LSSVM)
Least squares support vector machine (LSSVM) is proposed by Suykens and Vandewalle [15] where the formulation of LSSVM is given by the following optimization problem
subject to
where the input parameters C > 0; the vectors of slack variables ξ1 = (ξ11,...,ξ1m)t ∈ Rm and φ(xi) is the non-linear mapping which map the input example xi in higher dimensional space.
We introduce the Lagrangian multipliers λ = (λ1,...,λm)t such that λi ≥ 0 ,∀i = 1,...,m and take the gradient of Lagrangian function with respect to the primal variables w, b and ξ to zero. By eliminating w and ξ from the Lagrangian function, the solution is obtained by solving the following set of linear equations as
where Q = [φ(x1)ty1;...;φ(xm)tym],Y = [y1;...;ym] and \(\vec {1} =[1;...;1]\).
The decision function is given by
By applying the kernel trick [4, 25, 26], the non-linear decision function for any x ∈ Rn,f(.) is given as:
where k(xi, x) = φ(xi)tφ(x) is the kernel function.
2.2 Twin support vector machine (TWSVM)
In TWSVM [14], two non parallel hyperplanes are obtained instead of one hyperplane such that each of them is nearer to one of the class and as far as possible from the other class. Let us consider the input matrices X1 and X2 of size p × n and q × n where p is the number of data point belonging to ‘Class 1’ and q denotes the number of data points belonging to ‘Class 2’ such that total number of data samples m = p + q and n is the dimension of each data point. In non-linear case, twin support vector machine finds a pair of non parallel hyperplanes f1(x) = K(xt, Dt)w1 + b1 = 0 and f2(x) = K(xt, Dt)w2 + b2 = 0 from the solution of the following QPPs as
subject to
subject to
where ξ, η represent slack variables; C1, C2 are penalty parameters; D = [X1;X2]; e1, e2 are vectors of suitable dimension having all values as 1’s and K(xt,Dt) = (k(x, x1),...,k(x, xm)) is a row vector in Rm.
The Lagrangian functions of problems (4) & (5) are written as
where the vectors of Lagrangian multipliers α1 = (α11,...,α1q)t ∈ Rq,β1 = (β11,...,β1q)t ∈ Rq,α2 = (α21,...,α2p)t ∈ Rp and β2 = (β21,...,β2p)t ∈ Rp. The Wolfe dual of (6) and (7) is written by applying the Karush-Kuhn-Tucker (K.K.T) necessary and sufficient conditions [25] as
subject to
subject to
where S = [K(X1, Dt) e1] and T = [K(X2, Dt) e2].
We compute the value of w1, w2, b1 and b2 using the following equations as
Each new test data point x ∈ Rn is assigned to a given class ’i′ by using the following formula
2.3 Least squares twin support vector machine (LSTWSVM)
Kumar and Gopal [21] have proposed a new efficient approach which is known as least squares twin support vector machine (LSTWSVM) where non-parallel hyperplanes are constructed by solving a pair of two linear equations instead of solving a pair of quadratic programming problems in case of TWSVM. To find the kernel generated surfaces K(xt,Dt)w1 + b1 = 0 and K(xt,Dt)w2 + b2 = 0, the optimization problem for non-linear LSTWSVM is formulated as
subject to
and
subject to
where ξ, η represent slack variables, C1, C2 > 0 are penalty parameters and e is the vector of ones of suitable dimension.
Using the inequality constraints of (13) & (14) in its objective function, we get
and
Taking the gradient of (15) with respect to primal variables w1 and b1and equating to zero, we get
Combining (17) and (18) in matrix form and solving for w1 and b1 as
where U = [K(X1, Dt)e] and V = [K(X2, Dt)e]. Similarly, for the other hyperplane the unknowns are computed by the following formula
To predict the class of new data samplex ∈ Rn, we find the perpendicular distances from the hyperplanes K(xt,Dt)w1 + b1 = 0 and K(xt,Dt)w2 + b2 = 0 and assign the class label of the minimum distance hyperplane to the data sample. For more details, see [21].
2.4 Fuzzy twin support vector machine (FTWSVM)
Like FSVM, in FTWSVM weights are given to the different data samples on the basis of fuzzy membership values and the training gets biased towards the samples of interest. To calculate the fuzzy membership we have considered the centroid measure for the data samples of each class where the membership values are assigned based on the distance of the data points from the centroid of that class [32]. The membership values are used as a basis for giving weights to the error tolerance i.e. C for every data point.
The fuzzy membership function for centroid based membership is written as
where dcen is the Euclidean distance of each data point from the centroid of its class, δ is a small positive integer value for making the denominator non-zero.
The formulation of FTWSVM in primal is written as
subject to
subject to
where ξ, η represent slack variables; C1, C2 are penalty parameters; s1, s2 are vectors having the membership values of the data samples of the other class.
The Lagrangian function of the problems (21) & (22) are written as
where α1 = (α11,...,α1q)t, β1 = (β11,...,β1q)t,α2 = (α21,...,α2p)t and β2 = (β21,...,β2p)t are the vectors of Lagrange multipliers.
Now, we apply the Karush-Kuhn-Tucker (K.K.T) necessary and sufficient conditions to find the Wolfe dual of (21) and (22) as
where S = [K(X1, Dt) e1] and T = [K(X2, Dt) e2].
We compute the non-linear hyperplanes K(xt,Dt)w1 + b1 = 0 and K(xt,Dt)w2 + b2 = 0 by computing the values of w1, w2, b1 and b2 by using the following equations as
The resultant classifier is obtained by using (12).
2.5 New fuzzy twin support vector machine (NFTWSVM)
Recently, Chen and Wu [40] have proposed a fuzzy based variant of SVM named as new fuzzy twin support vector machine for pattern classification (NFTWSVM). It employs a fuzzy membership function based on Keller and Hunt [17] to give the weights to the data points where the fuzzy 2-partition is formed
The fuzzy membership function for a positive sample is written as
For a negative sample,
where the Euclidean distance between xi and the mean of the negative class is represented by d− 1, the distance between xi and the mean of the positive class is represented by d1, d is the distance between the means of the positive and negative classes and to control the membership function C0 is used as a constant.
The formulation of NFTWSVM in primal is written as
subject to
subject to
where η1, η2 represent slack variables; C1, C2, C3 and C4 are penalty parameters; Y 1 = diag(y1, y2,...,yp),Y 2 = diag(y1, y2,...,yq) for p positive samples and q negative samples with yi = 2mi − 1.
After applying the Karush-Kuhn-Tucker (K.K.T) necessary and sufficient conditions to find the Wolfe dual of (21) and (22), we get
where S = [K(X1, Dt) e1] and T = [K(X2, Dt) e2].
The non-linear hyperplanes K(xt,Dt)w1 + b1 = 0 and K(xt,Dt)w2 + b2 = 0 are obtained by computing the values of w1, w2, b1 and b2 by using the following equations as
For more details, see [40].
3 Proposed entropy based fuzzy least squares support vector machine for class imbalance learning (EFLSSVM-CIL)
To enhance the training speed of SVM for imbalanced data, we propose a new approach i.e. least squares version of entropy based fuzzy support vector machine which uses the information entropy of data samples. Recently, Fan et al. [30] have proposed a novel approach for fuzzy membership evaluation based on information entropy of the data samples. Entropy is helpful in giving less weight to the data points at the boundary of the classes, so it is used to solve the problem of class imbalance. Hence, one can assign the fuzzy membership to the data points by using the information entropy as the weighted parameter. The class of interest is given highest membership value and the other class is given membership values based on its entropy. The samples of majority class with high entropy are given less membership value and with low entropy are given higher membership values. This is done so as to increase the participation of lower entropy data points of the majority class in constructing the classifier and decreasing the role of high entropy data points of the majority class which are near the boundary of the classes. The entropy of any sample xi is given as:
where \(P_{pos\mathunderscore x_{i}} \) and \(P_{neg\mathunderscore x_{i}} \) are the probability of positive class and negative class of sample xi respectively. Further, we calculate the K −nearest neighbors of sample xi and assign the values to \(P_{pos\mathunderscore x_{i}} \) and \(P_{neg\mathunderscore x_{i}} \) based on count of total positive and negative class neighbors.
Further, the data points of the negative class are divided into l subsets based on increasing order of entropy. The fuzzy membership of each samples in each subset are calculated as
where Fq is the fuzzy membership for samples distributed in qth subset with fuzzy membership parameter \(\beta \in \left ({0,\frac {1}{l-1}} \right ]\) which control the scale of fuzzy membership of samples. The fuzzy membership function is given as
The majority class samples are given a membership of 1 and the minority class samples are given the membership based on the above formula.
In this paper, motivated by the work of Fan et al. [30] and Suykens and Vandewalle [15], we have proposed a new least squares version of entropy based fuzzy support vector machine based on information entropy for class imbalance learning where information entropy is used to compute the weights for fuzzy membership.
EFLSSVM-CIL finds a class separating hyperplane that maximizes the margin between the two classes from the formulations of EFSVM by modifying inequality constraints to equality constraints and considered the 2-norm slack variables with C/2 instead of 1-norm slack variable with C. Further, one can find the solution of the optimization problem by solving the system of linear equations instead of solving it by QPP which takes less computational time and applicable to large imbalance data. To classify the non-linear separable data points, the non-linear entropy based fuzzy least squares support vector machine for class imbalance learning (EFLSSVM-CIL) is formulated in primal form as
subject to
where input sample xi is transformed to φ(xi) in higher dimensional space.
By introducing the Lagrangian multipliers λ = (λ1,...,λm)t such that λi ≥ 0,∀i = 1,...,m, the Lagrangian function can be written as
Making the gradient of L with respect to the primal variables w, b, ξ and λ to zero, we obtain
where i = 1,2,.....m.
Further, the solution of primal EFLSSVM can be formulated in its dual form and solved by eliminating w and ξ which results to the following set of linear equations as
where s is the vector containing the membership values of majority class.
For any data sample x ∈ Rn, the non-linear decision function is given by (3).
4 Proposed entropy based fuzzy least squares twin support vector machine for class imbalance learning (EFLSTWSVM-CIL)
To further improve the generalization ability and reduce the training cost of fuzzy based LSSVM [8], we have proposed a twin version of fuzzy based least squares support vector machine using the information entropy which has good generalization performance and improved computational cost. Since there is not much work done with least squares twin support vector machine for class imbalance problem, motivated by the work of Fan et al. [30], we have proposed a entropy based fuzzy least squares twin support vector machine (EFLSTWSVM-CIL) for class imbalance.
The problem formulation of non-linear EFLSTWSVM is written as
and
where ξ, η represent slack variables, C1, C2 > 0 are penalty parameters, e is the vector of ones of suitable dimension and s1 and s2 are the vectors containing the membership values of positive class and negative class respectively which are computed in the same manner as in proposed EFLSSVM-CIL.
Using the equality constraints of (38) & (39) with its objective function, we get
and
Taking the gradient of (40) with respect to primal variables w1 and b1 and equate to zero, we get
Combining (42) and (43) in matrix form and solving for w1 and b1
One can write (44) in the following form
where G = [K(X1, Dt)e] and H = [K(X2, Dt)e].
Similarly for the other hyperplane the parameters are computed by the following formula
Using Sherman–Morrison–Woodbury (SMW) [12] formula, we rewrite the (45) and (46) so that we have to solve inverses of smaller dimension which leads increase in computation speed.
Below we discuss the solution of nonlinear EFLSTWSVM-CIL for two cases.
-
Case 1:
p < q
where Y = (HtH)− 1.
Using the regularization term εI, where ε > 0 for the possible ill conditioning of (HtH)− 1 and rewritten as
-
Case 2:
q < p
where Z = (GtG)− 1 which is rewritten using SMW formula as
To predict the class of new data sample x ∈ Rn, find the perpendicular distances from the hyperplanes K(xt,Dt)w1 + b1 = 0 and K(xt,Dt)w2 + b2 = 0 and assign the class label of minimum distance hyperplane.
5 Numerical experiments
To check the performance of the proposed methods, we have experimented on various linear and non-linear imbalanced datasets which are taken from KEEL imbalanced datasets [13] and UCI repository [28] for binary classification. The proposed EFLSSVM-CIL and EFLSTWSVM-CIL are compared with NFTWSVM, EFSVM, FTWSVM and TWSVM. All computations are carried-out on a PC running on Windows 7 OS with 64 bit, 3.20 GHz Intel®;coreTM i5-2400 processor having 2 GB of RAM under MATLAB R2008b environment. We have used MOSEK optimization toolbox to solve the quadratic programming problems which is taken from http://www.mosek.com. Gaussian kernel is used for non-linear classifier, defined as k(a, b) = exp(−μ||a − b||2) where vector a, b ∈ Rmand μ is the kernel parameter.
The value of the parameter C = C1 = C2 is taken from the set {10− 7,...,107} and μ is chosen from the range {2− 5,...,25} for all the cases. For FTWSVM, δ is taken as 0.5. For EFSVM, EFLSSVM-CIL and EFLSTWSVM-CIL, β is considered as 0.05, l is taken as 10, the value of K is chosen from the set {5,8,11}. For, NTWSVM the value of C1 = C2, C3 = C4 are taken from the set {10− 5,...,105} and C0 is selected from the set {0.5,1,1.5,2,2.5}.
All the results for the proposed method EFLSSVM-CIL and EFLSTWSVM-CIL with NFTWSVM, EFSVM, FTWSVM and TWSVM are shown in terms of prediction accuracy and training time both for linear and Gaussian kernel in Tables 1 and 3 respectively. One can observe from Tables 1 and 3 that EFLSTWSVM-CIL is much superior to TWSVM, FTWSVM, EFSVM, NFTWSVM and EFLSSVM-CIL in terms of better prediction accuracy for unknown samples. Also, our proposed method EFLSTWSVM-CIL takes very less training time in comparison with EFSVM, TWSVM, FTWSVM and EFLSSVM-CIL. EFLSTWSVM-CIL solves two systems of linear equations instead of a pair of QPP as in TWSVM and FTWSVM. In similar manner, EFLSSVM solves a system of linear equation instead of a QPP as in case of EFSVM which results in less computation time.
For linear kernel, note that the total number of times the best accuracy obtained by TWSVM, FTWSVM, EFSVM, NFTWSVM, EFLSSVM-CIL and EFLSTWSVM-CIL are 4, 0, 4, 6, 3 and 10 respectively from Table 1. This indicates the supremacy of proposed EFLSTWSVM-CIL. It is concluded from Table 1 that for all the datasets our proposed EFLSSVM-CIL and EFLSTWSVM-CIL have not performed better. So, we analyze the comparative performance of EFLSSVM-CIL and EFLSTWSVM-CIL with TWSVM, FTWSVM, EFSVM and NFTWSVM based on the average rank of all the methods which are shown in Table 2. One can clearly observe from Table 2 that the average rank of proposed EFLSTWSVM-CIL is 2.18 which is lowest among all the methods. Further, for statistical comparison on the performance of 6 algorithms using 25 datasets, we have performed the Friedman test with the corresponding post-hoc test [5]. We assume that all the methods are equivalent under null hypothesis, the Friedman statistic is computed from Table 2 as
where FF is distribution according to the F-distribution with (6 − 1, (6 − 1) × (25 − 1)) = (5, 120) is degree of freedom with 6 methods and 25 datasets. The critical value of F(5,120) is 2.2898 for the level of significance at α = 0.05. Since the value of FF = 5.3938 > 2.2898, so we reject the null hypothesis. Further, Nemenyi post-hoc test is performed for pair-wise comparison of methods and the significant difference between them is checked by computing the critical difference (CD) at p = 0.10 which should differ by at least \(2.589\sqrt {\frac {6\times (6 + 1)}{6\times 25}} \approx 1.37\).
The difference between the average ranks of NFTWSVM, EFSVM, FTWSVM and EFLSSVM-CIL with EFLSTWSVM-CIL are (3.56 − 2.18 = 1.38), (4.16 − 2.18 = 1.98),(3.66 − 2.18 = 1.48), and (4.36 − 2.18 = 2.18) respectively, which are greater than 1.37. So we conclude that EFLSTWSVM-CIL is significantly better than EFSVM, FTWSVM and EFLSSVM-CIL. Since the difference of average rank of TWSVM with EFLSTWSVM-CIL is (3.08 − 2.18 = 0.9) which is less than 1.37 that shows that there is no significant difference between EFLSTWSVM-CIL and TWSVM.
In non-linear case, the accuracy values are shown with the training time for the proposed EFLSSVM-CIL and EFLSTWSVM-CIL with TWSVM, FTWSVM, EFSVM and NFTWSVM in Table 3. It can be observed from Table 3 that the number of times the best accuracy obtained by TWSVM, FTWSVM, EFSVM, NFTWSVM, EFLSSVM-CIL and EFLSTWSVM-CIL are 4, 5, 9, 6, 5 and 19 respectively which indicates the supremacy of proposed EFLSTWSVM-CIL in terms of generalization performance. The learning speed of our proposed EFLSTWSVM-CIL is better than EFSVM and EFLSSVM-CIL in all the cases. It is noticeable from the table that the proposed EFLSTWSVM-CIL is not always better in terms of accuracy for all the datasets, so we compute the average rank of all the methods based on accuracy values which are shown in Table 4. One can conclude that among all the methods our proposed EFLSTWSVM-CIL has lowest average rank. Further, we have performed the Friedman statistical test with the post-hoc tests.
Now the Friedman statistic is computed for nonlinear kernel under null hypothesis by using Table 4:
The critical value of F(5,190) i.e. 2.2616 for the level of significance α = 0.05 is less than the value of FF. Thus, it rejects the null hypothesis. Further, the Nemenyi post-hoc test is used to find the significant difference between the pair-wise comparisons. We computed the critical difference (CD) at p = 0.10 which should differ by at least \(2.589\sqrt {\frac {6\times (6 + 1)}{6\times 39}} \approx 1.0969\).
The difference between the average ranks of EFLSTWSVM-CIL with TWSVM, FTWSVM, EFSVM, NFTWSVM and EFLSSVM-CIL are (4.0641 − 2.17949 = 1.88461), (3.74359 − 2.17949 = 1.5641),(3.29487 − 2.17949 = 1.11538), (3.73077 − 2.17949 = 1.55128) and (3.98718 − 2.17949 = 1.80769) respectively, which are greater than 1.0969. Hence, proposed EFLSTWSVM-CIL is significantly better than TWSVM, FTWSVM, EFSVM, NFTWSVM and EFLSSVM-CIL.
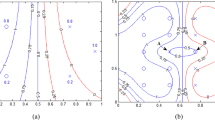
One can verify that the performance of our proposed EFLSSVM-CIL and EFLSTWSVM-CIL are not very sensitive to the values of its parameters C, μ and K. To illustrate this result, the sensitivity is shown for user defined parameters C and K for proposed EFLSSVM-CIL on Ecoli0137vs26, Monk2, Vehicle2 and Yeast-0-3-5-9_vs_7-8 datasets are shown in Fig. 1a, b, c and d respectively and for proposed EFLSTWSVM-CIL on Ecoli-0-1_vs_2-3-5, Monk2, Vehicle2 and Yeast-0-3-5-9_vs_7-8 datasets are shown in Fig. 3a, b, c and d respectively. In similar manner, the sensitivity analysis for user defined parameters μ and K for proposed EFLSSVM-CIL on Ecoli-0-6-7_vs_3-5, Pima, Vowel and Yeast-0-2-5-6_vs_3-7-8-9 are shown in Fig. 2a, b, c and d respectively and for proposed EFLSTWSVM-CIL on Cleveland, Ecoli2, Ecoli-0-3-4-6_vs_5 and Ecoli-0-1-4-7_vs_2-3-5-6 datasets are shown in Fig. 4a, b, c and d respectively. Also from the figures, note that better accuracy could be achieved for larger values of C and smaller values of μ in case of EFLSSVM-CIL (Figs. 1 and 2) and in case of EFLSTWSVM-CIL, the better accuracy could be achieved for smaller values of C and larger values of μ (Figs. 3 and 4).

Insensitivity performance of EFLSSVM-CIL for classification to the user specified parameters (C, K) on imbalance datasets using Gaussian kernel

Insensitivity performance of EFLSSVM-CIL for classification to the user specified parameters (μ, K) on imbalance datasets using Gaussian kernel

Insensitivity performance of EFLSTWSVM-CIL for classification to the user specified parameters (C, K) on imbalance datasets using Gaussian kernel

Insensitivity performance of EFLSTWSVM-CIL for classification to the user specified parameters (μ, K) on imbalance datasets using Gaussian kernel
6 Conclusions and future work
In this paper, we have proposed new efficient variants of SVM as EFLSSVM-CIL and EFLSTWSVM-CIL to solve class imbalance problem in binary class datasets where the fuzzy membership is calculated based on entropy values of samples. Here, our proposed EFLSSVM-CIL and EFLSTWSVM-CIL solve the set of linear equations rather than solving the QPPs as in case of EFSVM, TWSVM and FTWSVM to find the decision surface. We have carried out the experiments to analyze our proposed methods against TWSVM, FTWSVM, EFSVM and NFTWSVM. It can be concluded from the results that EFLSTWSVM-CIL shows better generalization performance as compared to TWSVM, FTWSVM, EFSVM, NFTWSVM and EFLSSVM-CIL which clearly illustrates its efficacy and applicability. It has been found that EFLSTWSVM-CIL outperforms in terms of learning speed in comparison to EFSVM and EFLSSVM-CIL for both linear and non-linear case. Some heuristic approaches can be used to improve the method for parameter selection which may result in better performance.
References
Chaudhuri, De K (2010) Fuzzy support vector machine for bankruptcy prediction. Appl Soft Comput 11 (1):2472–2486
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(2):273–297
Lin C-F, Wang S-D (2002) Fuzzy support vector machines. IEEE Trans Neural Netw 13(1):464–471
Burges CJC (1998) Geometry and invariance in kernel based methods. In: Scholkopf B, Burges CJC, Smola AJ (eds) Advances in kernel methods-support vector learning. MIT, Cambridge
Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Tomar D, Ojha D, Agarwal S (2014) An emotion detection system based on multi least squares twin support vector machine. Adv Artif Intell Article ID 282659:11
Tomar D, Agarwal S (2015) Hybrid feature selection based weighted least squares twin support vector machine approach for diagnosing breast cancer, hepatitis, and diabetes. Adv Artif Neural Syst. (Article ID 265637), 10
Tsujinishi D, Abe S (2003) Fuzzy least squares support vector machines. In: Proceedings of the international joint conference on neural networks. Portland, pp 1599–1604
Tian D-Z, Peng G-B, Ha M-H (2012) Fuzzy support vector machine based on non-equilibrium data. In: International conference on machine learning and cybernetics. Xi’an, pp 15–17
Borovikov E (2005) An evaluation of support vector machines as a pattern recognition tool. University of Maryland at College Park. http://www.umiacs.umd.edu/users/yab/SVMForPatternRecognition/report.pdf
Osuna E, Freund R, Girosi F (1997) Training support vector machines: an application to face detection. In: Proceedings of 1997 IEEE computer society conference on computer vision and pattern recognition. IEEE, pp 130–136
Golub GH, Van Loan C (1996) F, Matrix computations, 3rd edn. The John Hopkins University Press
Alcalá-Fdez J, Fernandez A, Luengo J, Derrac J, García S, Sánchez L, Herrera F (2011) KEEL data-mining software tool: data set repository, integration of algorithms and experimental analysis framework. J Multiple-Valued Logic Soft Comput 17(2–3):255–287
Jayadeva RK, Chandra S (2007) Twin support vector machines for pattern classification. IEEE Trans Pattern Anal Mach Intell (TPAMI) 29:905–910
Suykens JAK, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9:293–300
Suykens JAK, De Brabanter J, Lukas L, Vandewalle J (2002) Weighted least squares support vector machines: robustness and sparse approximation. Neurocomputing 48(1):85–105
Keller J, Hunt D (1985) Incorporating fuzzy membership functions into the perceptron algorithm. IEEE Trans Pattern Anal Mach Intell 6:693–699
Sartakhti JS, Ghadiri N, Afrabandpey H, Yousefnezhad N (2016) Fuzzy Least squares twin support vector machines. arXiv:1505.05451
Zhang J, Liu Y (2004) Cervical cancer detection using SVM-based feature screening. In: Proceedings of the seventh international conference on medical image computing and computer aided intervention, pp 873–880
Khan L, Awad M, Thuraisingham B (2007) A new intrusion detection system using support vector machines and hierarchical clustering. Int J Very Large Data Bases 16(3):507–521
Kumar MA, Gopal M (2009) Least squares twin support vector machines for pattern classification. Expert Syst Appl 36(3):7535–7543
Mehrkanoon S, Suykens JAK (2015) Learning solutions to partial differential equations using LS-SVM. Neurocomputing 159:105–116
Schmidt M, Gish H (1996) Speaker identification via support vector classifiers. In: Conference proceedings of 1996 IEEE international conference on acoustics, speech, and signa processing, 1996, ICASSP-96, vol 1. Atlanta, pp 105–108
Tanveer M, Khan MA, Ho S-S (2016) Robust energy-based least squares twin support vector machines. Appl Intell, https://doi.org/10.1007/s10489-015-0751-1
Cristianini N, Taylor JS (1999) An introduction to support vector machines: and other kernel-based learning methods. Cambridge University Press, New York
Mangasarian OL (1994) Nonlinear programming. SIAM
Phillips PJ (1998) Support vector machines applied to face recognition. In: Proceedings conference advances in neural information processing systems, vol 11, pp 803–809
Murphy PM, Aha DW (1992) UCI repository of machine learning databases. University of California, Irvine. http://www.ics.uci.edu/~mlearn
Michel P, el Kaliouby R (2003) Real time facial expression recognition in video using support vector machines. In: Proceedings of the 5th international conference on multimodal interfaces, pp 258–264, ISBN: 1-58113-621-8
Fan Q, Wang Z, Li D, Gao D, Zha H (2017) Entropy-based fuzzy support vector machine for imbalanced datasets. Knowl-Based Syst 115:87–99
Tong Q, Zheng H, Wang X (2005) Gene prediction algorithm based on the statistical combination and the classification in terms of gene characteristics. Int Conf Neural Netw Brain 2:673–677
Batuwita R, Palade V (2010) FSVM-CIL: fuzzy support vector machines for class imbalance learning. IEEE Trans Fuzzy Syst 18(2):558–571
Malhotra R, Malhotra DK (2003) Evaluating consumer loans using neural networks. Omega 31:83–96
Rastogi R, Saigal P (2017) Tree-based localized fuzzy twin support vector clustering with square loss function. Applied Intelligence. https://doi.org/10.1007/s10489-016-0886-8
Balasundaram S, Gupta D, Prasad SC (2017) A new approach for training Lagrangian twin support vector machine via unconstrained convex minimization. Appl Intell 46(1):124–134
Gunn SR (1998) Support vector machines for classification and regression. ISIS technical report 14, University of Southampton
Zhang S, Zhao S, Sui Y, Zhang L (2015) Single object tracking with fuzzy least squares support vector machine. IEEE Trans Image Process 24:5723–5738
Phu VN, Dat ND, Tran VTN, Chau VTN, Nguyen TA (2017) Fuzzy C-means for english sentiment classification in a distributed system. Appl Intell 46(2):717–738
Vapnik VN (1998) Statistical learning theory. Wiley, New York
Chen S, Wu X (2017) A new fuzzy support vector machine for pattern classification. Int J Mach Learn Cybern. https://doi.org/10.1007/s13042-017-0664-x
Shao Y, Chen W, Zhang J, Wang Z, Deng N (2014) An efficient weighted Lagrangian twin support vector machine for imbalanced data classification. Pattern Recogn 47(9):3158–3167
Shao YH, Deng NY, Yang ZM (2012) Least squares recursive projection twin support vector machine for classification. Pattern Recogn 45(6):2299–2307
Shao YH, Chen WJ, Wang Z, Li CN, Deng NY (2015) Weighted linear loss twin support vector machine for large-scale classification. Knowl-Based Syst 73:276–288
Bao Y-K, Liu Z-T, Guo L, Wang W (2005) Forecasting stock composite index by fuzzy support vector machines regression. In: Proceeding of international conference on machine learning and cybernetics, vol 6, pp 3535–3540
Wang Y, Wang S, Lai KK (2005) A new fuzzy support vector machine to evaluate credit risk. IEEE Trans Fuzzy Syst 13(6):820–831
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Gupta, D., Richhariya, B. Entropy based fuzzy least squares twin support vector machine for class imbalance learning. Appl Intell 48, 4212–4231 (2018). https://doi.org/10.1007/s10489-018-1204-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-018-1204-4