
Abstract
Consider independent observations \((X_i,R_i)\) with random or fixed ranks \(R_i\), while conditional on \(R_i\), the random variable \(X_i\) has the same distribution as the \(R_i\)-th order statistic within a random sample of size k from an unknown distribution function F. Such observation schemes are well known from ranked set sampling and judgment post-stratification. Within a general, not necessarily balanced setting we derive and compare the asymptotic distributions of three different estimators of the distribution function F: a stratified estimator, a nonparametric maximum-likelihood estimator and a moment-based estimator. Our functional central limit theorems generalize and refine previous asymptotic analyses. In addition, we discuss briefly pointwise and simultaneous confidence intervals for the distribution function with guaranteed coverage probability for finite sample sizes. The methods are illustrated with a real data example, and the potential impact of imperfect rankings is investigated in a small simulation experiment.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Ranked set sampling and judgment post-stratification are both sampling strategies in situations in which ranking several observations is possible and relatively easy without referring to exact values, whereas obtaining complete observations is much more involved. For instance, this occurs often in agriculture or forestry when the quantities of interest are yields on different plots or of different trees. Good overviews of theory and applications of ranked set sampling are given by Wolfe (2004, 2012) and Chen et al. (2004). Let us explain the two sampling schemes just mentioned in a simple hypothetical example: Suppose we want to estimate the distribution of body heights among all men of age 20–25 in a certain population. Whenever we have obtained a precise measurement \(X_i\) of such a man, we could compare him to \(k-1\) additional young men and note the rank \(R_i \in \{1,2,\ldots ,k\}\) of \(X_i\) within this small group without measuring the heights of the additional men precisely. This sampling scheme is called judgment post-stratification (JPS), see MacEachern et al. (2004). Alternatively, for each observation we could recruit a group of k young men, rank them with respect to their heights and then obtain the precise body height \(X_i\) of the person with rank \(R_i \in \{1,\ldots ,k\}\) only. Here the ranks \(R_1, R_2, \ldots , R_n\) have been specified in advance. This sampling scheme, called ranked set sampling (RSS), was introduced by McIntyre (1952). If the empirical distribution of the ranks \(R_i\) is (approximately) uniform on \(\{1,\ldots ,k\}\), one talks about balanced RSS, otherwise unbalanced RSS. For instance, if we are mainly interested in the upper tail of the distribution of body heights, we could favor larger ranks \(R_i\).
In general, we consider independent random pairs \((X_1,R_1)\), \((X_2,R_2)\), ..., \((X_n,R_n)\) with fixed or random ranks \(R_i \in \{1,2,\ldots ,k\}\). Conditional on \(R_i = r\), the random variable \(X_i\) has the same distribution as the r-th order statistic of a random sample of size k from F. That means, \(X_i\) has distribution function
where \(B_r : [0,1] \rightarrow [0,1]\) denotes the distribution function of the beta distribution with parameters r and \(k+1-r\). Thus for \(p \in [0,1]\),
with
see David and Nagaraja (2003). The vector \(\varvec{N}_{\!n}= (N_{nr})_{r=1}^k\) of stratum sizes
plays a key role. In RSS, the ranks \(R_1, R_2, \ldots , R_n\) and thus the whole vector \(\varvec{N}_{\!n}\) are fixed. In JPS, the \(R_i\) are independent and uniformly distributed on \(\{1,\ldots ,k\}\), whence \(\varvec{N}_{\!n}\) follows a multinomial distribution \(\mathrm {Mult}\, (n; 1/k, \ldots , 1/k)\).
Several estimators of the c.d.f. F have been proposed. Of course one could just ignore the rank information and compute the empirical c.d.f. \(\widehat{F}_n\),
In the JPS setting, this estimator is unbiased and \(\sqrt{n}\)-consistent. However, the stratified estimator
with the empirical c.d.f.
within stratum \(\{i : R_i = r\}\) is usually more efficient. It has been introduced and analyzed in a balanced RSS setting by Stokes and Sager (1988). Refinements and modifications of this estimator \(\widehat{F}_n^\mathrm{S}\) in the JPS setting have been proposed by Frey and Ozturk (2011) and Wang et al. (2012). In particular, these authors consider situations with small or moderate sample sizes so that some stratum sizes \(N_{nr}\) may be zero or the empirical c.d.f.s \(\widehat{F}_{nr}\) may fail to satisfy order relations which are known for their theoretical counterparts \(F_r\).
A second approach to estimating the c.d.f. F which can also handle empty strata was introduced by Kvam and Samaniego (1994). They propose to estimate F(x) by maximizing the conditional log-likelihood function
of the indicator vector \((1_{[X_i \le x]})_{i=1}^n\), given the rank vector \(\varvec{R}_{n}= (R_i)_{i=1}^n\). The resulting estimator \(\widehat{F}_n^\mathrm{L}\) is given by
Huang (1997) provides a detailed asymptotic analysis of this estimator \(\widehat{F}_n^\mathrm{L}\) in the special setting when \(n = k\ell \), \(N_{nr} = \ell \) for \(1 \le r \le k\), and \(\ell \rightarrow \infty \).
A third approach, introduced by Chen (2001), is to estimate F by a moment equality for the naive empirical c.d.f. \(\widehat{F}_n\). Note that
Hence, one can estimate F(x) by the unique number \(\widehat{F}_n^\mathrm{M}(x) \in [0,1]\) such that
In the RSS setting with proportions \(N_{nr}/n\) converging to fixed numbers \(\pi _r > 0\) as \(n \rightarrow \infty \), Chen (2001) proves asymptotic normality of \(\sqrt{n} \bigl ( \widehat{F}_n^\mathrm{M}(x) - F(x) \bigr )\) for finitely many points x and shows that the supremum norm of \(\widehat{F}_n^\mathrm{M}- F\) converges to zero in probability. (Note that Chen (2001) formulates the moment equality (1) with \(n \pi _r\) in place of \(N_{nr}\), but this would introduce an unnecessary estimation bias.)
In Sect. 2, we present some elementary properties of the estimators \(\widehat{F}_n^\mathrm{S}\), \(\widehat{F}_n^\mathrm{L}\) and \(\widehat{F}_n^\mathrm{M}\) and comment briefly on the computation of the latter two. In addition, we describe two methods to obtain pointwise and simultaneous confidence intervals for F, respectively. The former procedure is just an adaptation of a method by Terpstra and Miller (2006) and closely related to the estimator \(\widehat{F}_n^\mathrm{M}\). Inverting the underlying tests yields honest confidence intervals for any given quantile of F as proposed by Balakrishnan and Li (2006) for balanced RSS. The confidence bands are a generalization of the confidence bands described by Stokes and Sager (1988). Here it turns out that the estimator \(\widehat{F}_n^\mathrm{M}\) is particularly convenient to work with.
Section 3 provides a detailed analysis of the asymptotic distribution of the estimators \(\widehat{F}_n^\mathrm{S}\), \(\widehat{F}_n^\mathrm{L}\) and \(\widehat{F}_n^\mathrm{M}\) as \(n \rightarrow \infty \) while k is fixed and \(N_{nr}/n \rightarrow _p \pi _r > 0\) for \(1 \le r \le k\). Our analyses provide linear stochastic expansions and functional central limit theorems for the processes \(\sqrt{n}(\widehat{F}_n^\mathrm{Z} - F)\), \(\mathrm{Z} = \mathrm{S}, \mathrm{L}, \mathrm{M}\). These results generalize the findings of Stokes and Sager (1988) about \(\widehat{F}_n^\mathrm{S}\), of Huang (1997) about \(\widehat{F}_n^\mathrm{L}\) in balanced RSS and of Chen (2001) and Ghosh and Tiwari (2008) about \(\widehat{F}_n^\mathrm{M}\). We obtain explicit expressions for the asymptotic covariance functions of \(\sqrt{n}(\widehat{F}_n^\mathrm{Z} - F)\) which enable efficiency considerations. The most important findings are that (i) the estimator \(\widehat{F}_n^\mathrm{L}\) is always superior to the other two, (ii) the estimators \(\widehat{F}_n^\mathrm{S}\) and \(\widehat{F}_n^\mathrm{M}\) are asymptotically equivalent in case of \(\pi _1 = \cdots = \pi _k = 1/k\) and (iii) in unbalanced settings the estimator \(\widehat{F}_n^\mathrm{S}\) can be substantially worse than the other two estimators. Moreover, the efficiency gain of \(\widehat{F}_n^\mathrm{L}\) over \(\widehat{F}_n^\mathrm{M}\) is bounded and typically rather small. In addition, we analyze the estimators’ asymptotic behavior in the tails of the distribution F where they turn out to be essentially equivalent.
A detailed analysis of a real data example is presented in Sect. 4. It involves population sizes of Swiss municipalities and illustrates that sampling from finite populations without replacement may render our confidence regions conservative, even if the rankings are not perfect. The impact of imperfect rankings itself is investigated in a small simulation study based on the model of Dell and Clutter (1972).
The main proofs are deferred to an appendix. Further technical details and additional material, including references to computer code in R (R Core Team 2013), are collected in a supplement.
2 Computation of the estimators and exact inference
Computations In what follows let \(X_{(1)}< X_{(2)}< \cdots < X_{(n)}\) be the order statistics of \(X_1, X_2, \ldots , X_n\), augmented by \(X_{(0)} := -\infty \) and \(X_{(n+1)} := \infty \). One can easily verify that for \(\mathrm {Z} = \mathrm {S}, \mathrm {M}, \mathrm {L}\), the estimator \(\widehat{F}_n^\mathrm{Z}\) is constant on each interval \([X_{(y)}, X_{(y+1)})\), \(0 \le y \le n\), where \(\widehat{F}_n^\mathrm{Z}\equiv 0 \) on \([X_{(0)}, X_{(1)})\) and \(\widehat{F}_n^\mathrm{Z}\equiv 1\) on \([X_{(n)}, X_{(n+1)})\).
While the computation of the stratified estimator \(\widehat{F}_n^\mathrm{S}\) is straightforward, the estimators \(\widehat{F}_n^\mathrm{M}\) and \(\widehat{F}_n^\mathrm{L}\) may be computed numerically by running a suitable bisection algorithm \(n-1\) times. Concerning \(\widehat{F}_n^\mathrm{M}\), note that \(\sum _{r=1}^k N_{nr} B_r(p)\) is continuous and strictly increasing in \(p \in [0,1]\) with boundary values 0 and 1. Hence for \( 1 \le y < n\) and \(X_{(y)} \le x < X_{(y+1)}\), the estimator \(\widehat{F}_n^\mathrm{M}(x)\) is the unique solution \(p \in (0,1)\) of \(\sum _{r=1}^k N_{nr} B_r(p) = y\).
As to \(\widehat{F}_n^\mathrm{L}\), the next lemma provides some essential properties of the log-likelihood function \(L_n(\cdot ,\cdot )\). Its proof is given in the supplement.
Lemma 1
For any \(x \in \mathbb {R}\), the function \(L_n(x,\cdot ) : [0,1] \rightarrow [-\infty ,0]\) is continuous and continuously differentiable on (0, 1). Its derivative \(L_n'(x,p) := \partial L_n(x,p)/\partial p\) is strictly decreasing in \(p \in (0,1)\) and equals
with the auxiliary function
Moreover, in case of \(X_{(1)} \le x < X_{(n)}\), the limits of \(L_n'(x,\cdot )\) at the boundary of (0, 1) are equal to \(L_n'(x,0) = \infty \) and \(L_n'(x,1) = -\infty \).
According to this lemma, for \(y \in \{1,\ldots ,n-1\}\) and \(X_{(y)} \le x < X_{(y+1)}\), the value of \(\widehat{F}_n^\mathrm{L}(x)\) is the unique number \(p \in (0,1)\) such that
The computation of \(\widehat{F}_n^\mathrm{M}\) and \(\widehat{F}_n^\mathrm{L}\) for one single data set is of similar complexity. There is, however, an important difference: The vector \(\bigl ( \widehat{F}_n^\mathrm{M}(X_{(y)}) \bigr )_{y=1}^{n-1}\) depends solely on the vector \(\varvec{N}_{\!n}= (N_{nr})_{r=1}^k\) of stratum sizes. Hence, if we want to simulate the conditional distribution of \(\widehat{F}_n^\mathrm{M}\), given \(\varvec{R}_{n}\), we have to compute the vector \(\bigl ( \widehat{F}_n^\mathrm{M}(X_{(y)}) \bigr )_{y=1}^{n-1}\) only once. By way of contrast, the vector \(\bigl ( \widehat{F}_n^\mathrm{L}(X_{(y)}) \bigr )_{y=1}^{n-1}\) depends on the whole matrix \((N_{nry})_{1 \le r \le k, 1 \le y \le n}\) of frequencies \(N_{nry} = N_{nr} \widehat{F}_{nr}(X_{(y)}) = \sum _{i=1}^n 1_{[R_i = r, \, X_i \le X_{(y)}]}\). For given \(\varvec{N}_{\!n}\), there are
possibilities for that matrix, and this number grows exponentially with n, unless \(\varvec{N}_{\!n}\) is extremely unbalanced. As a consequence, for each new data set we have to compute \(\widehat{F}_n^\mathrm{L}\) anew, even if \(\varvec{N}_{\!n}\) remains unchanged.
Basic distributional properties From now on, we condition on the rank vector \(\varvec{R}_{n}= (R_i)_{i=1}^n\). Hence the vector \(\varvec{N}_{\!n}= (N_{nr})_{r=1}^k\) of stratum sizes is viewed as a fixed vector, and all probabilities, expectations and distributional statements refer to the conditional distribution of \(\varvec{X}_{\!n}= (X_i)_{i=1}^n\), given \(\varvec{R}_{n}\).
All estimators \(\widehat{F}_n\), \(\widehat{F}_n^\mathrm{S}\), \(\widehat{F}_n^\mathrm{M}\) and \(\widehat{F}_n^\mathrm{L}\) are distribution-free in the following sense: Let \(\widehat{B}_n\), \(\widehat{B}_n^\mathrm{S}\), \(\widehat{B}_n^\mathrm{M}\) and \(\widehat{B}_n^\mathrm{L}\) be defined analogously with raw observations from the uniform distribution on [0, 1]. That means, we replace the random variables \(X_1, X_2, \ldots , X_n\) with random variables \(\widetilde{X}_1, \widetilde{X}_2, \ldots , \widetilde{X}_n \in [0,1]\) which are independent, and \(\widetilde{X}_i\) has (conditional) distribution function \(B_r\) if \(R_i = r\). Then
where \(\mathrm{Z} = \mathrm{S}, \mathrm{M}, \mathrm{L}\). Consequently, it suffices to analyze the distribution of the random processes \(\bigl ( \widehat{B}_n^\mathrm{Z}(t) \bigr )_{t \in [0,1]}\).
Pointwise confidence intervals Recall that the estimator \(\widehat{F}_n^\mathrm{M}(x)\) was defined by matching \(n \widehat{F}_n(x)\) to its (conditional) mean. Comparing \(n \widehat{F}_n(x)\) with its distribution function yields exact confidence bounds for F(x). This approach has been used by Terpstra and Miller (2006) in the framework of balanced ranked set sampling. In the present general framework, this method works as follows: The (conditional) distribution of \(n \widehat{F}_n(x)\) depends only on \(\varvec{N}_{\!n}\) and F(x). Precisely, in case of \(F(x) = p\), it has the same distribution as \(\sum _{r=1}^k Y_{r,p}\) with independent random variables \(Y_{1,p}\), \(Y_{2,p}\), ..., \(Y_{k,p}\), where
Let \(G_{\varvec{N}_{\!n},p}\) be the corresponding distribution function, i.e.,
This is not a standard distribution but a convolution of binomial distributions which can be computed numerically quite easily. Elementary considerations reveal that for any \(y \in \{0,1,\ldots ,n-1\}\), the distribution function \(G_{\varvec{N}_{\!n},p}(y)\) is continuous and strictly decreasing in \(p \in [0,1]\) with boundary values \(G_{\varvec{N}_{\!n},0}(y) = 1\) and \(G_{\varvec{N}_{\!n},1}(y) = 0\). Further, \(G_{\varvec{N}_{\!n},p}(n) = 1\) and \(G_{\varvec{N}_{\!n},p}(-1) = 0\) for all \(p \in [0,1]\). Consequently, non-asymptotic p values for the null hypotheses “\(F(x) \ge p\)” and “\(F(x) \le p\)” are given by \(G_{\varvec{N}_{\!n},p}(n \widehat{F}_n(x))\) and \(1 - G_{\varvec{N}_{\!n},p}(n \widehat{F}_n(x) - 1)\), respectively. These imply two different \((1 - \alpha )\)-confidence regions for F(x), namely
Here \(b_\alpha (\varvec{N}_{\!n},y)\) is the unique solution \(p \in (0,1)\) of the equation \(G_{\varvec{N}_{\!n},p}(y) = \alpha \) if \(0 \le y \le n-1\), and \(b_\alpha (\varvec{N}_{\!n},n) = 1\). Likewise, \(a_\alpha (\varvec{N}_{\!n},y)\) is the unique solution \(p \in (0,1)\) of the equation \(G_{\varvec{N}_{\!n},p}(y-1) = 1 - \alpha \) if \(1 \le y \le n\), and \(a_\alpha (\varvec{N}_{\!n},0) = 0\). Obviously, one can combine lower and upper bounds and compute the Clopper and Pearson (1934) type \((1 - \alpha )\)-confidence interval \(\bigl [ a_{\alpha /2}(\varvec{N}_{\!n},n \widehat{F}_n(x)), b_{\alpha /2}(\varvec{N}_{\!n},n\widehat{F}_n(x)) \bigr ]\) for F(x).
Note that the computation of all these confidence bounds for F boils down to determining only finitely many values \(a_\lambda (\varvec{N}_{\!n},y)\) and \(b_\lambda (\varvec{N}_{\!n},y)\) for \(\lambda = \alpha , \alpha /2\) and \(y \in \{0,1,\ldots ,n\}\).
If we would ignore the ranks \(R_i\) and just pretend that \(X_1, X_2, \ldots , X_n\) are i.i.d. with distribution function F, then we would work with the distribution function \(G_{n,p}\) of the binomial distribution \(\mathrm {Bin}(n,p)\) instead of \(G_{\varvec{N}_{\!n},p}\). This would lead to the traditional confidence bounds \(a_{\alpha }^\mathrm{st}(n,n\widehat{F}_n(x))\), \(b_{\alpha }^\mathrm{st}(n,n\widehat{F}_n(x))\) and the confidence interval of Clopper and Pearson (1934) with endpoints \(a_{\alpha /2}^\mathrm{st}(n,n\widehat{F}_n(x))\), \(b_{\alpha /2}^\mathrm{st}(n,n\widehat{F}_n(x))\) for F(x).
Confidence bands We may compute Kolmogorov–Smirnov-type confidence bands for the unknown distribution function F as follows: Let \(\kappa _{}^\mathrm{Z}(\varvec{N}_{\!n},\alpha )\) be the \((1 - \alpha )\)-quantile of the random variable \(\Vert \widehat{B}_n^\mathrm{Z} - B\Vert _\infty = \sup _{t \in [0,1]} \bigl | \widehat{B}_n^\mathrm{Z}(t) - t \bigr |\). Then, we may conclude with confidence \(1 - \alpha \) that
The quantiles \(\kappa _{}^\mathrm{Z}(\varvec{N}_{\!n},\alpha )\) may be estimated via Monte Carlo simulations. As explained before, this procedure is particularly convenient to implement for the moment-matching estimator \(\widehat{F}_n^\mathrm{M}\), whereas for the likelihood estimator \(\widehat{F}_n^\mathrm{L}\) it would be very computer-intensive.
Numerical example Figure 1 shows for \(n = 210\) and \(\varvec{N}_{\!n}= (70,70,70), (100,70,40)\) the estimator value \(\widehat{F}_n^\mathrm{M}(X_{(y)})\) and the two-sided \(95\%\)-confidence bounds \(a_{2.5\%}(\varvec{N}_{\!n},y)\), \(b_{2.5\%}(\varvec{N}_{\!n},y)\), \(a_{2.5\%}^\mathrm{st}(n,y)\) and \(b_{2.5\%}^\mathrm{st}(n,y)\) as a function of \(y \in \{0,1,\ldots ,n\}\). One sees that the additional rank information leads to more accurate confidence bounds in the balanced setting. In the unbalanced situation, ignoring the rank information and pretending the \(X_i\) to be i.i.d. would induce a severe bias, and the coverage probabilities would be substantially smaller than \(95\%\).

Estimator \(\widehat{F}_n^\mathrm{M}\) and pointwise \(95\%\)-confidence intervals for F: For \(y \in \{0,1,\ldots ,n\}\) one sees the value \(\widehat{F}_n^\mathrm{M}(X_{(y)})\) (dashed), the exact confidence bounds \(a_{2.5\%}(\varvec{N}_{\!n},y)\) and \(b_{2.5\%}(\varvec{N}_{\!n},y)\) (solid), and the classical bounds \(a_{2.5\%}^\mathrm{st}(n,y)\) and \(b_{2.5\%}^\mathrm{st}(n,y)\) (dotted)
For Kolmogorov–Smirnov-type confidence bands centered at \(\widehat{F}_n^\mathrm{M}\), we estimated the quantiles \(\kappa _{}^\mathrm{M}(\varvec{N}_{\!n},5\%)\) in \(10^5\) Monte Carlo simulations and obtained
For the usual Kolmogorov–Smirnov confidence band with \(n = 210\) observations, the critical value would be \(\kappa (n,5\%) = 0.0927\).
Unequal group sizes The point estimators \(\widehat{F}_n^\mathrm{L}, \widehat{F}_n^\mathrm{M}\) and the confidence regions just described may be extended easily to a more general setting with independent observations \((X_i,R_i,k_i)\), \(1 \le i \le n\), where \(k_i \ge 1\) is a fixed integer, \(R_i\) is a fixed or random rank in \(\{1,2,\ldots ,k_i\}\), and
see, for instance, Bhoj (2001) or Chen (2001). Here \(B_{r,s}\) denotes the distribution function of the beta distribution with parameters r and s.
3 Asymptotic considerations
We consider the asymptotic behavior of the estimators \(\widehat{B}_n^\mathrm{S}\), \(\widehat{B}_n^\mathrm{M}\) and \(\widehat{B}_n^\mathrm{L}\) for fixed k as \(n \rightarrow \infty \) and
Recall that we condition on the rank vector \(\varvec{R}_{n}\). The former condition is satisfied with \(\pi _r = 1/k\) both in Huang’s (1997) setting and in the JPS setting almost surely. In general, we assume that
Linear expansions and limit theorems In what follows, let
for \(1 \le r \le k\). Each stochastic process \(\mathbb {V}_{nr}\) has the same distribution as a standardized empirical distribution function of \(N_{nr}\) independent random variables with uniform distribution on [0, 1], see also “Appendix.” Moreover, the processes \(\mathbb {V}_{n1}, \ldots , \mathbb {V}_{nk}\) are stochastically independent. Our first result shows that the three estimators \(\widehat{B}_n^\mathrm{S}\), \(\widehat{B}_n^\mathrm{M}\) and \(\widehat{B}_n^\mathrm{L}\) may be approximated by simpler processes involving \(\mathbb {V}_{n1}, \ldots , \mathbb {V}_{nk}\).
Theorem 2
(Linear expansion). For \(\mathrm{Z} = \mathrm{S}, \mathrm{M}, \mathrm{L}\) and any fixed \(\delta \in [0,1/2)\),
where
with continuous functions \(\gamma _{n1}^\mathrm{Z},\ldots ,\gamma _{nk}^\mathrm{Z} : [0,1] \rightarrow [0,\infty )\). Precisely, for \(t \in (0,1)\),
with \(w_r = \beta _r/(B_r(1 - B_r))\). Moreover,
The next theorem shows that all estimators \(\widehat{F}_n^\mathrm{S}, \widehat{F}_n^\mathrm{M}, \widehat{F}_n^\mathrm{L}\) are asymptotically equivalent in the tail regions. Moreover, the asymptotic behavior in the left and right tail is driven mainly by the processes \(\mathbb {V}_{n1}\) and \(\mathbb {V}_{nk}\), respectively.
Theorem 3
(Linear expansion in the tails). For \(\mathrm{Z} = \mathrm{S}, \mathrm{M}, \mathrm{L}\) and any fixed \(\kappa \in [1/2,1)\),
and
as \(n \rightarrow \infty \) and \(c \downarrow 0\), where
It follows from Donsker’s theorem for the empirical process that \(\mathbb {V}_{nr}\) behaves asymptotically like a standard Brownian bridge process \(\mathbb {V}= (\mathbb {V}(u))_{u \in [0,1]}\). Together with Theorem 2, this leads to the following limit theorem:
Corollary 4
(Asymptotic distribution). For \(\mathrm{Z} = \mathrm{S}, \mathrm{M}, \mathrm{L}\), the stochastic process \(\mathbb {V}_n^\mathrm{Z}\) converges in distribution in the space \(\ell _\infty ([0,1])\) to a centered Gaussian process \(\mathbb {V}^\mathrm{Z}\) with continuous paths on [0, 1]. Precisely, for \(t \in [0,1]\),
with independent standard Brownian bridges \(\mathbb {V}_1, \ldots , \mathbb {V}_k\) and continuous functions \(\gamma _1^\mathrm{Z}, \ldots , \gamma _k^\mathrm{Z} : [0,1] \rightarrow [0,\infty )\) given by
Theorem 2 and Corollary 4 show that all three estimators \(\widehat{F}_n^\mathrm{S}, \widehat{F}_n^\mathrm{M}, \widehat{F}_n^\mathrm{L}\) are root-n-consistent. In the asymptotically balanced case with
one can easily deduce from \(\sum _{s=1}^k \beta _s \equiv k\) that
Hence, in this particular case the estimators \(\widehat{F}_n^\mathrm{S}\) and \(\widehat{F}_n^\mathrm{M}\) are asymptotically equivalent. But otherwise \(\widehat{F}_n^\mathrm{S}\) may be substantially worse than \(\widehat{F}_n^\mathrm{M}\), as shown later.
Relative asymptotic efficiencies Let K be the covariance function of a standard Brownian bridge \(\mathbb {V}\), i.e., \(K(s,t) = \min \{s,t\} - st\) for \(s,t \in [0,1]\). Then the covariance function \(K^\mathrm{Z}\) of the Gaussian process \(\mathbb {V}^\mathrm{Z}\) in Corollary 4 is given by
In particular, for \(0< t < 1\) the asymptotic distribution of \(\sqrt{n} \bigl ( \widehat{B}_n^\mathrm{Z}(t) - t \bigr )\) equals \(\mathcal {N} \bigl ( 0, K^\mathrm{Z}(t) \bigr )\) with \(K^\mathrm{Z}(t) := K^\mathrm{Z}(t,t)\) given by
The latter equation follows from \(w_r = \beta _r/(B_r(1 - B_r))\). The next result provides a detailed comparison of these asymptotic variances.
Theorem 5
(Relative asymptotic efficiencies). For arbitrary \(t \in (0,1)\),
with equality for at most one \(t \in (0,1)\). Furthermore,
with equality if, and only if, \(t = 1/2\) and \(k = 2\). On the other hand,
where the suprema are over all tuples \((\pi _r)_{r=1}^k\) with strictly positive components summing to one, and
Numerical examples In case of \(k = 2\), the upper bound for \(K^\mathrm{M}(t)/K^\mathrm{L}(t)\) equals \(9/8 = 1.125\). More precisely,
with \(u := 2t - 1 \in [-1,1]\), see the supplement for more details.

Asymptotic variances of \(\widehat{B}_n^\mathrm{L}\), \(\widehat{B}_n^\mathrm{S}\equiv \widehat{B}_n^\mathrm{M}\), \(\widehat{B}_n\) (left panel) and relative efficiencies of \(\widehat{B}_n^\mathrm{L}\) versus \(\widehat{B}_n^\mathrm{Z}\) (right panel) in case of \(\pi _1 = \pi _2 = \pi _3 = 1/3\)
In case of \(k = 3\), the upper bound for \(K^\mathrm{M}(t)/K^\mathrm{L}(t)\) equals \(4/3 \approx 1.333\). Figures 2 and 3 show the asymptotic variance functions \(K(\cdot )\) of \(\widehat{B}_n\) and \(K^\mathrm{Z}(\cdot )\) of \(\widehat{B}_n^\mathrm{Z}\) for \(\mathrm{Z} = \mathrm{S}, \mathrm{M}, \mathrm{L}\) in the balanced and one unbalanced situation. Note that in the balanced setting, \(\widehat{B}_n^\mathrm{S}\equiv \widehat{B}_n^\mathrm{M}\) and thus \(K^\mathrm{S}(\cdot ) \equiv K^\mathrm{M}(\cdot )\). In addition, one sees the asymptotic relative efficiencies
of \(\widehat{B}_n^\mathrm{L}\) versus \(\widehat{B}_n^\mathrm{Z}\) together with the upper bound
for \(E^\mathrm{M}(t)\). One sees clearly that the inefficiency of \(\widehat{B}_n^\mathrm{M}\) versus \(\widehat{B}_n^\mathrm{L}\) is moderate, whereas the inefficiency of \(\widehat{B}_n^\mathrm{S}\) may become substantial in unbalanced settings. Note also that in case of \(\pi _1> \pi _2 > \pi _3\) the accuracy in the left tail increases at the expense of larger errors in the right tail.

Asymptotic variances of \(\widehat{B}_n^\mathrm{S}\), \(\widehat{B}_n^\mathrm{M}\), \(\widehat{B}_n^\mathrm{L}\) (left panel) and relative efficiencies of \(\widehat{B}_n^\mathrm{L}\) versus \(\widehat{B}_n^\mathrm{Z}\) (right panel) in case of \((\pi _1,\pi _2,\pi _3) = (10/21,7/21,4/21)\)
Implications for confidence intervals One can deduce from Corollary 4 that \(n^{1/2} \kappa _{}^\mathrm{Z}(\varvec{N}_{\!n},\alpha )\) converges to the \((1 - \alpha )\)-quantile of the random supremum norm \(\Vert \mathbb {V}^\mathrm{Z}\Vert _\infty \). Moreover, for any \(x \in \mathbb {R}\) with \(0< F(x) < 1\), the pointwise confidence bounds satisfy
with \(\Phi ^{-1}\) denoting the standard Gaussian quantile function, see the supplement.
4 A real data example and imperfect rankings
4.1 Population sizes of Swiss municipalities
Every 5 years, the Swiss Federal Office of Statistics releases data about all municipalities of Switzerland, including their population sizes. There are currently 2289 communities, and the two most recent data collections are from 2010 and 2015. Suppose we would have wanted to estimate the distribution function F of population sizes by the end of 2015 in early 2016. Back then only the data of 2010 would have been available, the data of 2015 having been released later in 2016 and corrected in 2017. In principle one could have approached each single municipality to obtain its population size by the end of 2015, but this would have been time-consuming of course. Hence, one could have applied RSS sampling as follows: One chooses randomly \(n = 210\) disjoint sets of \(k = 3\) communities. Within the i-th set, one determines the unit with rank \(R_i\) according to population sizes in 2010 and obtains its precise population size \(X_i\) by the end of 2015. The ranks \(R_1,\ldots ,R_n \in \{1,2,3\}\) are prespecified. If one is particularly interested in smaller municipalities, one could choose \(\varvec{R}_{n}\) such that, say, \(\varvec{N}_{\!n}= (100,70,40)\).
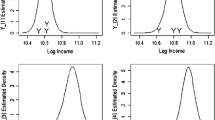
Having the complete data of 2010 and 2015, one can easily simulate this sampling scheme. Figure 4 shows for one such sample the estimated distribution function \(\widehat{F}_n^\mathrm{M}\) together with pointwise and simultaneous \(95\%\)-confidence intervals as described in Sect. 2. Since the distribution of population sizes is heavily right-skewed, the horizontal axis shows the decimal logarithms of population sizes. In the lower panel, the point estimator \(\widehat{F}_n^\mathrm{M}\) is replaced with the true distribution function F, i.e., the empirical distribution function of all 2289 population sizes in 2015.

Inference about the distribution of population sizes (Sect. 4.1) with \(\varvec{N}_{\!n}= (100,70,40)\). The smoother function is the true c.d.f. F. The inner and outer two step functions are the pointwise and simultaneous \(95\%\)-confidence band for F
We simulated this sampling scheme \(10^5\) times and analyzed the performance of both \(\widehat{F}_n^\mathrm{M}\) and the confidence intervals. The Monte Carlo estimator of
was everywhere between \(- 10^{-4}\) and \(10^{-3}\), whereas the MC estimator of
was nowhere larger than 0.0263. The left panel of Fig. 5 depicts these two functions \(\mathrm {BIAS}\) and \(\mathrm {RMSE}\). For each sample and any \(x \in \mathbb {R}\), we obtained a pointwise and simultaneous \(95\%\)-confidence interval, denoted by \(C_\mathrm{pw}(x)\) and \(C_\mathrm{sim}(x)\), respectively. The MC estimator of the error probability \(\mathop {\mathrm {I\!P}}\nolimits \bigl ( F(x) \not \in C_\mathrm{pw}(x) \bigr )\) was nowhere larger than \(4.22\%\), and the one of \(\mathop {\mathrm {I\!P}}\nolimits \bigl ( F(x) \not \in C_\mathrm{sim}(x) \ \text {for some} \ x \in \mathbb {R}\bigr )\) turned out to be smaller than \(2.8\%\). The confidence intervals being conservative are probably a consequence of sampling without replacement, which results in more accurate estimators than sampling with replacement. The right panel of Fig. 5 shows MC estimates of the average widths
Here one sees clearly the effect of unbalanced sampling with \(N_{n1}> N_{n2} > N_{n3}\), the benefit being shorter intervals in the left tail at the expense of longer intervals in the right tail.

Inference about the distribution of population sizes (Sect. 4.1) with \(\varvec{N}_{\!n}= (100,70,40)\). Left panel: bias and root mean squared error of \(\widehat{F}_n^\mathrm{M}\). Right panel: Average width of pointwise \(95\%\)-confidence band for F
Note that the ranking of municipalities within the n groups of size \(k = 3\) was based on the population sizes in 2010 and thus imperfect. Indeed, a reasonable model for the pairs of log-transformed population sizes in 2010 and 2015 seems to be a bivariate Gaussian distribution with correlation 0.9986. As a consequence, in our MC simulations the average proportion of imperfect ranks \(R_i\) turned out to be \(3.1\%\).
Analogous simulations for \(k = 4,5\) and different choices of \(\varvec{N}_{\!n}\) led to similar results. Enlarging k without changing n leads to larger coverage probabilities, presumably an effect of sampling without replacement, while the modulus of the bias of \(\widehat{F}_n^\mathrm{M}\) and the proportion of imperfect ranks get larger.
4.2 Imperfect rankings
In case of sampling with replacement, the previous data example would fit the model of Dell and Clutter (1972) for ranked set sampling with imperfect rankings quite well. They consider 2nk independent random variables \(X_{ij} \sim F\) and \(\varepsilon _{ij} \sim \mathcal {N}(0,\tau ^2)\) with \(1 \le i \le n\) and \(1 \le j \le k\). Instead of the true rank of \(X_{ij}\) among \(X_{i1}, \ldots , X_{ik}\) one obtains the ranks
of the concomitant variables \(Y_{ij} := X_{ij} + \varepsilon _{ij}\). If \(\sigma > 0\) denotes the standard deviation of the \(X_{ij}\), the correlation between \(X_{ij}\) and \(Y_{ij}\) equals \(\rho = (1 + \tau ^2/\sigma ^2)^{-1/2}\). Finally we obtain for \(1 \le i \le n\) the observation \((X_i,R_i) = (X_{i1}, R_{i1})\) in JPS and \((X_{iJ(i)}, R_i)\) in RSS, where J(i) is the unique index in \(\{1,\ldots ,k\}\) such that \(R_{iJ(i)} = R_i\).

Performance of \(\widehat{F}_n^\mathrm{L}\) in balanced setting with \(N_{n1} = N_{n2} = N_{n3} = 70\): Bias and root mean squared error (left panel) and relative efficiency versus \(\widehat{F}_n^\mathrm{S}\) (right panel) for correlations \(\rho = 1\) (dotted), \(\rho = 0.95\) (dashed) and \(\rho = 0.9\) (solid)
In this model, the stratified estimator \(\widehat{F}_n^\mathrm{S}\) is still unbiased, see Presnell and Bohn (1999) for the RSS setting with \(N_{n1},\ldots ,N_{nk} > 0\) and Dastbaravarde et al. (2016) for the JPS setting. For that reason, we considered \(\widehat{F}_n^\mathrm{S}\) as a gold standard in our simulation study: We simulated \(10^5\) RSS data sets from this model with standard Gaussian distribution function \(F = \Phi \), sample size \(n = 210\) and different options for \(\varvec{N}_{\!n}\) and \(\rho \). With these simulations, we estimated the bias and root mean squared error,
for \(\mathrm{Z} = \mathrm{S}, \mathrm{M}, \mathrm{L}\). In addition we estimated the relative efficiency
of \(\widehat{F}_n^\mathrm{Z}\) versus the stratified estimator \(\widehat{F}_n^\mathrm{S}\).
Firstly we considered \(N_{n1} = N_{n2} = N_{n3} = 70\). Here \(\widehat{F}_n^\mathrm{S}\equiv \widehat{F}_n^\mathrm{M}\equiv \widehat{F}_n^{}\). In Fig. 6, one sees on the left-hand side the functions \(\mathrm {BIAS}^\mathrm{L}\) and \(\mathrm {RMSE}^\mathrm{L}\) for three different values of the correlation \(\rho \). While \(\widehat{F}_n^\mathrm{S}\equiv \widehat{F}_n^\mathrm{M}\) is unbiased, the bias of \(\widehat{F}_n^\mathrm{L}\) gets worse as \(\rho \) decreases. For all three estimators \(\widehat{F}_n^\mathrm{Z}\), the root mean squared error increases as \(\rho \) decreases. The right-hand side of Fig. 6 depicts the relative efficiency function \(\mathrm {RE}^\mathrm{L}\). As predicted by asymptotic theory, \(\mathrm {RE}^\mathrm{L} > 1\) in case of \(\rho = 1\), but for smaller correlations the relative efficiency drops below 1 in the tails.
Secondly we considered the unbalanced situation with \(\varvec{N}_{\!n}= (100, 70, 40)\). Now the three estimators \(\widehat{F}_n^\mathrm{Z}\) are different, and only \(\widehat{F}_n^\mathrm{S}\) is unbiased. In Fig. 7, we show bias and root mean squared errors of \(\widehat{F}_n^\mathrm{M}\) and \(\widehat{F}_n^\mathrm{L}\). Clearly, the bias of \(\widehat{F}_n^\mathrm{M}\) and \(\widehat{F}_n^\mathrm{L}\) gets worse as \(\rho \) decreases, where \(\widehat{F}_n^\mathrm{M}\) is a bit more robust than \(\widehat{F}_n^\mathrm{L}\). Nevertheless, the plots of the relative efficiencies \(\mathrm {RE}^\mathrm{M}\) and \(\mathrm {RE}^\mathrm{L}\) show that for \(\rho = 0.95\) the moment-matching estimator outperforms the stratified one everywhere, and also the likelihood estimator is better at most places. For \(\rho = 0.9\), the likelihood estimator is less favorable than the other two.

Performance of \(\widehat{F}_n^\mathrm{M}\) and \(\widehat{F}_n^\mathrm{L}\) in unbalanced setting with \(\varvec{N}_{\!n}= (100,70,40)\): Biases and root mean squared errors (upper panels) and relative efficiencies versus \(\widehat{F}_n^\mathrm{S}\) (lower panels) for correlations \(\rho = 1\) (dotted), \(\rho = 0.95\) (dashed) and \(\rho = 0.9\) (solid)
5 Conclusions and future research
The present paper confirms and generalizes previous findings that the estimator \(\widehat{F}_n^\mathrm{L}\) is the most efficient one in case of perfect ranking, both in balanced and unbalanced situations. In terms of computational efficiency, however, the estimator \(\widehat{F}_n^\mathrm{M}\) has clear advantages and is particularly convenient as an ingredient for simultaneous confidence bands. Further, it is closely related to pointwise confidence bands for F. For now, we restricted ourselves to Kolmogorov–Smirnov-type bands, but other variants might be worthwhile to study.
The simulations in Sect. 4.2 indicate that even in case of imperfect rankings, both \(\widehat{F}_n^\mathrm{M}\) and \(\widehat{F}_n^\mathrm{L}\) perform well compared to \(\widehat{F}_n^\mathrm{S}\), as long as the ranking precision is high. While \(\widehat{F}_n^\mathrm{L}\) appears to be most sensitive to imperfect rankings, \(\widehat{F}_n^\mathrm{M}\) seems to offer a good compromise in terms of efficiency (for perfect rankings) and robustness against ranking errors. Investigating and understanding these differences thoroughly would be an interesting topic for future research.
References
Balakrishnan, N., Li, T. (2006). Confidence intervals for quantiles and tolerance intervals based on ordered ranked set samples. Annals of the Institute of Statistical Mathematics, 58, 757–777.
Bhoj, D. S. (2001). Ranked set sampling with unequal samples. Biometrics, 57(3), 957–962.
Chen, Z. (2001). Non-parametric inferences based on general unbalanced ranked-set samples. Journal of Nonparametric Statistics, 13(2), 291–310.
Chen, Z., Bai, Z., Sinha, B. K. (2004). Ranked set sampling. Theory and applications. New York: Springer.
Clopper, C. J., Pearson, E. S. (1934). The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika, 26(4), 404–413.
Dastbaravarde, A., Arghami, N. R., Sarmad, M. (2016). Some theoretical results concerning non parametric estimation by using a judgment poststratification sample. Communications in Statistics, Theory and Methods, 45(8), 2181–2203.
David, H. A., Nagaraja, H. N. (2003). Order statistics (3rd ed.). Hoboken, NJ: Wiley-Interscience.
Dell, T. R., Clutter, J. L. (1972). Ranked set sampling theory with order statistics background. Biometrics, 28(2), 545–555.
Frey, J., Ozturk, O. (2011). Constrained estimation using judgement post-stratification. Annals of the Institute of Statistical Mathematics, 63, 769–789.
Ghosh, K., Tiwari, R. C. (2008). Estimating the distribution function using \(k\)-tuple ranked set samples. Journal of Statistical Planning and Inference, 138(4), 929–949.
Huang, J. (1997). Properties of the Npmle of a distribution function based on ranked set samples. Annals of Statistics, 25(3), 1036–1049.
Kvam, P. H., Samaniego, F. J. (1994). Nonparametric maximum likelihood estimation based on ranked set samples. Journal of the American Statistical Association, 89(426), 526–537.
MacEachern, S. N., Stasny, E. A., Wolfe, D. A. (2004). Judgement post-stratification with imprecise rankings. Biometrics, 60, 207–215.
McIntyre, G. A. (1952). A method of unbiased selective sampling, using ranked sets. Australian Journal of Agricultural Research, 3, 385–390.
Presnell, B., Bohn, L. L. (1999). U-Statistics and imperfect ranking in ranked set sampling. Journal of Nonparamatric Statistics, 10(2), 111–126.
R Core Team. (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/. Accessed July 2018.
Shorack, G. R., Wellner, J. A. (1986). Empirical processes with applications to statistics. New York: Wiley.
Stokes, S. L., Sager, T. W. (1988). Characterization of a ranked-set sample with application to estimating distribution functions. Journal of the American Statistical Association, 83(402), 374–381.
Terpstra, J. T., Miller, Z. A. (2006). Exact inference for a population proportion based on a ranked set sample. Communications in Statistics, Simulation and Computation, 35(1), 19–26.
Wang, X., Wang, K., Lim, J. (2012). Isotonized CDF estimation from judgement poststratification data with empty strata. Biometrics, 68(1), 194–202.
Wolfe, D. A. (2004). Ranked set sampling: An approach to more efficient data collection. Statistical Science, 19(4), 636–643.
Wolfe, D. A. (2012). Ranked set sampling: Its relevance and impact on statistical inference. ISRN Probability and Statistics, 2012, 568385. https://doi.org/10.5402/2012/568385.
Acknowledgements
Constructive comments by an associate editor and two referees are gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
We first recall two well-known facts about uniform empirical processes, see Shorack and Wellner (1986).
Proposition 6
Let \(U_1, U_2, U_3, \ldots \) be independent random variables with uniform distribution on [0, 1]. For \(N \in \mathbb {N}\) and \(u \in [0,1]\) define
Then, as \(N \rightarrow \infty \), \(\mathbb {V}^{(N)}\) converges in distribution in \(\ell _\infty ([0,1])\) to a standard Brownian bridge \(\mathbb {V}\) on [0, 1]. Moreover, for any fixed \(\delta \in [0,1/2)\) and \(\epsilon > 0\),
For the estimators \(\widehat{F}_n^\mathrm{M}\), \(\widehat{F}_n^\mathrm{L}\) we need some basic facts and inequalities for the auxiliary functions \(w_k\) and \(B_k\) which are proved in the supplement:
Lemma 7
- (a):
-
For \(r = 1,2,\ldots ,k\), the function \(w_r\) on (0, 1) may be written as \(w_r(t) = \widetilde{w}_r(t) / (t(1-t))\) with \(\widetilde{w}_r : [0,1] \rightarrow (0,\infty )\) continuously differentiable. Moreover, for \(r = 1,2,\ldots ,k\) and \(t \in (0,1)\),
$$\begin{aligned} 1 \ \le \ \widetilde{w}_r(t) \ \le \ \max (r,k+1-r). \end{aligned}$$ - (b):
-
For any constant \(c \in (0,1)\) there exists a number \(c' = c'(k,c) > 0\) with the following property: If \(t,p \in (0,1)\) such that
$$\begin{aligned} \frac{|p - t|}{t(1-t)} \ \le \ c , \end{aligned}$$then for \(r = 1,2,\ldots ,k\),
$$\begin{aligned} \max \left\{ \left| \frac{w_r(p)}{w_r(t)} - 1 \right| , \left| \frac{B_r(p) - B_r(t)}{\beta _r(t) (p - t)} - 1 \right| \right\} \ \le \ c' \frac{|p - t|}{t(1-t)}. \end{aligned}$$
Proof of Theorem 2
We start with the weight functions \(\gamma _{nr}^\mathrm{Z}\): Note that by Lemma 7,
with the probability weights \(\pi _{nr} := N_{nr}/n\) and continuous functions \(\widetilde{w}_r : [0,1] \rightarrow [1,k]\). Since the beta densities \(\beta _r\) are also continuous with \(\beta _1(0) = \beta _k(1) = k\), this shows that \(\gamma _{nr}^\mathrm{Z}\) is well-defined and continuous, provided that its denominator is strictly positive, i.e.,
For sufficiently large n this is the case, because \(\lim _{n\rightarrow \infty } \pi _{nr} = \pi _r\) for all r. The functions \(\gamma _r^\mathrm{Z}\) in Corollary 4 are continuous, too, and elementary considerations reveal that
as \(n \rightarrow \infty \). In particular, \(\max _{t \in [0,1], 1 \le r \le k} \gamma _{nr}^\mathrm{Z}(t) = O(1)\).
Note that for \(n \ge 1\) and \(1 \le r \le k\), the empirical process \(\mathbb {V}_{nr}\) is distributed as \(\mathbb {V}^{(N_{nr})}\) in Proposition 6. Note also that the distribution functions \(B_r\) satisfy \(B_1 \ge B_2 \ge \cdots \ge B_k\), because for \(1 \le r < k\) the density ratio \(\beta _{r+1}/\beta _r\) is a positive multiple of \(t/(1 - t)\) and thus strictly increasing. Consequently, for \(1 \le r \le k\),
so
Consequently,
as \(n \rightarrow \infty \) and \(c \downarrow 0\). All in all, we may conclude that
It remains to be shown that the process \(\sqrt{n} (\widehat{B}_n^\mathrm{Z} - B)\) may be approximated by \(\mathbb {V}_n^\mathrm{Z}\). In case of \(\mathrm{Z} = \mathrm{S}\) it follows from \(\sum _{r=1}^k \beta _r \equiv k\) that \(\sum _{r=1}^k B_r = k B\), and this implies that
For \(\mathrm{Z} = \mathrm{M}, \mathrm{L}\) it suffices to show that for any fixed number \(b \ne 0\) and
the following statements are true: If \(b < 0\), then with asymptotic probability one,
If \(b > 0\), then with asymptotic probability one,
Here we use the conventions that \(L_n'(t,\cdot ) := \infty \) and \(B_r := 0\) on \((-\infty ,0]\) while \(L_n'(t,\cdot ) := -\infty \) and \(B_r := 1\) on \([1,\infty )\).
To verify these claims, we split the interval (0, 1) into \((0,c_n]\), \([c_n,1-c_n]\) and \([1-c_n,1)\) with numbers \(c_n \in (0,1/2)\) to be specified later, where \(c_n \downarrow 0\).
On \([c_n,1-c_n]\) we utilize Lemma 7: For \(t \in [c_n, 1 - t_n]\) and \(p \in (0,1)\) such that \(|p - t| \le t(1-t)/2\) we may write
and
where
Note that for \(t \in [c_n,1-c_n]\),
Hence we choose \(c_n\) such that \(c_n \downarrow 0\) but \(n c_n^{2(1-\delta )} \rightarrow \infty \). With this choice, we may conclude that uniformly in \(t \in [c_n,1-c_n]\),
On the other hand, since \(\beta _1(t) + \beta _k(t) \ge \beta _1(1/2) + \beta _k(1/2) = k 2^{2-k}\),
Consequently,
and
for some random functions \(\kappa _n^\mathrm{M}, \kappa _n^\mathrm{L} : [c_n,1-c_n] \rightarrow [-1,1]\). These considerations show that (8) and (9) are satisfied with \([c_n,1-c_n]\) in place of (0, 1).
It remains to verify (8) and (9) with \((0,c_n]\) in place of (0, 1); the interval \([1-c_n,1)\) may be treated analogously. Note first that for \(2 \le r \le k\),
so
Furthermore, since \(B_1(t) = 1 - (1 - t)^k\),
Hence for \(t \in (0,c_n]\) and \(p \in (0,2c_n]\),
and
where
Note also that
In particular, \(\sup _{t \in (0,c_n]} p_n^\mathrm{Z}(t) = c_n + o_p(n^{-1/2} c_n^\delta ) = c_n (1 + o_p(1))\), and in case of \(b > 0\), \(\mathop {\mathrm {I\!P}}\nolimits \bigl ( p_n^\mathrm{Z}(t) > 0 \ \text {for} \ 0 < t \le c_n \bigr ) \rightarrow 1\).
In case of \(b > 0\), these considerations show that for \(0 < t \le c_n\),
and
Analogously, in case of \(b < 0\), for any \(t \in (0,c_n]\) we obtain the inequalities
Hence, (8) and (9) are satisfied with \((0,c_n]\) in place of (0, 1). \(\square \)
Proof of Theorem 3
For symmetry reasons it suffices to prove the first part about the left tails. Let \((c_n)_n\) be a sequence of numbers in (0, 1 / 2] converging to zero. Then for \(t \in (0,c_n]\) and \(\delta := \kappa /2 \in (0,1/2)\),
Concerning \(\widehat{B}_n^\mathrm{M}\) and \(\widehat{B}_n^\mathrm{L}\), for any \(t \in (0,c_n]\) and \(p \in (0,1)\),
and
where
Now we proceed similarly as in the proof of Theorem 2, defining
for some fixed \(b \ne 0\). Note that for \(t \in (0,c_n]\),
because \(\kappa > \delta \). Note also that
because \(\widehat{B}_{n1} \ge 0\) and \(t \mapsto t - (1 - (1-t)^k)/k\) is strictly convex on [0, 1] with derivative 0 at 0. Thus \(p_n(t) > 0\) for all \(t \in (0,c_n]\) in case of \(b > 0\).
In case of \(b > 0\), we may conclude that
and
Hence for any fixed \(b > 0\),
Similarly we can show that for any fixed \(b < 0\), with asymptotic probability one, \(\sqrt{n} (\widehat{B}_n^\mathrm{Z}(t) - t) \le \mathbb {V}_n^{(\ell )}(t) + b t^\kappa \) for all \(t \in (0,c_n]\). \(\square \)
Proof of Corollary 4
It follows from Proposition 6 that
Together with (5) this entails that \(\sup _{t \in [0,1]} \bigl | \mathbb {V}_n^\mathrm{Z}(t) - \widetilde{\mathbb {V}}_n^\mathrm{Z}(t) \bigr | \rightarrow _p 0\), where \(\widetilde{\mathbb {V}}_n^\mathrm{Z} := \sum _{r=1}^k \gamma _r^\mathrm{Z} \, \mathbb {V}_{nr} \circ B_r\). But \(\gamma _r^\mathrm{Z} \equiv 0\) whenever \(\pi _r = 0\). In case of \(\pi _r > 0\) it follows from Proposition 6 that \(\mathbb {V}_{nr}\) converges in distribution to \(\mathbb {V}_r\). Consequently, \(\widetilde{\mathbb {V}}_n^\mathrm{Z}\) converges in distribution to the Gaussian process \(\mathbb {V}^\mathrm{Z} = \sum _{r=1}^k \gamma _r^\mathrm{Z} \, \mathbb {V}_r \circ B_r\). \(\square \)
Proof of Theorem 5
The asserted inequalities follow from Jensen’s inequality. On the one hand, it follows from \(w_r = \beta _r / (B_r(1 - B_r))\) and \(\sum _{r=1}^k \beta _r \equiv k\) that
Equality holds if, and only if,
But
so
is strictly decreasing in t. Hence there is at most one solution of the equation \(\pi _1 w_1(t) = \pi _k w_k(t)\).
Similarly, with \(a_r(t) := \pi _r \beta _r(t) \big / \sum _{s=1}^k \pi _s \beta _s(t)\),
Here the inequality is strict unless
But \(w_1(t) = w_k(t)\) implies that \(t = 1/2\). Moreover, \(w_1(1/2) = 2k/(1 - 2^{-k})\) and
are identical if, and only if, \(k^2 + k + 2 = 2^{k+1}\). But \(2^{k+1} = 2 \sum _{j=0}^k \left( {\begin{array}{c}k\\ j\end{array}}\right) \) is strictly larger than \(2(1 + k + k(k-1)/2) = k^2 + k + 2\) if \(k \ge 3\).
As to the ratios \(E^\mathrm{Z}(t) := K^\mathrm{Z}(t)/K^\mathrm{L}(t)\), note first that
On the other hand, with \(a_r(t)\) as above,
with a random variable W with distribution \(\sum _{r=1}^k a_r(t) \delta _{w_r(t)}\). But with \(\ell (t) := \min _r w_r(t)\) and \(u(t) := \max _r w_r(t)\), convexity of \(w \mapsto w^{-1}\) on \([\ell (t),u(t)]\) implies that
so
This upper bound for \(E^\mathrm{M}(t)\) is attained approximately, if the distribution of W approaches the uniform distribution on \(\{\ell (t),u(t)\}\). Hence we should choose \((\pi _r)_{r=1}^k\) as follows: Let r(1), r(2) be two different numbers in \(\{1,\ldots ,k\}\) such that \(w_{r(1)}(t) = \ell (t)\) and \(w_{r(2)}(t) = u(t)\). Then let
The inequality \(\rho (t) \le k\) follows from Lemma 7 and the fact that \(\rho (t)\) remains unchanged if we replace \(w_r(t)\) with \(\widetilde{w}_r(t) = t(1-t) w_t(t) \in [1,k]\). \(\square \)
About this article

Cite this article
Dümbgen, L., Zamanzade, E. Inference on a distribution function from ranked set samples. Ann Inst Stat Math 72, 157–185 (2020). https://doi.org/10.1007/s10463-018-0680-y
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10463-018-0680-y